1. GPOS
1.1 概念
GPOS,即通用操作系统或分时操作系统,是一种为通用计算场景设计的操作系统,通过虚拟内存、多任务调度、丰富驱动等机制,支持复杂应用并发运行,追求"整体效率"而非"单任务实时性"。
| 特征 | 说明 |
|---|---|
| 设计理念 | 公平 > 确定:所有任务共享资源,按需调度 |
| 内存管理 | MMU + 虚拟内存:进程隔离、按需分页、Swap 交换 |
| 调度策略 | 动态优先级 + 时间片轮转,优化吞吐量与响应平衡 |
| 系统服务 | 完整 POSIX/API、文件系统、网络栈、GUI 框架 |
| 可扩展性 | 支持动态加载模块、多用户、多进程、容器化 |
1.2 基石
虚拟内存系统(GPOS 的基石)关键能力:
- 进程隔离:每个进程拥有独立 4GB 虚拟空间,互不干扰
- 内存超售:虚拟内存总量 > 物理 RAM(依赖 Swap)
- 写时复制 (CoW):fork() 时共享物理页,写时才复制,提升效率
- 内存映射文件:文件直接映射到虚拟地址,零拷贝 I/O
1.3 调度策略
GPOS:
核心思想:让每个任务获得"公平的 CPU 时间"
调度逻辑:
1. 每个任务有一个"虚拟运行时间"(vruntime)
2. 调度器总是选择 vruntime 最小的任务执行
3. 即使高优先级任务,也要"适当等待"保证公平
问题:
- 紧急任务可能因为"公平"而延迟
- 无法保证"10ms 内必须响应"RTOS:
cpp
核心思想:高优先级任务必须立即执行
调度逻辑:
1. 任务有固定优先级(0~N,数字越大优先级越高)
2. 任何时候,只要高优先级任务就绪,立即抢占当前任务
3. 时间片轮转仅用于相同优先级的任务
优势:
- 紧急任务(如传感器中断)可微秒级响应
- 系统行为可预测,WCRT 可计算| 场景 | GPOS | RTOS |
|---|---|---|
| 任务 A(低优先级) 运行中,任务 B(高优先级) 就绪 | A 可能继续运行完当前时间片(取决于调度器实现) | B 立即抢占 A,延迟仅取决于中断响应 + 切换时间 |
| 两个同优先级任务 | 时间片轮转,公平分配 CPU | 时间片轮转,但可配置为"协作式"(任务主动让出) |
| 时间片到期 | 强制切换,保证公平 | 仅在同优先级时切换,高优先级任务不受限制 |
2. MPU (内存保护单元)
2.1 概念
核心目标:在资源受限的嵌入式系统中,提供轻量级的内存访问保护与区域管理
MPU 是一种硬件单元,用于定义和管理多个内存区域 (Regions),每个区域可独立配置:访问权限、缓存策略、执行权限等。
2.2 工作原理
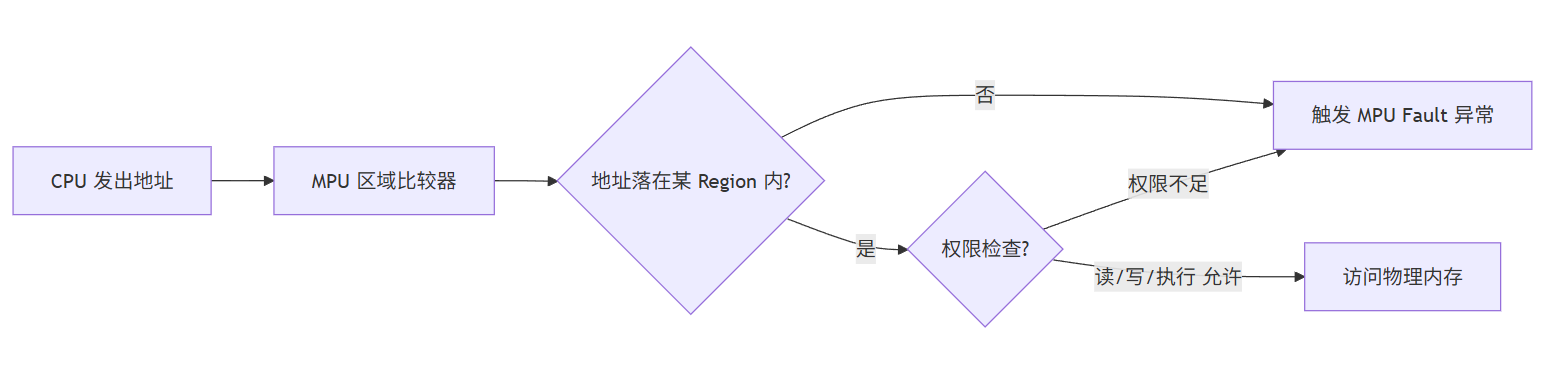
每个 MPU Region 通常包含以下配置字段:
| 字段 | 含义 | 典型取值 |
|---|---|---|
| Base Address | 区域起始地址 | 32B/1KB/1MB 对齐 |
| Size | 区域大小 | 2⁵B ~ 2³²B(2 的幂) |
| Enable | 是否启用该区域 | Enable / Disable |
| Access Permission | 访问权限 | Privileged/User + RW/R/O/NO |
| Execute Never (XN) | 是否禁止执行 | XN / Executable |
| Cache Policy | 缓存策略 | WT/WB/No-Cache/Shared |
| Subregion Disable | 子区域屏蔽 | 8 个子区域,可单独禁用 |
2.3 作用
常用于 RTOS 中的任务隔离:
cpp
RTOS + MPU 配置示例:
├── Region 0: 内核代码 (Flash, 只读, 可执行)
├── Region 1: 内核数据 (SRAM, 特权 RW)
├── Region 2: 任务 A 栈 (SRAM, 任务 A 可 RW, 其他禁止)
├── Region 3: 任务 B 栈 (SRAM, 任务 B 可 RW, 其他禁止)
├── Region 4: 共享外设 (Peripheral, 特权 RW, 用户只读)
└── Background: 未配置区域 → 触发 Fault(调试用)
效果:任务 A 栈溢出不会破坏任务 B 数据3. MMU (内存管理单元)
3.1 概念
MMU 是位于CPU 与 物理内存总线 之间的硬件组件。它负责将 CPU 发出的逻辑/虚拟地址 (Virtual Address, VA) 转换为 物理地址 (Physical Address, PA) ,并在转换过程中检查访问权限。
| 功能 | 说明 |
|---|---|
| 抽象层 | 让软件看到的内存是连续、独立、无限的(虚拟),隐藏物理内存的碎片与限制 |
| 隔离保护 | 进程间内存隔离,防止恶意/错误程序破坏系统或其他进程 |
| 内存超售 | 支持 Swap 交换,允许运行比物理 RAM 更大的程序 |
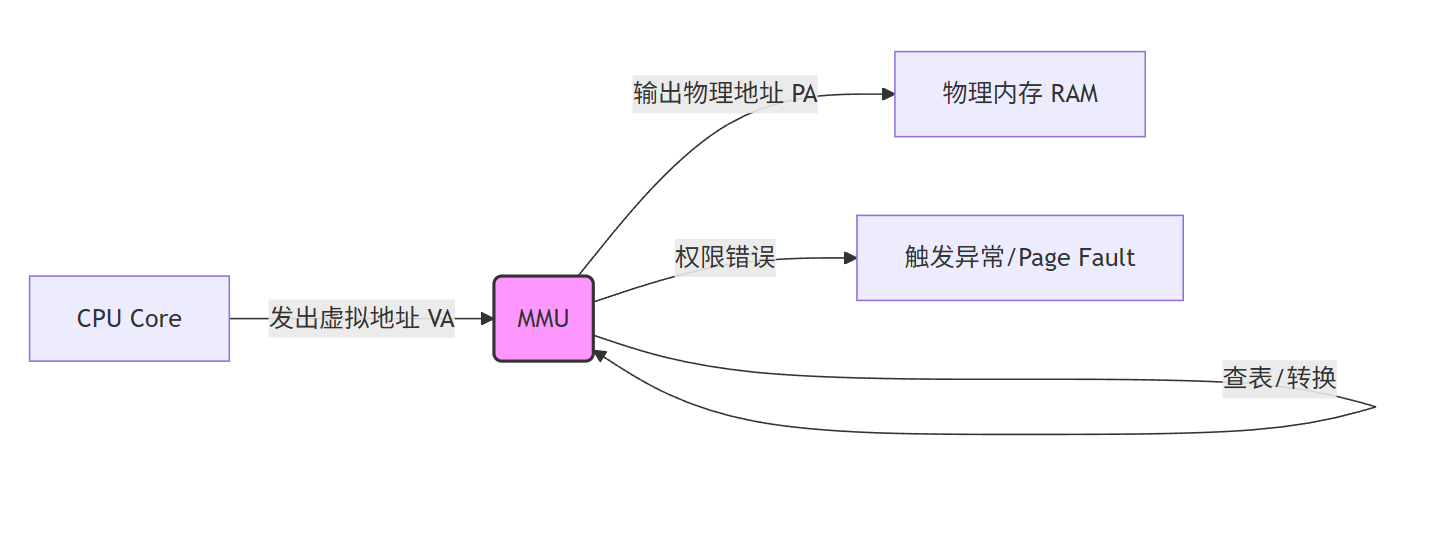
3.2 工作原理
3.2.1 地址转换流程
3.2.2 页表 (Page Table)
- 作用: 存储 VA 到 PA 映射关系的数据库。
- 结构: 通常多级结构(如 ARM 4 级页表,x86 4/5 级页表),节省内存开销。
- 页表项 (PTE) 内容:
- 物理页框号 (PFN)
- 权限位 (R/W/X, User/Kernel)
- 状态位 (Valid/Invalid, Dirty, Accessed)
- 缓存属性 (Cacheable, Bufferable)
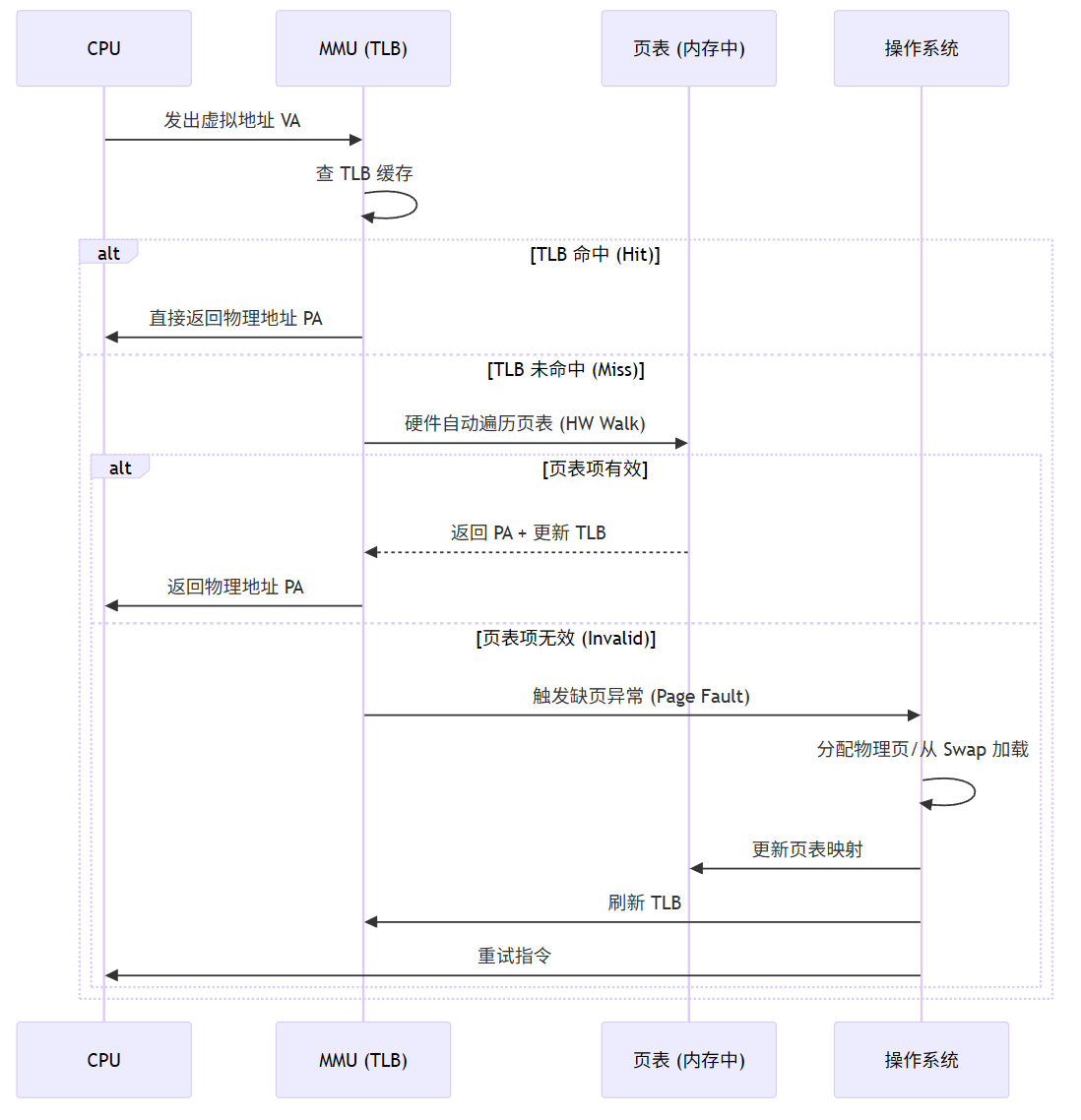
3.2.3 TLB (Translation Lookaside Buffer)
- 定义: 页表的高速缓存(Cache for Page Table)。
- 原因: 页表存储在内存中,每次访问都查内存太慢(需多次内存访问)。TLB 将常用映射存在 CPU 内部寄存器/SRAM 中。
- 性能影响:
- TLB Hit: 1 个时钟周期完成转换。
- TLB Miss: 需访问内存查页表,耗时数十~数百周期。
- TLB Flush: 进程切换时,若地址空间不同,需清空 TLB 防止错用映射(开销大)。
3.2.4 缺页异常 (Page Fault)
- 触发条件: MMU 查页表发现某虚拟页标记为"无效"(不在物理内存中)。
- 处理流程:
- CPU trap 到内核态。
- 操作系统判断原因(非法访问 vs 合法缺页)。
- 若合法:分配物理页,从磁盘 (Swap) 加载数据,更新页表。
- 重试指令。
- 意义: 实现按需分页 (Demand Paging) 和 虚拟内存交换 的核心机制。
3.3 核心功能与作用
3.3.1 虚拟内存管理 (Virtual Memory)
- 连续假象: 程序认为内存从 0 开始连续,物理内存可以是碎片化的。
- 内存超售: 虚拟地址空间总和 >> 物理 RAM 大小(依赖磁盘 Swap)。
- 按需加载: 程序启动时不加载全部代码/数据,访问到哪加载到哪。
3.3.2 内存保护 (Memory Protection)
- 权限控制: 每个页可独立设置 读/写/执行 (RWX)。
- 代码段:R + X (禁止写,防篡改)
- 数据段:R + W (禁止执行,防注入)
- 内核空间:特权级访问 (用户态访问触发 Fault)
- 进程隔离: 进程 A 无法访问进程 B 的虚拟地址(页表不同)。
3.3.3 缓存策略控制 (Cache Policy)
- MMU 页表项中可指定每个页的缓存属性:
- Write-Back: 写回模式(高性能,数据可能暂存 Cache)
- Write-Through: 直写模式(数据一致性高)
- Uncacheable: 不缓存(用于内存映射 I/O,如寄存器)
- 优势: 比全局缓存控制更精细,适合混合用途内存。
3.3.4 高级内存特性支持
- Copy-on-Write (CoW): fork() 时父子进程共享物理页,仅当写入时才复制。极大提升进程创建效率。
- 内存映射文件 (mmap): 将文件直接映射到虚拟地址空间,零拷贝 I/O。
- 共享内存: 多个进程映射到同一物理页,实现高效 IPC。