1主要研究内容
本文围绕供水管网漏损预测,主要从以下三方面展开研究:
-
数据集冗余与高维问题处理
针对原始数据中存在的不完整、异常及高维特征问题,通过探索性数据分析(EDA)、Lagrange插值填补、箱型图异常值处理及Min‑max归一化进行数据预处理。采用模糊层次分析法(FAHP)与随机森林(RF)相结合的方式筛选关键特征,降低维度,提升模型效率与可解释性。
-
数据类别分布不平衡问题优化
针对漏损样本远少于正常样本的类别不平衡问题,首先通过样本相似性分析剔除冗余多数类样本;随后针对不同模型类型采用相应的数据均衡策略:统计学习模型采用混合采样(欠采样+SMOTE过采样),深度学习模型采用加权交叉熵损失函数,集成学习模型采用改进的EE‑ADASYN算法,以提升模型对少数类的识别能力。
-
多模型融合的漏损预测模型构建
基于优化后的数据集,构建并优化三类预测模型:统计学习模型(逻辑回归、XGBoost)、集成学习模型(随机森林)以及深度学习模型(GCN‑SIM)。最后通过Stacking融合方法集成各单一模型的优势,形成综合性能更强的漏损预测模型,提升预测精度与泛化能力。
-
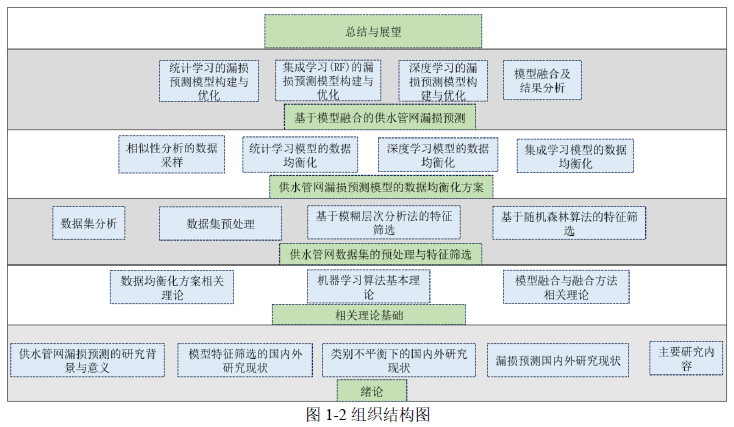
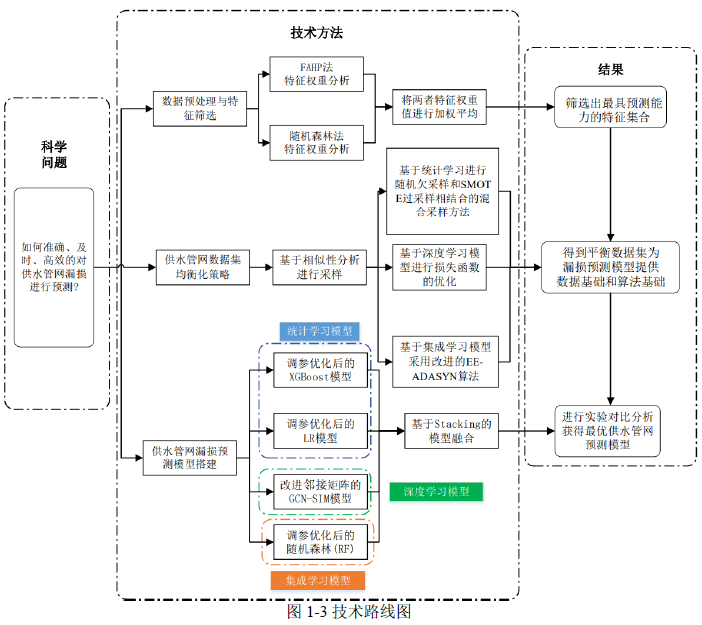
技术路线与组织结构
本文的数据来源于管网GIS 系统与巡检维修记录,在对数据集进行预处理与特征
工程之后建立漏损预测单模型,并对建好的模型进行模型融合,然后选出最优的供水
管网漏损预测模型。本文的组织结构如图1-2 所示,技术路线图如1-3 所示:
2 相关理论基础
2.1 机器学习相关理论
2.1.1 随机森林算法
随机森林算法(Random Forest,RF)通过结合多个决策树,采用样本和特征的随机抽样,提高模型的稳定性和适应性,每个子集都基于有放回的抽样独立训练。通过集成决策树的预测结果,采用投票或平均方法提高准确性和泛化性,有效避免过拟合并优化特征识别。
随机森林算法通过在不同的子集上构建多个决策树,并在树的节点分裂过程中随机选取特征,从而提升了模型的多样性和泛化表现。模型的最终分类是基于所有树的投票结果,这种方法减少树之间的相关性并且提升分类准确率。随机森林的有效性来源于集体决策,而非单一树的性能。图2-1为随机森林算法示意图。
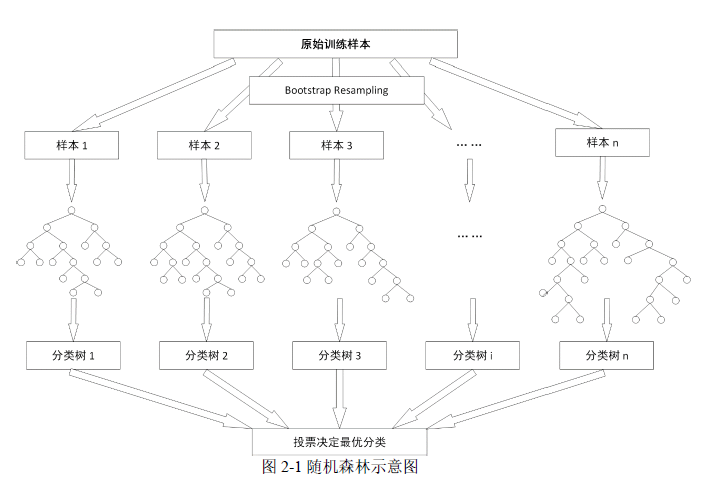
随机森林算法通过集成众多决策树,提升模型在分类和回归问题上的表现,并能较好地处理数据中的缺失值。避免归一化数据的需求,减少过拟合风险。尽管如此,随机森林在处理连续值的回归问题时不够精确,且在数据量不足时性能可能下降。
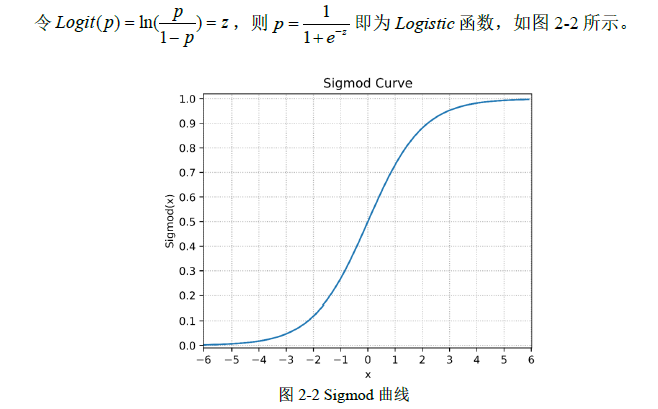
2.1.2 逻辑回归算法
逻辑回归(Logistic Regression, LR)模型,因变量有两种状态,例如可表示为"漏损"与"非漏损"45。假设存在 p 个相互独立的解释变量记为 x1,x2,...,xpx1,x2,...,xp,记 y 取 1 的概率是 p=P(y=1∣x)p=P(y=1∣x),取 0 的概率是 1−p1−p,两者概率之比记为优势比(odds),对优势比取自然对数得 Logistic。
逻辑回归算法以其简洁高效和易于理解的特点,在处理二分类问题时表现出色,且计算需求不高。然而,在处理非线性问题、数据不平衡以及对异常值的敏感性方面存在局限,且作为线性模型,其预测准确率可能受限。
2.1.3 极端梯度提升算法
极端梯度提升算法(eXtreme Gradient Boosting,XGBoost)是Boosting算法家族中的一个重要成员,代表该类算法的一个显著进步。在解决分类和回归任务方面展现出优异的性能。
XGBoost 因其处理大规模和高维度数据的高效稳健的特性而受到推崇。尽管如此,调整众多超参数可能会耗费大量时间,且在小数据集上 XGBoost 需警惕过拟合问题。
2.1.4 图卷积神经网络算法
图卷积神经网络(Graph Convolutional Networks,GCN)是为了有效处理非欧几里得、不规则图形数据结构的特征提取而开发的技术,在捕捉拓扑图的空间特性方面表现出色,尤其适用于 CNN 和 RNN 难以处理的场景。
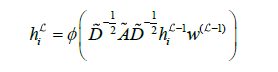
传统图卷积神经网络(GCN)在每一层的计算过程中需要处理整个图的所有节点,导致计算成本较高。相比之下,GraphSAGE(Graph Sample and aggregate)这一基于空间的方法能够有效地解决这一问题,降低计算的复杂度和开销。
2.1.5 GraphSAGE 模型
GraphSAGE(Graph Sample and aggregate)模型目的是实现图数据的归纳学习,专注于学习节点的表示,使得模型在推断阶段能够泛化到训练过程中未见过的节点。这种方法特别适用于现实世界中图结构数据的异常节点检测任务。
GraphSAGE 模型能够通过分析供水管网的邻接矩阵,挖掘并利用空间拓扑结构中的隐含信息,从而增强模型对图数据的表达和理解。得益于其优秀的采样机制,使得 GraphSAGE 模型不受限于初始图结构,能够对未见过的节点进行有效的泛化,这使得其特别适合应用于供水管网的漏损异常预测工作。
2.2 数据均衡化方案相关理论
2.2.1 数据层面优化方案
为解决数据不平衡问题,可以通过采样技术调整数据分布,使之平衡,以便更好地构建模型和进行预测。主要采样方法有三种:过采样少数类、欠采样多数类和混合采样,这是处理不平衡数据的有效手段。
(1)欠采样
随机欠采样从初始多数类样本集 Dorigin(max)Dorigin(max) 中通过随机抽样技术,选取部分数据以形成扩充的多数类数据集 Ddelete(max)Ddelete(max),在之后将该样本集 Ddelete(max)Ddelete(max) 从原始的多数类样本集 Dorigin(max)Dorigin(max) 中进行筛选,从而得到精简化的多数类样本集 DnewDnew。
(2)过采样
SMOTE (Synthetic Minority Oversampling Technique, SMOTE)计算少数类样本集 DminorDminor 中的样本 xx 到少数类样本集中其他所有样本的欧氏距离之和,得到其 k 近邻;考虑不均衡比例并预设要将少数类样本集扩大 N 倍的采样倍率 NN,从 k 个近邻少数类样本中随机选择 N 个样本 x1,x2,...,xNx1,x2,...,xN;最后构造新的少数类样本。
(3)混合采样
在处理不平衡数据集时,为了达到类别分布的平衡,可以采取一种综合策略,即结合欠采样(Undersampling)和过采样(Oversampling)的优点。
2.2.2 算法层面优化方案
面对不平衡数据集建模时,还可以通过改进算法本身来适应这种情况,如应用集成学习、代价敏感学习和调整损失函数等策略,以提高模型对不平衡数据的处理能力。
(1)集成学习
集成学习通过合并多个基学习器来增强预测效果,通过同质或异质的结合方式,可以形成一个表现更优的集成模型。
(2)损失函数优化:
处理不平衡数据时,优化损失函数十分有效。以下是几种常见的优化损失函数方法。
加权损失函数:权重损失函数通过给不同类别样本分配不同重要性权重来调整损失,使得少数类获得更高权重,多数类获得较低权重58。
类别加权交叉熵损失函数:类别加权交叉熵损失函数通过分配不同权重给各类样本,是平衡不平衡数据的常用手段。
聚焦损失函数:聚焦损失函数(Focal Loss)通过降低易分类样本的影响力,并提升难分类样本的重要性,引导模型更加关注那些难以识别的样本。
2.3 模型融合与融合方法相关理论
2.3.1 模型融合介绍
模型融合技术通过整合多个独立的学习模型,以达成对最终预测结果的共识。构成模型融合的各个独立学习器之间的差异主要表现在以下三个维度:
(1)训练数据的差异
每个学习器可能使用不同的数据子集、采用不同的数据预处理和特征选择方法。
(2)模型结构的差异
可能包括各种类型的模型,如树模型(例如随机森林、XGBoost)、神经网络(如CNN、LSTM)等,以及各自的变化。
(3)模型参数的差异
在模型配置时,如随机种子、权重初始化、损失函数等参数设置也会有所不同。这些差异性有助于提高融合模型的泛化能力。
2.3.2 模型融合方法介绍
模型融合方法包括投票法(Voting)、平均法(Avg)、排序法(Rank averaging)和堆叠法(Stacking)。
(1)投票法(Voting)
投票法依据"多数决"原则,对多个学习器预测结果综合集成。为确保有效性,至少需要三个多样化的学习器参与,以避免因模型间高度相关而降低预测效果。
(2)平均法(Avg)
平均法假设 nn 个不同的个体学习器模型的预测结果分别为 y^1,y^2,⋯ ,y^ny^1,y^2,⋯,y^n,计算方法如式(2-40)所示。
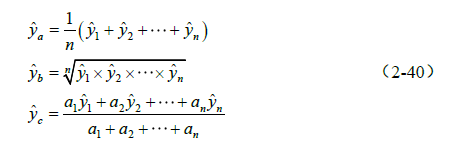
(3)排序法(Rank averaging)
排序法是一种利用多个模型的预测结果,在训练或测试阶段将这些结果按照一定规则进行排序、加权或组合,综合利用各个模型的优势,提高整体预测性能的方法。
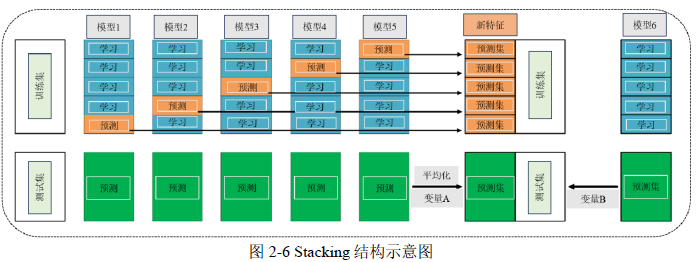
(4)堆叠法(Stacking)
Stacking算法是一种分层模型集成框架,算法通过两层结构集成多个模型:第一层基模型预测后,其结果作为第二层简单元模型的输入,经过训练得到最终模型。测试时,基模型预测后再由元模型处理得到结果。
2.4 本章小结
本章深入探讨了机器学习的核心理论,重点关注了随机森林、逻辑回归、XGBoost等算法,并讨论了数据不平衡问题的优化策略,包括数据层面和算法层面的改良,以及模型融合方法的介绍和应用,为理解和解决实际问题提供了坚实的理论基础。
3 供水管网数据集的预处理与特征筛选
在研究供水管网漏损预测时,确保数据集的高品质是构建有效预测模型的关键。本文的目标是通过一系列方法来提升数据集的质量和适用性,为模型开发和进一步分析提供坚实的基础。首先,探讨 GIS 系统在管理和维护供水管网数据方面的重要性,并详细分析数据集中的各个字段。随后,进行探索性数据分析(EDA),揭示数据的主要趋势、分布特征和可能存在的问题,为数据预处理提供方向。在数据预处理阶段,进行缺失值和异常值的处理,以及数据的标准化。最终结合模糊层次分析法(FAHP)和随机森林算法进行特征选择,以识别对漏损预测最为重要的特征,增强模型的预测性能和解释力。
3.1 数据集分析
本次实验选取的研究区域位于华中地区的一个城市,所依赖的数据资料来源于该城市 2015 年至 2021 年间的管线地理信息系统(GIS)以及巡检和维修的档案记录。这些数据由一家供水企业搜集整理,包含了正常运作的管线和发生漏损事件的管线信息,共计 16,476 条记录。
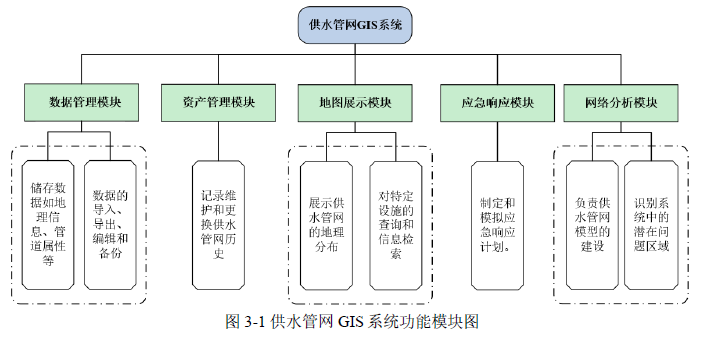
3.1.1 GIS 系统简述
GIS(Geographic Information System,地理信息系统)是一种集成化的地理空间数据处理平台,实现对空间数据的采集、归档、治理、处理、解析、仿真以及可视化展示。如图3-1所示。
3.1.2 数据集字段分析
本文实验所用的数据集共有十一个特征字段,分别是:管道长度(Pipe_Length)、管道铺设单位(Pipe_Laying units)、先前失效(Pipe_Previously failed)、管内流量大小(Pipe_Flow size)、管内压强(Pipe_Pressure)、余氯水平(Pipe_Chlorine residual)、管道埋设土壤性质(Pipe_Nature of buried soil)、管道材质(Pipe_Material)、铺设时间(Pipe_Laying time)、管道埋深(Pipe_Burial depth)、管道直径(Pipe_Diameter)以及是否发生漏损(Pipe_Leakage)。
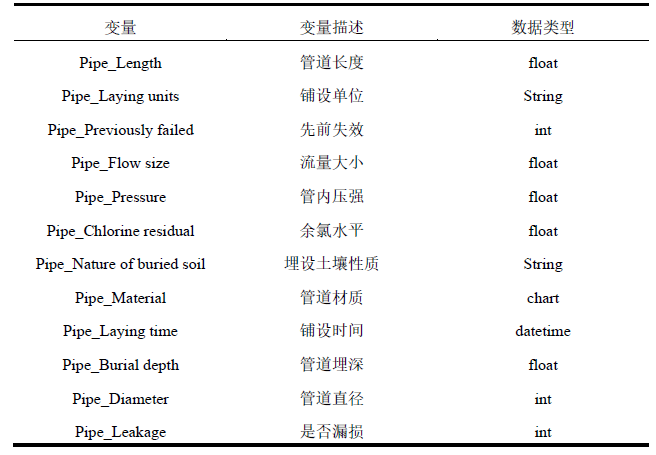
表3-1 变量描述
3.1.3 探索性数据分析
数据探索性分析(Exploratory Data Analysis,EDA)是对初始数据集进行的基础分析,目的是迅速理解数据的关键特性和内在规律。本研究应用此方法对选定的关键变量进行深入的可视化分析。
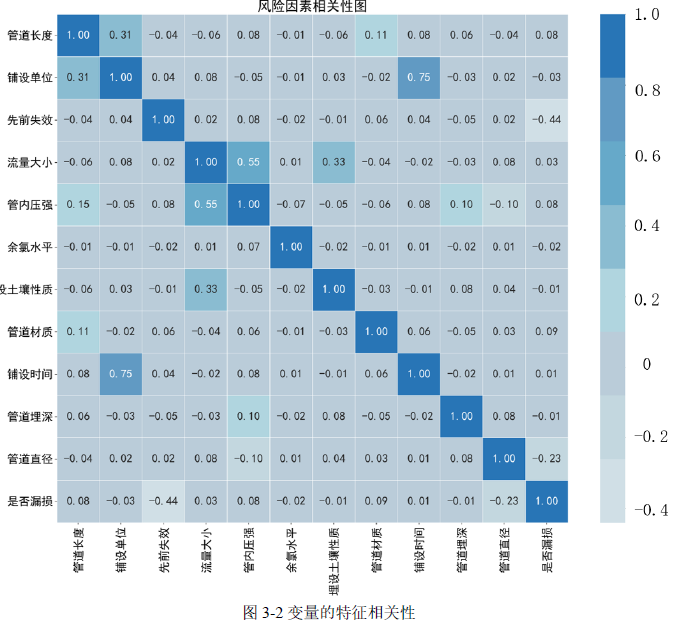
(1)变量的特征相关性
通过对供水管网漏损预测的相关特征详细分析,观察到某些特征与漏损发生的概率之间存在显著的关联性差异。铺设单位、余氯水平、土壤性质和流量大小与漏损的相关系数接近零,显示出这些特征与漏损之间在统计上没有显著的线性关联,从而意味着在预测漏损现象时不具备重要的作用。相对地,管道材质、历史失效记录和管内压强与漏损的相关系数较高,表明这些特征与漏损发生有较强的相关性,是影响漏损风险的关键因素,在建立漏损预测模型时应重点考虑。
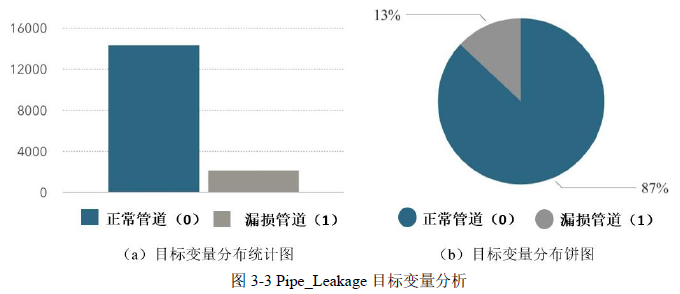
(2)Pipe_Leakage 目标变量分析
数据集包含 16476 条管道信息,其中正常管道占大多数,共有 14332 条,而漏损管道,即出现问题的管道,仅有 2144 条。这导致数据集存在明显的类别不平衡问题。
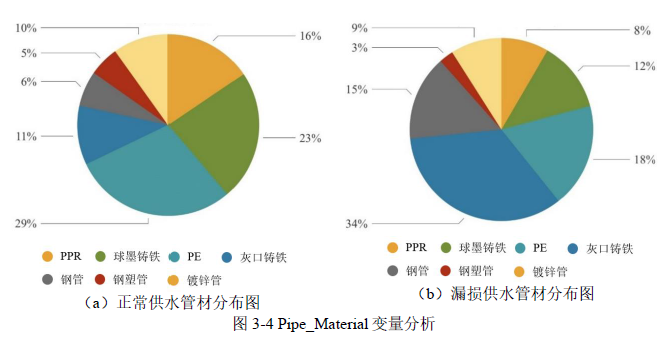
(3)Pipe_Material 变量分析
灰口铸铁管在事故管道中的占比从11%增加到34%,这表明灰口铸铁管在供水管网中存在着某种缺陷或易损性,导致其更容易发生漏损事故。球墨铸铁管在漏损管道中的占比相比正常管道有所减少。这反映球墨铸铁管具有更高的可靠性和更强的抗漏损能力。
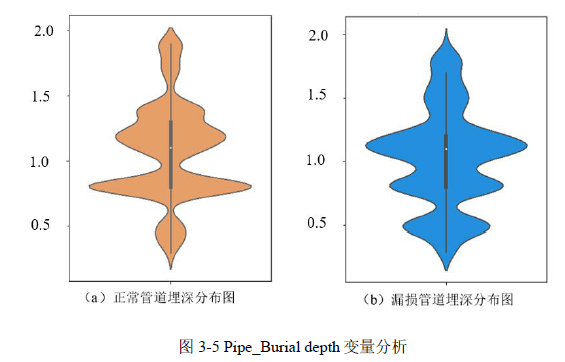
(4)Pipe_Burial depth 变量分析
在未发生事故即正常的管道中,没有明显观察到埋深在 0.5m 到 1m 范围内的分布比发生事故的管道多。而在发生事故的管道中,埋深分布在 1.5m 到 2m 范围内明显比正常管道多,同时离地较近的 0.5m 范围内,发生事故的管道也更多。
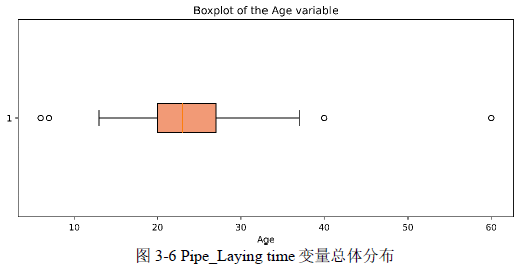
(5)Pipe_Laying time 变量分析
管道年龄主要集中在20到30年之间。未发生事故的管道的年龄分布集中在15到25年之间,而发生事故的管道的年龄集中分布在20到30年之间。此外,在30到40年之间,发生事故的管道占比明显比未发生事故的管道多。这些发现暗示着管道年龄与事故发生之间存在一定的关联性。
3.2 数据预处理
3.2.1 缺失值和异常值处理
由于GIS系统在数据收集过程中可能遇到设备故障或人为记录错误等问题,因此数据集中难免会出现缺失和异常值。
(1)供水管网缺失值处理
针对供水管网数据集,选择使用 Lagrange 插值法来完成供水管网的数据填充。
(2)供水管网异常值处理
为清除供水管网数据中的异常值,本文结合了拉依达法则(Grubbs准则)检测随机误差和箱型图法(Box-plot)来评估各个变量。基于算法的填充。如矩阵分解(Matrix Factorization) 算法、EM(Expectation-Maximization)算法、Lagrange 插值法等算法的填充方式。
针对供水管网数据集,选择使用Lagrange 插值法来完成供水管网的数据填充。插
值法原理根据数学分析可得,对二维空间中已知的n 个离散数据点集,有n-1 次多项式
y=a0+a1x+a2x2+...+ an-1xn-1,使多项式曲线过n 个点。

3.2.2 数据标准化处理
在对供水管网数据集进行初步分析后发现,数据集共有11个特征变量,且变量具有不同的量纲。为了提高模型创建效率和提升模型精度,针对数据集本文使用Min-max归一化技术对不同属性的供水管网数据特征进行标准化处理。
3.3 特征筛选
在供水管网的漏损预测模型构建过程中,选取恰当的特征变量扮演着至关重要的角色。为了确保所选特征能够有效提升模型的预测精确度和整体性能,本文采取了一种综合的方法来进行特征选择。这种方法结合模糊层次分析法(Fuzzy Analytic Hierarchy Process,简称 FAHP)和随机森林(Random Forest,简称 RF)算法的优势。
3.3.1 基于模糊层次分析法的特征筛选
模糊层次分析法(Fuzzy Analytical Hierarchy Process,FAHP)是一种融合模糊逻辑与层次决策过程的方法,有效捕捉决策中的主观模糊性72。
(1)建立供水管网漏损因素体系
结合《建筑给水排水设计规范》(GB50015-2019)行业规范,并结合本数据集,从获取到的管线特征确定指标层与子指标层。
(2)建立基于三角模糊数的判断矩阵
根据三角模糊互补判断矩阵构建方法和根据模糊标度,构造各因素两两比较的判断矩阵。
(3)计算各指标权重值与层次总权重值
按照公式计算各子指标的权重值 ωiωi,(i∈Ni∈N) ,可得到各层次指标权重。基于模糊层次分析 FAHP 分析法各因素权重统计图如图所示。
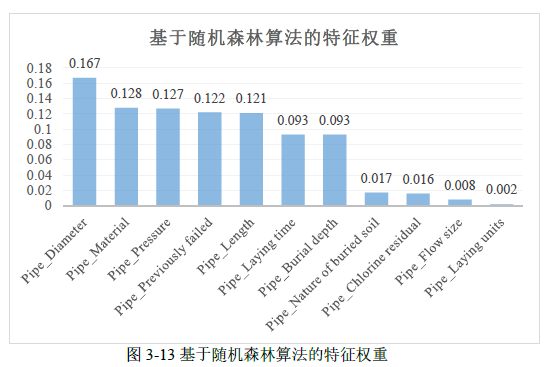
3.3.2 基于随机森林算法的特征筛选
随机森林(Random Forest,RF)借助于在众多决策树中变量出现的频次来评定其重要性。本研究采用此算法,对特征变量重要性评估可视化结果如图 3-13 所示。
3.3.3 供水管网漏损预测模型特征选定
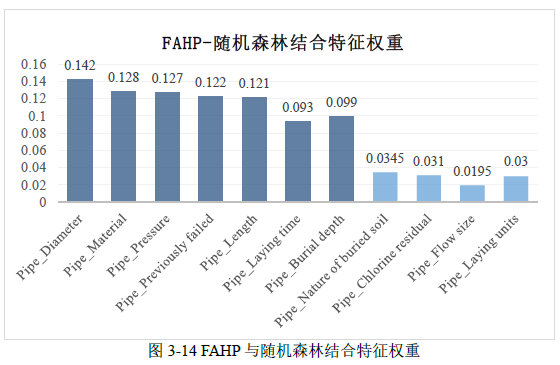
将模糊层次分析法(Fuzzy Analytical Hierarchy Process, FAHP)和随机森林算法(Random Forest, RF)结合在一起,进行供水管网漏损预测模型的特征筛选中优于单一方法的特征筛选。
经过公式计算得到最终特征权重,由此明显看出(Pipe_Nature of buried soil、Pipe_Chlorine residual、Pipe_Flow size、Pipe_Laying units)这四个特征权重值低于 0.04,属于不重要特征。因此研究主要漏损因素与后续进行漏损预测时,优先考虑(Pipe_Material、Pipe_Pressure、Pipe_Previously failed、Pipe_Length、Pipe_Diameter、Pipe_Burial depth、Pipe_Laying time)这七个因素。
3.4 本章小结
本章首先概述 GIS 理论基础,并对供水管网数据集进行详尽分析。通过探索性分析和预处理,解决数据缺失和异常问题,并实施了标准化。进一步分析特征变量与漏损的相关性,筛选特征为建立预测模型提供关键输入。
4 供水管网漏损预测的数据均衡化方案
在供水管网漏损预测的研究中,数据分布的不平衡性是一个普遍存在的问题,严重影响了模型预测的准确性和可靠性。本文围绕供水管网漏损预测数据分布优化策略展开讨论,目的是通过不同的方法来解决数据不平衡问题,从而提高模型的性能。首先通过计算样本之间的相似性,剔除重复或冗余的多数学样本,从而优化数据集。随后介绍了针对不同类型模型的数据均衡化策略。包括基于统计学习模型、深度学习模型和集成学习模型的特定策略。通过这些策略的应用,可以有效提高模型对漏损情况的识别能力,为供水系统的维护和管理提供更准确的数据支持。
4.1 基于相似性分析的数据采样
鉴于初步筛选后的数据量仍然较大,考虑到供水管网在一定时期内运行状态相对稳定,导致采集的数据在各特征变量上的变动较小,甚至信息高度一致。因此,通过分析样本间的相似性,并设定一个阈值来剔除那些高度相似的样本是合理的。
该算法的具体步骤如下:
(1)将原始非漏损状态样本数据进行标准化处理,计算标准化因子 δδ;
(2)计算非漏损状态样本 xi,xj(i≠j)xi,xj(i=j) 之间的相似度 RijRij;
(3)根据相似度设置阈值 ϵϵ,如果 Rij>ϵRij>ϵ,将样本 xixi 从数据集中删除;
(4)重复上述步骤,检查完所有样本,并动态调整阈值 ϵϵ。
为了减少冗余的样本数量,选取 ε=0.9997ε=0.9997,此时非漏损状态的样本数量剩余 90%,即此时经过样本相似性分析后,非漏损状态的样本数量比原来的 1.4w 多数类样本少了 1000 多的冗余样本。
4.2 供水管网数据均衡化方案
本文针对不平衡数据集的处理方式,主要是考虑依据对 GIS 数据前期的探索性分析剔除部分样本数据,在数据层面考虑数据之间的相似性。不同类型的模型具有不同的特性和学习方式,针对不同模型特性采用相应的数据不平衡处理方法,可以更好地发挥每种模型的优势,当利用统计学习模型建模时,如逻辑回归(LR)、XGBoost 时采用混合采样方法;当利用树模型建模时,采用改进的集成学习算法 EE−ADASYNEE−ADASYN;在应用深度学习模型时,使用经过优化的交叉熵损失函数作为改进的学习方法。
4.2.1 统计学习模型的数据均衡化方案
统计学习模型更侧重于利用数据的分布特征,针对供水管网漏损预测统计学习模型,如逻辑回归(LR)、XGBoost 模型,本文在处理不平衡数据集方面,结合了随机欠采样与 SMOTE 过采样的混合方法。这种策略有助于提升统计学习模型对不平衡数据的处理能力,从而增强模型的表现和泛化性。
4.2.2 深度学习模型的数据均衡化方案
深度学习模型通过精确优化损失函数来改善其在处理不平衡数据时的性能,特别是在图卷积神经网络(GCN)等供水管网漏损预测模型中。本研究通过权值平衡对损失函数改进,调整不同样本间的损失值权重大小,使得供水管网数据集分布趋于相对平衡。
针对供水管网漏损预测问题,本文使用交叉熵损失(Cross-entropy Loss)函数。针对不平衡数据集的分布情况进行进一步优化,考虑在交叉熵损失函数的基础上加入权重系数 α(α∈rand(0,1))α(α∈rand(0,1)),用来赋予漏损样品与正常样品在其中不同的重要性大小。
4.2.3 集成学习模型的数据均衡化方案
集成学习模型主要侧重于融合多个基础学习器的预测结果,EasyEnsemble 是一种基于集成学习的机器学习算法,旨在解决数据不平衡问题。为解决供水管网原始数据集极度不平衡,改善 EasyEnsemble 集成算法,加入综合自适应过采样(Adaptive Synthetic Sampling,ADASYN)算法来整体平衡数据集的分布。
EE-ADASYN 算法融合了 EasyEnsemble 集成思想与 ADASYN 方法,旨在解决数据不平衡问题。在本文 EE-ADASYN 算法处理流程中,供水管网漏损预测为二分类的数据集,其中正例(漏损管网)数量较少,而负例(正常管道)数量较多。
EE-ADASYN 算法采用随机森林算法(RF)作为分类器,并依据特征评估进行选择。实验结果表明,在采用随机森林(RF)作为分类器的实验中,EE-ADASYN 算法结合 RF 表现出色。相比之下,本文提出的采样方法结合 EE-ADASYN 和 RF 进一步提升了性能,表明特征评估在选择最佳采样方法和分类器组合时的重要性。
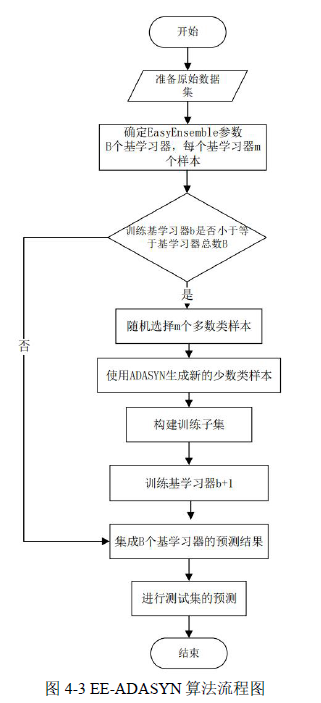
4.3 本章小结
本章详细介绍了针对供水管网漏损预测的数据分布优化策略,包括基于相似性分析的下采样方法和基于统计学习、深度学习和集成学习模型的多种数据均衡化技术。这些策略目的是改善数据不平衡问题,提升模型的预测准确性和泛化能力,并通过实践验证了其有效性。
5 基于模型融合的供水管网漏损预测模型构建
准确预测供水管网漏损对于提升供水系统效率和确保供水安全至关重要。本文系统地构建和评估了一系列模型,从统计学习到集成学习和深度学习,采用了逻辑回归、XGBoost、随机森林和图神经网络等多种算法。通过整合这些模型的优势,提出Stacking 融合模型以增强预测的准确性和稳定性,并深入探讨影响漏损预测的主要因素,为供水系统的优化管理提供科学的技术支持。
5.1 供水管网漏损预测模型的搭建与评估
5.1.1 模型构建方案
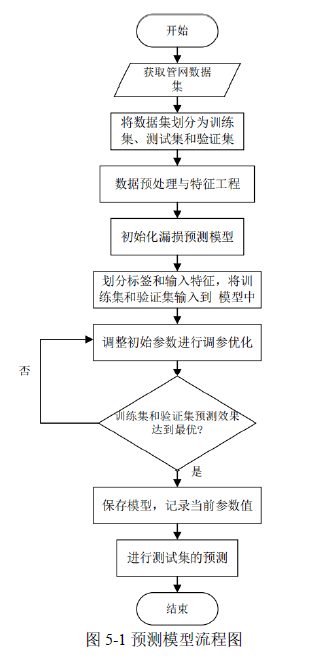
供水管网的漏损预测模型流程图如图 5-1 所示。具体流程如下所示:
(1)数据准备:初始阶段,将供水管网数据集分为训练、测试和验证集,以评估模型表现。
(2)数据预处理和特征处理:接着进行数据预处理和特征处理,包括数据清洗(处理缺失和异常值)及数据标准化与归一化。以及从原始数据中提取有助于模型学习的关键特征。
(3)模型选择和初始化:选择合适的机器学习算法或模型架构,并进行初始化,准备开始训练。
(4)数据分离:将数据集中的标签(即模型预测的目标变量)和输入特征分开,确保模型能够正确地学习如何从输入特征预测标签。
(5)模型训练和验证:使用训练集的数据来训练模型,并使用验证集来评估模型在训练过程中的性能,以便进行参数调整。根据验证集上的性能,对模型的参数进行调整,以优化模型的性能。这个过程可能涉及多次迭代,直到找到最优的参数配置。
(6)模型评估:最后,模型性能达到最优,就保存模型的状态,并记录此时的参数配置,最后用训练好的模型在测试集上预测,验证其性能和稳定性。
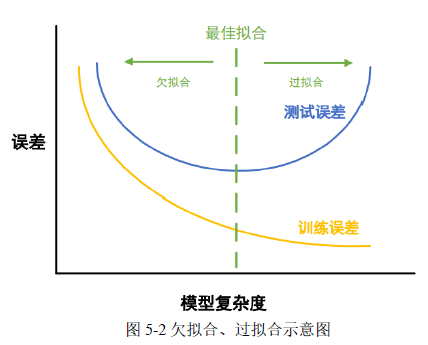
5.1.2 模型欠拟合和过拟合处理方法
机器学习模型可能遇到欠拟合或过拟合问题,这两种情形均有可能削弱模型对未知数据进行有效预测的精确度。欠拟合表现为模型在训练集和验证集上都未能有效捕获数据规律,通常由数据量不足或模型太简单导致,在损失曲线上表现为训练和验证损失都较高,且验证损失没有改善趋势。过拟合则是模型在训练集上表现良好,但在验证集上性能开始变差,这可能由于模型过于复杂或训练数据不足引起,在损失曲线上显示为训练损失持续降低而验证损失在某个点开始增加。针对这两种情况,在构建供水管网漏损预测模型时采取相应措施。
5.1.3 模型评价指标
供水管网漏损预测属于二分类问题,二分类混淆矩阵将分类器的输出结果分为四类:真正例(TruePositive, TP)、假正例(FalsePositive, FP)、真反例(TrueNegative, TN)、假反例(FalseNegative, FN)。
针对供水管网漏损预测模型的评估本文采用精确率(Precision)、准确率(Accuracy)、召回率(Recall)马修斯相关系数(MCC)与 ROC 曲线。
(1)精确率、准确率、召回率与马修斯相关系数
考虑到类别不平衡的数据集,为了尽量不受类别分布不均匀的影响,采用马修斯相关系数(Matthews Correlation Coefficient,MCC)评估模型性能。
(2)ROC 曲线
ROC 曲线的横坐标假定率(False Positive Rate, FPR),纵坐标真正率(True Positive Rate, TPR)。TPR 和 FPR 的计算基于正负样本的总数,不受样本不均衡的影响,准确评估模型。AUC,即 ROC 曲线下的面积,反映了分类器区分正负样本的能力,值越大,性能越好。
5.2 基于统计学习的漏损预测模型构建与优化
5.2.1 基于逻辑回归的模型构建与优化
构建逻辑回归预测模型的步骤如下:首先,从训练集中按比例随机抽取样本构建多个子样本集,针对每个子样本集训练一个逻辑回归模型。然后,在模型训练过程中,使用正则化技术来防止过拟合,并从全部特征变量中进行特征选择,以选取对预测目标最有影响力的特征。重复以上步骤构建多个逻辑回归模型,并组合成集成模型。最后,对所有逻辑回归模型的预测结果进行加权平均或多数投票等集成方法处理,得到最终预测结果。
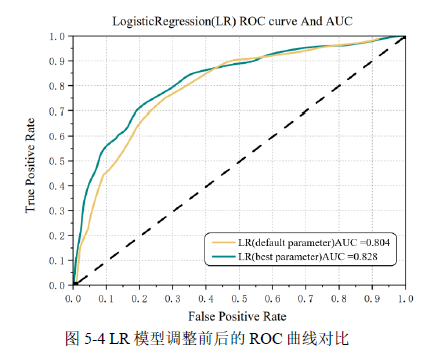
调参前后模型指标对比如表5-4所示,从表中可以看出,逻辑回归(LR)模型在按照参数调优后的召回率和AUC值分别为0.832和0.828,准确率比较高,说明对于多数学样本(非漏损状态)的误判较少。MCC提高到0.881表明预测模型具有较高的预测准确性和可靠性,其中该模型的ROC曲线在默认超参数以及调优后的对比如图5-4所示,其中调优前该模型的AUC值为0.804,调优后其模型的AUC值有了一些提高,说明调优后的模型对于少数类样本(漏损状态)的漏判相对减少。
5.2.2 基于 XGBoost 的构建与优化
构建 XGBoost 预测模型的步骤如下:首先,从原始训练集中采用随机抽样方法构建多个子样本集,对每个子样本集应用 XGBoost 算法独立训练出一个基模型。接着,在模型训练过程中,引入正则化项,如 L1 或 L2 正则化。通过梯度提升方法和最大化结构化损失函数,迭代优化每个基模型的参数。重复构建多个性能良好的 XGBoost 基模型,并通过集成学习的方法,如 Bagging 或 Boosting,组合成一个强大的集成模型。最后,根据各个基模型的预测结果,采用加权平均或投票机制等集成技术,整合模型的预测,得到最终的 XGBoost 集成预测模型的输出。
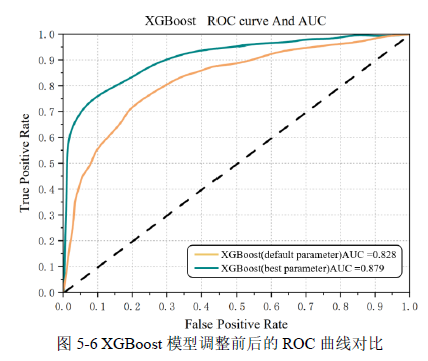

表5-6 中显示了在调参前后的XGBoost 模型指标对比。XGBoost 模型调整前后的ROC 曲线对比如图5-6 所示。通过调参优化,XGBoost 模型在各项指标上都取得了显著的提升,尤其是准确率和AUC 值的提升最为显著,这意味着调参过程中找到了更适合数据集的参数组合,提升了模型的整体性能和泛化能力。
5.3 基于集成学习的漏损预测模型构建与优化
本文选择随机森林模型(RF)作为集成学习中预测模型的研究对象,主要是因为随机森林具有出色的分类和回归能力,能够有效处理不平衡数据,提供特征重要性评估,并且具有鲁棒性、高效率和易于实现调优的特点。这些特性使得随机森林模型非常适合用于供水管网漏损预测,能够提供准确的预测结果并为实际的管网维护提供科学依据。
构建随机森林(RF)预测模型的步骤如下:首先使用自助法从训练集中随机抽取样本构建多个子样本集,针对每个子样本建立对应的n 棵决策树。接着,在决策树节点分裂前,从全部特征变量中随机抽取一定数量 M 的特征变量进行列抽样,再利用信息增益等方法选取最佳分裂属性对节点进行分裂。采用 CART(Classification and Regression Trees)回归树作为单一决策树,重复以上步骤构建多棵决策树,并组合成随机森林。最后对所有决策树的回归预测结果进行平均处理,得到基于随机森林的船舶能耗预测模型的预测结果 {y1,y2,...,yn}{y1,y2,...,yn}。
RF 模型调整前后的 ROC 曲线如图 5-8 所示。调参前后模型指标如表 5-8 所示,可以看出随机森林(RF)模型在参数调整后性能得到了显著提升。从模型指标对比看出,经过参数调整后的 RF 模型在精确度、召回率、准确率、MCC 以及 AUC 值上均有提高。通过参数调整,RF 模型在分类任务中的性能得到了显著提升。
5.4 基于深度学习的漏损预测模型构建与优化
5.4.1 邻接矩阵的构建
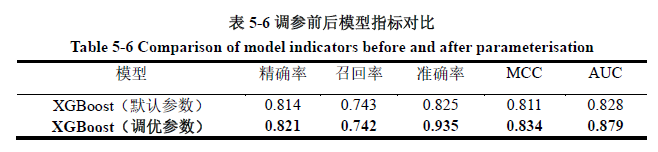
GraphSAGE 模型依赖于图的邻接矩阵来捕捉节点间的连接关系。空间邻接矩阵被用来反映节点在实际空间中的位置和连接,这有助于模型学习节点的空间特征,但也限制了模型捕捉远距离节点特征的能力。如果仅依赖供水管网的空间拓扑结构,模型可能无法识别出微小差异特征对漏损影响的不同因素。
因此,本文提出结合空间邻接矩阵和相似性邻接矩阵来构建综合的邻接矩阵。
(1)空间邻接矩阵(Spatial Adjacency Matrix):
利用管网 GIS 数据库中的管网管线图、地理位置信息、地理位置字段构建空间管网邻接矩阵,将每个管网抽象为图结构中的一个点,若两个管网在现实中的空间中相连接,则将两个节点相连接,得到空间连接图 G 与对应的空间邻接矩阵 AGAG。
(2)相似性邻接矩阵(Similarity Adjacency Matrix):
使用相似性邻接矩阵可以从语义角度反映不同实体之间的关系,进一步提高模型的学习能力与预测能力。相似性邻接矩阵的构造按照特定算法进行。
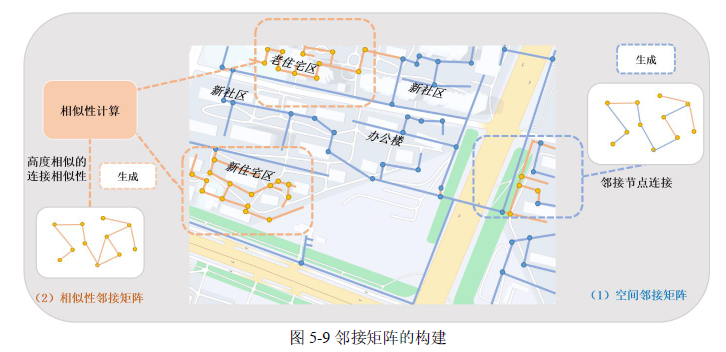
5.4.2 基于改进邻接矩阵的 GCN-SIM 模型设计
模型架构的设计是深度学习模型性能的关键因素之一,图 5-10 所示的模型架构中。图结构特征提取层:负责从原始的图结构数据中提取有用的信息。GraphSAGE 是一种强大的图卷积网络,能够生成节点的高质量表示。这种设计使得模型能够处理大规模图数据,并有效捕获节点间的复杂关系。
图节点表示学习层:为了提升模型的性能和稳定性引入 BatchNorm 层、ReLU 层和 Dropout 层。
异常评分层:根据学习到的节点表示来预测节点的异常程度。通过复杂的评分机制将节点的特征映射到连续的评分上,为后续的异常检测任务提供依据。
图结构特征提取层主要分为两个模块,一个是空间上邻居节点特征聚合模块,记为 NGME 模块,对邻居节点上的特征进行平均聚合,这个模块的主要目的是为了学习到供水管网拓扑空间中潜在的特征与联系;另一个模块是相似节点特征聚合模块,记为 NSMA 模块,该模块的主要目的是为了学习到相似特征的不同波动对图中节点的性质的影响程度,并对相似性近邻节点的特征进行 max-pooling 聚合。将由这两个不同模块学习到的节点表达在特征维度上进行拼接,类似于 ResNet 的残差连接结构,形成一个高维节点表示。
5.4.3 模型参数调优
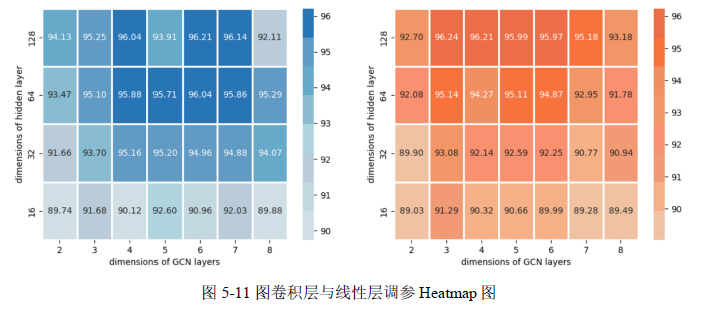
图卷积隐藏层维度(d): 从默认值64调整到128。调整可能后增加模型的学习能力,以便能够捕捉更复杂的特征和模式,从而提高模型对漏损预测的准确性。图嵌入向量维度(dm): 从32增加到64,可以帮助模型学习到更丰富的节点表示。线性层隐藏层维度(d): 从64增加到128。以此提供更多的参数来学习数据中的非线性关系,进而提高模型的性能。学习率(r): 保持默认值0.01不变。0.01是一个常见的起始学习率,在初步实验中表现良好,因此没有调整。BatchNorm (归一化): 默认值True不变,可以加速模型训练过程并提高模型稳定性。图卷积层数与线性层数的调参如图5-11所示。
5.4.4 模型对比分析与特征表达分析
在完成数据集的准备工作、选定评价指标以及模型参数调优之后,本研究所提出的模型将与四种常用的供水管网漏损预测模型进行比较,以此来验证其性能。这些模型包括随机森林(RandomForest, RF)、XGBoost、逻辑回归(Logistic Regression, LR)以及具有空间特征提取能力的图卷积网络(Graph Convolution Network,GCN)。比较结果将展示在表 5-5 中,以证明本模型在捕捉细微特征差异方面的优势。
实验结果表明,本模型在表达能力上超越了其他对比方法,但还需要验证模型生成的节点表达是否真正有助于预测任务,即是否学习到了有用的特征。为此,本文采用 Hook 函数技术提取模型深层的节点嵌入表示,这些表示位于多层感知器(MLP)的最后一个线性层。
通过将原始数据、初步训练后的节点表达和训练完成后的节点表达依次进行 TSNE-KDE 降维处理,生成相应的可视化图。随着训练的深入,本模型能够更有效地区分不同类别的节点。
5.4.5 模型消融实验设计与结果分析
消融实验通过单独测试模型的各个模块,展示每个模块对图中点异常检测任务准确率的贡献。在本文消融实验中,trick A 利用 NGME 模块对邻域节点采样并构建节点表示;trick B 通过 NSMA 模块对邻近节点进行采样;trick C 则应用 MLP 模块深化学习特征间复杂关系,进一步生成节点表示。
根据表 5-11 的结果显示,仅仅采用空间邻居采样模块会导致 AUC 表现较差,并且在训练集上出现了过拟合现象。但是,一旦引入相似性邻居节点采样模块,情况就发生了改善。这不仅提高了 AUC 值,还缓解了训练集的过程合问题。这表明,类残差网络结构通过将两种采样生成的节点表示向量进行拼接,有助于防止过度平滑的问题。更进一步的改进是同时集成空间邻居采样、相似性采样和深层特征学习 MLP 模块,这使得模型的准确率达到了最优水平。这进一步证实了模型中各个模块的结合不仅增强了其表达能力,而且有效地抑制了过拟合的发生。
5.5 模型融合及结果分析
5.5.1 供水管网漏损预测模型融合策略
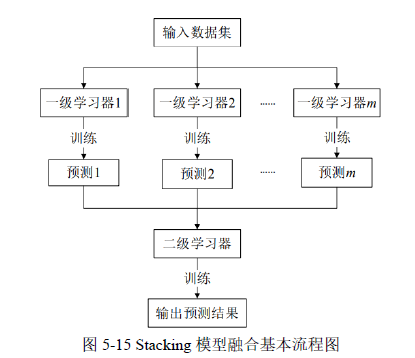
本文采用堆叠法(Stacking)的方法进行单模型融合。基于 Stacking 融合的模型流程图如 5-15 所示。
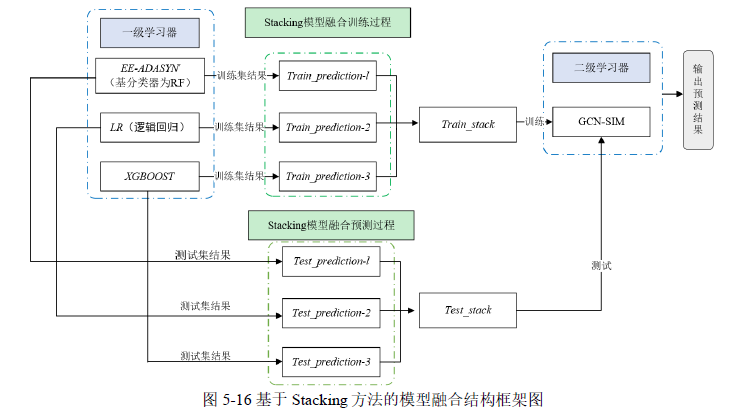
在前述研究的基础上,决定采用四种本质上具有显著差异的模型来进行集成学习。这些模型包括:一种集成学习模型,名为 EE-ADASYN,其基础分类器采用的是随机森林(RF)算法;一种统计学习方法,即逻辑回归(LR)模型;以及一种高效的机器学习算法,极端梯度提升算法(XGBoost)。除此之外,还引入了一种改进的深度学习模型,称为 GCN-SIM。通过将这四种模型进行融合,获得更为准确和可靠的预测结果。
在构建 Stacking 模型融合的过程中,首先选择三种不同的机器学习算法作为一级学习器,分别是随机森林(Random Forest, RF)、逻辑回归(Logistic Regression, LR)和极端梯度提升算法(XGBoost)。这些算法在训练集上独立进行预测,它们的预测结果随后被用作二级学习器的训练输入数据,每种算法对训练集的预测输出,将被整合起来,形成一个综合的特征集,这个特征集将被用于训练二级学习器。当这些一级学习器在测试集上进行预测时,预测结果同样被用作输入,但这次是作为二级学习器在测试阶段的输入数据。采用 GCN-SIM 模型构建二级学习器。GCN-SIM 模型利用图形网络的优势,能够处理图结构数据,并从中学习到复杂的模式和关系。通过训练,GCN-SIM 模型将学习如何最好地结合一级学习器的预测结果,以产生最终的预测输出。
在构建 Stacking 模型时,采用了 5 折交叉验证来避免过拟合,确保模型具有良好的泛化能力。交叉验证后,将各验证集数据合并,作为二级学习器的训练数据。测试阶段,使用一级学习器对测试集的平均概率预测作为二级学习器的输入。这种方法提高了模型的稳定性和预测准确性,使其在实际应用中更为可靠。
5.5.2 供水管网漏损预测融合模型结果分析
对于采用 Stacking 模型融合之后的供水管网漏损预测模型,将其与单独的优化模型对比,实验结果如表 5-12 所示:
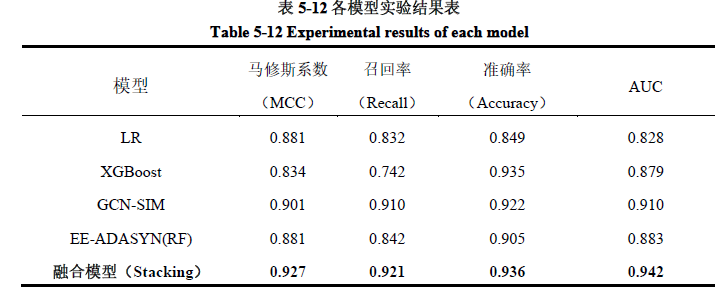
表 5-12 汇总了各模型的实验结果,各模型的 ROC 曲线如图 5-17 所示。实验涵盖了逻辑回归(LR)、XGBoost、基图卷积网络(GCN-SIM)、EE-ADASYN(随机森林,RF)以及融合模型(Stacking)。结果表明,融合模型(Stacking)在所有指标上均取得了高分,其中 MCC 为 0.927,召回率为 0.921,准确率为 0.936。这表明融合模型有效地整合不同模型的优势,提升了整体的预测性能。特别是在 MCC 上达到 0.927,显示出模型在正负样本分类上具有很好的平衡性。高召回率(Recall)和准确率(Accuracy)进一步证实模型在识别漏损事件方面的高效率和可靠性。AUC 值 0.942 接近于 1,意味着模型在区分正常和异常样本方面具有极高的能力,即使在随机选择的情况下,也能正确地将正样本排在负样本之前。
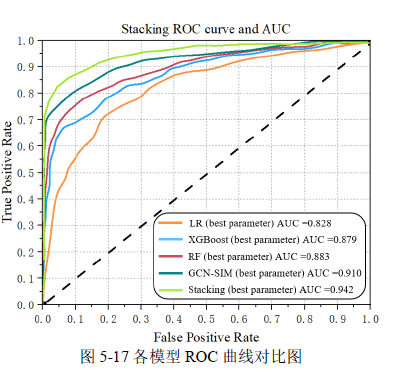
综合来看,融合模型(Stacking)不仅在供水管网漏损预测任务中的表现优越,而且在处理复杂数据和泛化能力上表现强大。这种模型的集成方法能够显著提高预测的准确性和鲁棒性,为实际应用中的漏损检测和管理提供有力的技术支持。
5.5.3 供水管网漏损影响因素分析
在获得最优模型的基础上,深入探讨供水管网漏损的影响因素。这样不仅有助于更好地把握模型的决策过程,还能为减少供水管网漏损提供科学依据。为此,采用SHAP(SHapley Additive exPlanations)分析方法。SHAP是一种基于Shapley值理论的新型解释机器学习模型的技术。Shapley值源自博弈论,用于评估多方博弈中各个参与者的贡献。在机器学习中,SHAP方法通过分配每个特征的"力",即影响力,来解释模型的预测结果。通过计算特征的有效值来揭示模型的决策过程,提供有意义的洞察。本文计算了供水管网特征的SHAP值,并得出如图5-18所示的结果图。
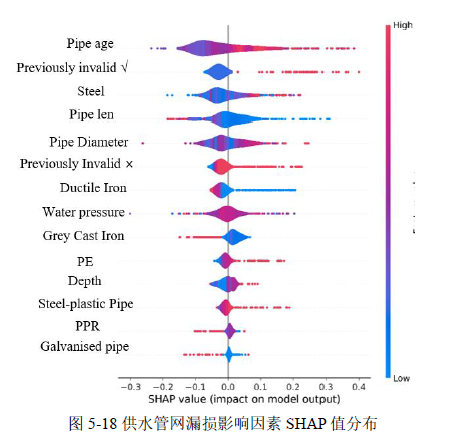
由图5-18可以看出,管道年龄可能是影响漏损风险的重要因素。根据SHAP值,较老的管道可能与较高的漏损风险相关联(正值表示正向影响)。先前失效(Previously invalid)SHAP值表明特征对模型输出有负面影响。在管材中钢管(Steel)与镀锌管(Galvanised pipe)属于可能导致漏损(正值)的材料,这可能因为钢材管道因为腐蚀、接头问题或管道老化而导致漏损,虽然镀锌可以提供一定程度的保护,但随着时间的推移,镀锌层可能会磨损,导致钢管腐蚀。管长(Pipe_len)SHAP值的正向表明较长的管道可能更容易导致漏损。管径(Pipe_Diameter)SHAP值的分布表明不同直径的管道对漏损风险的影响不同,可能是管径影响水流和压力分布,从而影响漏损风险。水压(Water_pressure)SHAP值表明水压的变化对漏损风险有显著影响。
根据上述 SHAP 分析结果,可以为供水管网漏损预防和管理提出以下建议:
(1)重点关注老旧管道:由于管道年龄是导致漏损的最重要因素之一,建议对老旧管道进行定期检查和必要的维护或更换。特别是那些已经使用了很长时间的管道,应该优先考虑进行升级或修复。
(2)监测和控制水压:水压是影响漏损风险的一个重要因素。建议安装水压监测设备,并根据需要调整水压,以减少因高压导致的管道破裂或接头泄漏的风险。
(3)使用耐用材料:在选择新的管道材料时,应考虑使用耐用性更高的材料,如 PPR 和灰口铸铁,这些材料在 SHAP 分析中显示出较低的漏损风险。
(4)深度和长度管理:管道的埋深和长度也与漏损风险相关。在设计和安装新管道时,应考虑这些因素,以减少未来漏损的可能性。
(5)定期维护和检查:对于已知存在问题或曾经被标记为无效的管道,应制定定期的维护和检查计划,以预防潜在的漏损问题。
通过实施这些建议,供水公司可以更有效地管理和减少漏损,提高供水系统的可靠性和效率。
5.5.4 供水管网漏损预测模型应用
本文针对郑州某区域供水管网进行漏损分析,该区域原始供水管网 GIS 图如图 5-21 所示。
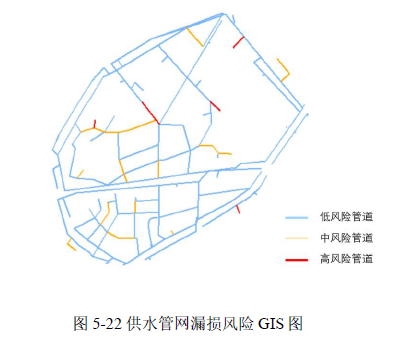
将模型输出转换为概率可以提高结果的可解释性、风险评估准确性和决策支持能力,在管网漏损预测模型的应用阶段,为了使维修人员能清晰的处理漏损问题,首先,使用 Sigmoid 函数将模型输出的节点表示映射到概率空间,得到预测的漏损概率 Y^Y^。
为了提升模型的预测精度,采用交叉熵损失函数来衡量预测漏损概率与实际漏损情况之间的误差,并据此调整模型参数。根据漏损概率的实际阈值,将风险等级划分为三类:概率超过 0.8 的视为高风险,0.8 至 0.5 的为中等风险,低于 0.5 的为低风险。将区域内供水管网的物理和空间信息输入至模型中,根据计算出的漏损风险概率,用不同颜色进行标记,如图 5-22 所示。图中大部分管线显示为蓝色,表示状态良好,而少数红色和橙色管线则表示高风险区域。维护团队可以针对这些高风险区域优先制定维护和修复计划,减少漏损风险;对于中等风险的管线,则可以安排定期检查和维护,以预防潜在的漏损问题。
5.6 本章小结
本章详细分析逻辑回归、XGBoost 和随机森林等模型的机制与调优,并对比它性能并评估模型融合技术的优缺点,以提高预测准确性和泛化能力。通过郑州市某区域的案例,展示在实际漏损风险评估中的应用效果,证明模型对维修工作的指导价值。
6 总结与展望
6.1 总结
供水管网系统的稳定运行对保障居民生活和工业生产至关重要。供水管道的漏损问题不仅影响供水效率,还导致资源浪费和经济损失。为了在管网漏损发生前以经济高效的方式预测管道状态,本文通过建立漏损预测模型对供水管网的运行故障进行了深入研究。研究内容包括:
(1)制定解决供水管网数据集复杂性和高维性方案。供水管网 GIS 系统存储的数据庞大且管网特征结构度高。通过探索性数据分析(EDA),揭示管网数据的分布特征。数据预处理阶段,采用 Lagrange 插值法进行缺失值补充和箱型图法(Box-plot)异常值去除,以及 Min-max 归一化。最后通过 FAHP 与随机森林算法结合进行对高维特征变量进行筛选,做好数据建模的前期特征工程。
(2)提出供水管网漏损预测的数据分布优化策略。以相似性度量的方法进行多数学样本的降采样,在统计学习模型方面,文章采用了随机欠采样和 SMOTE 过采样相结合的混合采样方法,以改善模型对不平衡数据的学习能力。对于深度学习模型,特别是图表神经网络(GCN),文章通过权值平衡对损失函数进行改进,调整不同样本的损失值权重,使得数据集的整体分布趋于平衡。在集成学习模型方面,文章提出了 EDADASYN 算法,结合了随机森林和 ADASYN 过采样算法的优势,以提高模型对少数类样本的识别能力。结果表明,这些优化策略有效地提升了模型的预测准确性和泛化能力。
(3)构建基于模型融合的供水管网漏损预测模型。通过构建和评估多种机器学习模型,包括逻辑回归、XGBoost、随机森林和图表神经网络,对供水管网漏损进行预测。并通过模型融合技术 Stacking 提高了预测准确性。最后利用 SHAP 值分析了关键影响因素,将模型应用于郑州某区域供水管网的漏损风险分析,通过 GIS 地图可视化漏损风险,为实际的管网维护提供了决策支持。实验结果表明,本文提出的模型在处理供水管网漏损预测任务中表现出色,能够有效地提升预测性能和泛化能力。
6.2 展望
基于本文的研究工作以及当前领域的研究现状和方法,未来的研究方向可以从以下三个维度进行深入探索:
(1)模型的实际应用优化
未来的研究可以着重于如何将模型更好地应用于实际的供水管网漏损检测和管理中。这包括模型的部署策略、用户界面的友好性设计、以及模型在不同类型和规模的供水系统中的适用性分析。同时,也需要考虑模型在实际运行中的维护和更新机制,确保模型能够随着时间的推移和数据的积累而持续优化。
(2)模型实时性的提升
实时性是供水管网漏损预测模型的重要特性之一。未来的研究可以探索如何提高模型的响应速度和实时处理能力,以便能够及时地发现和预警潜在的漏损事件。这涉及到模型的轻量化设计、高效的数据处理算法、以及与物联网(IoT)设备的集成,实现数据的实时采集和分析。
(3)模型建立的多样化选择
模型的选择和构建是漏损预测的关键环节。未来的研究可以探索更多的机器学习和深度学习算法,以及它们的组合和集成方式,以寻找更适合供水管网漏损预测的模型结构。同时也可以考虑引入新的数据源和特征工程方法,提高模型的预测准确性和泛化能力。此外模型的可解释性和透明度也是未来研究的重要方向,有助于用户理解和信任模型的预测结果。