零样本参考到视频生成的扩展
paper是Meta 发布在Arxiv 2025的工作
paper title:Scaling Zero-Shot Reference-to-Video Generation
Code:链接
Abstract
参考到视频(R2V)生成旨在合成既与文本提示对齐又能保留参考图像中主体身份的视频。然而,现有的 R2V 方法受制于对显式参考图像-视频-文本三元组的依赖,而这类数据的构建成本极高且难以扩展。我们通过引入 Saber 来绕过这一瓶颈。Saber 是一个可扩展的零样本框架,不需要显式的 R2V 数据。Saber 仅在视频-文本对上进行训练,采用带掩码的训练策略和专门定制的基于注意力的模型设计,以学习在身份上一致且具备参考感知的表征。我们进一步集成了掩码增强技术,以减轻参考到视频生成中常见的"拷贝-粘贴"伪影。此外,与在 R2V 数据上训练的方法相比,Saber 在不同数量参考条件下展现出显著的泛化能力,并在 OpenS2VEval 基准上取得了更优的性能。
1 Introduction
参考到视频(R2V)生成旨在合成既与给定文本提示对齐,又能保留参考图像中主体身份与外观的视频。该任务是迈向个性化视频生成的重要一步,使得诸如个性化故事讲述(Rahman et al., 2023; Wang et al., 2024; Zhou et al., 2024b)和虚拟化身(Guo et al., 2024a; Yuan et al., 2025b; Gao et al., 2025a; Shen et al., 2025)等应用成为可能。尽管文本到视频(T2V)和图像到视频(I2V)生成已经取得了长足进展(Hong et al., 2023; Yang et al., 2025; Liu et al., 2024; HaCohen et al., 2024; Kong et al., 2024; Wan et al., 2025; Gao et al., 2025b; Zhang et al., 2025),R2V 仍然独具挑战性,因为它必须在确保与文本语义对齐的同时,保持来自参考图像的高保真主体身份信息。
现有的 R2V 方法(Zhou et al., 2024a; Liu et al., 2025; Jiang et al., 2025; Deng et al., 2025; Fei et al., 2025; Hu et al., 2025b; Xue et al., 2025; Li et al., 2025)通常依赖构建显式的 R2V 数据集(例如 OpenS2V-5M(Yuan et al., 2025a)和 Phantom-Data(Chen et al., 2025b)),这些数据集包含参考图像、视频和文本提示的三元组。构建这类数据集需要复杂的数据采集、标注、聚类和过滤流水线,成本高昂且难以扩展。此外,这些数据集中参考图像多样性的不足限制了模型的泛化能力,使得其难以处理未见过的主体类别。
为此,我们提出 Saber,一个可扩展的零样本框架,用以绕过这一数据瓶颈。Saber 仅在大规模视频-文本对上进行训练,使用与 T2V 和 I2V 模型相同的数据范式。这样的设计使 Saber 能够充分利用丰富的视频-文本数据集(Chen et al., 2024b; Wang et al., 2025; Team),从而完全消除对定制 R2V 数据构建的需求。
具体而言,我们的方法引入了一种带掩码的训练策略:在训练过程中,将随机采样并部分加掩码的视频帧作为参考图像使用,其中掩码的随机性提供了多样的参考条件,并提升了跨主体类别的泛化能力。这个过程迫使模型从参考上下文中学习在身份和外观上一致的表征,从而在不使用 R2V 数据的情况下有效模拟 R2V 任务。该策略还配合了一种定制的注意力机制:在注意力掩码的引导下,模型被鼓励聚焦于具备参考感知的特征,同时抑制背景噪声。
为进一步提升视觉保真度并缓解参考到视频生成中常见的"拷贝-粘贴"伪影(Liu et al., 2025; Fei et al., 2025; Hu et al., 2025a),我们集成了一系列空间掩码增强策略,从而有效提高生成视频的视觉质量。
Saber 的设计在本质上具有良好的可扩展性。它自然支持可变数量的参考图像(见图 1 和图 4),无需额外的数据准备或对训练流水线进行修改,从而允许更丰富的多主体定制。带掩码训练策略的随机性还使得 Saber 能够稳健地处理同一主体的多视角参考图像(见图 7)。

图 1 Saber 是一种仅在视频-文本对上训练的零样本参考到视频方法。它在保持身份和外观的同时,能够在文本提示的引导下,将单个或多个参考图像连贯地融入生成视频中。
我们在 OpenS2V-Eval(Yuan et al., 2025a)基准上对 Saber 进行了评估,结果表明它持续优于那些在显式 R2V 数据上训练的模型(Zhou et al., 2024a; Liu et al., 2025; Jiang et al., 2025; Deng et al., 2025; Fei et al., 2025; Hu et al., 2025b; Li et al., 2025)。此外,只需在训练中简单调整掩码比例,Saber 便可以适配将参考图像视作前景主体或背景场景的不同设定(见图 1)。
我们的贡献可总结如下:
- 我们提出了 Saber,这是第一个通过在视频-文本对上进行带掩码训练,从而无需显式 R2V 数据的零样本 R2V 框架。
- Saber 在 OpenS2V-Eval(Yuan et al., 2025a)上超越了先前基于 R2V 数据训练的方法,并展现出强大的泛化性和可扩展性,为未来在大规模参考到视频生成方向的研究铺平了道路。
2 Related Work
2.1 Video Generation
扩散模型(Rombach et al., 2022)的快速发展极大地推动了视频生成技术的进步。早期方法(Blattmann et al., 2023; Guo et al., 2024b; Chen et al., 2024a)通过在预训练文本到图像模型(Rombach et al., 2022; Podell et al., 2023)上加入时间模块来合成视频。最近,基于 Diffusion Transformer(Peebles and Xie, 2023)并在大规模视频-文本数据集(Chen et al., 2024b; Wang et al., 2025)上训练的大模型,在视频生成方面取得了最先进的高保真效果(Yang et al., 2025; Kong et al., 2024; Chen et al., 2025a; Wan et al., 2025; Gao et al., 2025b; Zhang et al., 2025)。尽管取得了这些进展,现有方法主要聚焦于文本到视频和图像到视频任务。而参考到视频生成所需的这种细粒度、主体驱动的控制仍然是一个重大挑战,且 R2V 数据集(Yuan et al., 2025a; Liu et al., 2025)复杂而高昂的数据构建过程,使得在该任务上进行类似 T2V 和 I2V 的大规模训练变得不可行。
2.2 Reference-to-Video Generation
在文本到视频和图像到视频模型(Hong et al., 2023; Yang et al., 2025; Kong et al., 2024; HaCohen et al., 2024; Wan et al., 2025)进展的基础上,参考到视频生成(Yuan et al., 2025b; Jiang et al., 2025; Liu et al., 2025; Hu et al., 2025a,b; Li et al., 2025)也取得了显著发展。早期研究(Gao et al., 2025a; Yuan et al., 2025b; Shen et al., 2025)主要关注于人类参考图像,被称为"身份保持视频生成",通过向模型注入人脸或身体特征来维持身份一致性。随后,参考图像从人类扩展到各类物体与背景(Liu et al., 2025; Jiang et al., 2025; Hu et al., 2025a),从而实现了更加灵活的控制。一些工作(Liu et al., 2025; Yuan et al., 2025a)也将该任务称为主体一致或主体到视频生成,这与参考到视频生成本质上是等价的。
具有代表性的工作包括 Phantom(Liu et al., 2025),它通过图像-视频-文本三元组数据,并使用文本-图像联合注入模型来学习跨模态对齐。VACE(Jiang et al., 2025)引入了一个上下文适配器来处理参考图像,并在统一框架内实现时空特征交互。SkyReels-A2(Fei et al., 2025)构建了图像-文本联合嵌入模型,以注入多元素表征,在一致性与连贯性之间取得平衡。HunyuanCustom(Hu et al., 2025a)采用基于 LLaVA(Liu et al., 2023)的融合模块和图像 ID 增强模块,以强化多模态理解与身份一致性。MAGREF(Deng et al., 2025)使用区域感知掩码和逐像素拼接来实现高效的多参考交互。PolyVivid(Hu et al., 2025b)加入了 3D-RoPE 增强以及注意力继承式的身份注入,以减缓身份漂移。BindWeave(Li et al., 2025)利用多模态大模型(MLLM, Bai et al., 2025)将复杂文本提示与视觉主体关联起来,从而提升视频生成质量。
然而,这些方法存在一个共同的关键局限:它们依赖显式的参考图像-视频-文本三元组数据集,而这类数据集的构建成本高昂且难度巨大。诸如 OpenS2V-5M(Yuan et al., 2025a)和 Phantom-Data(Chen et al., 2025b)等数据集,都需要复杂的构建流程,包括候选样本提取、低质样本过滤、样本聚类、跨对匹配,以及用于生成参考图像的高成本 API 调用。这样的流程导致数据质量难以控制、可扩展性差且构建复杂度高。相比之下,我们提出了一个仅在视频-文本对上训练的零样本 R2V 框架,并在公开基准上取得了优异表现。
3 Preliminary
3.1 Video Generation Models
视频生成模型(Hong et al., 2023; Yang et al., 2025; Kong et al., 2024; HaCohen et al., 2024; Wan et al., 2025)已经取得了显著进展,并获得了广泛关注。其中,Wan Video 系列(例如 Wan2.1(Wan et al., 2025))是最受欢迎的开源框架之一。我们的方法建立在 Wan2.1-14B 模型(Wan et al., 2025)之上,该模型由变分自编码器(VAE)(Kingma and Welling, 2013)、Transformer 主干网络(Vaswani et al., 2017; Peebles and Xie, 2023)以及文本编码器(即 umt5-xxl(Chung et al., 2023))构成。VAE 将视频编码为在时间和空间上压缩的潜在表示 z 0 z_0 z0,并将其解码回像素空间,从而减少 token 数量和计算量。Wan2.1 使用 Flow Matching(FM)(Lipman et al., 2022)来训练扩散模型 Ψ \Psi Ψ,其中前向过程在数据与噪声之间进行线性插值。对于时间步 t ∈ 0 , 1 t \in 0, 1 t∈0,1,向 z 0 z_0 z0 添加高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I) 以获得 z t z_t zt,满足 z t = ( 1 − t ) z 0 + t ϵ z_t = (1 - t) z_0 + t \epsilon zt=(1−t)z0+tϵ。模型通过以下目标函数来优化,以预测目标速度:
L FM = E z 0 , ϵ , t , c ∥ ( z 0 − ϵ ) − Ψ θ ( z t , t , c ) ∥ 2 2 , \mathcal{L}\text{FM} = \mathbb{E}{z_0,\epsilon,t,c} \big \\lVert (z_0 - \\epsilon) - \\Psi_\\theta(z_t, t, c) \\rVert_2\^2 \\big, LFM=Ez0,ϵ,t,c∥(z0−ϵ)−Ψθ(zt,t,c)∥22,
其中 θ \theta θ 表示扩散模型 Ψ \Psi Ψ 的可学习参数, c c c 表示由给定文本提示和参考图像提取的条件特征。
3.2 Task Definition and Notations
给定 K 个参考图像 { I k ∈ R H k × W k × 3 } k = 1 K \{ I_k \in \mathbb{R}^{H_k \times W_k \times 3} \}{k=1}^K {Ik∈RHk×Wk×3}k=1K 和一个文本提示 P P P,参考到视频方法生成一个视频 { I f ∈ R H × W × 3 } f = 1 F \{ I_f \in \mathbb{R}^{H \times W \times 3} \}{f=1}^F {If∈RH×W×3}f=1F,其主体在遵循文本提示 P P P 中指令的同时,保留参考图像中主体的身份和外观。这里, H k H_k Hk 和 W k W_k Wk 分别表示第 k k k 个参考图像 I k I_k Ik 的高度和宽度,而 F F F、 H H H 和 W W W 分别表示生成视频的帧数、高度和宽度。
4 Method
我们的目标是训练一个扩散模型 Ψ θ \Psi_\theta Ψθ,使其能够生成视频 { I f } f = 1 F \{I_f\}{f=1}^F {If}f=1F,在遵循给定文本提示 P P P 的同时,保留给定参考图像 { I k } k = 1 K \{I_k\}{k=1}^K {Ik}k=1K 中主体的身份与外观。以往方法(Liu et al., 2025; Jiang et al., 2025; Hu et al., 2025a,b; Li et al., 2025)依赖参考图像-视频-文本三元组,这类数据成本高且难以扩展。相比之下,Saber 仅使用视频-文本对(与 T2V 和 I2V 训练相同的数据范式)就实现了 R2V 能力。
Saber 的核心思想是:在训练过程中,用随机加掩码的视频帧替代显式收集的参考图像,从而模拟 R2V 任务。这一带掩码训练策略由两个关键组件支撑,以增强鲁棒性和视觉质量:i)一系列掩码增强操作,用于降低"拷贝-粘贴"伪影;ii)一种定制的注意力机制,引导模型聚焦在相关的参考特征上。
我们首先在第 4.1 节介绍掩码帧的构建过程,包括掩码生成与增强。接着在第 4.2 节给出模型的架构设计,详细说明输入格式和基于 Transformer 的注意力机制。最后,第 4.3 节描述零样本 R2V 的推理流程。
4.1 Masked Frames as Reference
标准的 R2V 模型会从参考图像 { I k } k = 1 K \{I_k\}{k=1}^K {Ik}k=1K 中学习提取身份和外观特征,并将这些特征注入到生成的视频 { I f } f = 1 F \{I_f\}{f=1}^F {If}f=1F 中。然而,现有的 R2V 数据集(Yuan et al., 2025a; Chen et al., 2025b)主要由人类和常见物体构成,导致主体多样性不足且泛化能力较差。为了解决这一问题,我们在训练过程中不再依赖预先收集的参考图像,而是使用随机加掩码的帧作为动态替代。这一策略自然地引入了高度多样的参考样本,使模型能够学习更有效的主体融入方式,并获得更强的泛化能力。
如图 2 所示,对于从视频中随机采样得到的每个第 k k k 个参考图像 I k I_k Ik,我们首先使用一个掩码生成器产生一个二值掩码 M k ∈ { 0 , 1 } H × W M_k \in \{0,1\}^{H\times W} Mk∈{0,1}H×W。为缓解 R2V 任务中的"拷贝-粘贴"问题(Liu et al., 2025),我们执行掩码增强,以打破被加掩码参考与其对应视频帧之间的空间对应关系。具体而言,我们对 I k I_k Ik 和 M k M_k Mk 施加同一组空间增强操作,得到 I ˉ k \bar I_k Iˉk 和 M ˉ k \bar M_k Mˉk。随后,掩码帧 I ^ k \hat I_k I^k 通过
I ^ k = I ˉ k ⊙ M ˉ k \hat I_k = \bar I_k \odot \bar M_k I^k=Iˉk⊙Mˉk
得到。重复这一过程,即可构造出完整的 K K K 个掩码帧集合 { I ^ k } k = 1 K \{\hat I_k\}_{k=1}^K {I^k}k=1K,作为参考条件使用。
掩码生成器。我们从预定义的形状类别(例如椭圆、Fourier blob、凸/凹多边形等)中随机选择一种掩码类型,以生成一个二值掩码 M ∈ { 0 , 1 } H × W M \in \{0,1\}^{H\times W} M∈{0,1}H×W,其目标前景面积比为 r ∈ r min , r max r \in r_{\\min}, r_{\\max} r∈rmin,rmax。具体来说,我们首先随机选取一个前景中心。为了确保生成的掩码满足期望的前景面积比 r r r,我们为每一种形状类别定义一个连续的尺度参数,使掩码的前景面积随尺度单调增加。随后在该尺度上执行二分搜索,以满足面积比约束。当像素离散化导致无法精确匹配时,我们会施加一些保持拓扑结构的小幅调整:"growth" 操作膨胀背景边界像素,而 "shrinkage" 操作则抹去背景边界像素。这样的设计在保持掩码形状多样性的同时,确保了前景面积比的可控性。若干掩码示例展示在图 2 顶部。
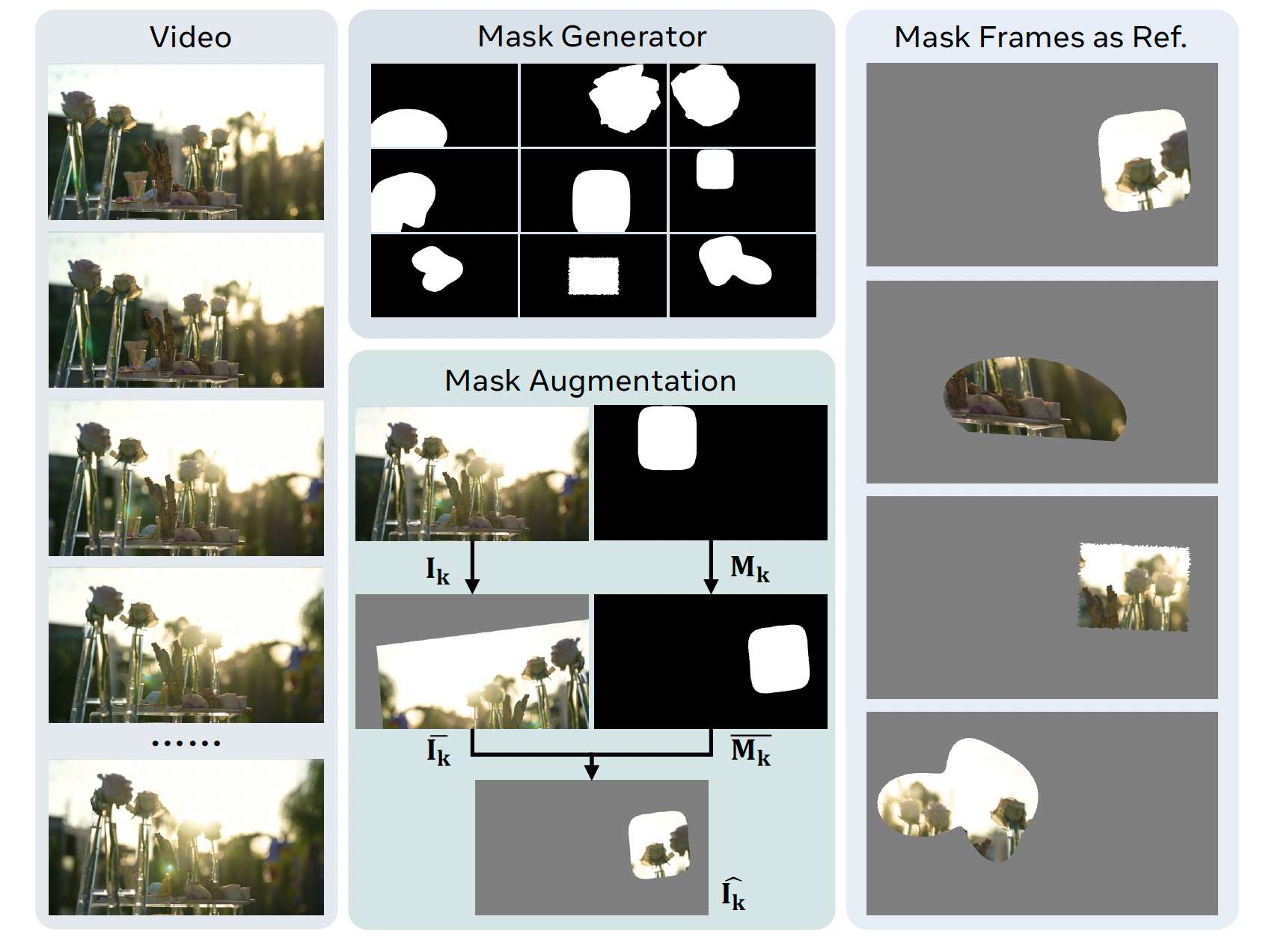
图 2 掩码参考生成。给定一个视频,掩码生成器产生多样的随机掩码,然后通过掩码增强,将其应用到每一个随机采样的视频帧上。
掩码增强。我们对图像 I k I_k Ik 及其掩码 M k M_k Mk 同时施加随机仿射变换,包括旋转、缩放、剪切、平移以及可选的水平翻转,以确保被掩码区域始终完全处于画面内部。变换参数在预设范围内均匀采样,并经过验证以避免越界。对图像和掩码应用相同的仿射变换,其中图像使用双线性插值,掩码使用最近邻插值。
掩码生成器和掩码增强的参考代码在附录材料中给出。
4.2 Model Design
在获得掩码帧 { I ^ k } k = 1 K \{\hat I_k\}_{k=1}^K {I^k}k=1K 作为参考图像之后,我们详细介绍用于 R2V 任务的模型设计。我们采用一种简单而有效的输入格式:在潜空间中沿时间维度,将参考图像拼接到目标视频帧的末尾。这样可以使模型在每个 Transformer 块中的注意力机制下,管理目标视频潜变量与参考潜变量之间的交互。
输入格式。给定一个视频-文本对 { I f } f = 1 F \{I_f\}{f=1}^F {If}f=1F 和文本提示 P P P,以及作为参考图像的掩码帧 { I ^ k } k = 1 K \{\hat I_k\}{k=1}^K {I^k}k=1K,我们使用 VAE 将视频从像素空间编码到潜空间,得到
z 0 = { z f ^ ∈ R h × w × d } f ^ = 1 F ^ z_0 = \{z_{\hat f} \in \mathbb{R}^{h \times w \times d}\}_{\hat f=1}^{\hat F} z0={zf^∈Rh×w×d}f^=1F^。
其中, F ^ = ⌊ ( F − 1 ) / 4 ⌋ + 1 \hat F = \lfloor (F-1)/4 \rfloor + 1 F^=⌊(F−1)/4⌋+1, 4 4 4 是 Wan2.1 VAE(Wan et al., 2025)的时间压缩比, h , w , d h,w,d h,w,d 分别表示视频潜变量的高度、宽度和特征维度。按照第 3.1 节,我们在时间步 t t t 处得到 z t z_t zt。对于参考图像,我们使用 VAE 分别编码每个 I ^ k \hat I_k I^k,得到
z ref = { z k ∈ R h × w × d } k = 1 K z_{\text{ref}} = \{z_k \in \mathbb{R}^{h \times w \times d}\}_{k=1}^K zref={zk∈Rh×w×d}k=1K。
相应地,我们将每个 M k M_k Mk 重新调整大小以匹配潜空间分辨率,得到
m ref = { m k ∈ { 0 , 1 } h × w × 4 } k = 1 K m_{\text{ref}} = \{m_k \in \{0,1\}^{h \times w \times 4}\}_{k=1}^K mref={mk∈{0,1}h×w×4}k=1K,
其中 0 0 0 表示非参考区域, 1 1 1 表示参考区域。Transformer 的输入 z in z_{\text{in}} zin 定义如下式 (2):
z in = cat cat \[ z t z ref temporal cat m zero m ref temporal cat z zero z ref temporal ] channel , z_{\text{in}} = \operatorname{cat} \begin{bmatrix} \operatorname{cat}\\,z_t \\quad z_{\\text{ref}}\\,{\text{temporal}} \\ \operatorname{cat}\\,m_{\\text{zero}} \\quad m_{\\text{ref}}\\,{\text{temporal}} \\ \operatorname{cat}\\,z_{\\text{zero}} \\quad z_{\\text{ref}}\\,{\text{temporal}} \end{bmatrix}{\text{channel}}, zin=cat catztzreftemporalcatmzeromreftemporalcatzzerozreftemporal channel,
其中, cat ⋅ temporal \operatorname{cat}\\cdot{\text{temporal}} cat⋅temporal 和 cat ⋅ channel \operatorname{cat}\\cdot{\text{channel}} cat⋅channel 分别表示在时间维度和通道维度上的拼接。 z zero z_{\text{zero}} zzero 是零值视频经过 VAE 编码得到的潜变量, m zero m_{\text{zero}} mzero 是全零掩码,它们的形状都被调整为与视频部分的时间维度一致。需要注意的是, z ref z_{\text{ref}} zref 保持无噪声,以确保精确的条件信息。
注意力机制。在获得 Transformer 输入 z in z_{\text{in}} zin 之后,我们将文本提示 P P P 编码为文本特征 z P z_P zP,并与时间步 t t t 一起送入 Transformer。每个 Transformer 块由自注意力、交叉注意力和前馈(FFN)模块组成。
在自注意力中, z in z_{\text{in}} zin 的视频部分和参考部分彼此交互。为避免关注到非参考区域,我们将每个 M k M_k Mk 调整大小以匹配展平后的潜变量形状,从而形成注意力掩码;在该掩码下,视频 token 之间可以双向注意,而在参考部分中,只对有效的参考区域进行注意。
随后,自注意力的输出被送入交叉注意力模块与 z P z_P zP 进行交互。在这里,视频 token 由文本提示引导,而参考 token 学习其语义对齐,从而在文本约束下实现参考图像信息的融合。FFN 模块对结果进一步精炼,并将时间步 t t t 注入潜变量中,用于控制时间步信息。经过多个 Transformer 块后,Transformer 模型输出预测的潜变量 z t − 1 z_{t-1} zt−1。模型设计如图 3 所示。
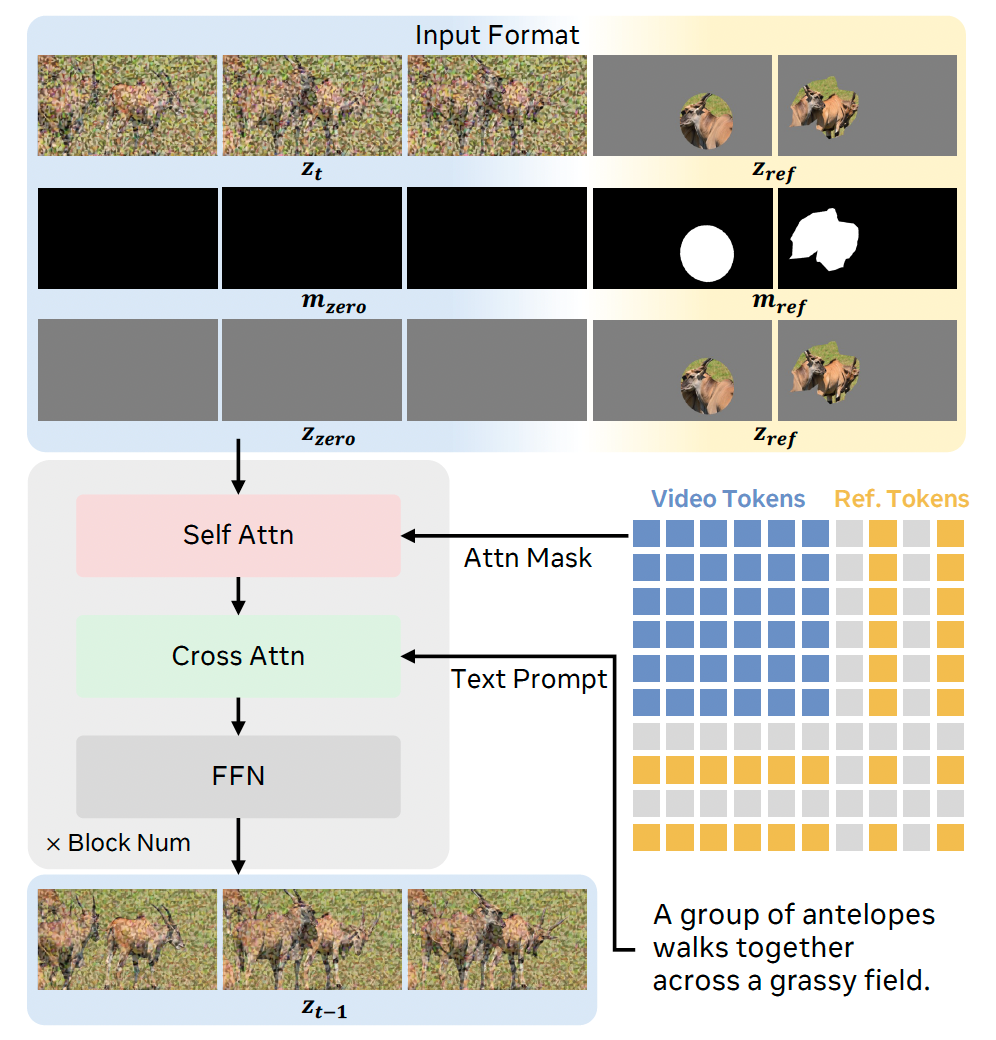
图 3 模型设计概览。掩码帧作为参考图像,在潜空间中与视频 token 进行拼接。自注意力在注意力掩码的约束下,使视频 token 与参考 token 之间能够交互;而交叉注意力则引入文本引导,实现语义对齐。为便于展示,图中省略了 VAE、文本编码器以及时间步等组件。
4.3 Zero-Shot Inference
在本节中,我们介绍一种方法,使得使用掩码帧训练得到的模型能够进行零样本 R2V 推理。在推理阶段,对于每一张参考图像 I k I_k Ik,我们首先使用一个预训练的目标分割器(Ren et al., 2024; Zheng et al., 2024)来提取前景主体区域掩码 M k M_k Mk。随后,我们将参考图像 I k I_k Ik 归一化到 − 1 , 1 -1, 1 −1,1 范围内,并用零值(灰色)填充被掩码的背景区域。需要注意的是,这一步分割是可选且灵活的:如果参考图像的目的在于提供背景场景而非前景主体,则跳过分割步骤,此时我们使用完整、未加掩码的参考图像以及全为 1 的掩码 M k M_k Mk,将整张图像视作参考区域。
接着,我们对 I k I_k Ik 和 M k M_k Mk 同时执行缩放加填充操作:将 I k I_k Ik 从其原始尺寸 ( H k , W k ) (H_k, W_k) (Hk,Wk) 缩放到目标视频尺寸 ( H , W ) (H, W) (H,W) 内,在保持长宽比的同时,用零填充其余区域,从而得到尺寸为 ( H , W ) (H, W) (H,W) 的居中参考图像。最后,处理后的参考图像和掩码按照第 4.2 节中的输入格式送入模型,并依照 Wan 的推理流程(Wan et al., 2025)进行预测。
5 Experiments
5.1 Datasets, Metrics and Implementation Details
数据集。得益于掩码训练策略,Saber 仅在视频-文本对数据集上进行训练,从而可以使用来自 T2V 和 I2V 源的数据。具体来说,我们使用 ShutterStock Video(Team)数据集,并通过 Qwen2.5-VL-Instruct(Bai et al., 2025)为所有视频片段生成描述,从而构建相应的视频-文本对用于训练。
评价指标。为确保公平比较,我们采用 OpenS2V-Eval(Yuan et al., 2025a)基准,并遵循其官方协议,对参考到视频生成进行细粒度评估。该基准包含 7 个类别的 180 条文本提示,覆盖单参考(人脸、人物、实体)和多参考(多脸、多人物、人物-实体)两类场景。我们报告的自动化指标中,分数越高代表性能越好,包括:Aesthetics(视觉质量)、MotionSmoothness(时间一致性)、MotionAmplitude(运动幅度)以及 FaceSim(身份保持)。此外,我们还使用三个 OpenS2V-Eval 指标 NexusScore、NaturalScore 和 GmeScore,分别衡量主体一致性、自然度以及文本-视频对齐程度。
实现细节。Saber 在视频-文本对数据集上,基于我们提出的掩码训练策略,从 Wan2.1-14B(Wan et al., 2025)模型进行微调。对于掩码生成器,我们对前景面积比 r r r 采用一种概率采样策略:以 10% 的概率将 r ∈ 0 , 0.1 r \in 0, 0.1 r∈0,0.1,用来模拟极少或无参考信息,使模型能够处理不同数量的参考图像;以 80% 的概率将 r ∈ 0.1 , 0.5 r \in 0.1, 0.5 r∈0.1,0.5,以表示典型的主要主体;而在剩余 10% 的概率下,将 r ∈ 0.5 , 1.0 r \in 0.5, 1.0 r∈0.5,1.0,以帮助模型从大尺寸参考图像或背景场景中学习。对于掩码增强,我们随机施加旋转(角度范围 − 10 , 10 -10, 10 −10,10)、缩放(范围 0.8 , 2.0 0.8, 2.0 0.8,2.0)、50% 概率的水平翻转,以及剪切(角度范围 − 10 , 10 -10, 10 −10,10)。我们发现,这些增强在克服"拷贝-粘贴"伪影方面具有经验上的有效性。我们使用式 (1) 中定义的目标函数训练模型,并采用 AdamW 优化器,学习率为 1 e − 5 1e^{-5} 1e−5,全局 batch size 为 64。在推理阶段,我们使用 BiRefNet(Zheng et al., 2024)从参考图像中分割前景主体。按照 Wan2.1(Wan et al., 2025)的标准设定,我们以 50 步去噪生成视频,并将 CFG(Ho and Salimans, 2022)指导系数设为 5.0。