目的:根据病人的入院记录的标签判断病人在短期时间内是否可能再次入院
Y标签:按照患者是否会在 30 天内再次入院划分为:0,1
包含特征:种族、性别、年龄、入院类型、住院时间、检测次数、HbA1c 检测结果、胰岛素释放试验结果、用药数量、糖尿病药物、门诊诊断记录、急
诊就诊数等47个属性
一 、 缺失值处理
1、缺失值处理思路
缺失类型:完全随机缺失、随机缺失、非随机缺失
2、缺失值的处理方法
计算每列缺失比例
- 缺失率极高且该特征并不重要 → 考虑直接删掉
- 缺失率极高且该特征重要→ 特征保留
- 缺失率低 → 考虑插补(填充)/样本删除/不做处理
- 缺失率中等时,不宜插补
如果缺失本身可能有业务意义 → 保留缺失标志作为一个新特征(-8887)
3、缺失值处理方案
删除法:横向删样本(适用于缺失比例极低,不影响样本代表性),纵向删变量(高缺失)
简单插补:均值、中位数、众数、指定值
高级插补:KNN插补,回归插补,多重插补,基于模型的插补(XGB等)
缺失值作为信息保留:例如信用评分系统里"不提供收入信息"可能意味着高风险。
在算法中直接处理缺失:树模型能自动处理分支
其他:预测场景中注意,训练集和测试集处理要一致
【论文中的考虑】
1、选出缺失的特征(47个特征中有9个特征有缺失(3极低+3中等+3高缺失))
2、基于缺失率与含义,删除 weight,payer_code、medical_specialty 进行删除处理 ,因
为 payer_code 表示支付类型,例如医疗保险和自付费用;medical_specialty 对应着接诊医生的专业领
域。这些变量与预测没有显著的关系且缺失比例较高,可以进行删除处理。
高缺失的糖化血红蛋白检测结果范围与max_glu_serum 表示病人的血糖检测结果范围保留 。
3、其他处理:缺失率较低的采取了样本删除+填充的方式(删除的是性别空的几个;填充是众数填充,虽然数值型,但实际含义就几个)
二 、 数据 类型 转换
区间中值代替区间(年龄和收入用的多);论文中仅针对年龄
三 、 数据 均衡
初试比例9:1
欠采样
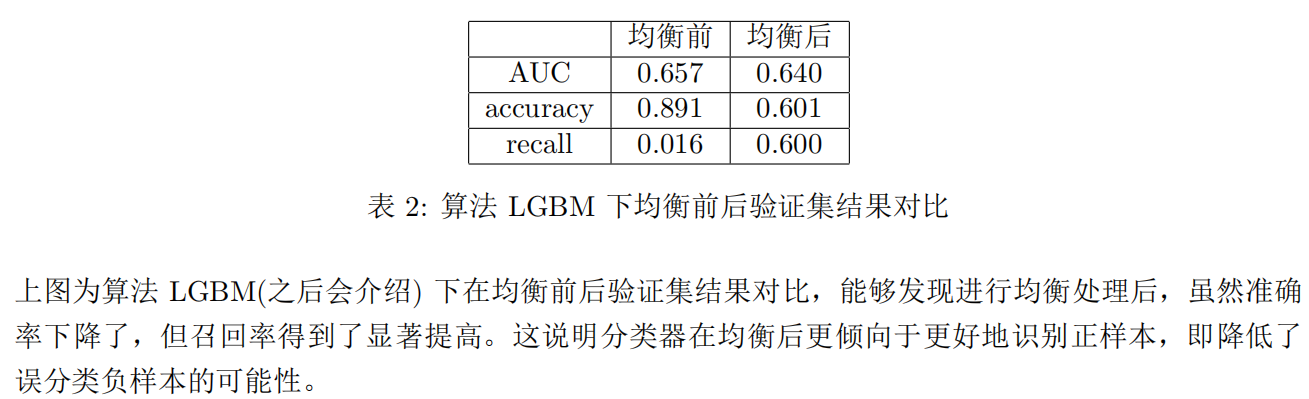
四、算法介绍
LightGBM 在理解上可以看做为 XGBoost + Histogram + GOSS + EFB