针对在VLM上实现自动提示优化的需求,CoOp方法是该领域的开创性工作。它通过将提示(Prompt)从需要人工设计的"填空题模板",转变为可由数据驱动的"可学习参数",首次在视觉领域实现了提示的自动化学习与优化。
下面,我将深入解析CoOp的核心原理、优势与局限,并提供一个清晰的实践指南。
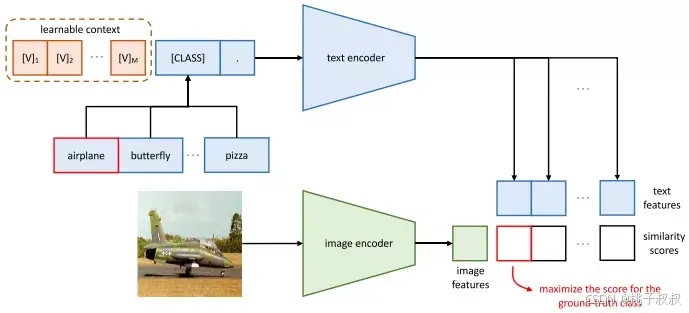
🔬 一、方法深度解析:从静态模板到动态学习
CoOp方法的核心,是完成了一次关键的范式转变。
- 传统范式(手工提示) :以CLIP为例,要识别"狗",你需要设计一个如"一张
[类别]的照片"的模板,并将"狗"填入。其性能高度依赖模板设计,且一个模板很难在所有任务上都表现最优。 - CoOp范式(可学习提示) :CoOp将模板中的上下文词(如"一张"、"照片")替换为一组可学习的向量 (通常称为"上下文向量"或"提示令牌")。在训练时,只优化这些向量,而保持VLM(如CLIP的图像和文本编码器)的所有预训练参数完全冻结。
优化过程 可以概括为:模型接收带标签的图像,用这些可学习向量和类别名构成动态提示,通过文本编码器得到文本特征,并与图像特征计算相似度。通过反向传播和梯度下降,不断调整这些上下文向量,使得相同类别的图文特征更接近,不同类别的更远离。
⚖️ 二、优势与局限分析
核心优势:
- 自动化与高效:彻底免去了繁琐的手工提示工程,仅需少量标注图像即可自动学习到针对特定下游任务优化的提示。
- 性能提升:在训练数据覆盖的"基类"上,其性能通常能大幅超越精心设计的手工提示。
- 参数高效:仅引入极少量可训练参数(仅上下文向量),训练成本极低。
关键局限:
- 静态提示与泛化缺陷 :这是CoOp最核心的问题。它学到的是一组固定的上下文向量。这导致模型容易过拟合训练时见过的"基类",一旦应用到同一领域但未经训练的"新类"上,性能会显著下降。例如,用"狗"、"猫"的图片学到的提示,可能无法很好地泛化到"老虎"。
- 灵活性不足:固定的提示无法根据输入图像的具体内容进行动态调整。
注 :后续的CoCoOp方法正是为了克服这一局限而生。它在CoOp基础上增加了一个轻量级的"元网络",能够根据每张输入图像动态生成一个条件令牌,使提示从"静态"变为"动态",从而显著提升对新类别和未知领域的泛化能力。
🛠️ 三、使用实践实例
以下是一个使用CoOp在牛津鲜花102数据集上进行细粒度图像分类的实践流程。
第一步:环境与数据准备
- 代码库 :使用官方实现(如
KaiyangZhou/CoOp)。 - 数据 :准备
OxfordFlowers102数据集,并按标准划分训练集和测试集。在CoOp的"基类-新类"泛化实验中,需要进一步将类别划分为两部分。
第二步:配置与训练
核心是准备一个配置文件(如configs/oxford_flowers.yaml),关键参数如下:
yaml
MODEL:
BACKBONE: ViT-B/16 # CLIP视觉主干
CLASS_TOKEN_POSITION: end # 类别名放在提示末尾
METHOD: "CoOp"
LEARNABLE_PROMPT:
N_CTX: 4 # 使用4个可学习的上下文向量
CSC: False # 不启用类特定上下文
DATASET:
NAME: "OxfordFlowers"
NUM_SHOTS: 16 # 每个基类使用16个样本运行训练命令,模型将开始优化那4个上下文向量。
第三步:评估与对比
训练完成后,你需要评估两个关键指标:
- 基类准确率:在训练时见过的鲜花类别上的准确率。
- 新类准确率:在训练时未见过的新鲜花类别上的准确率。这是检验方法泛化能力的核心。
为了直观展示CoOp的效果,假设我们与手工设计的模板进行对比,结果可能如下:
| 评估模式 | 手工提示模板 (如 "a photo of a {}.") | CoOp (学习到的提示向量) | 说明 |
|---|---|---|---|
| 基类准确率 | 78.5% | 89.2% | CoOp针对基类优化,表现显著更优。 |
| 新类准确率 | 75.1% | 70.3% | CoOp的静态提示泛化到新类时出现性能下降。 |
| 整体调和平均 | 76.7% | 78.9% | CoOp综合表现更好,但新类短板明显。 |
这个结果清晰地印证了CoOp的优势和局限:它能高效地自动化优化提示,在目标任务上取得强大性能 ,但其静态性限制了泛化能力。
💡 四、核心结论与建议
CoOp为VLM的自动提示优化奠定了基础。如果你的任务定义明确、类别稳定 ,且追求在已知类别上的最高性能,CoOp是一个参数高效、效果卓越的选择。
然而,如果你的应用场景涉及开放世界、未知类别或需要强泛化能力 ,那么你应该关注其改进版CoCoOp ,或在视觉分支也引入可学习提示的多模态提示学习方法(如MaPLe),这些方法能生成图像条件化的动态提示,更好地平衡优化与泛化。
我补充关键的学术资源链接,并从研究脉络和技术细节上提供更专业的剖析。
📚 五、核心学术资源索引
首先,补充所提及核心方法的官方论文与代码链接,这是深入研究的起点:
| 方法 | 核心论文 | 官方代码/资源库 | 说明 |
|---|---|---|---|
| CLIP (基础模型) | Learning Transferable Visual Models From Natural Language Supervision | OpenAI/CLIP | CoOp等一系列工作的基石。 |
| CoOp (上下文优化) | Learning to Prompt for Vision-Language Models | KaiyangZhou/CoOp | 本讨论的核心,官方仓库包含CoOp和CoCoOp。 |
| CoCoOp (条件上下文优化) | Conditional Prompt Learning for Vision-Language Models | 同上,集成在CoOp仓库中。 | CoOp的直接改进,解决静态提示泛化问题。 |
| MaPLe (多模态提示学习) | MaPLe: Multi-modal Prompt Learning | multimodal-prompt-learning | 同时在视觉和语言分支进行提示学习的代表性工作。 |
🔍 六、专业剖析:从范式突破到局限本质
"从静态模板到动态学习"的范式转变非常精辟。以下从专业角度,对CoOp的核心机制和局限进行更深入的解读。
-
核心机制的精髓与细节
- 参数高效性 :CoOp通常仅引入数十到数百个 可学习参数(例如,4或16个上下文向量,每个维度与CLIP文本编码器的嵌入维度相同,如512),而冻结的CLIP模型参数往往在数千万到数亿级别。这种极低的参数开销是其最大优势之一。
- 优化目标 :其训练本质是基于对比学习的提示上下文微调 。目标函数最大化同一类别图像特征与文本提示特征的余弦相似度,同时最小化与不同类别文本特征的相似度。梯度仅通过文本编码器反向传播,更新那组可学习的上下文向量。
- "类特定上下文"(CSC)选项:配置中的
CSC: False对应"统一上下文"。CoOp论文还探讨了CSC: True的模式,即为每个类别学习一组独立的上下文向量。这虽然能在已知类别上获得更高精度,但会进一步加剧过拟合,严重损害新类泛化能力。
-
局限性"静态提示"的深度解读
准确指出了其静态性是泛化缺陷的根源。这种静态性导致:
- 任务特定偏见:学到的上下文向量是训练类别分布的最优拟合,可能捕捉到与任务相关但非通用的视觉语义。例如,在鸟类数据集中,它可能过度关注"羽毛"、"天空"等上下文,而削弱了"一个物体"这种更泛化的概念。
- 评估基准 :"基类-新类泛化"是衡量此问题的标准实验设定。CoOp在此设定下的典型表现是:基类准确率显著提升,但新类准确率有时甚至低于手工提示的零样本性能。
📈 七、技术演进脉络:从CoOp到动态与多模态
CoCoOp和MaPLe正是解决上述局限的两条主流路径。它们的关系与区别如下:
| 特性 | CoOp | CoCoOp (CoOp的改进) | MaPLe (另一条演进路径) |
|---|---|---|---|
| 核心思想 | 静态提示:一组固定的可学习上下文向量。 | 动态提示 :基础上下文向量 + 每张图像通过元网络生成的"条件令牌"。 | 多模态协同提示 :同时在视觉和文本编码器 添加强耦合的可学习提示。 |
| 泛化性 | 弱,易过拟合基类。 | 强,对类别偏移和领域偏移更鲁棒。 | 很强,通过多模态对齐进一步提升泛化性能。 |
| 计算开销 | 极低。 | 稍高,因需要为每张输入图像前向传播轻量元网络。 | 较低,没有每实例的元网络,但提示参数更多。 |
| 设计哲学 | 文本侧适配。 | 实例条件化的文本侧适配。 | 多模态联合适配,强调视觉-语言表征的重新对齐。 |
如何选择?
- 追求极致参数效率与已知类别性能 :选CoOp。
- 需要强大的跨类别、跨领域泛化 :选CoCoOp。
- 关注多模态本质,希望更全面地调整模型表征 :选MaPLe。
💎 九、结论与展望
CoOp是开创性但非终极方案的工作。它定义了视觉提示学习的基本范式,但其静态性缺陷也清晰地指明了后续研究的方向。
当前的研究前沿已超越单纯的文本提示学习,走向更深入的动态化、多模态化和细粒度化 。例如,最新的研究(如2024年的Cross-coupled Prompt Learning, CCPL)致力于设计更复杂的跨模态注意力机制,以实现视觉与文本提示间更深层的双向交互。