在多模态大模型(LMM)爆发的今天,Qwen2.5-VL 凭借其强大的视觉理解能力成为了开源界的佼佼者。然而,通用模型在特定垂直领域(如医疗影像、工业质检、保险理赔)的表现往往难以达到生产级要求。
今天,我们将手把手教你如何使用 Unsloth 框架,对 Qwen2.5-VL-3B 进行高效微调(LoRA),打造一个专门识别车辆里程表、分析车况的"汽车保险承保专家"。
💡 为什么选择 Unsloth + Qwen2.5-VL?
- Qwen2.5-VL: 阿里通义千问最新视觉模型,OCR 能力和图像推理能力极强,3B 版本轻量高效。
- Unsloth: 目前最强的微调加速库。它能将显存占用降低 60% 以上,训练速度提升 2 倍,使得在单张 RTX 3090/4090(24G显存)上微调多模态模型成为可能。
- 应用场景: 保险公司每天需要处理数万张车辆照片。自动提取里程数、识别车型、判断受损部位,能极大降低人工成本。
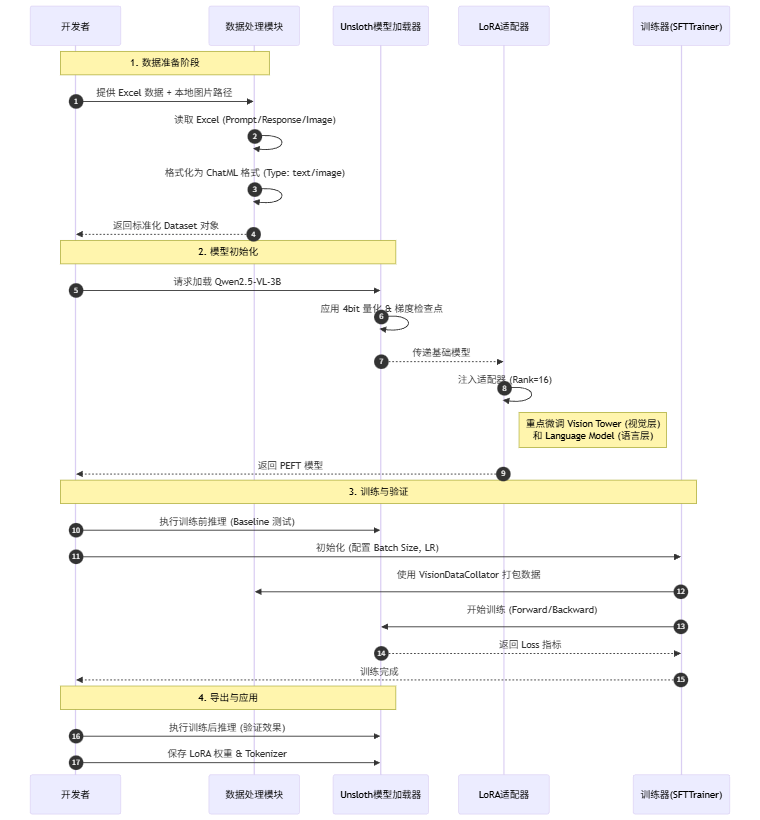
🛠️ 核心流程时序图
在开始写代码前,让我们通过一张时序图理清整个微调流水线的工作逻辑:
💻 代码实战详解
1. 环境准备与模型加载
首先,我们需要加载模型。Unsloth 的 FastVisionModel 处理了所有复杂的底层优化。
python
import torch
from unsloth import FastVisionModel
from PIL import Image
# 路径配置 (建议使用绝对路径)
MODEL_PATH = "/root/autodl-tmp/models/Qwen/Qwen2.5-VL-3B-Instruct"
# 1. 加载模型
print("正在加载模型...")
model, tokenizer = FastVisionModel.from_pretrained(
model_name = MODEL_PATH,
load_in_4bit = False, # 显存大于24G可选False,否则建议True
use_gradient_checkpointing = "unsloth", # 显存优化关键参数
)
# 2. 配置 LoRA
# 我们不仅要微调语言部分,还要微调视觉部分(Vision Tower),这对识别特定物体至关重要
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True, # 开启视觉层微调
finetune_language_layers = True, # 开启语言层微调
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16, # LoRA Rank
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3407,
)2. 多模态数据处理
Qwen2-VL 对数据格式有严格要求。我们需要将 Excel 中的数据转换为包含 Pillow Image 对象的格式。
数据格式示例 :Excel 表格需包含
image(图片路径),prompt(指令),response(专家回复) 三列。
python
import pandas as pd
import os
def load_and_process_data(file_path):
"""读取Excel并转换为Qwen2-VL训练格式"""
df = pd.read_excel(file_path)
converted_data = []
for idx, row in df.iterrows():
image_path = row["image"]
if pd.notna(image_path) and os.path.exists(image_path):
# 关键:必须将图片转为 RGB 模式
image = Image.open(image_path).convert('RGB')
# 构建对话结构
conversation = {
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": row["prompt"]},
{"type": "image", "image": image}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": row["response"]}
]
}
]
}
converted_data.append(conversation)
return converted_data
# 加载数据
train_dataset = load_and_process_data("qwen-vl-train.xlsx")
print(f"成功加载 {len(train_dataset)} 条训练数据")3. 配置训练器 (SFTTrainer)
这里使用 HuggingFace TRL 库的 SFTTrainer,但必须配合 Unsloth 提供的 UnslothVisionDataCollator,否则处理图片 Batch 时会报错。
python
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
# 切换到训练模式
FastVisionModel.for_training(model)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
data_collator = UnslothVisionDataCollator(model, tokenizer), # 视觉微调必需!
train_dataset = train_dataset,
args = SFTConfig(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4, # 等效 Batch Size = 8
warmup_steps = 5,
max_steps = 60, # 快速演示用,实际建议跑 3-5 个 Epoch
learning_rate = 2e-4, # LoRA 常用学习率
optim = "adamw_8bit", # 8bit 优化器,进一步节省显存
logging_steps = 1,
output_dir = "checkpoints",
report_to = "none",
# 必须配置:跳过默认的文本处理,因为我们在数据加载时已经处理好了
remove_unused_columns = False,
dataset_text_field = "",
dataset_kwargs = {"skip_prepare_dataset": True},
),
max_seq_length = 2048,
)
# 开始训练
trainer_stats = trainer.train()4. 效果验证与保存
微调完成后,我们通过一张测试图片来验证模型是否学会了"专家口吻"和精准识别。
python
from transformers import TextStreamer
# 切换推理模式
FastVisionModel.for_inference(model)
# 准备测试
test_image_path = "images/1-vehicle-odometer-reading.jpg"
image = Image.open(test_image_path).convert("RGB")
instruction = "你是一名汽车保险承保专家。这里有一张车辆里程表的图片。请从中提取关键信息。"
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": instruction}
]}
]
# 生成输入 Tensor
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
# 流式输出结果
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128, use_cache=True, temperature=0.2)
# 保存模型
model.save_pretrained("car_insurance_lora_output")
tokenizer.save_pretrained("car_insurance_lora_output")📊 显存占用分析
很多同学关心配置要求,以下是实测数据(基于 3B 模型):
| 阶段 | 显存占用 (VRAM) | 备注 |
|---|---|---|
| 模型加载 (4-bit) | ~3.5 GB | 极其轻量 |
| 模型加载 (16-bit) | ~7.8 GB | 无量化模式 |
| 训练峰值 (LoRA) | ~14 - 18 GB | 取决于 Batch Size 和图片分辨率 |
结论 :使用 Unsloth,你完全可以在 单张 RTX 3090 / 4090 (24GB) 甚至 RTX 4080 (16GB, 需开4-bit) 上完成这个视觉多模态模型的微调任务!
📥 完整代码
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Qwen2.5-VL 3B 视觉模型微调完整脚本 - 汽车保险承保专家
基于 Unsloth 框架进行高效微调 (LoRA)
环境依赖安装建议:
pip install unsloth
pip install --no-deps "trl<0.9.0" peft accelerate bitsandbytes
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install pandas openpyxl
"""
import os
import json
import torch
import pandas as pd
from PIL import Image
from unsloth import FastVisionModel
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
from transformers import TextStreamer
# ==========================================
# 1. 配置路径与参数
# ==========================================
# 请根据你的实际环境修改这些路径
MODEL_PATH = "/root/autodl-tmp/models/Qwen/Qwen2.5-VL-3B-Instruct" # 模型路径或 HuggingFace ID
DATA_PATH = "qwen-vl-train.xlsx" # 训练数据路径
TEST_IMAGE_PATH = "images/1-vehicle-odometer-reading.jpg" # 用于测试的图片路径
OUTPUT_DIR = "car_insurance_lora_output" # 结果保存目录
# 训练参数
MAX_SEQ_LENGTH = 2048
LORA_RANK = 16
BATCH_SIZE = 2
GRAD_ACCUM_STEPS = 4
MAX_STEPS = 60 # 演示用,正式训练建议设大一点或使用 epochs
# ==========================================
# 2. 模型加载与 LoRA 初始化
# ==========================================
print(f"正在加载模型: {MODEL_PATH} ...")
model, tokenizer = FastVisionModel.from_pretrained(
model_name=MODEL_PATH,
load_in_4bit=False, # 如果显存 < 24GB,建议设为 True
use_gradient_checkpointing="unsloth",
)
print("配置 LoRA 适配器...")
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=True,
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
r=LORA_RANK,
lora_alpha=LORA_RANK,
lora_dropout=0,
bias="none",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
# ==========================================
# 3. 数据集加载与处理
# ==========================================
print(f"正在处理数据集: {DATA_PATH} ...")
def load_and_process_data(file_path):
"""读取Excel并转换为Qwen2-VL训练格式"""
if not os.path.exists(file_path):
print(f"错误: 找不到文件 {file_path}")
return None
try:
df = pd.read_excel(file_path)
except Exception as e:
print(f"读取Excel失败: {e}")
return None
converted_data = []
success_count = 0
for idx, row in df.iterrows():
try:
image_path = row.get("image", "")
prompt = row.get("prompt", "")
response = row.get("response", "")
if pd.notna(image_path) and os.path.exists(str(image_path)):
# 加载图片并转为RGB
image = Image.open(image_path).convert('RGB')
# 构建对话格式
conversation = {
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": str(prompt)},
{"type": "image", "image": image}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": str(response)}
]
}
]
}
converted_data.append(conversation)
success_count += 1
else:
# print(f"跳过无效图片路径: {image_path}") # 调试时可开启
pass
except Exception as e:
print(f"处理第 {idx} 行数据时出错: {e}")
print(f"数据处理完成: 成功 {success_count} / 总计 {len(df)}")
return converted_data
train_dataset = load_and_process_data(DATA_PATH)
if not train_dataset:
print("没有有效的训练数据,程序退出。")
exit()
# ==========================================
# 4. 训练前推理测试 (Baseline)
# ==========================================
print("\n=== 执行训练前基准测试 ===")
FastVisionModel.for_inference(model)
test_instruction = "你是一名汽车保险承保专家。这里有一张车辆里程表的图片。请从中提取关键信息。"
test_image = None
if os.path.exists(TEST_IMAGE_PATH):
test_image = Image.open(TEST_IMAGE_PATH).convert('RGB')
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": test_instruction}
]}
]
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
inputs = tokenizer(
test_image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
print(">>> 训练前模型输出:")
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128,
use_cache=True, temperature=1.5, min_p=0.1)
else:
print(f"警告: 测试图片 {TEST_IMAGE_PATH} 不存在,跳过基准测试。")
# ==========================================
# 5. 模型训练
# ==========================================
print("\n=== 开始训练 ===")
FastVisionModel.for_training(model)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer),
train_dataset=train_dataset,
args=SFTConfig(
per_device_train_batch_size=BATCH_SIZE,
gradient_accumulation_steps=GRAD_ACCUM_STEPS,
warmup_steps=5,
max_steps=MAX_STEPS,
learning_rate=2e-4,
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="checkpoints",
report_to="none",
# 视觉微调特定配置
remove_unused_columns=False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
),
max_seq_length=MAX_SEQ_LENGTH,
)
# 打印显存状态
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
print(f"初始显存使用: {start_gpu_memory} GB")
# 开始微调
trainer_stats = trainer.train()
# 打印训练统计
end_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
print(f"训练结束显存使用: {end_gpu_memory} GB")
print(f"训练耗时: {trainer_stats.metrics['train_runtime']} 秒")
# ==========================================
# 6. 训练后推理测试
# ==========================================
if test_image:
print("\n=== 执行训练后验证测试 ===")
FastVisionModel.for_inference(model)
# 重新构建输入(为了安全起见重新tokenize)
inputs = tokenizer(
test_image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
print(">>> 训练后模型输出:")
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128,
use_cache=True, temperature=1.5, min_p=0.1)
# ==========================================
# 7. 保存模型
# ==========================================
print(f"\n正在保存模型至 {OUTPUT_DIR} ...")
model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
print("全部完成!")
# 保存为 GGUF (可选,按需取消注释)
# model.save_pretrained_gguf(OUTPUT_DIR, tokenizer, quantization_method = "q4_k_m")相关资源:
百度网盘:https://pan.baidu.com/s/1jCfexDfiAOHP32-ytUgCIQ?pwd=fjdd
