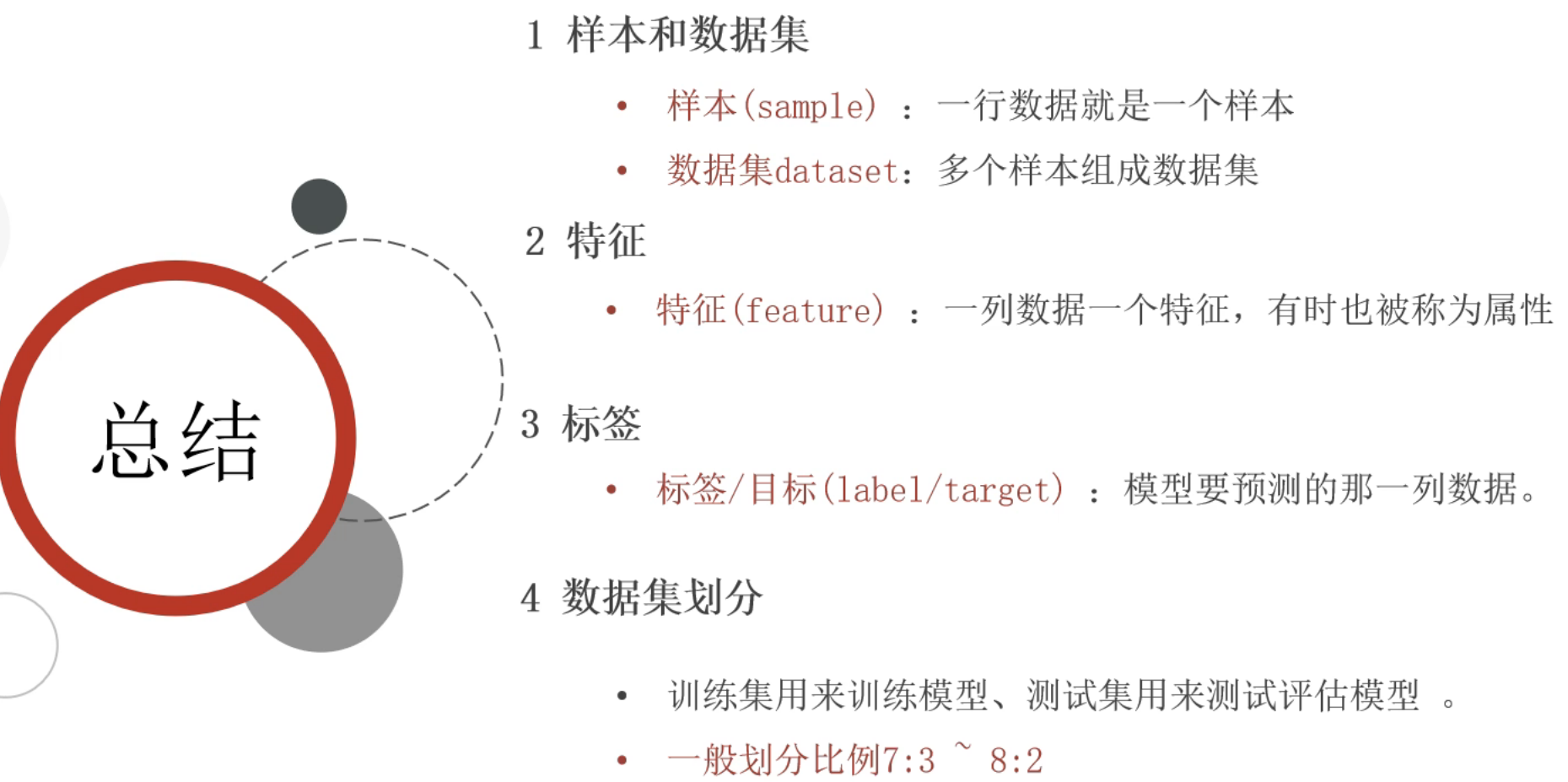
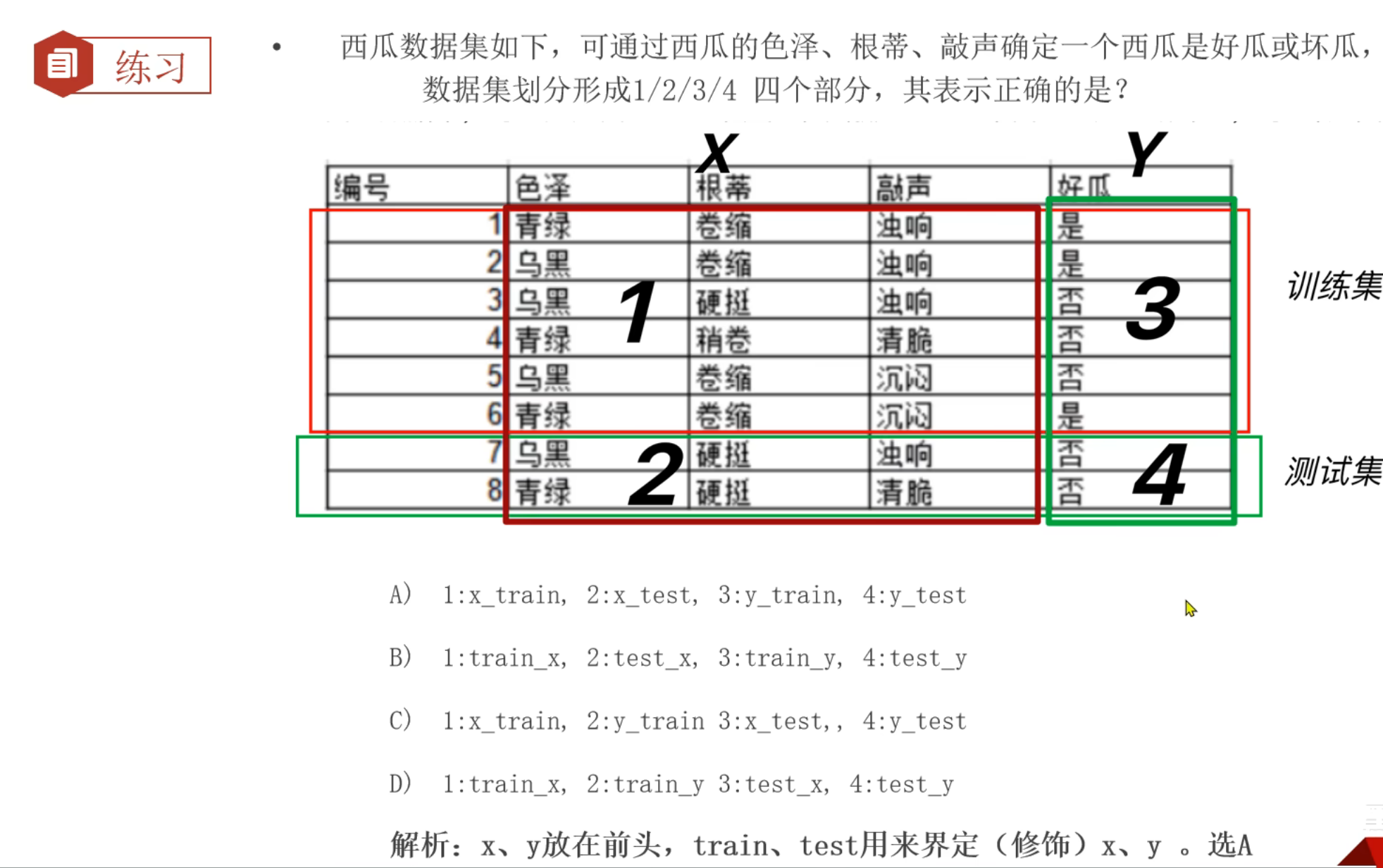
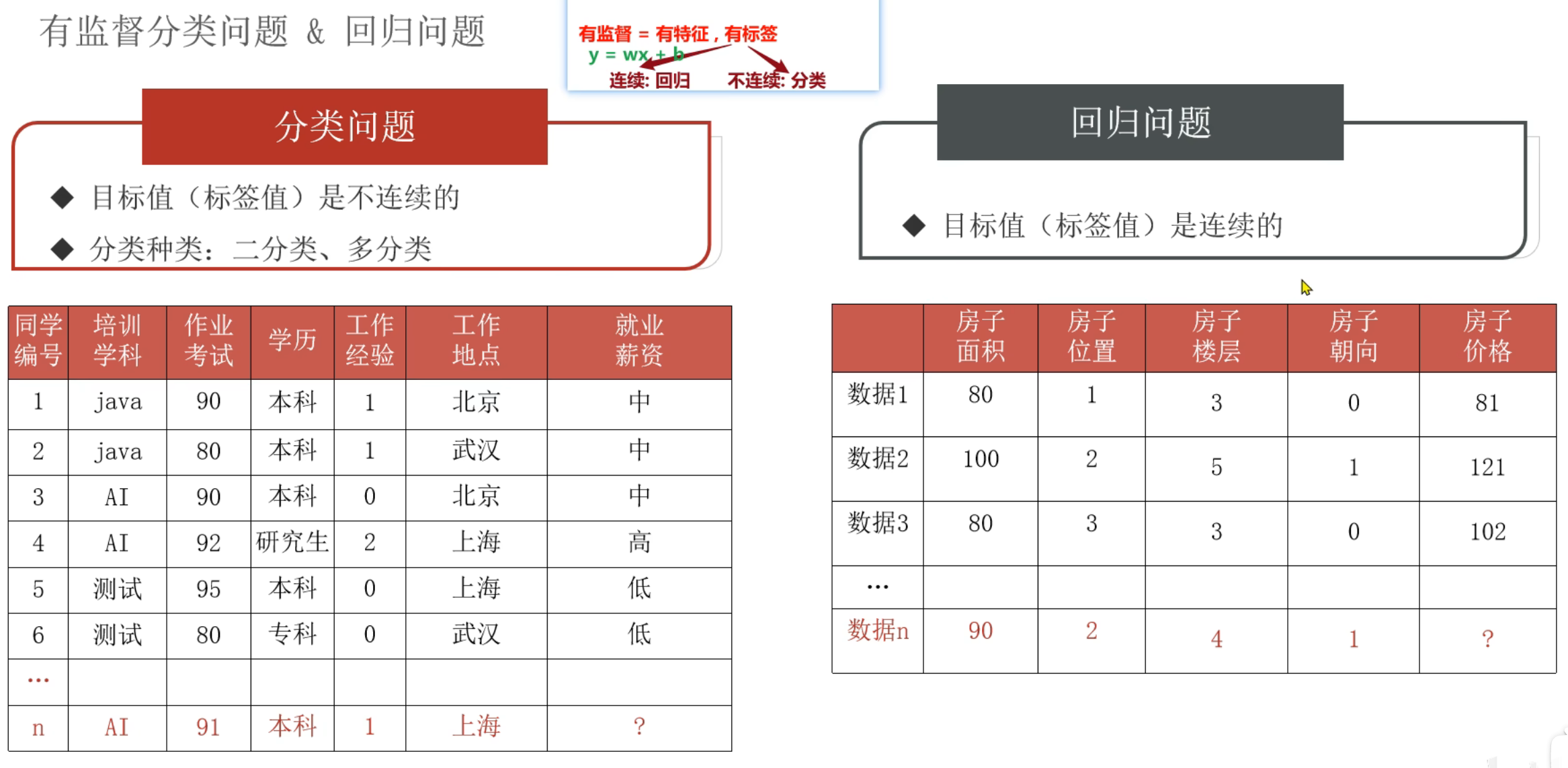
目录
[3、XGBoost API介绍](#3、XGBoost API介绍)
一、前言
这个课程我学习的时间还是比较长的,一是和比较早的期末考试撞上了,所以分心效率有点低。然后这个机器学习的课程的话,因为我确实没有看过其他的机器学习课程,所以评价可能不够全面。我个人感觉这个课程在数学推导方面讲的比较一般,很多算法的公式直接看当然看不懂,所以有很多口语化的解释很正常,但是老师确实一到数学就会混淆或者讲错一些小点。然后我感觉在数学基础知识的部分篇幅过长,而在比较复杂的推导感觉讲的有点乱,整体有点头重脚轻。但是这个老师一路跟过来,我认为代码水平和讲解都还是可以的,只能说培训班模式对于这种牵扯数学可能还是比不上纯讲代码吧
最后提醒一下,最后的项目案例是缺失了一部分视频的,不过有完整的项目代码。结合ai看懂还是可以的,然后评论区说机器学习还有向量机啥的知识点。我后面去网上找资源是有看到的(网上几块钱也能买到网盘资源),后续如果我学习就补充在这里面吧
二、机器学习概述
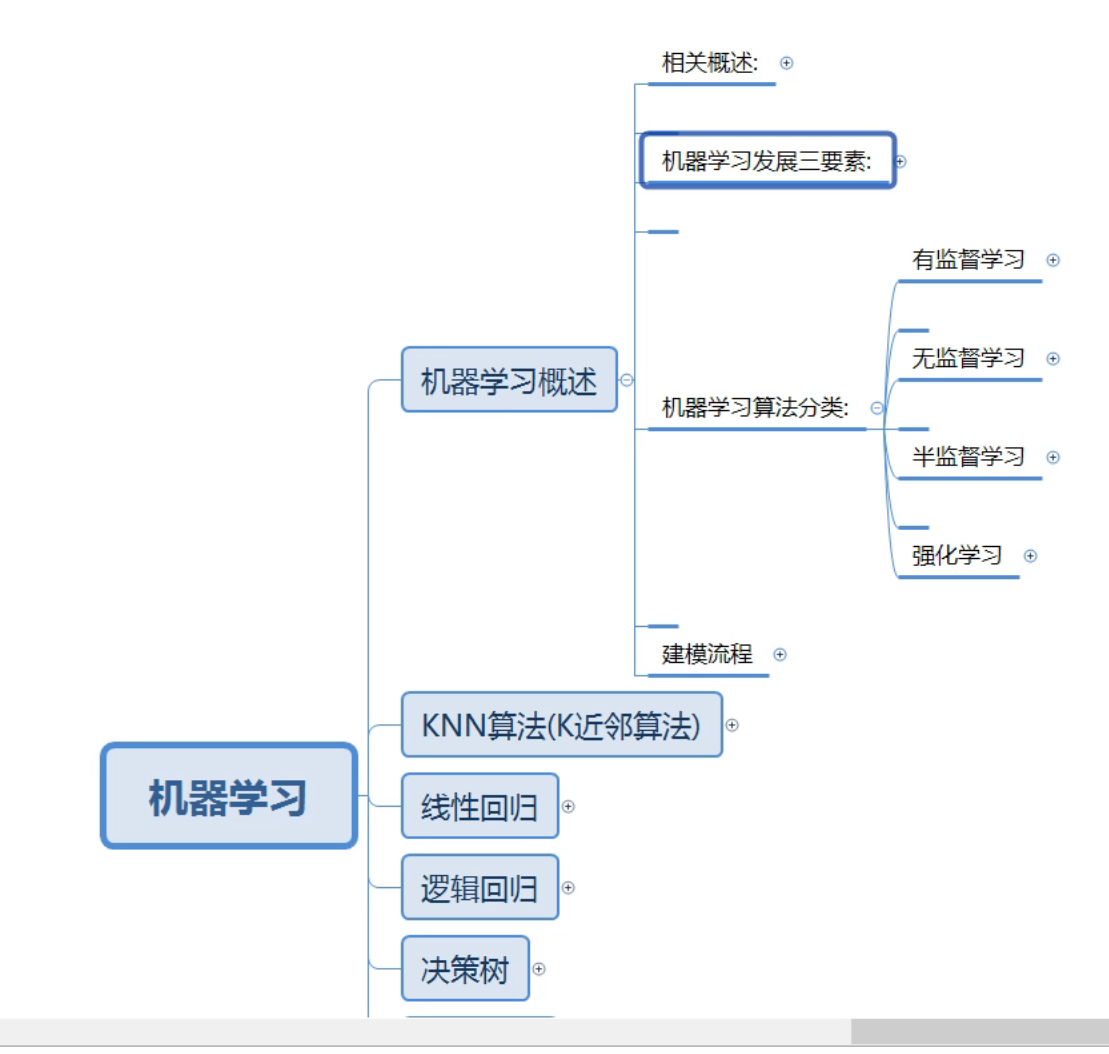
1、机器学习_大纲介绍
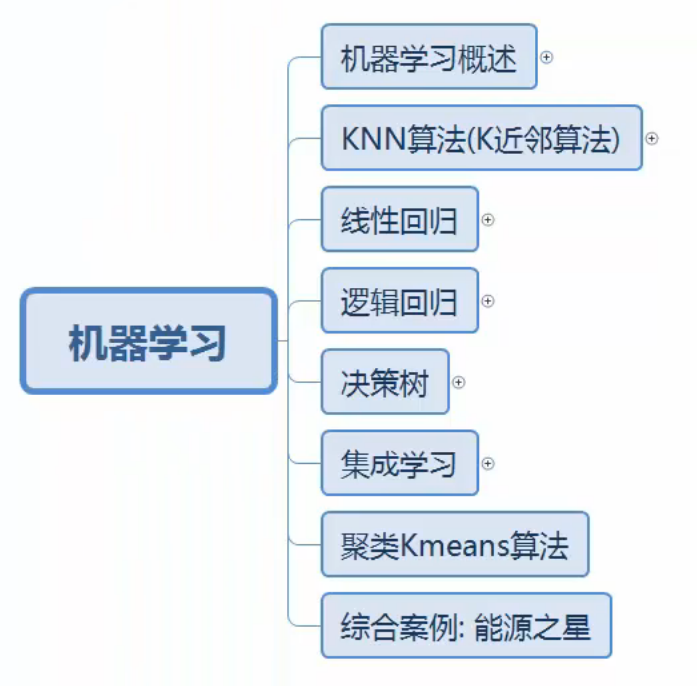
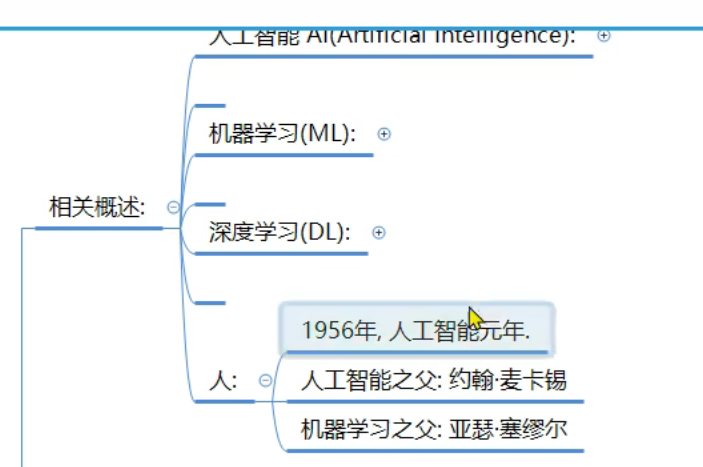
2、机器学习_相关概述目录介绍

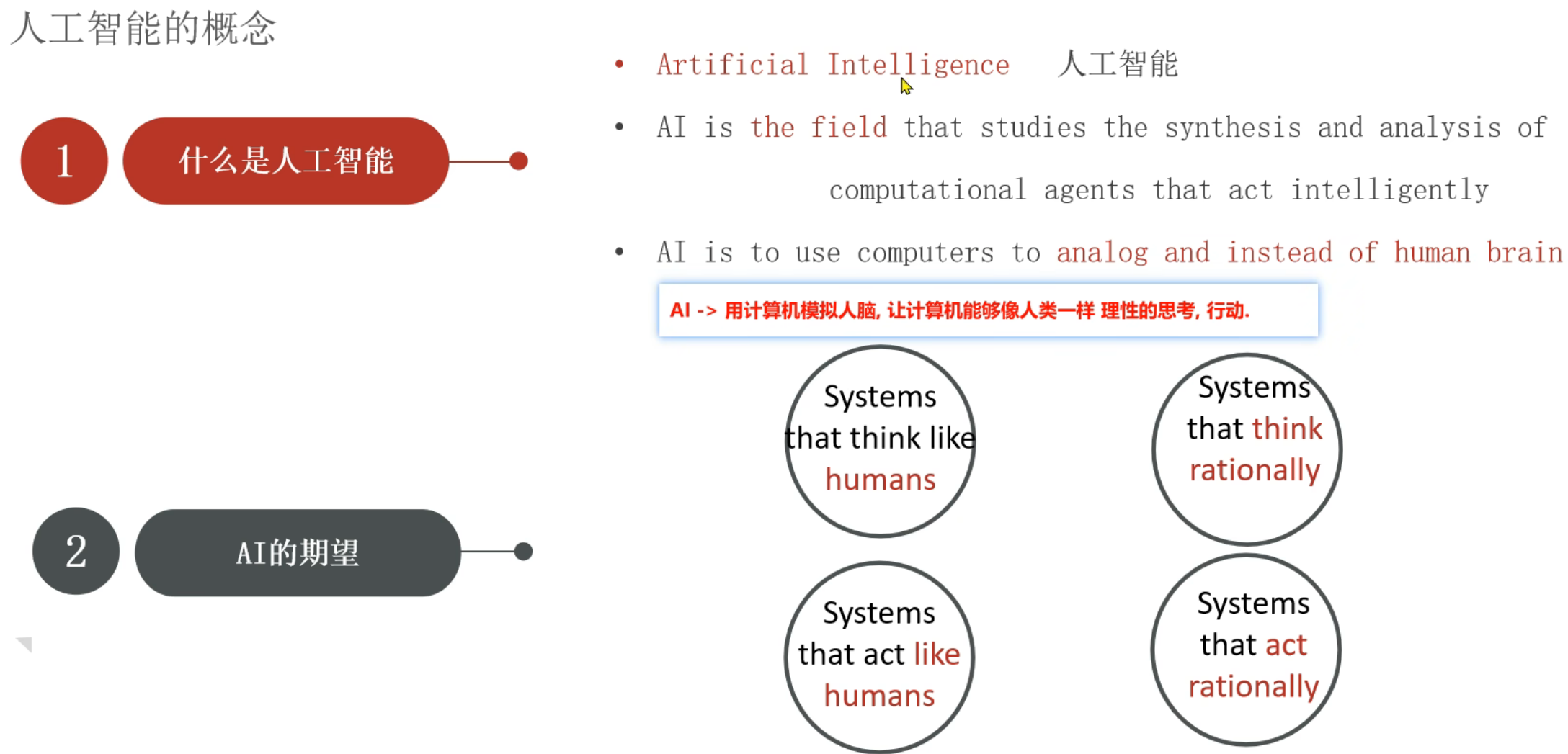
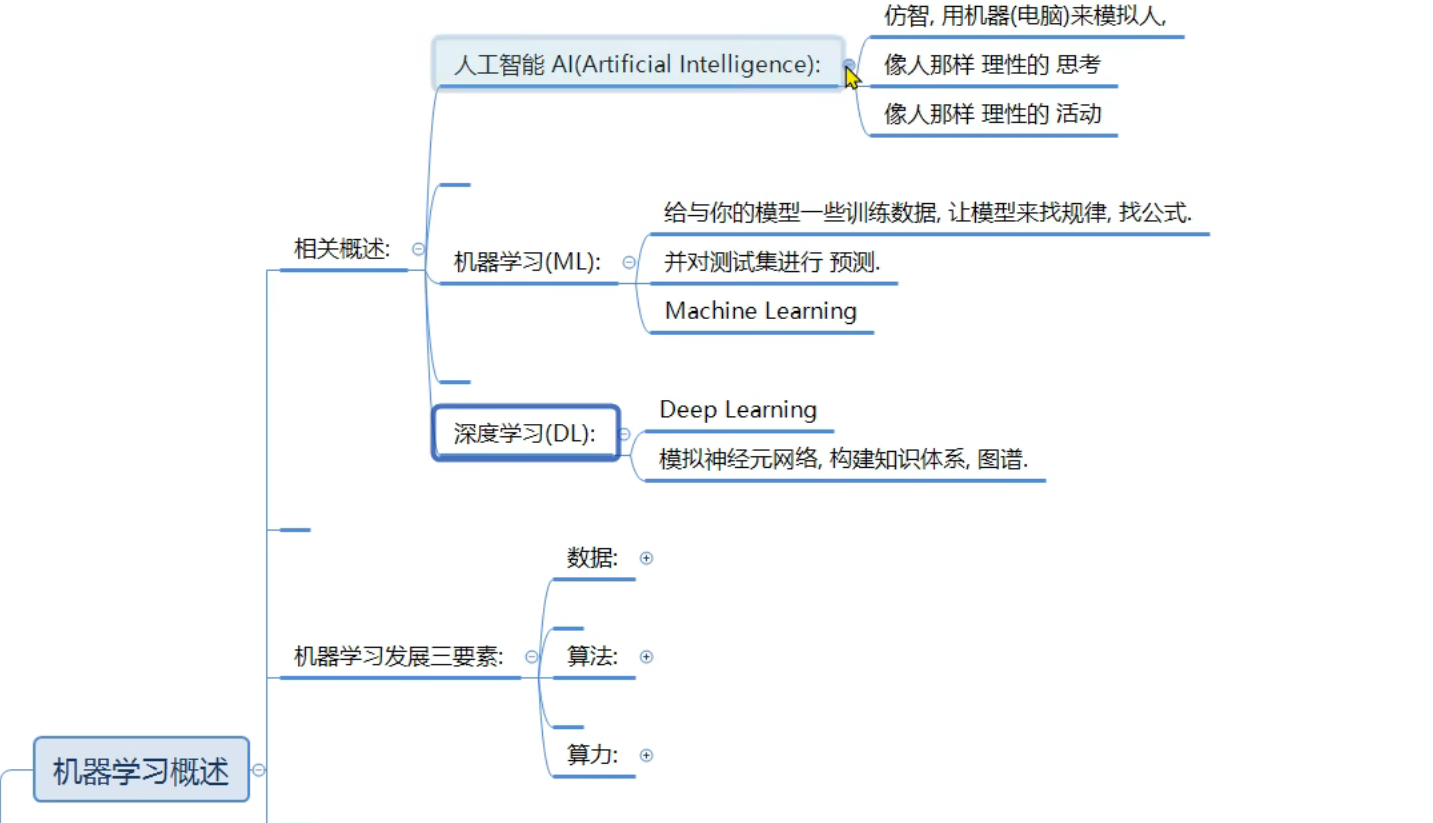
3、机器学习_AI_ML_DL介绍
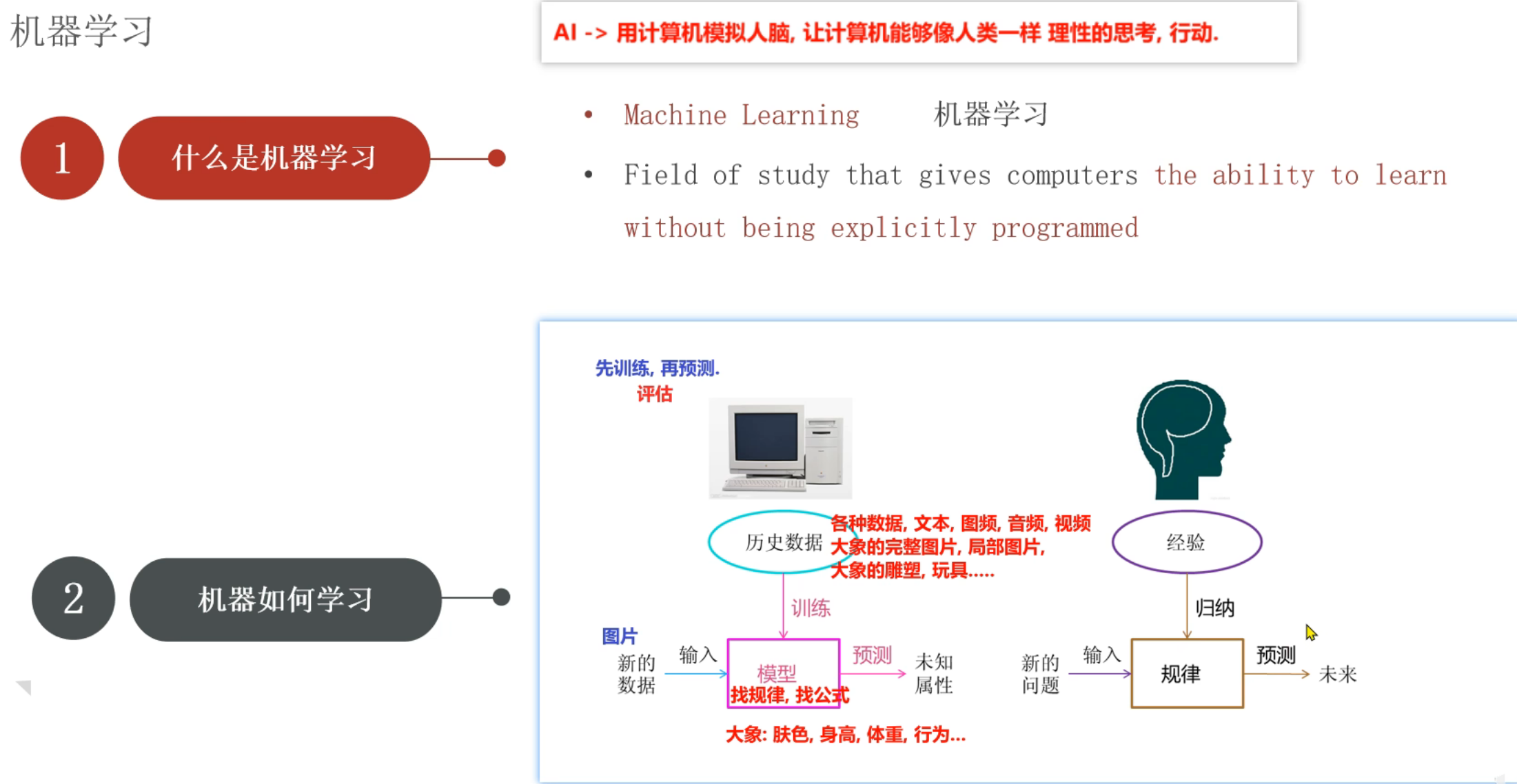
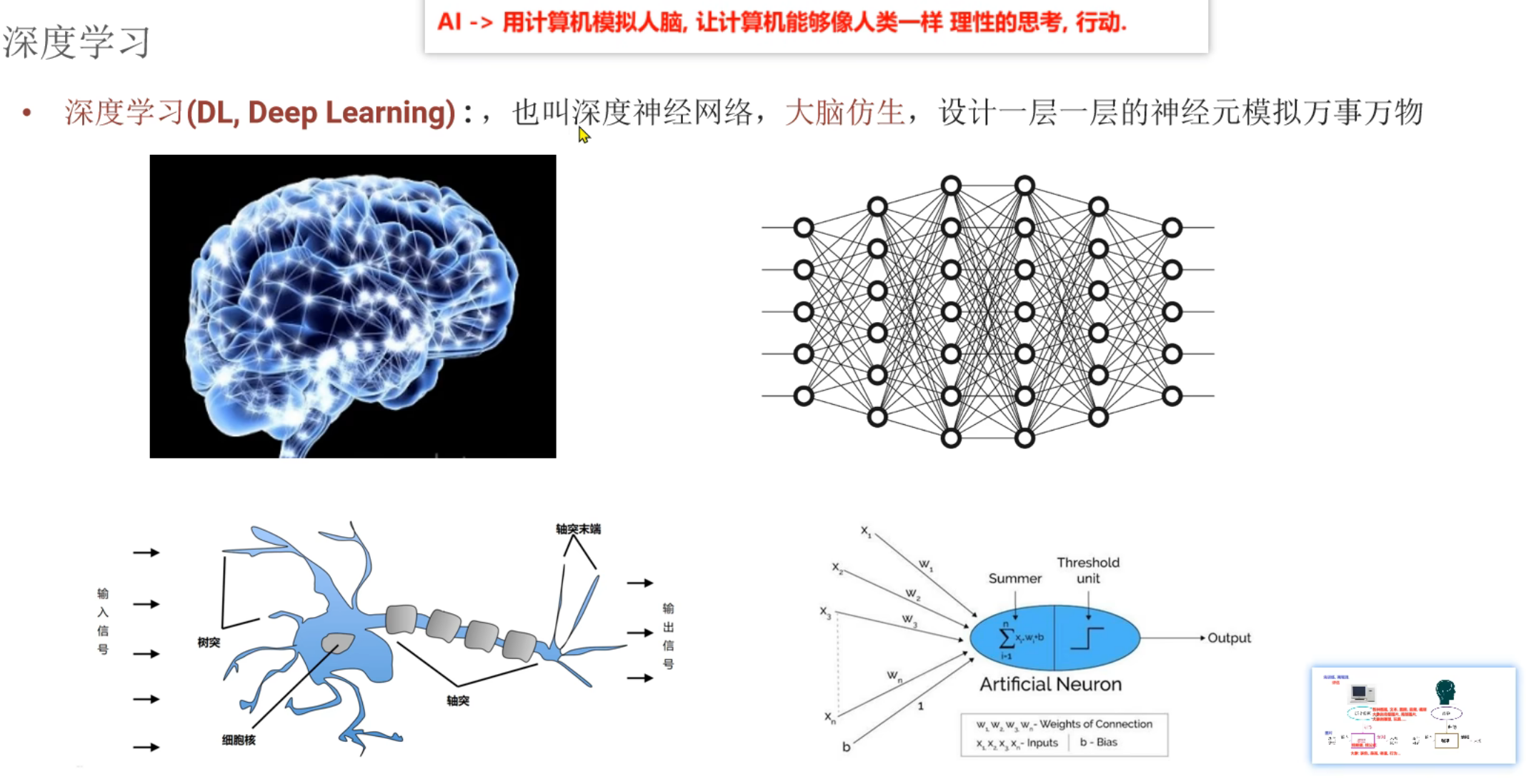


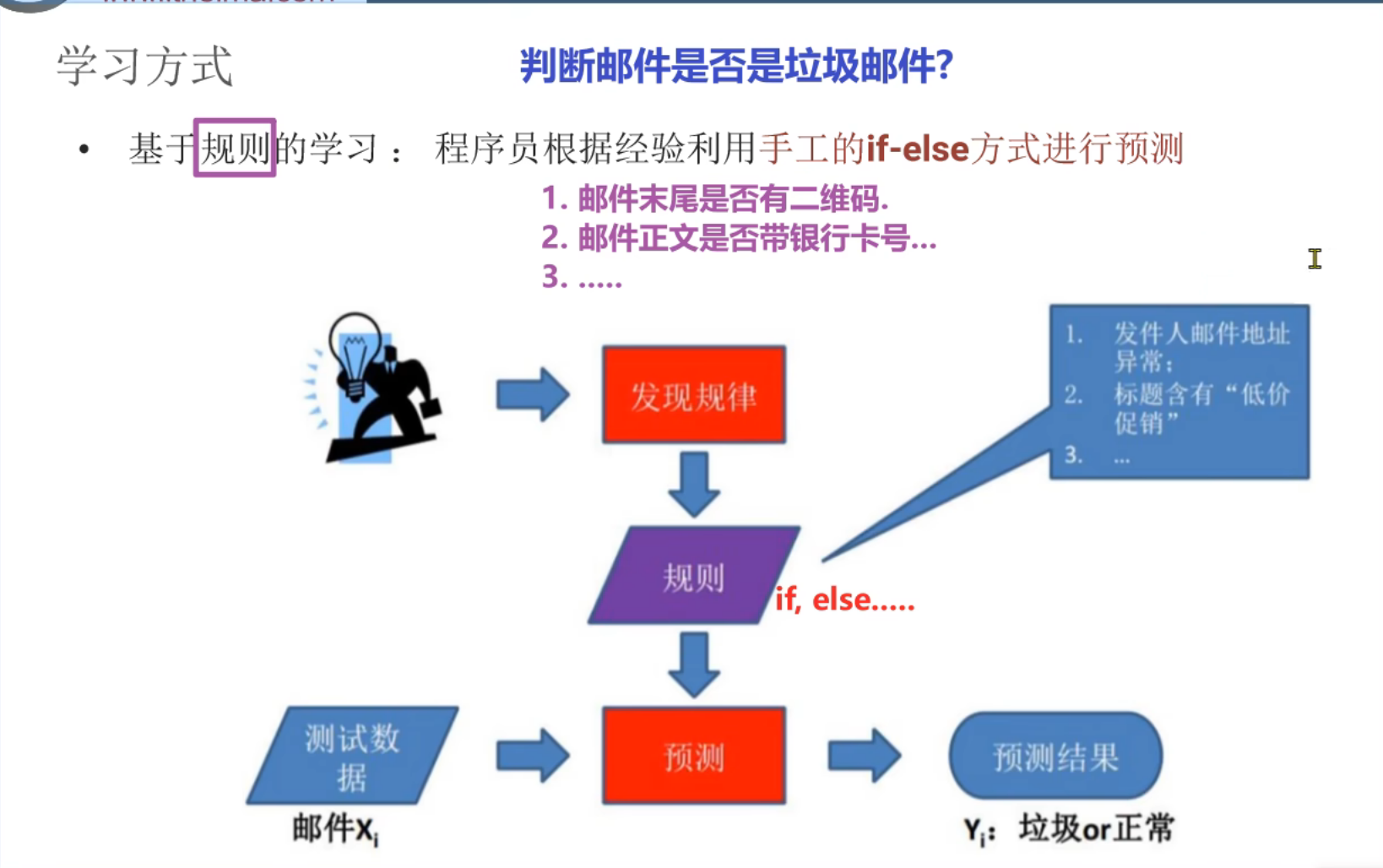
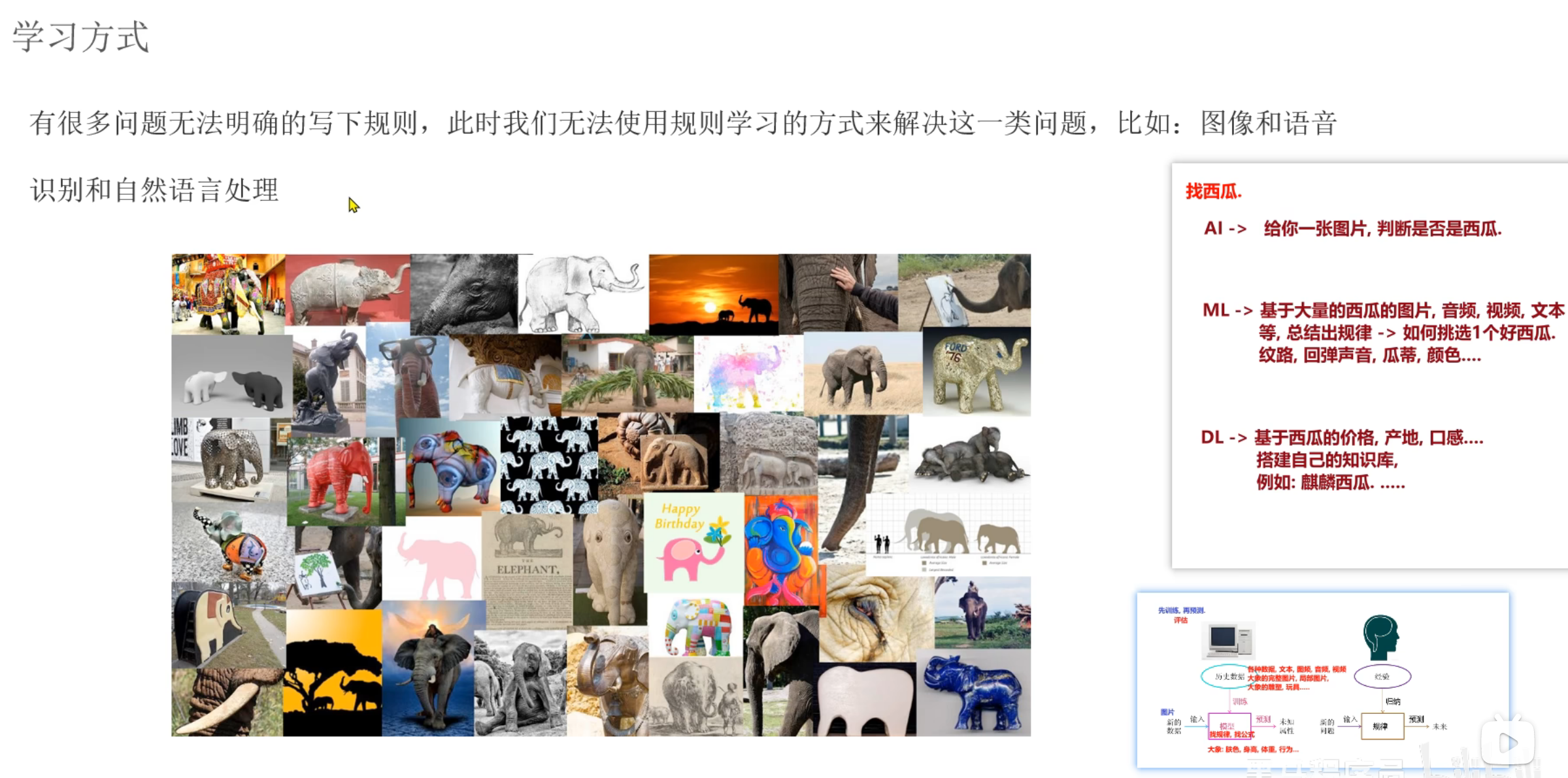
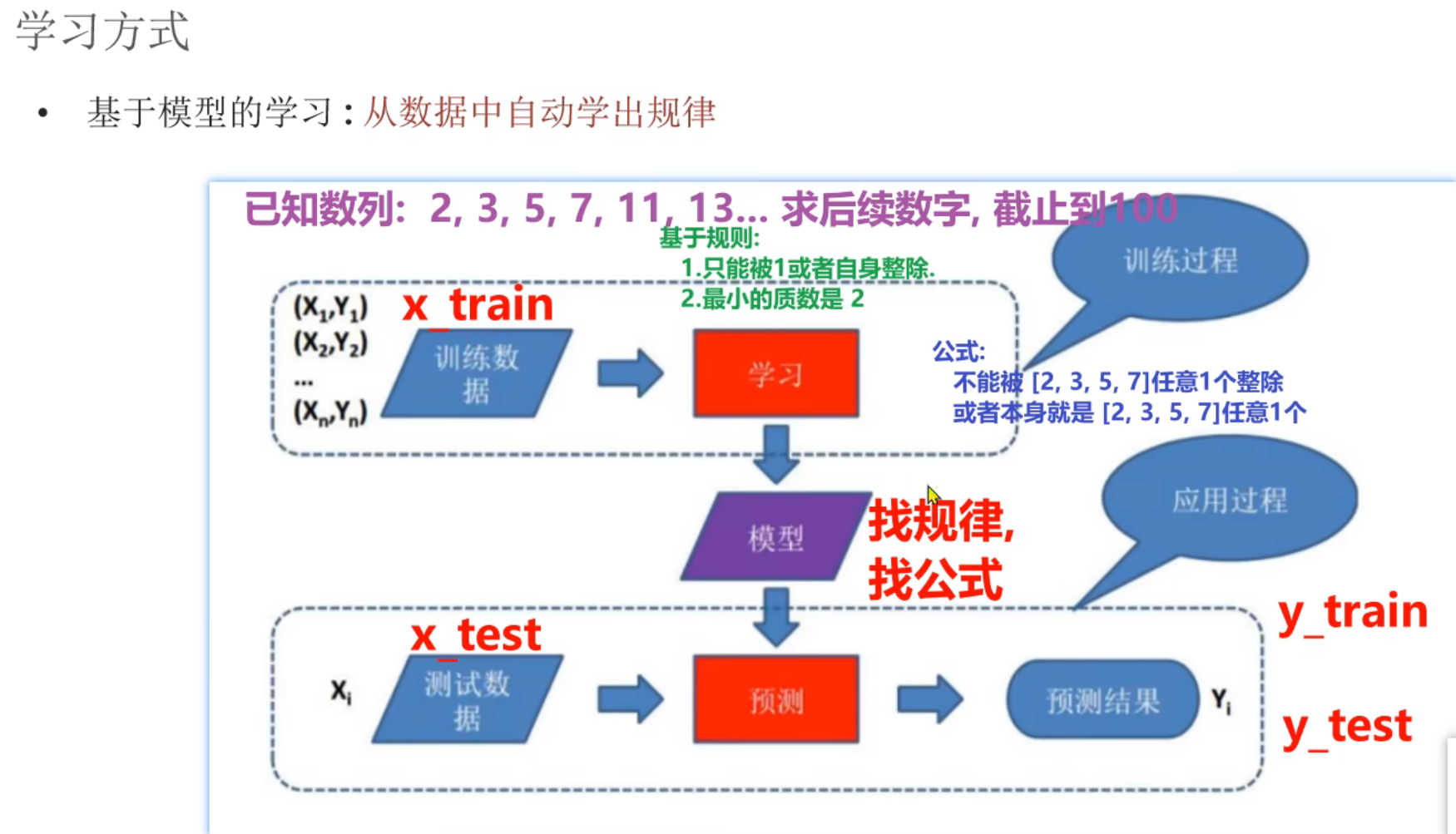
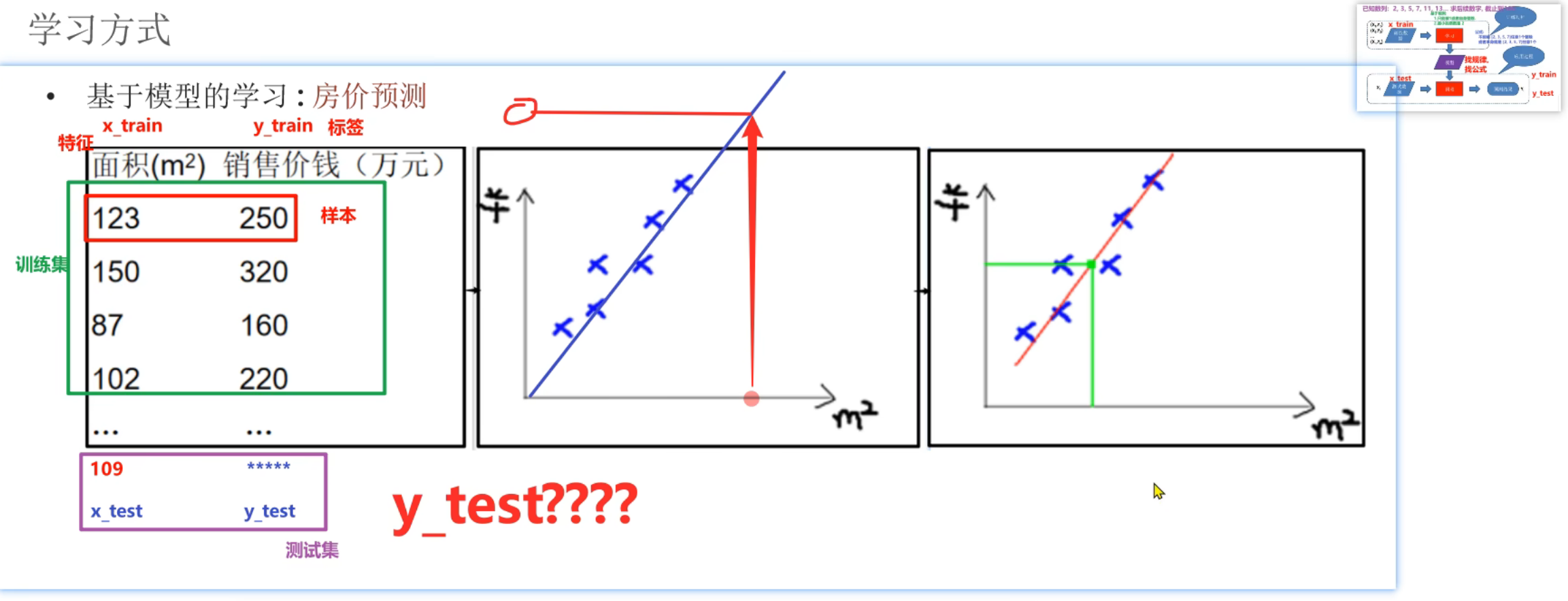
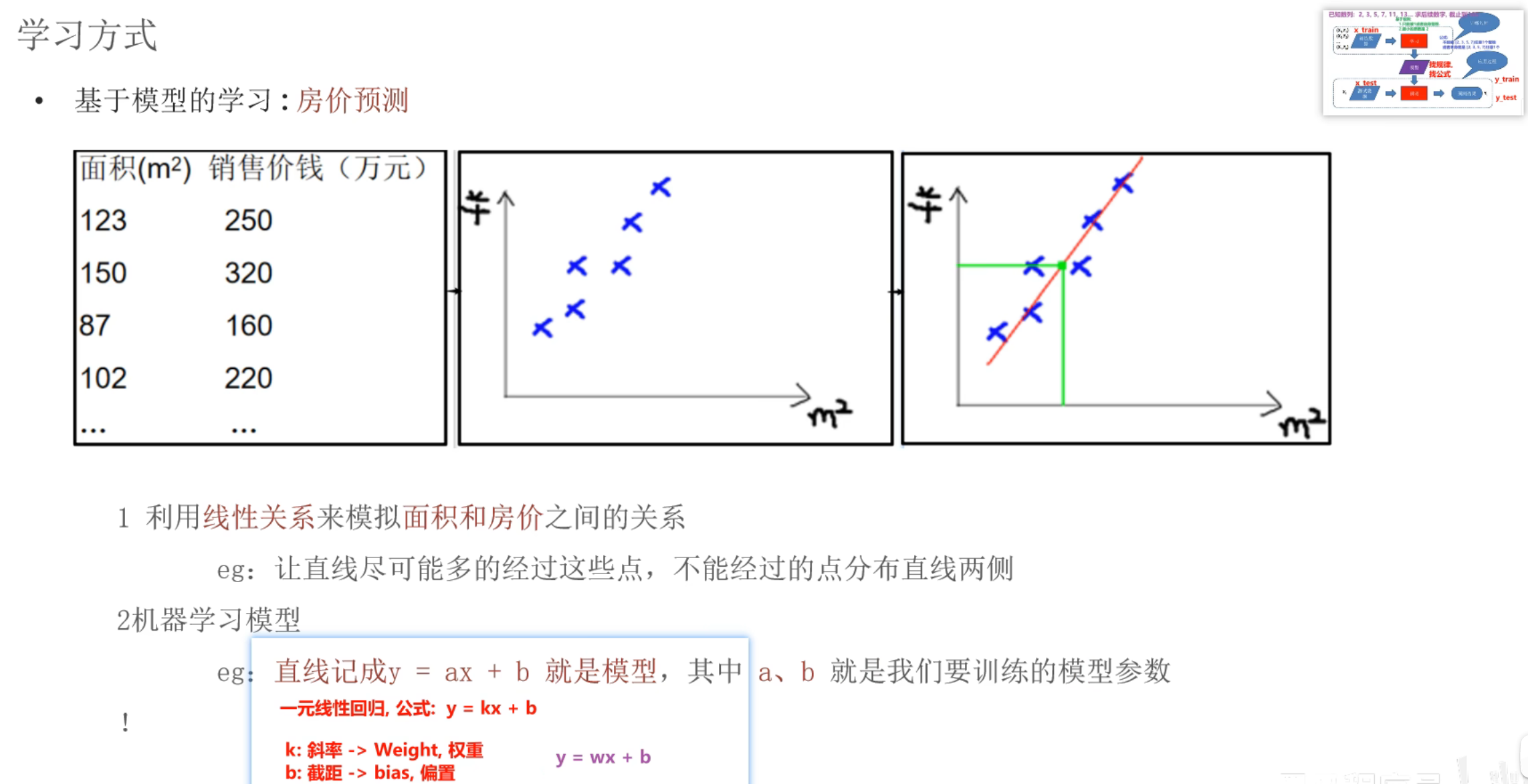
4、机器学习_基于规则和模型的介绍


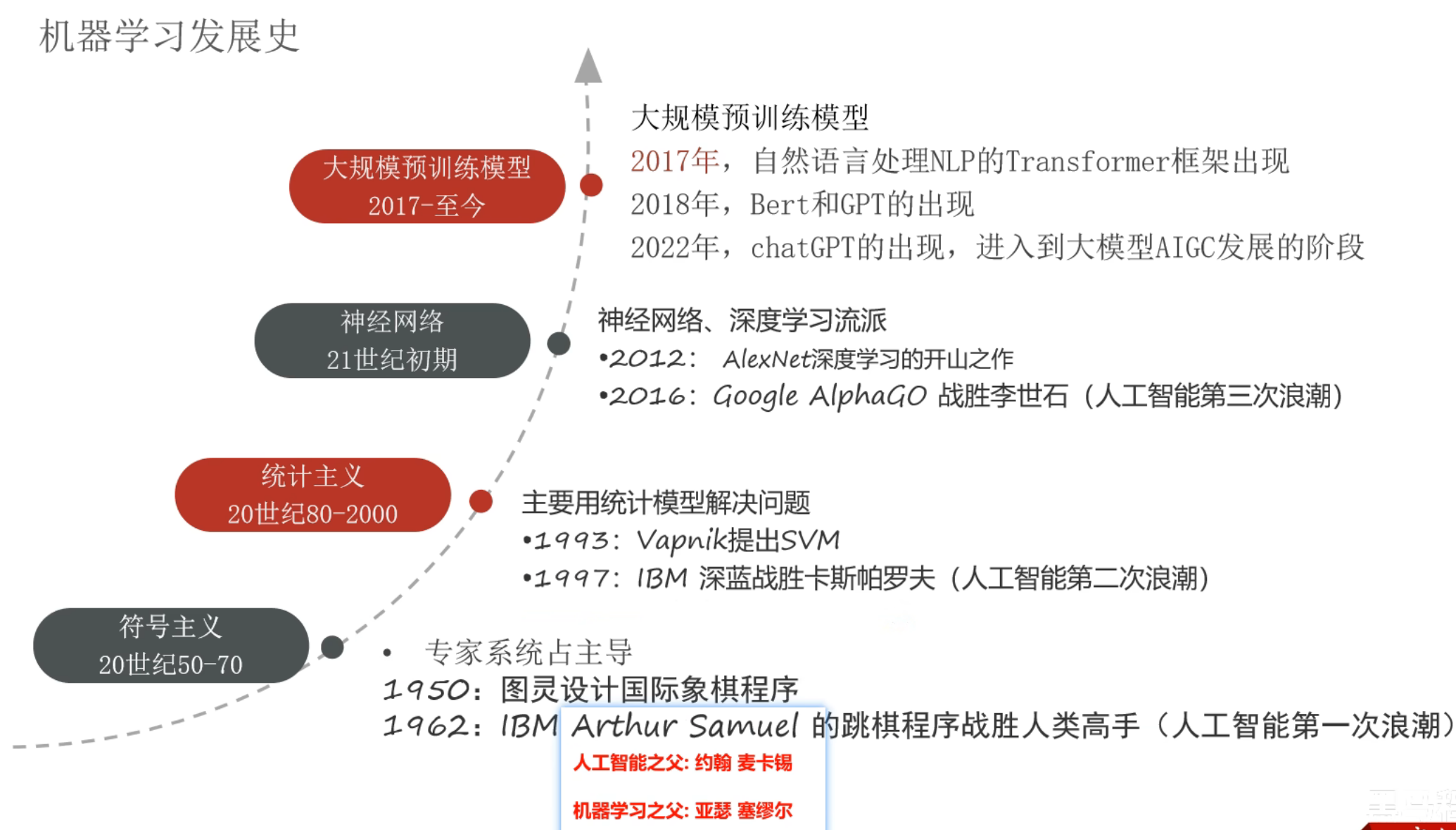
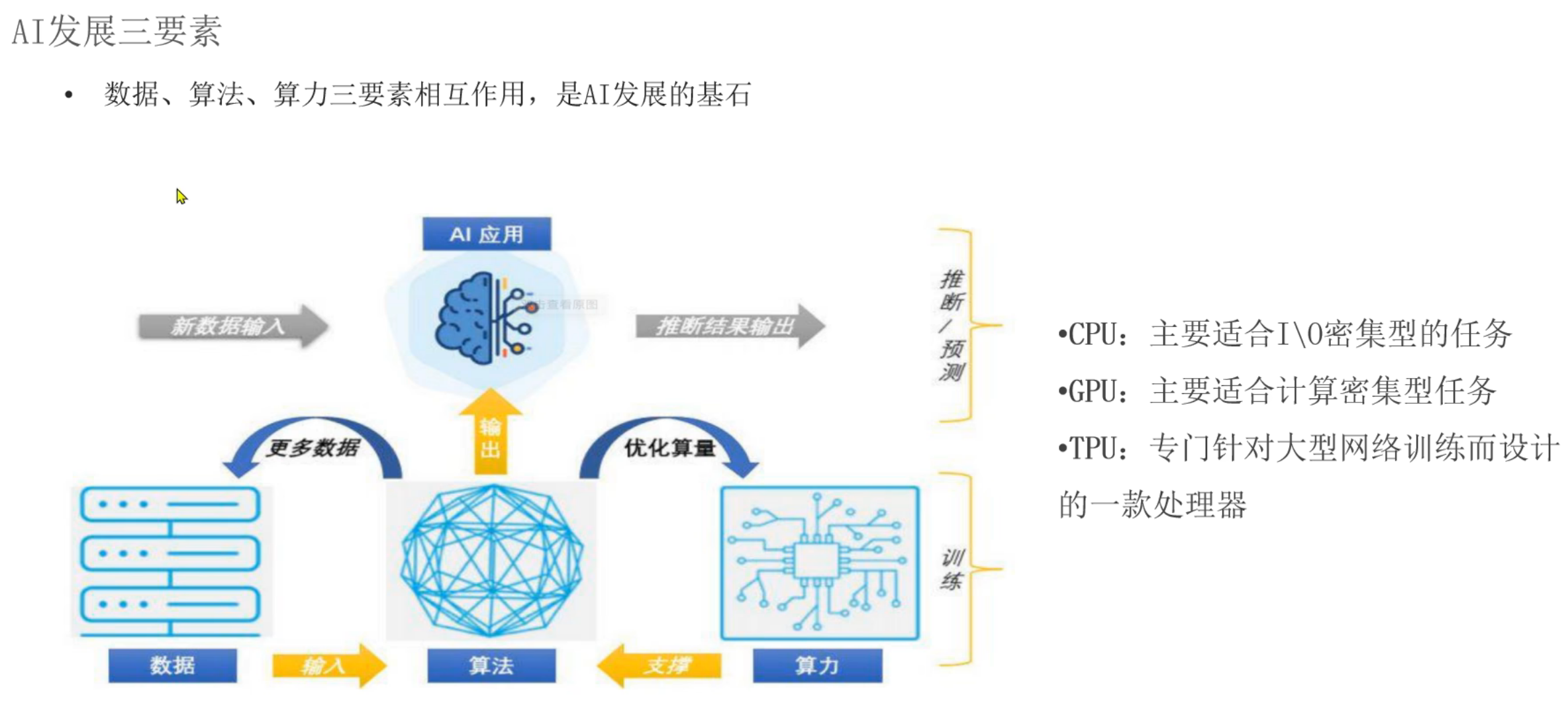
5、机器学习_应用领域和发展史介绍
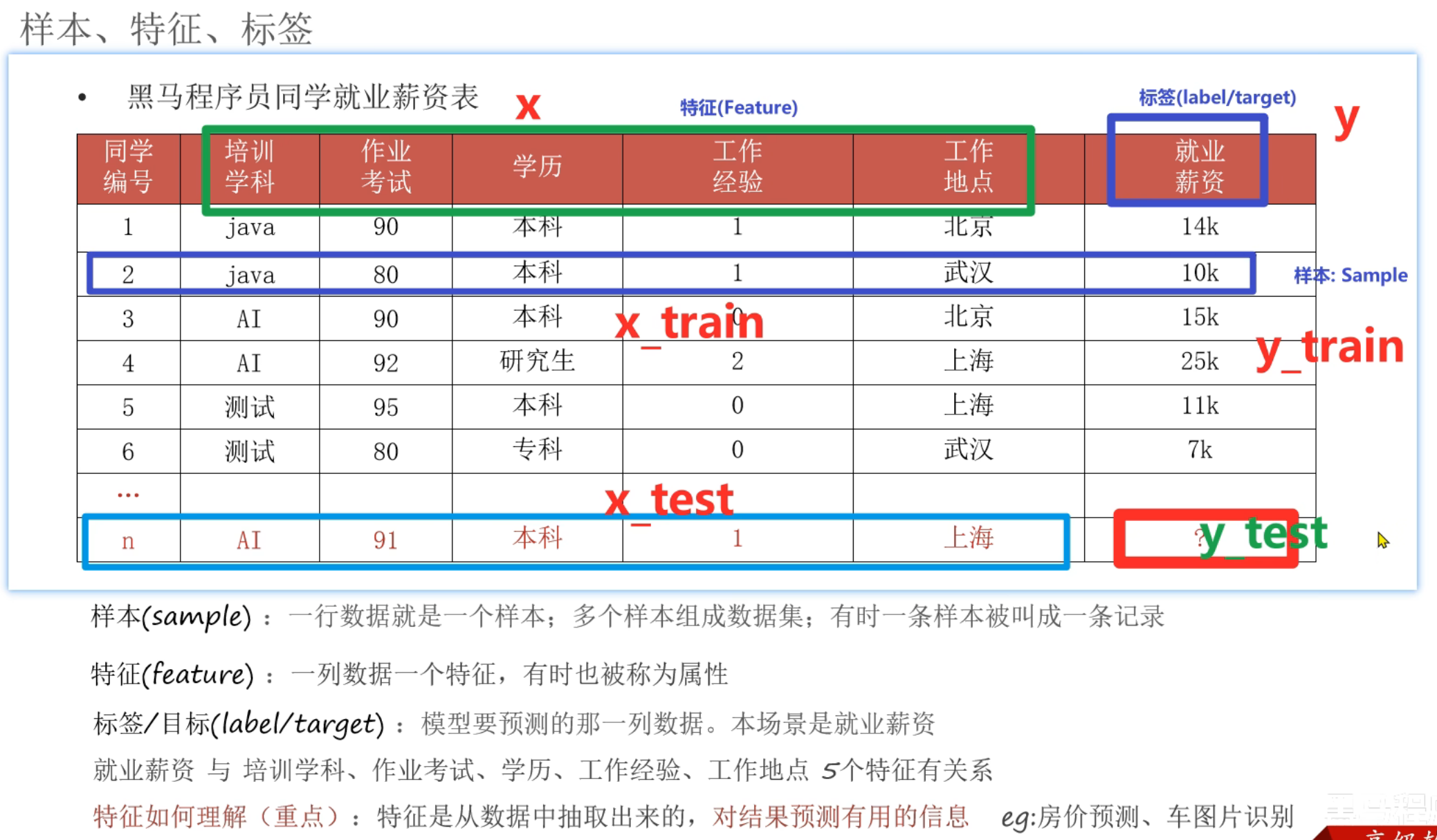
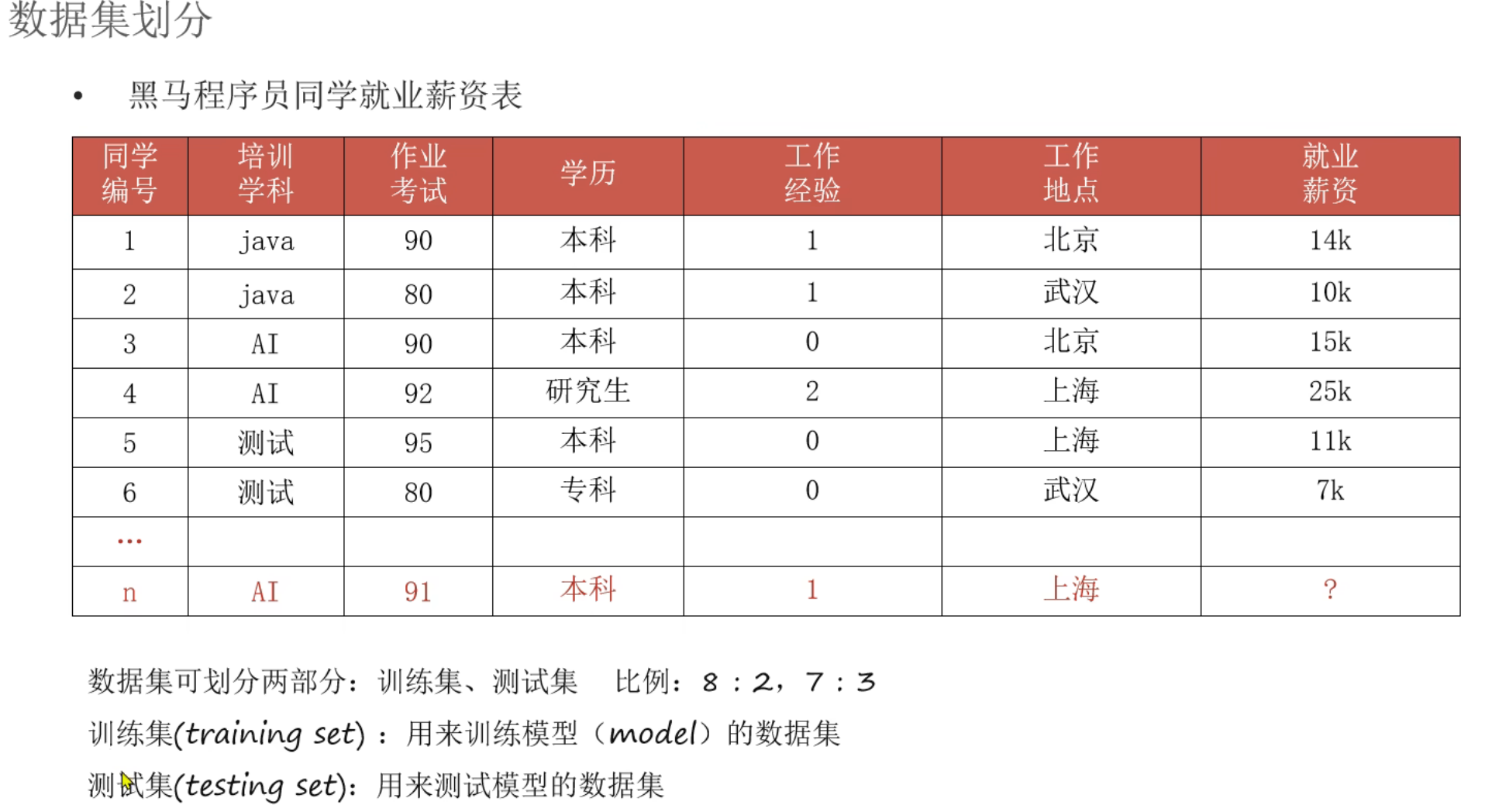
6、机器学习_名词介绍
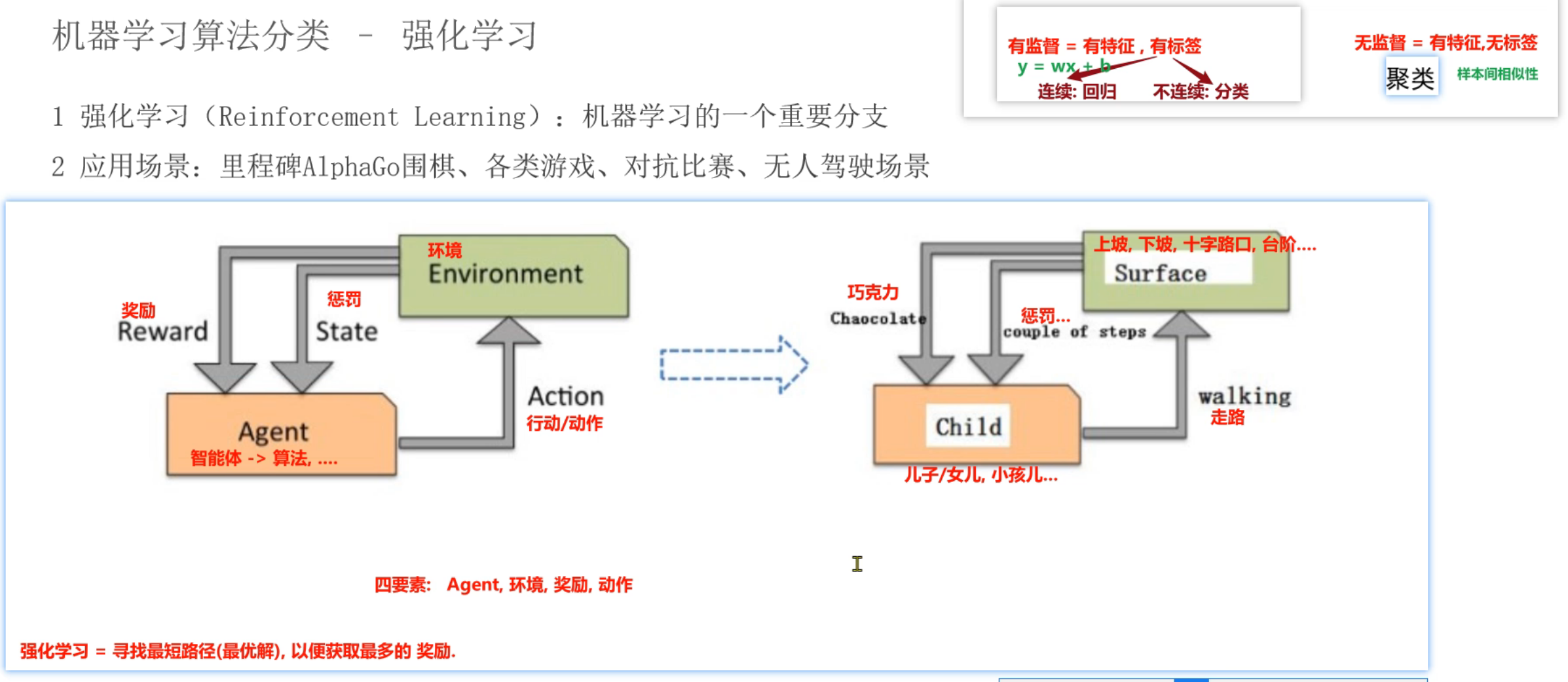
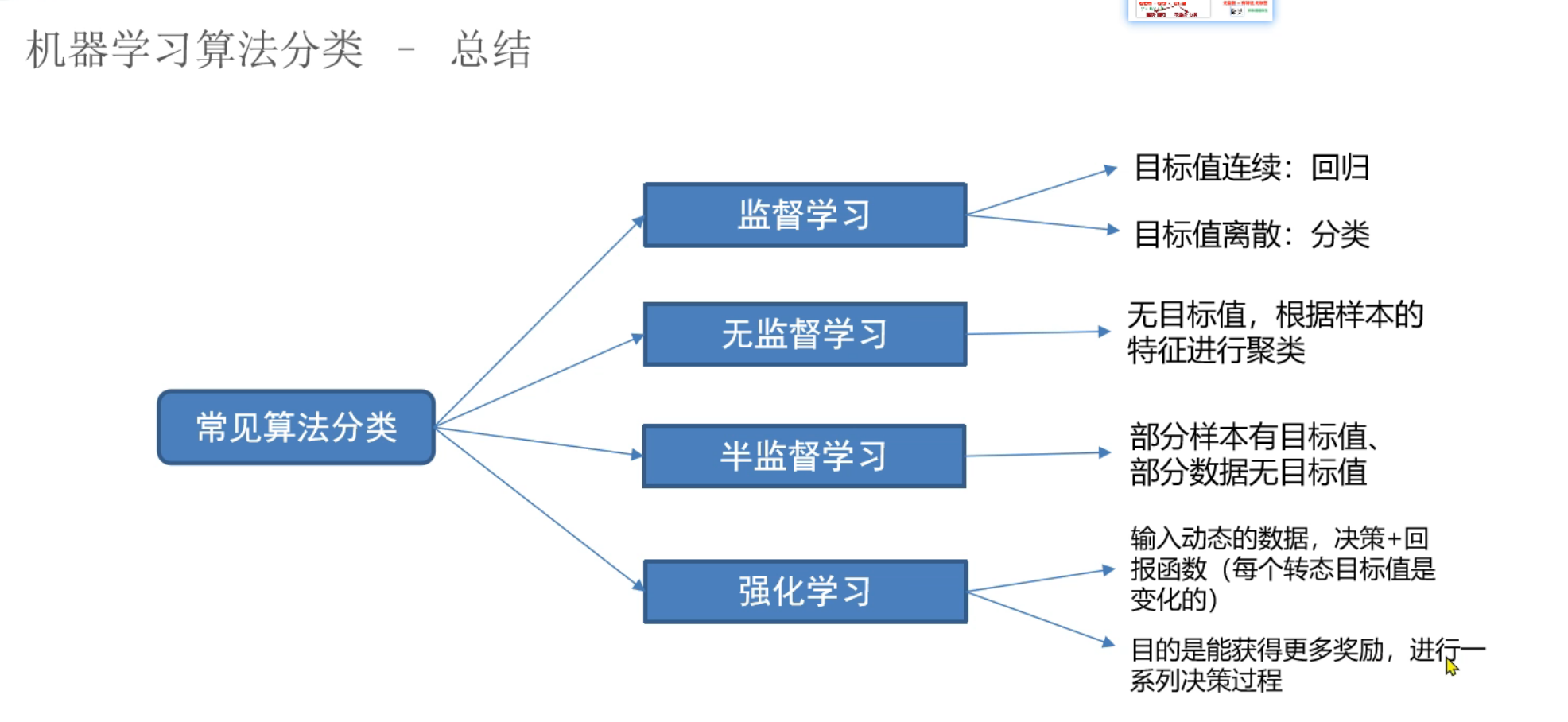
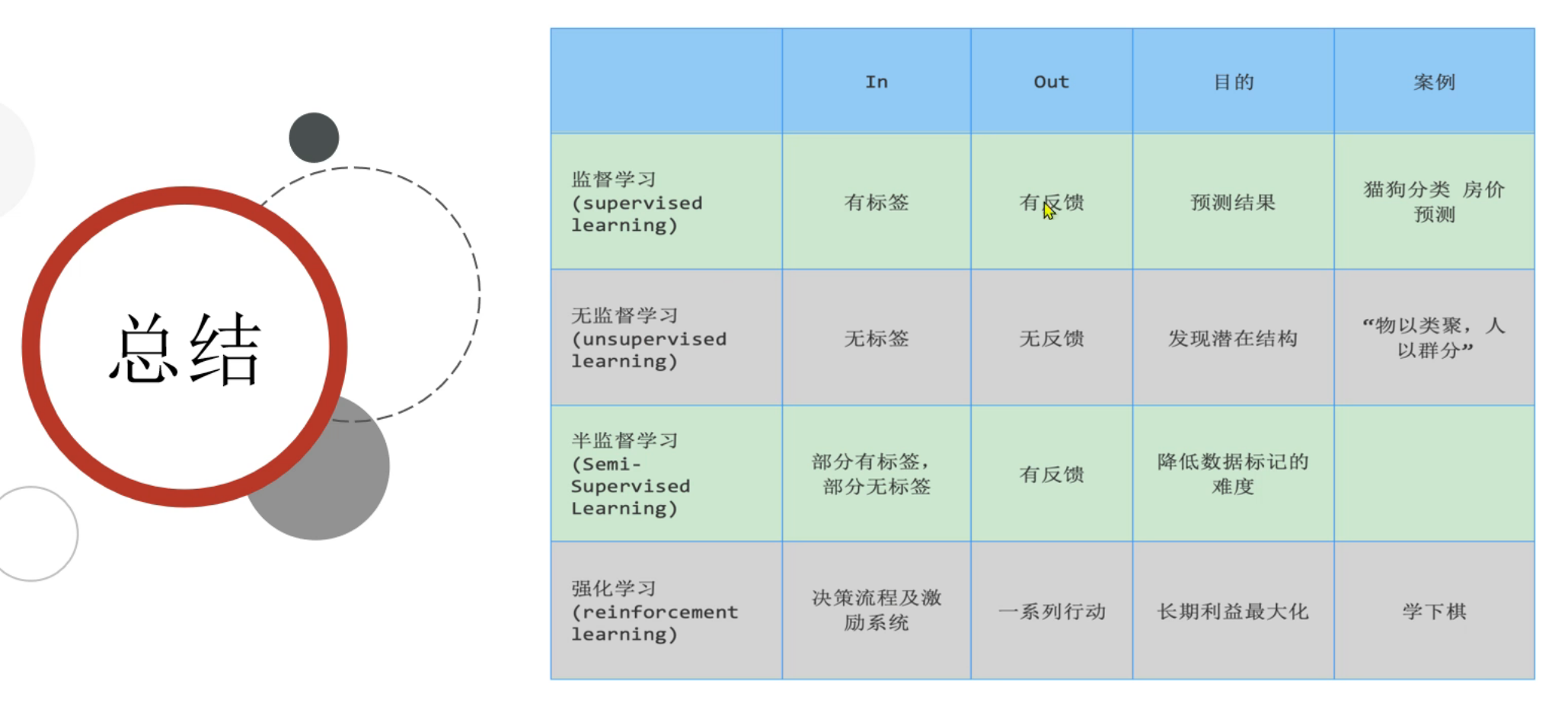
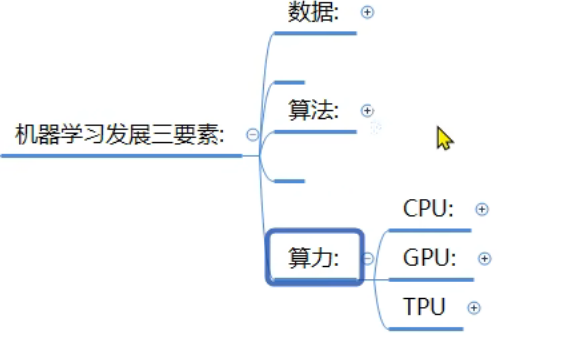
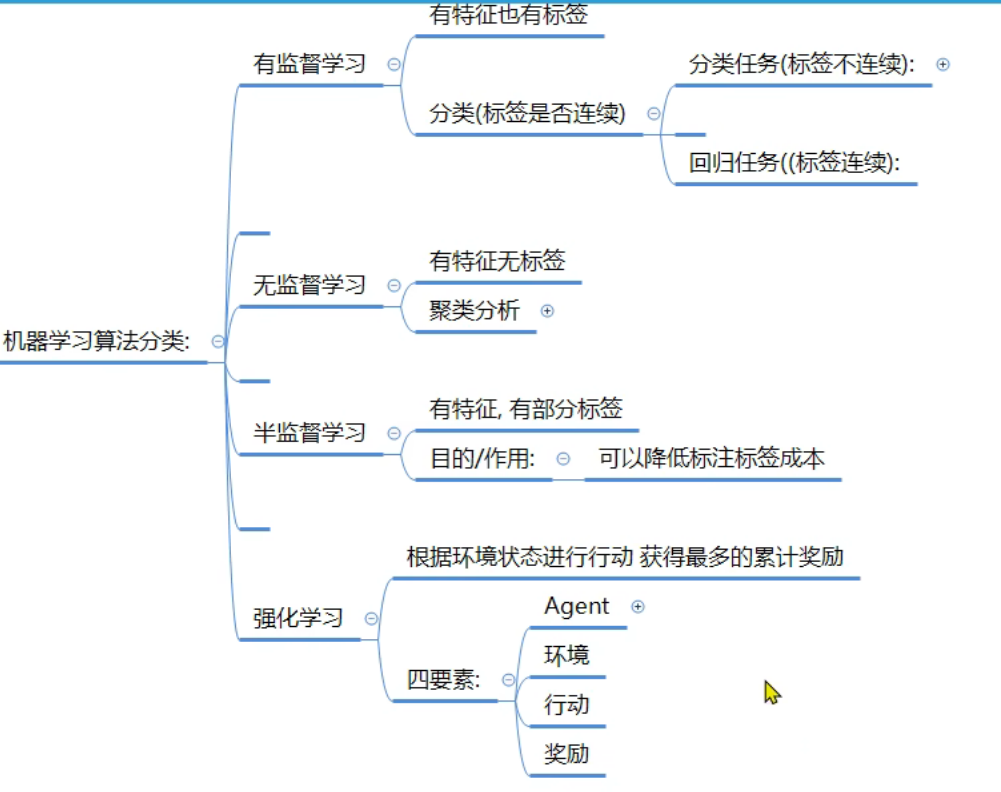
7、机器学习_算法分类

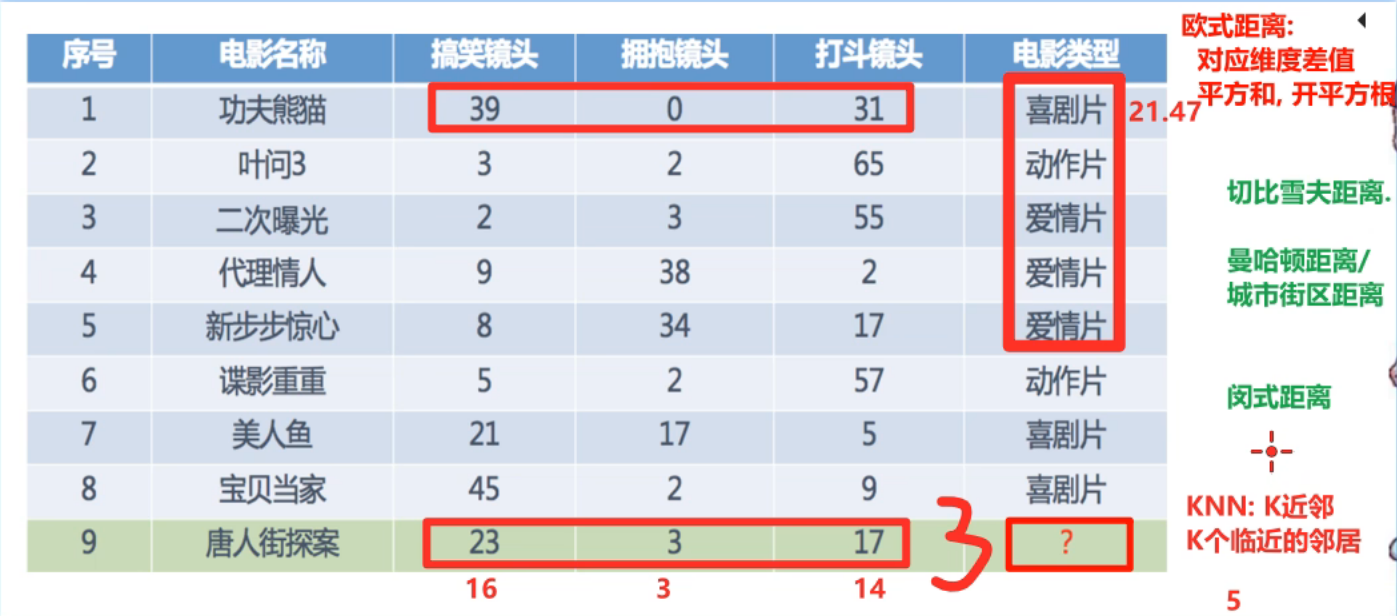
假设序号1~5就是5个临近的邻居,数类型发现爱情片票数最多有3票,则预测类型就是爱情片


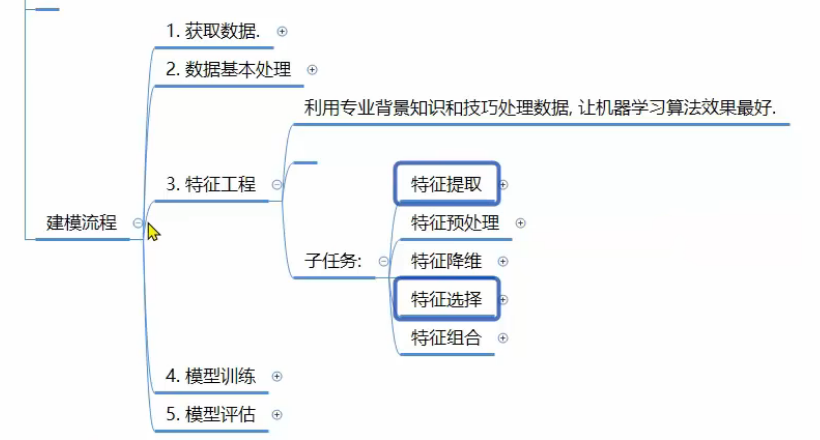
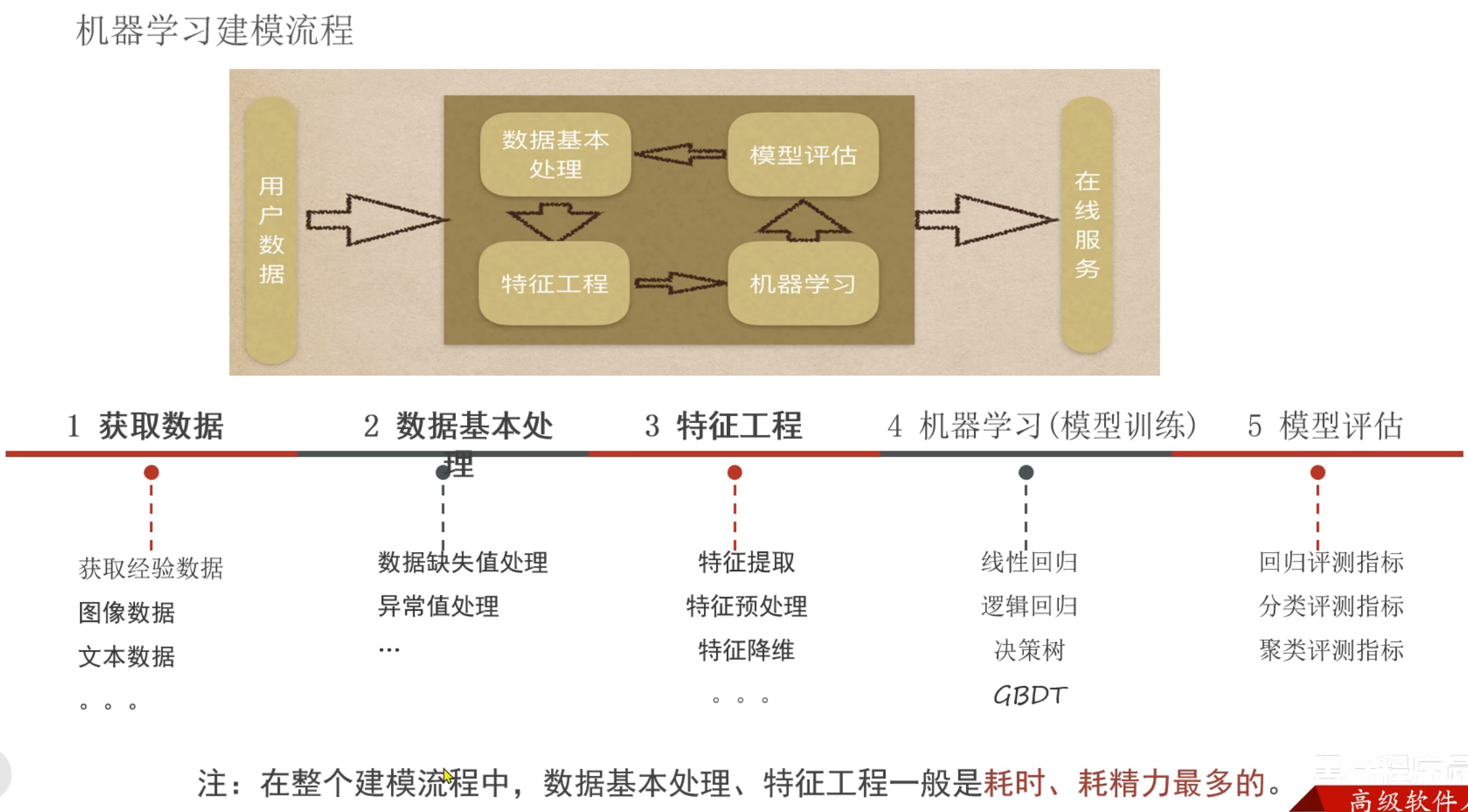
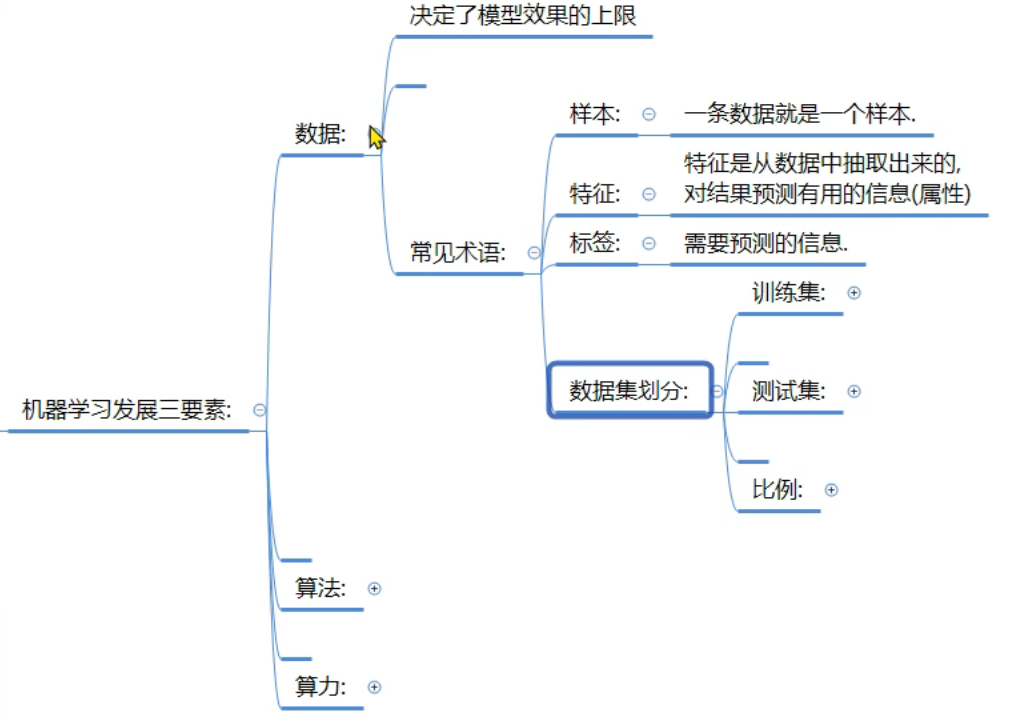
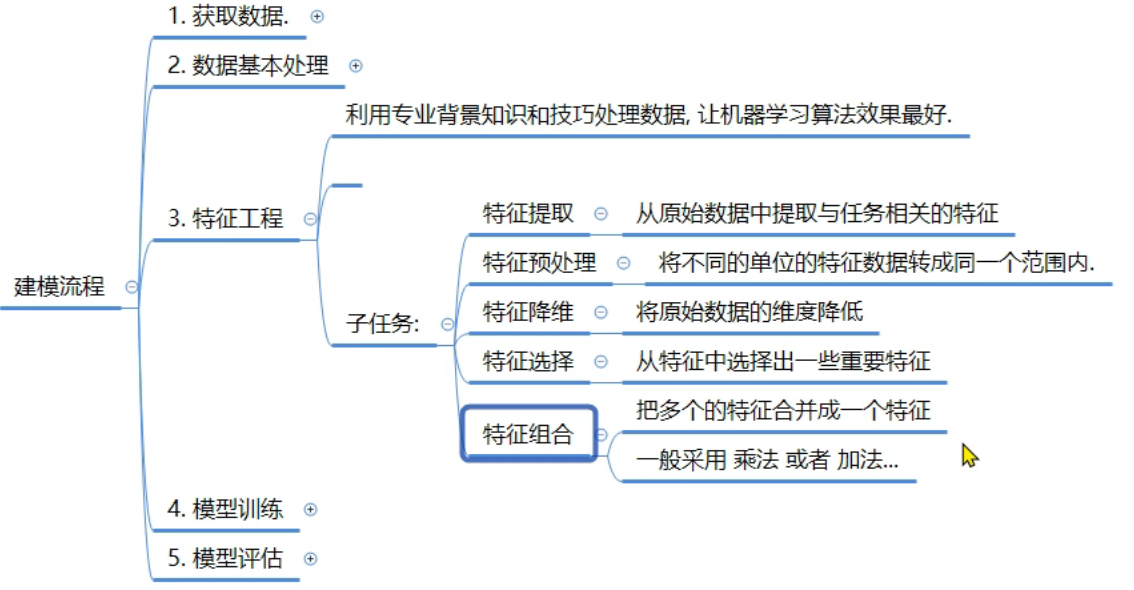
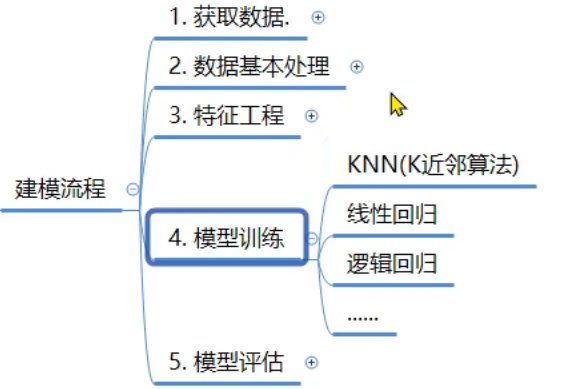
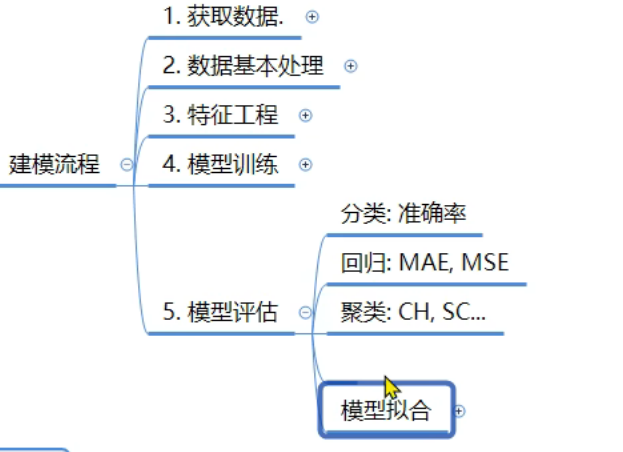
8、机器学习_建模流程
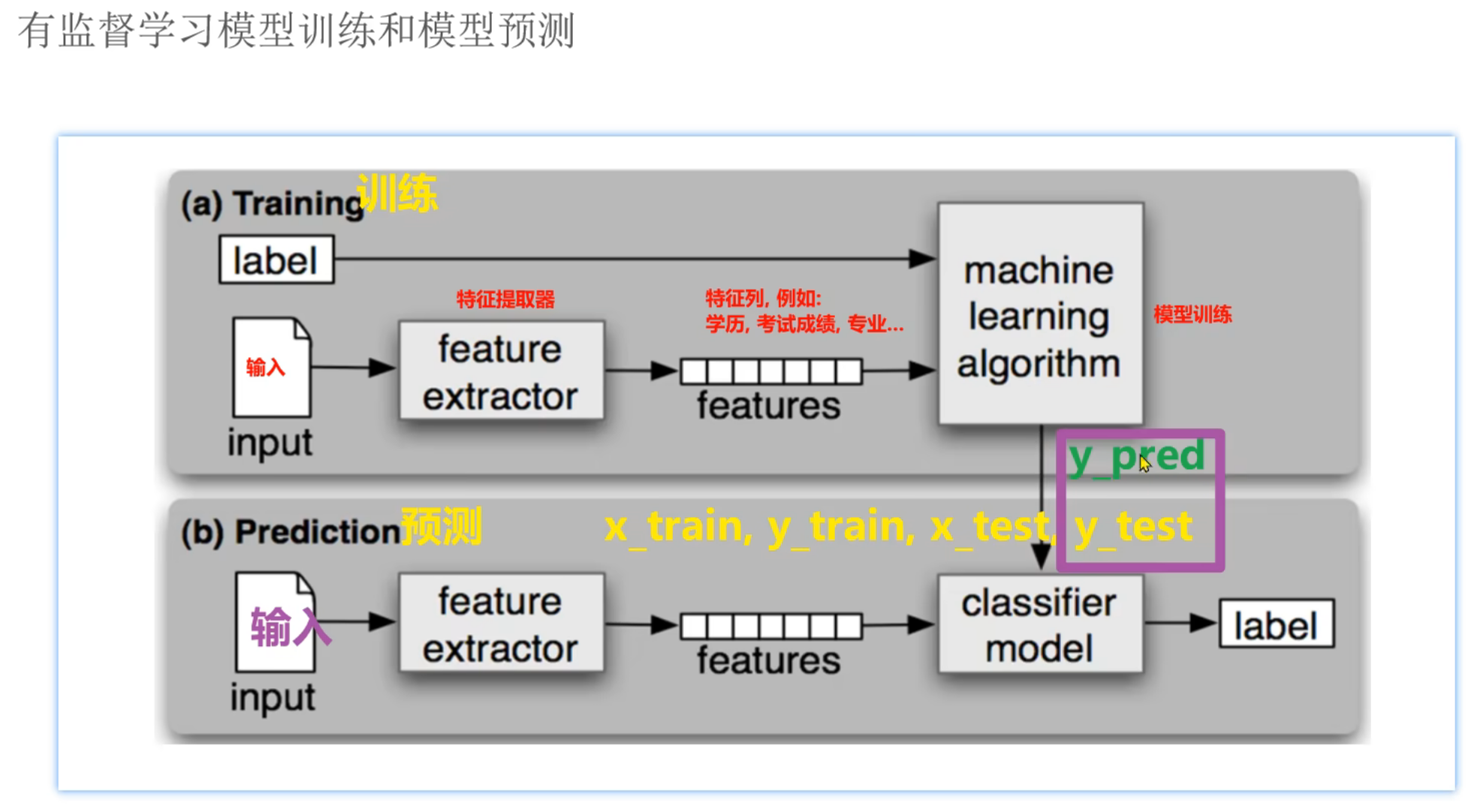


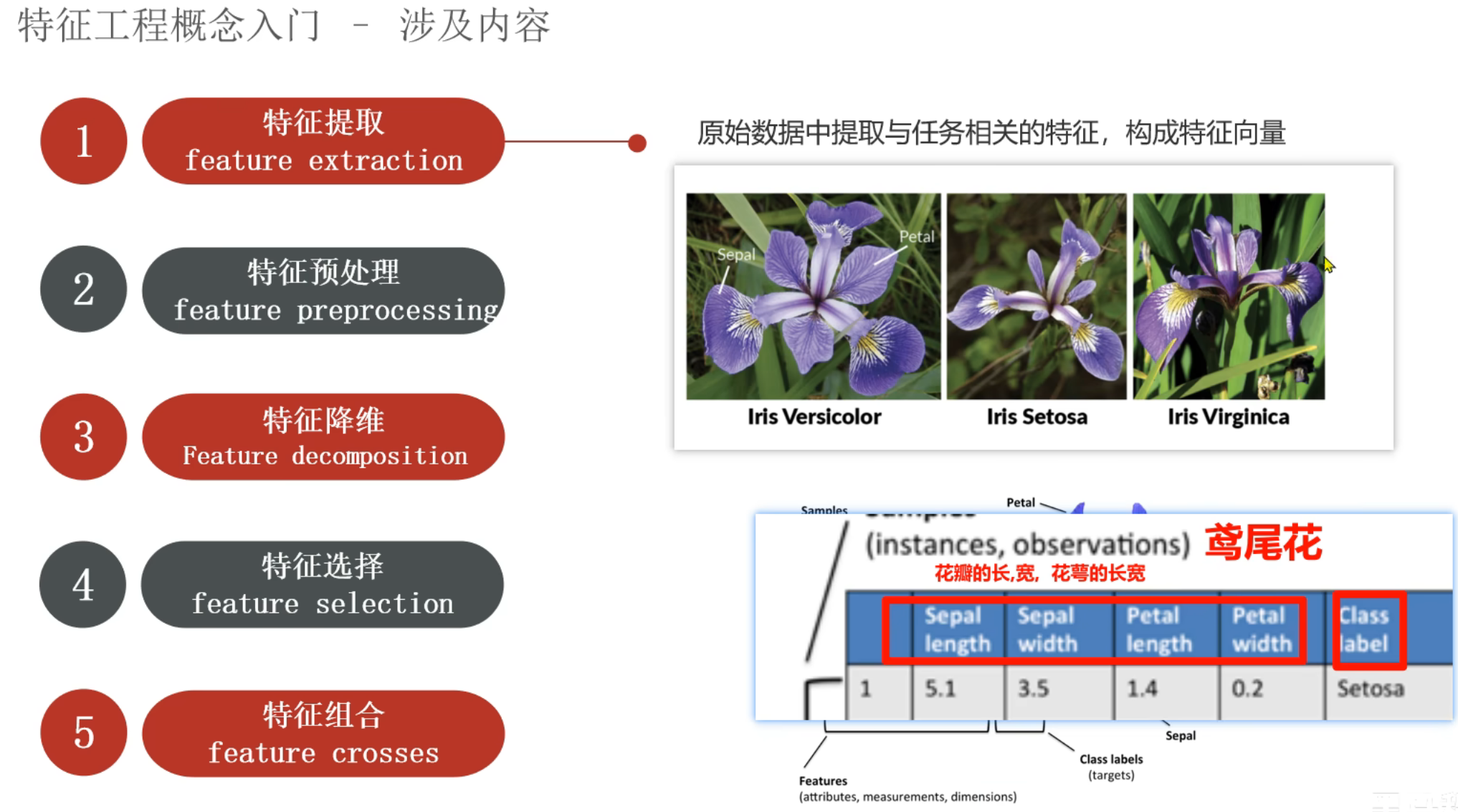
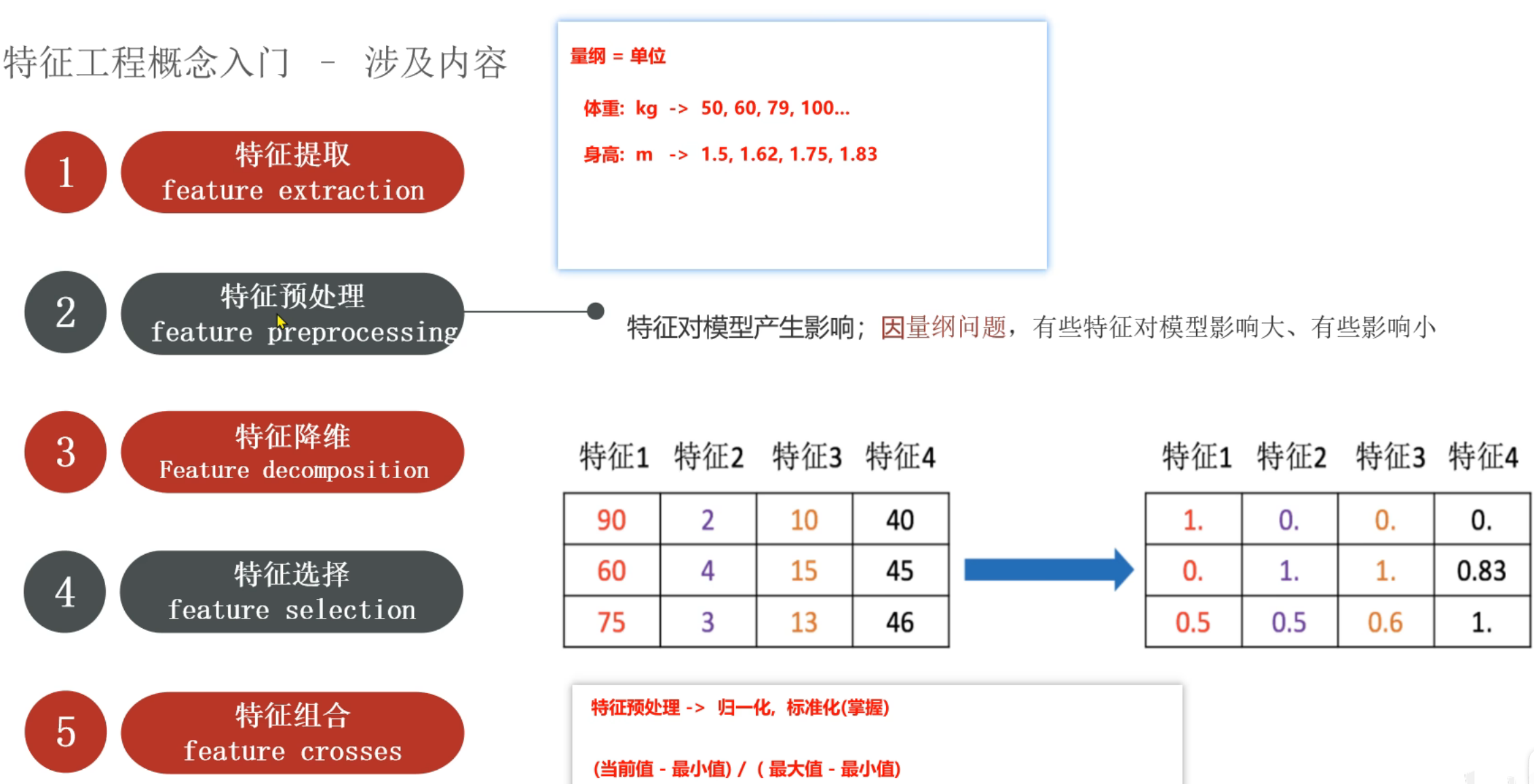
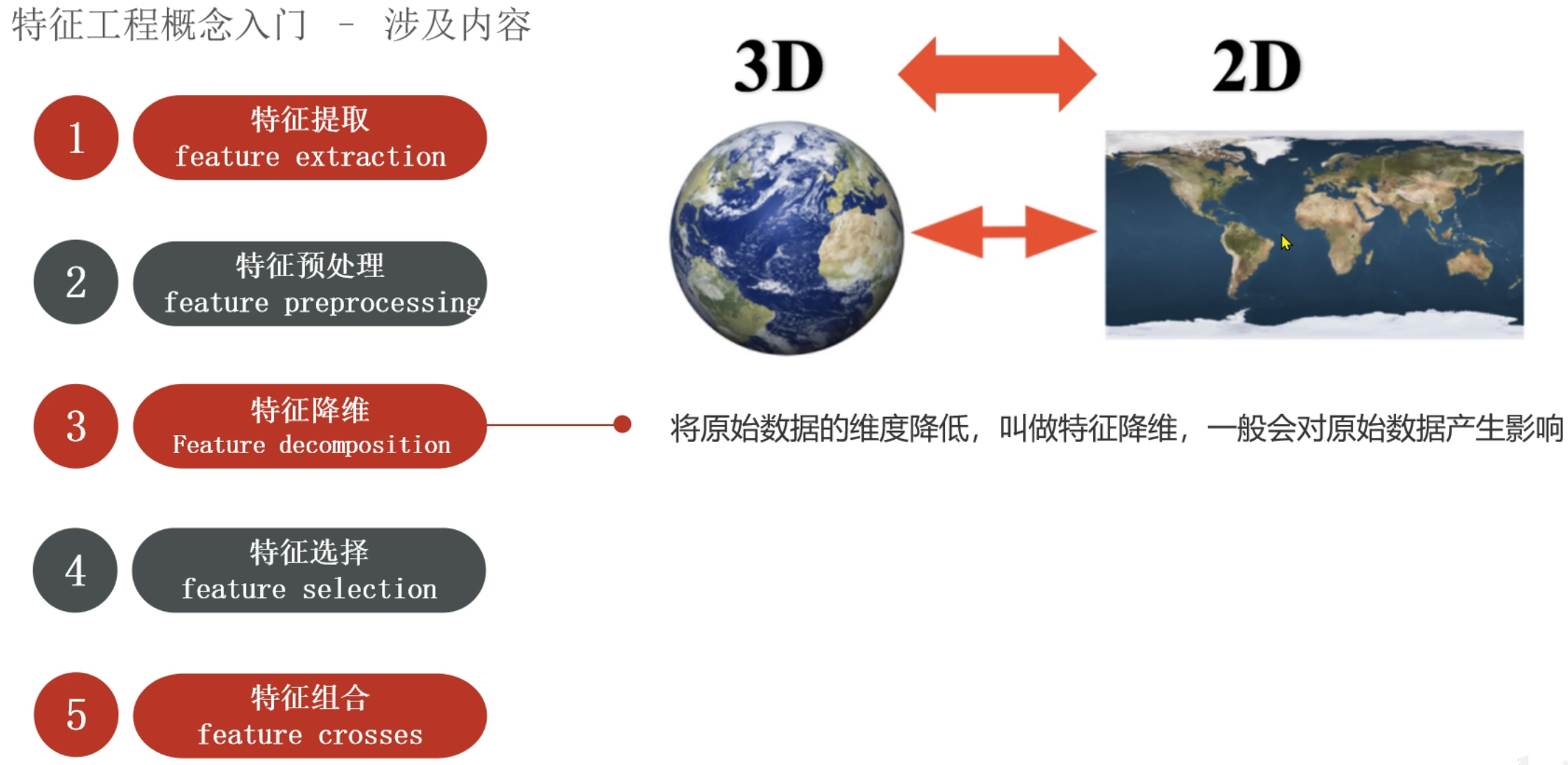
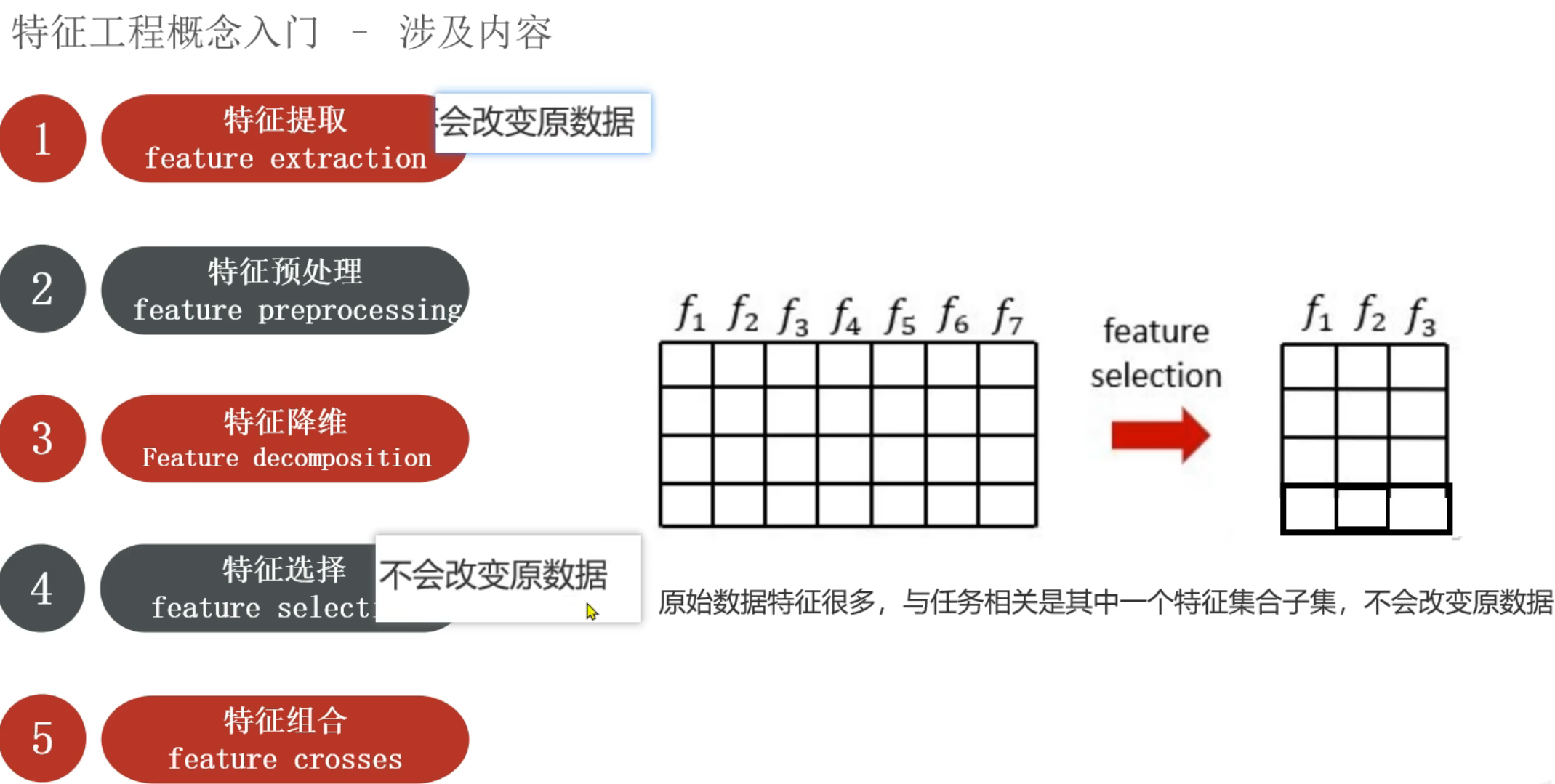
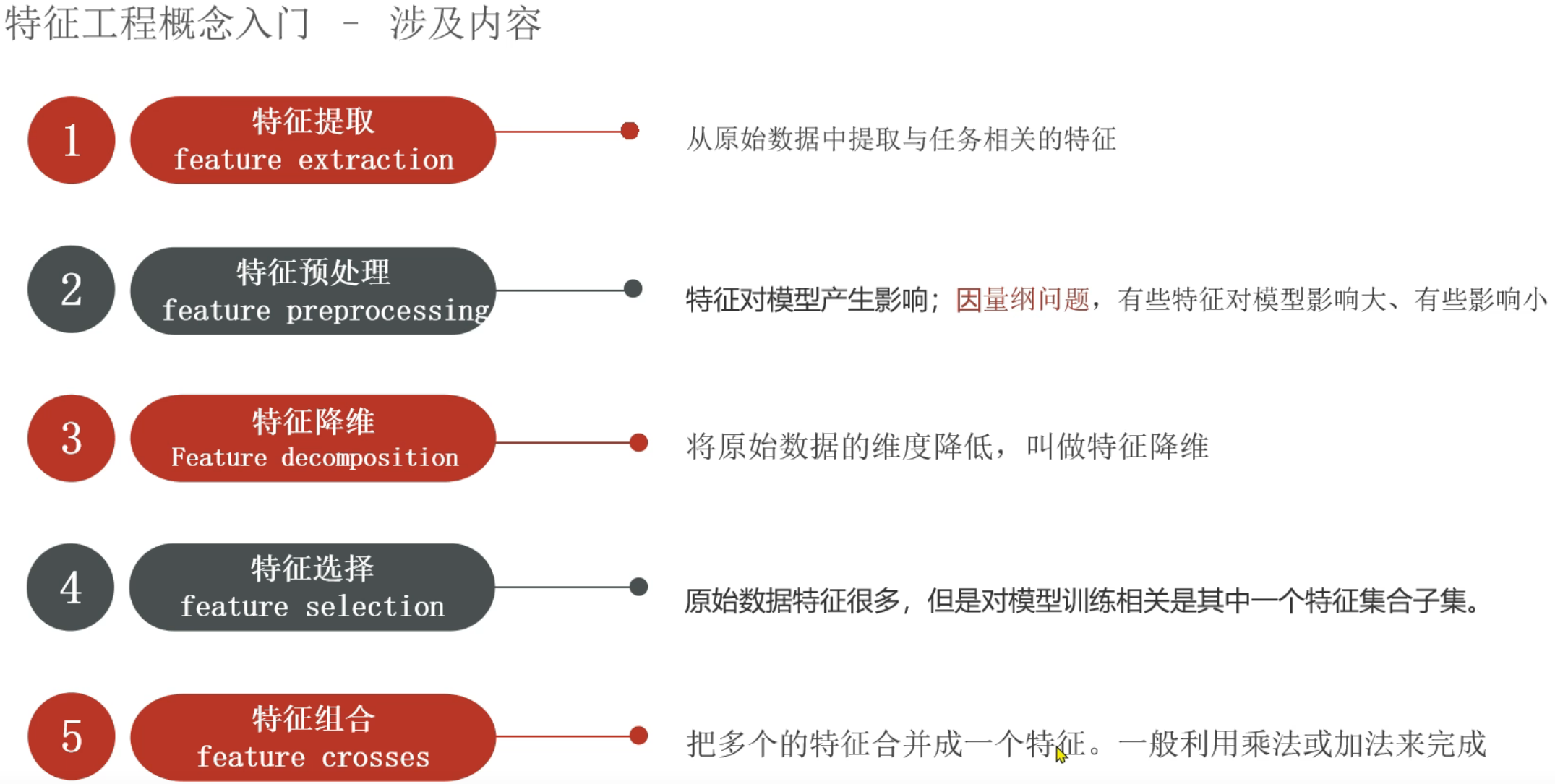
9、机器学习_特征工程介绍





10、上午内容回顾
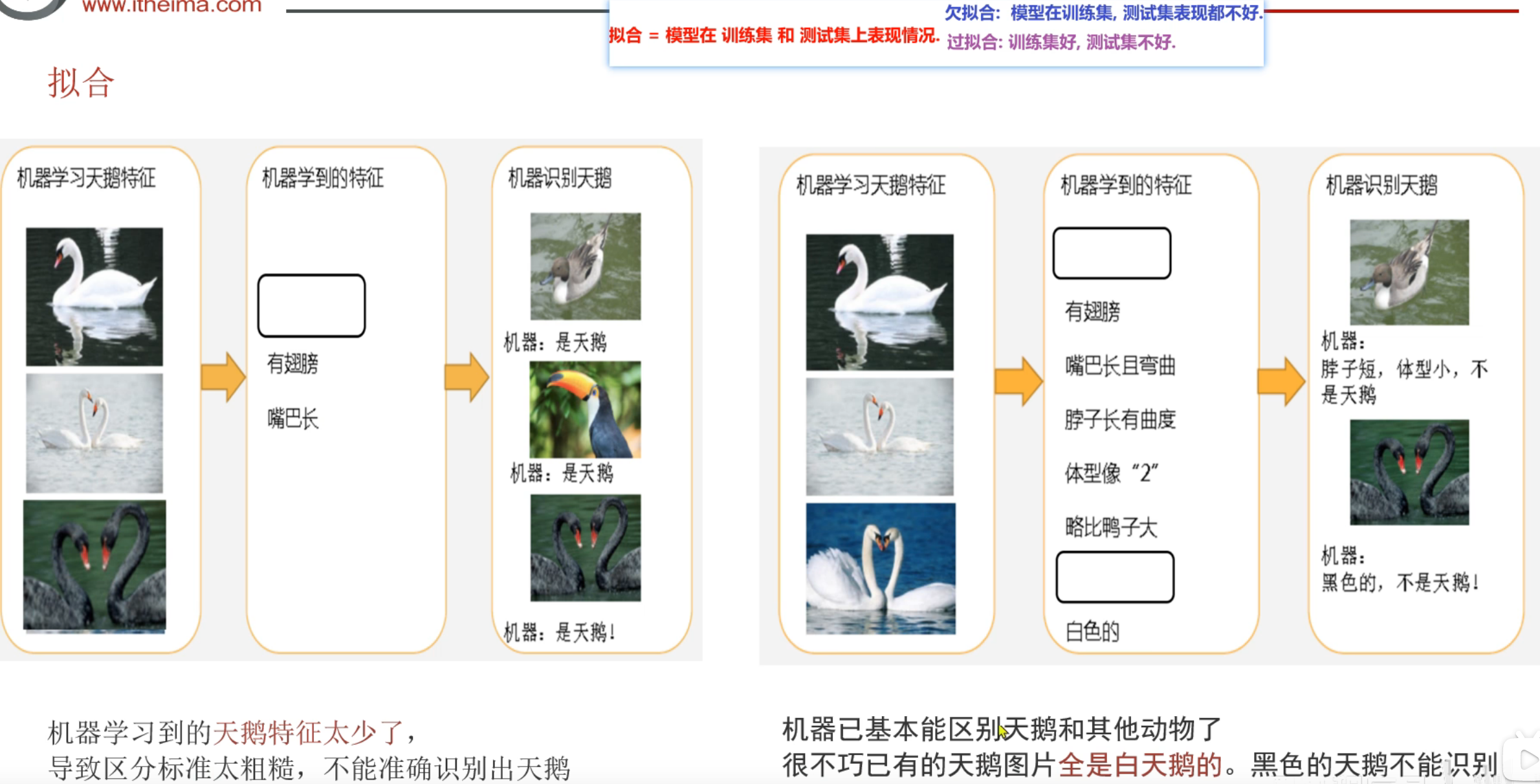
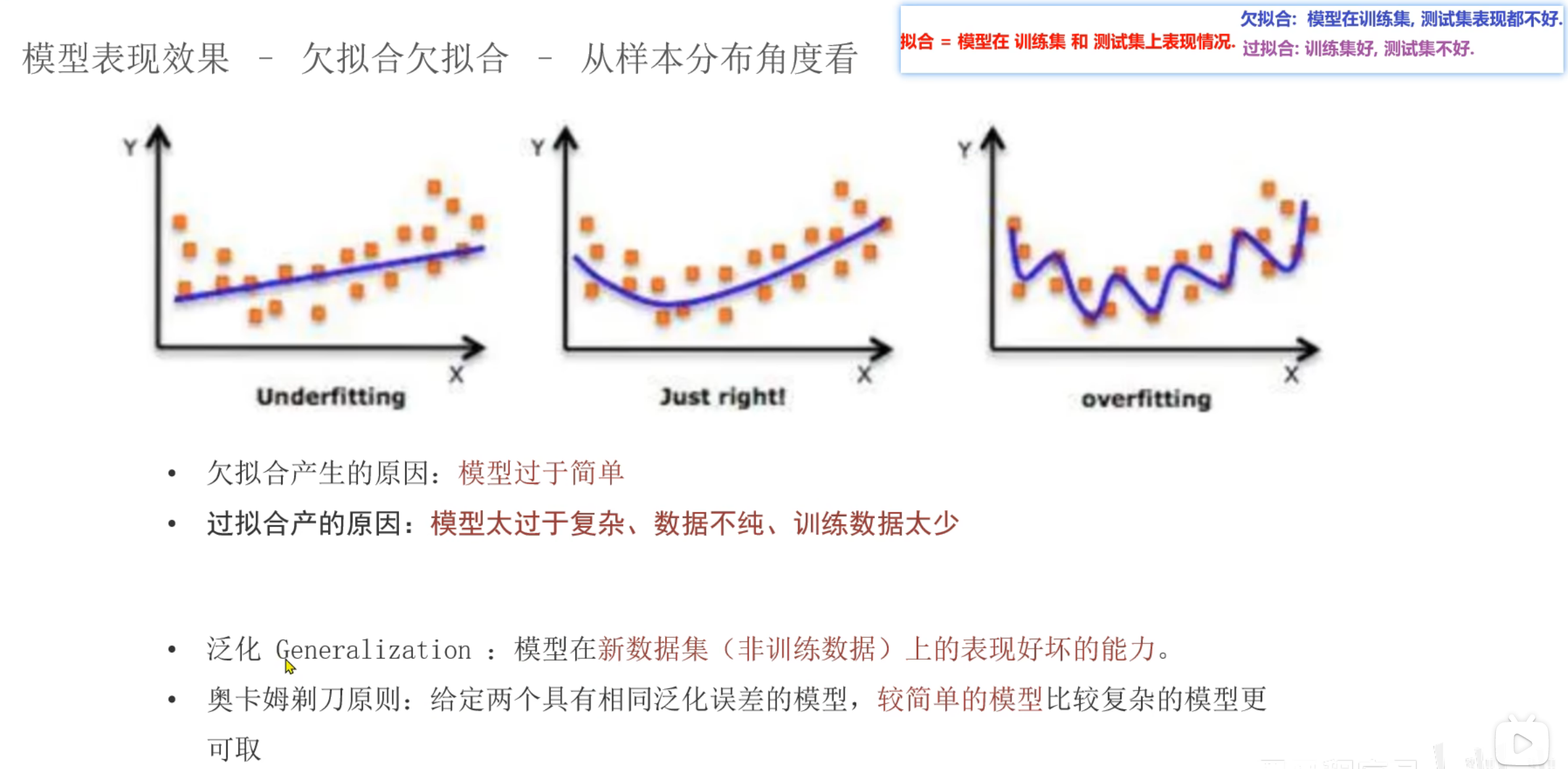
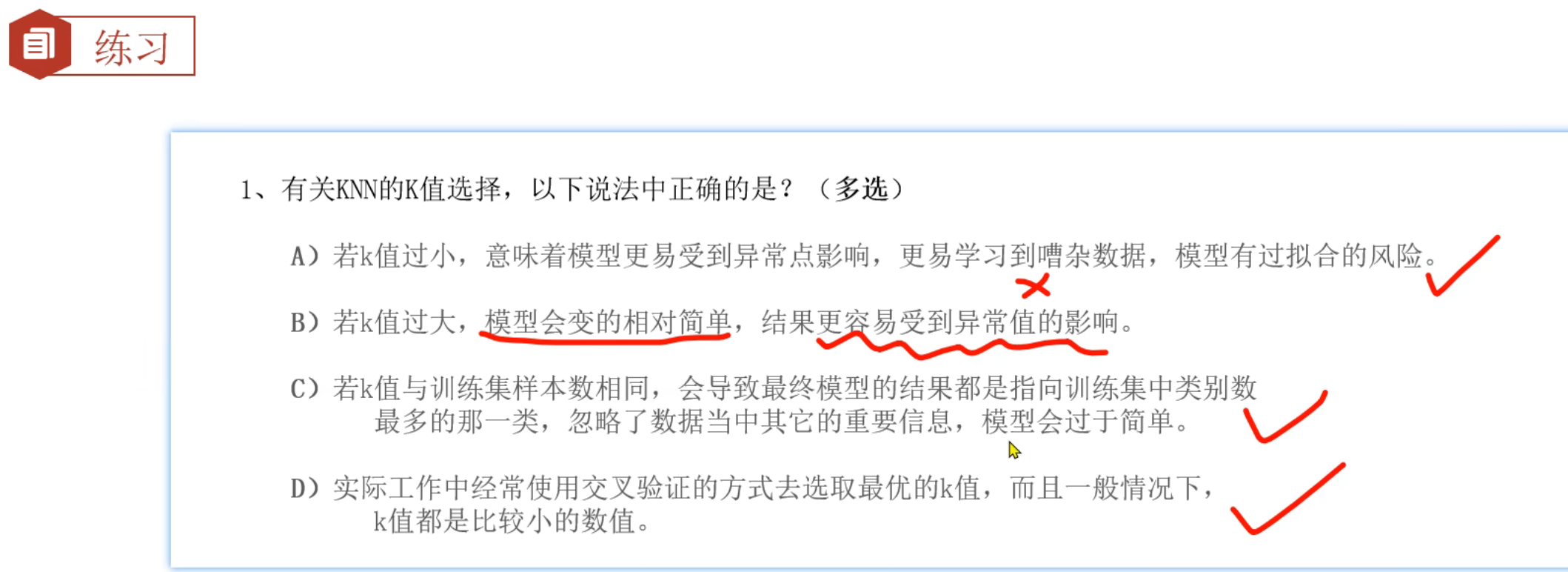
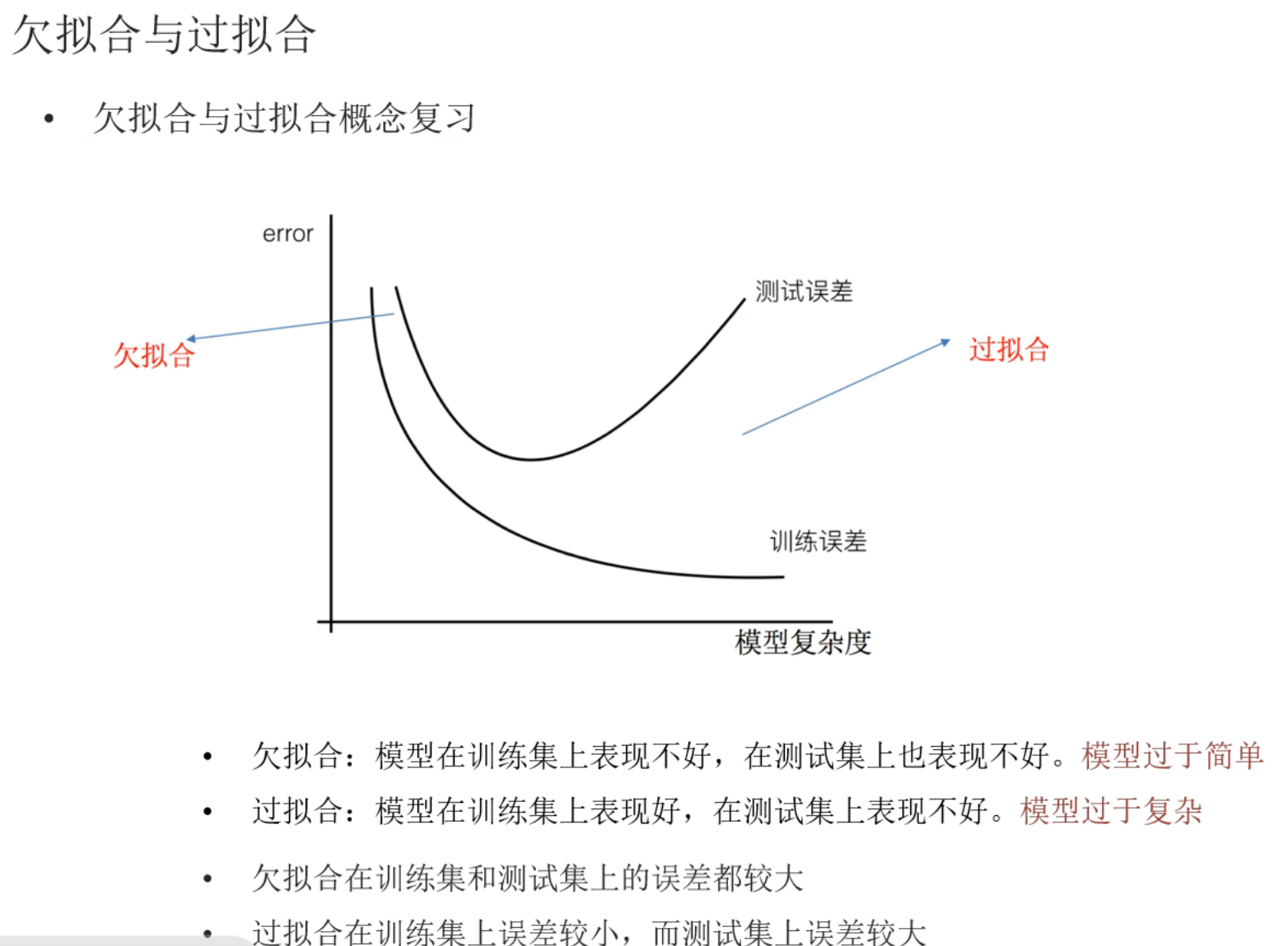
11、机器学习_模型拟合问题



12、机器学习_环境搭建


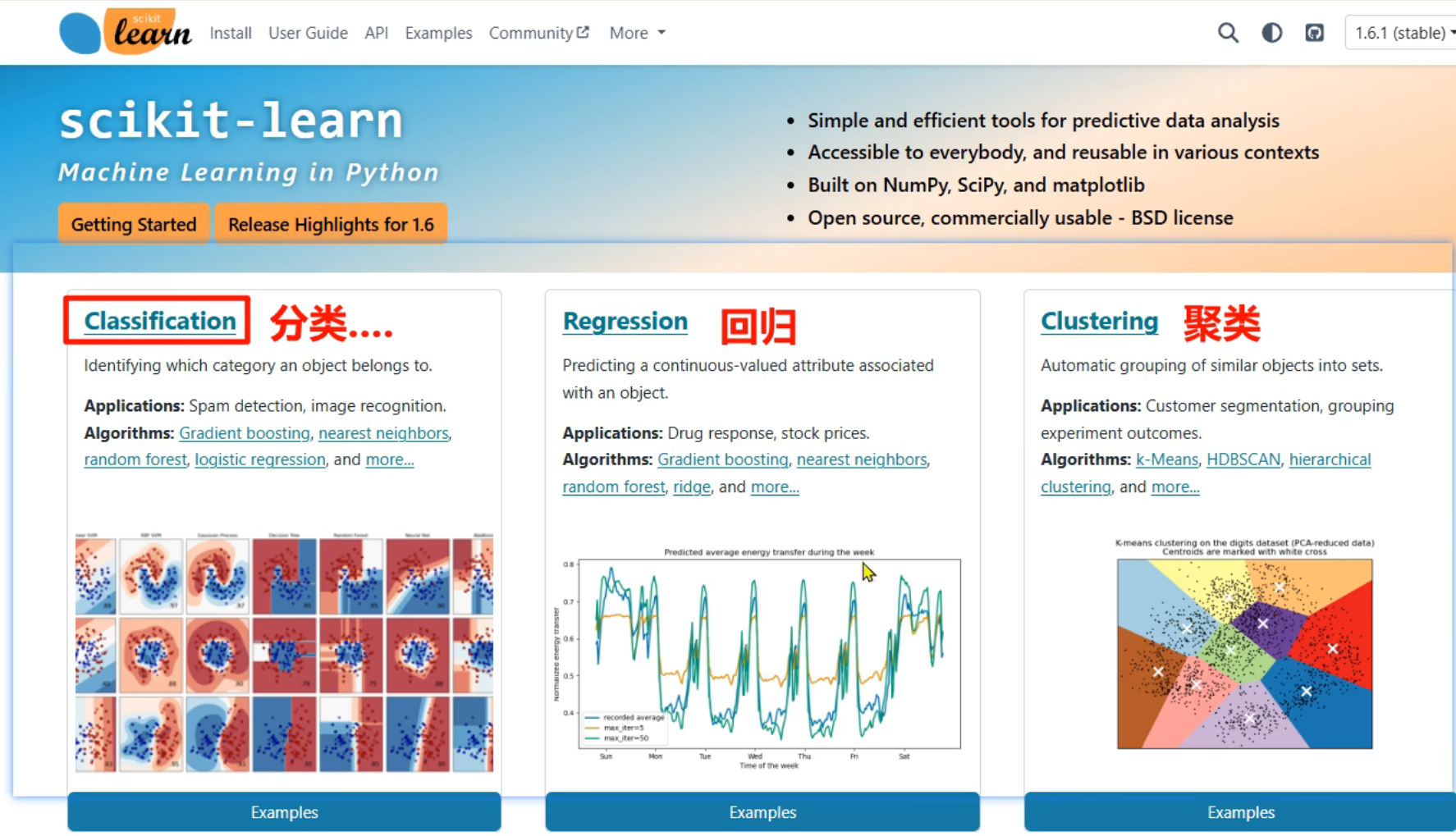
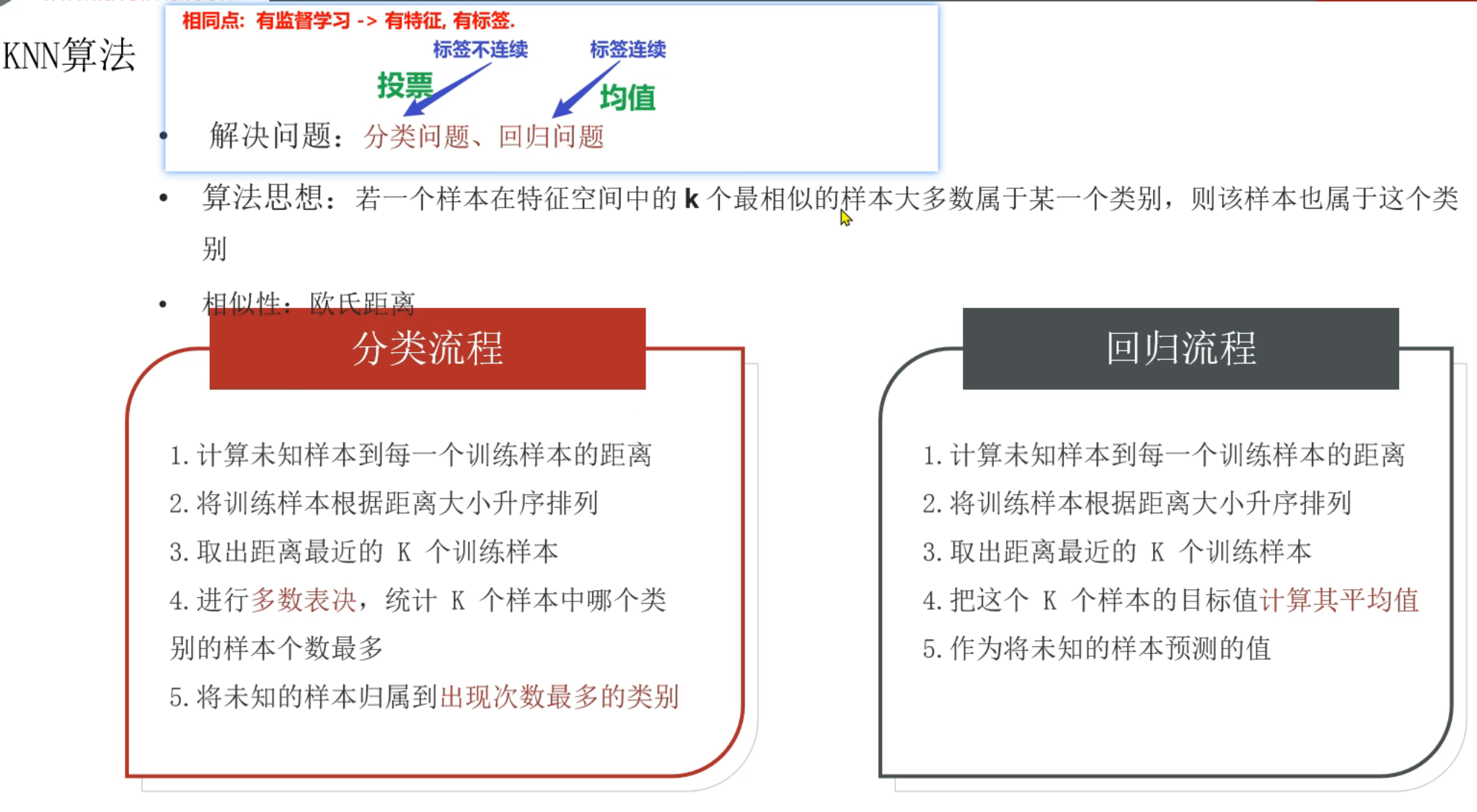
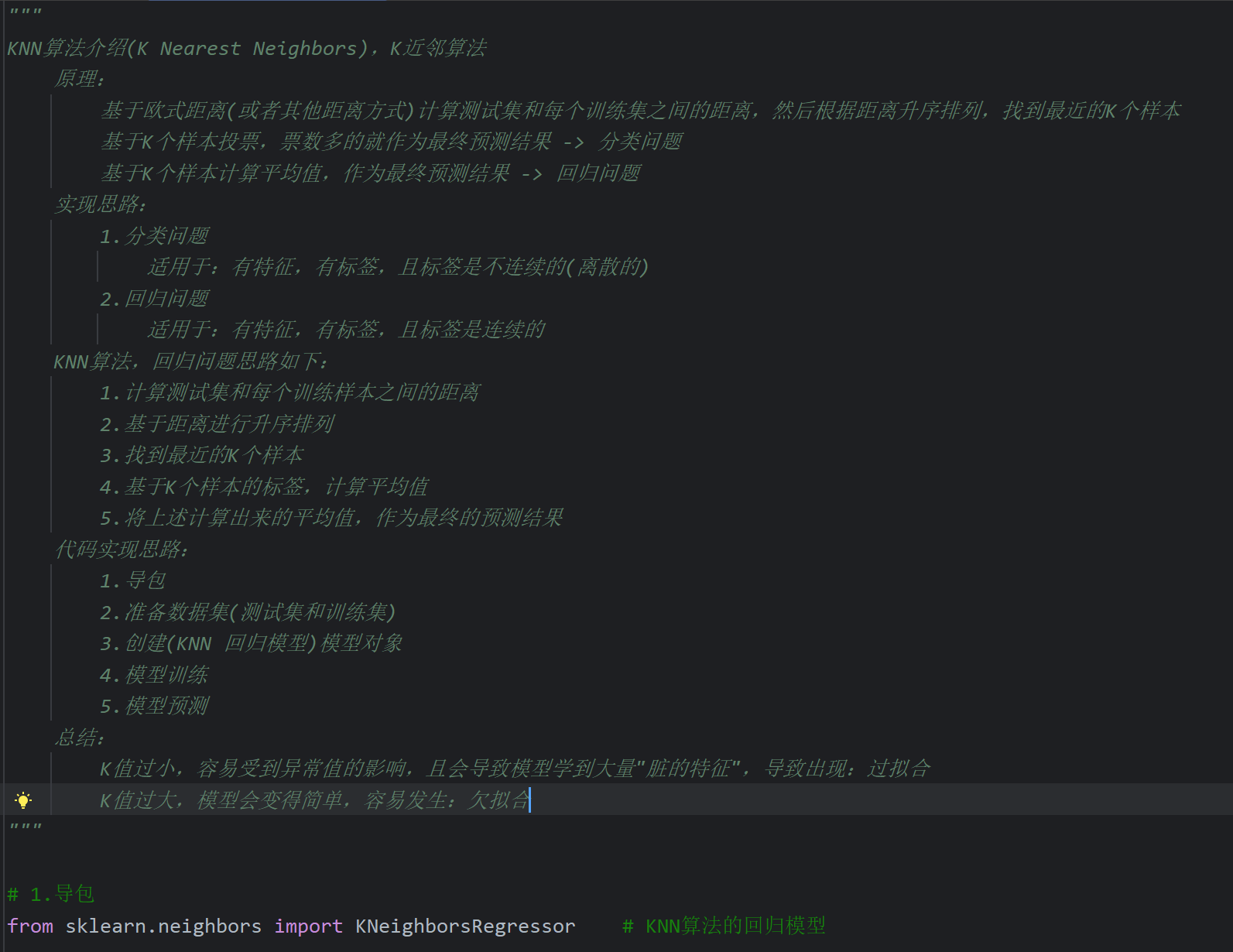
13、KNN算法_简介

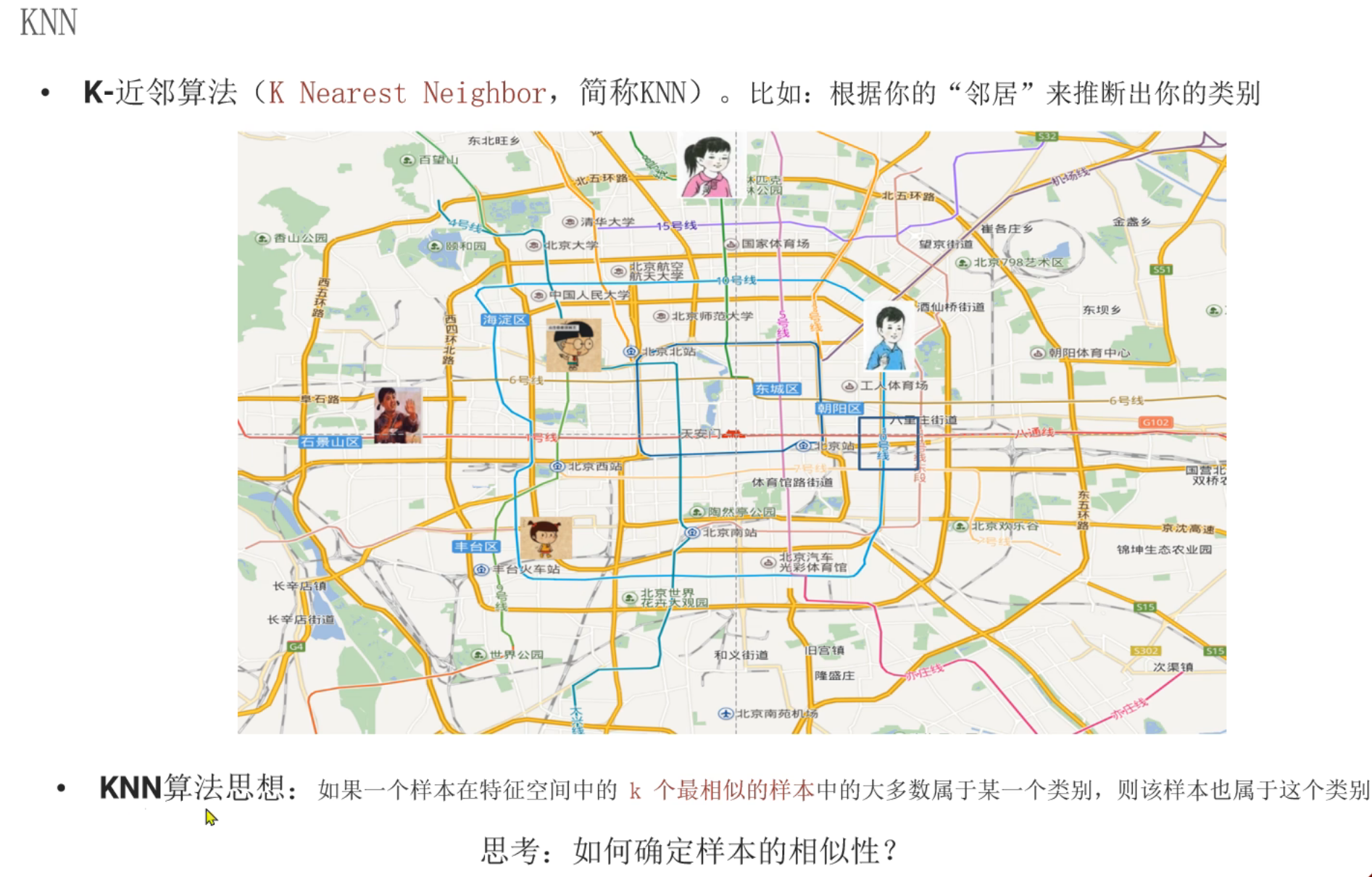
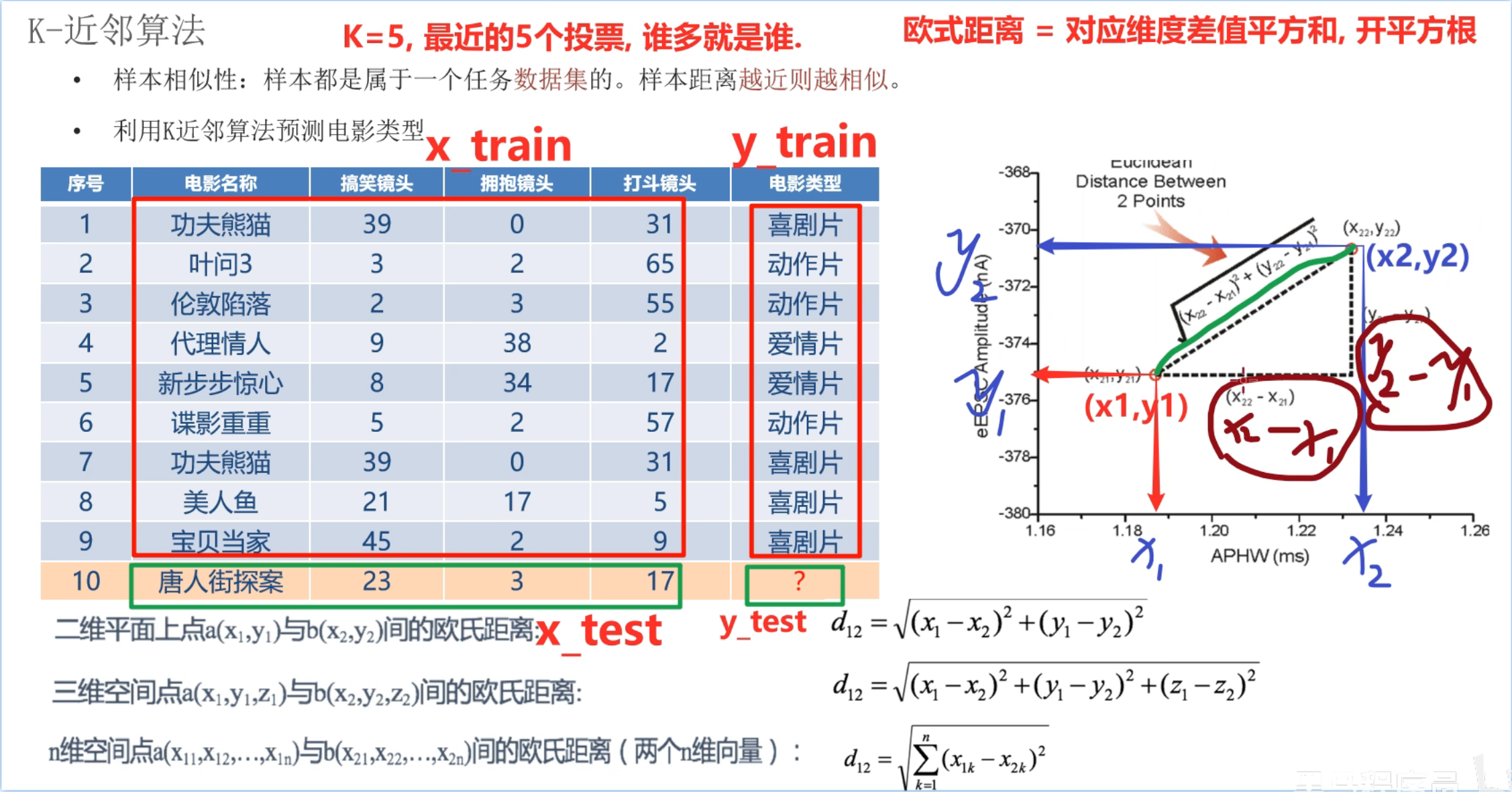
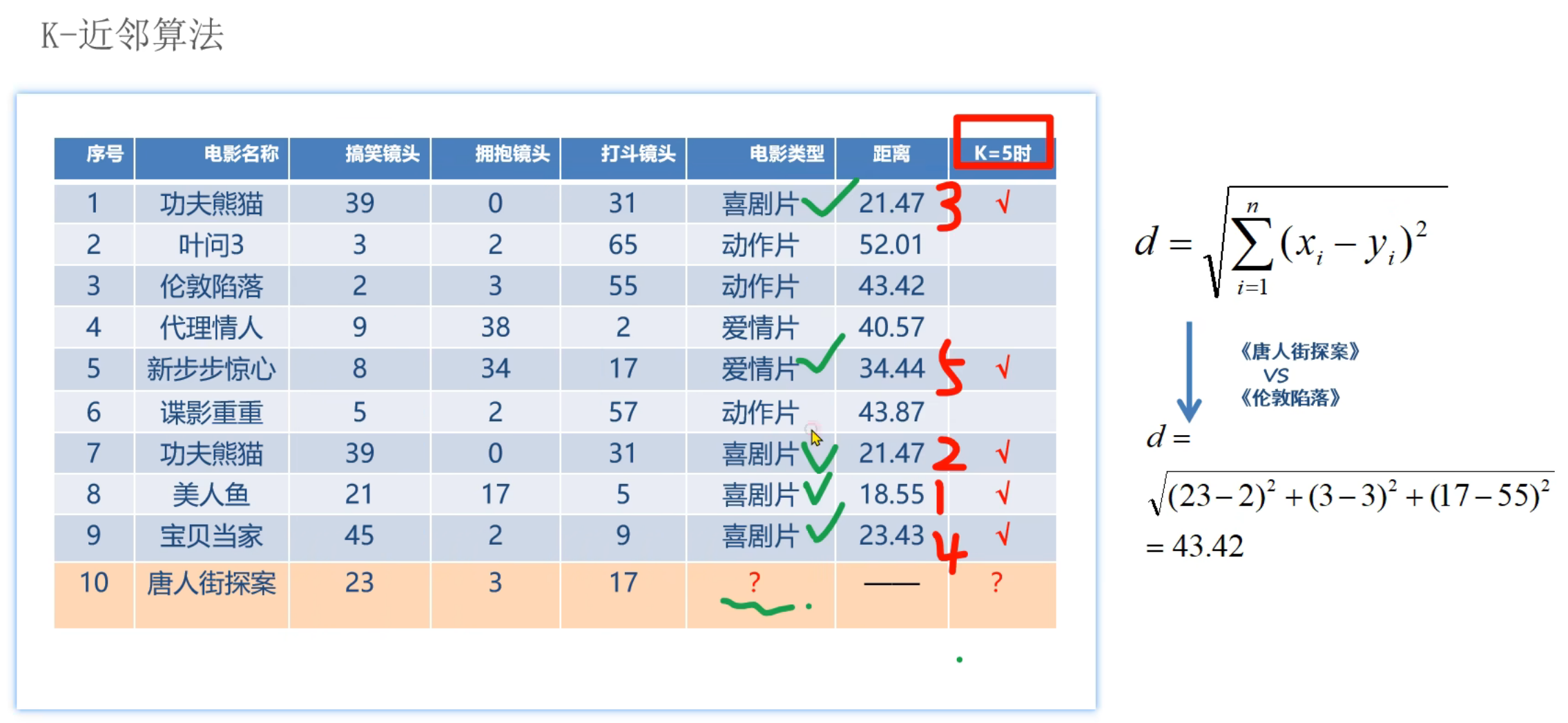
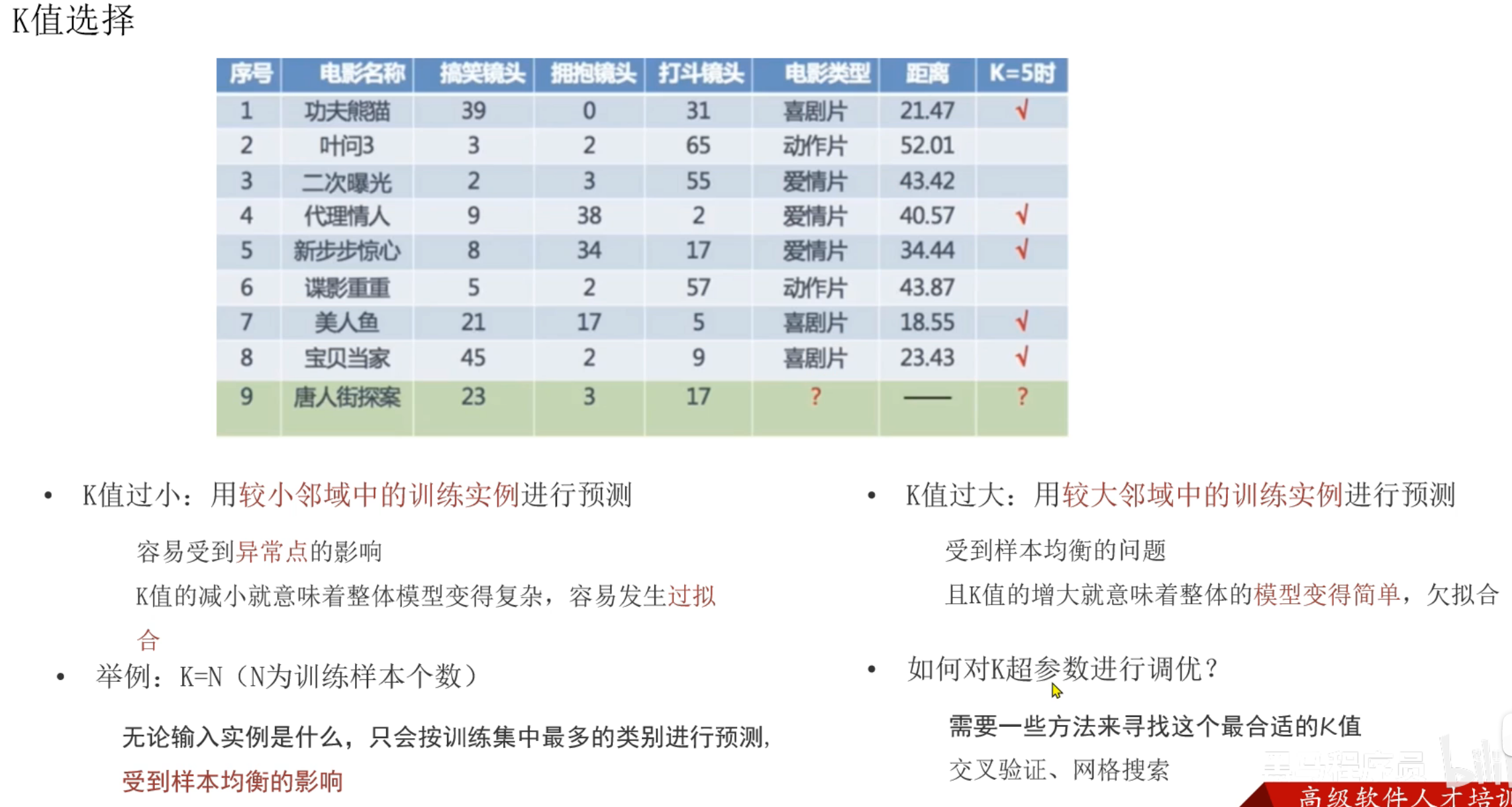
14、KNN算法_思路分析
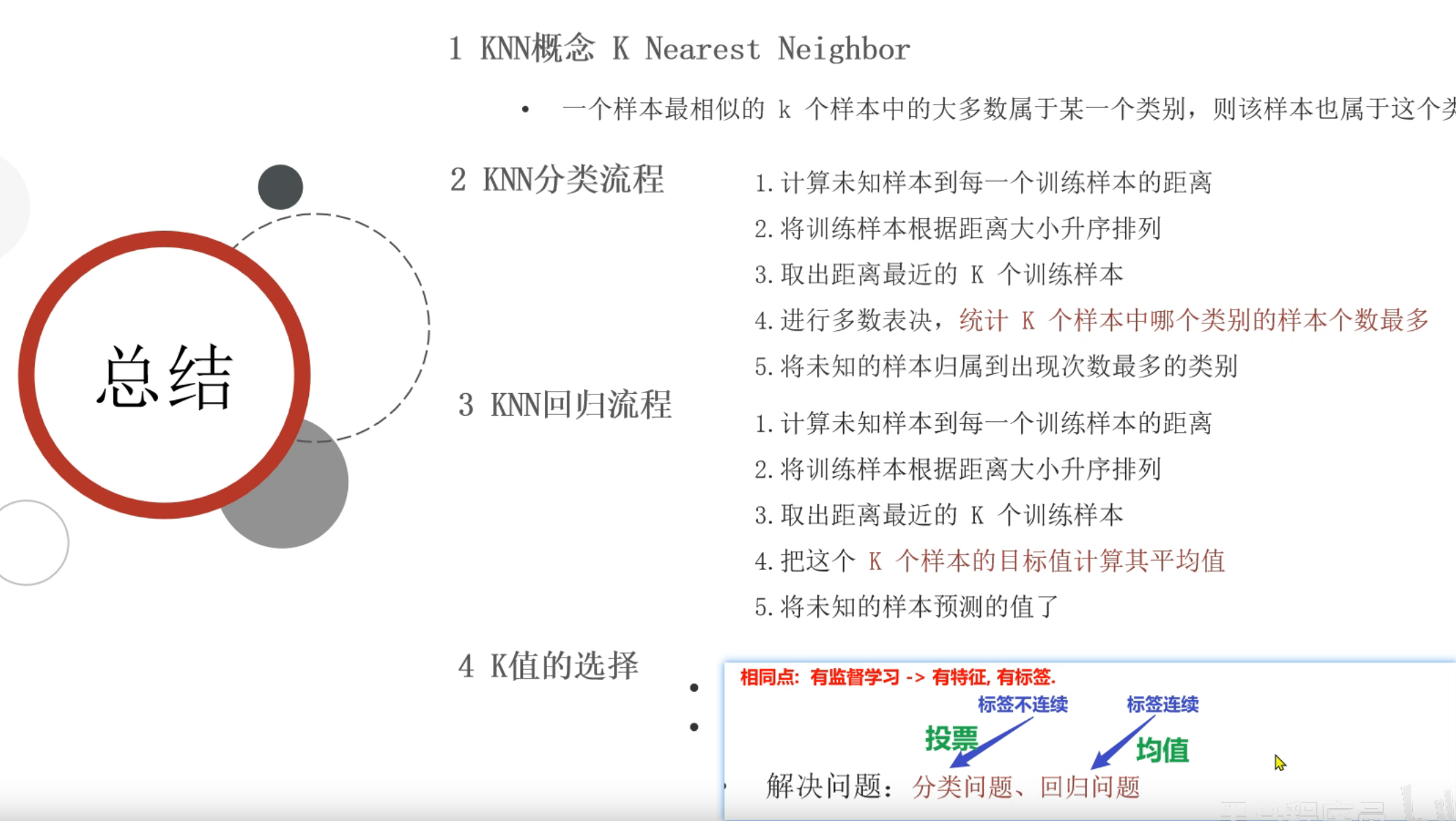


15、KNN算法_分类思想代码实现


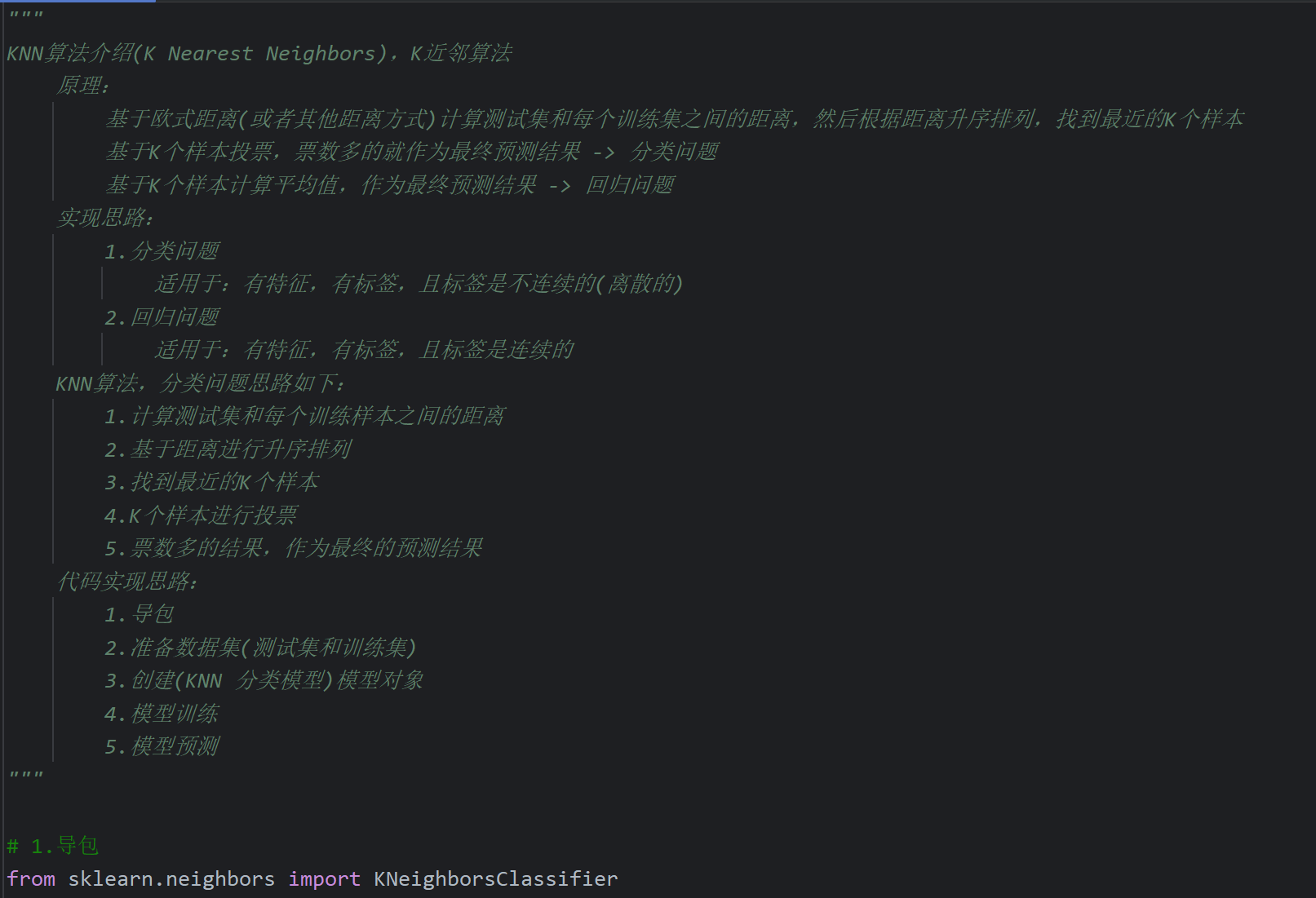
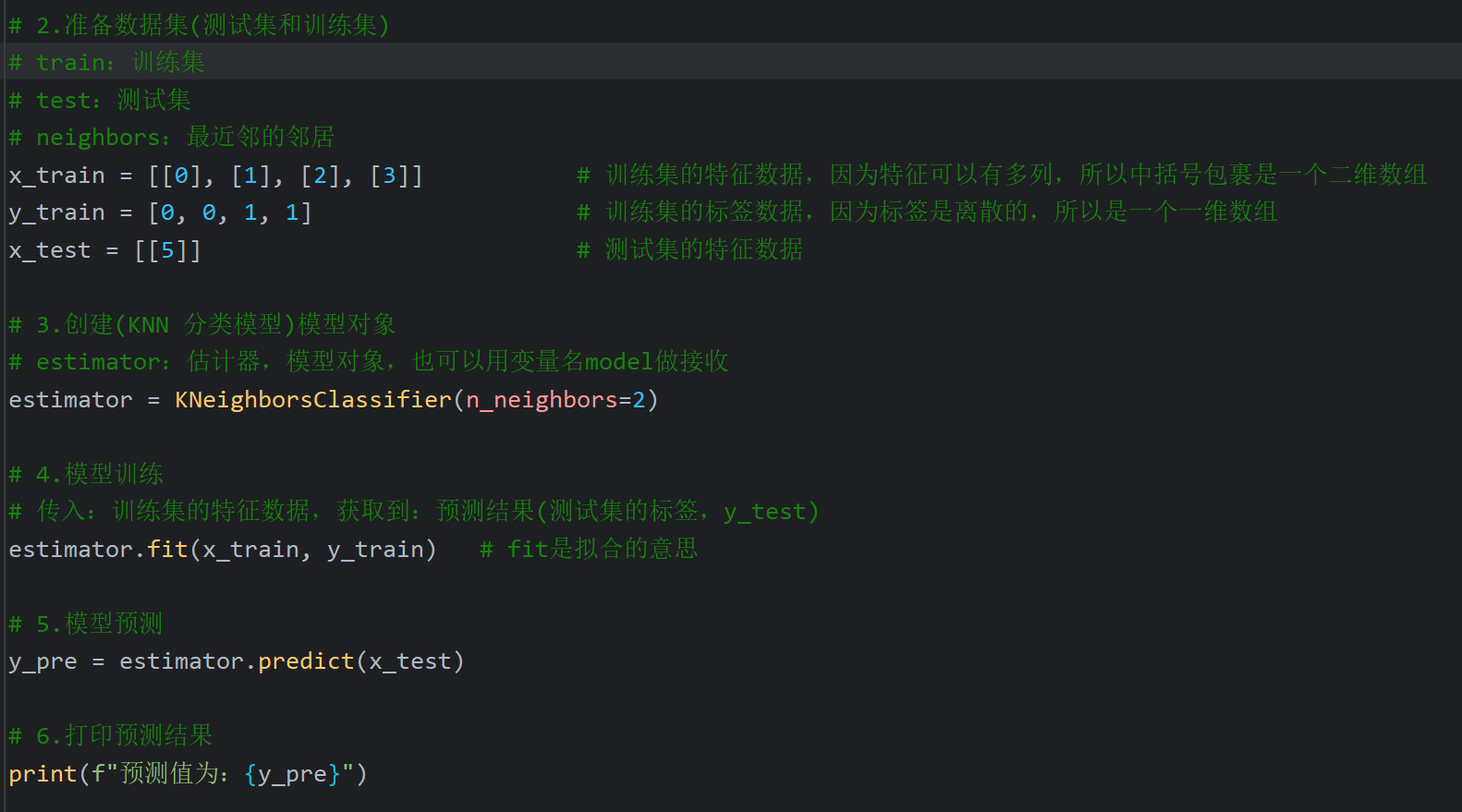
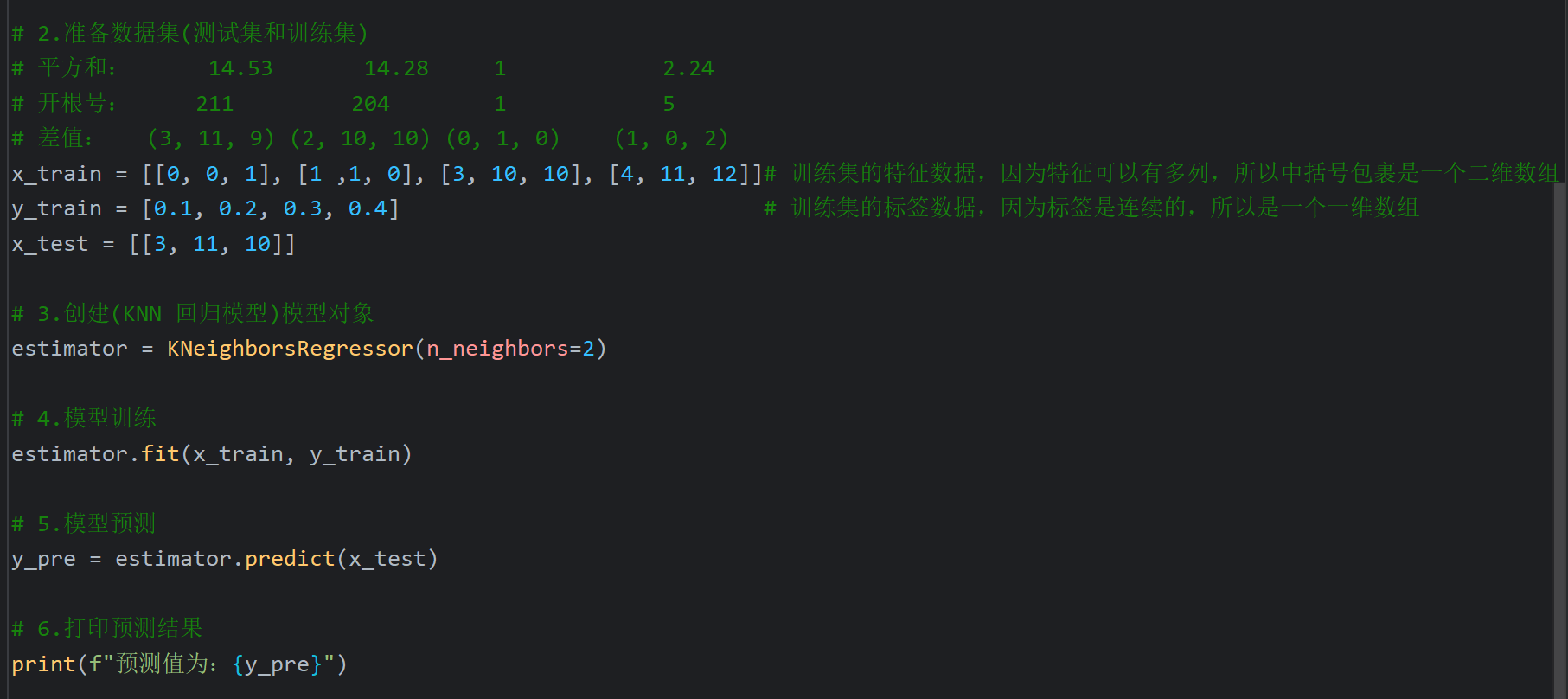
16、KNN算法_回归思想代码实现

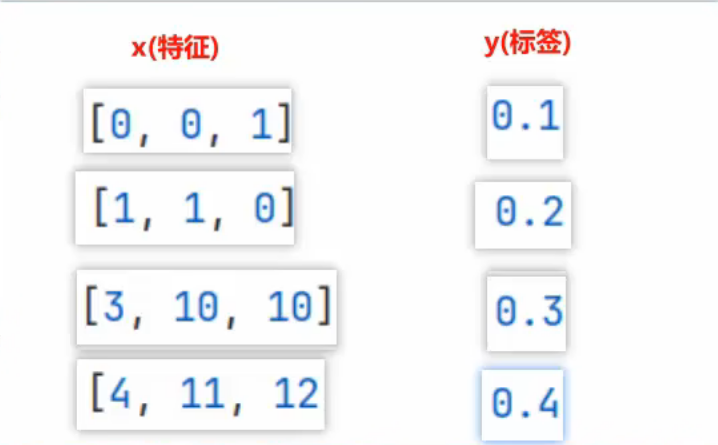


三、KNN算法
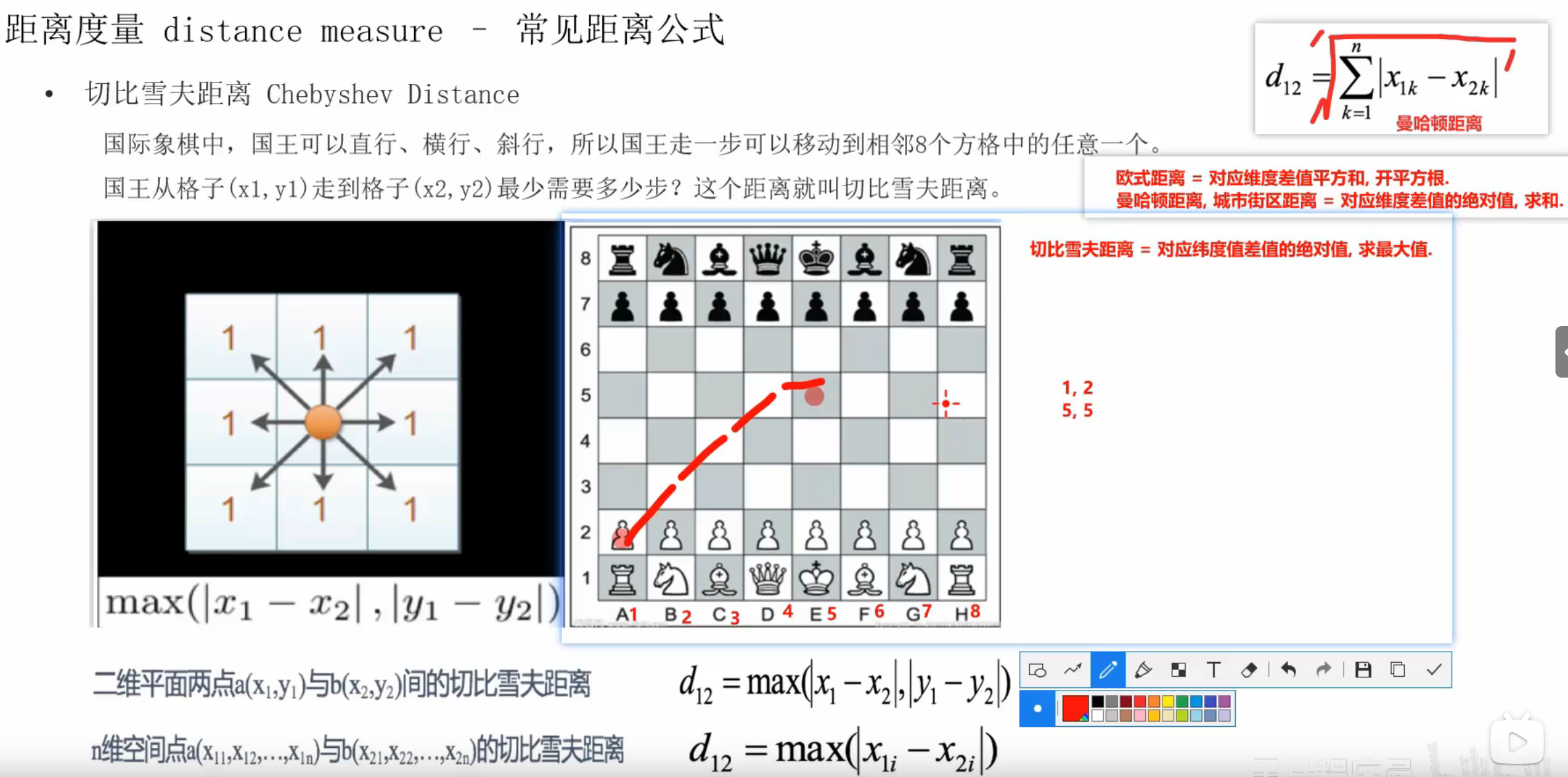
1、常用的距离度量方式
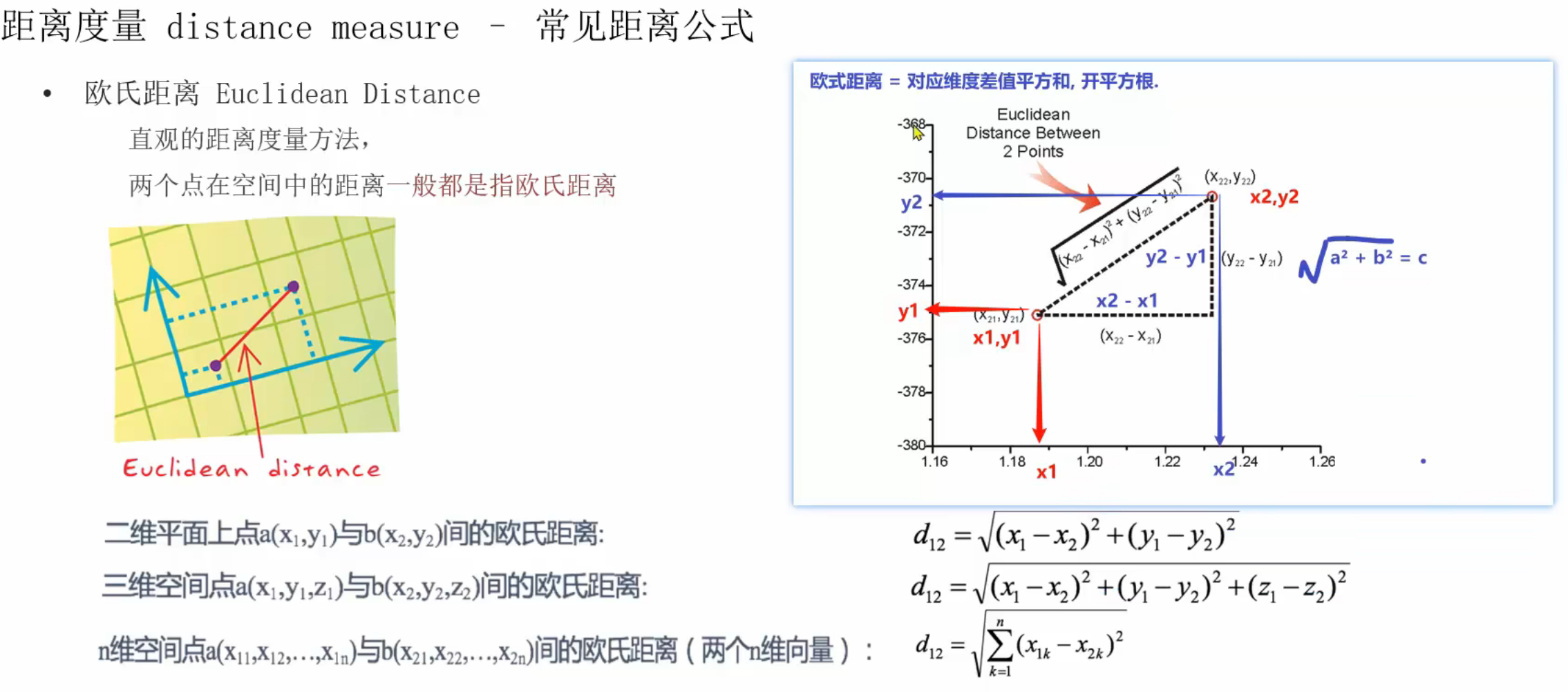
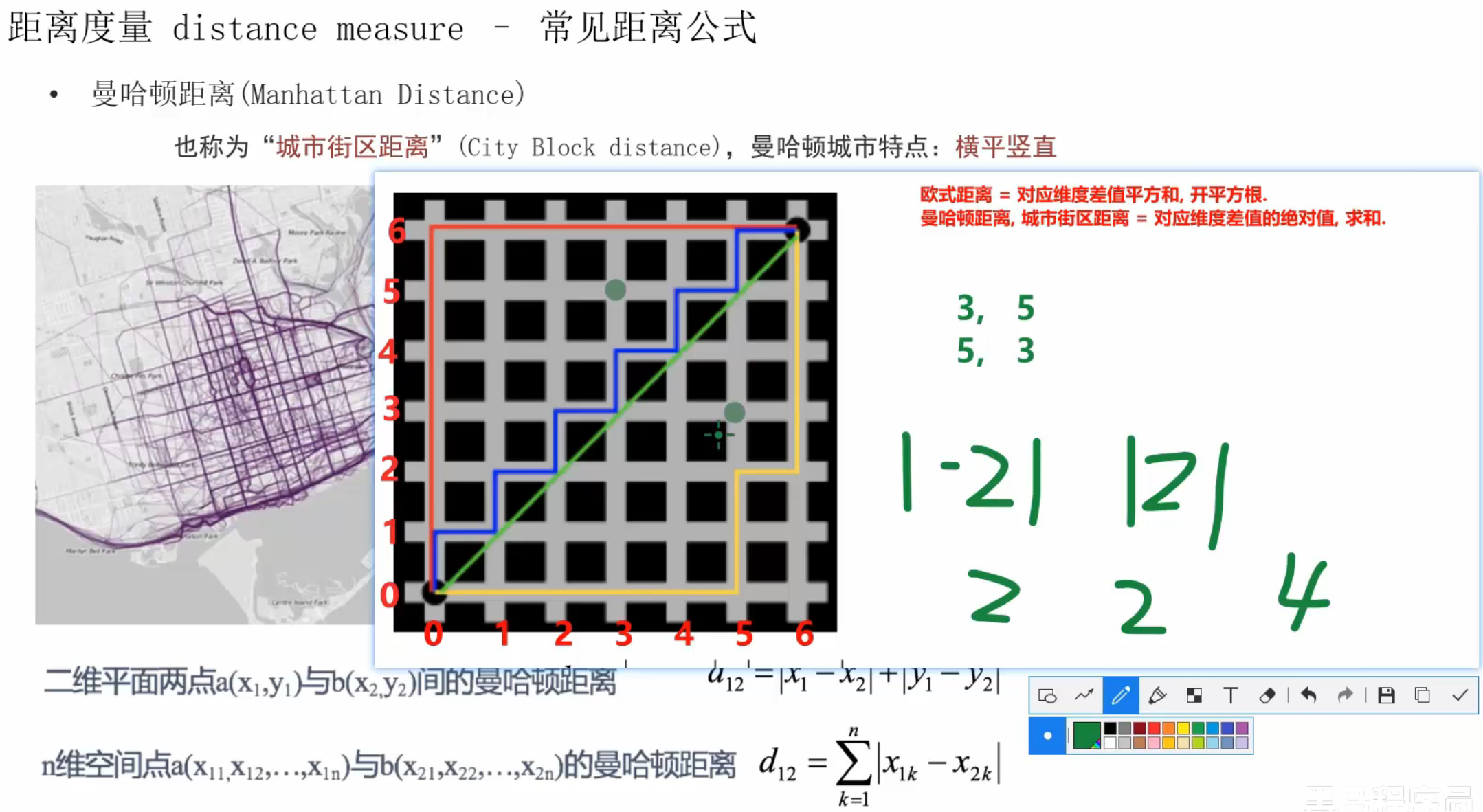
平方,再开平方根就是欧氏距离



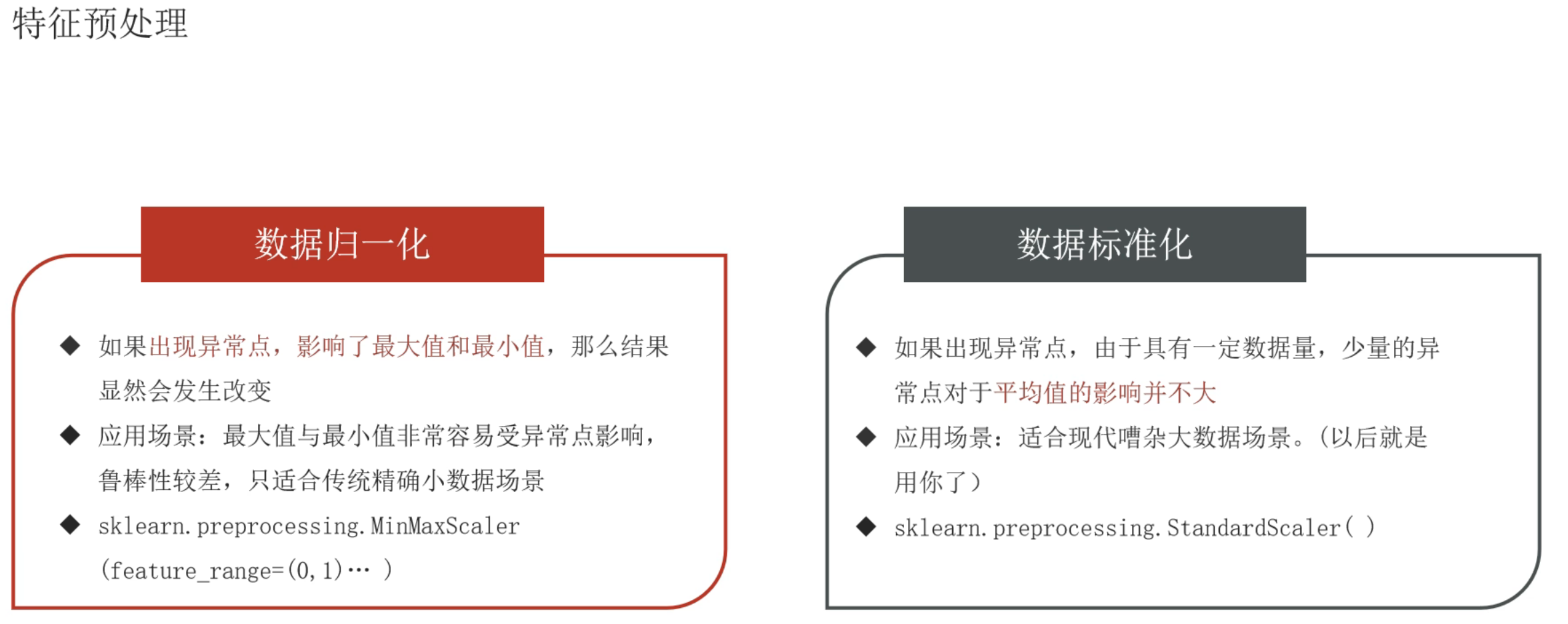
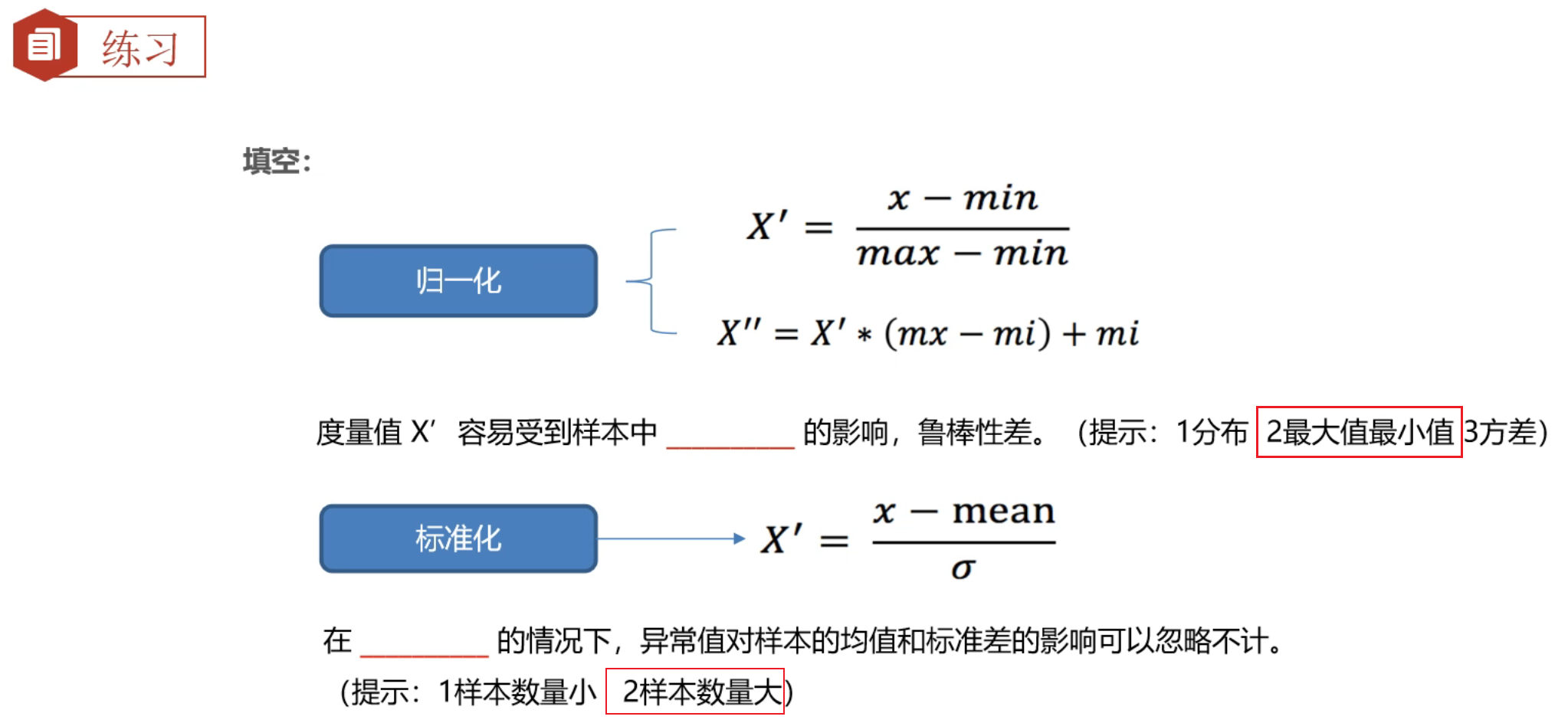
2、特征预处理_归一化
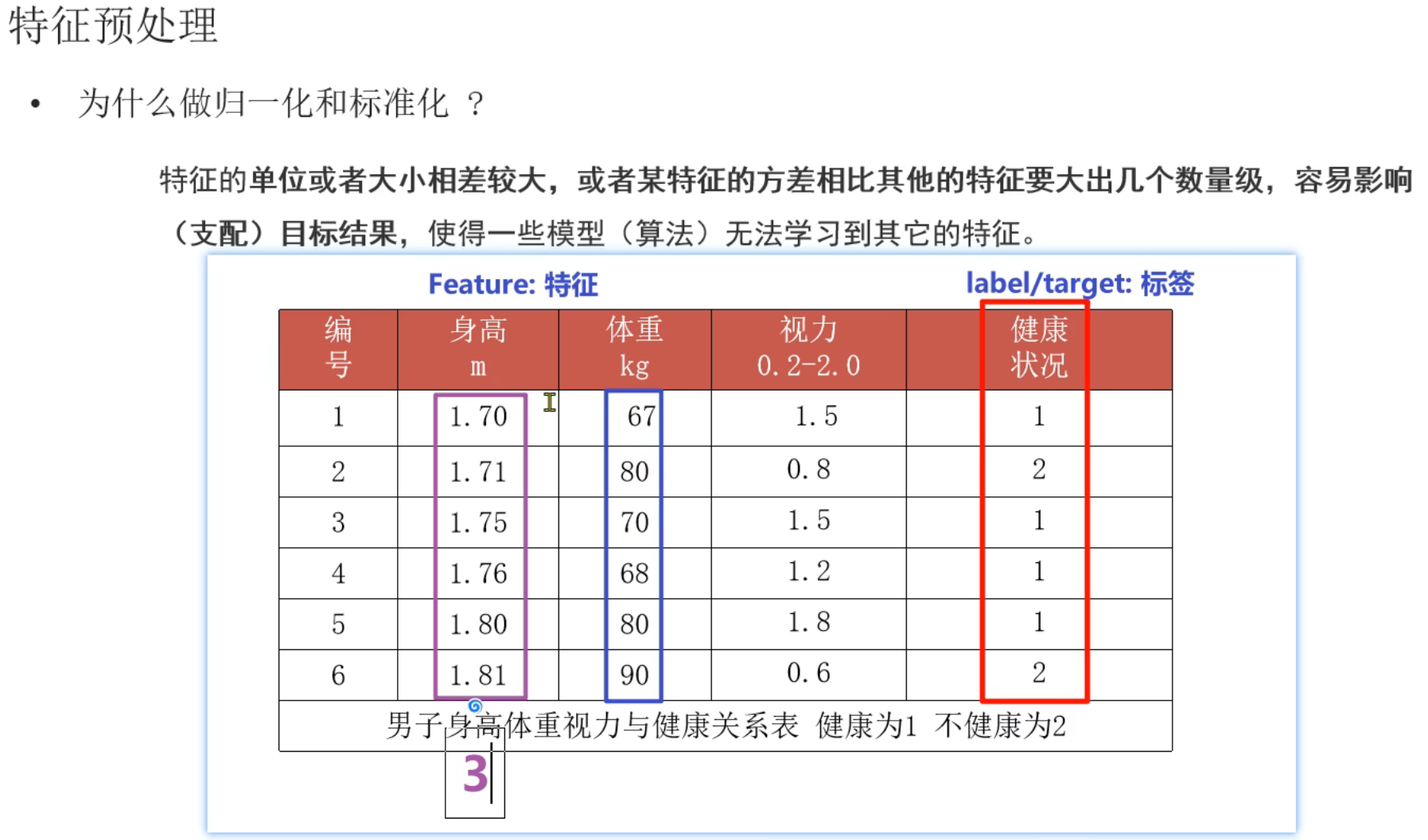
归一化适用于小数据集的处理,因为假设数据集有300W条数据,但是实际影响结果的主要是最大值和最小值,与数据条数没有关系。同时因为主要由最大值和最小值影响,所以如果出现恰好最大值和最小值是异常值的情况归一化就很不准确了。最常用的是标准化,并且标准化适用于大数据集的处理


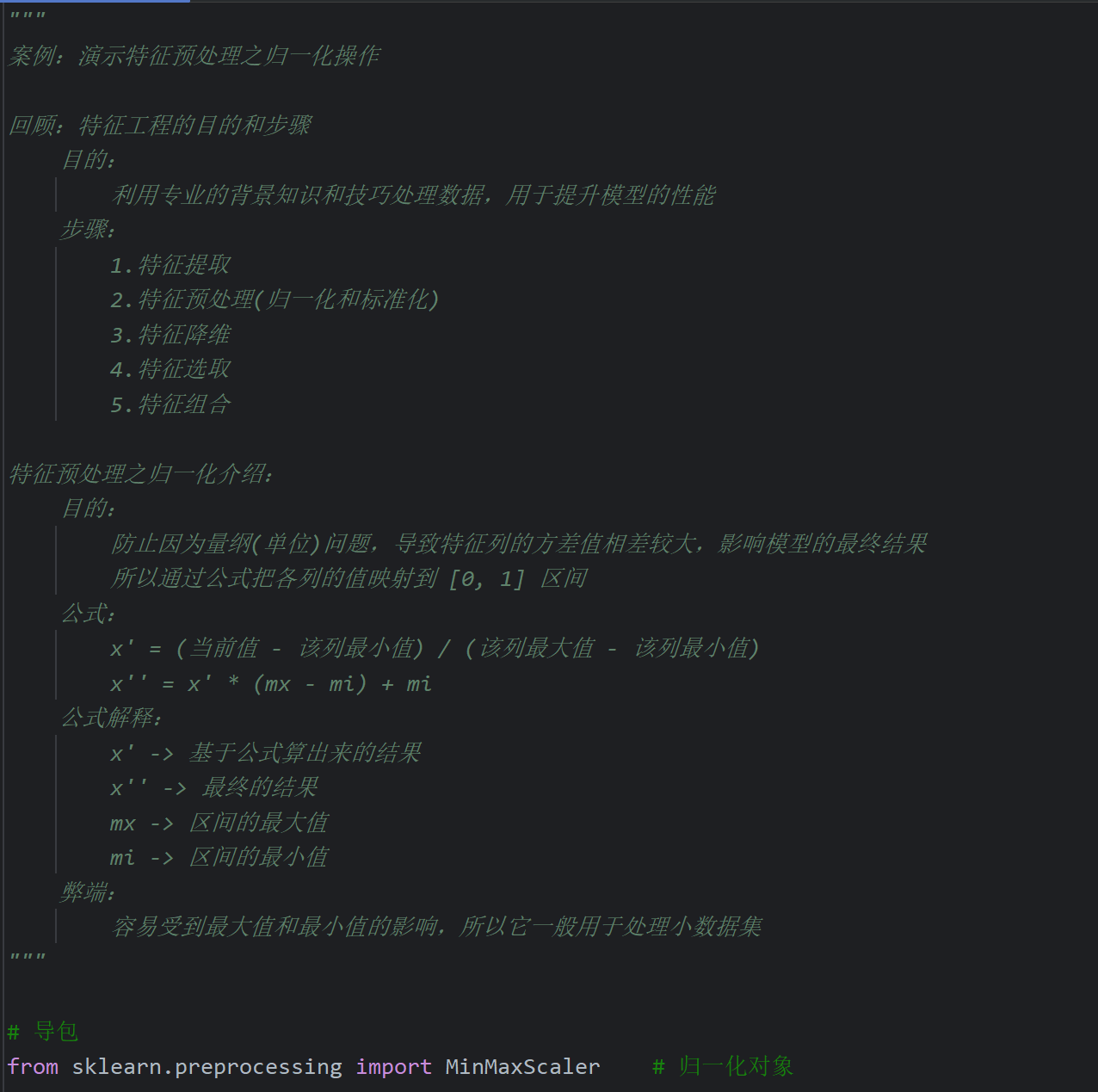
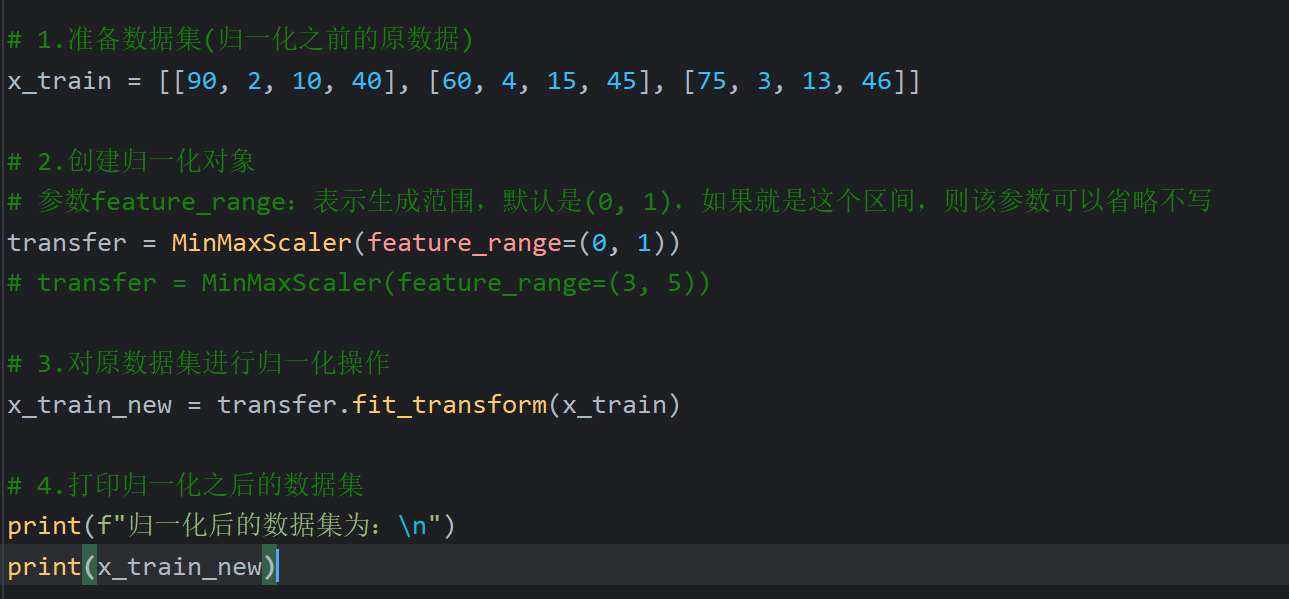
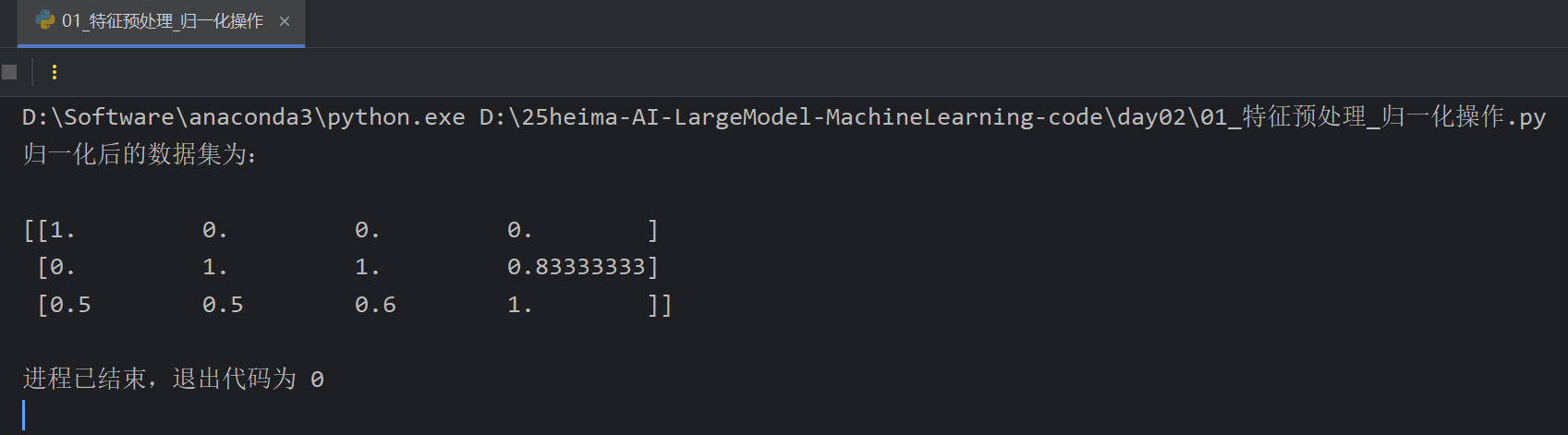
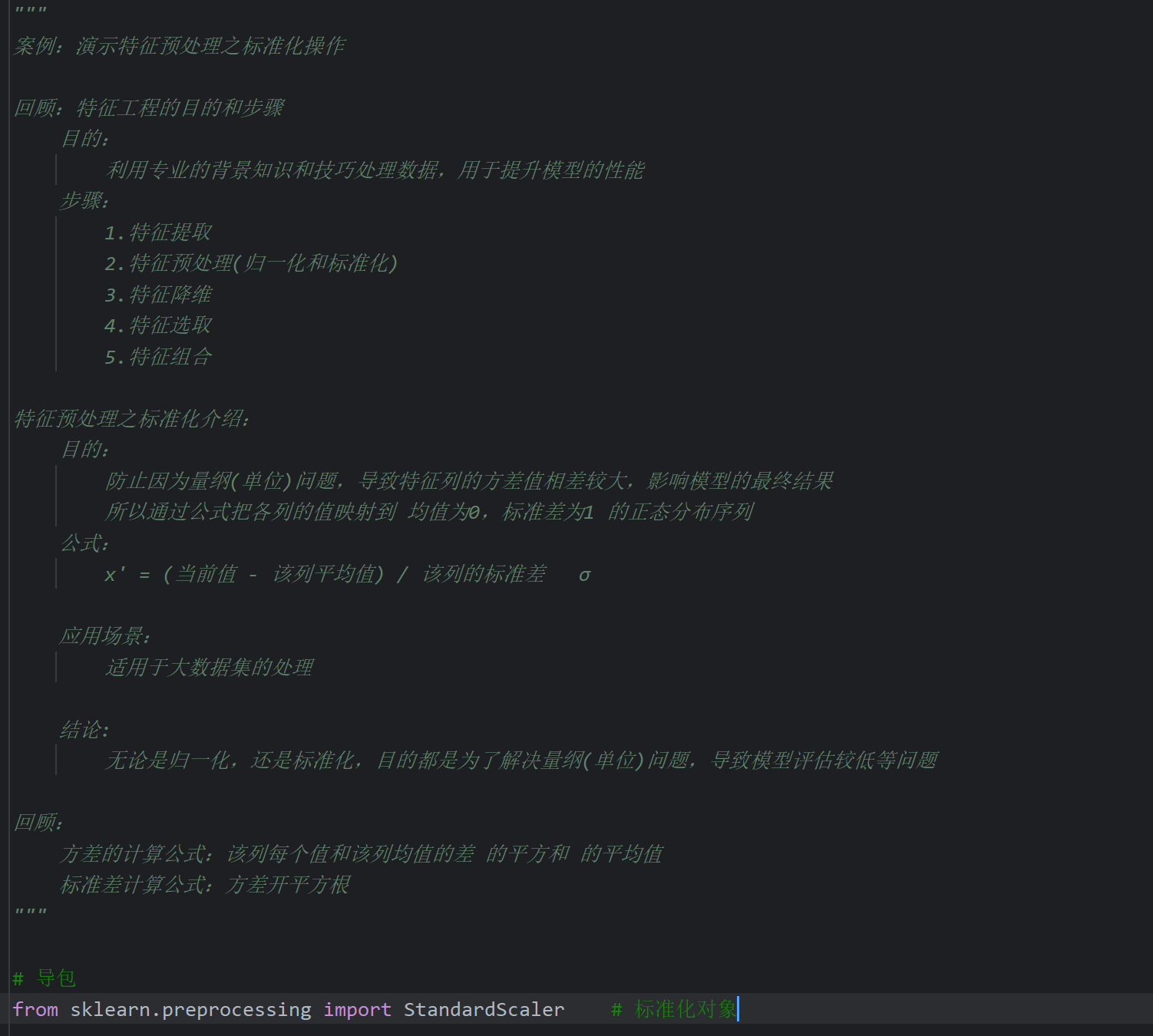
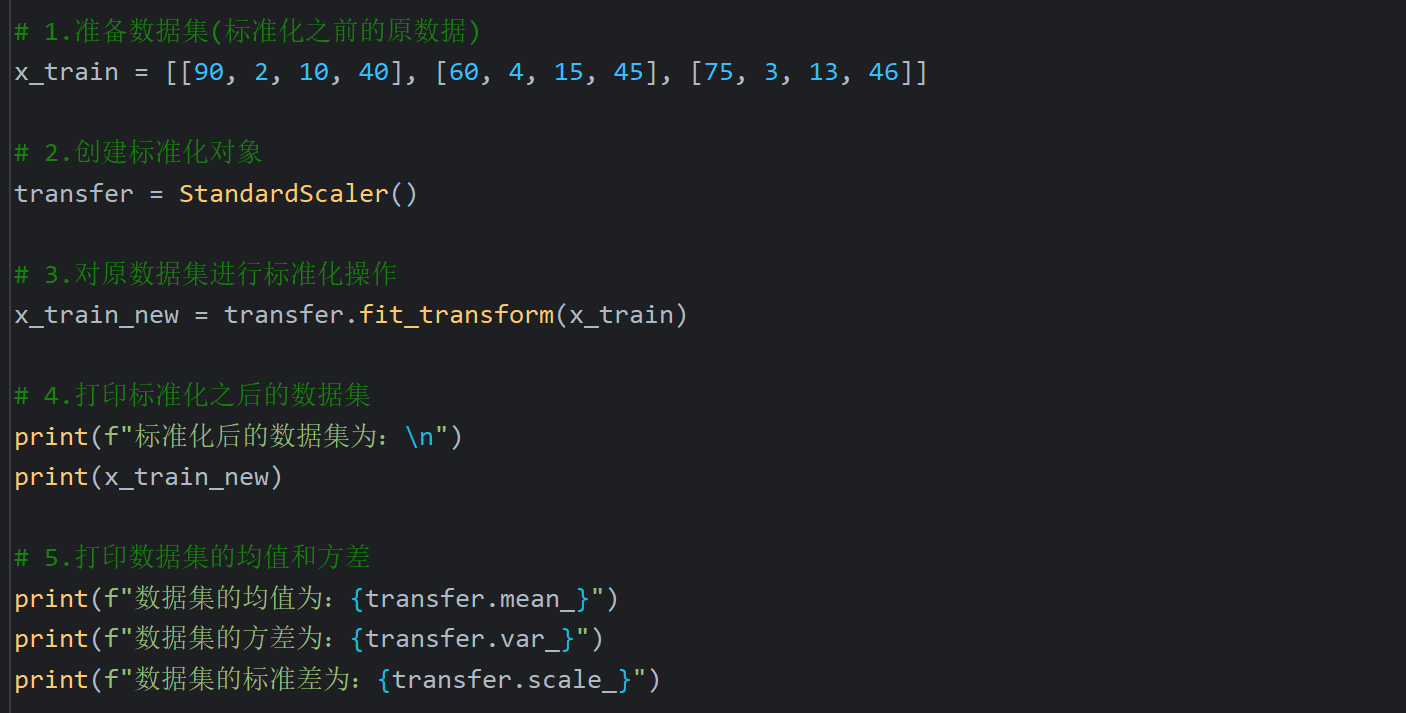
3、特征预处理_标准化

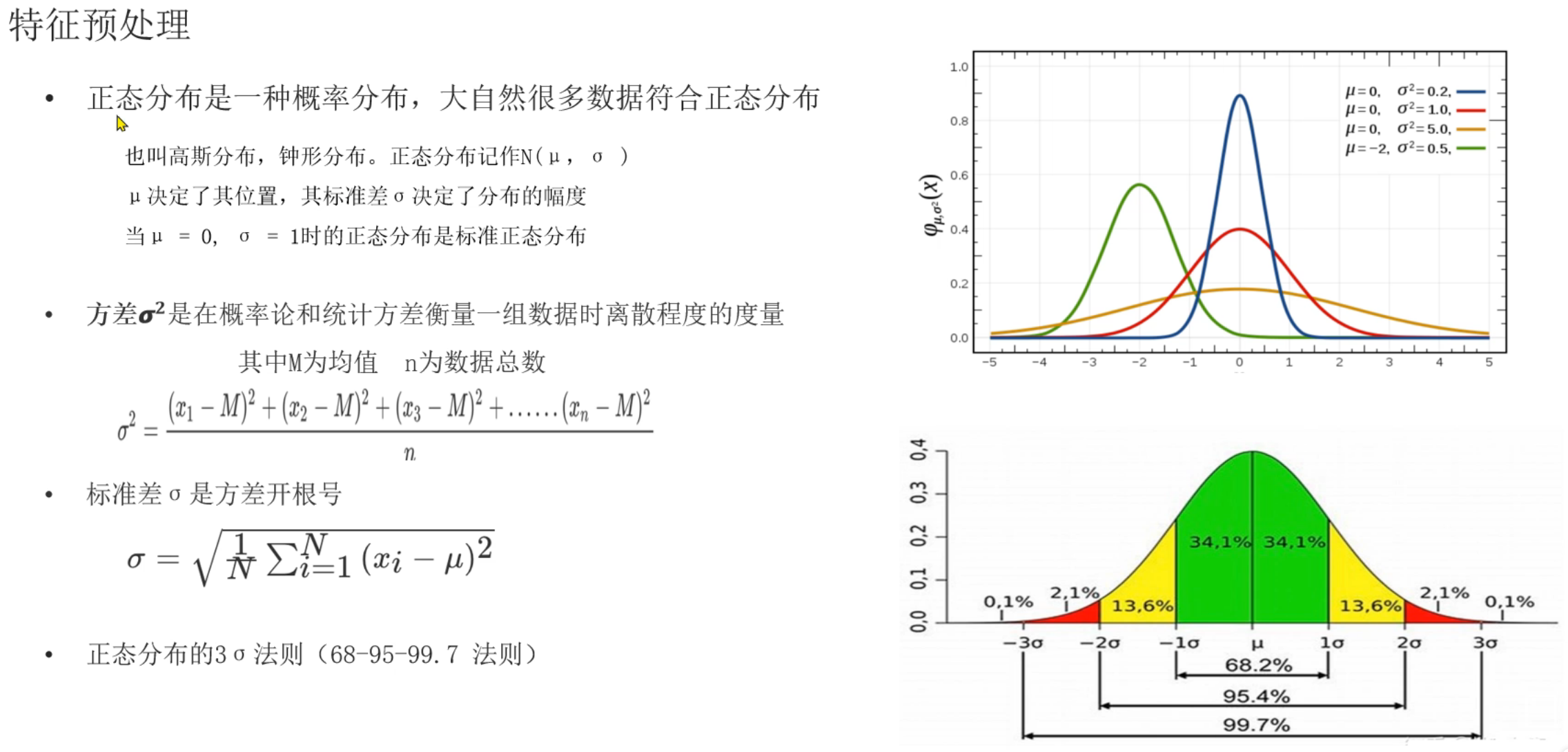

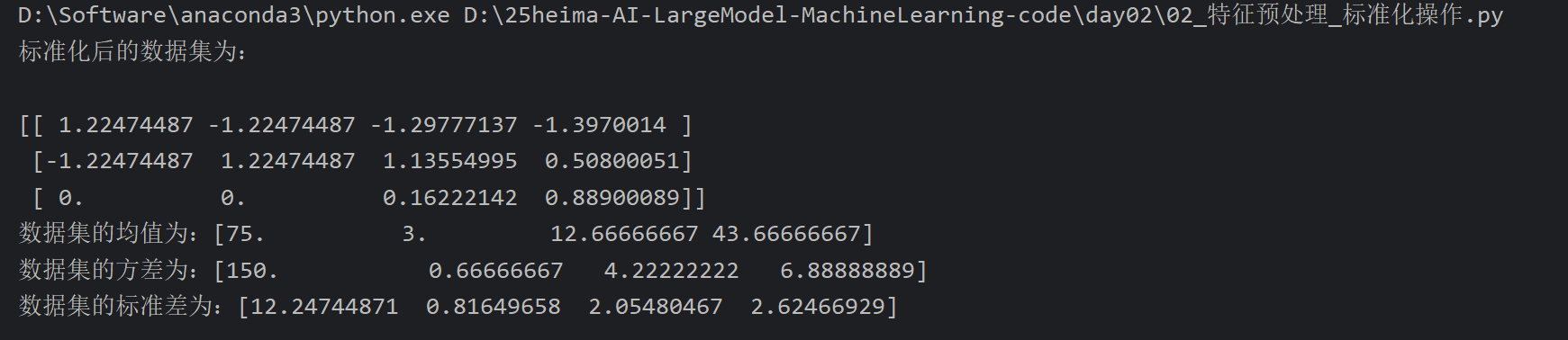
4、鸢尾花案例_查看数据集

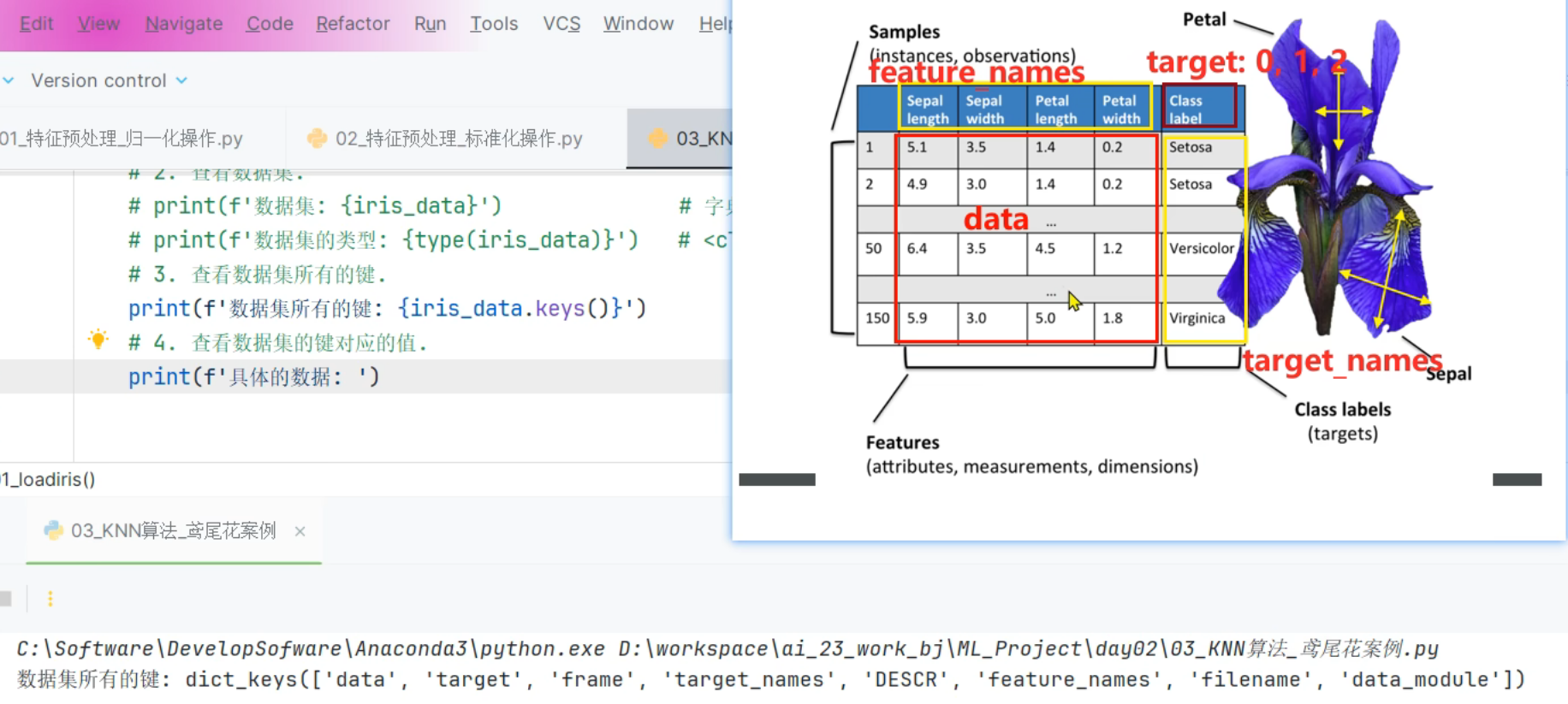
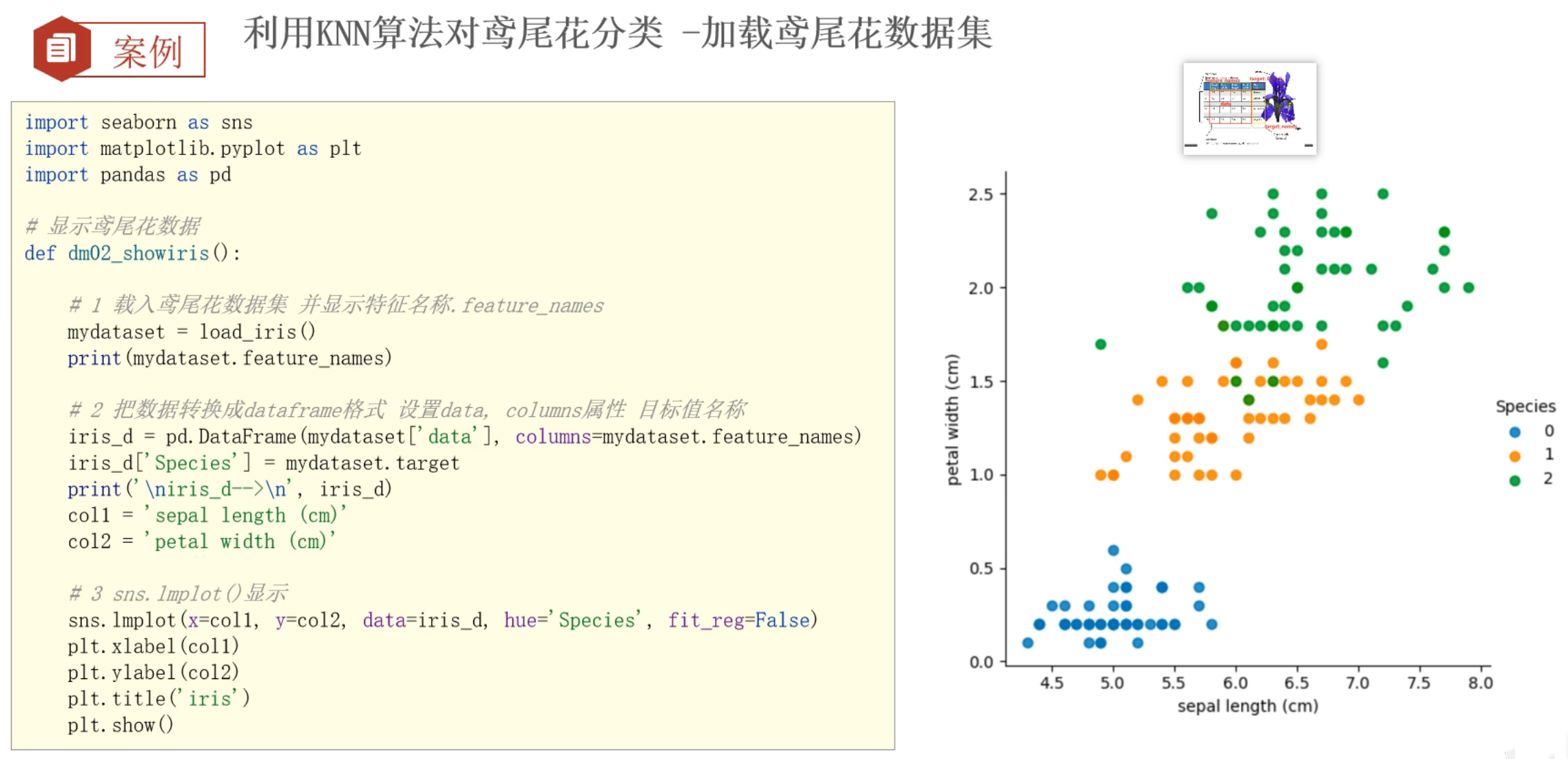
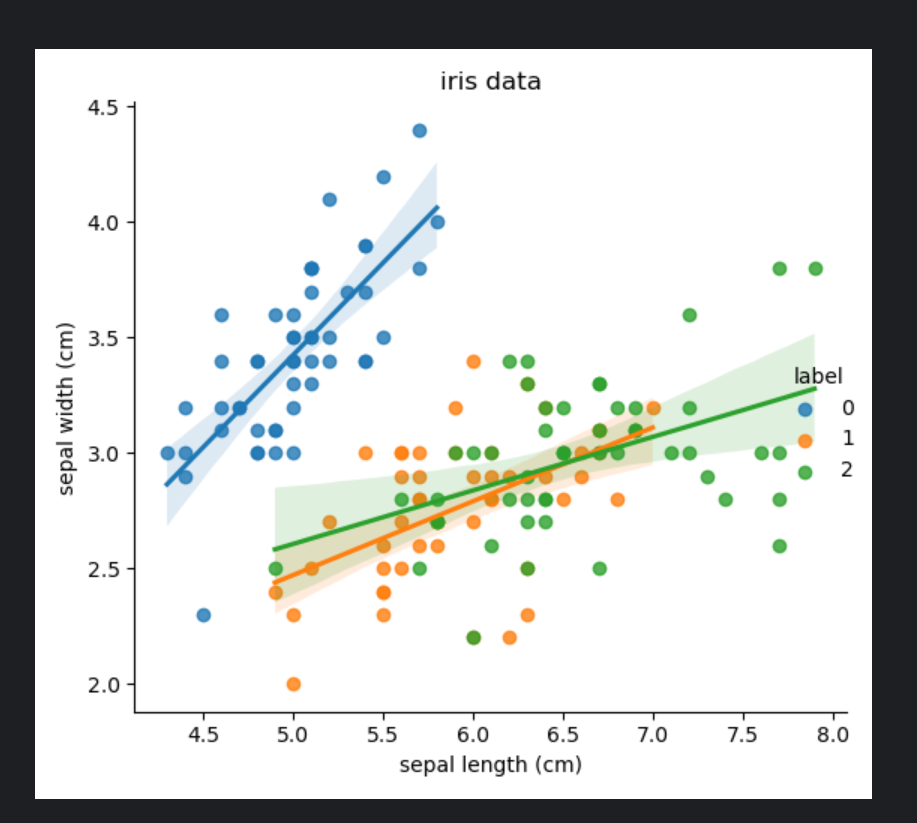
5、鸢尾花案例_数据集可视化
6、鸢尾花案例_切分训练集和数据集

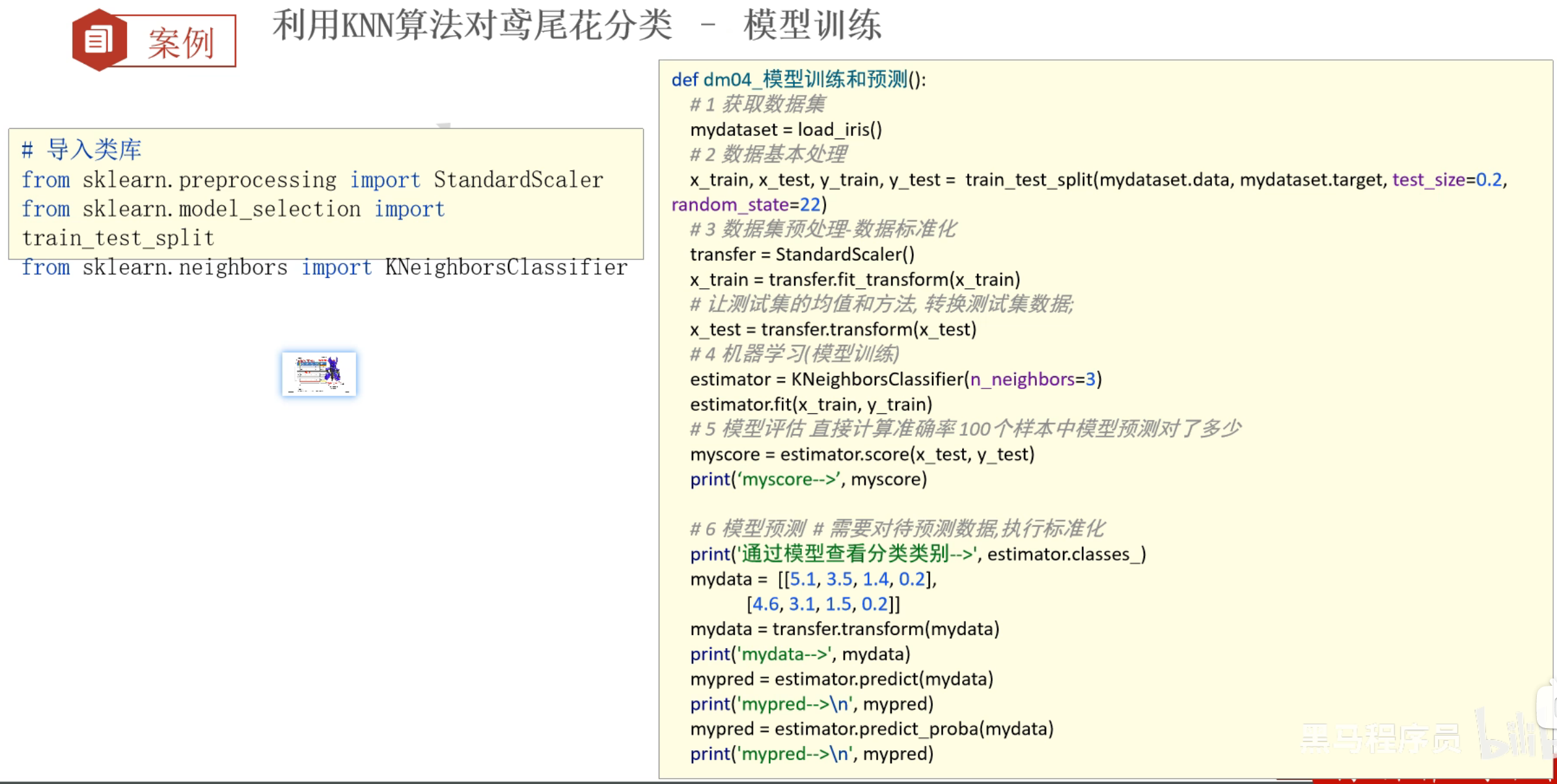
7、鸢尾花案例_模型的评估和预测
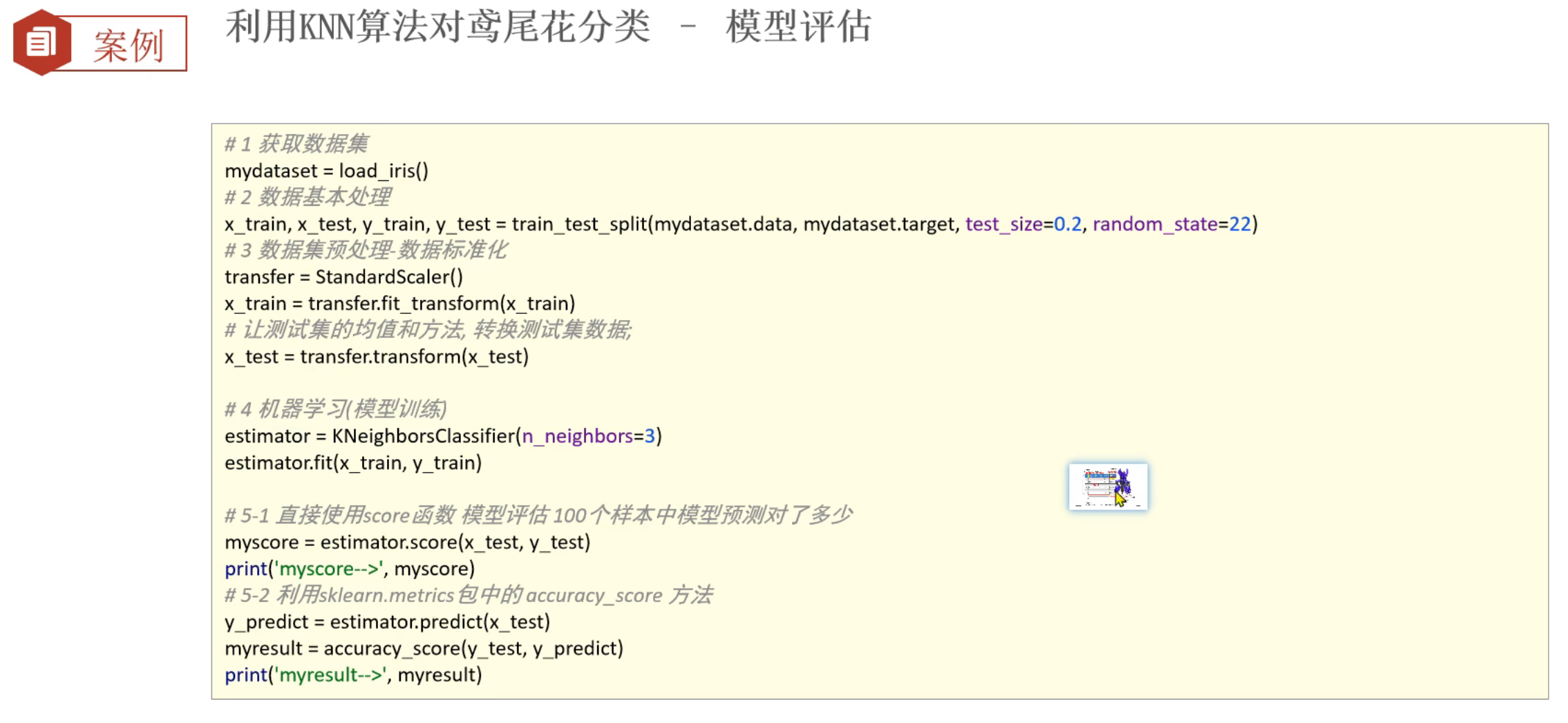
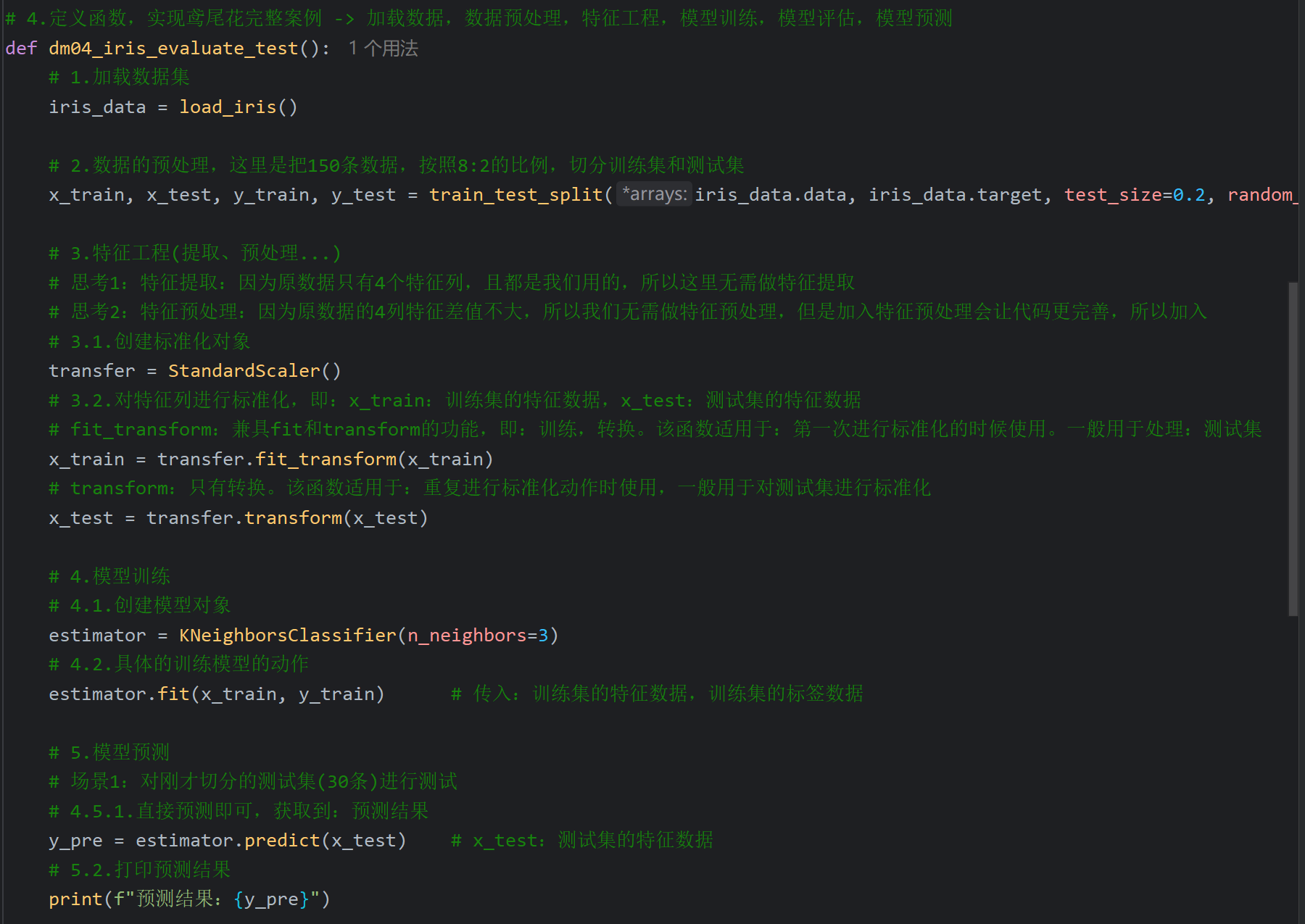
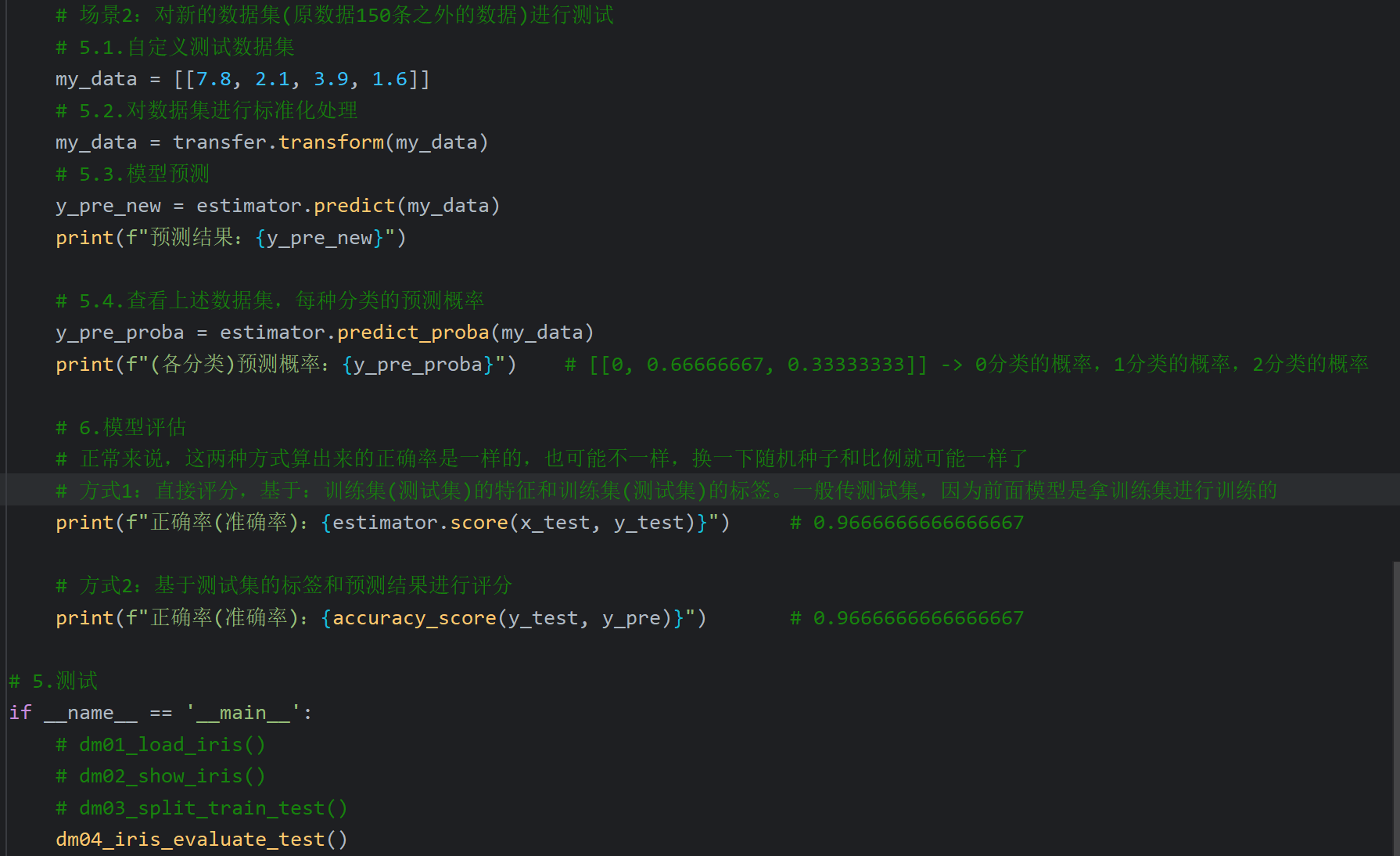
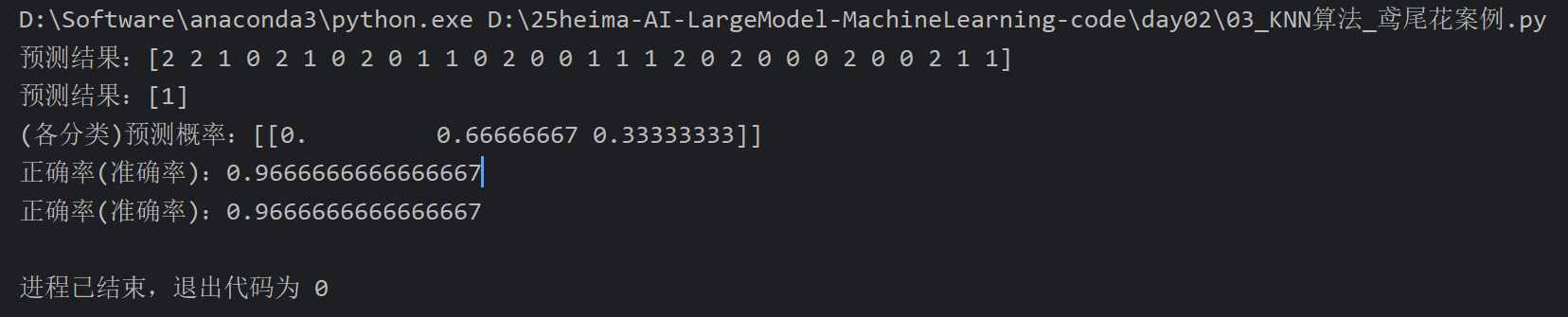

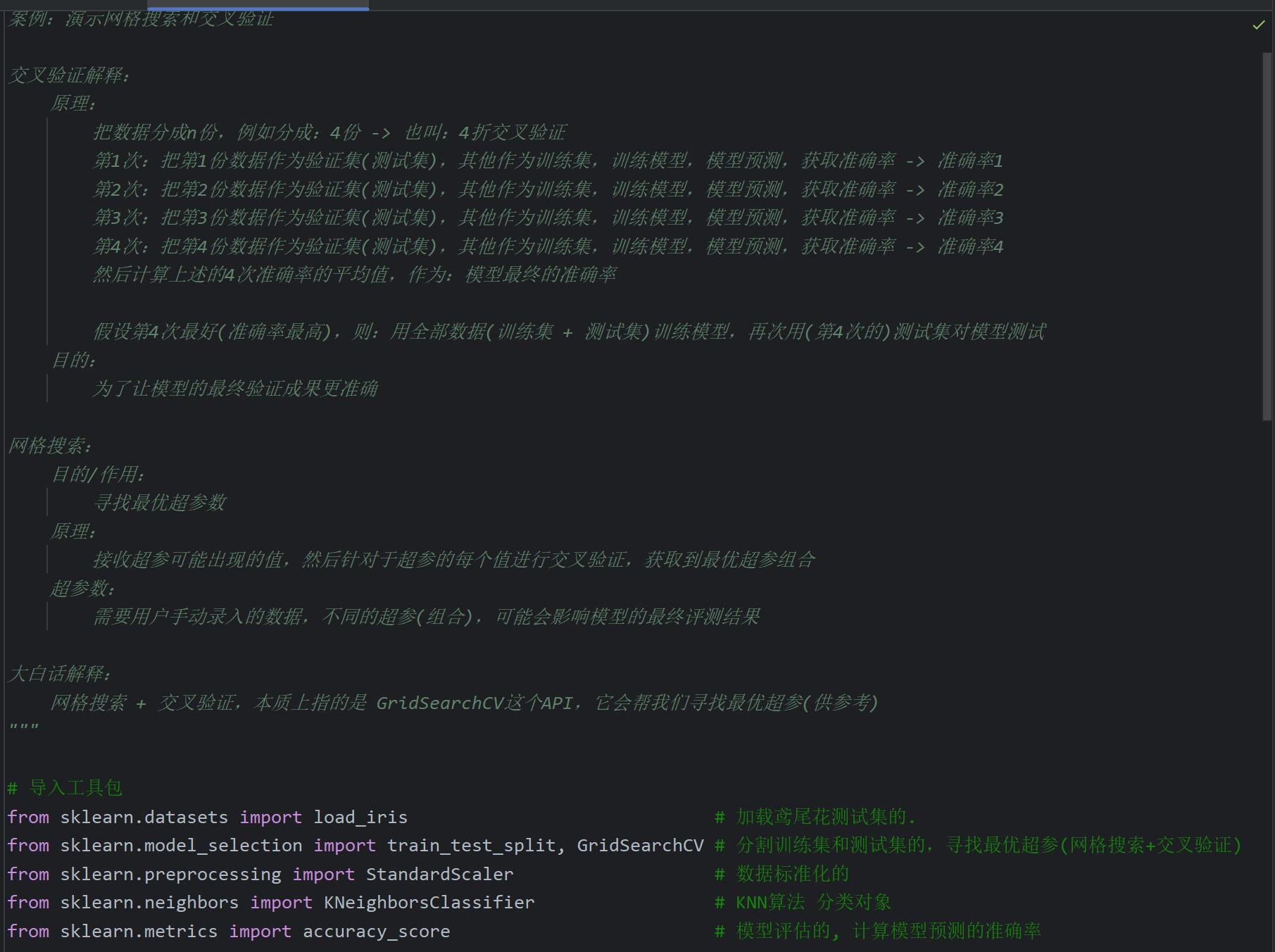
8、交叉验证和网格搜索_介绍



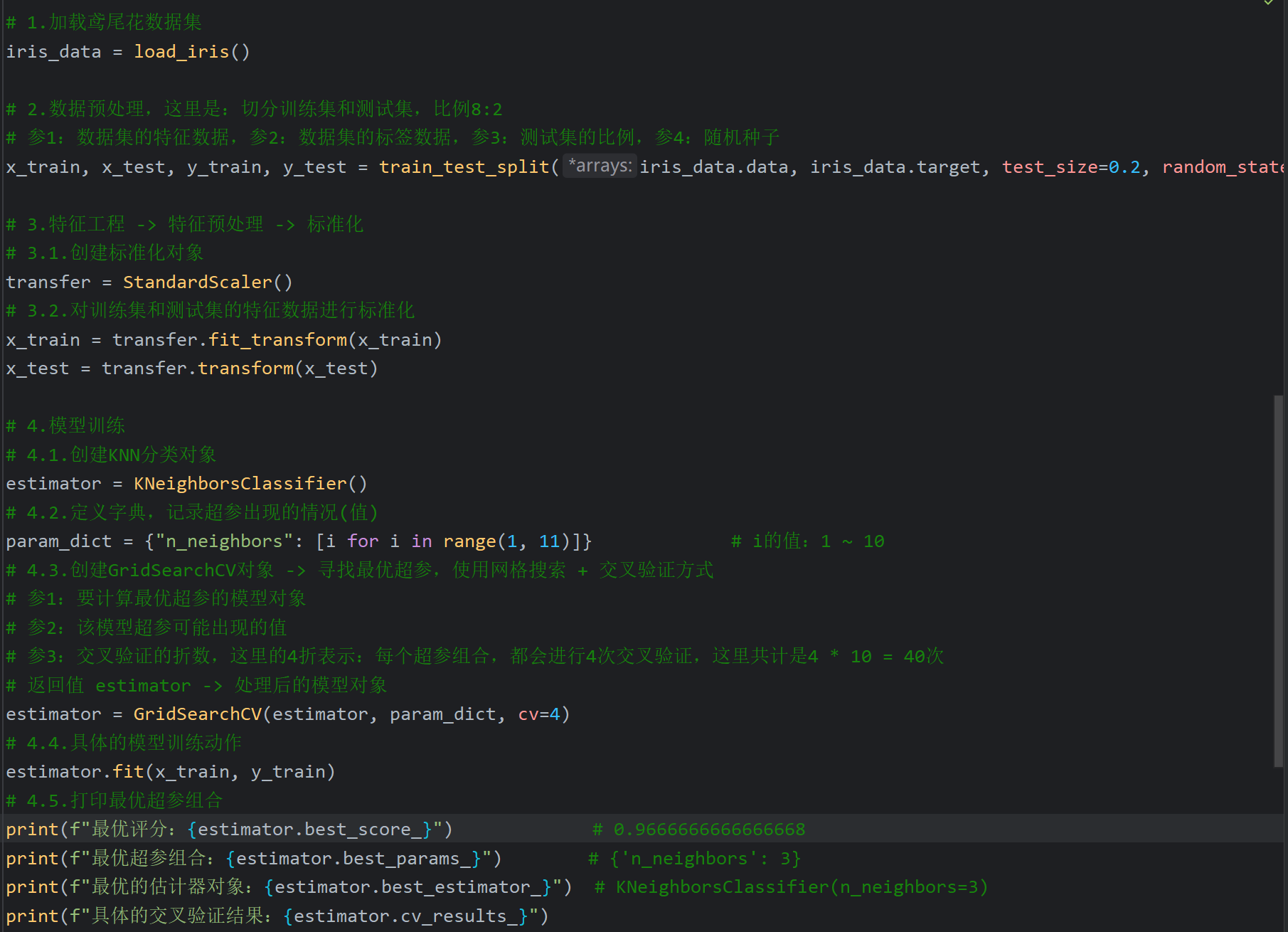
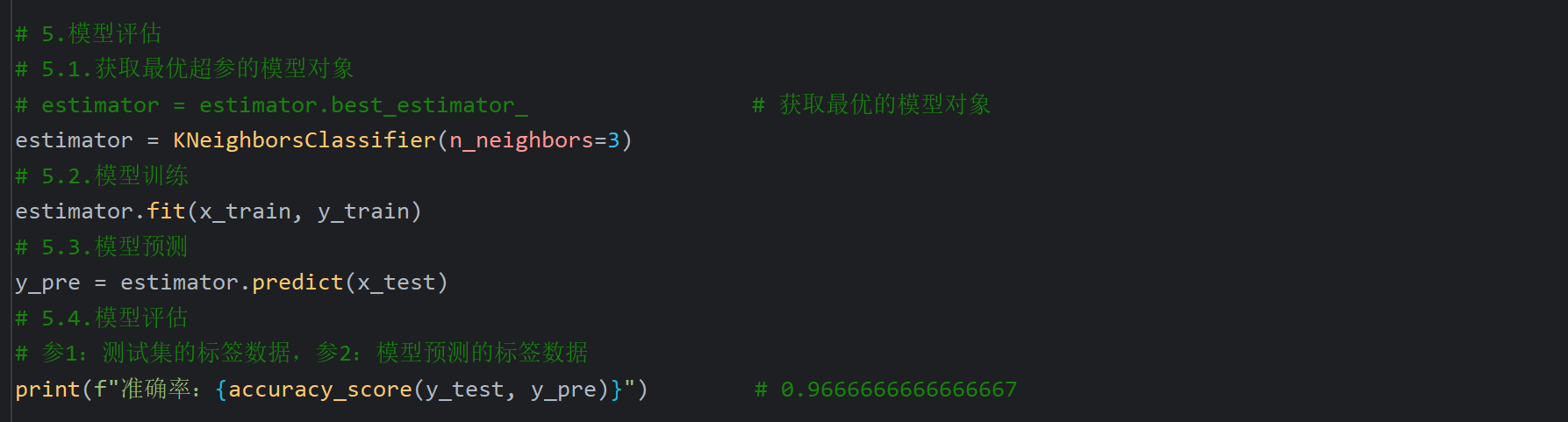
9、交叉验证和网格搜索_代码实现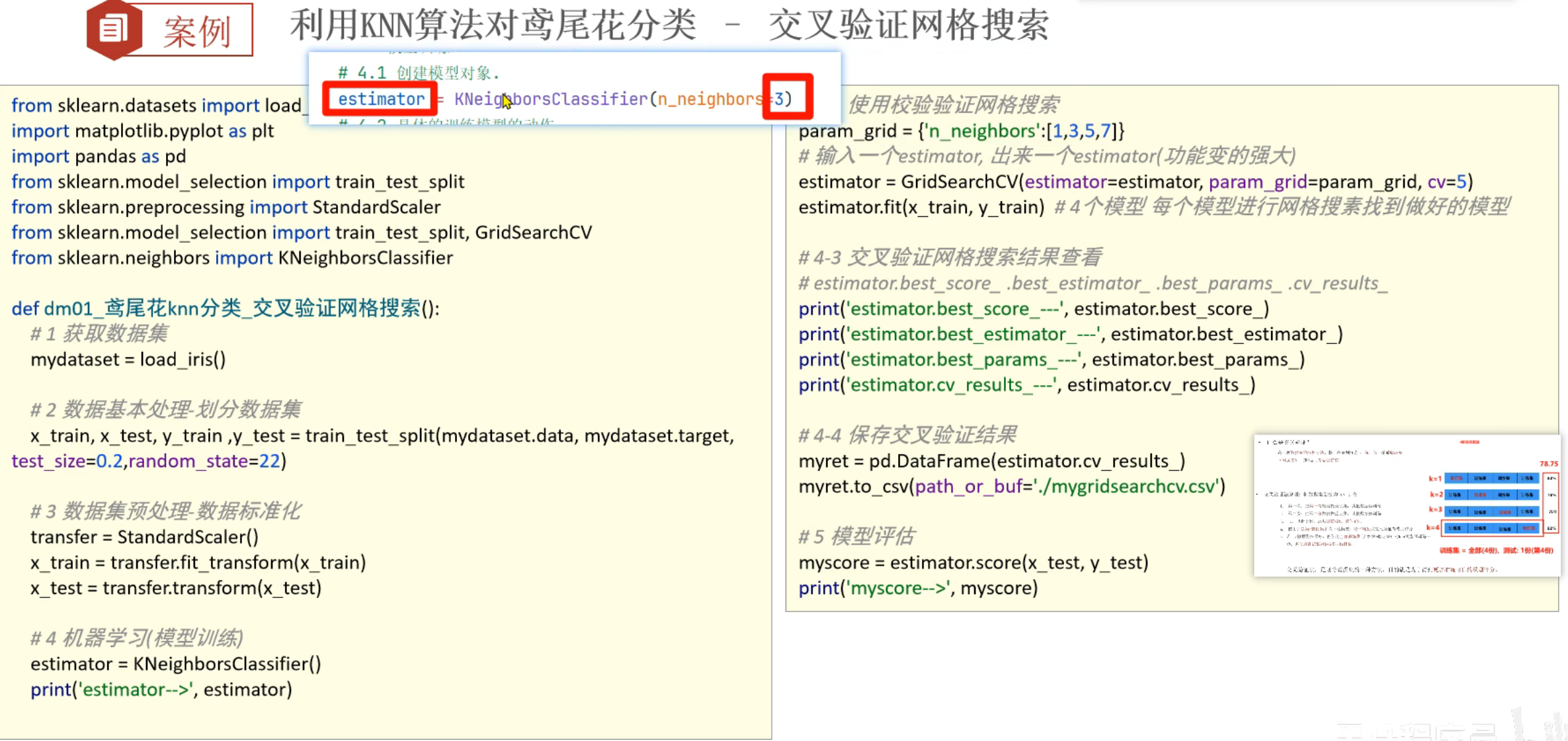

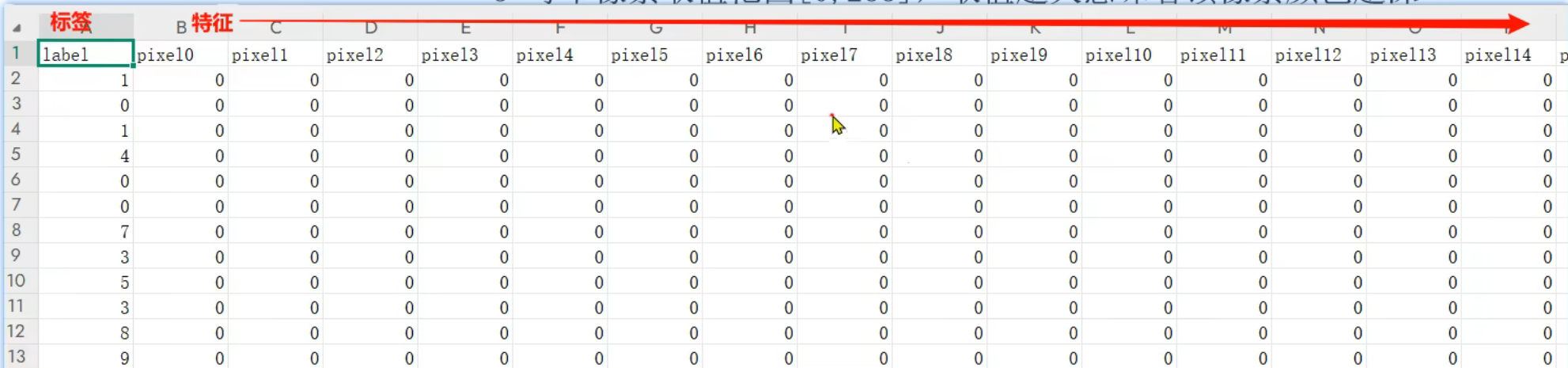
10、手写数字识别_数据集介绍

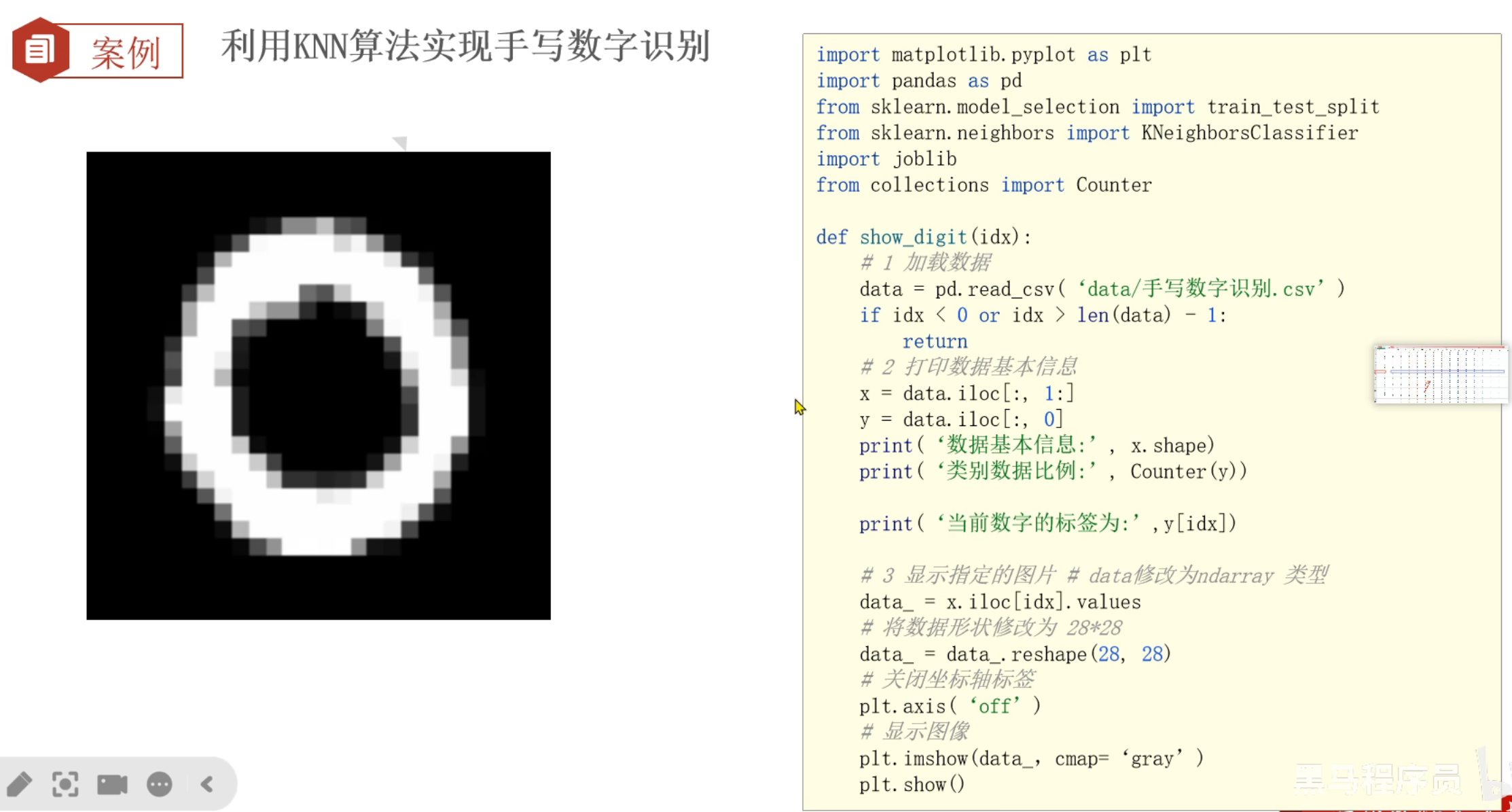
11、手写数字识别_绘制数字
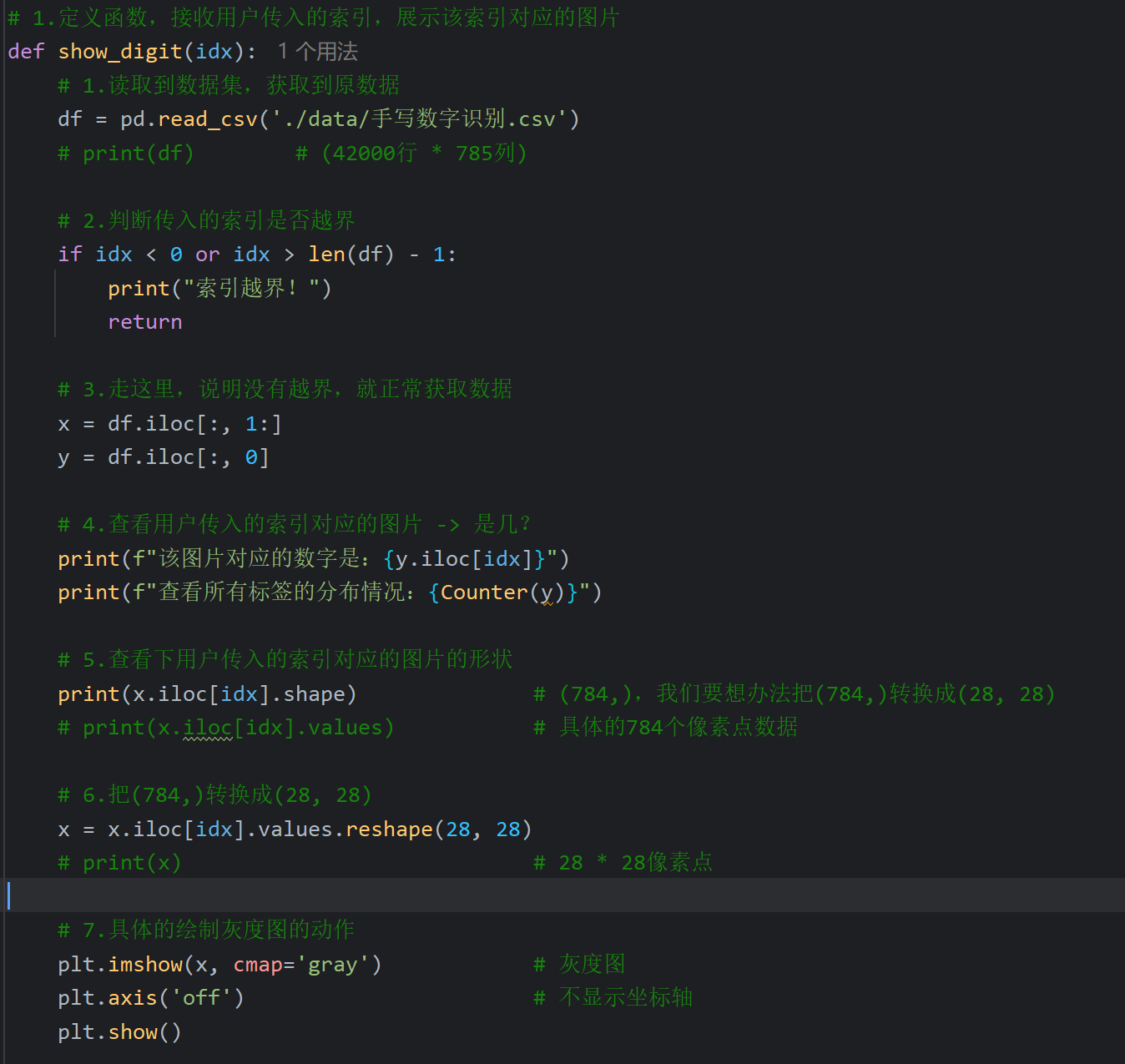


12、手写数字识别_训练和保存模型

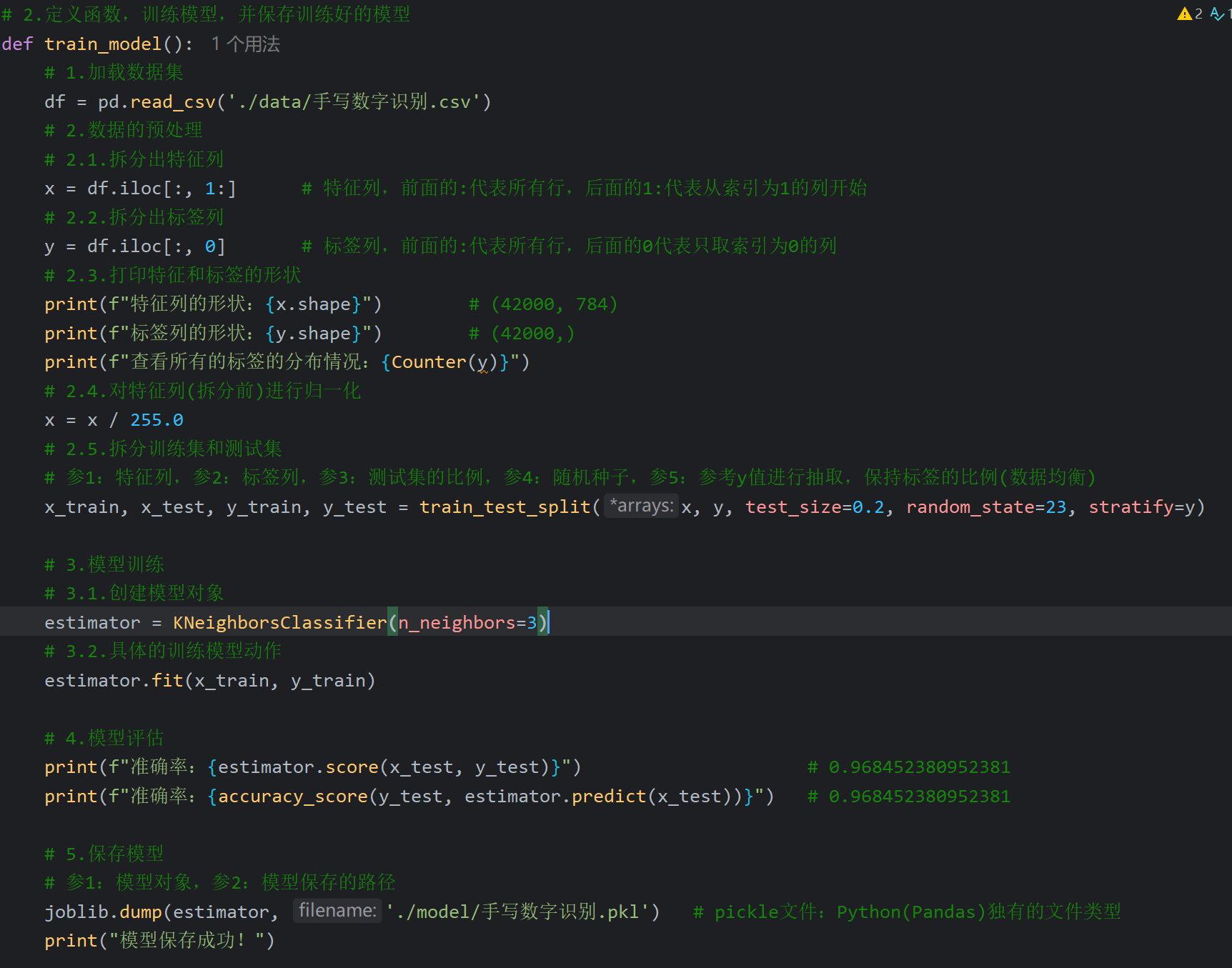


13、手写数字识别_加载和使用模型

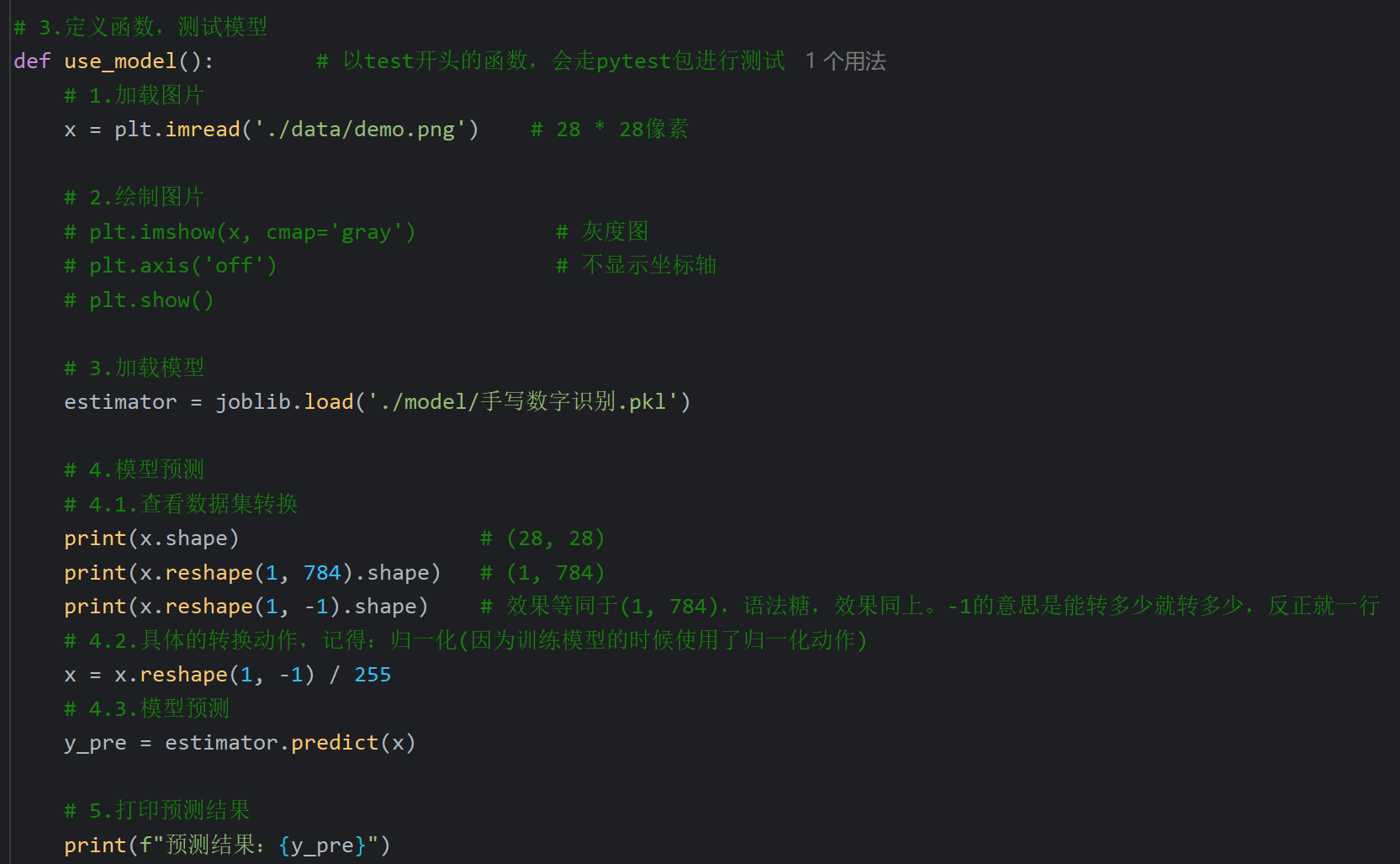


显然预测结果是错误的,下一个视频讲解了为什么出错
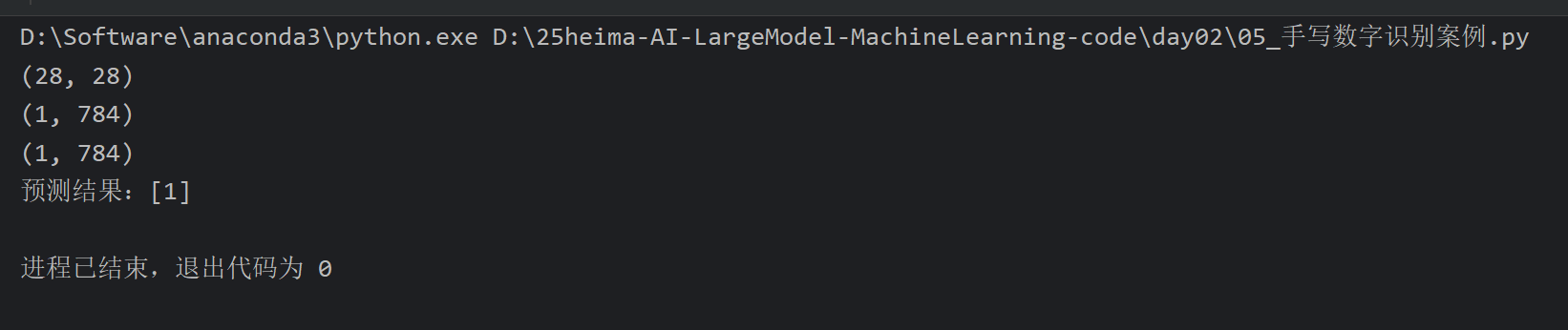
14、解决预测错误的Bug
我跟着老师一样做把 / 255去掉了,结果发现预测结果依旧是1
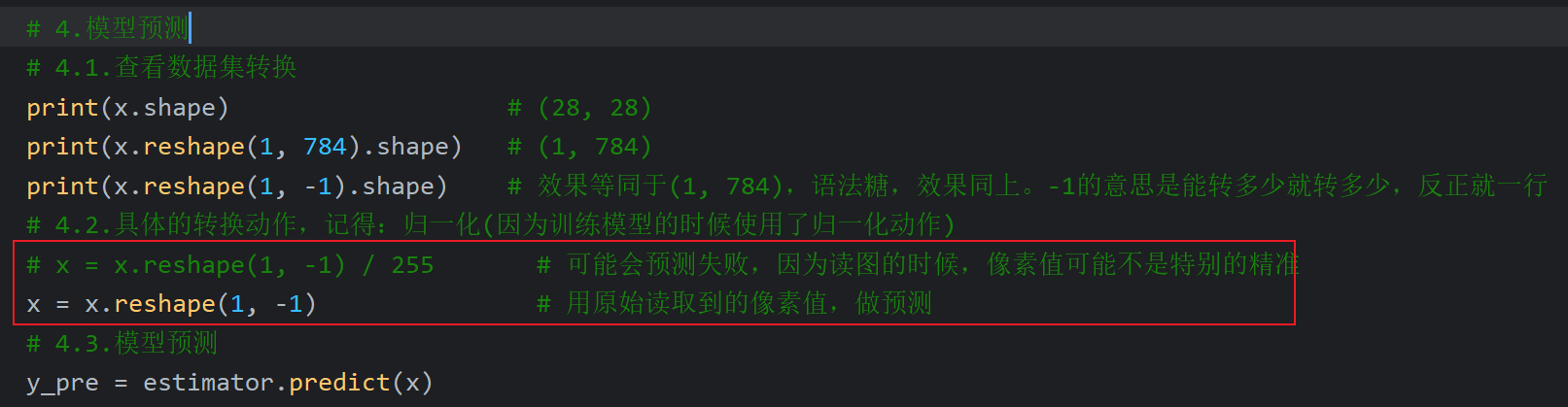
后续看了弹幕和评论区,我把随机种子从23改为了22,然后解开训练并保持模型的注释,重新跑又预测成功了。至于为什么我也不是很懂,不过评论区好像也没看到正经回答

四、线性回归
1、今日内容大纲介绍
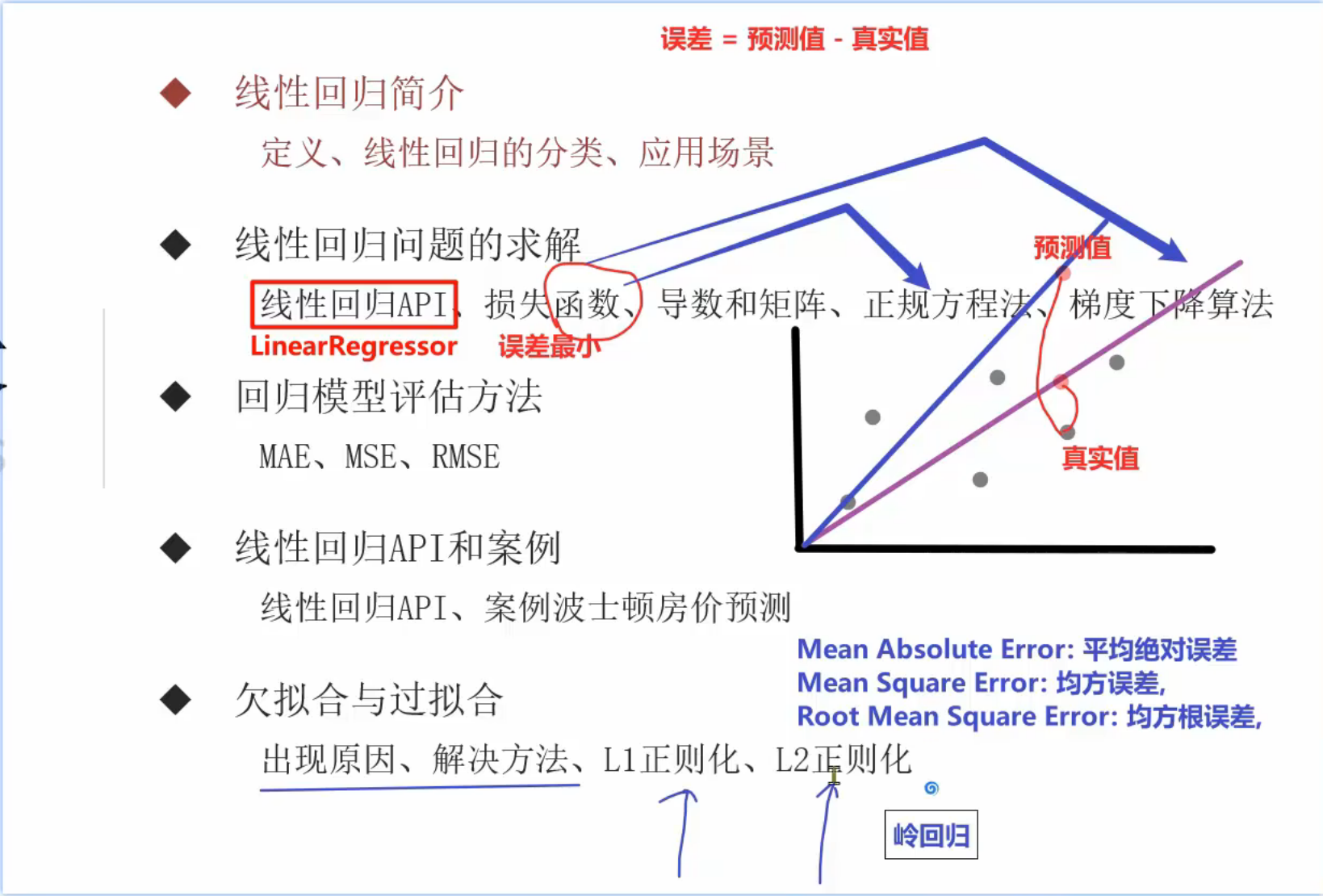

2、线性回归简介


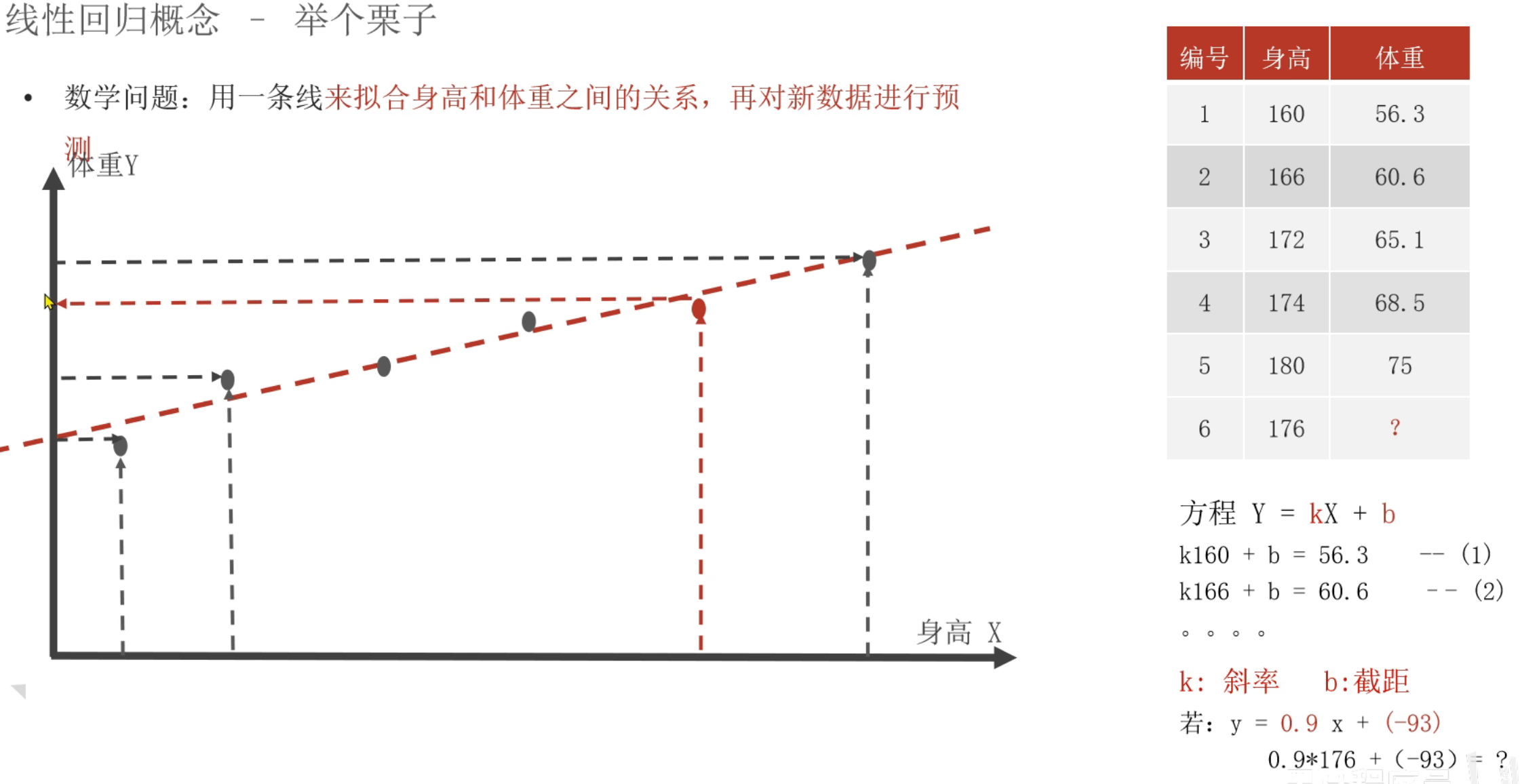


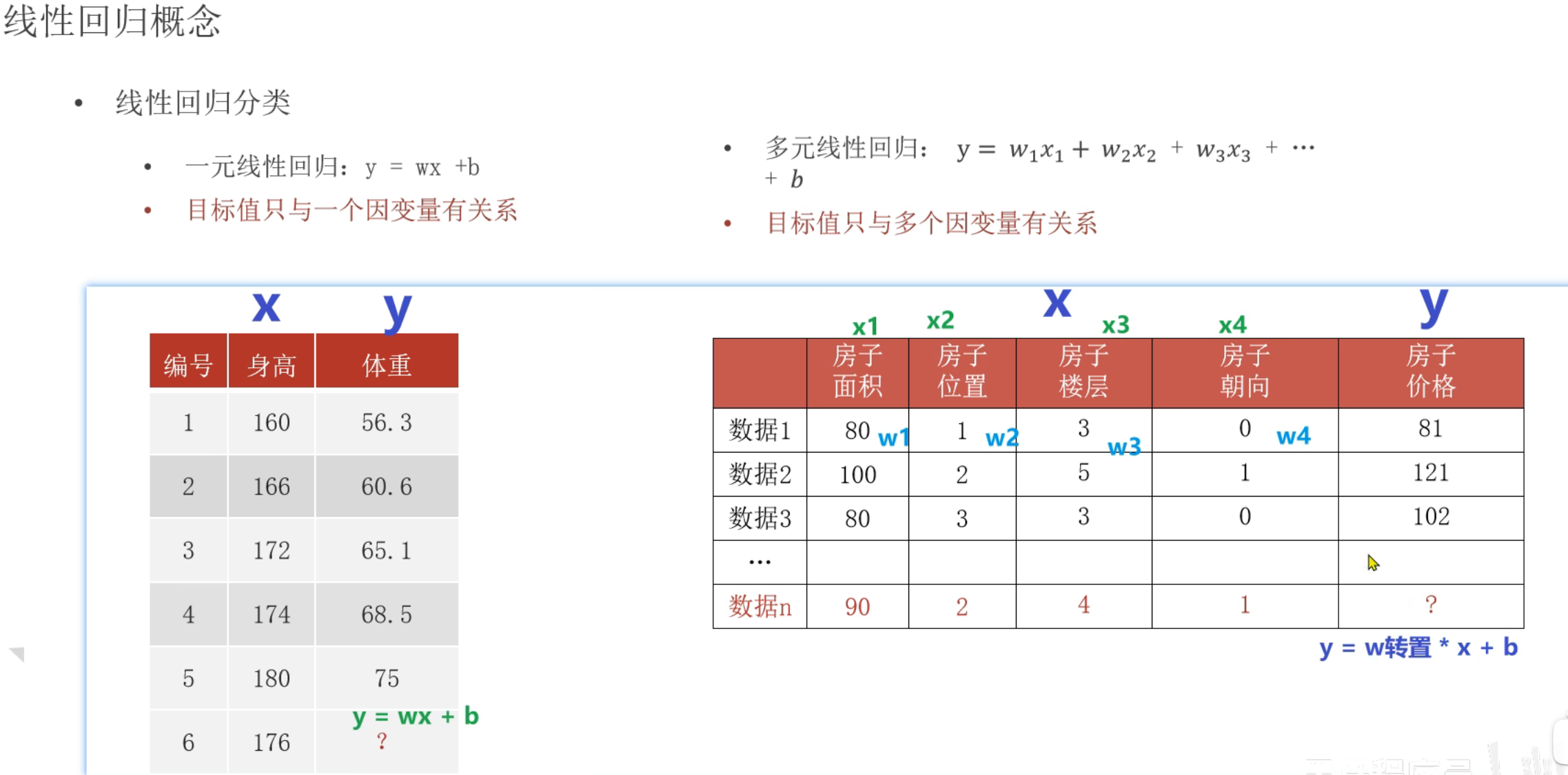
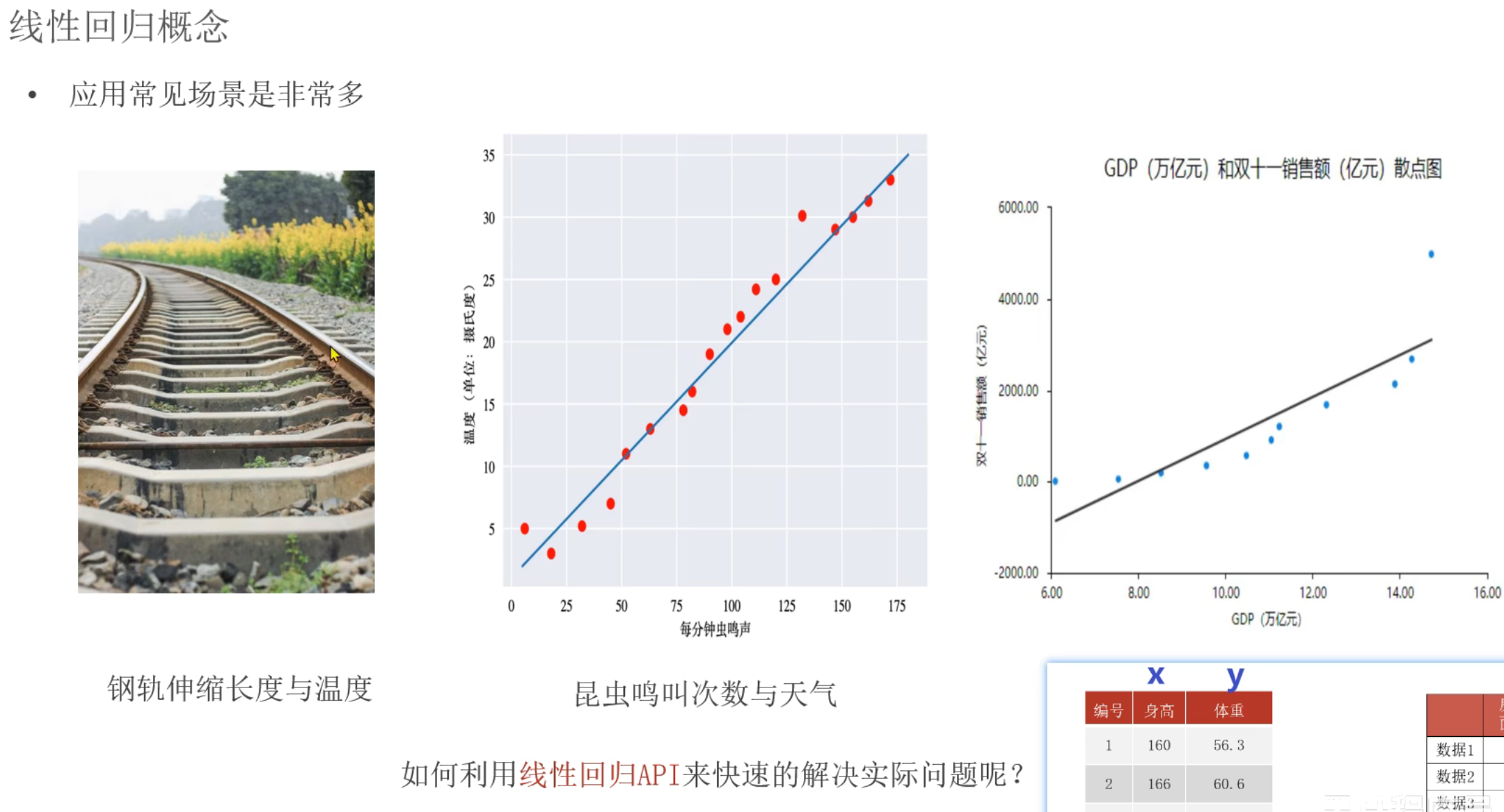

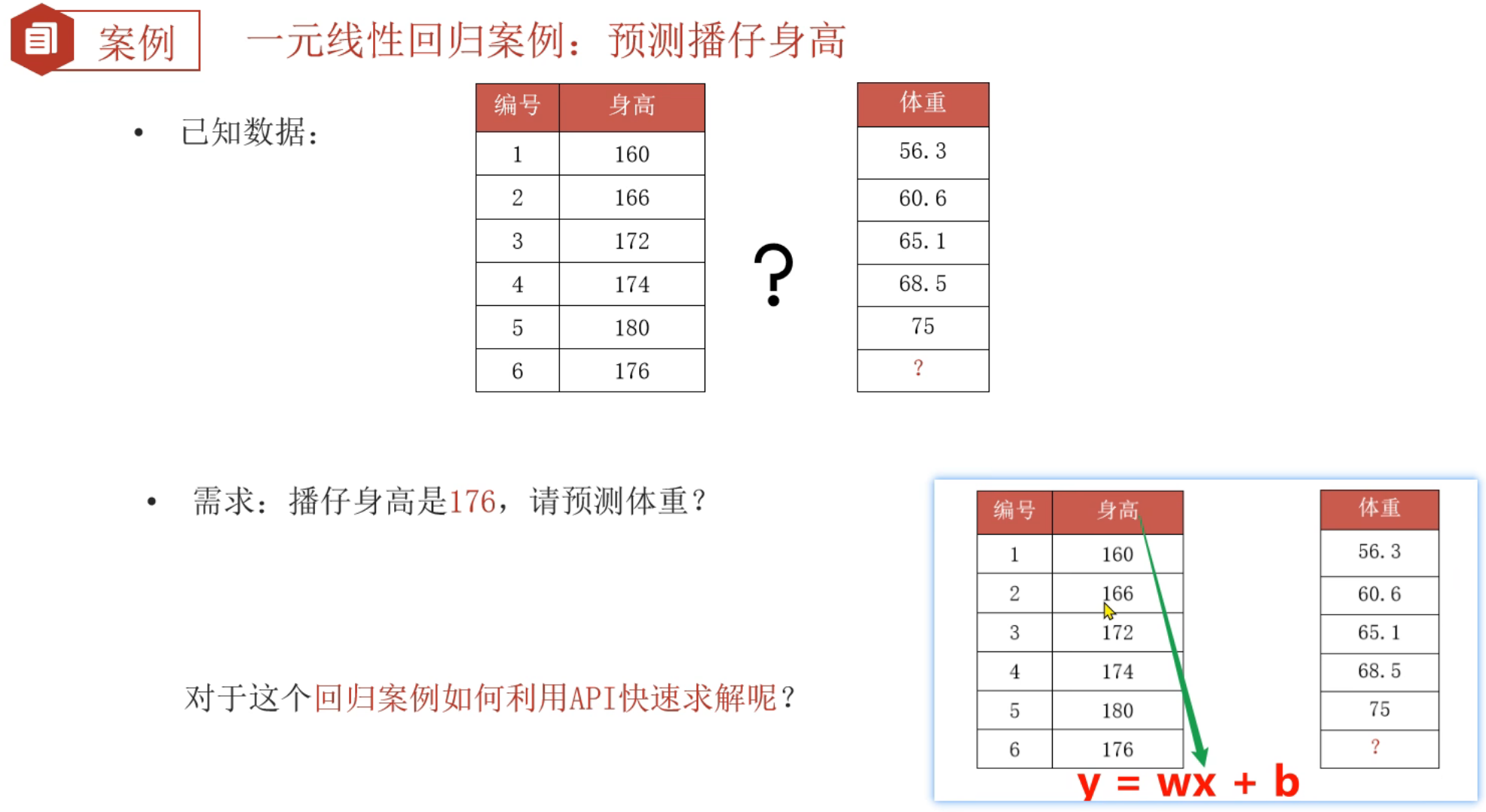
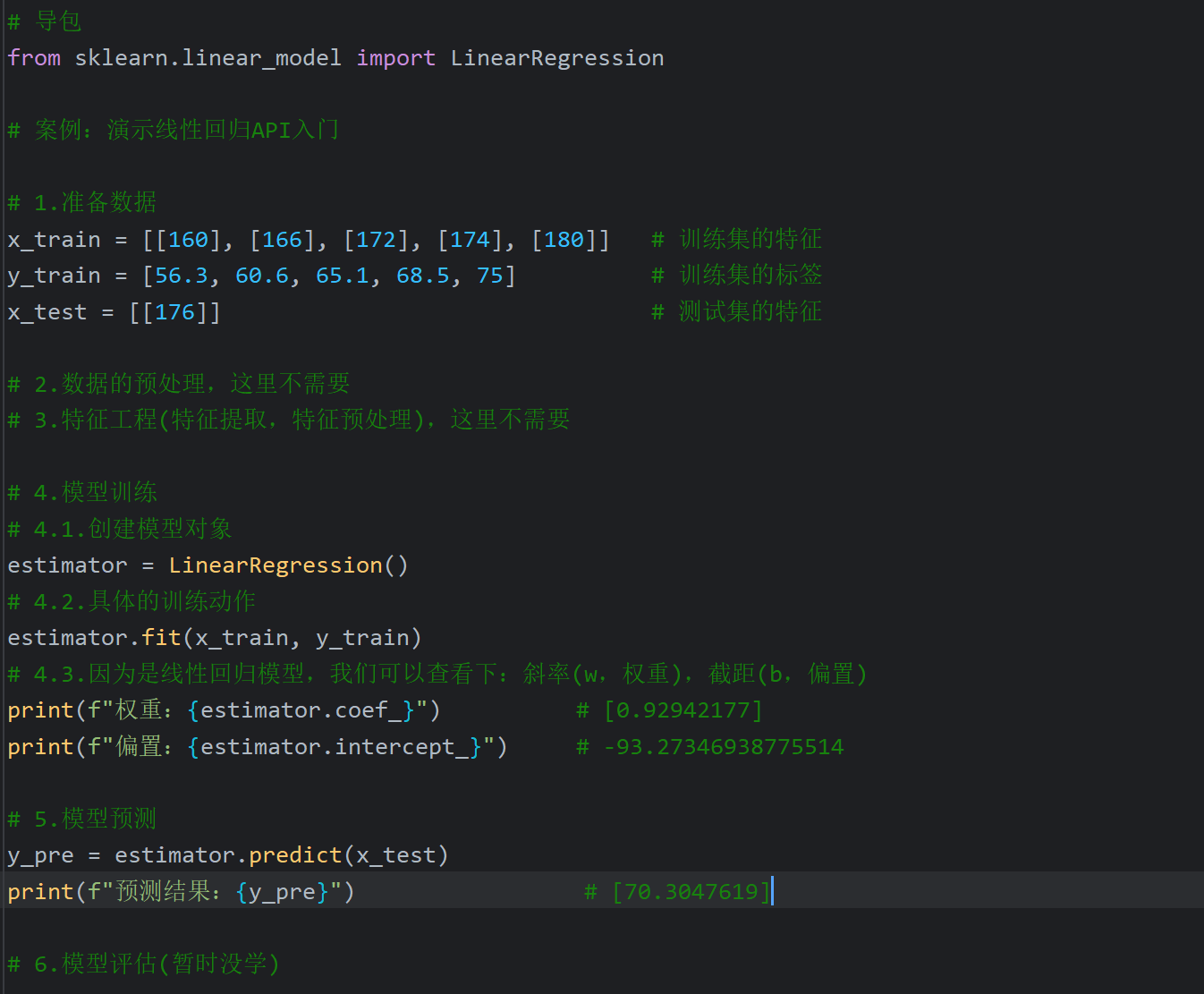
3、线性回归API_入门




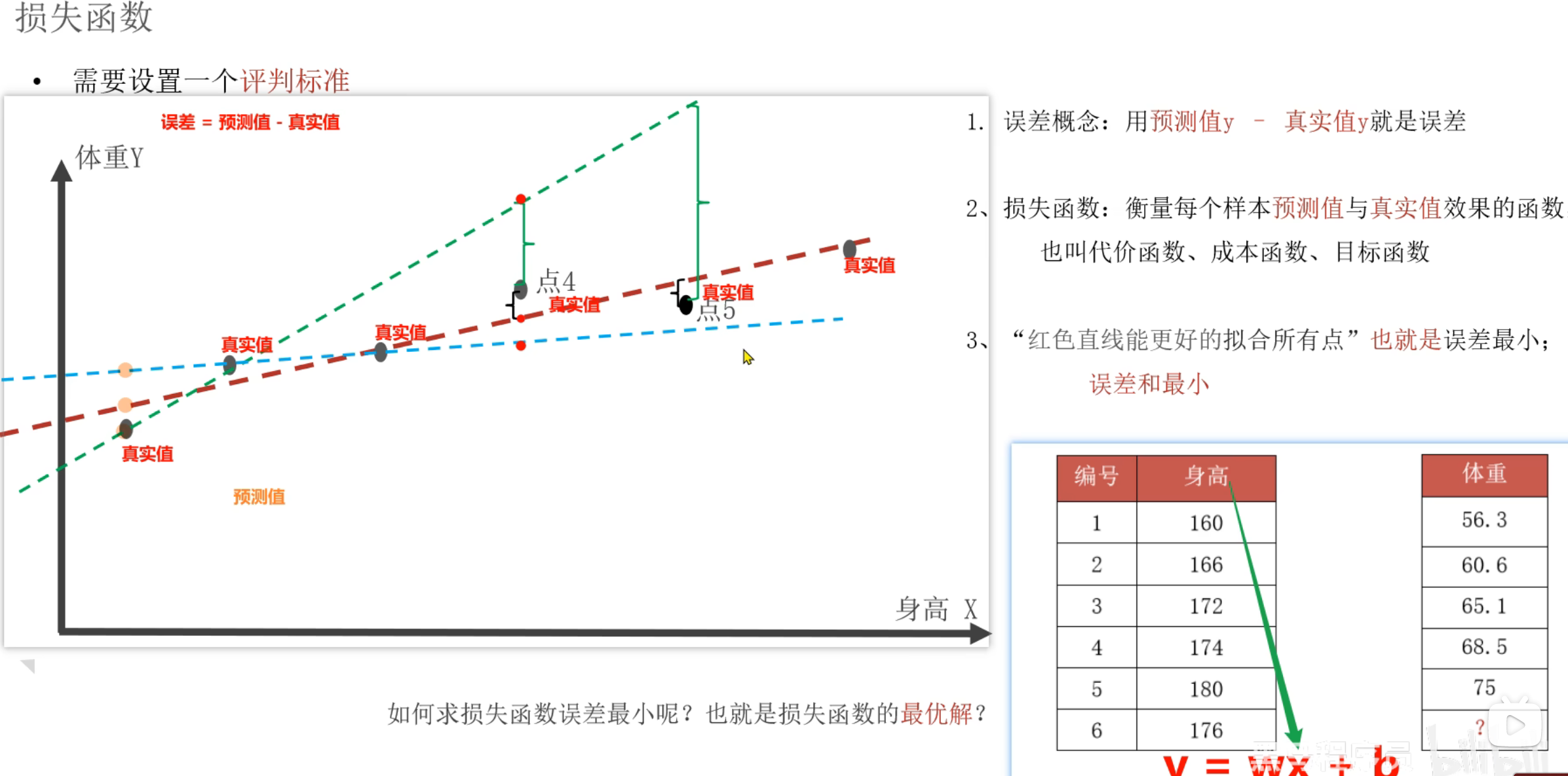
4、损失函数介绍

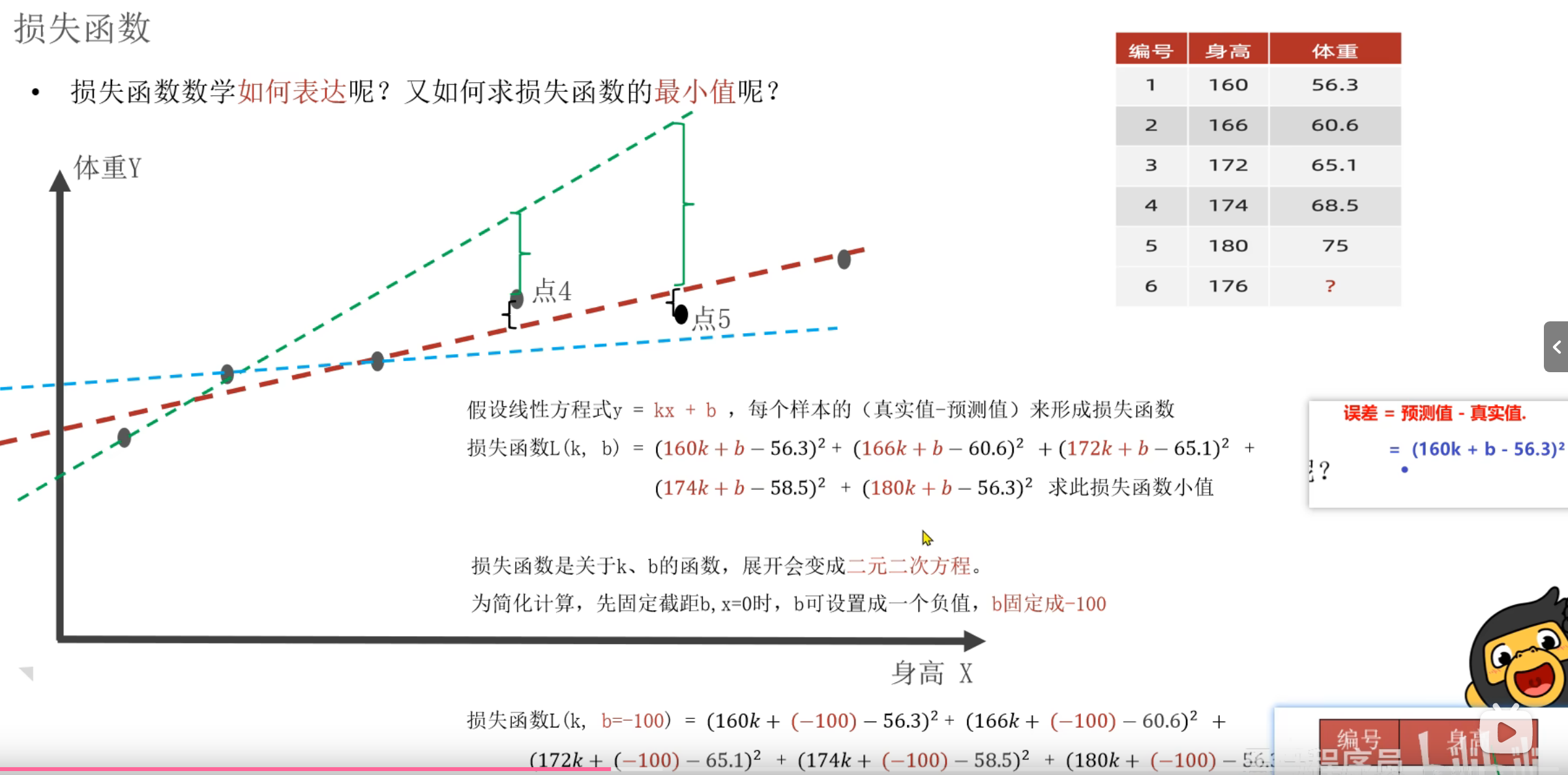







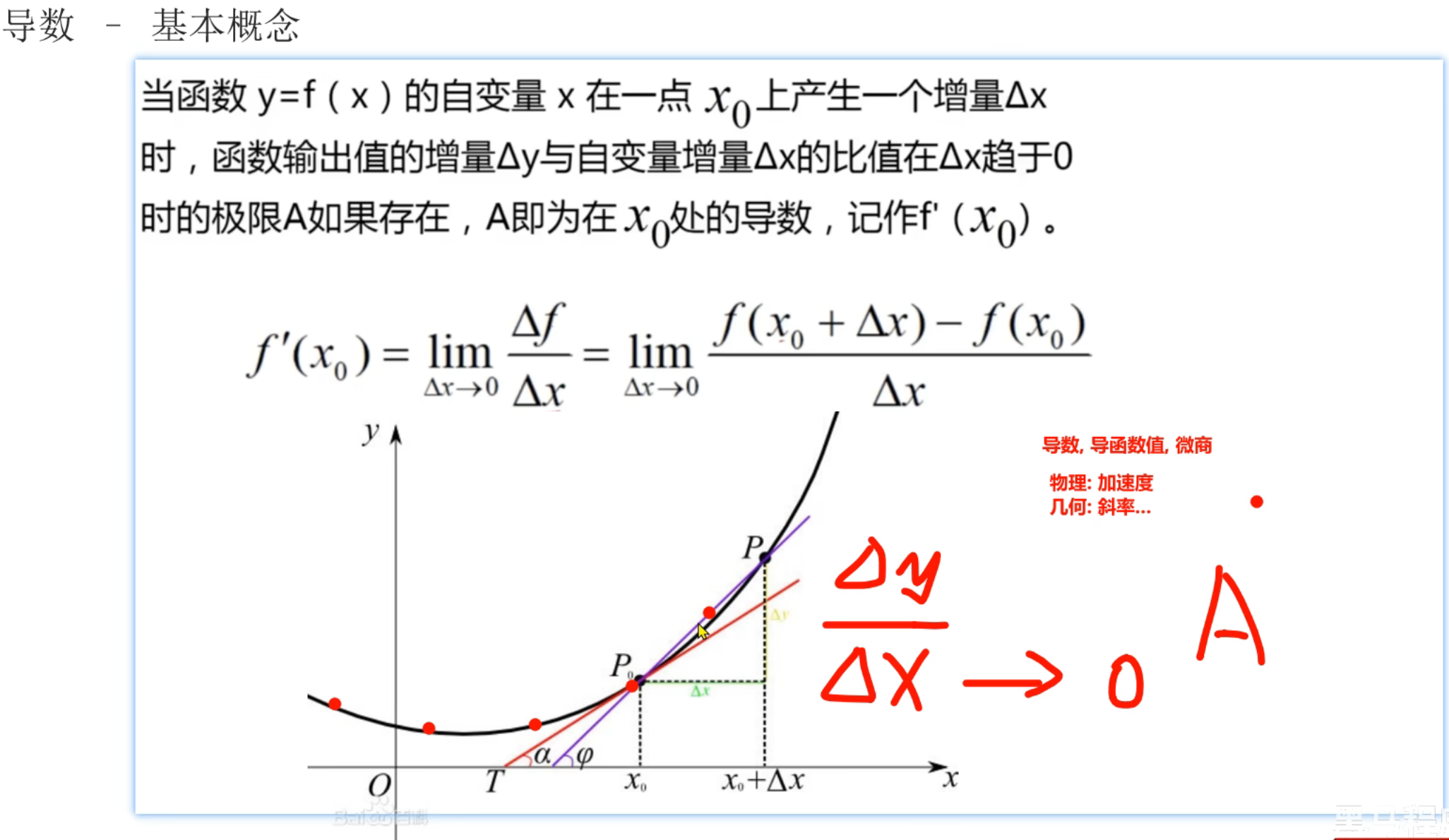
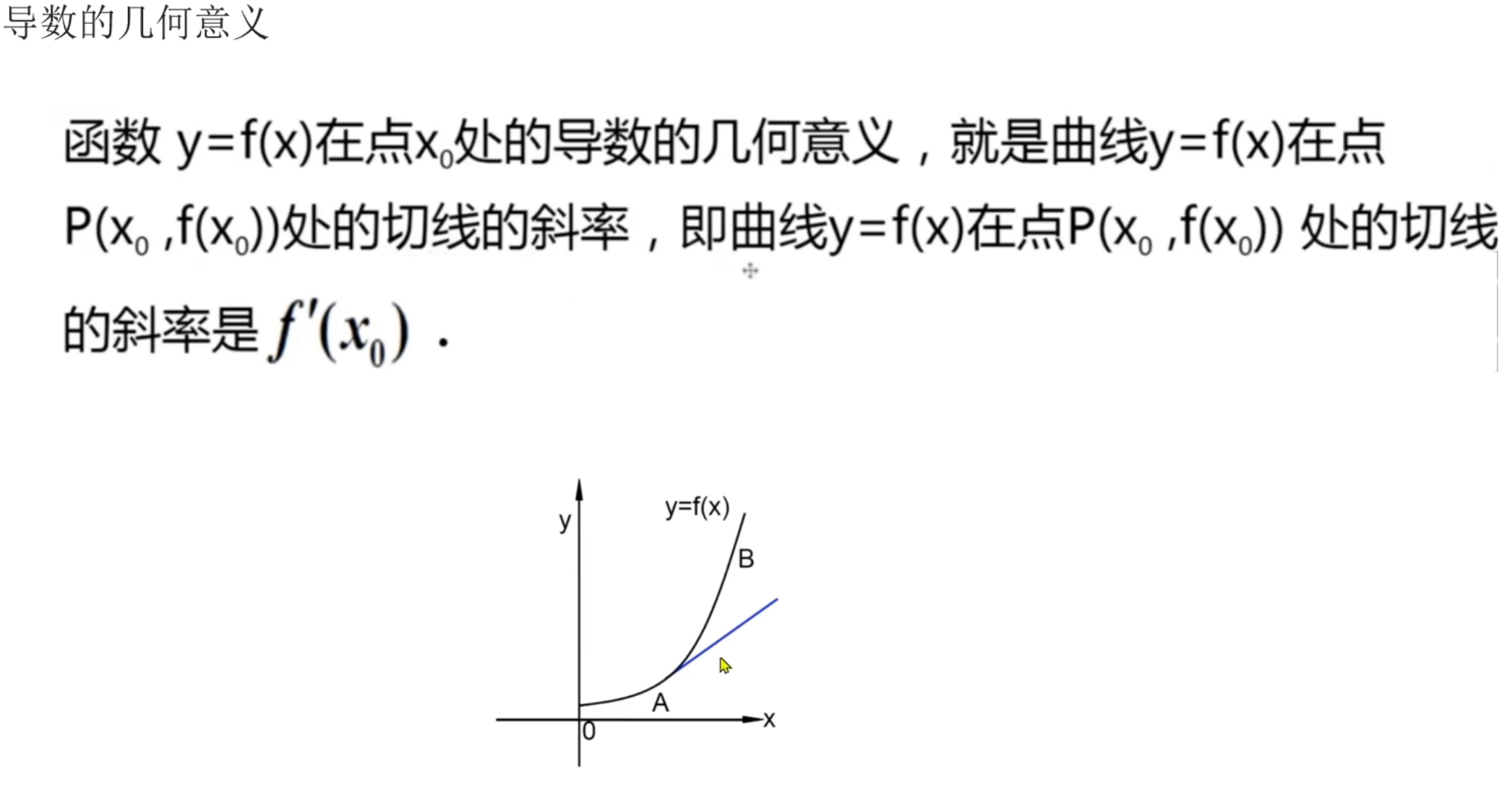
5、导数_复习




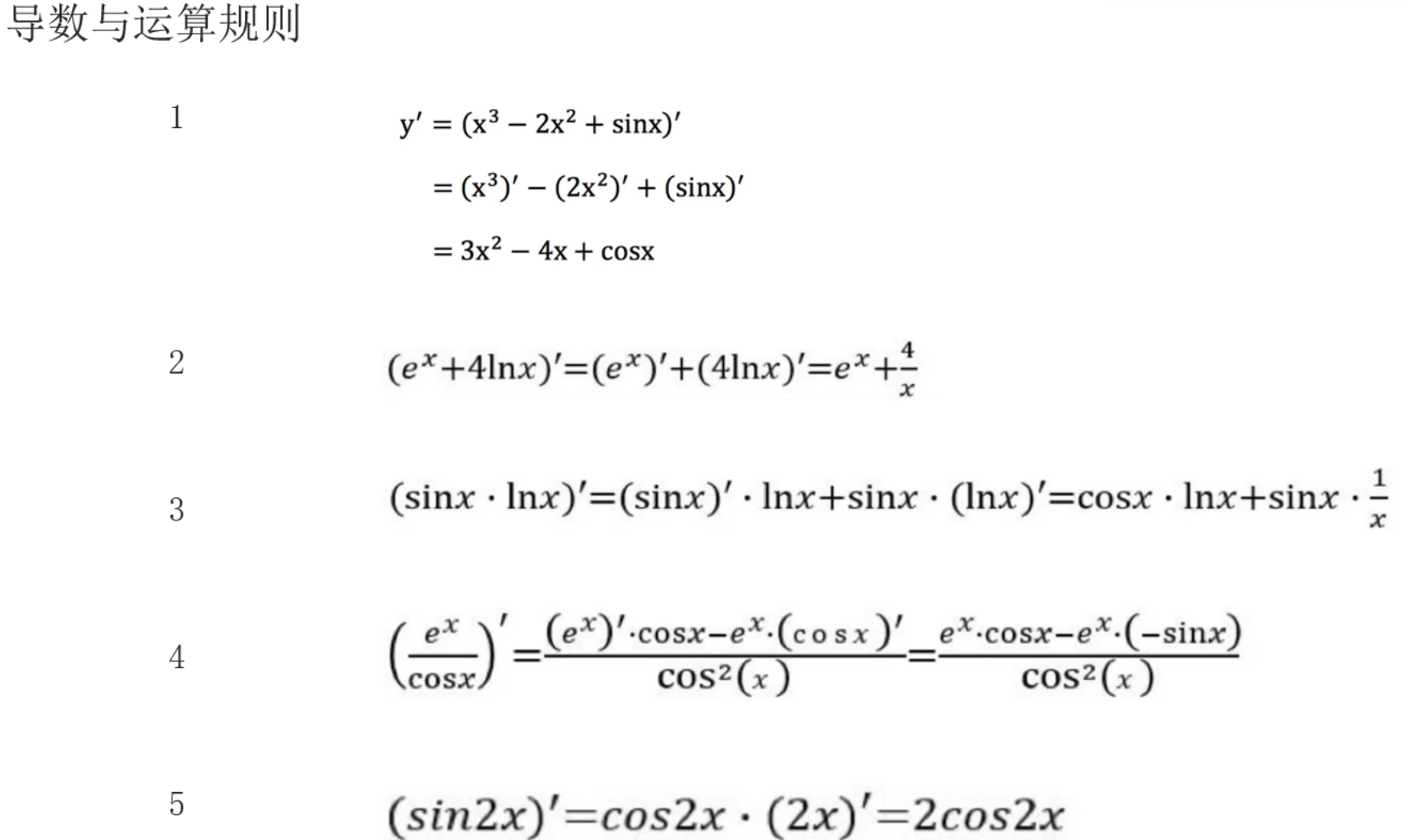
6、偏导数_复习




7、上午内容回顾
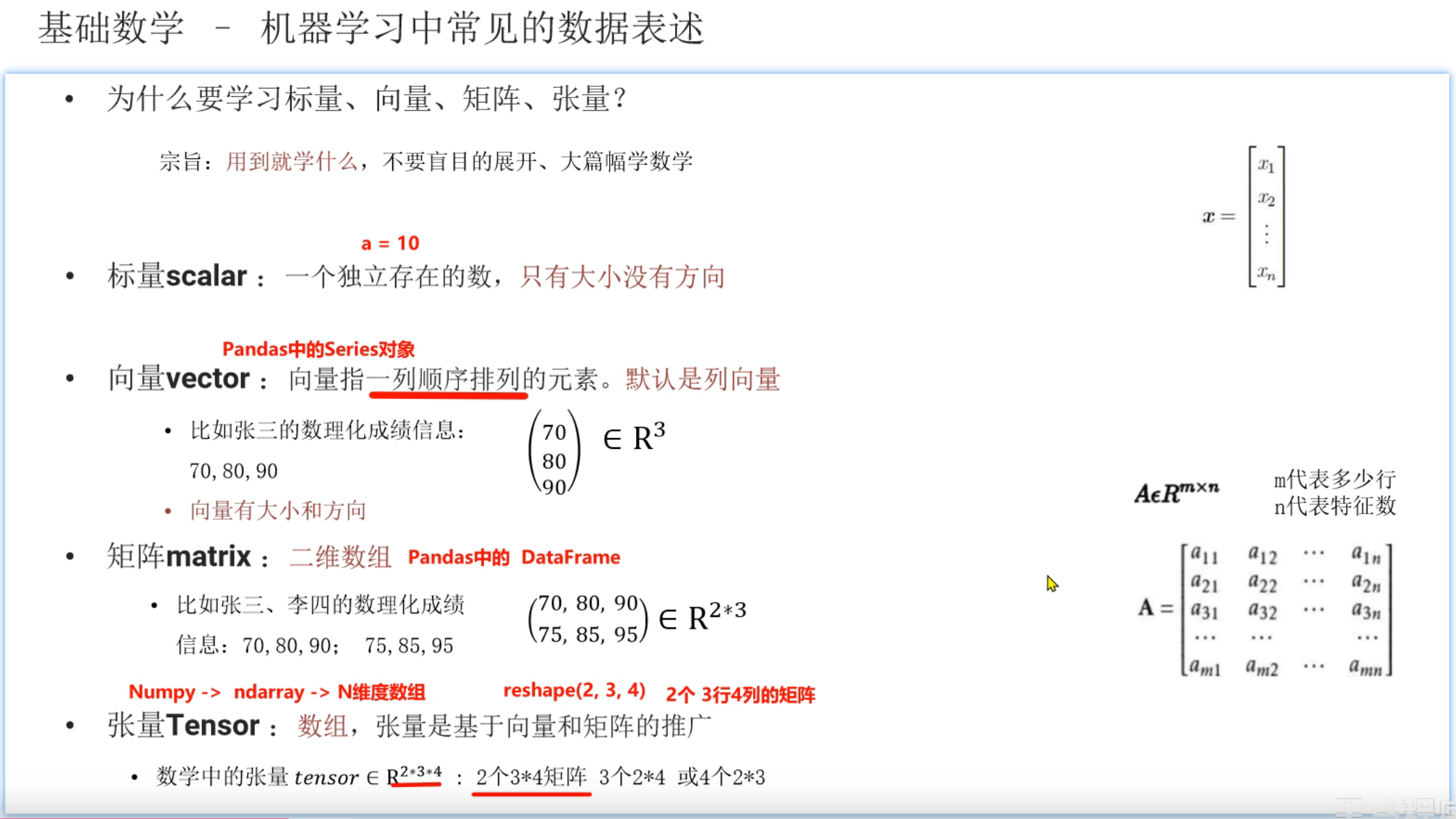
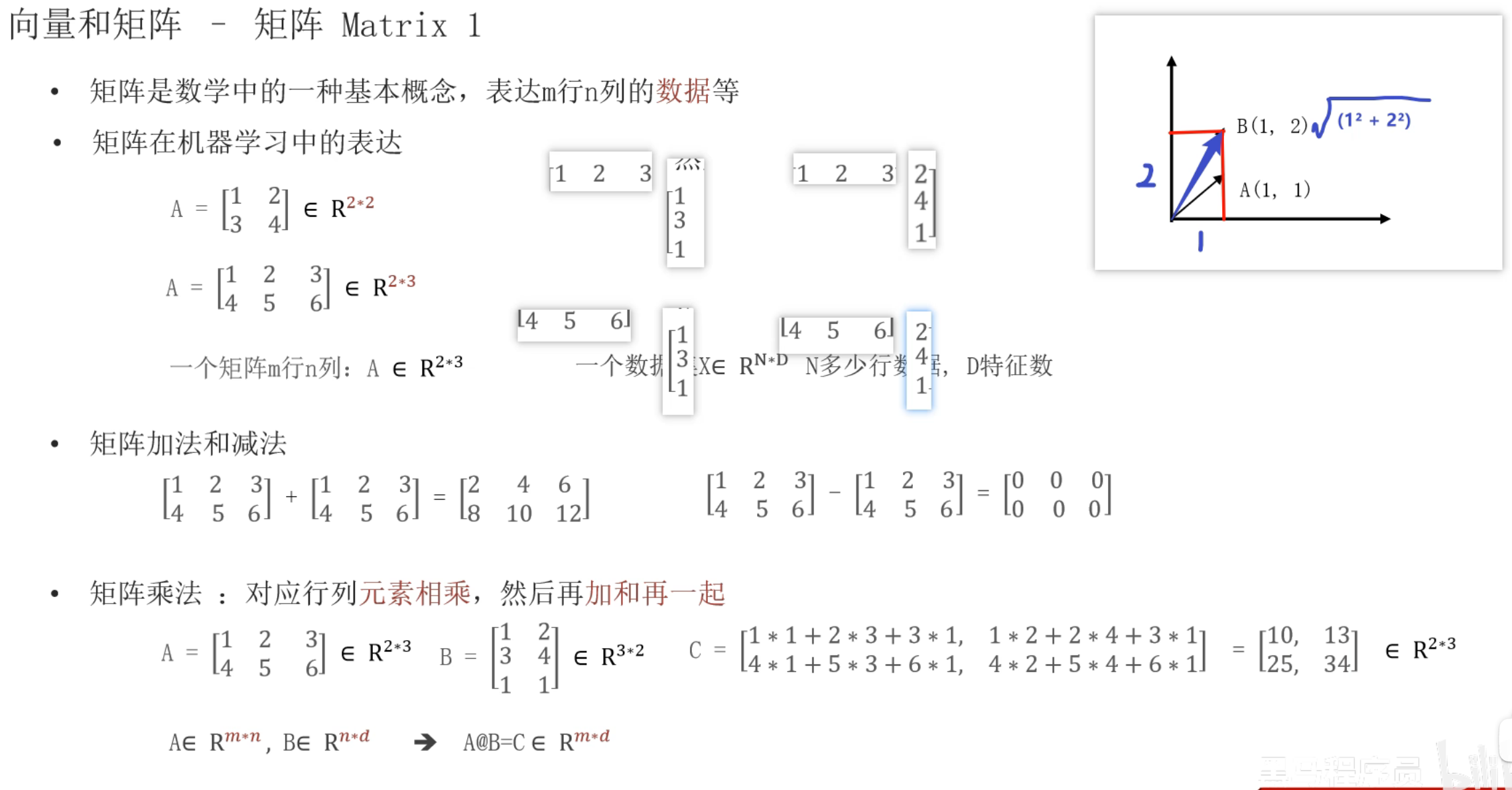
8、矩阵_复习
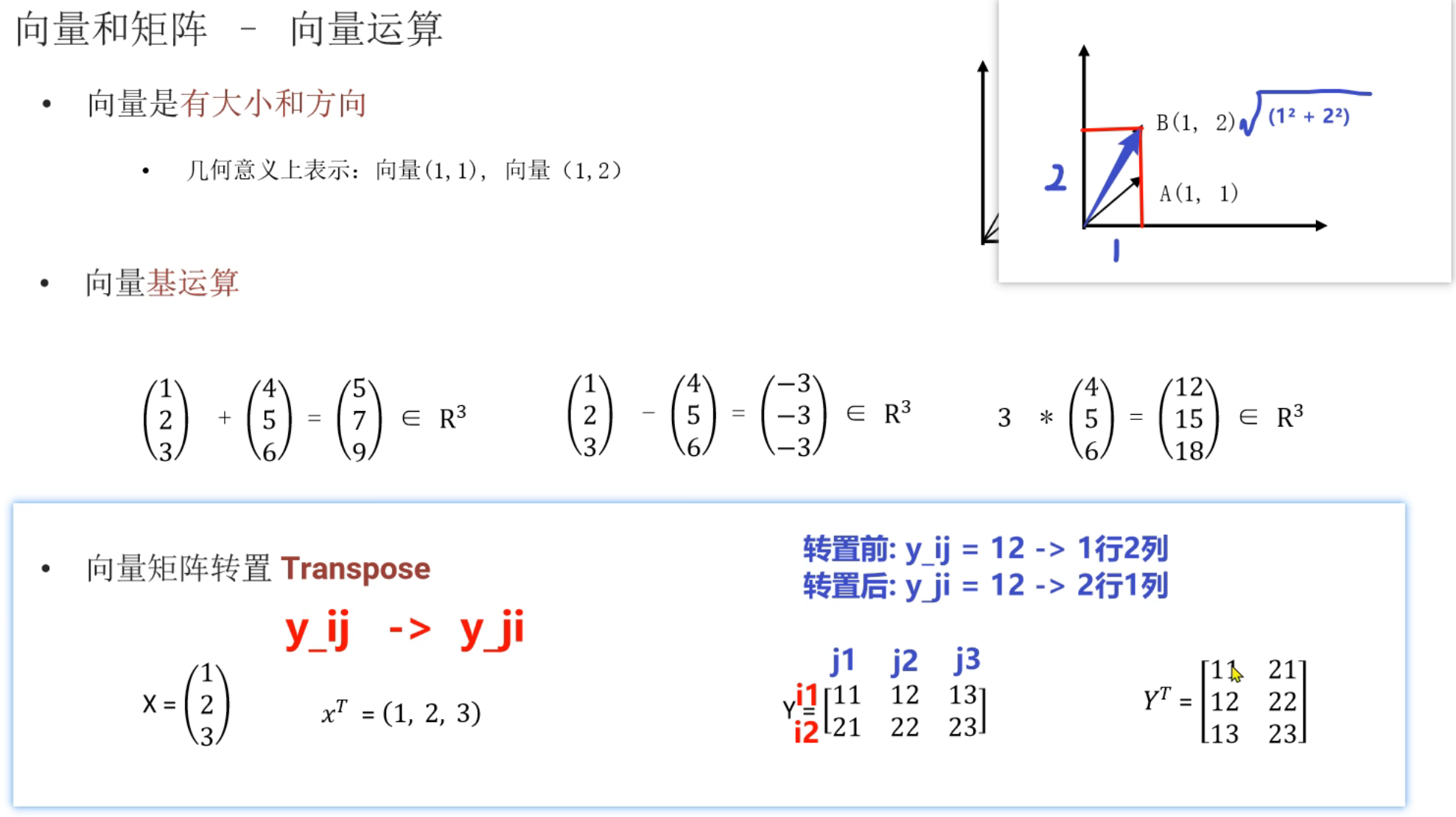

矩阵乘法最后是2行2列,ppt打错了






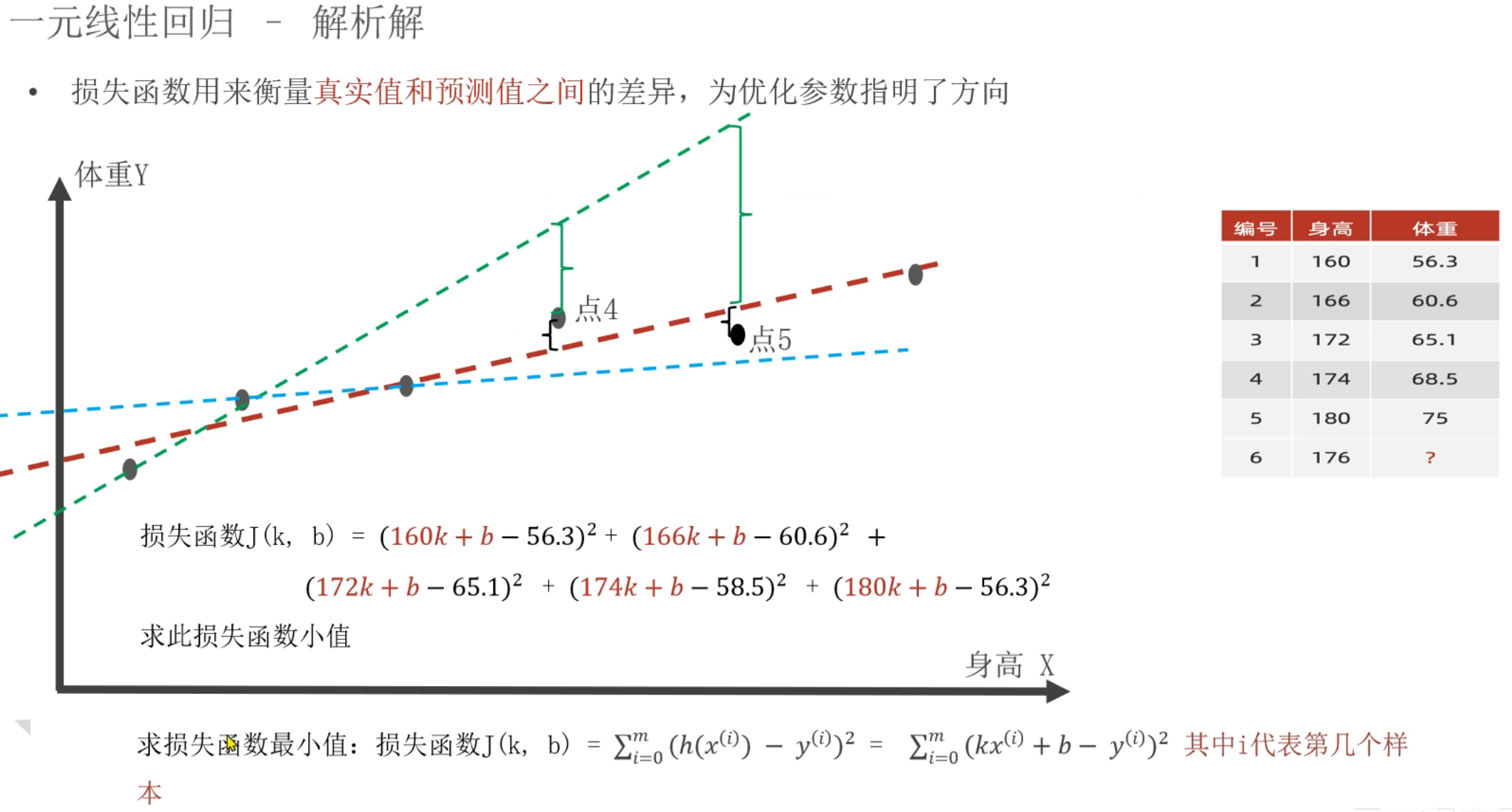
9、一元线性回归_正规方程法



10、多元线性回归_正规方程法(上)


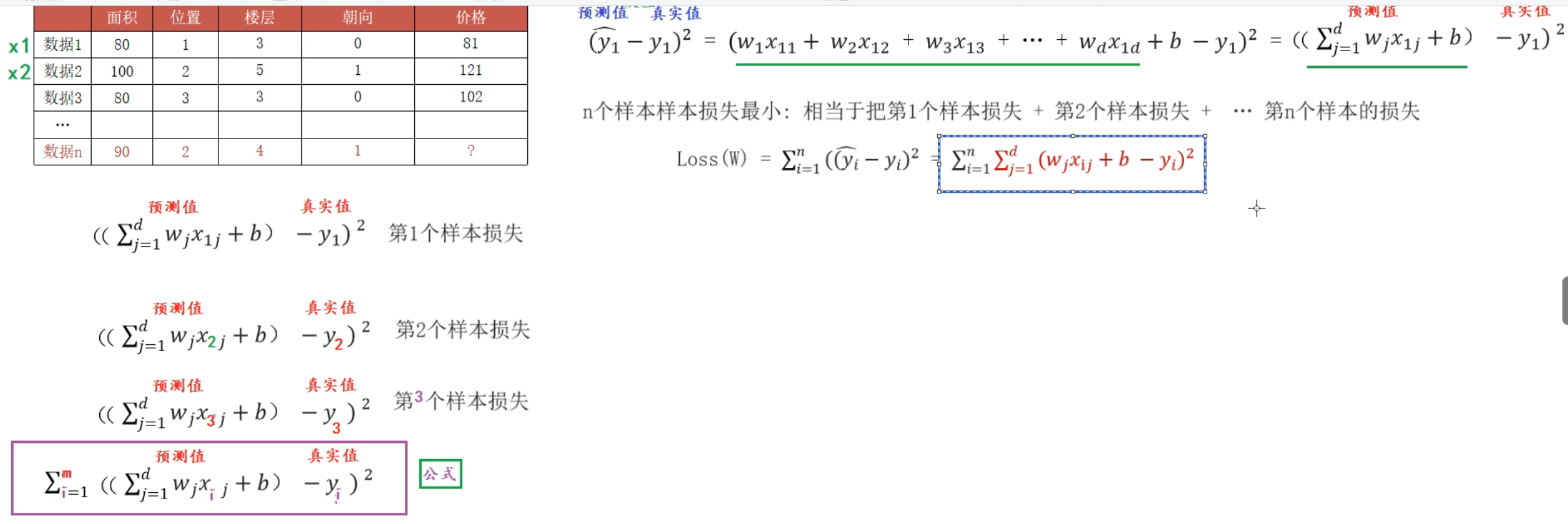


这里乘上X的转置矩阵是为了化成方阵(非方阵一定没有逆矩阵),然后再乘上逆矩阵化为单位阵1(前提是逆矩阵存在,这里假设存在)

11、多元线性回归_正规方程法(下)
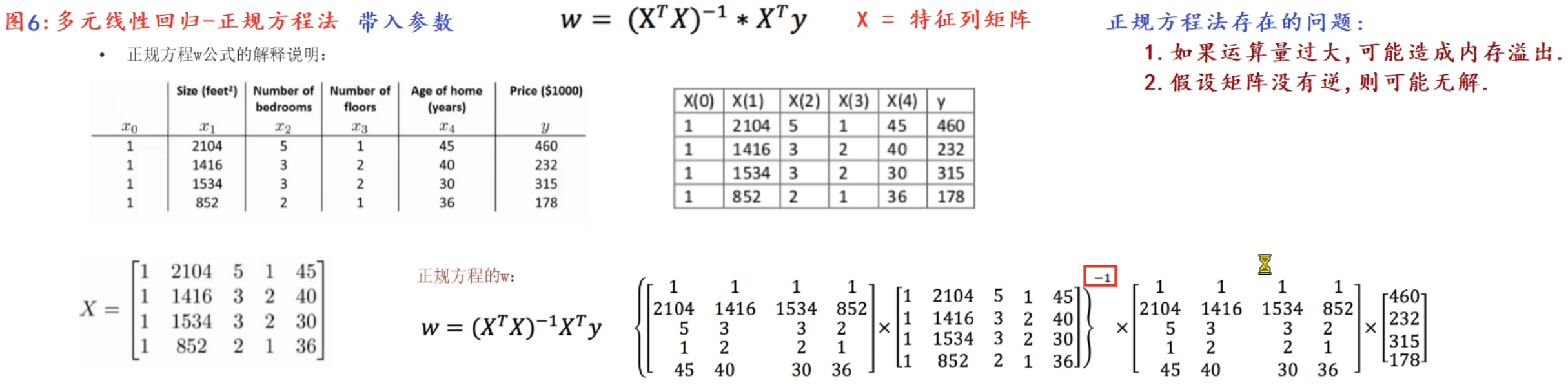

12、补充_转换时为啥是Xw

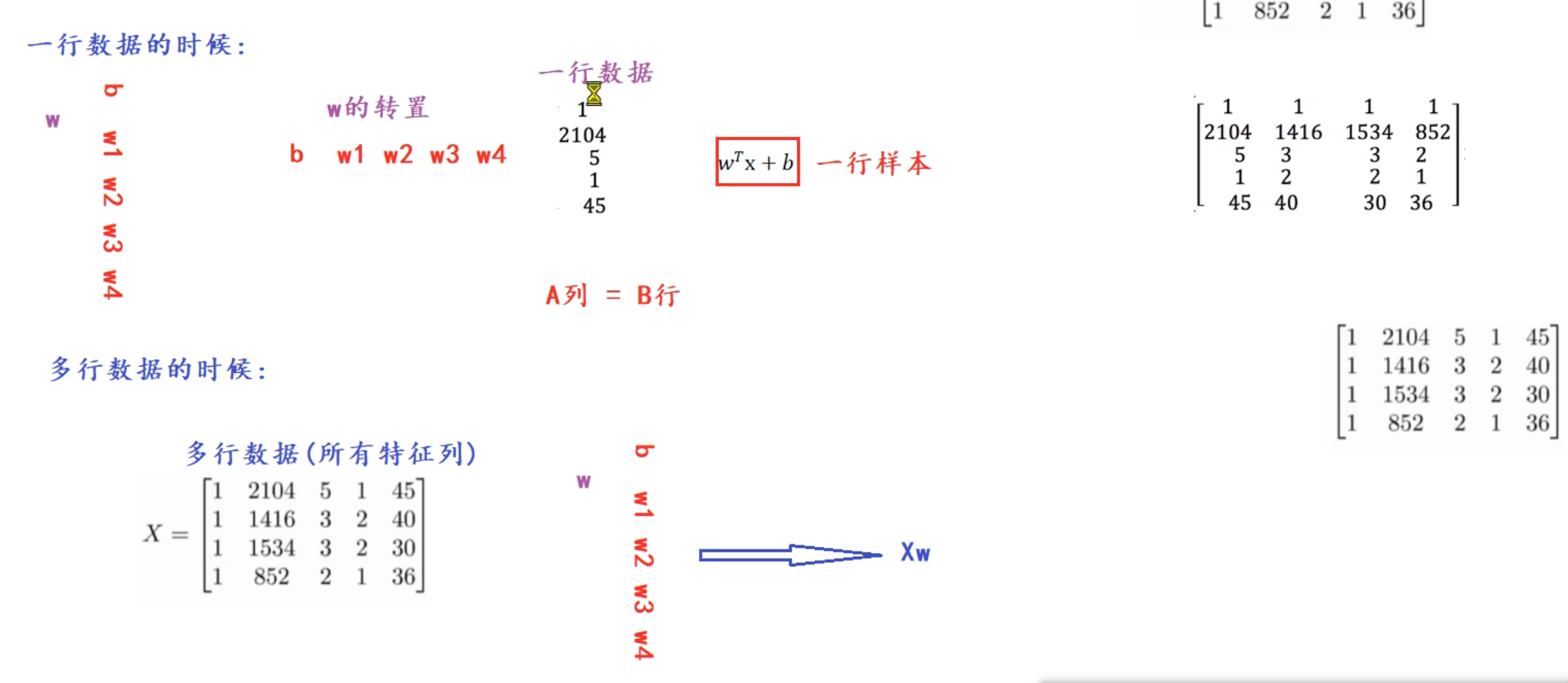
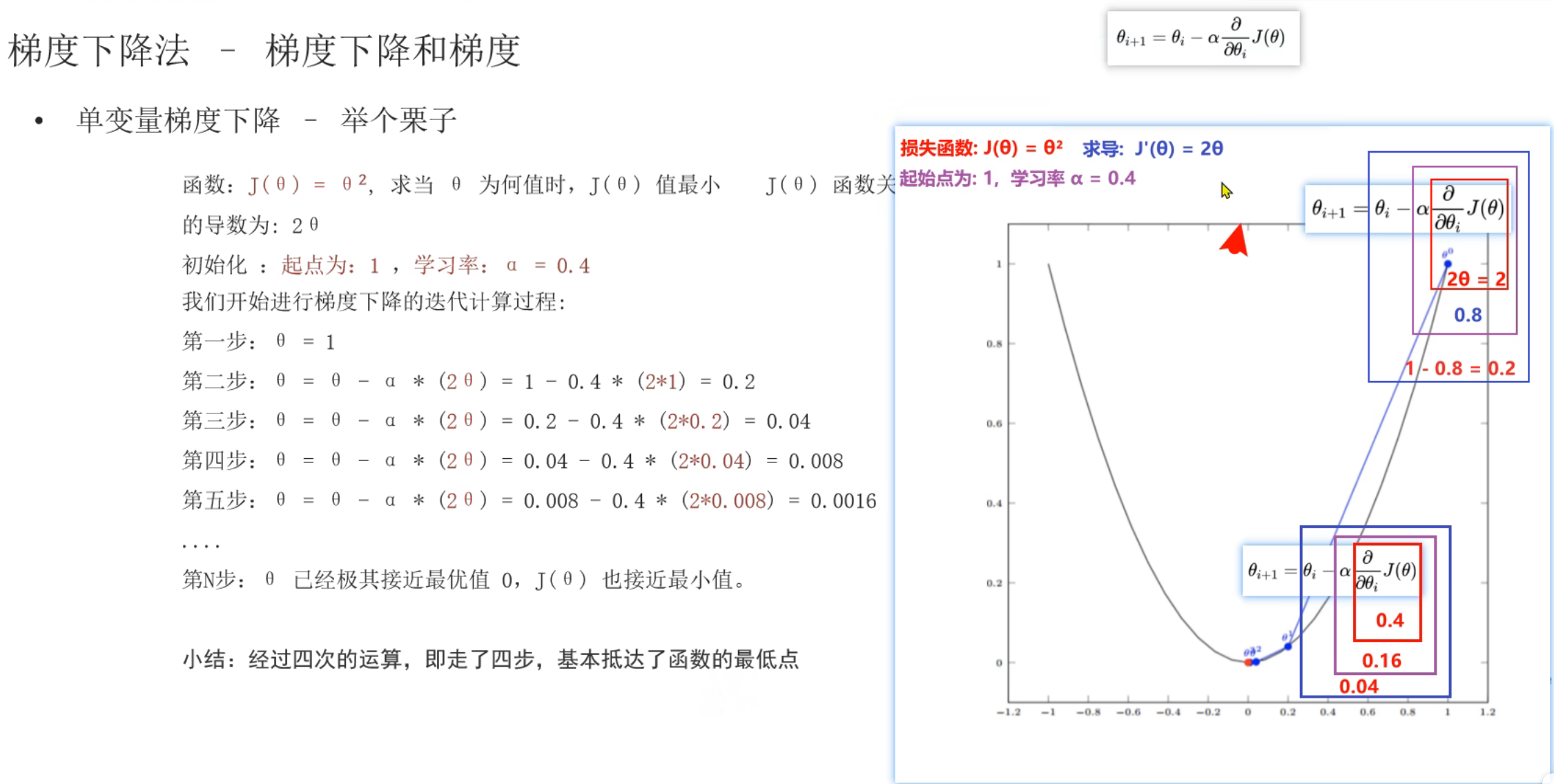
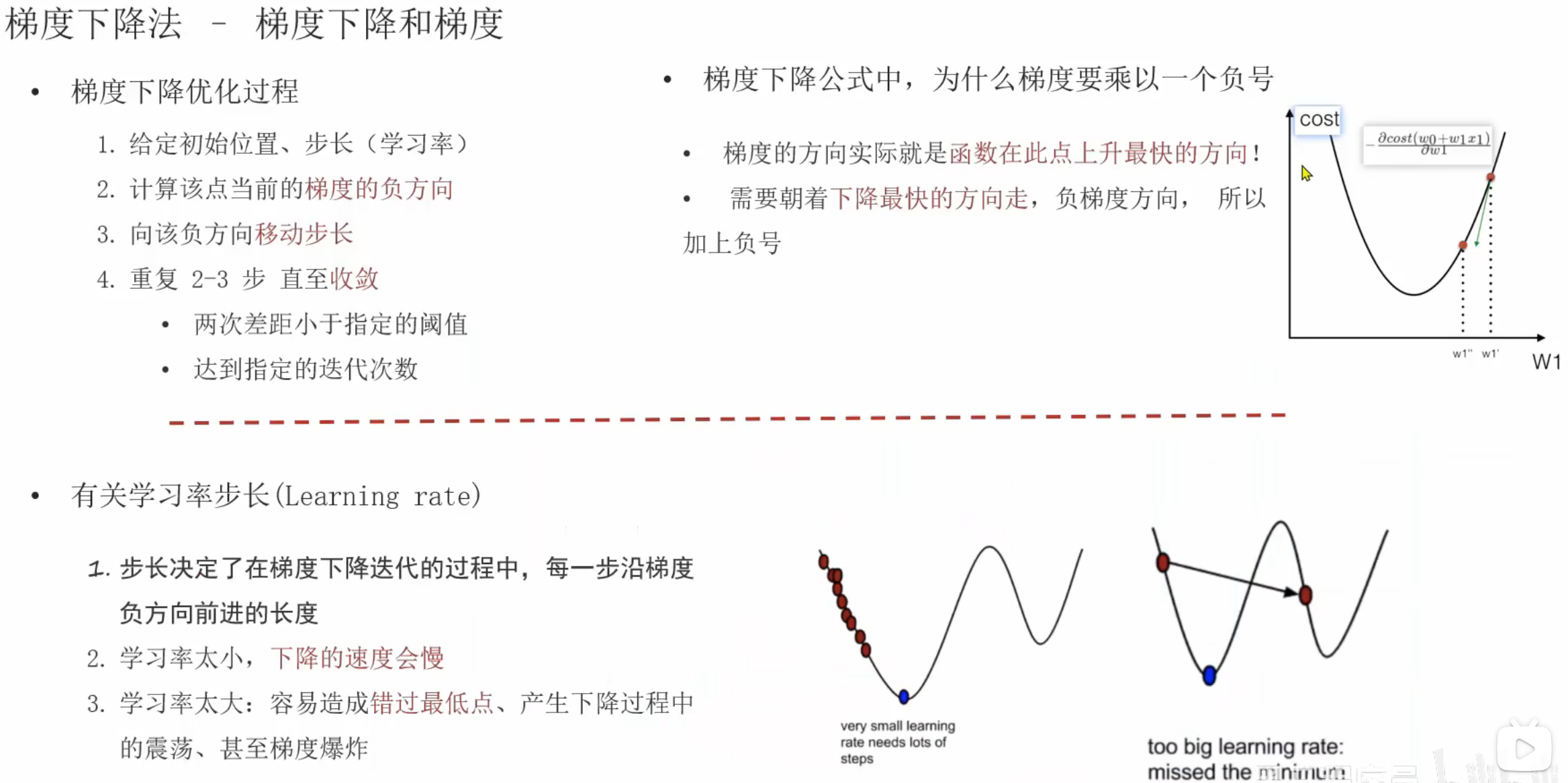
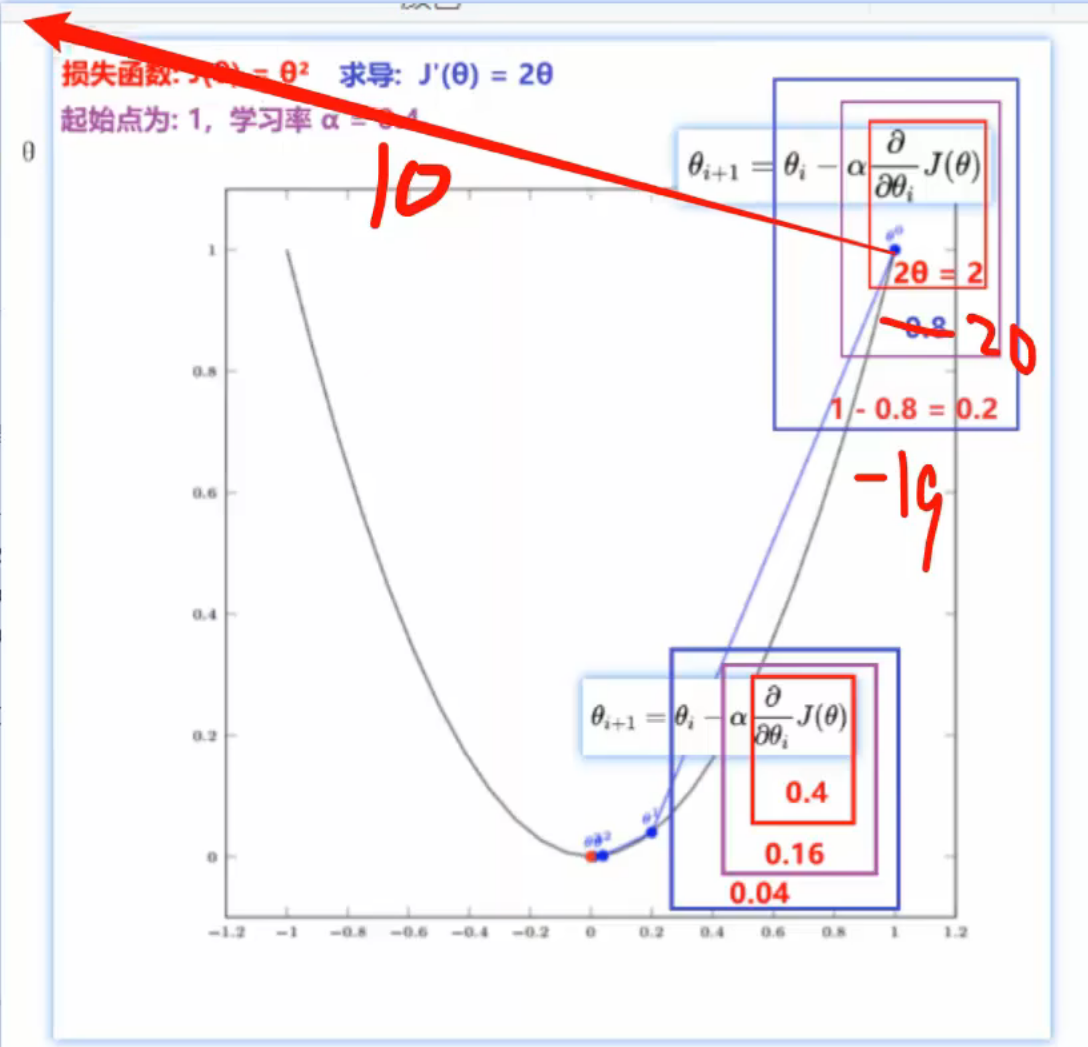
13、单变量_梯度下降法
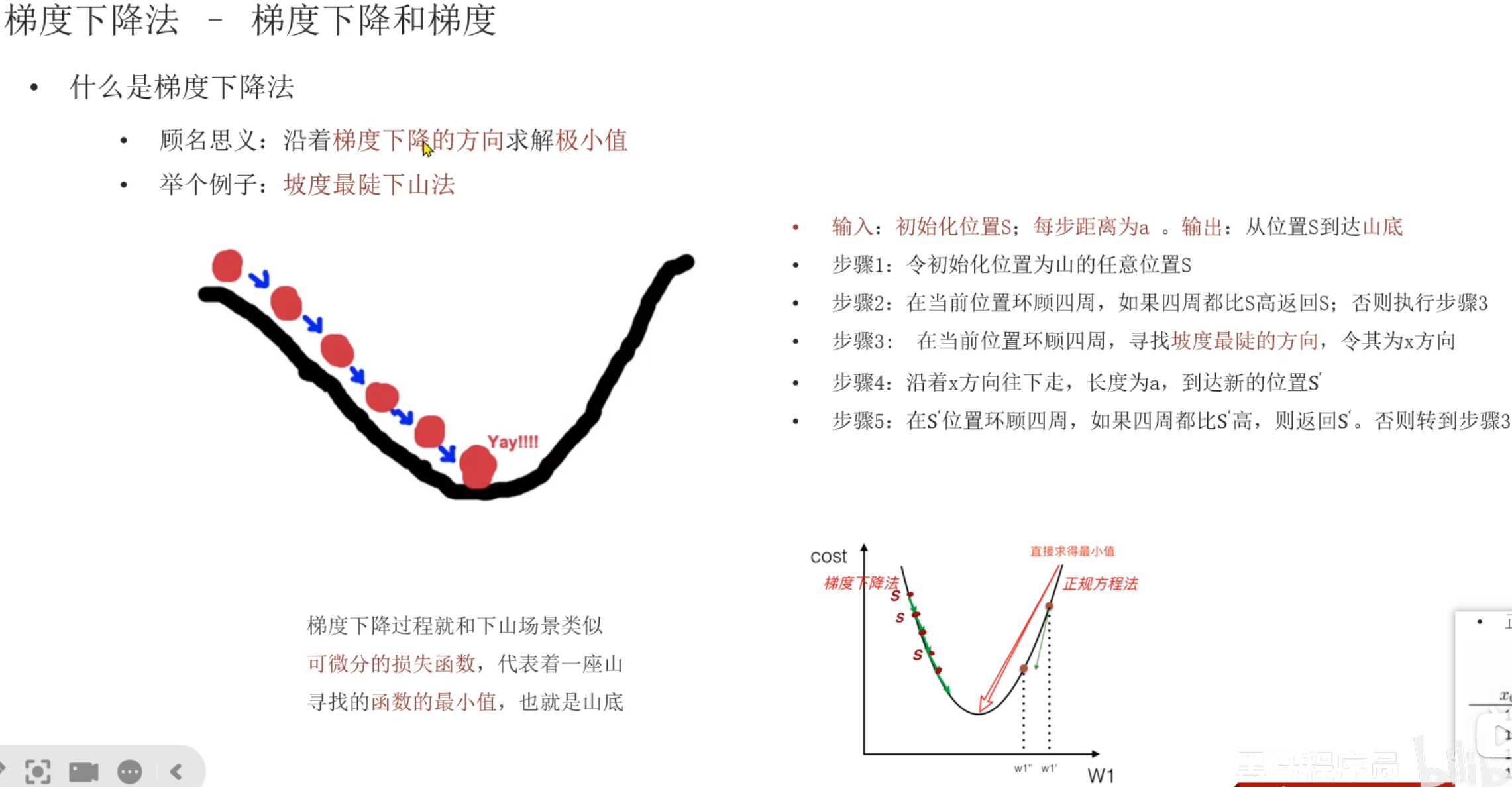
老师公式的写法是:下个点 = 当前点 - 学习率 * 损失函数,其实老师讲解的是没有问题的,但是这个公式会有点误导,我自己当前也是混淆了一下。这里混淆了损失函数和损失函数对当前参数的梯度,正确的公式为:下一个参数值 = 当前参数值 - 学习率 * 损失函数对当前参数的梯度(至于什么是梯度在下图讲的很清楚了)
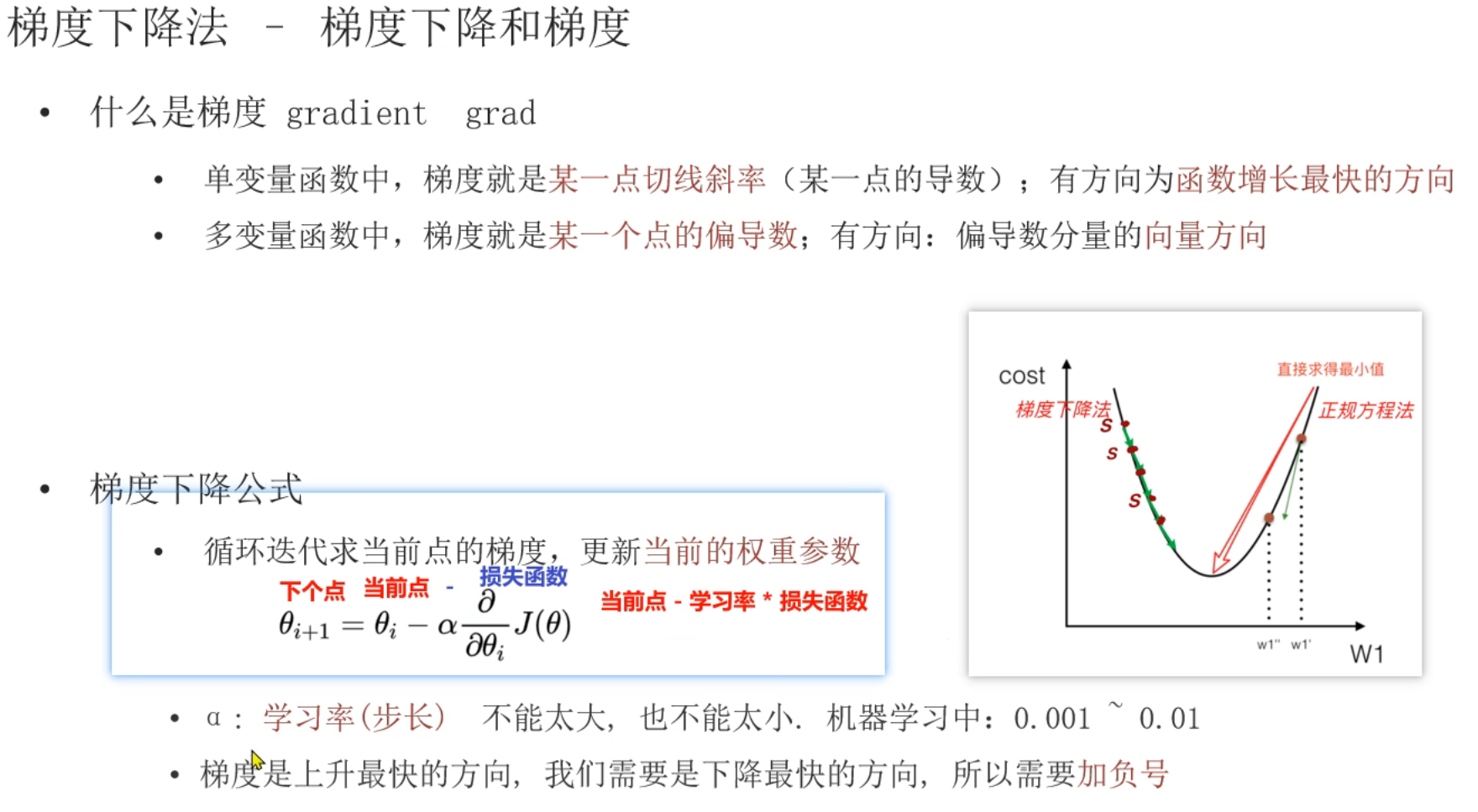
14、多变量_梯度下降法

五、线性回归
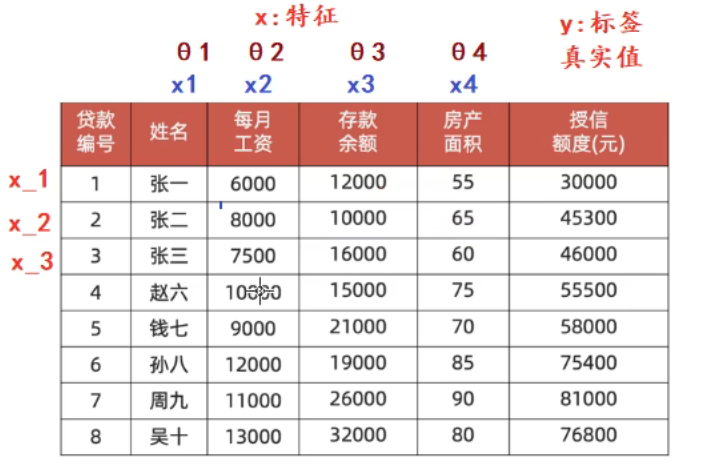
1、银行信贷案例_梯度下降法







2、梯度下降算法分类



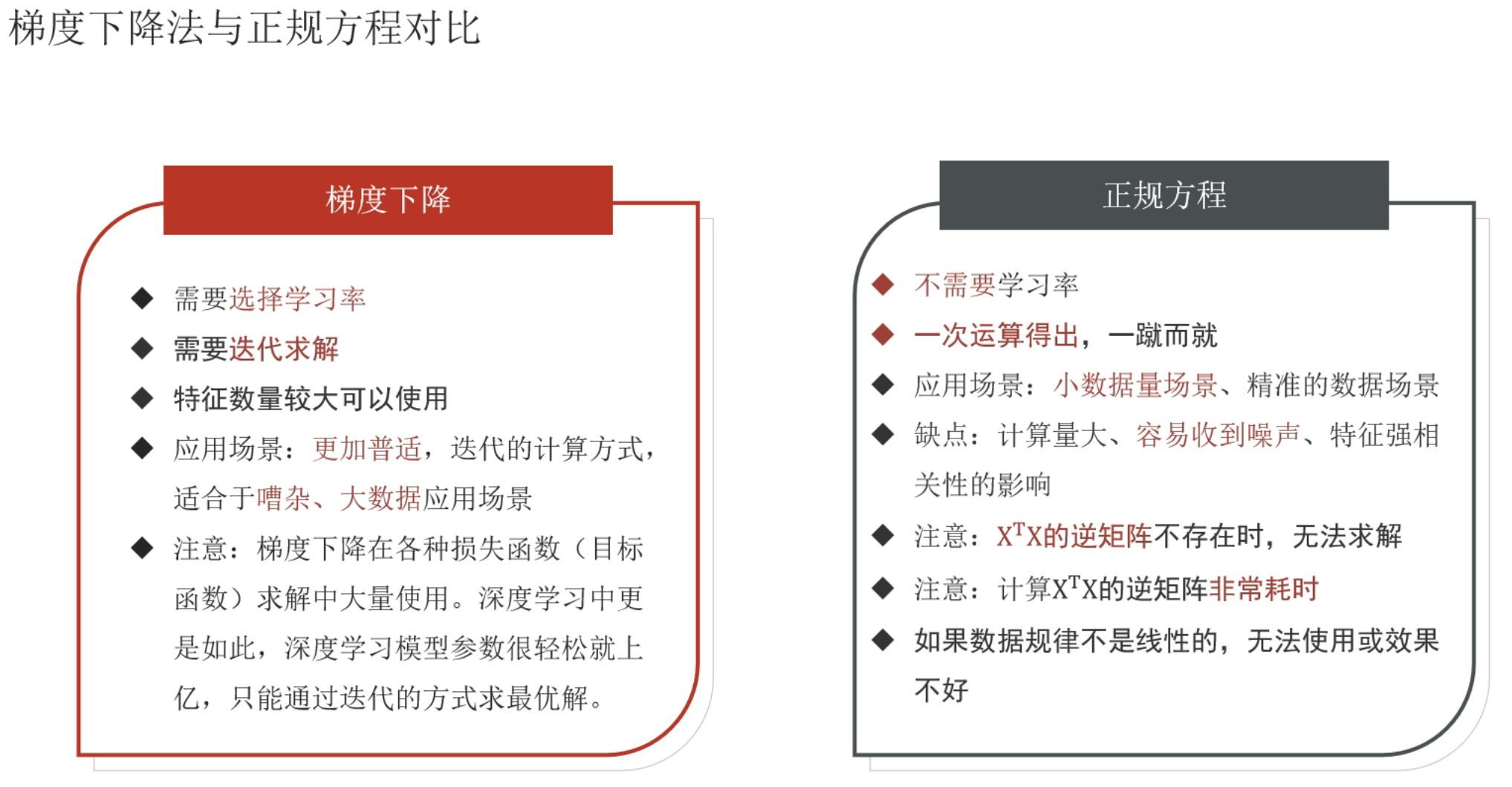



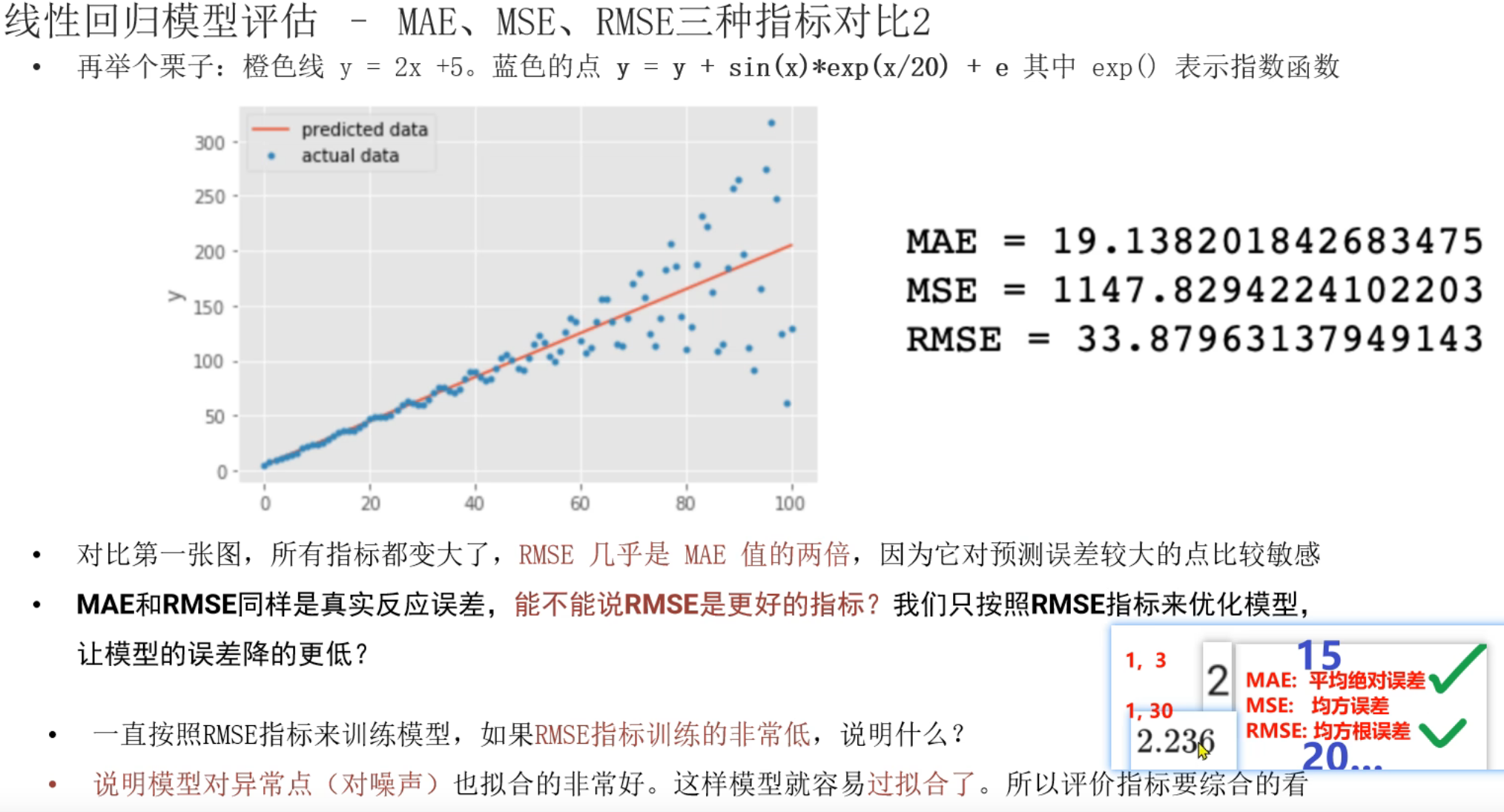
3、回归模型_评估方法


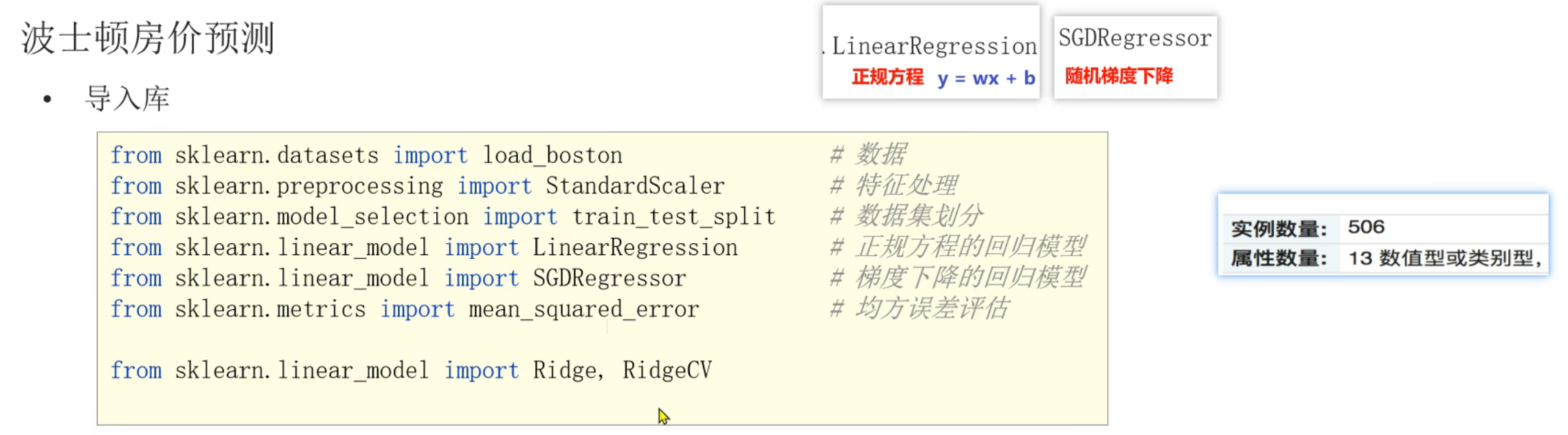
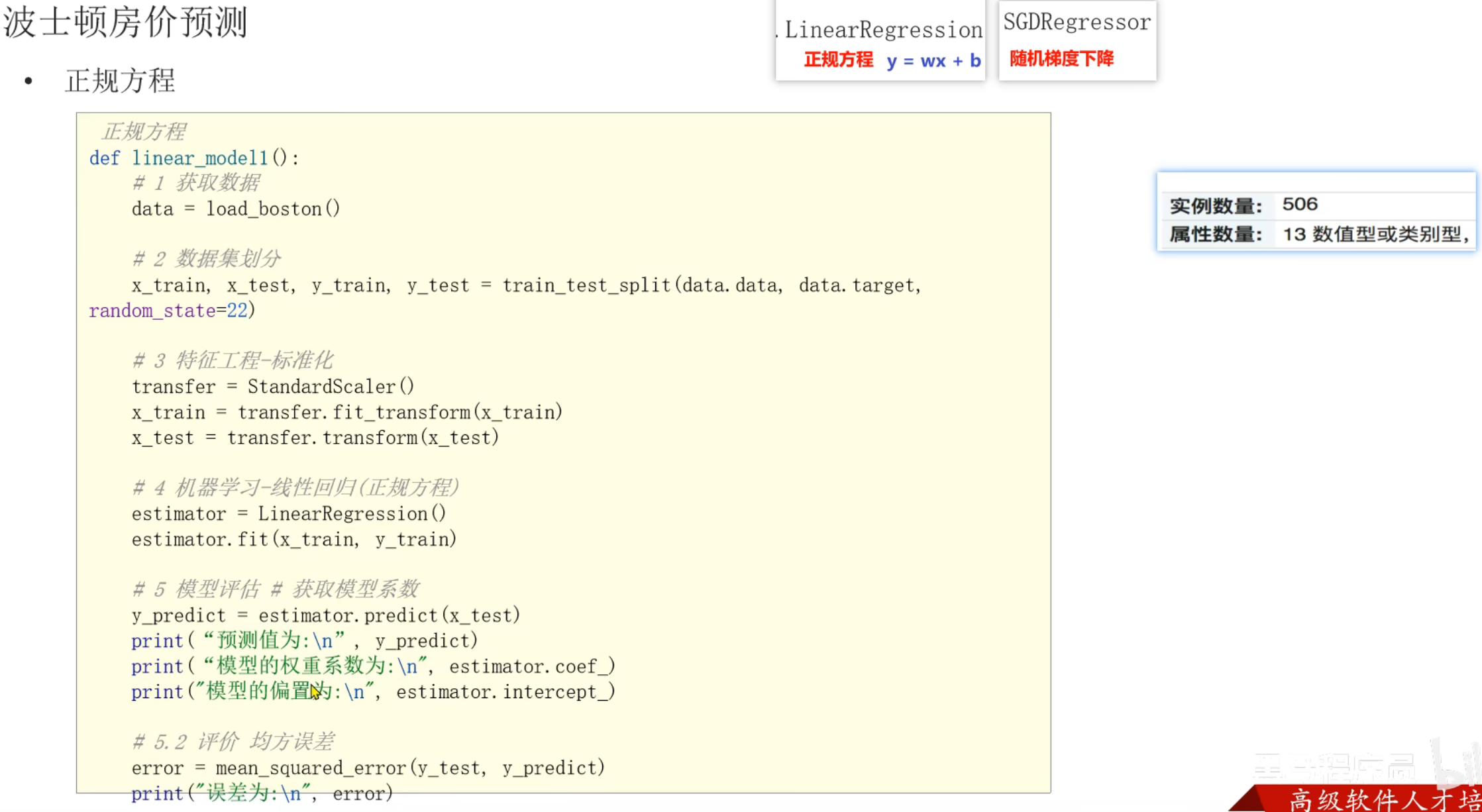
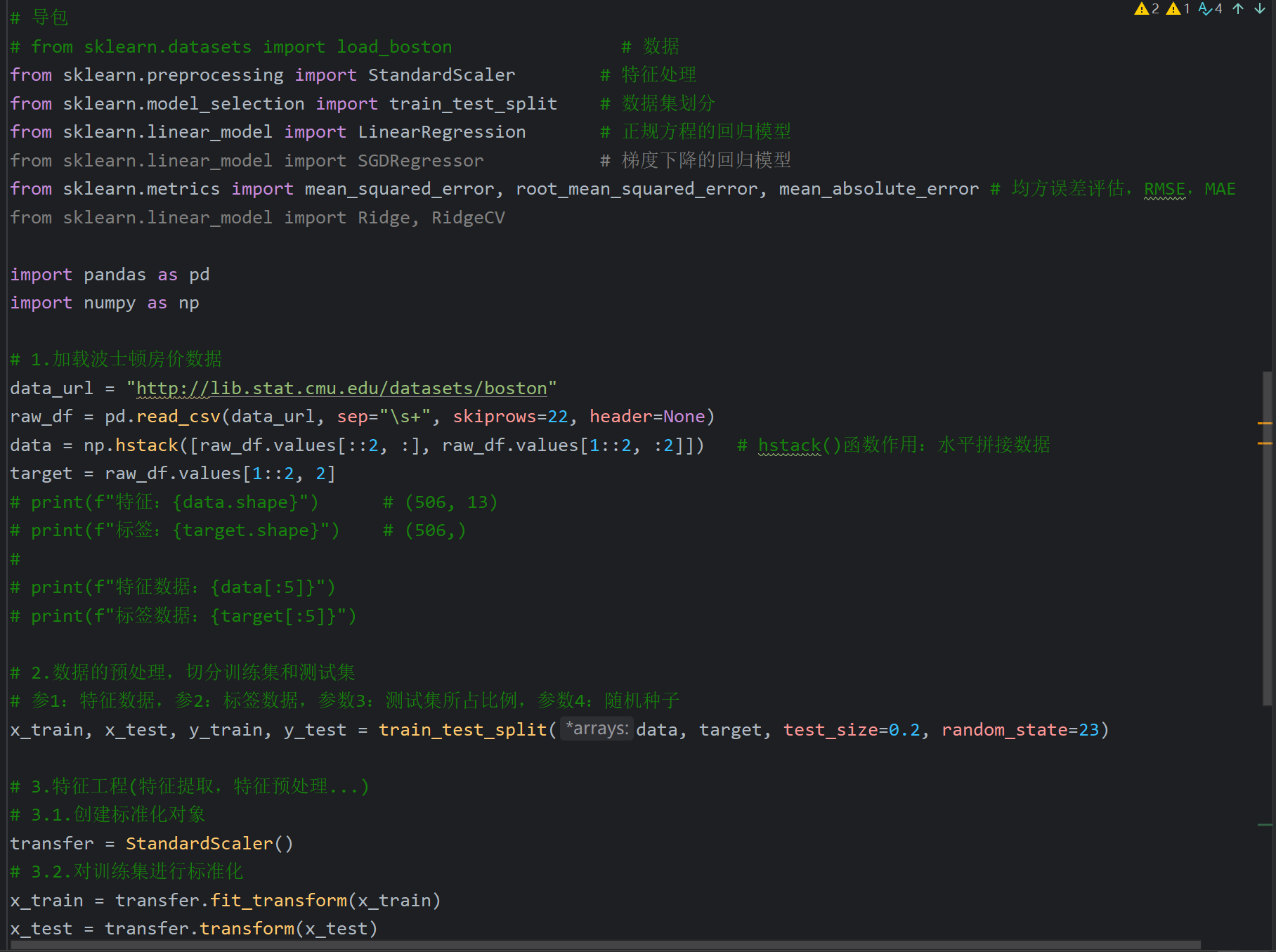
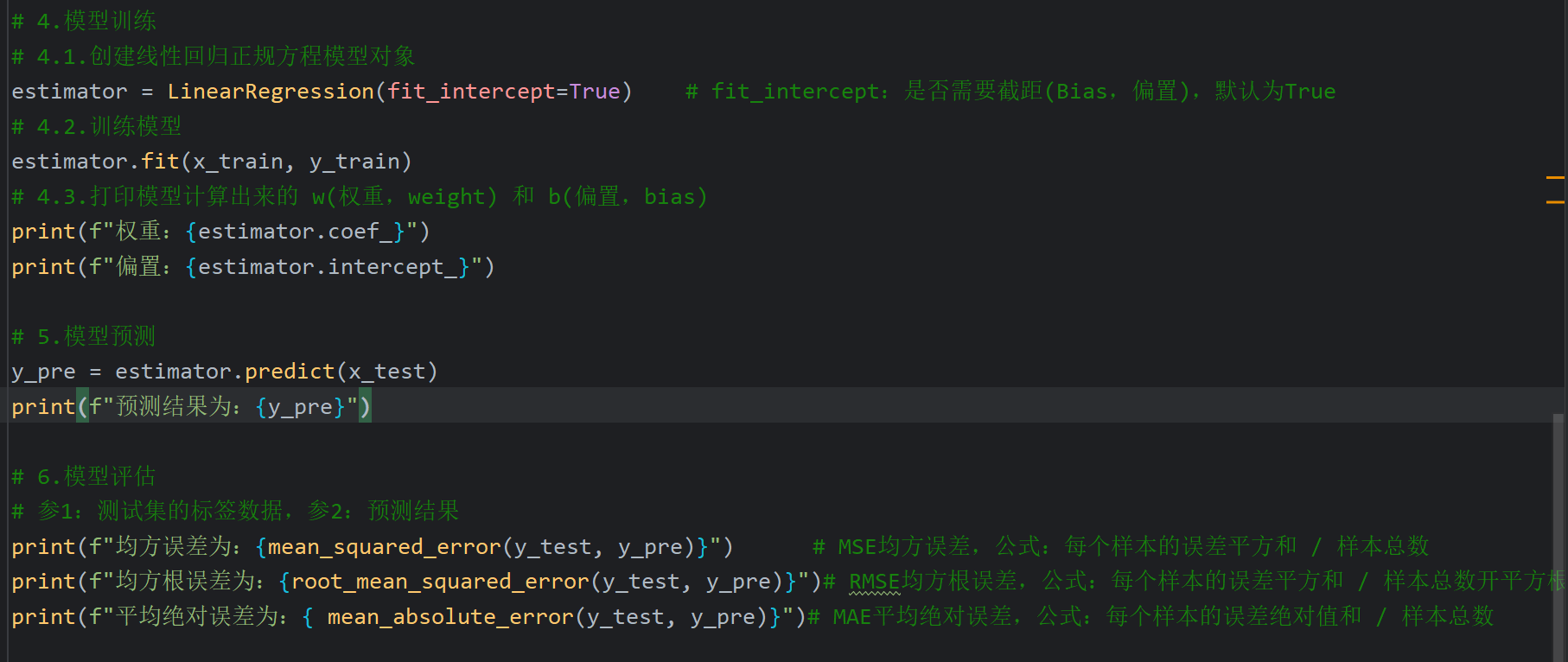
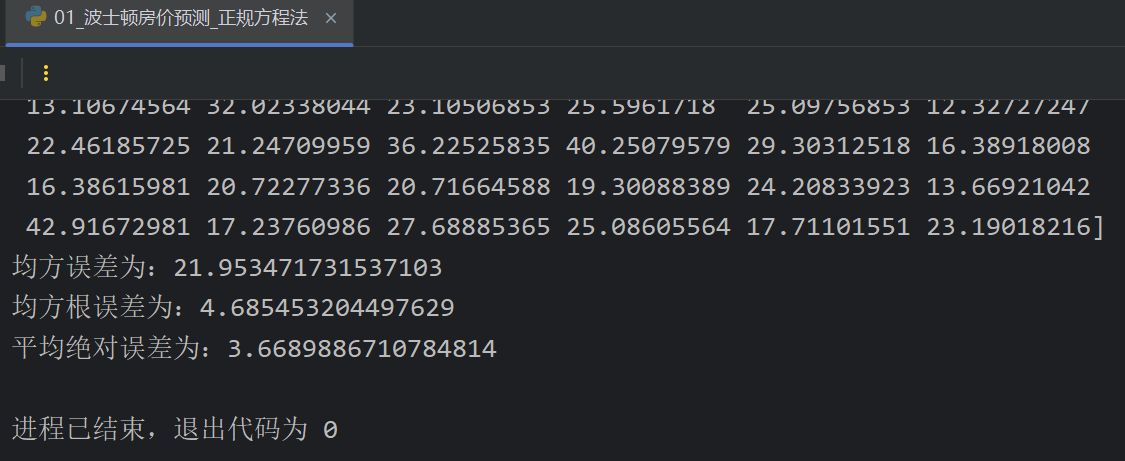
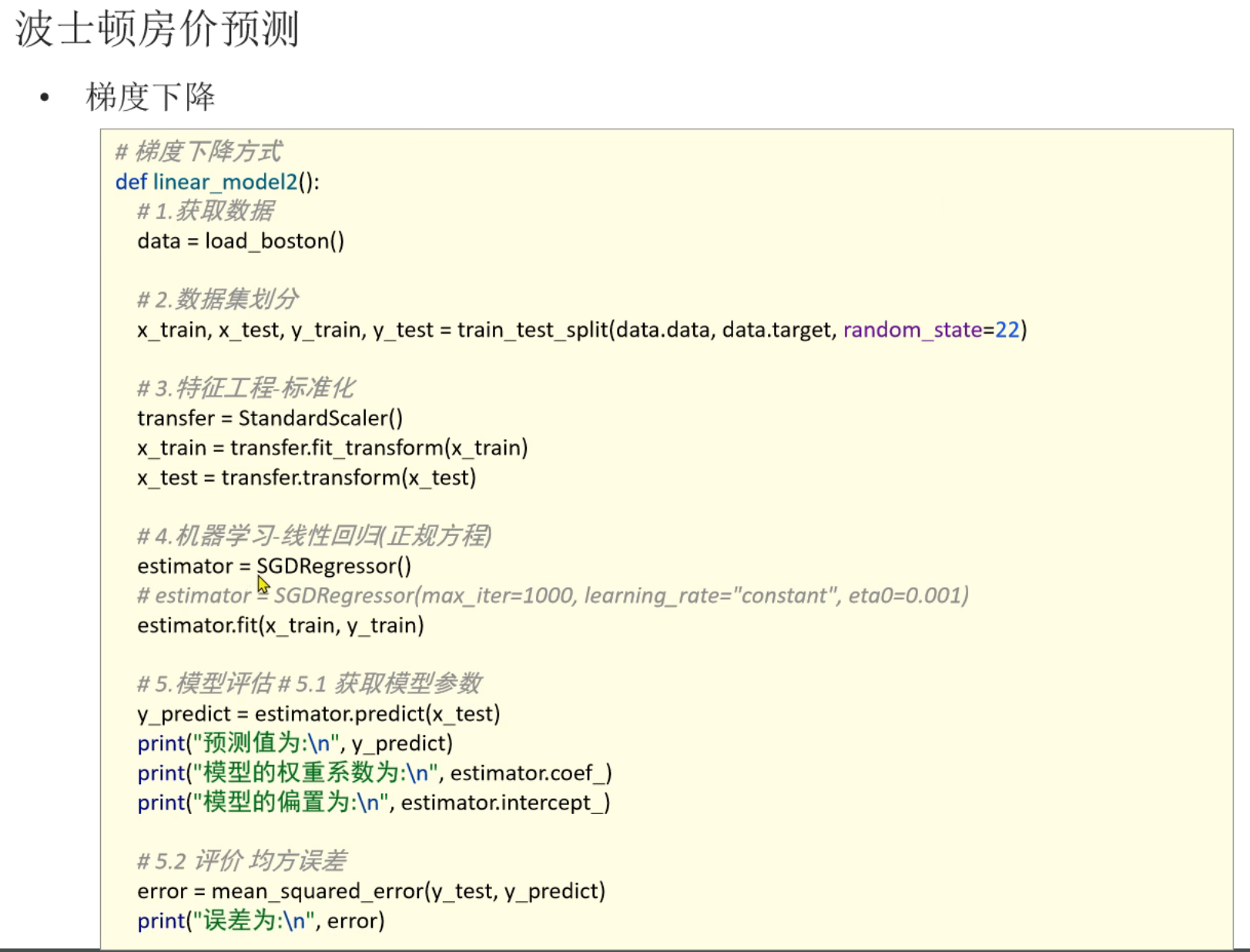
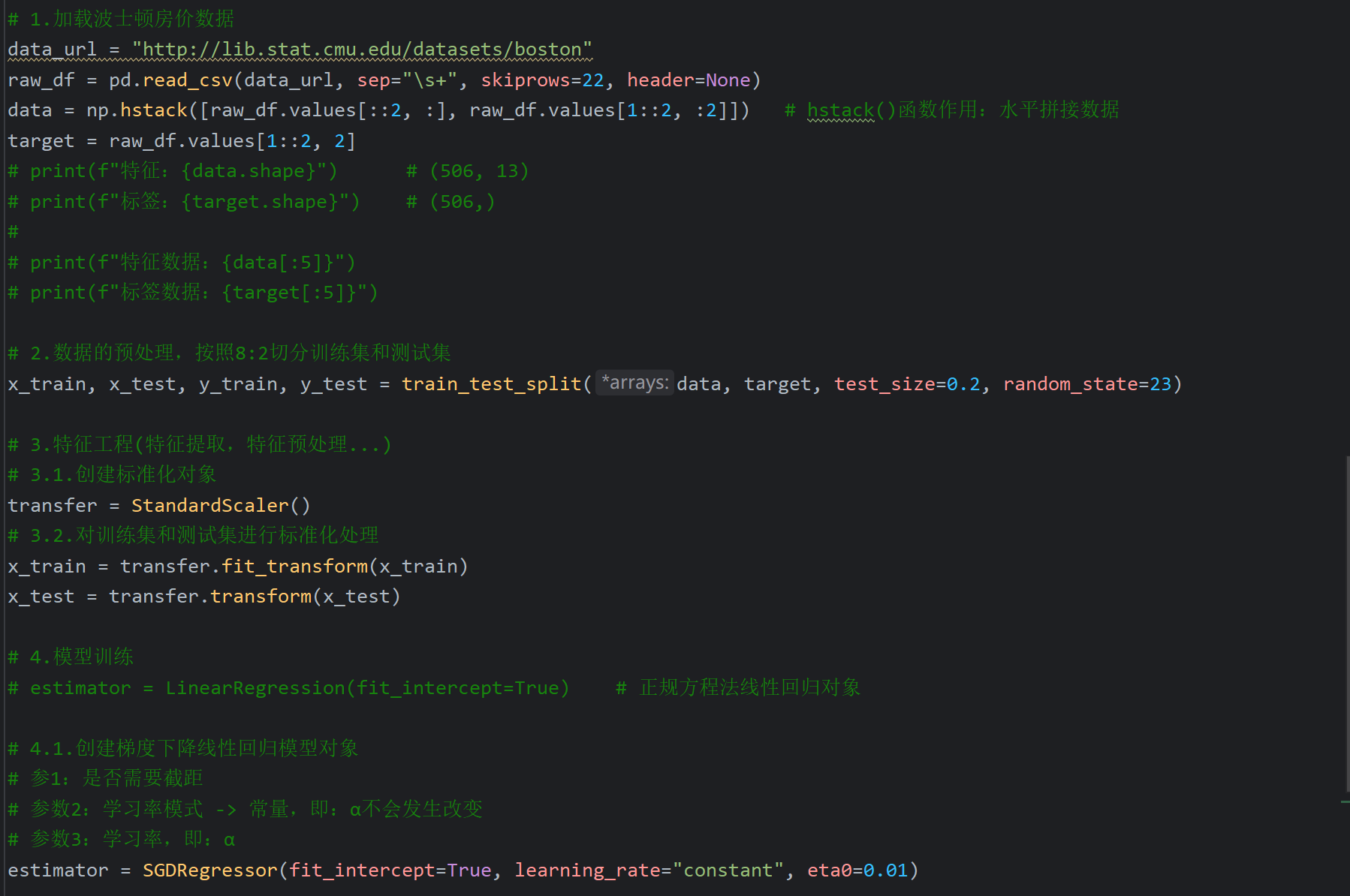
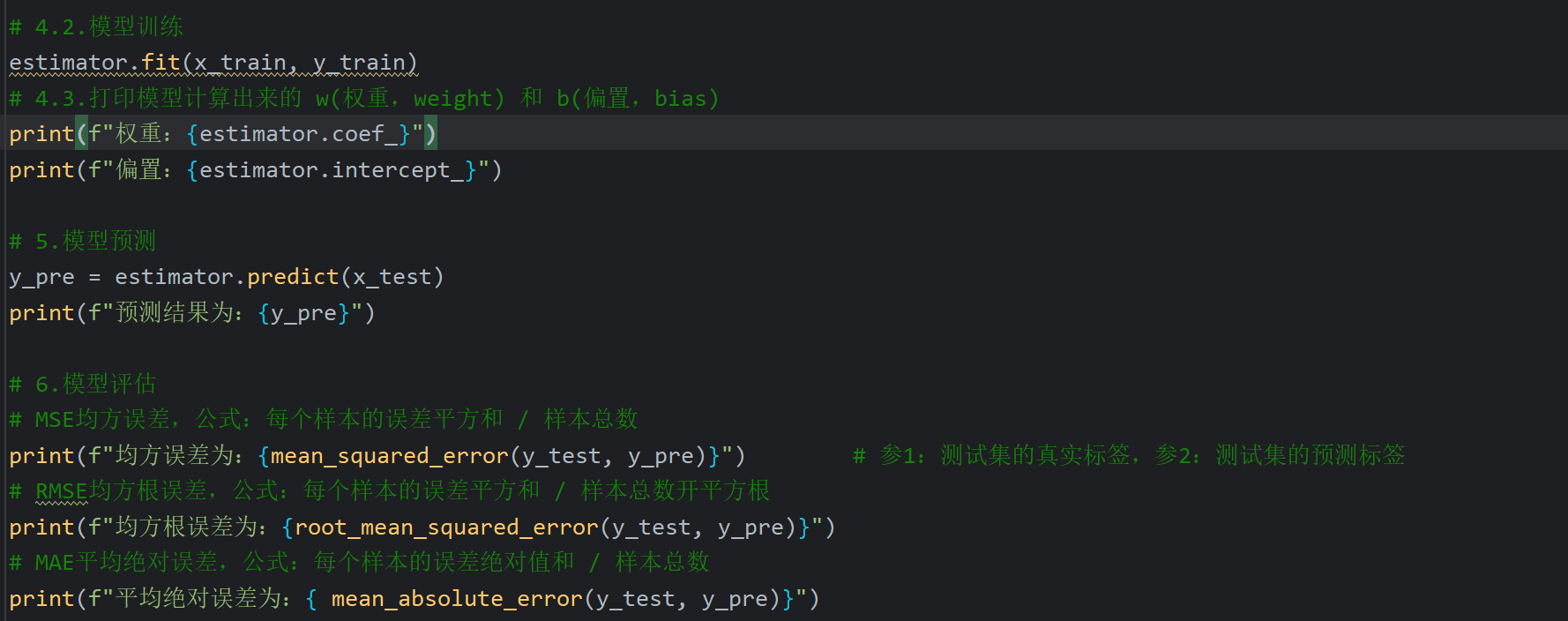
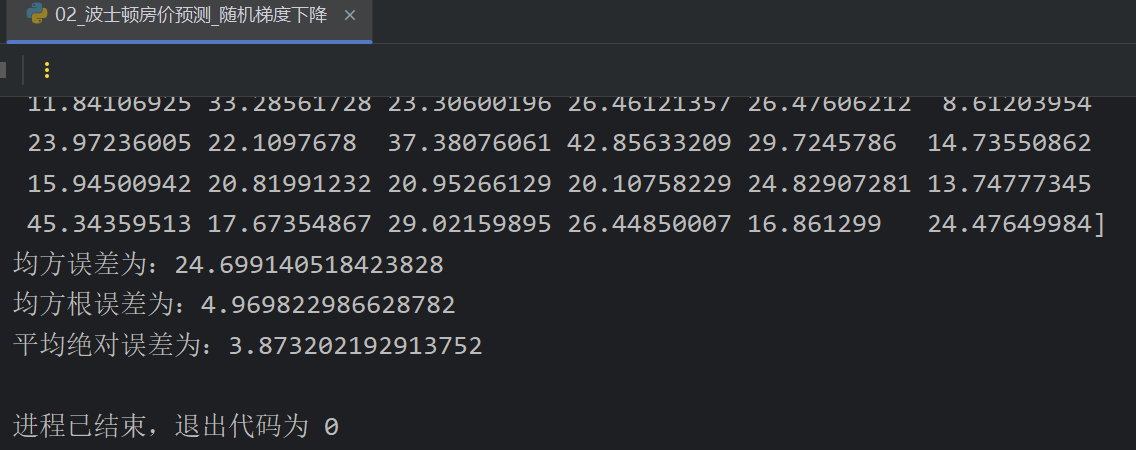
4、正规方程_线性回归对象API介绍



5、梯度下降_线性回归对象API介绍

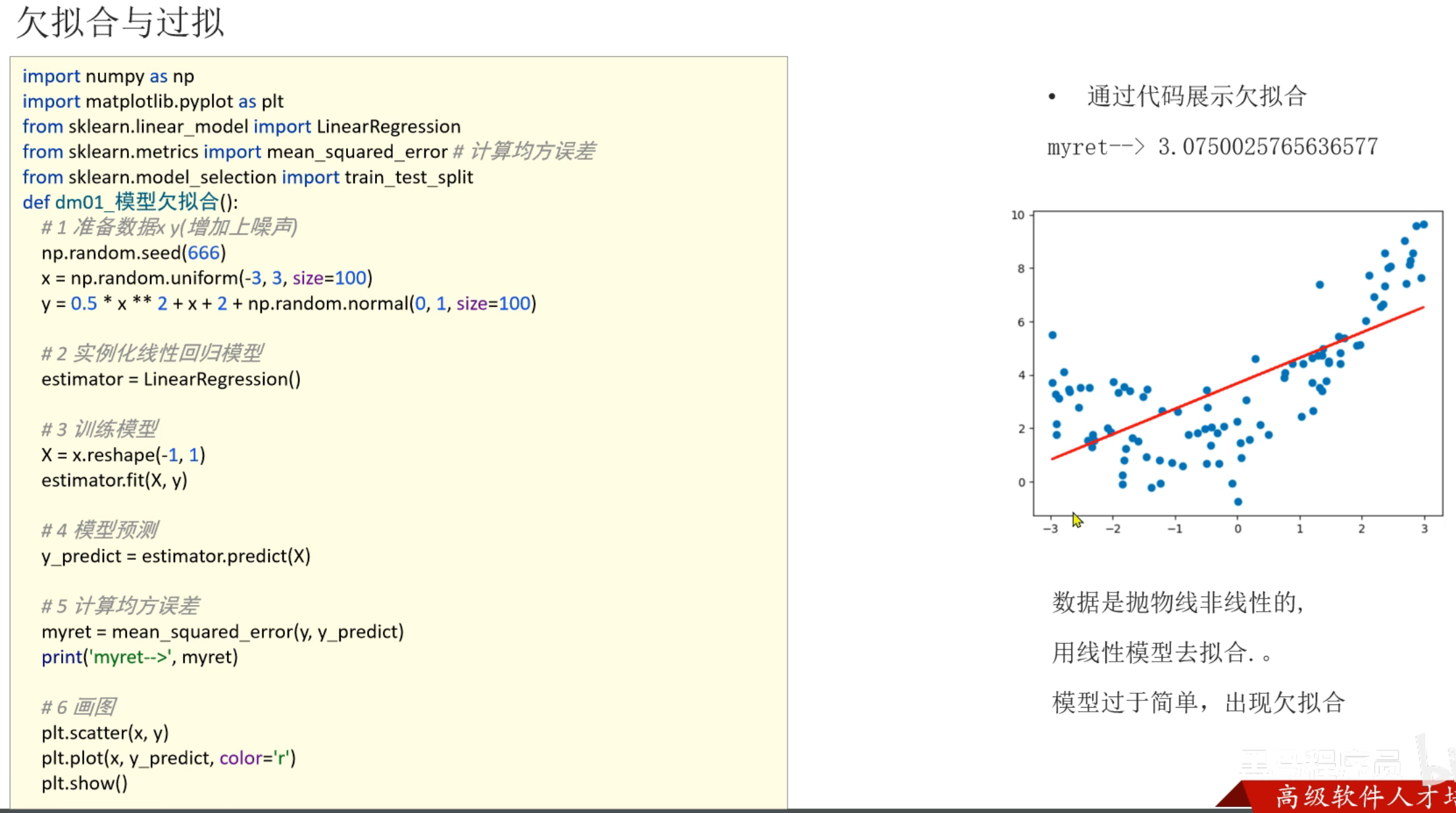
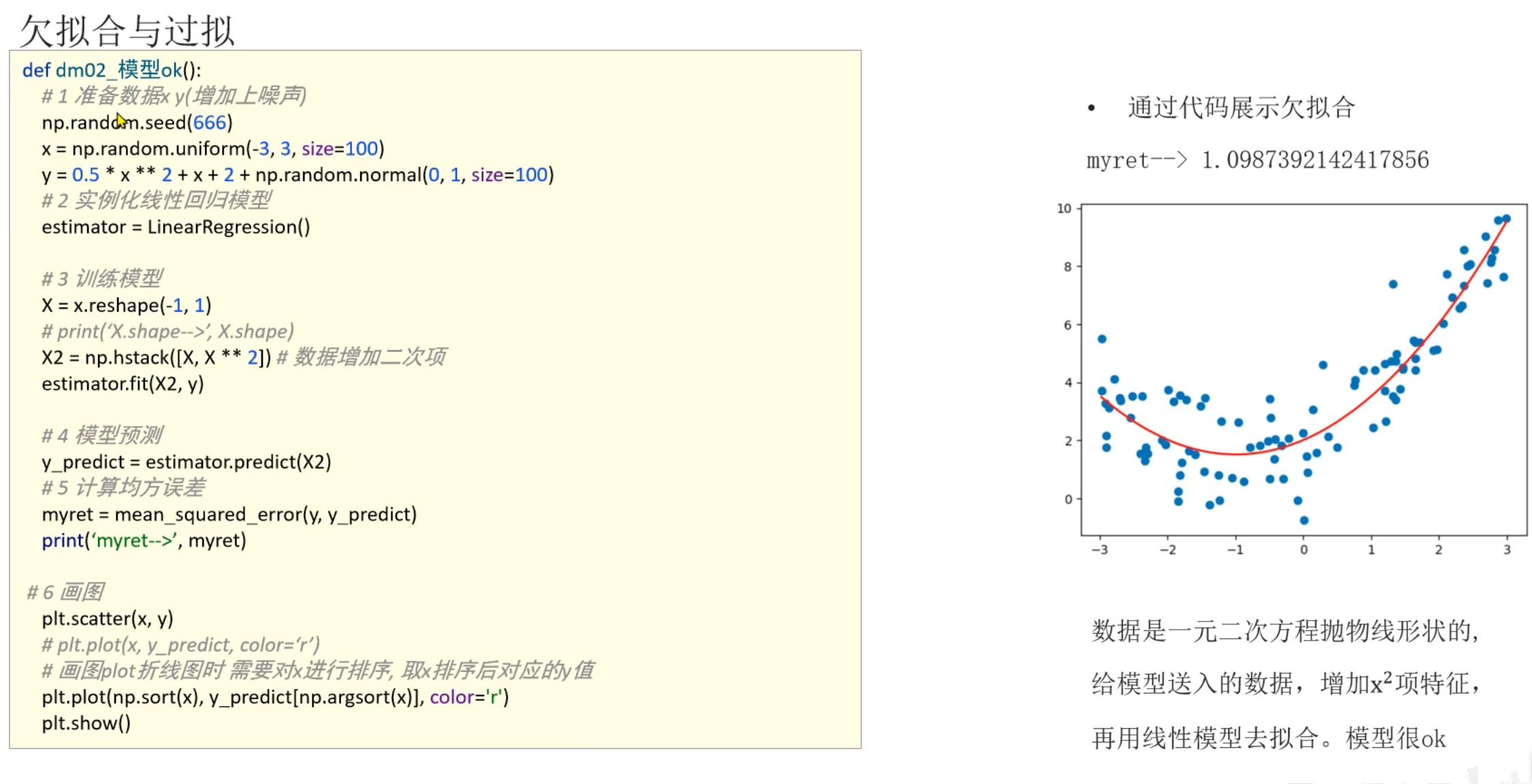
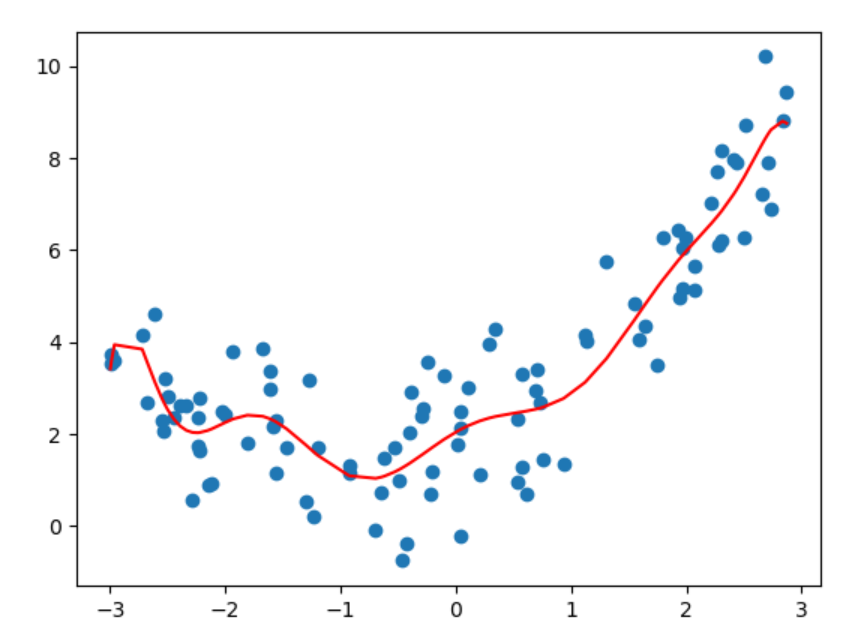
6、代码演示_欠拟合
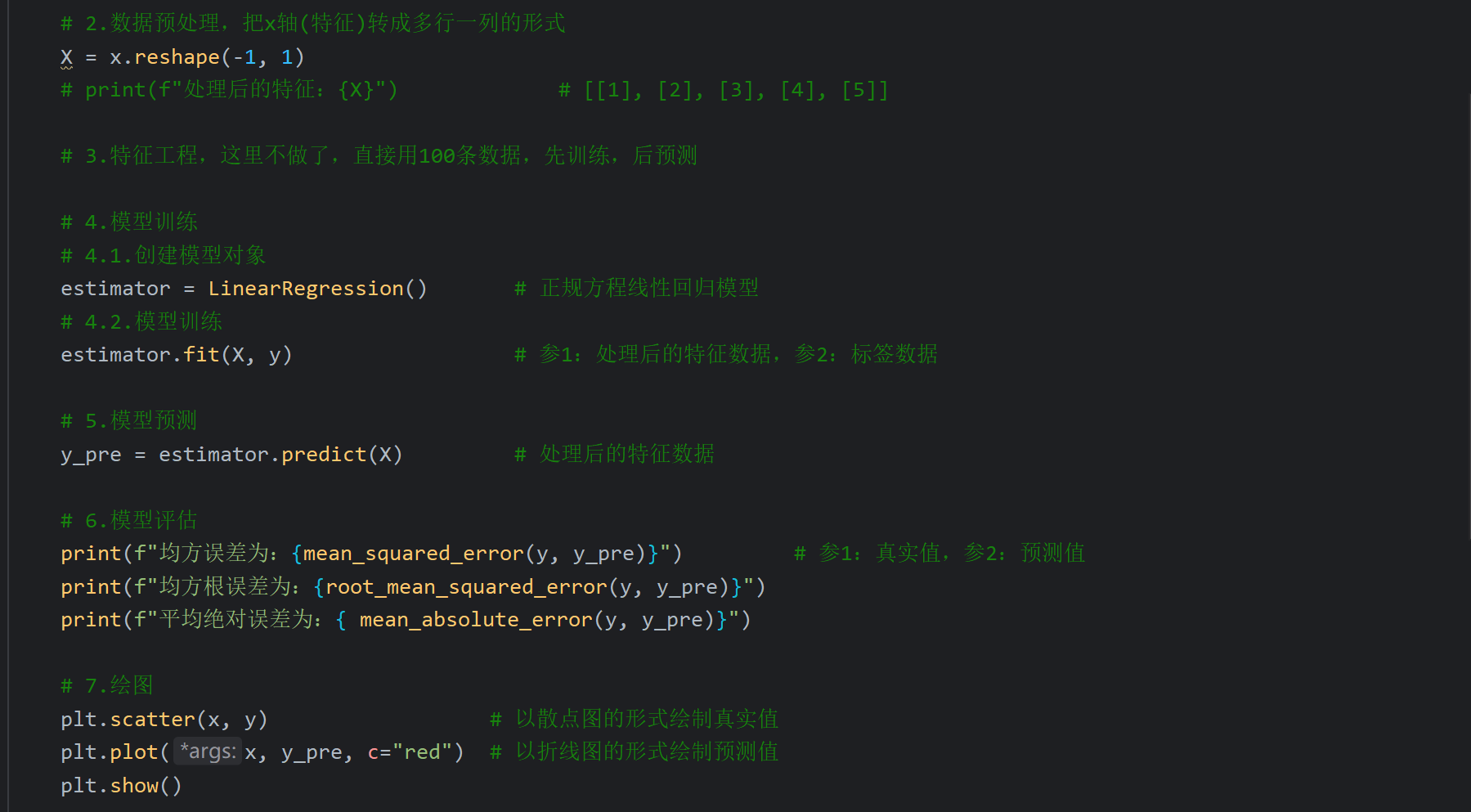

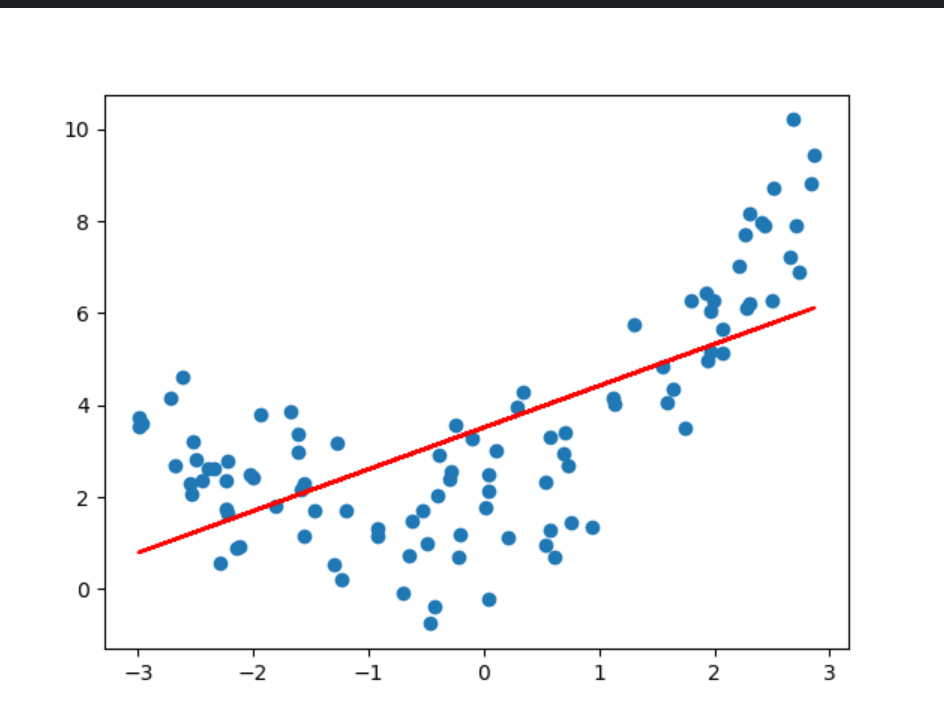

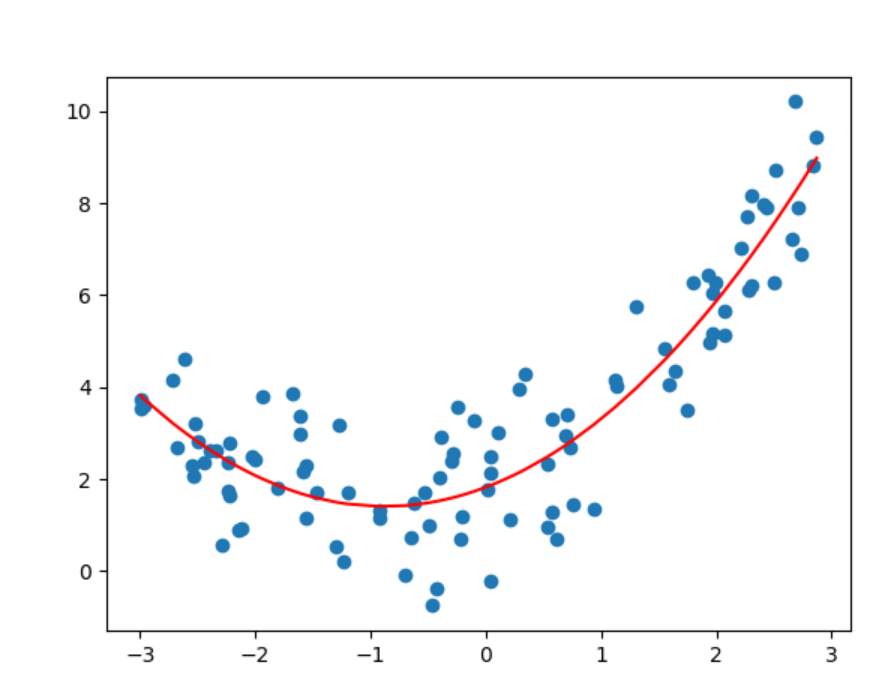
7、代码演示_正好拟合

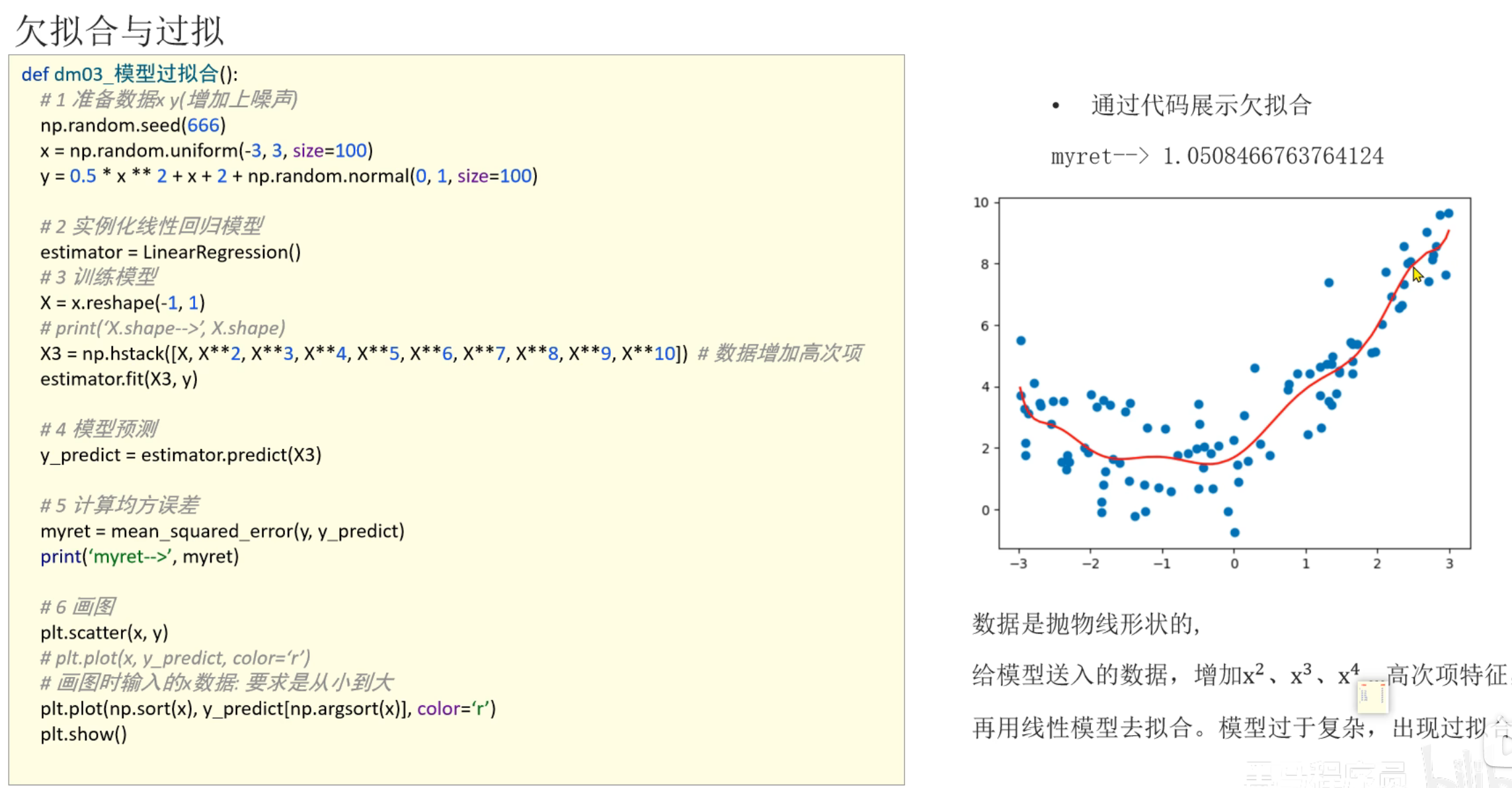
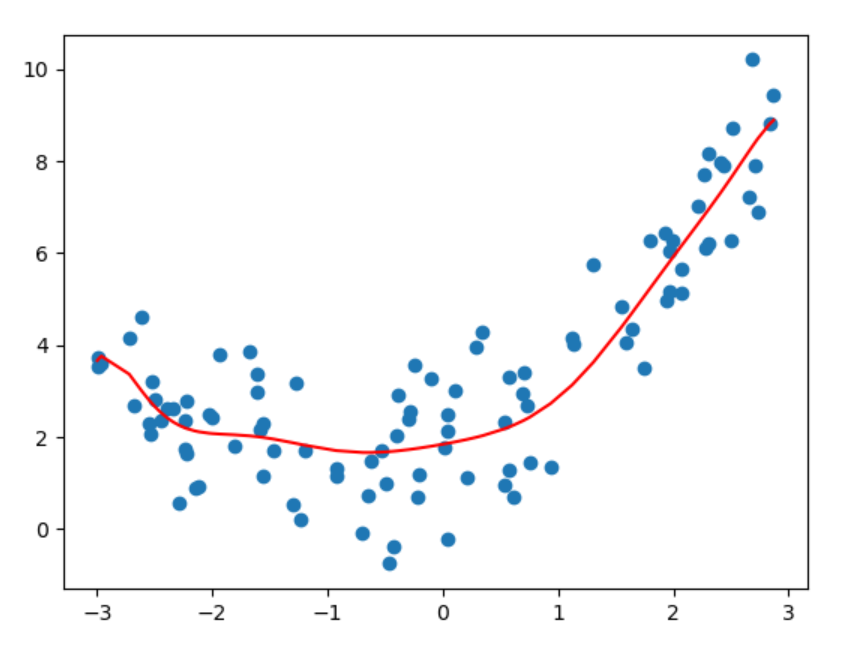
8、代码演示_过拟合
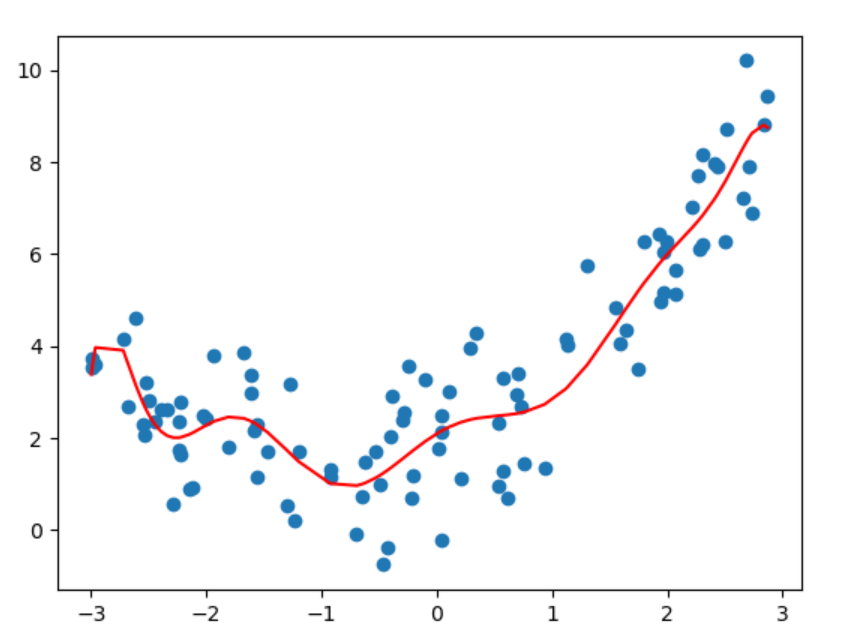

9、L1和L2正则化介绍





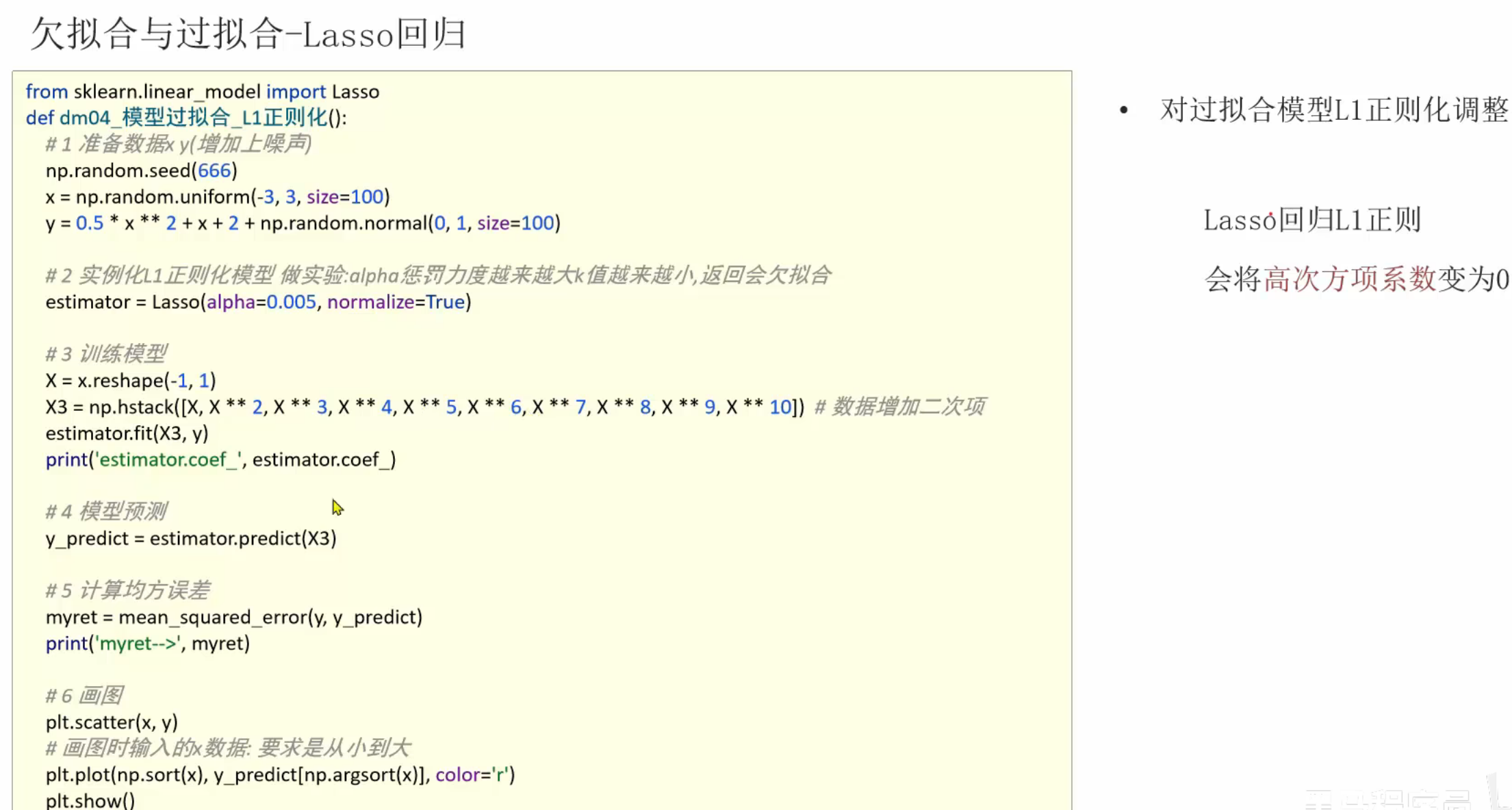

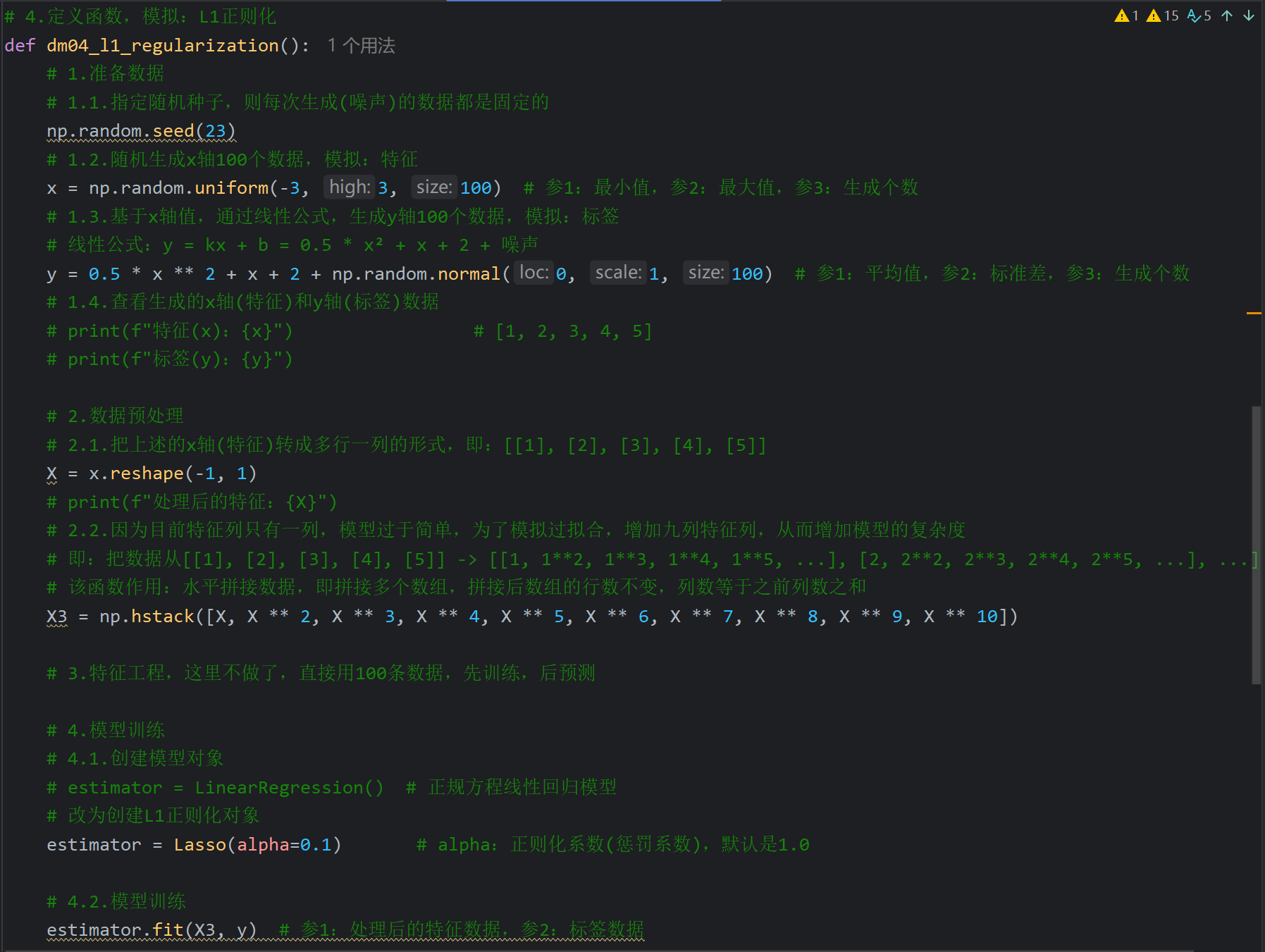
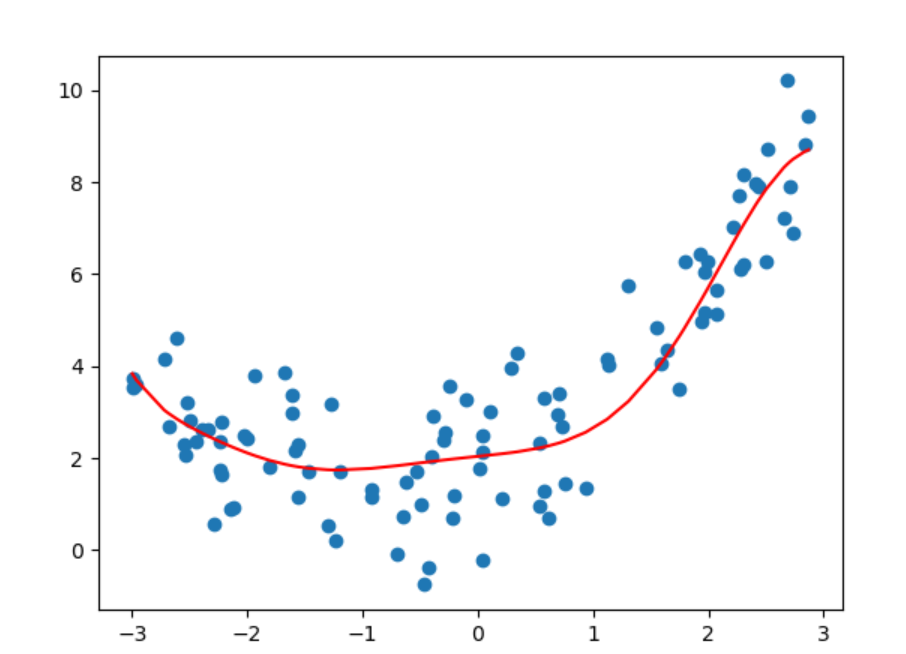



将L2正则化的惩罚系数从0.1改为10





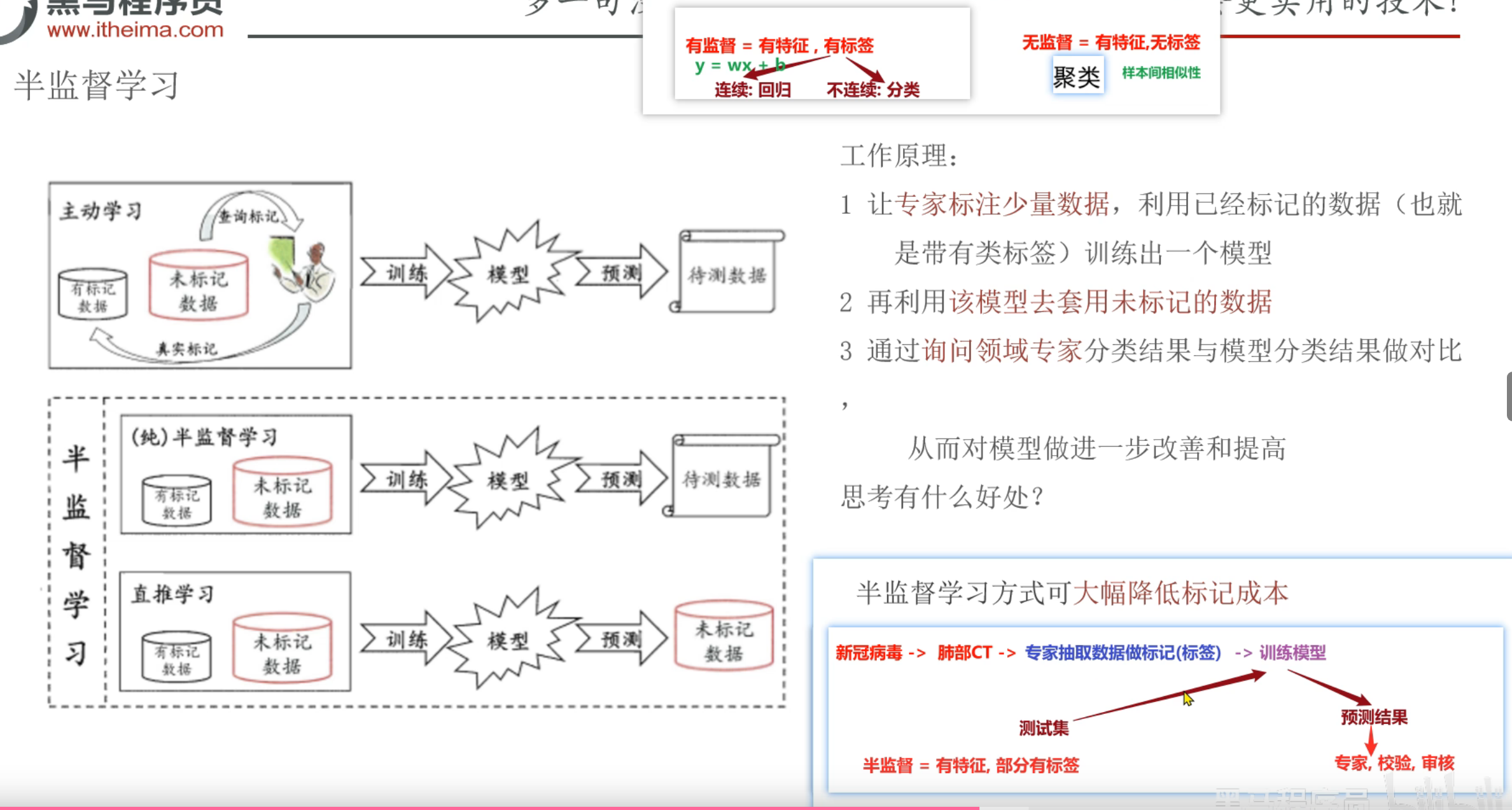
六、逻辑回归
1、今日内容大纲介绍

2、逻辑回归_简介

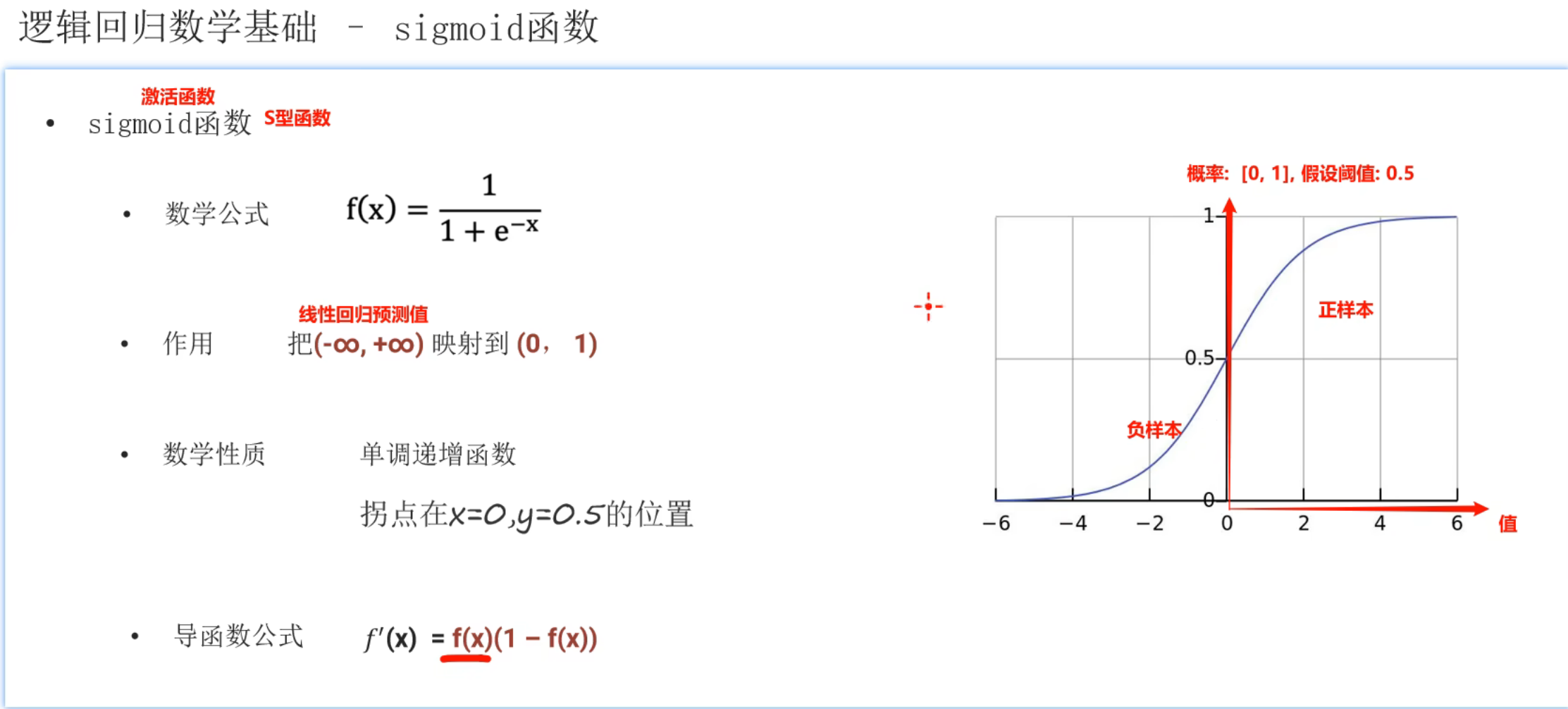

接下来讲的条件概率公式是错的,正确的条件概率公式为:P(B | A) = P(AB) / P(A),表示事件B在事件A已经发生条件下的发生概率
3、概率相关知识回顾
下面这个条件概率也是错的


这里还不如自己推一下,这老师讲代码还行,讲数学知识挺一般的


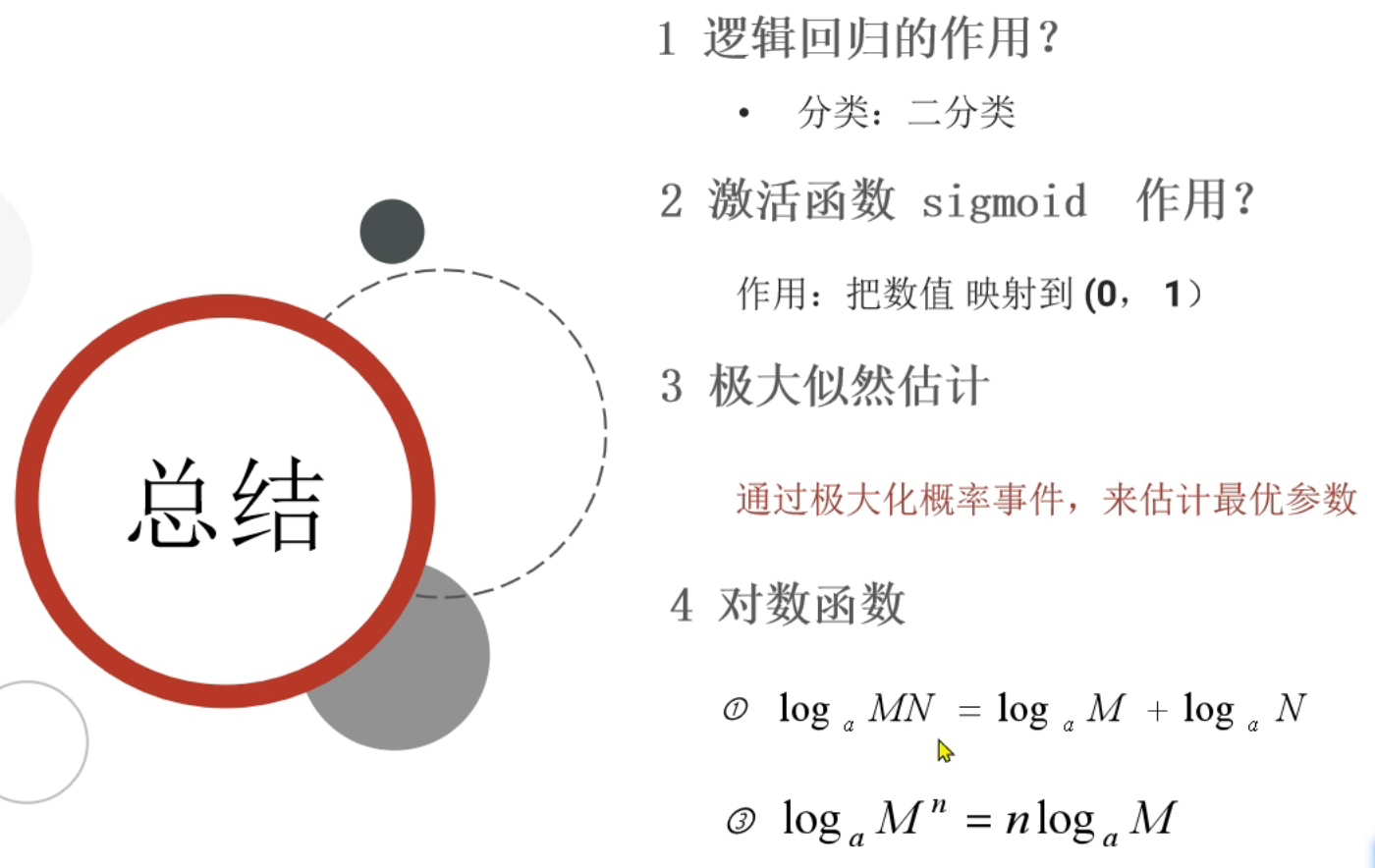
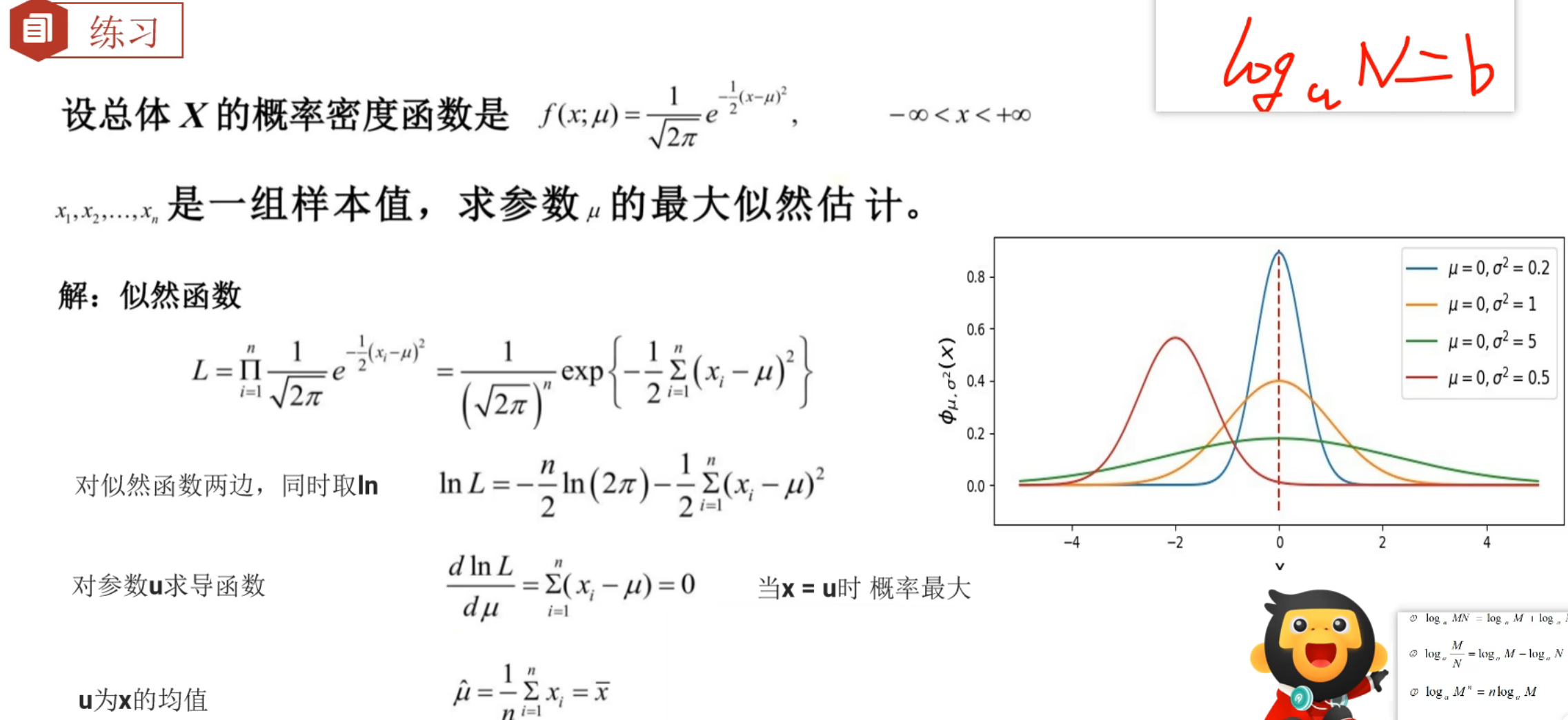
4、逻辑回归_原理介绍

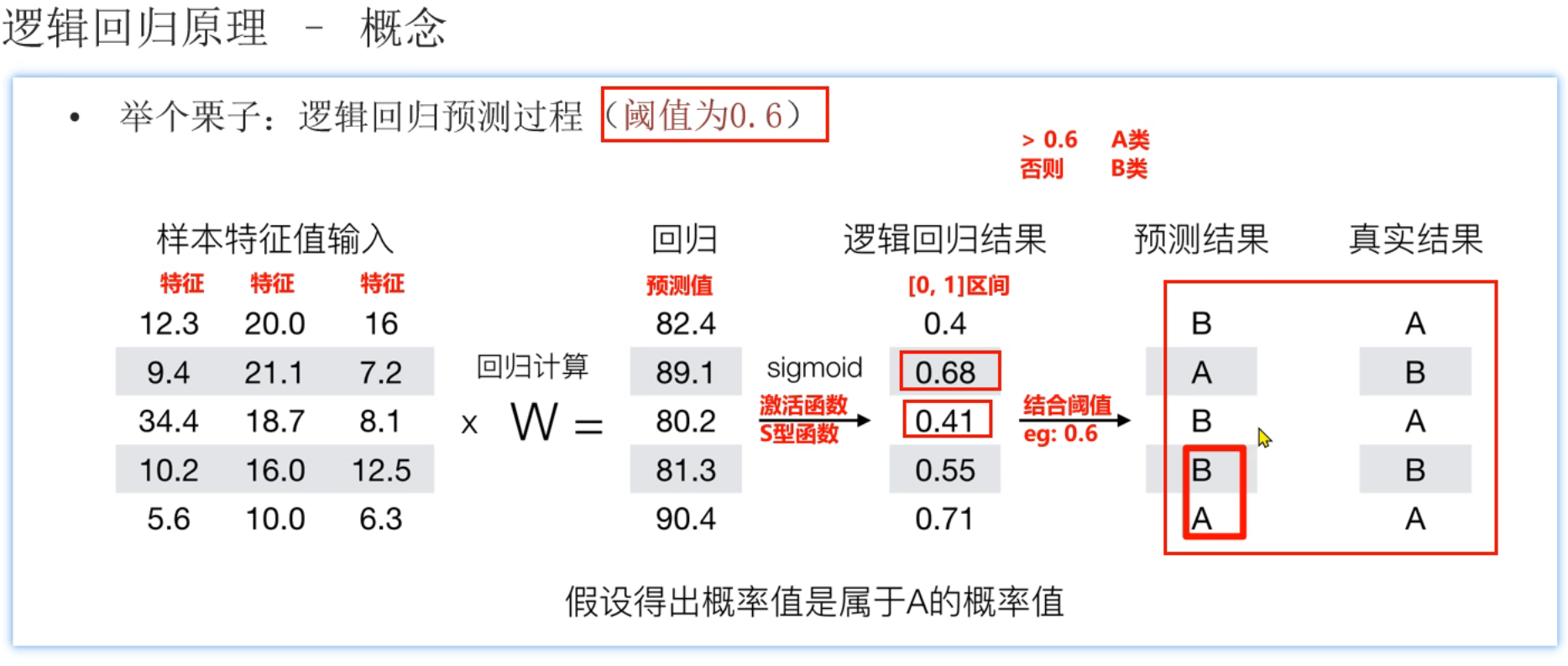
这个地方的y也是错的,下面案例明显可以看出y是真实结果的类别,而不是逻辑回归预估的类别

下面是我结合ai纠正后的总结





C选项有瑕疵,应该是0, 1

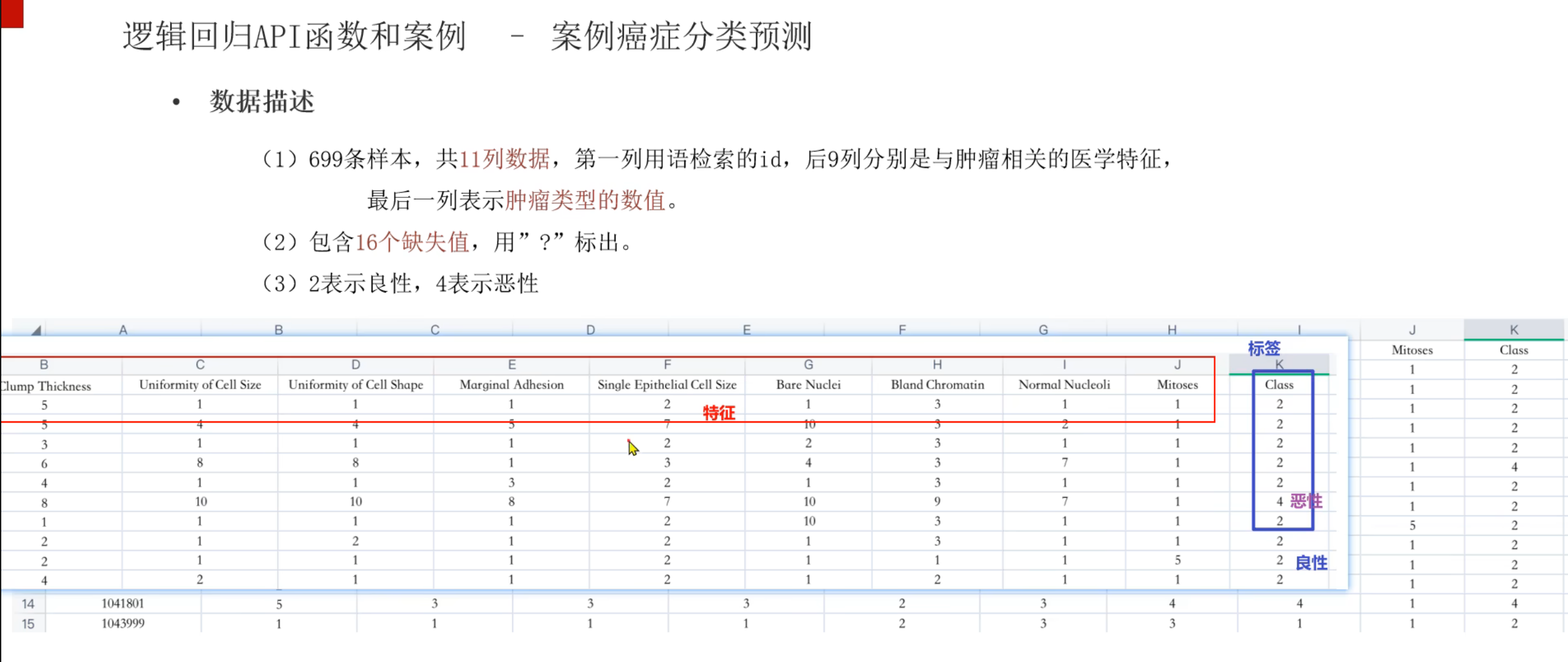
5、逻辑回归案例_癌症预测


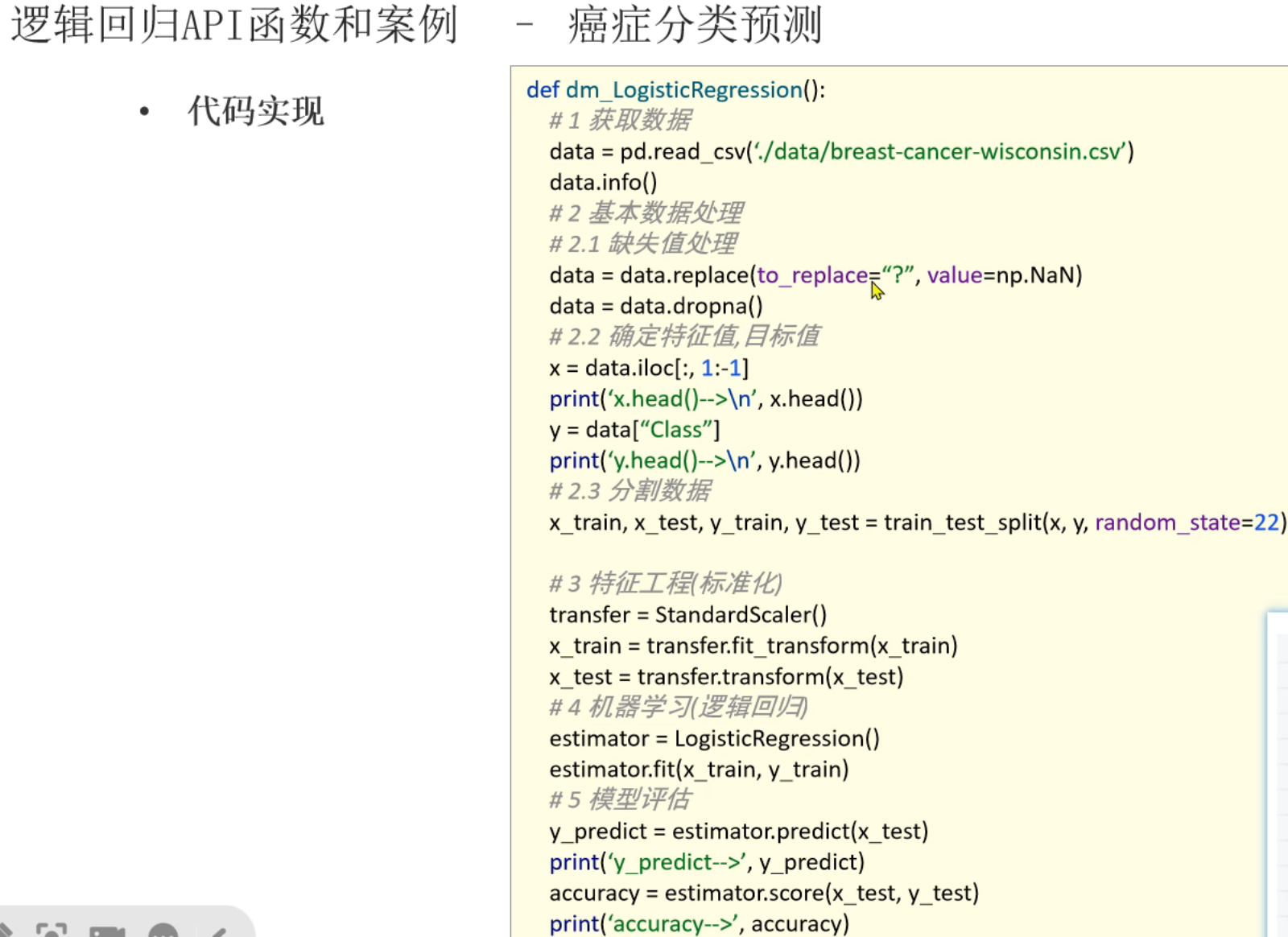
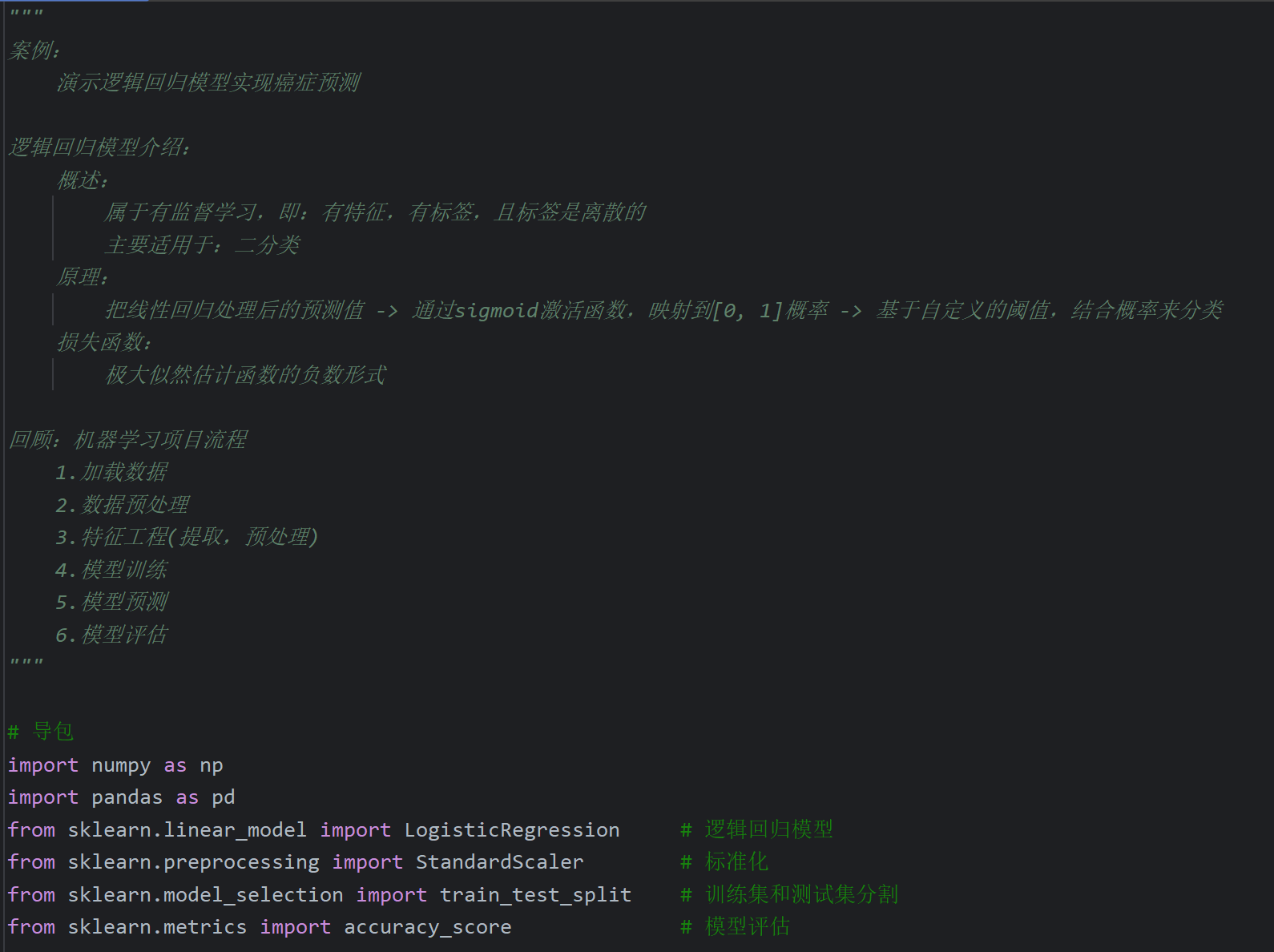
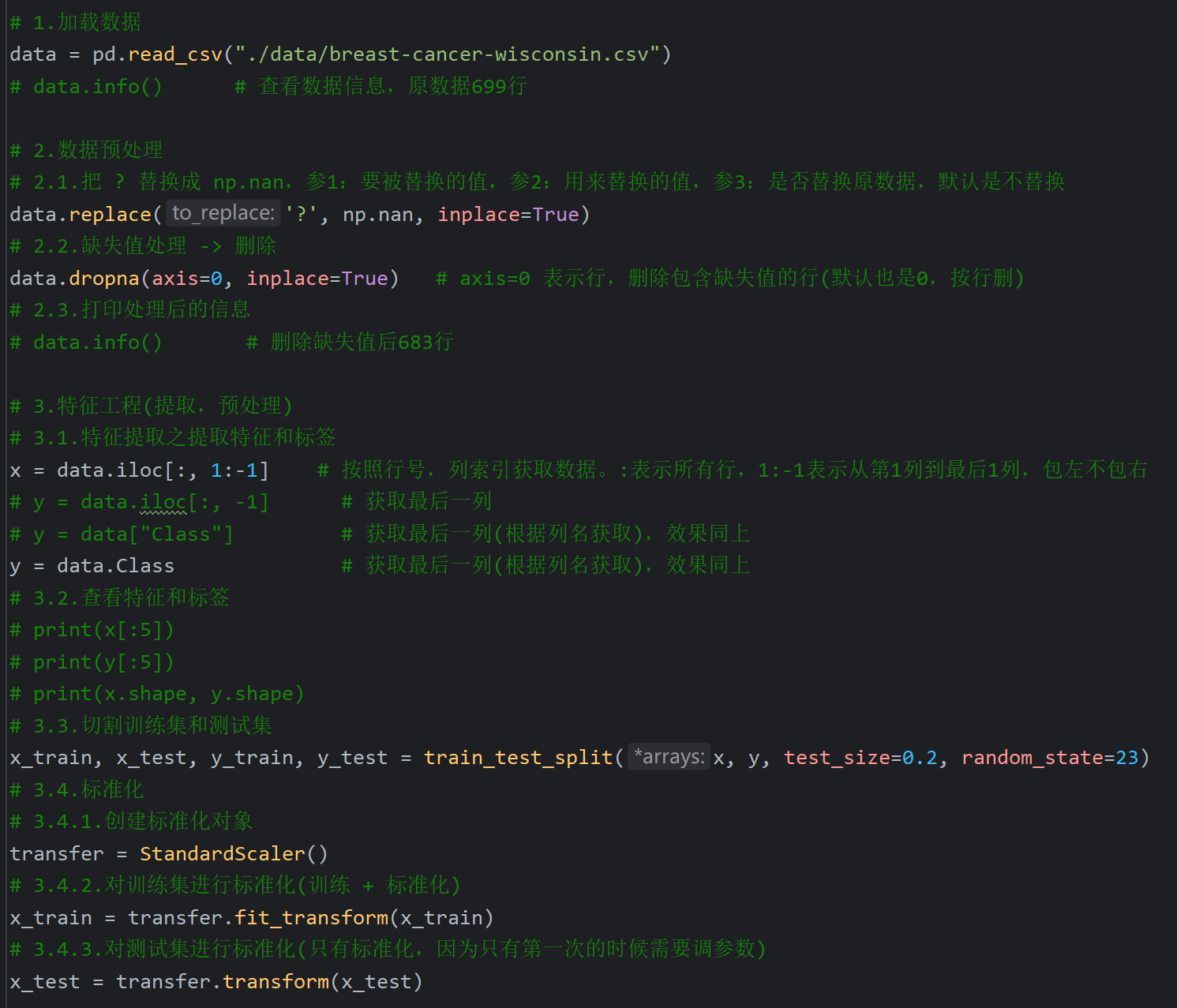
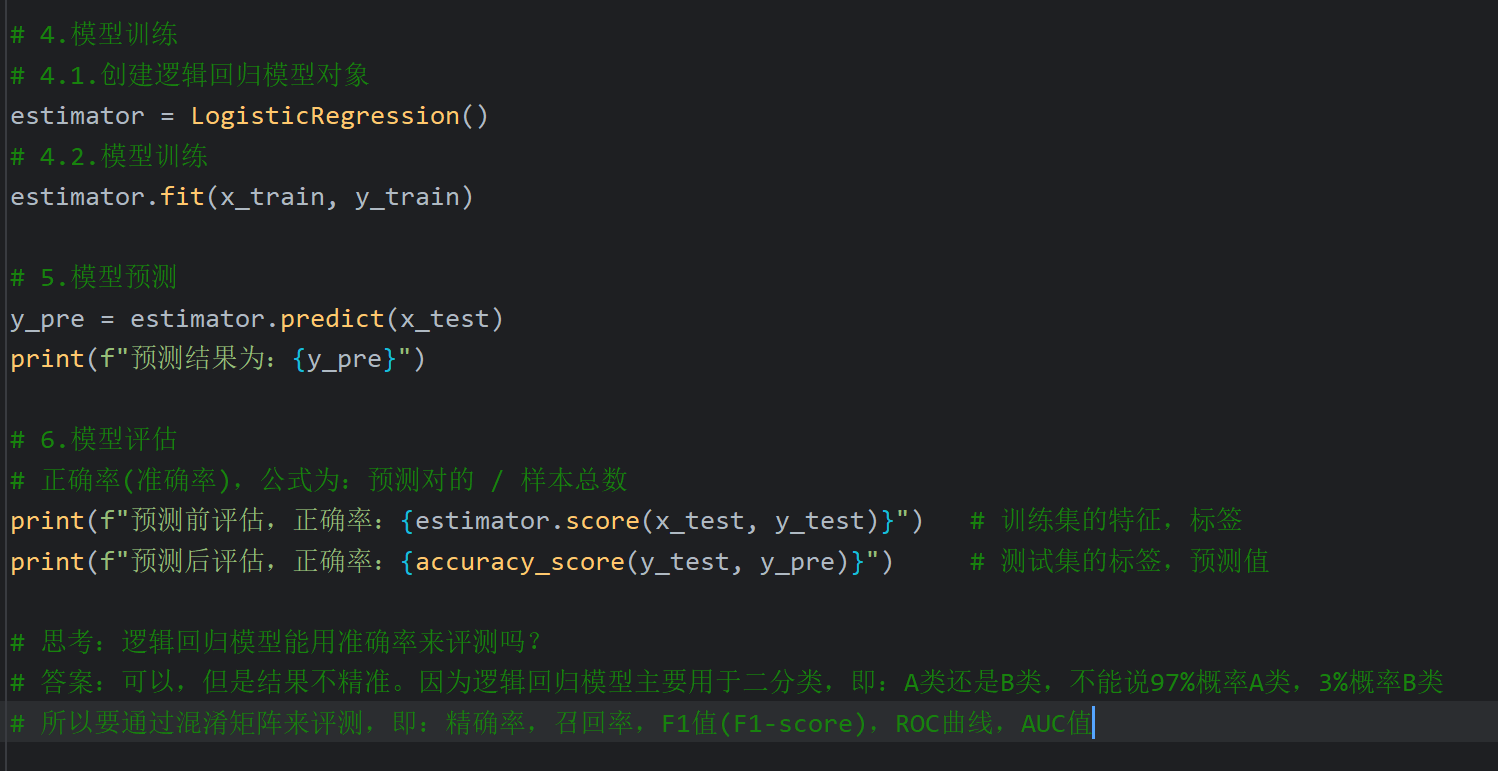
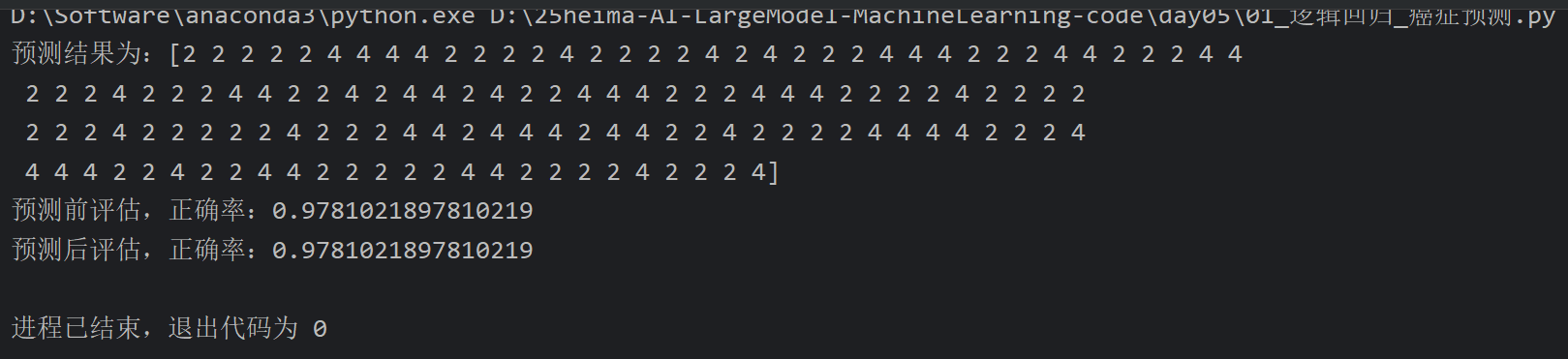

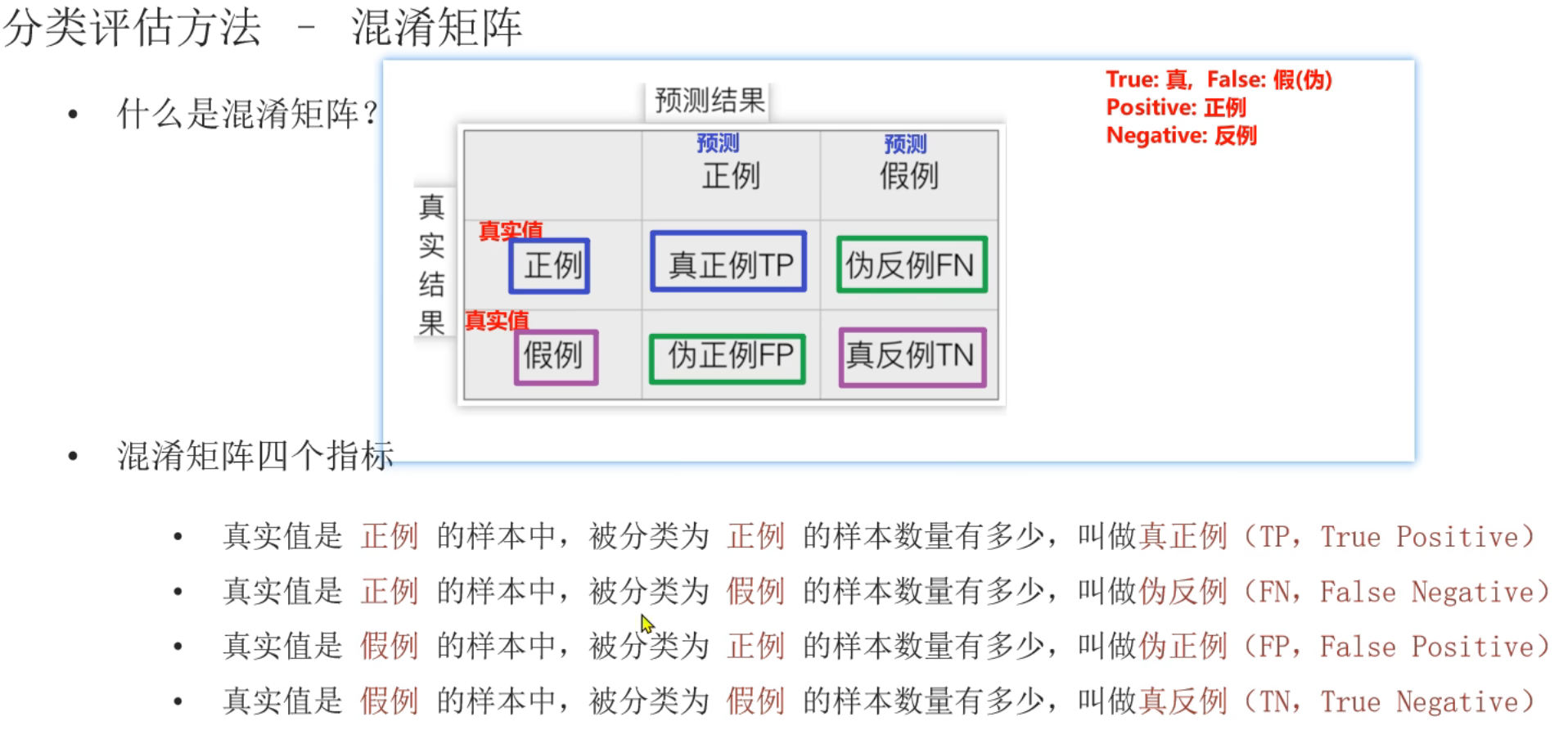
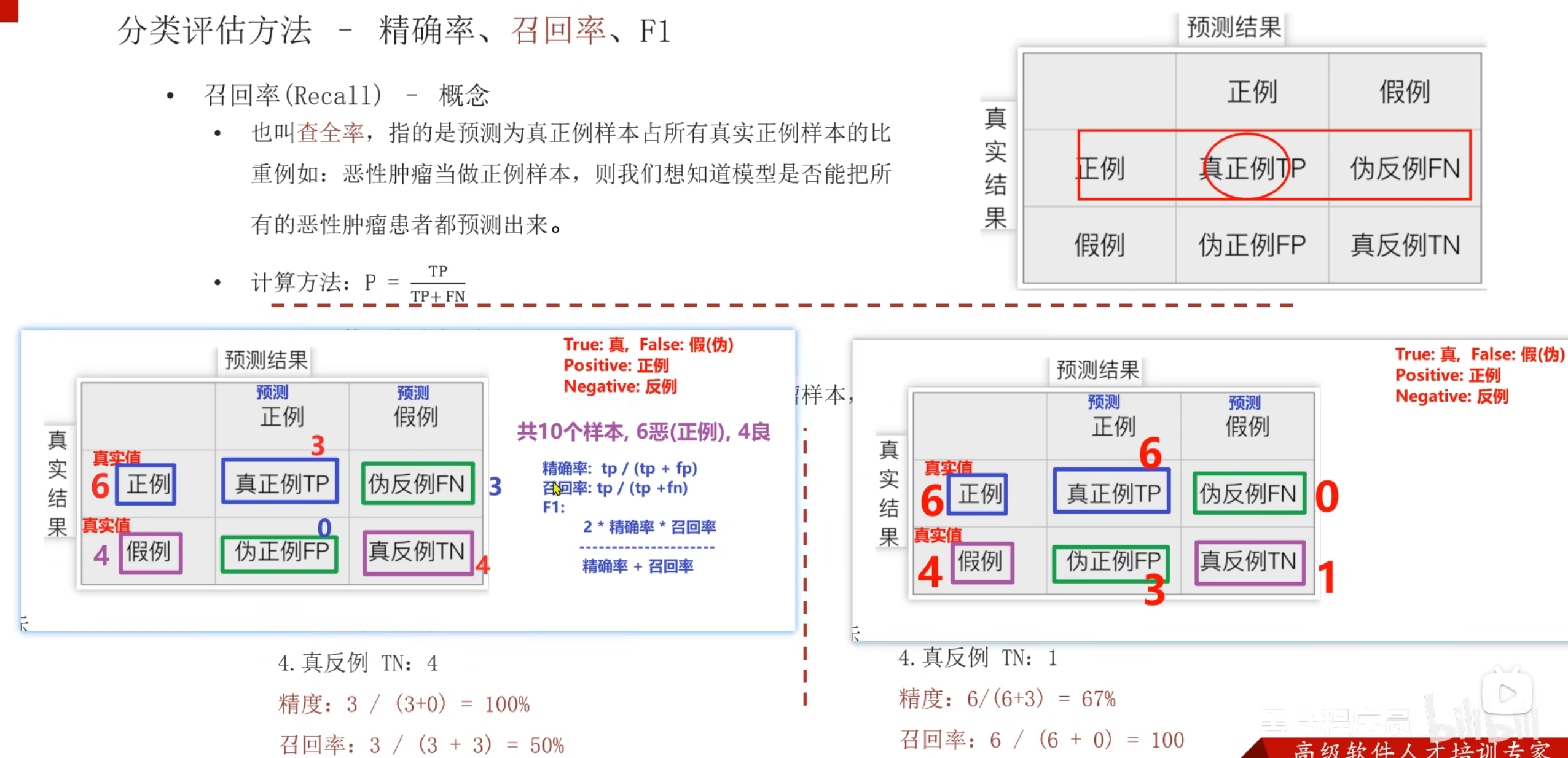
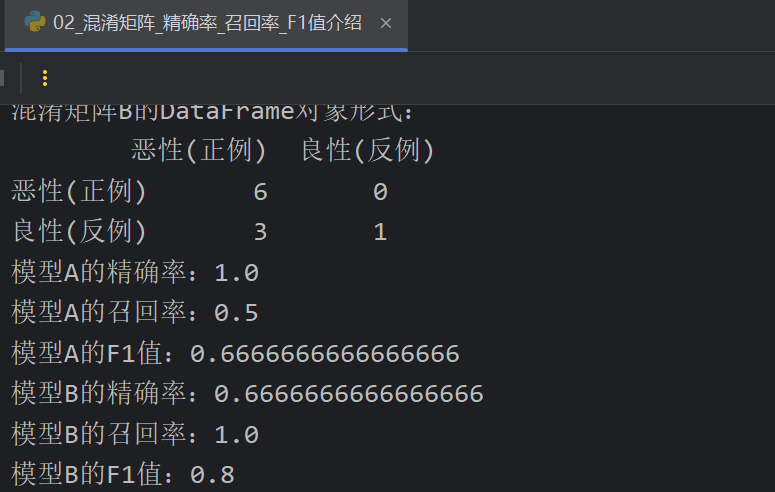
6、混淆矩阵及精确率,召回率,F1值介绍

记录一下弹幕的总结:
真、正看成1,假、反看成-1。乘起来是实际真假,靠后的是预测的真假
带P都是预测为真,带N都是预测为假。带T就是预测正确,带F就是预测错误

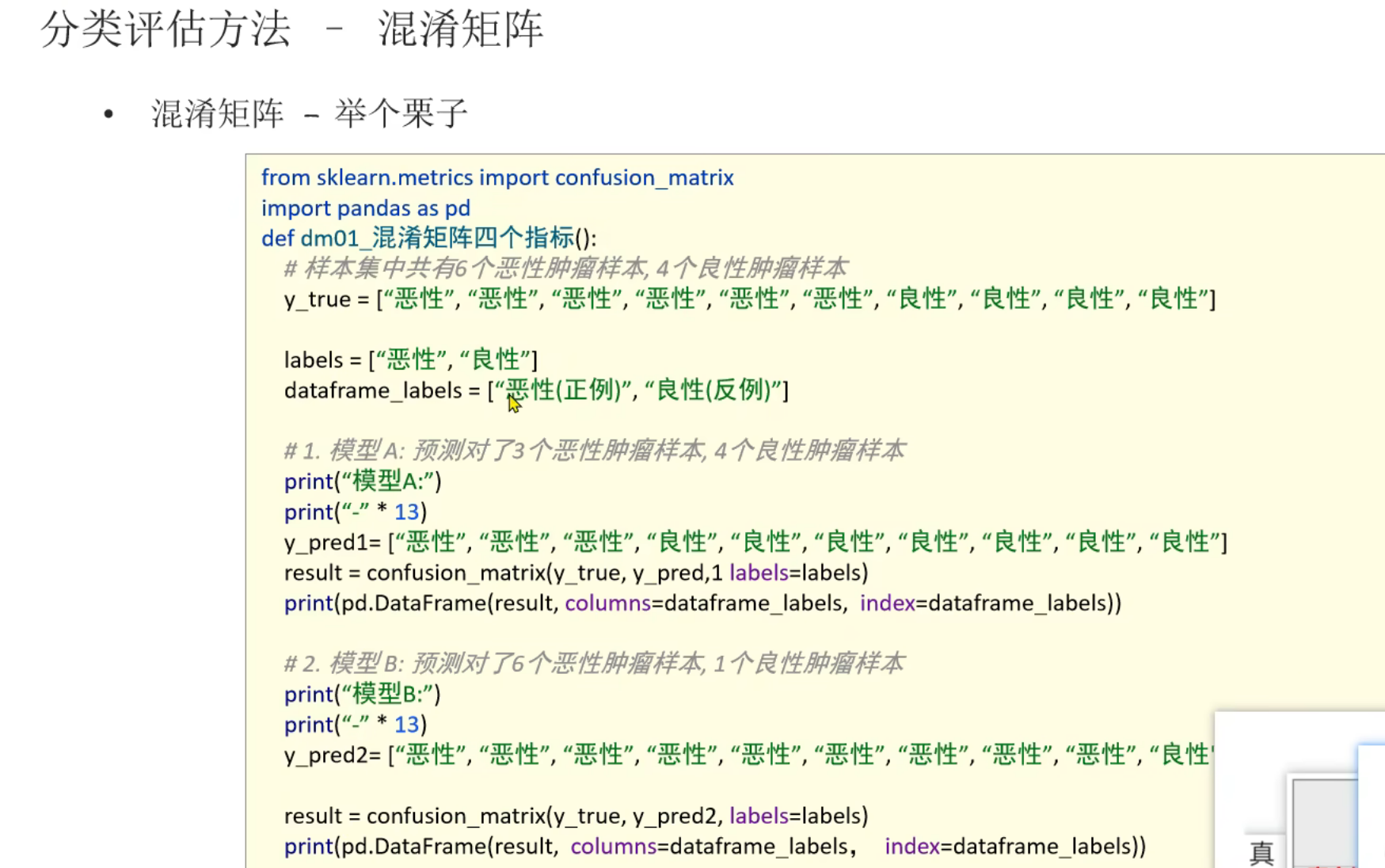
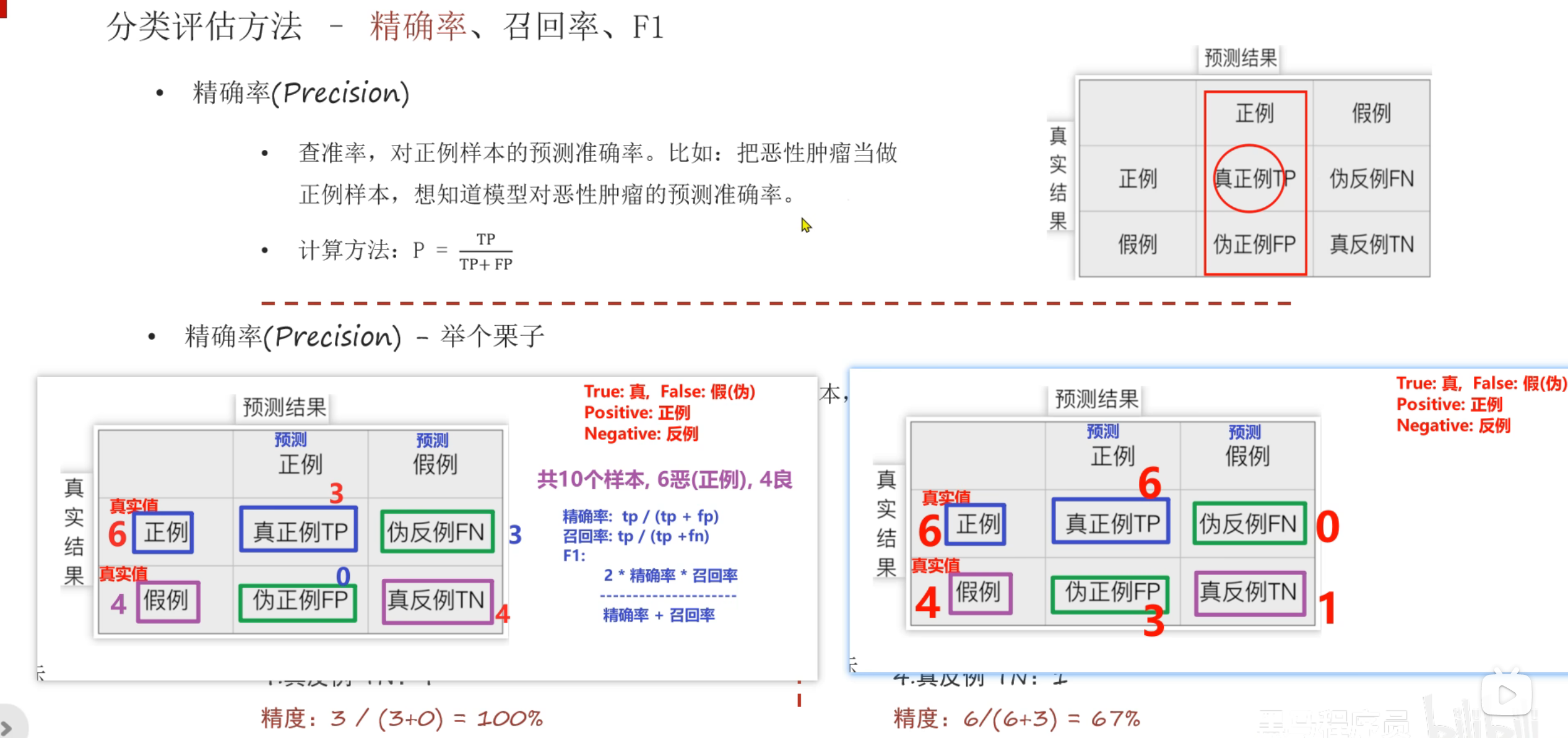


7、混淆矩阵_精确率_召回率_F1值_代码演示
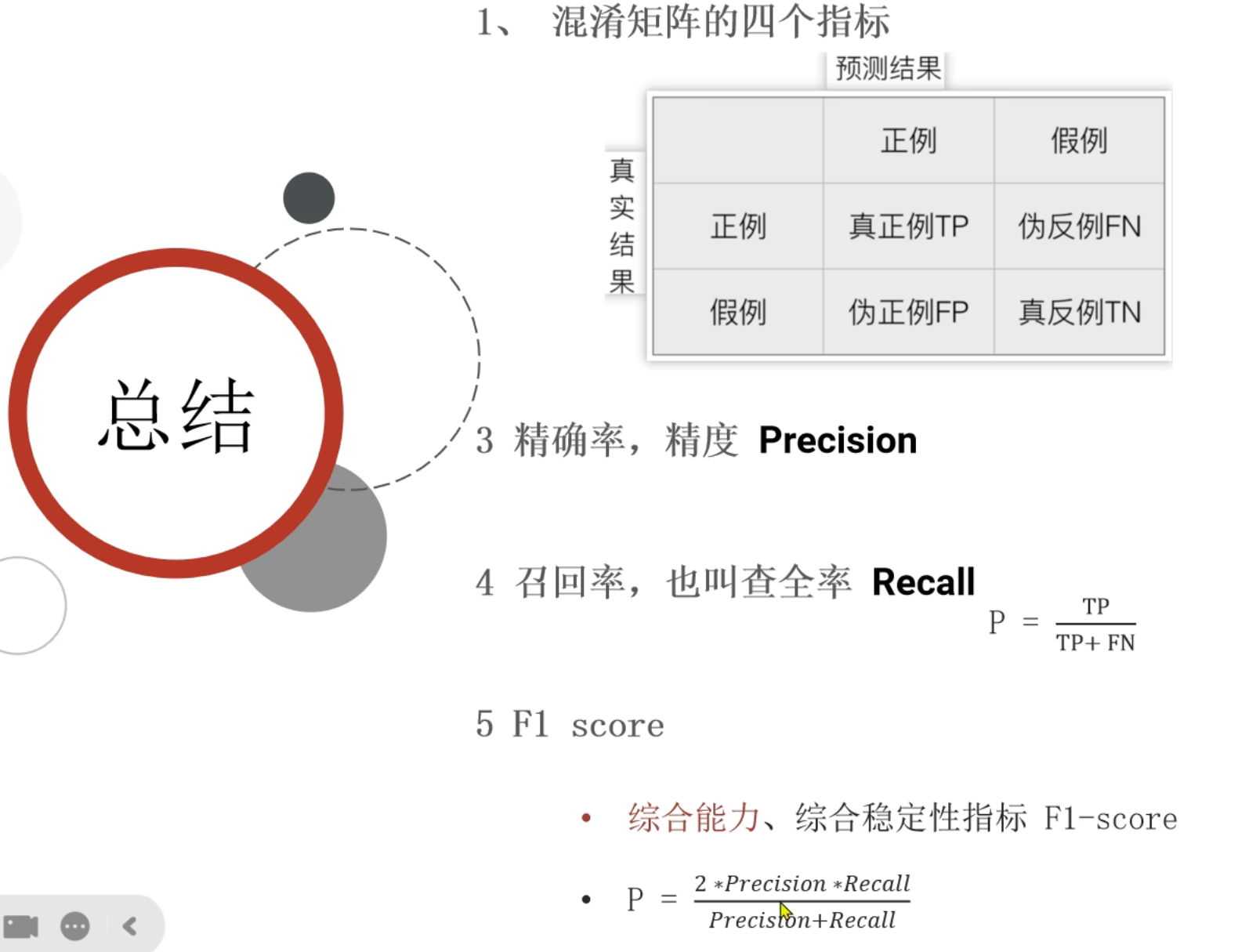
8、混淆矩阵_总结


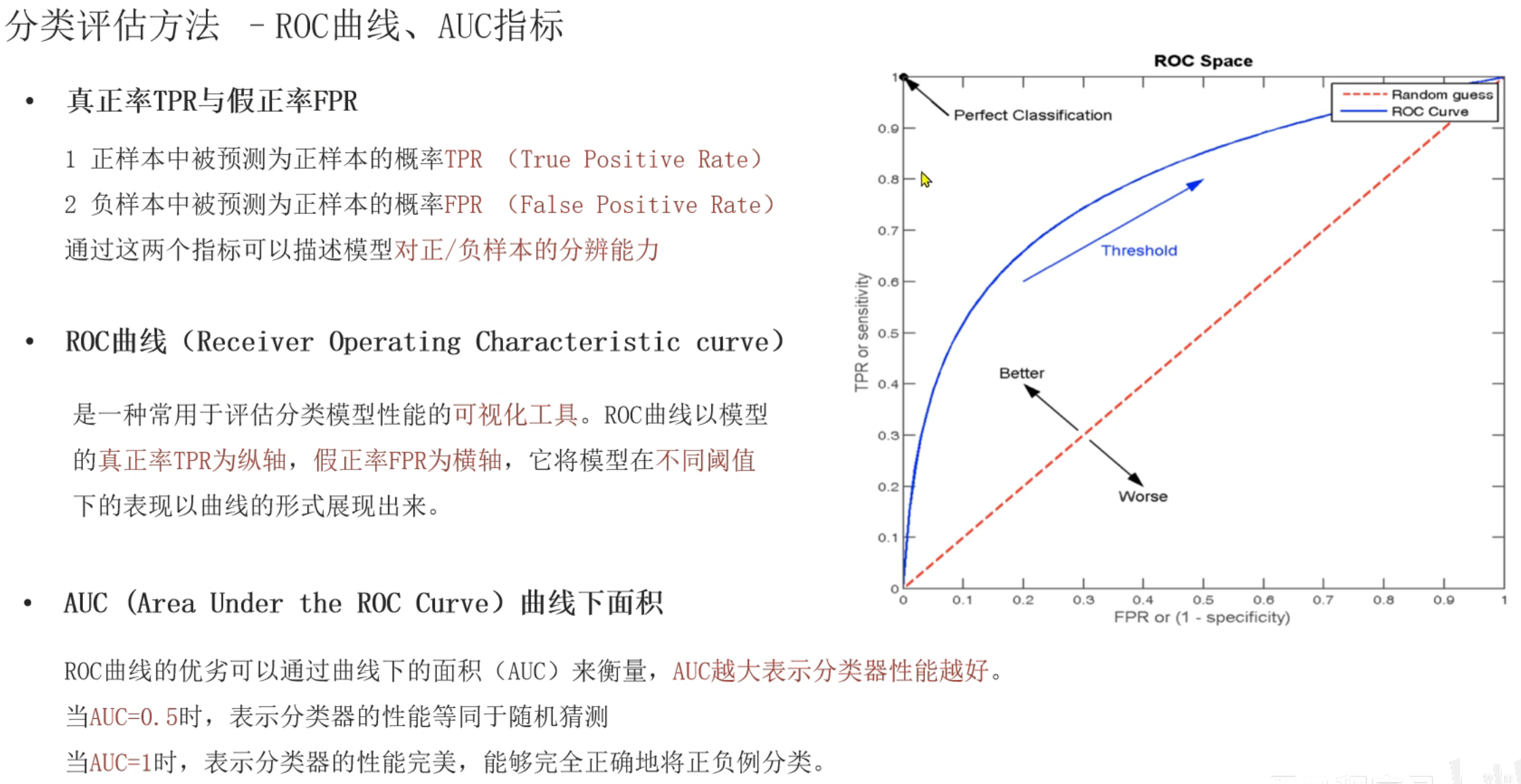
9、ROC曲线和AUC指标介绍(了解)
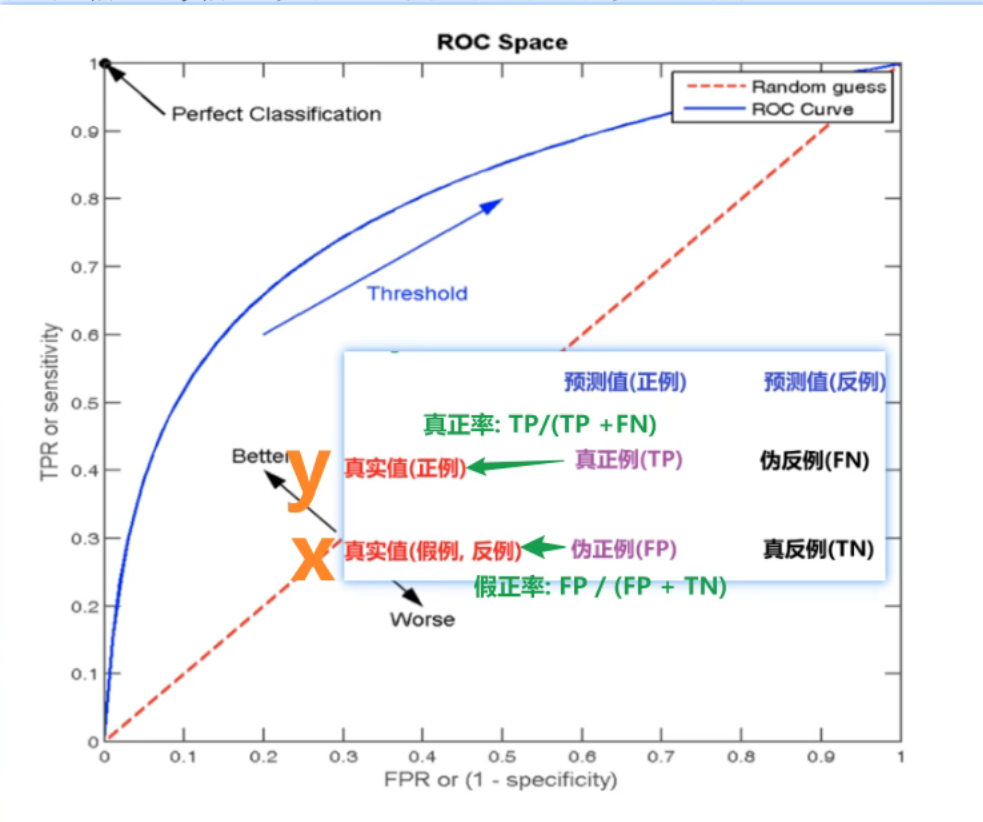
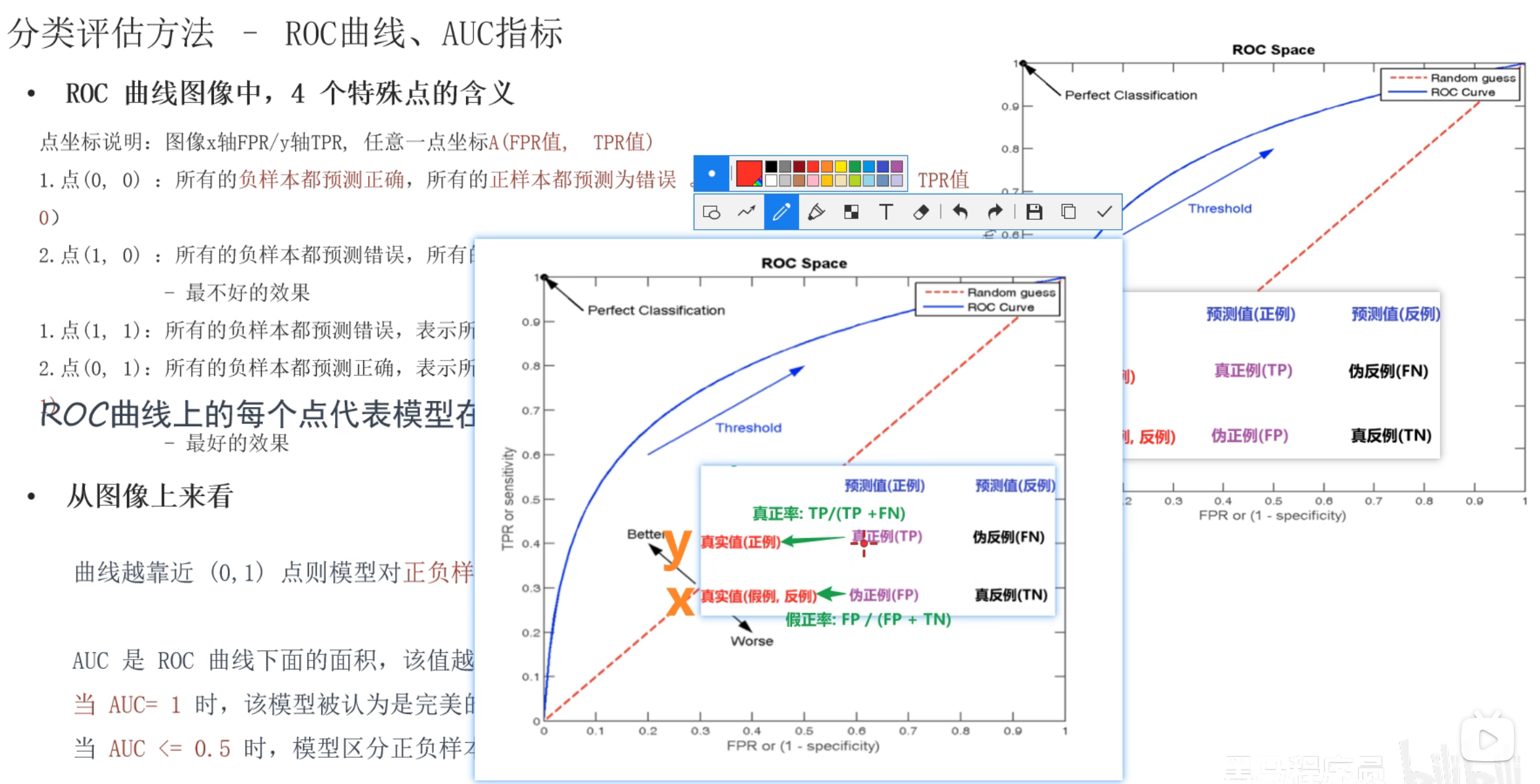
10、ROC曲线_案例(了解)
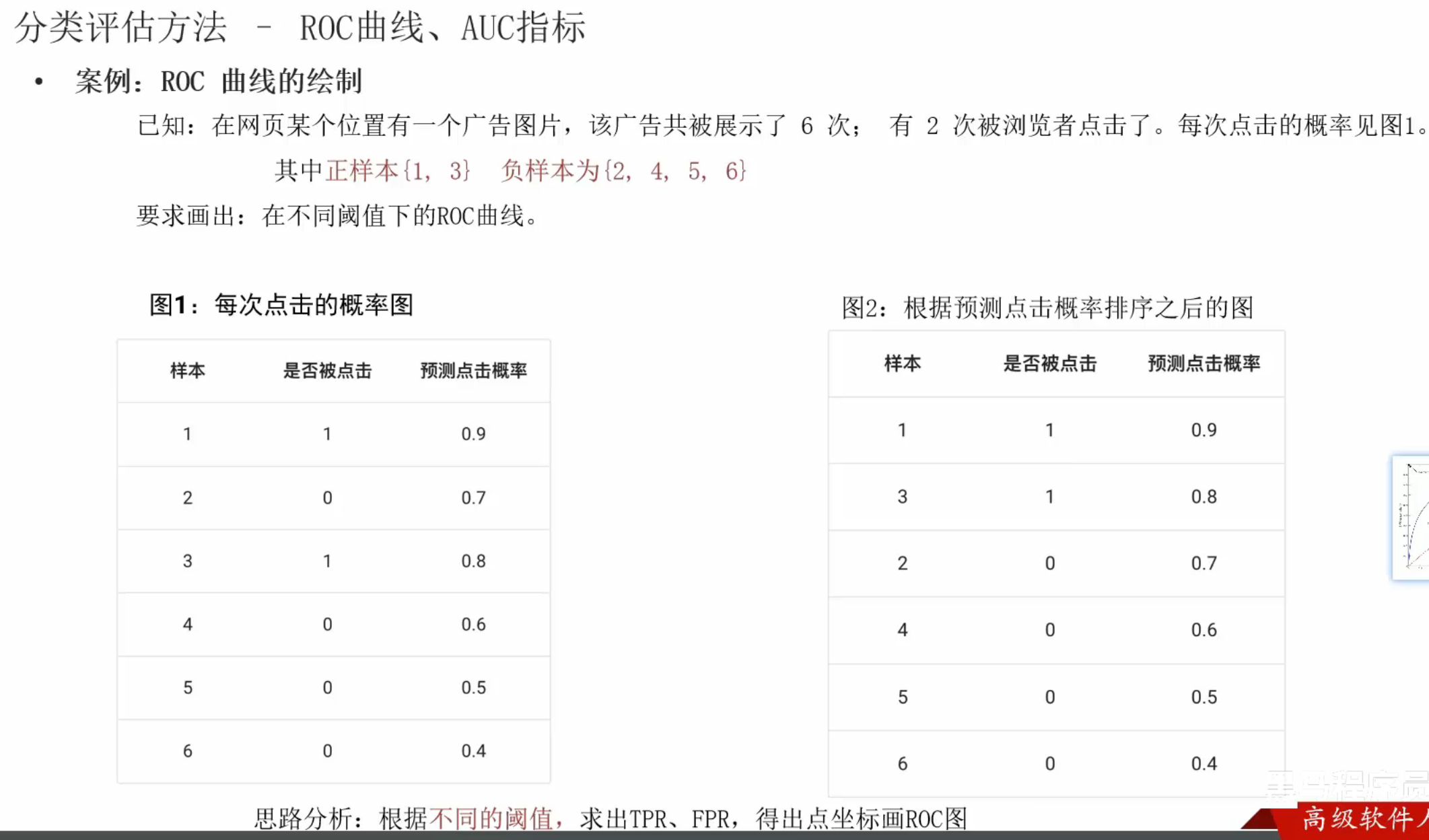







七、决策树
1、逻辑回归_电信用户流失预测_数据预处理

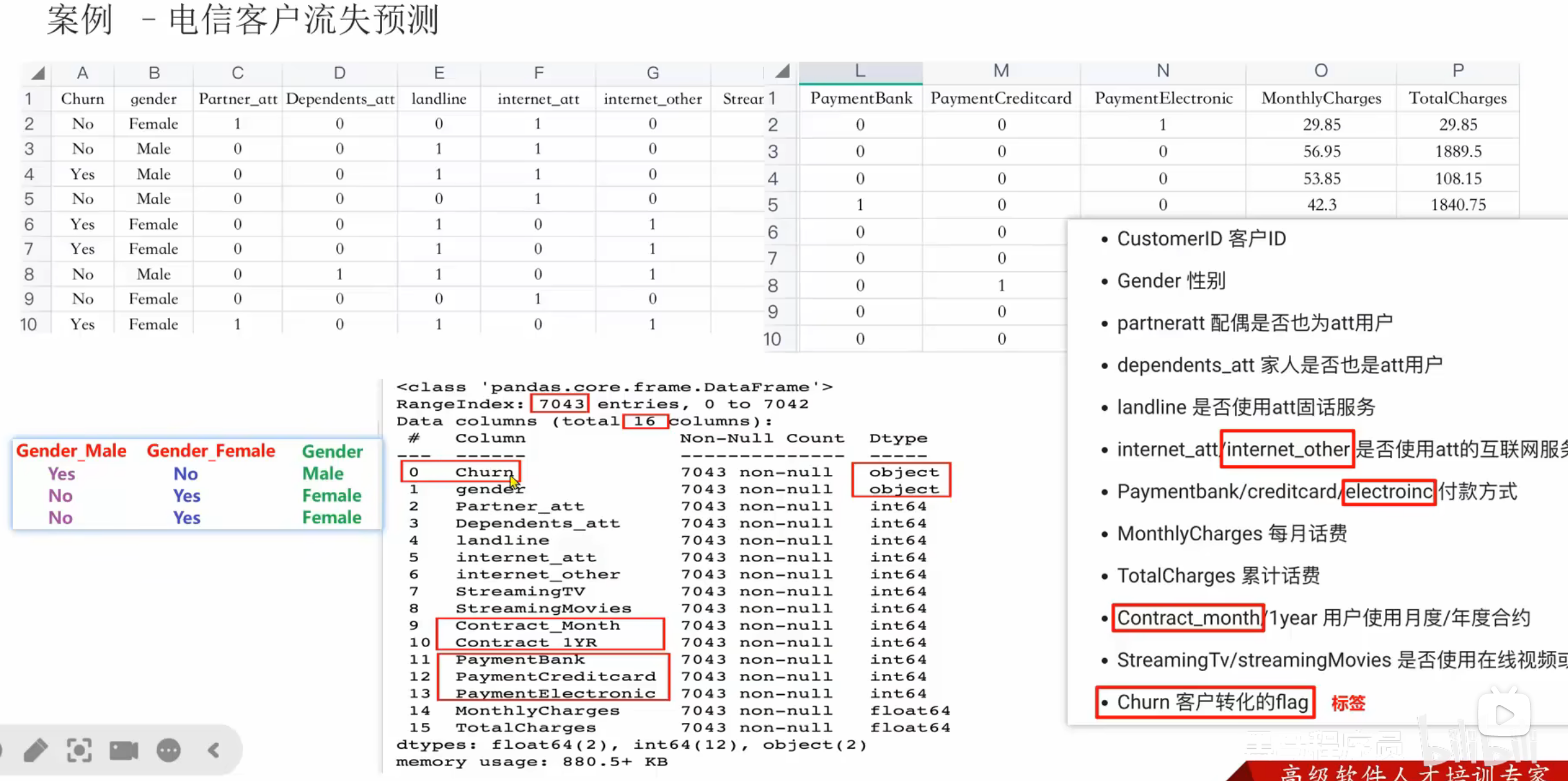

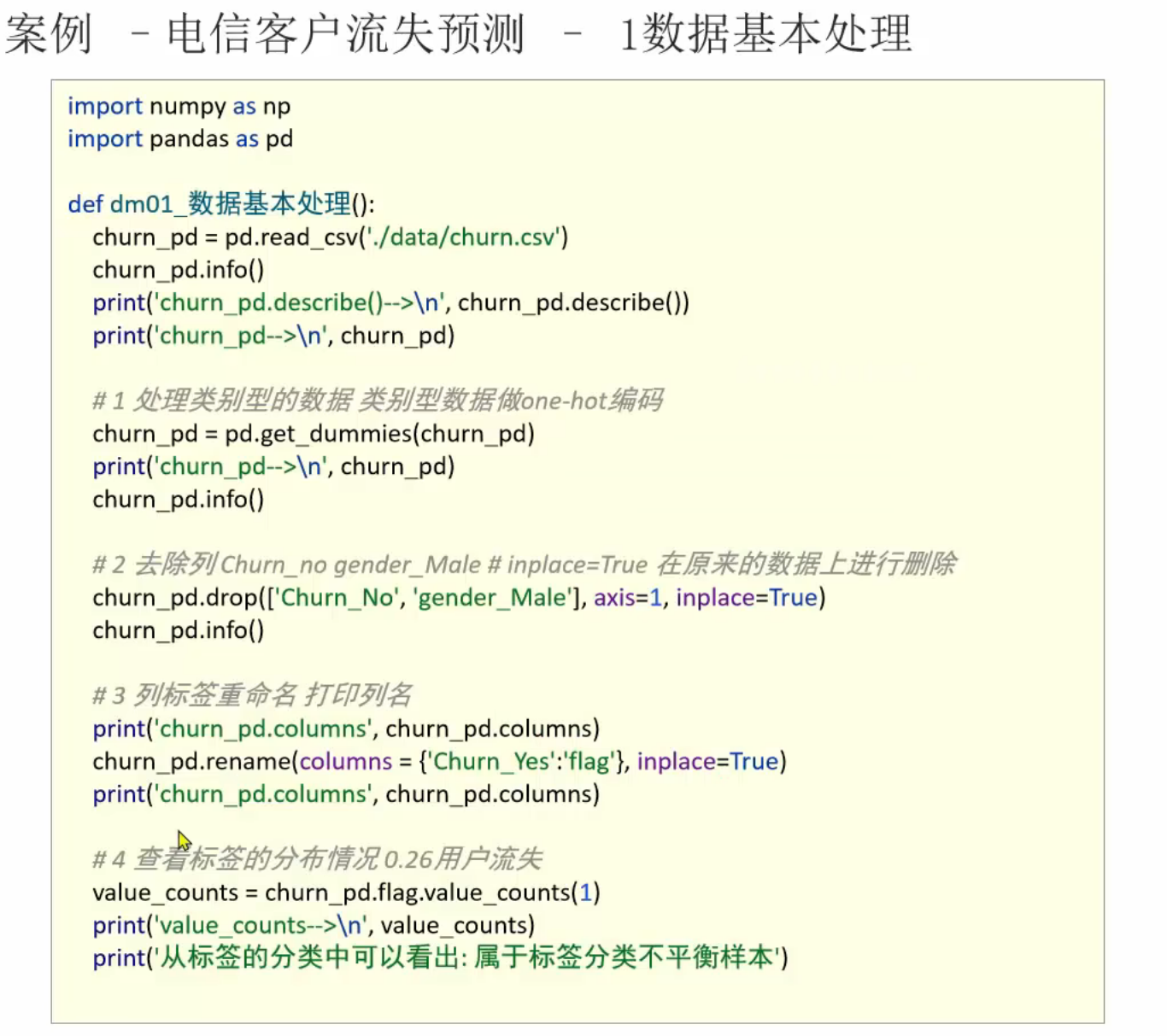
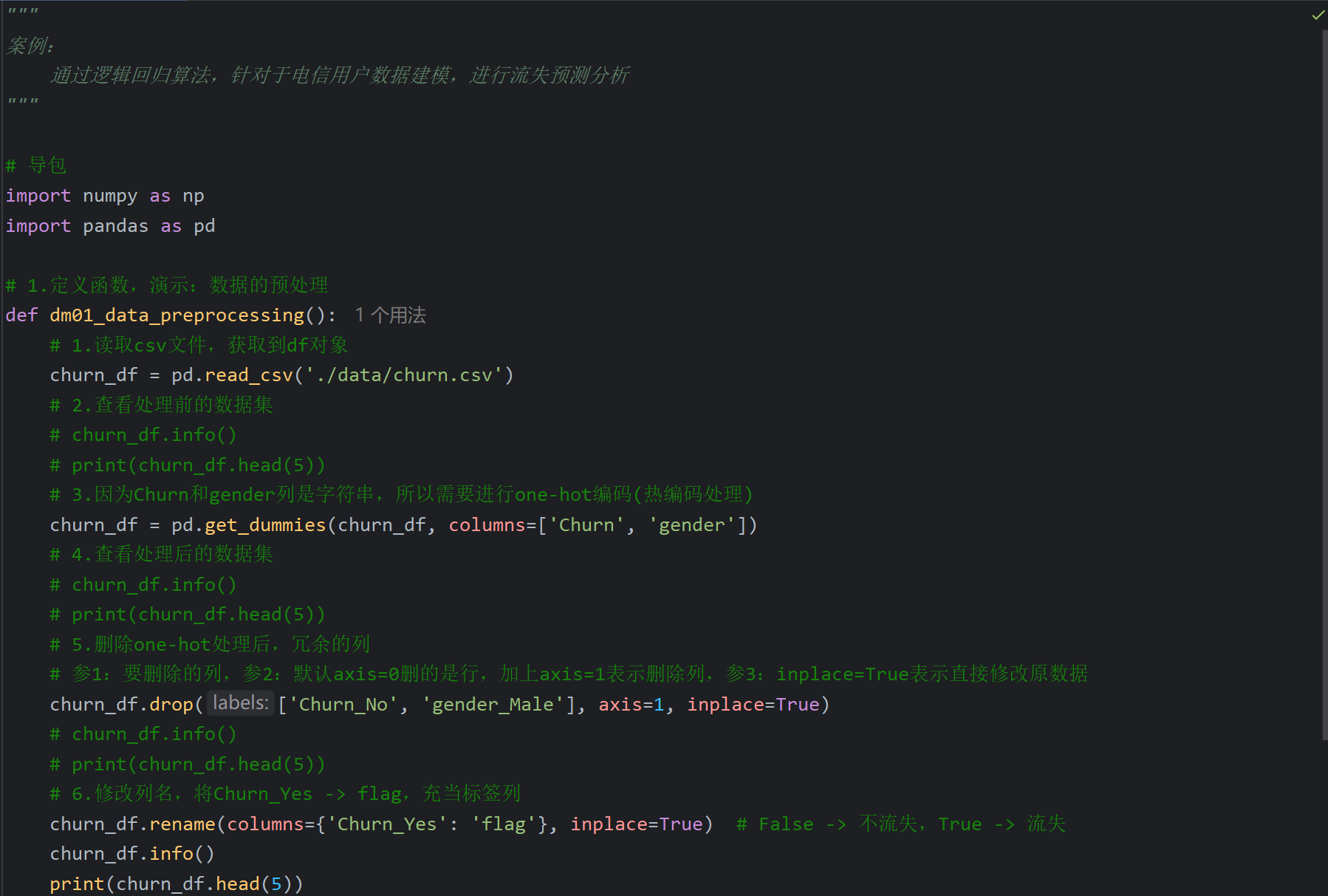
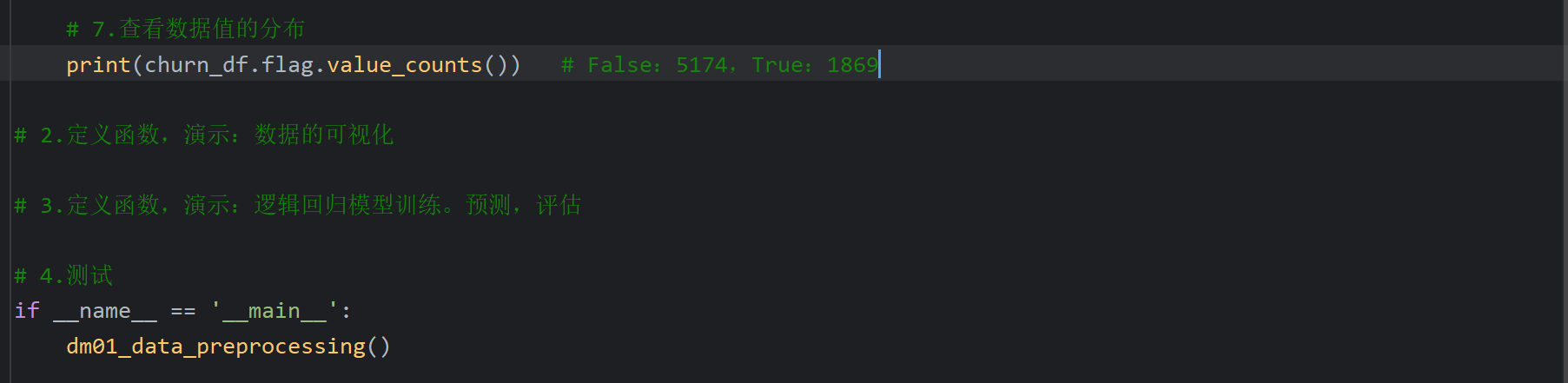
2、逻辑回归_电信用户流失预测_数据可视化
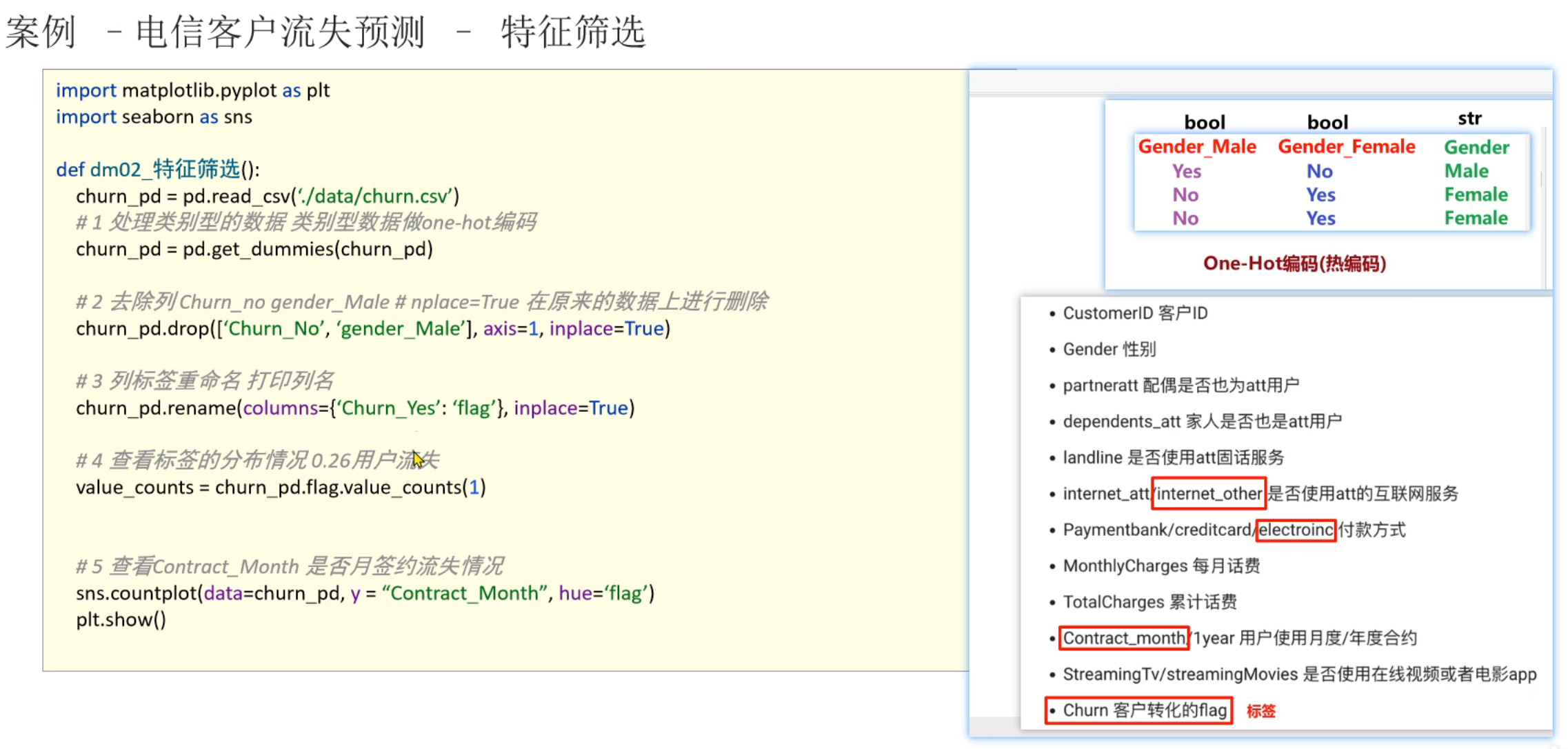
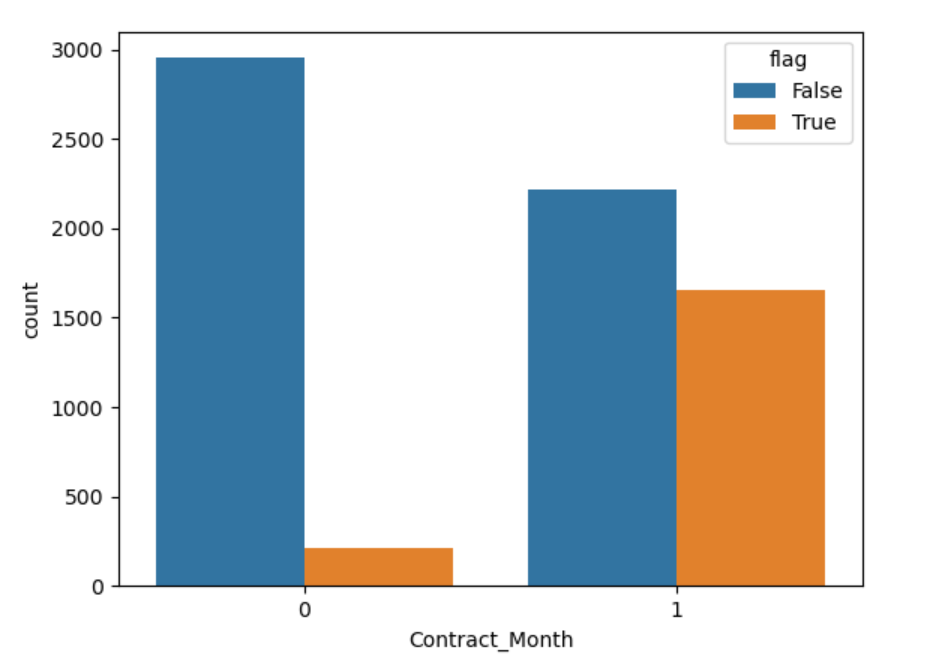
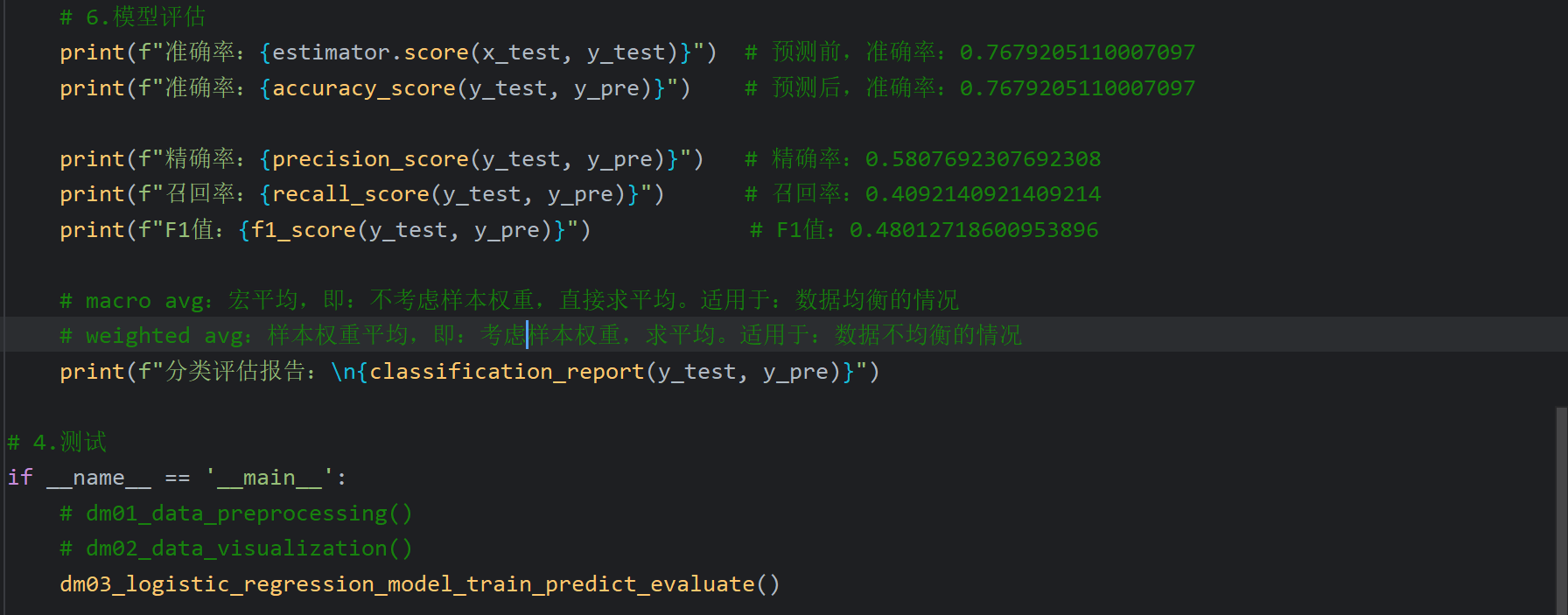
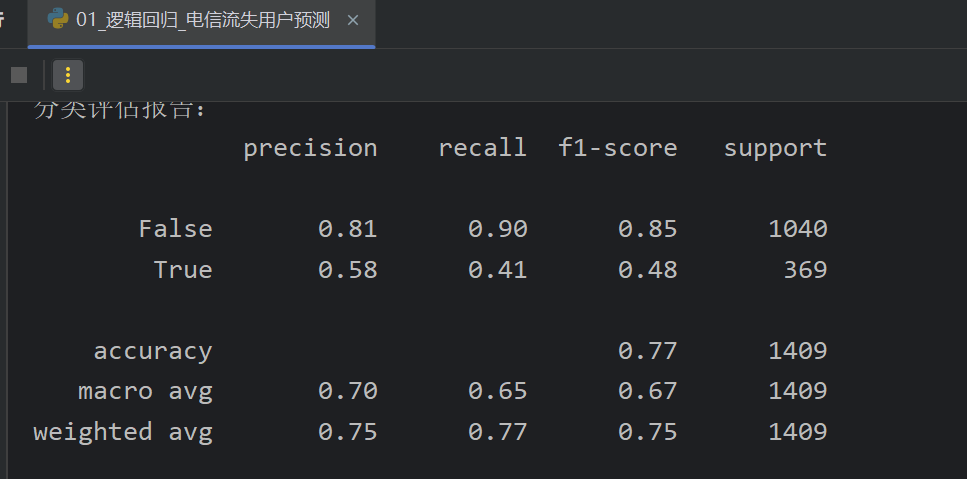
3、逻辑回归_电信用户流失预测_模型训练预测评估

4、决策树_简介
蓝色勾是面试可能要问的,红色勾是重点内容需要掌握

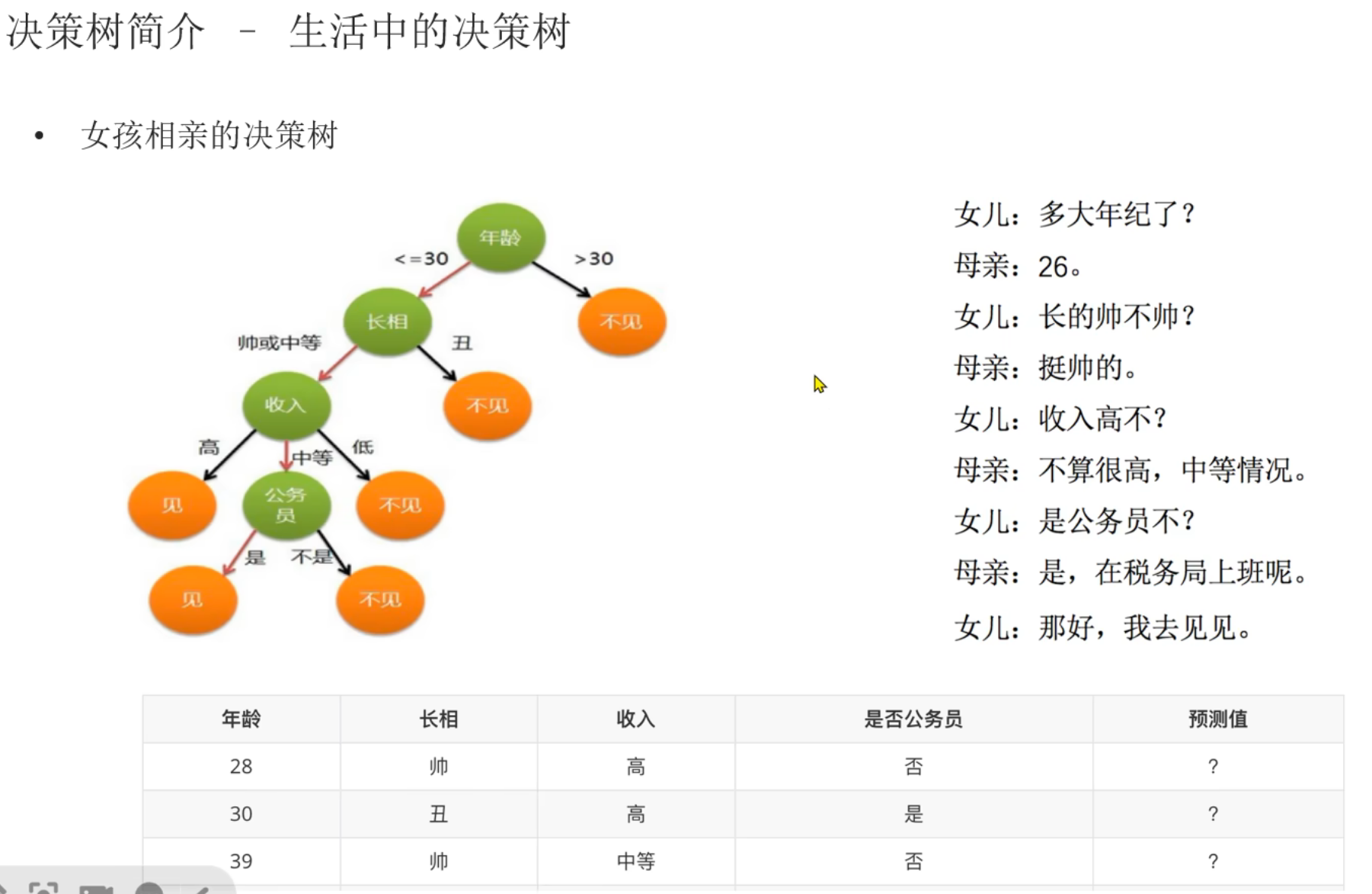
叶子节点:没有子节点的节点
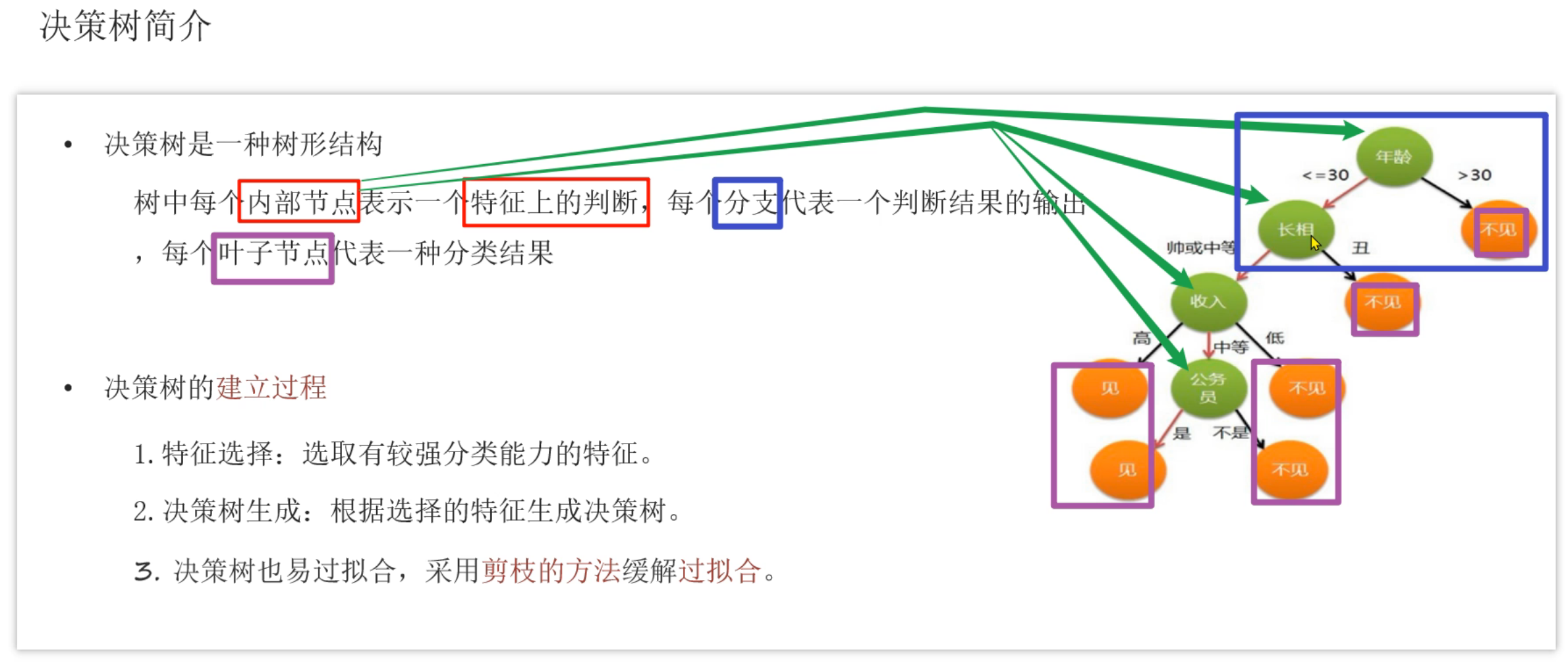

5、决策树_信息熵简介
大白话解释熵:代表数据的混乱程度



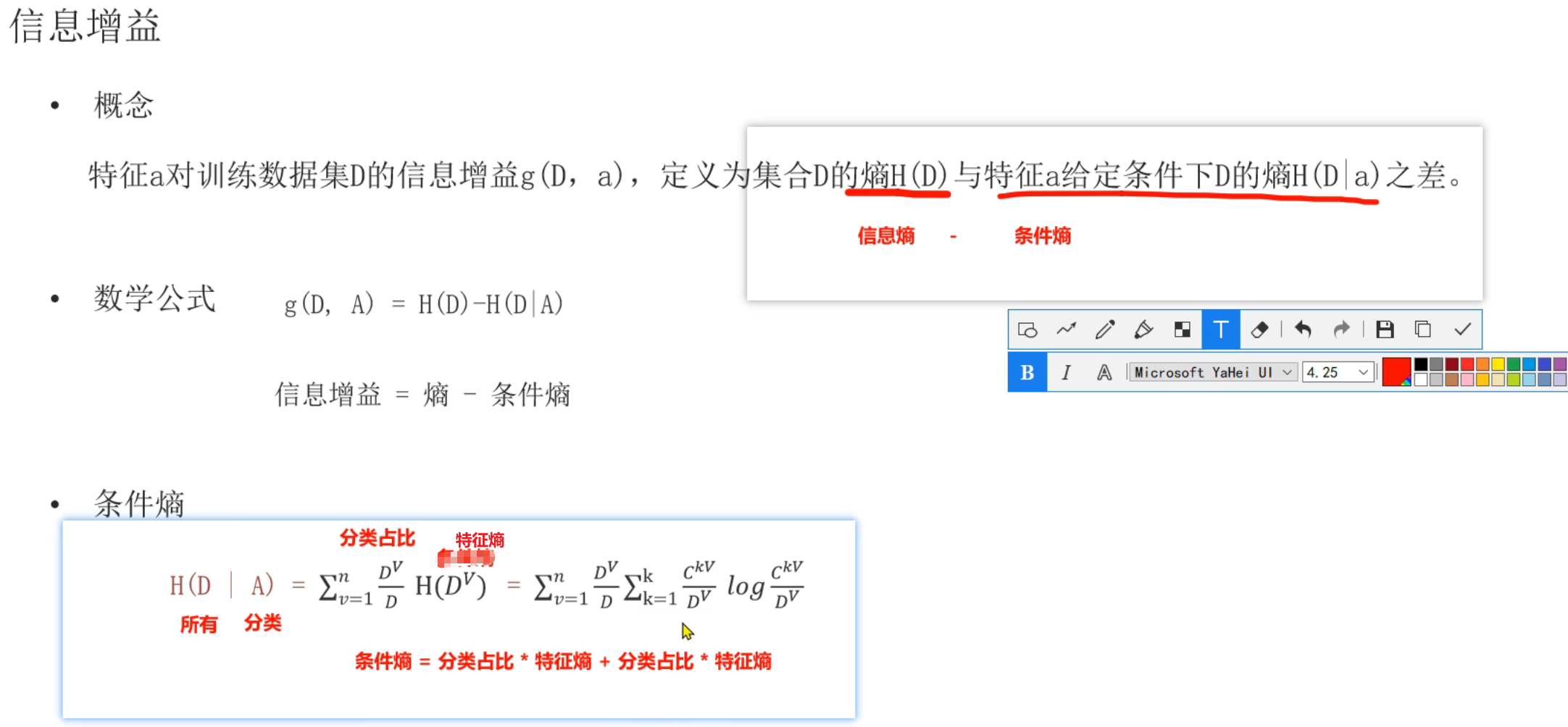
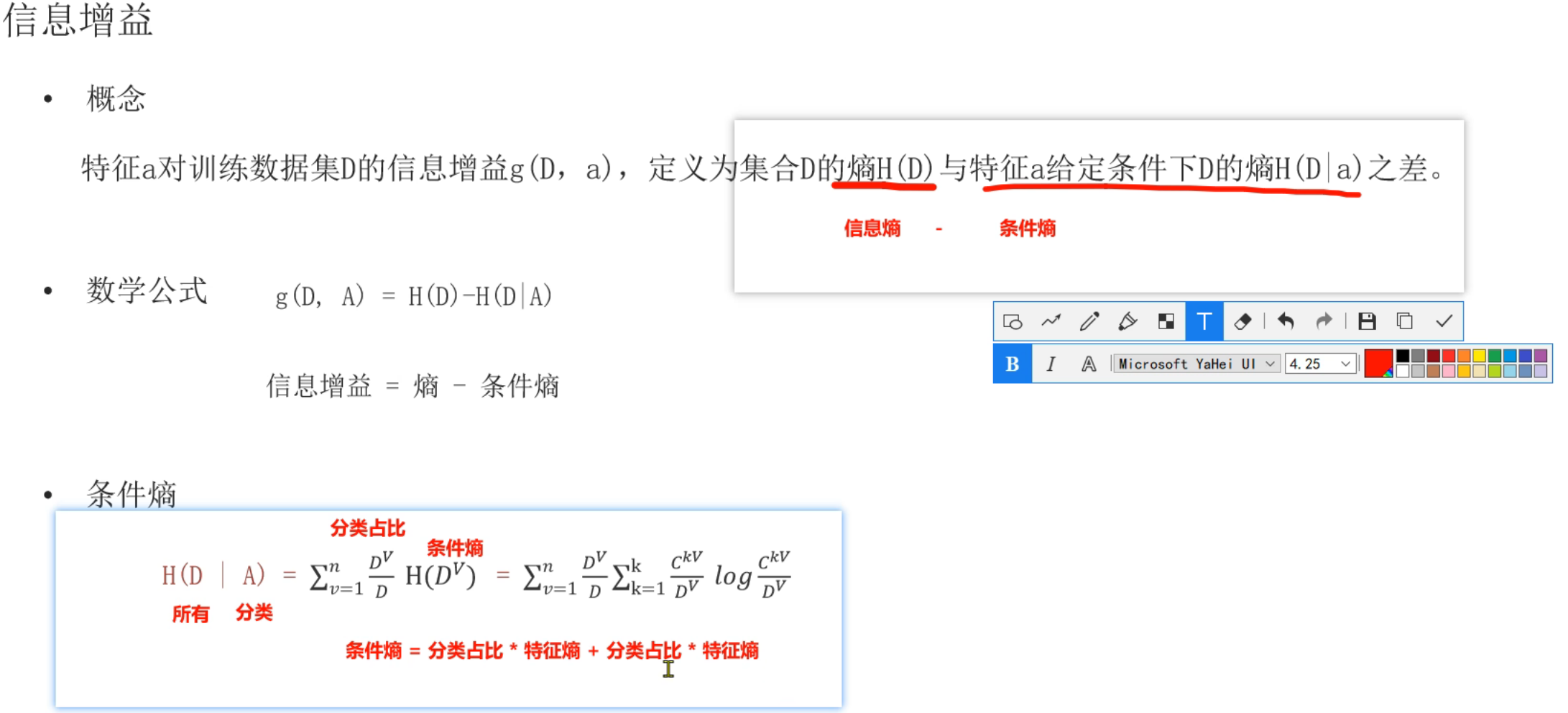
6、决策树_信息增益计算
原图分类占比右边标错了,正确应该是标特征熵。这部分我个人对信息熵、条件熵、特征熵这三个概念不太清晰,所以下面给出我询问ai得到的总结,有助于理解这三个概念






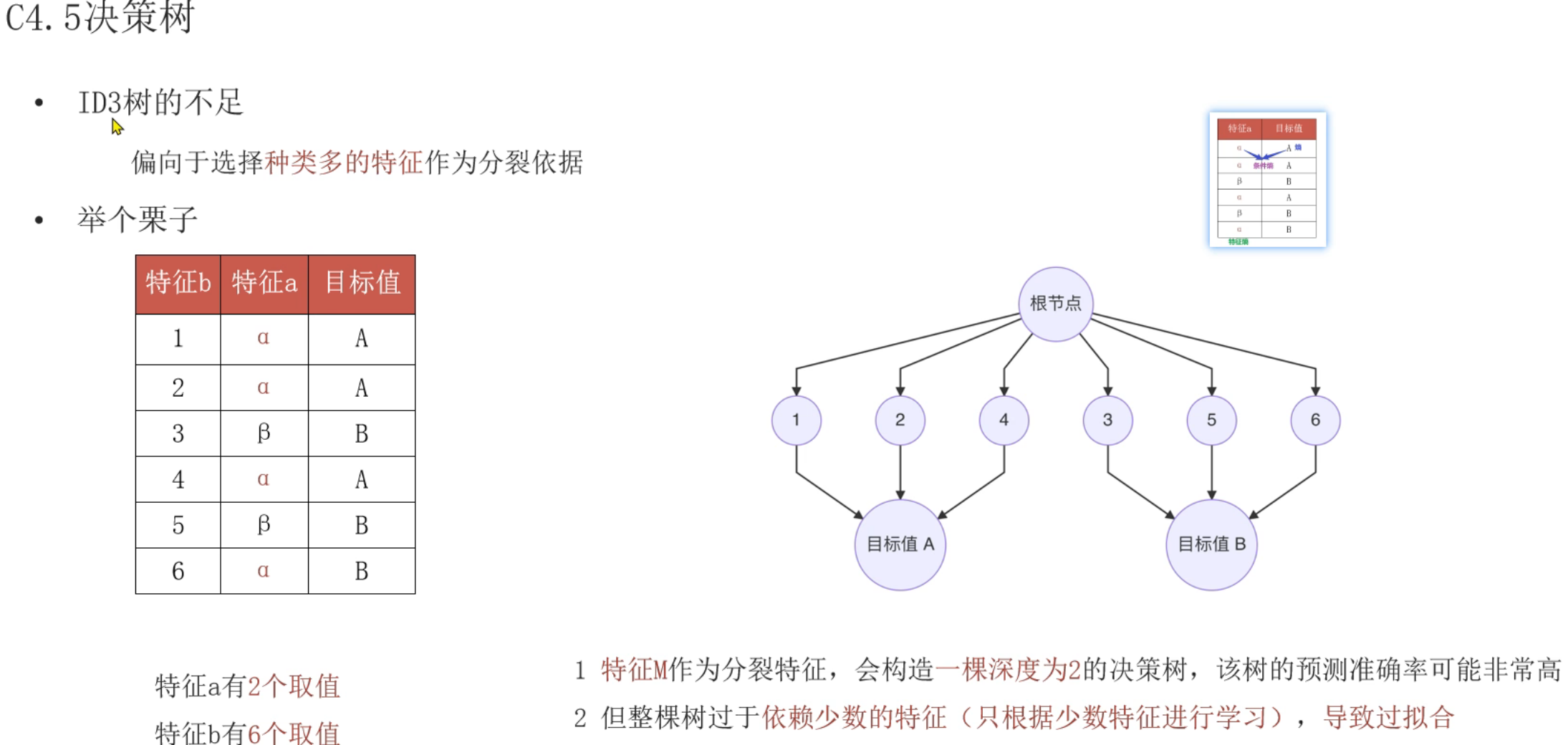
7、ID3决策树_搭建





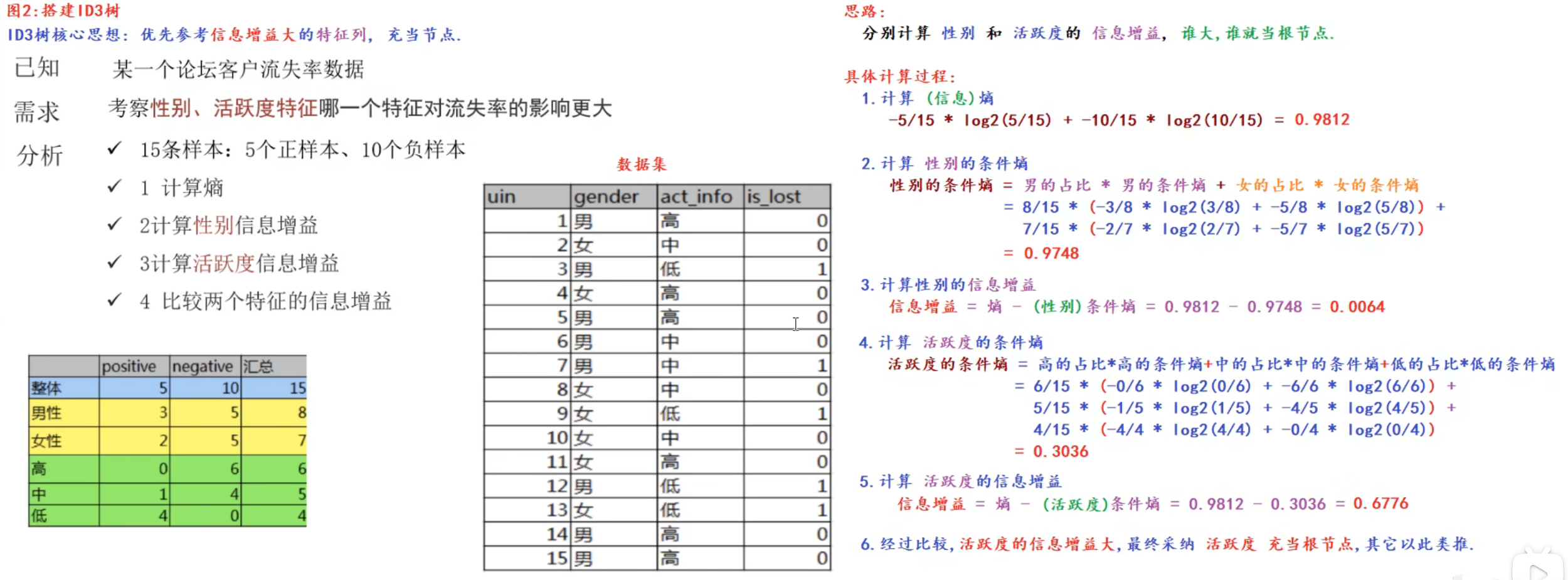
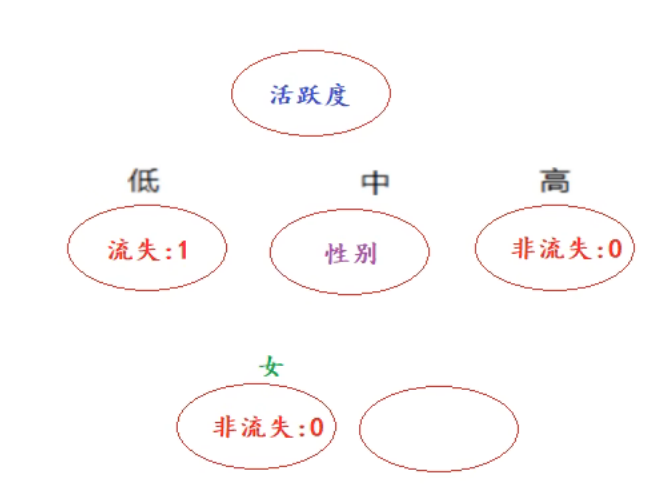



8、上午内容回顾

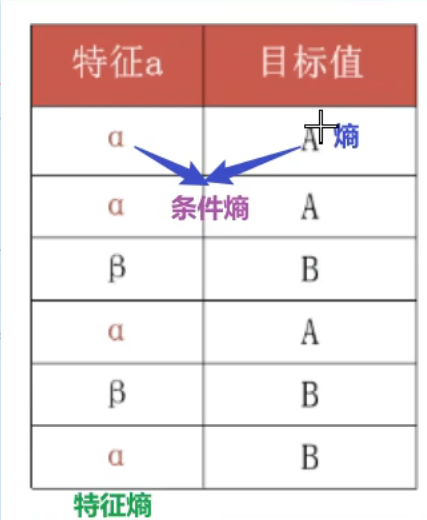
9、C4.5树_信息增益率
特征熵的倒数 = 惩罚系数,老师那里打的还是有点问题的,但是结合起来看不难理解,单纯不严谨而已





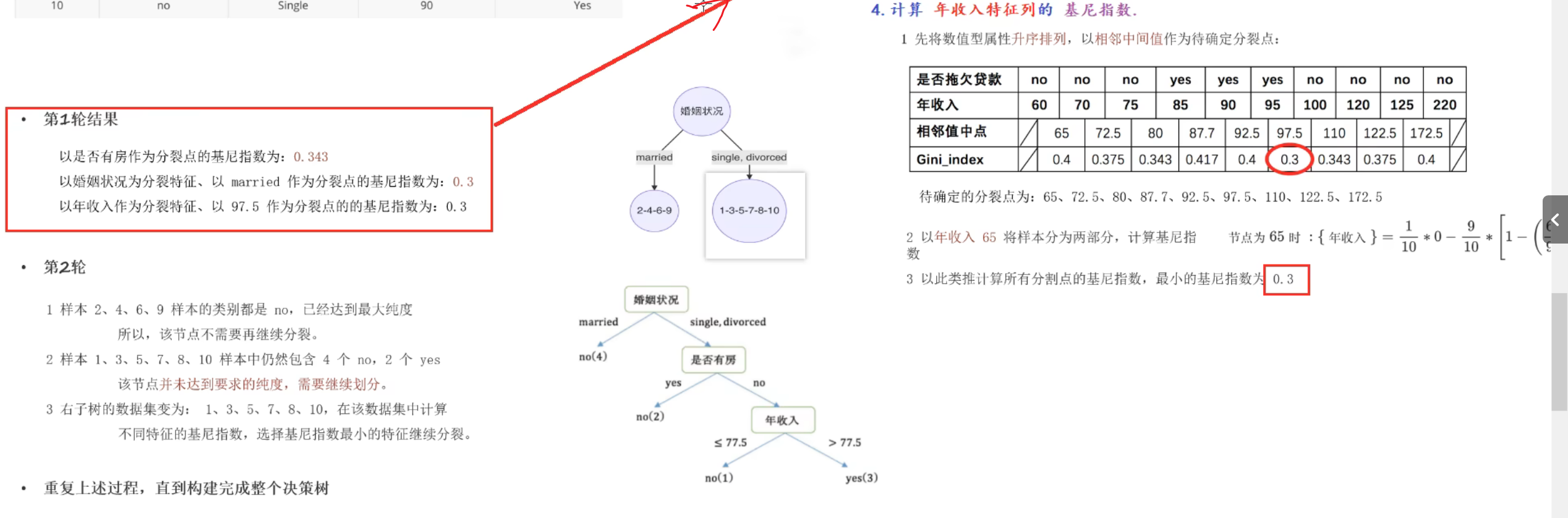
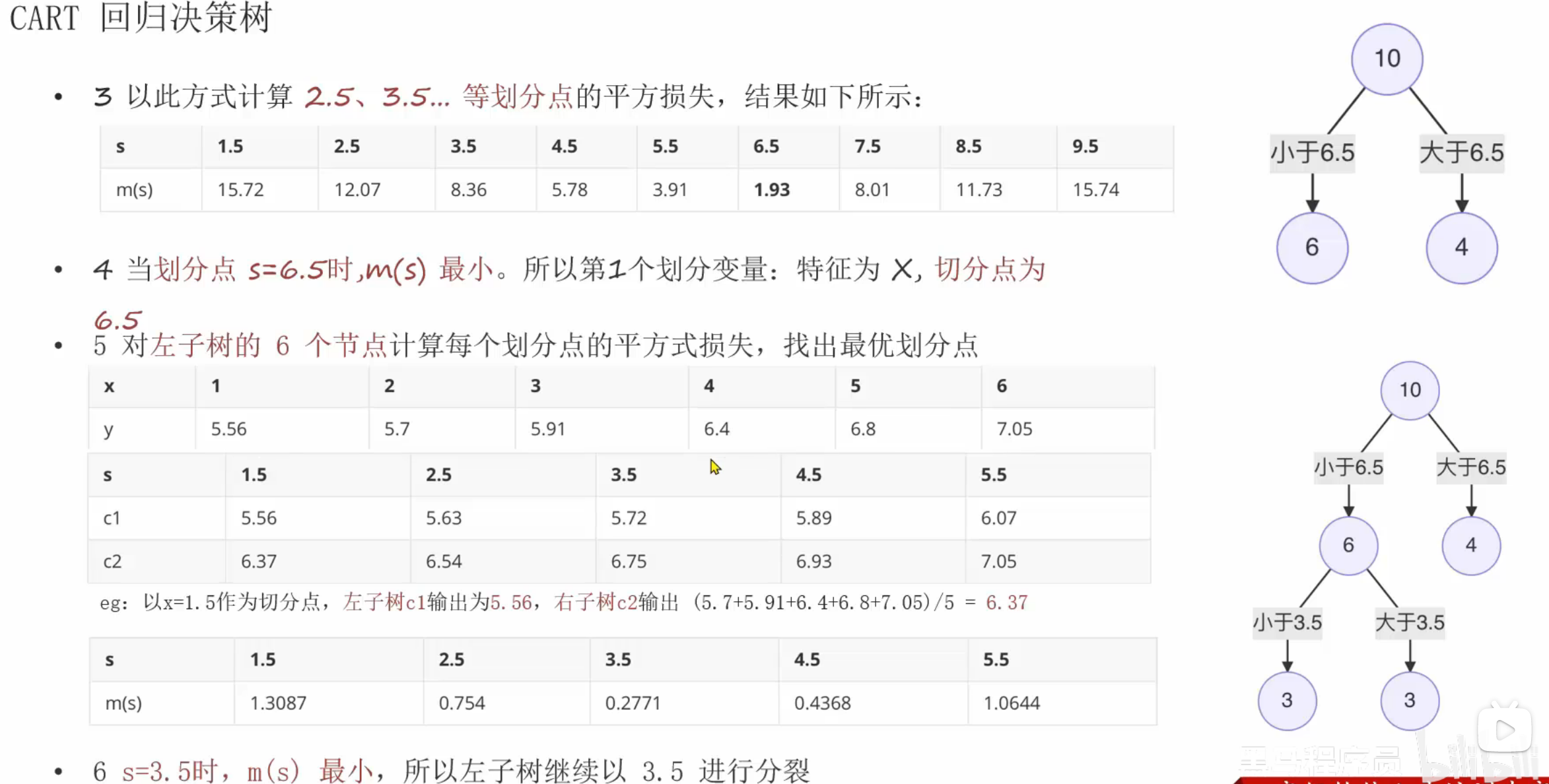
10、Cart树原理介绍

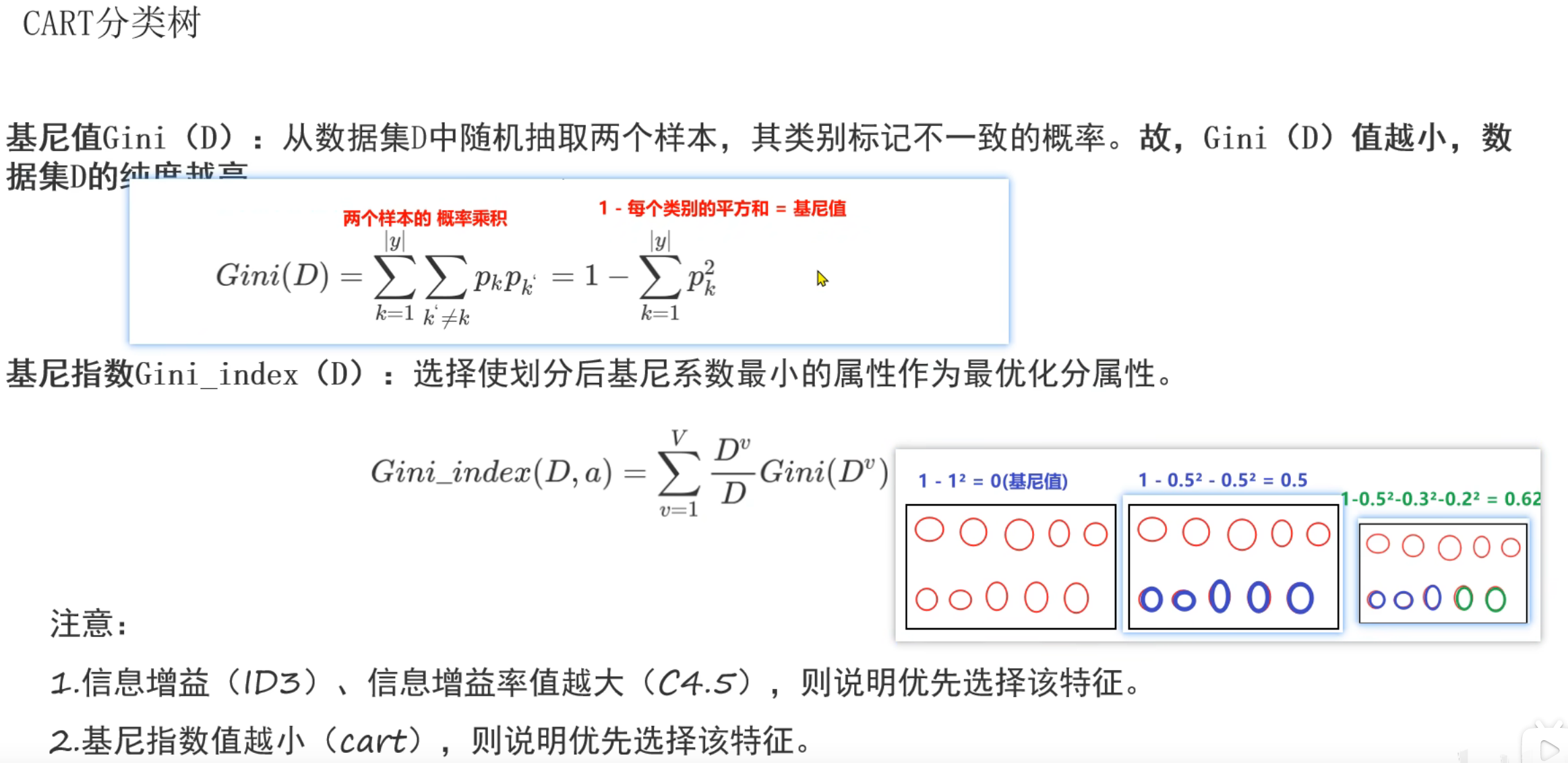
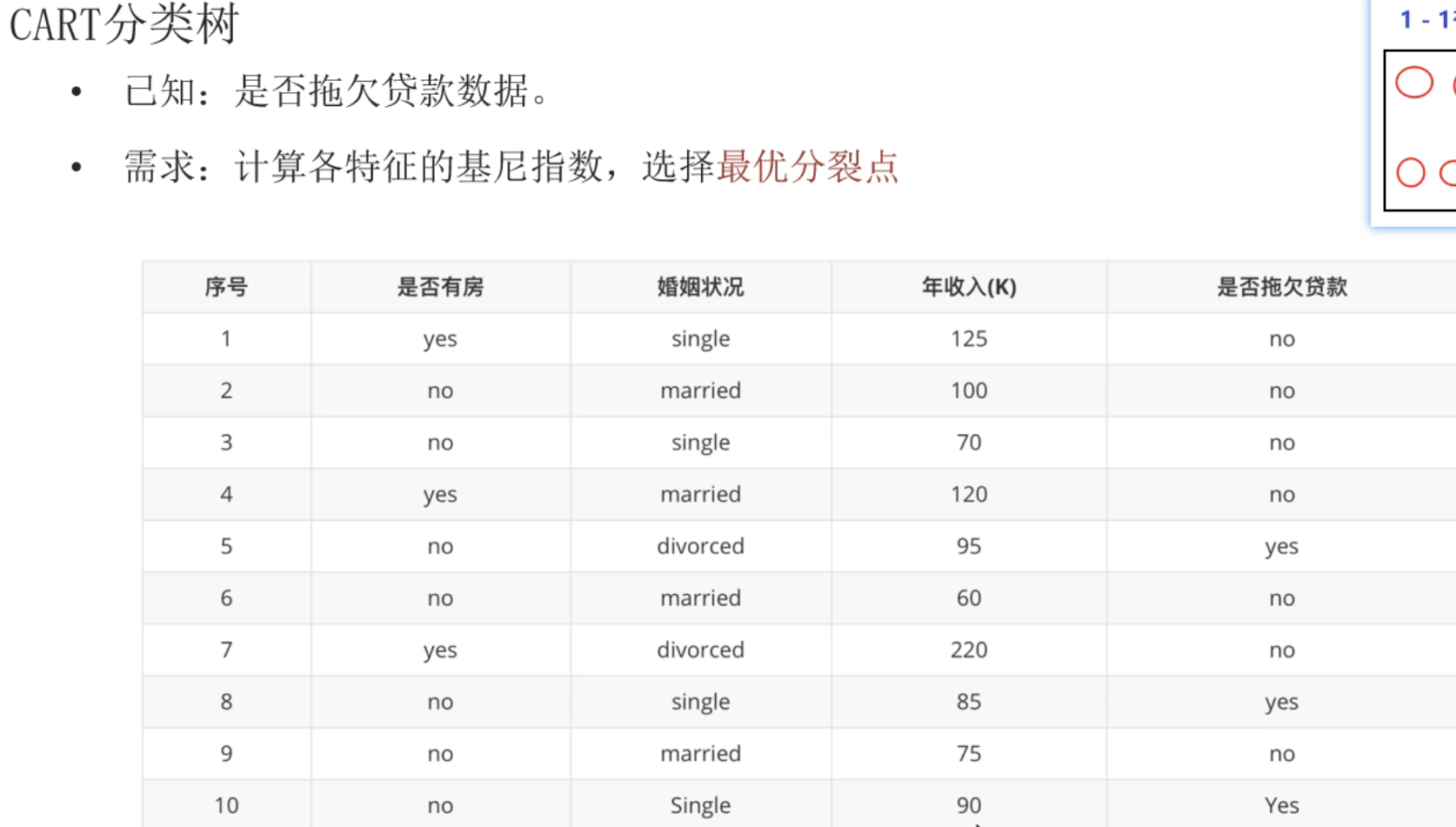


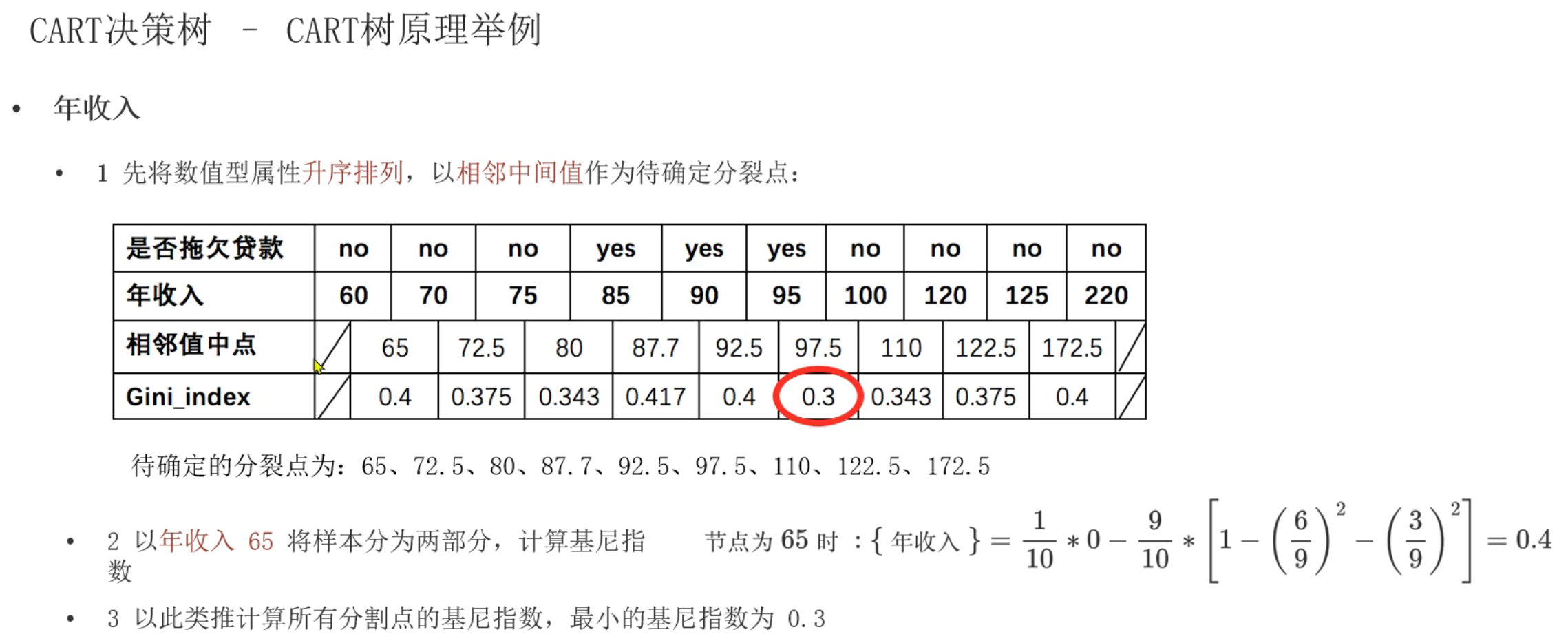
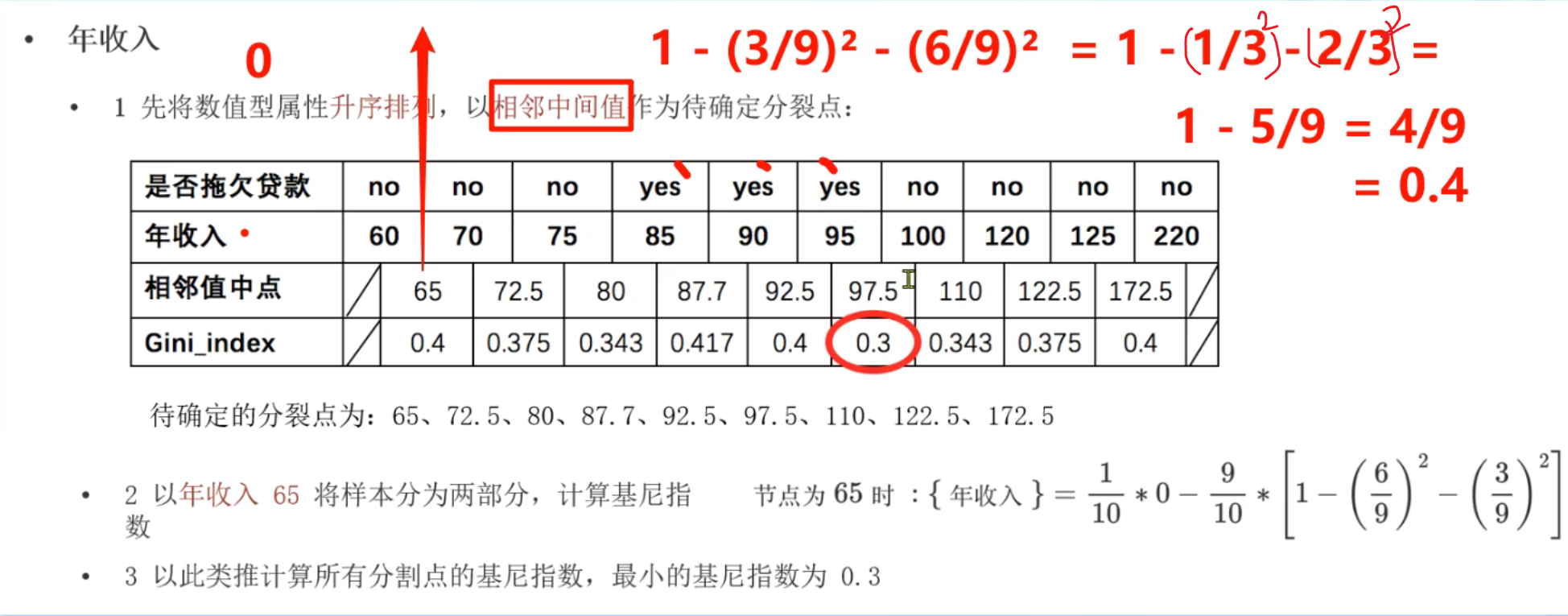
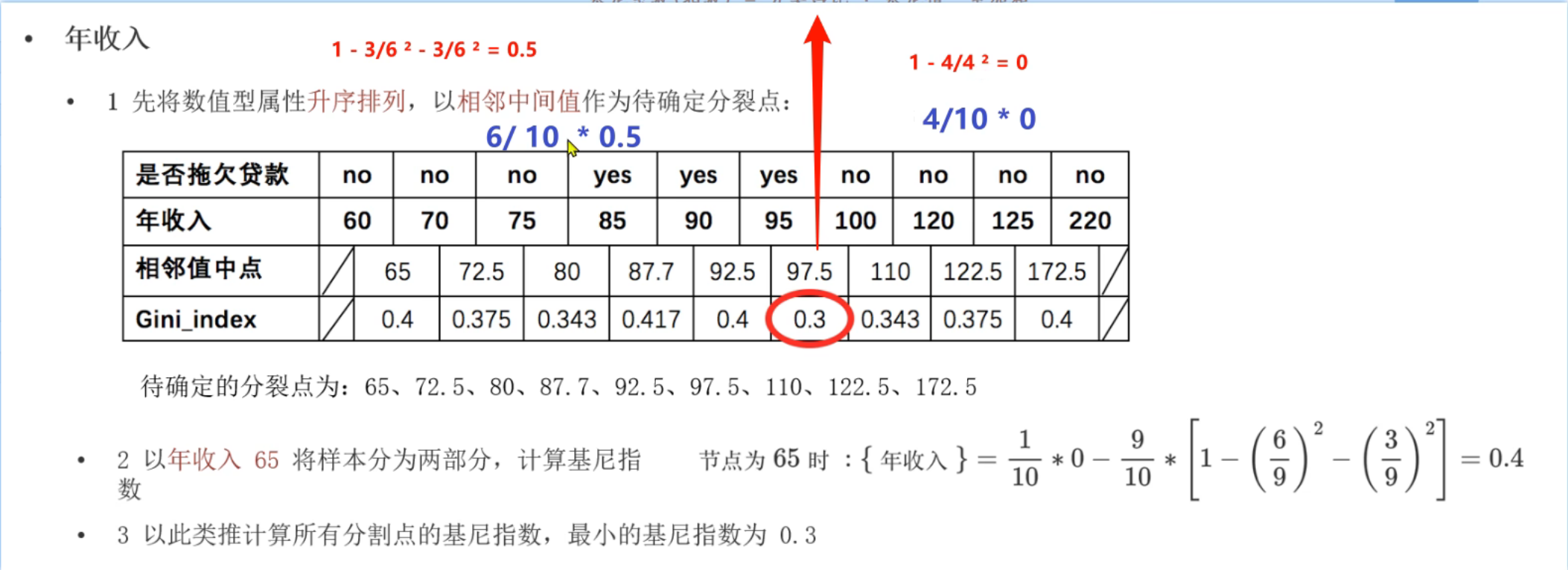
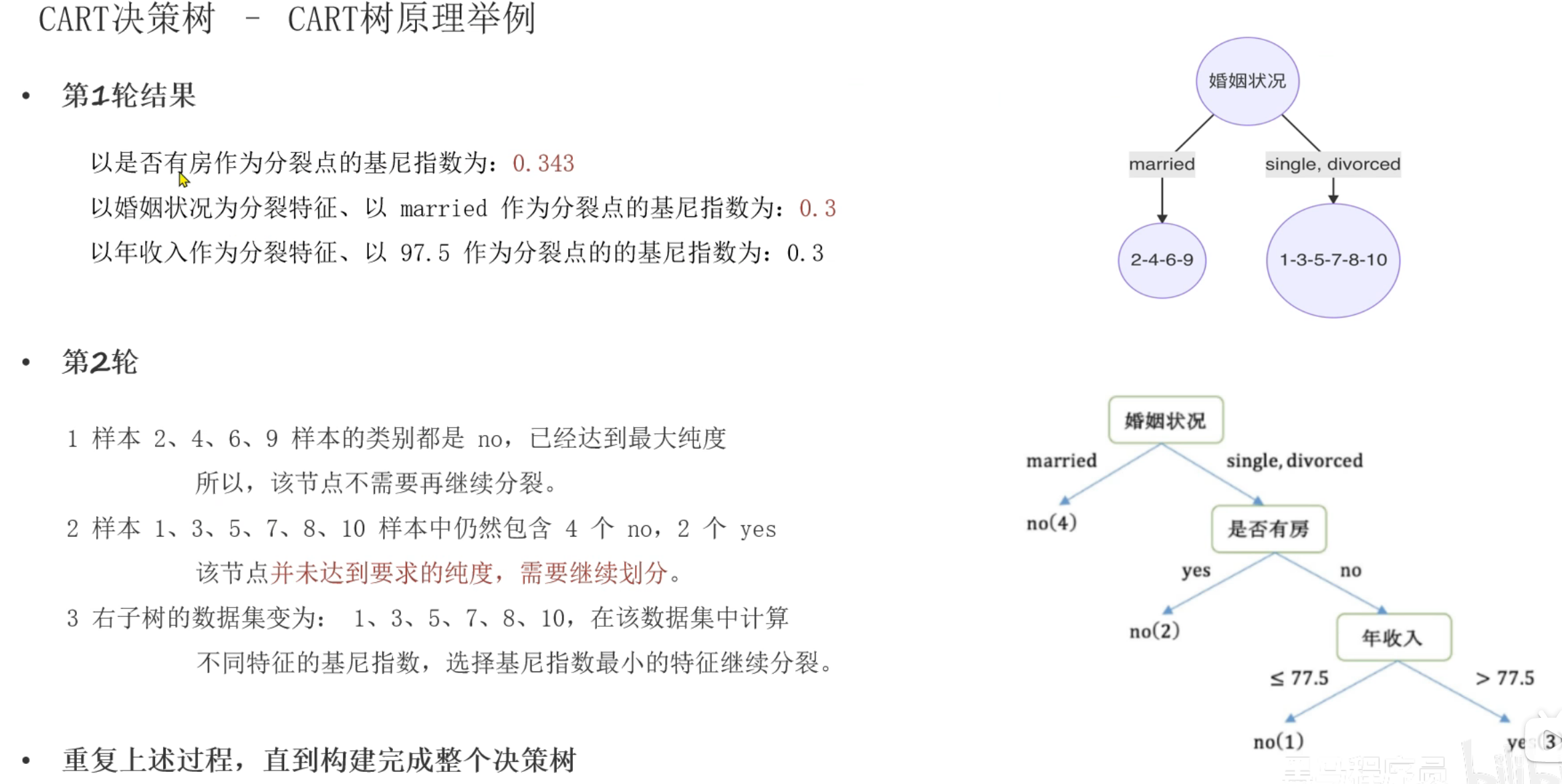
第1轮结果,婚姻状况和年收入的最小基尼指数并列为0.3,此时根据奥卡姆剃刀原则选择简单的,所以根节点选择婚姻状况。到第2轮的节点时,数据集已经改变,所以此时又得根据新的数据集计算是否有房和年收入的最小基尼指数(不能使用第1轮的基尼指数进行比较)

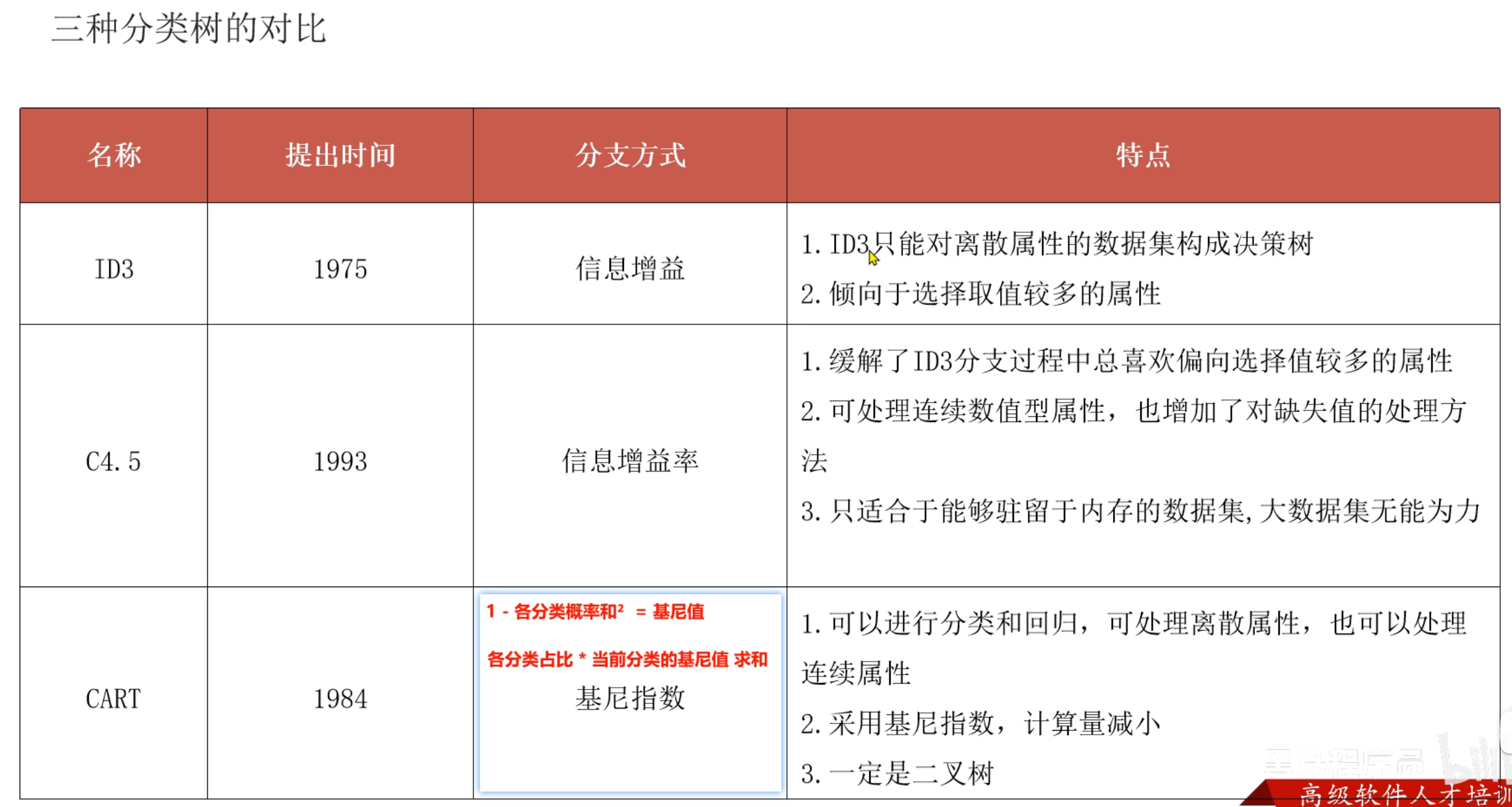
11、3种决策树总结


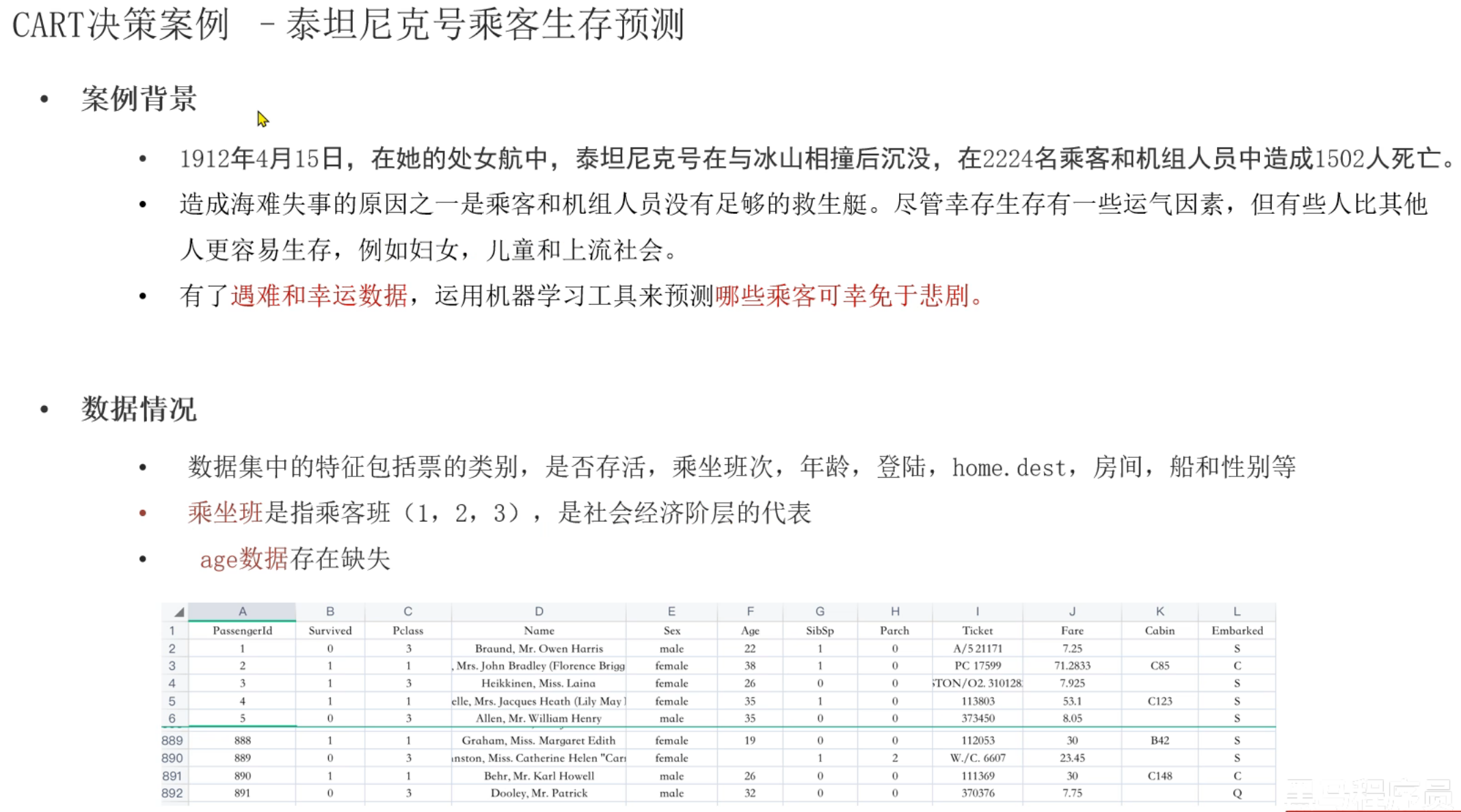
12、泰坦尼克号案例_数据集介绍
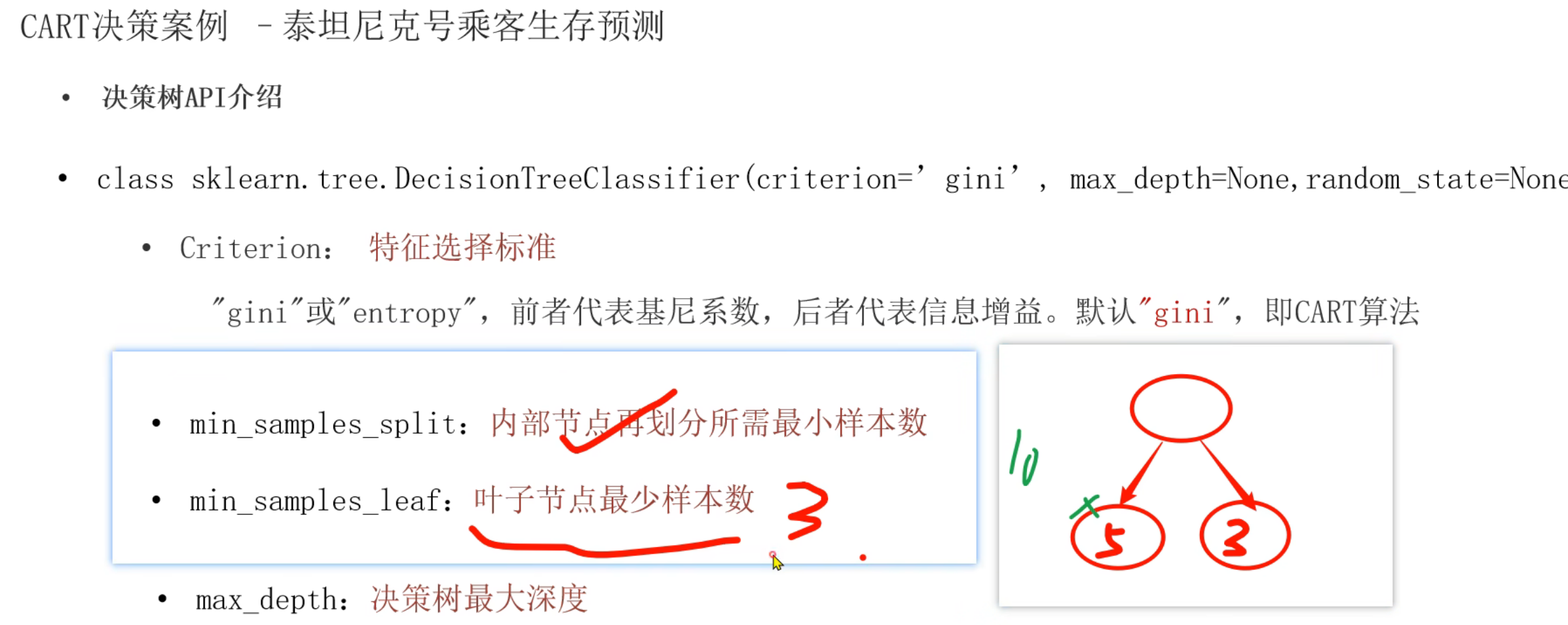


13、泰坦尼克号案例_代码演示

14、CART决策树_回归用法



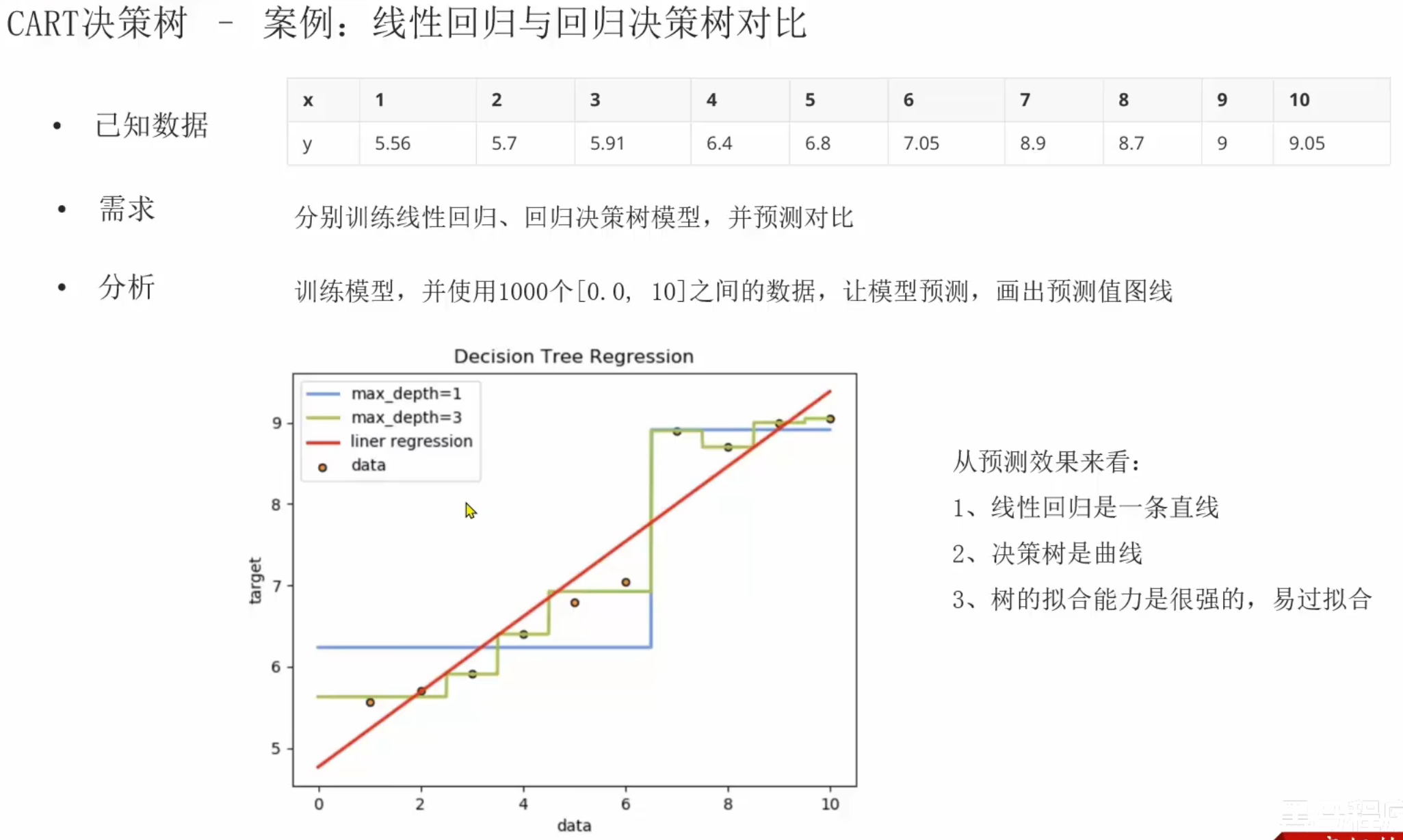
八、集成学习
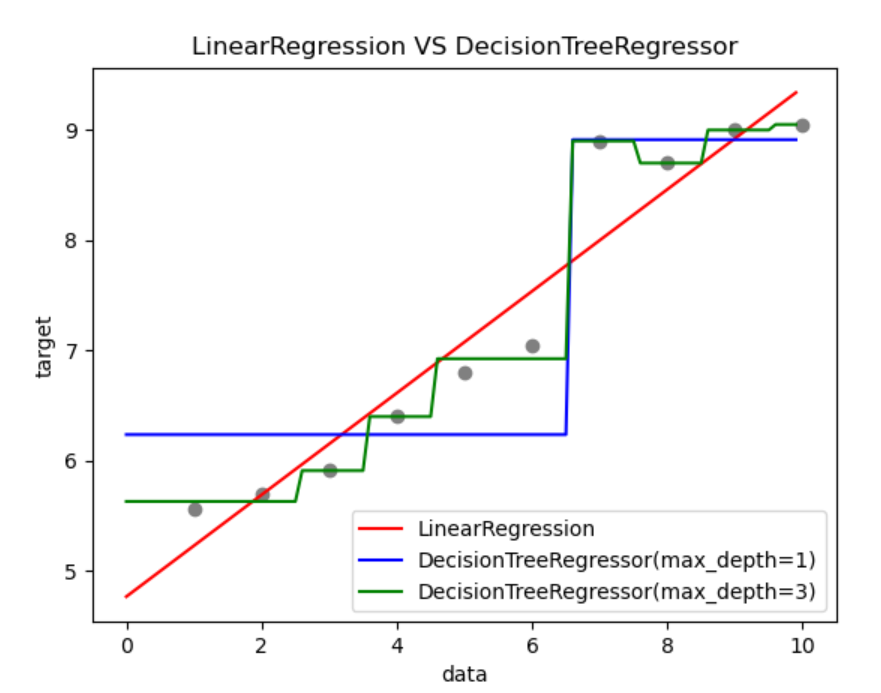
1、回归决策树和线性回归对比

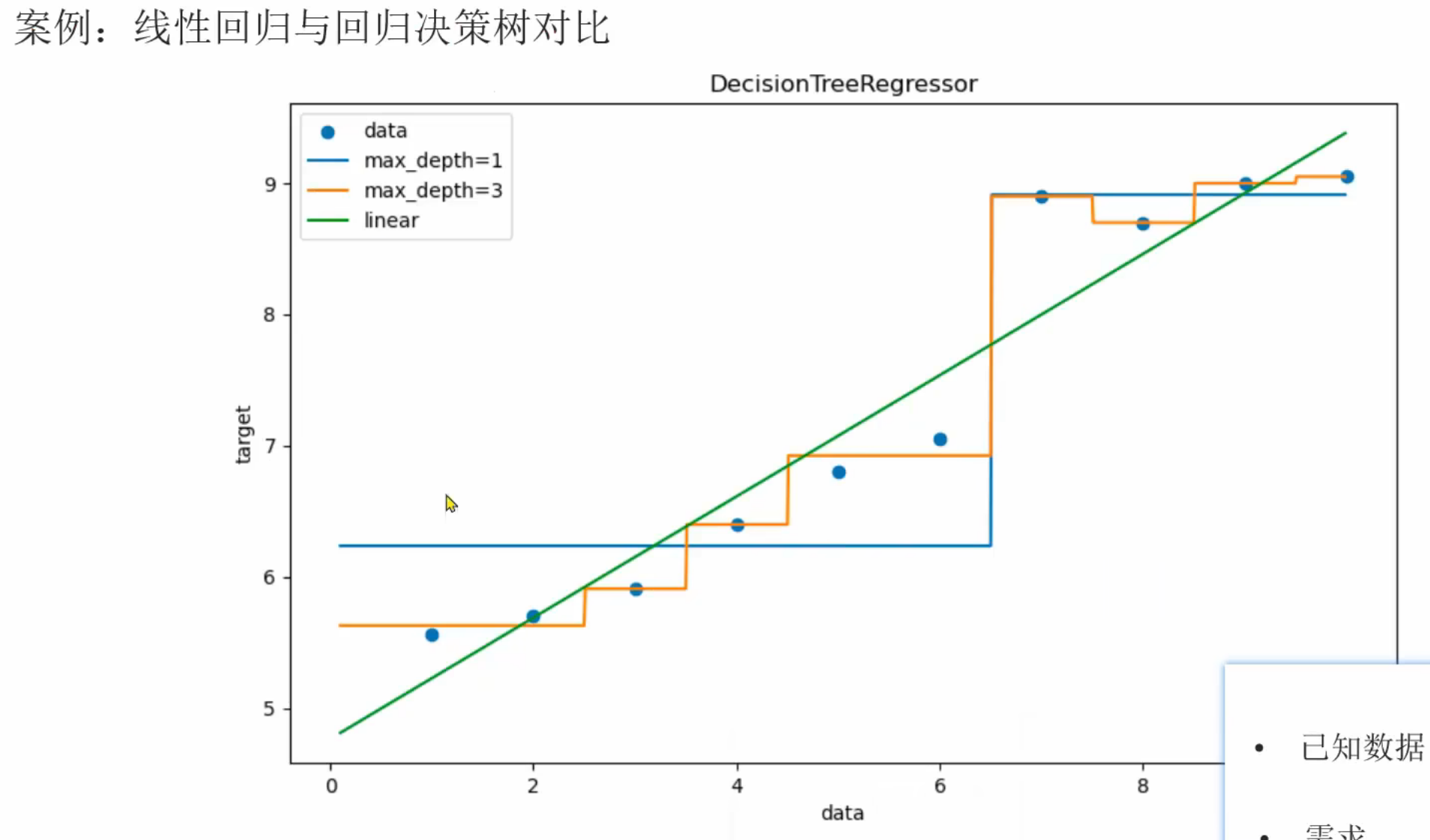
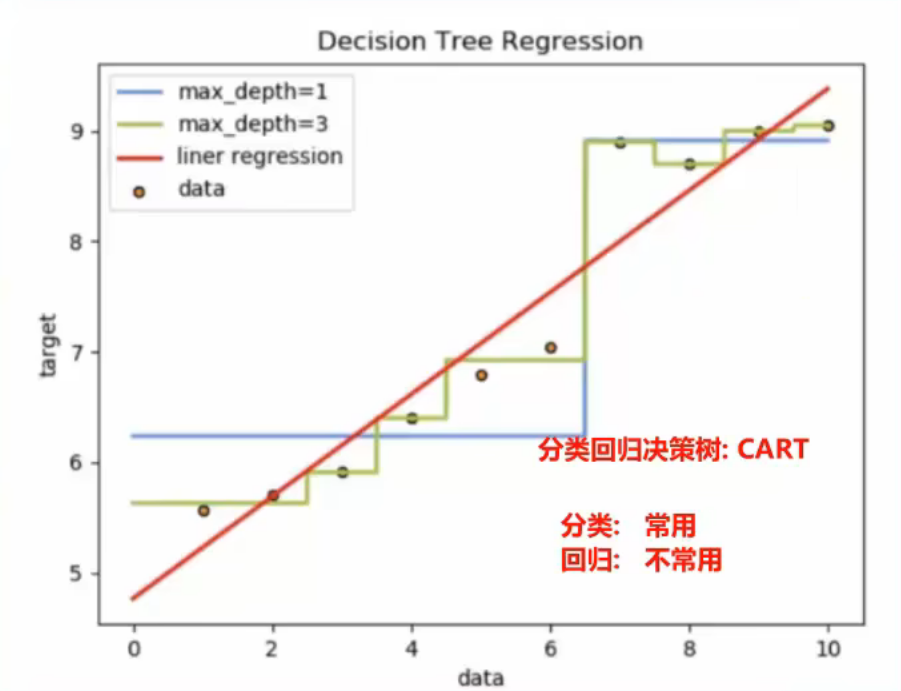
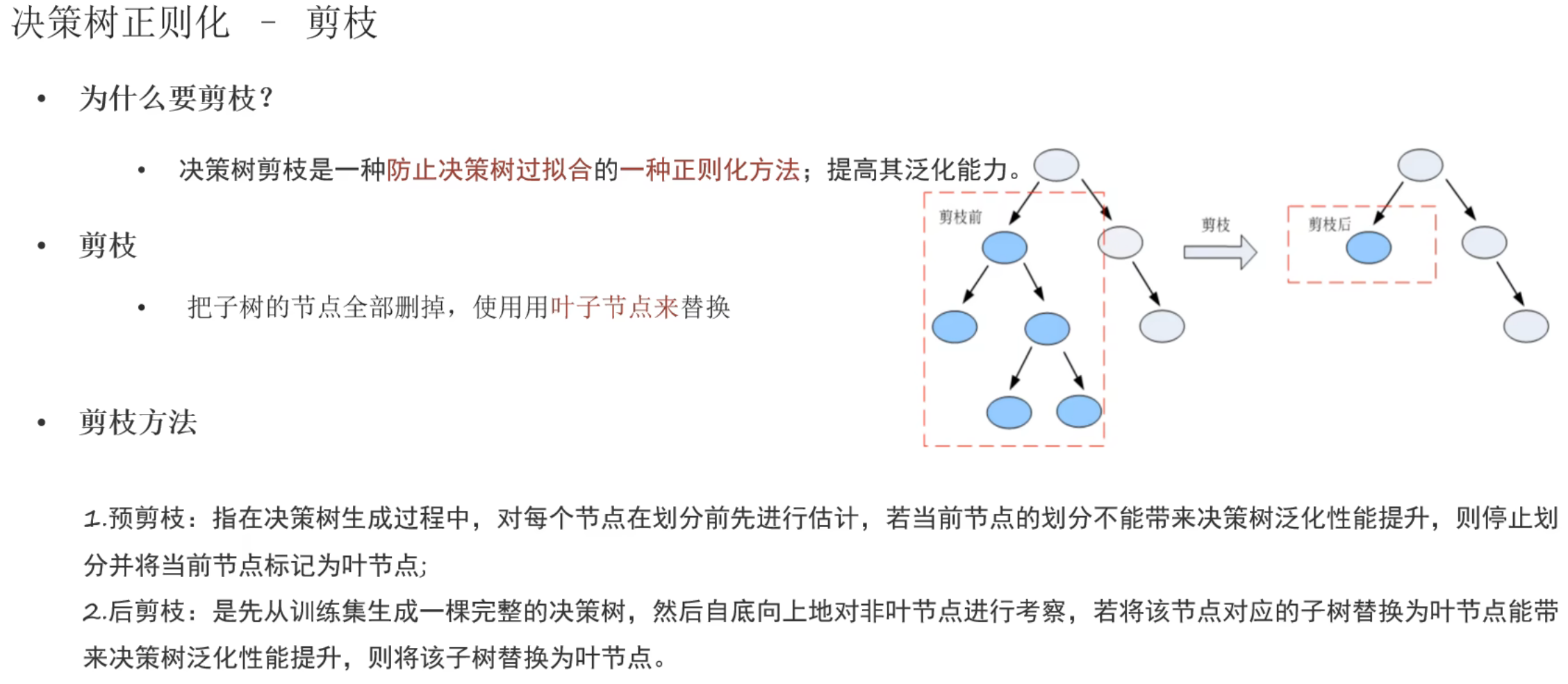
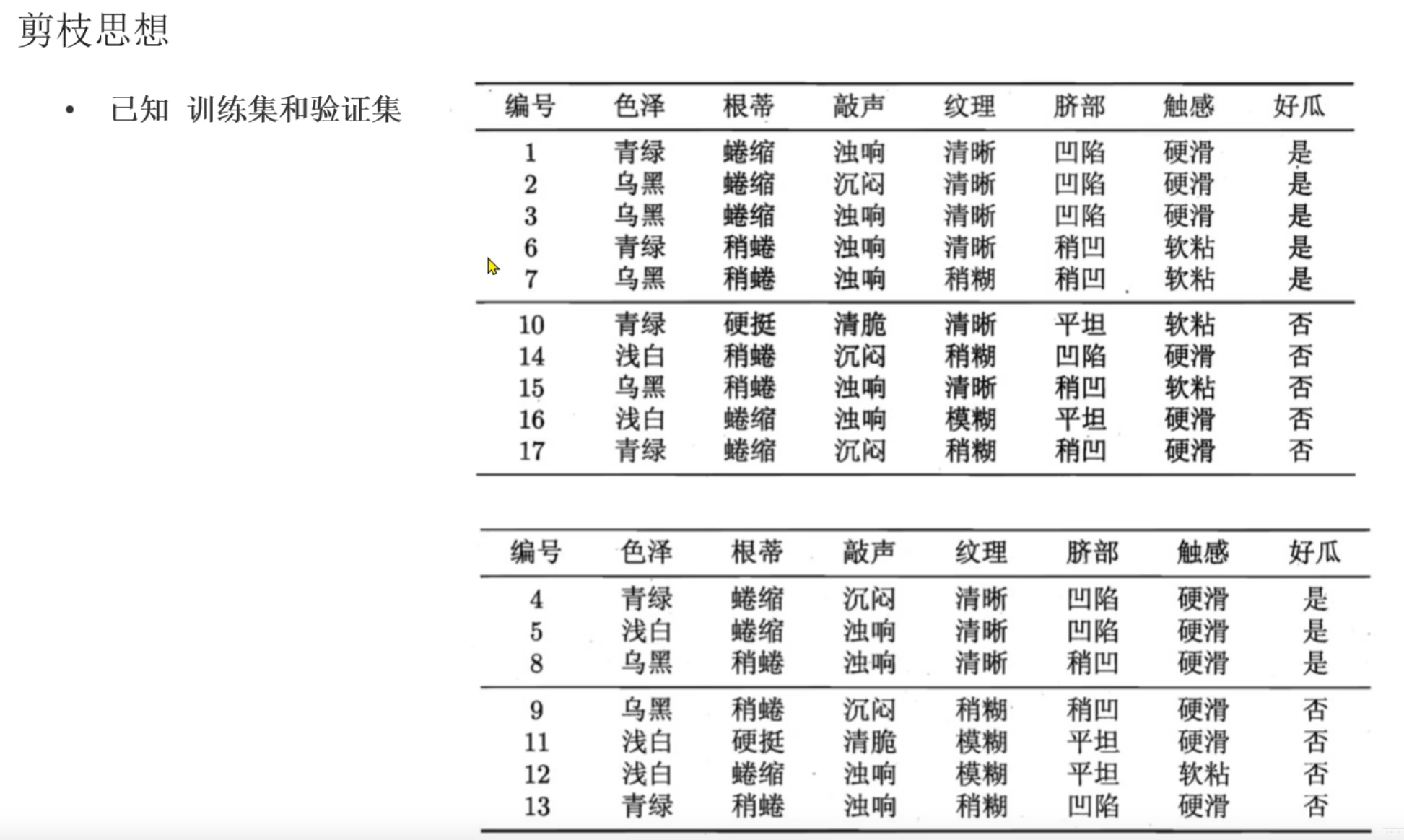
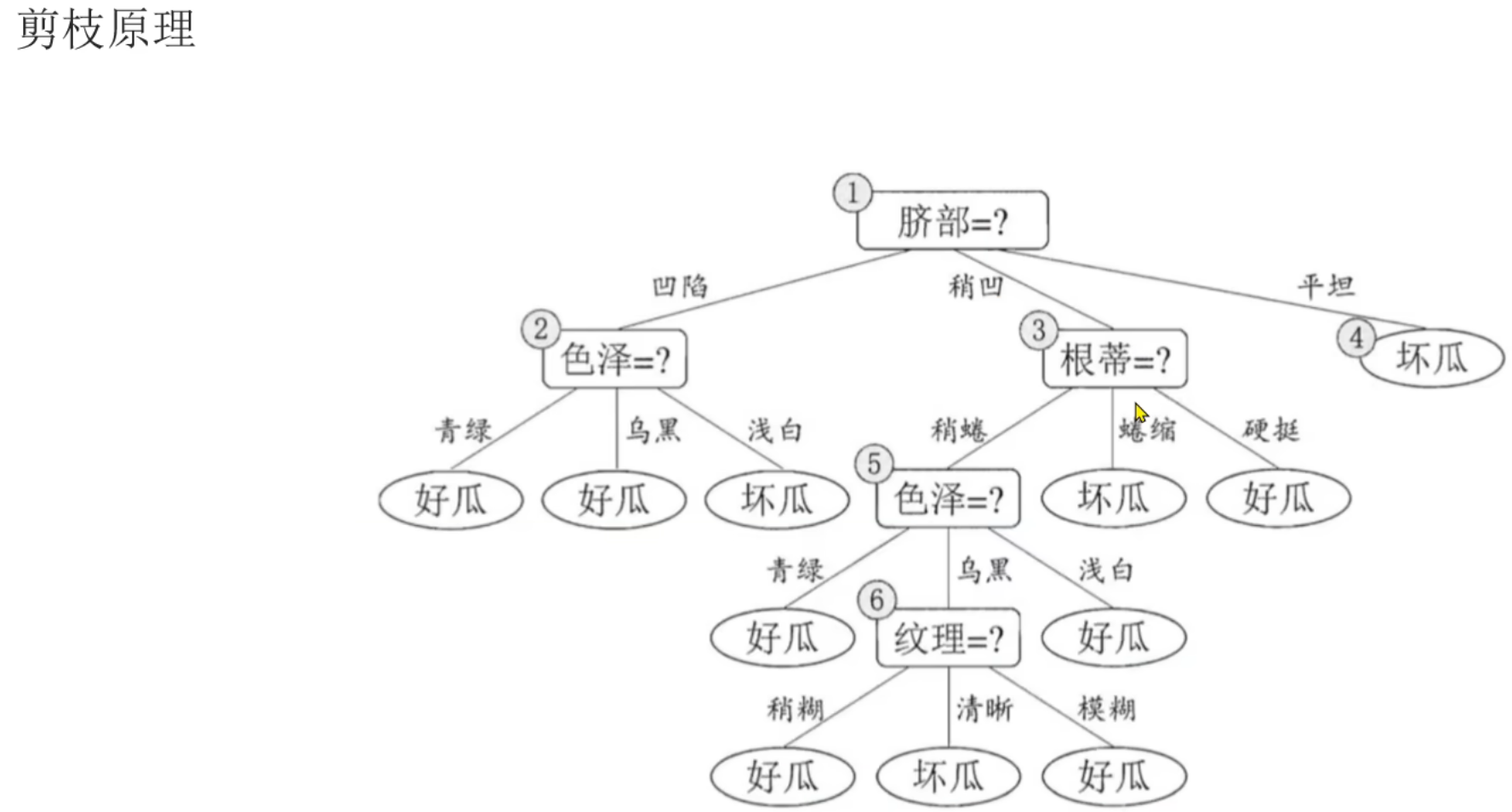
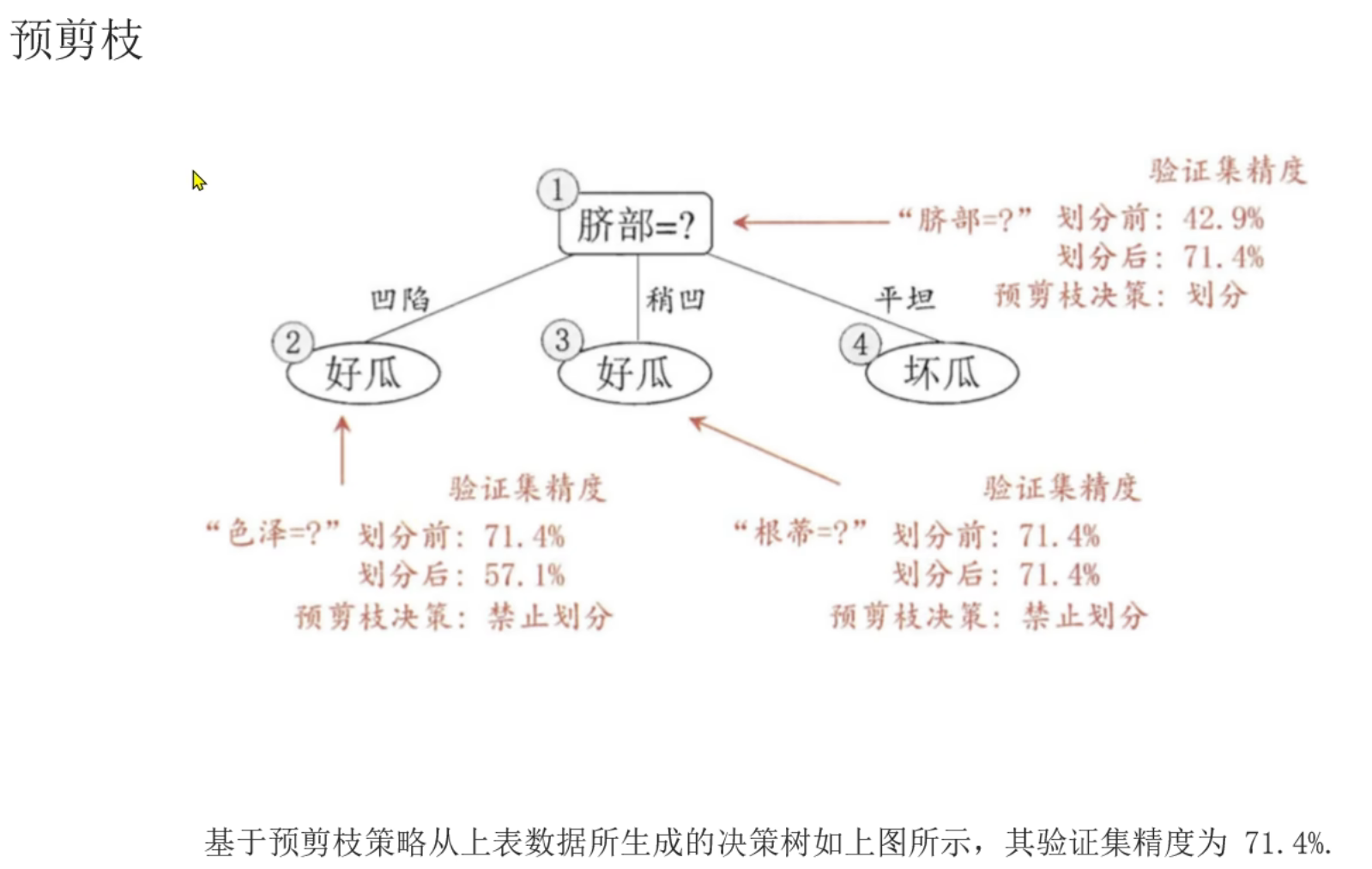
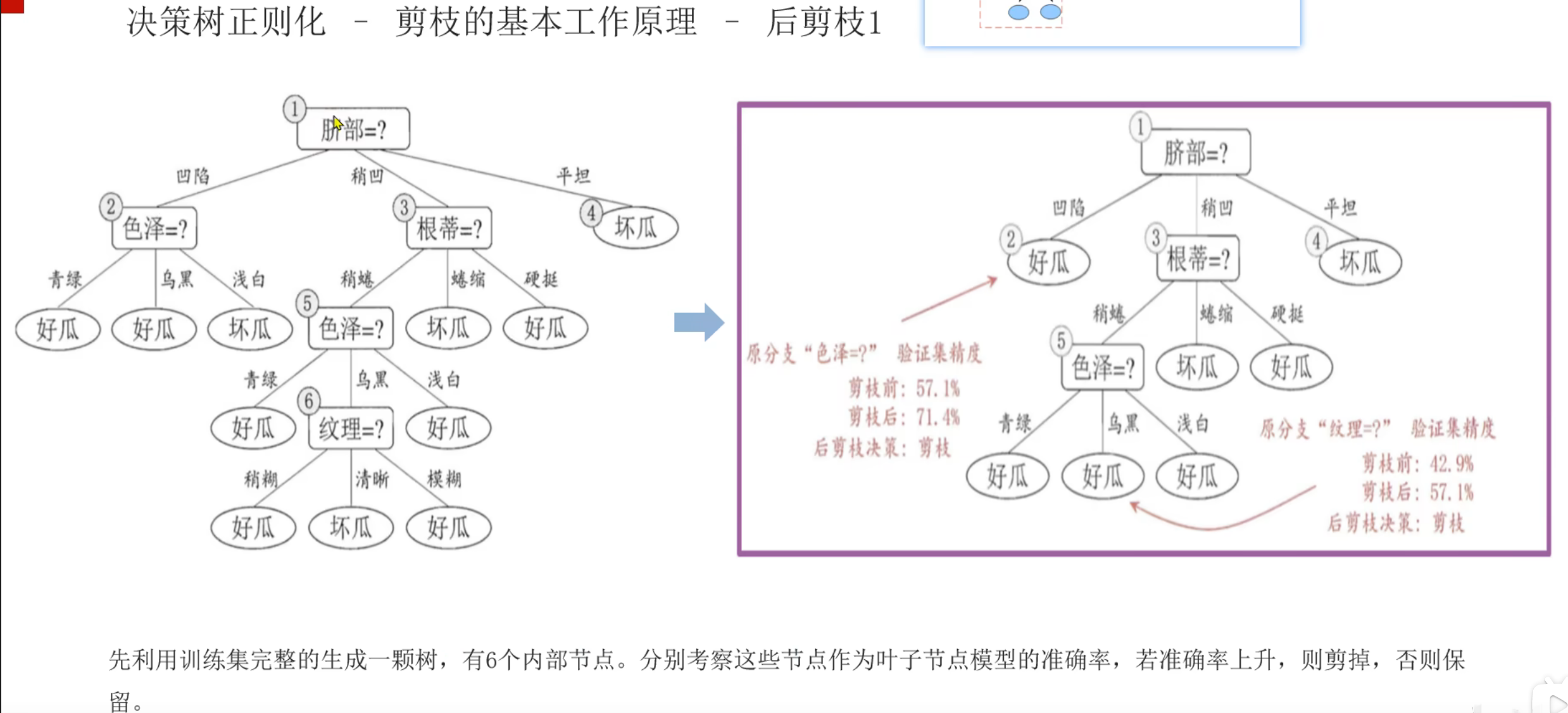
2、决策树_剪枝介绍
后剪枝更消耗资源但是更精准



3、集成学习_大纲介绍
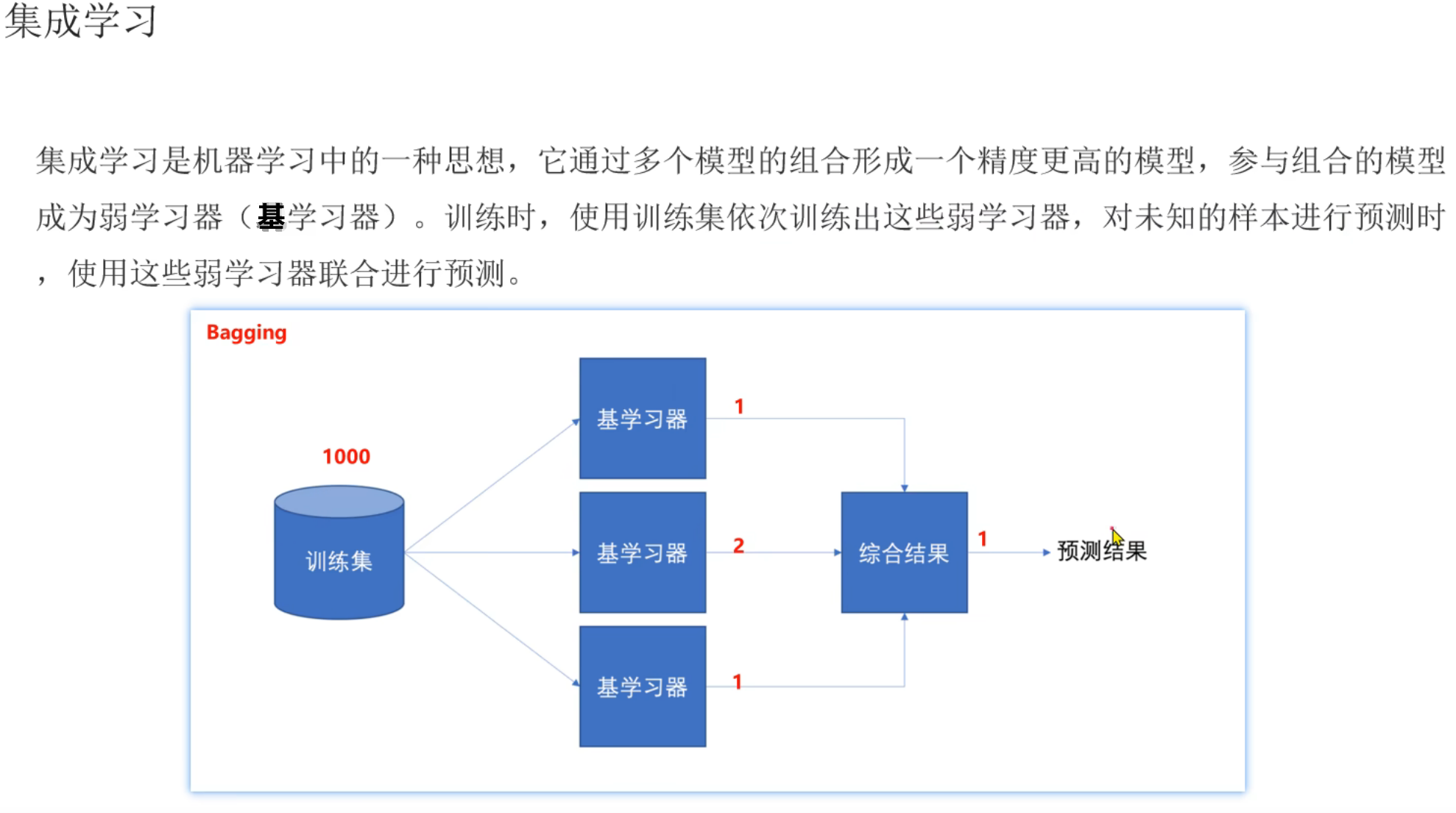
4、集成学习_简介
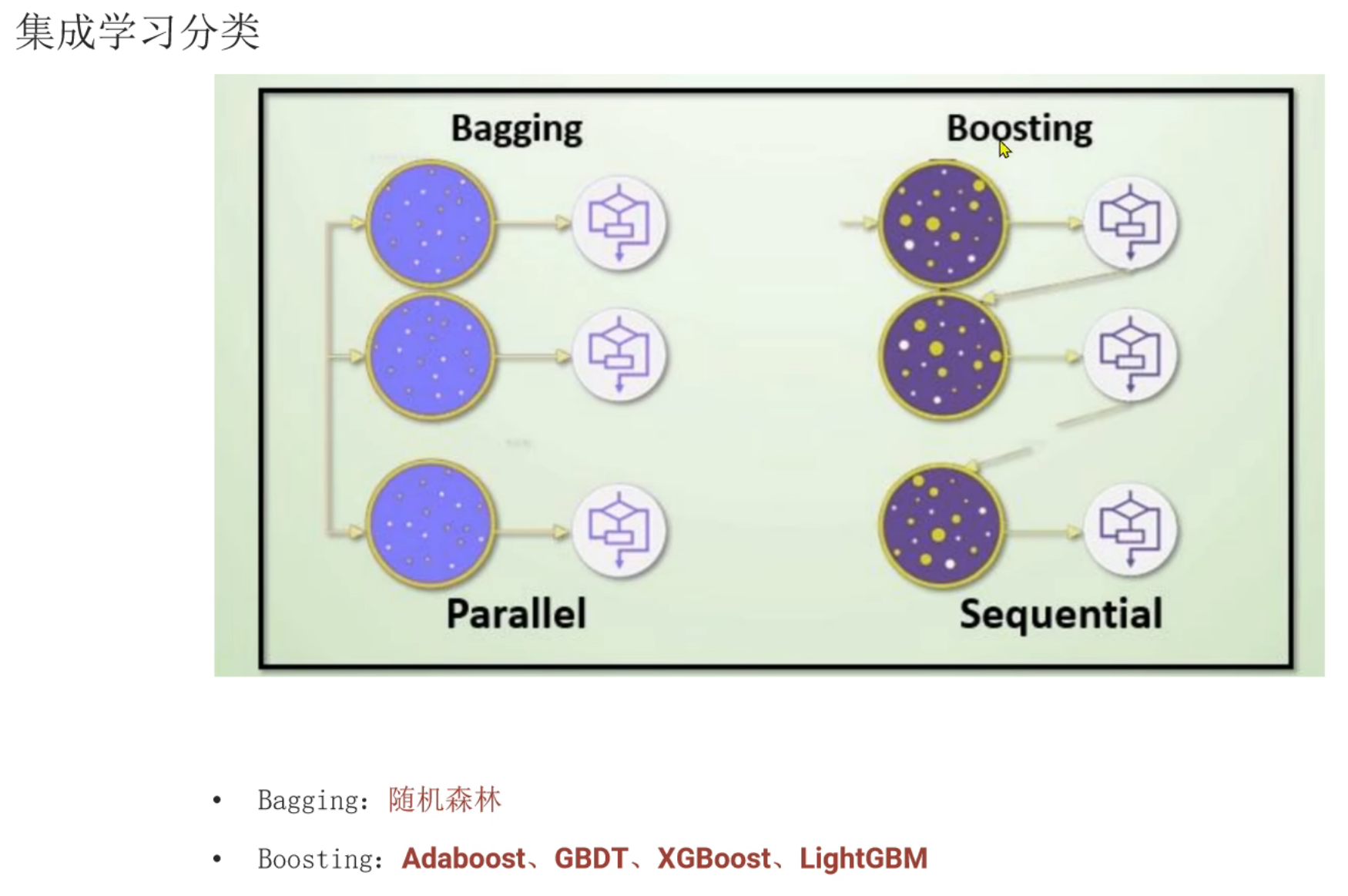
5、集成学习_Bagging和Boosting思想介绍
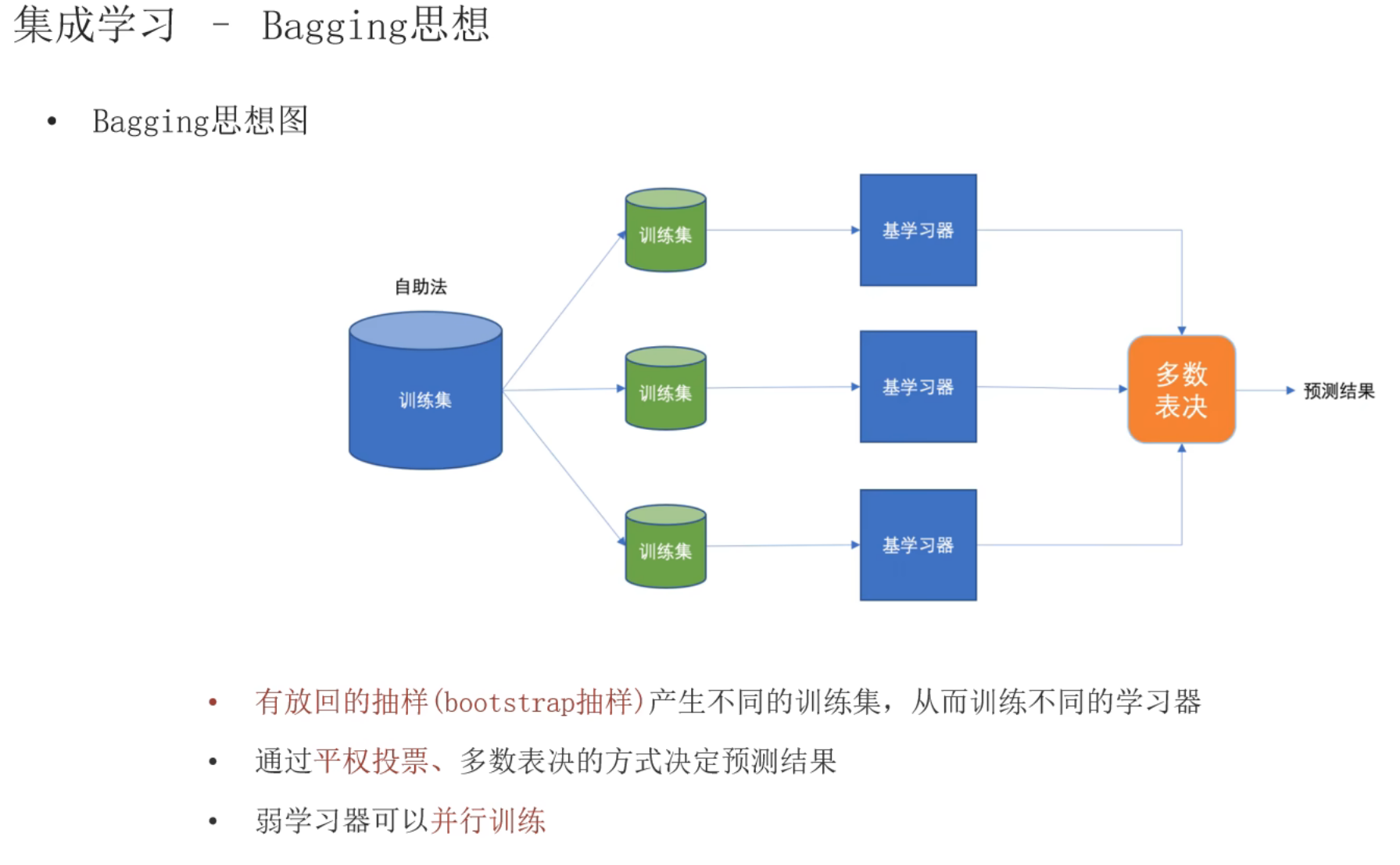
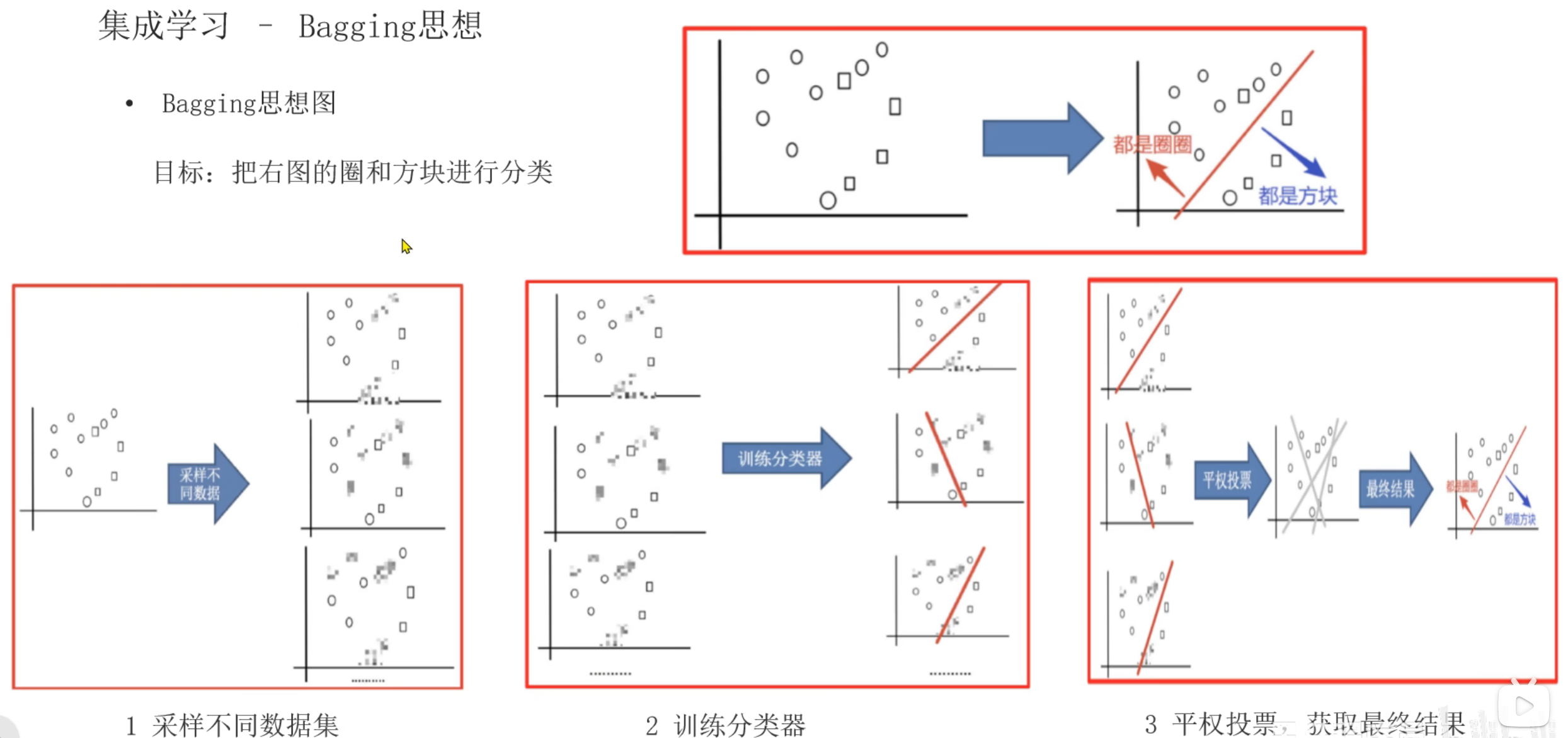
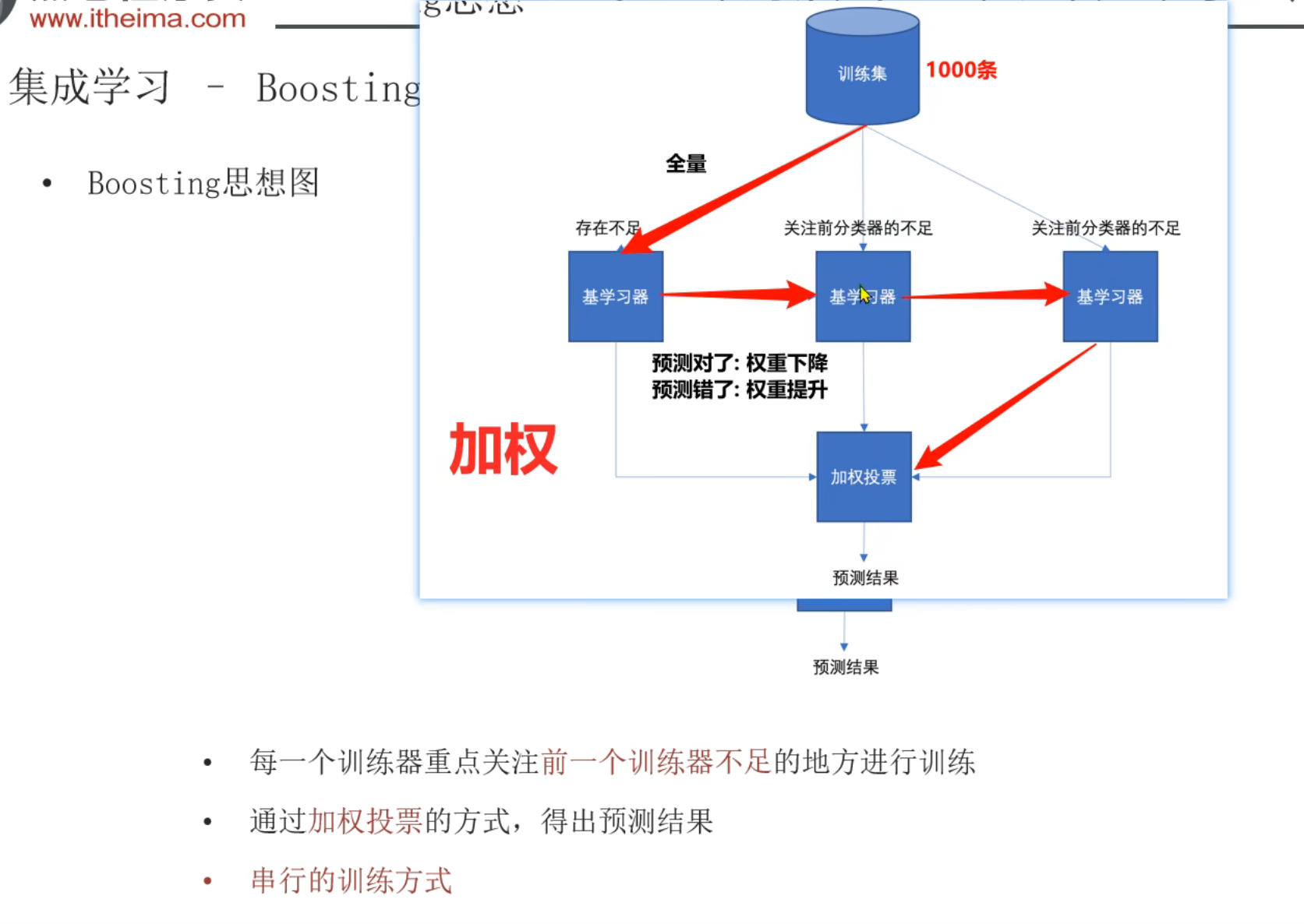

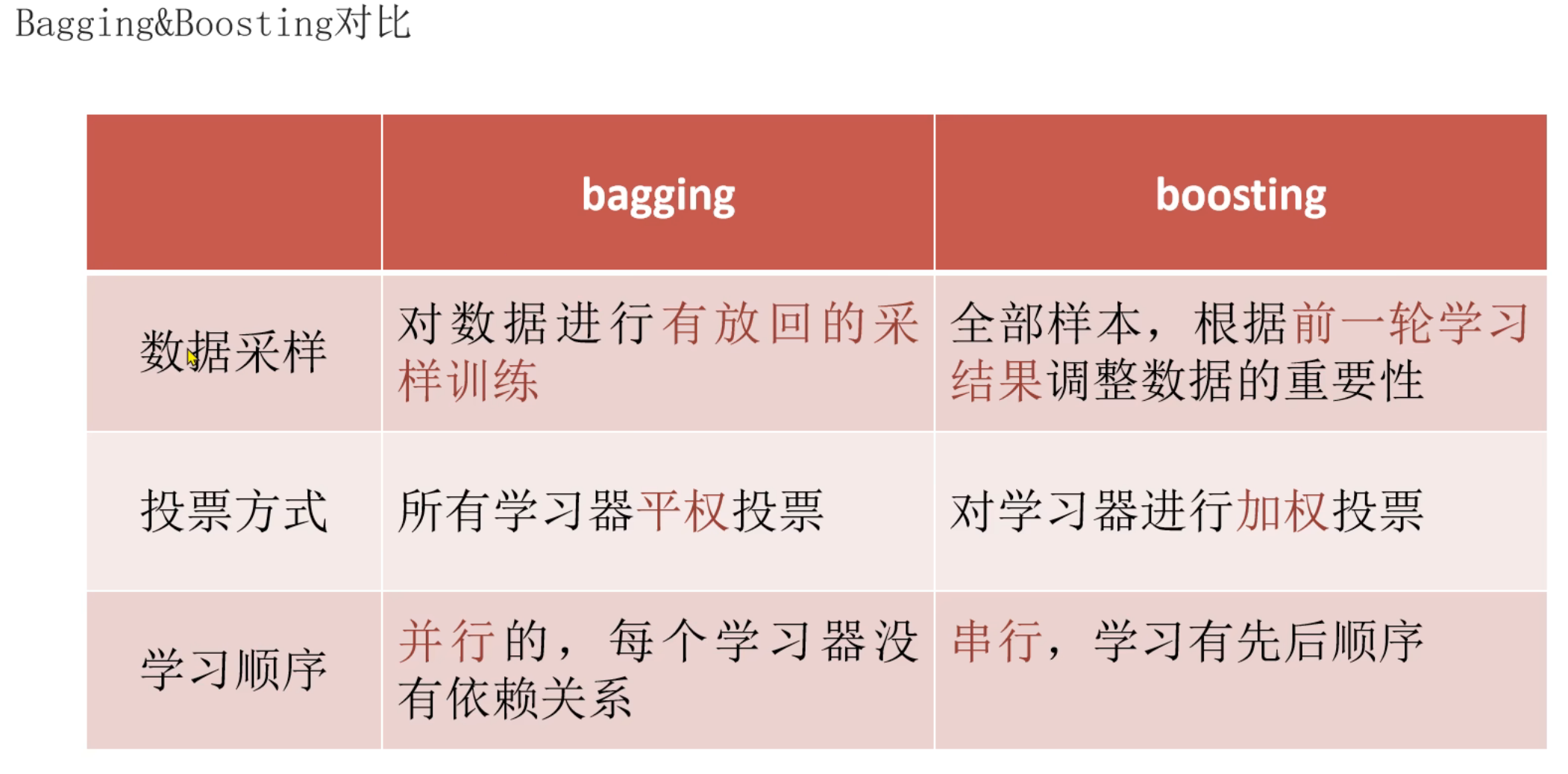


6、Bagging思想_随机森林算法介绍
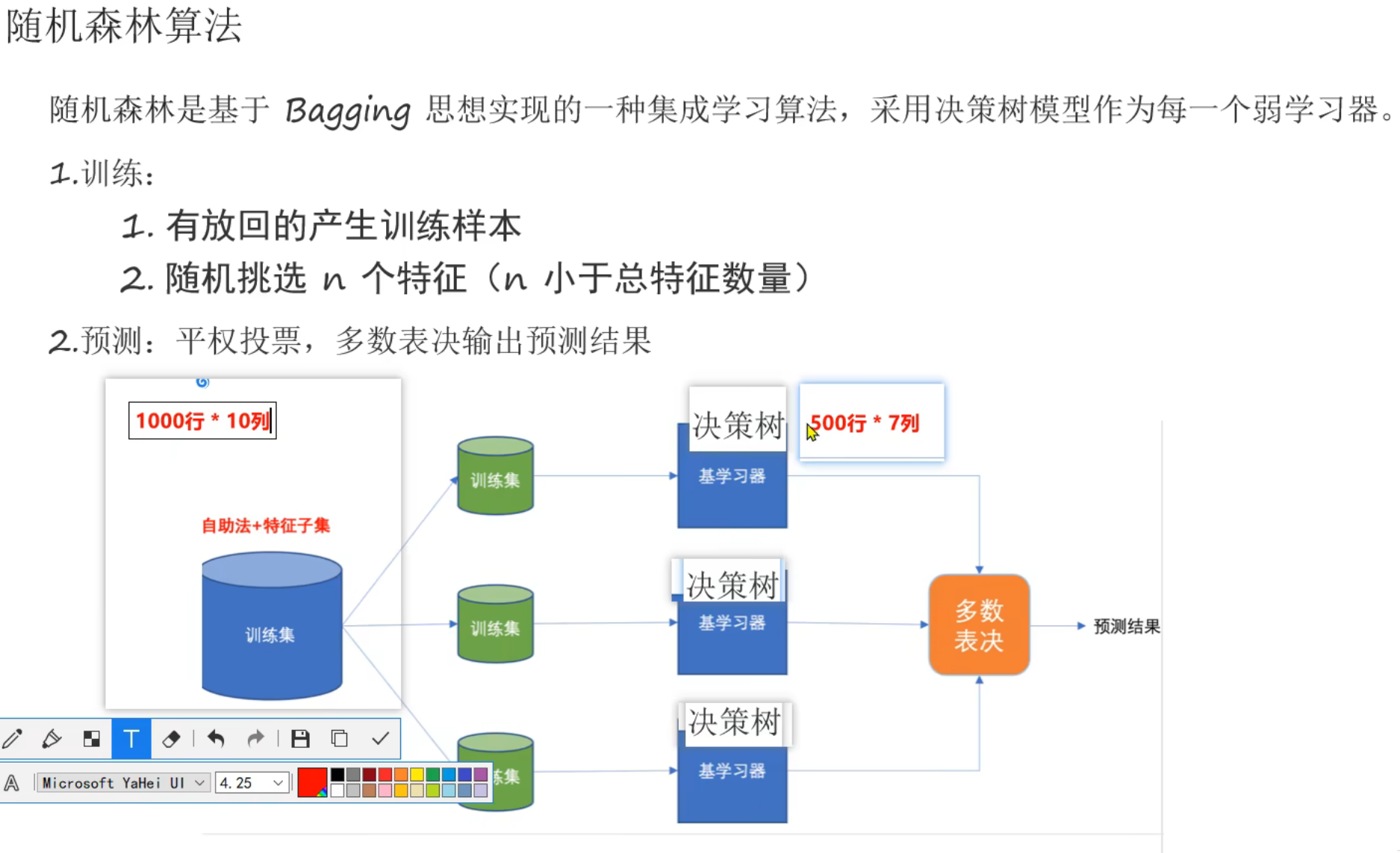
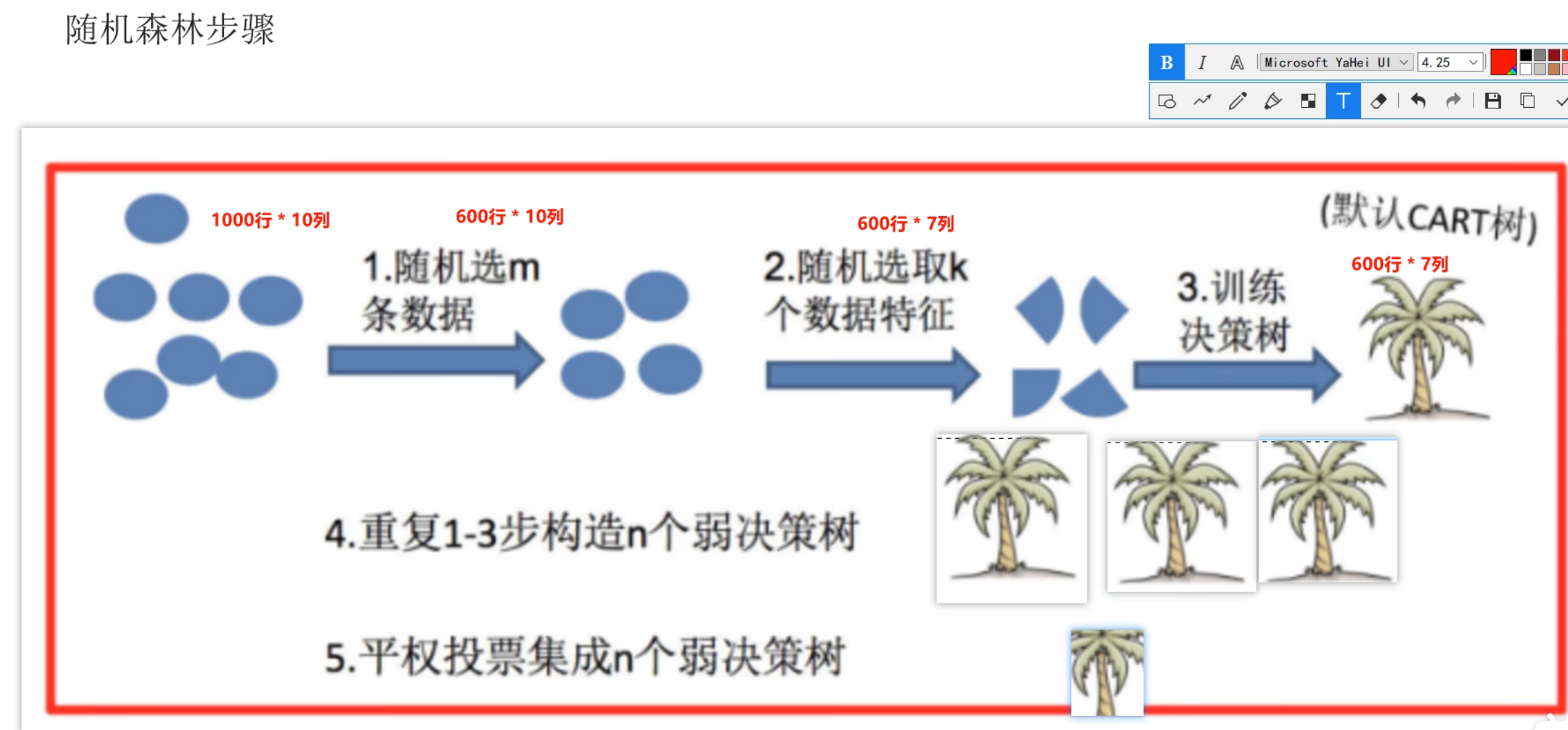



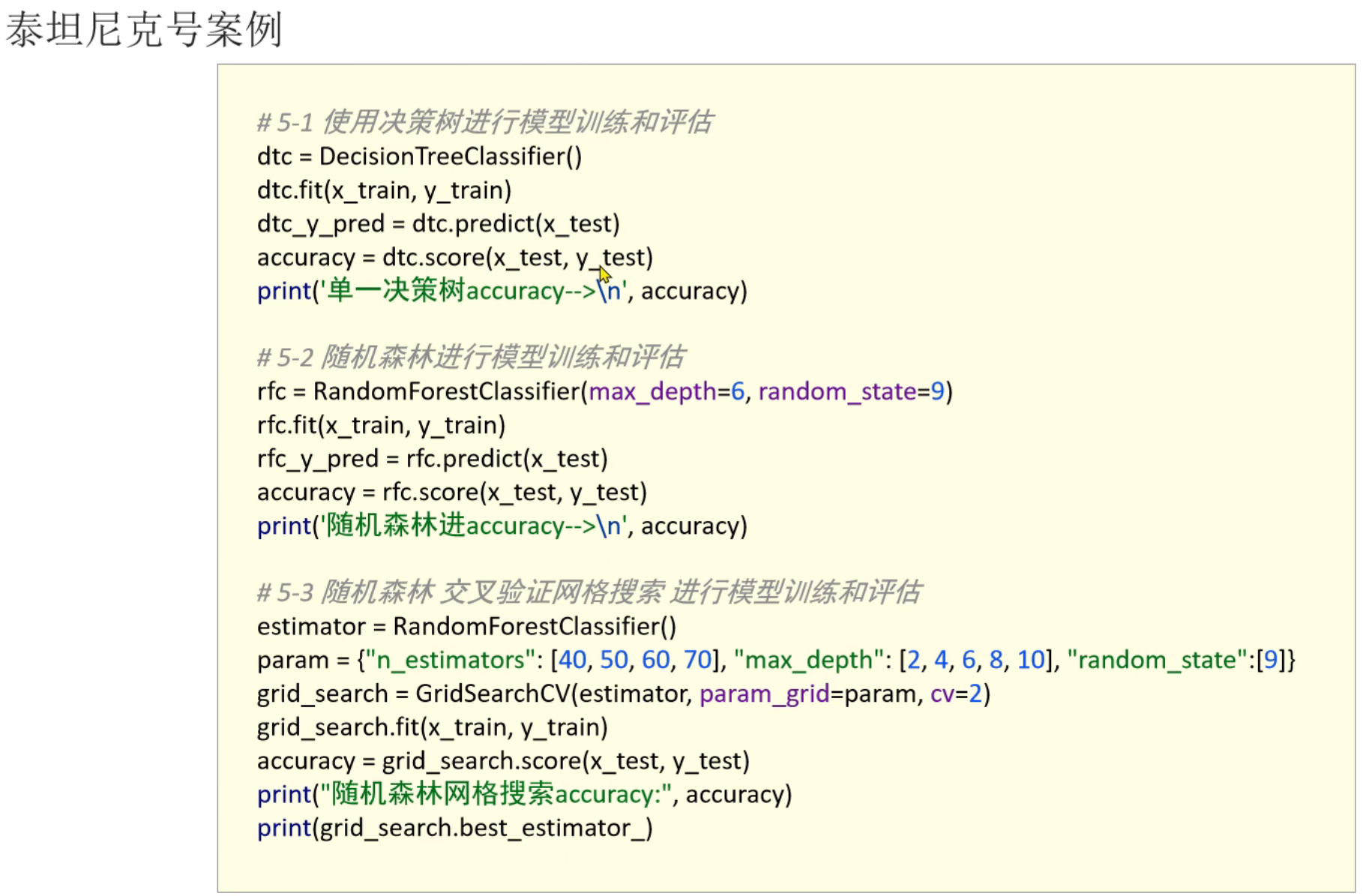
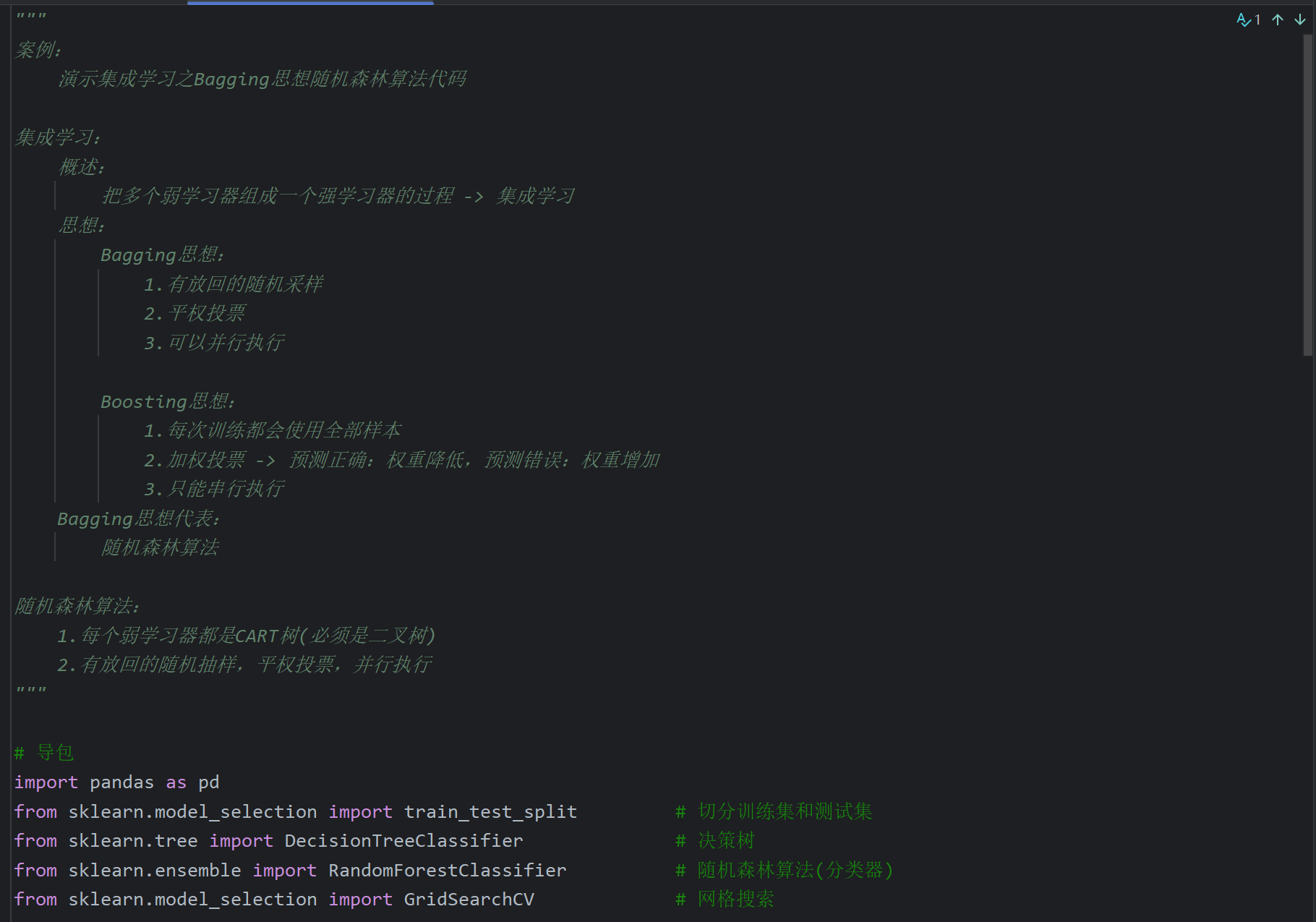
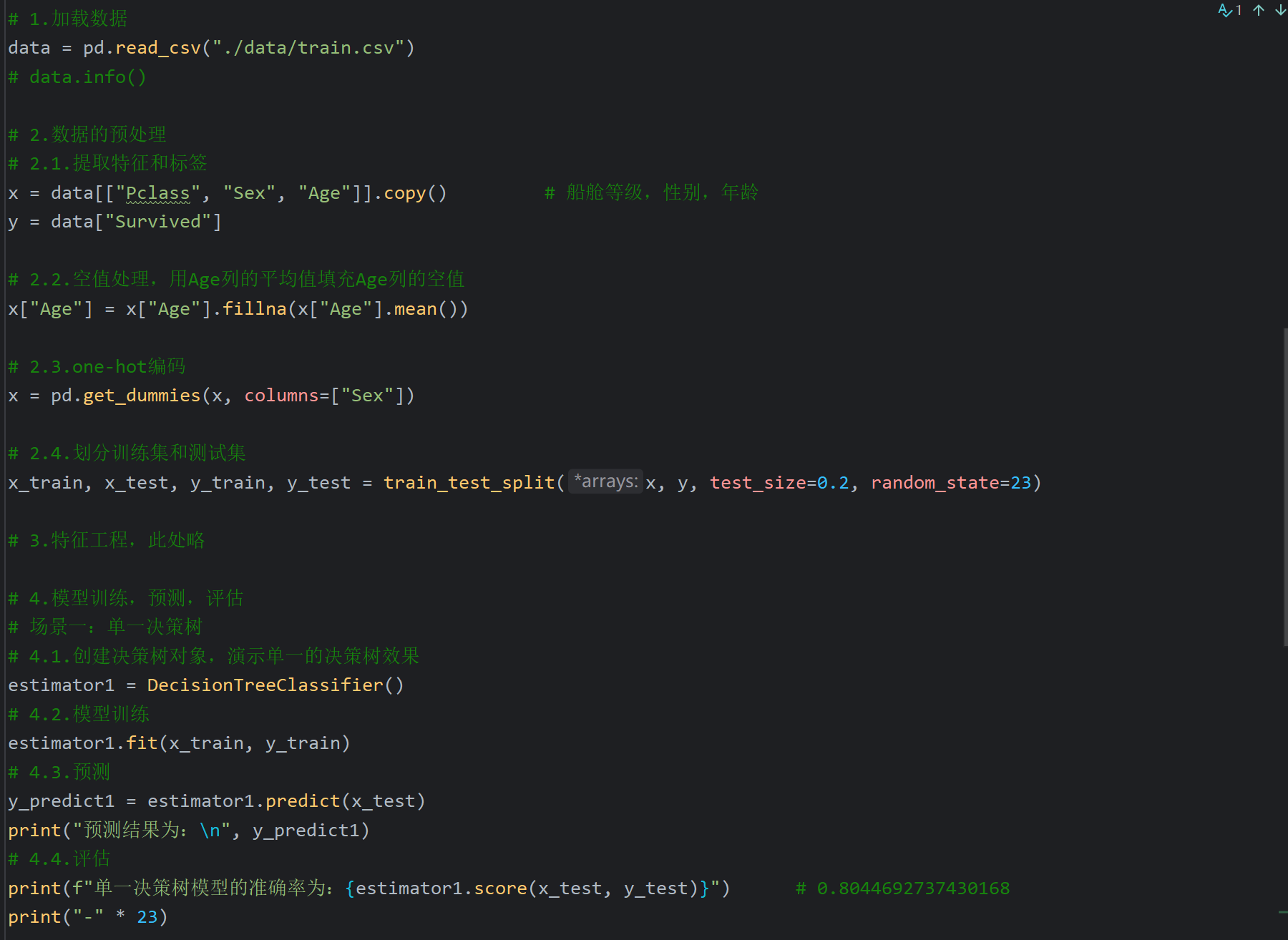
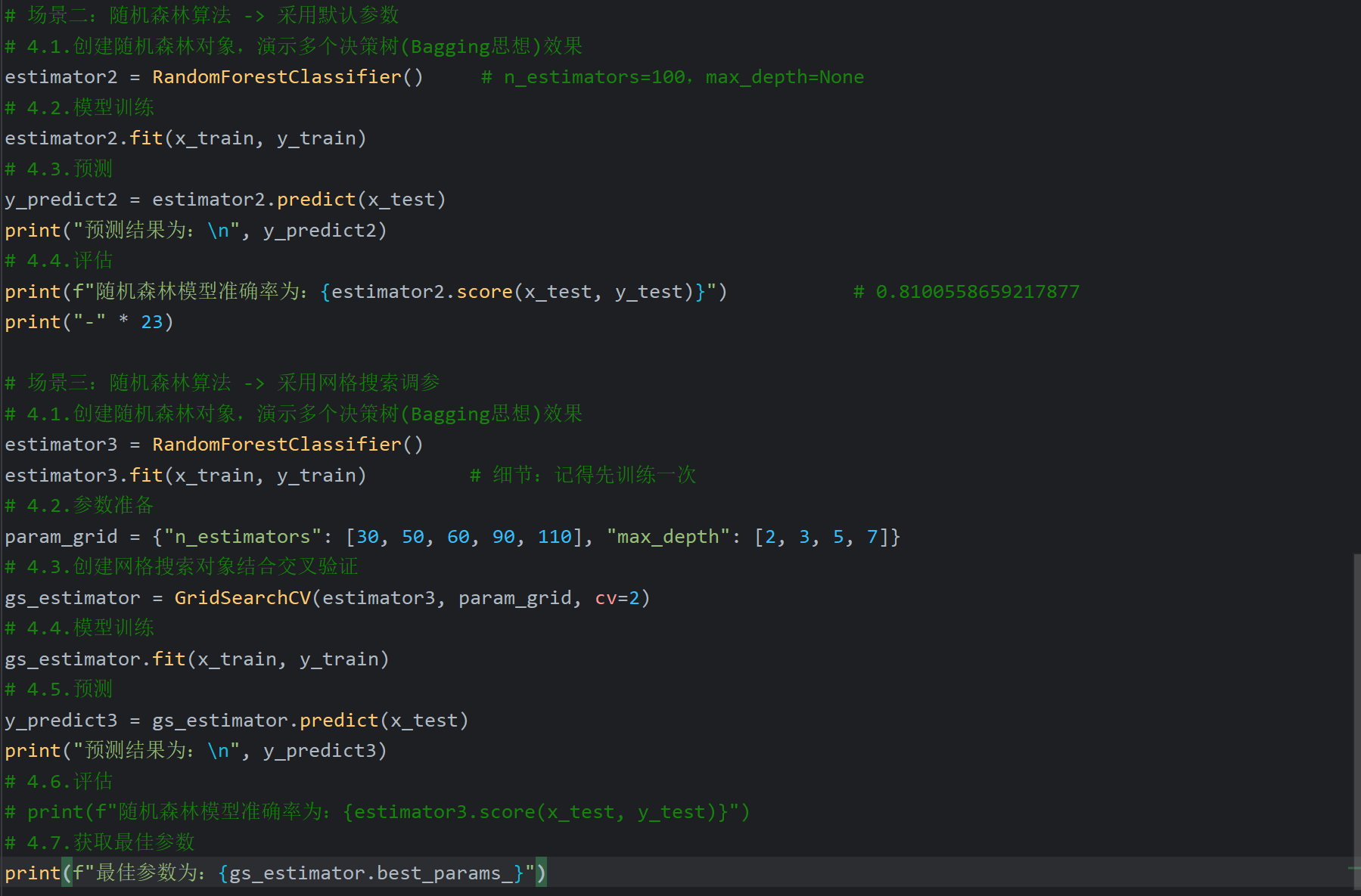
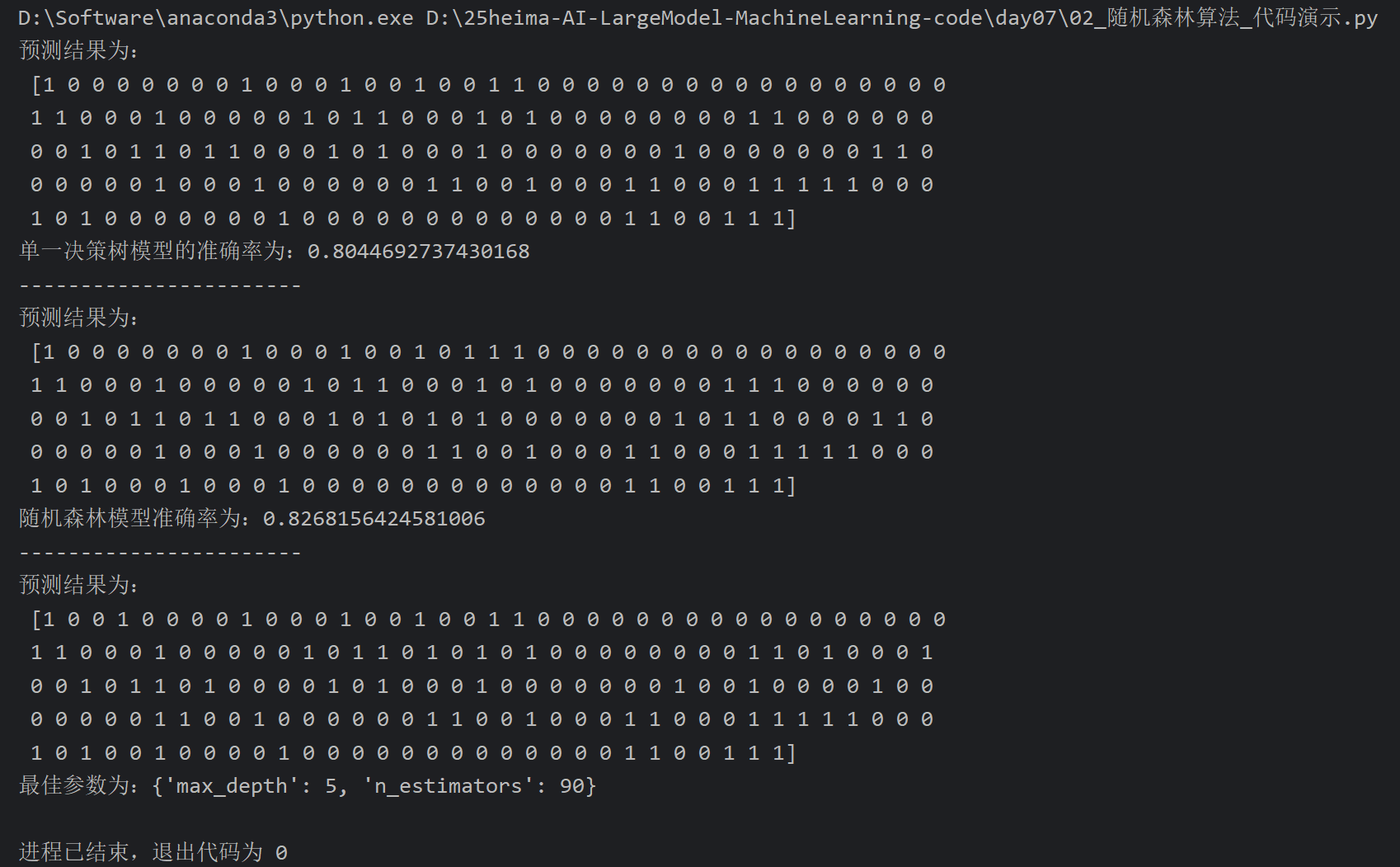
7、随机森林API_泰坦尼克号案例



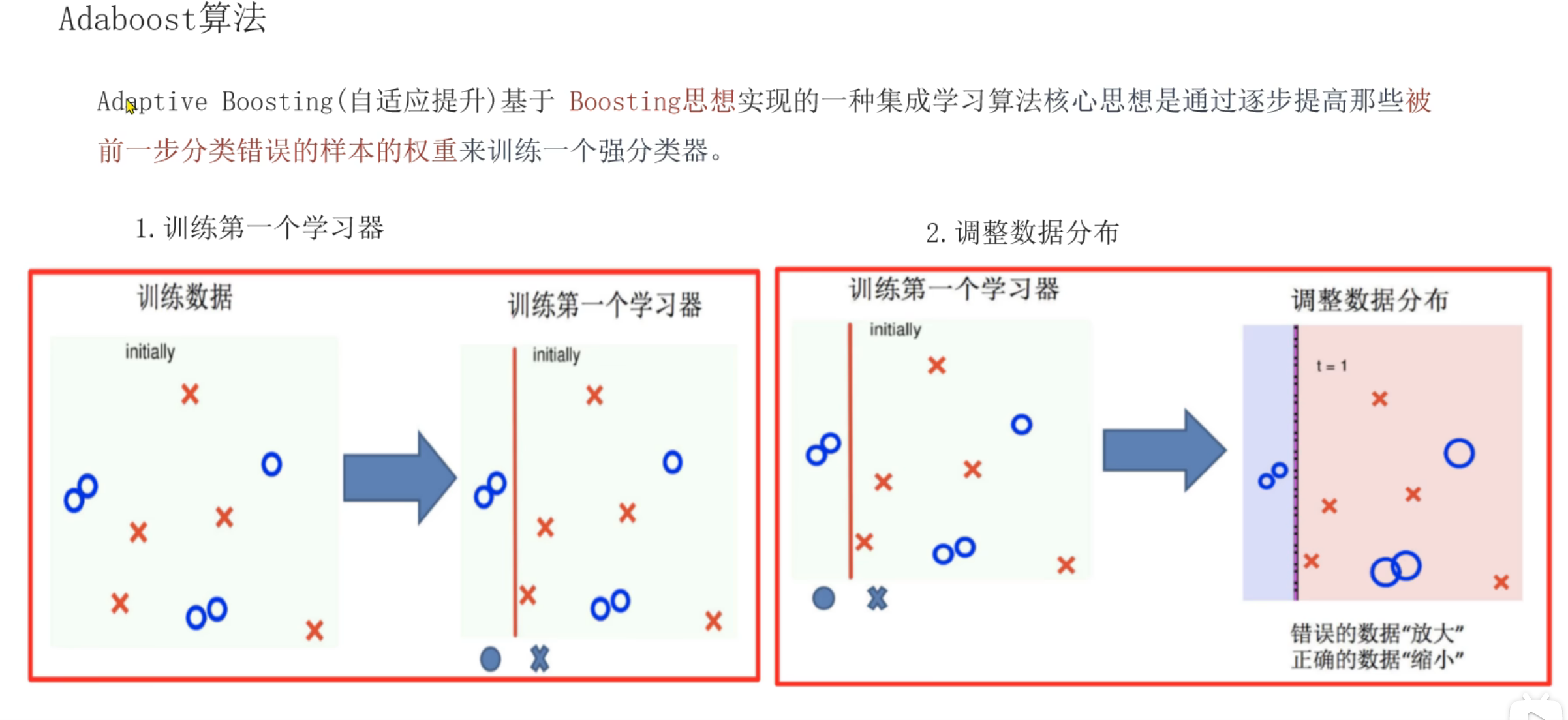
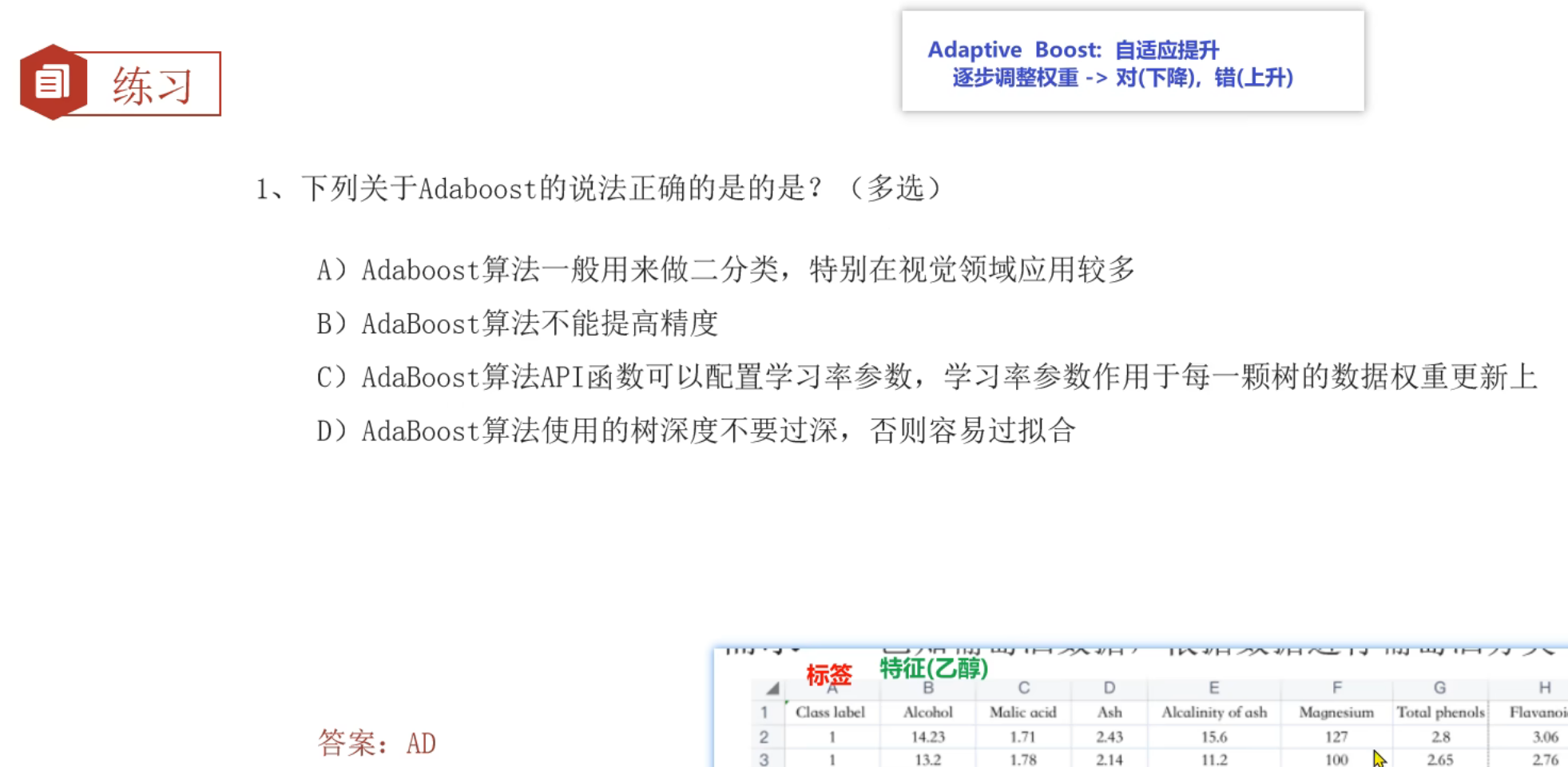
8、Boosting思想_AdaBoost自适应提升树介绍
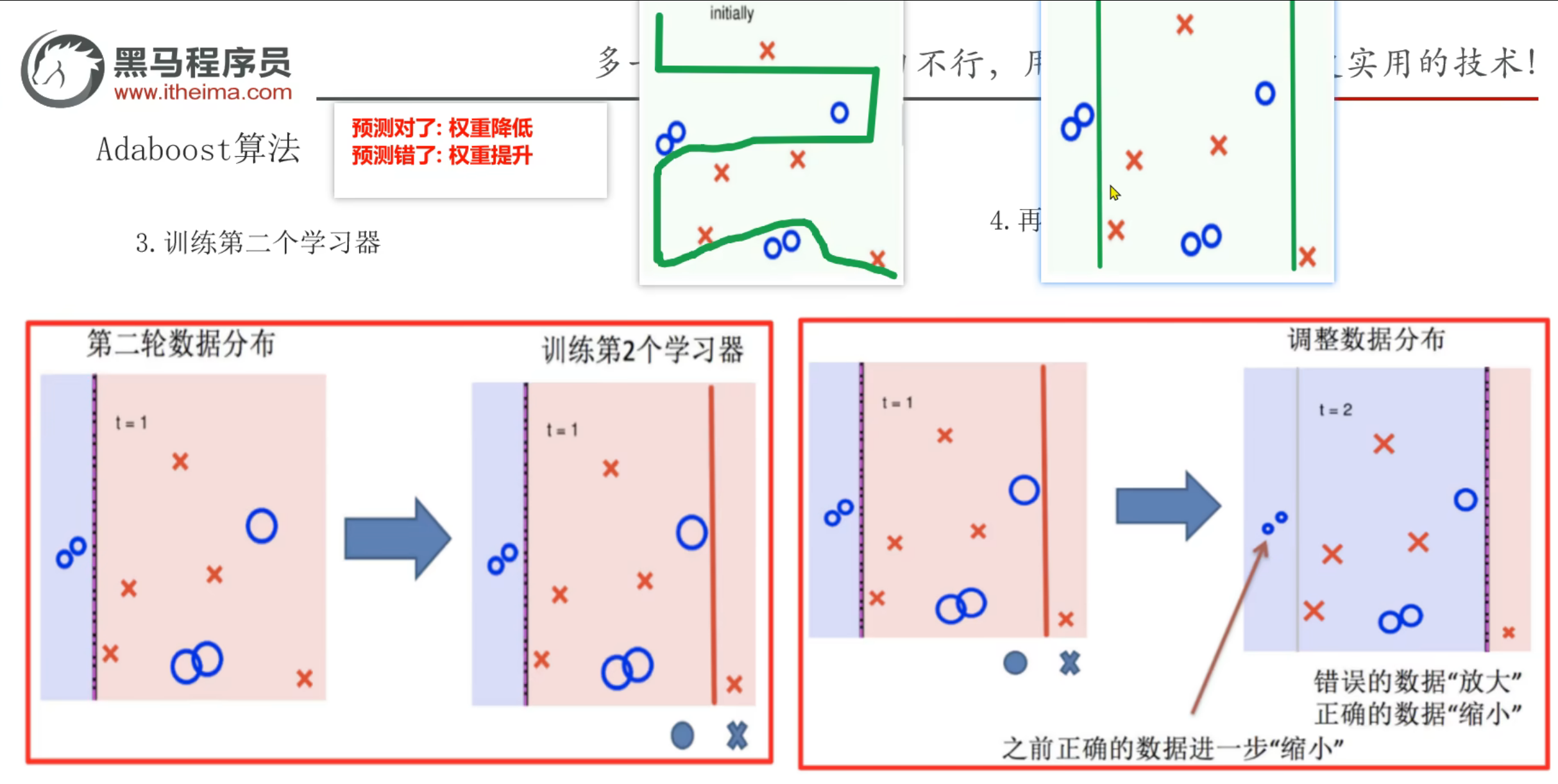
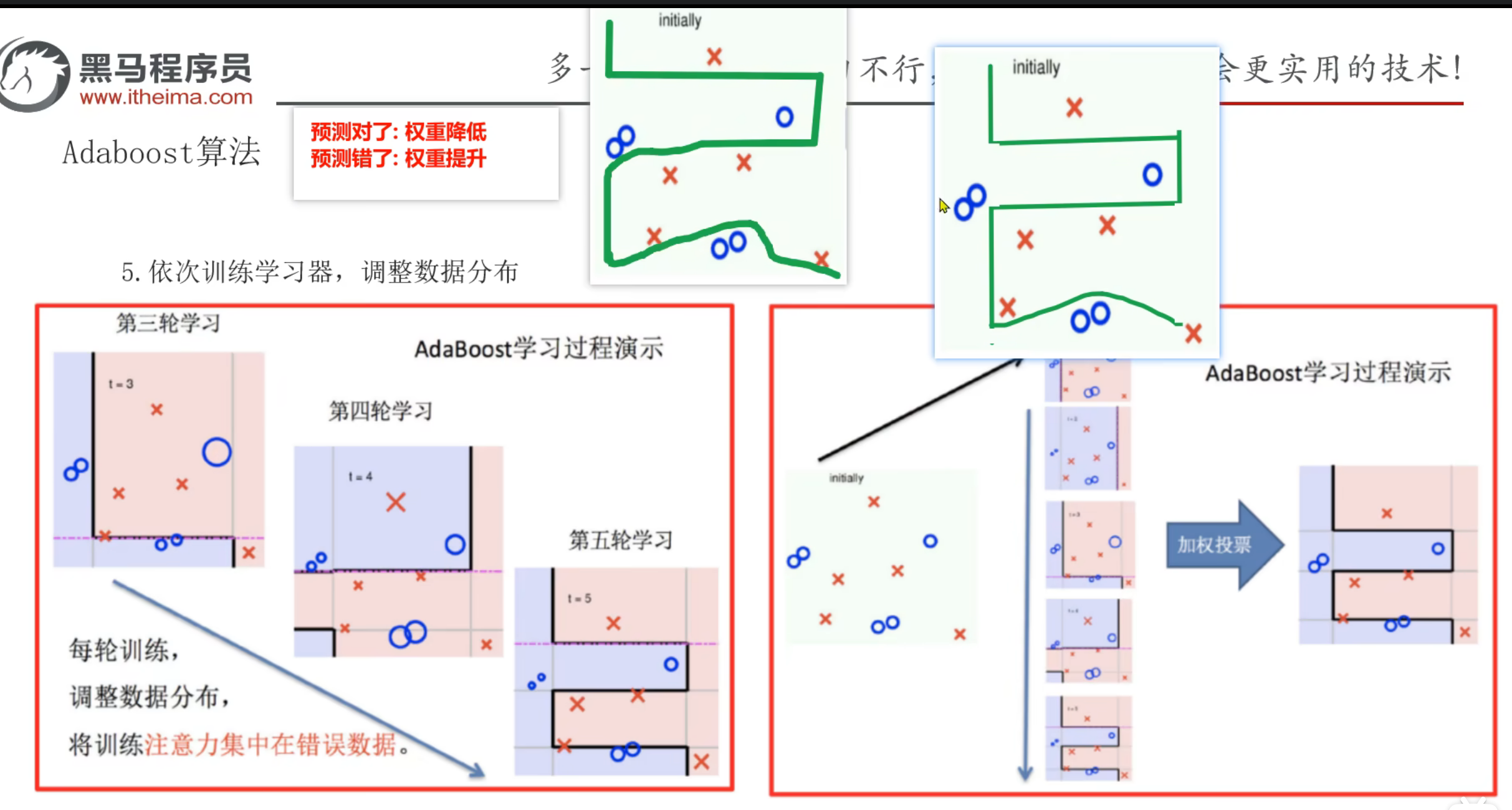


9、AdaBoost算法_推导过程

错误率最小为0.3,有两个分裂点并列为0.3,一个是2.5的分裂点,另一个是8.5的位置。根据奥卡姆剃刀,选择2.5这个分裂点

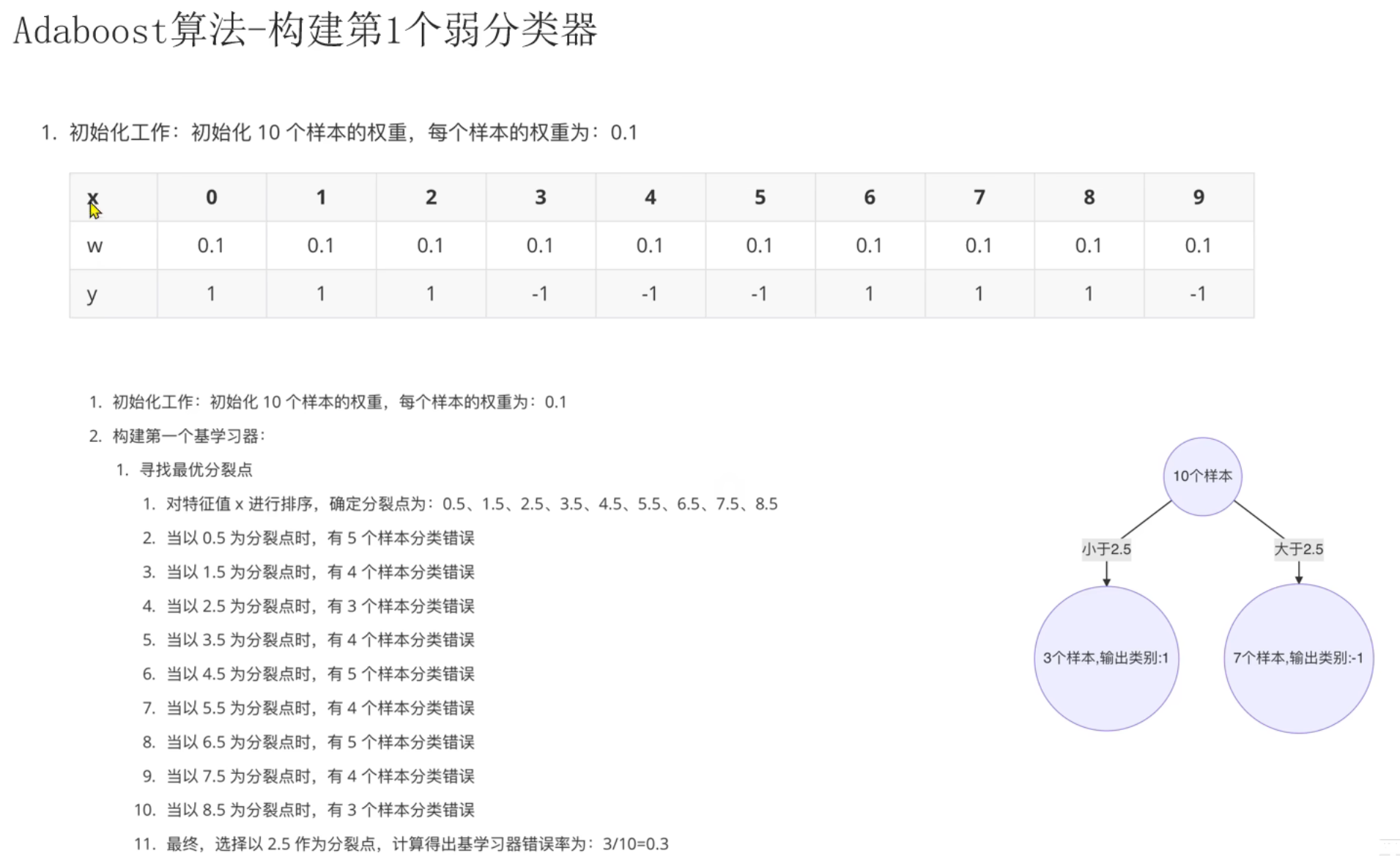

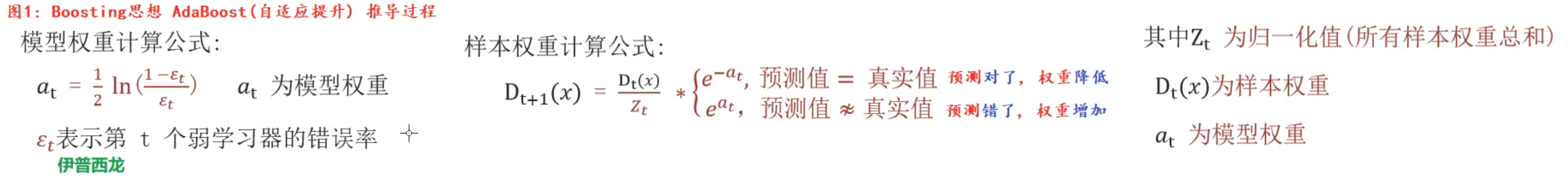
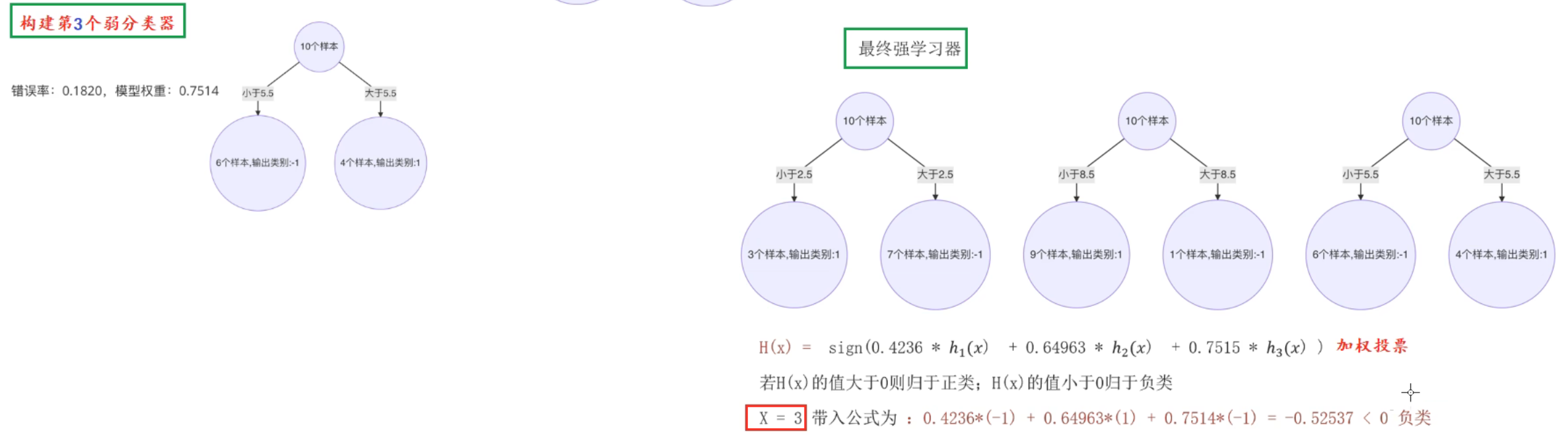
样本x,这个x数字是按序号来说的,所以有样本10
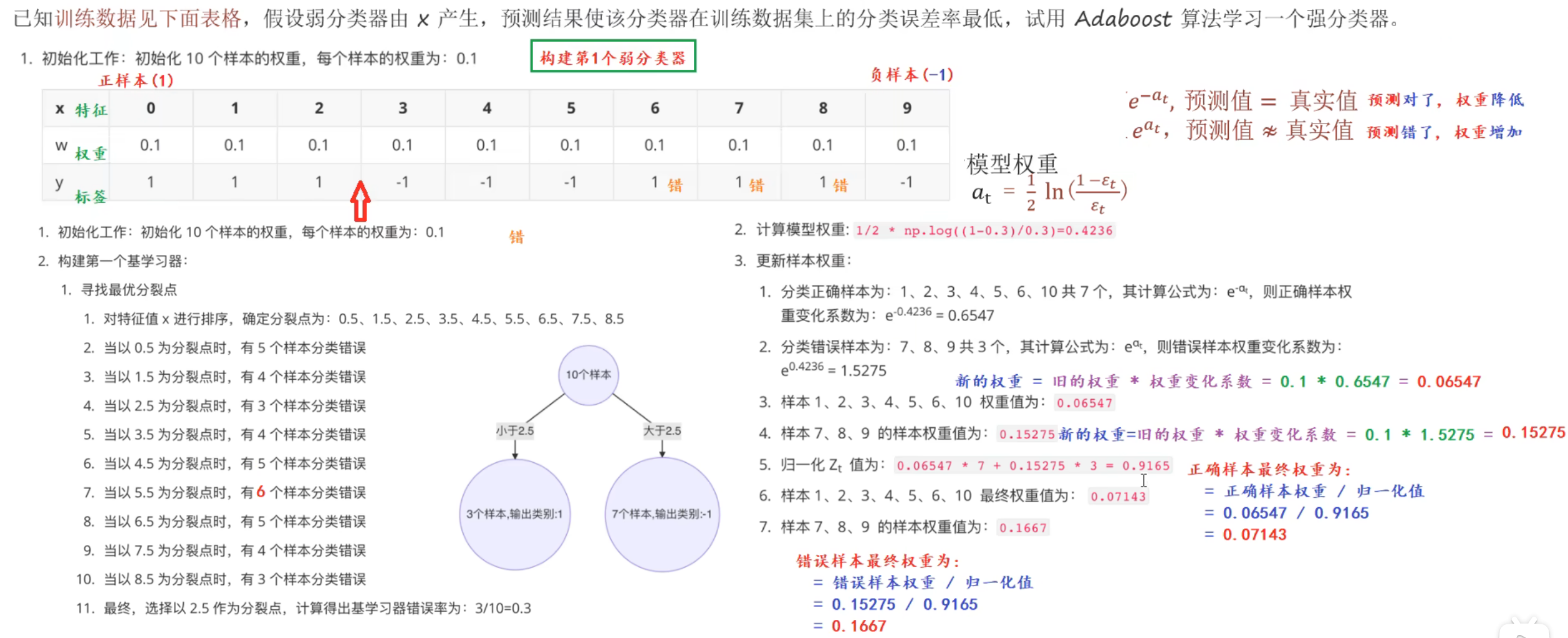
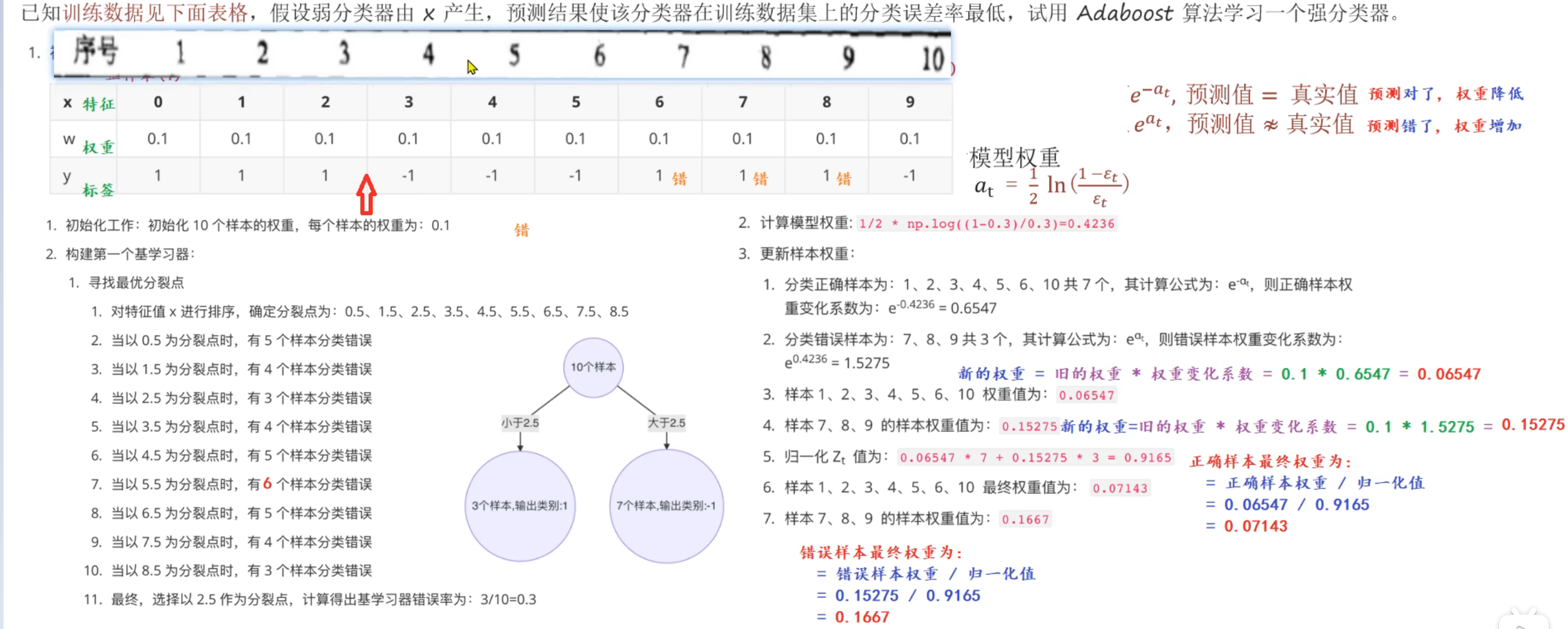
下图种2.当以0.5为分裂点时,后面错误率写错了

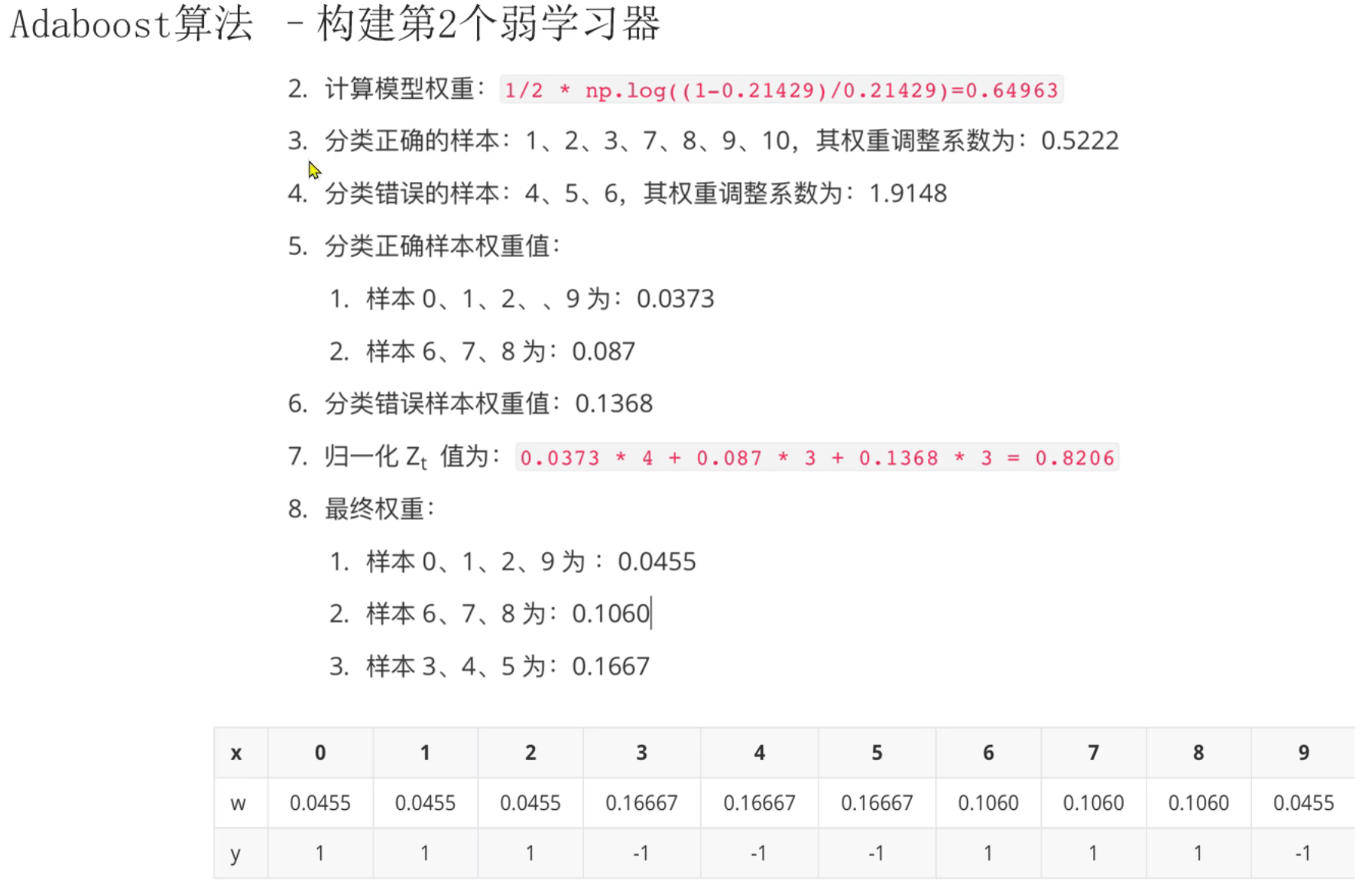

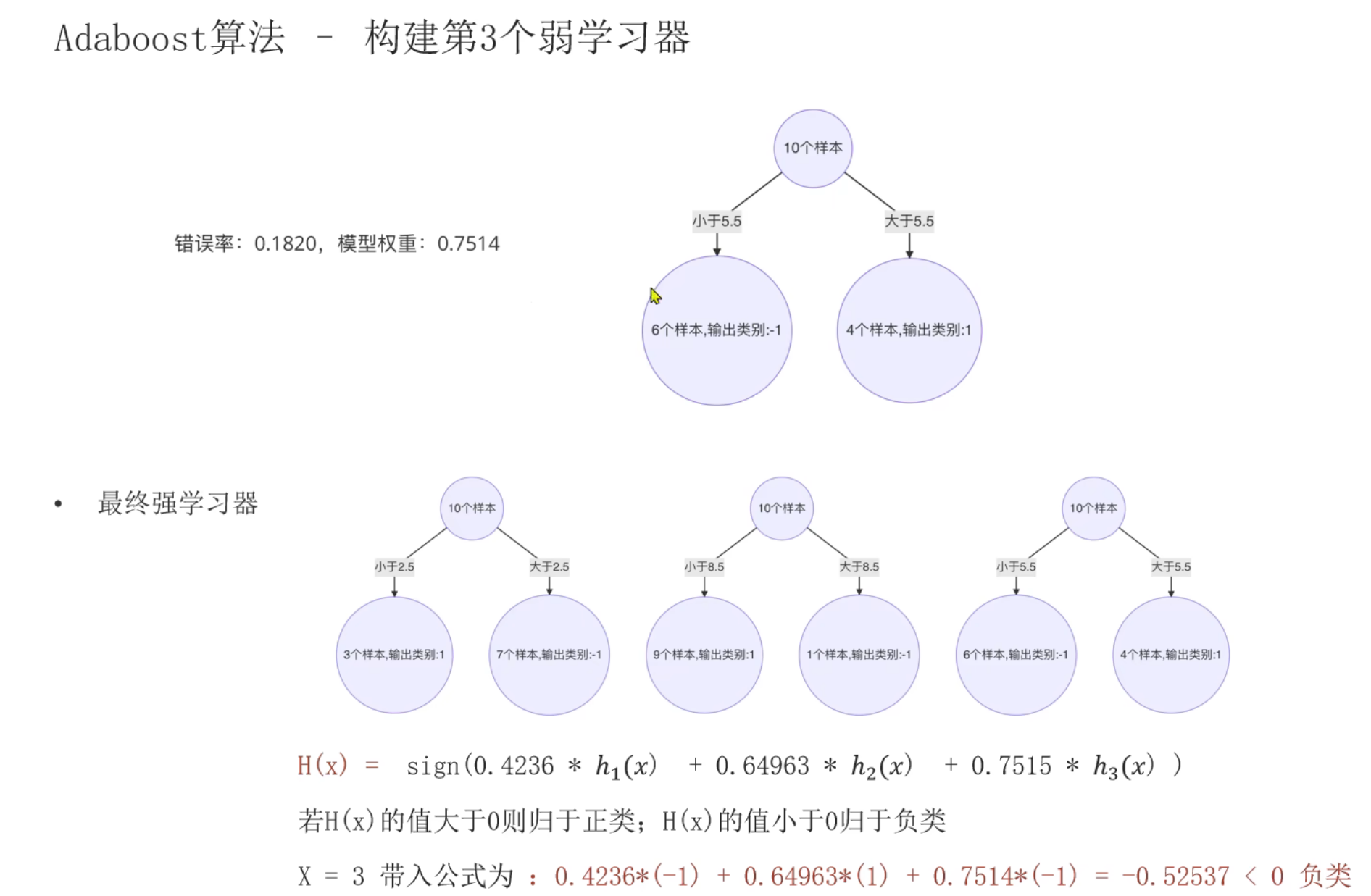
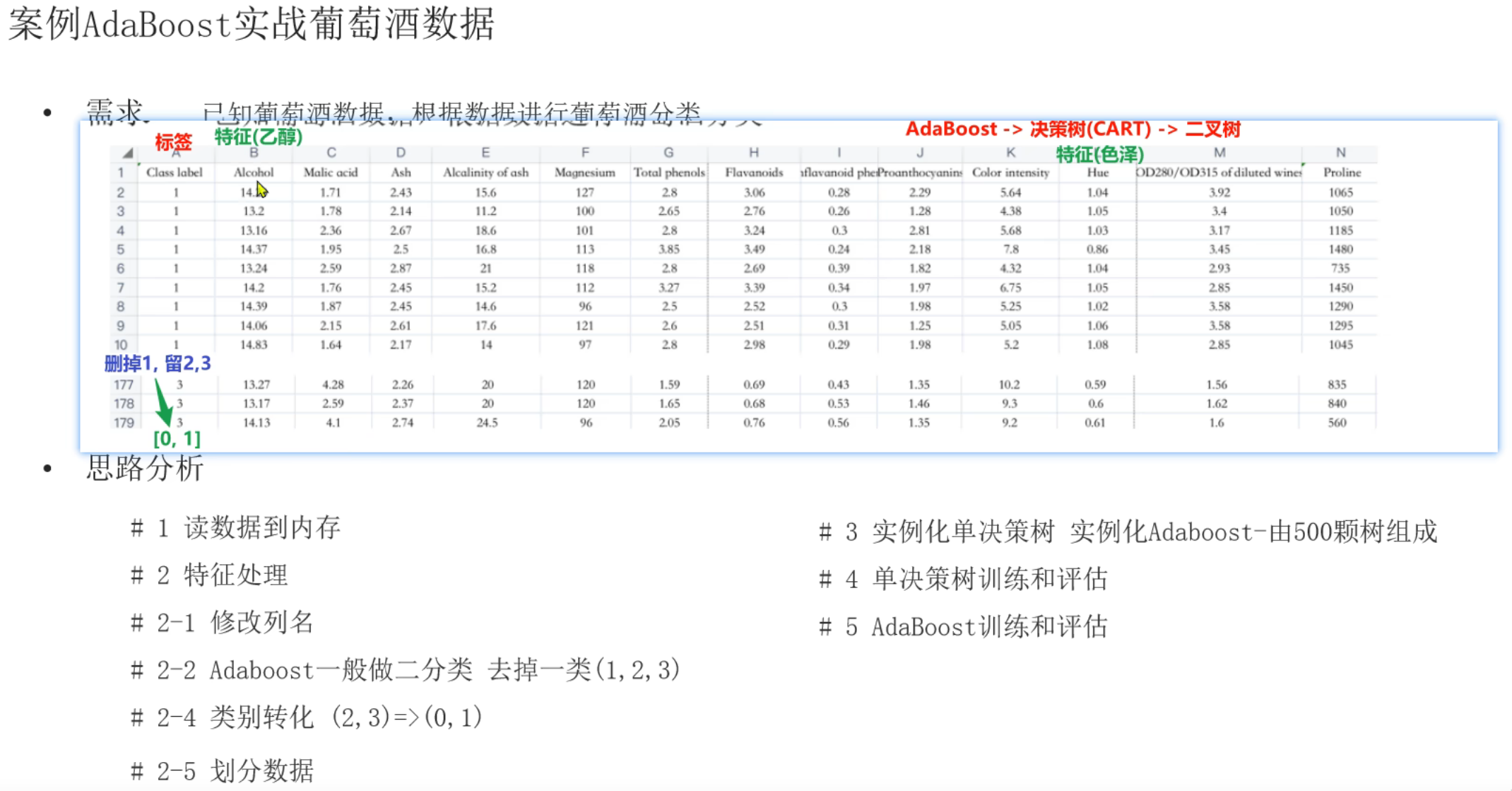
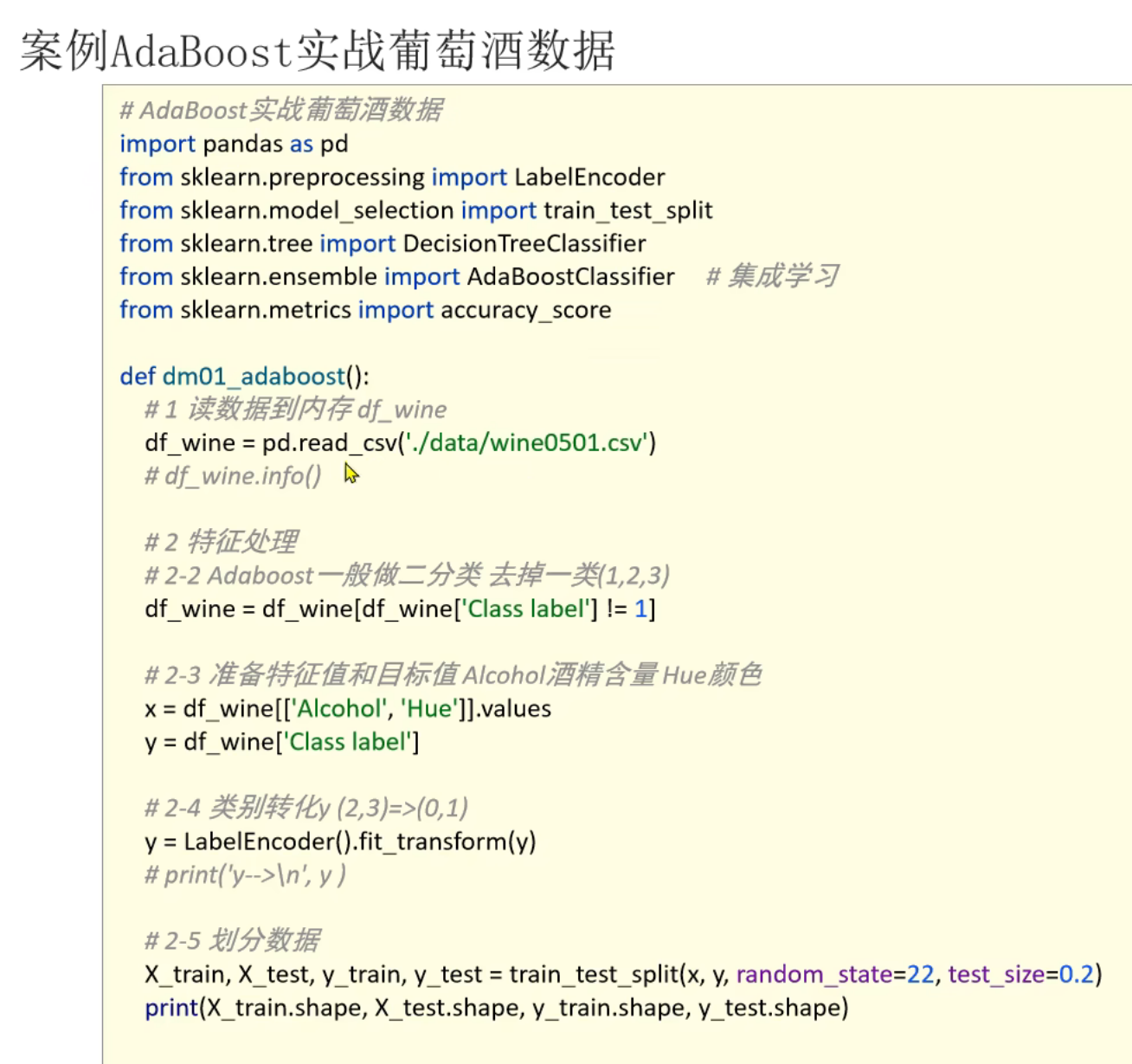
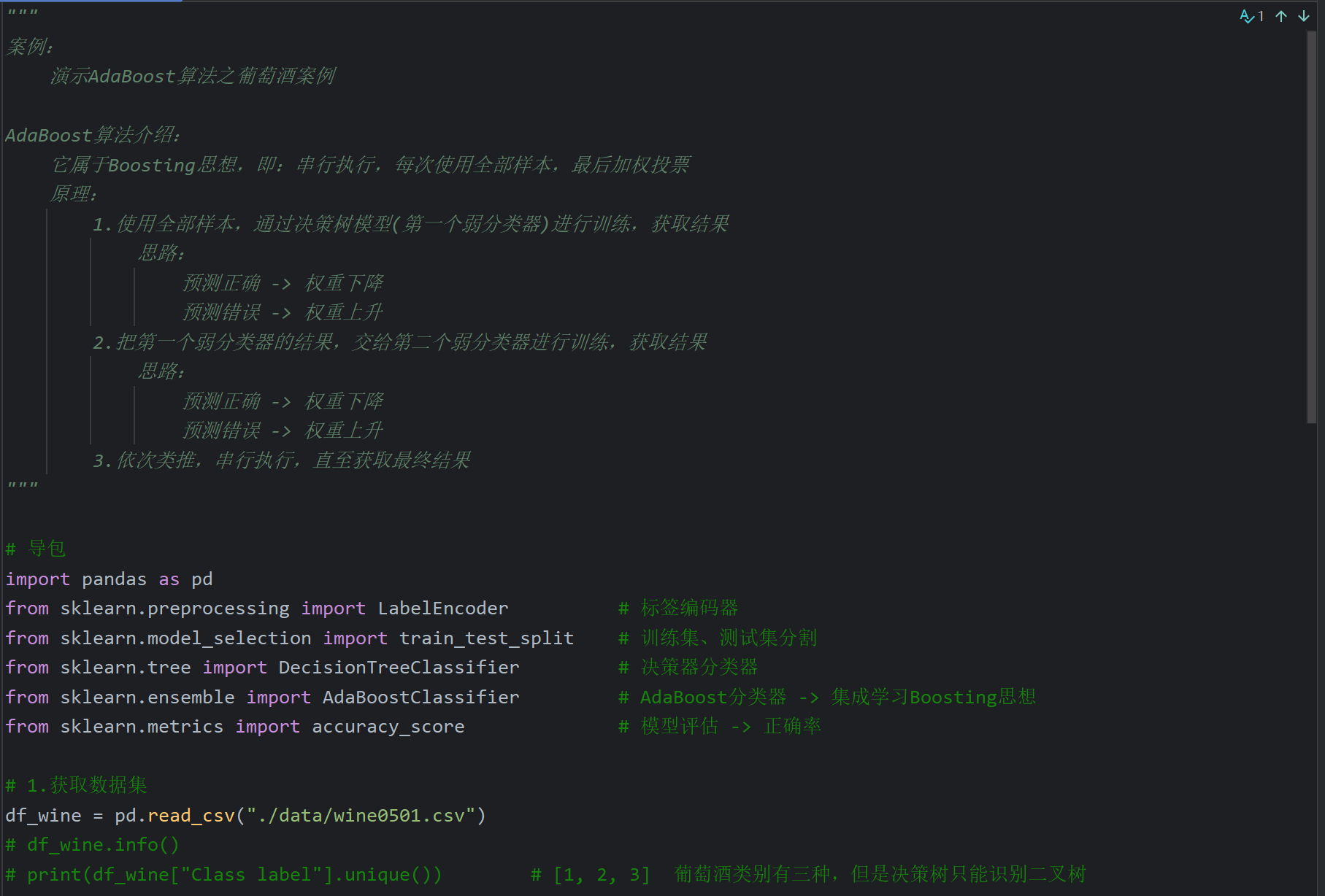
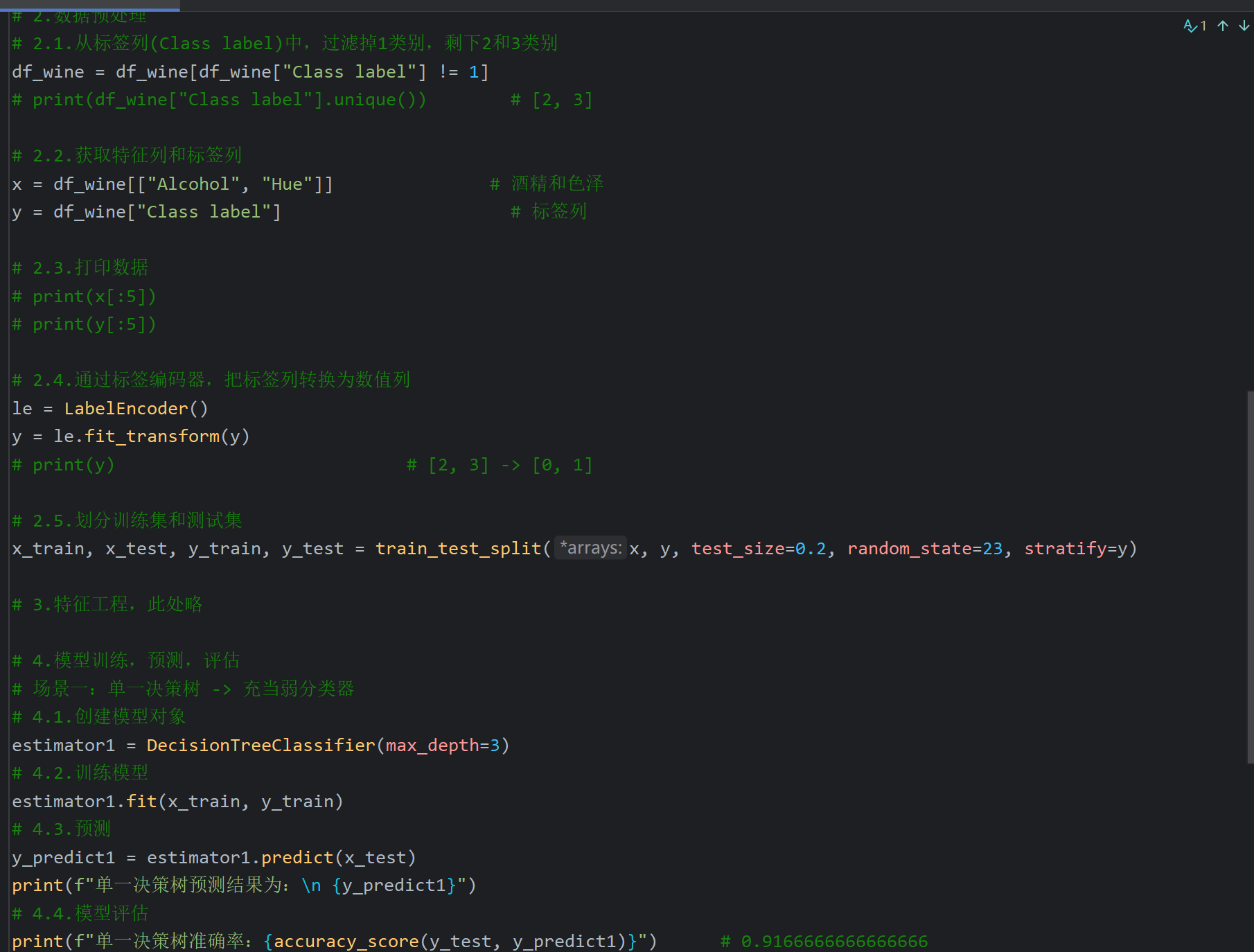
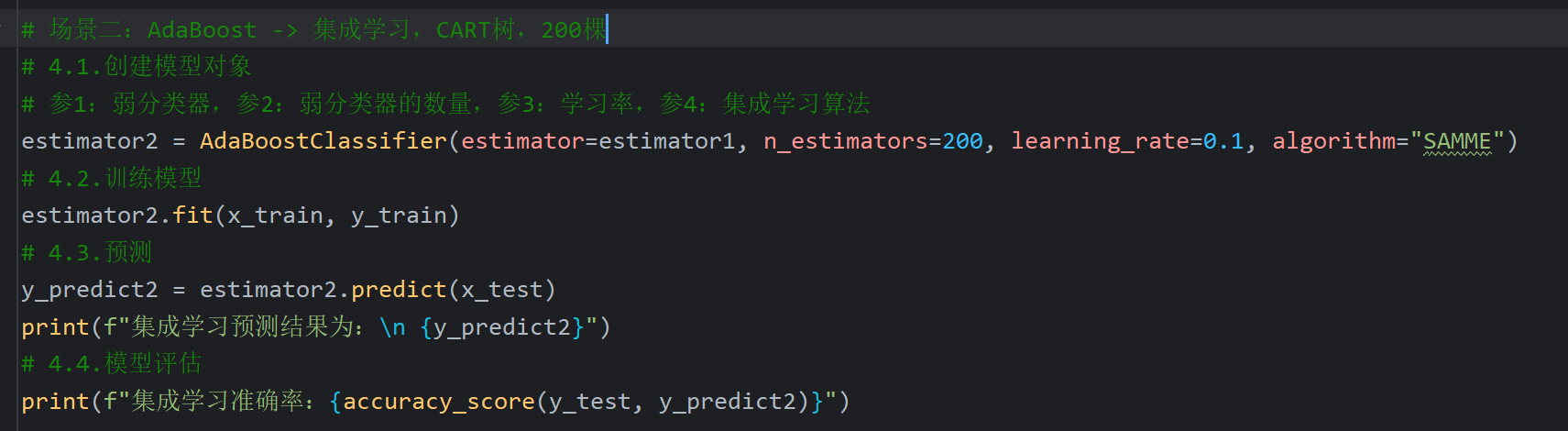
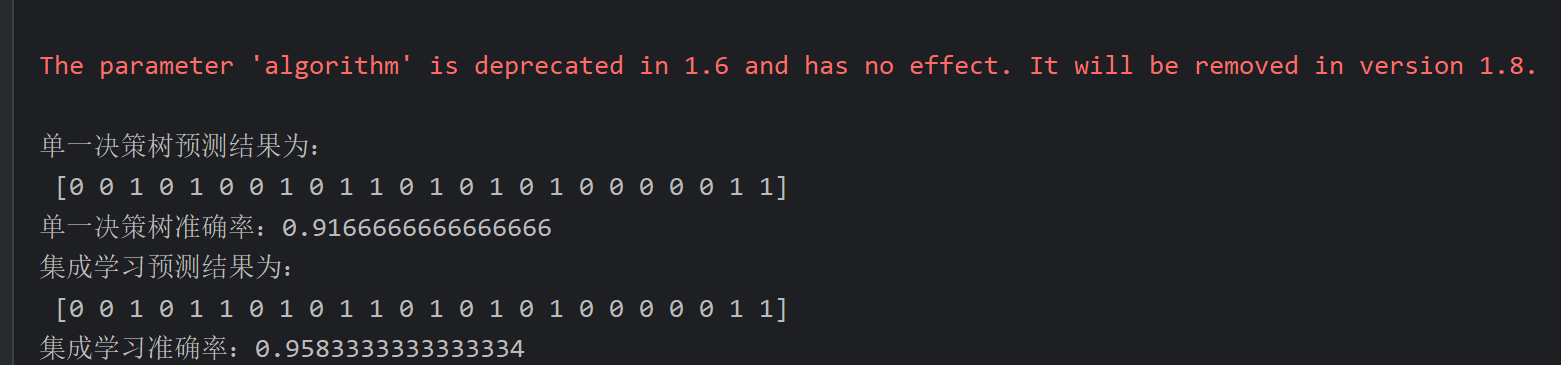
10、AdaBoost算法_葡萄酒案例


11、GBDT算法_梯度提升树介绍
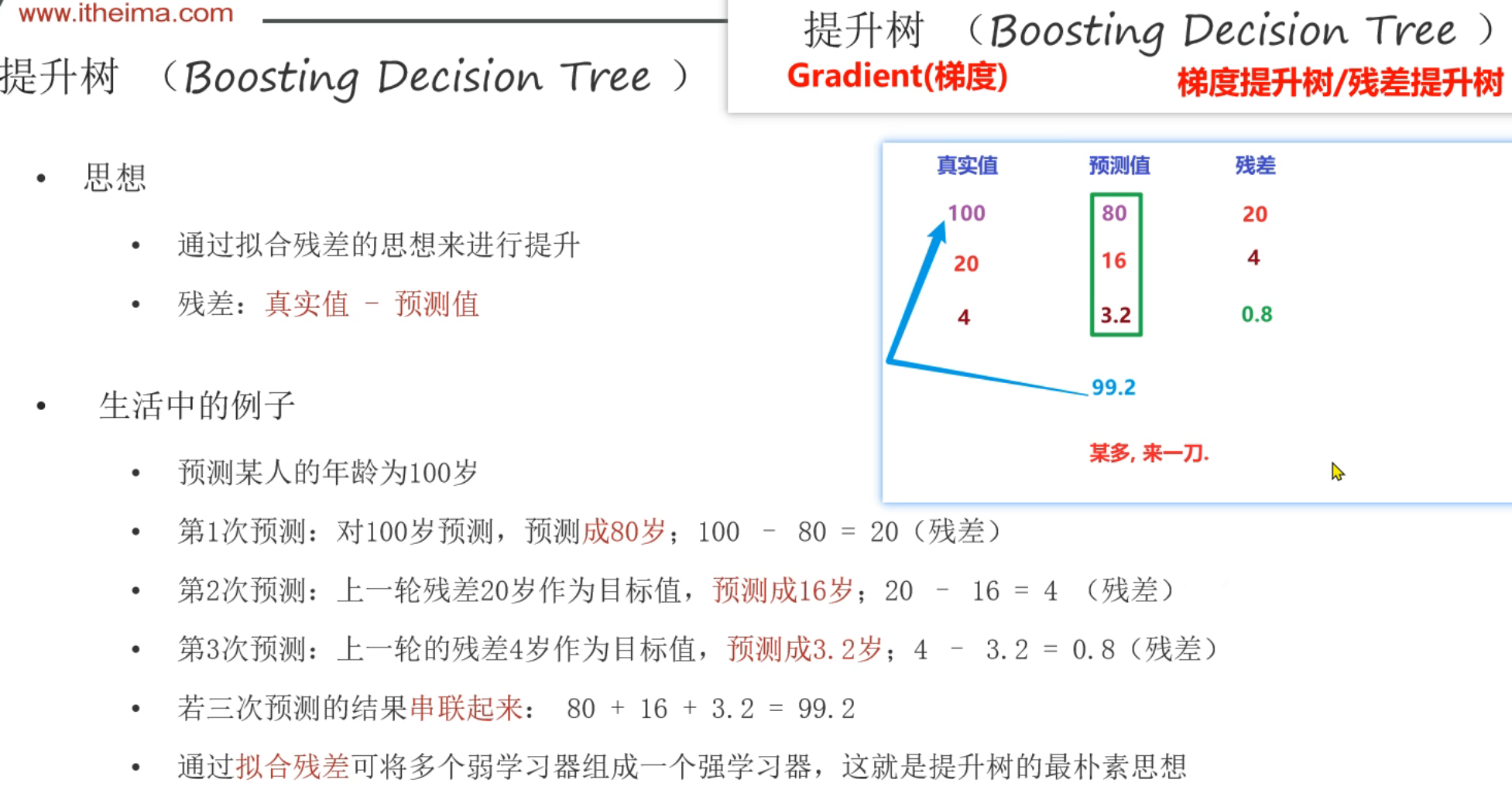


12、GBDT算法_推导过程

下图倒数第二行写的:残差 = 真实值求和,求平均值是错的
应该是预测值 = 真实值求和,求平均值

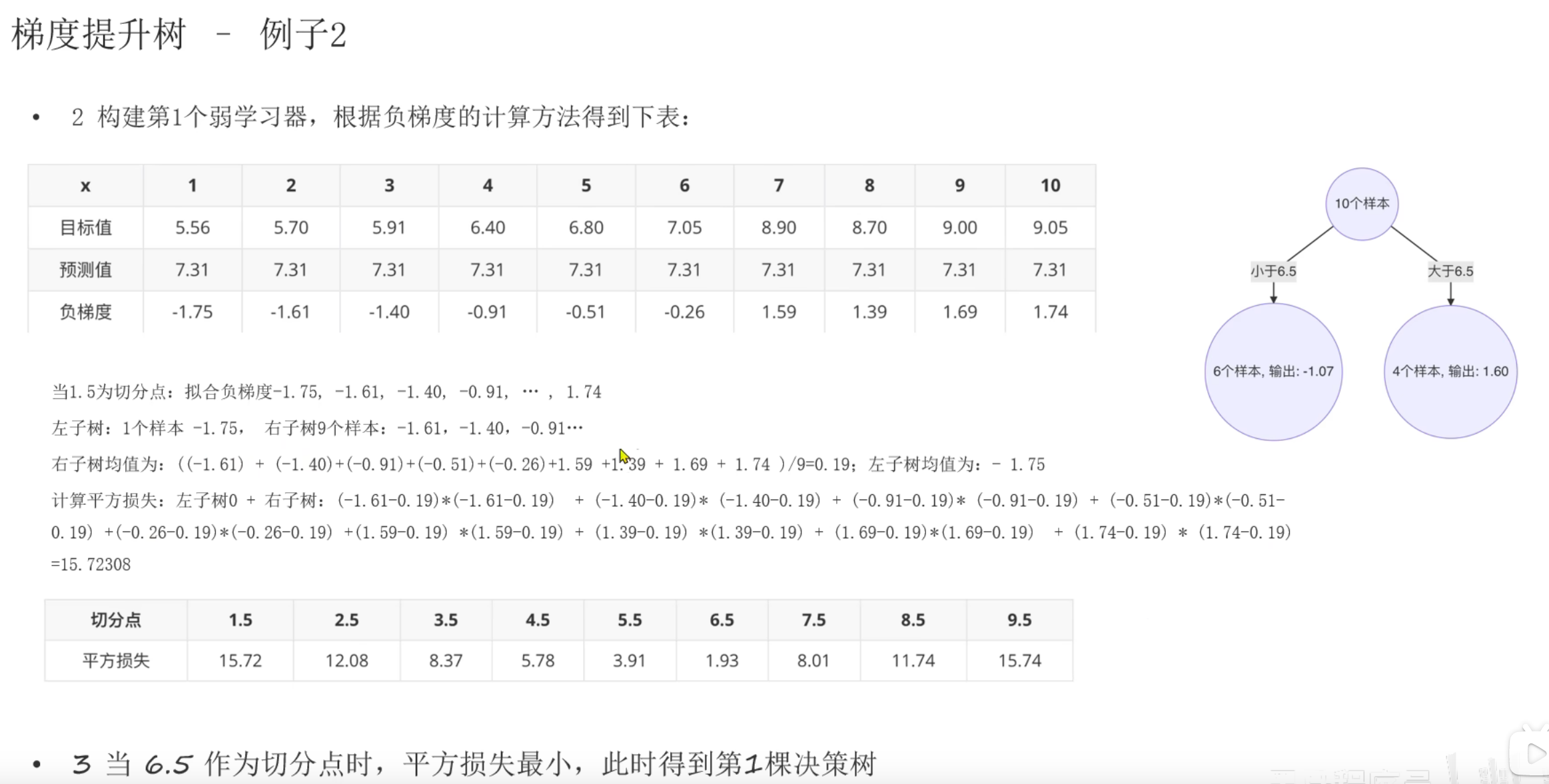
第一次构建,直接以原数据目标值的均值作为预测值
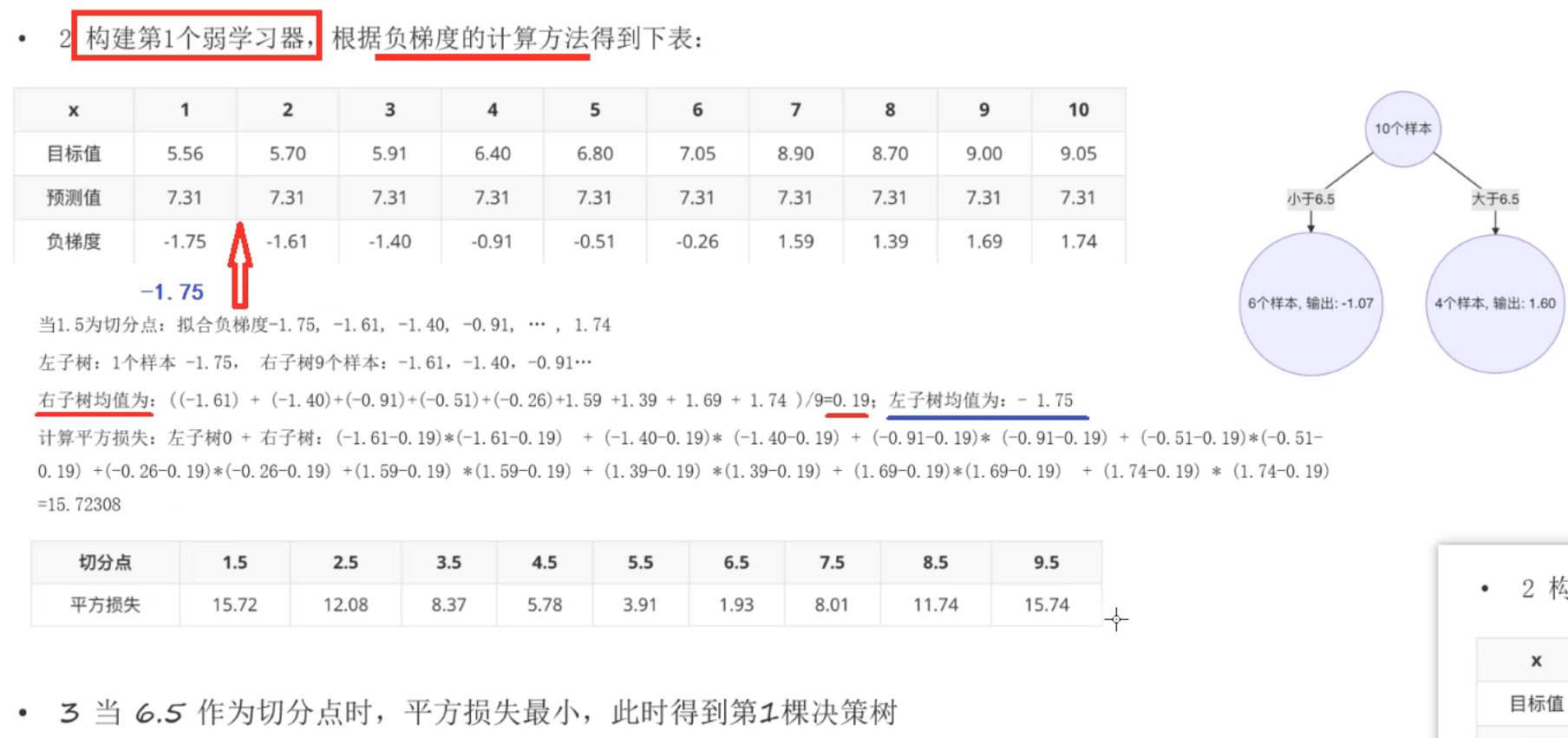
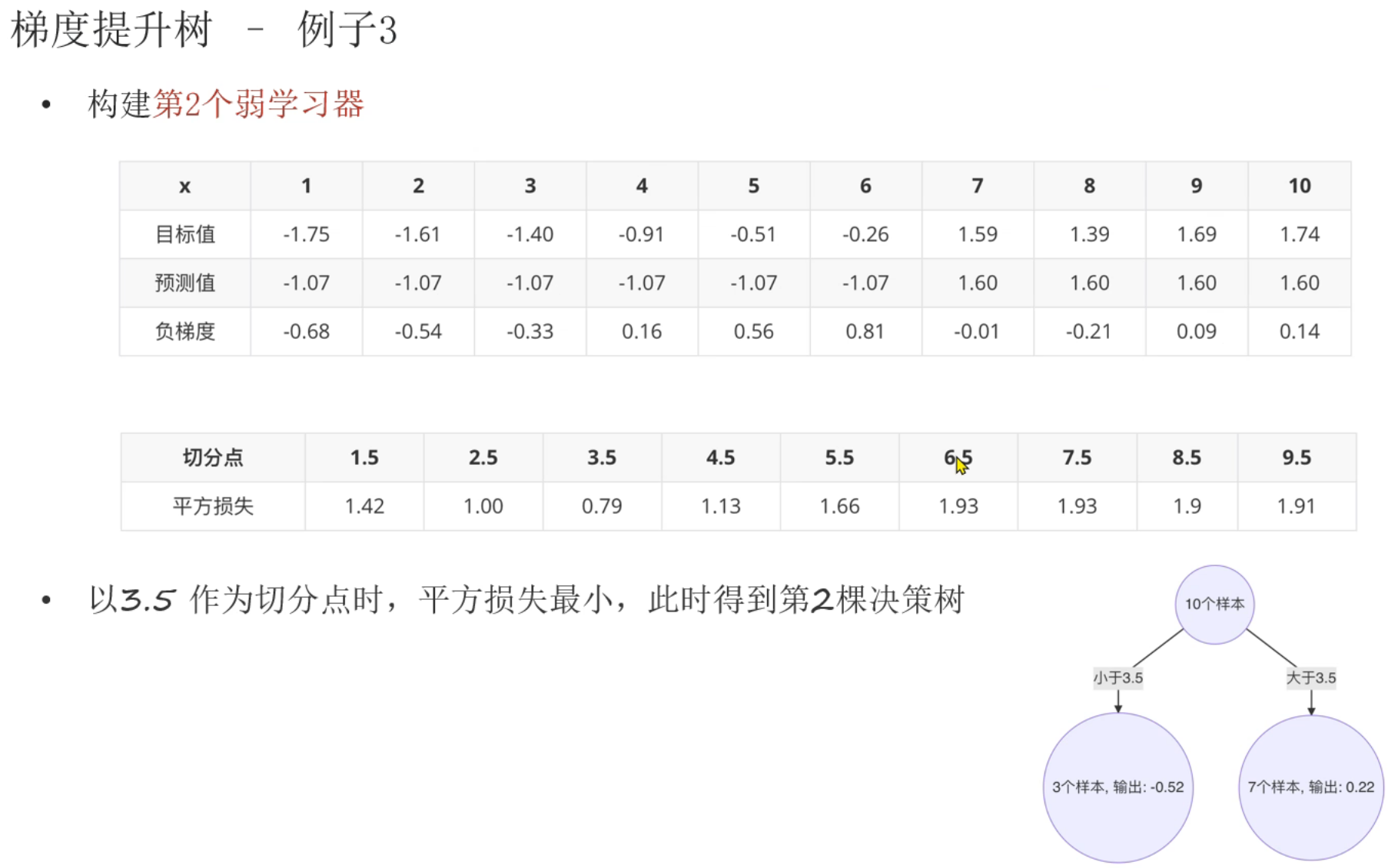
构建第2个弱学习器时,把上次的负梯度直接当作这次的目标值。然后本次的预测值是基于本次的目标值(上次的负梯度)结合上次切分点的位置再进行求和平均填入的。然后才是算本次的负梯度,本次的平方损失,确认本次的切分点


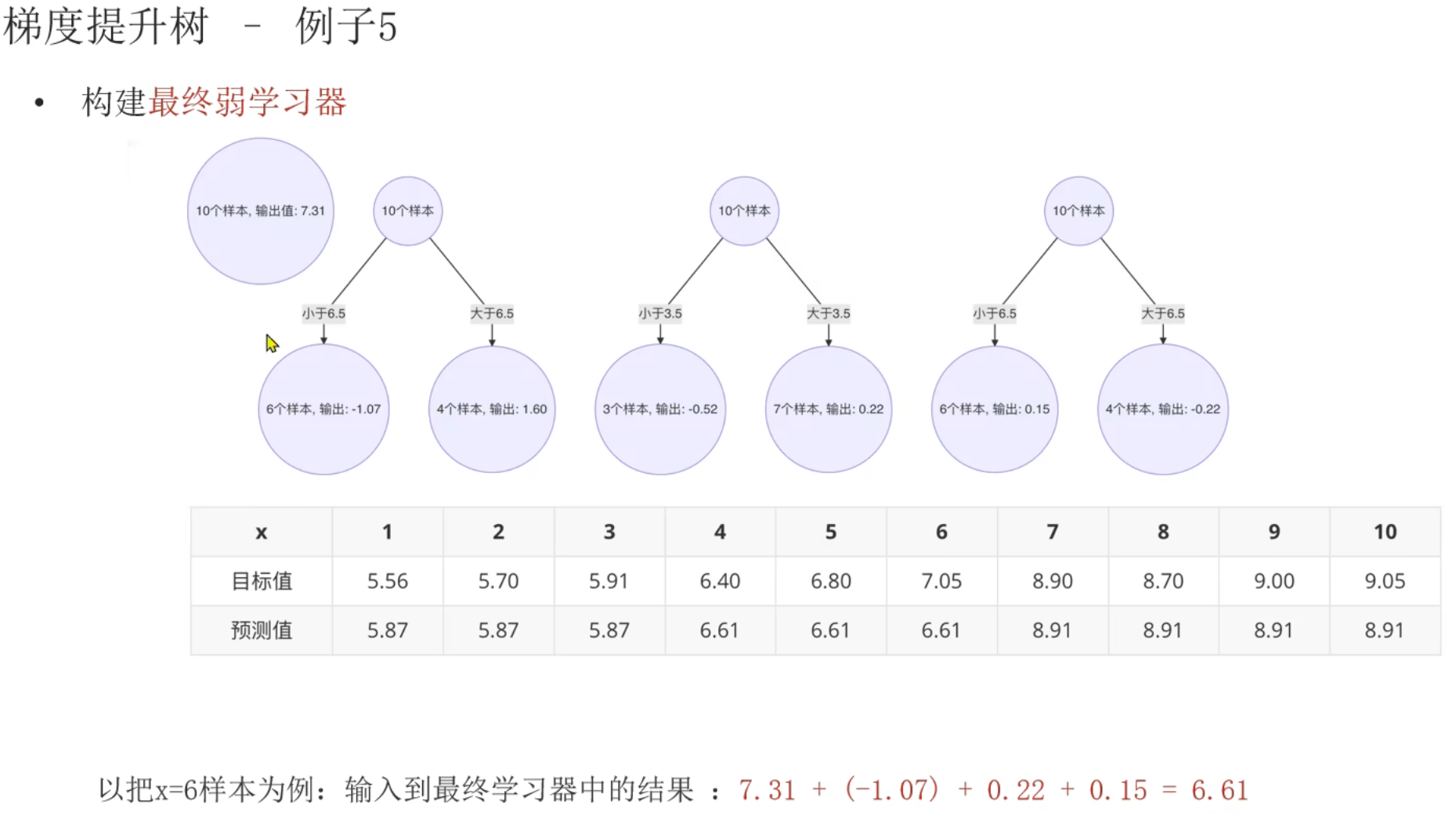
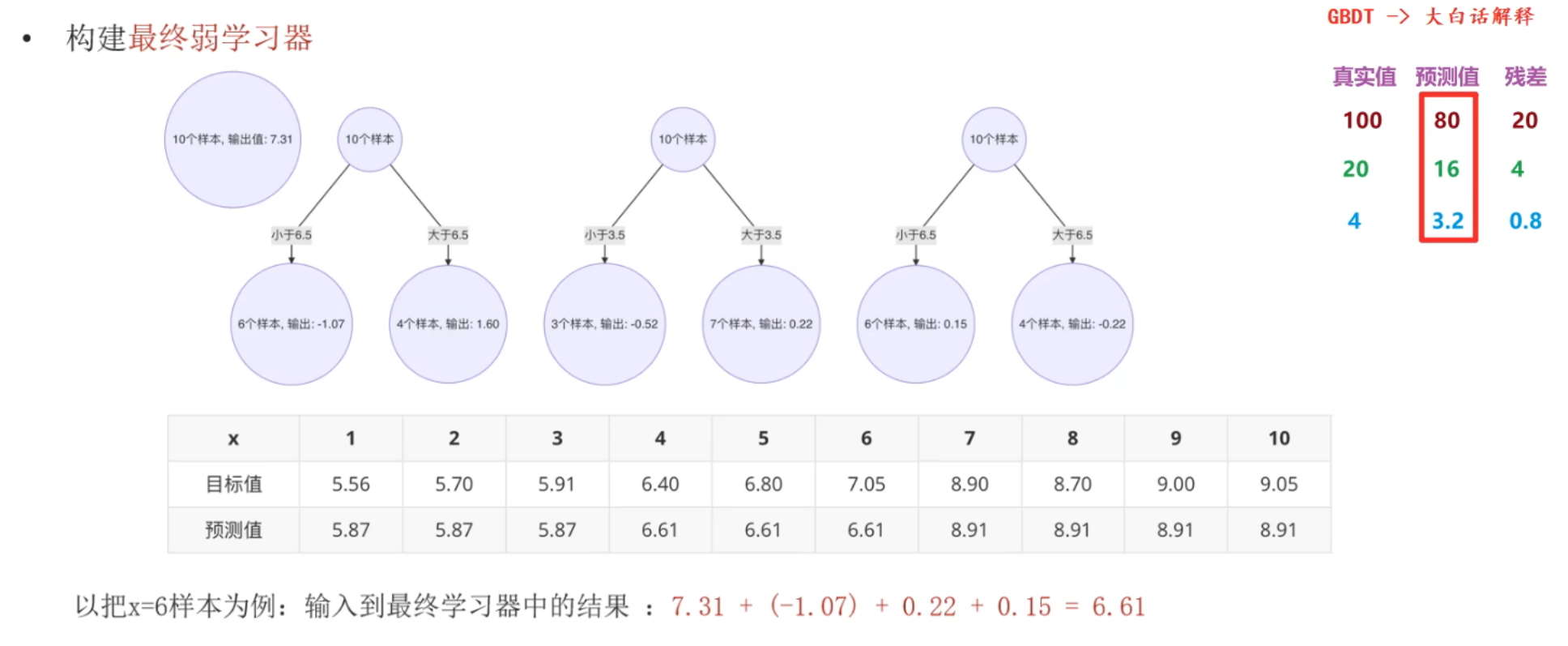
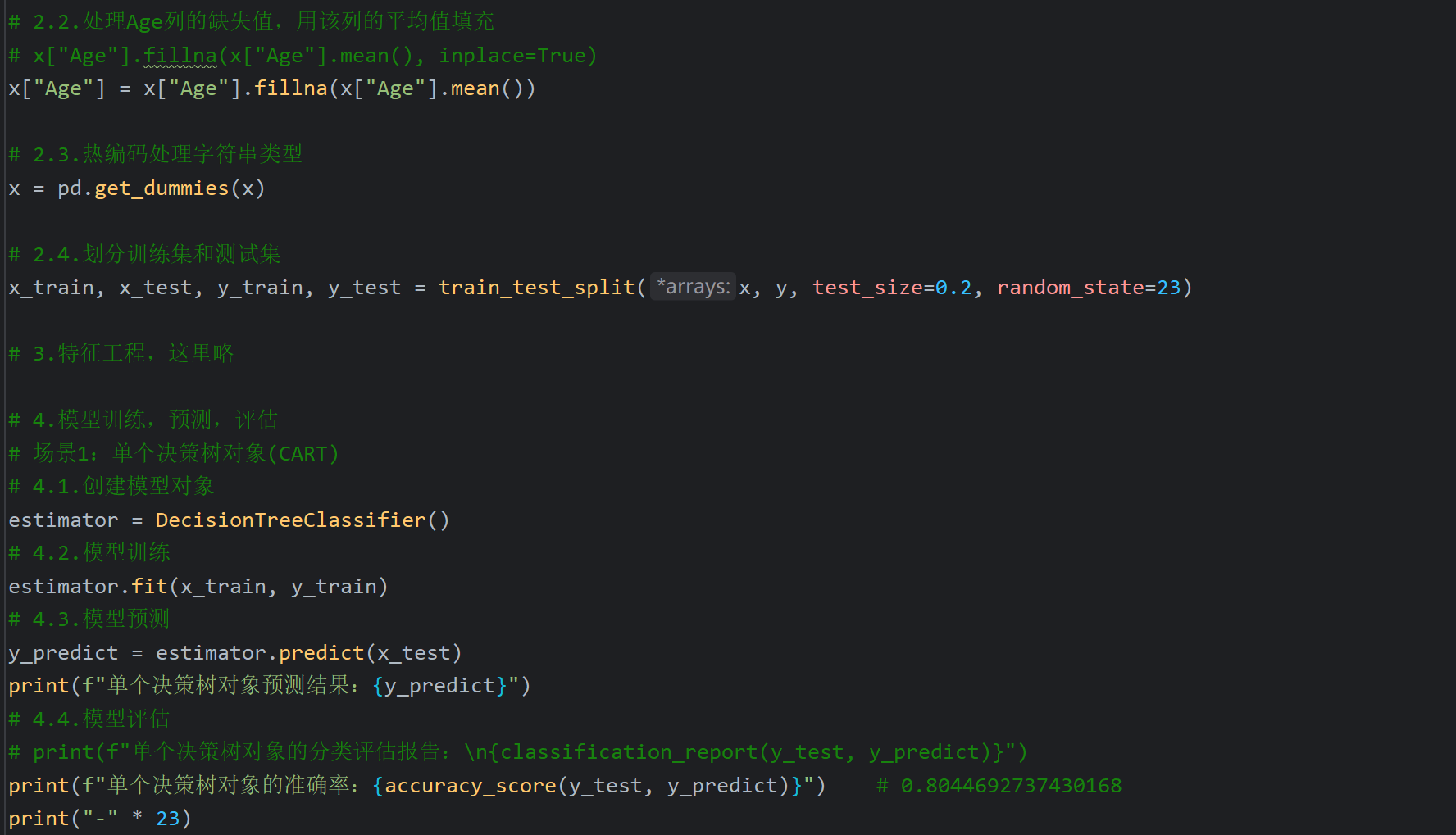
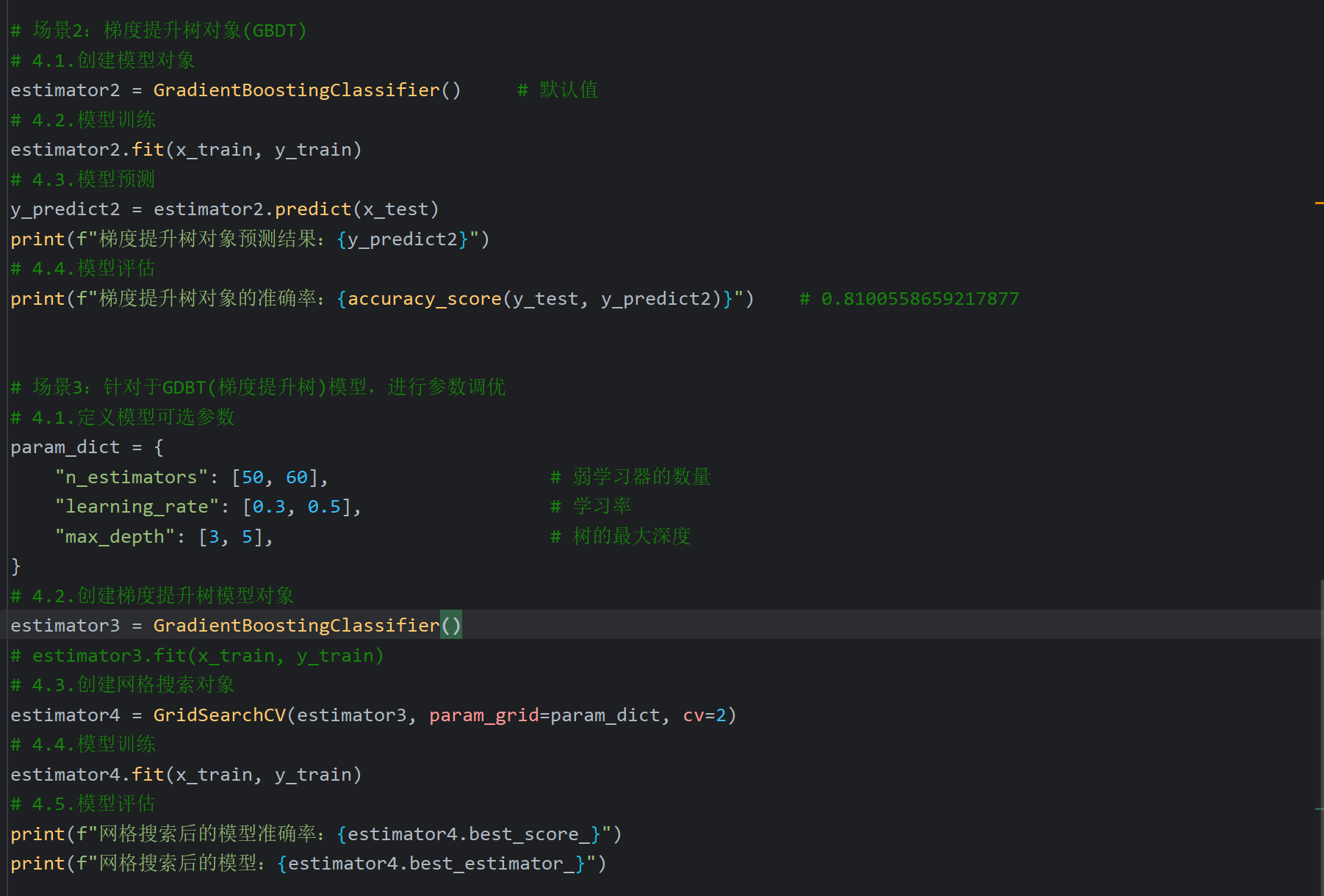
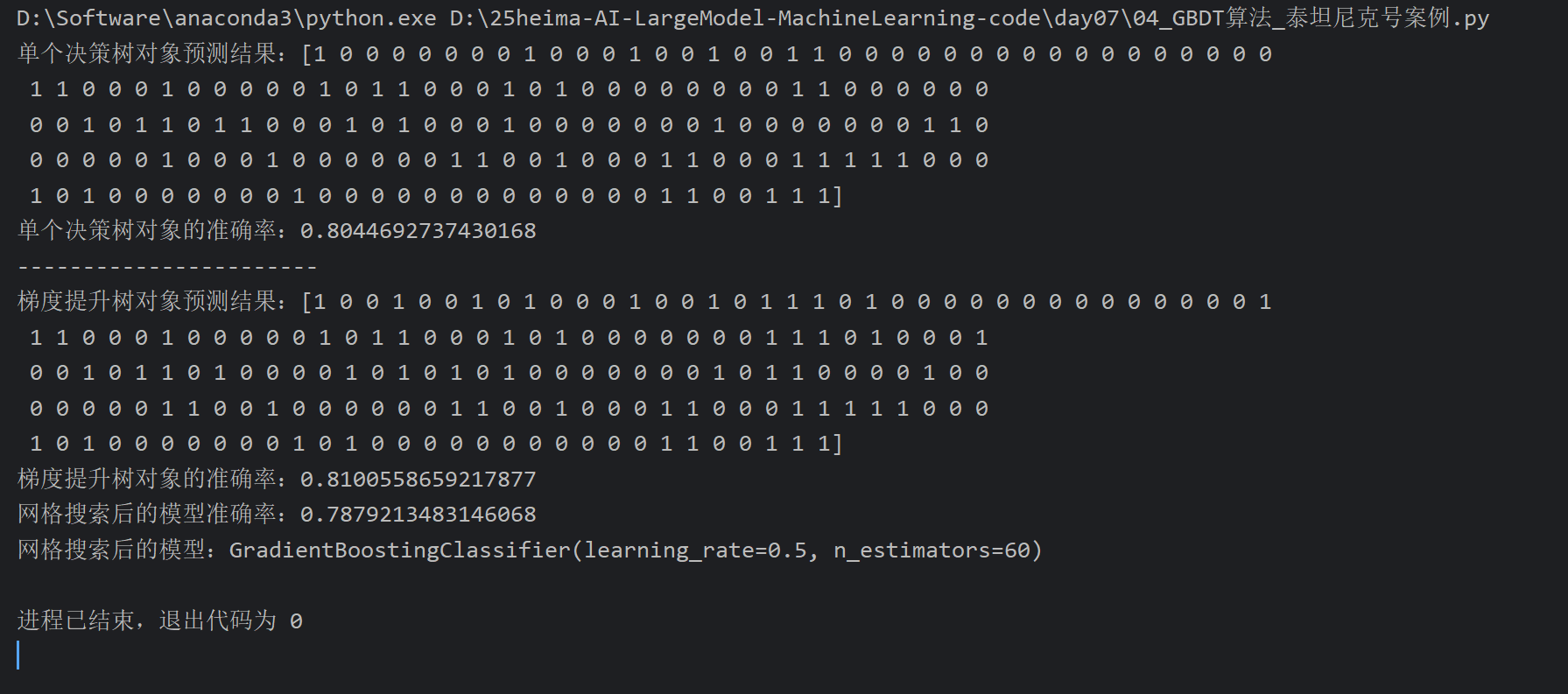
13、GBDT算法_泰坦尼克号案例



九、KMeans算法
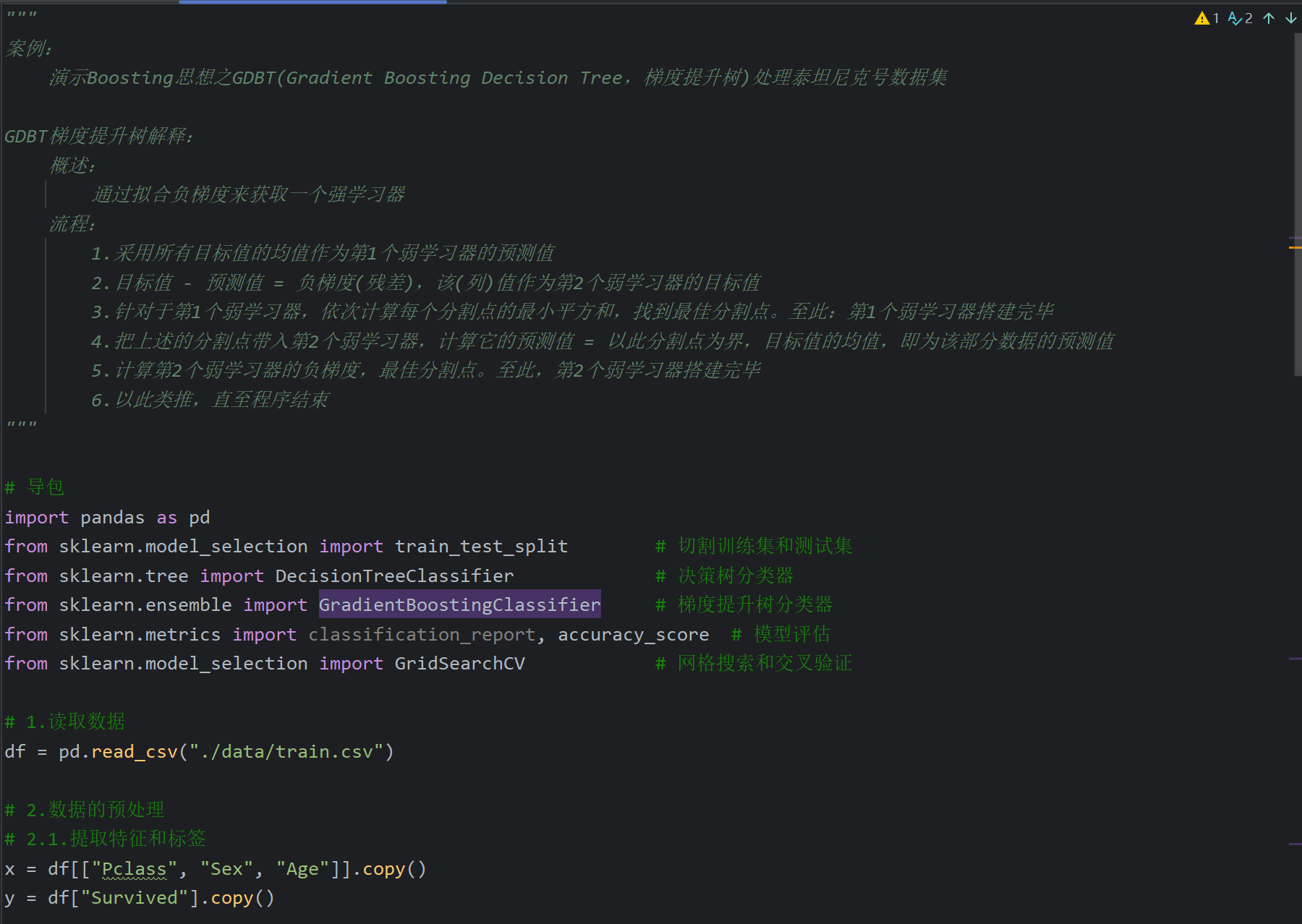
1、XGBoost极限梯度提升树_简介
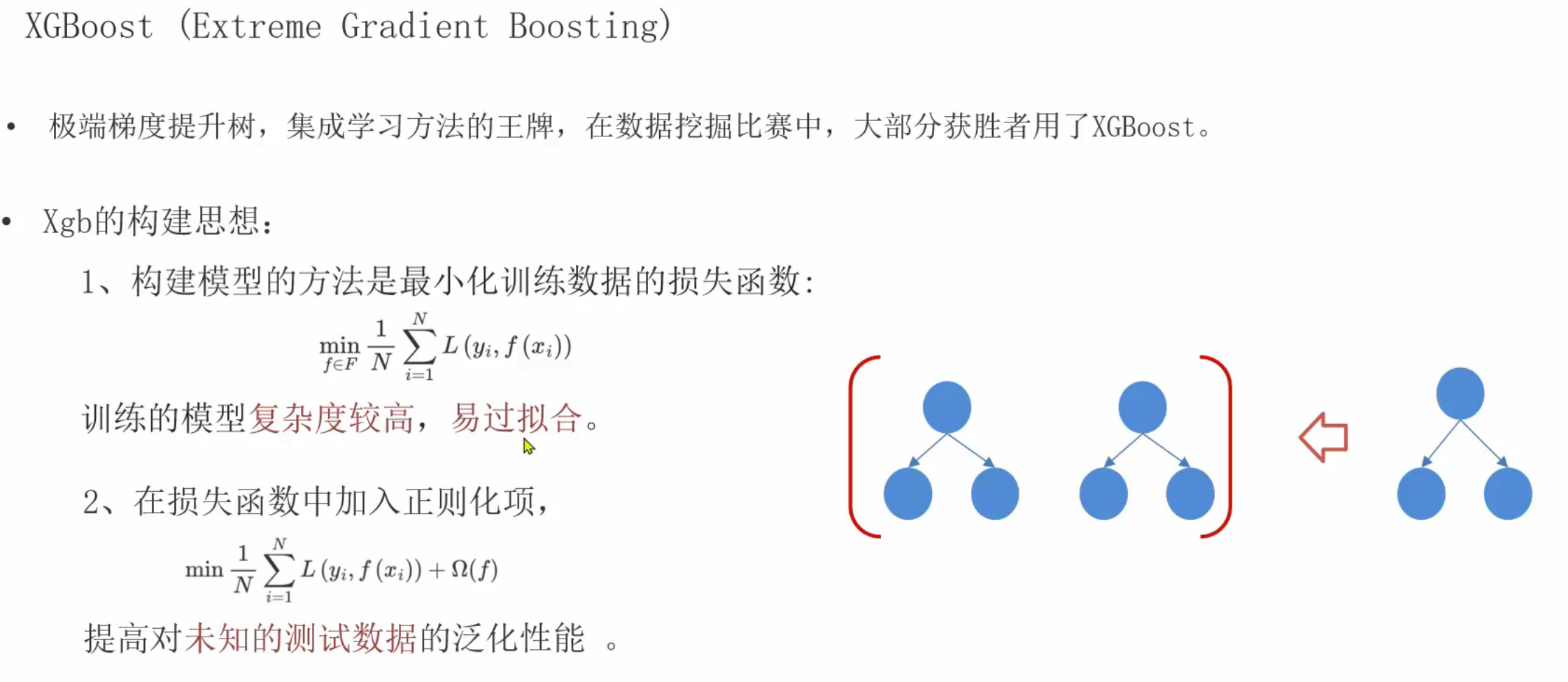

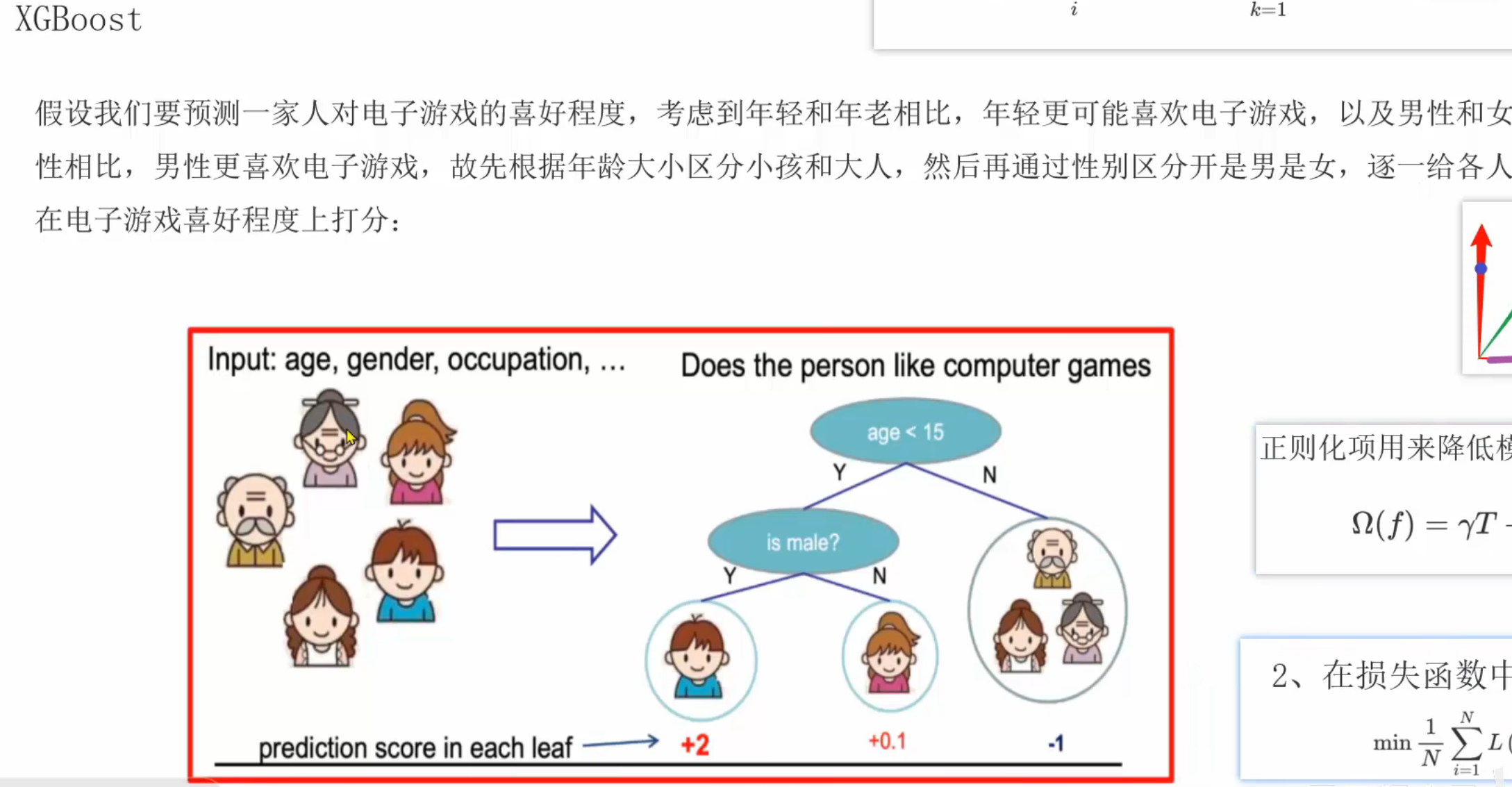
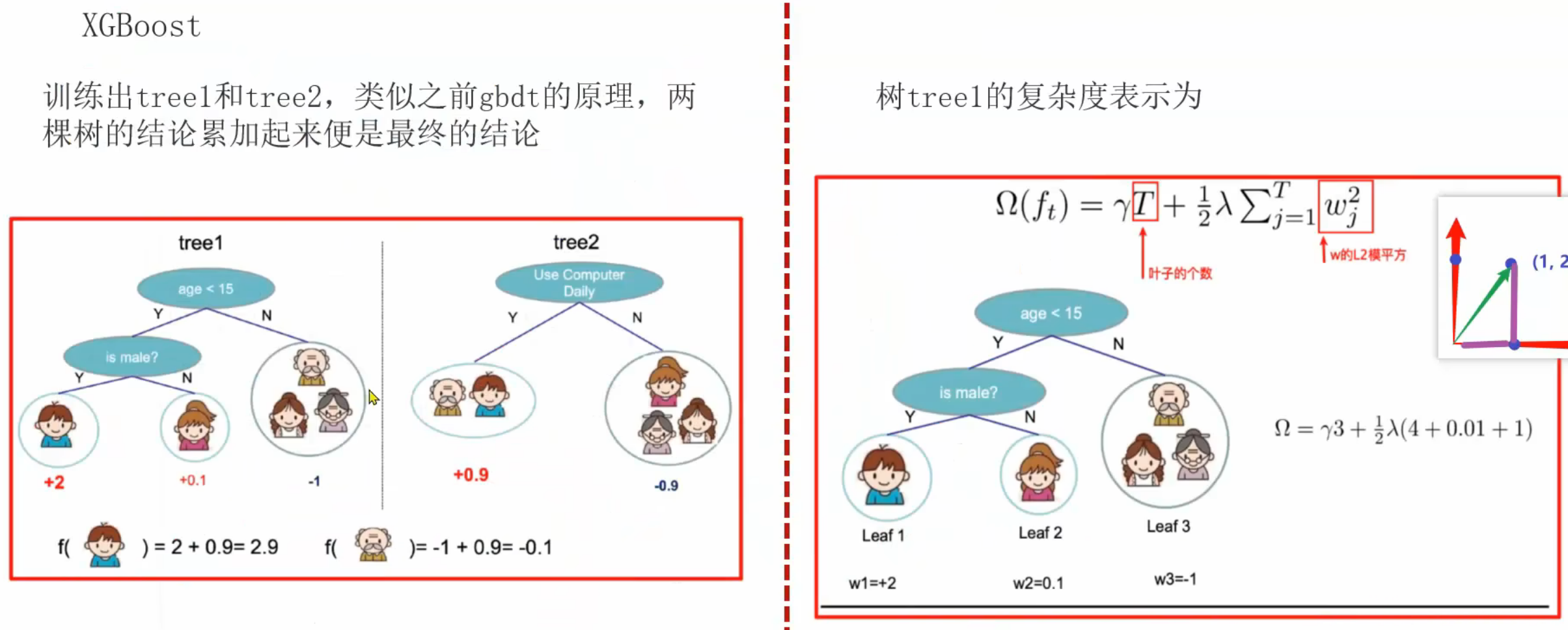
2、XGBoost极限梯度提升树_推导







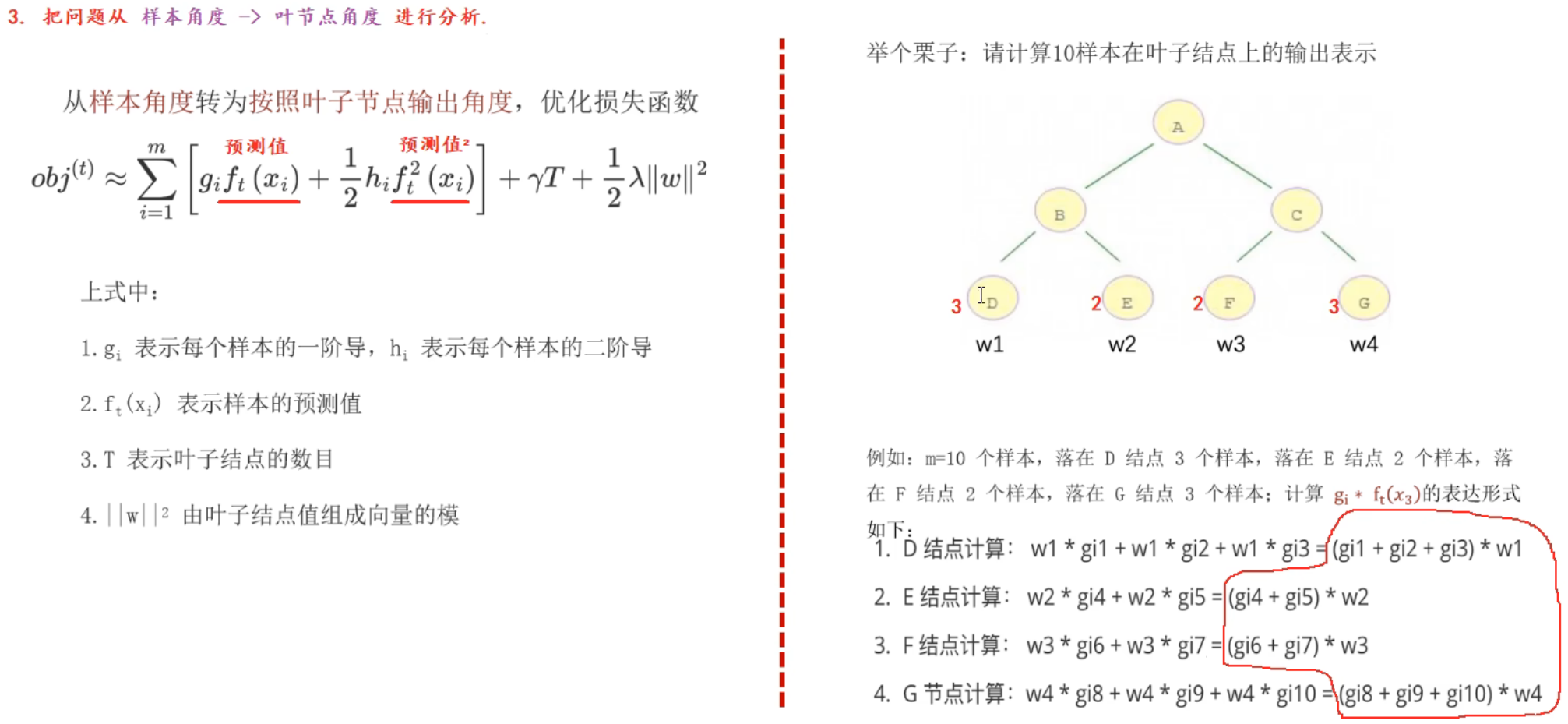


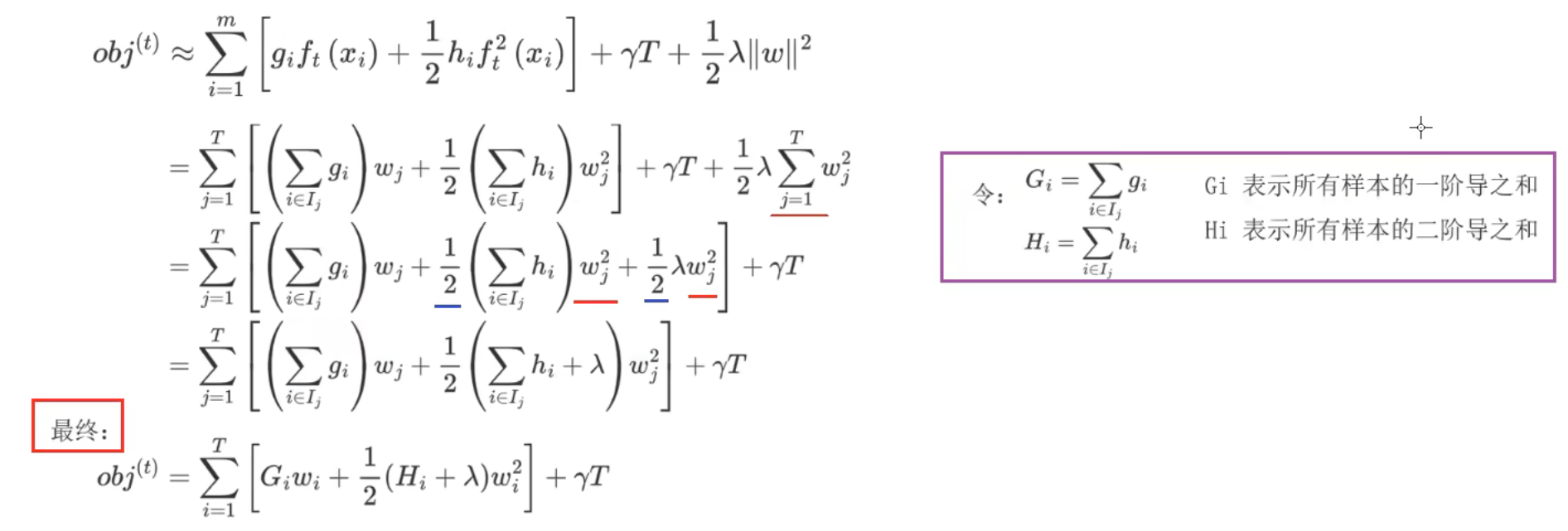



要求:能用自己的话讲解下面四句话

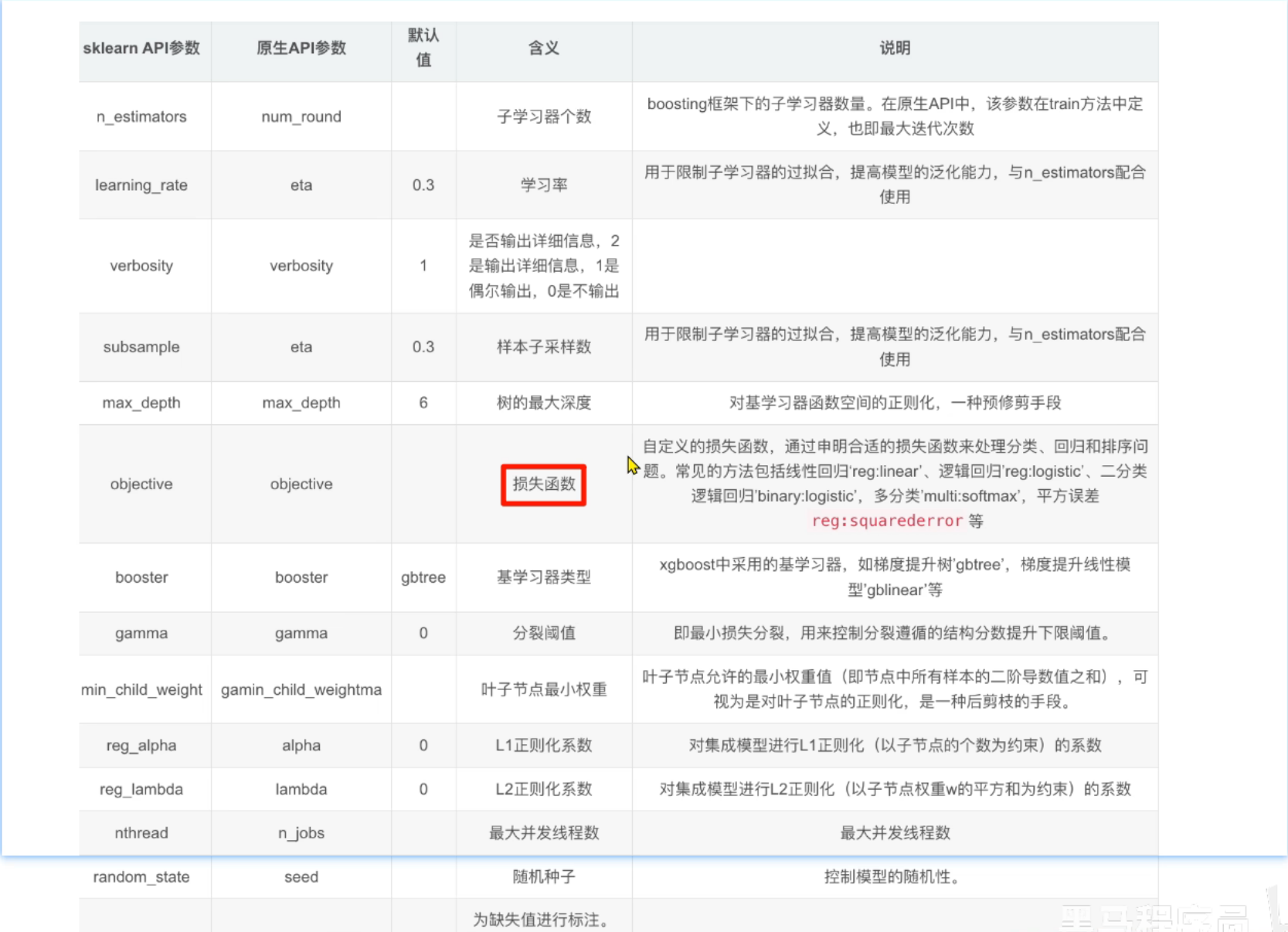
3、XGBoost API介绍

4、XGBoost案例_红酒品质分类_数据预处理


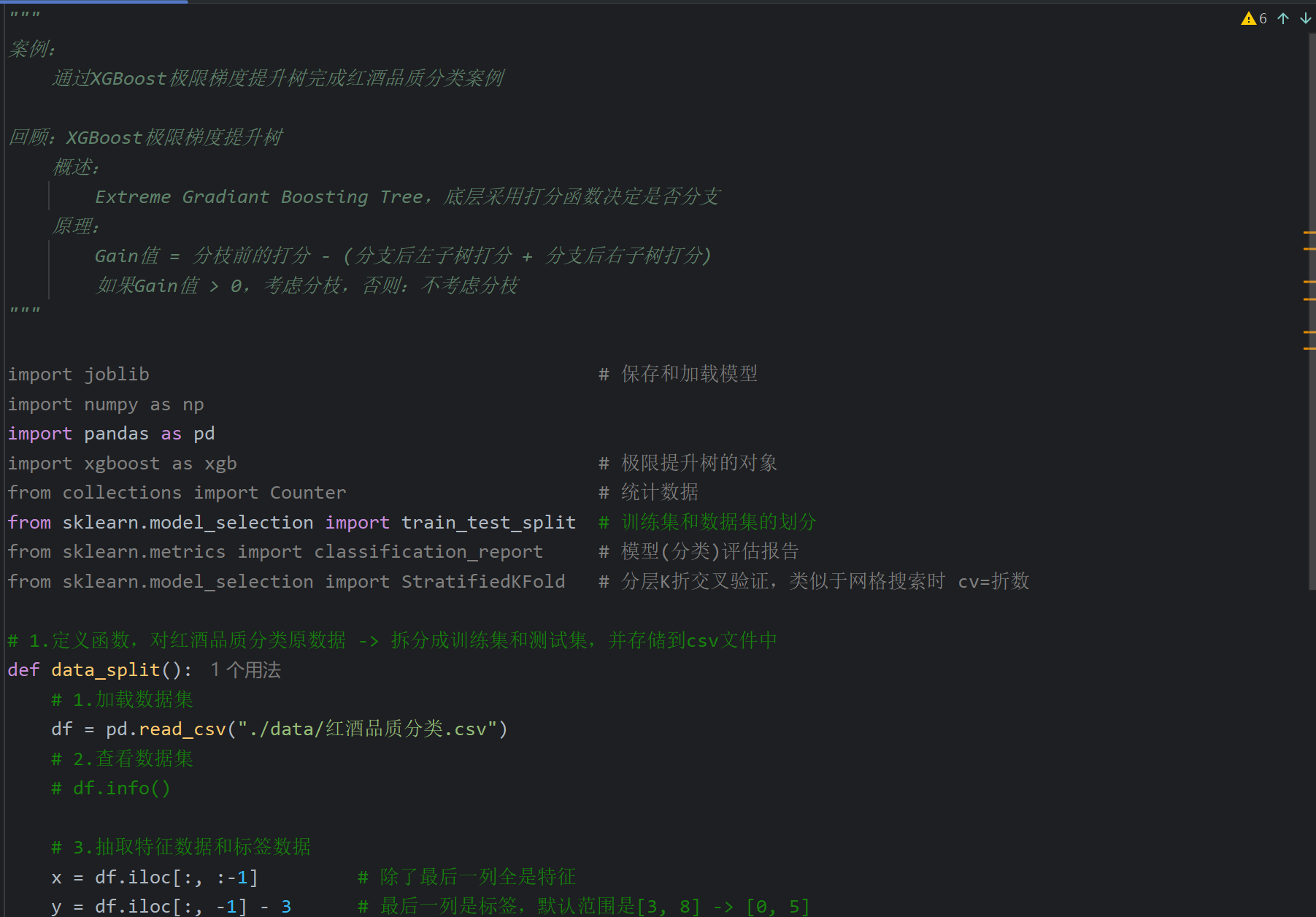
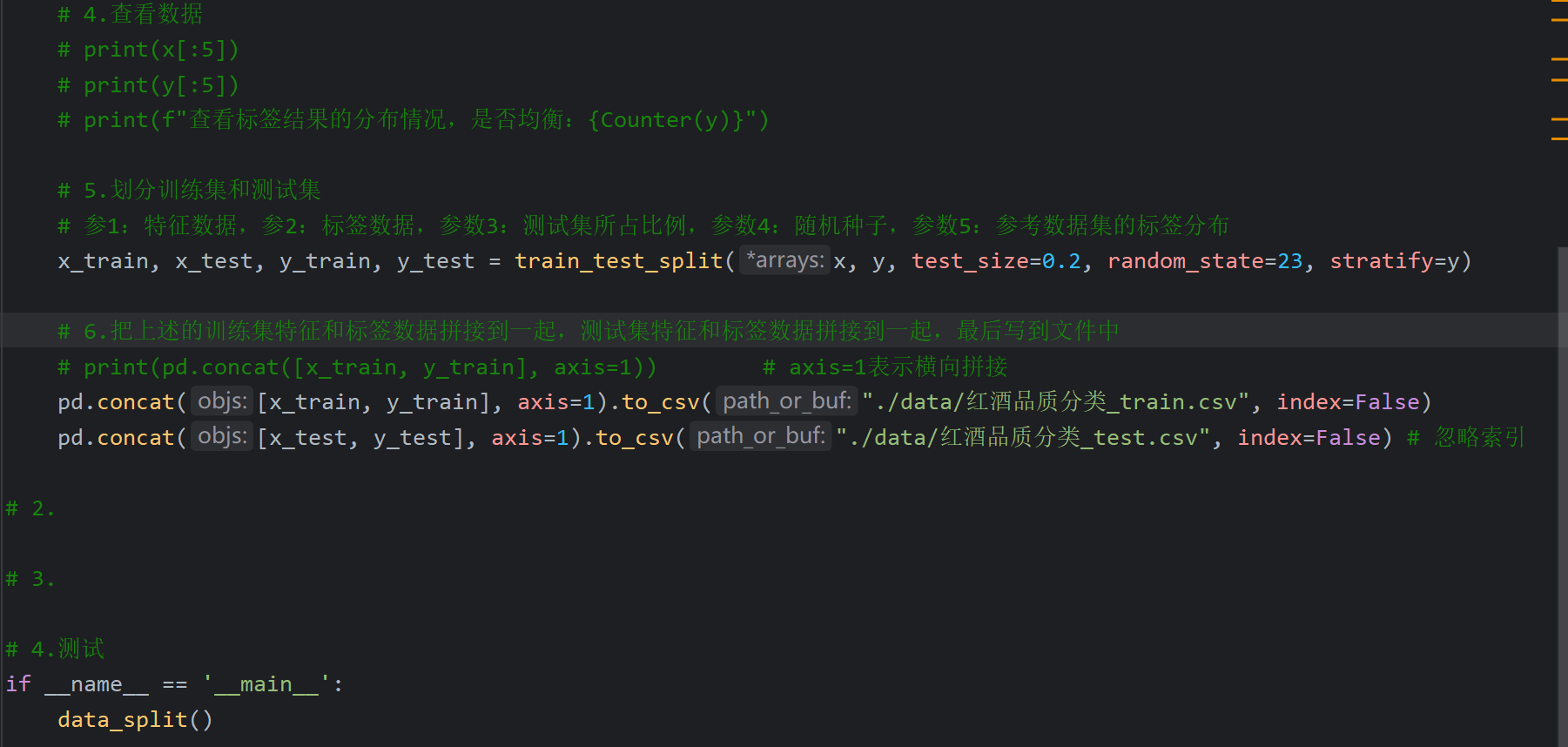
5、XGBoost案例_红酒品质分类_模型训练
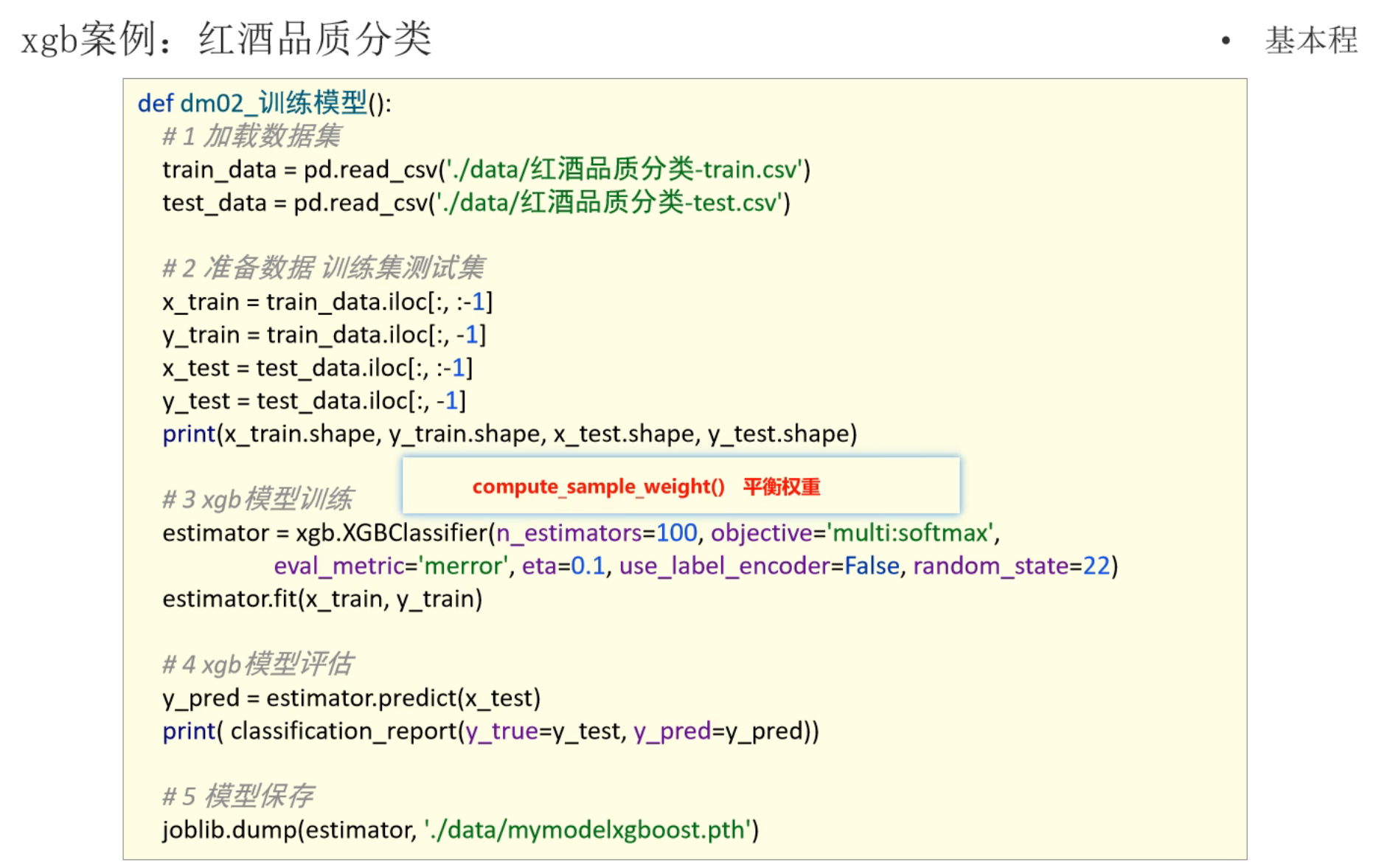
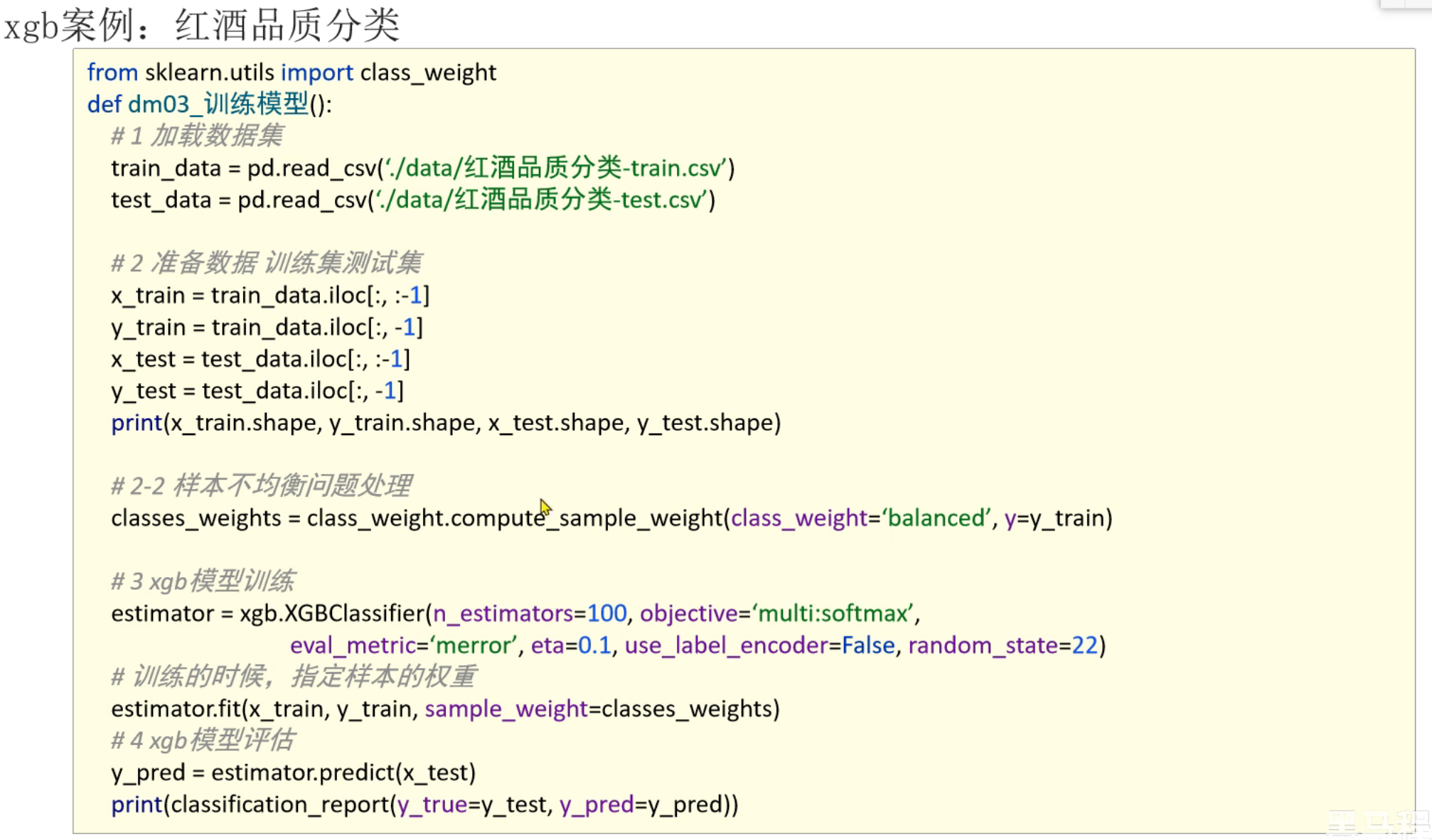
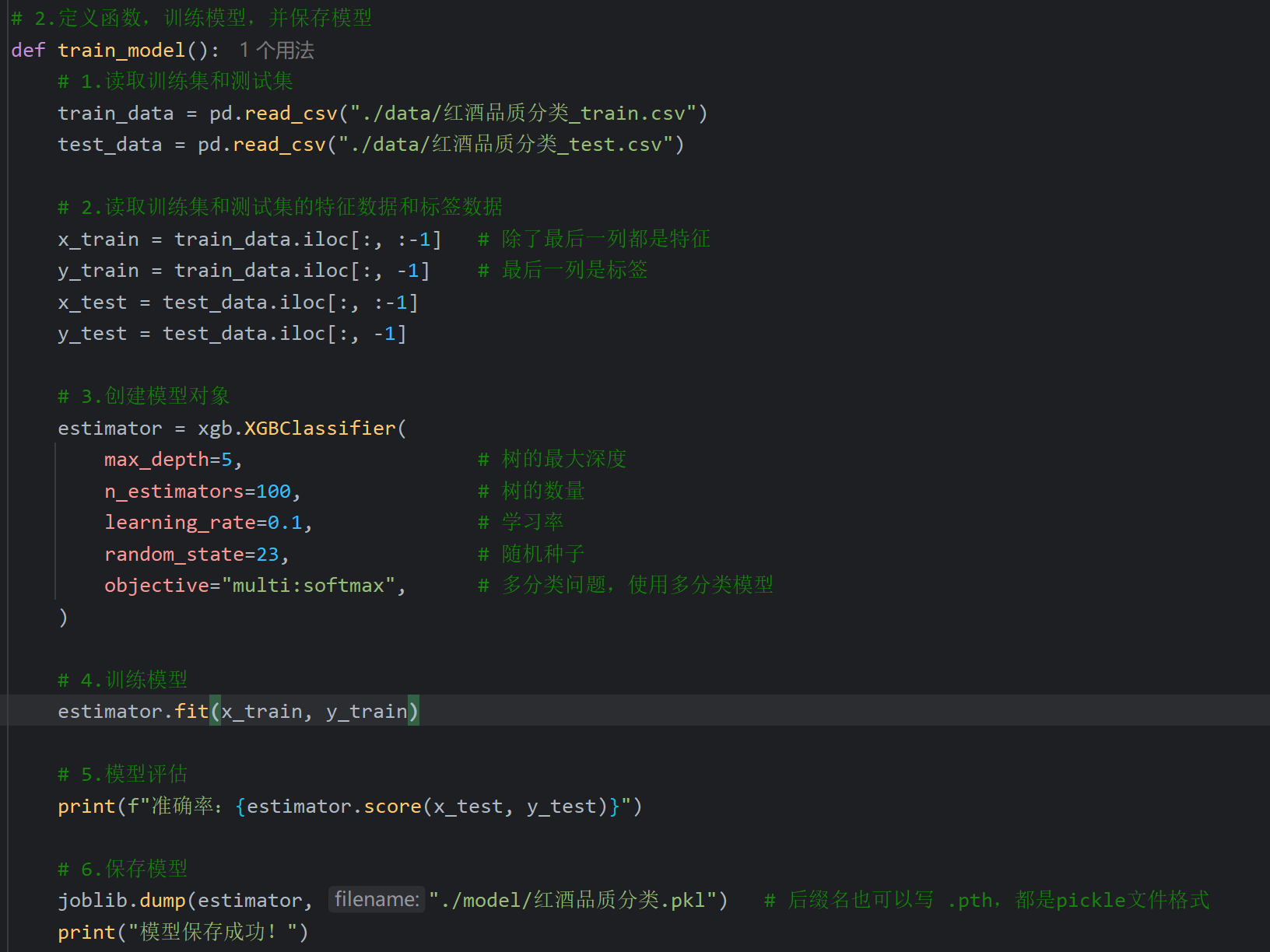

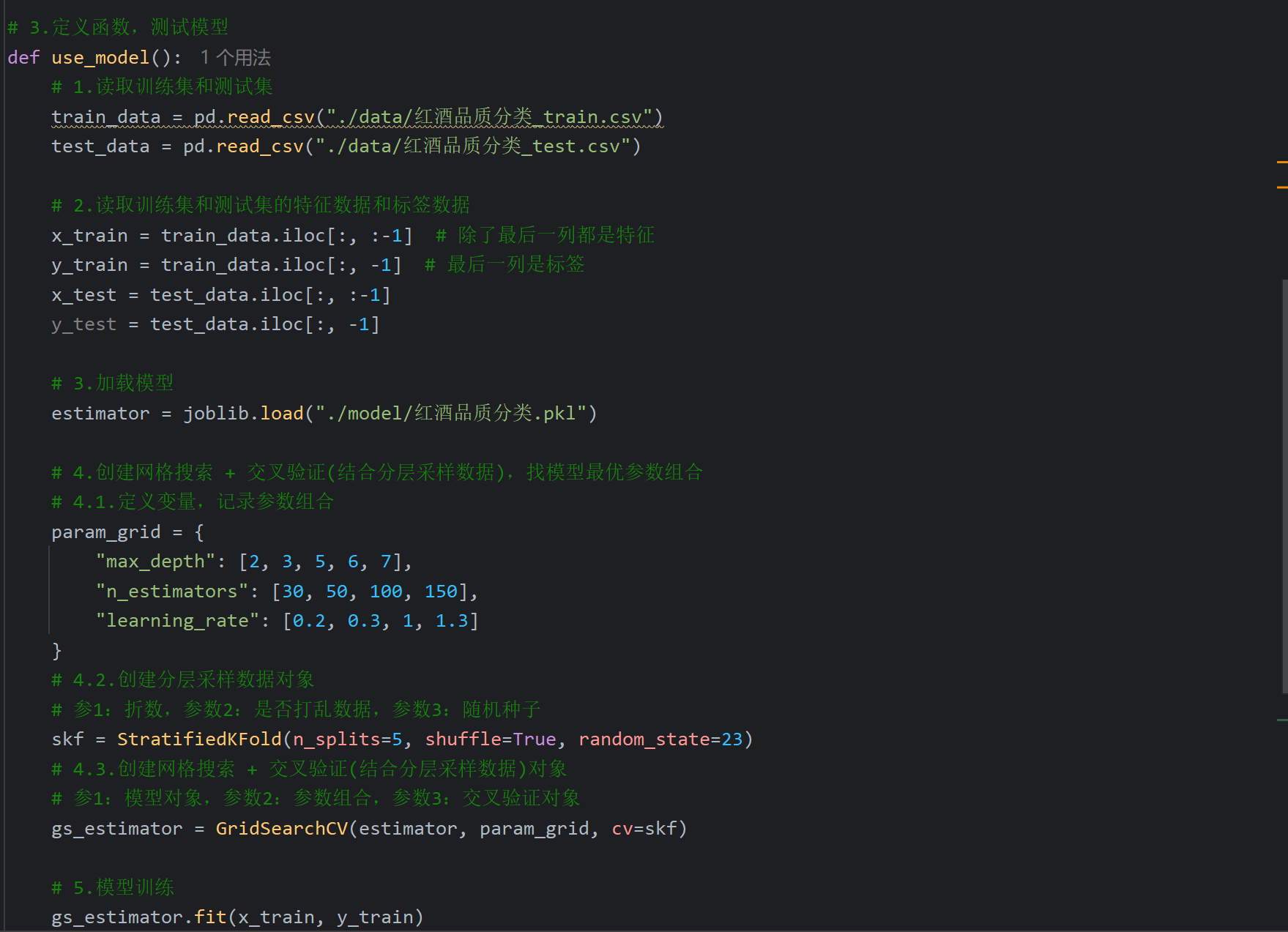
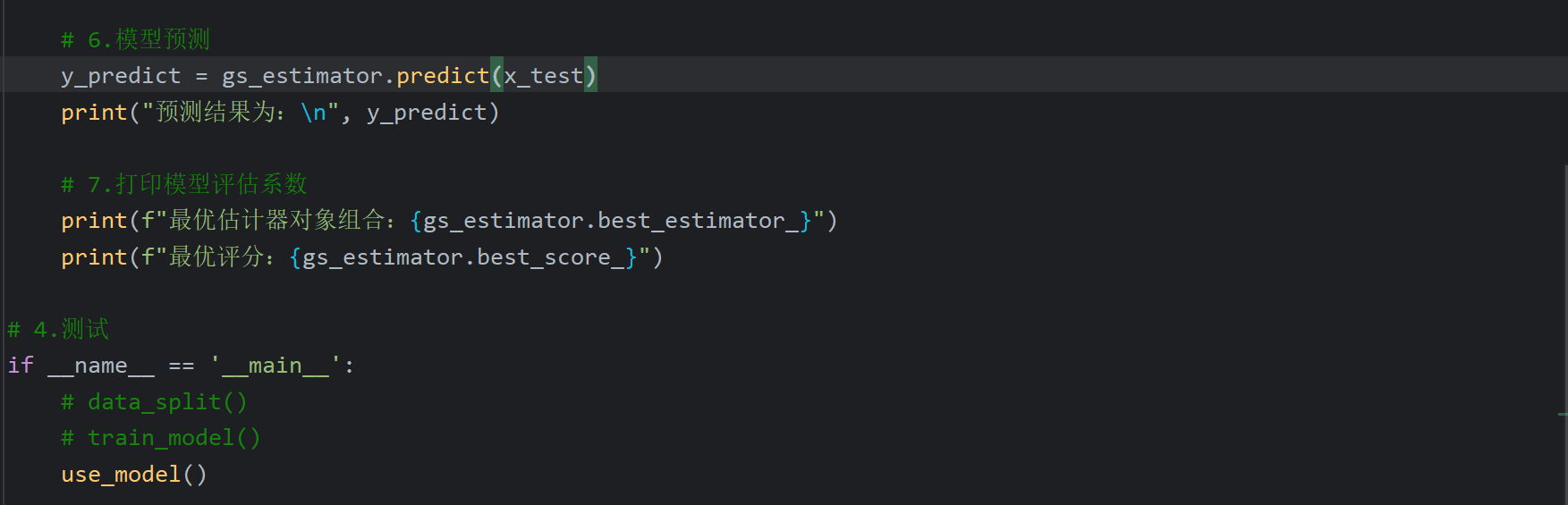
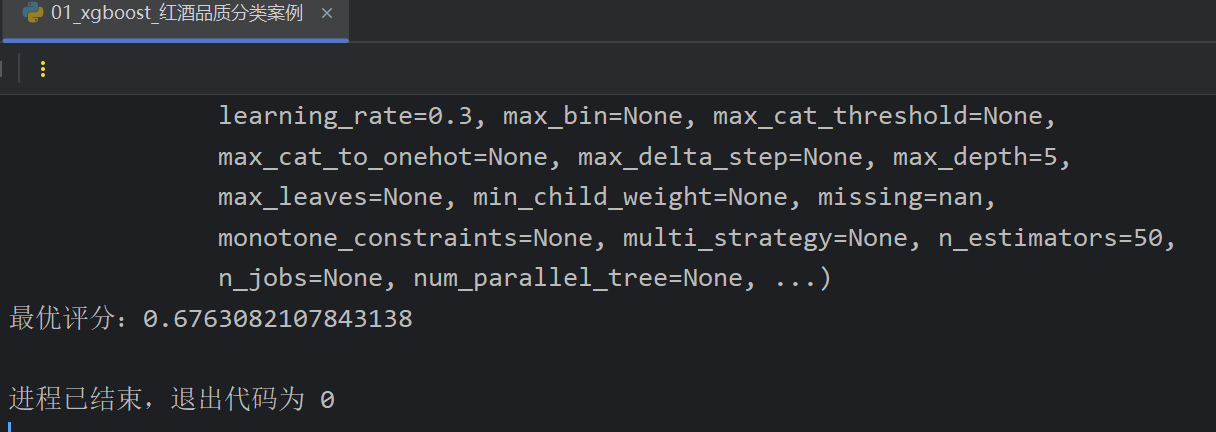
6、XGBoost案例_红酒品质分类_模型评测

平衡权重这个参数如果按老师的填是会报错的,修改一下




7、朴素贝叶斯_简介
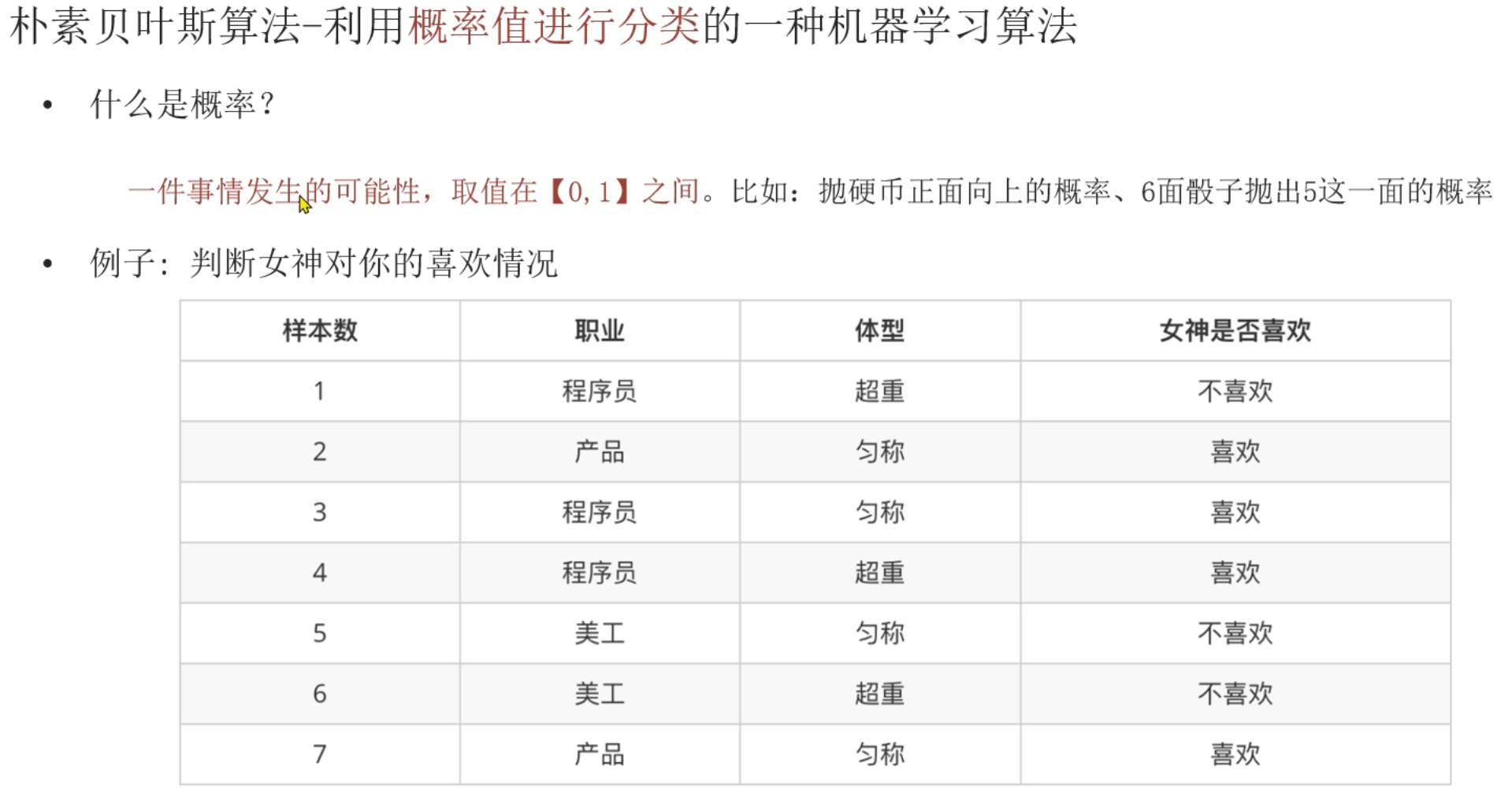


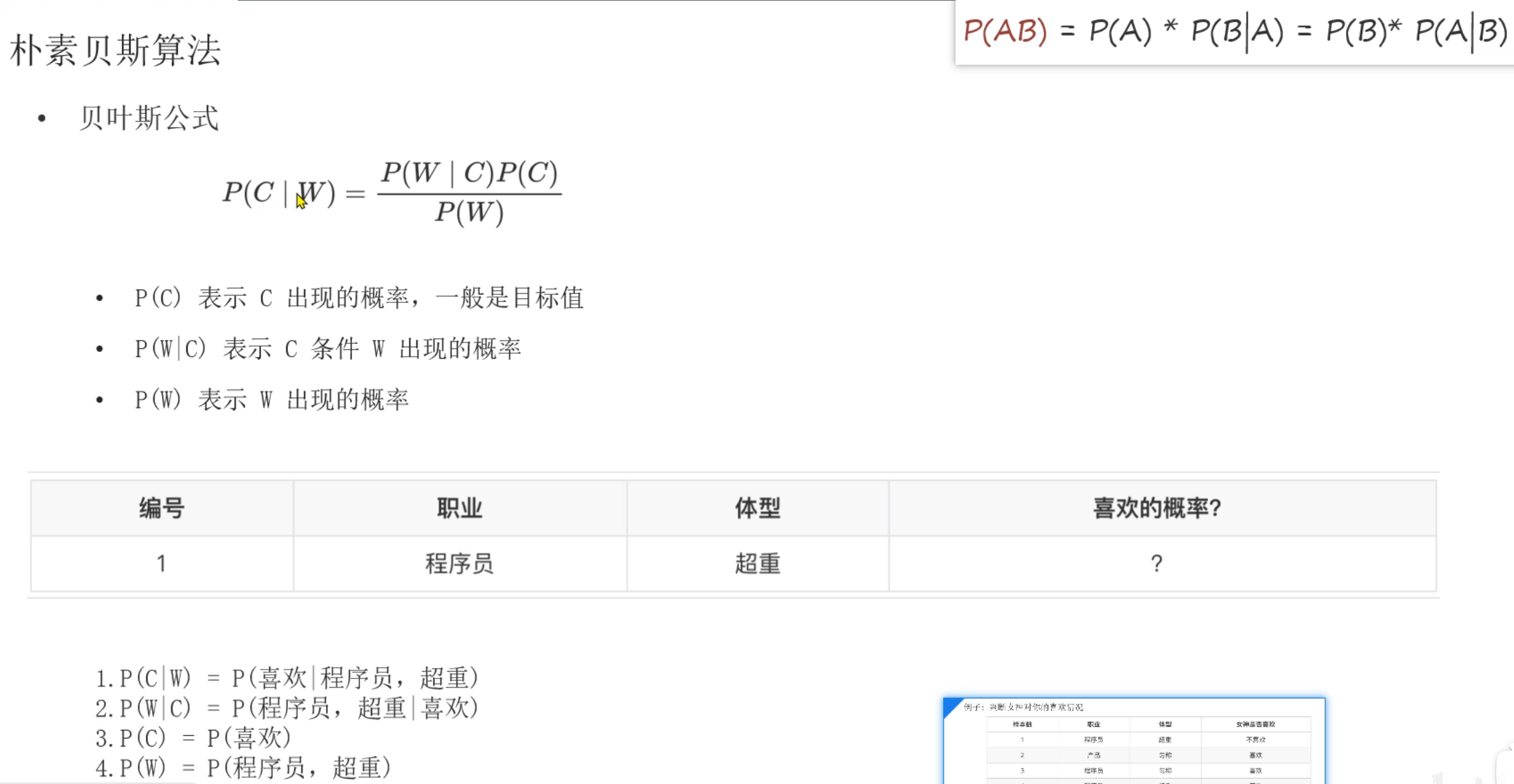


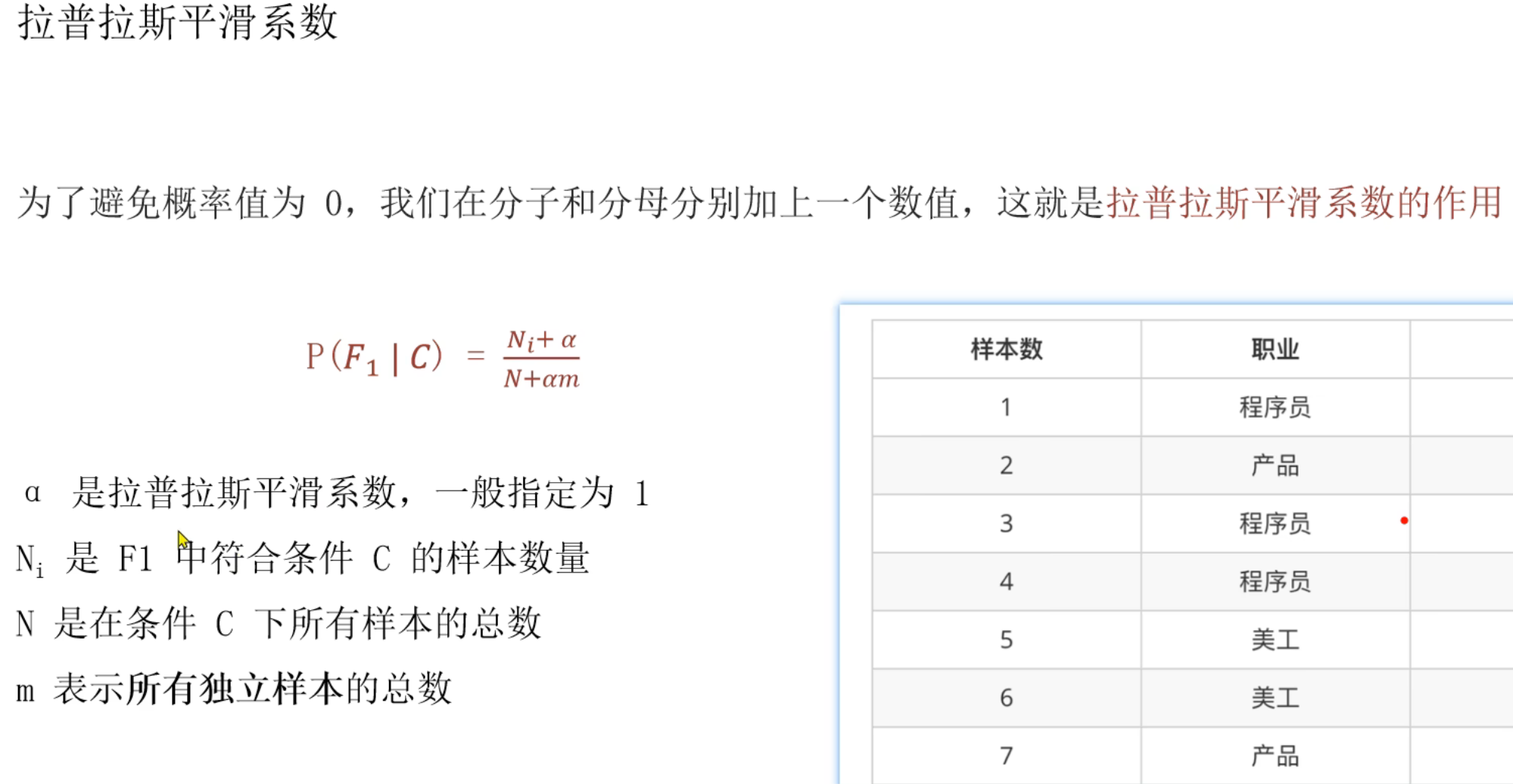

样本是每一行的数据,样本之间本来就是独立的。朴素贝叶斯是假设特征之间是相互独立的
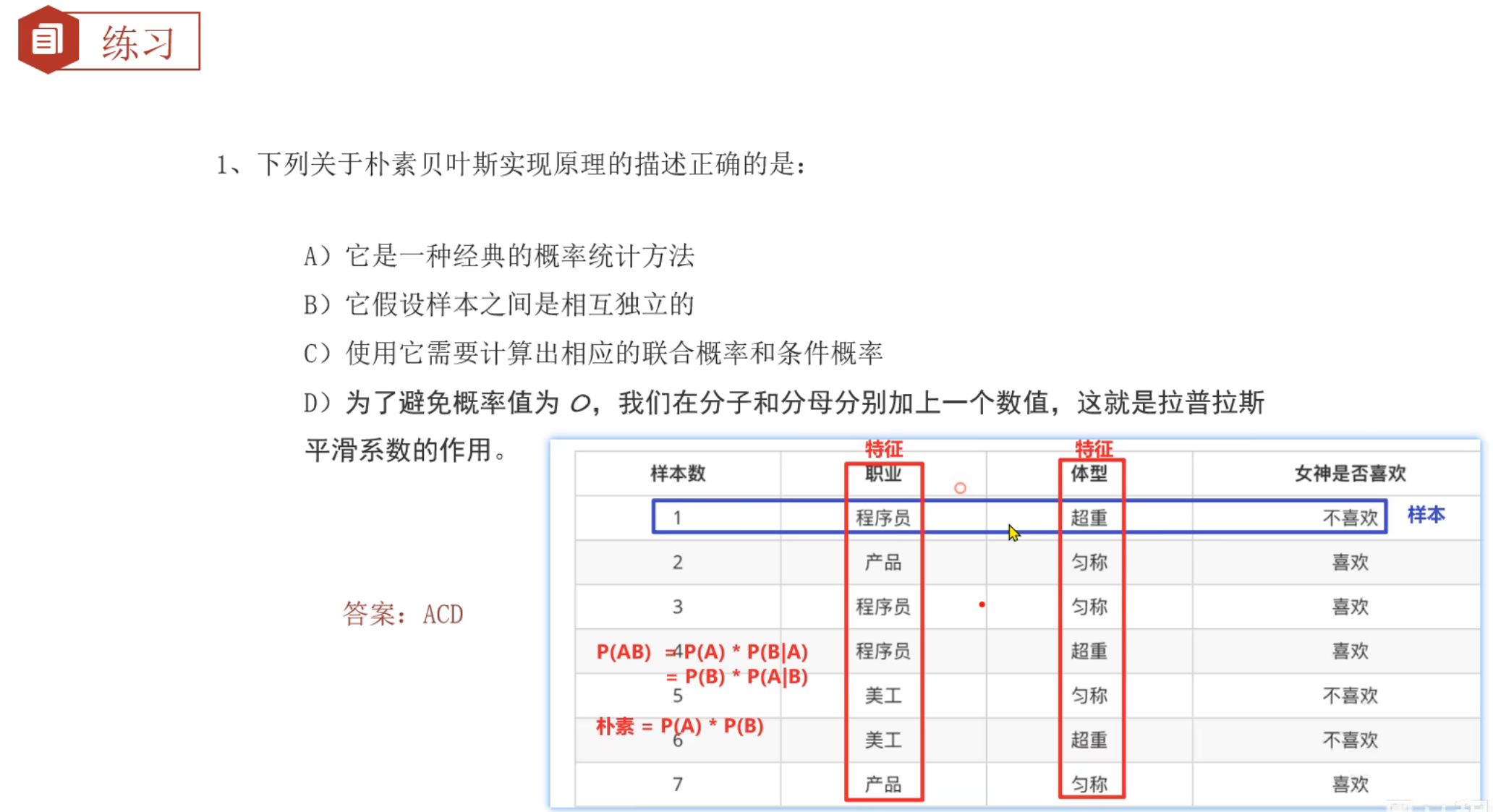
8、商品评论情感分析_思路分析

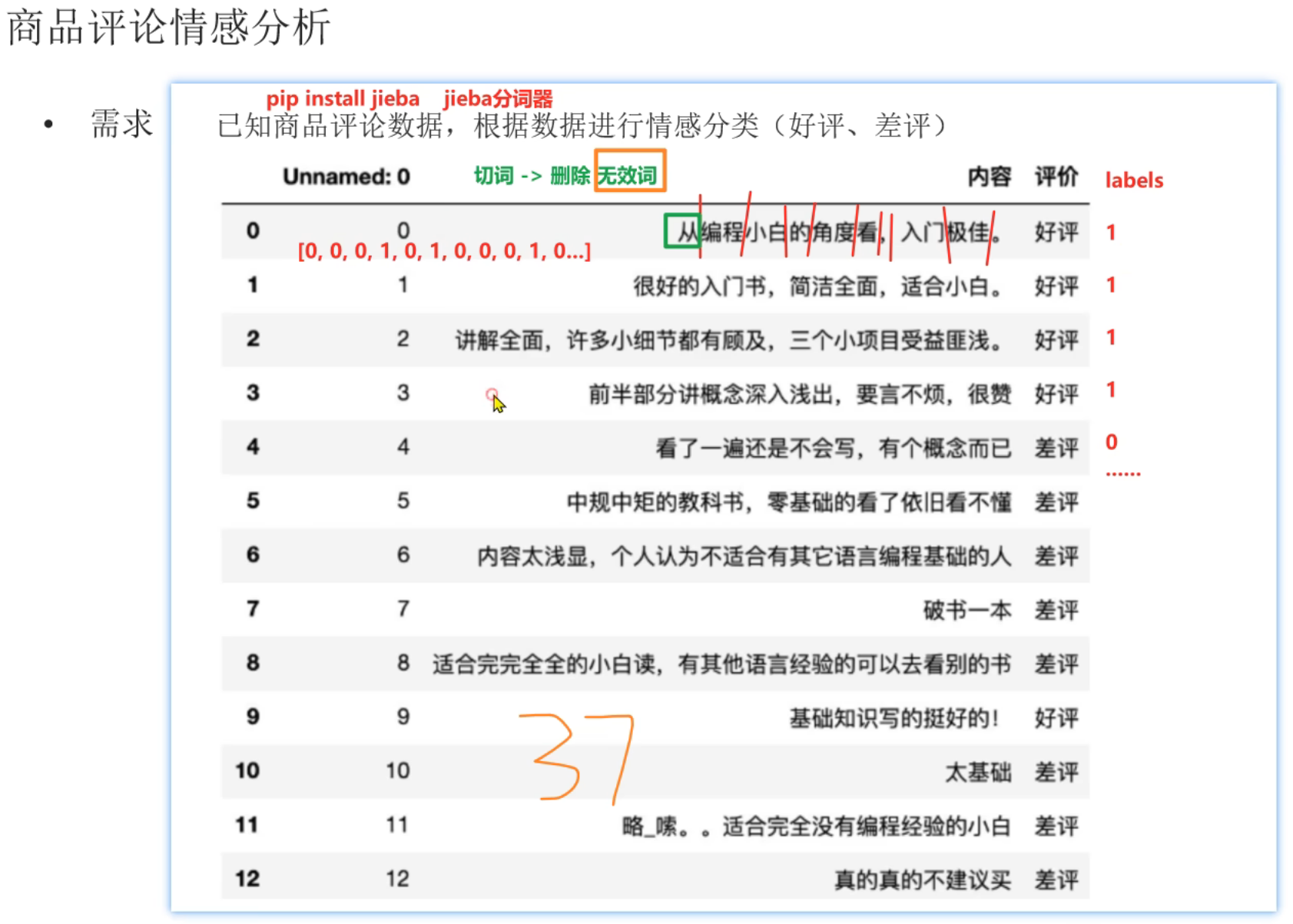

9、商品评论情感分析_数据预处理
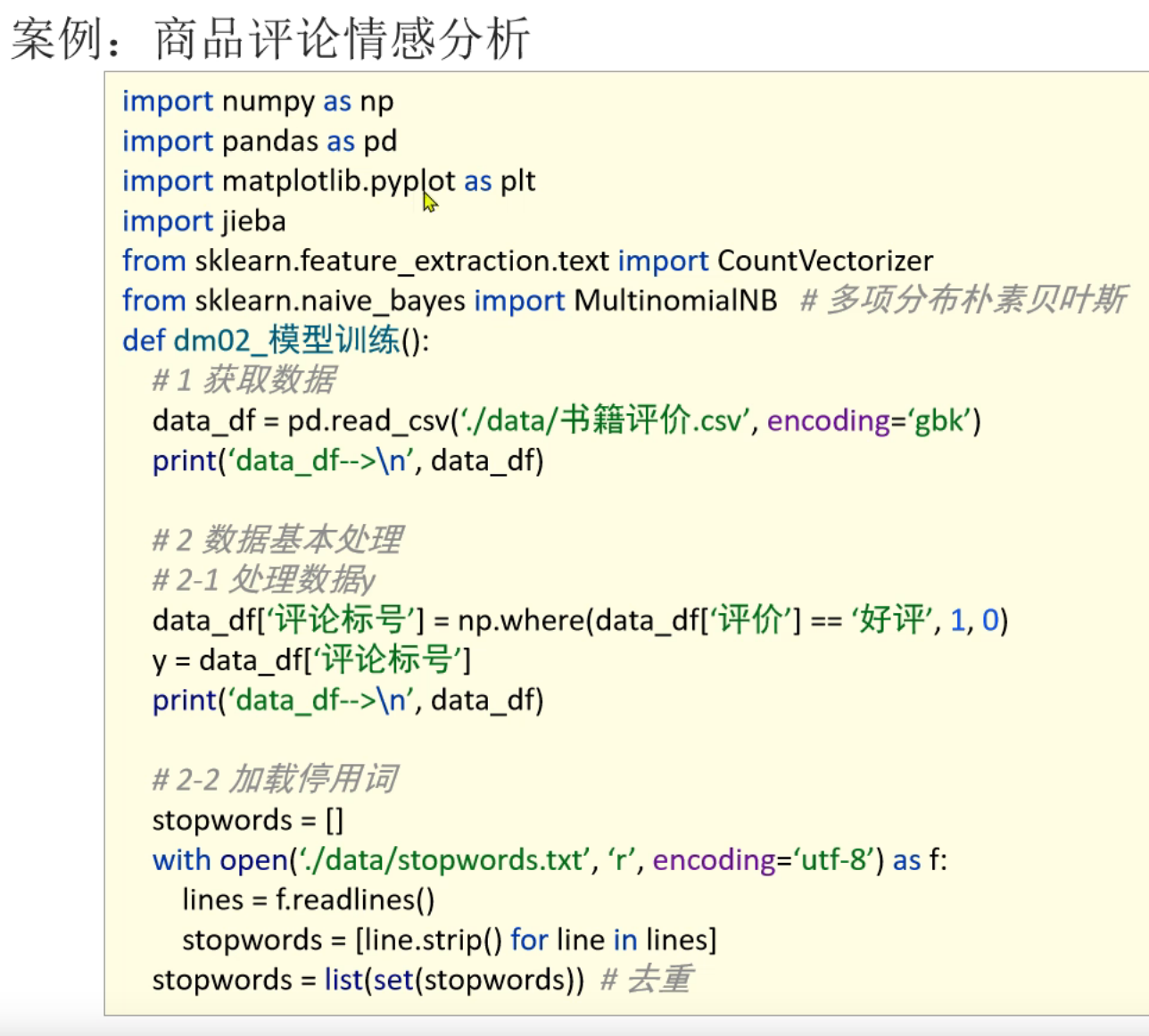
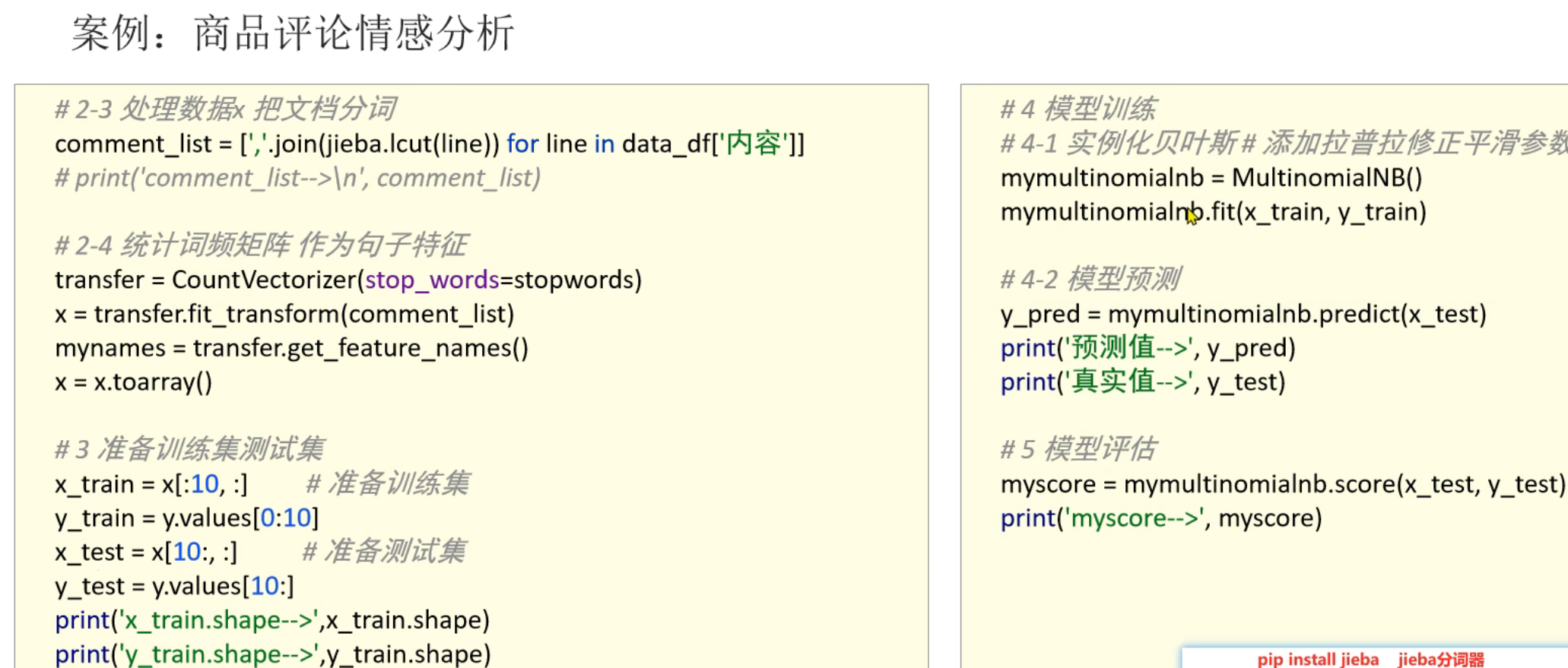
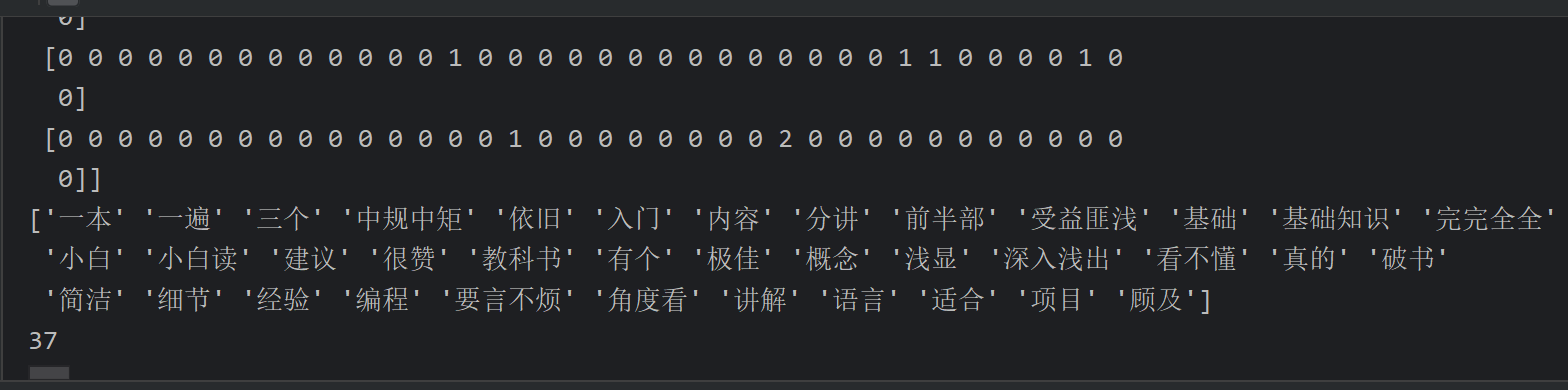
10、商品评论情感分析_模型训练和预测
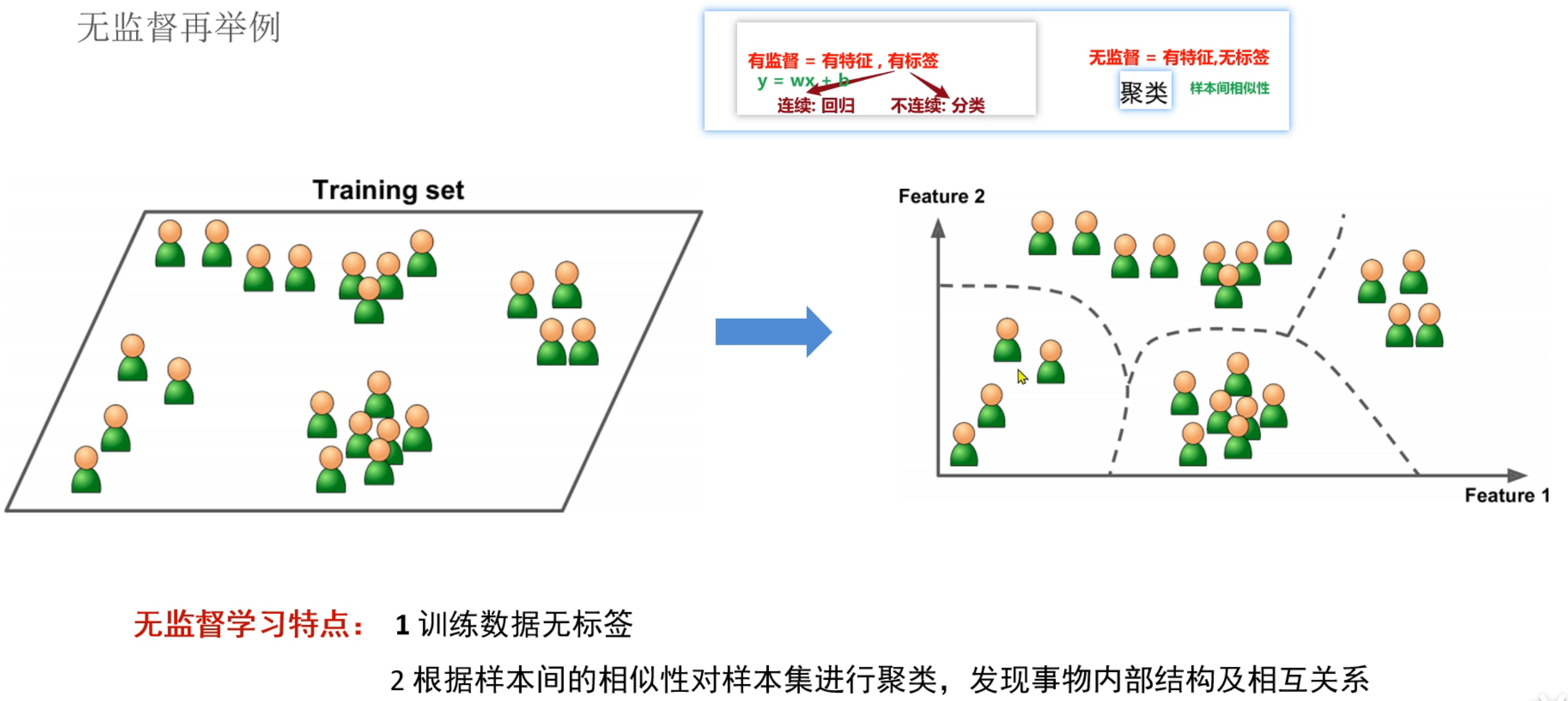
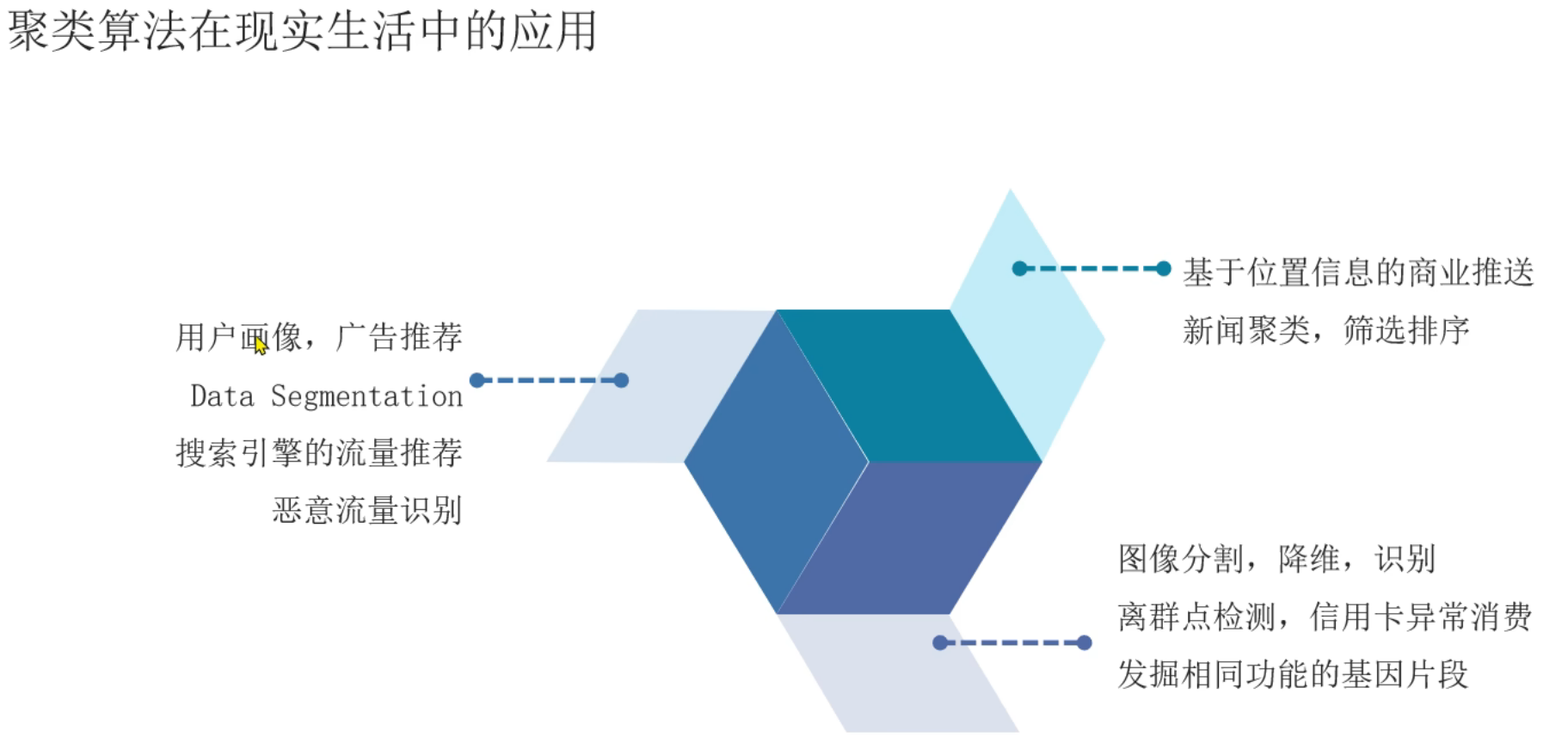
11、聚类算法_简介

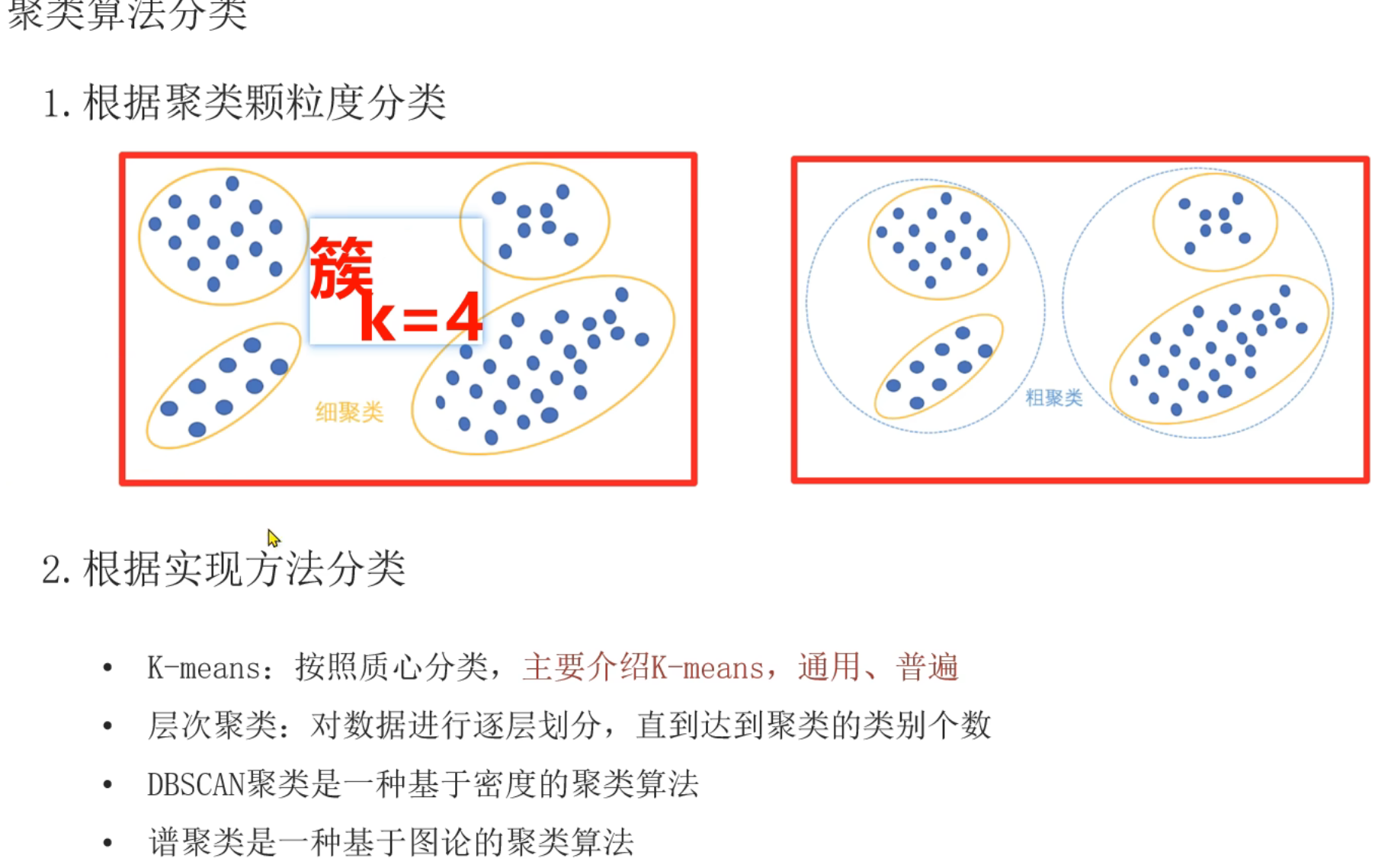


12、聚类算法_API初识

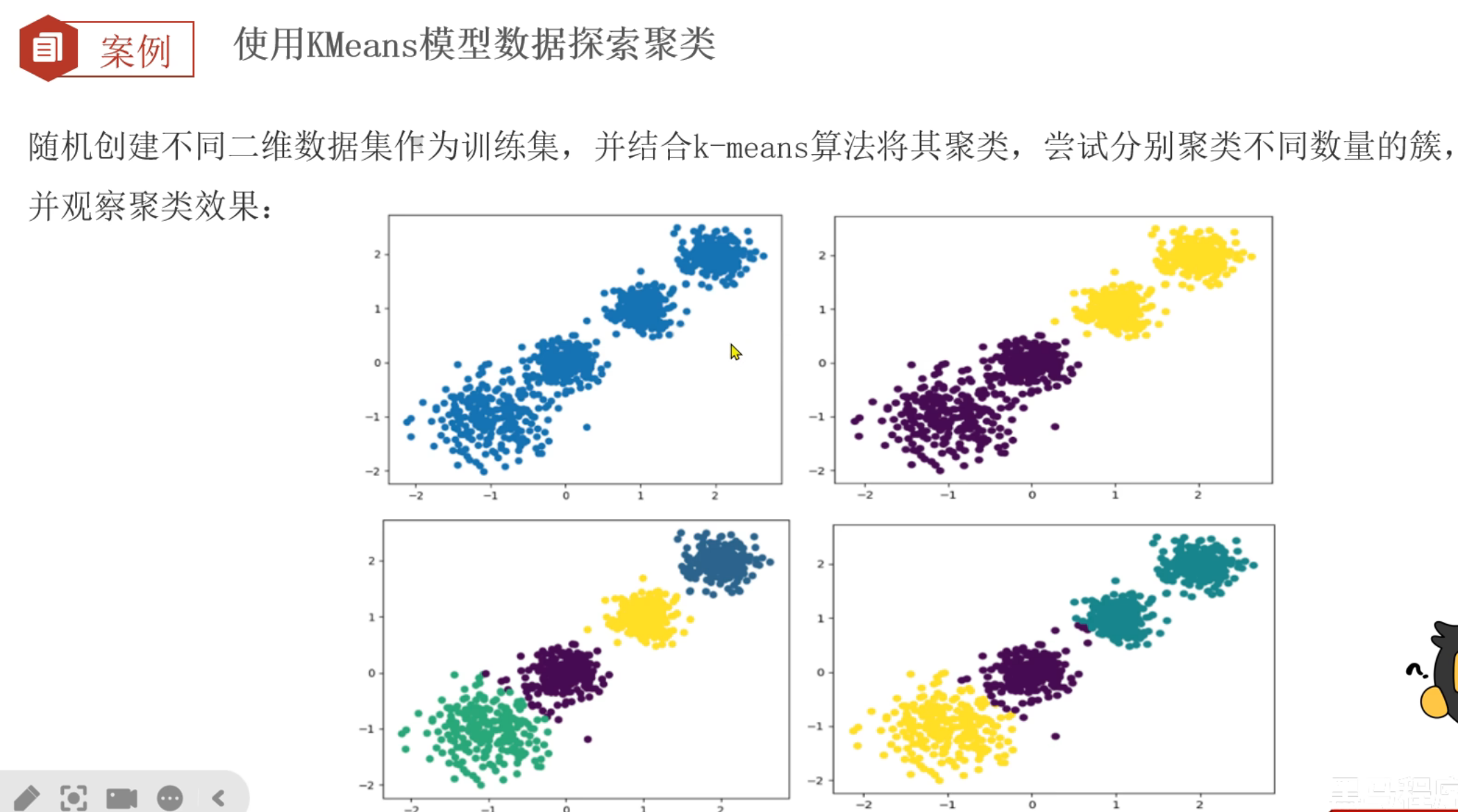


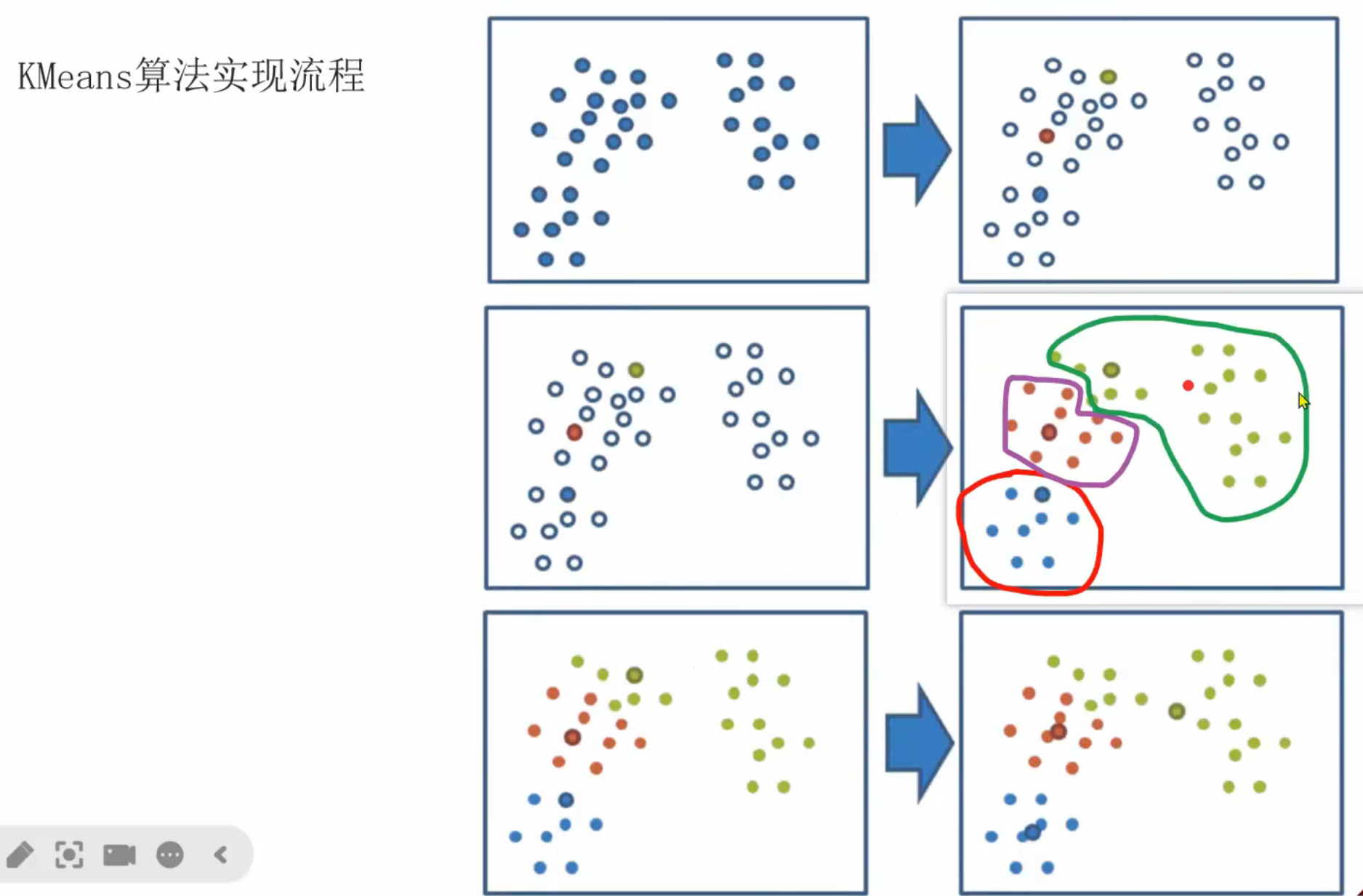
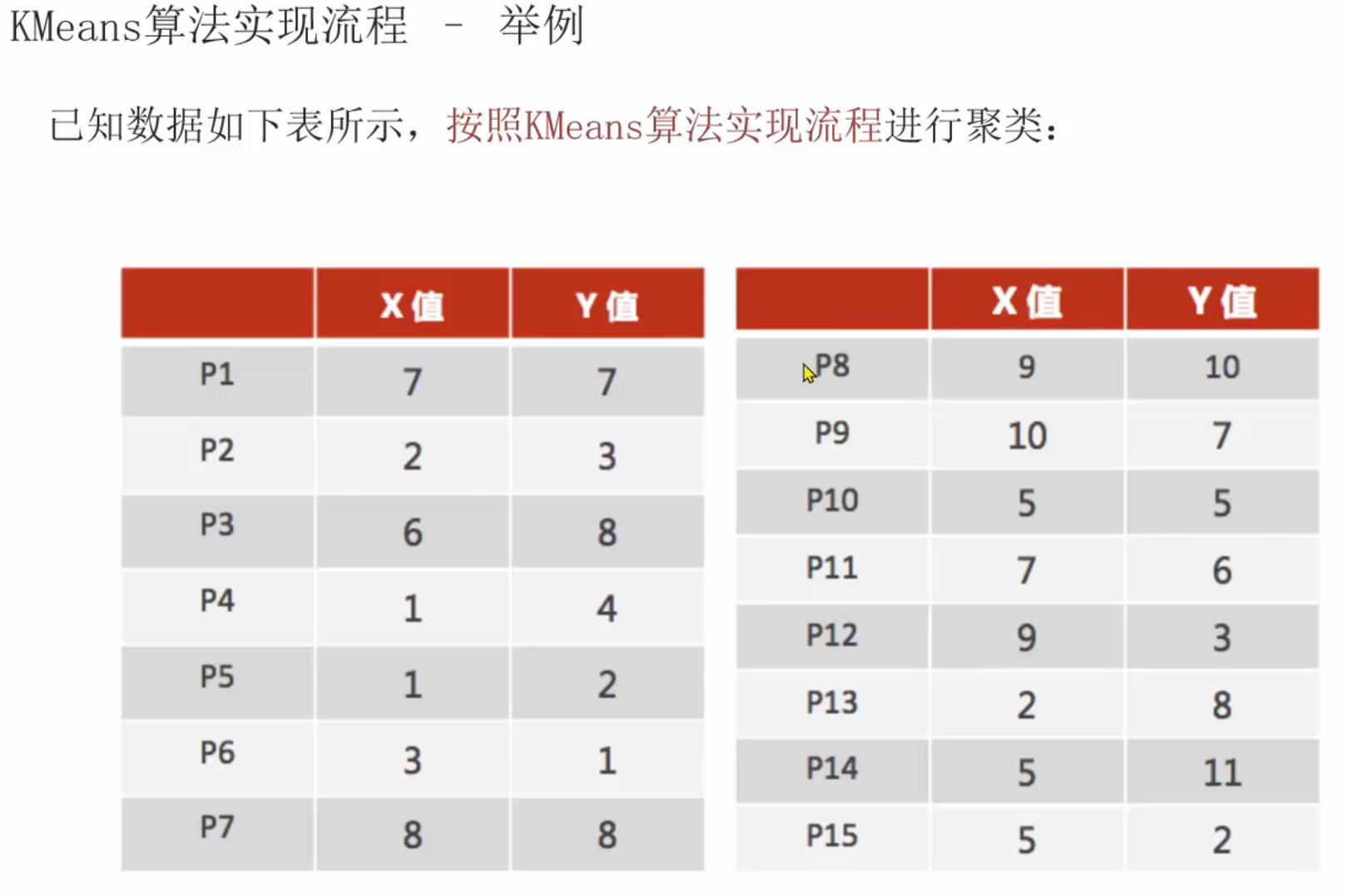
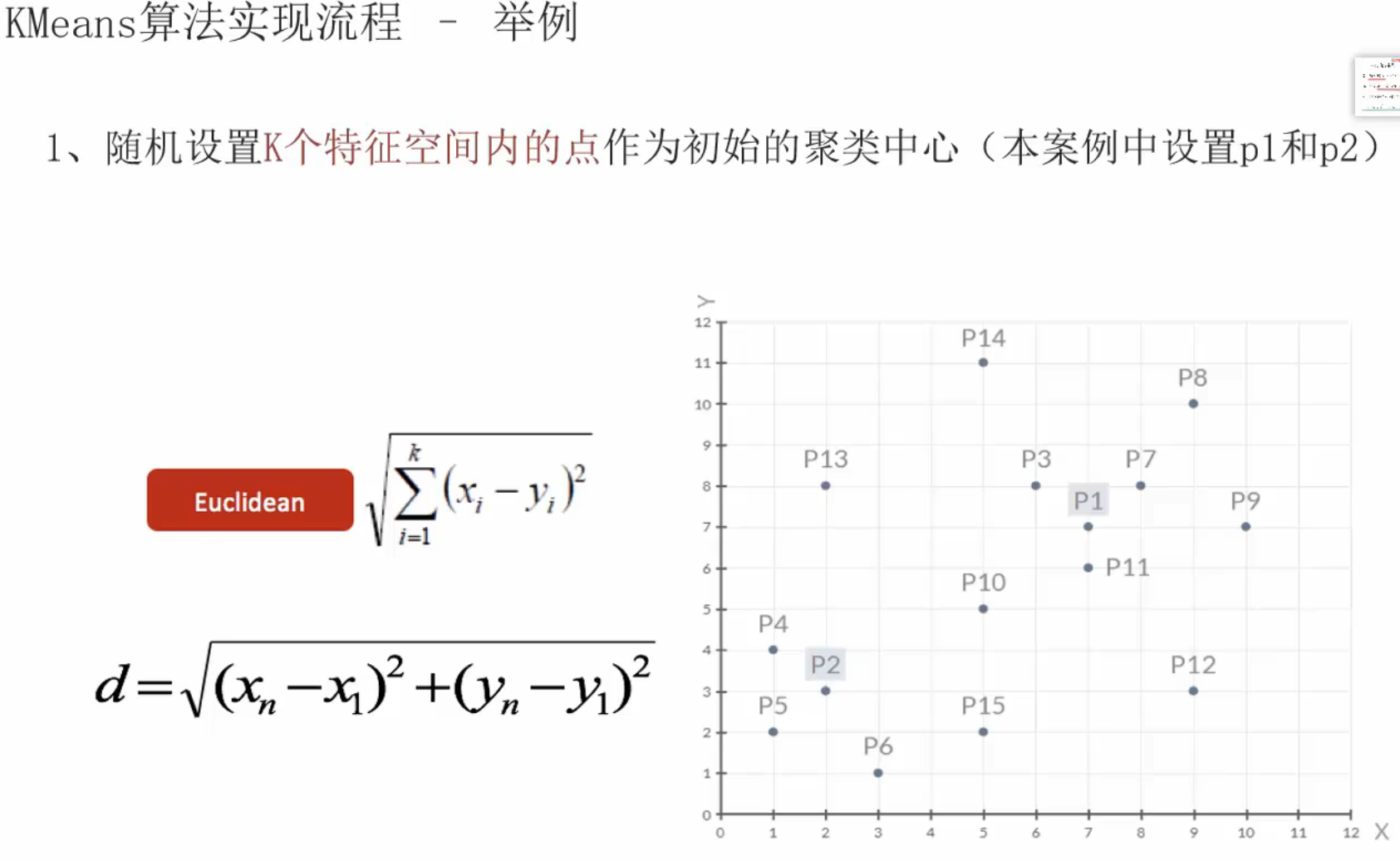
13、聚类算法_推导流程



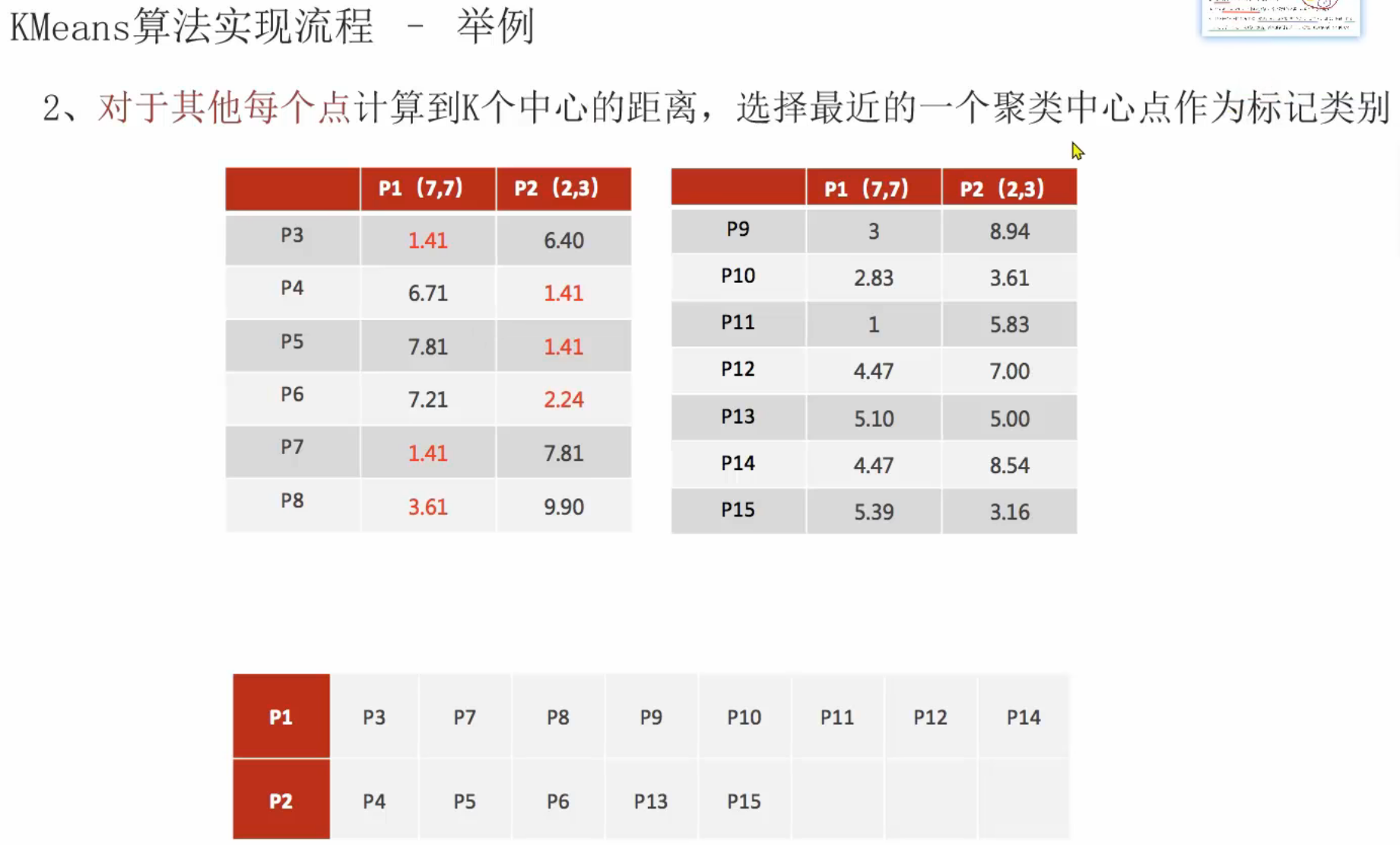
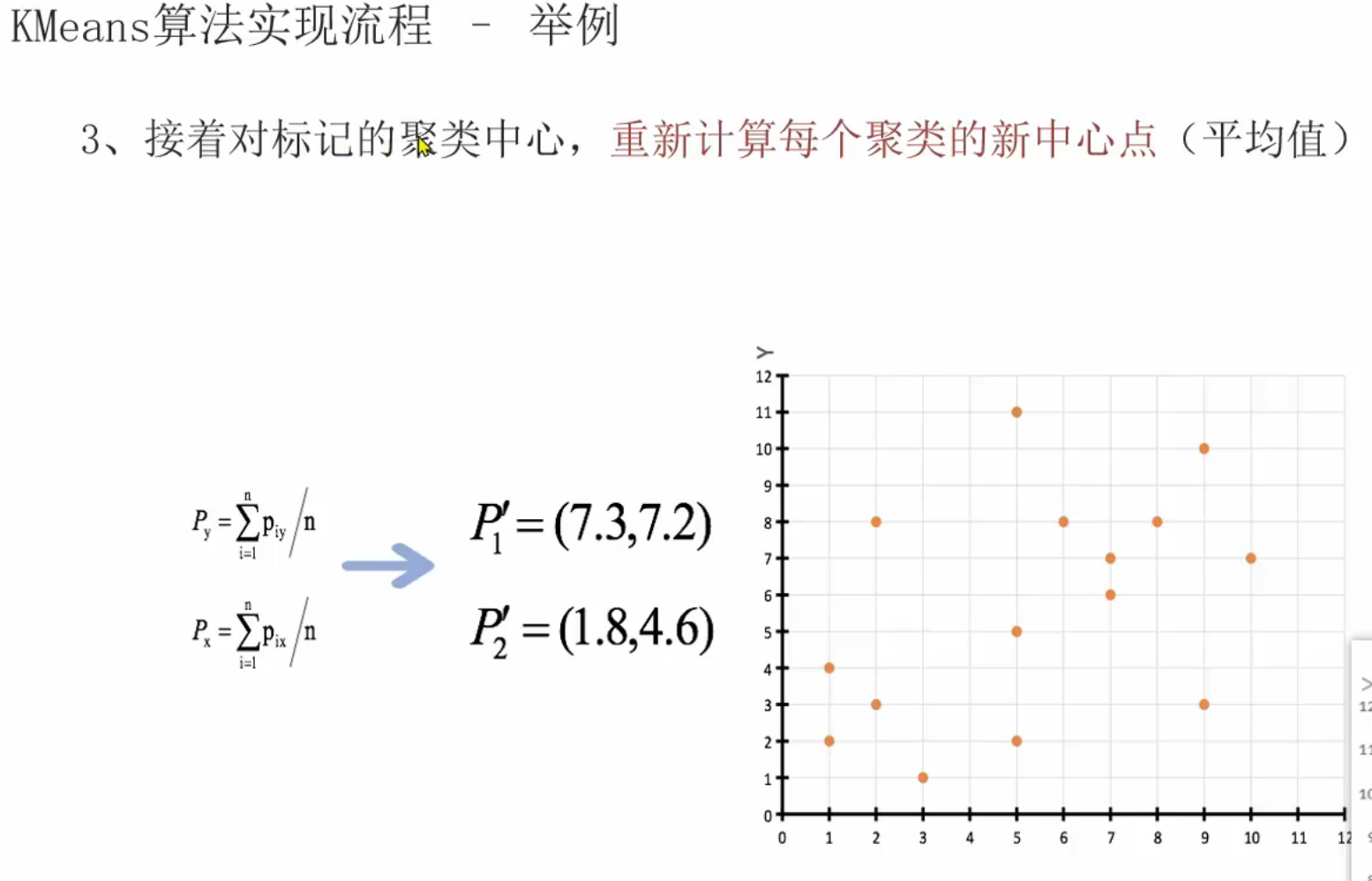
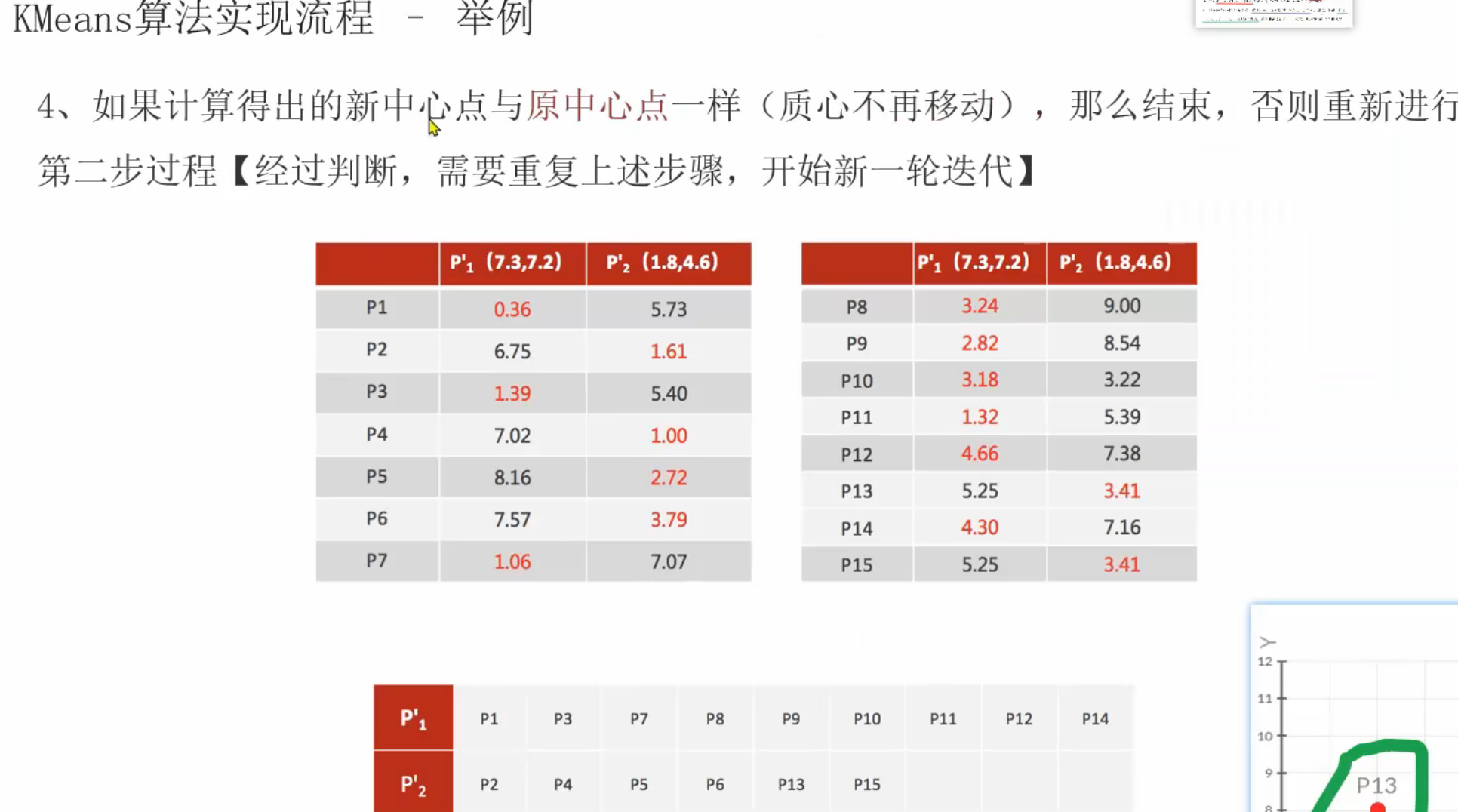
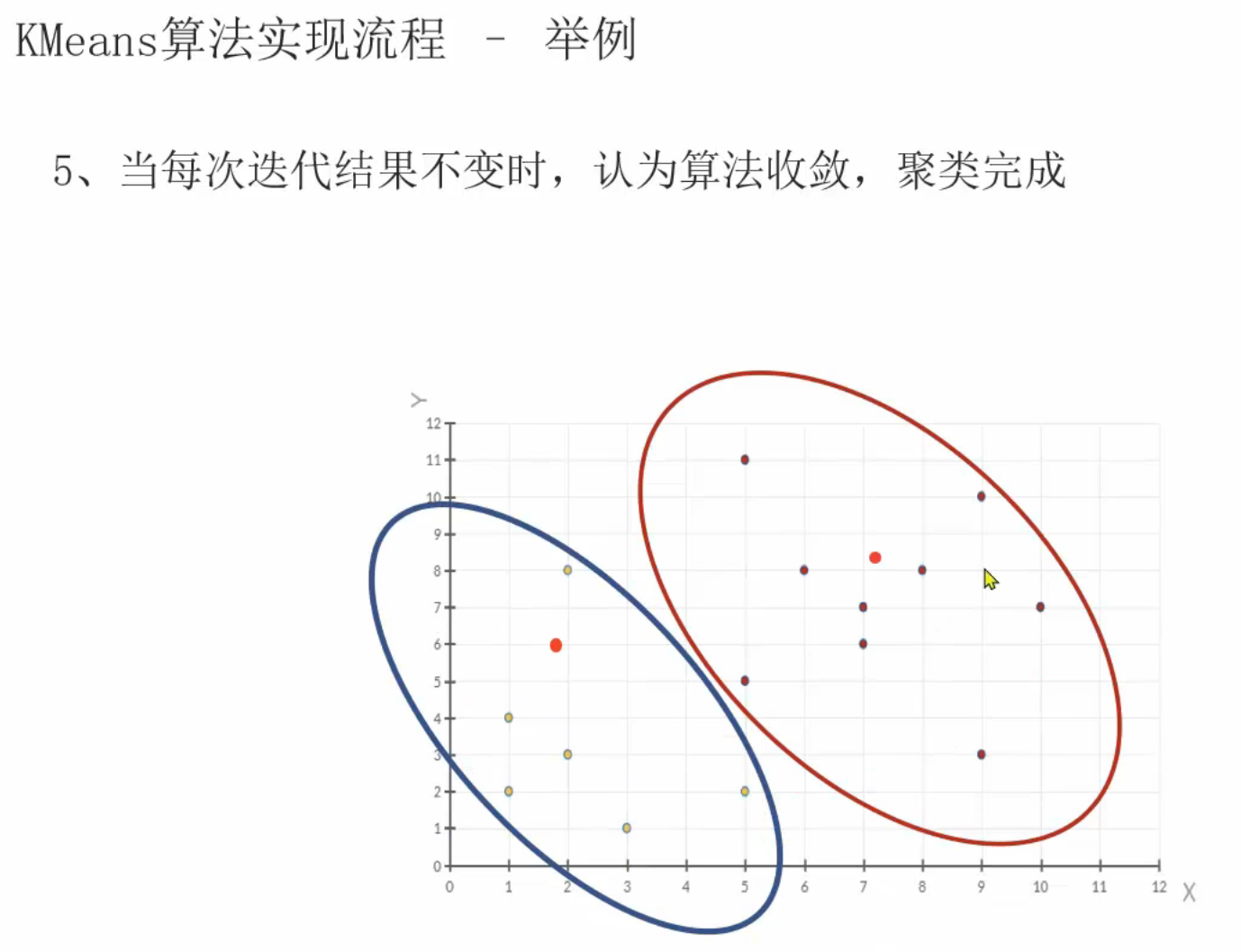


十、数据挖掘实战项目
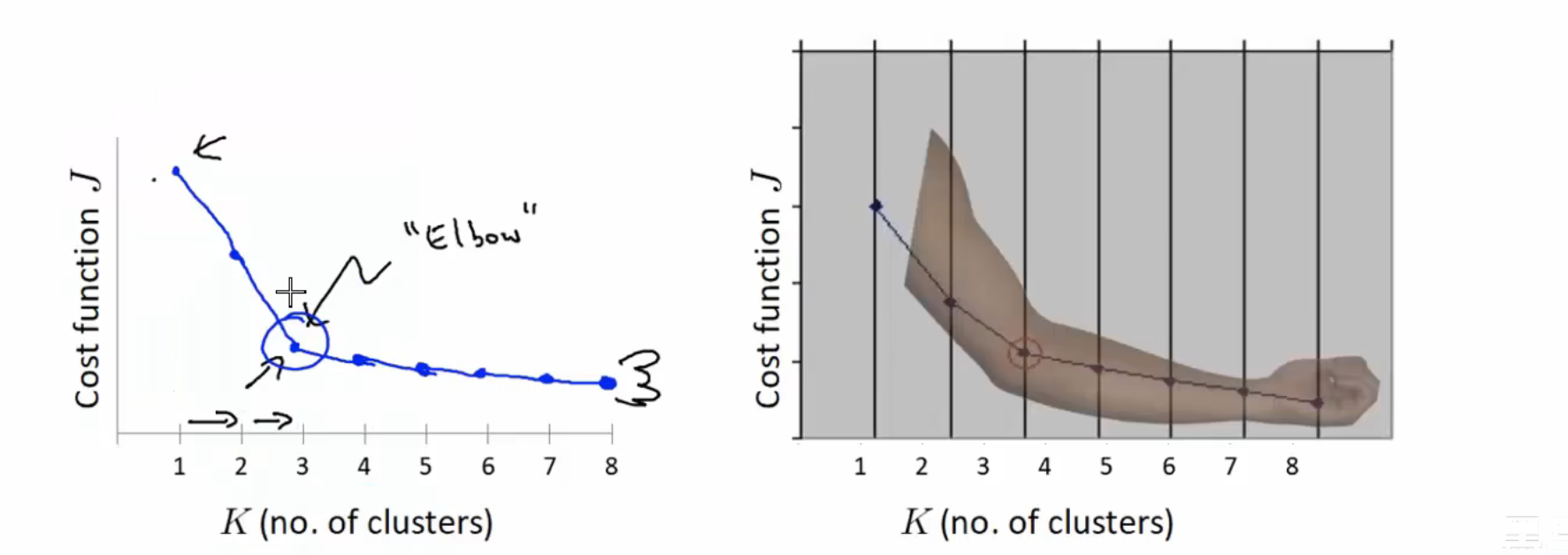
1、聚类算法评估指标_SSE介绍


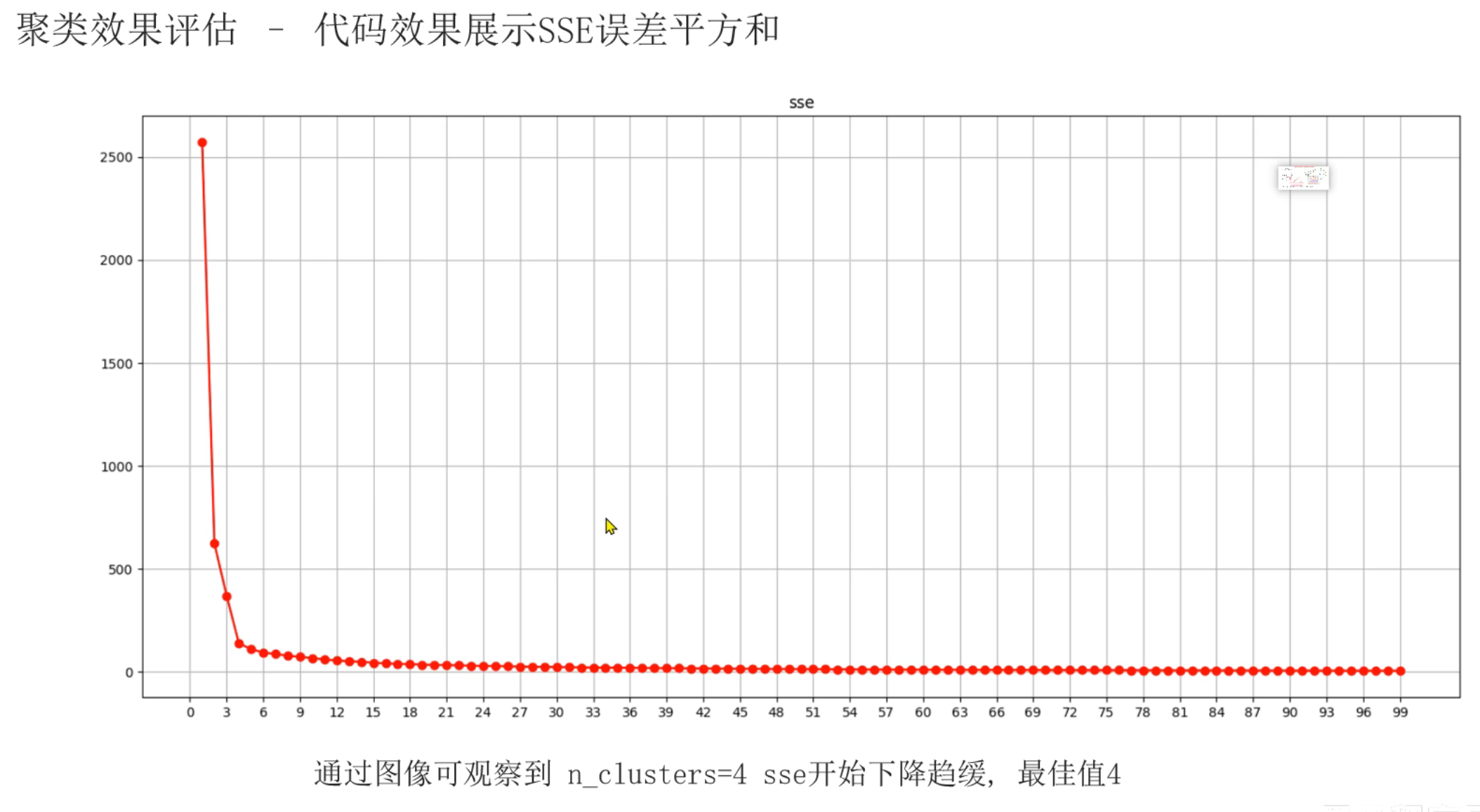
2、聚类算法评估指标_SSE代码实现

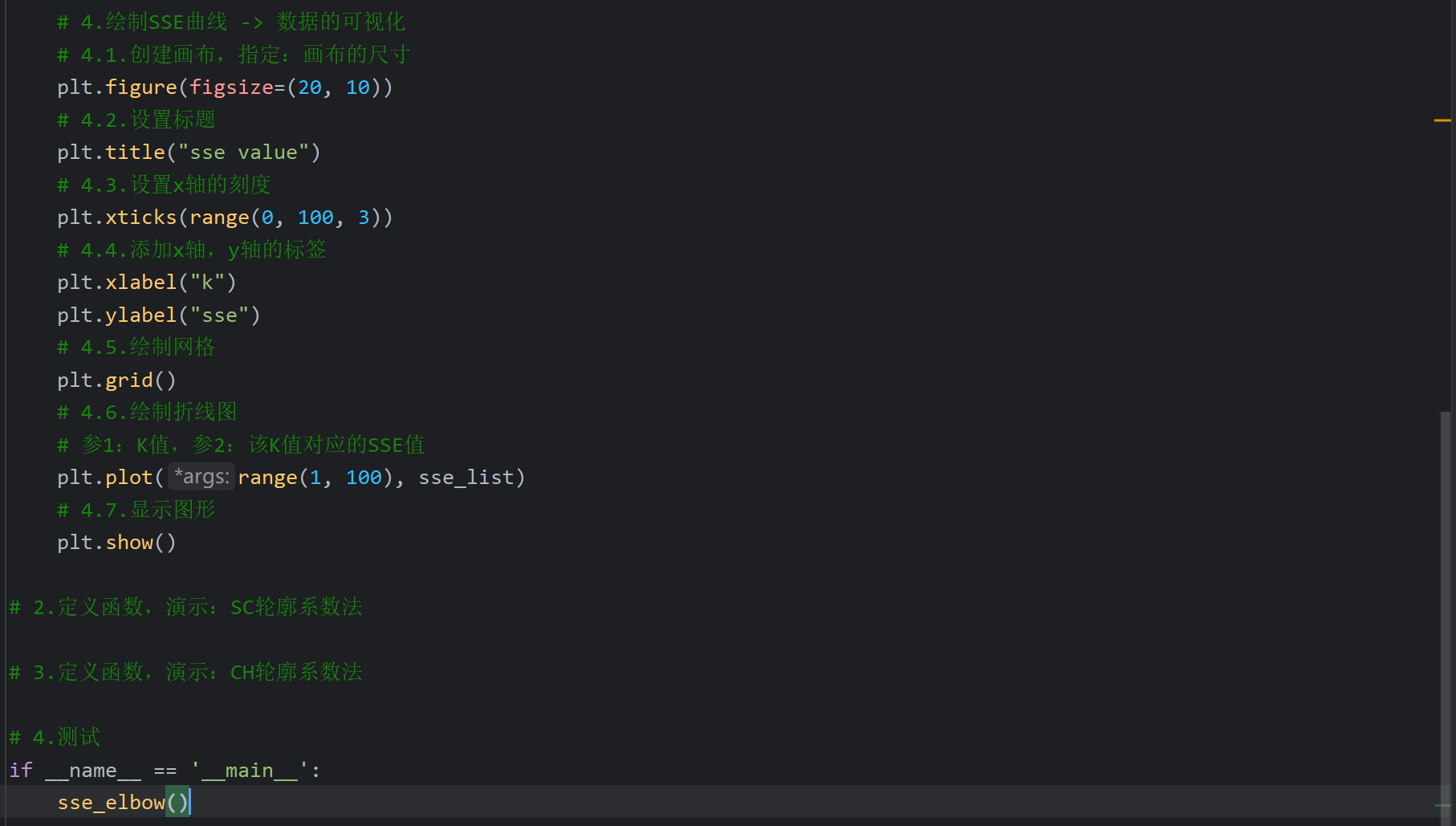
我画这个图画的挺慢的,感觉画了几分钟,不知道是电脑配置问题还是啥
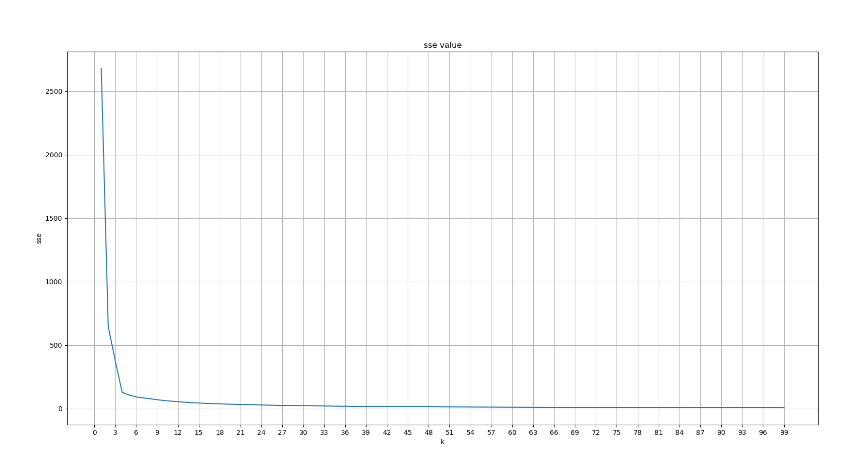
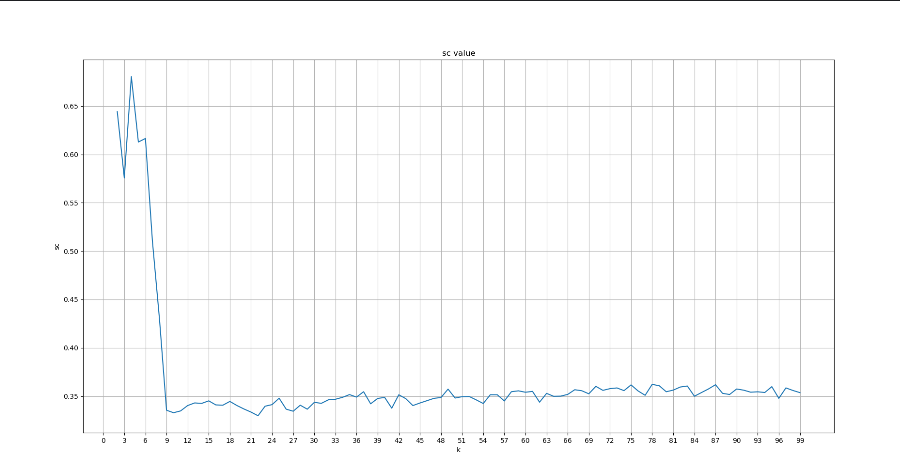
3、聚类算法评估指标_sc,ch轮廓系数介绍




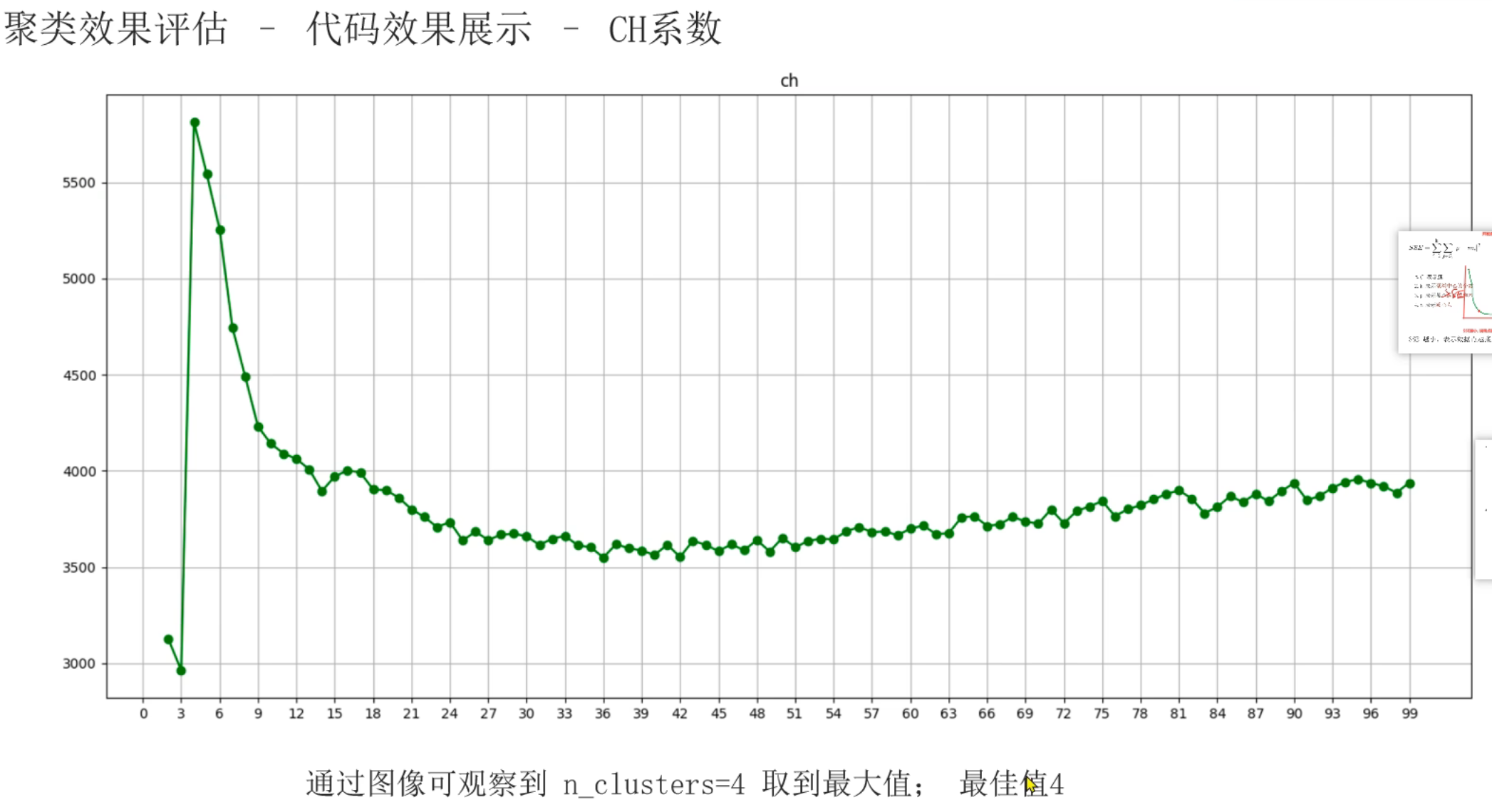
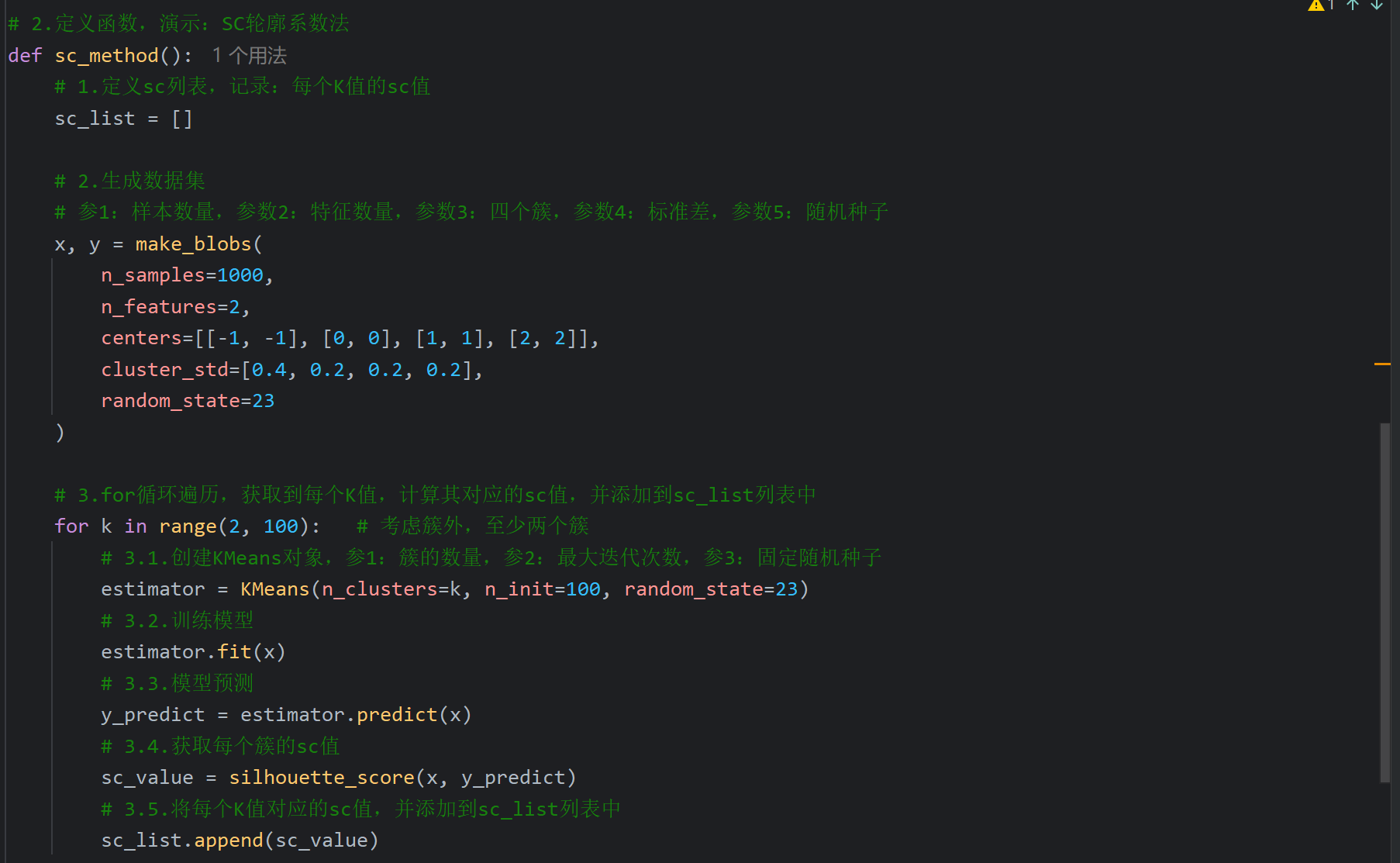
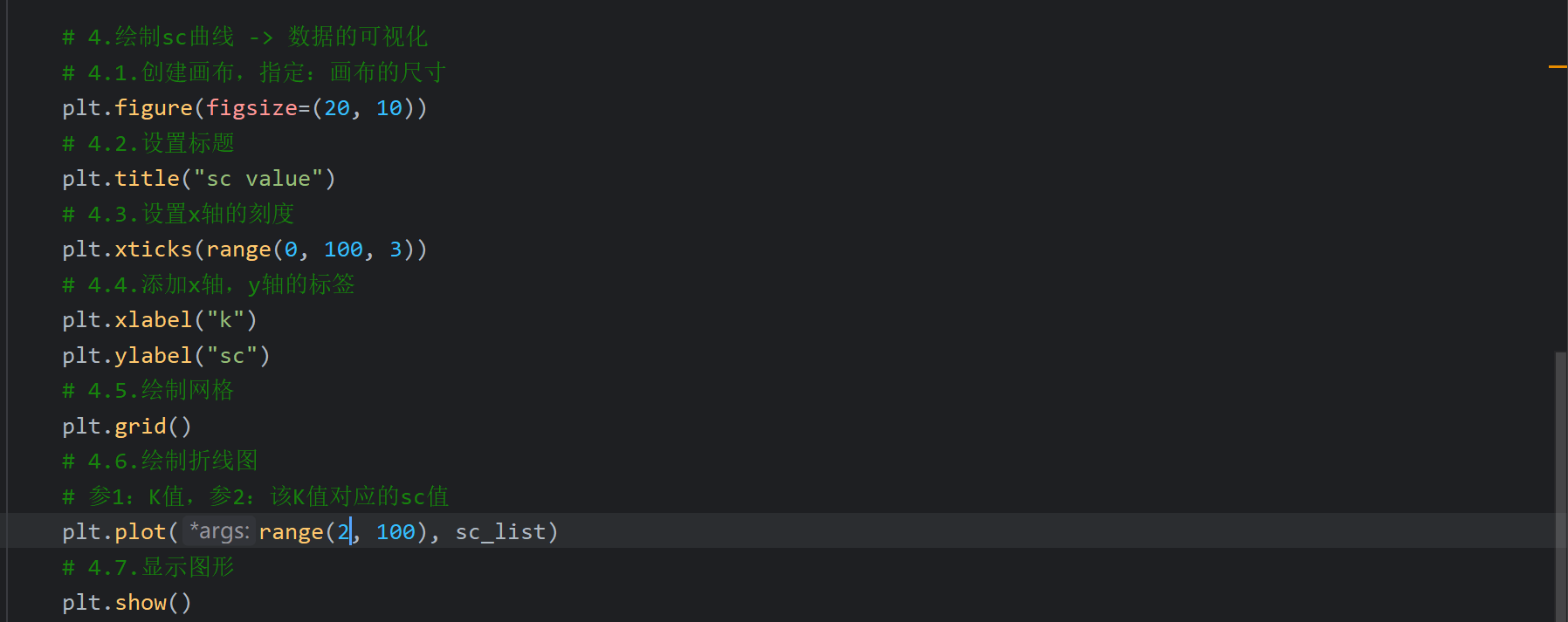
4、sc,ch轮廓系数_代码演示
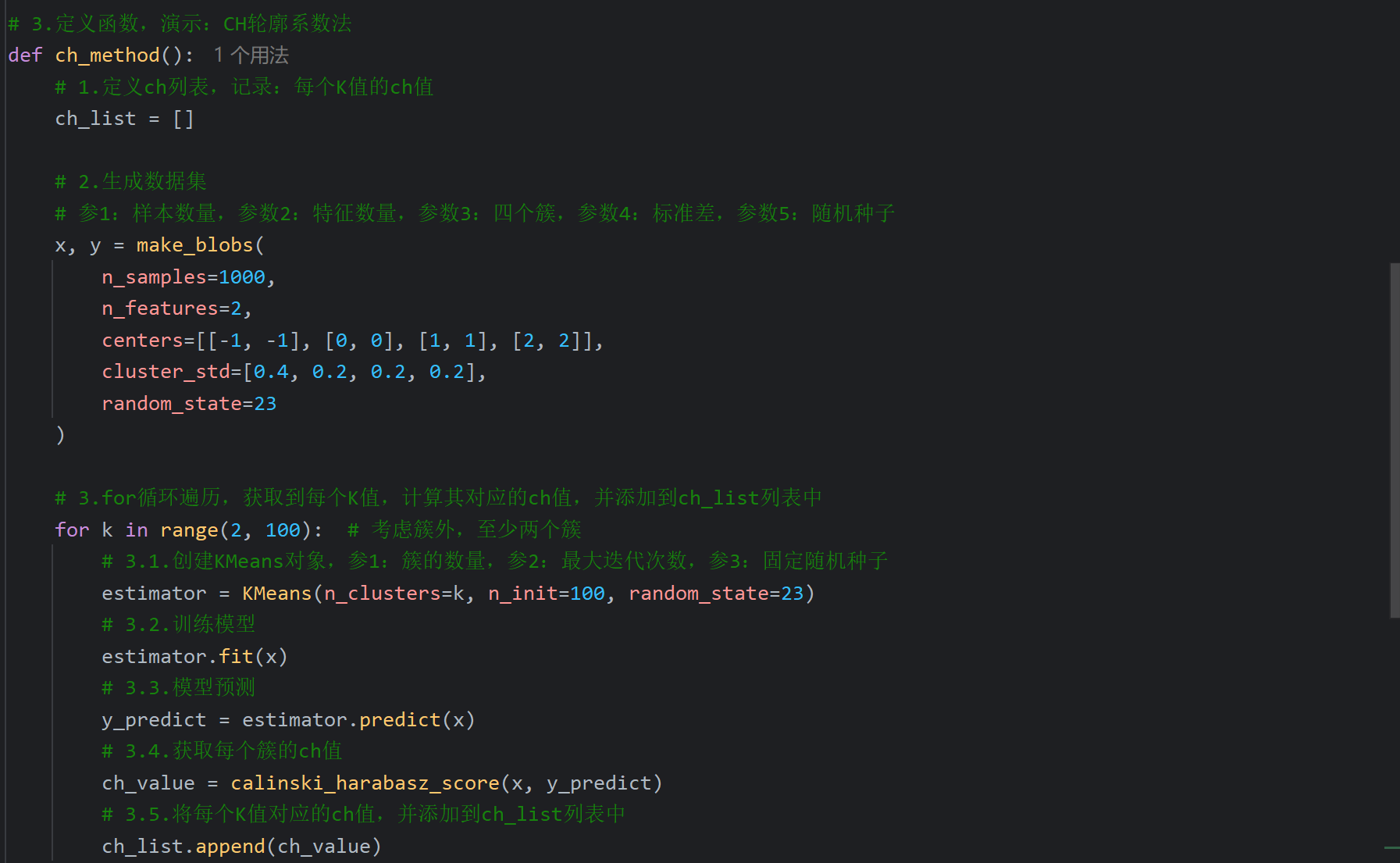
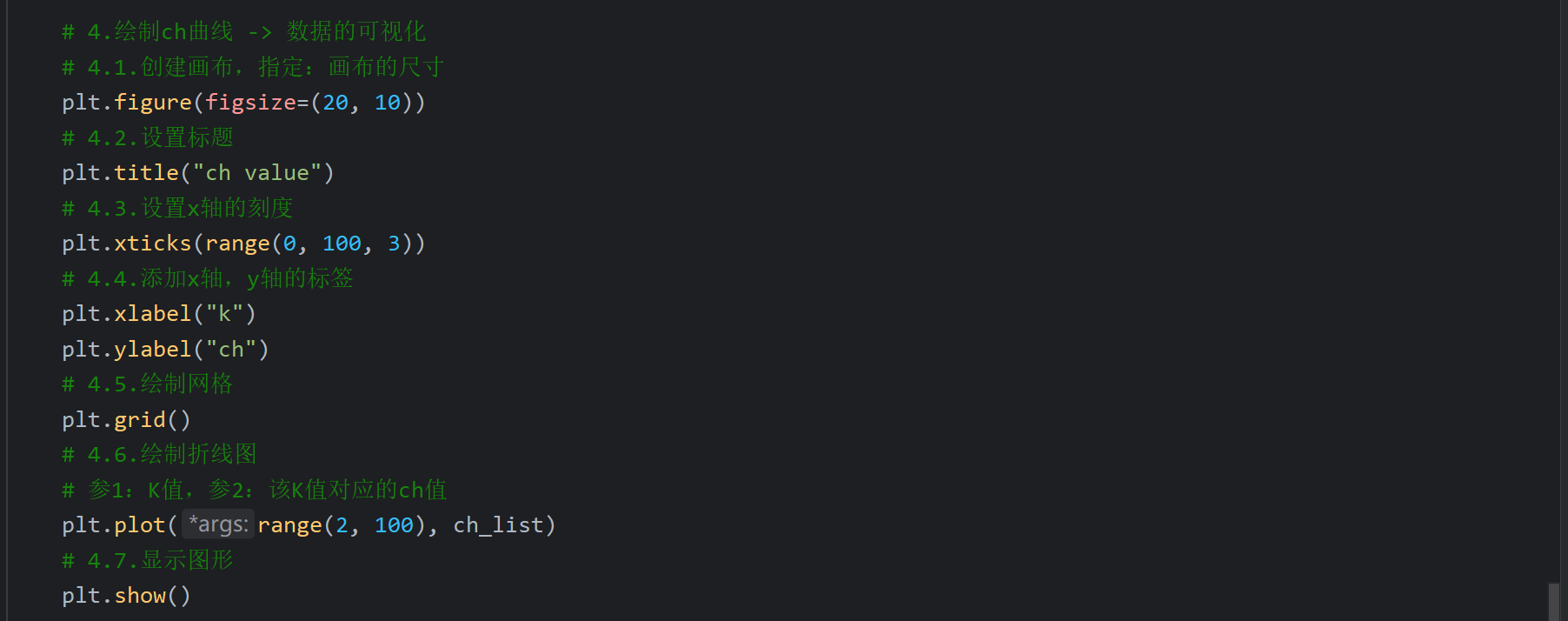
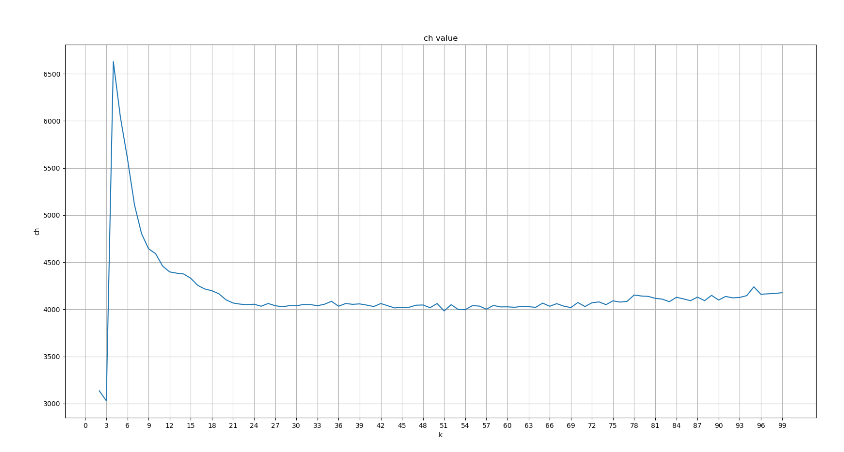


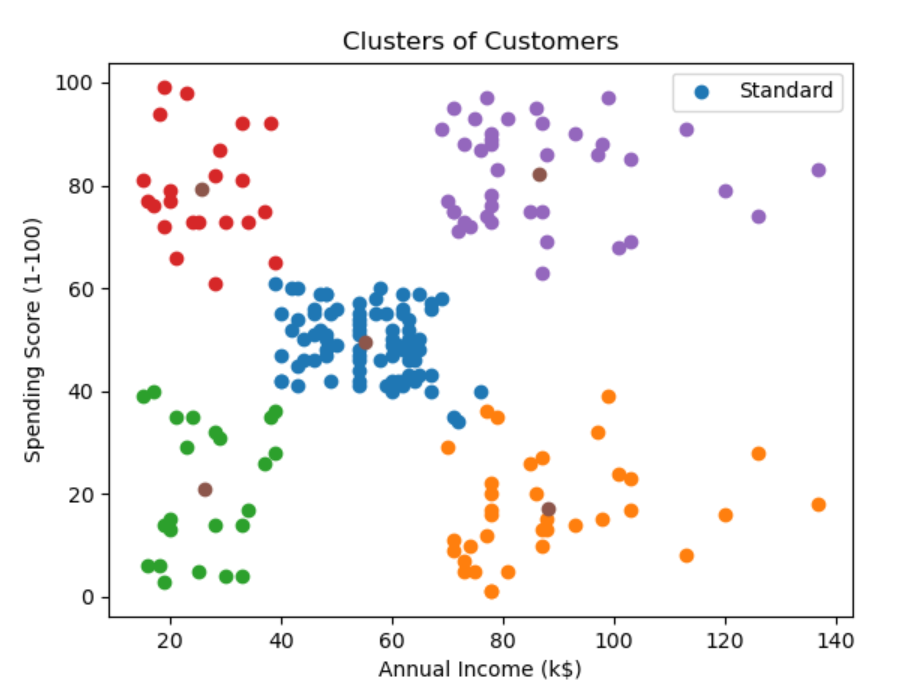
5、用户分群_求解最优K值
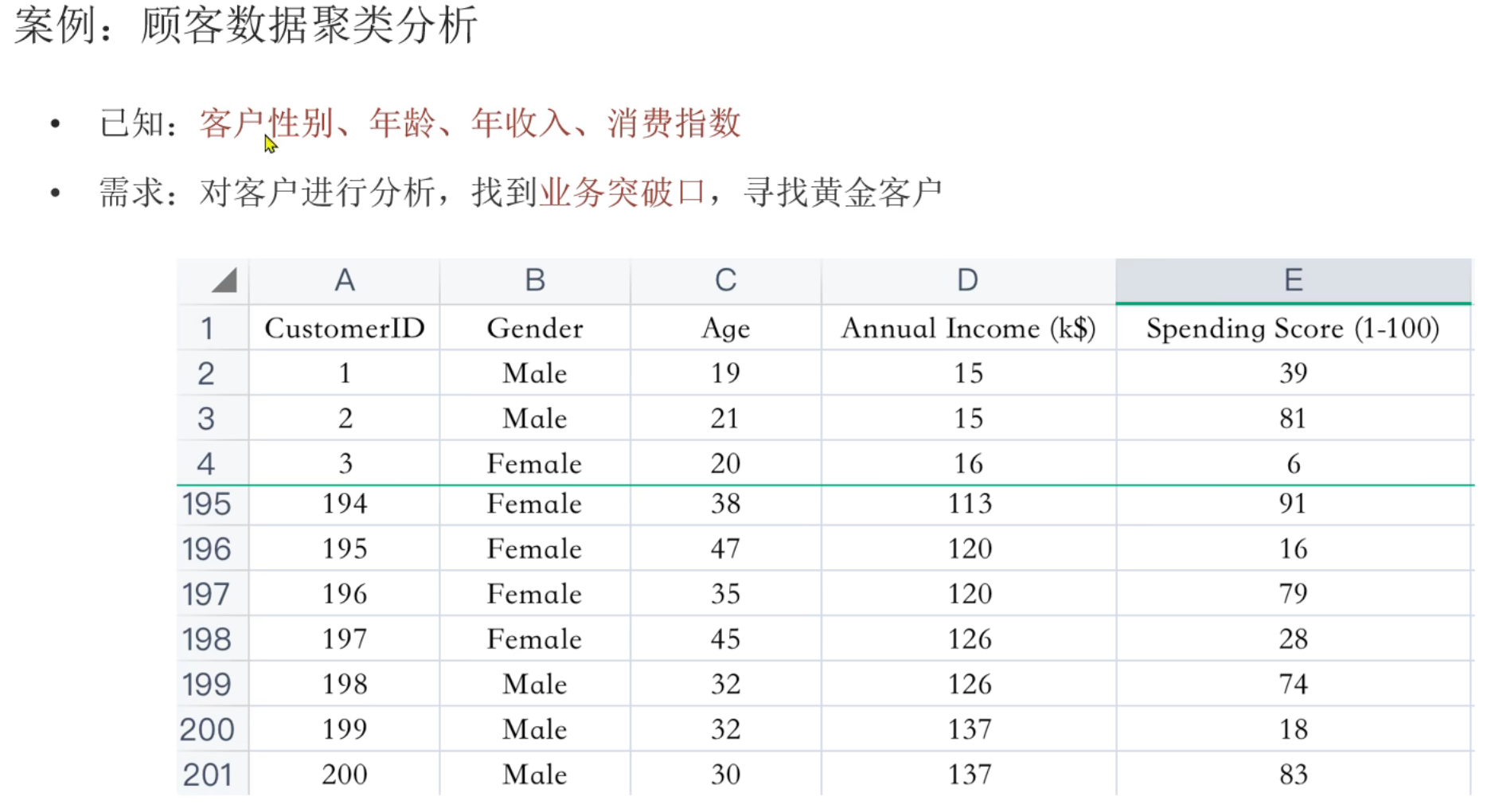
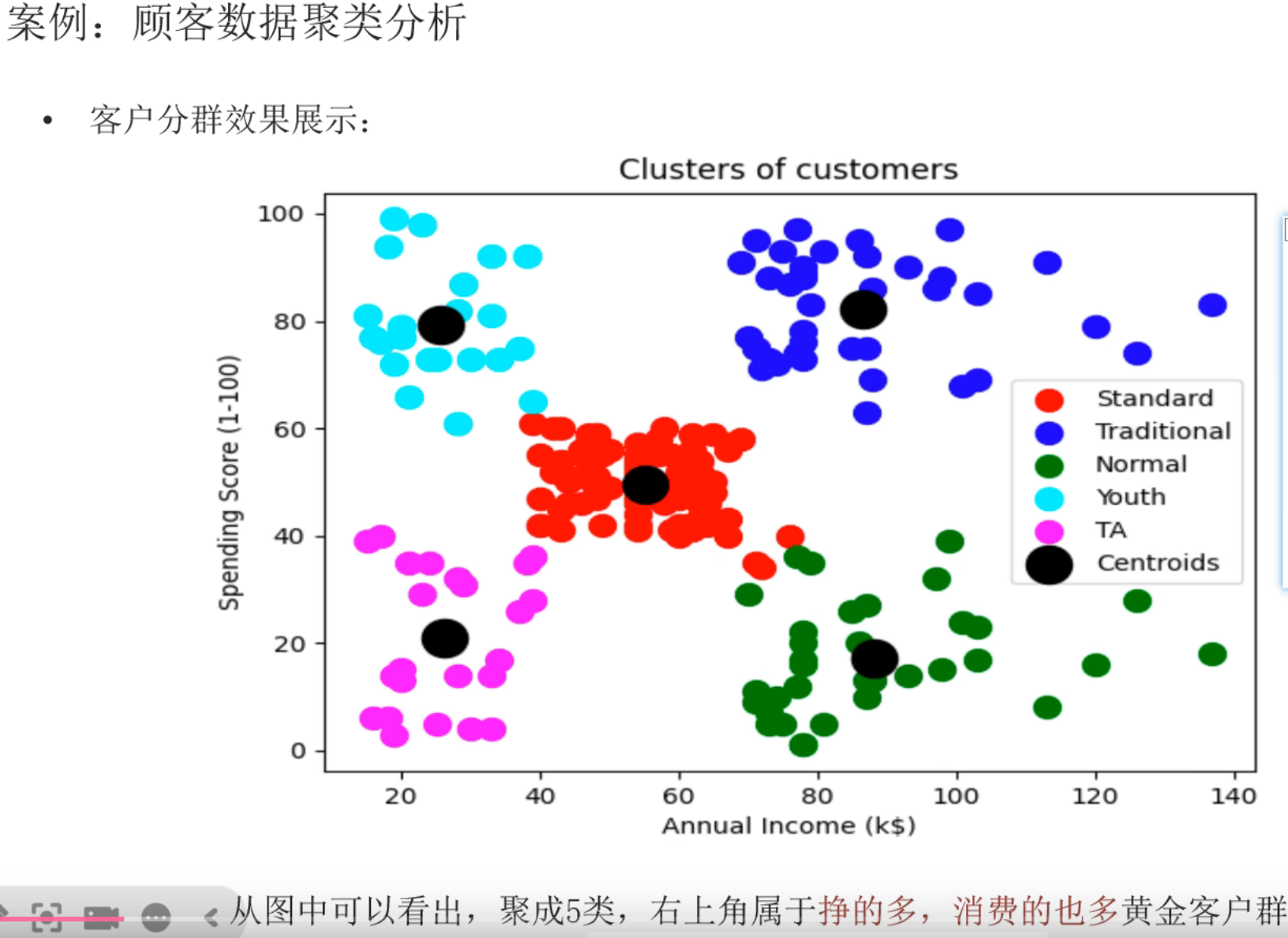
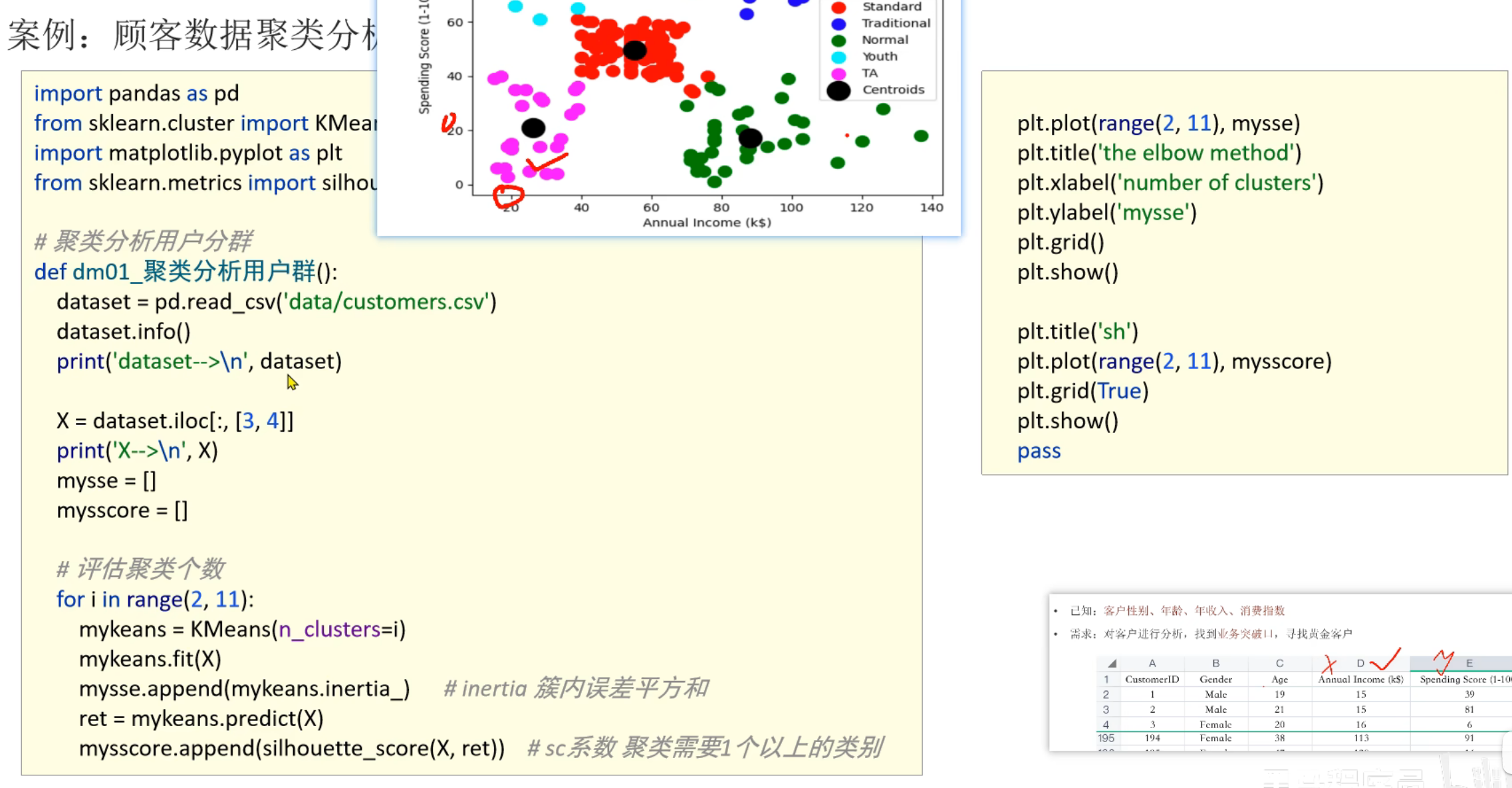
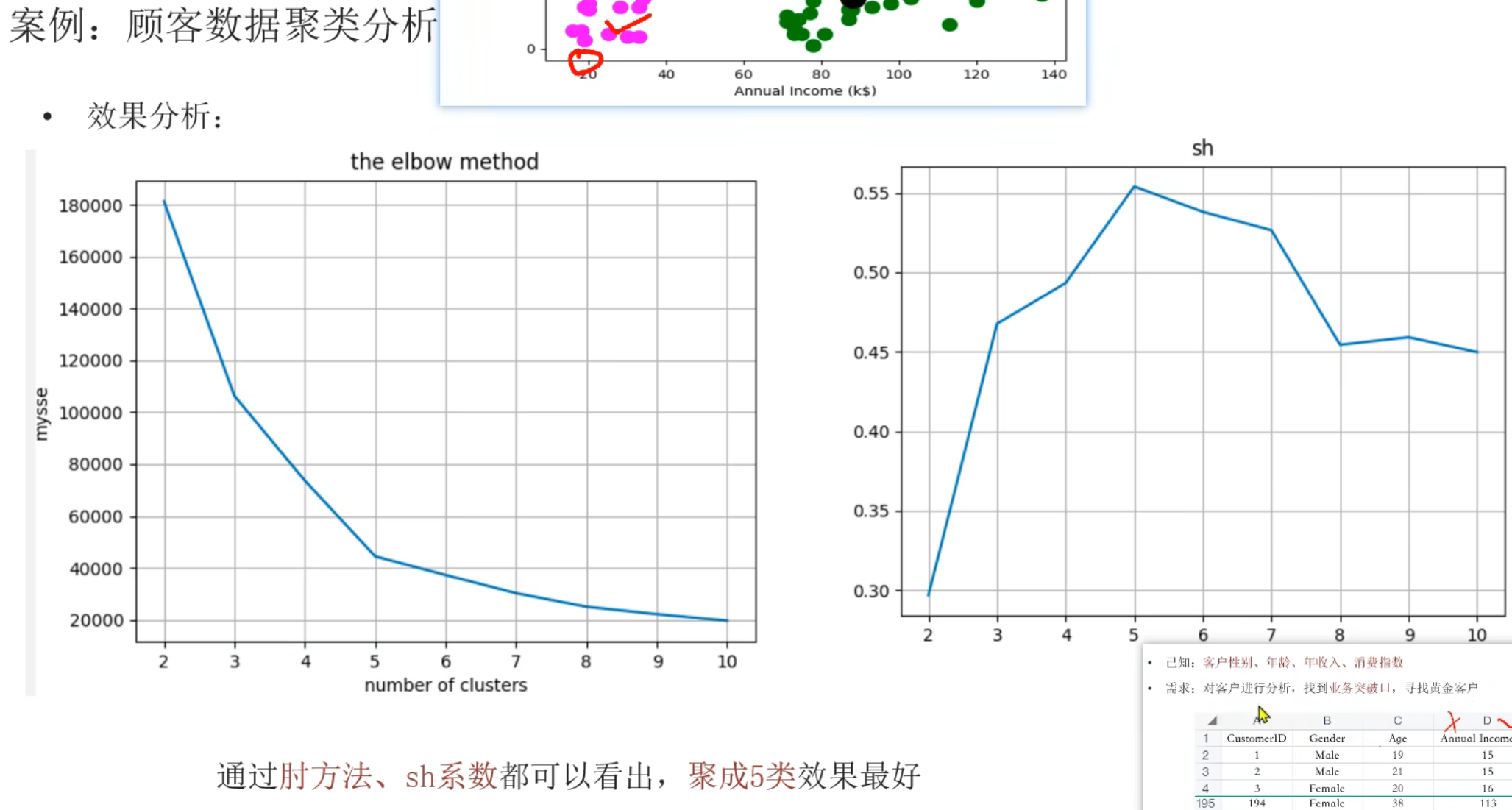
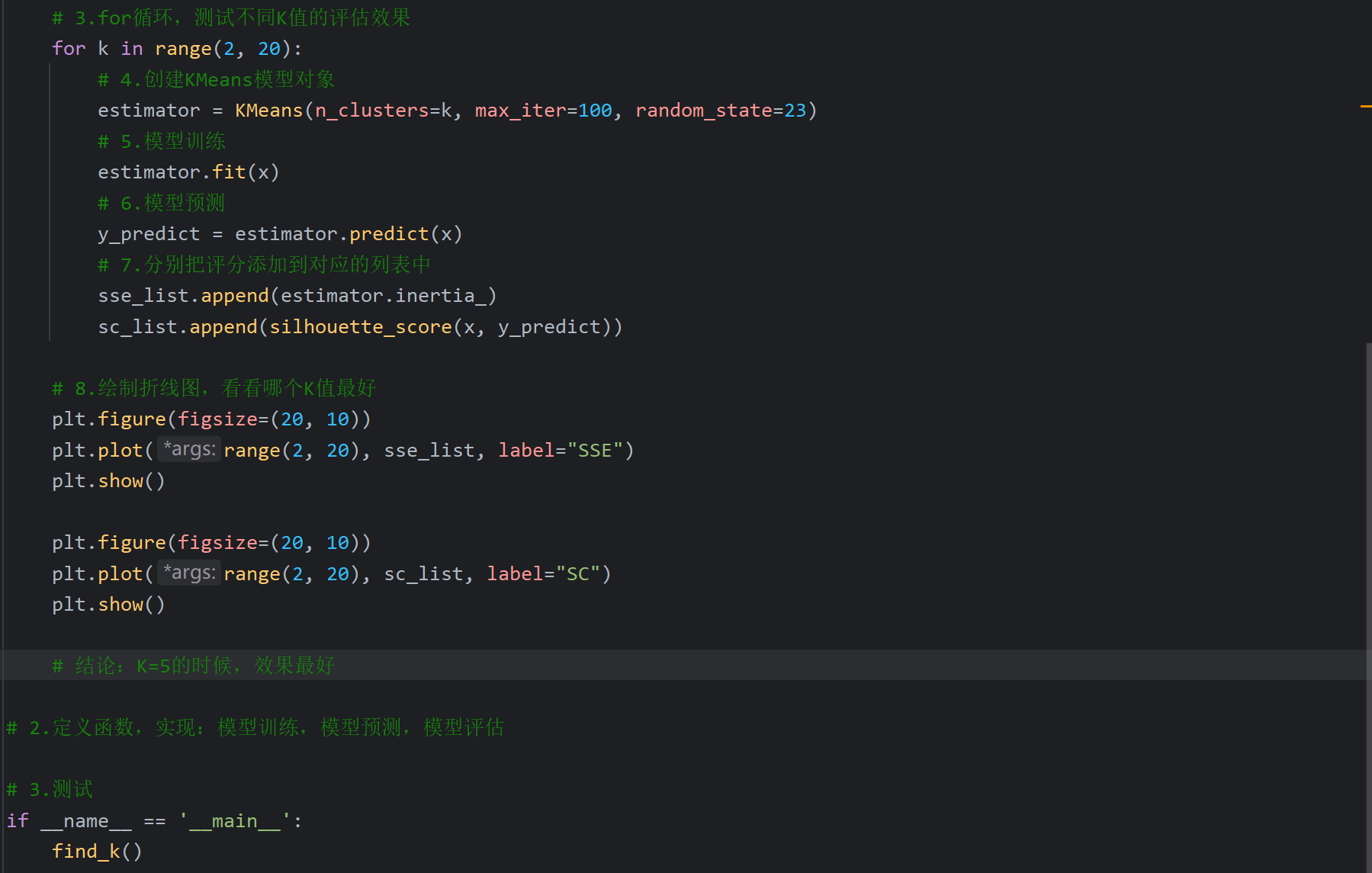
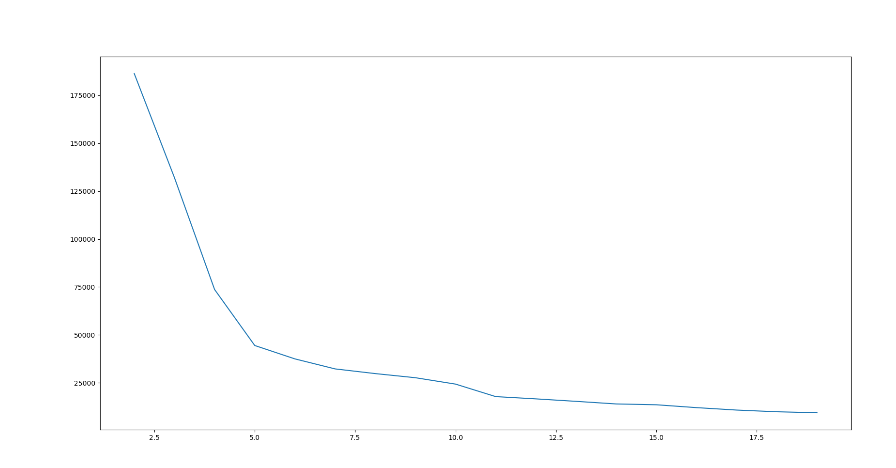
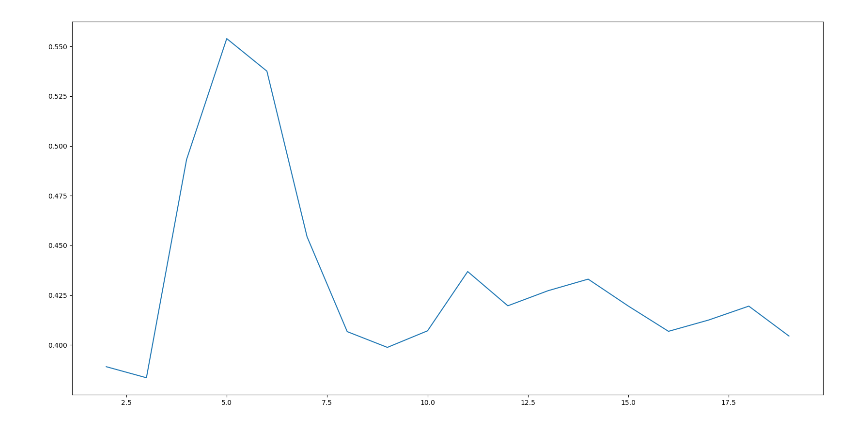
6、用户分群_代码实现

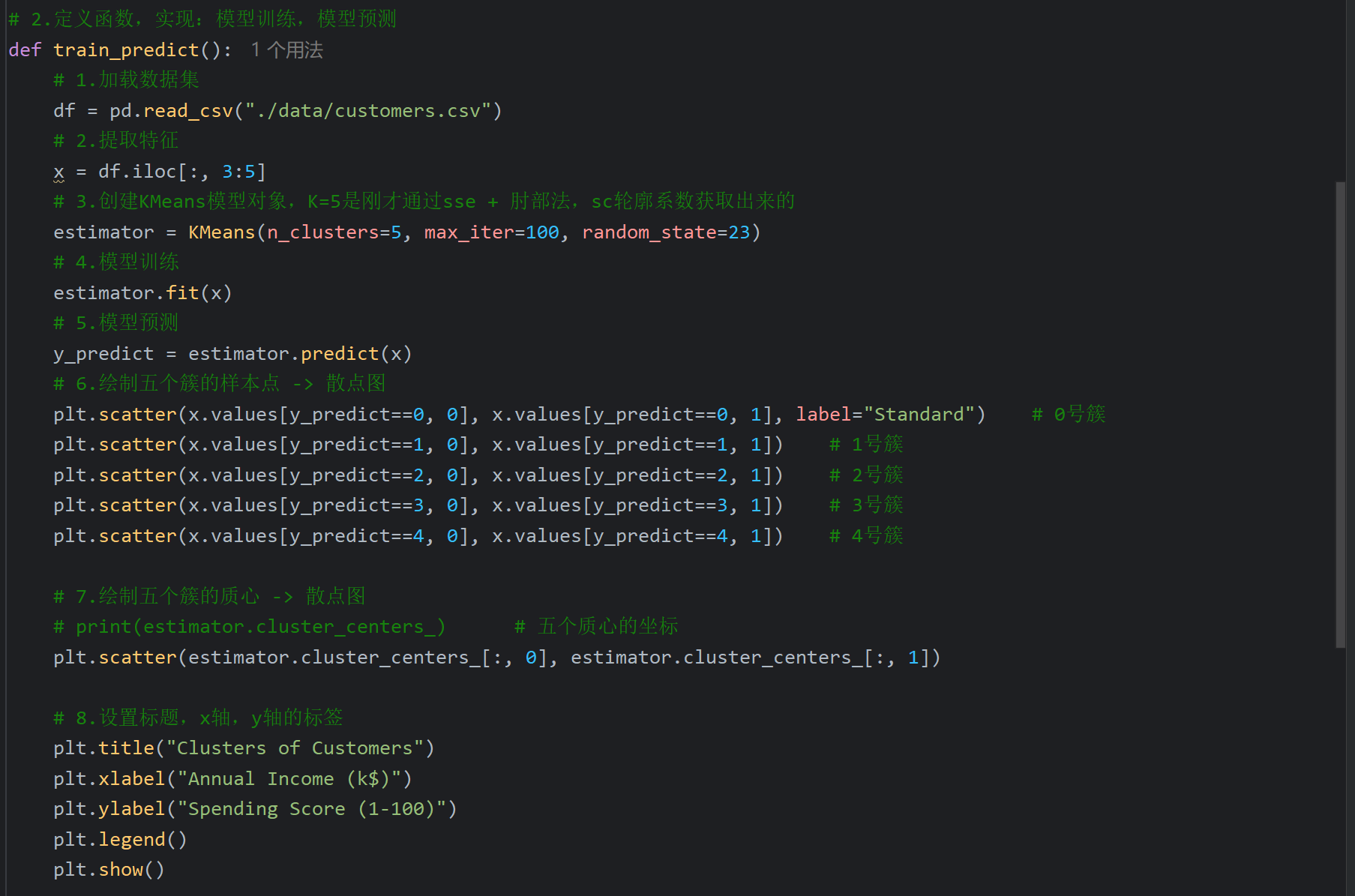
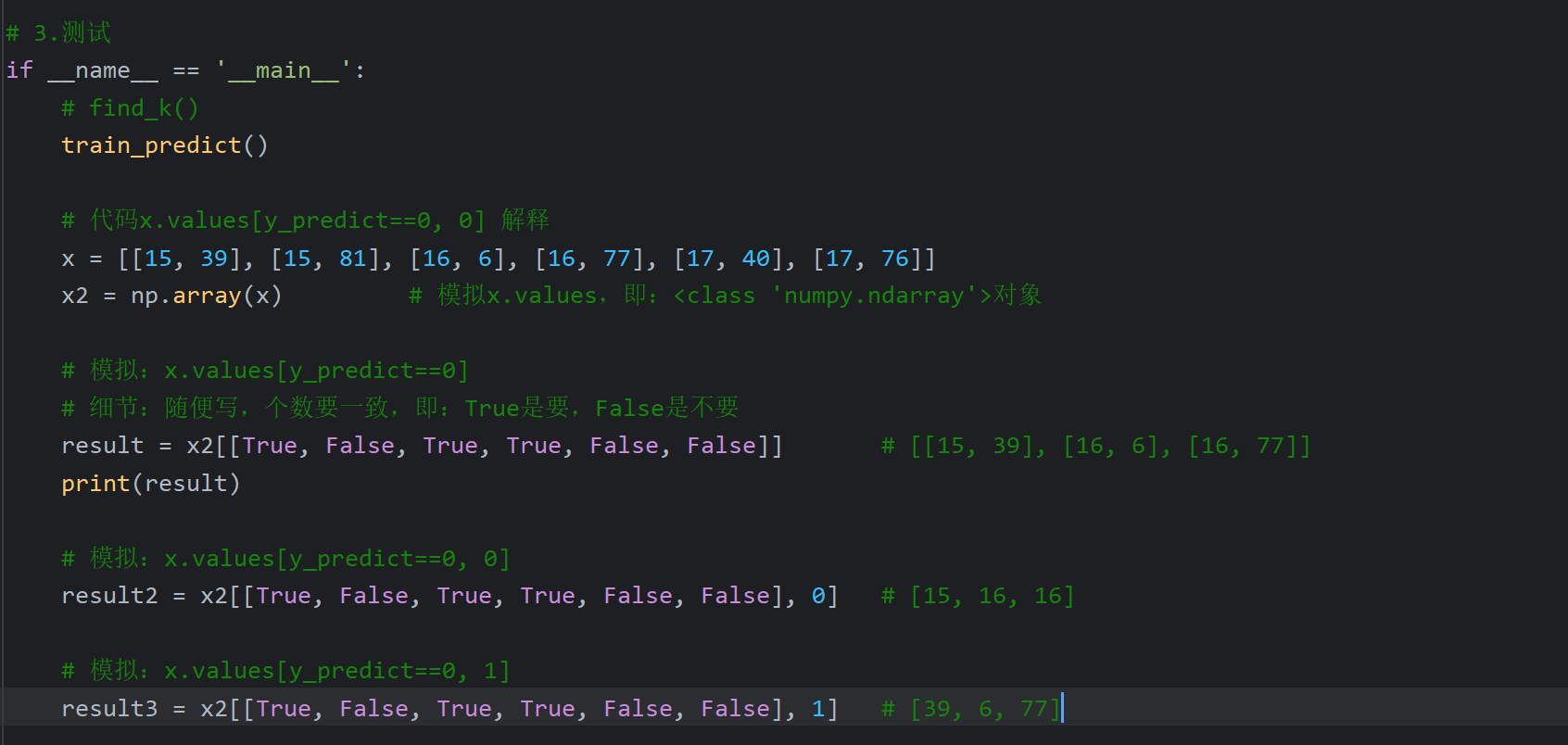
7、时序数据介绍
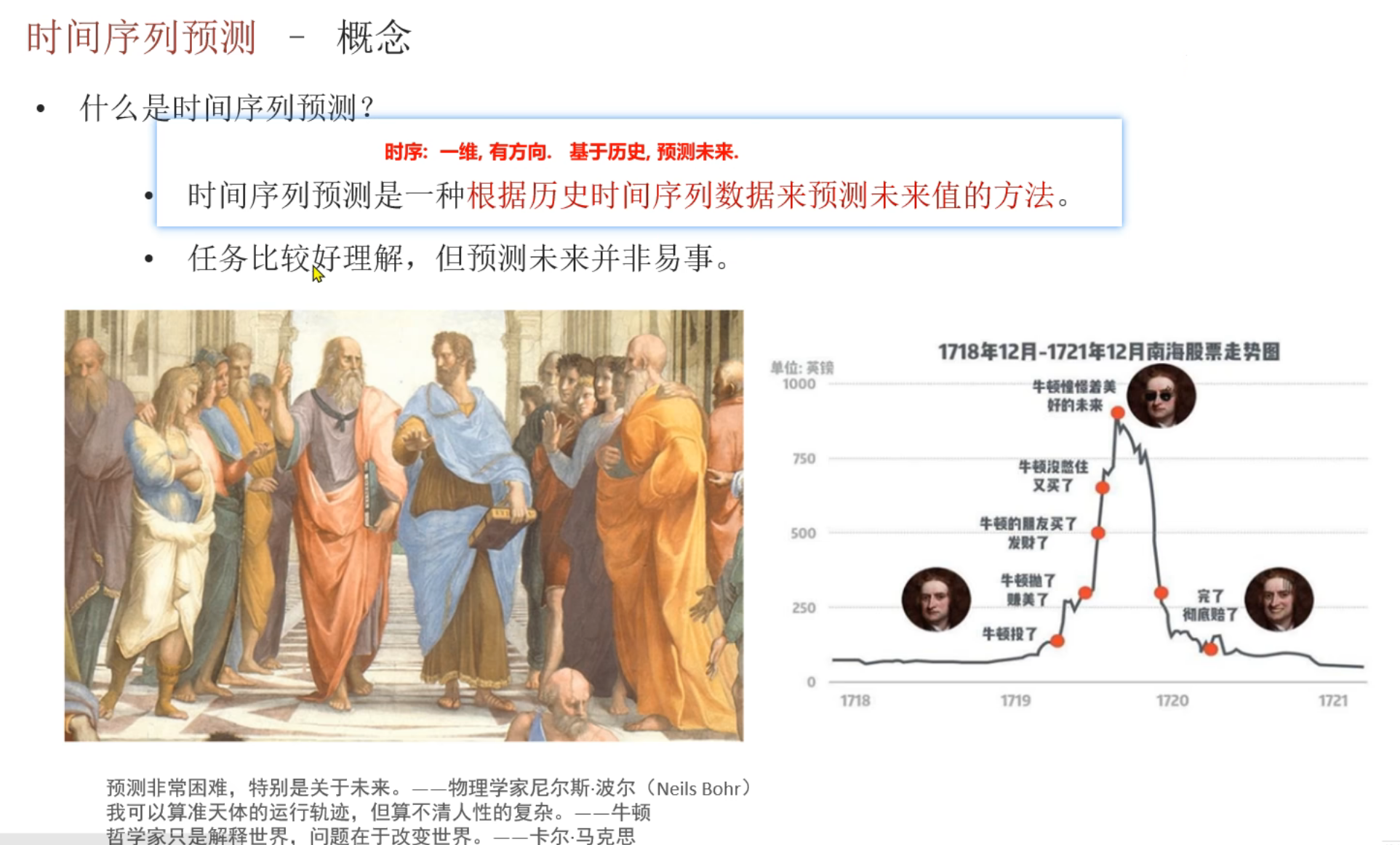
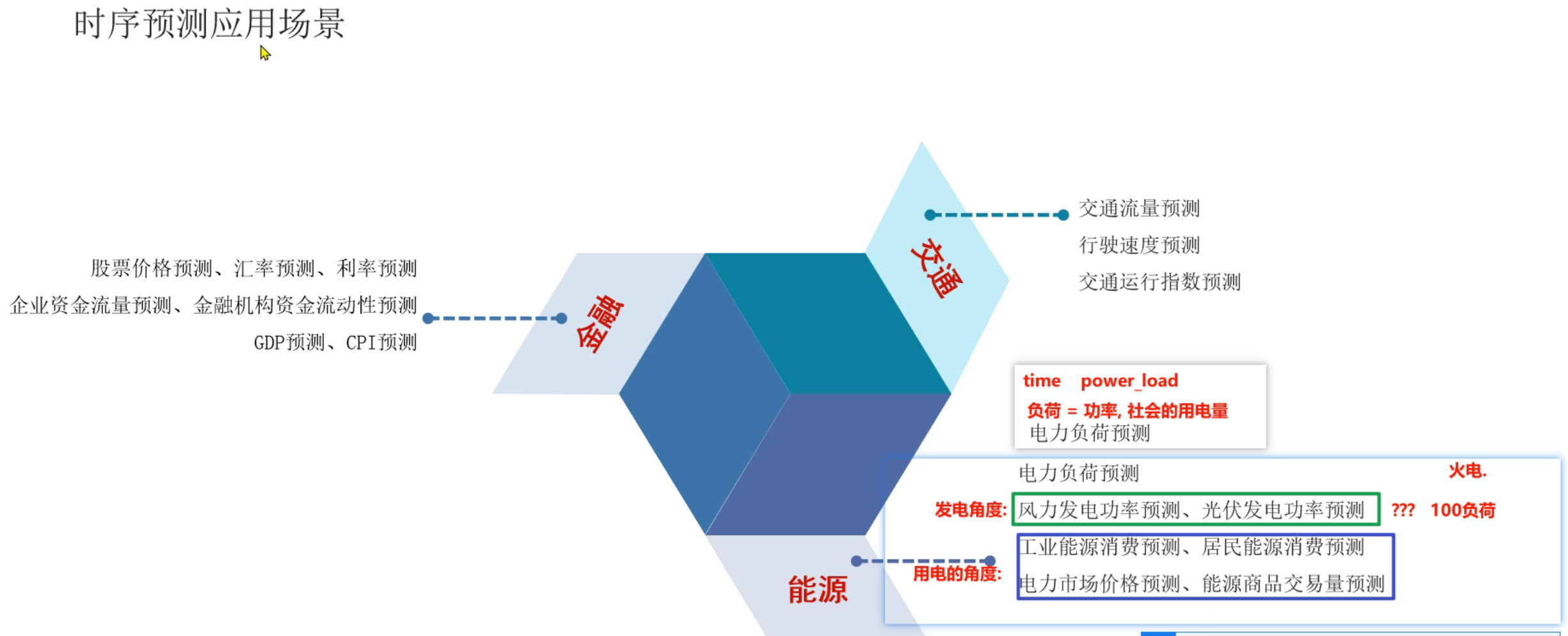
8、时序数据分类介绍
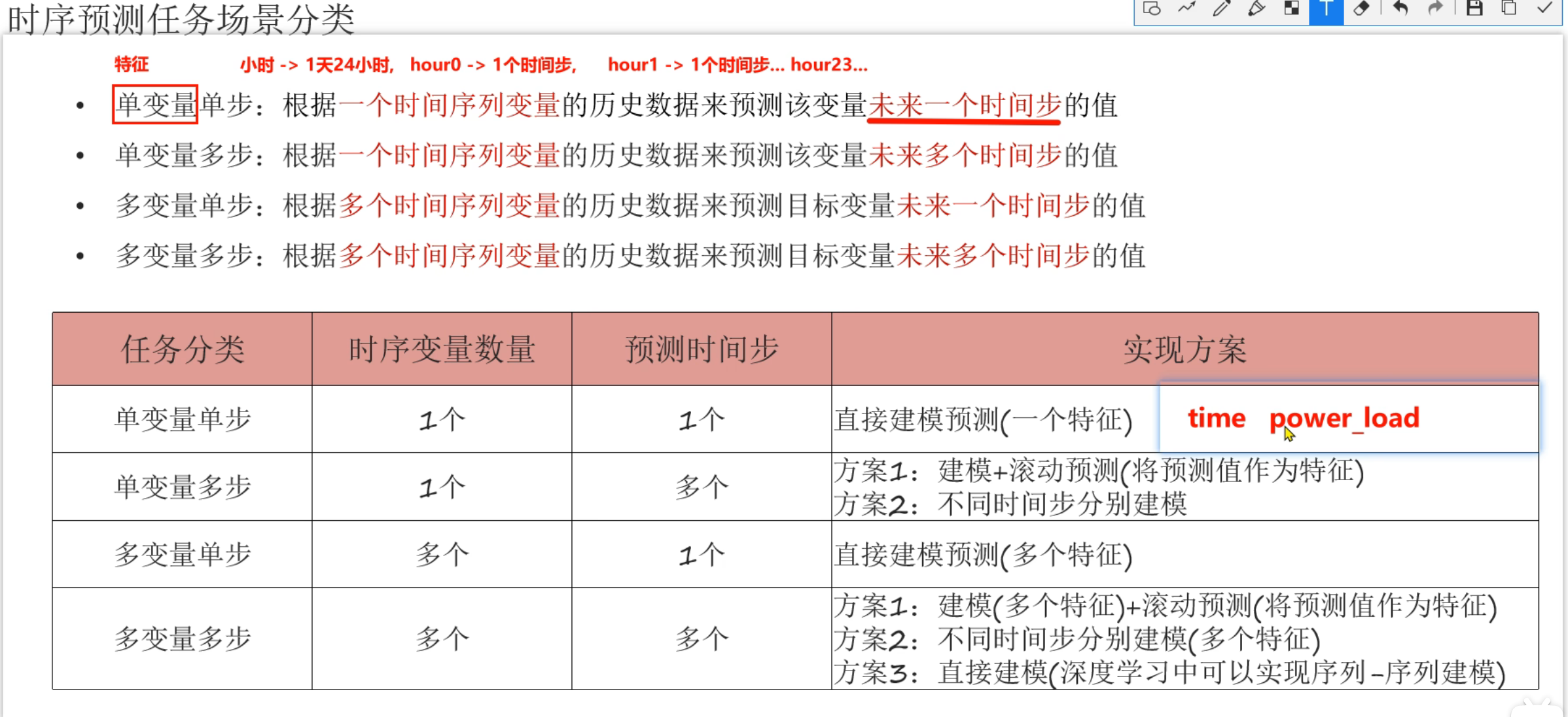
9、时序预测_算法介绍
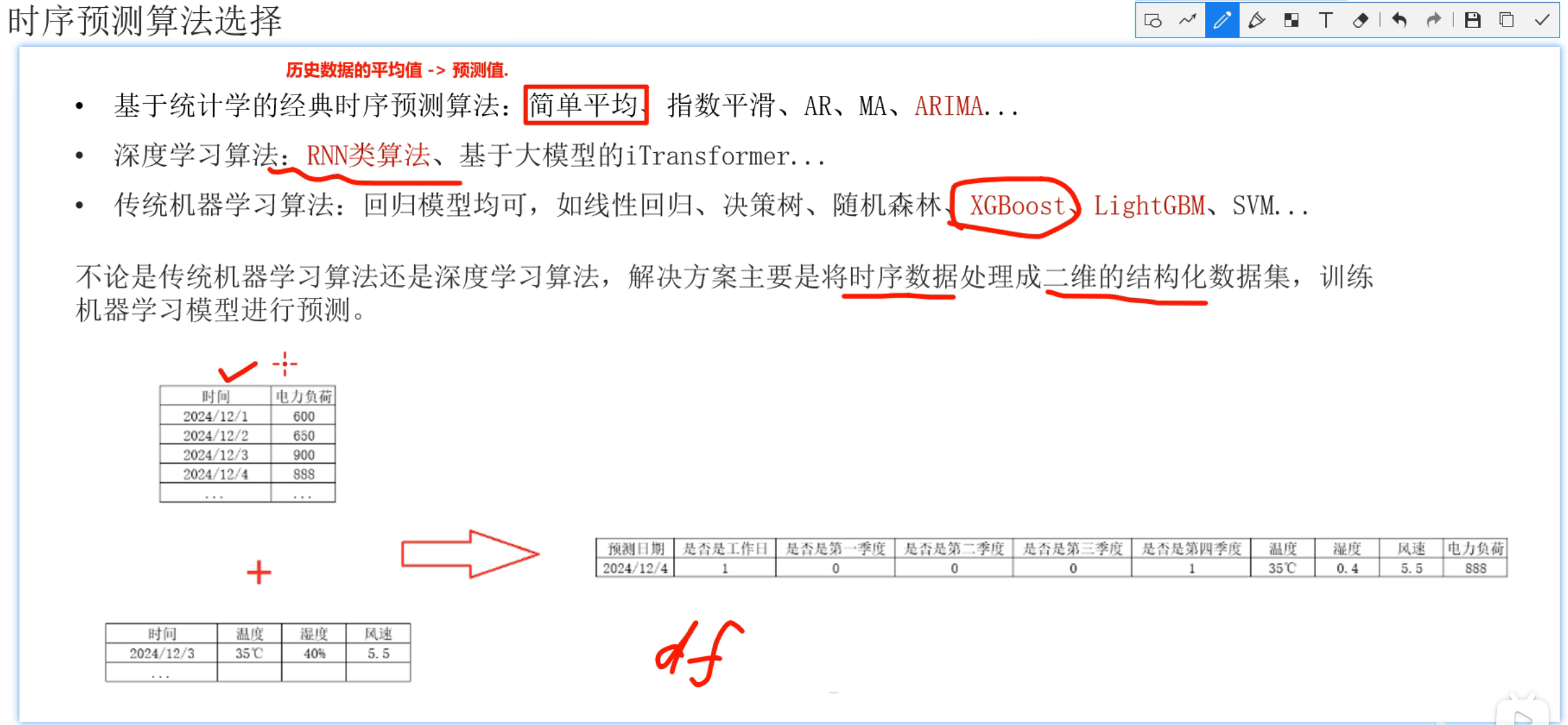



10、电力负荷预测案例_背景介绍


11、电力负荷预测案例_项目搭建


12、电力负荷预测案例_日志功能介绍
13、电力负荷预测案例_数据预处理

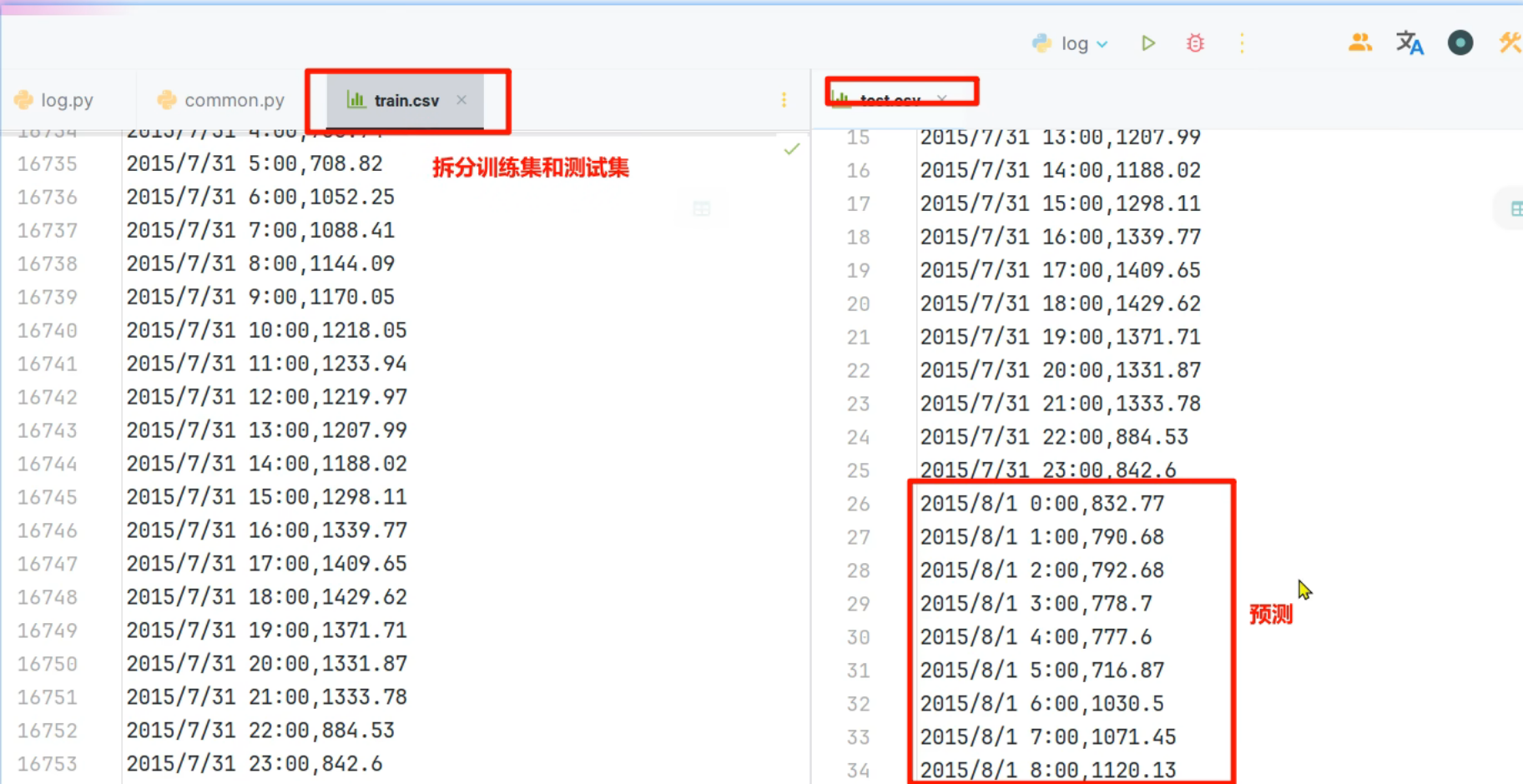
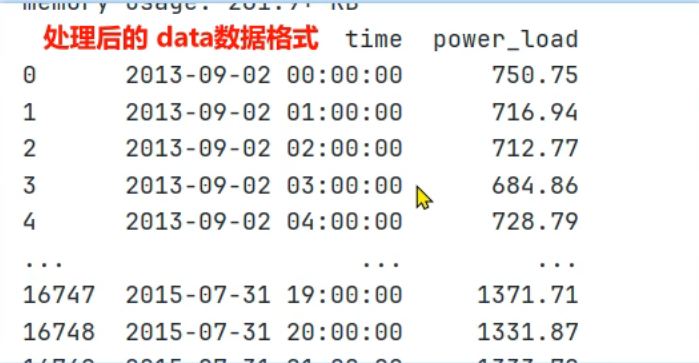
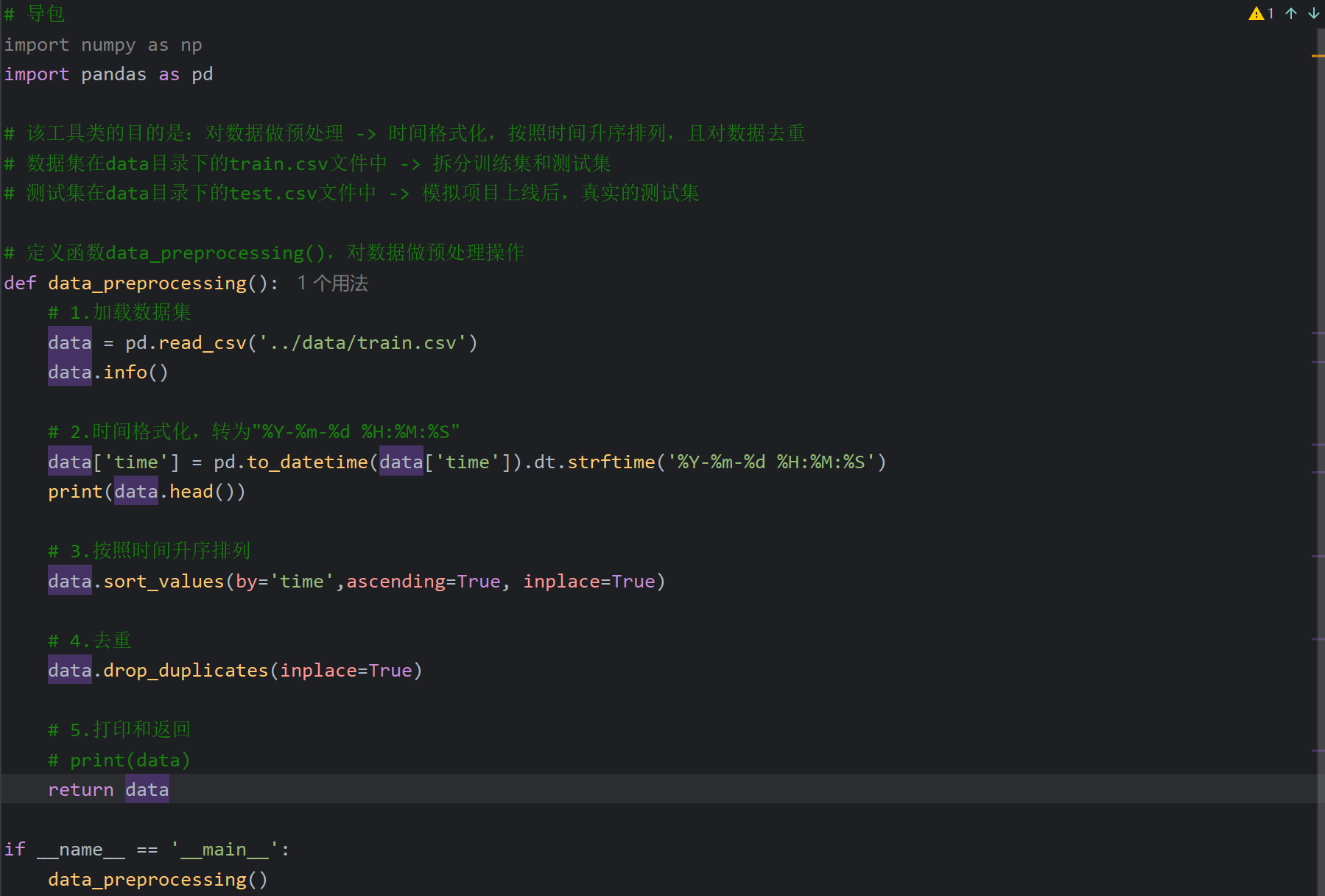
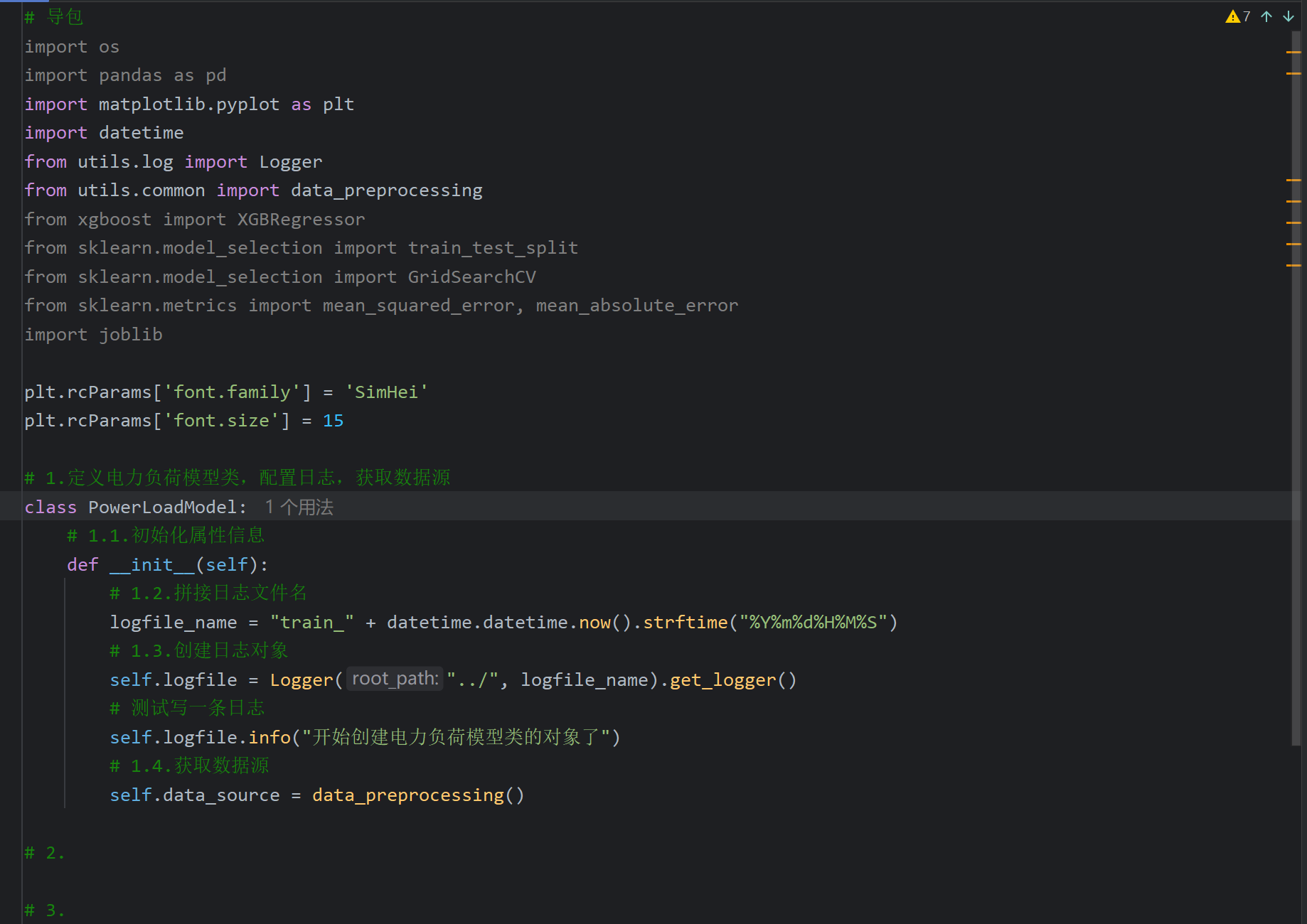
14、电力负荷预测案例_定义电力负荷模型类
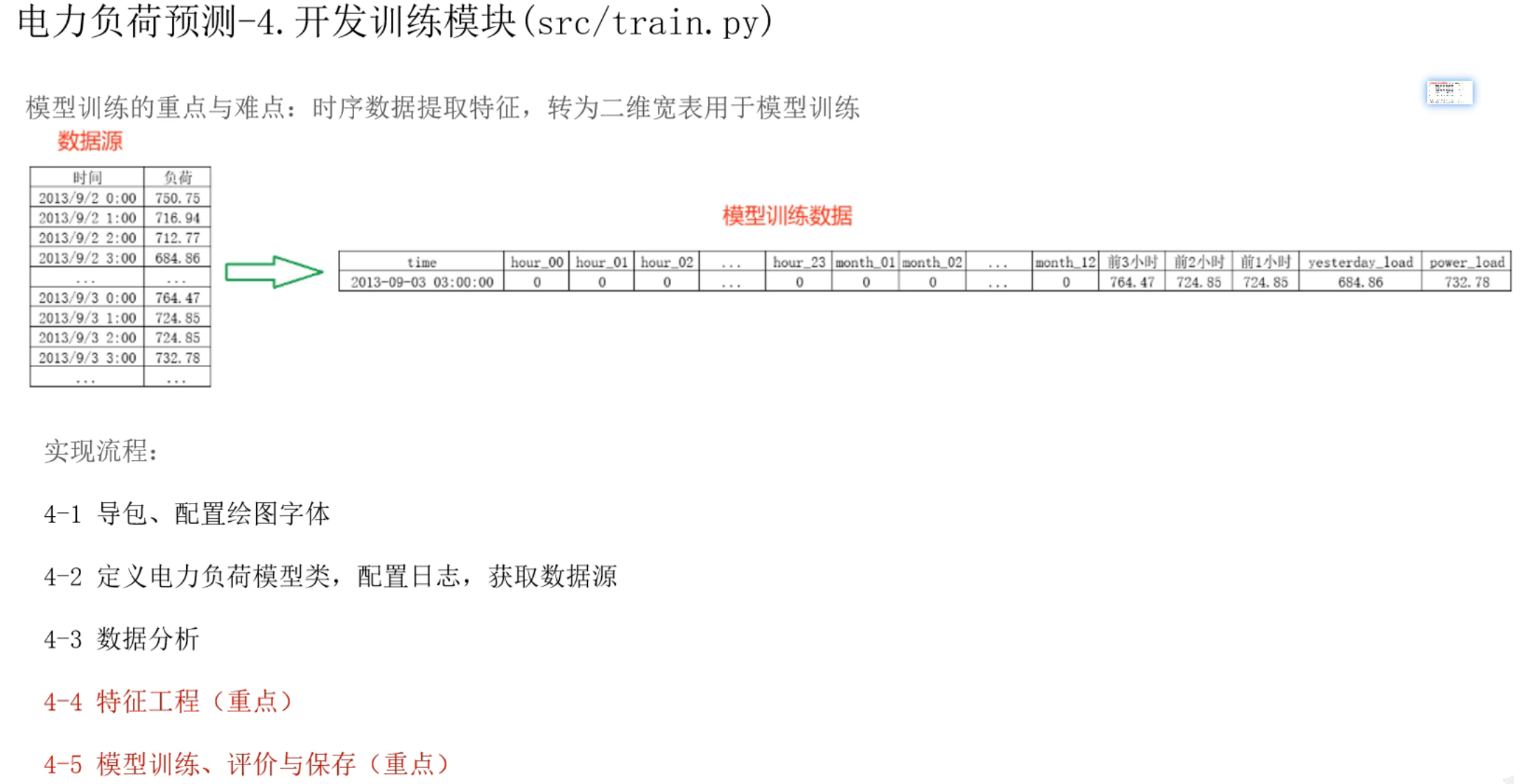


这里多提一嘴,之前我一直都是按照自己的方式来创建目录的。如下图day1啥的都是在D:/25heima-AI-LargeModel-MachineLearning-code下直接创建,所以一开始的load_predict_project我也是直接复制放到和day08平级的位置了,后面死活from utils import Logger爆红而且拷打ai半天一直解决不了(ai一直叫我尝试用os、sys啥的配根目录路径啥的)。最后我回去翻了一下22年的Python基础视频(因为我印象中那里有讲解自定义包),然后发现正确的应该就是得按老师那种方式,相当于创建一个新项目才行,如下我新建一个项目而不是在原来项目加目录就解决了


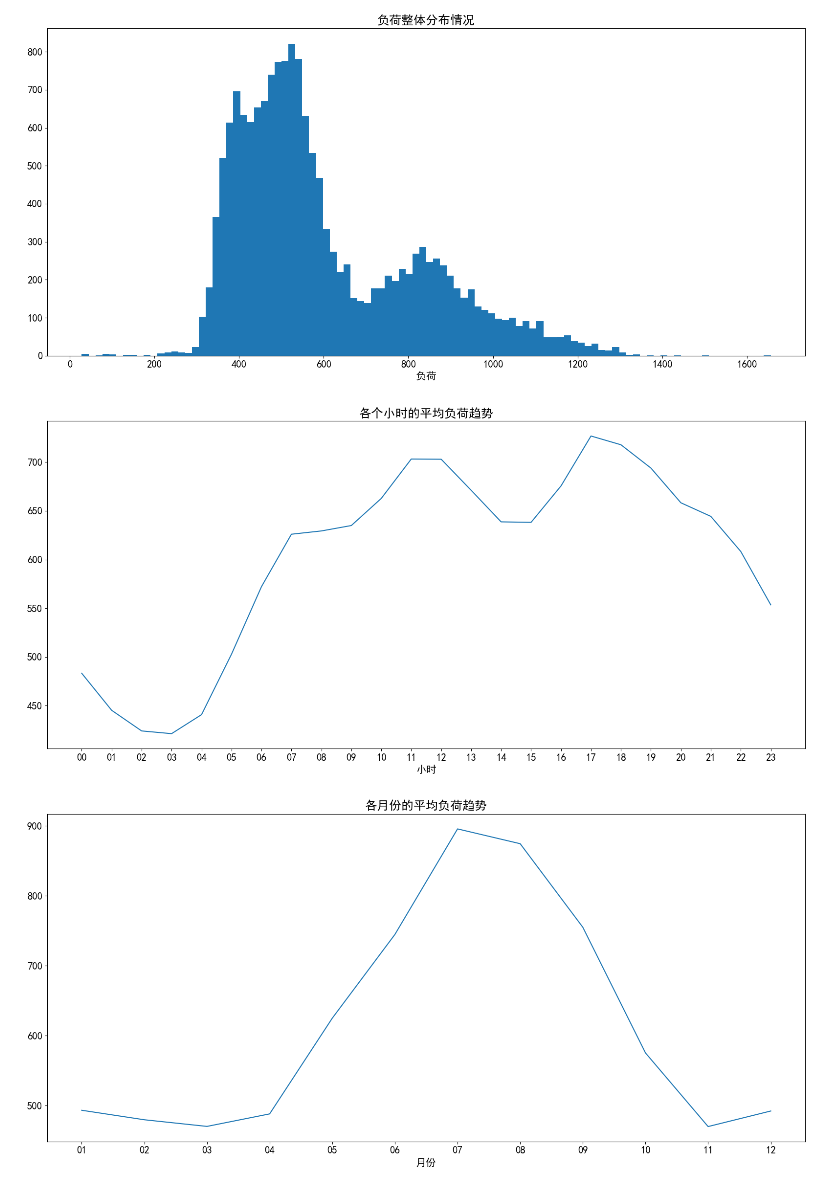
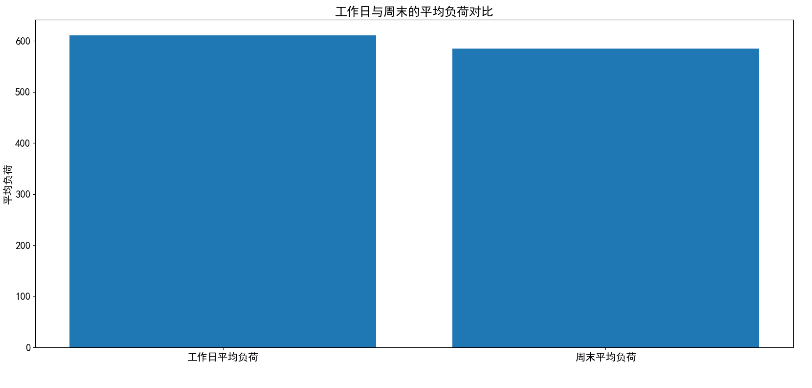
15、电力负荷预测案例_查看数据整体和各小时负荷分布
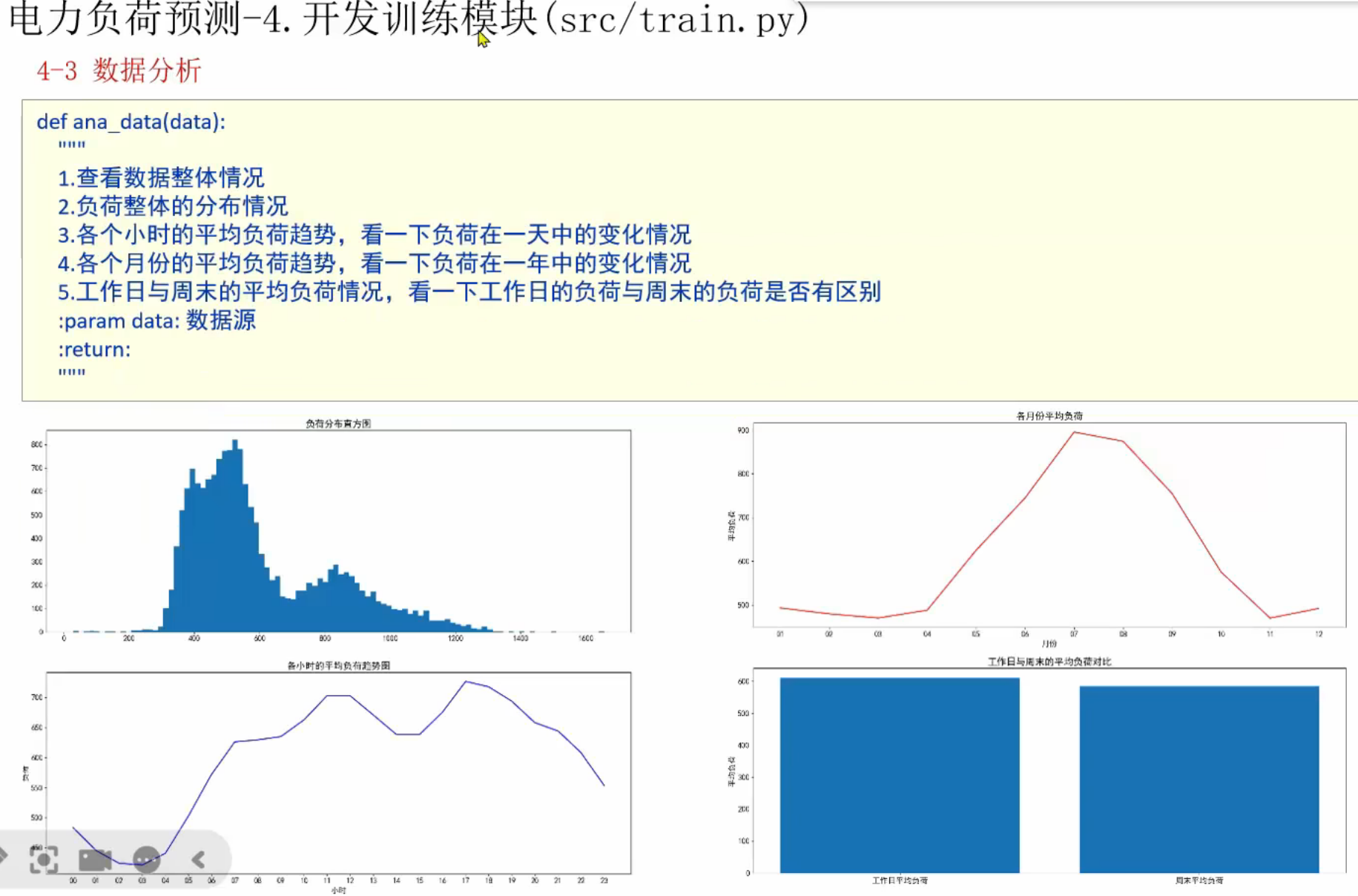
各月份的平均负荷趋势和老师写的各个小时的平均负荷趋势一样,如下图将索引5、6的部分截取出来充当月份
然后到此B站原视频就完结了,大概率是遗漏后面的视频。不过提供了完整的项目代码资料,所以后续我就结合ai和资料自行补充代码,同时会添加更多的注释,有需要的可以参考我的代码
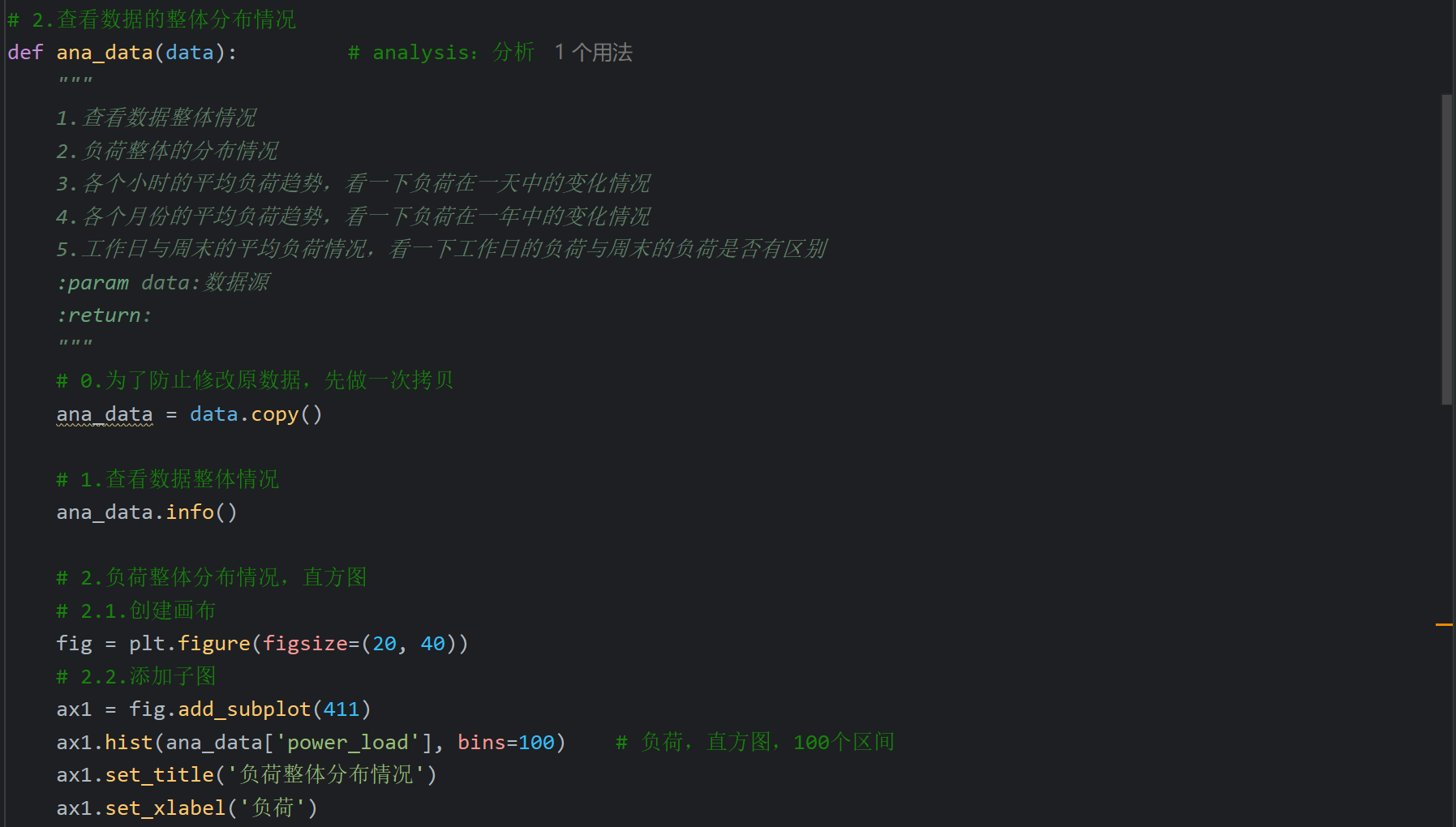
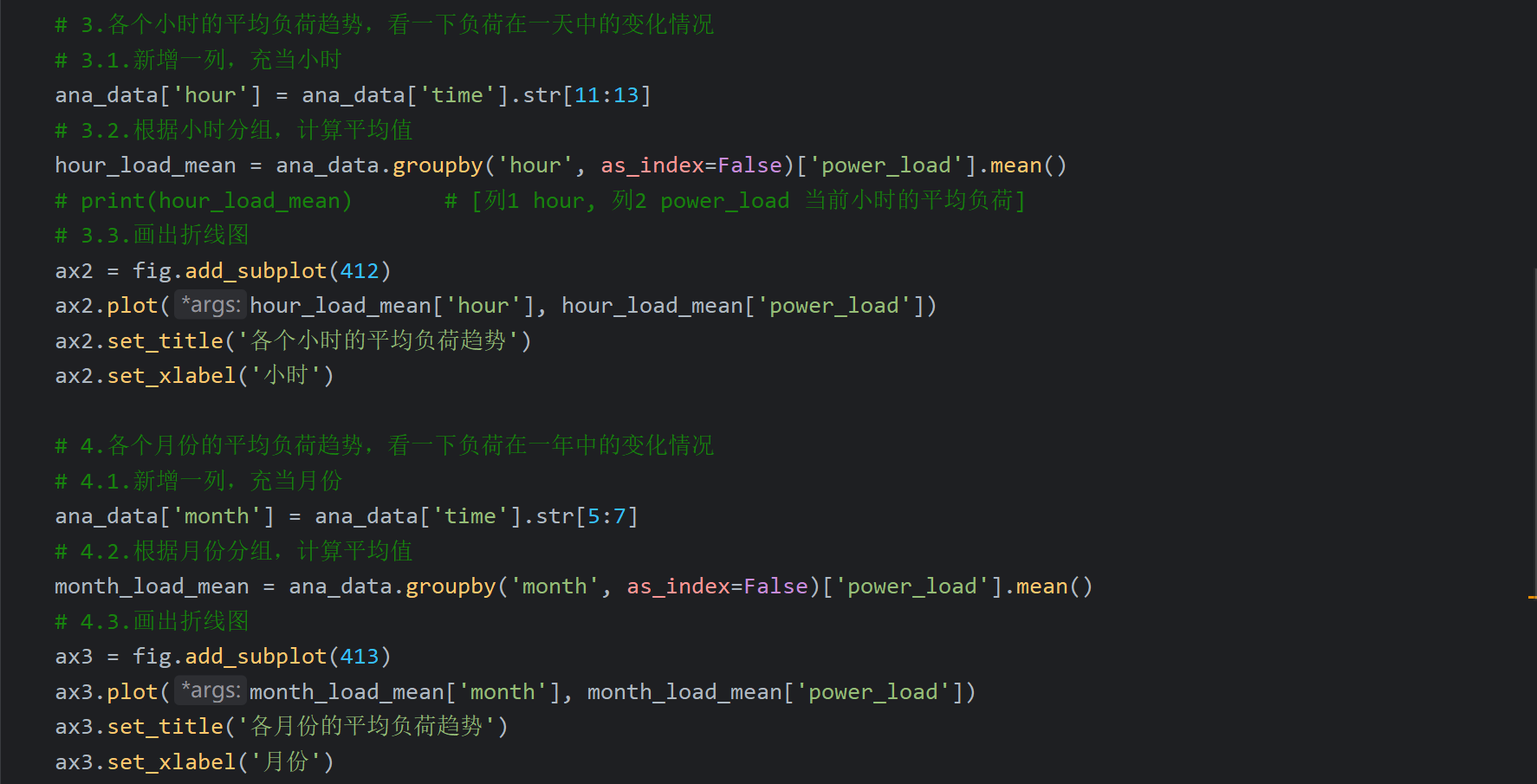
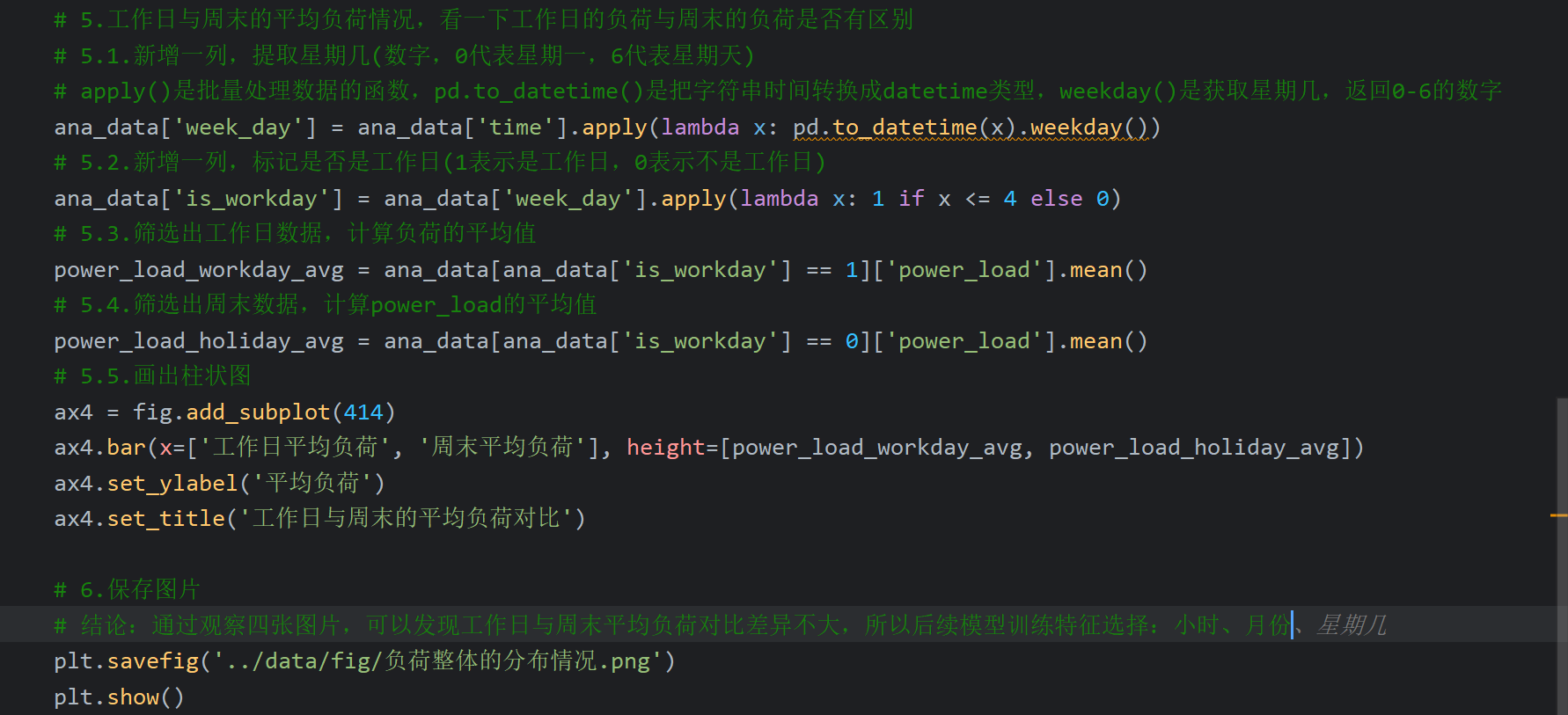

由于四个画出的图挤在一张图片中,所以在PyCharm中显示会比较小,不过放大看还是很清晰的。如果想得到够大且清晰的图片,可以打开项目文件夹下的图片打开,会比PyCharm更清晰且好放大
16、自己后补的内容_特征工程
原B站视频遗漏了特征工程和后面的模型训练、评估,但是资料中有完整的项目代码,所以以下代码都是参考完整代码,我只是在原代码基础上看懂并加了一些注释
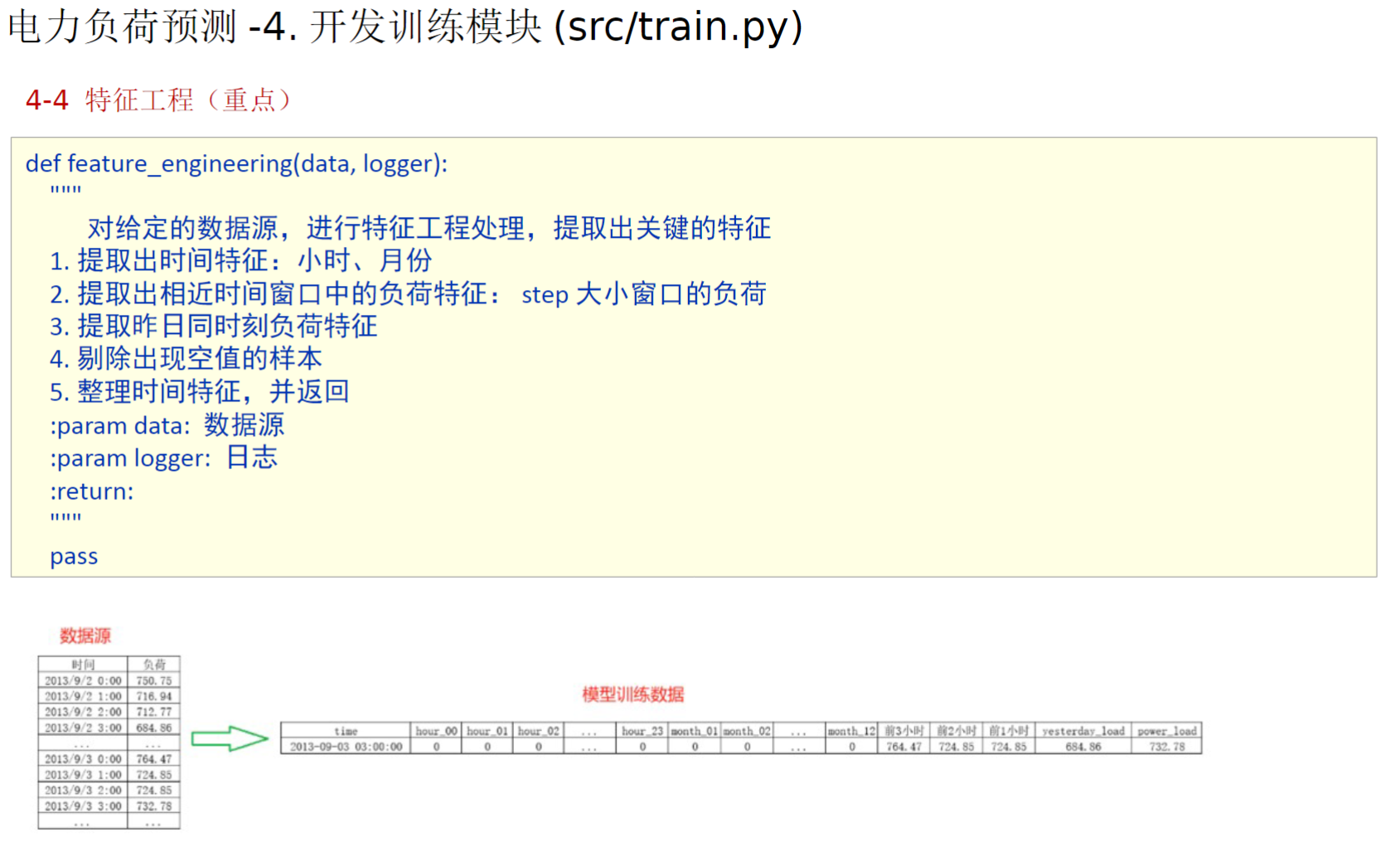
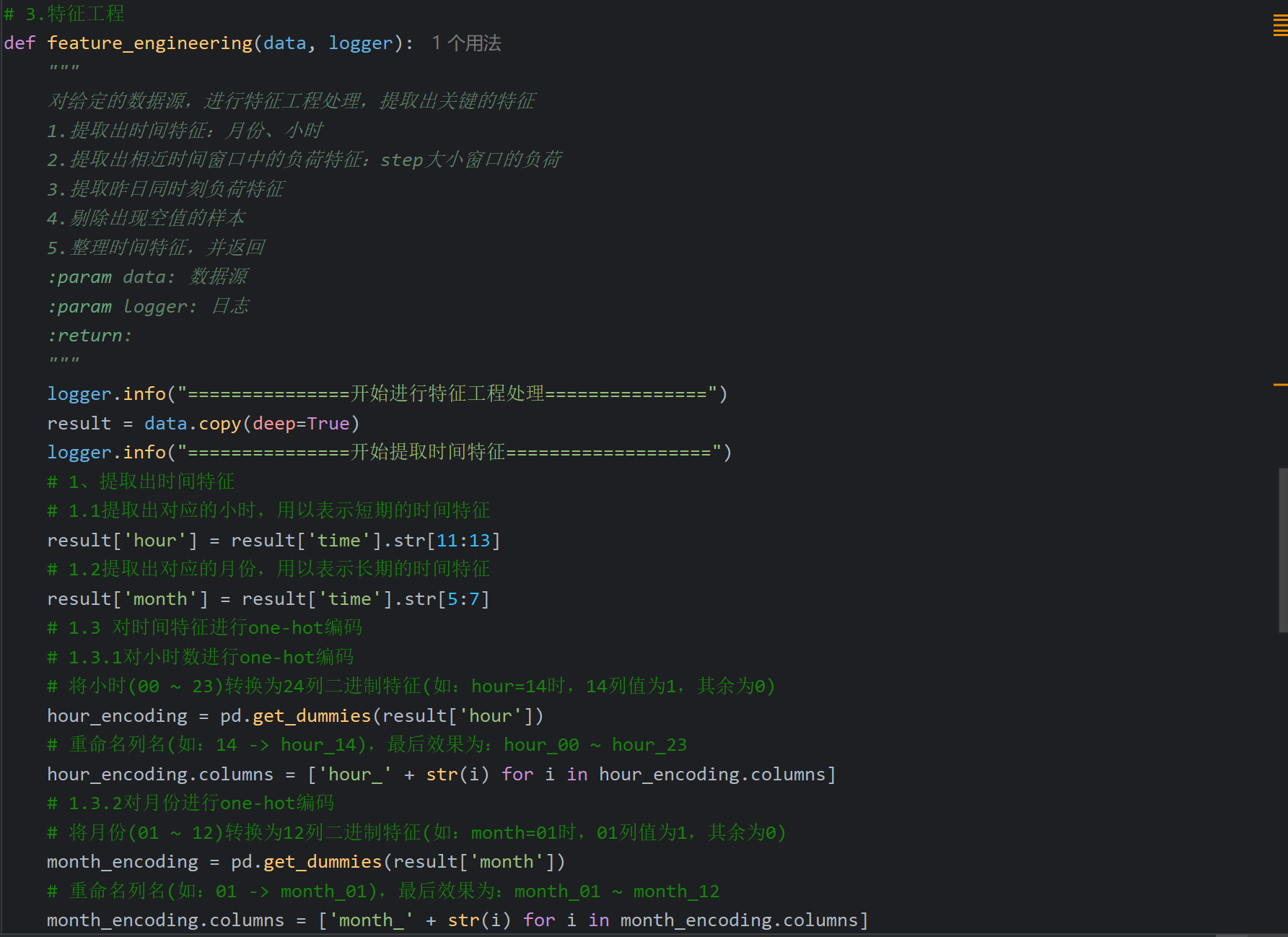
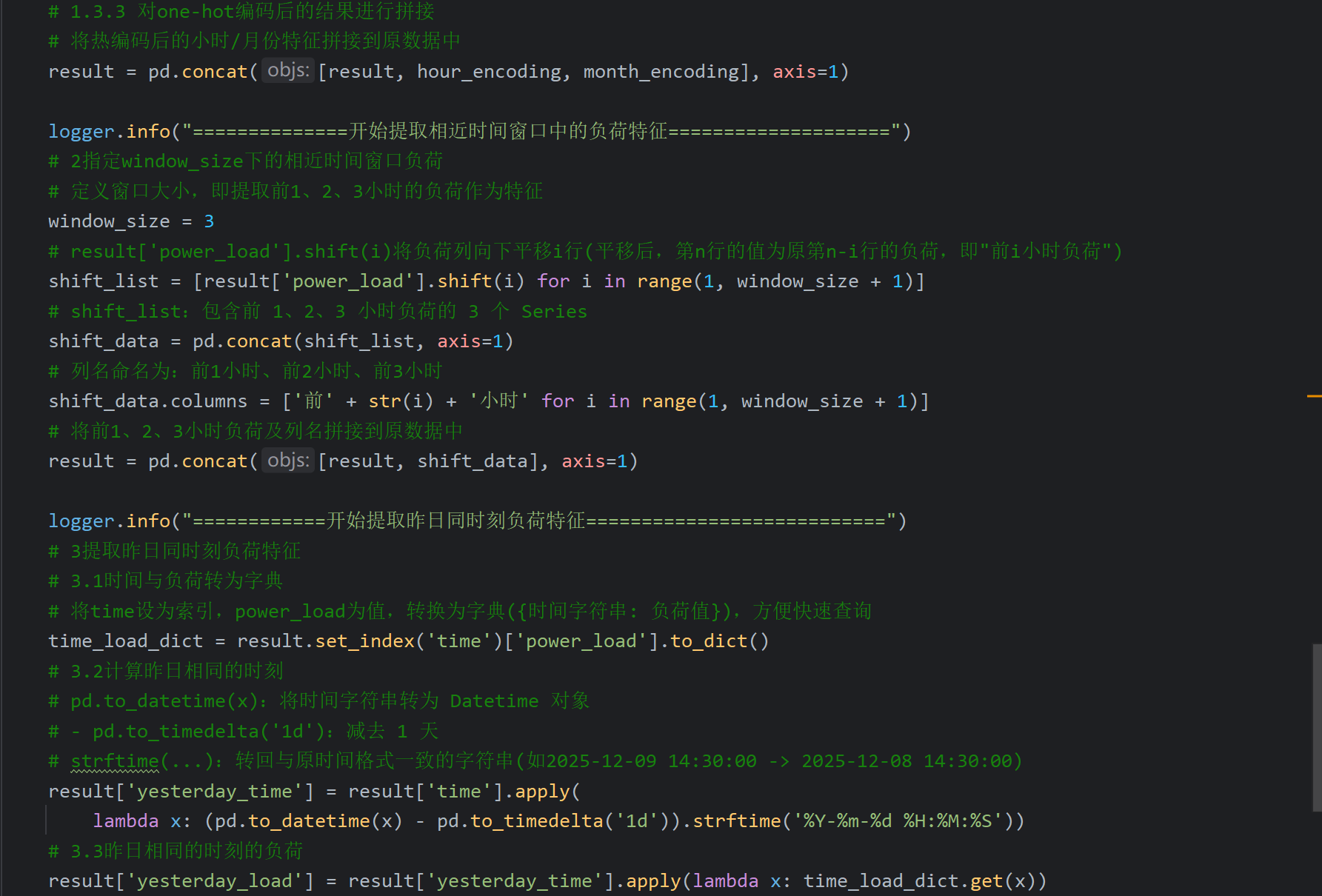
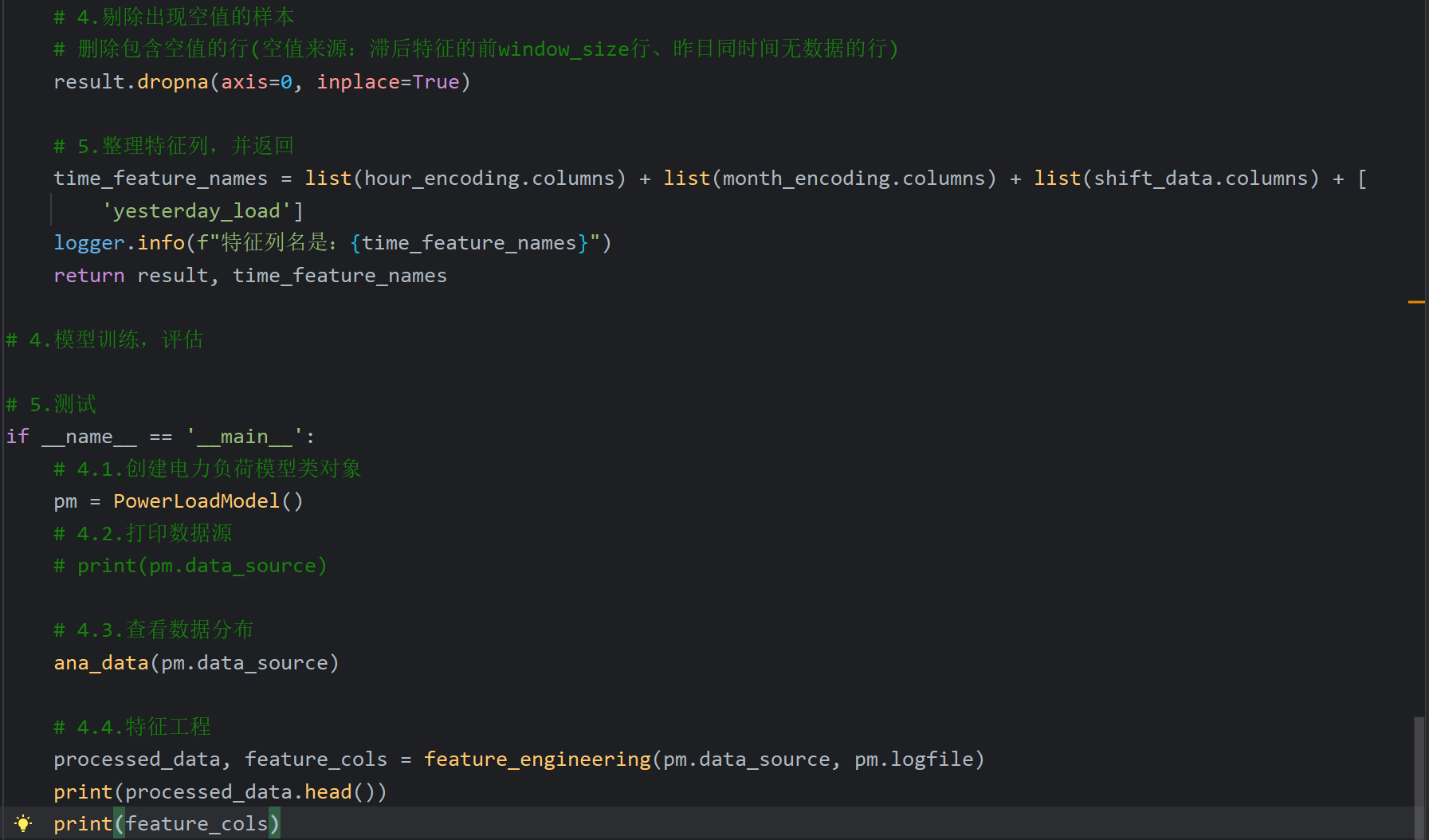
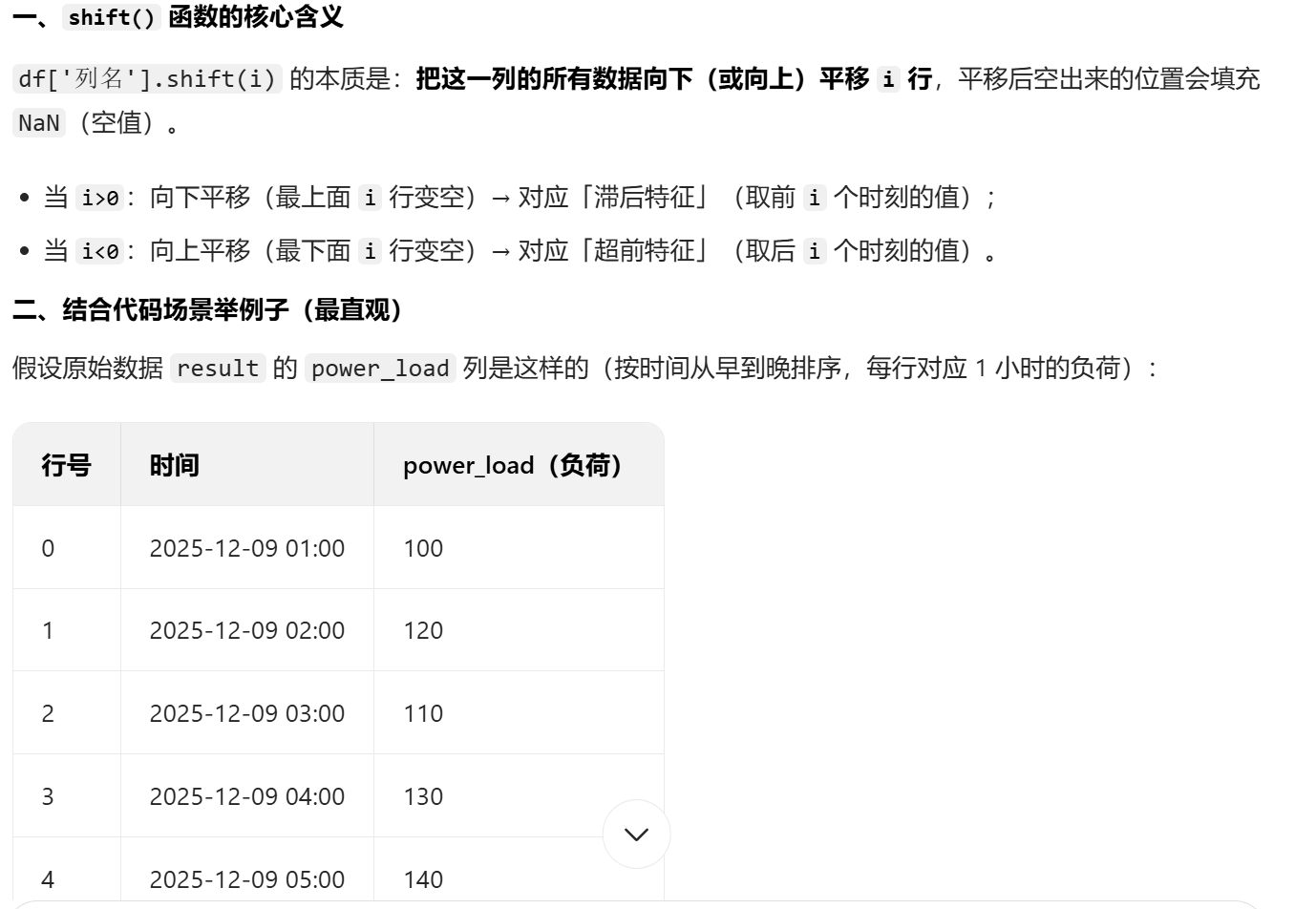
对于代码中的shift()函数和删除空值的部分,我结合ai理解了一下,下面给出总结方便梳理
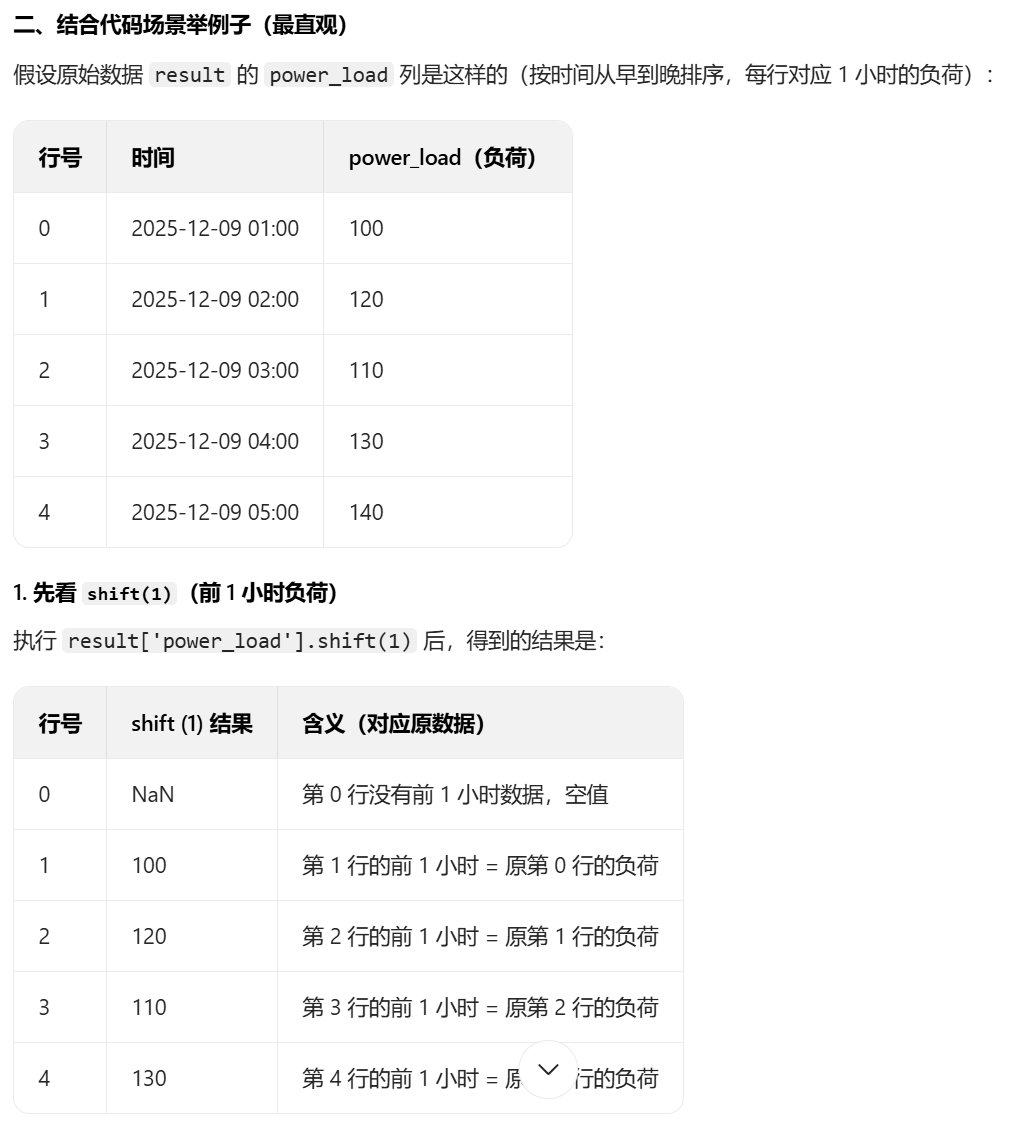
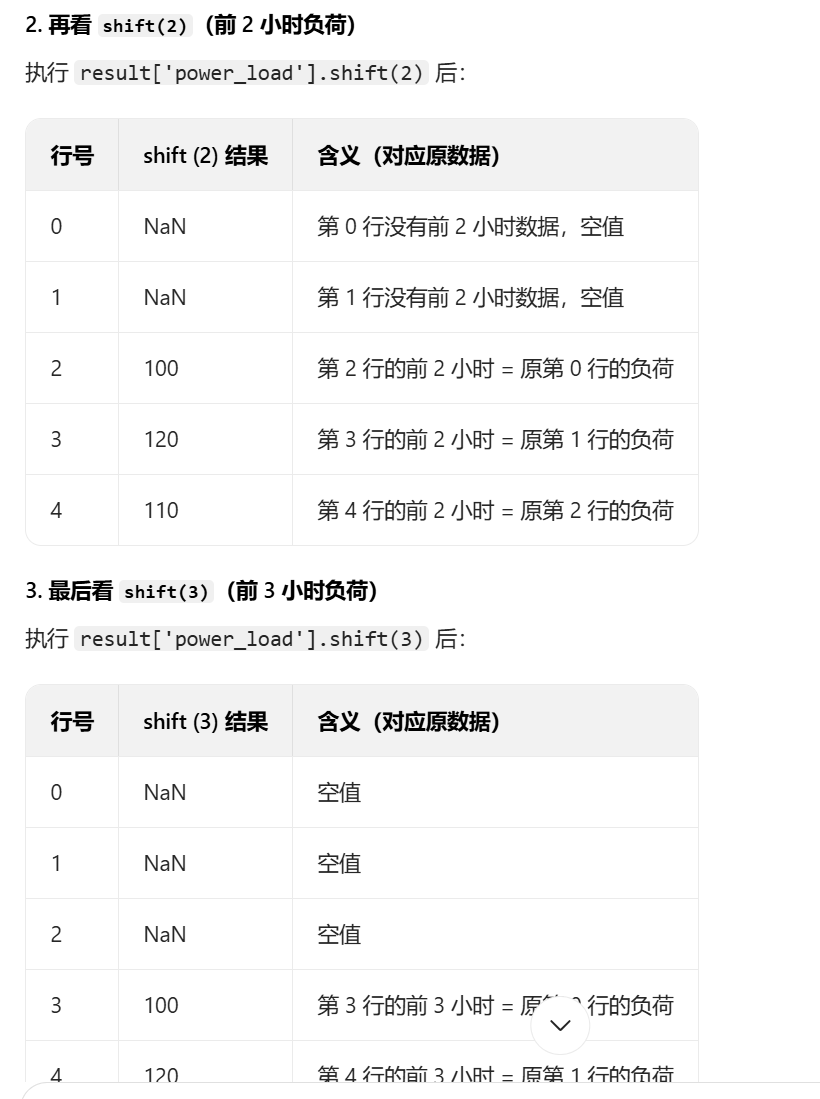
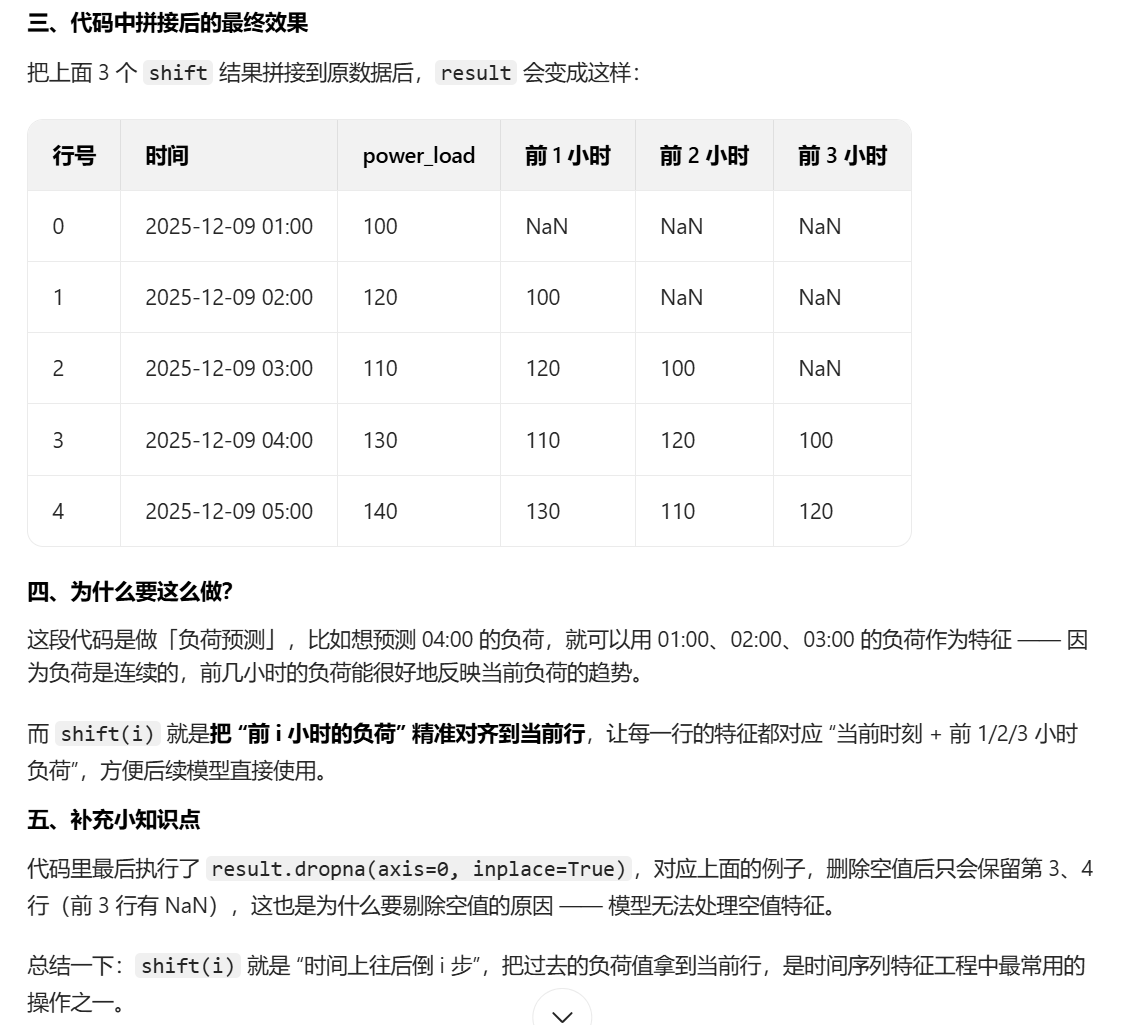
特征工程的代码不好展示效果,所以在测试的时候,打印一下返回的processed_data和feature_cols数据验证一下
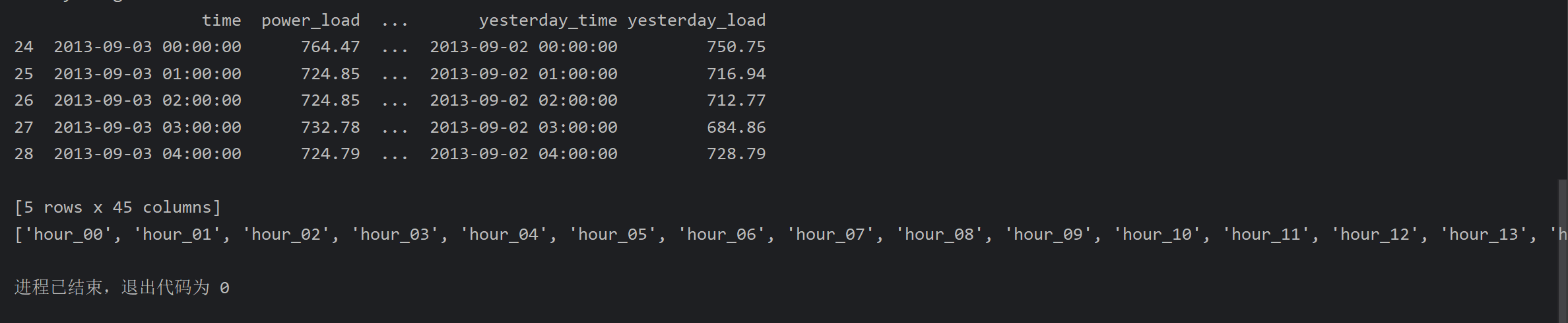

17、自己后补的内容_模型训练、评估、保存
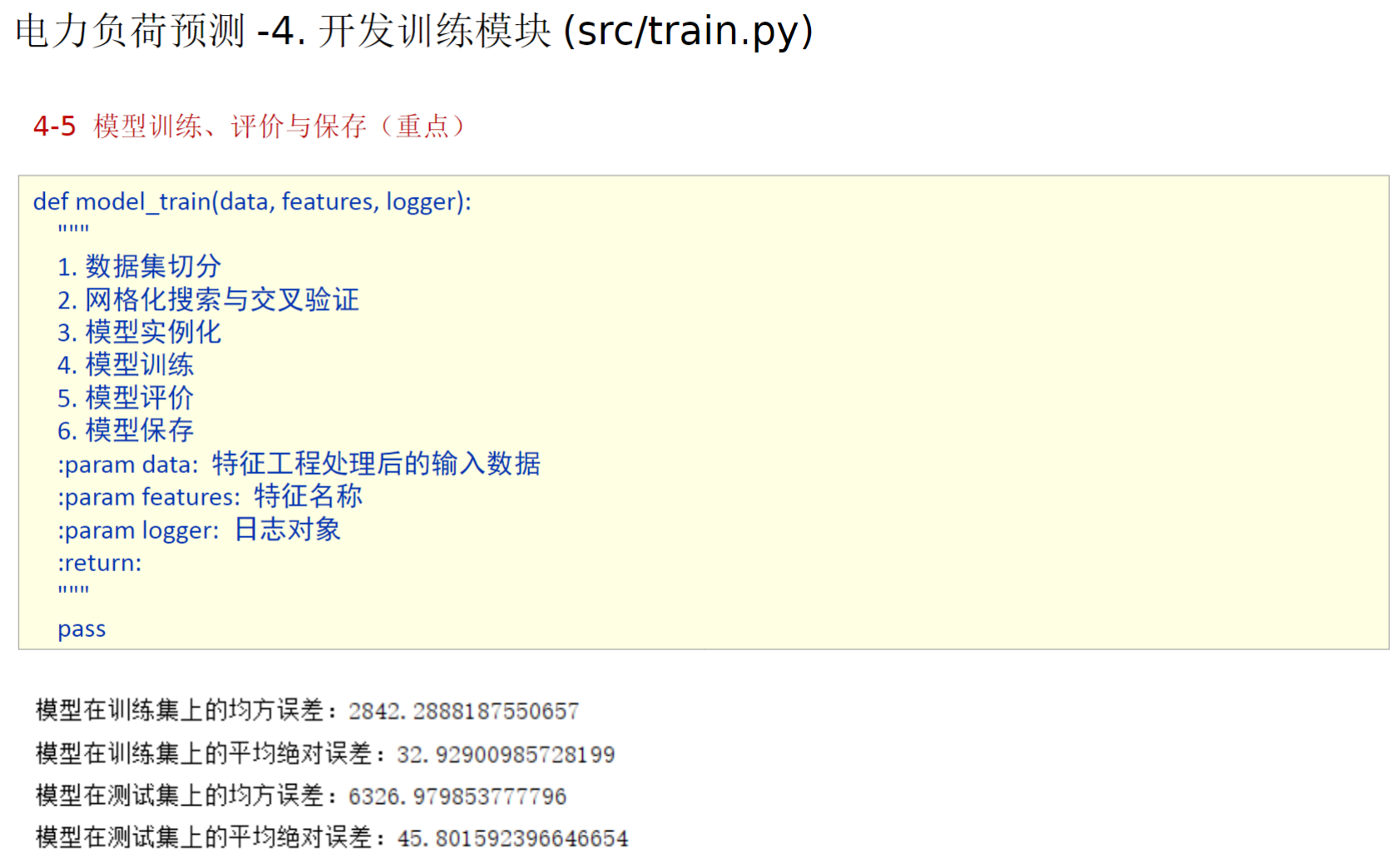
从参考代码的大片注释不难看出,这里应该是先进行网格化搜索寻找最优超参组合,所以我也先复制一部分代码验证一下
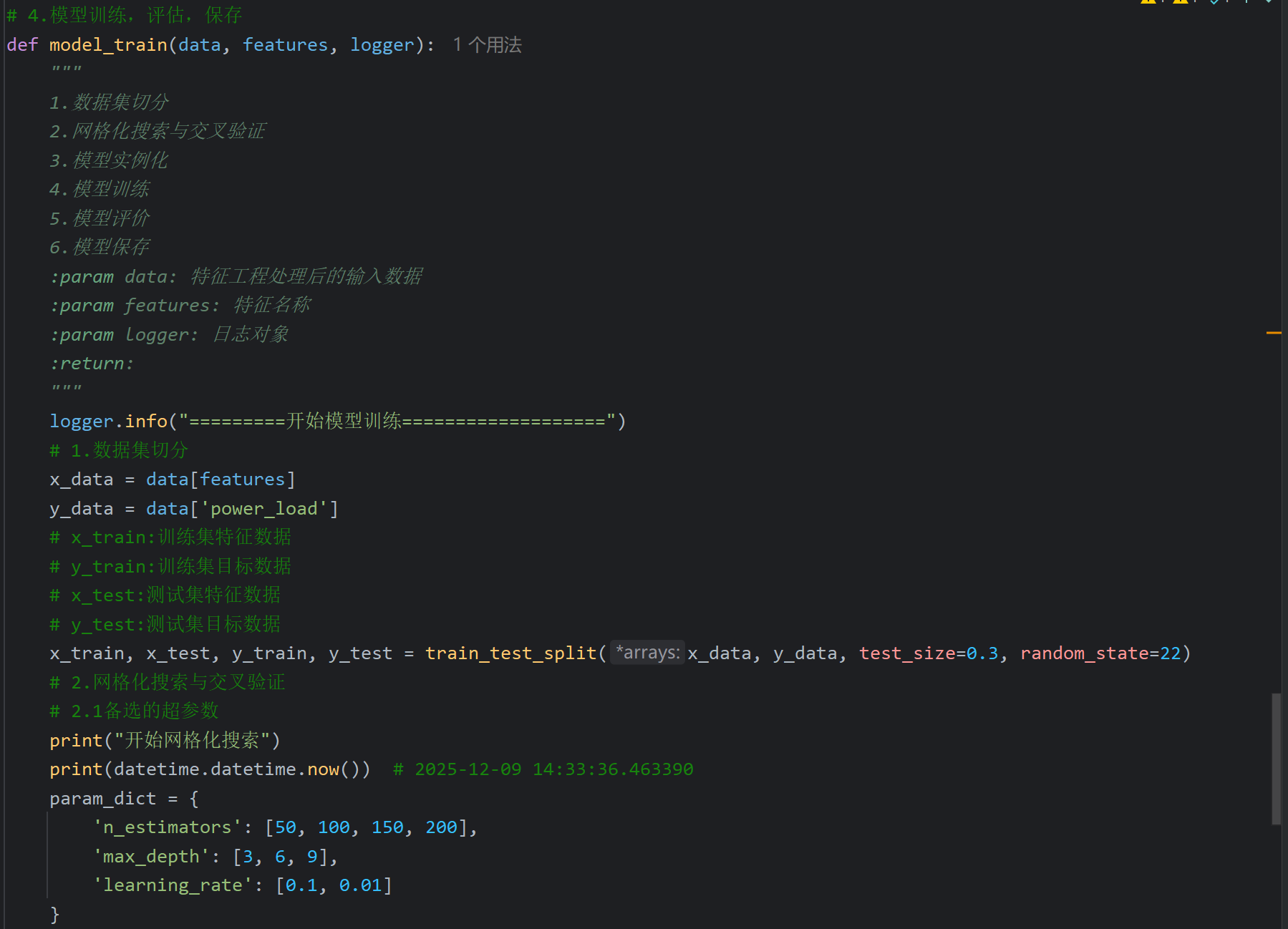
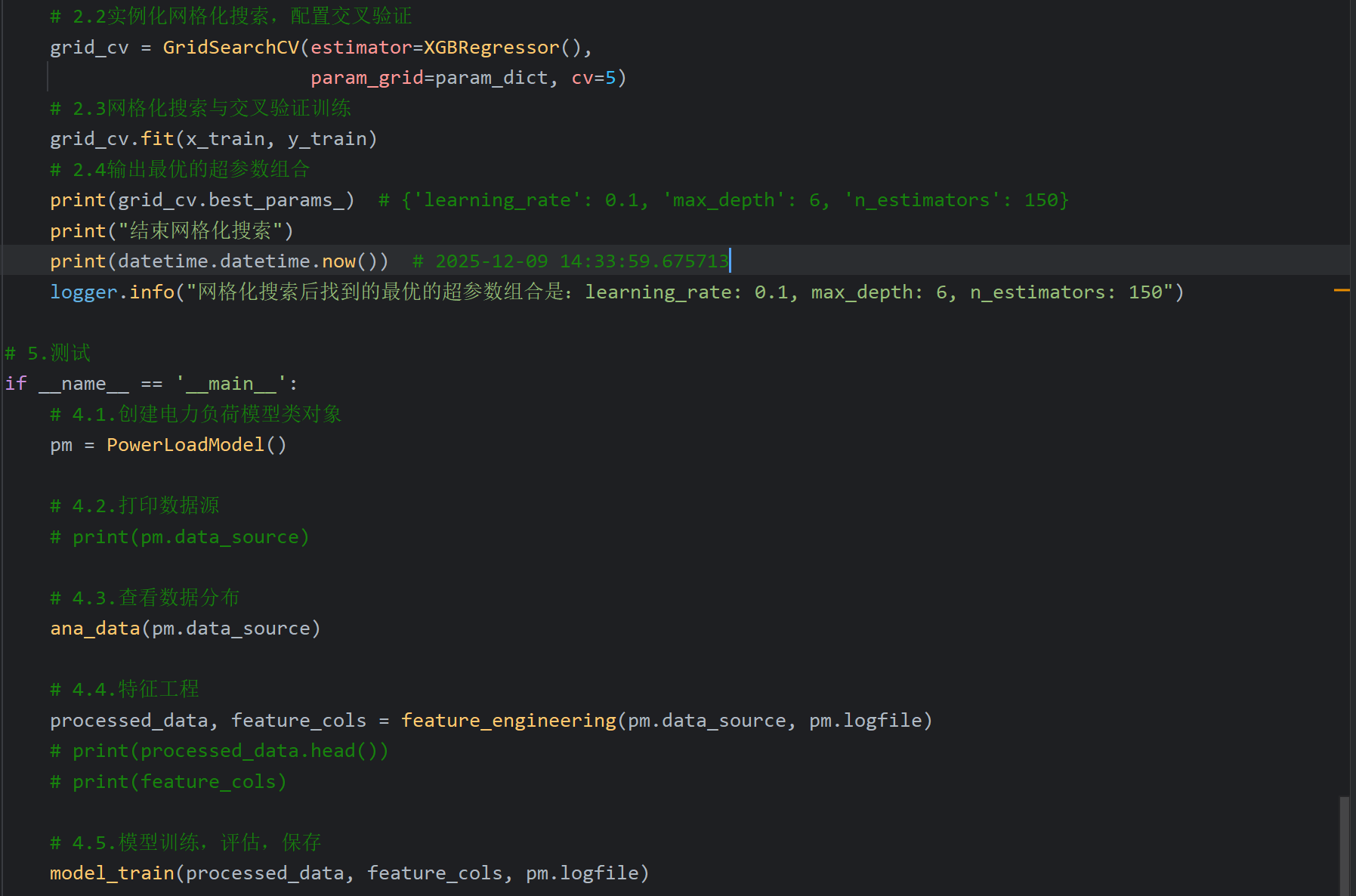
自己跑一遍发现超参组合确实就是logger.info打印的,然后原代码时间是2024-11-26,我还看了一下老师注释网格搜索跑了一分钟,我跑了23秒还比老师快一点
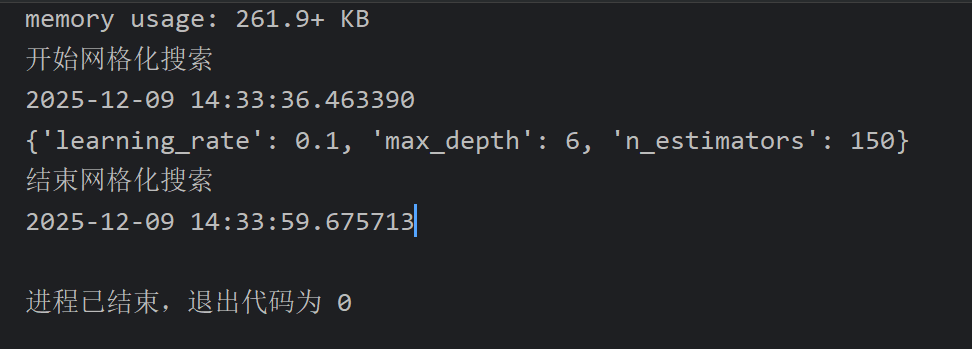
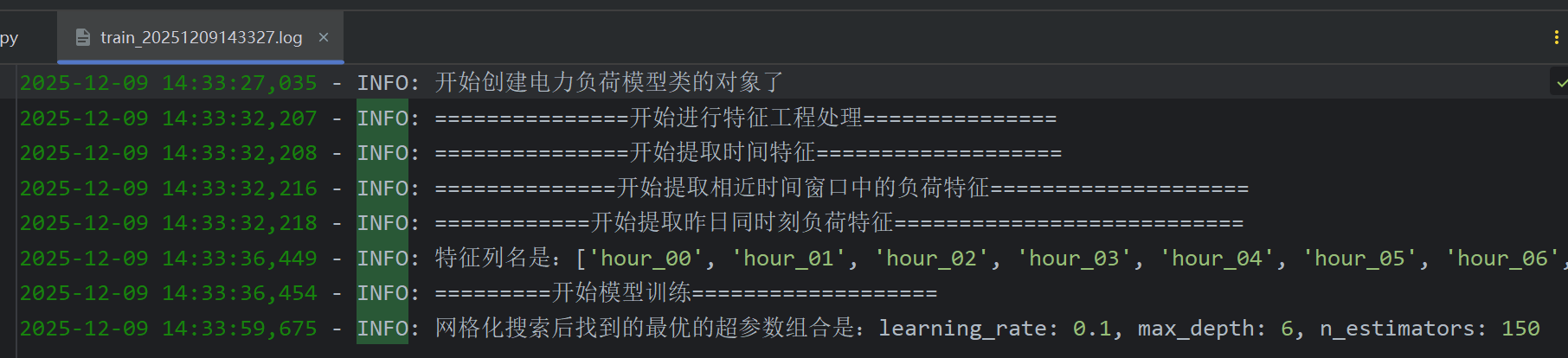
下面就是完整的代码了
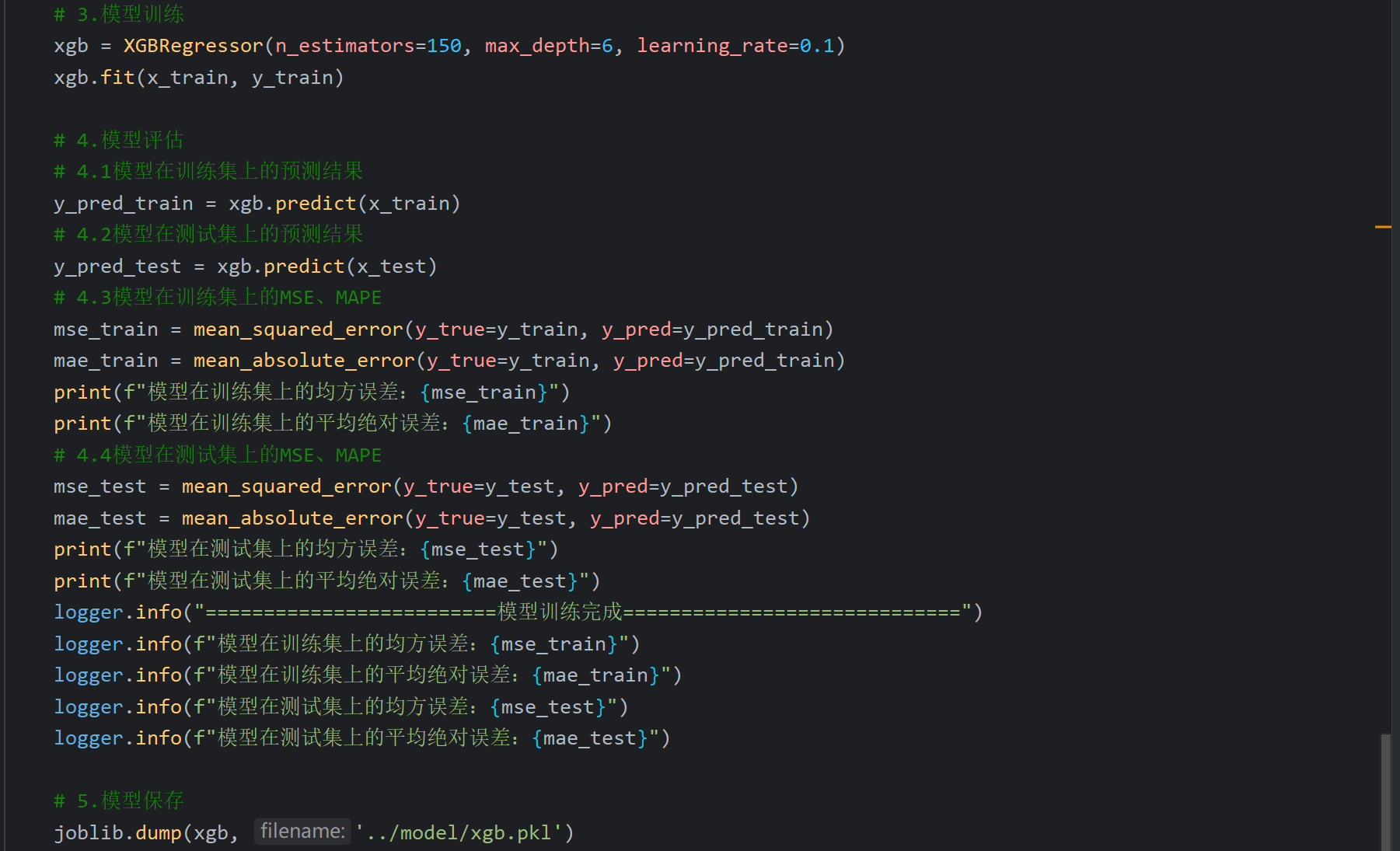
评估的误差和ppt差不多,反正代码也是复制过来的,应该没问题
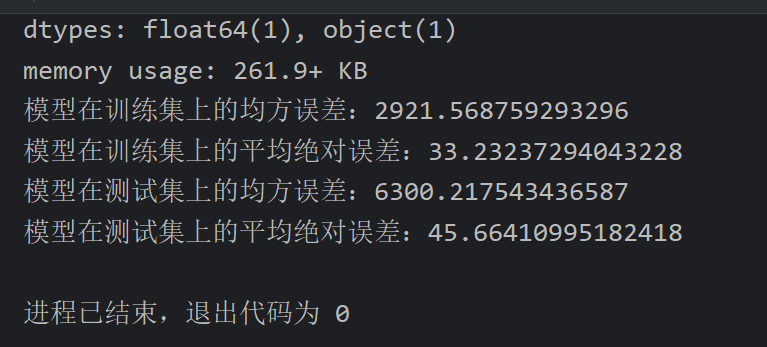
模型也成功保存了
18、自己后补的内容_模型预测模块前置代码
我大概看了一眼代码和ppt,预测模块内容也是很多的,所以我也模仿老师的节奏先实现1、2、3步

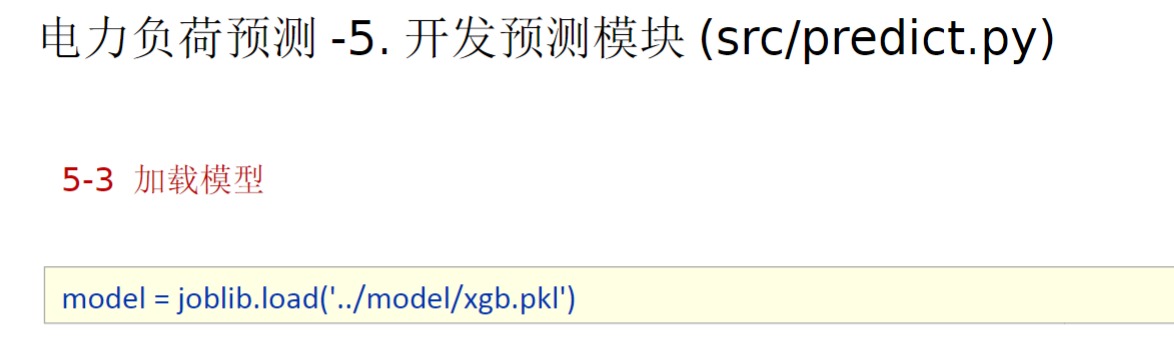
复制到加载模型的代码之后,我运行测试发现报错了,然后发现这里要先修改utils包下的common.py代码。因为这个common.py还是跟着老师视频一起完成的,当时他是直接把加载数据集的路径写死了并测试看一看效果的。实际上我们这里要改为传入路径
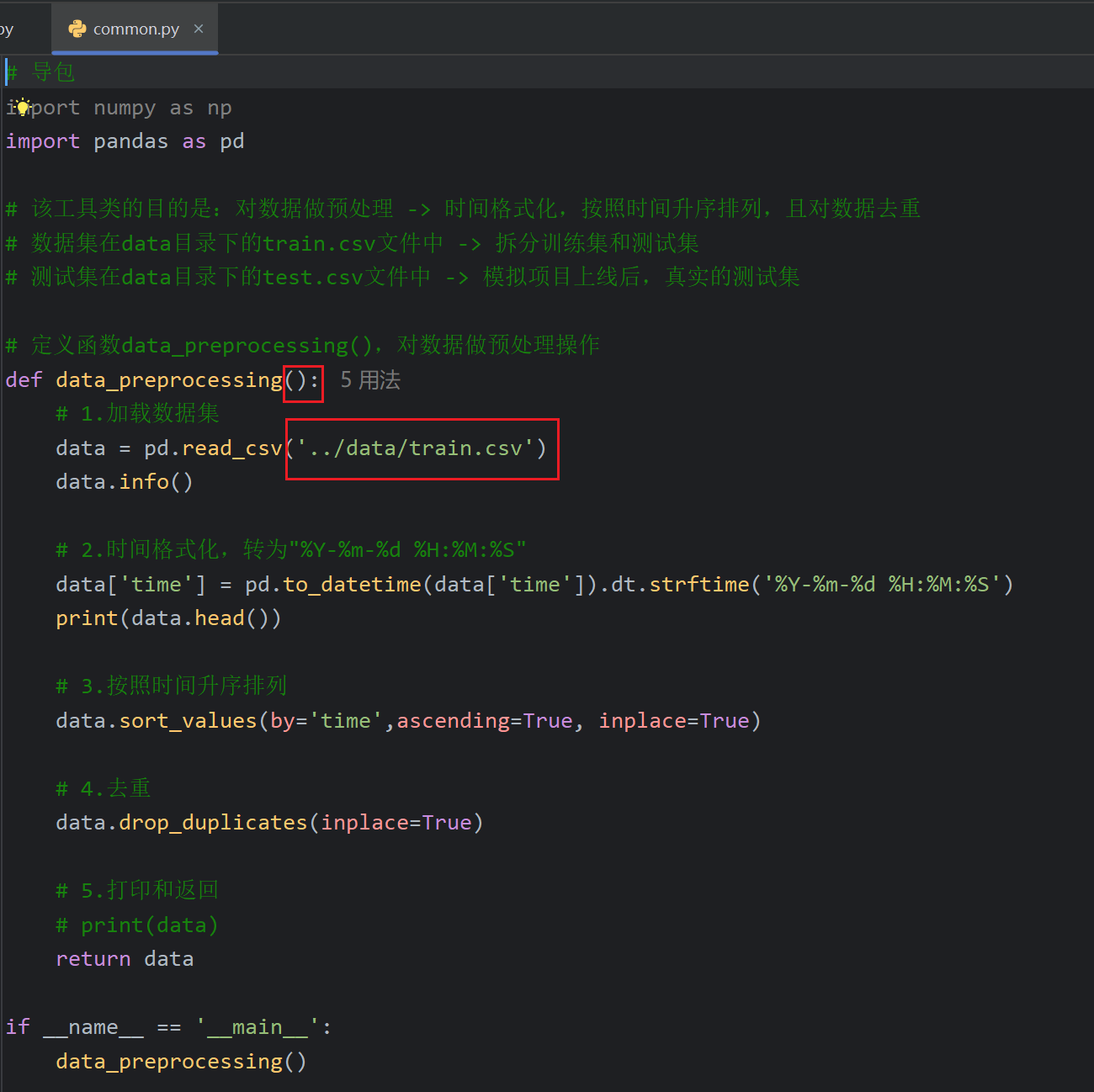
修改之后的common.py代码如下,资料中的common还有另一个函数。但是我版本比较新应该不用写,总之这个common自己改一下或者是直接复制资料里的代码都可以
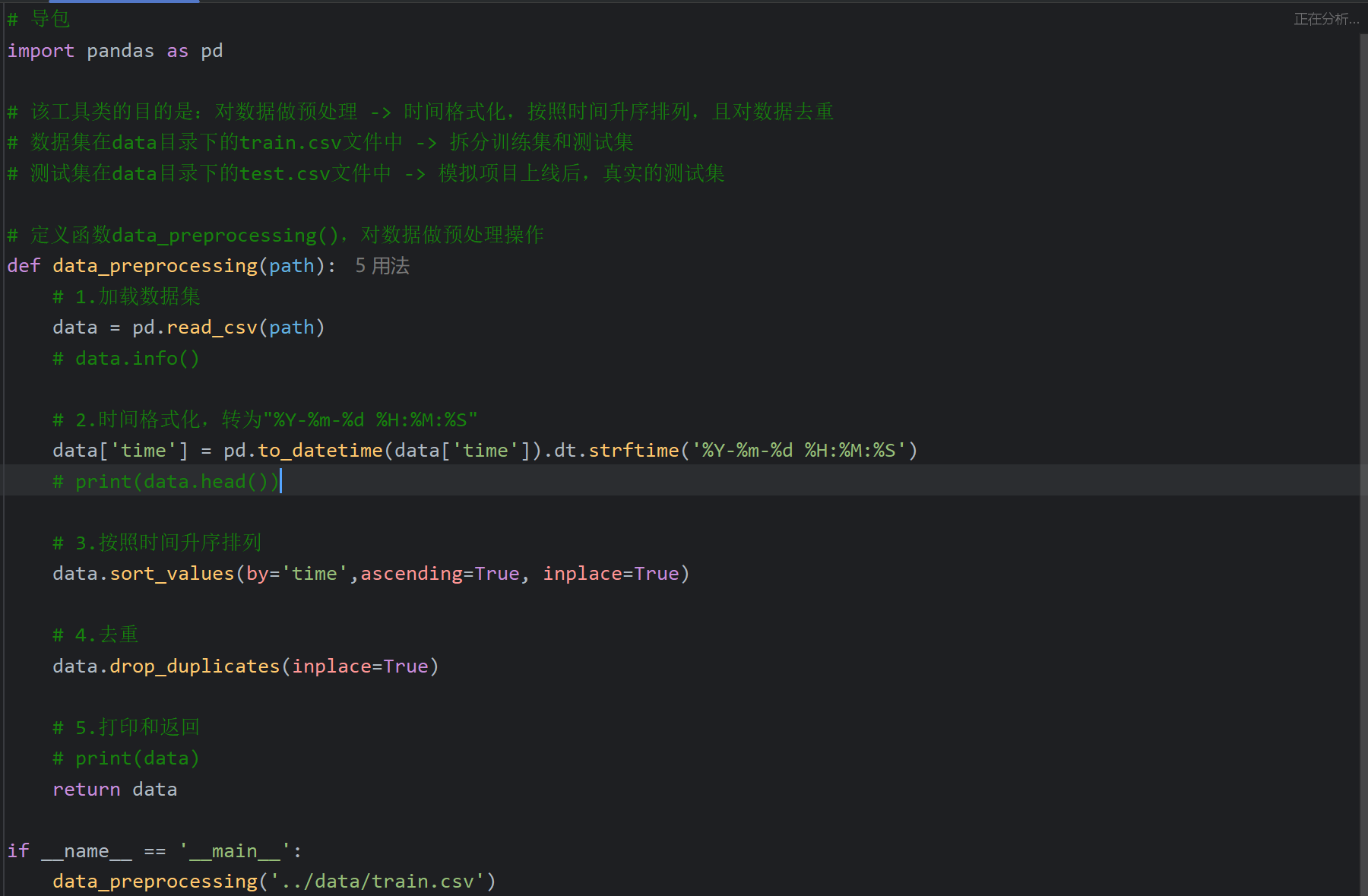
然后就是predict.py的代码,先从资料里复制到加载模块为止
也可以跑一下先看看有没有问题,不报错同时log下出现predict_时间的日志文件就可以了。如果有输出就回去common里面看看是不是有没注释的打印语句,打印问题也不大

19、自己后补的内容_模型预测模块重点代码
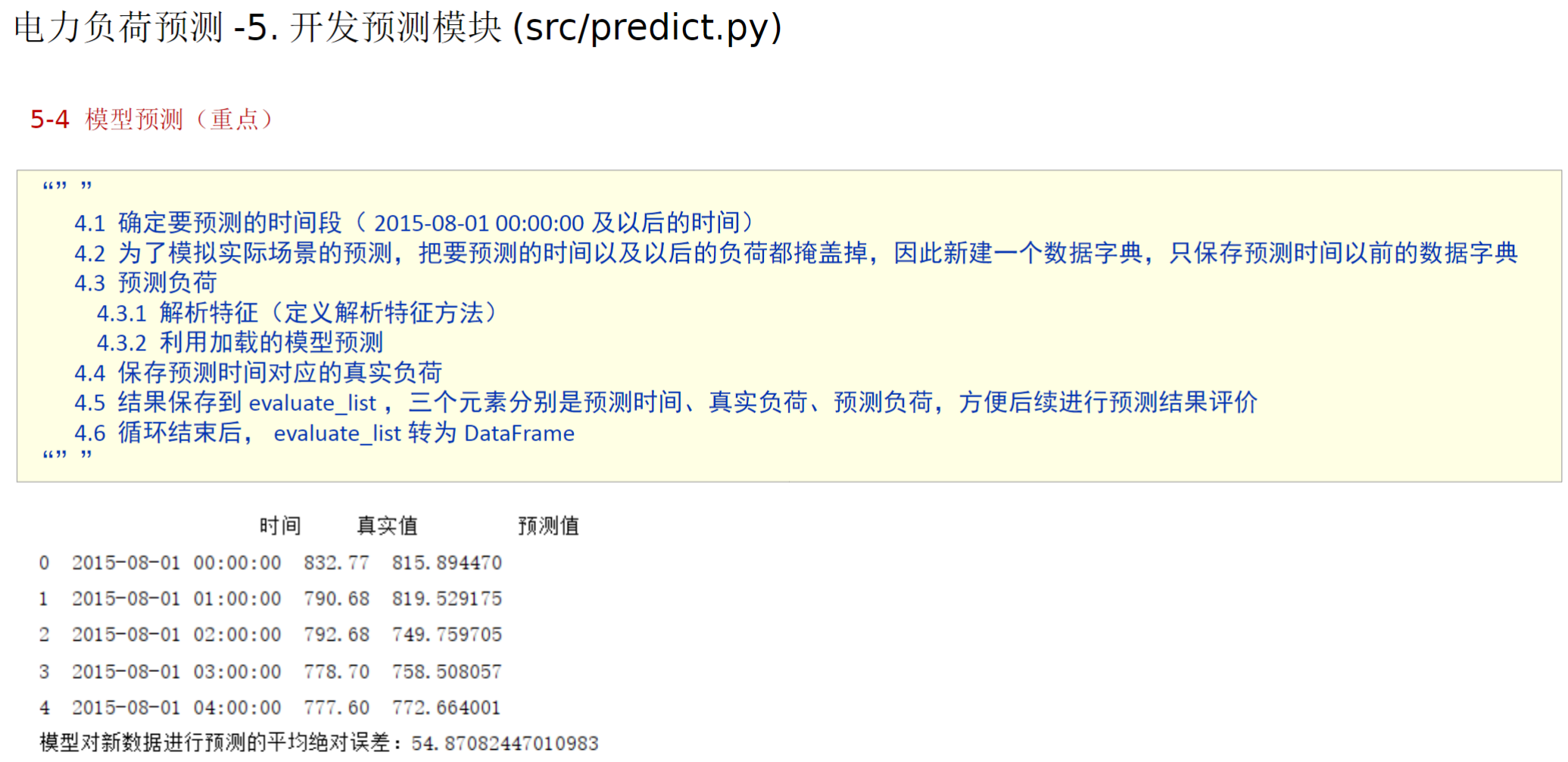
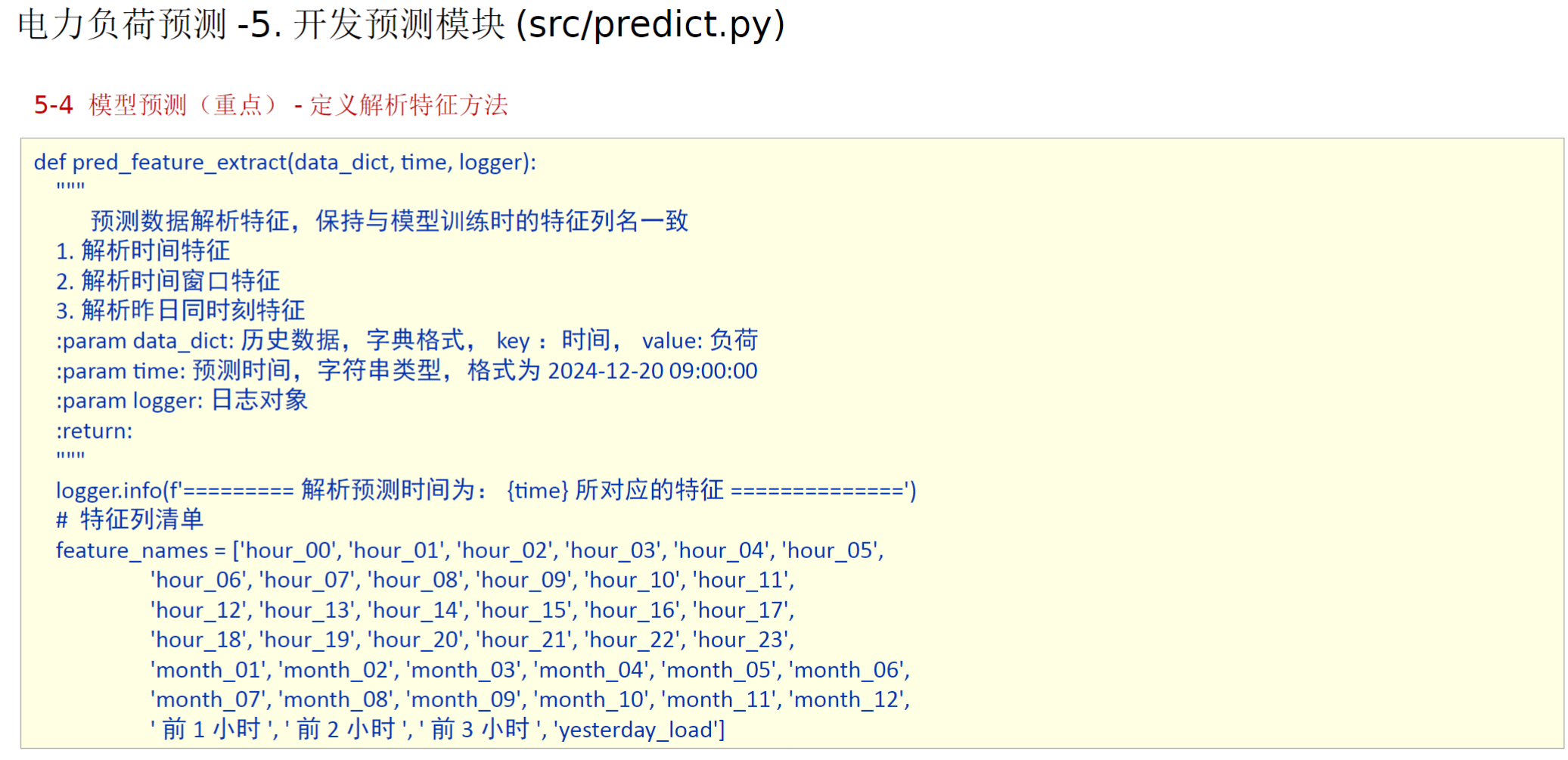
在刚刚定义电力负荷预测类的下面加入如下的代码(从资料里复制的)
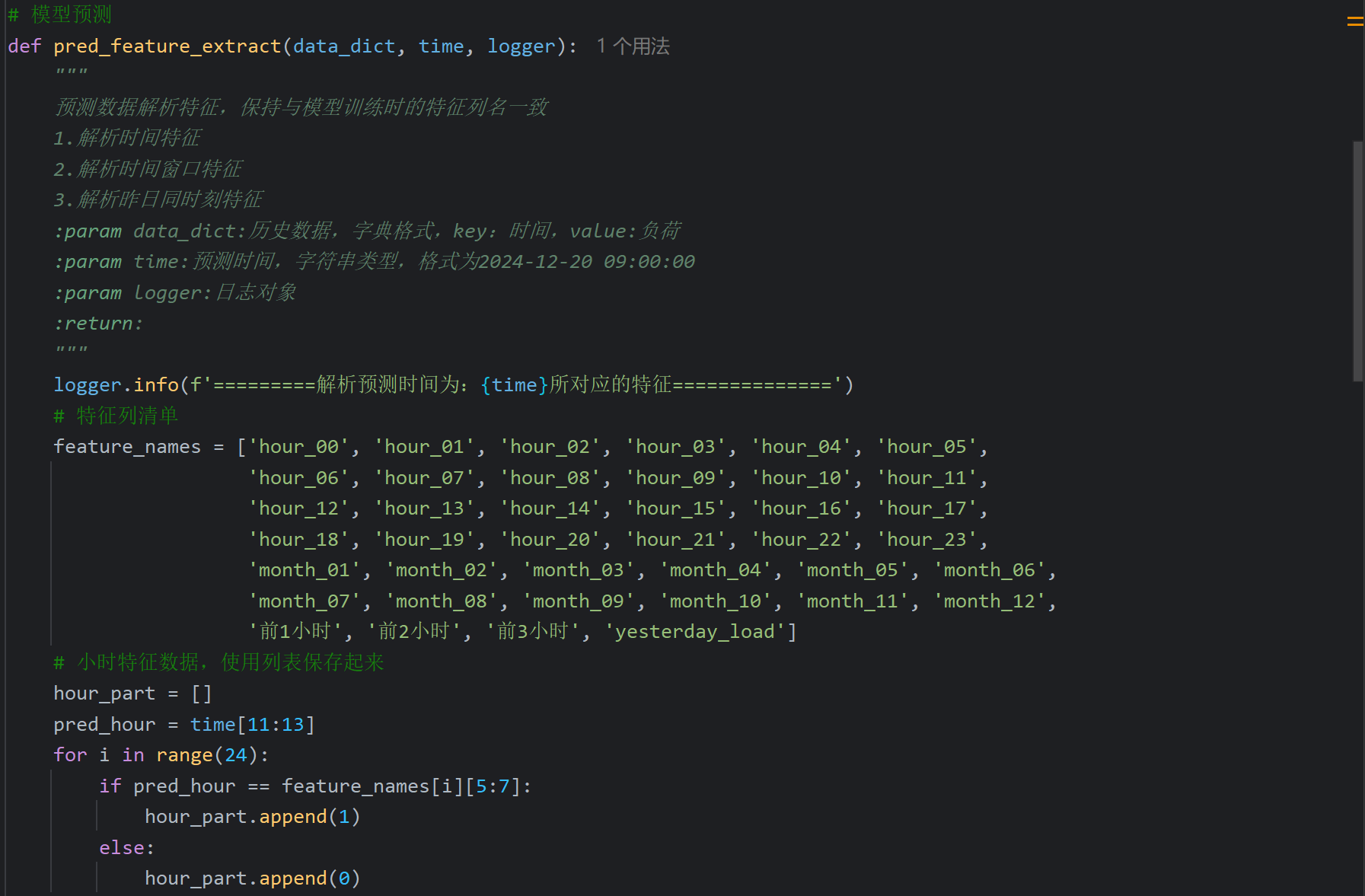
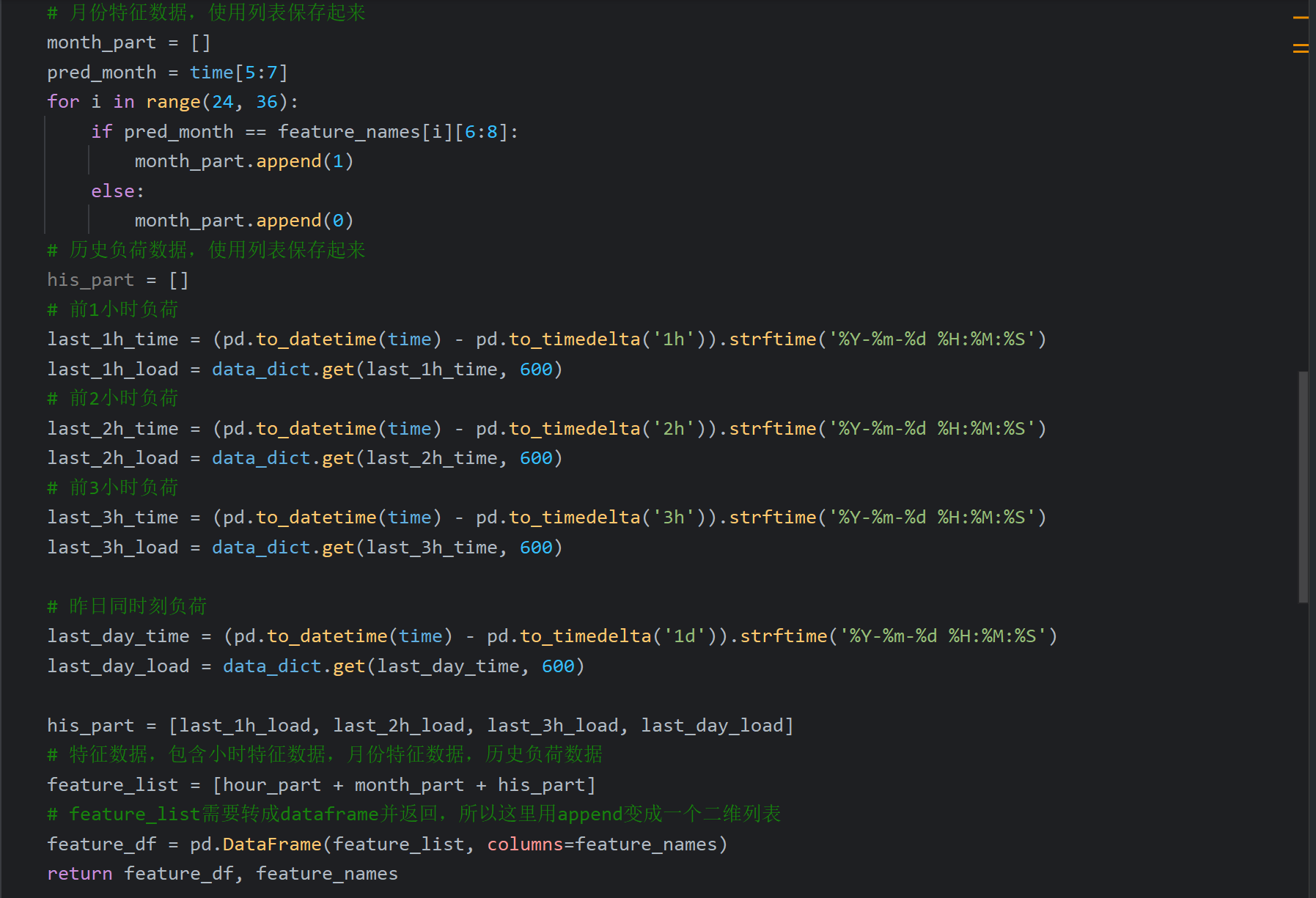
在测试中在加载模型的下面加入如下代码,最后我加了个打印语句看看evaluate_df
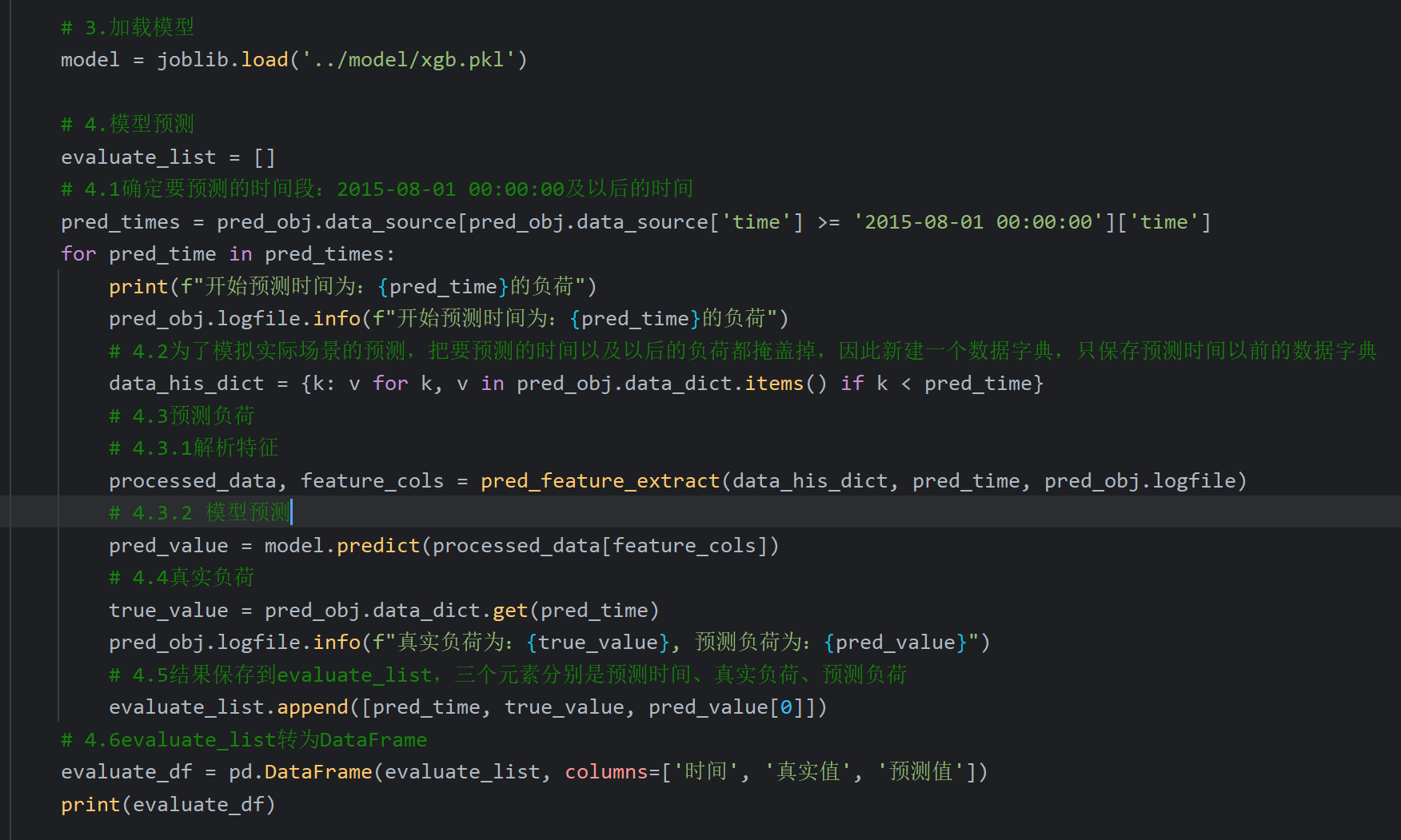
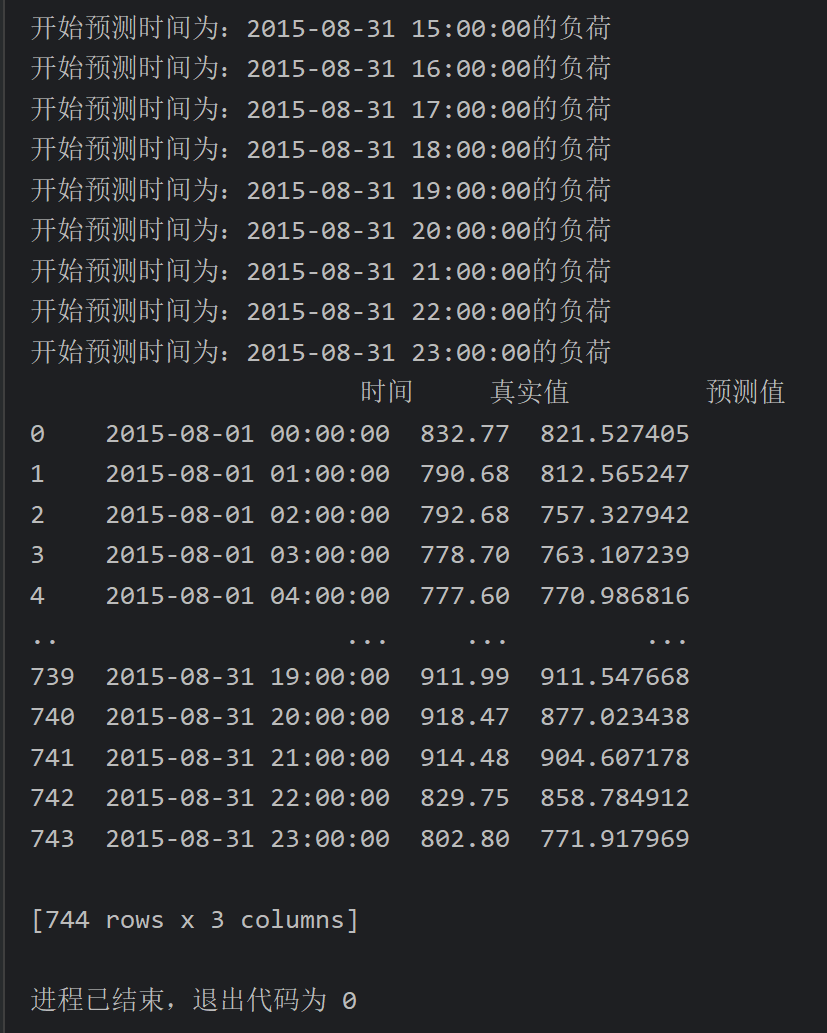
20、自己后补的代码_模型预测模块结果评价代码
复制代码同理
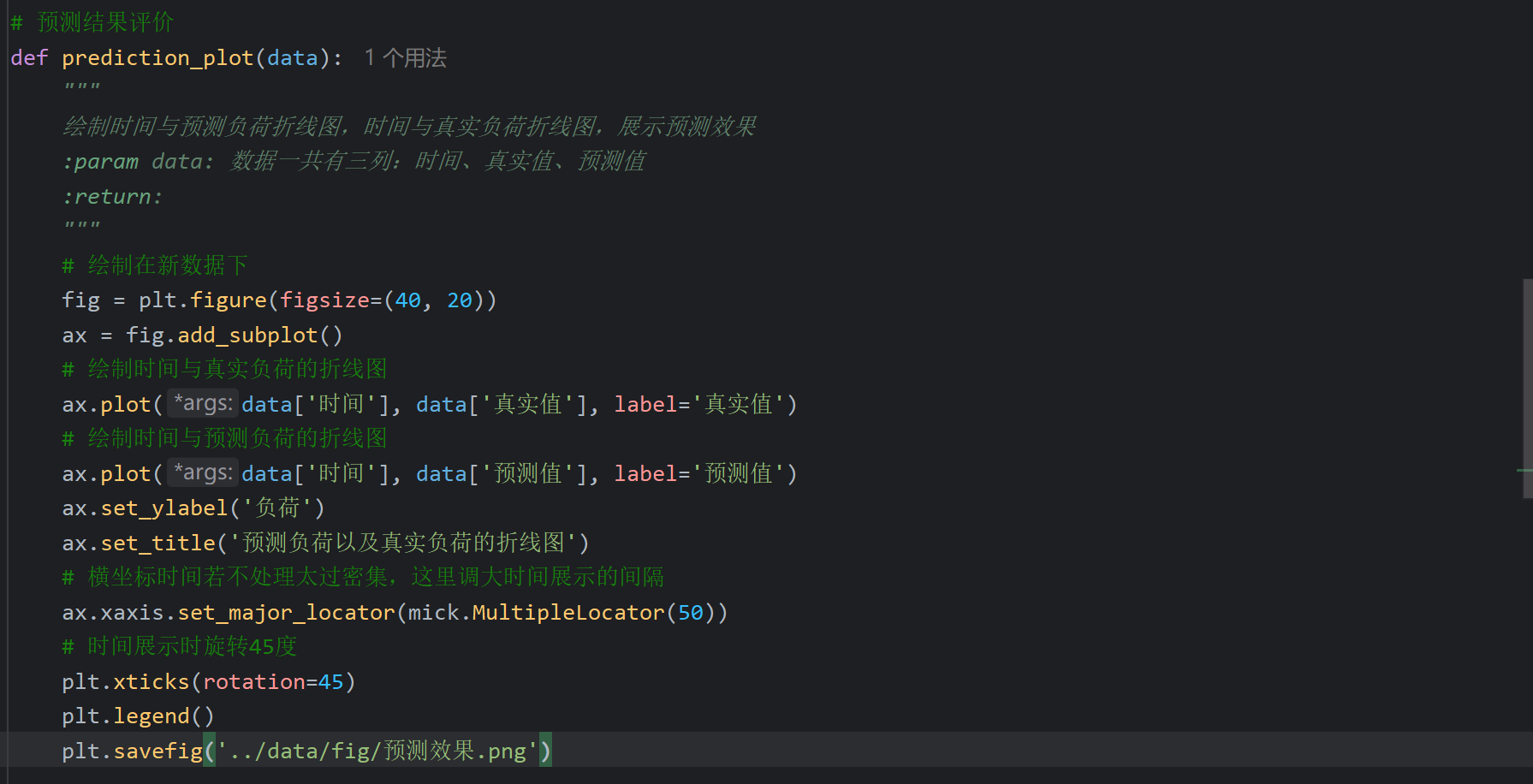

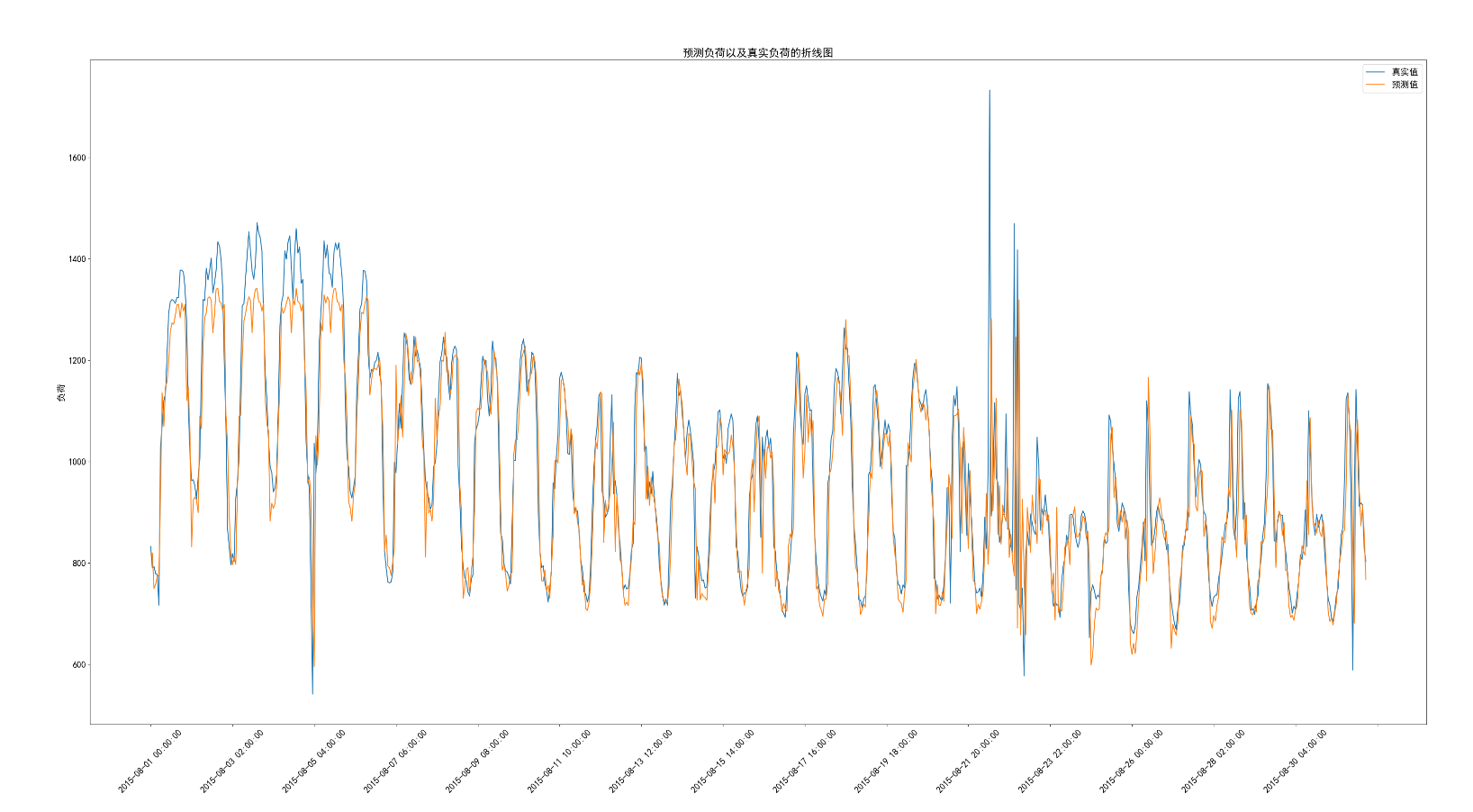
运行成功之后可以对比一下自己的图和老师资料里的参考图
资料里的图我改了个名,对比发现差不多有一点点不一样

第一个是我的,前面黄色的波峰对比起来低一点点
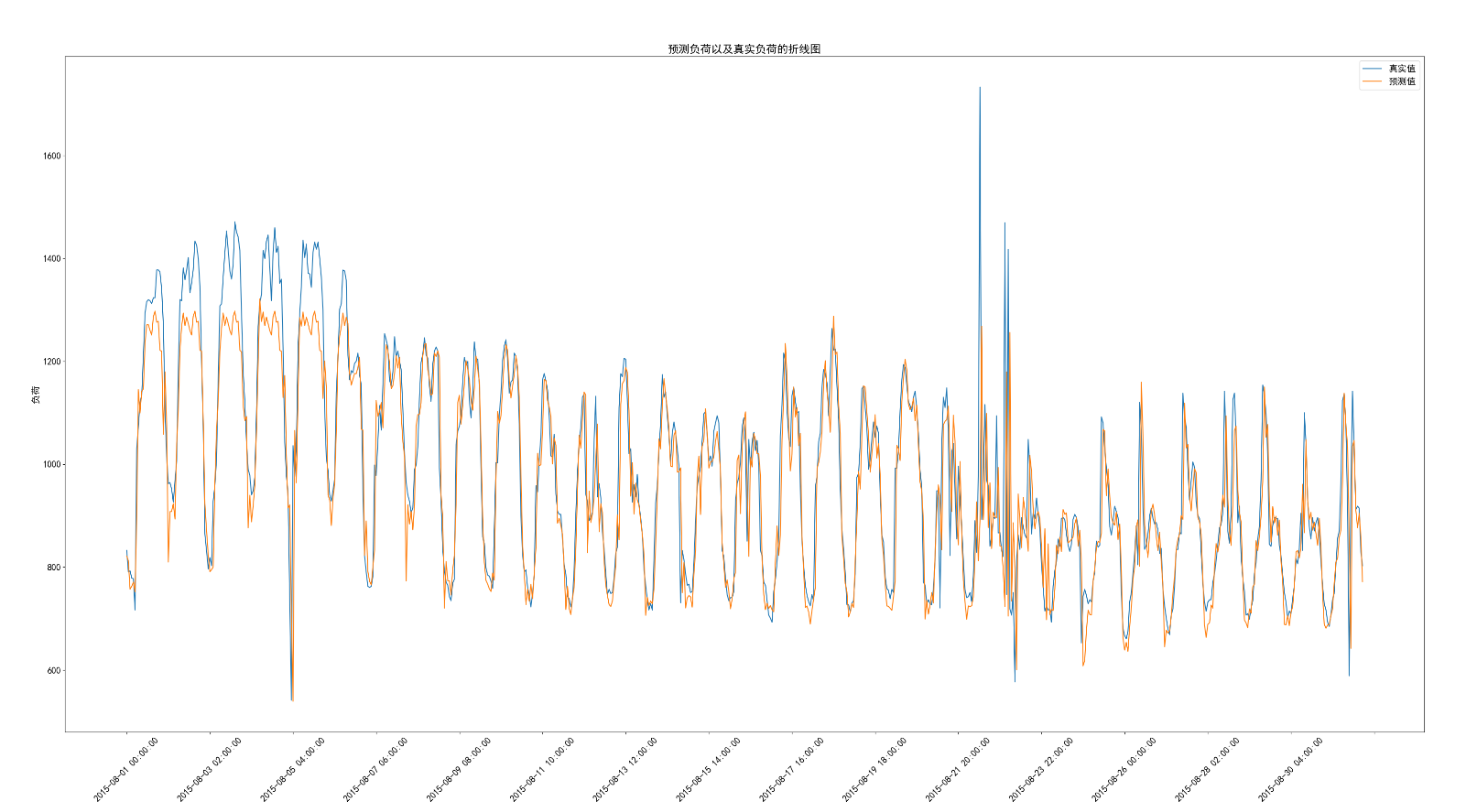
这个是参考图