Abstract
摘要------ 随着传感器技术的发展,RGB+X 系统将传统 RGB 相机与另一种辅助传感器相结合,从而增强感知能力,并为语义分割等重要任务提供更丰富的信息。然而,由于需要特定的采集设备,获取大规模 RGB+X 数据较为困难。因此,传统的 RGB+X 分割方法通常会利用相对丰富的 RGB 数据进行预训练。然而,这些方法缺乏能够充分挖掘预训练模型潜力的相应机制,而且预训练所用 RGB 数据集的规模本身也仍然有限。近年来,一些工作采用提示学习(prompt learning)来挖掘预训练基础模型的潜力,但这些方法采用的是一种单向提示 方式,即利用 X 模态或 RGB+X 模态去提示基于 RGB 模态预训练的基础模型,而忽略了非 RGB 模态中的潜力。本文致力于同时开发预训练基础模型在 RGB 模态和非 RGB 模态中的潜力,但由于模态之间存在语义鸿沟,这并不是一件容易的事情。具体而言,我们提出了 CPAL(Cross-prompting Adapter with LoRAs) ,这是一个包含新型双向适配器 的框架,能够同时充分利用不同模态之间的互补性,并弥合模态间的语义差距。此外,CPAL 还引入了低秩适配 (LoRA),用于对每个模态对应的基础模型进行微调。在这些设计的支持下,我们成功地同时释放了 RGB 基础模型在 RGB 模态和非 RGB 模态中的潜力。我们的方法在五个多模态基准上取得了最先进(SOTA)性能,这些基准包括 RGB+Depth、RGB+Thermal、RGB+Event 以及一个多模态视频目标分割基准 ;同时,在四个多模态显著目标检测基准 上也取得了优异表现。代码和结果已公开于:https://github.com/abelny56/CPAL
关键词------ RGB+X 语义分割;预训练视觉基础模型;提示微调;跨提示适配器;LoRA
I. INTRODUCTION
图像语义分割 旨在将图像中的每个像素归类到一个特定类别中,已广泛应用于机器人视觉、自动驾驶等多个领域,并取得了显著进展 1, 2, 3, 4, 5。然而,仅依赖 RGB 图像的语义分割方法仍然容易受到成像条件的影响,例如光照变化、雨雪天气、运动模糊等。引入辅助传感器(即 RGB+X )可以在一定程度上缓解这些问题。例如,深度传感器 6, 7, 8, 9, 10, 11, 12 能够获取场景的三维几何信息,热成像相机 13, 14, 15 可以捕获场景的温度信息,而事件相机则能够以低延迟检测并输出像素级亮度变化 16, 17, 18。然而,对这些设备的依赖也使得获取成对的 RGB+X 数据更加不便,导致 RGB+X 分割数据集的规模明显小于仅包含 RGB 的数据集。因此,大多数方法都会先在相对丰富的 RGB 数据上对模型进行预训练。然而,如何充分利用预训练模型,同时最大限度地从不同模态中提取有用信息,以实现高精度分割,仍然是一个具有挑战性的问题。
传统方法通常在网络的不同阶段设计各种融合策略 19, 20, 21 来挖掘不同模态中的有用信息,如图 1(a-c) 所示。尽管这些方法已经取得了显著进展,但其性能仍然受限于模型容量不足,以及缺乏专门用于充分挖掘预训练模型潜力的机制。
近年来,自然语言处理领域中大语言模型 22, 23 的快速发展,也推动了预训练视觉基础模型 (Vision Foundation Models, VFMs )的发展。得益于相对丰富的 RGB 数据,这些模型展现出了优异的泛化能力。然而,对于 RGB+X 视觉任务而言,由于缺乏大规模成对的 RGB+X 数据,直接训练 RGB+X 的视觉基础模型目前仍然非常困难。因此,将 RGB 视觉基础模型微调到 RGB+X 任务上,是一个更为可行的选择。近年来已有若干方法尝试这样做 24, 25。然而,这些方法采用的是单向方案 :即使用非 RGB 模态 24,或者同时使用 RGB 与非 RGB 模态 25 去提示 RGB 模态上的视觉基础模型,如图 1(d) 所示。这种方案忽略了基础模型在非 RGB 模态 中的潜力。由于 RGB 训练数据规模更大,视觉基础模型往往具有更强的泛化能力。因此,同时挖掘视觉基础模型在 RGB 和非 RGB 模态中的能力,并弥合不同模态之间的语义鸿沟,成为我们的主要设计目标。
为此,我们提出了一种新的双向提示框架 ,如图 1(e) 所示。在该框架中,一个预训练的(RGB)基础模型被同时应用于 RGB 分支和非 RGB 分支,并且其参数保持冻结状态。两个模态的冻结模型同时由本文提出的跨提示适配器 (cross-prompting adapter)进行提示。具体而言,在该适配器中,多个多模态跨提示器 (Multi-modal Cross Prompter, MCP )模块作用于基础模型的不同阶段,能够充分融合 RGB 与非 RGB 模态的信息,并为两种模态的冻结模型提供提示。各阶段得到的提示结果会通过本文提出的门控感知模块 (Gated Perception Module, GPM )进行收集与净化,从而生成用于解码和预测的特征图。此外,为了进一步考虑不同模态之间的差异,我们还引入了低秩适配(LoRA),对冻结模型分别进行面向各模态的微调,以学习模态特定的表征。大量在不同类型 RGB+X 分割数据集上的实验结果证明了本文方法的有效性。
我们工作的主要贡献总结如下:
- 我们提出了一种用于 RGB+X 语义分割 的双向跨提示学习框架,能够同时挖掘预训练(RGB)基础模型在 RGB 和非 RGB 模态中的潜力。
- 在上述框架中,我们提出了跨提示适配器 ,其中包含多个作用于基础模型不同阶段的 MCP 和 GPM 模块,用于产生高质量的特征以供解码和预测。
- 同时,我们引入 LoRA,分别对 RGB 和 X 模态下的视觉基础模型进行模态特定微调。
- 我们将上述策略应用到了不同参数规模的视觉基础模型上,构建了三个达到 SOTA 性能的模型,为精度和推理速度之间的不同应用需求提供了多样化选择。
II. RELATED WORK
A. Multi-Modal Semantic Segmentation
通用语义分割(以 RGB 为输入)旨在预测输入 RGB 图像的逐像素分割掩码,其中每个像素都被划分为某一特定类别。大规模数据集 26, 27, 28 的持续扩展,以及深度神经网络 29, 30 的快速发展,共同推动了这一领域的进步。尽管许多语义分割模型 31, 32, 33, 34, 35, 36 在分割精度方面取得了显著突破,但在真实场景条件下,它们仍面临挑战,例如当 RGB 相机无法提供足够信息时,包括强光或弱光照明、复杂天气场景等。
考虑到这一点,多模态语义分割受到了越来越多的关注,因为深度 21, 37、热红外 19, 38 和事件 17, 39 等不同模态能够提供互补信息,从而提升在复杂场景下的分割性能,而这些场景是仅依赖单模态图像难以有效处理的。近年来,40, 41 的工作进一步推动了研究方向从模态特定融合 向统一的 RGB+X 融合 转变。Sigma 42 中还引入了 Mamba 网络作为编码器和融合模块,并取得了令人印象深刻的性能。
上述大多数方法主要关注复杂的融合策略,却忽视了充分利用通过大规模 RGB 数据预训练所带来的优势。近年来,GoPT 24 推动了参数高效微调 (PEFT)在多模态语义分割中的应用,它利用非 RGB 模态去提示一个预训练的 RGB 基础模型。DPLNet 25 则进一步迈出了一步,同时利用 RGB 和非 RGB 模态去提示该 RGB 基础模型。尽管这两种方法在提示方式上有所不同,但它们都只探索了基础模型在 RGB 模态中的潜力。
我们的方法旨在通过一种跨提示微调 方式,充分挖掘预训练视觉基础模型(VFMs)在 RGB 和非 RGB 两种模态 中的潜力。这使得模型能够有效利用不同模态之间的信息,从而在复杂环境下实现更好的互补性能。此外,不同于以往那些专注于某一种特定模态融合的方法 19, 21, 37, 38,我们的方法通过采用可适用于多种 RGB+X 模态环境的通用融合策略 ,展现出更强的通用性和灵活性 ;同时还利用门控结构来过滤噪声信息。
B. Parameter-Efficient Fine-Tuning
预训练视觉基础模型(VFMs)能够从海量数据中获得强大的特征表示能力。因此,如何有效利用这些预训练基础模型以适应下游任务,已成为一个重要问题 43, 44, 45。参数高效微调 (PEFT)方法 46, 47, 48, 49 正是为提高微调过程的效率而设计的。近年来,前缀调优 (prefix-tuning)作为一种新型的参数高效微调方法 47, 50,在许多下游自然语言处理任务中受到了广泛关注。VPT 51 将提示调优(prompt-tuning)引入视觉任务中,提出通过微调提示 token 和任务头来获得优异性能,并降低训练成本。低秩适配(LoRA)48 则利用低秩近似对预训练模型中的某些层进行重新参数化,从而实现对大规模语言模型的高效微调。
不同于以往方法 24 中由非 RGB 模态去提示主模态的方式,本文提出了一种面向 RGB+X 语义分割 的跨提示框架 。在该框架中,RGB 与 X 两种模态通过精心设计的模块进行双向跨提示,从而释放预训练基础模型的潜力。
III. METHOD
在本研究中,我们提出了一种 CPAL ,可有效且高效地将预训练的大规模RGB语义分割模型适配至多模态任务。不同于对基础模型进行全参数微调, CPAL 采用轻量级的跨提示适配器与低秩自适应(LoRA)技术实现参数高效调优,从而获得卓越的多模态协同效果与更优的分割精度。该框架中的跨提示适配器由两部分构成:多模态跨提示器(MCP)和门控感知模块(GPM)。值得注意的是,为增强模态感知能力,适配器内所有模块均采用多尺度设计。本 CPAL 的整体架构如图2所示。
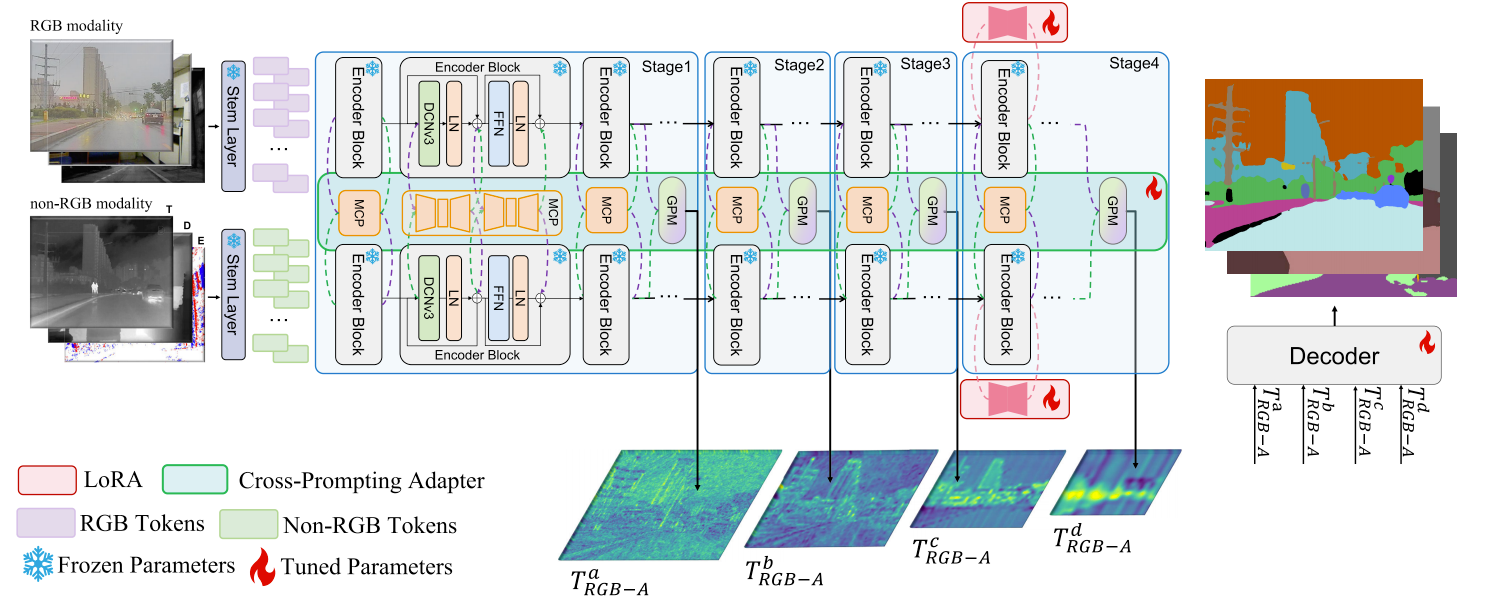
A. Multi-Modal Semantic Segmentation and Foundation Model
**1)问题定义:**在RGB语义分割任务中,目标是学习一个分割模型 SRG B: IRG B→OMask,其中 IRG B为输入的RGB图像,OMask为图像中每个像素的预测类别。对于多模态语义分割任务,模型输入会增加一个额外参数,扩展为( IRG B,IA),下标A表示深度、热红外或事件信息等非RGB模态。因此,多模态分割模型的公式可表示为 SRG B−A:( IRG B,IA)→OMask,其中 SRG B−A即为多模态分割模型。
**2) 基础模型:**尽管 PEFT 方法在语言模型领域已取得显著成效52,但其在多模态密集预测任务中的应用尚未得到充分探索。与语言模型不同,为更好地适配密集预测任务,我们精心选择了近期 VFM Internimage53作为基础模型。该模型采用专为语义分割设计的多阶段编码器架构,能够提取不同尺度的特征。总体而言,基础分割模型 SRG B可分解为编码器Enc•解码器Dec:其中Enc: IRG B→ TRG B表示作为特征提取功能的编码器基础, TRG B代表输入图像的输出特征;解码器Dec: TRG B→OMask则用于对编码器输出的特征图进行上采样,实现像素级预测。

B. Cross-Prompting Adapter With LoRAs

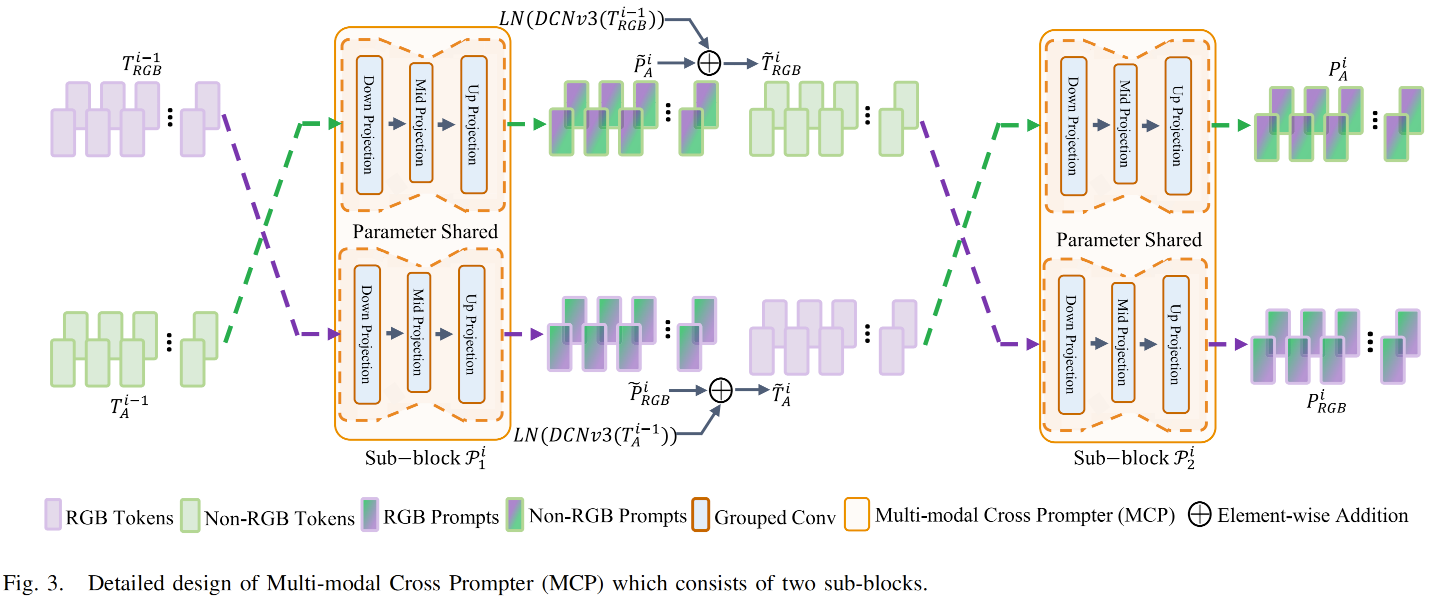
1) 多模态交叉提示器(MCP): 传统多模态语义分割方法主要采用全参数微调策略,不同模态间的融合方案往往需要专门设计。这类方法通常存在训练参数量过大、泛化能力不足的问题。最新微调方法24未能充分考虑不同模态在主次角色中的差异性。这些方法同样未能充分挖掘预训练模型在非 RGB 模态 上的潜力。为了增强对冻结视觉基础模型(VFMs)的微调效果,并提升跨提示适配器在 RGB+X 环境中对不同模态的感知能力,我们提出了一个通用的 MCP 模块(Multi-modal Cross Prompter,多模态跨提示器),以便更好地利用 RGB 与非 RGB 模态之间的互补信息。


我们的MCP架构如图3所示。每个MCP层由两个子模块构成,每个子模块包含三个投影层:下投影层、中投影层和上投影层。每个投影层采用分组卷积结构,这种设计既保持了简洁性,又展现出强大的表征能力,同时有效减少了参数量。来自不同模态的标记依次通过这些层,生成模态互补提示。这些提示随后被输入到对应模态的编码器中,实现双向跨模态提示。
- Gated Perception Module (GPM):尽管MCP生成的提示能让编码器呈现不同模态的特征,但其中仍包含大量冗余和噪声信息。这些信息可能干扰关键的跨模态交互信号,导致原始模态信息在最终分割结果中占据主导地位------这正是现有模态融合方法尚未有效解决的难题。为使跨提示适配器具备选择性过滤冗余信息并激活相关跨模态信号的能力,我们提出了GPM(全局模式聚合器)机制。
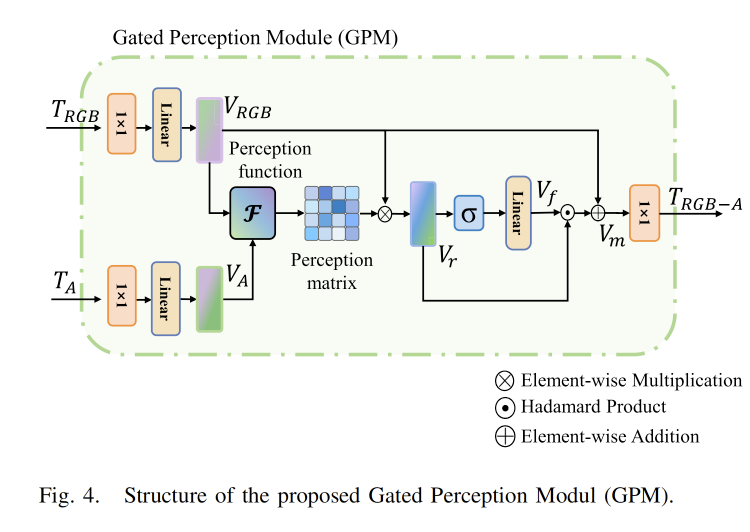
如图 4 所示,我们为网络分配了一个 GPM ,用于接收由 MCP 和冻结编码器共同生成的双向适配信息 TRGB 和 TA。为了使跨提示适配器能够感知 RGB+X 环境中的不同模态,并制定相应的融合策略,GPM 构建了一个记忆向量 和一个遗忘门,用于调节噪声信息和不匹配信息的流入。GPM 主要包含五个阶段:将多模态 token 投影到低维潜在嵌入空间;计算用于交叉融合和记忆向量的感知矩阵;计算遗忘向量;生成跨模态融合特征;将特征投影回原始维度。

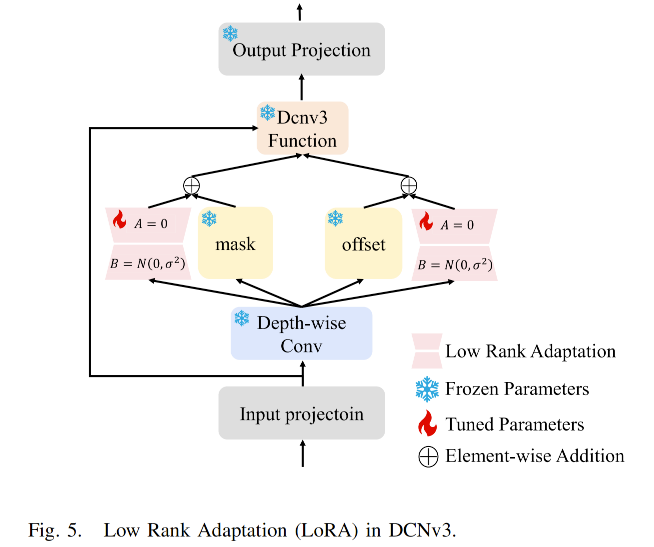
3) LoRA in Frozen Encoder: 首先简要回顾低秩自适应(LoRA)的设计原理。LoRA是一种高效微调预训练模型的方法,通过低秩方法调整模型的辅助权重。与全参数微调相比,该方法能显著减少总参数量,从而降低训练成本。CPAL 中的 LoRA 策略如图 5 所示。考虑到每一层编码器中由 MCP 生成的提示信息已经足够丰富,同时最后一个 stage 包含更高层次的语义信息,能够为解码器提供更有力的支持,因此我们只在最后一个 stage 的核心 DCNv3 模块 中应用 LoRA。在 DCNv3 中,offset 层 决定卷积核在输入特征图上的位移。通过调整这些偏移量,可变形卷积能够捕获更加灵活的特征,这对于处理形变目标、视角变化和复杂背景尤为关键。mask 层则为每个采样位置生成权重,这些权重用于衡量各采样点的贡献。通过调整各个采样点的权重,mask 层进一步增强了模型对特征的选择能力,使其在处理多样化特征时具有更大的灵活性。因此,LoRA 微调被应用于这两个最关键的组件。

IV. EXPERIMENTS
A. Datasets
基于多模态语义分割方法的通用实验框架,我们在RGB-depth、RGB-thermal和RGB-event等五大常用数据集上开展了大量实验。
- NYU Depth V2数据集54包含1449幅480×640分辨率的RGB-depth图像,其中795幅用于训练,654幅用于测试,标注了40个语义类别。
- SUN- RGBD 数据集55涵盖37个类别的10335幅RGB-depth图像,本实验采用与文献55相同的训练/测试划分方案。
- FMB 数据集56作为创新性数据集,包含1500对经过精密校准的RGB-thermal图像对,其中训练集1220对,测试集280对。该数据集涵盖多种复杂场景,包括存在廷德尔效应、雨雾天气及强光环境的场景。
- PST900数据集14为DARPA地下挑战赛提供了894幅720×1280分辨率的洞穴及地下环境RGB-thermal图像,标注了五类对象标签,包含一个未标注的背景类别和四个物体类别。
- DDD17数据集1657包含超过12小时的戴维斯传感器记录,每段记录分辨率为260×346像素,涵盖高速公路和城市驾驶的多样化场景。
B. Implementation Details
我们所有实验均在单张 NVIDIA 3090 GPU 上完成,全局 batch size 为 2 ,训练迭代次数为 40k 。优化器采用 AdamW 75,权重衰减设为 0.05 。初始学习率设置为,并按照 power 为 1.0 的多项式衰减策略 进行衰减。模型中的固定参数由预训练基础模型初始化。此外,我们采用与 53 相同的损失函数。一些近期工作 40, 63, 65, 76, 77 在推理阶段采用了多尺度推理策略 作为数据增强手段。而在本文中,为了展示 CPAL 本身的有效性,我们仅采用单尺度测试 。按照现有方法的惯例,我们报告常用的 平均交并比 (mIoU)、像素准确率 (pAcc)和平均准确率(mAcc)作为主要评价指标,以衡量分割性能。为了更深入地评估 CPAL 的有效性,并为不同应用场景提供不同参数规模的模型选择,我们设计了三个基于不同容量基础模型和解码头的变体:
-
CPAL-T:InternImage-S 53 + Hamburger Head 78
-
CPAL-S:InternImage-H 53 + Hamburger Head 78
-
CPAL-L:InternImage-H 53 + Uper Head 79
其中,-T、-S 和 -L 分别表示 tiny、small 和 large 。InternImage-H 和 InternImage-S 的参数量分别为 10.7 亿(1.07 billion) 和 5110 万(51.1 million) 。根据 InternImage 53 的描述,InternImage-H 在预训练时利用了超过 4 亿张大规模 RGB 图像 ,而 InternImage-S 则是在 ImageNet 80 上进行预训练的,这与 DPLNet 25 的设置相同。
C. Comparison With State-of-the-Arts
1)RGB-Depth 数据集上的结果: 我们在 NYU Depth V2 数据集 54 和 SUN-RGBD 数据集 55 上,将本文提出的 CPAL 与 14 种当前的 RGB-Depth 语义分割方法 进行了对比分析。如表 I 所示,即使仅采用单尺度推理 ,我们的方法仍然以较大优势超过了此前的最先进方法。最新的微调方法 GoPT 24 利用冻结的预训练模型提取 RGB 特征,对非 RGB 分支进行微调,并使用非 RGB 模态去提示 RGB 模态,但它忽略了预训练模型在提取非 RGB 模态特征 方面的潜力。DFormer 63 则先在 RGB-D 数据集上进行预训练,随后再执行全面的全量微调过程,这种流程看起来较为复杂。相比之下,我们的方法直接利用一个基于 RGB 预训练的模型 ,并结合轻量级跨提示适配器 和 LoRA ,将来自 RGB 与深度模态的跨模态提示无缝嵌入到模型中。通过引入适配器的模态感知能力以及跨模态提示机制,我们的方法能够高效挖掘冻结预训练基础模型中的潜在能力,从而简化训练流程。在 mIoU 指标上,CPAL-L 在 NYU Depth V2 上比此前最优方法提升了 4.9% ,在 SUN-RGBD 上提升了 5.7% 。此外,令人惊讶的是,我们的 CPAL-S 模型在仅使用更少训练参数的情况下,也在 NYU Depth V2 数据集上取得了更优性能。CPAL-T 仅有 52.7M 推理参数 和 1.6M 可训练参数 ,却仍然达到了最先进(SOTA)性能 。本文方法与现有最优网络在 NYU Depth V2 数据集上的定性可视化对比结果如图 6 所示。
2) Results on RGB-Thermal Datasets:
对于 RGB-T 语义分割 ,我们在 PST900 14 和 FMB 56 两个数据集上进行了实验。表 II 报告了 CPAL 及对比方法在 FMB 数据集上的定量性能。CPAL-L 以显著优势超过了此前的最先进算法,相比 SegMiF 56 在 mIoU 上提升了 9.8%。这一显著的性能差距凸显了 CPAL 在利用热红外信息方面的有效性,也展示了其在夜间等复杂场景中的良好适应能力。
表 III 将我们提出的 CPAL 与 9 种最先进的 RGB-thermal 语义分割模型 在 PST900 数据集上进行了比较。我们的方法与 HAPNet 74 均以 89.0% mIoU 并列第一。从图 7 的可视化结果可以看出,我们的模型在细节处理方面表现更好,分割性能也更优。此外,我们的方法显著优于近期的微调方法 GoPT 24,证明了其在克服以往技术缺陷方面具有更强的能力。
**3) Results on RGB-E Datasets:**我们将方法与前沿的RGB-E语义分割方法进行对比,如表IV所示。值得注意的是,我们仅使用源自原始事件数据而非事件流的事件图像, CPAL -L实现了77.42%的mIoU,较CMNeXt81提升了4.75%的mIoU。此外,所收集的数据集为灰度图像而非RGB图像。这表明,尽管缺乏颜色信息,我们的 CPAL 微调过程仍使预训练的RGB模型在灰度图像上展现出泛化能力。
D. Generalization to Other Multi-Modal Task
为了验证我们方法的泛化能力 ,我们在一个多光谱视频目标分割基准 MVSeg 84 以及四个 RGB-D 显著目标检测基准 NJU2K 89、NLPR 90、DES 91 和 SIP 92 上开展了实验。
1)多光谱视频目标分割:
我们采用了与第 IV-B 节相同的实验设置。表 V 所示结果表明,尽管我们没有利用连续帧之间的时序信息,而只是对单帧图像进行语义分割,我们的微调方法仍然取得了显著性能,在 mIoU 上比此前的最先进结果提升了 2.29%。
2)RGB-D 显著目标检测:
为了评估模型对**领域偏移(domain shift)**的鲁棒性,我们在四个流行的 RGB-D 显著目标检测数据集 上对 CPAL-S 进行了微调和测试。微调训练集共包含 2,195 个样本 ,其中 1,485 个 来自 NJU2K-train 89,另外 700 个样本 来自 NLPR-train 90。我们的模型在四个数据集上进行评估,即 DES 91、NLPR-test 90、NJU2K-test 89 和 SIP 92。
在性能评估方面,我们采用了该任务的四个经典指标,即结构度量 (Structure-measure, S )98、平均绝对误差 (mean absolute error, M )99、最大 F-measure (F )100 和 最大 E-measure (E )101。为了使语义分割模型适配显著目标检测任务,我们采用与 DPLNet 25 相同的实验配置,并将解码头的输出通道数设为 1 。如表 VI 所示,我们的方法在大多数指标上均排名第一,证明了其良好的可迁移性 以及应对领域偏移的能力。
E. Ablation Study
为验证 CPAL 的有效性,我们采用 CPAL 在三种模态(RGB-T、RGB-D和RGB-E)上开展详细消融研究,分别对应 FMB 、SUN- RGBD 和DDD17数据集。
1) Component Analysis: 我们的 CPAL 由跨提示适配器 (MCP + GPM)和低秩适配 (LoRA)组成。为了更好地理解各个组件的作用及其贡献,我们分别从 CPAL-L 中移除了这三个组件进行分析。如表 VII 所示:
(1) 表示仅使用基于 RGB 的基础模型、且不包含 non-RGB 分支的情况;
(2) 表示通过 MCP 将基于 RGB 的模型适配到多模态分割任务中,并在每个阶段加入加性特征融合;
(3) 表示带有 GPM 的双流模型;
(4) 表示通过 LoRA 对 RGB 基础模型进行微调的方法;
(5) 表示在 (2) 的基础上,在第四个 stage 中插入 LoRA 进行微调;
(6) 表示移除 LoRA 后的模型。
与 (2) 相比,(6) 取得了更好的性能,这突出了 GPM 在模态感知中的关键作用。随后,最终模型 CPAL-L 获得了最佳性能,这表明利用跨提示适配器 能够帮助 LoRA 激活更深层次、更高语义层面的信息。
我们观察到,相比 MCP 和 GPM ,这里 LoRA 带来的性能提升相对较小。一个可能的原因是,MCP 和 GPM 已经较为充分地挖掘了基础模型的潜力,因此可供进一步提升的空间有限,而这部分剩余空间则由 LoRA 来补充发掘。
此外,我们还对 CPAL-T 和 CPAL-L 采用了全量微调 (FFT)方法,即训练所有参数。实验结果表明,FFT 方法的表现反而不如本文提出的 PEFT 方法。对此,可能有两个原因:
第一,重新训练所有参数(FFT)可能会破坏模型在预训练阶段获得的知识,而 PEFT 能够在最大程度上保留这些预训练知识。
第二,RGB+X 数据集的规模相对较小,新注入的 RGB+X 领域知识不足以弥补因破坏预训练知识而造成的损失。
尽管 PEFT 在学习 RGB+X 特定领域知识方面可能不如 FFT 直接,但它能够充分利用 RGB+X 信息,进一步激发和挖掘预训练知识中的潜力。
2) The Effectiveness of Multi-Modal Cross Prompter(MCP):
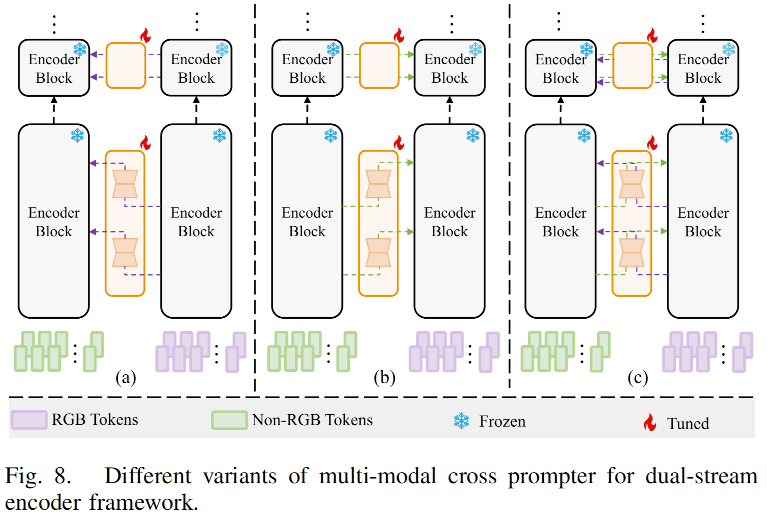
为了评估 MCP 的有效性以及模态互补性,我们在表 VIII 中给出了仅使用 RGB / 非 RGB 输入 以及 MCP 的三种变体 下的基础实验结果。模型a、b、c分别对应图 8 中的 (a)、(b) 和 (c)。其中c 表示我们模型 CPAL-L 所采用的跨提示策略。
仅使用 RGB 或仅使用非 RGB 模态的结果表明,单一模态信息是不充分的 。此外,仅使用一种模态去提示另一种模态也是无效的。这种做法无法考虑不同模态之间的动态关系。另外,那些只利用预训练模型从单一模态中提取特征的方法,也没有充分挖掘预训练模型的潜力。
相比之下,我们提出的跨提示策略将预训练模型同时应用于两个模态分支,从而能够有效利用不同模态之间的互补信息。
3) Inserting Stages of CPAL Block: 我们通过实验研究了在 CPAL-L 中,各个组件模块插入到不同 stage 时的影响,并将结果汇总于表 IX 中。该表展示了各模块的参数量以及在 FMB 数据集上的 mIoU 得分。从 MCP 和 GPM 的实验结果可以看出,随着插入 stage 数量的增加,mIoU 持续上升 。相比之下,LoRA 的结果表明,仅将其嵌入到第四个 stage ,不仅能够减少参数量,而且还能获得最优性能。这验证了这样一种观点:编码器最后一个 stage 中的高层语义信息最具价值,也最有利于性能提升。
4) Different Foundation and Fine-Tuning Method: 为了进一步验证我们方法的有效性,我们在 FMB 数据集上针对基础模型(foundation) 、适配器(adapter)以及提示调优(prompt tuning)方法 进行了消融实验,并保持其他实验设置不变,结果如表 X、表 XI 和表 XII 所示。实验结果验证了我们方法的有效性。表 XI 对三种 adapter 方法 进行了比较。Series Adapter 102 在原始编码器层之后串行地 插入额外的 adapter 层,从而在保留原始参数的同时实现微调。相比之下,Parallel Adapter 103 将多个 adapter 模块并联 到原始层旁边,使其能够独立进行特征提取与聚合。此外,LoRA 采用权重矩阵的低秩分解 方式,仅通过更新少量低秩参数即可实现高效微调,因此与其他方法相比,它更适合资源受限的应用场景。
5) Visualization Results: 为了进一步研究 CPAL 在模态互补性方面的作用,我们分别对分割结果和特征图进行了可视化,如图 9 和图 10 所示。具体而言,我们选取了两对低照度环境下的 RGB-thermal 图像 ,并对其特征图进行了可视化。我们将仅使用 RGB 的基础模型所得到的特征图,与加入 CPAL-L 增强后的特征图进行了比较。结果表明,后者融合了 RGB 和热红外信息,其特征图表现出更清晰的轮廓 和更丰富的纹理细节。
F. Model Parameters and FPS Analysis
如表XIII所示,我们在NYUDepthV2数据集上比较了 SOTA 方法的参数、推理速度和分割性能。我们的轻量级 CPAL -T模型展现出相对更快的推理速度和令人满意的性能,这不仅凸显了我们提出的框架的有效性,也验证了其实际应用价值。
G. Failure Cases
图11展示了RGB-T/D/E语义分割的若干失败案例。结果表明,尽管我们的 CPAL 方法取得了一定改进,但仍存在提升空间。具体而言,处理小型且距离较远的物体(如第一行的路灯和第三行的行人)以及透明物体(如第二行的玻璃淋浴房)仍存在挑战。
H. Discussion on Limitations
本文成功挖掘了预训练视觉基础模型在多模态语义分割 中的潜力,并取得了最先进(SOTA)性能 。然而,随着视觉-语言任务的发展,视觉-语言模型 也逐渐兴起。未来,我们有可能将语言模态 进一步纳入到 CPAL 框架中。此外,目前在使用 CPAL 处理 RGB+X 语义分割 任务时,针对每一种不同的 X 模态都需要进行单独训练。未来,我们希望能够开发出一种统一的多模态模型 ,通过一次训练同时应对多种多模态挑战。