使用演示:
https://qhstaticva-cos.kujiale.com/media/yun/help/video/UID_968a53d4_2300_4c7a_1765188797221.mp4
1 核心技术亮点
1.1 三工具统一接口
系统设计了三工具智能调用模式,将工具发现和调用过程简化为三个核心操作:
-
• query_tools: 语义搜索匹配工具,支持自然语言查询
-
• get_tool_info: 获取工具完整参数说明和使用示例
-
• execute_tool: 直接执行指定工具,无需了解底层协议
1.2 向量化智能路由
基于OpenAI text-embedding-3-large模型,将工具描述向量化存储在ChromaDB中,实现:
-
• 语义相似度匹配: 支持中英文混合查询的智能匹配
-
• 多策略路由: 语义搜索、精确匹配、模糊匹配、性能优先等策略
-
• 实时性能优化: 缓存机制和回退策略确保响应速度
1.3 中文优化算法
专门针对中文查询场景优化,实现:
-
• 智能分词: 支持单字、词组、短语的多级分词
-
• 混合匹配: 中英文关键词同时提取和匹配
-
• 容错机制: 拼写错误和表达差异的智能处理
2 MCP协议背景与挑战
MCP(Model Context Protocol)是Anthropic提出的模型上下文协议,旨在标准化AI应用与外部工具之间的交互。然而,在实际应用中,我们面临着几个关键挑战:
-
- 工具数量爆炸:随着AI生态发展,工具数量呈指数级增长
-
- 协议多样化:不同工具支持不同的通信协议(SSE、Stdio、HTTP等)
-
- 路由效率:如何从海量工具中快速找到最合适的工具
-
- 管理复杂度:如何统一管理分散的工具服务
3 系统整体架构
Kuai智能MCP系统采用三层架构设计:
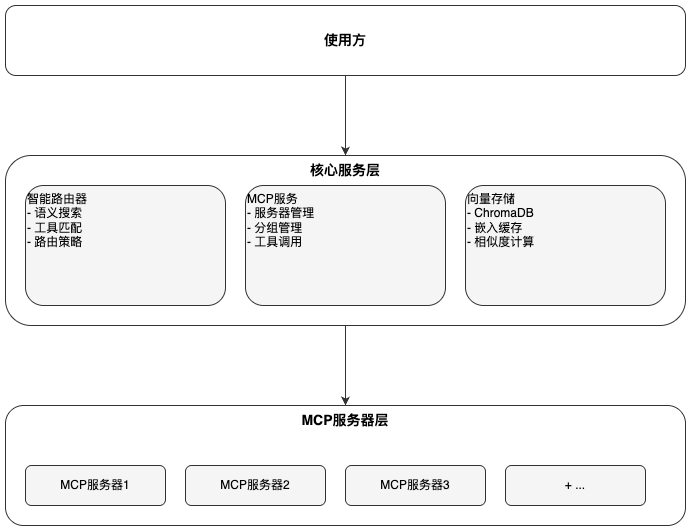
核心组件说明:
-
• 智能路由器: 负责工具发现和匹配,支持多种路由策略
-
• MCP服务: 管理MCP服务器生命周期,处理工具调用请求
-
• 向量存储: 存储工具向量化描述,支持语义搜索
4 智能路由核心设计
4.1 路由策略体系
智能路由器支持多种路由策略,适应不同场景需求:
go
class RoutingStrategy(str, Enum):
SEMANTIC_SEARCH = "semantic_search" # 语义搜索
EXACT_MATCH = "exact_match" # 精确匹配
FUZZY_MATCH = "fuzzy_match" # 模糊匹配
PERFORMANCE_BASED = "performance_based" # 性能优先
LOAD_BALANCE = "load_balance" # 负载均衡
PRIORITY_BASED = "priority_based" # 优先级4.2 语义搜索实现
语义搜索是系统的核心功能,通过向量化工具描述实现智能匹配。其工作流程如下:
语义搜索步骤
go
输入: 用户自然语言查询
输出: 按相似度排序的工具列表
1. 查询向量化
├─ 调用OpenAI嵌入模型
├─ 生成3072维向量表示
└─ 支持中英文混合查询
2. 工具匹配
├─ 向量数据库模式:
│ ├─ ChromaDB相似度搜索
│ ├─ 设置相似度阈值过滤
│ └─ 返回Top-N最相关工具
└─ 内存模式:
├─ 遍历缓存的工具嵌入
├─ 计算余弦相似度
└─ 过滤低分工具
3. 结果排序
├─ 按相似度分数降序排列
├─ 生成匹配信息
└─ 返回结构化结果
4. 返回结果
├─ 工具名称和服务器信息
├─ 相似度分数
└─ 匹配原因说明关键技术特点
-
• 高质量嵌入: 使用OpenAI text-embedding-3-large模型
-
• 双模式支持: 向量数据库和内存模式并存
-
• 实时计算: 支持动态工具添加和更新
-
• 多语言支持: 优化的中英文混合查询处理
4.3 中文优化策略
针对中文查询的特殊性,系统实现了专门的分词和匹配策略。
中文分词步骤
go
输入: 中英文混合查询文本
输出: 关键词集合
1. 文本预处理
├─ 输入: "读取文件内容"
└─ 目标: 提取有用关键词
2. 英文关键词提取
├─ 匹配模式: [a-zA-Z]+
├─ 过滤条件: 长度 > 1
└─ 结果处理: 转换为小写
示例: "readFile" → ["read", "file"]
3. 中文关键词提取
├─ 识别中文字符: [\u4e00-\u9fff]+
├─ 单字级别: 提取每个汉字
│ └─ "读取文件" → {"读", "取", "文", "件"}
├─ 词组级别: 生成2-4字符组合
│ ├─ 2字符: {"读取", "取文", "文件"}
│ ├─ 3字符: {"读取文", "取文件"}
│ └─ 4字符: {"读取文件"}
└─ 合并所有关键词
4. 数字和特殊标识提取
├─ 提取数字: [0-9]+
└─ 提取连字符组合: [a-zA-Z]+[-_][a-zA-Z]+
5. 结果去重和返回
├─ 合并所有类型关键词
├─ 去除重复项
└─ 返回关键词集合匹配策略应用
go
工具匹配示例:
查询: "读取文件内容"
1. 分词结果
├─ 中文: {"读", "取", "文", "件", "读取", "取文", "文件", "读取文", "取文件", "读取文件"}
└─ 英文: {}
2. 工具匹配
工具A: "read_file - 读取指定路径的文件内容"
├─ 中文分词: 包含"读取", "文件"
├─ 匹配分数: 高 (2个关键词匹配)
└─ 匹配类型: 精确匹配
工具B: "write_file - 写入数据到文件"
├─ 中文分词: 包含"文件"
├─ 匹配分数: 中 (1个关键词匹配)
└─ 匹配类型: 部分匹配
3. 结果排序
└─ 工具A 排名 > 工具B 排名优化特点
-
• 多粒度分词: 单字、词组、短语多级别匹配
-
• 中英文混合: 同时处理中英文关键词
-
• 容错机制: 支持拼写错误和表达差异
-
• 动态组合: 自动生成不同长度的词组组合
-
• 高效匹配: 基于集合的快速关键词匹配
5 智能工具调用接口
系统提供了统一的三工具智能调用接口,简化了工具发现和使用流程:
5.1 核心工具设计
go
@self.server.list_tools()
async def list_tools() -> List[types.Tool]:
"""列出智能路由服务器提供的3个核心工具"""
return [
types.Tool(
name="query_tools",
description="查询符合条件的工具,只返回描述等信息。支持自然语言搜索或关键词匹配。",
inputSchema={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索查询,可以是自然语言描述或工具名称关键词"
},
"strategy": {
"type": "string",
"description": "路由策略:semantic_search、exact_match、fuzzy_match",
"enum": ["semantic_search", "exact_match", "fuzzy_match"],
"default": "semantic_search"
}
},
"required": ["query"]
}
),
types.Tool(
name="get_tool_info",
description="传入具体方法名,返回该工具的完整信息包括详细参数说明。",
inputSchema={
"type": "object",
"properties": {
"tool_name": {
"type": "string",
"description": "完整的工具名称,格式为:server_name.tool_name"
}
},
"required": ["tool_name"]
}
),
types.Tool(
name="execute_tool",
description="执行指定的工具。需要提供完整的工具名称。",
inputSchema={
"type": "object",
"properties": {
"tool_name": {
"type": "string",
"description": "完整的工具名称,格式为:server_name.tool_name"
},
"arguments": {
"type": "object",
"description": "工具执行参数",
"additionalProperties": True
}
},
"required": ["tool_name", "arguments"]
}
)
]5.2 使用流程示例
-
- 查询工具:
go
# 自然语言搜索
query_tools({
"query": "读取文件内容",
"strategy": "semantic_search"
})
# 返回匹配结果
[
{
"tool_name": "filesystem.read_file",
"score": 0.89,
"match_type": "semantic_similarity",
"reasoning": "语义相似度: 0.89"
}
]-
- 获取详细信息:
go
get_tool_info({
"tool_name": "filesystem.read_file"
})
# 返回完整工具信息
{
"tool_name": "filesystem.read_file",
"description": "读取指定路径的文件内容",
"parameters": {
"path": {
"type": "string",
"description": "文件路径",
"required": true
}
},
"example": {
"tool_name": "filesystem.read_file",
"arguments": {
"path": "/path/to/file.txt"
}
}
}-
- 执行工具:
go
execute_tool({
"tool_name": "filesystem.read_file",
"arguments": {
"path": "/etc/hosts"
}
})
# 返回执行结果
{
"content": "127.0.0.1 localhost\n..."
}6 向量存储优化
为了支持大规模工具的高效检索,系统实现了向量数据库集成和优化策略。
6.1 数据存储方式
系统使用ChromaDB作为向量数据库,数据的存储结构如下:
存储的数据格式
go
每个工具记录包含:
├─ 向量数据 (3072维)
│ ├─ 来自工具描述的嵌入向量
│ └─ 使用OpenAI text-embedding-3-large模型生成
├─ 元数据信息
│ ├─ 工具ID: "server_name.tool_name"
│ ├─ 工具名称: "read_file"
│ ├─ 服务器名称: "filesystem"
│ ├─ 工具描述: "读取指定路径的文件内容"
│ └─ 嵌入模型: "text-embedding-3-large"
└─ 原始文本
└─ "read_file: 读取指定路径的文件内容"批量处理流程
go
工具嵌入生成流程:
1. 准备阶段
├─ 收集所有工具信息
├─ 构建"工具名: 描述"格式的文本
└─ 生成唯一ID标识
2. 批量嵌入生成
├─ 分批处理(默认100个/批)
├─ 调用OpenAI API生成向量
└─ 错误重试和降级处理
3. 数据存储
├─ 向量数据 + 元数据存储到ChromaDB
├─ 建立向量索引
└─ 持久化到本地存储
4. 内存缓存(回退方案)
└─ 保存向量到内存字典6.2 缓存与性能优化
路由缓存机制
go
缓存策略:
1. 缓存键生成
├─ 使用MD5哈希查询文本
└─ 确保相同查询命中缓存
2. 缓存内容
├─ 匹配的工具列表
├─ 路由策略和执行时间
└─ 缓存创建时间
3. 缓存管理
├─ TTL过期机制(默认1小时)
├─ 缓存命中率统计
└─ LRU清理策略性能优化措施
-
• 批量处理: 减少API调用次数,降低延迟
-
• 分批存储: 避免单次处理大量数据导致内存溢出
-
• 缓存复用: 相同查询直接返回缓存结果
-
• 异步处理: 所有向量操作都是异步执行
-
• 内存优化: 支持向量数据库和内存模式动态切换
7 总结
Kuai智能MCP系统通过以下设计解决了工具管理的核心挑战:
-
• 智能路由:基于向量搜索的语义匹配,提升工具发现效率
-
• 多协议支持:统一接口支持SSE、Stdio、HTTP等多种通信协议
-
• 高可用架构:分层缓存、降级策略保证系统稳定性
-
• 易于扩展:微服务架构支持水平扩展和模块化开发