本文要介绍的是 VLDB'25 论文《From Scale-Up to Scale-Out: PolarDB's Journey to Achieving 2 Billion tpmC》。阿里云 PolarDB 今年登顶 TPC-C 基准测试,以 20.55 亿 tpmC 的成绩刷新世界记录,该论文主要介绍了 PolarDB 达成这一成绩所做的一些关键优化。
前言
在过去十年里,基于高扩展性和低成本的考虑,越来越多的应用选择迁移上云,而作为核心组件的数据库当然也必须跟上(OLTP上云,哪种架构最划算?·VLDB'25)。
阿里云 PolarDB 就是一款云原生数据库,基于存算分离架构,以 PolarFS 分布式文件系统作为后端存储,计算节点无状态弹性扩缩容,提供高扩展性、低成本的能力。

最开始,PolarDB 是单主架构,可以扩展多个只读从节点,但只能有一个读写主节点。这能够避免分布式事务,极大简化系统架构。
然而,对于写密集型业务,主节点很容易成为性能瓶颈。
我们很容易想到通过 Scale-up 的方式,把主节点部署在 CPU 核数更多的机器上,提升写性能。
但受限于工艺、散热、成本等原因,CPU 核数无法一直扩展下去(为什么CPU不能有更多的核?)。
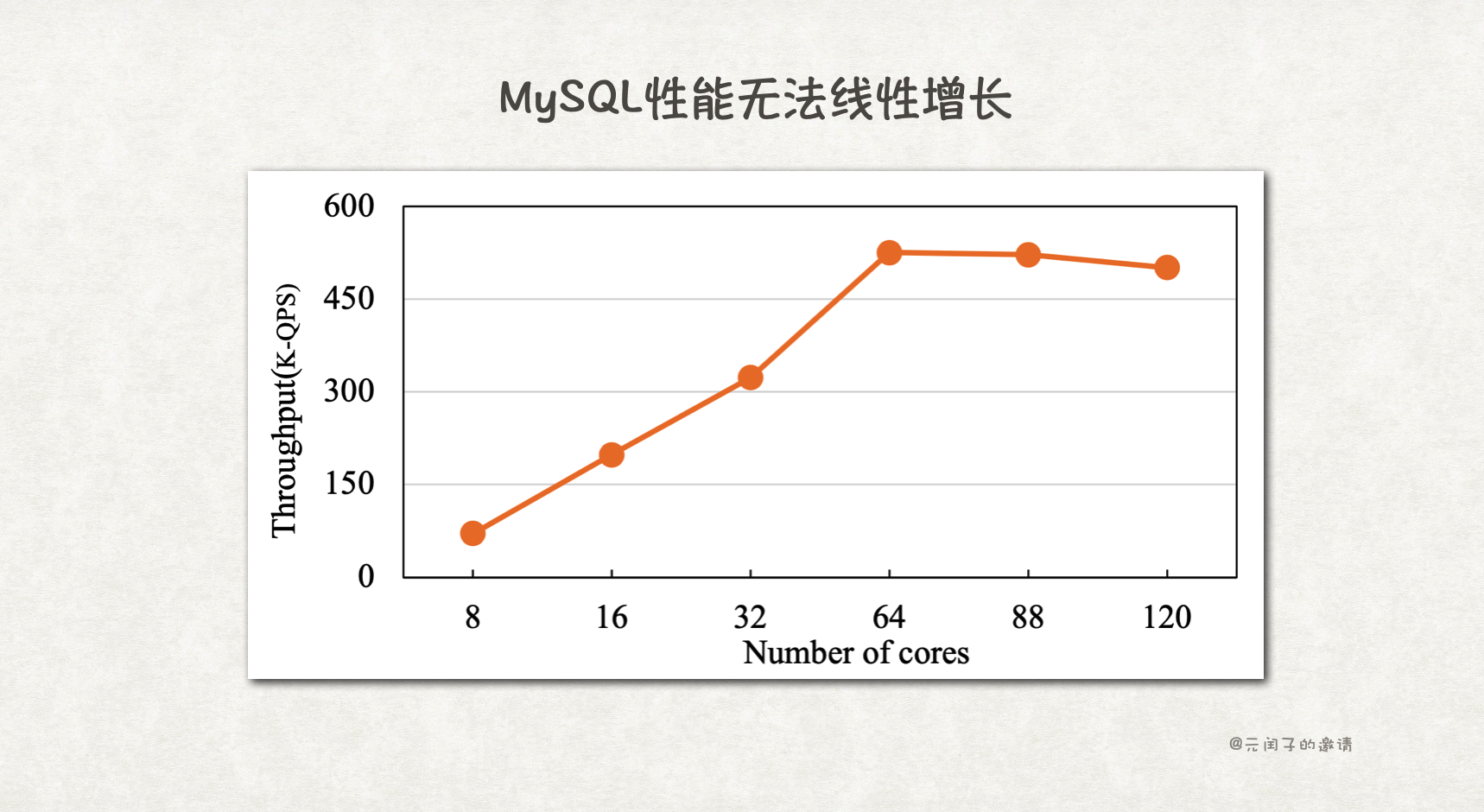
而且,更多的核也并不意味着更高的性能,传统数据库的 B+ Tree、MVCC 等机制实现,并发冲突严重,限制了性能的线性增长。比如 MySQL 在扩展至 64 核后,性能不升反降。
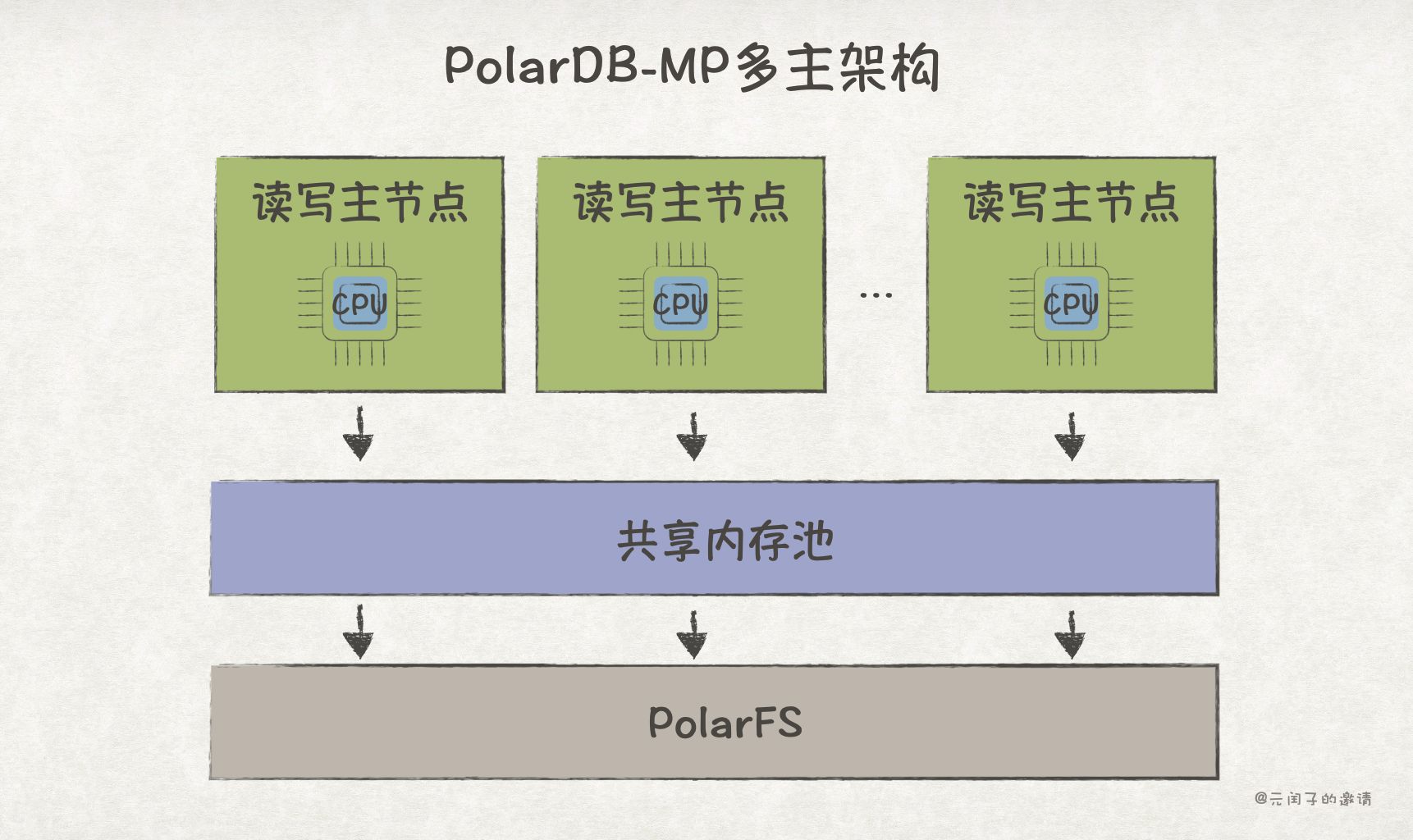
突破主节点瓶颈的另一种方法是,将数据库改造成多主架构,能够有多个读写节点。
实现多主架构的主流方法有两种:1)共享内存,走 Shared-Everthing 路线;2)数据分片,走 Shared-Nothing 路线。
PolarDB-MP 采用共享内存架构,在存算分离的基础上,把内存从计算节点中分离出来,各计算节点共享同一份内存。因此可以避免分布式事务带来的复杂性和网络通信损耗。
但把本地内存访问变成跨节点的远端内存访问,性能损耗很大。本地访存时延大概在百纳秒级别,而传统 TCP/IP 网络通信,即使不考虑传输,时延也在百微秒级别,足足差了 3 个数量级(怎么让程序更高效地连起来?)。
为此,PolarDB-MP 采用了性能更好的 RDMA 通信,更近一步的优化,就是不久前在 SIGMOD'25 发表的基于 CXL 实现的 PolarCXLMem 了(怎么用 CXL 加速数据库?· SIGMOD'25)。
目前,受限于分离内存的硬件限制,PolarDB-MP 很难扩展至百节点以上。
如果业务需要一个上百、甚至上千节点的超大规模数据库,目前最可行的仍是基于数据分片的分布式数据库架构。
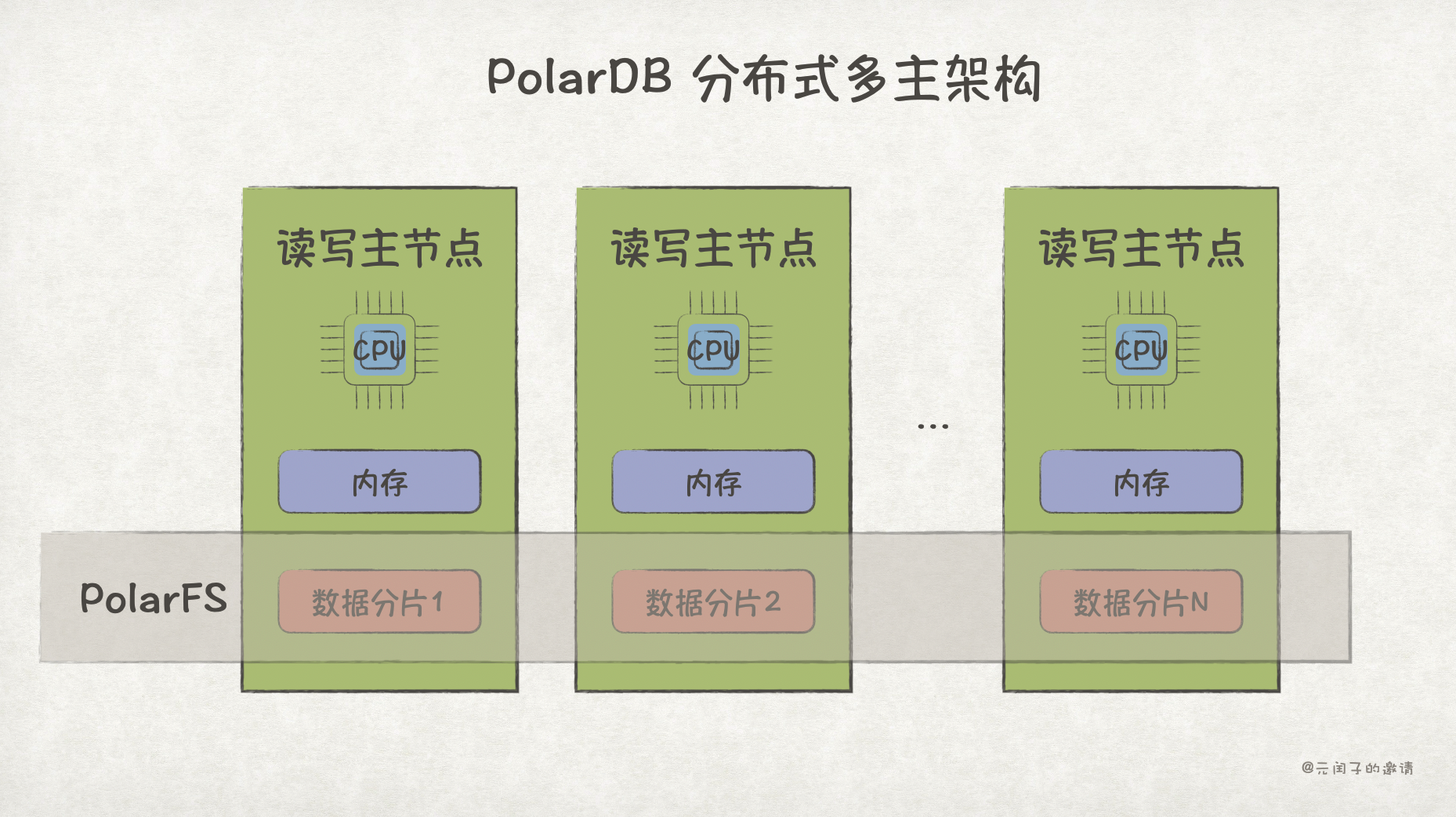
虽然可以优化数据分片方式,让业务尽可能地减少跨分片数据争用,但对分布式数据库来说,分布式事务是绕不开的。
分布式事务的性能瓶颈,很大程度来源于两阶段提交(2PC)流程,传统基于 TCP/IP 通信的 2PC 协议,无疑雪上加霜。
针对上述问题,PolarDB 通过 PolarIndex、PolarTrans、Polar2PC 几个关键优化,交出了 20.55 亿 tpmC 的成绩,刷新了 TPC-C 基准测试的世界记录。
优化一:PolarIndex
B+ Tree 被广泛应用于数据库索引,比如 MySQL,以及以 MySQL 为基础的 PolarDB。
B+ Tree 每个节点的 Key 数量是固定的,当插入数据导致节点 Key 的数量超出上限时,就会引发节点分裂,即 SMO(Structural Modification Operation)。
如果不加以保护,SMO 很容易引发并发问题,如下所示:

线程1 要查询 15,线程2 要插入 9,它们都发生在 P1 页中。假设 线程2 先插入,并引发了 SMO,导致 15 被分裂到 P2 页中;线程 1 随后将会在 P1 中查找不到 15。
防止 SMO 并发问题最简单的方式是,发生 SMO 时:
- 先对全局 B+ Tree index 加 X latch 写锁,确保没有其他线程读写。
- 从 root page 开始,沿途不加锁的方式遍历到 leaf page。
- 对 leaf page 及其左右兄弟节点加 X latch 写锁,对 leaf page 进行分裂。
- 对 parent page 加 X latch 写锁,新增指向新 page 的指针。
- 释放所有锁,结束 SMO。
这就是 MySQL 5.6 的做法。

这个方案会使得 SMO 过程,无法对其他 page 进行读写,即使这个 page 不再 SMO 范围内。
对此,MySQL 5.7 和 8.0 进行了优化,对 index 的加锁从 X latch 改成了 SX latch,SMO 过程允许读线程并发。
因为读线程在自顶向下 遍历时,会沿途加 S latch。而 MySQL 5.6 方案中 SMO 线程会自底向上 加 X latch。容易形成死锁。
所以,还需要让 SMO 线程的加锁顺序改成自顶向下,流程变成这样:

虽然 MySQL 5.7/8.0 的方案允许了 SMO 线程与读线程并发,但 SMO 之间仍不支持并发,写密集场景锁冲突严重。
观察上述流程可发现:
- 每次 SMO 只会涉及少量 page,原则上没有必要对整个 index 加锁。
- 另外,leaf page 分裂过程中,也没有必要对 parent page 加锁。加锁只是为了避免死锁。
那么,有没有更近一步的优化方案呢?
针对上述两个问题,PolarDB 给出了他们的答案:PolarIndex。
首先,PolarIndex 取消了 index latch。
其次,PolarIndex 将一个 page 的 SMO 过程拆分成两个阶段,以 P1 分裂为例:
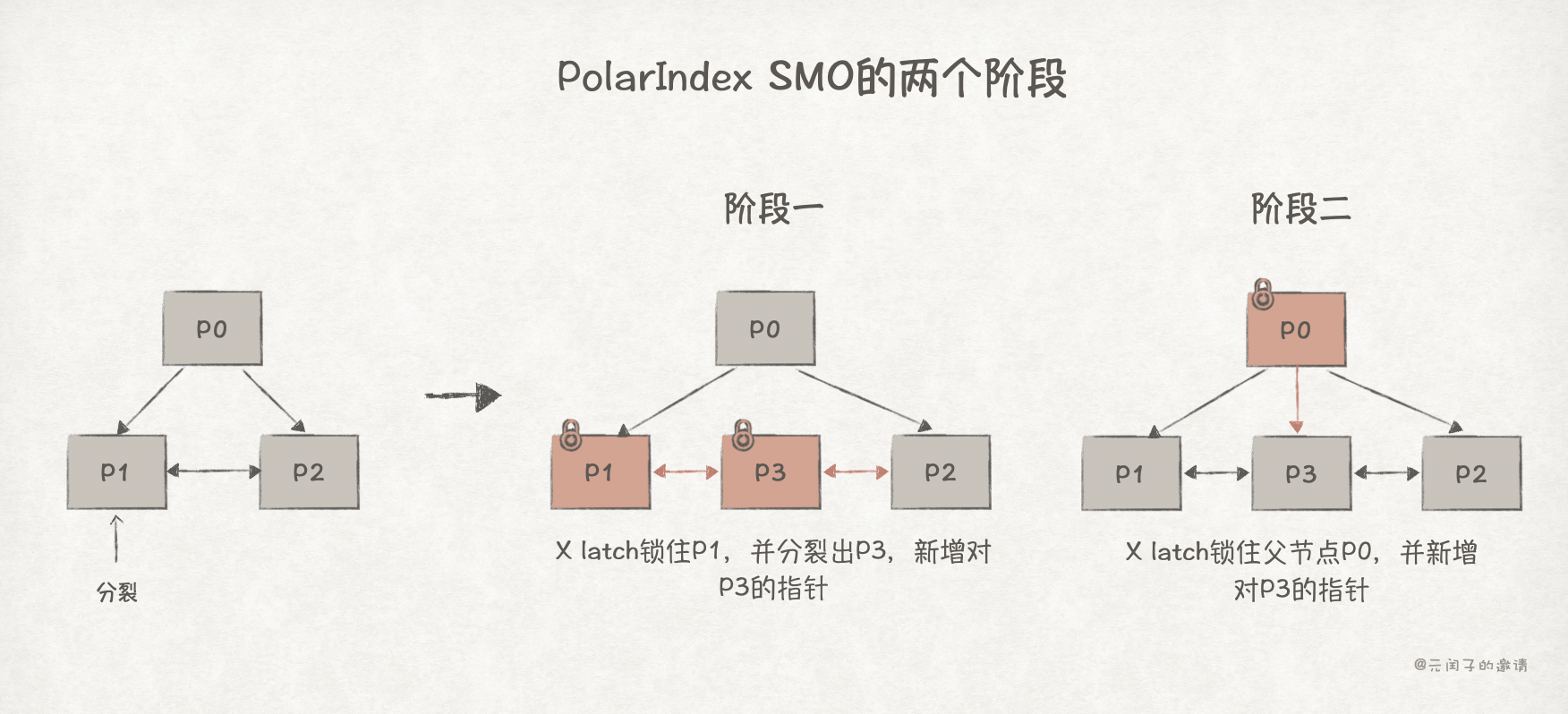
阶段一只对叶子节点 P1 和 P3 加锁,分裂结束后释放锁;阶段二只对父节点 P0 加锁,新增指向 P3 的指针后释放锁。
而在阶段一和阶段二之间的中间状态下,就可能出现并发读,从而导致前文所述数据不一致的问题。
对此,PolarIndex 参考了 B-Link Tree 的方法,当读线程在 P1 中找不到数据时,说明该节点出现了分裂,只需继续往右再 P3 中查询即可。

PolarIndex 通过设计更细粒度的锁,以及更短的锁持有时间,减缓了 PolarDB 的锁冲突问题,实现吞吐量的提升和时延的降低。

优化二:PolarTrans
MySQL 事务管理的核心是 trx_sys_t 数据结构,所有事务的开始、提交、回滚都需要经过它,它是全局唯一的单例。
trx_sys_t 的 3 个重要属性为:
rw_trx_ids: 保存当前活跃的事务 ID,是一个数组。next_trx_id_or_no: 用于申请事务 ID,是一个原子变量。mutex: 互斥锁,在事务流程中多处被使用。
下图为一个简单的事务流程:

事务启动时会从 next_trx_id_or_no 申请 trx_id,并追加到 rw_trx_ids。
当需要一致性读时,会在 trx_sys_t->mutex 的保护下创建一个 MVCC 读快照 read_view_t,关键属性如下:
m_ids: 复制rw_trx_ids得到。m_creator_trx_id: 当前事务的trx_id。m_up_limit_id: 当trx_id小于该值时,表示是当前事务开始之前创建的事务,而且已经提交,数据修改可见。m_low_limit_id: 当trx_id大于等于该值时,表示是当前事务开始之后创建的事务,数据修改不可见。
当 trx_id 落在 m_up_limit_id 和 m_low_limit_id 之间时,如果 trx_id 仍在 m_ids 里,表示事务活跃,数据修改不可见;否则数据修改可见。
另外,事务提交结束后,需要在 trx_sys_t->mutex 的保护下遍历 m_ids,删除当前事务。
可以看到,trx_sys_t->mutex 会被频繁调用到,容易成为性能瓶颈点。
针对该瓶颈,PolarTrans 做了如下优化:
- 使用基于 RingBuffer 实现的 TIT(Transaction Information Table)替代数组实现的
rw_trx_ids用作活跃事务的管理。TIT 的每个槽位 slot 保存指向事务对象的 trx pointer 和事务的提交时间戳 CTS(Commit Timestamp),而且可以做到无锁更新。 trx_id只用作寻找 TIT 中的 slot,比如基于哈希取模的方式。- 使用基于 Lamport timestamp 实现的 CTS 替代
trx_id用作判断数据修改的可见性。 - read view 不再需要拷贝
rw_trx_ids数组,仅需拷贝CTS_max_committed变量即可。 - 使用后台清理线程释放事务资源,避免事务提交后仍需遍历
rw_trx_ids。
如下为 PolarTrans 一个简单的事务流程:
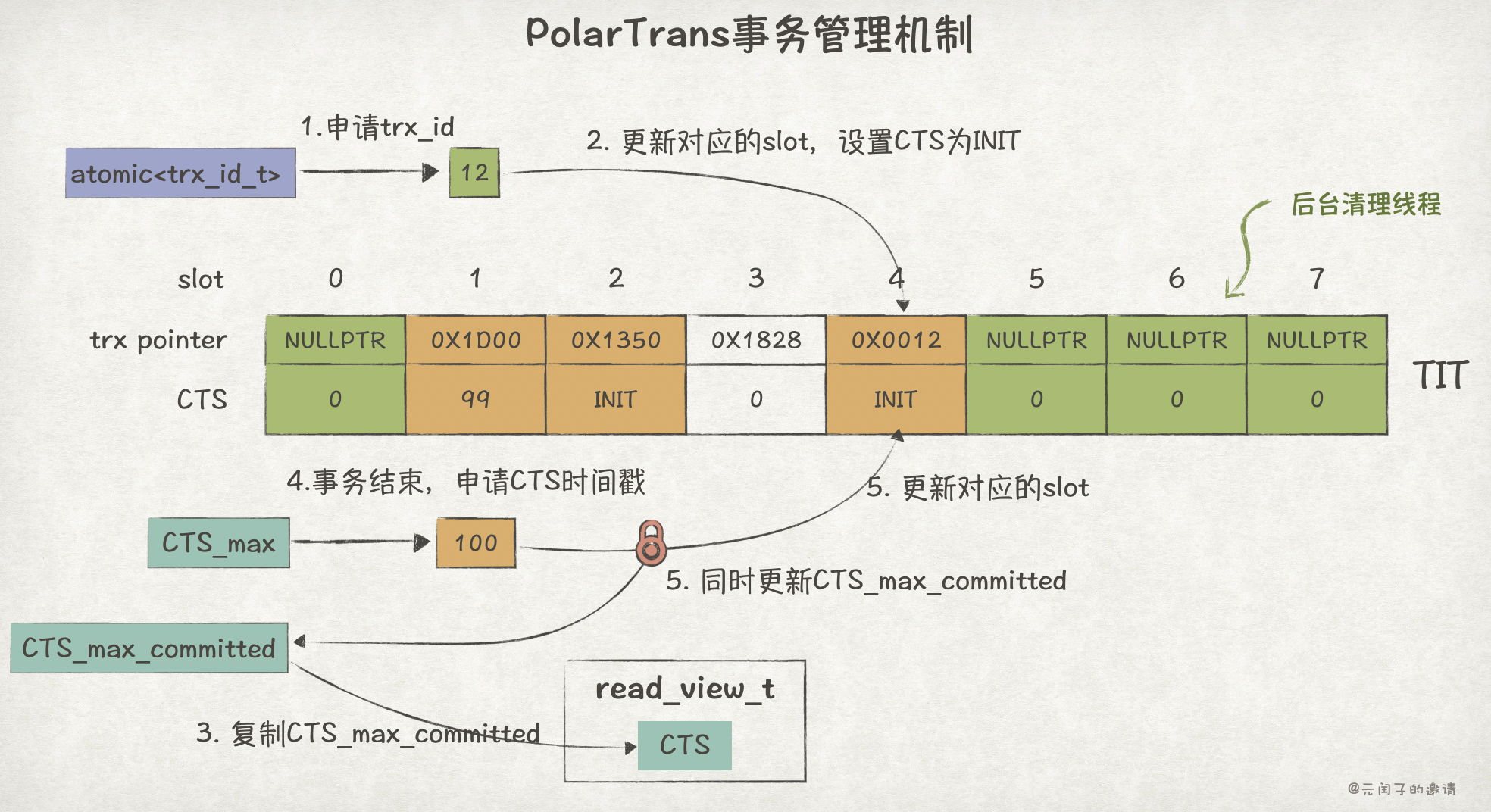
事务开启时,申请 trx_id,找到对应的 slot,无锁更新,设置 CTS 为 INIT。
CTS_max 的作用类似于 next_trx_id_or_no,用于分配 CTS,会一直递增;CTS_max_committed 表示最新提交事务的 CTS。
事务结束后,从 CTS_max 全局变量中申请 CTS,同时更新 TIT 和 CTS_max_committed ,这一步需要加锁保证原子性。
针对某条记录修改可见性的判断,会根据该记录最后修改事务的 trx_id1 在 TIT 中对应的 slot:
- 如果该 slot 已经被新的事务覆盖了,表示该事务已提交,可见。
- 如果事务人在 slot 中,且 CTS 为 INIT,表示事务仍处于活跃状态,不可见。
- 如果 CTS 小于等于读快照中的
CTS_max_committed,表示在本事务开始前已提交,可见;否则,不可见。
后台清理线程释放事务资源时,会检查当前所有活跃的 read view 中最小的 CTS,假设为 CTS_min,如果 TIT 中的事务 CTS 小于 CTS_min,表示该事务的修改对所有事物均可见,可以被释放了。
然而,这可能会导致这样的情况,某个事物长时间未结束,导致 TIT slot 无法被回收,新事务被阻塞的问题,如下:

针对该问题,PolarTrans 会将长事务的 slot 卸载到一个 Hash Table 中,避免阻塞 TIT 的回收。当然,此时可见性判断和后台清理线程都需要遍历 Hash Table,会带来一定的性能影响。
不过,出现长事务的情况比较少,Hash Table 大部分时间都是空的,所以影响不大。
通过减少事务锁竞争、简化可见性判断逻辑,PolarTrans 在不同的场景带来了 26.47%--50.0% 的吞吐量提升,21.3%--33.2% 的平均时延降低。

优化三:Polar2PC
PolarIndex 和 PolarTrans 都属于 Scale-up 的优化,下面即将介绍的 Polar2PC 属于 Scale-up 的优化。
2PC(Two-Phase Commit,两阶段提交协议) 是一种在分布式事务中保证多个参与节点原子提交/回滚的协议。
它将数据库节点分成了负责发起和协调整个事务提交过程的协调节点 CN ,和多个实际执行本地事务的参与节点 PN。
- Prepare 阶段 :CN 向所有 PN 发起
PREPARE请求,PN 确认本地满足提交条件后,返回YES,否则NO。 - Commit 阶段 :如果 Prepare 阶段所有 PN 返回
YES,则发起COMMIT请求,各 PN 执行本地事务提交,并应答ACK;如果在 Prepare 阶段有 PN 返回NO,则发起ROLLBACK请求,各 PN执行本地事务回滚,并应答ACK。

2PC 性能开销大,一方面是相比单机事务多了一个 Prepare 阶段;另一方面,多次的 TCP/IP 往返通信容易成为瓶颈。
针对该问题,Polar2PC 基于 RDMA 通信协议重新设计了 2PC 流程。
RDMA(Remote Direct Memory Access),远程直接内存访问,是一种能够绕过 CPU 和操作系统内核的通信技术。它支持单边内存读写操作,也就是在不需要远端节点 CPU 参与的情况下,完成对远端节点内存的读写。RDMA 可以达到微妙级的时延,对比 TCP/IP 的百微秒级时延性能提升巨大。
Polar2PC 的流程如下:
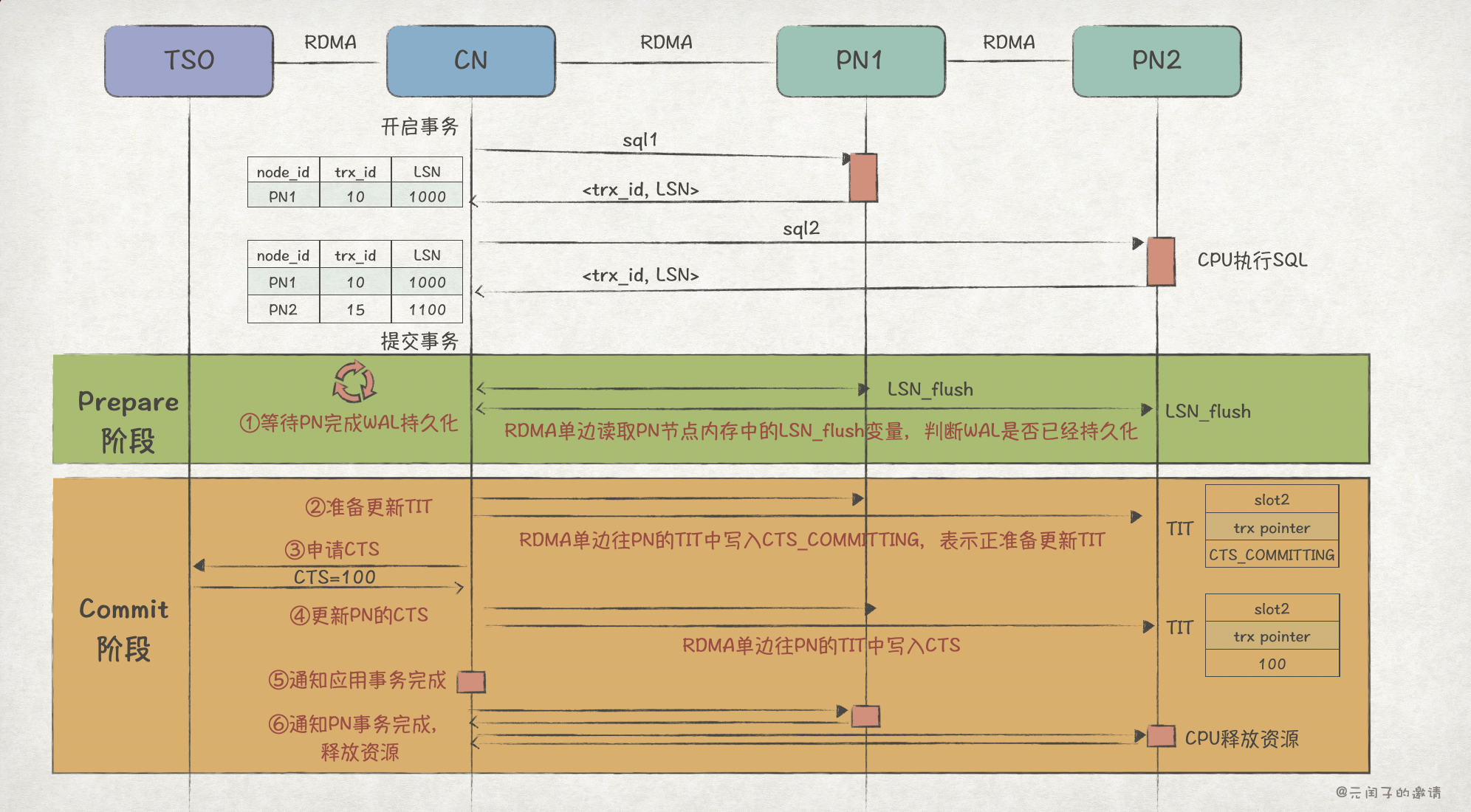
在执行 SQL 阶段,PN 节点会返回 <trx_id, LSN> 给 CN 节点,后者在本地维护一份全局的 <node_id, trx_id, LSN> 数据,在后面事务提交时会有用到。
Polar2PC 也分成 Prepare 阶段和 Commit 阶段,但有所不同。
① Prepare 阶段,Polar2PC 会默认 PN 已经具备提交事务的条件,所以只需等待 PN 完成 WAL 日志持久化后,即可进入 Commit 阶段 。PN 本地内存中 LSN_flush 变量表示当前已持久化的最大 LSN 值,CN 通过单边 RDMA 读取 PN 的 LSN_flush,并与本地保存的 <node_id, trx_id, LSN> 中 LSN 对比。当 LSN_flush > LSN 时,表示 WAL 日志已完成持久化。
接下来,进入 Commit 阶段。
② 准备更新 TIT,因为 CN 无法保证在同一时刻更新所有 PN 的 TIT 的 CTS 值,为避免出现数据不一致的情况,CN 会先将 CTS_COMMITTING 写入 PN 的 TIT 表。如果 PN 发现 TIT 中某个事务的 CTS 值为 CTS_COMMITTING,会重复读取,直到 CTS 刷新。
③ 申请 CTS,会有一个专门的 TSO(timestamp oracle)节点用于生成 CTS,CN 节点从 TSO 得到 CTS 值。
④ CN 通过 RDMA 单边操作更新 PN 的 TIT 的 CTS 值。
⑤ 到这里,可以认为事务已完成,CN 通知应用。
⑥ 最后再通知 PN 节点事务已完成,让它们释放资源。
Polar2PC 充分发挥了 RDMA 单边操作的优势,PN 节点在 Prepare 和 Commit 阶段大部分时间都不需要 CPU 介入,只在最后释放资源消耗了 CPU。
可以看到,RDMA 不仅时延更低,而且降低了 PN 节点的 CPU 开销,从而带来了吞吐量的提升。
最后
通过 Scale-up 和 Scale-out 的优化,PolarDB 扩展了 2340 个节点(48vCPU512GB),最终达成了 20.55 亿 tpmC 的 TPC-C 打榜第一的成绩,并且在性价比上也取得了 37% 以上的领先。

不过,分布式 PolarDB 不见得在真实业务场景能达到如此高的性能。
论文里提到,TPC-C 数据集已经过良好的数据分片,所以跨分片事务很少,这无疑放大了分布式架构的优势。
另外,2340 节点这种超大规模的数据库集群,真实业务中,很少见。
所以,在大部分场景下,内存分离共享的多主架构可能是更好的选择。
这可能也是 PolarDB 在今年大力推广基于 CXL 实现的共享内存架构的原因?
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
1 From Scale-Up to Scale-Out: PolarDB's Journey to Achieving 2 Billion tpmC, PolarDB
2 路在脚下, 从BTree 到Polar Index, 陈宗志
3 InnoDB btree latch 优化历程, 陈宗志
4 PolarDB MySQL · PolarTrans事务系统介绍(一), 华洛
5 MySQL · 引擎特性 · InnoDB MVCC 相关实现, mianren
(完)