文章目录
- AI(学习笔记第十五课)从langchain的v0.3到v1.0
-
- [1. `langchain v1.0`的`semantic search`](#1.
langchain v1.0的semantic search) -
- [1.1 从`semantic search`开始](#1.1 从
semantic search开始) - [1.2 从`pdf loader`开始练习](#1.2 从
pdf loader开始练习) -
- [1.2.1 `pdf file`的准备](#1.2.1
pdf file的准备) - [1.2.2 `pdf loader`将`pdf`分成`documents`对象](#1.2.2
pdf loader将pdf分成documents对象) - [1.3 使用`text splitter`对docs进行`split`](#1.3 使用
text splitter对docs进行split) - [1.4 使用`embeddings`的`model`构建向量库`embeding vector`](#1.4 使用
embeddings的model构建向量库embeding vector)
- [1.2.1 `pdf file`的准备](#1.2.1
- [1.1 从`semantic search`开始](#1.1 从
- [2. 执行`vector stores and retrievers`](#2. 执行
vector stores and retrievers) -
- [2.1 使用`InMemoryVector`来保存`vector`](#2.1 使用
InMemoryVector来保存vector) - [2.2 使用`InMemoryVector`来进行`query`](#2.2 使用
InMemoryVector来进行query) -
- [2.2.1 执行代码](#2.2.1 执行代码)
- [2.2.2 执行结果](#2.2.2 执行结果)
- [2.1 使用`InMemoryVector`来保存`vector`](#2.1 使用
- [1. `langchain v1.0`的`semantic search`](#1.
AI(学习笔记第十五课)从langchain的v0.3到v1.0
-
langchain v1.0的semantic search -
Documents and document loaders -
Text splitters -
Embeddings -
Vector stores and retrievers
1. langchain v1.0的semantic search
从这里开始继续学习。
1.1 从semantic search开始
这里需要解释的是,在前面的文章AI(学习笔记第四课) 使用langchain进行AI开发 load documents(pdf)
中,已经学习过同样的内容,但是全新的langchain v1.0已经开始了,从这里继续学习。
1.2 从pdf loader开始练习
1.2.1 pdf file的准备
示例的代码工程中已经准备好了pdf文件,可以作为示例使用。
langchain_from_v1.0/docs/examples_data/nke-10k-2023.pdf
1.2.2 pdf loader将pdf分成documents对象
python
from langchain_core.documents import Document
from langchain_community.document_loaders import PyPDFLoader
def main():
"""Main entry point for the application."""
print("Starting My Python Project...")
file_path = "./docs/examples_data/nke-10k-2023.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs))
print(f"{docs[0].page_content[:200]}\n")
print(docs[0].metadata)这里看到,整个一个pdf文件已经被load成复数的docs。
1.3 使用text splitter对docs进行split
python
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
print(len(all_splits))可见,langchain对文本的处理是基于split之后的chunk的。
- 每个
chunk的size可以设定,这里设定成1000。 - 另外这里的
chunk_overlap=200也是有意义的,这里表示每个chunk之间的互相overlap的size,因为如果不互相overlap,那么chunk交界的部分很容易就会弄错,因为边界的文本会有很大的关系。
1.4 使用embeddings的model构建向量库embeding vector
python
embeddings = OllamaEmbeddings(
model="nomic-embed-text",
base_url=OLLAMA_BASE_URL)
vector_1 = embeddings.embed_query(all_splits[0].page_content)
vector_2 = embeddings.embed_query(all_splits[1].page_content)
# Example command line arguments
assert len(vector_1) == len(vector_2)
print(f"Generated vectors of length {len(vector_1)}\n")
print(vector_1[:10])执行结果如下
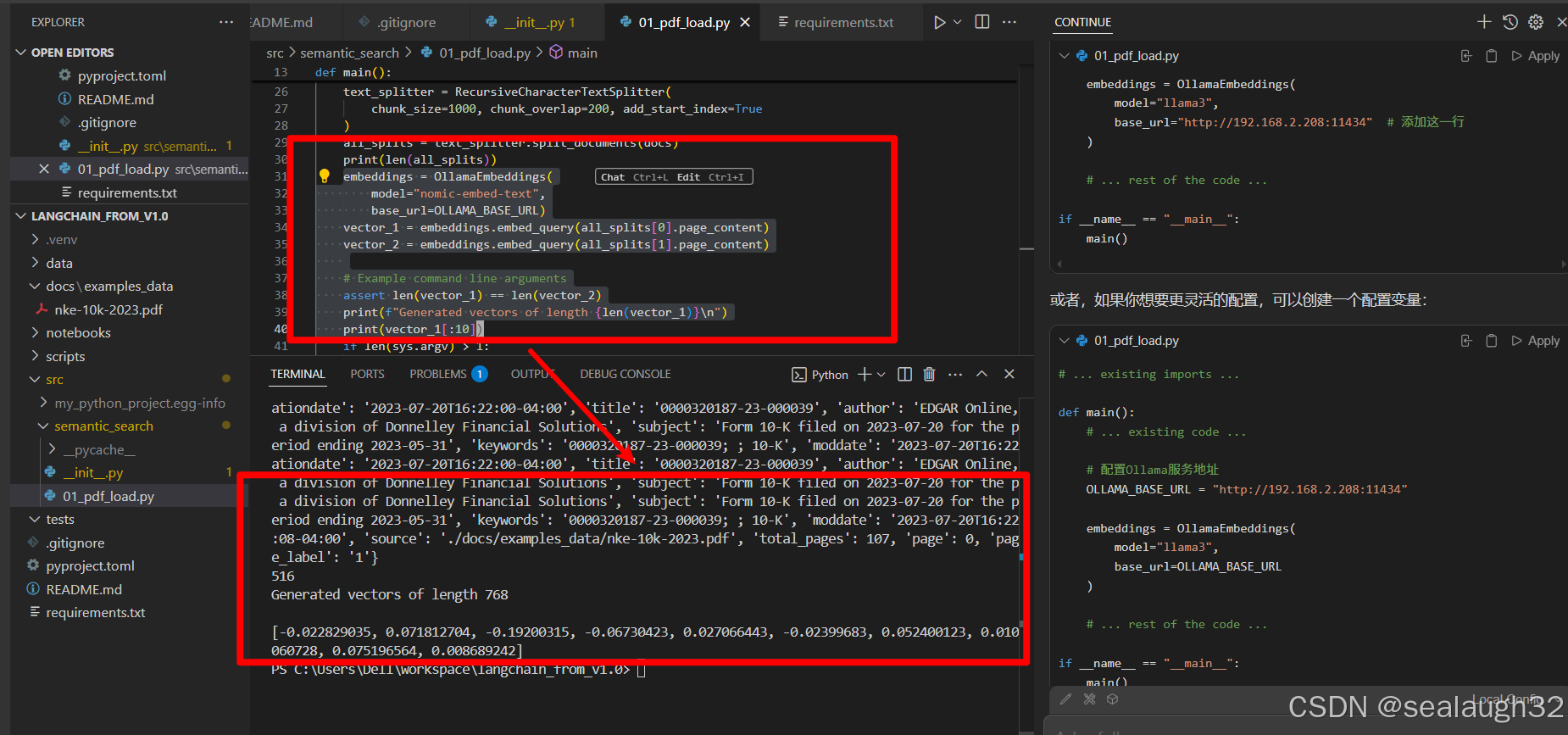
可见,每个chunk的size是1000,但是最终被embeding model向量化之后,每个chunk的vector的尺寸就是768,这个vector就代表了这个chunk。这些vector是可以做相似性(cosine similarity)比较。
2. 执行vector stores and retrievers
2.1 使用InMemoryVector来保存vector
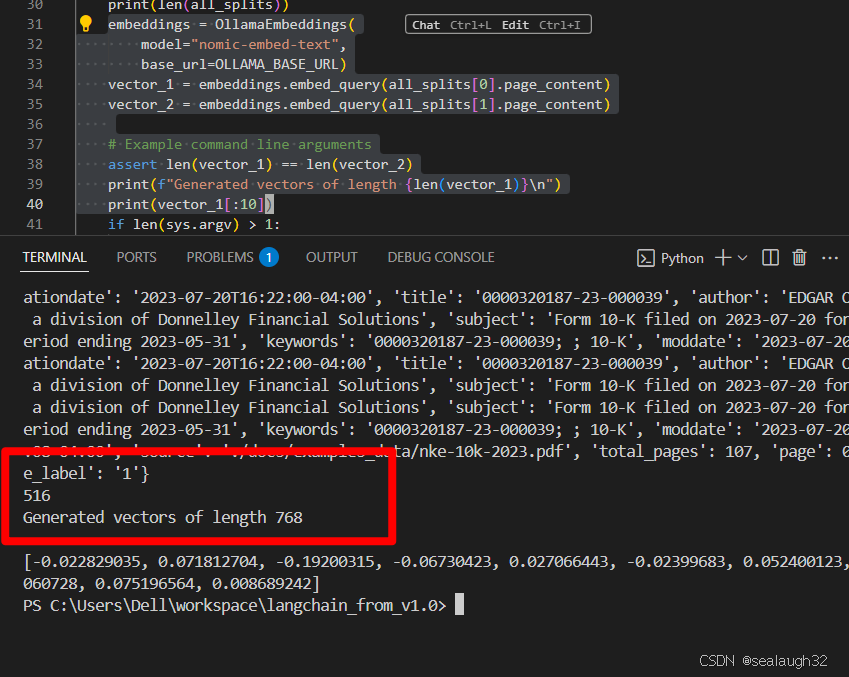
这里可以看到,516个chunks都被生成了768的固定长度的vector。接下来学习如何进行InMemoryVector的使用。
python
# create an empty InMemoryVectorStu'using embeding model
vector_store = InMemoryVectorStore(embeddings)
# add documents into vector store
ids = vector_store.add_documents(documents=all_splits)2.2 使用InMemoryVector来进行query
2.2.1 执行代码
python
results = vector_store.similarity_search(
"How many distribution centers does Nike have in the US?"
)
print(results[0])2.2.2 执行结果
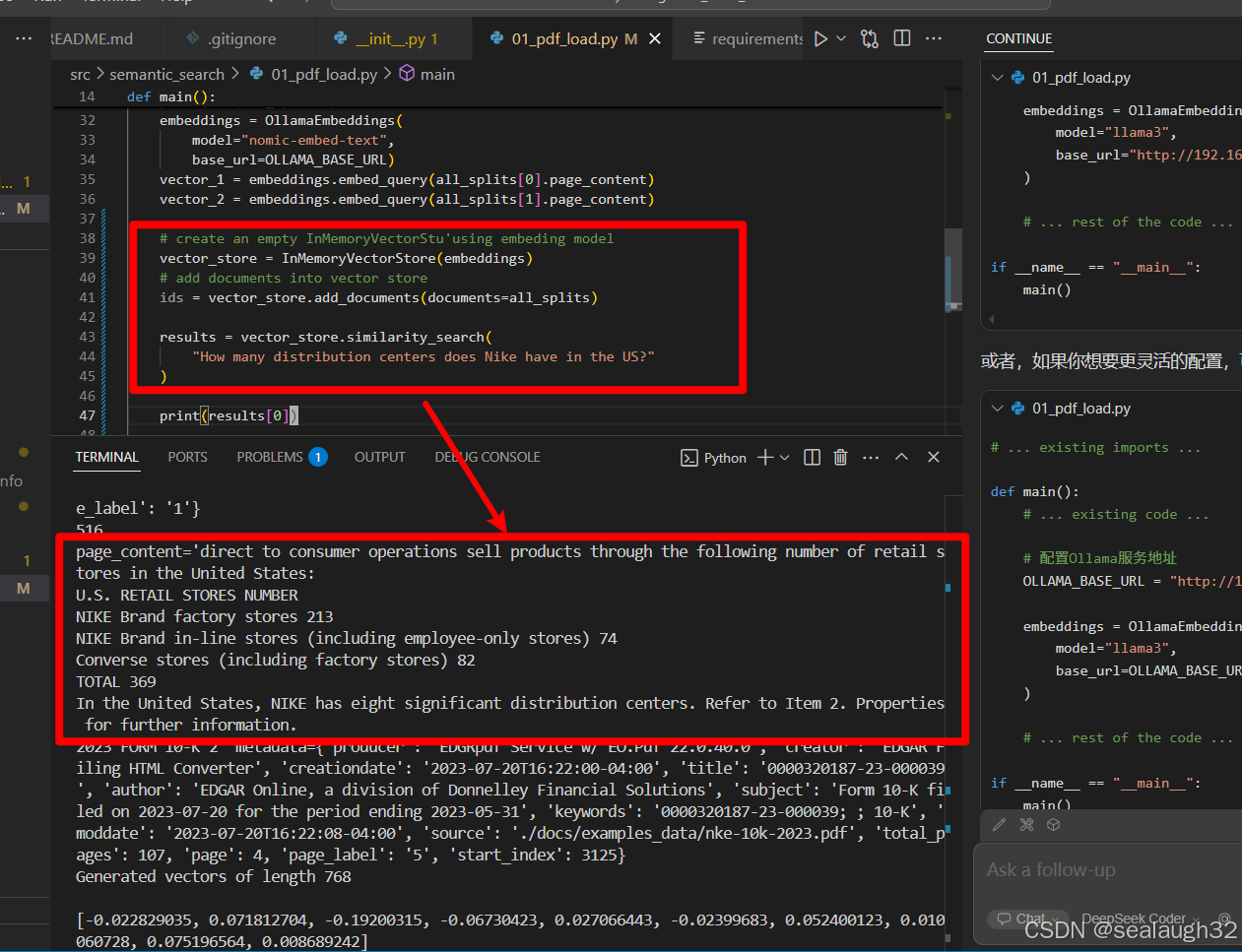
可见,使用vector store很容易将需要的文本查询到,但是这里还没有使用big model进行分析,还只是使用了embeding model。
到这里,从langchain v0.3过渡到了langchain v1.0,接下俩继续学习langchain v1.0。