前言
大家好,我是萍雨。
在开始聊技术之前,我想先分享一个我刚学编程时踩过的坑。那时候我习惯了用 Java 的思维去处理一切,遇到需要从几万条数据里找几个特定用户,我的第一反应是:写个 for 循环,加几层 if-else。
结果显而易见,电脑直接卡死。那时候我才意识到,有些脏活累活,必须要交给专业的工具去干。
这个工具就是 SQL。
很多人觉得数据库高深莫测,那是被那些厚如砖头的教科书吓到了。其实,只要你用对了方法,SQL 比 Excel 还要直观。这篇教程就是为了完全零基础的小白准备的,我会推翻那些枯燥的定义,用大白话带你重装大脑。
看完这一篇,你将掌握:
-
数据库和 Excel 的本质区别。
-
像剪刀一样裁剪数据的
SELECT。 -
像漏斗一样筛选数据的
WHERE。 -
以及那个连老手都会翻车的
NULL隐形陷阱。
如果你已经准备好把那些低效的循环逻辑丢进垃圾桶,那我们就开始吧。
1. 数据库到底是个啥?
很多零基础的朋友听到 "数据库" 这三个字就觉得高深莫测。其实,把它拉下神坛,它就是一个 "打了激素的超级 Excel"。
你可能会问:"我平时记账、存资料,用 Excel 挺好用的呀,为啥非要搞个数据库?"
想象你开了一家奶茶店,每天 100 个订单,用 Excel 记账毫无压力。但如果你的店变成了全国连锁,每天产生 1000 万个订单呢?此时 Excel 会面临三个必死结局:
-
装不下:Excel 一个表格最多只能存 104 万行数据,强行存千万数据,电脑会直接罢工。
-
没法同时写:如果全国 500 个店长同时往一个 Excel 里填数据,系统会提示"文件被占用"。而数据库可以支持成千上万人同一秒钟同时写入。
-
极易填错:Excel 太自由了,年龄那一列填个"哈哈"也能存。数据库则像个严厉的质检员,只要设置了必须是数字,乱填直接拒收。
为了解决这些问题,专门存海量、高频率数据的软件诞生了,这就是数据库(比如最常见的 MySQL)。
2. SQL 干啥用的?(声明式哲学)
既然不用 Excel 了,我们就不能用鼠标去点"筛选"了。我们需要一种语言来命令数据库干活,这就是 SQL。
SQL 是一种 "声明式" 语言。什么意思?就像你去餐厅点菜。你只需要对服务员说:"给我来一盘西红柿炒蛋,不要放葱。"你完全不需要关心后厨是怎么打蛋、切菜的,你只管"下命令",数据库内部的机器人会自动用最快的速度把菜端给你。
不用担心各个数据库的 SQL 差别很大,它就像"普通话",虽然 MySQL 或 Oracle 偶尔带点"方言",但骨子里是相通的。
前面这两小节,请记住:数据库是扛并发的数据仓库,SQL 是你指挥仓库管理员的"普通话"。
3. 纵向抽数据:SELECT 这把剪刀
假设数据库里有一个名叫 user 的超级大表格。它就像一个有 100 列的巨型 Excel:
| 姓名 (name) | 年龄 (age) | 手机号 (phone) | 家庭住址 (address) | ...还有96列 |
|---|---|---|---|---|
| 图图 | 5 | 138xxxx | 翻斗大街大耳朵图图家 | ... |
| 萍雨 | 20 | 139xxxx | 翻斗花园二号楼 | ... |
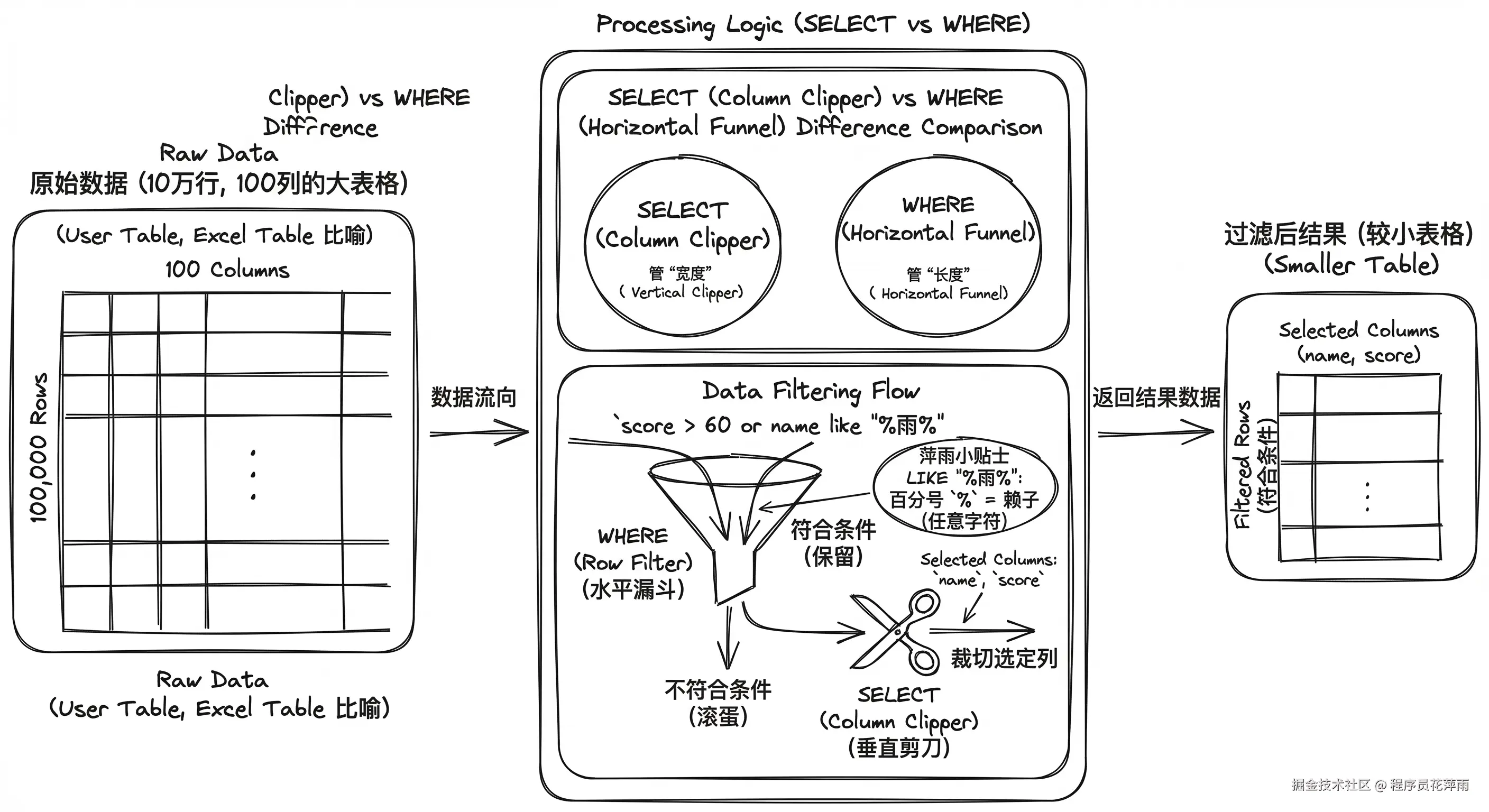
现在我们要一份"点名册",上面只要姓名 。怎么让数据库别把剩下 99 列隐私信息都吐出来浪费内存?这就要用到:SELECT 和 FROM。
SQL
-- 这是一条便利贴(注释),数据库不会管它
SELECT name FROM user;-
FROM user:定位数据源。告诉数据库去翻哪张表。 -
SELECT name:它是一把极其锋利的垂直剪刀 。它不关心表里装的是谁,只负责自上而下,把name这一列剪下来,剩下的直接扔进垃圾桶。
一个极度反常识的真相:
现实中我们是先找表再剪列,所以逻辑上是先 FROM 后 SELECT。虽然写 SQL 时 SELECT 在前,但数据库引擎执行时是先看 FROM 的! 它们的逻辑和人类是一致的。(关于整个 SQL 庞大语句的完整执行顺序,我在后续会给大家拼起一张完整的版图)
4. 横向筛数据:WHERE 这个漏斗
现在我们出现了新的需求。
如果我们只想看"及格"的人,或者是名字里带 "雨" 的人,上一节的 SELECT 剪刀好像办不到了。因为它一剪就是一整列,成绩好的学生和成绩差的学生都被一起剪下来了。
有没有什么办法能像"过筛子"一样,把不符合条件的人直接漏掉?
这就轮到 WHERE 出场了。
这时可能有细心的小伙伴( ̄ω ̄〃)要问了:
"既然
SELECT和WHERE都有筛选作用,那它们之间到底有什么区别呢?"
问得太好了!我们依然拿 Excel 那个拥有 100 列、10万行的大表格来做例子:
-
SELECT管的是"宽度"(列): 它决定了你最后拿到手的表格有几列(比如只要姓名和成绩)。 -
WHERE管的是"长度/条数"(行): 它像一个严格的水平漏斗 。数据库在扫描每一行数据时,都会让这行数据穿过WHERE漏斗,符合条件的留下,不符合的直接滚蛋。
比如我们现在的需求:"找出成绩大于 60 分,或者名字里带 '雨' 的人"。在 SQL 里,我们可以这样写:
SQL
select name, score from user where score > 60 or name like "%雨%";(💡 萍雨小贴士 :这里的 LIKE 叫做"模糊查询"。百分号 % 就像扑克牌里的赖子,代表"任意字符"。"%雨%" 的意思就是:不管你叫"萍雨"、"听雨",还是"大雨",只要名字里包含"雨"字,统统给我捞出来!)
逻辑运算符的陷阱
在实际的数据分析中,筛选条件往往是很复杂的。比如我们现在遇到了一个终极需求:
找"成绩及格"【且】"家住翻斗花园"的人,或者"姓王"【或】"姓李"的人。
这里出现了我们在 SQL 里最常用的两个逻辑运算符:
-
AND(且): 要求极高,必须同时满足。成绩及格但不住翻斗花园的?淘汰。住翻斗花园但没及格的?淘汰。只有两样都占的才能留下。 -
OR(或): 比较宽容,满足一个就行。姓王的或者姓李的,都可以留下。
现在,我们要把这个需求翻译成 SQL。很多初学者(包括我自己刚开始的时候 😅)会顺手写出这样一段破绽百出的代码:
SQL
-- ❌ 错误示范,千万别抄!
select name from user
where score > 60 and address = "翻斗花园" OR name like "王%" or "李%";这段代码有两个极其致命的错误:
第一个致命错误:"把电脑当人"。
结尾的 or "李%" 在人类听来很顺畅(姓王或李),但数据库是个笨机器,它不知道"李"要和哪个字段比。在 OR 的两边,必须是完整的句子!必须老老实实写成:or name like "王%" or name like "李%"。
第二个致命错误:"优先级的灾难"。
当 AND 和 OR 混在一起时,数据库会先算哪一个?
这就要掏出我们小学学的数学定律了:"先乘除,后加减"。
在 SQL 里,AND 的优先级永远高于 OR (我们可以把 AND 当成乘法,OR 当成加法)。如果不加控制,数据库的理解会和我们的本意十万八千里。
正确的姿势是:遇到多个条件,永远用括号 () 把它们包裹起来,明明白白地告诉数据库先算谁!
SQL
-- ✅ 正确写法:用括号圈出逻辑边界
select name from user
where (score > 60 and address = "翻斗花园")
OR (name like "王%" OR name like "李%");SQL 的真实执行顺序:
接着,我们来填一个上一节留下的坑。
在现实逻辑中,我们肯定是:先去仓库找到表格(FROM),然后用漏斗把不符合条件的人筛掉(WHERE),最后用剪刀剪下我们要的信息(SELECT)。
我们在写 SQL 语句时,WHERE 也是紧紧跟在 FROM 后面的。
它的真实执行顺序排在第二位:FROM -> WHERE -> SELECT。
也就是说,数据库在还没有决定用剪刀剪哪一列之前,就已经用 WHERE 漏斗把该淘汰的行全部淘汰掉了。这就叫底层的执行效率!
5. 隐形地雷:NULL 的致命陷阱
掌握了条件筛选,我们是不是能精准狙击任何数据了?直到有一天,老板让你查一个数据:"找出所有成绩不是 60 分的学生"。
你轻蔑一笑,敲下这行代码:
SQL
select name from user where score != 60;结果报表交上去,老板大发雷霆:"那几个缺考的人去哪了?他们难道考了 60 分吗?为什么不在名单里!"
你翻烂了代码也找不到 Bug。恭喜你,你踩中了 SQL 世界里最经典的隐形地雷:NULL(空值)。
很多小伙伴(包括当年的我)对 NULL 有一种极其致命的误解,认为 NULL 就是 0,或者就是啥也不填的"空格"。
大错特错!我们拿考试来做个比喻:
-
0:代表这人参加了考试,但是交了白卷,考了 0 分。 -
" "(空格):代表这人参加了考试,但在卷子上画了一个隐形的空格交上去了(空格在电脑里是一个实实在在的字符,占内存)。 -
NULL:代表这人根本没参加考试,连卷子都不存在!
SQL 独有的"三值逻辑"
现实世界的编程往往非黑即白:真(True)和假(False)。
但 SQL 的世界有第三种状态:不知道(Unknown)。
当我们用 where score != 60 去筛人时:
-
遇到考 80 分的人,数据库判断:80 != 60 成立(True)。漏斗放行。
-
遇到缺考(NULL)的人,数据库懵了。它会想:"这个人连成绩都没有,我不确定他是不是 60 分。" 于是给出结论:不知道(Unknown)。
请死死记住上一节的一句话:WHERE 漏斗极其冷血,它只放行明确为 True 的数据!
因为缺考的人得出的结论是"不知道",所以他们被数据库无情地、静默地抹杀了。
如何把这群"缺考"的人抓出来?
有小伙伴可能会耍小聪明:既然他们是 NULL,那我直接用等号抓不就行了?
SQL
-- ❌ 极其惨烈的错误示范
select name from user where score = null;写出这种代码,你这辈子都查不出任何数据。
因为 NULL 是"未知"。你去问数据库:"未知 等于 未知 吗?" 数据库的回答依然是:"不知道!"
在 SQL 里,想要抓捕 NULL,必须抛弃所有的数学符号(=, !=, >, <),使用数据库专门为它打造的雷达探测器:IS NULL 或者 IS NOT NULL。
SQL
-- ✅ 正确抓捕缺考人员的姿势
select name from user where score is null;
-- ✅ 抓捕所有正常考了试的人
select name from user where score is not null;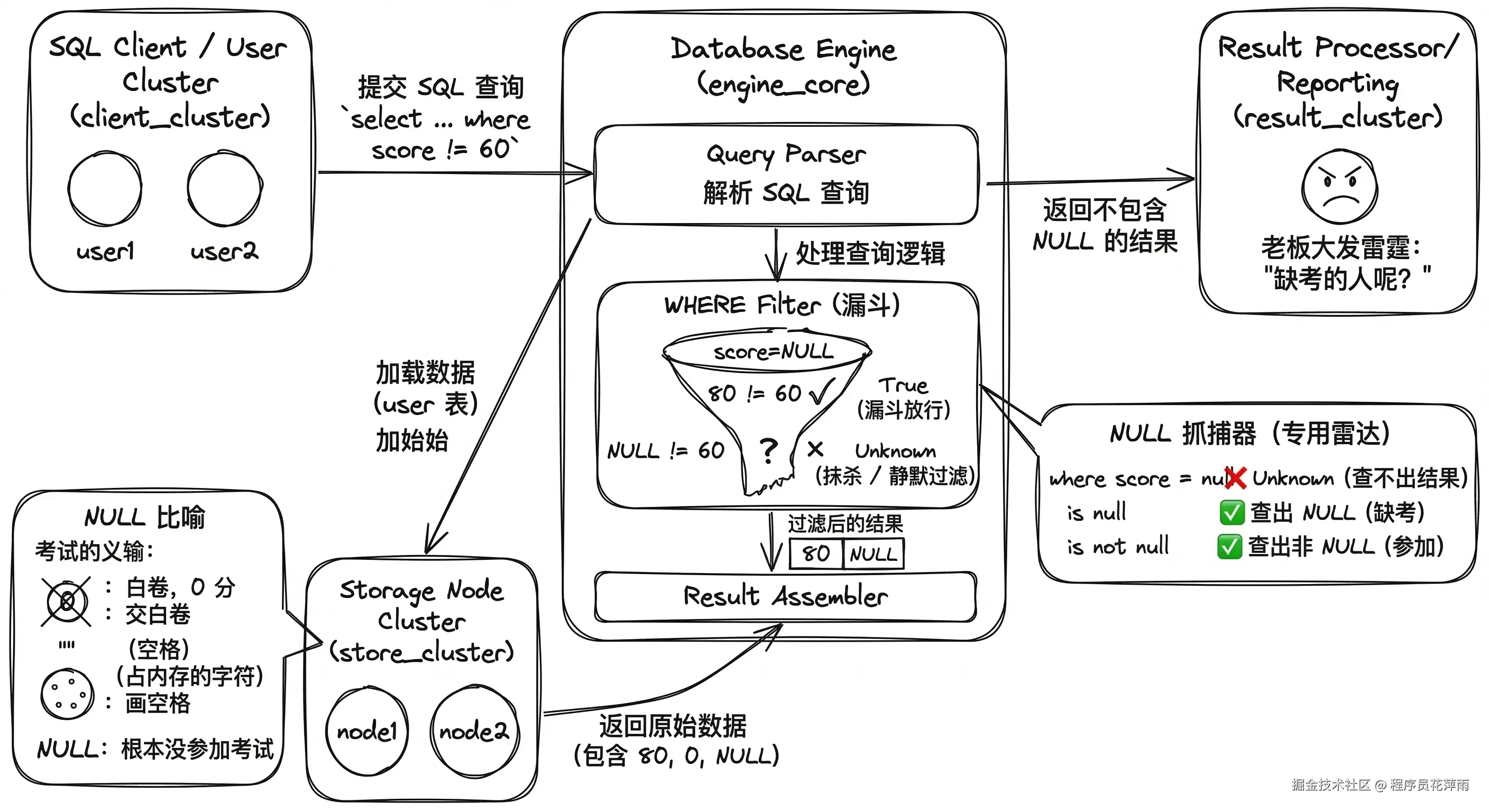
6. 最后
至此,我们的第一篇《数据捞取指南》正式合龙。回头看看,你已经不再是那个只会用 Excel 鼠标点点点,或者企图把海量数据塞进 Java 里的"麻瓜"了。
你拥有了三件底层兵器:
-
FROM:精准定位数据源的导航仪。 -
WHERE:极其严格的水平漏斗(千万当心AND/OR的优先级,以及NULL的暗杀)。 -
SELECT:自上而下的垂直剪刀。
用这三件兵器,你已经能从千万级的数据废料中,精准榨取任何你想要的信号。
**但不要高兴得太早。
我们捞出来的数据,依然是极其粗糙的"底层原石"。
如果产品经理提了一个变态要求:数据库里存的日期是 2026-03-14 12:39:00,但他在页面上非要只看 2026-03-14;数据库里存的状态是 1 和 2,但他非要你导出的时候直接变成"正常"和"封禁"。
难道我们又要绝望地把数据拉回后端代码里,去写成百上千行的 if-else 转换吗?
我是萍雨,我们下期再见ヾ( ̄▽ ̄)ByeBye~