相关性是搜索最基础最重要的信号,旨在衡量搜索结果与用户查询的匹配程度。传统判别式模型直接输出标签或分数,在复杂语义建模方面能力有限。推动相关性建模从判别式向生成式演进,并融入思维链(Chain-of-Thought)推理能力,已成为重要研究方向。

相关性是搜索最基础最重要的信号,旨在衡量搜索结果与用户查询的匹配程度。传统判别式模型直接输出标签或分数,在复杂语义建模方面能力有限。推动相关性建模从判别式向生成式演进,并融入思维链(Chain-of-Thought)推理能力,已成为重要研究方向。然而,现有方法大多依赖大量人工标注或合成的思维链数据进行监督微调,导致模型泛化能力不足,同时领域无关、自由形式的推理往往过于笼统,难以满足工业场景中复杂的业务标准。为解决上述问题,小红书搜索团队提出分段优势掩码策略(Stepwise Advantage Masking, SAM),在多步骤推理中引入轻量级过程监督,改进强化学习中的信用分配机制,从而提升模型对复杂业务相关性标准的理解与内化能力。该方法在业务实践中取得显著效果,相关研究成果已被 KDD 2026 录用。
01、背景
在当今互联网时代,搜索引擎已经成为人们获取信息的第一入口。无论是谷歌还是小红书,每天都有海量用户在搜索框中输入问题,希望得到最合适、最有价值的内容列表。然而,想要真正让用户满意,并不是把"最热门"的结果排在前面那么简单------核心挑战在于:什么才是"相关"的?系统怎样判断一条内容和用户的搜索意图是否真的匹配?
传统的搜索相关性模型大多是判别式模型,它们接收一个"查询 + 内容"的组合,然后输出一个分数或概率,表示两者是否相关。这类模型虽然运行稳定,但有两个长期痛点:(1)像黑盒一样,不解释理由:模型给出"相关/不相关",却无法说明为什么,导致搜索业务同学也难以判断模型犯错的原因;(2)理解能力有限:用户搜索意图越来越复杂,仅靠单一分值,很难捕捉语义细节,比如隐含需求、场景差异、跨概念关联等。
随着大语言模型(Large Language Models,LLMs)的快速发展,搜索行业开始尝试一种全新的相关性建模方式 ------ 生成式相关性模型(Generative Relevance Models, GRMs)。与传统只输出一个数字的模型不同,GRMs 会像人一样"解释过程":先分析,再推理,然后再给结论,使搜索排序不仅更准确,也更可解释。

一个实例说明了显式推理增强了相关性评估的可解释性和有效性。对于查询"为什么植物需要光来生长?",基于推理的模型利用与光合作用相关内容识别出部分相关性,而没有推理的模型则无法识别这种联系。
但目前行业方案仍面临两大瓶颈:(1)大多数方法依赖人工或其他模型合成的推理数据,成本极高且最终模型泛化性不足;(2)开域搜索语义复杂、意图多变,仅靠通用推理很难稳定泛化,尤其是小红书这种开放内容生态中,用户搜索话题覆盖生活、商品、问答、知识等多维场景,推理逻辑如果没有领域规则指引,往往会"想太多或者想错方向",和业务团队的预期相差较远。
02、方法
针对以上挑战,我们提出了一种在小红书搜索中生成式相关性建模新范式:基于强化学习的生成式推理相关性建模框架。
核心思想是 ------ 让模型像人类评审员一样遵循规则、循序推理,而不是一上来拍脑袋给答案。
整个方案有两个关键设计:
2.1 将相关性建模转化为基于相关性标准的分步推理任务
模型不再直接输出标签,而是通过类似 Chain-of-Thought 的方式进行多步推理。我们直接接入:
- 小红书内部专家制定通用的相关性标准
- 针对模糊场景的细则
这些规则就像"行业版数学公理",让模型不再盲猜,而是**带着业务知识思考。**这也是我们能在开放领域搜索中取得显著提升的关键原因。

总的来说共分为三大步:
- **通用语义理解:**查询与内容是否同类目、同主题、关键词是否有命中、核心内容占比是否足够多、通用的相关性打分是多少
- **规则约束:**是否触发业务发展所积累的特殊case(如多实体对比、问答等特殊场景)
- **结果反思:**依据前两步综合得出最终等级(共 5 档分级)
这样,模型输出的不仅是一个无法解释的相关性档位,而是一条有解释、有逻辑、有依据的推理链。
2.2 Stepwise Advantage Masking(SAM):让 RL 真正学会"思考相关性"
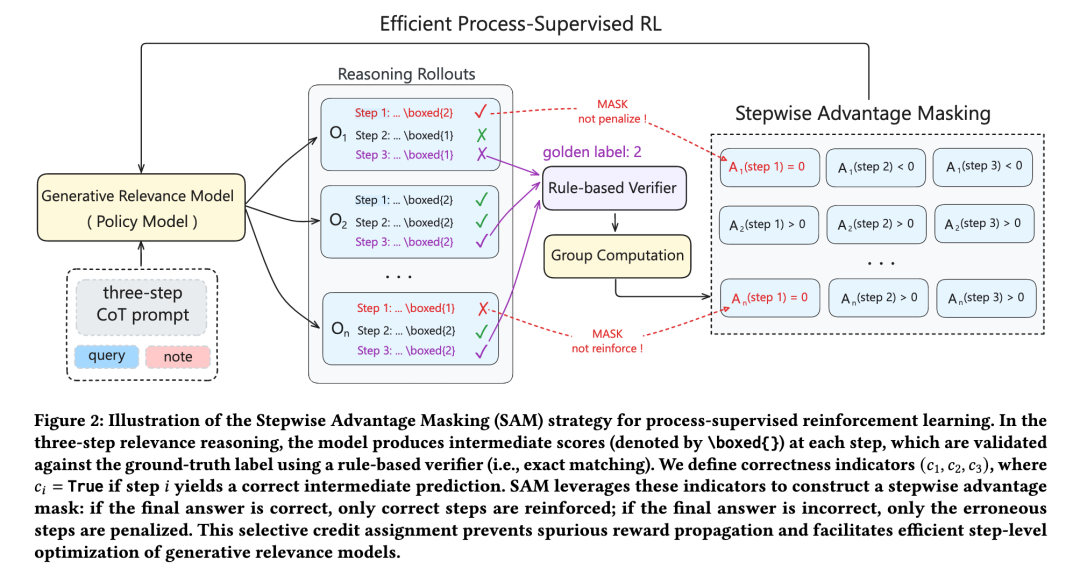
传统强化学习做相关性任务只看最终结果对不对,但在推理任务中:
- 最终答案错,不代表前面每步都错;
- 最终答案对,也可能是瞎蒙的。
SAM 的贡献就在于解决这一痛点:
- 在推理链每一步让模型给出中间分数;
- 自动比对每一步是否正确;
- 只奖励正确的推理步骤,只惩罚真正有问题的步骤。
这让模型能够:
- 学到可复用的推理逻辑;
- 避免错误逻辑被强化;
- 过程监督的训练效率远高于人工训练过程监督模型或在线价值估计;
一句话总结:SAM 让强化学习从"只看结果"变为"理解过程"

总的来说,我们的工作首次在小红书搜索中验证了一条可规模化落地的新路径:用 RL 驱动生成式相关性判断,通过规则引导推理链,并利用 SAM 精准分配奖励信号。
03、实验结果与分析
3.1 离线指标
为了全面地衡量线上分布,我们使用了两个基准数据集:RANDOM (随机分布)和 LONGTAIL(长尾分布),每个数据集包含 15000 个 人工标注的 查询-笔记对。
3.1.1 推理机制对监督微调(SFT)有益还是有害?
实验设置:
基于相同SFT初始化模型,在固定数据、提示和奖励定义下,在SFT范式下,对比不同数据类型(w/wo reasoning)差异。
监督基线模型对比:
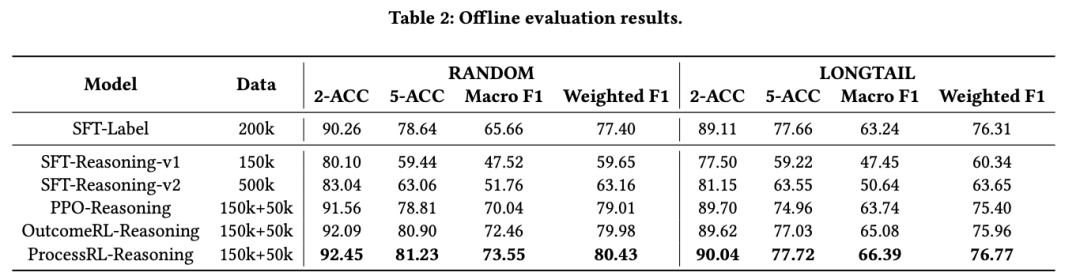
- SFT-Label(标签监督模型) 使用20万条纯标签数据训练,在RANDOM数据集上的2-ACC/5-ACC达90.26/78.64,在LONGTAIL数据集上达89.11/77.66,确立强基准性能。
- 监督推理模型SFT-Reasoning v1: 15万条思维链(CoT)数据训练RANDOM:80.10/59.44LONGTAIL:77.50/59.22SFT-Reasoning v2: 50万条CoT数据训练(数据量提升3.3倍)RANDOM:83.04/63.06LONGTAIL:81.15/63.55**关键发现:**即使增加3.3倍训练数据,推理模型性能仍显著落后于纯标签模型(RANDOM数据集差距>7%)
**结论:**直接引入多步推理链进行监督训练非但未提升效果,反而导致性能下降,这说明"多步推理并不能天然提升排序质量"。我们考虑,相较于纯优化 label 的 sft 方式,没有额外优化的带思维链的建模方式,由于其优化目标的增多,故而会导致指标天然不如前者。
3.1.2 过程监督强化学习能否真正增强相关性推理?
基于上述发现,我们认为引入强化学习(RL)对思维轨迹进行额外的筛选优化是十分必要的
实验设置:
基于相同SFT初始化模型,在固定数据、提示和奖励定义下,对比三种RL变体(PPO、OutcomeRL、ProcessRL),聚焦信用分配机制差异。
核心发现:
1. PPO-Reasoning:
- 在SFT基础上采用PPO进行训练,依赖价值函数估计进行信用分配。优点是相对SFT有提升;缺点是价值估计偏差与不稳定的信用分配,难以充分利用推理结构,性能仅在random测试集上优于基线。
2. OutcomeRL-Reasoning:
- 采用组级奖励归一化(归因到整条轨迹),避免价值估计误差并稳定策略优化。优点是整体性能优于PPO;局限是对轨迹中所有token均匀分配优势,无法区分各步对最终决策的真实贡献。
- 性能:RANDOM(80.90 5-ACC)、LONGTAIL(77.03 5-ACC),多数指标超越PPO
- 局限:轨迹内均匀分配奖励,忽略步骤贡献。
3. ProcessRL-Reasoning(SAM机制):
- 该机制进行分步信用分配,将奖励更精确地归因到关键推理步骤,缓解虚假奖励传播,改善过程层面的学习信号质量。
- 综合性能最优:
RANDOM:81.23 5-ACC / 73.55 Macro F1
LONGTAIL:77.72 5-ACC / 66.39 Macro F1 - 显著提升稳健性与泛化能力(Macro F1指标)
结论:
- 分步信用分配(SAM)较均匀分配(OutcomeRL)带来持续增益,尤其在复杂场景(LONGTAIL)。
- 信用分配机制是优化推理模型的关键因素,SAM机制实现最均衡的性能提升。
3.2 在线指标
teacher model 效果蒸馏到一个轻量级的 0.1B BERT 模型中进行在线实验
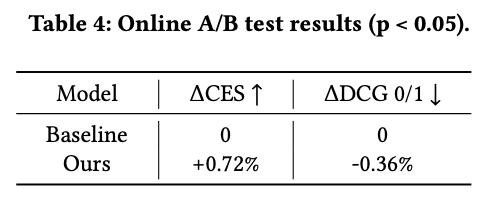
我们做了为期7天的线上实验,在用户互动 与检索结果相关性 两方面均取得了显著且可量化的双重提升。结果证明了方案的有效性。
04、未来展望
我们的长期目标是一次性训练模型,使业务团队能够在提示词中动态更新准则,从而让模型适应不断演变的业务逻辑。
我们将这一概念称为"Instruction Relevance-LLM"。该模型能够通过利用一套持续更新的规则来适应变化的业务需求。然而,实验结果显示,当前经强化学习(RL)微调的模型对训练期间使用的固定规则集发生了过拟合。当在推理阶段修改规则时,模型仍倾向于基于训练中学到的原始逻辑进行推理。我们推测,这种现象的原因在于RL训练期间的准则体系是静态的,模型未曾接触到动态的规则变化。未来工作将重点在训练过程中引入动态准则的变化,以提升鲁棒性并降低过拟合,确保模型在推理阶段能更有效地处理准则修改。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量