引言
"运营给了半年规划 ------DAU 要冲 30 万,到时候每天的对话消息量估计得超 5 千万,现在这张 message 表撑不住啊!"
周一的技术评审会上,后端组长老张说:当前 message 表数据量不到 9 千万,但按日增 5 千万的预期算,半年后数据量会飙到 60 亿。
更棘手的是,最近几次压测显示,单表数据量突破 1 亿后,查询延迟就从 50ms 涨到了 300ms,要是真等撑到 60 亿,系统绝对会崩。
作为公司后台技术负责人,杨萧心里清楚 "提前布局" 的重要性:后台架构最忌 "临时抱佛脚",等数据量真上来了再分表,不仅迁移风险高,还可能影响业务增长。
可业务团队也有要求 ------ 现在每天有上百万用户在用,分表时 "不能停机、不能影响现有数据",还要确保半年后能平滑扛住 60 亿数据量。

接下来的三周,杨萧带着团队反复测算、验证,最终拿出了一套 "按数据语言 + 用户对话" 的分层分表方案,既解决了当前的性能隐患,又为后续 60 亿数据量预留了扩容空间。
今天苏三就从后台开发的视角,拆解这套 "提前布局" 的分表方案,以及那些从压测和预演中踩出的坑。
一、先搞懂:为什么要 "提前分表"?等数据到 60 亿再分不行吗?
刚开始讨论时,有同事提出 "现在才 9 千万数据,先凑合用,等快到 2 亿再分表也不迟"。杨萧直接否定了这个想法:"等数据到 2 亿,再算方案、做开发、搞迁移,至少要 1 个月,到时候日增 5 千万数据,没等分完表,单表就撑爆了。"
更关键的是,这张 message 表有个核心业务属性 ------language字段(存储繁中、英文、日语),80% 的查询都是 "按语言 + userId+dialogId 筛选",比如 "查询用户 A 在英文对话 B 中的历史消息"。如果等数据量上来再分表,会面临两个更棘手的问题:
-
跨表扫描风险:若只按 userId Hash 分表,查某类语言的消息要遍历所有分表,性能只会更差;
-
迁移成本激增:数据量从 9 千万涨到 2 亿,迁移时间会从 3 天变成 1 周,期间业务还要正常运行,风险翻倍。
最终我们确定了 "先按语言垂直分片,再按用户对话 Hash 水平分片" 的分层策略,核心是 "提前适配业务属性,为后续 60 亿数据量铺路":
-
业务隔离:不同语言的消息存到独立表集群(如message_zh_hant、message_en),现在查询能精准路由,未来数据量增长也不会相互影响;
-
弹性扩容:多语言数据量预期差异大(繁中占 60%、英文 30%、日语 10%),独立集群可单独扩缩容 ------ 比如繁中数据先到 36 亿,就先给繁中集群加表,不用动英文和日语集群;
-
查询友好:userId+dialogId是查询核心条件,Hash 分片能让同一对话的消息集中存储,哪怕未来数据量到 60 亿,查某条对话的消息也不用跨表。
举个具体的例子:现在一条英文消息(language=en),userId=123,dialogId=456,会先路由到 message_en 集群,再通过 hash(123_456) 计算落到对应分表;
半年后数据量涨到 60 亿,这条消息的路由逻辑不变,只是 message_en 集群的分表数从 4 个扩到 8 个,完全不影响查询体验。
二、实战细节:分多少表?虚拟节点设多少?按 60 亿预期算清楚
提前分表的核心是 "按预期数据量算参数",不能只看当前 9 千万数据 ------ 要是按现在的量分表,半年后还是要二次扩容,反而麻烦。我们所有参数都按 "半年后 60 亿数据量" 测算,同时兼顾当前的性能需求。
2.1 分表数量:按 60 亿预期,单表预留 4.5 亿行空间
MySQL 单表的性能上限,我们按 "8 核 16G 实例、机械硬盘" 算(公司数据库大多是机械盘,SSD 成本太高,且 60 亿数据用 SSD 投入太大):
- 单表数据量≤5000 万行:当前查询延迟能稳定在 50ms 内;
- 单表数据量≤4.5 亿行:半年后数据量上来,查询延迟也能控制在 100ms 内(预留 5000 万行冗余,避免频繁扩容)。
结合 60 亿总预期数据量和语言占比(繁中 60%、英文 30%、日语 10%),我们算出各语言集群的初始分表数:
- 繁中:60 亿 ×60%=36 亿 → 分 8 个表(36 亿 ÷8=4.5 亿 / 表,刚好卡准性能上限);
- 英文:60 亿 ×30%=18 亿 → 分 4 个表(18 亿 ÷4=4.5 亿 / 表);
- 日语:60 亿 ×10%=6 亿 → 分 2 个表(6 亿 ÷2=3 亿 / 表,预留 1.5 亿行空间,未来可扩到 4 个表)。
这里踩过一个坑:一开始想给繁中集群多加分表(比如 16 个),但运维提醒 "单 MySQL 实例承载分表数最好 ≤32 个"------ 现在把繁中 8 个表分到 2 个实例(每个实例 4 个表),未来扩容到 16 个表,也只需再加 2 个实例,不用重构架构,成本和复杂度都可控。
2.2 虚拟节点:100 个 / 物理表,提前解决未来数据倾斜
老张第一次做压测时发现,哪怕现在只有 9 千万数据,日语 2 个分表的数据分布也不均:一个表存了 5200 万行,另一个只存了 3800 万行 ------ 这要是到了 6 亿数据,差距会变成 3.5 亿和 2.5 亿,性能差距会更明显。
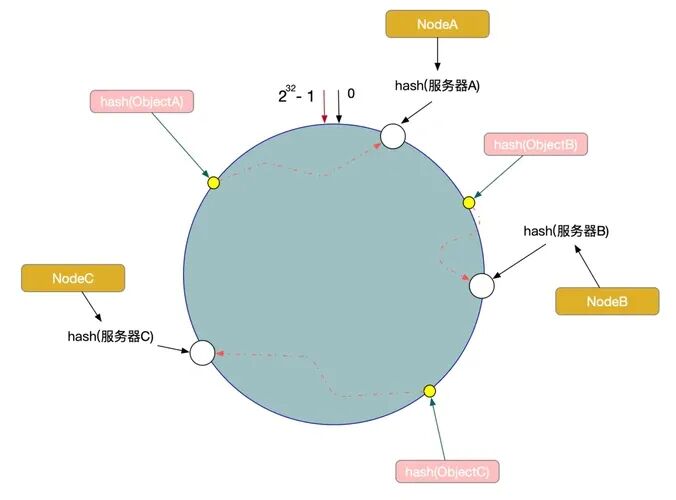
解决办法是加 "虚拟节点"------ 给每个物理分表映射多个虚拟节点,让它们在 Hash 环上分布更均匀,提前适配未来数据量增长。我们最终确定 "每个物理表设 100 个虚拟节点",理由有三个:
- 倾斜率可控:当前 9 千万数据下,倾斜率从 15% 降到了 3% 以内;未来 60 亿数据量,倾斜率也能稳定在 5% 以下;
- 路由开销小:100 个虚拟节点,Hash 计算和路由耗时只有微秒级,不会影响当前查询性能;
- 扩容兼容:未来新增分表,只需给新表加 100 个虚拟节点,就能无缝融入现有 Hash 环,不用调整旧节点。
具体实现时,我们用 CRC32 算法计算 Hash 值(比 MD5 快 3 倍,适合高频写入场景),伪代码如下:
// 计算虚拟节点位置:物理表名+虚拟节点索引,生成Hash值(适配未来新增表)•
funccalcVirtualNodeHash(tableNamestring, virtualIdxint) uint32 {•
key :=fmt.Sprintf("%s_%d", tableName, virtualIdx)•
returncrc32.ChecksumIEEE([]byte(key))•
}•
•
// 消息路由:先按语言找集群,再按Hash找物理表(当前和未来逻辑一致)•
funcrouteMessage(msgMessage) string {•
// 1. 按语言找集群(如message_en,未来新增语言直接加集群)•
cluster :=getClusterByLanguage(msg.Language)•
// 2. 计算消息Hash值(userId+dialogId,确保同一对话消息聚合)•
msgHash :=crc32.ChecksumIEEE([]byte(fmt.Sprintf("%s_%s", msg.UserId, msg.DialogId)))•
// 3. 找Hash环上最近的虚拟节点,映射到物理表•
virtualNode :=findNearestVirtualNode(cluster, msgHash)•
returngetPhysicalTable(cluster, virtualNode)•
}三、最关键的坑:无停机迁移!当前 9 千万数据怎么迁?未来扩容怎么办?
提前分表的迁移压力比 "数据量大了再迁" 小很多,但业务要求 "不能停机"------ 现在每天有上百万用户发消息,哪怕停 10 分钟,都会丢数据。
我们把迁移分成 "当前 9 千万→分表集群" 和 "未来分表→扩容" 两个阶段,核心是 "双写 + 灰度,最小化影响"。
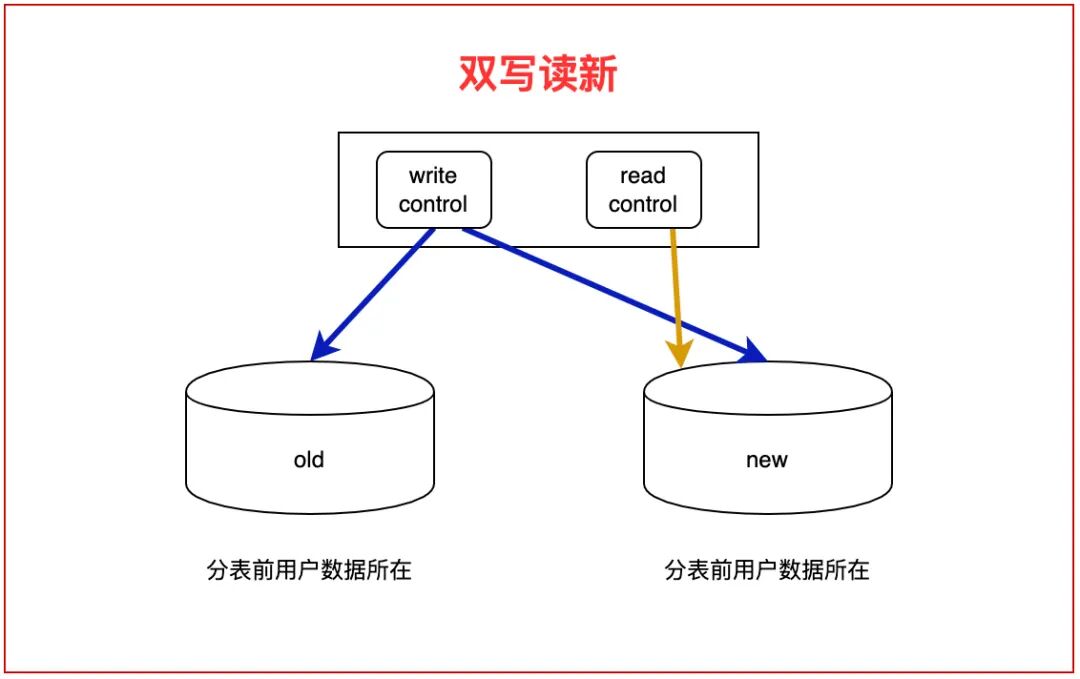
阶段 1:当前 9 千万数据→分表集群(3 天搞定,无感知迁移)
现在数据量小,迁移难度低,但我们还是走了 4 步,确保万无一失:
(1)双写初始化(1 天)
- 开发路由中间件:所有新写入的消息,同时写入旧单表和新分表(按语言 + Hash 路由)------ 当前日增数据量小,双写完全不影响性能;
- 用 Canal 解析 MySQL binlog:同步旧单表的 9 千万历史数据,按语言拆分后写入对应分表(繁中数据写入message_zh_hant,英文写入message_en);
- 这里做了个优化:同步时按 "分批次 + 错峰" 来 ------ 每批次同步 50 万行,白天同步 30%,凌晨 2-6 点同步 70%,避免影响白天业务的写入和查询。
(2)数据校验(半天)
- 量校验:每个分表的行数是否等于旧单表对应语言的行数(比如message_en4 个表总行数,是否等于旧单表中 language=en 的行数);
- 质校验:随机抽 5 万条消息,对比旧单表和分表的内容(消息内容、发送时间、语言),确保没丢数据、没改数据;
- 性能校验:跑线上 TOP10 的查询 SQL,看分表的查询耗时是否比旧单表快(比如原来查一条消息要 80ms,分表后只要 30ms,符合预期)。
(3)灰度切换读路由(1 小时)
- 先切 5% 流量:让 5% 的用户查询走分表,其他 95% 还走旧单表 ------ 当前用户量小,5% 流量只有几万用户,即使出问题影响也小;
- 观察 20 分钟:如果分表查询没报错、耗时稳定,再切 30% 流量;
- 全量切换:30% 流量稳定后,把所有查询都切到分表 ------ 留了回滚方案:如果分表出问题,1 分钟内就能切回旧单表。
(4)停止双写 + 清理旧表(1 周)
- 确认分表读写稳定 3 天后,关闭双写(只写分表);
- 旧单表设为只读,保留 7 天(防止分表出问题能回滚),7 天后逐步删除(每次删 1000 万行,避免删表时锁表)。
阶段 2:未来分表→扩容(比如繁中 8→16 表,应对 36 亿数据)
半年后繁中数据涨到 36 亿,8 个表不够用了,需要扩到 16 个表。这时候一致性 Hash 的优势就体现出来了 ------ 迁移量特别小,完全不影响业务。
(1)新增分表 + 更新 Hash 环
- 新增 8 个繁中表,每个表设 100 个虚拟节点,加入原来的 Hash 环;
- 路由中间件支持动态加载配置,不用重启服务,直接更新 Hash 环即可。
(2)双写 + 增量迁移(6 小时)
- 新写入的消息,同时写入旧分表和新增分表(按新 Hash 环路由);
- 计算 "需要迁移的数据范围":新增分表的虚拟节点,在 Hash 环上会覆盖旧分表的部分数据(比如新增表 A 的虚拟节点覆盖 Hash 值 1000-2000,这部分数据原来存在旧表 B);
- 只迁移这部分数据:从旧表 B 读取 Hash 值 1000-2000 的消息,写入新增表 A------ 总共只迁移 36 亿 ×(1/16)=2.25 亿行,仅 6.25% 的迁移量,6 小时就能完成。
(3)切换读路由 + 清理旧表
- 灰度切换读路由(5%→30%→100%),和第一次迁移逻辑一致;
- 稳定后停止双写,删除旧表中已迁移的数据。
四、后台开发必记:3 个核心注意事项(提前分表更要避坑)
提前分表看似简单,但要是细节没做好,未来数据量上来还是会出问题。我们从压测和迁移中总结了 3 个要点,尤其适合 "预期数据量远大于当前量" 的场景:
索引别贪多!按 60 亿数据量算 "最小必要索引"
一开始我们想给每个分表加 4 个索引(userId、dialogId、createTime、language),但压测发现,到 60 亿数据量时,写入性能会下降 30%------MySQL 每个索引都是 B + 树,写入时要同步更新所有索引,索引越多,写入越慢。
最后只保留了 2 个 "最小必要索引",既能覆盖当前查询,又能支撑未来 60 亿数据量:
- 主键:用雪花 ID(全局唯一,避免分表主键冲突,未来扩容也不用改);
- 联合索引:idx_user_dialog_create(userId+dialogId+createTime)------ 覆盖了 90% 的查询场景(比如 "查用户 A 在对话 B 中最近 7 天的消息",直接走这个索引,不用回表)。
分布式锁提前加!避免未来并发冲突
迁移时我们发现,即使现在数据量小,双写阶段也会出现 "同一消息被写入两次" 的问题 ------ 旧单表和分表的写入有延迟,同一个消息 ID 可能被重复写入分表。要是等未来日增 5 千万数据,这个问题会更严重。
解决办法是提前加 Redis 分布式锁:写入分表前,先拿 "messageId" 当锁键,用 SETNX 命令获取锁,获取成功才写入,写入完释放锁 ------ 这样即使未来日增 5 千万数据,也能避免重复数据,保证数据一致性。
监控按 "集群 + 未来" 设计!别只看当前数据
单表时只监控 "表行数、慢查询数",分表后发现不够 ------ 未来繁中集群有 16 个表,某个表 CPU 飙高,单看整体监控根本发现不了。

我们设计了 "三级监控",提前适配未来 60 亿数据量:
- 集群维度:每个语言集群的总 QPS、总延迟、错误率(比如繁中集群未来日增 3 千万数据,QPS 会涨到 1000,提前设告警阈值);
- 实例维度:每个 MySQL 实例的 CPU、IO、连接数(未来每个实例承载 8 个分表,IO 阈值设为 80%,避免过载);
- 分表维度:每个分表的行数、索引大小、慢查询数(未来单表到 4.5 亿行,设行数告警,提前准备扩容);
- 还加了 "增长趋势监控":按日增数据量测算,提前 1 个月预警 "某集群即将达性能上限",不用等数据满了再慌。
小结
这次 "从 9 千万到 60 亿预期" 的分表项目,最核心的收获不是 "分了多少表、设了多少虚拟节点",而是后台开发在做架构设计时,要始终记住 "提前适配业务增长,用最小成本扛住未来压力":
- 分片策略要贴合 "未来业务属性"(比如多语言、高查询频率字段),别只看当前数据,否则未来还要重构;
- 参数要按 "预期数据量" 算清楚(单表行数、实例承载量),预留扩容空间,避免频繁调整;
- 无停机迁移的核心是 "双写 + 灰度",哪怕当前数据量小,也要走完整流程,为未来大数量迁移积累经验。
现在这套分表方案已经稳定运行 6 个月,message 表数据量涨到 1.5 亿,查询延迟始终稳定在 30ms 以内。按当前增长趋势,半年后支撑 60 亿数据量完全没问题。
最后,后台架构不是 "一次性工程",而是 "跟着业务增长持续优化的过程"------ 提前布局看似麻烦,但能避免未来业务崩掉的风险,这才是最省成本的做法。
如果你的项目也面临 "业务增长快、预期数据量大" 的问题,欢迎在评论区交流,一起避坑~