Redis 核心机制详解:线程模型、原子性与 Bigkey
一、Redis 到底是单线程还是多线程?
准确说法 :
Redis 的核心命令处理(网络 I/O + 键值操作)是单线程的,但部分后台任务使用多线程。
✅ 正确解释:
1. 主线程(单线程)
- 负责:接收客户端请求、解析命令、执行读写操作、返回响应。
- 基于 I/O 多路复用(如 epoll),一个线程可高效处理成千上万个并发连接。
- 所有 键值操作(GET/SET/HGETALL 等)都在此线程串行执行,保证了命令的原子性和顺序性。
✅ 正因如此,Redis 避免了传统数据库中的并发问题(如脏读、不可重复读),但注意:这不等于"事务隔离级别",因为 Redis 本身没有 MVCC。
2. 后台多线程(辅助线程)
从 Redis 6.0 开始 ,引入了多线程用于 网络 I/O 读写 (默认关闭,需配置 io-threads):
- 主线程仍负责命令执行(保持单线程语义)
- 多个 I/O 线程负责 socket 读写(减少主线程阻塞)
此外,以下操作始终由独立子线程完成(与主线程无关):
- RDB 快照生成(
bgsave) - AOF 重写(
bgrewriteaof) - 异步删除(
UNLINK) - 主从复制的数据同步
📌 总结:
- 命令执行 = 单线程(保证简单、高效、无锁)
- I/O 与持久化 = 多线程(提升吞吐,不影响核心逻辑)
二、Redis 的原子性
原子性:指一个操作或一组操作要么全部执行,要么完全不执行,中间不会被其他操作打断。
由于 Redis 命令在主线程中串行执行 ,单个命令天然具有原子性。但多个命令组合时,可能被其他客户端插入,导致非预期结果。
示例问题
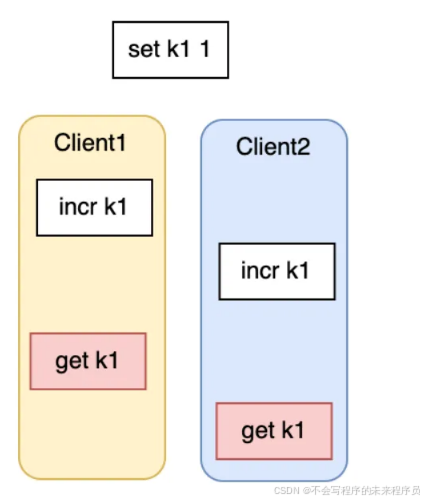
→ 最终 k1 的值可能是1 或 2,取决于执行顺序。
为保证多命令的原子性,Redis 提供以下机制:
1. 复合命令(推荐优先使用)
Redis 提供了多个原生原子命令,避免拆分为多条指令:
| 命令 | 作用 |
|---|---|
MSET / MSETNX |
批量设置多个 key |
GETSET |
设置新值并返回旧值 |
SET key value NX EX 10 |
原子地实现"分布式锁" |
HINCRBY, ZINCRBY |
哈希/有序集合的原子增减 |
✅ 优点:简单、高效、无需事务。
2. 事务(Transaction)
Redis 事务通过 MULTI / EXEC 实现:
bash
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> SET k2 2
QUEUED
127.0.0.1:6379(TX)> INCR k2
QUEUED
127.0.0.1:6379(TX)> GET k2
QUEUED
127.0.0.1:6379(TX)> EXEC
1) OK
2) (integer) 3
3) "3"⚠️ 重要特性(与 MySQL 不同):
- 不支持回滚 :即使某条命令出错(如对 string 执行
HSET),后续命令仍会执行。 - 仅保证命令不被"加塞" :事务内命令连续执行,但不保证业务逻辑一致性。
✅ 如何实现"条件执行"? → 使用 WATCH
bash
WATCH balance
GET balance # 读取当前值
MULTI
DECRBY balance 50 # 基于读取值做操作
EXEC # 若 balance 被他人修改,EXEC 返回 nil,事务取消✅
WATCH是 Redis 实现 CAS(Compare-And-Set) 的关键。
❗ 事务失败场景:
WATCH的 key 被修改 →EXEC返回nil,整个事务不执行- 命令语法错误 → 在
EXEC时跳过该命令,继续执行后续命令
💾 持久化与事务
EXEC执行前,命令会先写入 AOF 缓冲区- 若 Redis 在执行中宕机,AOF 可能包含不完整事务
- 启动时可用
redis-check-aof --fix修复
3. 管道(Pipeline)
管道用于批量发送命令,减少网络往返(RTT):
text
普通模式:N 条命令 → N 次 RTT
Client → Server: SET key1 value1 → 等待响应
Client → Server: SET key2 value2 → 等待响应
...
Client → Server: GET keyN → 等待响应
管道模式:N 条命令 → 1 次 RTT
Client → Server: [SET key1 v1, SET key2 v2, ..., GET keyN]
Server → Client: [OK, OK, ..., valueN]⚠️ 注意事项:
- 管道 ≠ 事务 :命令在服务器端仍是逐条执行,可能被其他客户端插入操作
- 不保证原子性:仅优化网络,不提供并发控制
- 适合只读或独立写操作(如批量初始化缓存)
✅ 最佳实践 :将管道与事务结合使用(pipeline.multi())以兼顾性能与一致性。
4. Lua 脚本(强一致性方案)
lua原生的语参考网站:https://wiki.luatos.com/ 这个网站可以直接在线调试lua语法

Lua 脚本在 Redis 中原子执行,是实现复杂逻辑的首选:
lua
-- 原子扣款
local current = redis.call('GET', KEYS[1])
if tonumber(current) >= tonumber(ARGV[1]) then
redis.call('DECRBY', KEYS[1], ARGV[1])
return 1
else
return 0
end✅ 优势:
- 脚本执行期间,其他命令无法插入
- 支持复杂逻辑(条件、循环、多 key 操作)
⚠️ 注意事项:
- 脚本必须快速执行 (默认超时 5 秒,由
lua-time-limit控制) - 超时后只能用
SCRIPT KILL终止(仅限只读脚本) - 写操作脚本超时会导致 Redis 拒绝所有请求,直到重启
🔍 只读脚本可用
EVAL_RO执行,并支持随时SCRIPT KILL。
5. Redis Function(Redis 7.0+)
Function 是 Lua 脚本的升级版,支持预加载、命名空间、版本管理:
lua
#!lua name=mylib
local function my_hset(keys, args)
local time = redis.call('TIME')[1]
return redis.call('HSET', keys[1], '_last_modified_', time, unpack(args))
end
redis.register_function('my_hset', my_hset)使用方式:
bash
# 加载函数
cat mylib.lua | redis-cli FUNCTION LOAD REPLACE
# 调用
FCALL my_hset 1 myhash field1 value1⚠️ 注意:
- 集群模式下需手动在每个节点加载
- 函数存储在内存中,不宜过大过多
三、Redis 中的 Bigkey 问题
Bigkey:指占用内存过大或元素数量极多的 key(如 List 含 200 万项、String 存 10MB JSON)。
危害:
- 阻塞主线程(
HGETALL、LRANGE等耗时操作) - 主从同步延迟
- 内存碎片增加
- OOM 风险
🔍 生产环境排查方法:
1. 使用 --bigkeys(按元素数量)
bash
redis-cli --bigkeys -i 0.1- 显示每种类型中元素最多的 key
- 对 String 显示字节数,对其他类型显示元素个数
2. 使用 --memkeys(按内存占用,Redis 4.0+)
bash
redis-cli --memkeys -i 0.1- 使用
MEMORY USAGE精确计算内存(含内部开销)
3. 结合 SLOWLOG 定位慢查询
bash
redis-cli SLOWLOG GET 10→ 若发现 HGETALL、SMEMBERS 耗时高,立即检查对应 key。
✅ 优化建议:
- 拆分:大 Hash 拆为多个小 Hash
- 分页 :用
HSCAN/ZRANGE ... LIMIT替代全量命令 - 异步删除 :用
UNLINK代替DEL
四、为什么 Redis 要做成单线程?
尽管现代 CPU 是多核的,但 Redis 选择单线程有其深刻原因:
✅ 核心原因:
- 性能瓶颈不在 CPU ,而在 内存带宽 和 网络 I/O
- 单线程避免锁竞争,极大简化代码逻辑,提升执行效率
- 减少上下文切换开销,提高吞吐量
- I/O 多路复用 已能高效处理高并发连接
💡 从 Redis 6.0 起,网络 I/O 可开启多线程 ,但命令执行仍保持单线程------这是对"简单性"与"性能"的最佳平衡。
✅ 总结
| 机制 | 是否原子 | 是否阻塞 | 适用场景 |
|---|---|---|---|
| 复合命令 | ✅ | 否 | 简单原子操作(推荐优先) |
| 事务 + WATCH | ✅(条件执行) | 否 | "读-改-写"一致性 |
| 管道 | ❌ | 否 | 批量操作(性能优化) |
| Lua 脚本 | ✅ | 是 | 复杂逻辑、强一致性 |
| Function | ✅ | 是 | 可复用脚本(Redis 7.0+) |
作者:不会写程序的未来程序员
首发于 CSDN
版权声明:本文为原创文章,转载请注明出处。