文章目录
前言
栅格数据和矢量数据相关的知识点比较多,因此建议根据网络上的案例边练边学。本次列举了三个简单的例子,分别是地形因子的提取,影像数据处理,计算植被覆盖度。
官方说明:
Shapefile 是一种用于存储地理要素的几何位置和属性信息的非拓扑简单格式。 shapefile 中的地理要素可表示为点、线或面(区域)。 包含 shapefile 的工作空间还可以包含 dBASE 表,它们用于存储可连接到 shapefile 的要素的附加属性。下面是 shapefile 在 ArcCatalog 中显示方式的示例。 您还可以看到 dBASE 文件(可能与 shapefile 关联)。
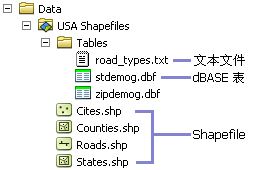
要素数据集是共用一个通用坐标系的相关要素类的集合。要素数据集用于按空间或主题整合相关要素类。它们的主要用途是,将相关要素类编排成一个公用数据集,用以构建拓扑、网络数据集、地形数据集或几何网络。

矢量数据处理
栅格数据处理有很多方法,推荐找几个例子练习一下就容易记住,下面是我随便找的几个数据做的练习,因为涉及到数据处理,所以代码的很大部分也是需要熟悉Python内部的一些文件操作方法和函数
生成随机采样点
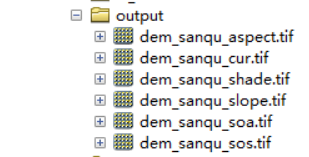
这个代码提取了六种地形因子,其中山体阴影需要根据实际情况进行修改;主要涉及到表面分析工具的关于DEM的方法
原始数据:

输出数据:
代码:
python
# -*- coding:utf-8 -*-
# -------------------------------------------------------------------------------
# Description : python 2.7, calculate some terrain factors
# @Time : 2024-07-23 20:34
# @Author : zbh
# -------------------------------------------------------------------------------
import arcpy
from arcpy.sa import *
import os
# 设置环境
workspace = r".\data"
arcpy.CheckOutExtension("spatial")
arcpy.env.parallelProcessingFactor = '0'
arcpy.env.overwriteOutput = "True"
arcpy.env.workspace = workspace
def calculate_all_factors(input_raster, output_folder):
# 获取dem数据的文件信息
raster = arcpy.Raster(input_raster)
raster_name = os.path.basename(input_raster)
base_name, ext = os.path.splitext(raster_name)
# 计算坡度
output_slope = Slope(raster, "Degree")
output_slope_path = os.path.join(output_folder, base_name + "_" + "slope" + ext)
output_slope.save(output_slope_path)
# 计算sos
output_sos = Slope(output_slope, "Degree")
output_sos_path = os.path.join(output_folder, base_name + "_" + "sos" + ext)
output_sos.save(output_sos_path)
del output_slope
del output_sos
# 计算坡度
output_aspect = Aspect(raster)
output_aspect_path = os.path.join(output_folder, base_name + "_" + "aspect" + ext)
output_aspect.save(output_aspect_path)
# 计算soa
output_soa = Slope(output_aspect, "Degree")
output_soa_path = os.path.join(output_folder, base_name + "_" + "soa" + ext)
output_soa.save(output_soa_path)
del output_aspect
del output_soa
# 计算曲率
output_cur = Curvature(raster)
output_cur_path = os.path.join(output_folder, base_name + "_" + "cur" + ext)
output_cur.save(output_cur_path)
del output_cur
# 计算山体阴影
output_shade = Hillshade(raster, 90, 45, "SHADOWS")
output_shade_path = os.path.join(output_folder, base_name + "_" + "shade" + ext)
output_shade.save(output_shade_path)
del output_shade
print("calculate_all_factors() success!")
if __name__ == '__main__':
calculate_all_factors(r'.\data\dem_sanqu.tif', r'.\data\output')
print("ok")ESDA
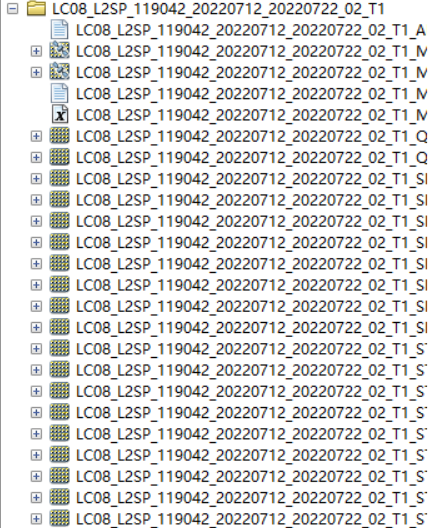
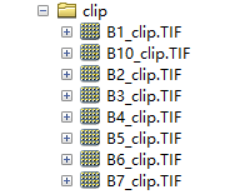
以一幅Landsat 8-9的 C2L2级别数据为例,批量裁剪,放缩与偏移,波段合成;主要涉及到os模块、正则表达式与Arcpy批量处理的结合
原始数据:
输出数据:
代码:
python
# -*- coding:utf-8 -*-
# -------------------------------------------------------------------------------
# Description : python 2.7, process Landsat8-9 C2L2 data batch
# @Time : 2024-07-23 22:36
# @Author : zbh
# -------------------------------------------------------------------------------
import arcpy
from arcpy.sa import *
import os
import re
import fnmatch
workspace = r".\data"
arcpy.CheckOutExtension("spatial")
arcpy.env.parallelProcessingFactor = '0'
arcpy.env.overwriteOutput = "True"
arcpy.env.workspace = workspace
# 批量裁剪
def clip_batch(input_folder, clip_feature, output_folder=None):
# 输出文件路径不存在
if not os.path.exists(output_folder):
try:
os.makedirs(output_folder)
except OSError as e:
raise OSError("Error creating output folder: {}".format(e))
else:
pass
raster_list = []
# 从文件夹中获取输入数据, 并添加至列表
files = os.listdir(input_folder)
tif_files = [f for f in files if fnmatch.fnmatch(f, '*B*.TIF')]
for tif_file in tif_files:
full_path = os.path.join(input_folder, tif_file)
if arcpy.Exists(full_path):
raster_list.append(full_path)
# 栅格数据批量裁剪
for raster in raster_list:
filename = os.path.basename(raster)
base_name, ext = os.path.splitext(filename)
last_underscore_index = base_name.rfind('_')
if last_underscore_index != -1:
extracted_name = base_name[last_underscore_index + 1:]
else:
extracted_name = base_name
out_clip_path = os.path.join(output_folder, extracted_name + "_clip" + ext)
arcpy.management.Clip(raster, "#", out_clip_path, clip_feature, 0, "ClippingGeometry")
print("clip_batch() sucess!")
# 批量放缩和偏移
def process_batch(input_folder, is_composite=None, output_folder=None):
# 输出文件路径不存在
if not os.path.exists(output_folder):
try:
os.makedirs(output_folder)
except OSError as e:
raise OSError("Error creating output folder: {}".format(e))
else:
pass
raster_list = []
# 从文件夹中获取输入数据
files = os.listdir(input_folder)
pattern = r'B(?:[1-9]|10)_clip+\.TIF$'
tif_files = [f for f in files if re.match(pattern, f)]
for tif_file in tif_files:
full_path = os.path.join(input_folder, tif_file)
if arcpy.Exists(full_path):
raster_list.append(full_path)
process_raster_str = ""
for raster in raster_list:
filename = os.path.basename(raster)
base_name, ext = os.path.splitext(filename)
out_process_path = os.path.join(output_folder, base_name + "_process" + ext)
if "B10" in filename:
raster = (arcpy.Raster(raster) * 0.00341802) + 149 - 273.15
process_raster = Con(raster < -123, -123, Con(raster > 86, 86, raster))
else:
raster = (arcpy.Raster(raster) * 0.0000275) - 0.2
process_raster = Con(raster < 0, 0, Con(raster > 1, 1, raster))
process_raster_str += (out_process_path + ";")
process_raster.save(out_process_path)
if is_composite == "Composite":
arcpy.CompositeBands_management(process_raster_str, os.path.join(output_folder, "L8" + ext))
else:
pass
print("process_batch() success!")
if __name__ == '__main__':
# 要搜索的路径
clip_input_folder = r"G:\WATER_TEST\LC08_L2SP_119042_20220712_20220722_02_T1"
# 裁剪要素
clip_feature = r".\data\fz_sub\fz_sub.shp"
# 构建 clip 文件夹的路径
clip_output_folder = os.path.join(r".\data\clip")
# 裁剪
clip_batch(clip_input_folder, clip_feature, clip_output_folder)
# 要搜索的路径
process_input_folder = r".\data\clip"
# 构建 process 文件夹的路径
process_output_folder = os.path.join(r".\data\process")
# 像元值转换与波段合成
process_batch(process_input_folder, "Composite", process_output_folder)
print("OK")叠置分析
使用处理好的Red和NIR波段,计算NDVI,之后再计算FVC。主要涉及到RasterToNumPyArray和RasterCalculator_sa的相关操作
原始数据:
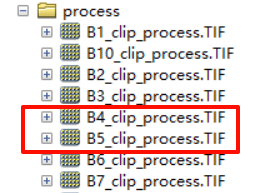
输出数据:
代码:
python
# -*- coding:utf-8 -*-
# -------------------------------------------------------------------------------
# Description : python 2.7, calculate fvc
# @Time : 2024-07-24 0:42
# @Author : zbh
# -------------------------------------------------------------------------------
import arcpy
from arcpy.sa import *
import os
import numpy as np
workspace = r".\data"
arcpy.CheckOutExtension("spatial")
arcpy.env.parallelProcessingFactor = '0'
arcpy.env.overwriteOutput = "True"
arcpy.env.workspace = workspace
# 计算ndvi和植被覆盖度
def ndvi_fvc(red, nir, left_percent, right_percent, output_folder):
# 输出文件夹不存在
if not os.path.exists(output_folder):
try:
os.makedirs(output_folder)
except OSError as e:
raise OSError("Error creating output folder: {}".format(e))
else:
pass
# 计算ndvi
ndvi_raster_path = os.path.join(output_folder, "ndvi.tif")
red_band = arcpy.Raster(red)
nir_band = arcpy.Raster(nir)
ndvi_raster = Float(arcpy.sa.Minus(nir_band, red_band)) / Float(arcpy.sa.Plus(nir_band, red_band))
# 异常值处理
ndvi_bounded = Con(ndvi_raster < -1, -1, Con(ndvi_raster > 1, 1, ndvi_raster))
ndvi_bounded.save(ndvi_raster_path)
# 计算置信区间值
arr = arcpy.RasterToNumPyArray(ndvi_raster)
nodata_value = ndvi_raster.noDataValue
valid_values = arr[arr != nodata_value]
flat_arr = np.sort(valid_values)
left_index = int(len(flat_arr) * float(left_percent))
right_index = int(len(flat_arr) * float(right_percent))
left_value = flat_arr[left_index]
right_value = flat_arr[right_index]
# 计算fvc
values_range = float(right_value) - float(left_value)
condition_fvc = r"""Con(("{0}"<={1}),0,Con(("{0}">={2}),1,("{0}"-{1})/{3}))""".format(ndvi_raster, left_value,
right_value, values_range)
fvc_raster_path = os.path.join(output_folder, "fvc.tif")
arcpy.gp.RasterCalculator_sa(condition_fvc, fvc_raster_path)
print(ndvi_raster_path, left_value, right_value, fvc_raster_path)
print("ndvi_fvc() success!")
if __name__ == "__main__":
# red和nir波段
red = r".\data\process\B4_clip_process.TIF"
nir = r".\data\process\B5_clip_process.TIF"
# 构建输出文件夹的路径
ndvi_output_folder = os.path.join(r"./data/veg")
ndvi_fvc(red, nir, 0.05, 0.95, ndvi_output_folder)
print("OK")一些注意点
数据量的问题
栅格数据如果较大的话,建议裁剪后再处理或者分块处理,有条件可以使用Python3处理数据,因为Python2在运行时会限制空间
栅格计算器
在通过Arcpy使用栅格计算器时,如果表达式过长或者有太多不同的符号可能会报错,需要将表达式进行拆解
总结
本次列举了三个简单的例子,分别是地形因子的提取,影像数据处理,计算植被覆盖度;Arcpy2适合小型的栅格数据处理,不然效率太低或者容易溢出;还有很多操作需要边看边学,直接找个小项目写一写功能记得比较快。
参考
ArcGIS的官方文档