| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | DexVLG |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | DexVLG: Dexterous Vision-Language-Grasp Model at Scale |
| 4 | 创新点 | 1:DexGraspNet 3.0 数据集(目前最大、最强)。包含 1.7 亿 个抓取姿态,覆盖 17.4 万 个物体,是目前规模最大的灵巧抓取数据集。 (1)语义与部件感知 (Part-Aware): 不同于以往"瞎抓"的数据集,它引入了语义理解 。利用 SAMesh (做几何分割)和 GPT-4o(做语义标注),让数据清楚地知道"这是杯柄"、"那是刀刃"。 (2)物理校验与场景真实化: 所有抓取都经过 Isaac Gym 物理仿真验证(不穿模、掉不下来)。特别构建了 桌面场景 (Table-top) 数据,模拟物体自然掉落在桌上的姿态,而非不切实际的"空中悬浮",缩小了仿真与现实的差距。 2. DexVLG (听得懂话的抓取模型),解决了"如何用大模型控制灵巧手"的问题。 (1)提出了一个整合了视觉、语言和动作的统一端到端VLM框架。用 Uni3D 处理点云(对齐 CLIP 特征,懂语义)。用 Florence-2 理解指令。两者特征拼接,输入大模型。 (2) 引入流匹配 : 摒弃了传统的回归或扩散方法,采用基于流匹配的去噪头来生成抓取姿态。这种方法生成的路径更直、效率更高、质量更好。 (3) 单视角输入 : 模型只需要看一眼(单视角点云)就能脑补出抓取姿态,非常贴合真实机器人的工作场景。 3.算法与优化细节,为了生成上述高质量数据 ,作者在传统解析法基础上做了关键改进。 (1)部件感知初始化 : 抓取生成不再是全物体随机撒点,而是先算目标部件的 OBB(有向边界框),在指定部件上初始化手的位置。 (2) 新型能量函数 : 设计了特殊的部件接触能量。利用势垒函数,强制优化算法"惩罚"那些碰到非目标区域的手指,确保"让抓手柄就只抓手柄"。 造了最大的库(1.7亿带语义),用了最火的流匹配(Flow Matching),搞定了听话抓东西(语言对齐),仿真真机都能行。 |
| 5 | 引用量 | 这篇文章主要是针对灵巧手方面的工作,核心贡献是要给数据集(彩色点云数据),其次就是一个模型DexVLG(端到端的VLM)。较大的篇幅是在介绍数据集相关的内容,总的来说如果关注灵巧手任务可以看一下。 |
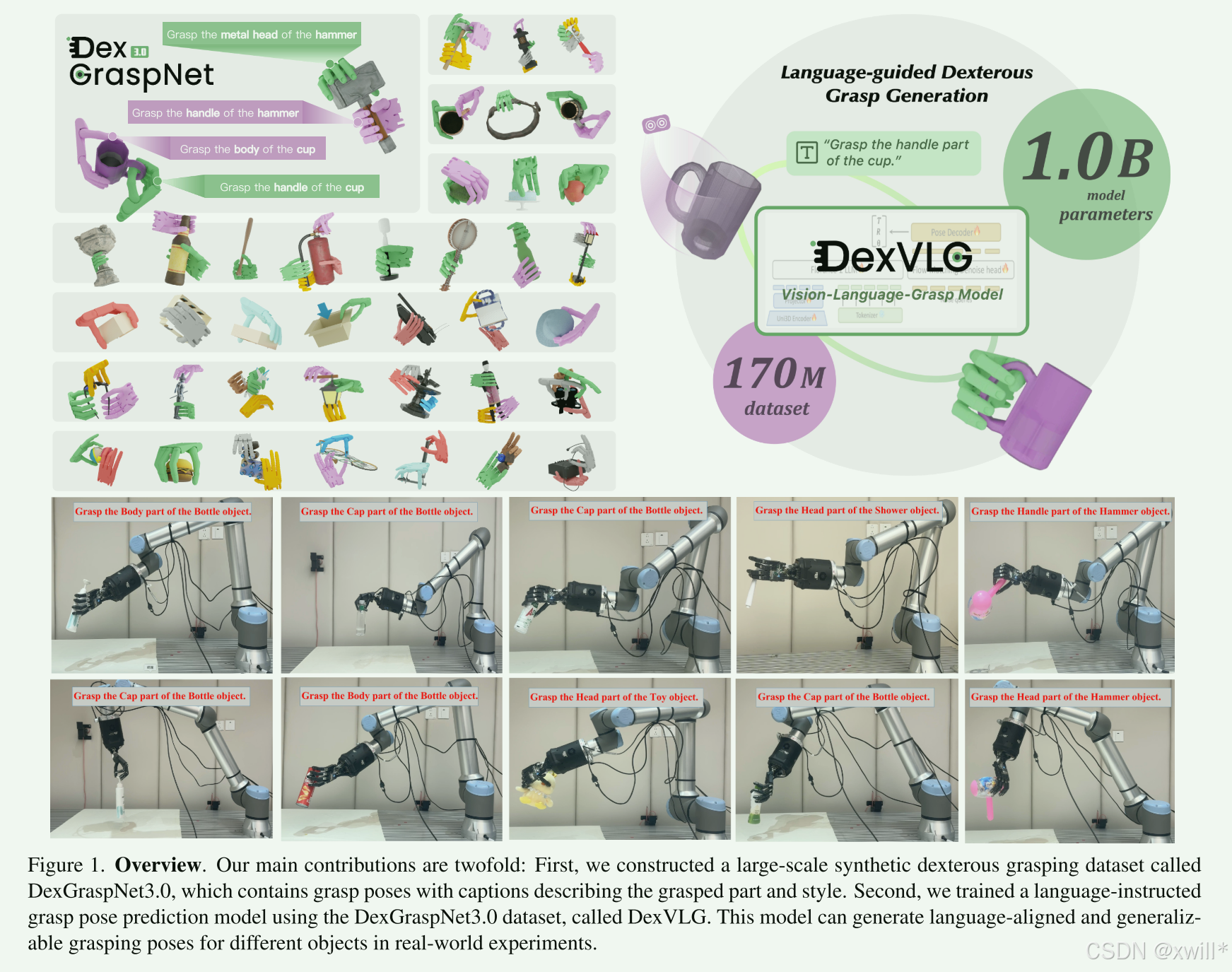
一:提出问题
随着大模型的兴起,视觉-语言-动作(VLA)系统让机器人能处理更复杂的任务。而现阶段的研究有以下的问题:数据难收集: 导致目前的研究主要局限于控制简单的"二指夹爪"(simple gripper)。研究缺失: 很少有研究关注如何利用大模型来控制"类人灵巧手"(dexterous hands)进行功能性抓取(即针对特定功能的抓取,而非随便抓起来)
现有的大型视觉-语言-动作模型在复杂任务中表现出色,主要归功于十亿级的参数量 和十亿级的训练数据 。这些模型目前主要局限于控制平行夹爪 ,无法控制灵巧手 。 其根本原因是缺乏适用于灵巧抓取的大规模数据。
本文提出了一个新的模型DexVLG (Method),这是一个大型的视觉-语言-抓取模型(Vision-Language-Grasp model)。其输入由单视角 RGBD 图像和语言指令构成。输出是一个灵巧抓取的姿态。模型的核心架构由两部分组成,分别是:
-
VLM(视觉语言模型): 处理视觉和文本信息。
-
基于流匹配的姿态头(Flow-matching-based pose head): 负责生成具体的抓取姿态。
能够根据语言指令,预测出与之对齐的抓取姿态(即你说"抓杯柄",它就生成抓杯柄的姿态)。
为了训练DexVLG (Method) 。本文构建了一个大规模的数据集DexGraspNet 3.0 (Dataset) 。包含 1.7 亿(170 million)个灵巧抓取姿态, 覆盖仿真环境中的 17.4 万(174,000)个物体。语义映射: 抓取姿态映射到了物体的具体语义部件上。文本配对: 配有详细的部件级描述。
作者提出了两个解决方案:
一:DexGraspNet 3.0 数据集 (Dataset)
为了解决数据短缺问题,作者提出了 DexGraspNet 3.0:
部件感知与功能性: 引入了"部件感知能量"(part-aware energies)来区分语义。
物理验证: 每个姿态都在物理仿真中验证过。
文本标注: 包含抓取部件名称和风格的描述(Captions)。
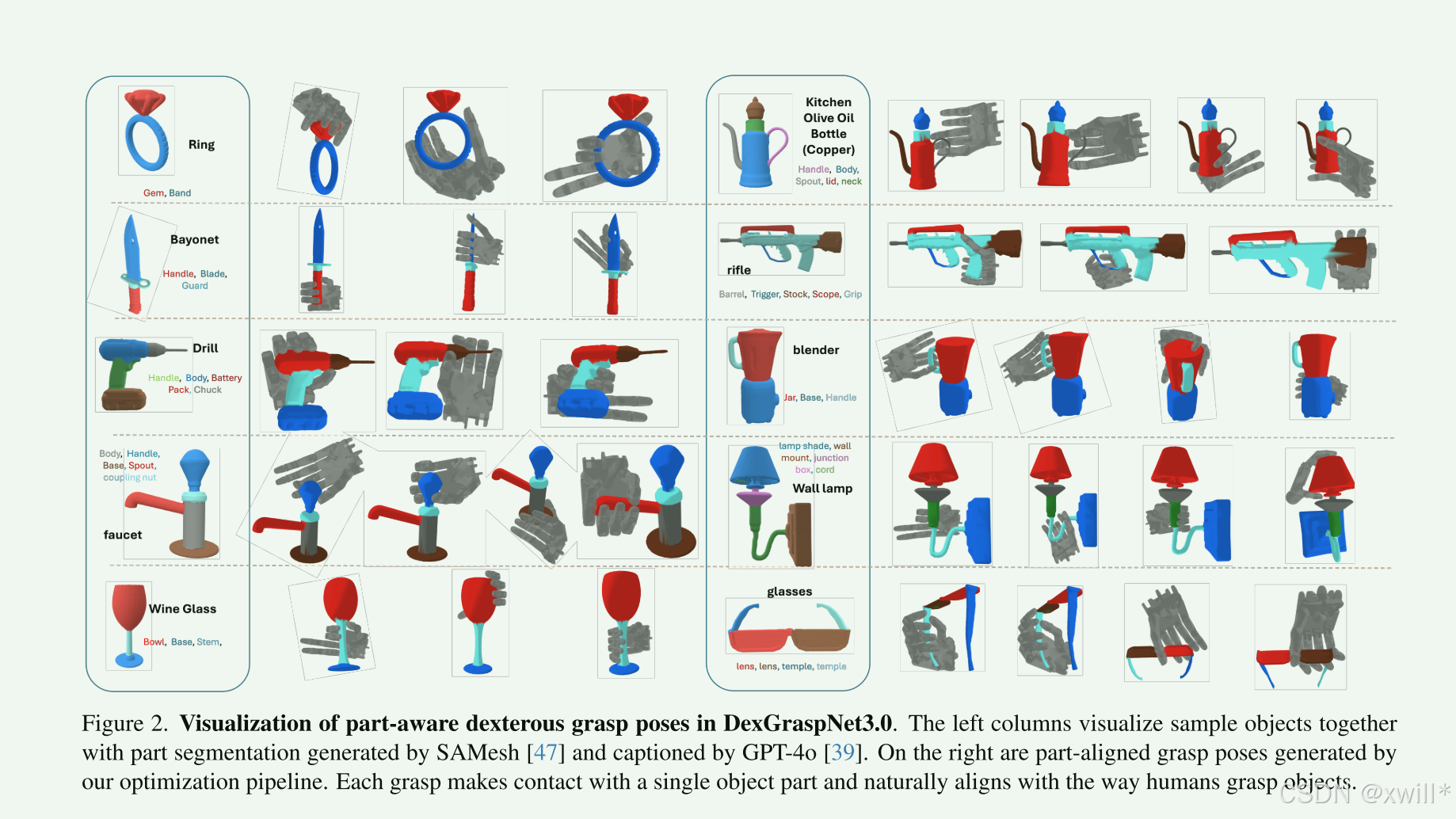
沿用了 DexGraspNet 的合成方法,并结合了 SAMesh 和 GPT-4o 进行部件分割和文本生成。
二:DexVLG 模型 (Model)
基于上述数据集,作者开发了 DexVLG 模型:
输入: 语言指令 + 桌面物体的单视角彩色点云。
架构:
利用预训练的基础模型提取特征。
采用**流匹配(flow-matching)**去噪范式预测姿态。
拥有数十亿参数,并进行端到端微调。
输出: 根据指令生成的灵巧抓取姿态。
二:解决方案

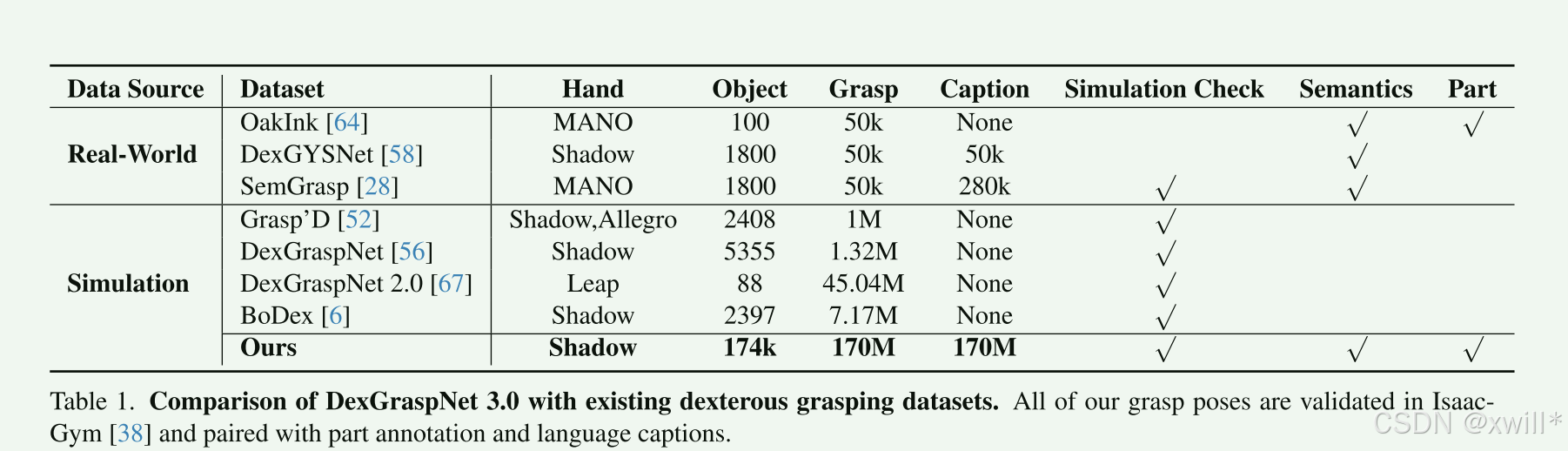
表 1 总结了 DexGraspNet 3.0 数据集的关键特征。DexGraspNet 3.0 包含跨越 17.4 万个物体的 1.7 亿个灵巧抓取,使其成为迄今为止在抓取姿态数量和物体数量上最大的灵巧抓取数据集 。每个抓取都使用基于物理的模拟器 IsaacGym 38 进行了验证,并配有语义说明(captions)和部件级标注**,产生了 1.7 亿个用于训练 VLG 模型的"姿态-说明"对**。数据集的可视化如图 2 所示。
**数据集包含1.7 亿抓取姿态,17.4 万个物体。**是目前规模最大。每个样本包含"抓取姿态"和对应的"文本说明"(pose-caption pairs)。所有抓取都在 IsaacGym 物理仿真中验证过成功率。
物体处理流程:
-
来源与过滤: 选自 Objaverse,用 GPT-4o 过滤掉不好的物体。
-
网格处理: 使用 ManifoldPlus 和 CoACD 生成碰撞网格(Collision meshes),这是物理仿真必需的。
-
尺寸归一化: 用 GPT-4o 估算物体真实尺寸并归一化。
-
部件分割: 使用 SAMesh 模型进行几何分割(即使没有颜色也能分)。
-
部件标注: 渲染多视角图像,用 GPT-4o 结合 Set-of-Mark 技术自动给部件起名(Labeling)。
抓取生成方法:基于现有的解析方法和 cuRobo,利用 GPU 并行加速。为了实现"部件感知"(即想抓哪就抓哪),作者修改了原来的流程,引入了特定的初始化策略和能量函数。
初始化策略:基于梯度的优化方法非常依赖"初始值"(Initial pose)。原来的方法是针对整个物体的,不适合针对特定部件。首先,先计算目标部件的有向边界框(OBB) 。然后在部件表面采样点。通过基于规则设定初始姿态: 根据 OBB 的几何特征,设定手掌位置和关节角度。通过添加随机抖动: 增加随机性以保证数据的多样性。
1 DexGraspNet 3.0 Dataset
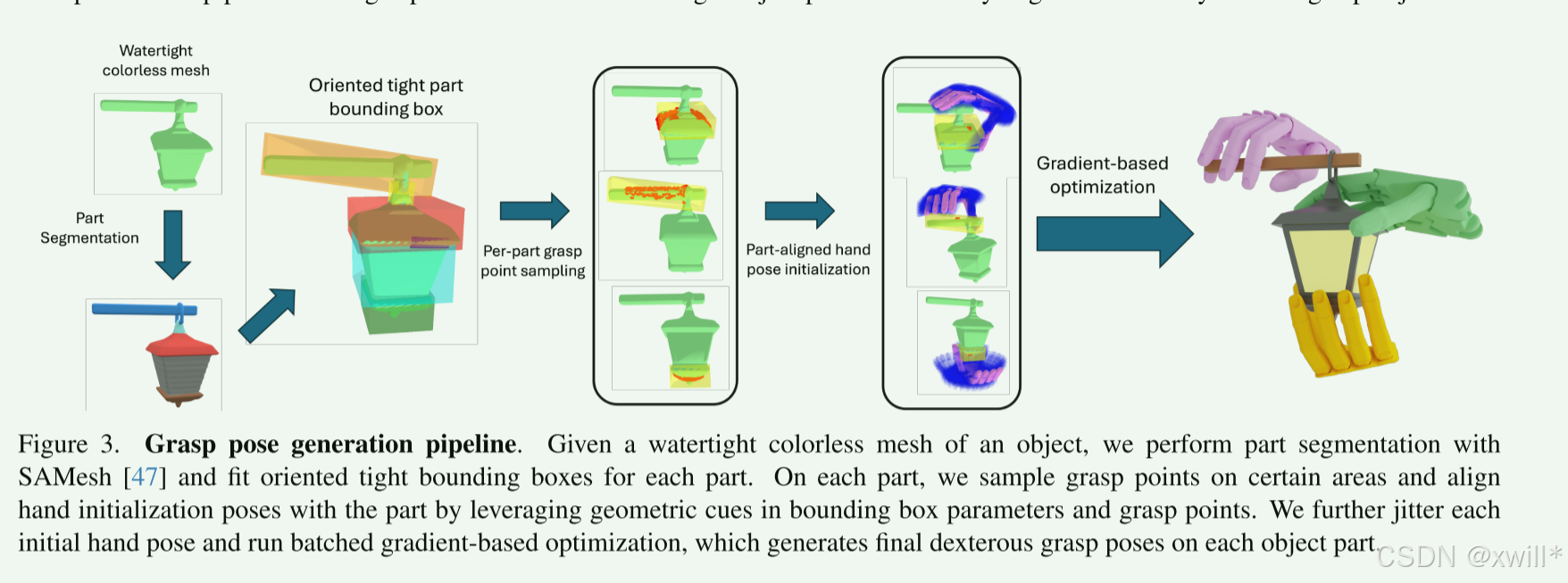
1 优化Q目标函数 (Optimization Objectives)
了让初始生成的抓取姿态更合理、更稳定,作者定义了一个总能量函数 E进行优化,包含四个部分:
EFC **(力封闭能量):**保证抓得稳(Grasp quality)。采用基于线性规划(LP)的方法。相比传统方法,它不要求接触力相等(更灵活),且假设无摩擦(避免了复杂的二次规划计算,速度更快)。
Ebar (部件接触能量): 强制手只抓"指定的部件",别碰其他地方。使用势垒函数(Barrier function)。如果手指碰到了非目标部件区域,能量值会激增至无穷大,从而迫使优化算法避开这些区域。
Edis (距离能量): 调整手与物体的距离。让指尖贴近物体(确保接触),同时让手掌保持约 1cm 的距离(避免贴太死或太远)。
Ereg **(正则化能量):**防止物理上不可能的情况。避免手穿入物体内部、避免手指互穿、引导用手指内侧(正面)接触物体。
2. 抓取验证标准 (Validation Criteria)
优化后的姿态必须经过 IsaacGym 物理仿真验证,只有同时满足以下 4 点才会被收入数据集:
-
穿透检查: 手与物体穿透 < 3mm(稍微穿透一点是允许的,模拟软接触,但不能太多)。
-
自穿透检查: 手指自己不能穿插自己 (< 3mm)。
-
稳定性检查: 物体在重力作用下,从 6 个方向(上下前后左右)都不会掉落。
-
部件对齐检查: 这是关键点。 确认真正接触物体的手部部位,确实是离"目标部件"最近的,而不是离其他部件更近(防止名为抓杯柄,实则抓杯身)。
3. 说明文字生成 (Captioning)
基于模板填充的方法。模板: "Grasp the {part} of the {object} object, with contacts on {fingers}"。部件名和物体名来自 GPT-4o,手指接触信息来自仿真检测。
4. 桌面场景生成 (Scene Generation)
之前的抓取都是物体悬浮在空中的,不符合现实(现实中物体在桌上)。因此本文采用以下的方式来解决这个问题:
-
物理掉落模拟: 让物体从空中掉落到桌面上,模拟 5 秒,看它怎么停稳。
-
去重: 收集 1000 种掉落姿态并去重。
-
过滤: 把之前的抓取姿态应用到这些桌上的物体上。如果手撞到了桌子,这个抓取就废弃。
-
渲染: 使用 Blender 模拟 RealSense D415 相机,从 8 个角度拍摄 RGBD 图像,作为模型的视觉输入数据。
2 DexVLG Model
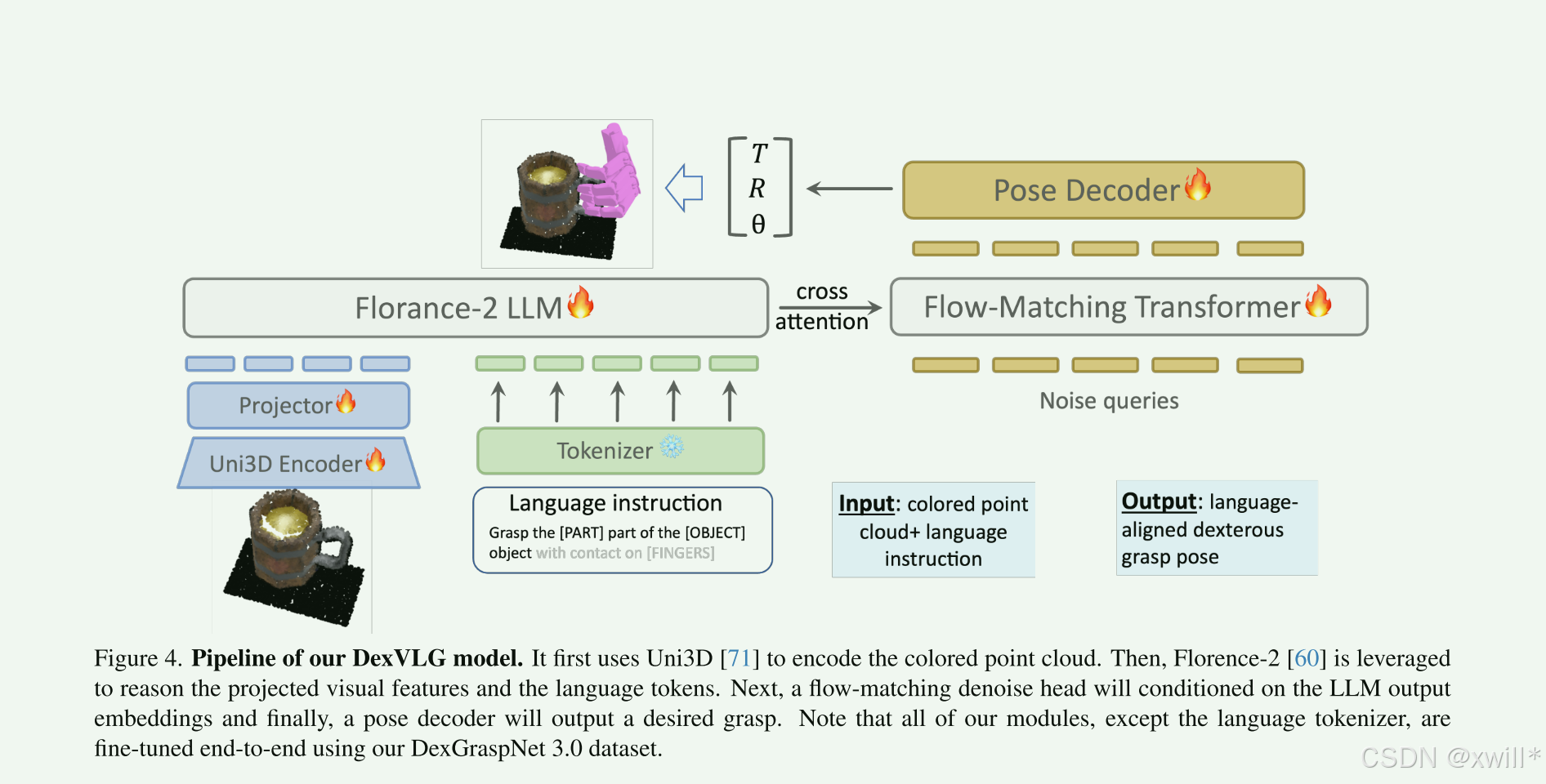
DexVLG 接收单视角点云观测和语言指令作为输入,并输出满足语言指令要求的抓取姿态。
1. 视觉模块:点云编码器
模型主要以点云信息(注意这里的单视角彩色点云包含有集合坐标和颜色信息(RGB))作为输入,因此选用Uni3D模型来处理点云信息 ,而DexVLG 的基座是基于 ViT,提供了不同参数规模的版本(Small 到 Large)。
**单视角彩色点云 (Single-view colored point cloud):**模型不仅仅接受几何坐标(XYZ),还包含颜色信息(RGB)。
单视角意味着模型只能看到物体的一面(就像人坐在桌子对面看东西一样),看不到物体的背面。这对模型的推理能力要求更高,因为它需要根据看到的局部推测整体结构。
彩色信息对于"语义理解"非常重要(例如指令是"抓取红色的手柄",如果没有颜色信息,模型就无法区分)。
点云的处理流程:
采样: 输入的点云会被预处理,使用最远点采样(Furthest Point Sampling) 算法,固定采样为 10,000 个点。
编码: 这些点云随后进入 Uni3D 编码器提取特征。
因为Uni3D 经过了预训练 ,并且通过对比学习与 CLIP 特征对齐。这意味着它不仅能理解几何形状,还能理解"语义"(比如知道这是个杯子,那是手柄),这对于处理语言指令至关重要。
预处理: 使用"最远点采样"技术(也就是先随机找一个点,然后再找这个点最远的地方的点,然后再找两个都最远的点,一次找到需要的点数 )。将点云数量统一固定为 10,000 个点。使用了一个 MLP 投影层(MLP projector),把提取出的 3D 特征转换到和 LLM(大语言模型)能理解的同一特征空间里。
CLIP 特征对齐"就是给冷冰冰的 3D 几何数据装上了"能看懂图、读懂字"的翻译器。
1. 什么是 CLIP?(打通"图"与"文")
CLIP 是 OpenAI 开发的一个非常著名的模型。它的核心能力是把图像 和文本映射到同一个数学空间里。
以前的模型: 看到一张猫的图,只是识别出"这是猫(类别 ID: 001)"。
CLIP 的做法: 它学习到,一张"猫的照片"产生的特征向量,和文字"一只猫"产生的特征向量,是非常相似的(距离很近)。
CLIP 建立了一个"通用的语义空间",在这个空间里,图和文是可以互相匹配的。
2. 什么是 Uni3D 的"特征对齐"?(打通"3D"与"CLIP")
论文中提到的 Uni3D 是一个处理 3D 点云的模型。3D 点云只是一堆坐标点(XYZ),它知道物体的形状(圆的、扁的),但不知道这叫"杯子"还是"碗"。
- 对齐的过程: Uni3D 在训练时,通过对比学习,强制让**"一个 3D 杯子的点云特征"** ,尽可能去靠近**"CLIP 里的 2D 杯子图片特征"**(进而也靠近了文字"杯子")。
这就是"对齐"。Uni3D 学会了用 CLIP 的"语言"来描述 3D 物体。
3.在 DexVLG 这篇论文里有什么用?
这对于 DexVLG 能够听懂指令 至关重要:你输入文字指令:"抓那个红色的马克杯手柄"。
CLIP 空间: 大语言模型(LLM)理解了"红色"、"马克杯"、"手柄"这些词,并在特征空间里找到了对应的位置。
Uni3D 的作用: 因为 Uni3D 已经和 CLIP 对齐了,当它看到桌面上的一堆 3D 点云时,它能迅速定位出哪一团点云的特征符合"红色马克杯手柄"的描述。
即使模型以前从未见过这个具体的杯子,只要它在 CLIP 的知识库里(CLIP 见过类似的图或文),Uni3D 就能认出它,并引导手去抓。
- 语言模块:基础模型选用 Florence-2 (包含 Base 和 Large 两个版本)。** 将"视觉特征"(来自上面的 PC Encoder)和"语言嵌入"直接拼接 (Concatenate)在一起,作为 LLM 的整体输入。借鉴了 Transfusion 和 π0 两个模型的设计 ,让 LLM 与负责预测抓取的"姿态头"共享交叉注意力(Cross-attention)。这意味着语言模型在处理信息时,会直接影响抓取姿态的生成过程。
3.生成模块:基于流匹配的姿态头。流匹配(Flow Matching)是一种生成式模型技术(类似于扩散模型,但路径更直),通过去噪过程来生成数据。通过最小化均方误差来训练模型。

X0是噪声,X1是真实的正确抓取姿态。模型学习在这个过程中如何从噪声插值逐步变化到真实姿态。生成过程是条件化 的(Conditioned),依赖于 LLM 输出的隐藏状态。也就是说,生成的姿态是严格受前面的视觉和语言信息控制的。
使用一个 MLP 解码器,输出具体数值:手腕的平移(Translation)。手腕的旋转(Rotation)。每个手指的关节角度(Joint angles)。
再复习一遍流匹配:
流匹配(Flow Matching) 是一种目前非常前沿的生成模型技术。在 DexVLG 这篇论文里,它的作用是把"一堆随机乱动的数字"变成"一个精准的抓取姿态"。
1. 核心概念:从"混沌"到"秩序"
起点(噪声 X0**):** 一开始,模型的猜测是完全随机的。这就好比草原上散落着一群羊(随机的关节角度、手腕位置),乱七八糟,根本不是一个抓取姿态。
终点(目标 X1**):**我们希望得到的一个完美的抓取姿态。好比羊圈,羊进去后排列得整整齐齐。
流(Flow): 就是羊群从草原跑到羊圈的轨迹。
2. 流匹配是在做什么?
传统的生成模型(比如扩散模型 Diffusion)像是一个醉汉,跌跌撞撞地把羊赶回去(去噪过程很曲折)。流匹配 则试图找到一条最直、最快、最顺滑的路径。
定义速度场(Velocity Field): 模型通过学习,给草原上的每一个位置都设定了一个"风向标"。
训练过程: 模型看着成千上万个成功的抓取案例,学习一种规律:"如果手现在的姿态是张开的(在A点),目标是抓杯柄(在B点),那每一个手指关节应该往哪个方向移动、移动多快,才能走直线到达 B 点?"
匹配(Matching): 所谓的"匹配",就是让模型生成的这个"风向" ,尽可能去拟合那些能让羊群走直线的理想风向。
3. 在 DexVLG 里的具体表现
在论文中,这个过程是这样的:
**输入:**视觉看到的杯子 + 文字指令"抓杯柄"。*初始状态是一个随机生成的、毫无意义的手部姿态(噪声)。
流匹配过程:
模型根据"条件",计算出一个"流"(变化趋势)。
它告诉那个随机的手:"大拇指往左移一点,食指弯曲一点,手腕向前推一点......"
随着时间步的推进(t从 0 到 1),这个随机的手部姿态就像流体一样,顺滑地变形、移动。
结果: 最终,"流"停止,那只原本随机的手,这就变成了紧紧握住杯柄的姿态。
总的来说,流匹配 就是一种**"导航技术"** 。它不直接画出结果,而是告诉随机的初始数据:"往这个方向走,速度快一点,你就能变成完美的抓取姿态。" 它的优点是生成的质量高 ,且相比传统的扩散模型,它的路径更直,计算效率往往更高。
三:实验
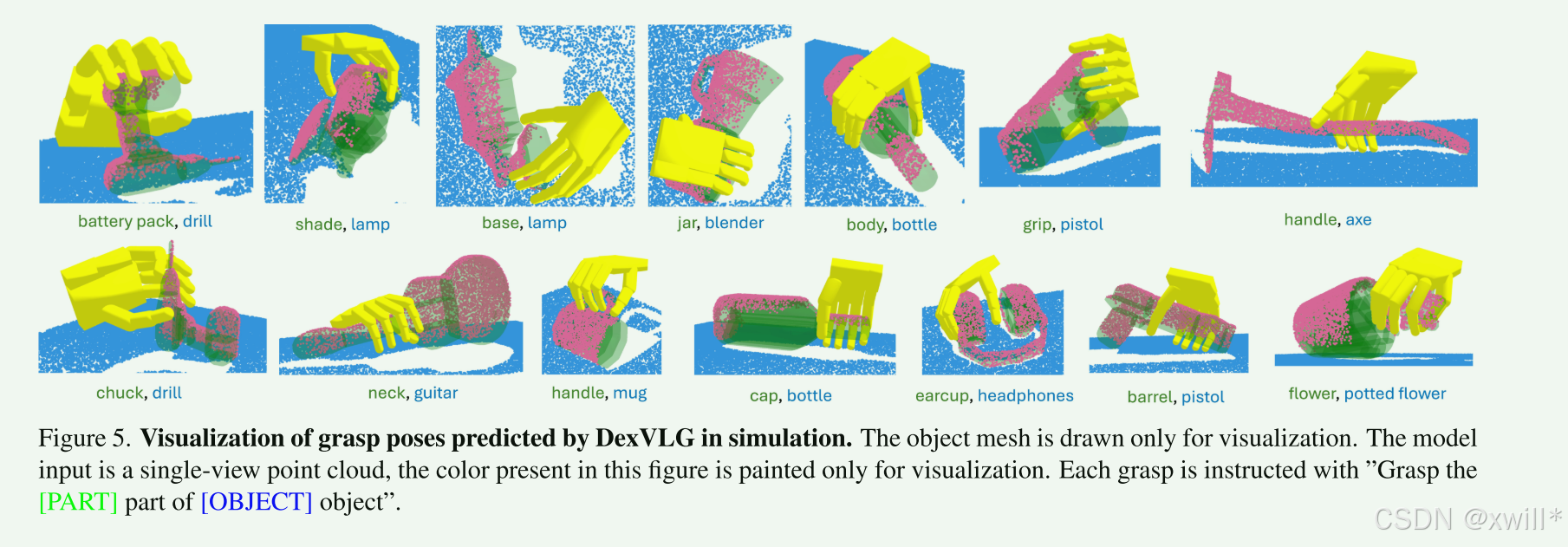
将 DexVLG 与基准模型进行对比评估,以回答以下问题:
- DexVLG 能否在各种物体和语义部件上 ,实现高质量灵巧抓取姿态的零样本生成?
- DexVLG 预测的抓取姿态与语言指令的对齐程度如何?
四:总结
本文提出了 DexVLG ,这是一个端到端的、与语言对齐的灵巧抓取生成模型,它利用了大型 VLM 的能力,并使用本文所合成的大规模 DexGraspNet 3.0 数据集进行训练。DexVLG 在仿真的抓取成功率和部件准确率方面均达到了最先进的性能,并且在真实世界中抓取简单物体时达到了 80% 的成功率。
尽管如此,作者承认目前的工作仍有几个局限性:
-
安全性问题 :由于 DexGraspNet 3.0 数据集中的训练姿态是使用悬浮手 合成的,没有考虑手-臂的工作空间,因此 DexVLG 采样的许多姿态在真实世界中执行是不安全的。
-
排序难题(模型生成了一堆候选抓取姿态,但很难从中挑选出"最好"的那一个) :作为另一个局限性,文中的方法不支持对生成的抓取姿态进行有效排序 。像文献 67 中那样通过似然分数 18 对大批量样本进行排序,对于基于 VLM 的模型来说是不可行的,因为保留关于 VLM 参数的梯度会消耗巨大的 GPU 显存。