数据分析师成长之路
-- 从SQL恐惧到数据掌控者的蜕变
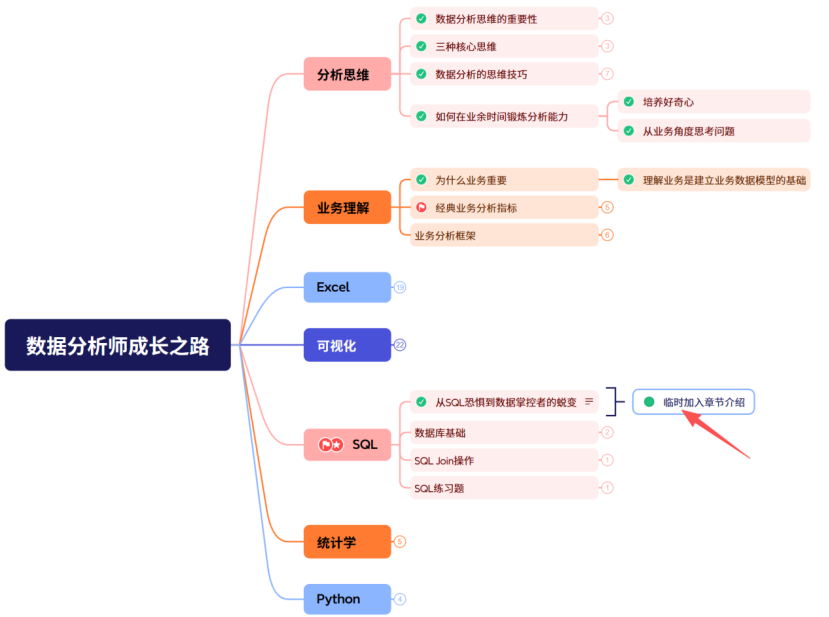
理论是骨架,实践是血肉,而SQL是连接两者的神经网络
技术说明: 本文所有SQL示例均基于MySQL 8.0版本 ,采用SQL99标准语法 (SQL99标准语法是SQL语言的现代标准规范,它通过引入JOIN连接、CTE公共表表达式、窗口函数等结构化语法,使SQL代码更清晰、更强大、更易于维护)。MySQL 8.0相比早期版本在窗口函数、CTE(公共表表达式)等方面有显著增强,更适合现代数据分析需求。
在数据分析师的成长道路上,我们常常面临一个有趣的矛盾:我们都知道分析思维和业务理解至关重要,但当真正面对数据库时,许多人的第一反应却是------"SQL好难"。
最近收到不少读者私信:"看了很多分析理论,但一到写SQL就卡壳"、"业务指标都懂,但不知道如何从数据库中取出来"、"担心自己SQL基础不牢,影响职业发展"。
这让我意识到:我们可能把学习顺序搞反了。就像学游泳,先学再多浮力理论,也不如下水实践一次。数据分析也是如此------SQL不是理论的后续,而是实践的起点。
今天,我们就临时调整一下学习路径,增加从最实践的SQL开始,先让你能"取到数据",再谈如何"分析数据"。当你能够自如地从数据库中提取信息时,所有的分析理论和业务知识都会找到落地的土壤。
数据准备:建立练习环境
在开始学习SQL之前,我们需要创建一个练习环境。以下是完整的建表语句和样例数据,你可以在MySQL 8.0中直接运行这些代码。
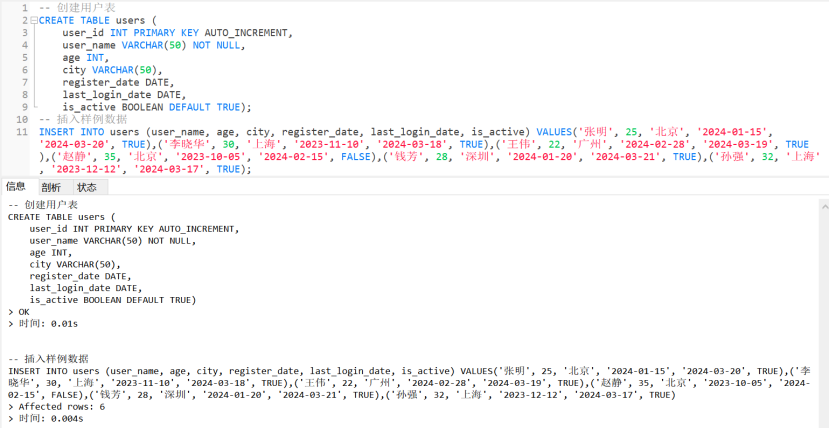
- 用户表 (users)
Sql
-- 创建用户表
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(50) NOT NULL,
age INT,
city VARCHAR(50),
register_date DATE,
last_login_date DATE,
is_active BOOLEAN DEFAULT TRUE);
-- 插入样例数据
INSERT INTO users (user_name, age, city, register_date, last_login_date, is_active) VALUES('张明', 25, '北京', '2024-01-15', '2024-03-20', TRUE),('李晓华', 30, '上海', '2023-11-10', '2024-03-18', TRUE),('王伟', 22, '广州', '2024-02-28', '2024-03-19', TRUE),('赵静', 35, '北京', '2023-10-05', '2024-02-15', FALSE),('钱芳', 28, '深圳', '2024-01-20', '2024-03-21', TRUE),('孙强', 32, '上海', '2023-12-12', '2024-03-17', TRUE);
-- 运行结果
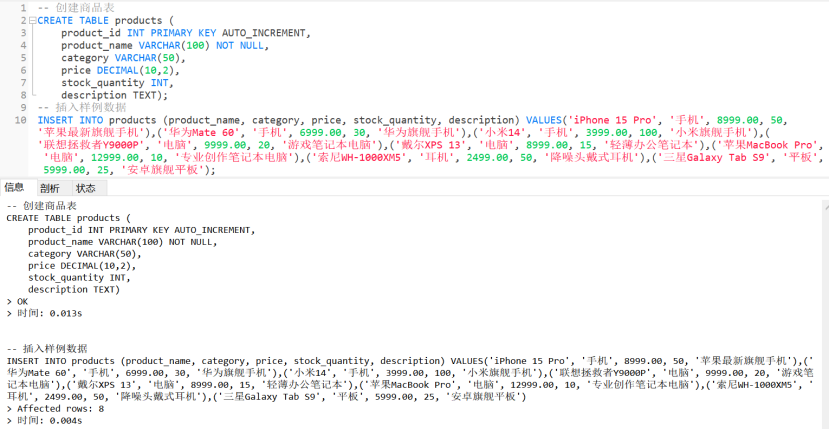
2. 商品表 (products)
sql
-- 创建商品表
CREATE TABLE products (
product_id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50),
price DECIMAL(10,2),
stock_quantity INT,
description TEXT);
-- 插入样例数据
INSERT INTO products (product_name, category, price, stock_quantity, description) VALUES('iPhone 15 Pro', '手机', 8999.00, 50, '苹果最新旗舰手机'),('华为Mate 60', '手机', 6999.00, 30, '华为旗舰手机'),('小米14', '手机', 3999.00, 100, '小米旗舰手机'),('联想拯救者Y9000P', '电脑', 9999.00, 20, '游戏笔记本电脑'),('戴尔XPS 13', '电脑', 8999.00, 15, '轻薄办公笔记本'),('苹果MacBook Pro', '电脑', 12999.00, 10, '专业创作笔记本电脑'),('索尼WH-1000XM5', '耳机', 2499.00, 50, '降噪头戴式耳机'),('三星Galaxy Tab S9', '平板', 5999.00, 25, '安卓旗舰平板');
-- 运行结果
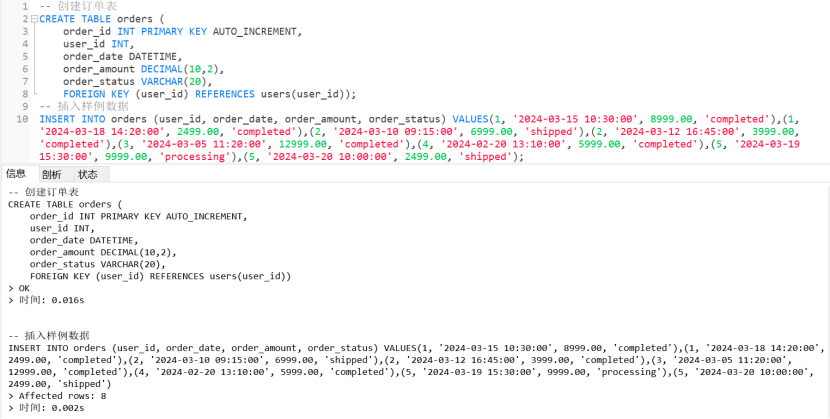
3. 订单表 (orders)
sql
-- 创建订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
order_date DATETIME,
order_amount DECIMAL(10,2),
order_status VARCHAR(20),
FOREIGN KEY (user_id) REFERENCES users(user_id));
-- 插入样例数据
INSERT INTO orders (user_id, order_date, order_amount, order_status) VALUES(1, '2024-03-15 10:30:00', 8999.00, 'completed'),(1, '2024-03-18 14:20:00', 2499.00, 'completed'),(2, '2024-03-10 09:15:00', 6999.00, 'shipped'),(2, '2024-03-12 16:45:00', 3999.00, 'completed'),(3, '2024-03-05 11:20:00', 12999.00, 'completed'),(4, '2024-02-20 13:10:00', 5999.00, 'completed'),(5, '2024-03-19 15:30:00', 9999.00, 'processing'),(5, '2024-03-20 10:00:00', 2499.00, 'shipped');
-- 运行结果
4. 订单明细表 (order_items)
sql
-- 创建订单明细表
CREATE TABLE order_items (
item_id INT PRIMARY KEY AUTO_INCREMENT,
order_id INT,
product_id INT,
quantity INT,
price DECIMAL(10,2),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id));
-- 插入样例数据
INSERT INTO order_items (order_id, product_id, quantity, price) VALUES(1, 1, 1, 8999.00),(2, 7, 1, 2499.00),(3, 2, 1, 6999.00),(4, 3, 1, 3999.00),(5, 6, 1, 12999.00),(6, 8, 1, 5999.00),(7, 4, 1, 9999.00),(8, 7, 1, 2499.00);
-- 运行结果

5. 员工表 (employees)
sql
-- 创建员工表
CREATE TABLE employees (
employee_id INT PRIMARY KEY AUTO_INCREMENT,
employee_name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10,2));
-- 插入样例数据
INSERT INTO employees (employee_name, department, salary) VALUES('周涛', '技术部', 15000.00),('吴静', '技术部', 18000.00),('郑勇', '市场部', 12000.00),('王芳', '市场部', 10000.00),('冯军', '销售部', 8000.00),('陈丽', '销售部', 9000.00),('褚峰', '人力资源部', 11000.00),('卫华', '人力资源部', 10000.00);
-- 运行结果
6. 销售表 (sales)
sql
-- 创建销售表
CREATE TABLE sales (
sale_id INT PRIMARY KEY AUTO_INCREMENT,
product_category VARCHAR(50),
sale_date DATE,
sales_amount DECIMAL(10,2));
-- 插入样例数据
INSERT INTO sales (product_category, sale_date, sales_amount) VALUES('手机', '2024-03-01', 15000.00),('手机', '2024-03-02', 22000.00),('电脑', '2024-03-01', 12000.00),('电脑', '2024-03-02', 18000.00),('耳机', '2024-03-01', 5000.00),('耳机', '2024-03-02', 7500.00),('平板', '2024-03-01', 8000.00),('平板', '2024-03-02', 6000.00);
-- 运行结果
7. 用户登录表 (user_logins)
sql
-- 创建用户登录表
CREATE TABLE user_logins (
login_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
login_time DATETIME,
login_date DATE,
FOREIGN KEY (user_id) REFERENCES users(user_id));
-- 插入样例数据
INSERT INTO user_logins (user_id, login_time, login_date) VALUES(1, '2024-03-20 08:30:00', '2024-03-20'),(1, '2024-03-20 14:20:00', '2024-03-20'),(2, '2024-03-20 09:15:00', '2024-03-20'),(3, '2024-03-20 10:45:00', '2024-03-20'),(5, '2024-03-20 11:30:00', '2024-03-20'),(5, '2024-03-20 16:00:00', '2024-03-20'),(5, '2024-03-20 20:15:00', '2024-03-20');
-- 运行结果
8. 客户表 (customers)
sql
-- 创建客户表
CREATE TABLE customers (
customer_id INT PRIMARY KEY AUTO_INCREMENT,
customer_name VARCHAR(50),
age INT,
city VARCHAR(50));
-- 插入样例数据
INSERT INTO customers (customer_name, age, city) VALUES('张明', 25, '北京'),('李晓华', 30, '上海'),('王伟', 22, '广州'),('赵静', 35, '北京'),('钱芳', 28, '深圳'),('孙强', 32, '上海'),('周涛', 40, '杭州'),('吴静', 27, '南京');
-- 运行结果

现在我们已经准备好了所有需要的表和数据,可以开始SQL学习了!
SQL规范说明:写出专业、易读的代码
在开始编写SQL之前,了解一些基本的编码规范非常重要。良好的编码习惯不仅能让你写出更易维护的代码,还能提高团队协作效率。
1. 命名规范
sql
-- ❌ 不推荐
select * from usertable;
-- ✅ 推荐
SELECT * FROM user_table;
-- 表名、字段名使用小写字母,单词间用下划线分隔-- 使用有意义的名称,避免使用缩写(除非是公认的缩写)
2. 关键字大小写
sql
-- ❌ 不推荐(混用大小写)
Select * From users Where age > 25;
-- ✅ 推荐(SQL关键字大写)
SELECT * FROM users WHERE age > 25;
-- 推荐(表名、字段名小写)
SELECT user_id, user_name FROM users;
3. 缩进与换行
sql
-- ❌ 不推荐(所有内容写在一行)
SELECT user_id,user_name,register_date FROM users WHERE is_active=1 AND city='北京' ORDER BY register_date DESC;
-- ✅ 推荐(合理换行和缩进)
SELECT
user_id,
user_name,
register_date
FROM users WHERE is_active = 1
AND city = '北京'
ORDER BY register_date DESC;
4. 注释规范
sql
-- 单行注释:使用两个减号
SELECT * FROM users WHERE age > 18; -- 查询成年用户
-- 多行注释:使用/* */
/*
功能:查询用户订单统计
作者:数据分析团队
创建时间:2025-12-05
*/
SELECT
u.user_id,
u.user_name,
COUNT(o.order_id) AS order_count
FROM users u
LEFT JOIN orders o
ON u.user_id = o.user_id
GROUP BY u.user_id, u.user_name;
5. 使用别名
sql
-- ❌ 不推荐(不使用别名或使用无意义的别名)
SELECT users.user_id, users.user_name, orders.order_amount FROM users, orders WHERE users.user_id = orders.user_id;
-- ✅ 推荐(使用有意义的表别名)
SELECT
u.user_id,
u.user_name,
o.order_amount
FROM users u
INNER JOIN orders o
ON u.user_id = o.user_id;
-- ✅ 推荐(使用有意义的列别名)
SELECT
user_id AS "用户ID",
user_name AS "用户名",
register_date AS "注册日期"FROM users;
6. 避免使用SELECT *
sql
-- ❌ 不推荐
SELECT * FROM users;
-- ✅ 推荐(只选择需要的列)
SELECT
user_id,
user_name,
register_date
FROM users;
7. 使用CTE(公共表表达式)提高可读性
sql
-- 对于复杂查询,使用WITH子句
WITH active_users AS (
SELECT user_id, user_name
FROM users
WHERE is_active = 1),
user_orders AS (
SELECT
u.user_id,
COUNT(o.order_id) AS order_count
FROM active_users u
LEFT JOIN orders o ON u . user_id = o . user_id
GROUP BY u.user_id)
SELECT * FROM user_orders ORDER BY order_count DESC;
遵循这些规范,你的SQL代码将更加专业、易读、易维护。
SQL开发必备工具:UltraEdit
在开始编写SQL之前,选择合适的开发工具同样重要。UltraEdit 是一款功能强大的文本编辑器,特别适合SQL开发,以下是它的几个核心优势:
为什么选择UltraEdit进行SQL开发?
- 强大的语法高亮
- 支持SQL、MySQL、PostgreSQL等多种数据库语法
- 智能识别关键字、函数、数据类型
- 自定义颜色方案,保护眼睛
- 代码折叠与大纲视图
- 折叠复杂SQL语句的各个部分
- 大纲视图快速导航到特定子查询或CTE
- 保持代码结构清晰
- 列模式编辑
- 同时编辑多行数据(批量修改INSERT语句中的值)
- 对齐SQL代码,提高可读性
- 快速处理大量相似数据
- FTP/SFTP集成
- 直接连接远程数据库服务器
- 编辑服务器上的SQL脚本文件
- 一键上传执行
- 高级搜索与替换
- 正则表达式搜索复杂模式
- 跨文件搜索SQL代码片段
- 批量修改表名或字段名
UltraEdit在SQL开发中的实际应用
sql
-- UltraEdit可以帮助你更好地编写和维护这样的复杂查询
WITH monthly_sales AS (
SELECT
DATE_TRUNC('month', order_date) AS month,
product_category,
SUM(order_amount) AS total_sales
FROM orders o
JOIN products p ON o.product_id = p.product_id
WHERE order_date >= '2024-01-01'
GROUP BY DATE_TRUNC('month', order_date), product_category),
category_growth AS (
SELECT
month,
product_category,
total_sales,
LAG(total_sales) OVER (
PARTITION BY product_category
ORDER BY month
) AS prev_month_sales
FROM monthly_sales)SELECT
month,
product_category,
total_sales,
ROUND(
(total_sales - prev_month_sales) / prev_month_sales * 100,
2
) AS growth_rateFROM category_growthORDER BY month DESC, total_sales DESC;
其他推荐工具
除了UltraEdit,以下工具也值得考虑:
- ****MySQL Workbench:****官方图形化管理工具
- ****DBeaver:****开源的多数据库管理工具
- ****Navicat:****商业数据库管理工具,功能全面
- ****VS Code:****轻量级编辑器,通过插件支持SQL开发
- 其它开发工具
选择适合自己的工具,可以大幅提升SQL开发效率。现在,让我们开始正式的SQL学习之旅!
第一部分: 20 段日常SQL取数代码------从基础到熟练
一、入门必备:基础查询四式
1. 全表扫描(初识数据结构)
sql
SELECT * FROM users LIMIT 10; -- 快速了解表结构,查看数据样例
-- 运行结果
2. 精准选择(只取所需字段)
sql
SELECT user_id, user_name, register_date FROM users WHERE is_active = 1; -- 只查询活跃用户的核心信息
-- 运行结果
3. 字段重命名(让结果更可读)
sql
SELECT
order_id AS "订单编号",
order_amount AS "订单金额",
order_date AS "下单时间" FROM orders;
-- 运行结果
4. 去重查询(消除重复数据)
sql
SELECT DISTINCT department FROM employees; - - 查看公司有哪些部门
-- 运行结果
二、条件过滤:像搜索引擎一样筛选数据
5. 基础条件筛选
sql
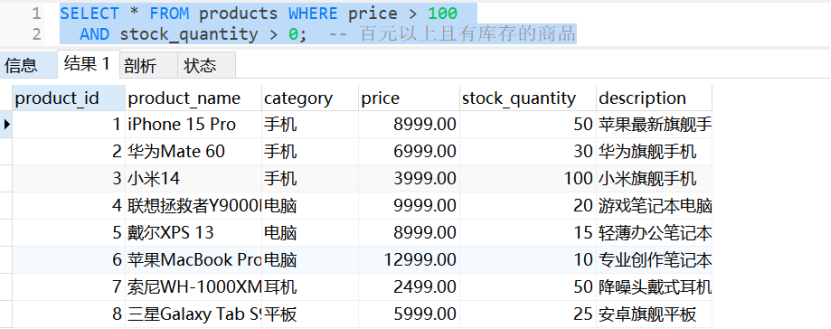
SELECT * FROM products WHERE price > 100
AND stock_quantity > 0; -- 百元以上且有库存的商品
-- 运行结果
6. 多条件组合查询
sql
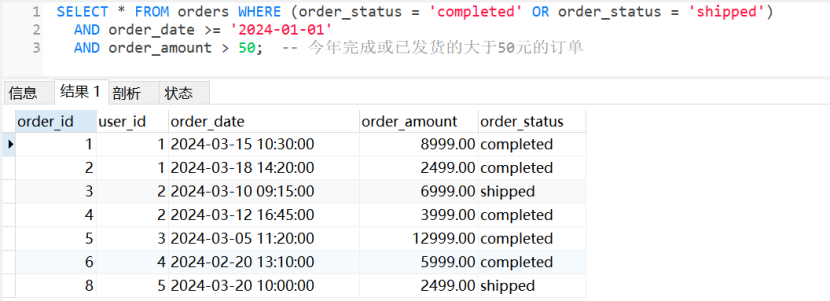
SELECT * FROM orders WHERE (order_status = 'completed' OR order_status = 'shipped')
AND order_date >= '2024-01-01'
AND order_amount > 50; -- 今年完成或已发货的大于50元的订单
-- 运行结果
7. 范围与列表查询
sql
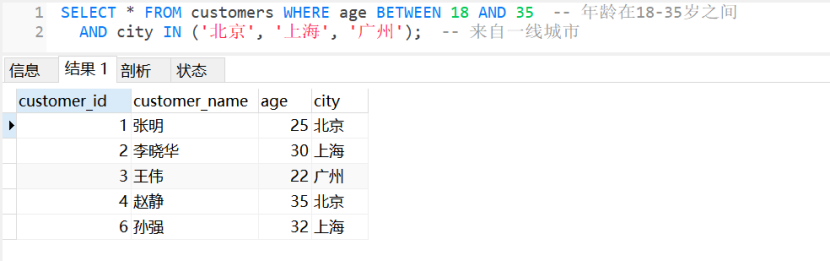
SELECT * FROM customers WHERE age BETWEEN 18 AND 35 - - 年龄在18-35岁之间
AND city IN ('北京', '上海', '广州'); -- 来自一线城市
-- 运行结果
8. 模糊匹配与空值处理
sql
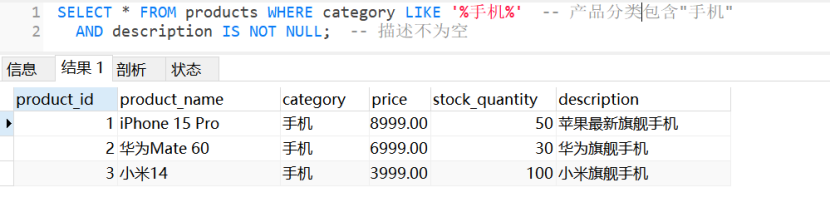
SELECT * FROM products WHERE category LIKE '%手机%' -- 产品 分类 包含"手机"
AND description IS NOT NULL; -- 描述不为空
-- 运行结果
三、数据聚合:从细节到宏观
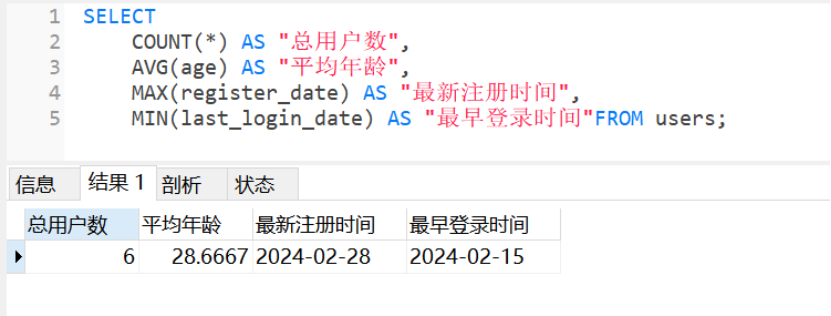
9. 基础统计聚合
sql
SELECT
COUNT(*) AS "总用户数",
AVG(age) AS "平均年龄",
MAX(register_date) AS "最新注册时间",
MIN(last_login_date) AS "最早登录时间"FROM users;
-- 运行结果
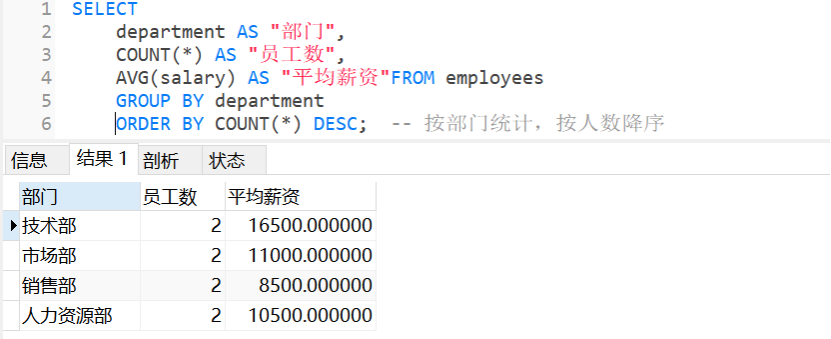
10. 分组统计(理解业务分布)
sql
SELECT
department AS "部门",
COUNT(*) AS "员工数",
AVG(salary) AS "平均薪资"FROM employees
GROUP BY department
ORDER BY COUNT(*) DESC; -- 按部门统计,按人数降序
-- 运行结果
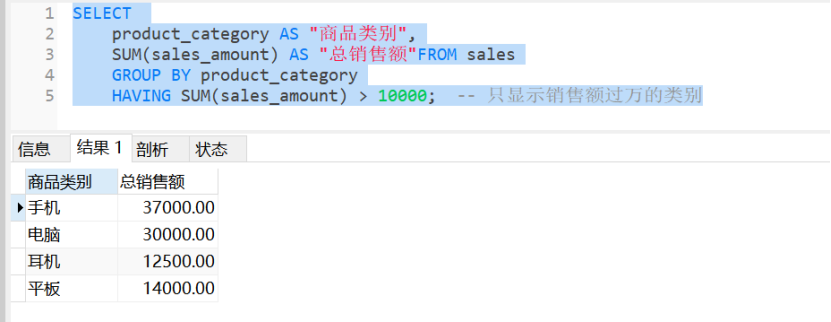
11. 分组后过滤(HAVING子句)
sql
SELECT
product_category AS "商品类别",
SUM(sales_amount) AS "总销售额"FROM sales
GROUP BY product_category
HAVING SUM(sales_amount) > 10000; -- 只显示销售额过万的类别
-- 运行结果
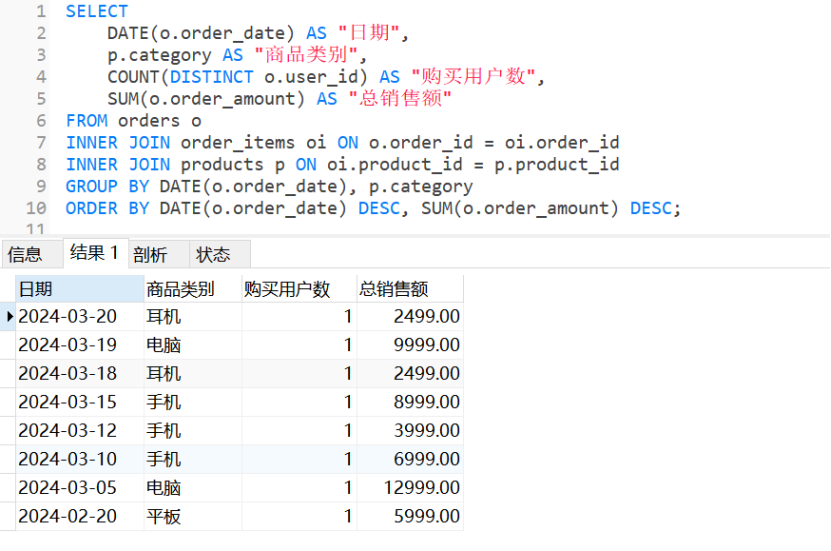
12. 多维度交叉分析
sql
SELECT
DATE(o.order_date) AS "日期",
p.product_category AS "商品类别",
COUNT(DISTINCT o.user_id) AS "购买用户数",
SUM(o.order_amount) AS "总销售额"FROM orders oINNER JOIN order_items oi ON o.order_id = oi.order_idINNER JOIN products p ON oi.product_id = p.product_idGROUP BY DATE(o.order_date), p.product_categoryORDER BY DATE(o.order_date) DESC, SUM(o.order_amount) DESC;
-- 运行结果
四、表连接:关联多个数据视角
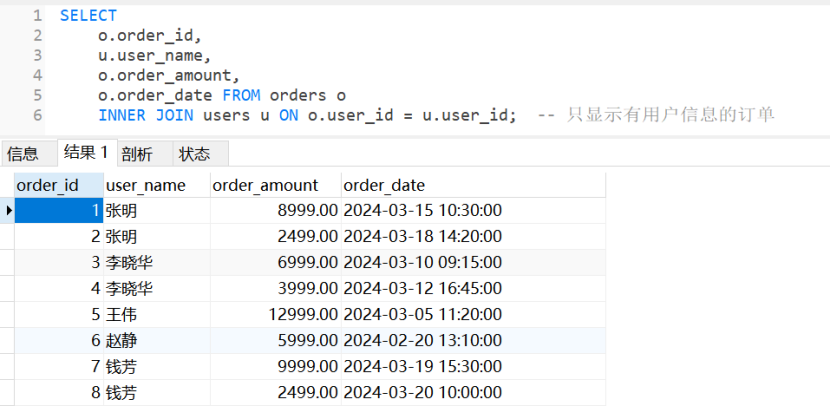
13. 内连接(查找匹配数据)
sql
SELECT
o.order_id,
u.user_name,
o.order_amount,
o.order_date FROM orders o
INNER JOIN users u ON o.user_id = u.user_id; -- 只显示有用户信息的订单
-- 运行结果
14. 左连接(保留主表所有记录)
sql
SELECT
u.user_id,
u.user_name,
COUNT(o.order_id) AS "订单数量"FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
GROUP BY u.user_id, u.user_name; - - 显示所有用户,包括未下单的
-- 运行结果

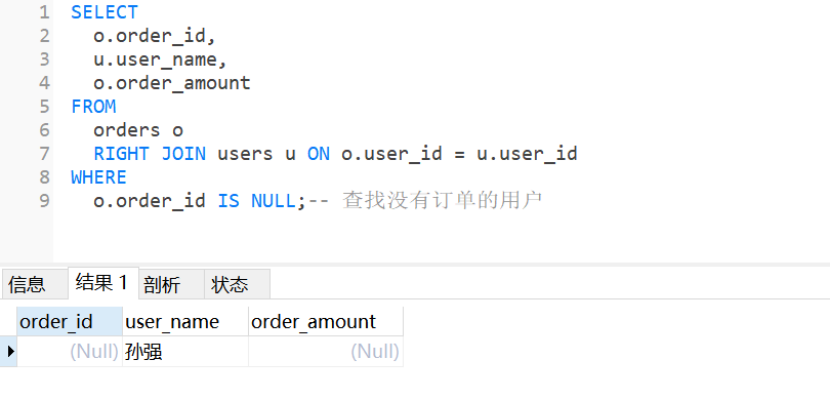
1 5. 右连接(RIGHT JOIN)
sql
-- 右连接:返回右表的所有记录,即使左表中没有匹配-- 注意:实际工作中右连接使用较少,通常用左连接替代
SELECT
o.order_id,
u.user_name,
o.order_amount
FROM orders o
RIGHT JOIN users u ON o.user_id = u.user_id
WHERE o.order_id IS NULL; -- 查找没有订单的用户
-- 运行结果
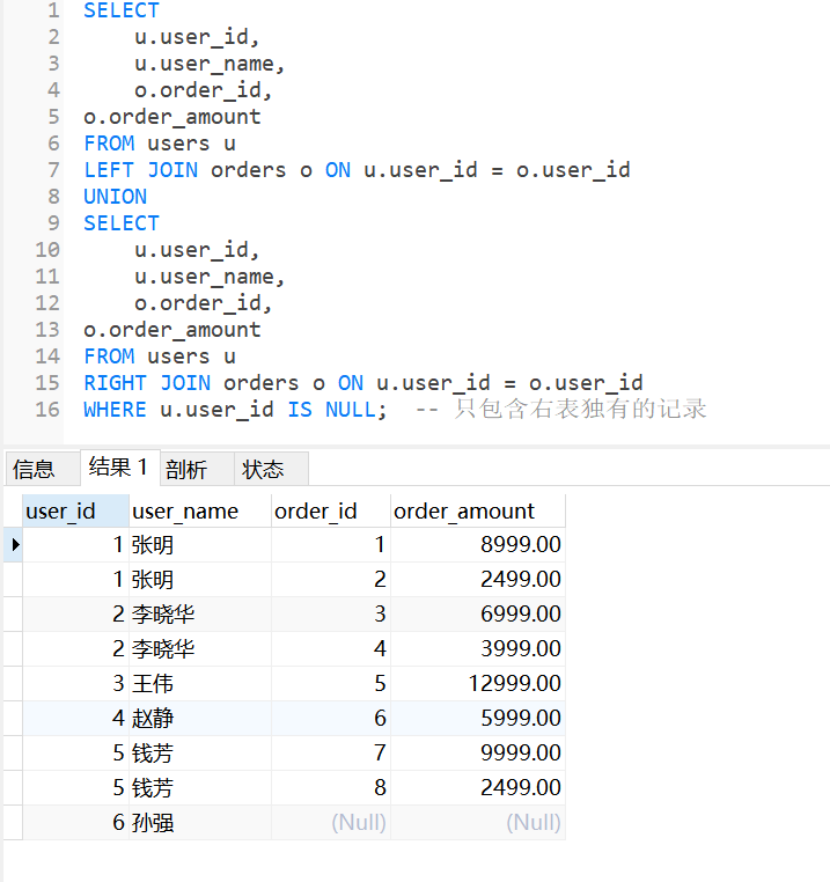
1 6. 全连接(FULL JOIN)
sql
-- MySQL不支持FULL JOIN,但可以通过LEFT JOIN和RIGHT JOIN的UNION模拟-- 全连接:返回左表和右表中的所有记录
SELECT
u.user_id,
u.user_name,
o.order_id,
o.order_amount
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
UNION
SELECT
u.user_id,
u.user_name,
o.order_id,
o.order_amount
FROM users u
RIGHT JOIN orders o ON u.user_id = o.user_id
WHERE u.user_id IS NULL; -- 只包含右表独有的记录
-- 运行结果
1 7 . 多表关联(完整业务视图)
sql
-- 使用INNER JOIN获取完整的订单业务视图
SELECT
u.user_name,
o.order_id,
p.product_name,
oi.quantity,
oi.price
FROM users u
INNER JOIN orders o ON u.user_id = o.user_id
INNER JOIN order_items oi ON o.order_id = oi.order_id
INNER JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01';
-- 也可以使用其他连接方式,根据业务需求选择:
-- 1. LEFT JOIN:包含所有用户,即使没有订单
-- 2. RIGHT JOIN:包含所有订单,即使没有对应的用户信息(理论上不应存在)
-- 3. 混合使用:根据需要组合不同的连接类型
-- 运行结果

连接类型总结:
- ****INNER JOIN:****只返回两个表都匹配的记录(交集)
- ****LEFT JOIN:****返回左表所有记录,右表匹配的记录
- ****RIGHT JOIN:****返回右表所有记录,左表匹配的记录
- ****FULL JOIN:****返回两个表的所有记录(并集),MySQL通过UNION模拟
五、日期处理:时间维度分析基础
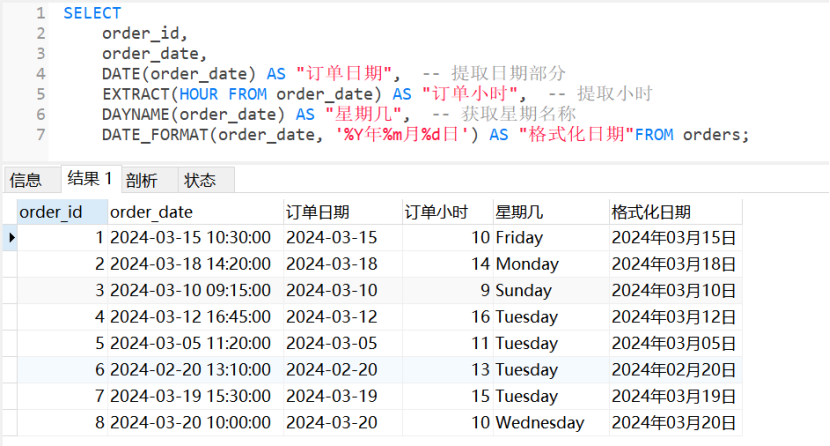
1 8 . 日期提取与格式化
sql
SELECT
order_id,
order_date,
DATE(order_date) AS "订单日期", -- 提取日期部分
EXTRACT(HOUR FROM order_date) AS "订单小时", -- 提取小时
DAYNAME(order_date) AS "星期几", -- 获取星期名称
DATE_FORMAT(order_date, '%Y年%m月%d日') AS "格式化日期"FROM orders;
-- 运行结果
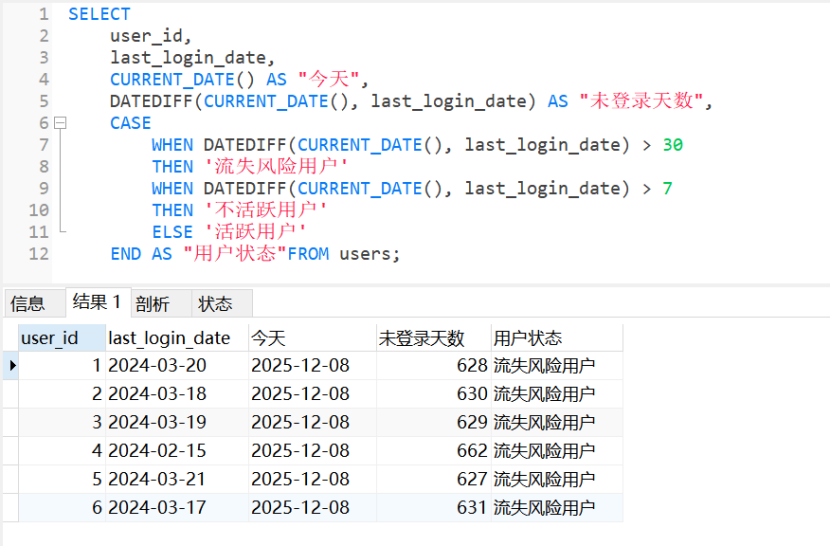
1 9 . 日期计算与比较
sql
SELECT
user_id,
last_login_date,
CURRENT_DATE() AS "今天",
DATEDIFF(CURRENT_DATE(), last_login_date) AS "未登录天数",
CASE
WHEN DATEDIFF(CURRENT_DATE(), last_login_date) > 30
THEN '流失风险用户'
WHEN DATEDIFF(CURRENT_DATE(), last_login_date) > 7
THEN '不活跃用户'
ELSE '活跃用户'
END AS "用户状态"FROM users;
-- 运行结果
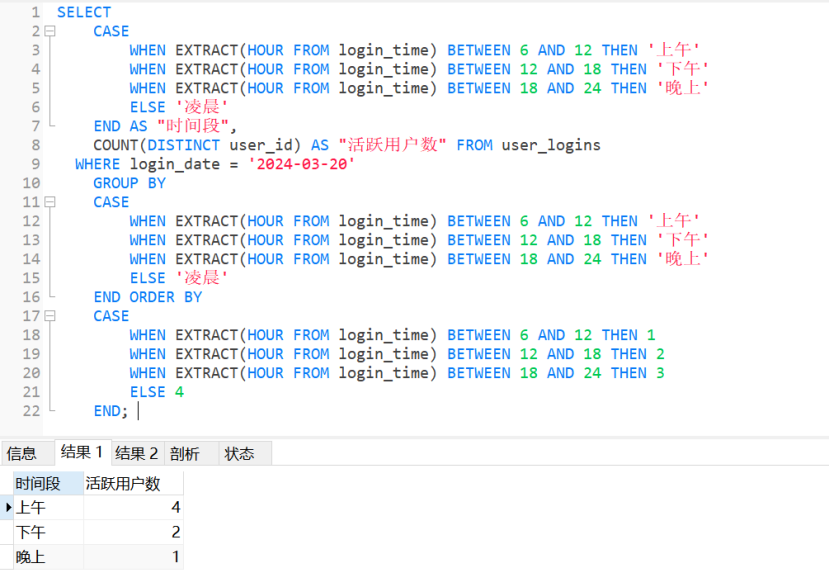
20 . 时间段分析
sql
SELECT
CASE
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 6 AND 12 THEN '上午'
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 12 AND 18 THEN '下午'
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 18 AND 24 THEN '晚上'
ELSE '凌晨'
END AS "时间段",
COUNT(DISTINCT user_id) AS "活跃用户数" FROM user_logins
WHERE login_date = '2024-03-20'
GROUP BY
CASE
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 6 AND 12 THEN '上午'
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 12 AND 18 THEN '下午'
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 18 AND 24 THEN '晚上'
ELSE '凌晨'
ENDORDER BY
CASE
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 6 AND 12 THEN 1
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 12 AND 18 THEN 2
WHEN EXTRACT(HOUR FROM login_time) BETWEEN 18 AND 24 THEN 3
ELSE 4
END;
-- 运行结果
第二部分:从取数工具到分析利器------SQL高手的进阶之路
掌握了基础取数,你会发现SQL的能力远不止于此。真正的SQL高手,能用简单的查询回答复杂的业务问题。
业务场景实战:用SQL解决真实问题
用户留存分析进阶版
sql
WITH user_cohort AS (
SELECT
user_id,
DATE(MIN(order_date)) AS first_order_date,
DATE(MAX(order_date)) AS last_order_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(order_amount) AS total_spent
FROM orders
GROUP BY user_id),
retention_analysis AS (
SELECT
first_order_date AS "首购日期",
CASE
WHEN DATEDIFF(CURRENT_DATE(), last_order_date) <= 30
THEN '活跃用户'
WHEN DATEDIFF(CURRENT_DATE(), last_order_date) <= 90
THEN '沉默用户'
ELSE '流失用户'
END AS "用户状态",
COUNT(DISTINCT user_id) AS "用户数",
AVG(total_orders) AS "人均订单数",
AVG(total_spent) AS "人均消费金额"
FROM user_cohort
GROUP BY first_order_date,
CASE
WHEN DATEDIFF(CURRENT_DATE(), last_order_date) <= 30
THEN '活跃用户'
WHEN DATEDIFF(CURRENT_DATE(), last_order_date) <= 90
THEN '沉默用户'
ELSE '流失用户'
END)SELECT * FROM retention_analysis ORDER BY "首购日期" DESC;
-- 运行结果

性能优化:让查询快人一步
EXPLAIN计划解读实战
sql
EXPLAIN SELECT
u.user_id,
u.user_name,
COUNT(o.order_id) AS order_count,
SUM(o.order_amount) AS total_spent
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
WHERE u.register_date >= '2024-01-01'
AND u.city = '北京'GROUP BY u.user_id, u.user_name
HAVING COUNT(o.order_id) > 0
ORDER BY total_spent DESC
LIMIT 100;
-- 运行结果
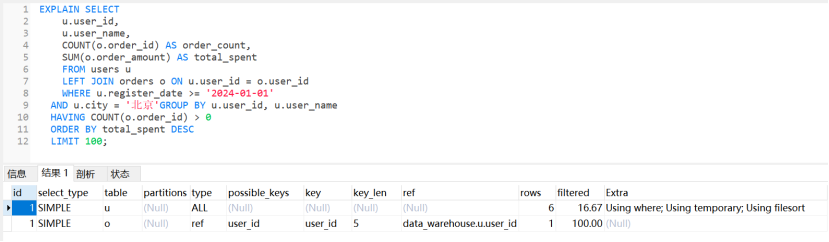
EXPLAIN使用技巧
快速诊断三步法
- 看type:确保不是ALL(全表扫描)
- 看key:确认使用了合适的索引
- 看Extra:警惕Using temporary和Using filesort
关键指标参考
- ✅ 优秀:const、eq_ref、ref(索引查找)
- ⚠️ 待优化:range(范围扫描)、index(全索引扫描)
- ❌ 需要优化:ALL(全表扫描)
常见问题与解决
|-------|-----------------------|-------------------|
| 问题 | 现象 | 解决方案 |
| 全表扫描 | type = ALL | 添加WHERE条件索引 |
| 临时表 | Extra含Using temporary | 优化GROUP BY或JOIN条件 |
| 文件排序 | Extra含Using filesort | 添加ORDER BY字段索引 |
| 索引未使用 | key为NULL | 检查索引字段匹配度 |
****一句话记住:****EXPLAIN帮你看透SQL执行过程,重点关注type、key、Extra三个字段,及时识别和优化性能瓶颈。
核心原则:
- 尽量使用索引查找(避免全表扫描)
- 减少临时表和文件排序操作
- 预估扫描行数要合理
通过定期使用EXPLAIN分析关键查询,你可以逐步优化数据库性能,让SQL查询跑得更快更稳。
自动化监控:SQL成为业务预警系统
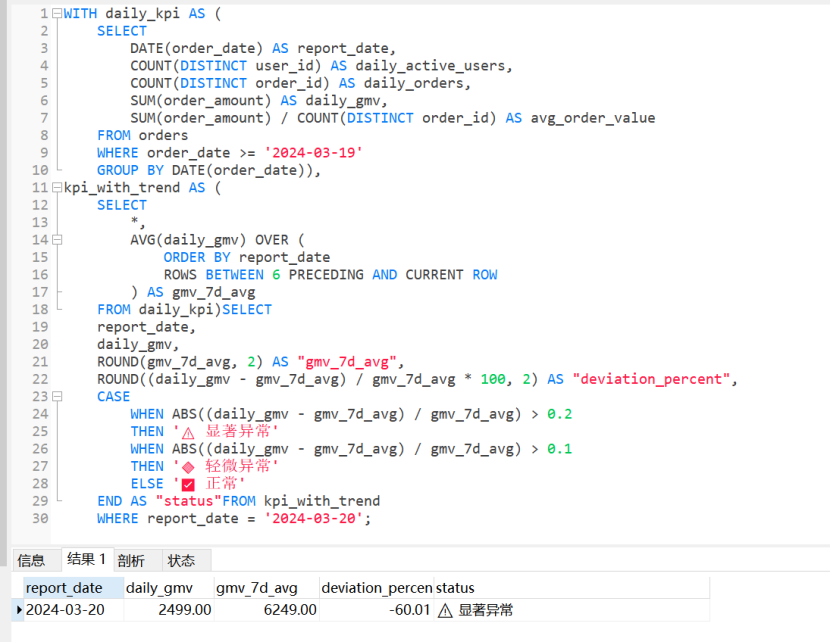
业务指标异常自动检测
sql
WITH daily_kpi AS (
SELECT
DATE(order_date) AS report_date,
COUNT(DISTINCT user_id) AS daily_active_users,
COUNT(DISTINCT order_id) AS daily_orders,
SUM(order_amount) AS daily_gmv,
SUM(order_amount) / COUNT(DISTINCT order_id) AS avg_order_value
FROM orders
WHERE order_date >= '2024-03-19'
GROUP BY DATE(order_date)),
kpi_with_trend AS (
SELECT
*,
AVG(daily_gmv) OVER (
ORDER BY report_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS gmv_7d_avg
FROM daily_kpi)
SELECT
report_date,
daily_gmv,
ROUND(gmv_7d_avg, 2) AS "gmv_7d_avg",
ROUND((daily_gmv - gmv_7d_avg) / gmv_7d_avg * 100, 2) AS "deviation_percent",
CASE
WHEN ABS((daily_gmv - gmv_7d_avg) / gmv_7d_avg) > 0.2
THEN '⚠️ 显著异常'
WHEN ABS((daily_gmv - gmv_7d_avg) / gmv_7d_avg) > 0.1
THEN '�� 轻微异常'
ELSE '✅ 正常'
END AS "status"FROM kpi_with_trend
WHERE report_date = '2024-03-20';
-- 运行结果
第三部分:数据分析师成长之路------构建完整知识体系
现在,当你已经掌握了SQL这个强大的工具,我们可以更从容地回到数据分析师的完整成长路径上来:
1. 分析思维:SQL是思维的数字表达
- ****假设驱动:****每个SQL查询都在验证一个业务假设
- ****结构化思考:****FROM → WHERE → GROUP BY → SELECT的顺序就是分析逻辑
- ****数据敏感度:****在写JOIN时思考数据关系,在写WHERE时思考业务边界
2. 业务理解:SQL是业务问题的翻译器
当你说"我想知道用户留存情况"时,你的大脑应该自动翻译成:
sql
WITH user_first_order AS (
SELECT user_id, MIN(order_date) AS first_order_date
FROM orders
GROUP BY user_id)SELECT
DATE(first_order_date) AS "首购日期",
COUNT(DISTINCT user_id) AS "首购用户数",
COUNT(DISTINCT CASE
WHEN DATEDIFF(CURRENT_DATE(), first_order_date) <= 30
THEN user_id
END) AS "30日留存用户数"FROM user_first_order
GROUP BY DATE(first_order_date);
-- 运行结果

每个业务指标(GMV、转化率、复购率)都能对应一个或多个SQL查询
3. 工具链整合:SQL是数据生态的枢纽
- ****SQL + Excel:****导出数据进一步分析
- ****SQL + Python:****复杂分析和大数据处理
- SQL + ETL工具+ ****可视化工具:****ETL预处理数据后直接连接Tableau/Power BI/Redash
- ****SQL + 调度系统:****实现自动化数据报表
4. 学习路径建议:从SQL出发,辐射式学习
- 新手阶段(1-3个月):
SQL基础 → 业务指标 → Excel分析 → 简单可视化
- 进阶阶段(3-12个月):
SQL优化 → 统计基础 → ETL/Python → 仪表板制作
- 高手阶段(1年以上):
复杂SQL与存储过程 → 机器学习应用 → 数据产品思维 → 业务驱动分析
给初学者的特别建议
如果你刚开始学习数据分析,感到SQL有难度:
- ****先运行,后理解:****把上面的18个例子在你自己数据库中运行一遍
- ****修改参数:****改改数字、换换条件,观察结果变化
- ****从模仿开始:****找到工作中的一个实际需求,用类似语句解决
- ****建立查询库:****把常用的查询保存下来,形成自己的"工具箱"
- ****每月回顾:****回头看一个月前写的SQL,你会发现进步惊人
结语:SQL是起点,不是终点
我们今天调整了学习顺序------从最实践的SQL开始,不是因为SQL最重要,而是因为它最具体、最能给你正反馈。当你能独立取出需要的数据时,你会获得数据分析路上的第一次成就感。
但这只是开始。SQL是打开数据世界的钥匙,而门后的世界更加广阔:业务理解让你知道该分析什么,统计知识让你知道如何分析得更科学,ETL、可视化、Python等工具让你能处理更大规模的数据。
记住这个成长框架:
- ****SQL取数:****获取数据的能力
- ****业务理解:****提出问题的能力
- ****分析思维:****解决问题的能力
- ****工具整合:****高效执行的能力
现在,打开你的数据库,运行第一个查询吧------所有的数据分析师,都是从这一行代码开始的。
学习检查点:
- 能独立写出基础SELECT查询
- 理解WHERE、GROUP BY、JOIN的作用
- 能计算简单的业务指标(用户数、订单量、销售额)
- 保存了至少5个常用查询模板
- 在工作中实际应用过SQL解决问题
无论你现在SQL水平如何,记住:每个数据分析高手,都曾是你现在的样子。重要的是开始,持续,然后重复。