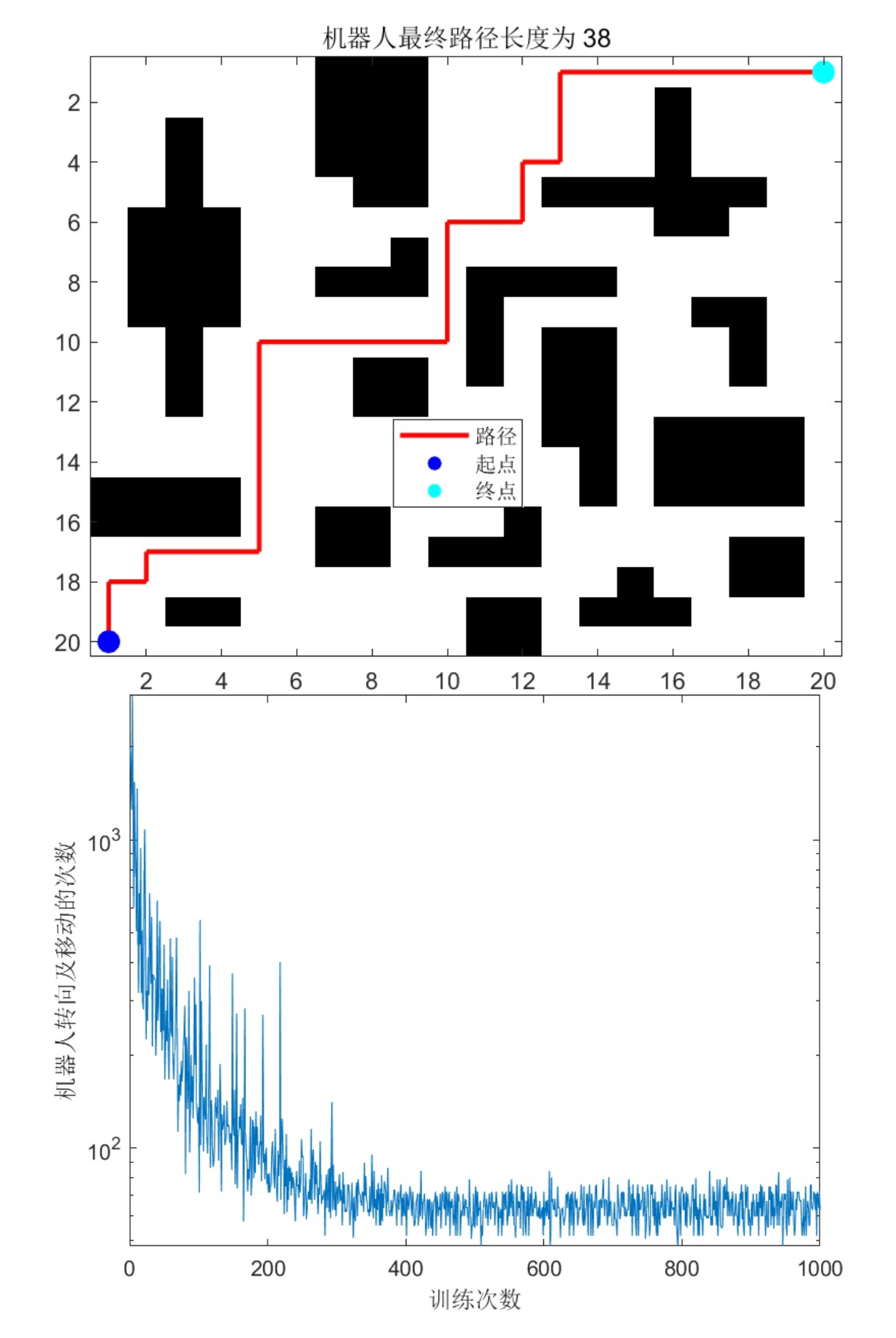
机器人路径规划:基于Q-learning算法的移动机器人路径规划的,可以自定义地图,修改起始点,提供MATLAB代码
今天咱们来聊聊怎么用Q-learning教机器人走迷宫,这玩意儿可比遥控赛车刺激多了。只要一台能跑MATLAB的电脑,你就能亲手训练出个会自己找路的智能体。直接上干货,先看效果------给个5x5的网格地图,机器人从左上角出发,分分钟给你规划出避开障碍的最短路径。
先整张地图玩玩(MATLAB矩阵就是直观):
matlab
map = [1 1 1 1 1;
1 0 0 0 1;
1 1 1 0 1;
1 0 0 0 1;
1 1 1 1 1];
% 1是障碍,0是可通行区域
start_point = [1,1];
goal_point = [5,5];看到没?中间那个十字形障碍摆明了要考验算法的绕路能力。这时候Q-learning的核心登场------Q表。这个表格记录了每个状态下采取各个动作的预期收益,初始化起来超简单:
matlab
Q = zeros(prod(size(map)), 4); % 状态数x动作数(上下左右)
alpha = 0.1; % 学习率别太高,容易过冲
gamma = 0.9; % 未来奖励折扣
epsilon = 0.7; % 探索概率这里有个小技巧,状态编号用线性索引代替行列坐标,用sub2ind函数转换更方便。训练时机器人每走一步都要做选择题:是贪婪地选当前最优动作(exploit)还是随机探索(explore)?代码实现这个策略只需要几行:
matlab
if rand < epsilon
action = randi(4); % 随机探索
else
[~, action] = max(Q(current_state,:)); % 选择最优动作
end但别急着跑训练,奖励机制才是灵魂所在!碰到障碍直接给-10分惩罚,到达终点给+100分大奖,普通移动就扣1分鼓励找最短路径:
matlab
if next_pos == goal_point
reward = 100;
elseif map(next_pos) == 1
reward = -10;
else
reward = -1;
end更新Q表的核心公式一定得配上代码才够味:
matlab
Q(current_state, action) = Q(current_state, action) + alpha * (reward + gamma * max(Q(next_state,:)) - Q(current_state, action));跑个2000次迭代后,用热力图看看Q表,明显能看到靠近终点区域的动作价值更高。最后提取路径时就像玩贪吃蛇,从起点开始每一步都选最大Q值的动作:
matlab
path = start_point;
while ~isequal(path(end,:), goal_point)
[~, action] = max(Q(state_sequence(end),:));
% 根据动作更新位置...
end实测发现调参是门艺术------ε设0.7时探索效率最高,α超过0.3就容易震荡。想要可视化效果?用scatter画路径,gif函数保存训练过程动态图,朋友圈装X必备。
完整代码已打包在GitHub,改地图只需要动matrix那几个数字。下次试试在复杂迷宫加个移动障碍物?Q-learning照样能玩得转,不过那就是另一个故事了...