想给影视片段换配音却担心口型对不上?数字人直播几小时后就出现 "脸崩""身份漂移"?遮挡场景下编辑口型直接效果崩溃?这些长期困扰 AI 影视创作、数字人应用的口型编辑痛点,终于被可灵团队的 OmniSync 技术攻克啦!
作为视频生成领域的核心刚需,口型编辑(输入视频 + 目标音频,输出口型精准匹配的新视频)在内容创作、虚拟直播、影视后期等场景中应用广泛。尽管 DiT 等视频生成技术推动口型效果不断进步,但三个核心痛点始终难以突破:口型与原视频纹理的耦合干扰、复杂场景下的身份(ID)保持难题、长时长推理的稳定性不足。
快手可灵团队提出OmniSync,凭借无 mask 训练范式、流匹配推理策略和动态时空 CFG 技术,实现了 "无限时长、强 ID 保持、遮挡鲁棒" 的三重突破,重新定义了视频口型编辑的行业标准。该研究成果入选NeurIPS 2025 Spotlight,成果均分排名第三。

🔮 论文标题 :
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
📖 论文地址 :https://arxiv.org/pdf/2505.21448
📝 项目主页 :https://ziqiaopeng.github.io/OmniSync/
一、行业痛点:传统口型编辑的三大 "致命伤"
-
口型和底板视频耦合难题:原视频的说话状态会带动口型、面部表情、脖子纹理、下巴阴影等一系列联动反应,这种深度耦合让音频驱动的口型编辑效果大打折扣。传统 "遮挡嘴部 mask" 方案只能勉强缓解,无法从根本上解耦。
-
复杂场景下的id保持:为了解耦而遮挡下半张脸的 mask 方案,会同时丢失人物身份信息。即便通过额外路径注入 ID,在人脸角度大幅变化、出现遮挡时,仍会出现 "认不出人" 的效果崩溃。
-
长时长推理:mask方案本质上就是mask区域能视频的可控生成,长时长推理中极易出现id漂移,通常只能保证几十秒内有效,无法满足电影剪辑、超长直播等场景需求。
二、OmniSync技术创新
针对上面的痛点问题,OmniSync的方法引入了一种无mask训练推理范式,使用dit进行直接帧编辑,无需显式掩模,彻底解耦口型和底板,实现 SOTA的口型效果的同时实现了无限持续时间的推理。id方面支持大幅度的角度变化、遮挡,甚至支持动态id(例如底板视频上有动态特效)。
2.1 通用的唇形同步框架
OmniSync创新地提出一个基于扩散 Transformer(DiT)通用的唇形同步框架,消除了对参考帧和显式mask的依赖,彻底解耦id和口型,实现了跨不同视觉表示的准确语音同步。
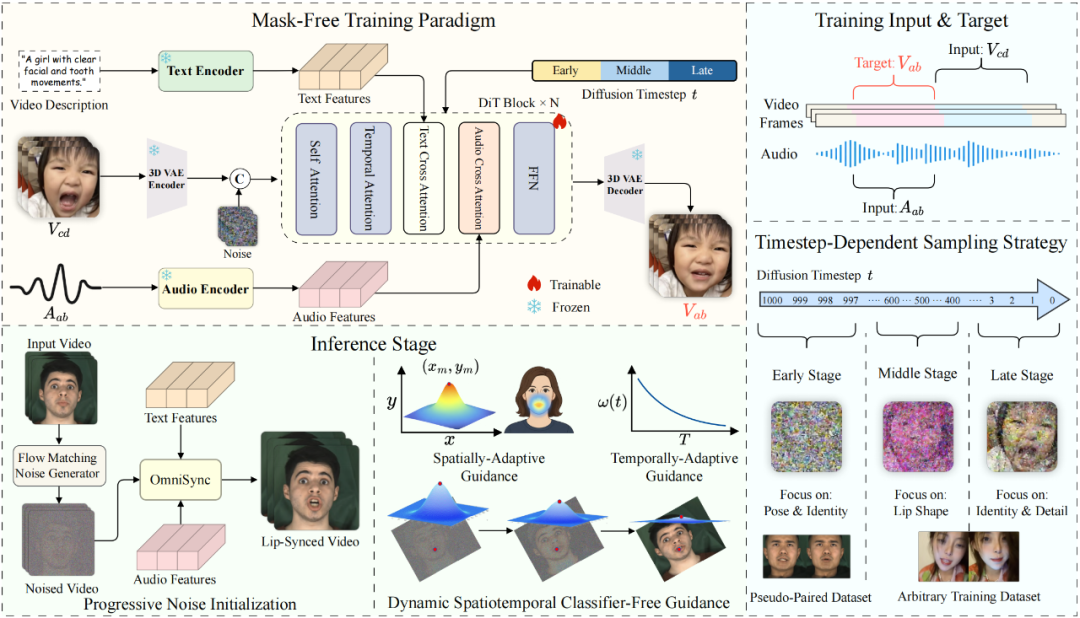
其核心逻辑是让训练中模型学习映射函数(Vcd,Aab)→ Vab,其中 V 代表视频帧,A 代表音频,索引(a:b,c:d)代表从同一视频中采样的不同片段,仅根据目标音频修改与语音相关的区域,无需显式掩码或参考帧。
这种训练方式类似图像到视频(i2v)的生成逻辑:(I,Aab)→ Vab。原视频(Vcd)仅提供人物身份(ID)信息,口型完全由目标音频(Aab)驱动,从根源上实现了 ID 与口型的彻底解耦,既保证了口型精准度,又完整保留了原视频的面部纹理、姿态特征。
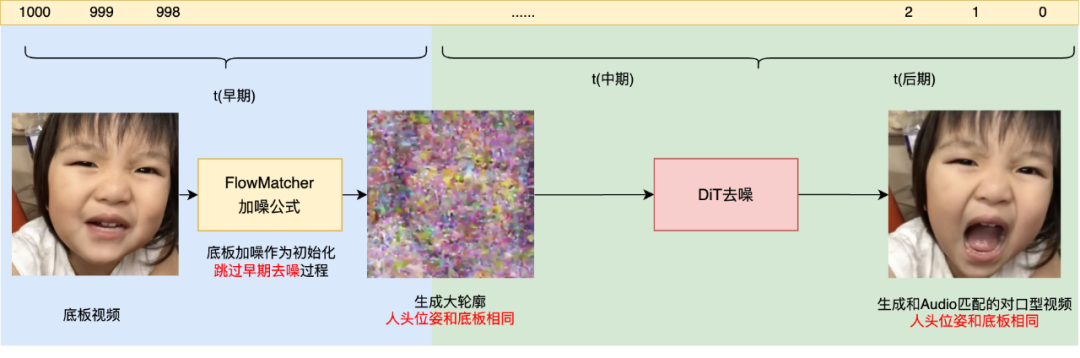
2.2 无限时长推理
传统推理方式虽能保证口型对齐,但会改变原视频中人物的姿态和位置,违背口型编辑的核心诉求。OmniSync 设计了基于流匹配的渐进式噪声初始化策略,完美解决这一问题:
-
去噪初期先锁定人物轮廓等低频信息(口型编辑无需改变的部分),直接对原视频加噪得到 "姿态位置固定" 的初始状态;
-
后续由 DiT 模型完成针对性去噪,仅优化口型相关区域。
这一策略不仅避免了姿态不一致和ID漂移,还让模型能就近参考帧维度的 ID 信息 ------ 相比额外注入统一 ID 的方案,在人脸角度剧变、遮挡等复杂场景下 ID 保持更稳定,且无累计误差,真正实现无限时长推理。
2.3 动态时空CFG
推理中CFG是加大音频->口型控制力的有效方法,并可以通过CFG系数调整强度,系数较大时能有较大控制力,但同时会带来纹理异常等badcase,OmniSync通过动态CFG解决了这个矛盾,明显改善口型精度。
如下图所示:
-
t维度:CFG随着去噪过程逐渐减小,因为在后期口型已经形成,CFG对口型无影响,只会带来异常纹理。
-
空间维度:以嘴部为中心,高斯分布,通过CFG重点加强口型效果。

三、效果展示
OmniSync能够在真人、卡通、动物、复杂光影、遮挡等复杂场景下都能够有较好的唇形同步效果。
Demo1:即使有部分面部遮挡也能保持准确的口型同步。
occlusion1 (1)
Demo2:与风格化角色和艺术表现无缝协作。
stylistic5 (1)
四、总结
OmniSync,一个针对多样化内容的通用唇形同步框架,消除了对参考帧和显式mask的依赖,彻底解耦id和口型,实现无限时长推理和复杂场景id保持。它解决了传统方案中:口型、id保持、时长三大痛点问题。大量实验表明,OmniSync在具有挑战性的场景中表现出卓越的性能,为将精确唇形同步集成到更广泛的AI视频生成生态系统中奠定了坚实的基础。