一、动机 & 问题背景
1. 自动化 EDA的价值
- 数据科学家平均 40% 的时间 花在手动 EDA 上(加载数据、画图、分组、箱型图、分布图等)。
- 自动生成 EDA Notebook 具有提升效率的巨大价值。
2. LLM-only 自动 EDA 的痛点
纯 LLM 推理 的方法(如 LIDA),存在三个核心问题:
- 准确性低:选图错误、列用错、图类型不对;私有企业数据结构千奇百怪,LLM 很容易失效。
- 代码执行不可靠:Pass rate 往往 <80%。
- 小模型表现差:商业模型(GPT-4o等)效果不错但成本高;企业更倾向的本地小模型在 EDA 质量极差。
为了解决这些问题,该论文提出了一种 用于生成可执行的EDA代码的RAG框架RAGvis,该框架基于知识图谱,将EDA操作代码与其语义和所使用的数据列联系起来。
二、方法概览
本论文提出的 RAGvis:两阶段图引导的 RAG EDA 框架 ,分为 离线 与 在线 两个阶段:
- 离线 阶段(Offline): Knowledge Graph (KG) Generation and Semantic Enrichment. 即 EDA知识图谱生成与丰富。
- 在线 阶段(Online): EDA notebook generation 即 EDA notebook的生成。
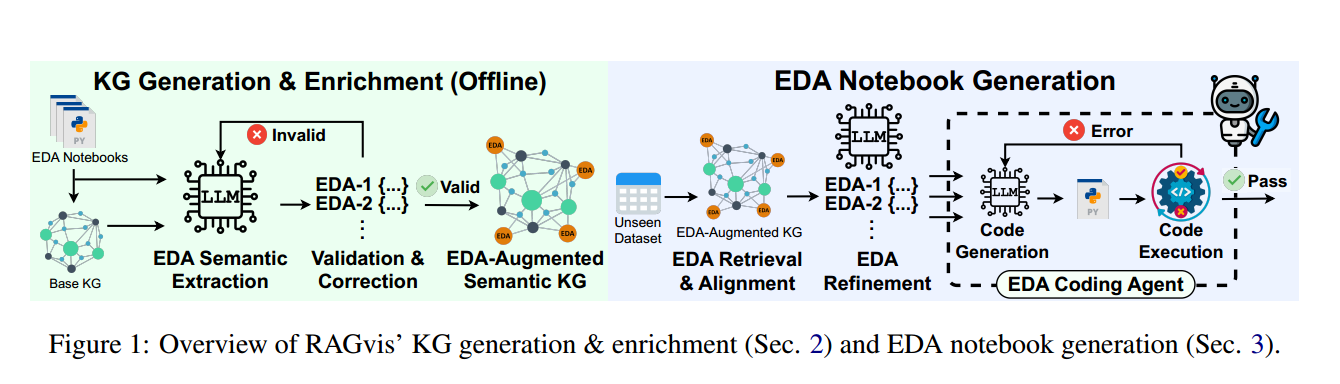
三、离线阶段(Offline)
包括两个步骤:①构建EDA知识图谱 与 ②注入 EDA语义
该论文的离线阶段是参考其前序工作 KGLiDS 来进行构建知识图谱的,感兴趣可以查看其解读与原文。
① 构建EDA知识图谱
从 1600 份 Kaggle EDA Notebooks 中抽取信息:
实体:
- 每行代码
- 每个数据集列
关系:
- 代码依赖关系
- 数据列使用关系
嵌入表示:
- 利用 KGLiDS 生成列向量 embeddings
但是,此时EDA知识图谱 没有 EDA Semantic (不知道是 histogram 还是 bar chart)。

② 注入 EDA Semantic
目的是为了使LLM 能够区分 Notebook 中的分类,如:
图类型、 变量数目、使用的列、是否分组
具体步骤包括KG-Guided EDA Semantic Extraction 从收集的Kaggle笔记本中提取EDA特定的语义来丰富KG;以及Knowledge Graph Augmentation抽取得到的 EDA 语义要写入EDA 知识图谱,形成一个「EDA-aware图谱」
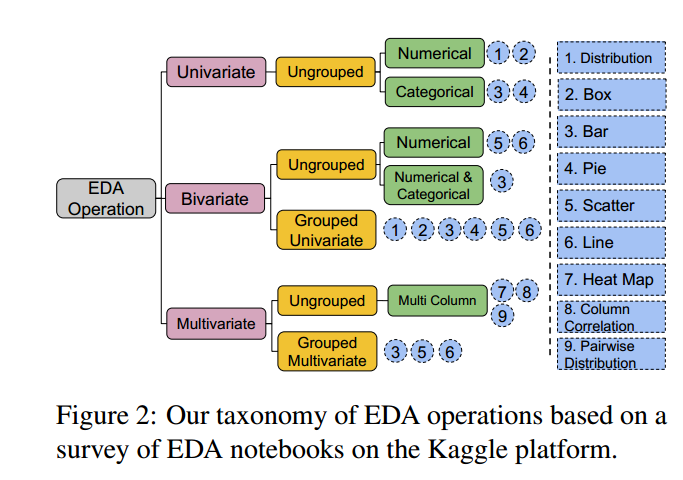
一、EDA 通用分类体系
划分为:Univariate 、 Bivariate 、Multivariate
再细分 9 大类图类型(Bar, Pie, Box, Distribution, Scatter, Line...)。
LLM 最终按这个分类来 解析 Notebook。
二、Semantic Extraction 与 KG Augmentation
Notebook 中的画图代码(EDA cell)通常依赖前面出现的数据处理步骤,比如重命名列、派生新列等。
如果仅靠 EDA cell 本身,LLM 很容易识别错误的列名或图语义。
论文为解决该问题,预先构建了一个包含每行代码的 EDA 知识图谱。
对每个 EDA cell,从 KG 中查询其 data-flow parents(数据流父语句)即会影响该图使用数据的上游语句(如 rename、fillna、赋值等)。
将这些父语句按顺序 拼接到 EDA cell 前面,作为 LLM 的上下文。
这样即给 LLM 充分的语义线索,又避免把整个 Notebook 输入导致 token消耗过多。
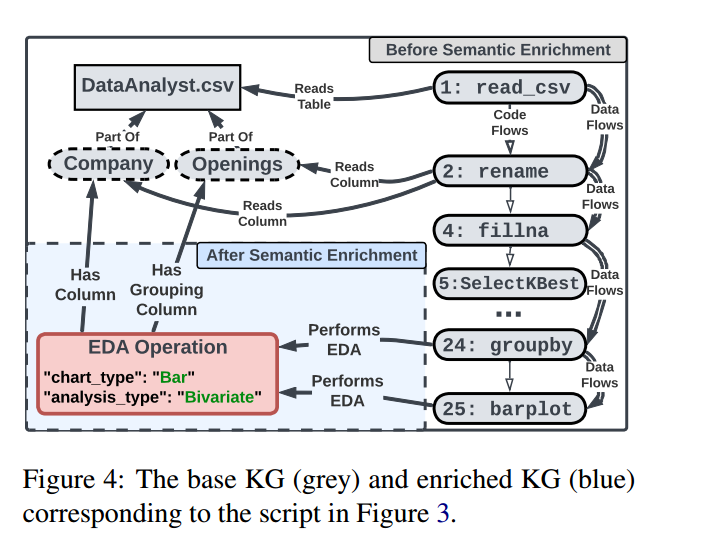
再将抽取得到的 EDA 语义要写入 KG,形成一个「EDA-aware图谱」。为每个成功解析的可视化操作创建
1、新的 "EDA Operation Node",该节点存储:
chart_type
analysis_type
columns
grouping-
建立三类关键关系(边)
Performs EDA : EDA 操作 → 执行的代码语句节点
Has Column : EDA 操作 → 被分析的列节点
Has Grouping Column : EDA 操作 → Notebook 单元(可选)
四、 Online 阶段
基于离线阶段得到的EDA知识图谱 做 EDA Retrieval(检索) + EDA Alignment(对齐) + EDA Refinement(优化) + EDA Coding Agent(代码生成)。
用户输入一个新数据集,RAGvis 执行上述步骤,并给出最终的EDA代码。
这里新的数据集视为原KG没见过的数据(unseen dataset),用下角标u来表示。 C u C_u Cu表示输入的新数据集的列,
EDA Retrieval(检索)
对于数据集中的每一列 C u C_u Cu:
- 在 EDA知识图谱 中找最相似的列(基于 embedding)
- 检索这列 C u C_u Cu的历史 EDA 操作
- 得到候选操作集合
EDA Alignment(对齐)
对检索结果进行 跨数据集列对齐:
例如检索到:
Bar chart on ["Company", "Openings"]但新数据集根本没有 Company,而有:
- region
- job_type
Alignment 会依据:
- 列类型是否匹配
- embeddings 相似度
选出最合理的对应列。
如果一个操作无法完整映射到新数据集 → 丢弃。

EDA Refinement(优化)
把所有对齐过的 EDA 操作按操作频次排序,交给 LLM,要求从中:
- 选 top-K 个更合适的
- 也允许 LLM 新增一些操作
这是可选的 EDA 的「智能排序器」。
EDA Coding Agent(代码生成)
EDA Coding Agent 将每个结构化的 EDA 操作(JSON)交给 LLM 生成单图 Python 代码,然后在本地执行。
出现错误时,Agent 会把错误反馈给 LLM;触发自动化的"生成→执行→纠错"循环,直到代码能在目标数据集上成功运行或达到重试上限。
最终输出是若干已验证无错的代码段(并可合并为去重后的 Notebook)。
该机制把"生成可视化"从高风险的单次 LLM 产出变成了一个可靠、可验证的闭环管道,从而把 pass rate 提升到接近 100%。
下面的简要表示上述文字的等同内容:
- LLM 生成图代码
- 执行代码
- 如果报错 → 把 error message 反馈给 LLM → 再生成一次
→ 循环纠错,直到成功(或超过 retry 次数)
因此 pass rate 接近 100%。
五、实验设置与结果
实验使用两个 Benchmark:
Benchmark 1:KaggleVisBench(作者构建)
- 来自 50 个 Kaggle 数据集(未用于构建 KG)
- 平均每数据集 20+ 个图
- Ground truth 由论文的 EDA Extractor 自动提取
Benchmark 2:VisEval
- 人工标注的图
- 平均 2.9 个图/数据集(更精简)
1. EDA Retrieval (Recall@K)
RAGvis 相比 LIDA,Recall 提升巨大:
VisEval Recall@30:
- RAGvis(Gemini-Pro):0.77
- LIDA(Gemini-Pro):0.49
提升 +0.28
KaggleVisBench Recall@30:
- RAGvis:0.43
- LIDA:0.14
提升 +0.29
2. Code Pass Rate
几乎所有环境中:
RAGvis:≈100%
LIDA:60--95%
原因:RAGvis 的 self-correcting coding agent。
3. 图质量(VLM Score)
RAGvis 始终比 LIDA 高:
- 图更清晰
- 标注更准确
- 图形选择更合理
4. Token 成本
RAGvis token 数比 LIDA 减少 56--68%。
原因:
- Retrieval 机制减少了 prompt 内容
- 少依赖 LLM 推理
5. 小模型表现
Gemma-3 12B 在 RAGvis 下:
- 效果 ≈ GPT-4o-mini 的水平
LIDA 在小模型上表现崩溃。这是该论文最亮眼结果之一
六、贡献总结
论文的主要贡献可概括为:
1. 首个 EDA 专用的大规模知识图谱
- 基于 1600 EDA notebooks
- 包含代码依赖、列向量、EDA 语义
2. 通用 EDA 操作类别
- 覆盖最常见 9 类图
- 统一 EDA 语义结构
3. 可对齐跨数据集 EDA 的 Retrieval & Alignment 机制
- 解决图选择的准确性问题
4. Self-correcting Code Agent
- 实际 EDA 代码可执行
- Pass rate 近乎 100%
5. 小模型在 RAGvis 下表现接近商业模型
- 做到 cost-effective + privacy-friendly
七、局限与未来方向
论文在结尾明确讨论了以下限制:
1. 仅支持单表 Tabular 数据
- 还不能处理:
- 多表 / 外键
- 图数据
- 时间序列
- 图像数据
2. EDA 操作类别尽管通用,但仍不够完备
- 高度专业领域可能需要新增图类型
- 医疗、金融等领域的特殊 EDA 不在 Kaggle 中
3. 评估指标不足以刻画 EDA 的"洞察性"
目前只能评估:
- 图是否正确(Recall)
- 图是否能执行(Pass)
- 图是否好看(VLM Score)
目前无法评估:
- 图是否有洞察价值
- 是否能让分析者"更懂数据"
这是 AutoEDA 的长期难题。
原文链接
Reliable and Cost-Effective Exploratory Data Analysis via Graph-Guided RAG