AI视频概览
一、AI核心概念谱系厘清
要理解AI视频,首先需梳理AI领域的关键概念,明确其技术定位:
(一)AI的核心分类维度
- 按智能水平划分:分为狭义AI(ANI)与通用AI(AGI)。狭义AI即当前主流的弱人工智能,专注特定任务,如AlphaGo、Midjourney等,核心价值在于提升效率、提高准确性、降低成本;通用AI是具备人类级认知能力的强人工智能,能解决各类未知任务,目前尚未实现。
- 按实现范式划分:早期为基于规则的AI(符号AI),依赖人类专家预设逻辑规则,如传统专家系统,虽易于控制但缺乏灵活性;现代主流是基于学习的AI,通过海量数据自主归纳模式,适用于图像识别、自然语言处理等复杂场景。
- 按学习方式划分:监督学习依赖带标签数据,学习输入输出映射关系,应用于分类、回归问题(如疾病诊断、垃圾邮件过滤);无监督学习从无标签数据中发现内在结构,用于聚类、降维等场景(如客户细分、异常检测)。
- 按任务目标划分:决策式AI专注分析现有数据进行预测判断,广泛应用于金融、医疗等领域;生成式AI则创造全新原创内容,是AIGC(AI生成内容)的核心技术支撑。
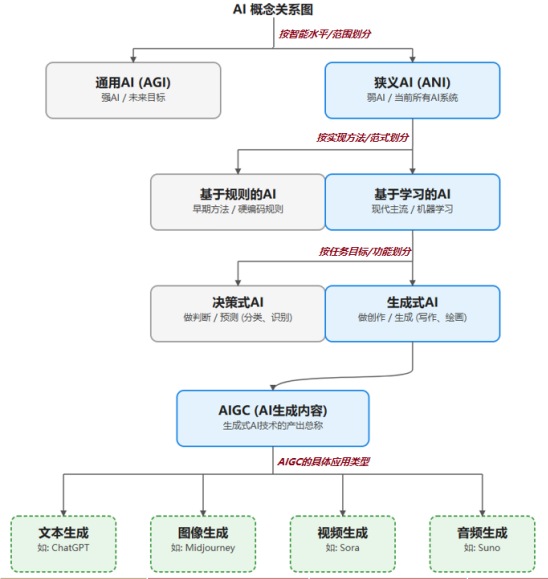
(二)AIGC的多模态应用场景
AIGC涵盖文本、图像、视频、音频及跨模态生成,其中视频生成是技术最复杂、发展最迅速的分支:
- 文本生成:含内容创作、信息整合、辅助写作、智能对话、代码生成等场景;
- 图像生成:包括文生图、图像编辑修复、可控图像生成等功能;
- 视频生成:核心涵盖内容生成、智能剪辑、增强特效、数字人驱动等方向;
- 音频生成:涉及语音合成、声音克隆、音乐音效生成等应用;
- 跨模态生成:实现视觉内容理解、多模态交互、3D模型生成等跨领域能力。
二、AI视频:定义、分类与发展历程
(一)AI视频的核心定义
AI视频指利用人工智能(尤其是机器学习和计算机视觉技术)实现视频内容的生成、编辑、分析或增强,是生成式AI在动态影像领域的重要应用,代表了AI从"分析预测"到"创造生成"的关键跃迁。
(二)三大核心任务分类
- 视频生成:从零开始创造全新视频序列,包括文生视频、图生视频、音频生视频、3D/世界模型生成、数字人生成等,是本文重点讨论方向;
- 视频编辑:在现有视频基础上优化修改,涵盖内容修改、时序编辑、视觉属性编辑、视觉质量增强等功能;
- 视频理解:解析视频内容的语义与结构,包括高层语义分析、内容摘要交互、时空感知、多模态理解等能力。
(三)三种典型生成方式
- 文生视频:根据文本提示词生成符合描述的视频;
- 图生视频:将静态图像转换为动态视频(严格意义上属于视频编辑范畴);
- 视频到视频:对已有视频进行增强或风格转换。
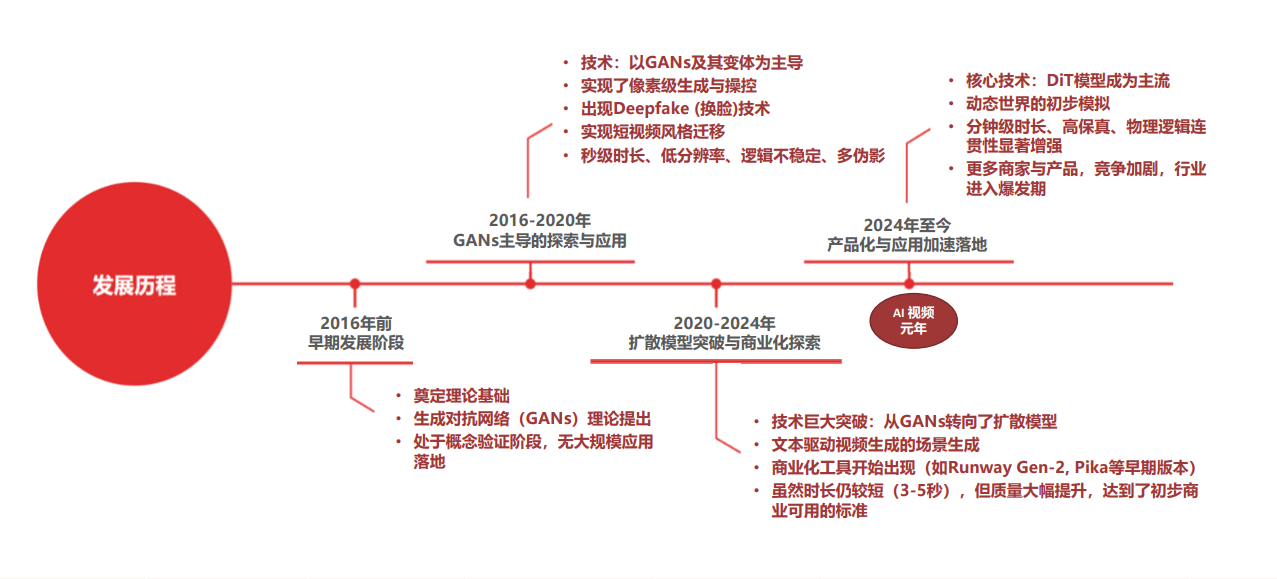
(四)技术发展历程
- 2016年前:早期发展阶段,GANs(生成对抗网络)理论提出,处于概念验证阶段,无大规模应用;
- 2016-2020年:GANs主导的探索期,实现像素级生成与操控,出现Deepfake技术,可完成短视频风格迁移,但存在时长短、分辨率低、逻辑不稳定等问题;
- 2020-2024年:扩散模型突破与商业化探索,Runway Gen-2、Pika等工具出现,文本驱动视频生成技术大幅提升,达到初步商用标准;
- 2024年至今:产品化与应用加速落地,以Sora模型为代表,DiT模型成为主流,实现分钟级时长、高保真视频生成,物理逻辑连贯性显著增强,行业进入爆发期。
三、主流AI视频工具与平台盘点
(一)垂直视频生成平台
| 厂商名称 | 工具名称 | 发布时间 | 核心特点 |
|---|---|---|---|
| OpenAI | Sora | 2024年 | 2024年2月首次展示60秒演示视频,12月正式发布;对物理世界理解深刻,支持复杂场景、多角度镜头生成,已集成进ChatGPT,可生成20秒视频 |
| 快手 | 可灵AI | 2024年 | 支持2分钟、1080p、30fps视频生成;采用DiT架构,迭代迅速,2025年9月推出的Kling 2.5 Turbo成本降低30%,全球用户超4500万 |
| 字节跳动 | 即梦AI | 2024年 | 画面审美、光影质感及中文语义理解出色;背靠抖音与剪映生态,打通"生成-剪辑-发布"全链路,月活5400万 |
| Minimax | 海螺AI | 2024年 | 综合AI助手,视频生成是其多模态能力之一,侧重文本、语音、图像、视频等多能力融合体验 |
| 爱诗科技 | PixVerse | 2024年 | 2024年1月发布V1版本,免费额度高;动漫和艺术风格表现突出,靠特效模版在社交媒体破圈,APP月活2300万 |
| Runway | Runway | 2023年 | 早期AI视频商业化公司,提供运动笔刷、镜头控制等专业编辑功能,Gen-4模型在运动、物理真实感上表现突出 |
| Pika Labs | Pika | 2023年 | 创意社区热门工具,艺术感和电影感出色;支持文生视频、图生视频及局部修改等编辑功能,通过Discord积累大量用户 |
| 生数科技 | Vidu | 2024年 | 国内首个类Sora架构(U-ViT)模型;支持16秒1080p视频生成,时空连贯性好,对中国文化理解深入 |
| Luma Labs | Luma AI | 2024年 | Dream Machine模型生成速度快、质量高;以3D高斯溅射和NeRF技术闻名,2025年9月推出的Ray3号称"能思考和推理" |
| 阿里巴巴 | 通义万相 | 2024年 | WAN模型被誉为"开源界的Sora";支持1080p高清视频生成,模型开源可本地部署,降低开发者使用门槛 |
(二)通用大模型平台的视频生成功能
| 平台/厂商 | 通用大模型产品 | 核心特点与策略 |
|---|---|---|
| OpenAI | ChatGPT | 集成Sora模型,支持"文本构思-图像生成-视频创作"全流程,打造全能创意与生产力平台 |
| Gemini(生态) | Veo为专属视频生成工具,植入YouTube、Google Photos及Vertex AI,Veo 3支持对话及环境音效 | |
| Meta | Meta AI | 集成于Facebook、Instagram等社交应用,通过Emu Video生成创意短视频,布局元宇宙/AR眼镜内容生成 |
| 阿里巴巴 | 通义千问 | 通义万相提供视频生成能力,面向普通用户及企业客户,通过阿里云提供API服务赋能产业 |
| 字节跳动 | 豆包 | 生成内容可无缝衔接剪映编辑功能,直接在抖音/TikTok分发,形成"生成-剪辑-分发"闭环 |
四、AI视频技术的核心价值与发展现状
AI视频技术已从实验性"技术炫技"阶段,迅速发展为影视预演、广告创意、短视频制作、在线教育等领域的实用工具。其核心价值在于重构视频内容创作范式,降低创作门槛、提升生产效率,同时拓展创意表达的边界。
当前,AI视频技术已实现从秒级到分钟级、从低分辨率到高清画质的跨越,物理逻辑连贯性与视觉真实感显著提升,但在可控性、逻辑一致性和成本控制方面仍面临挑战。随着头部科技公司的持续布局与技术迭代,行业变革的临界点已清晰可见,未来将在更多场景实现规模化应用。