在 vk_lod_clusters 和 Nanite 的设计哲学中,Cluster LOD 和 DAG 是支撑起"无限几何细节"的两根支柱。前者重新定义了渲染的原子单位,后者重新定义了多级细节的组织形式。
https://github.com/nvpro-samples/vk_lod_clusters
Cluster:渲染原子的再定义
1.1 为什么是 Cluster?
传统渲染管线以"模型(Mesh)"为单位。然而,模型是一个不可控的变量------它可能包含 10 个三角形,也可能包含 1000 万个。这种方差极大的输入数据让 GPU 的并行调度(Warp Scheduling)极其痛苦。
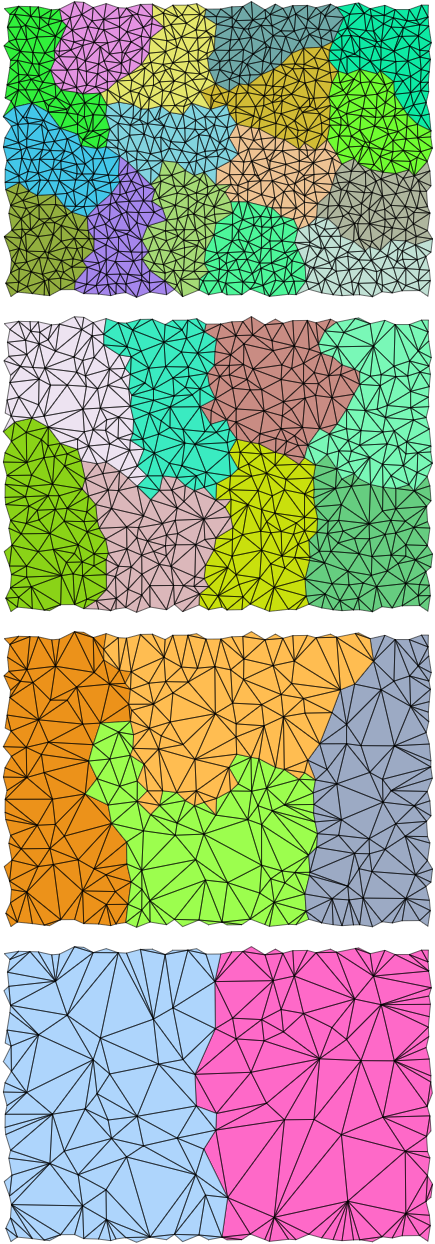
Cluster(簇)的出现,本质上是将不规则的几何数据标准化。
-
固定载荷: 每个 Cluster 被严格限制在 64~128 个三角形(或 255 个顶点)之间。
-
硬件亲和: 这个大小并非随意设定,它完美契合 NVIDIA 显卡的一个 Warp (32线程) 或 Mesh Shader 的 Workgroup 的处理能力。
-
空间局部性: Cluster 不仅仅是三角形的列表,它在空间上是紧凑聚类的。这意味着它的包围盒(Bounding Box)非常紧凑,剔除效率极高。
1.2 Cluster 的几何特性
一个标准的 Cluster 数据结构通常包含:
-
顶点数据: 本地化的顶点位置(通常相对于 Cluster 包围盒中心进行量化压缩,极大节省显存)。
-
索引数据: 0-255 的微小索引。
-
误差项 (LOD Error): 记录当前 Cluster 与原始高模之间的几何误差(通常是 Hausdorff 距离)。
-
父/子指针: 指向 DAG 中的关联节点。
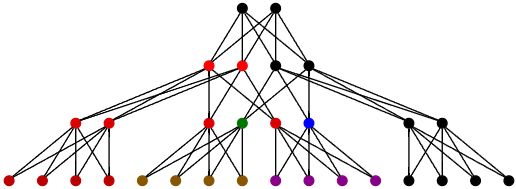
DAG:超越 Octree 的数据结构
为什么这些技术使用 DAG (Directed Acyclic Graph) 而不是传统的 Octree 或 Bounding Volume Hierarchy (BVH)?
2.1 多对多与边界共享
在传统的 Octree LOD 中,一个节点细分就是简单的 1 分 8。但在几何简化中,情况要复杂得多:
-
几何融合: 为了减少三角形数量,我们需要将相邻的多个 Cluster 合并,简化成更少量的 Cluster。
-
边界锁定问题: 两个相邻的 Cluster 在简化时,它们共享的边界(Edge)必须保持一致,否则就会出现裂缝。
DAG 结构允许我们将多个子 Cluster(Children)归组,简化后生成多个父 Cluster(Parents),并正确表达它们之间的依赖关系。如果一个 Cluster 的边界被修改,依赖它的所有层级都必须知晓。
2.2 核心算法:分组-简化-分裂 (Group-Simplify-Split)
这是构建 Cluster DAG 的核心算法(离线处理阶段),也是让 LOD 能够无缝过渡的秘密武器。
该过程是**自底向上(Bottom-Up)**构建的:
-
输入(Level 0): 原始的高精度网格,被切分为成千上万个基础 Cluster。
-
分组 (Group):
使用图划分算法(如 METIS),将空间上相邻的 N 个 Cluster 聚合成一个Group(通常 N=4 或 8)。
-
合并与锁定 (Merge & Lock):
将 Group 内的所有三角形合并。关键步骤: 识别出这个 Group 的"外部边界"(即与该 Group 无关的那些边)。这些外部边界在当前级别的简化中被严格锁定(Locked),不允许移动或坍缩。
-
简化 (Simplify):
使用二次误差度量(QEM)等算法对 Group 内部 的三角形进行减面(例如减至 50%)。因为边界被锁定了,所以简化后的网格依然能和周围的网格完美拼接,绝对无裂缝。
-
分裂 (Split):
将简化后剩下的大网格,再次切分(Split)成新的 M 个标准 Cluster(通常 M \\approx N/2)。这些新的 Cluster 就构成了 DAG 的 Level 1。
重复上述步骤,直到生成的 Cluster 数量少到可以直接作为根节点。由此,我们构建出了一个金字塔般的 DAG 结构。
The Cut:运行时选择与感知误差
构建好 DAG 后,渲染时的核心任务就是找到一条**"切割线 (The Cut)"**。
3.1 什么是"Cut"?
Cut 是 DAG 图中的一个横截面。
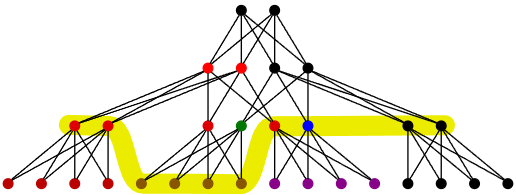
在每一帧,我们需要从 DAG 中选择一组 Cluster,这组 Cluster 必须满足两个条件:
-
覆盖全貌: 它们组合起来必须代表完整的物体,不能有空洞。
-
互斥性: 既然选择了某个父节点,就不能再选择它的子节点(避免重复绘制)。
3.2 误差度量公式 (The Error Metric)
如何决定使用 DAG 中的哪一层?这取决于屏幕空间误差 (Screen Space Error)。
对于 DAG 中的每一个 Cluster,我们实时计算其投影误差 :
-
: 该 Cluster 预计算的几何误差(世界空间)。
-
-
3.3 并行选择逻辑 (Parallel Selection Logic)
这是 vk_lod_clusters 高效的关键。不需要 CPU 递归遍历树,GPU Compute Shader 对所有当前可能可见的 Cluster 并行执行逻辑:
对于每一个 Cluster,判断是否绘制的逻辑如下:
-
条件 A (自身够细): 我的
-
条件 B (父级太粗): 我的父节点
如果一个 Cluster 同时满足这两个条件,它就被选中进入"Cut",被送往 Rasterizer(光栅化)。
四、 总结 Cluster LOD 的革命性
通过上述机制,Cluster LOD + DAG 彻底解决了传统 LOD 的顽疾:
-
粒度极细: 我们可以只让物体的"鼻子"部分切换到高精度 LOD,而"后脑勺"部分保持低精度。传统 LOD 只能整个头切换。
-
无 Popping: 因为切换发生在微小的 Cluster 级别(64个三角形),且切换阈值控制在 1 像素误差内,人眼根本无法察觉几何体的变化。
-
流送友好: 我们只需要将 DAG 中"Cut"附近的节点流送到显存。即使模型有 1TB 大,只要你在屏幕上只能看到 4K 分辨率,显存占用就是常数级的。
这就是 vk_lod_clusters 乃至 Nanite 技术背后的核心数学与逻辑之美。