MySQL官方对于索引的定义: 是基于存储引擎用来快速查找记录的一种数据结构。
- 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。
- 索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价
Mysql使用的是B+Tree数据结构来的
B+Tree是由二叉树 平衡二叉树(AVL)和B-Tree逐步优化而来的
不使用索引
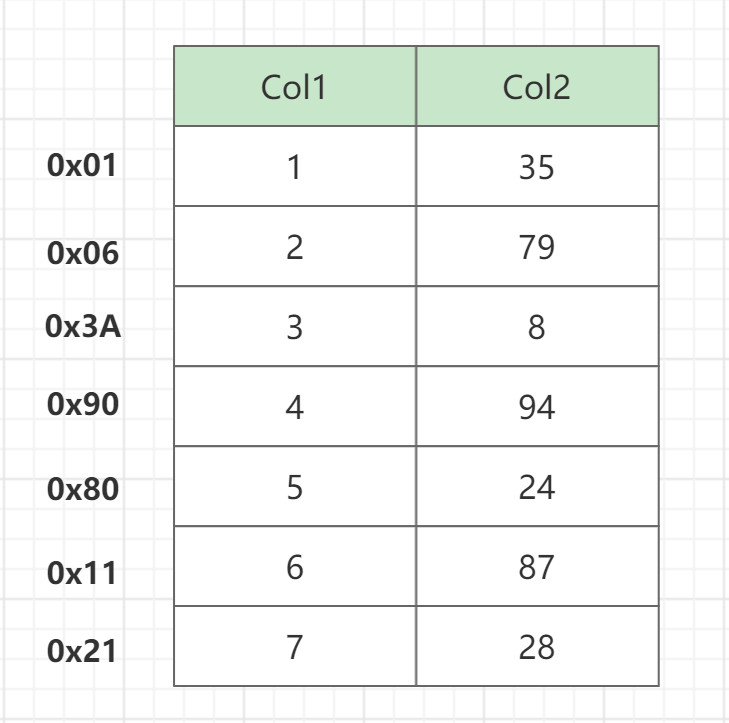
如果不使用任何索引
select from a where col2=87
如果执行上面的sql 一条一条记录要遍历到末尾才能得到数据 非常消耗性能。
二叉树优化:
二叉查找树的特点:
- 左子树键值小于根节点的键值
- 右子树的键值大于根节点的键值
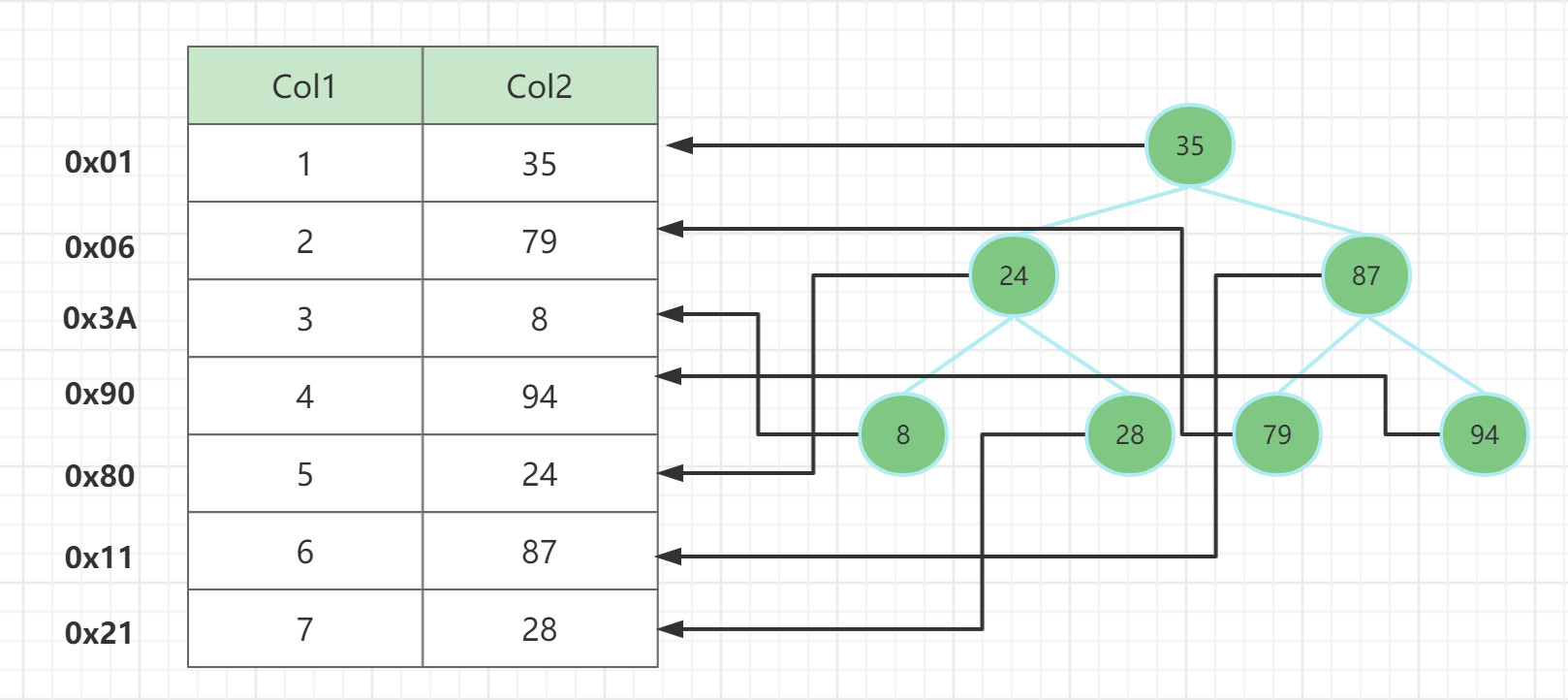
查找顺序:执行上面的sql 87比35大走右边的节点 找到87 IO次数为1
对该二叉树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n (1+2+2+3+3+3+3) / 6 = 2.8次.
二叉树的缺点:
二叉树在存储一个有序的数据时 最终排列结构形成一个单向链表 对于读取链表尾部的数据会效率很低 深度很深。
平衡二叉树(AVL)的优化:
平衡二叉树的特点:
在符合二叉树的条件下,还会满足任何节点的两个子树的高度最大差为1.
AVL树和非AVL树的对比
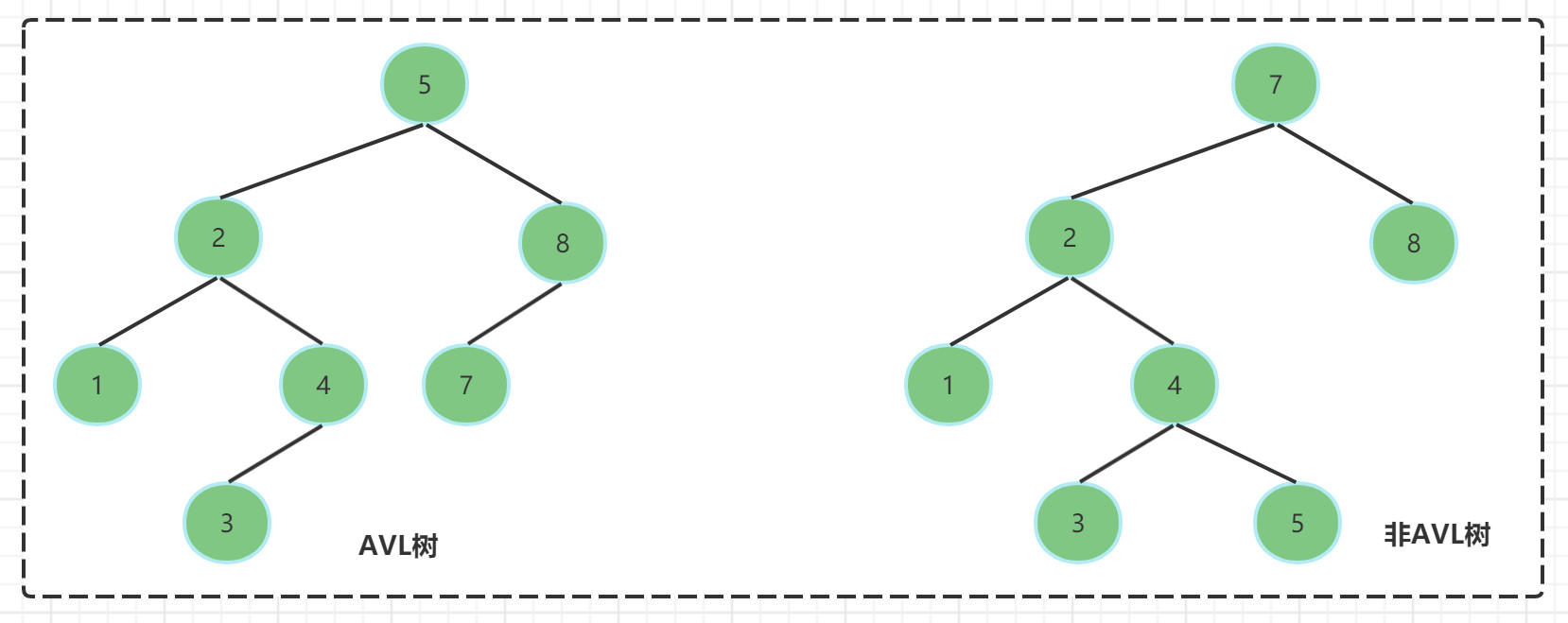
- 左边是AVL树,它的任何节点的两个子树的高度差<=1
- 右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1;
AVL的旋转方式来解决平衡的问题:
AVL树失去平衡之后,可以通过旋转使其恢复平衡.
- LL旋转: 左左旋转 根节点的左子树的高度比右子树高度高2,需要进行旋转 恢复平衡
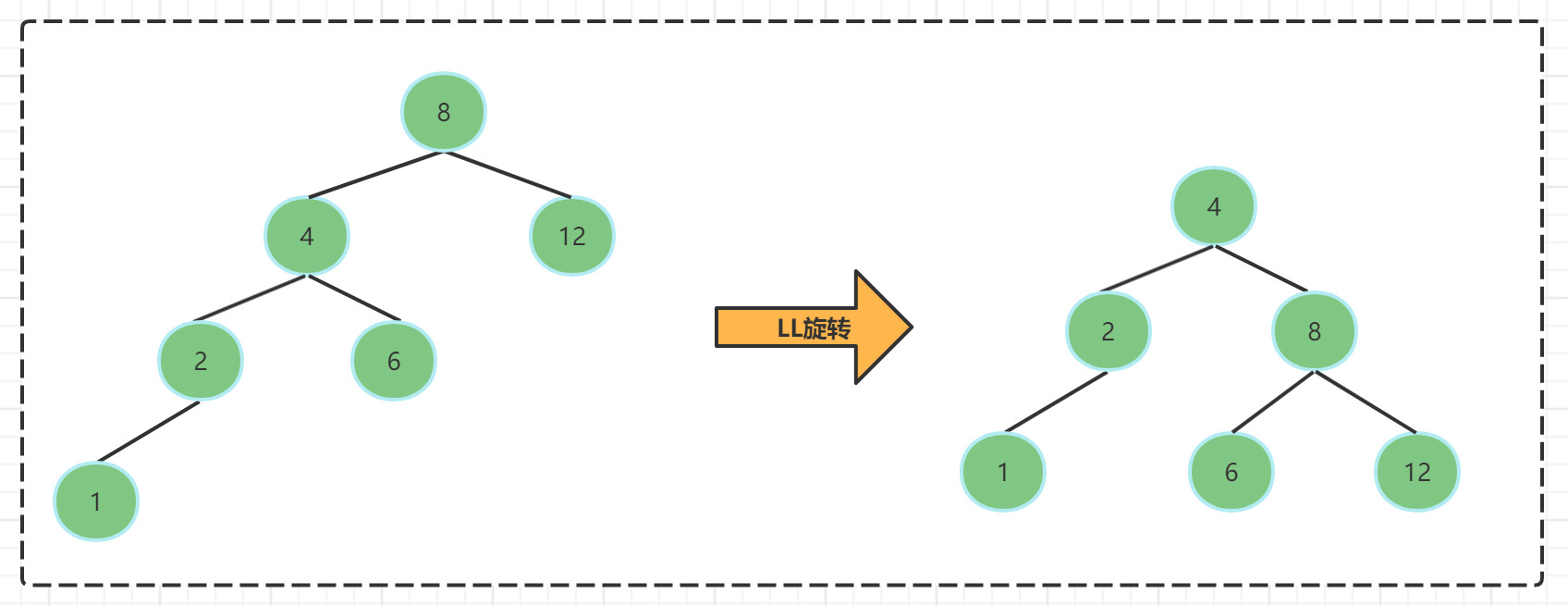
LL旋转步骤:
-
- 将根节点的左孩子作为新根节点
- 将原根节点作为新根节点的右孩子
- 将新根节点的右孩子作为原来根节点的左孩子
- RR旋转(右右旋转): 根节点的右子树的高度比左子树的高度高2,需要进行旋转 进行恢复
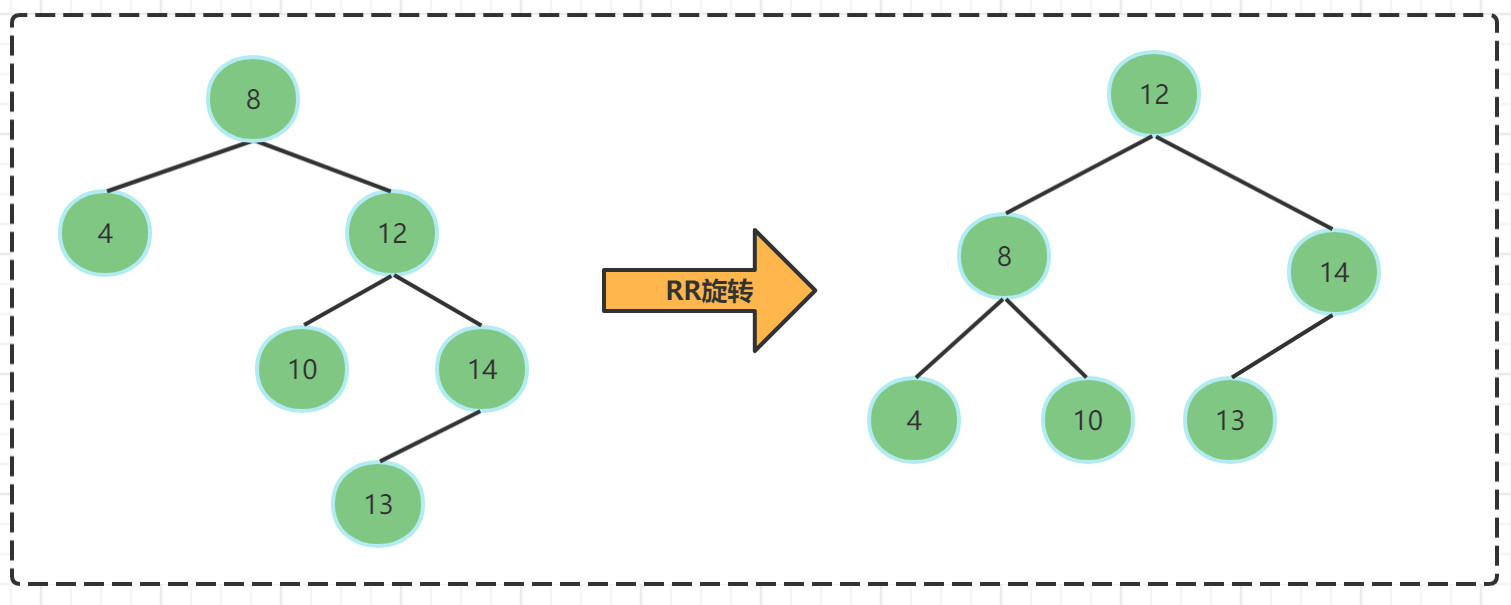
RR旋转的步骤:
- 将根节点的右孩子作为新根节点
- 将原根节点作为新根节点的左孩子
- 将新根节点的左孩子作为原来根节点的右孩子
AVL树的优缺点:
优点:
- 叶子节点的层级减少
- 形态上能够保持平衡
- 查询效率提升,大量的顺序插入也不会导致性能的降低
缺点:
- 一个节点最多分裂两个子节点,树的高度太高 导致IO次数过多
- 节点中只保存着一个关键字,每次操作的目标数据太少
B-Tree的优化:
- B-Tree是一种平衡的多路查找树,B树允许一个节点存储多个数据 (把瘦高的树变的矮胖)
- B树中的所有节点的子节点的个数的最大值称为B-Tree的阶,用m表示
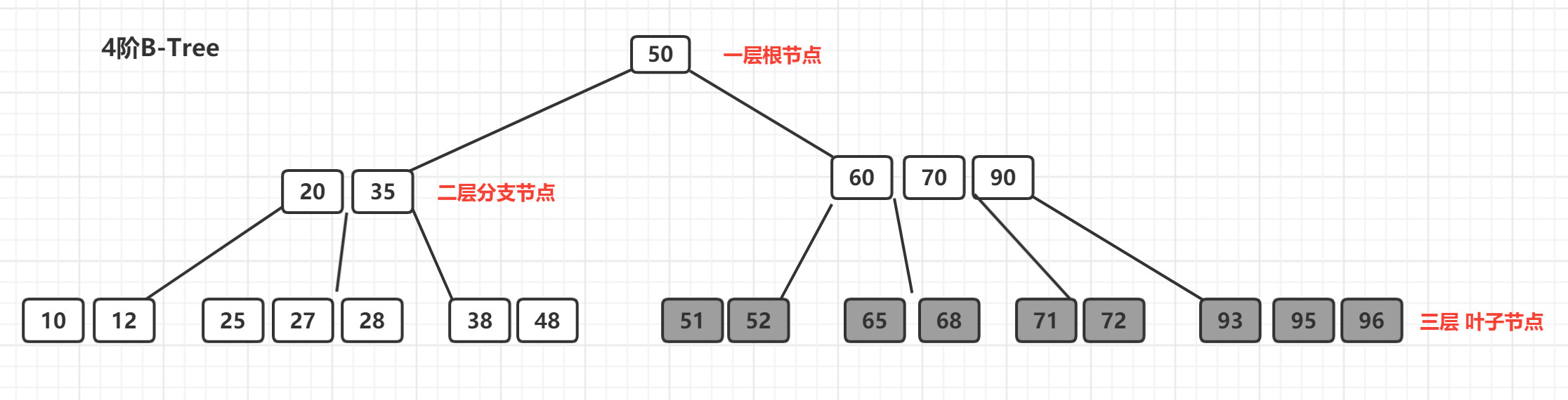
m阶的B-Tree需要满足以下条件:
- 每个节点最多拥有m个子树
- 根节点最少要有两个子树(如果只有一个子树,就退化成二叉树)
- 分支节点至少要有(m/2)颗子树
- 所有的叶子节点都在同一层,并且以升序排序
什么是B-Tree的阶 ?
所有节点中,节点【60,70,90】拥有的子节点数目最多,四个子节点(灰色节点),所以可以上面的B-Tree为4阶B树
B-Tree结构存储索引的特点:
B-Tree会定义一条记录为一个键值对【key,value】 key就是一条记录的主键,对应的value就是表中除主键以外的数据data。
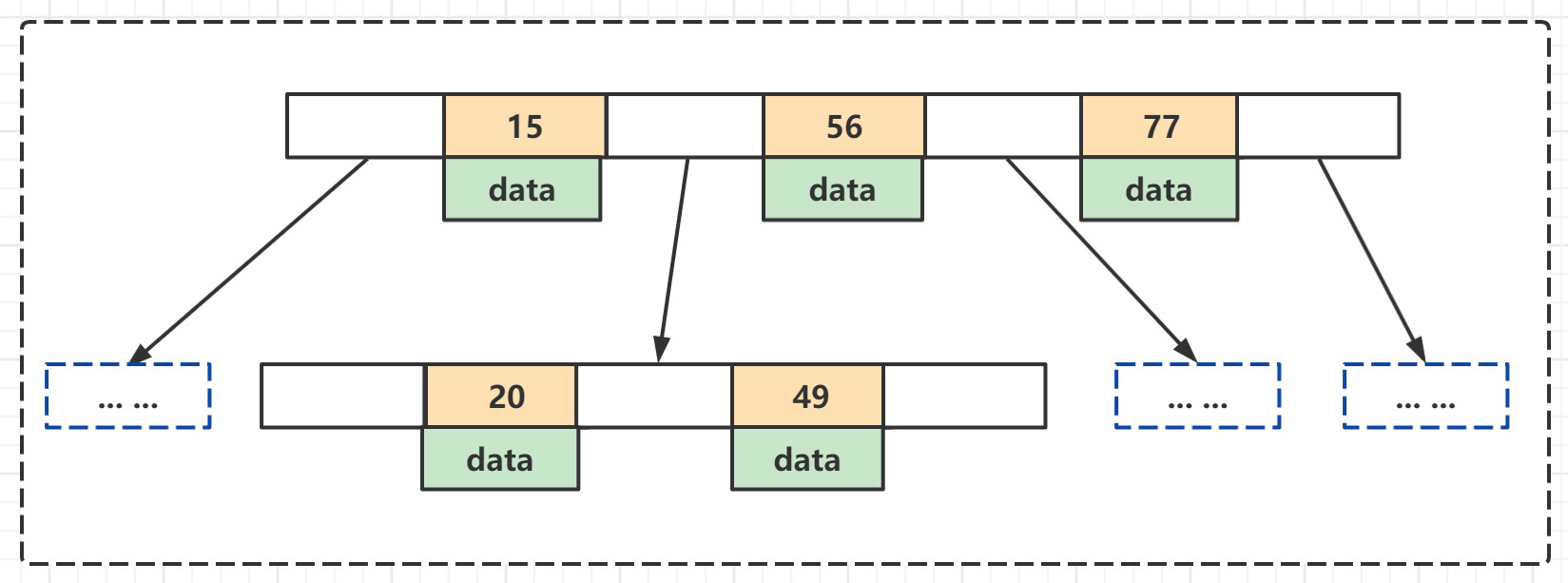
- 索引值和data数据是分布在整棵树的结构中的
- 白色块是指针,存储着子节点的地址信息
- 每个节点是可以存储多个索引值和对应的data数据的
- 树节点的多个索引值按照升序排序 从左往右排列
B-Tree的查找操作
- B-Tree的每隔节点元素可以看做是一次IO读取
- 树的高度表示最多的IO的次数
- 在相同数量的总元素个数下,每个节点存储的元素个数越多,高度越低所需查询的次数就越少
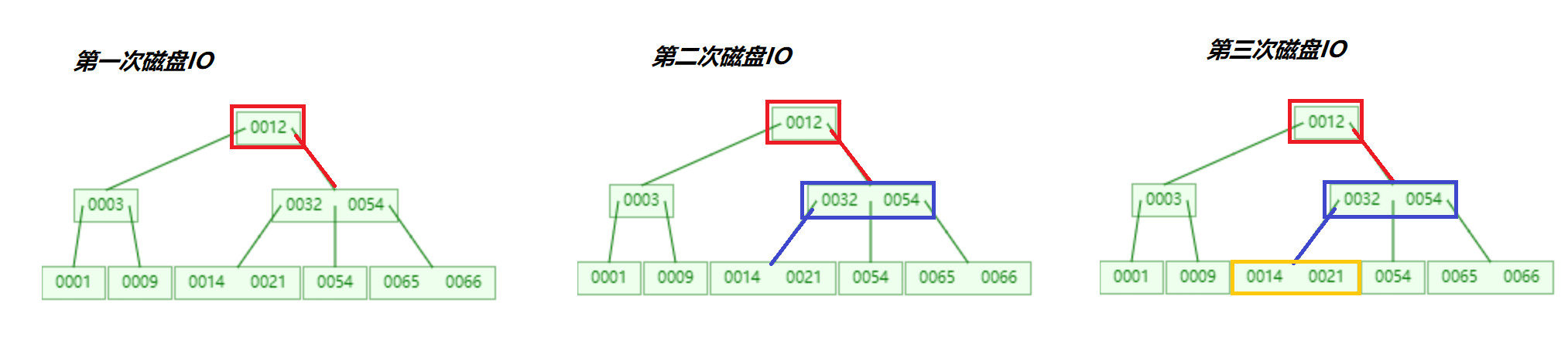
B-Tree的查找可以分为3步:
- 首先要查找节点,因为B-Tree通常是在磁盘上存储的,所以这步需要进行磁盘IO操作
- 第二步查找关键字,当找到某个节点后将该节点读入内存中, 然后通过顺序或者折半查找来查找关键字,如果命中就结束查找。
- 若没有找到关键字,则需要判断大小来找到合适的分支继续查找,如果已经找到了叶子节点,就结束查询
B-Tree的优缺点:
- 优点:B树的内部节点可以存储关键字和相关数据,如果把频繁访问的数据放在靠近根节点的位置,就会大大提升热点数据的查询效率。
- 缺点:B树当中每个节点不仅有关键字和数据,如果当数据较大的时,它就会导致每个节点存储的key值减少了,会导致B数的层数变高,增加查询的IO次数.
- 使用场景: B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现
B+Tree的优化 :
B+Tree是在B-Tree的基础上做的一种优化,使其更加合适存储索引结构,InnoDB存储引擎就是使用B+Tree实现其索引结构的.
B+Tree特征
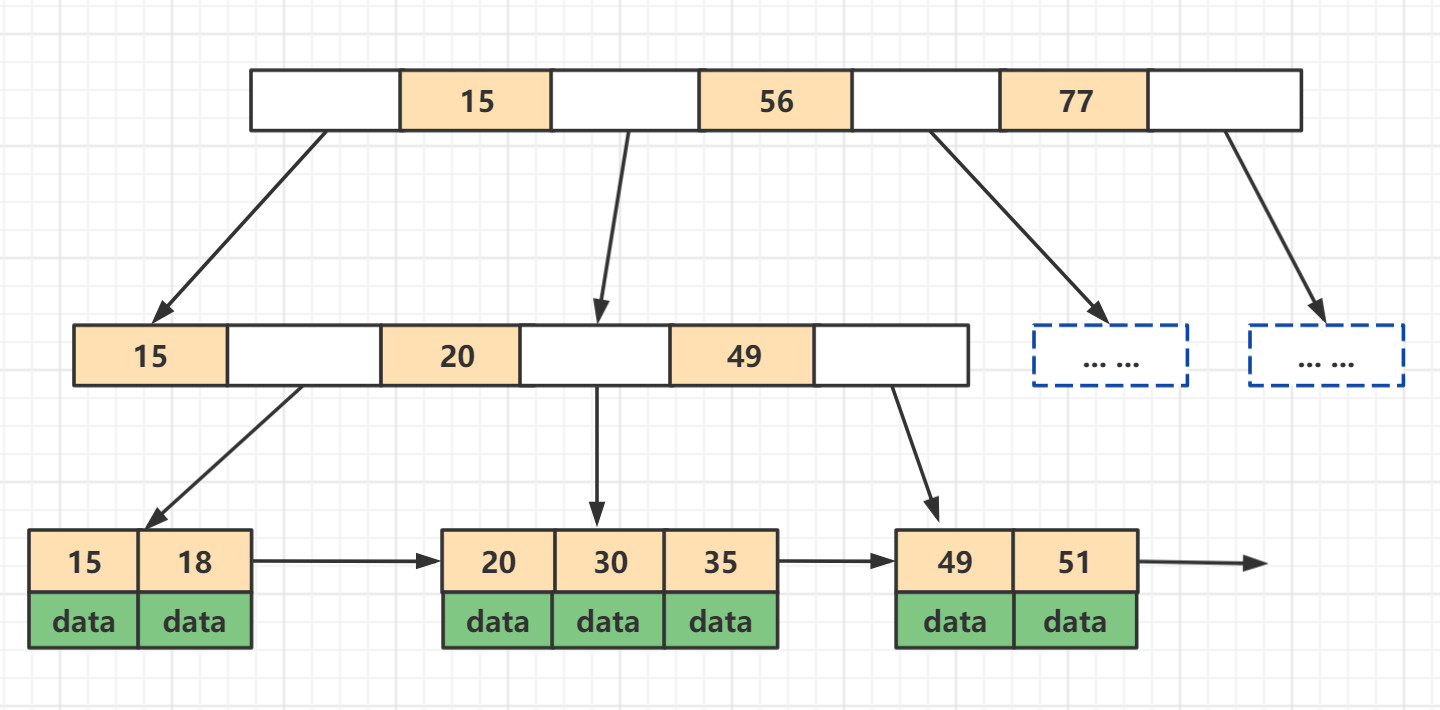
- 非叶子节点只存储索引值(键值信息)
- 数据记录都保存在叶子节点中
- 所有叶子节点之间都有一个链指针
B+Tree的优势
- B+树的磁盘读写代价更低
B+树的非叶子节点并没有指向关键字具体信息的指针。因此其非叶子节点相对B 树更小。非叶子节点所能容纳的关键字的数量也就越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
- B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率稳定
- B+树便于范围查询
相比B树,B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子节点的指针进行遍历即可。而B树需要遍历范围内所有的节点和数据,显然B+Tree效率高。
一颗B+树可以存储多少数据?
- B+Tree的节点大小等于一个页的大小(16KB)
- B+Tree的根节点是在内存中保存的,子节点才是存储在磁盘上
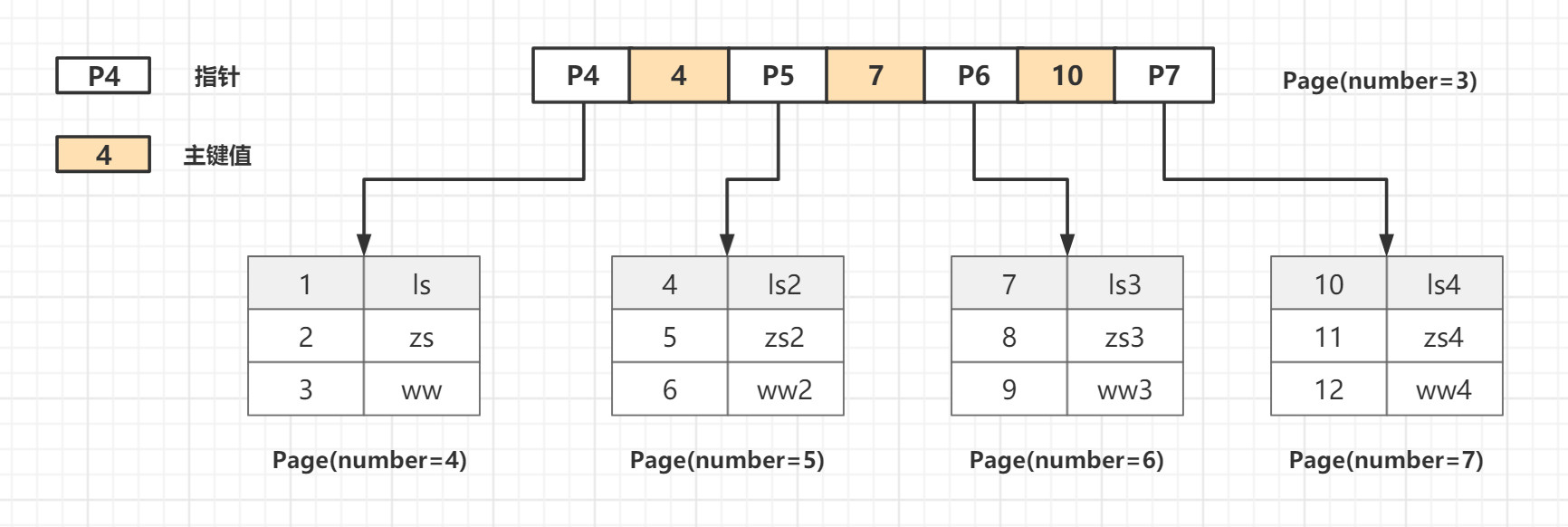
高度为2的B+Tree能存放的总记录数: 根节点的指针数*单个叶子节点的总记录行数
- 计算根节点的指针数: 关键字=4b 指针=6b 16384/(4+6)=1638,一个非叶子节点最多可以存储1638指针
- 计算每个叶子节点的记录数: 一行数据1kb,16KB/1KB=16,一个叶子节点可以存储16行数据
- 高度为2的B+Tree最多存储的记录数=1638*16=26208条数据记录,同样我们可以推算出高度为3的B+tree可以存放1638*1638*16=4292904万条数据.
所以一个高度为3的B+Tree就可以满足千万级别的数据存储,InnoDB中B+Tree的高度一般就是1-3层.
Hash索引:
MySQL中索引的常用数据结构有两种: 一种是BTree,另一种则是Hash.
Hash索引是由Hash表来实现的,是根据键值<key,value>存储数据的结构
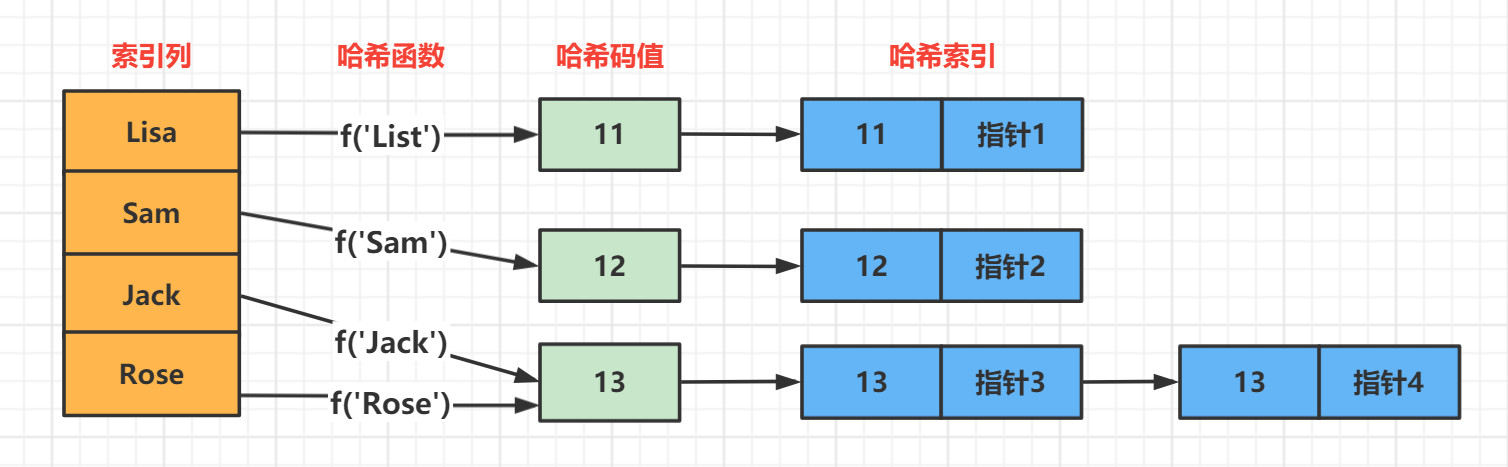
Hash索引的优缺点:
优点:在做等值查询的时候,在没有Hash冲突的情况下,通过Hash索引访问数据是非常快的.
缺点:
- 哈希索引只包括了哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行。
- 哈希索引只支持等值查询.不支持任何的范围查询和部分索引列的匹配查找的。
- 哈希索引数据不是按照索引值的顺序存储的,所以也无法用于排序
- 如果发生哈希冲突,存储引擎必须遍历整个链表,来逐行比较,直到找到符合条件的所有行
聚簇索引和非聚簇索引
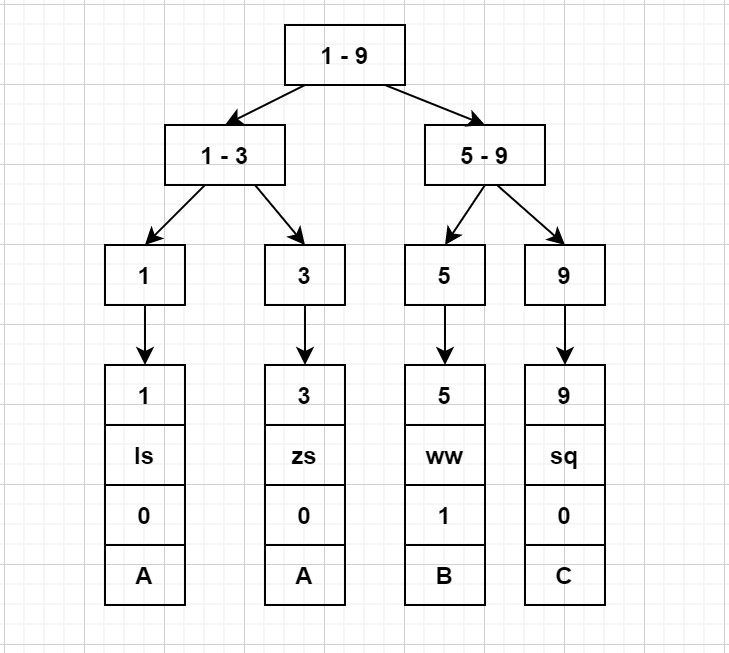
聚簇索引: 主键索引将数据和索引存储在一起,索引结构的叶子节点保存了行数据.
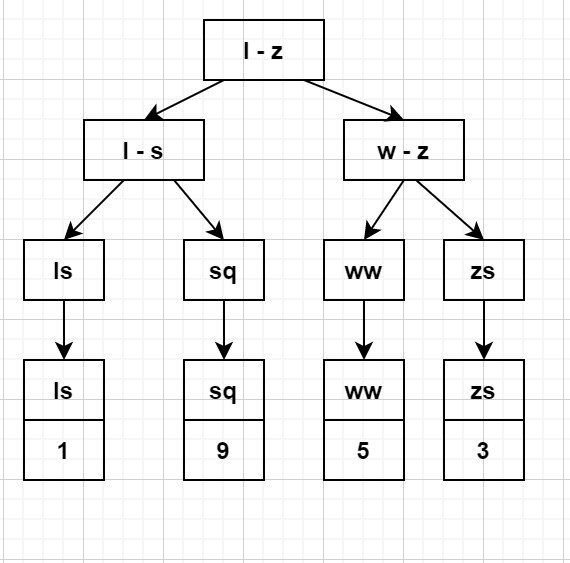
非聚簇索引:二级索引将数据和索引分开存储,二级索引的索引结构叶子节点中只保存了索引列和主键信息.
|--------|----------|---------|-----------|
| id | name | sex | level |
| 1 | ls | 0 | A |
| 3 | zs | 0 | A |
| 5 | ww | 1 | B |
| 9 | sq | 0 | C |
InnoDB的表要求必须要有聚簇索引:
- 如果表中定义了主键,这个主键索引就是聚簇索引.
- 如果表没有主键,第一个非空unique列作为聚簇索引
- 否则Innodb会创建一个隐藏的row-id列作为聚簇索引
非聚簇索引(二级索引)
InnoDB的二级索引,是根据索引列构建 B+Tree结构。但在 B+Tree 的叶子节点中只存了索引列和主键的信息。二级索引占用的空间会比聚簇索引小很多, 通常创建辅助索引就是为了提升查询效率。一个表InnoDB只能创建一个聚簇索引,但可以创建多个辅助索引。
使用聚簇索引和非聚簇索引要注意的问题:
聚簇索引注意问题: 主键最好不要用UUID,建议使用int类型 自增主键
非聚簇索引注意问题:
回表问题:回表指的是先根据普通索引找到主键值,然后再根据主键值去聚簇索引中找到完整的数据记录,这就是回表.
我们来执行这样一条 select * from A where name = 'ls'; , MySQL在执行这条SQL时的过程是这样的:
- 在通过name进行查询时,需要扫描两遍索引树
第一遍: 先通过普通索引定位到 主键值 = 1
第二遍: 根据主键值在聚集索引中定位到具体的记录
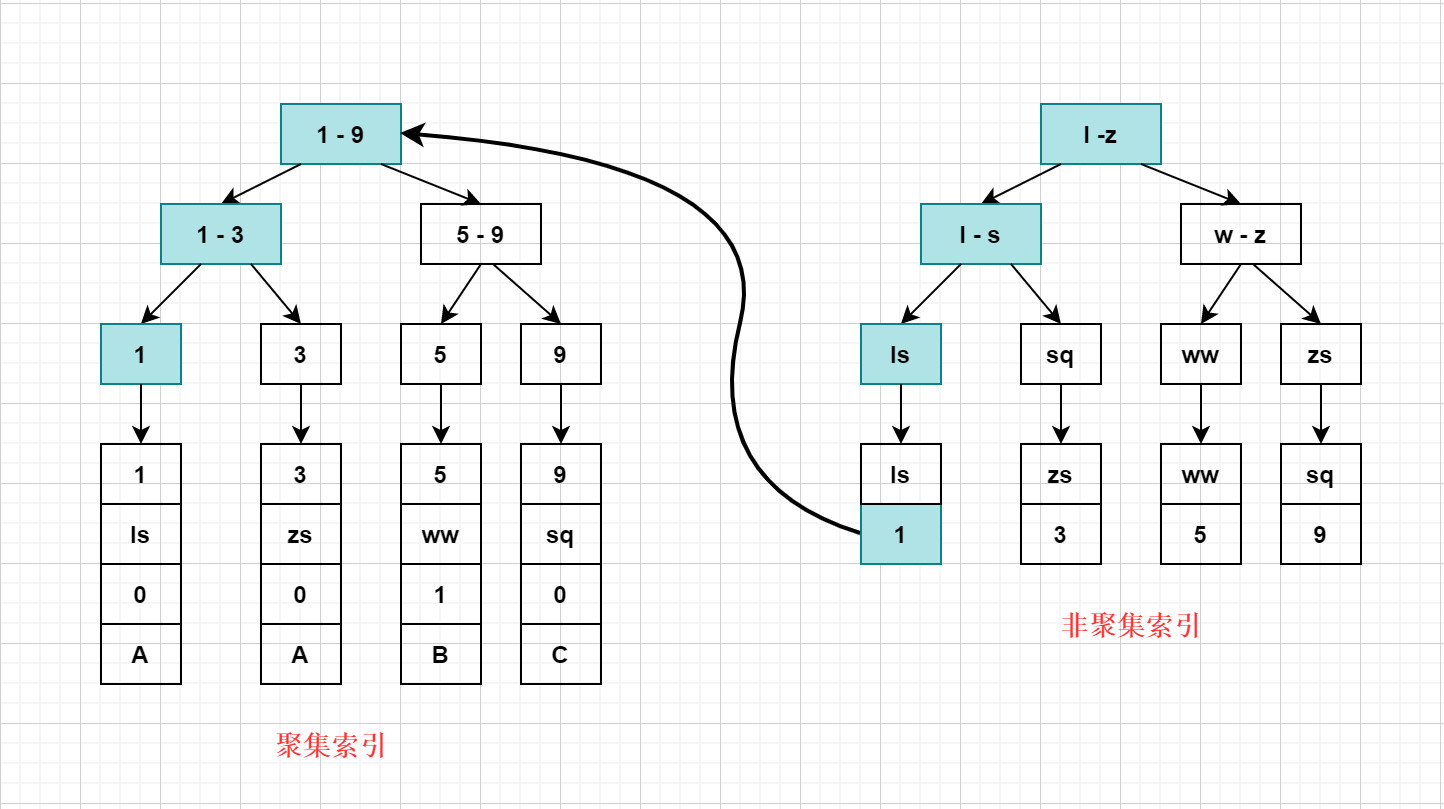
回表: 先根据普通索引查询到主键值,再根据主键值在聚集索引中获取行记录,这就是回表. 回表查询,相对于只扫描一遍聚集索引树的性能 要低一些
使用覆盖索引来避免回表
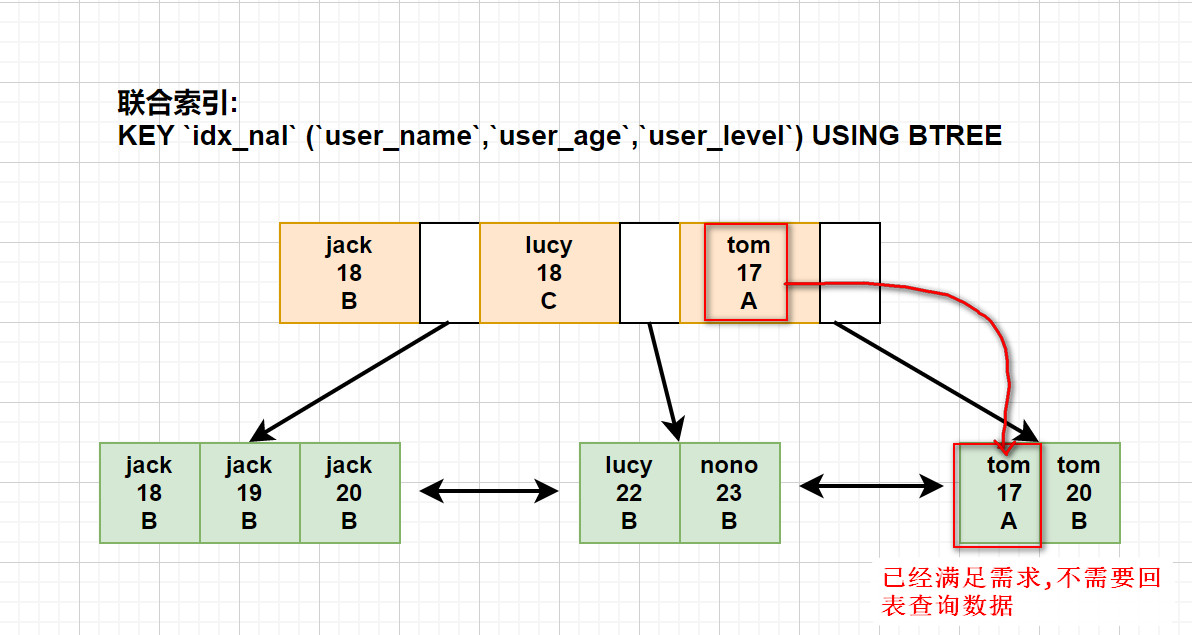
如果一个索引包含了所有需要查询的字段的值 (不需要回表),这个索引就是覆盖索引。
覆盖索引是一种避免回表查询的优化策略: 只需要在一棵索引树上就能获取 SQL所需的所有列数据,无需回表,速度更快。
具体的实现方式:
将被查询的字段建立普通索引或者联合索引,这样的话就可以直接返回索引中的数据,不需要再通过聚集索引去定位行记录,避免了回表的情况发生。
比如: 下面这样一条SQL语句,就使用到了覆盖索引
SELECT user_name,user_age,user_level FROM users
WHERE user_name = 'tom' AND user_age = 17;