TL;DR
- 场景:refresh 频繁产生小段,段数暴涨拖慢搜索;同时想看懂 ES 数据目录与 Lucene 文件
- 结论:段合并是后台常态动作;手动合并用 _forcemerge,且必须按版本区分可调项与风险
- 产出:可复用的 merge 调优清单 + shards/indices/_state/translog/index 目录定位方法

版本矩阵
| 版本/分类 | 说明 |
|---|---|
| ES 5.0+ | _optimize 已移除,使用 _forcemerge 替代 |
| ES 1.x--2.x | indices.store.throttle.max_bytes_per_sec 常见默认被认为是 20MB/s |
| ES 6.x+ | 多数"固定 20MB/s 节流"的调参经验不可直接照搬;需按当前版本的合并 I/O 机制重新评估 |
| ES 6.1.x(代码层) | index.merge.policy.floor_segment 等 merge policy 名称与语义在代码文档可查 |
| 通用(所有版本) | Force merge 会显著消耗 I/O/CPU,可能出现"段少了但查询更慢"等反直觉结果,需要灰度验证 |
索引文档存储段合并
段合并机制
由于自动刷新流程每秒创建一个新的段,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存、CPU运行周期。更重要的是,每个搜索请求必须轮流检查每个段,所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题,小的段合并到大的段,然后这些大的段被合并到更大的段,段合并的时候会将那些旧的已删除文档从文件系统中清除,被删除的文档(或被更新文档的旧版本)不会拷贝到新的大段中。 启动段合并在进行索引和搜索时会自动进行,这个流程像在下图中提到的一样工作:
- 第一步:当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用
- 第二步:合并进程选择一小部分大小相似的段,并且在后台将他们合并到更大的段中,这并不会中断索引和搜索。
两个提交了的段和一个未提交的段正在合并到一个更大的段:
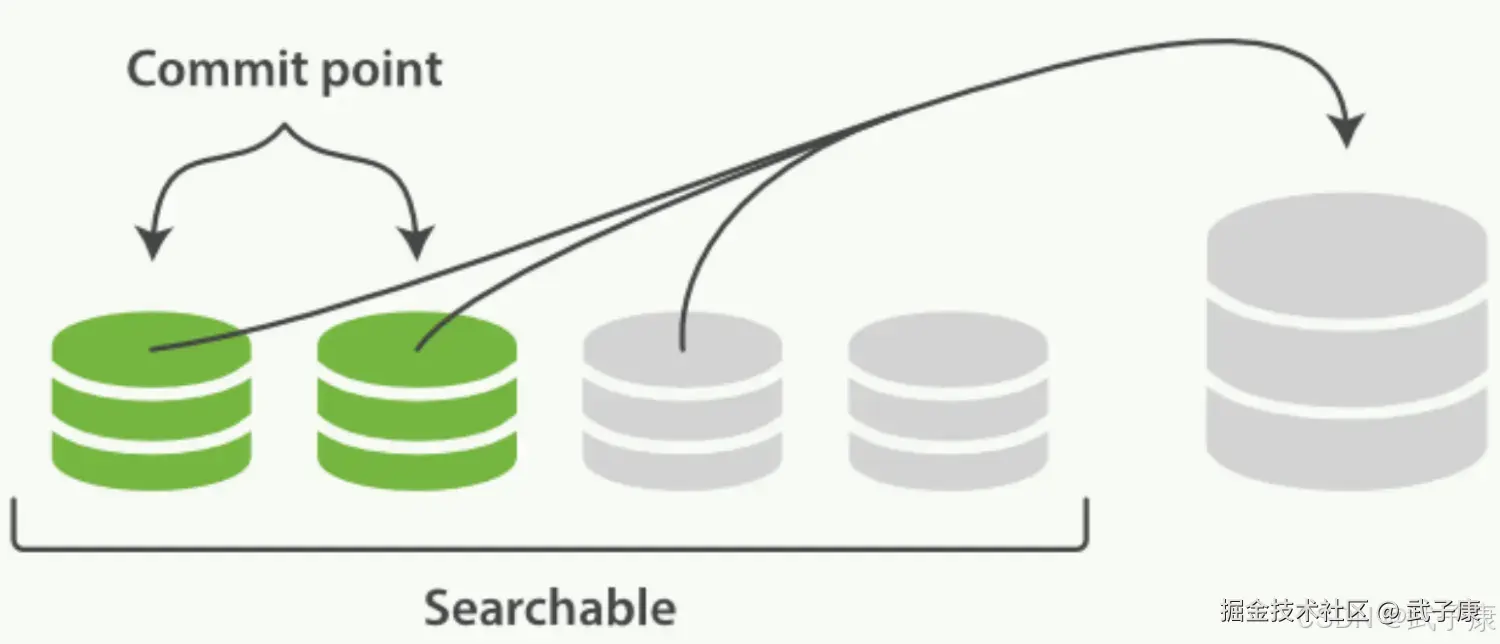 第三步:合并完成时的活动:
第三步:合并完成时的活动:
- 新的段被刷新(flush)到了磁盘,写入一个包含新段且排除旧的和较小的段的新提交点
- 新的段被打开用来搜索
- 老的段被删除 一旦合并结束,老的段被删除
 合并大的段需要消耗大量的 I/O和CPU资源,如果任其发展会影响搜索性能,Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好的执行。 默认情况下,归并线程的限速配置:indices.store.throttle.max_bytes_per_sec是20MB。 对于写入量较大,磁盘转速较高,甚至使用SSD盘的服务器来说,这个限速是明显过低的。对于 ELK Stack应用,建议可以适当调大到100MB或者更高。
合并大的段需要消耗大量的 I/O和CPU资源,如果任其发展会影响搜索性能,Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好的执行。 默认情况下,归并线程的限速配置:indices.store.throttle.max_bytes_per_sec是20MB。 对于写入量较大,磁盘转速较高,甚至使用SSD盘的服务器来说,这个限速是明显过低的。对于 ELK Stack应用,建议可以适当调大到100MB或者更高。
json
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}用于控制归并线程的数目,推荐设置为CPU核心数的一半,如果觉得自己磁盘性能跟不上,可以降低配置,免得IO性能瓶颈。(index.merge.scheduler.max_thread_count)
归并策略
归并策略 policy 归并线程是按照一定的运行策略来挑选Segment进行归并的,主要有以下的几条:
- index.merge.policy.floor_segement 默认2MB,小于这个大小的Segment,优先被并归
- index.merge.policy.max_merge_at_once 默认一次最多归并10个 Segment
- index.merge.policy.max_merge_at_once_explicit 默认optimize 时一次最多归并30个Segment
- index.merge.policy.max_merged_segment 默认5GB,大于这个大小的Segment,不用参与归并,optimize除外。
Optimize API
Optimize API大可看做强制合并API,它将一个分片强制合并到max_num_segments参数指定大小的段数目,这样做的意图是减少段的数量(通常减少到一个),来提升性能。在特定情况下,使用OptimizeAPI颇有益处。 例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。老的索引实质上是只读的,它们也并不太可能发生变化,在这种情况下,使用Optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了,这样既可以节省资源,也可以搜索更加迅速:
shell
POST /Logstash-2024-08/_optimize?max_num_segments=1存储文件详解
信息查看
 通过 ES-Head 插件可以查看到一个索引分片的信息,图中一个绿色的方块就代表一个分片Shard。 ES使用Lucene来处理Shard级别的索引和查询,因此数据目录中的文件由Elasticsearch和Lucene共同编写。 Lucene负责编写和维护Lucene索引文件,而Elasticsearch在Lucene之上编写与功能相关的元数据,例如字段映射,索引设置和其他集群元数据,用户和支持功能由Elasticsearch提供。
通过 ES-Head 插件可以查看到一个索引分片的信息,图中一个绿色的方块就代表一个分片Shard。 ES使用Lucene来处理Shard级别的索引和查询,因此数据目录中的文件由Elasticsearch和Lucene共同编写。 Lucene负责编写和维护Lucene索引文件,而Elasticsearch在Lucene之上编写与功能相关的元数据,例如字段映射,索引设置和其他集群元数据,用户和支持功能由Elasticsearch提供。
存储目录
我们登录到服务器上,进入到ES集群的数据存储目录中,根据我们之前配置好的服务
shell
cd /opt/servers/es/data/nodes/0执行结果如下图所示:  我们进入 indices 目录,这个目录下的数据有:
我们进入 indices 目录,这个目录下的数据有:
shell
root@h121:/opt/servers/es/data/nodes/0# cd indices/
root@h121:/opt/servers/es/data/nodes/0/indices# ll
total 28
drwxrwxr-x 7 es_server es_server 4096 Aug 15 13:50 ./
drwxrwxr-x 4 es_server es_server 4096 Aug 15 10:14 ../
drwxrwxr-x 4 es_server es_server 4096 Aug 15 11:50 GFUQVFGeR1OMxYpP84kADw/
drwxrwxr-x 4 es_server es_server 4096 Aug 15 10:14 nP7CcjJqRGyTSRZFe-ws7Q/
drwxrwxr-x 3 es_server es_server 4096 Aug 15 13:50 pLcZj7mpQZ2sj489LCI8PA/
drwxrwxr-x 6 es_server es_server 4096 Aug 15 10:43 ppzCzxaxQAegLEM7C3W-ng/
drwxrwxr-x 4 es_server es_server 4096 Aug 15 10:14 wF9_Ay68Qhyx8X89TRNl0Q/
root@h121:/opt/servers/es/data/nodes/0/indices# 对应的截图如下图所示: 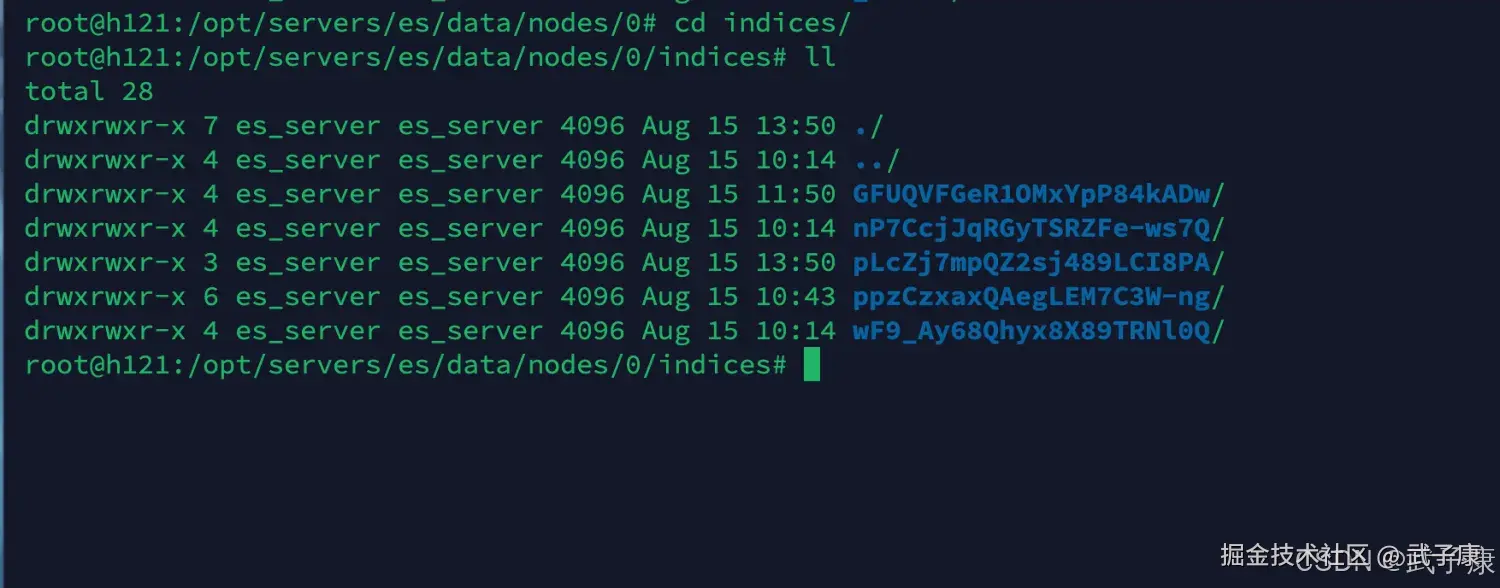 如何找到它们的对应关系呢? 可以在ES-Head中,点击索引的Info => IndexStatus => 弹窗中有一个 UUID,这个就是我们需要的值,对应的关系如下图所示:
如何找到它们的对应关系呢? 可以在ES-Head中,点击索引的Info => IndexStatus => 弹窗中有一个 UUID,这个就是我们需要的值,对应的关系如下图所示: 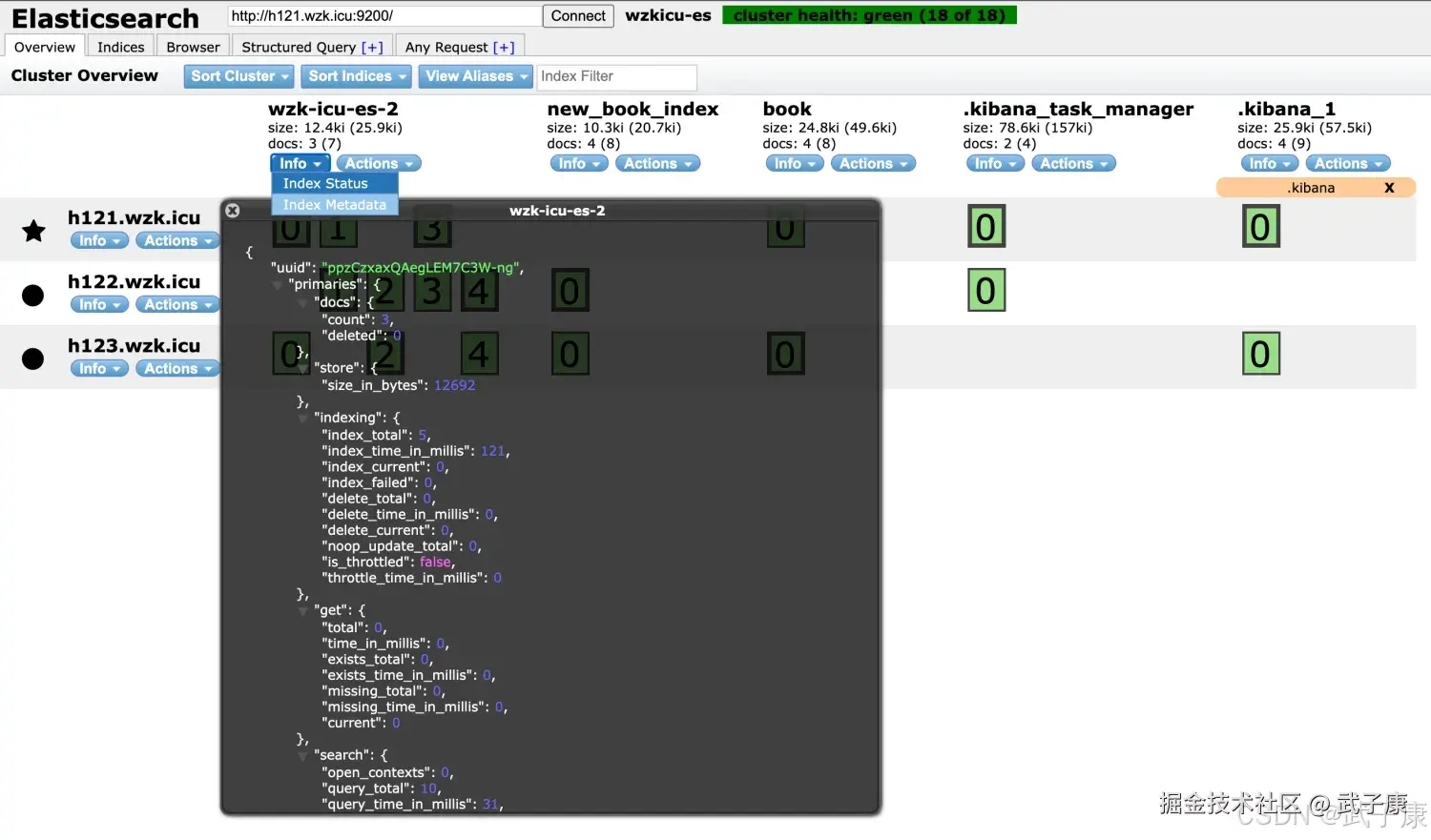
我们需要的是进入这个目录:(你的和我的不一样):
shell
cd ppzCzxaxQAegLEM7C3W-ng目录当中的内容如下图所示: 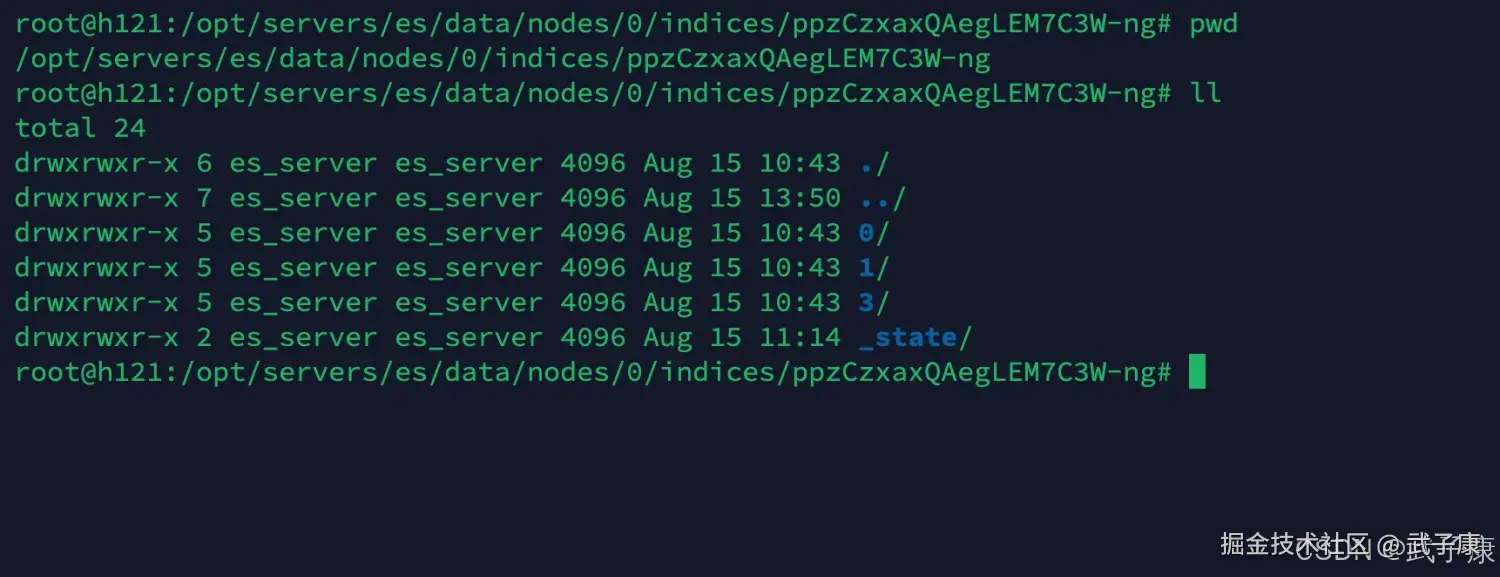 我们对上述的内容进行解释:
我们对上述的内容进行解释:
- 0、1、3 是标识 shard编号
- _state 存储了索引状态,包括setting,mapping等文件
进入_state目录,查看当前目录下的内容,如下图所示:
shell
cd _state执行结果如下图: 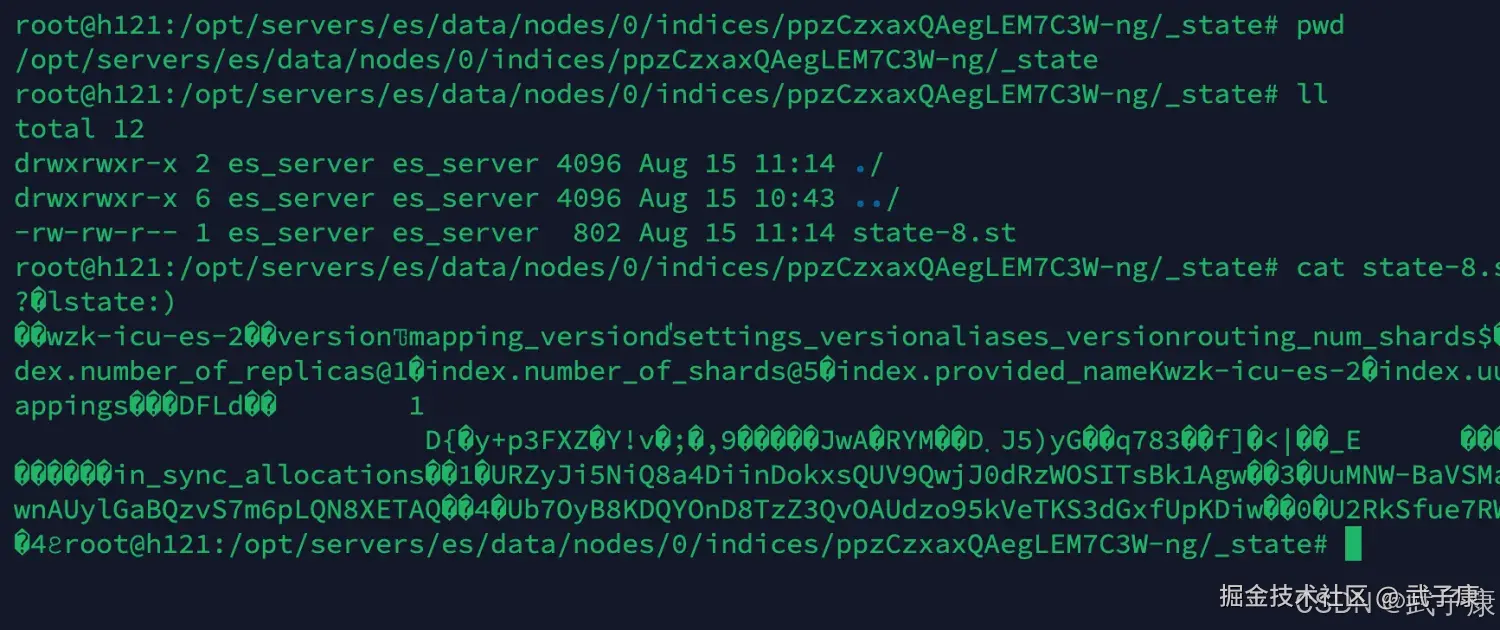
我们回到上一级,回到刚才的数字编号目录(0、1、3文件夹)
shell
cd ..执行结果如下,有0、1、3,我们随便进入一个 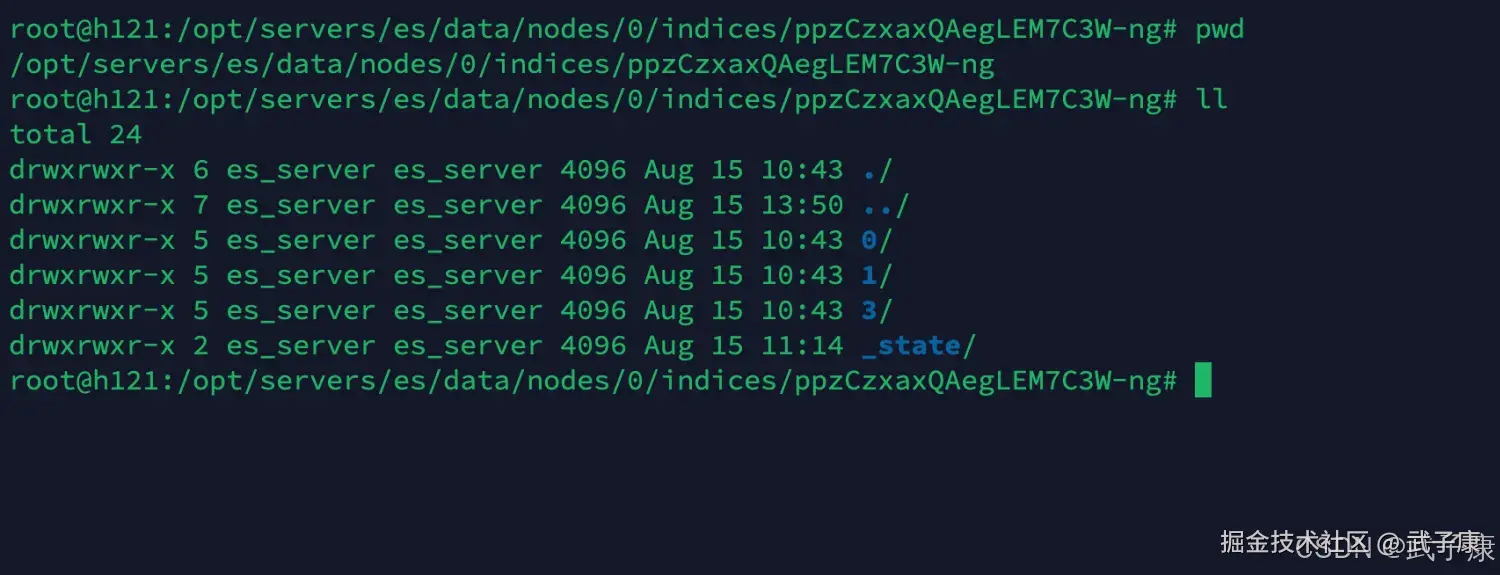
shell
cd 0我们进入文件夹之后,可以看到下面有这些内容: 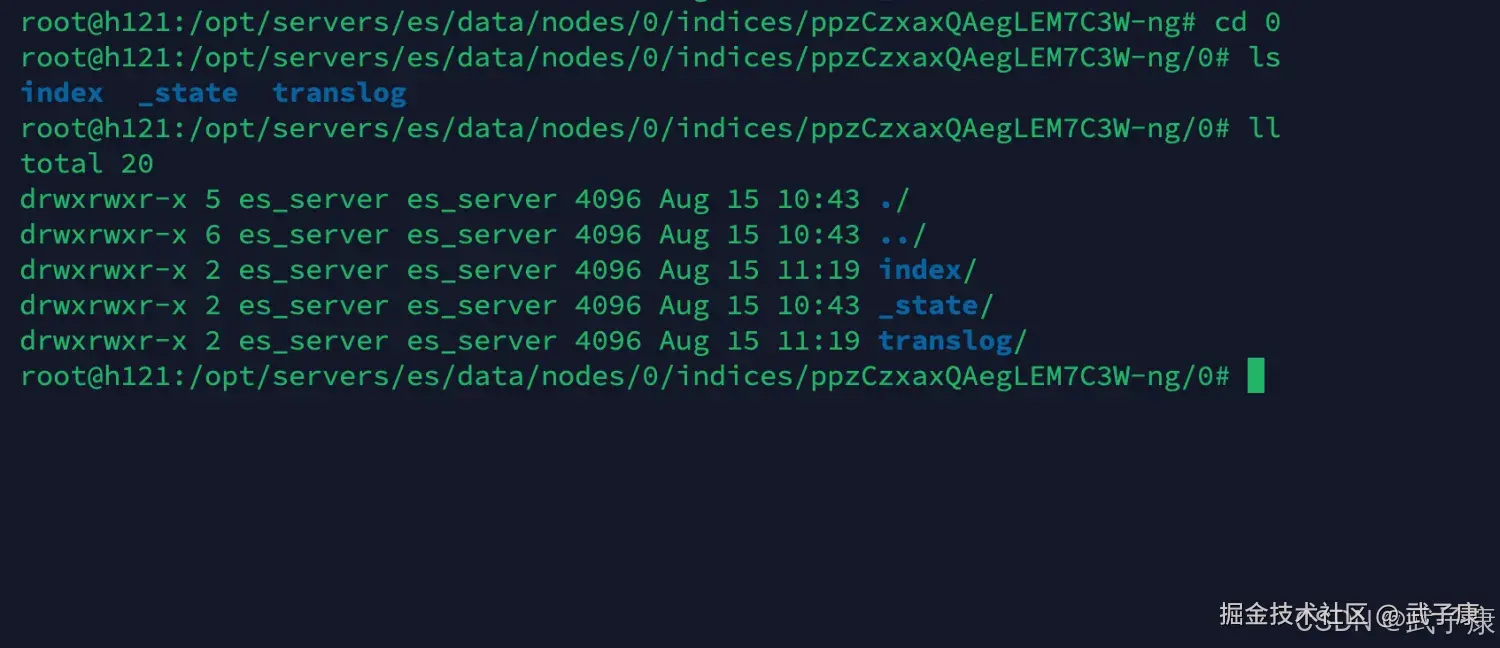 我们进行解释:
我们进行解释:
- index ES的数据目录
- _state 当前shard的信息,比如是主、副分片等信息
- translog保证数据写入的安全事务日志数据
我们进入 index 数据目录:
shell
cd index
ll可以查看到如下的内容: 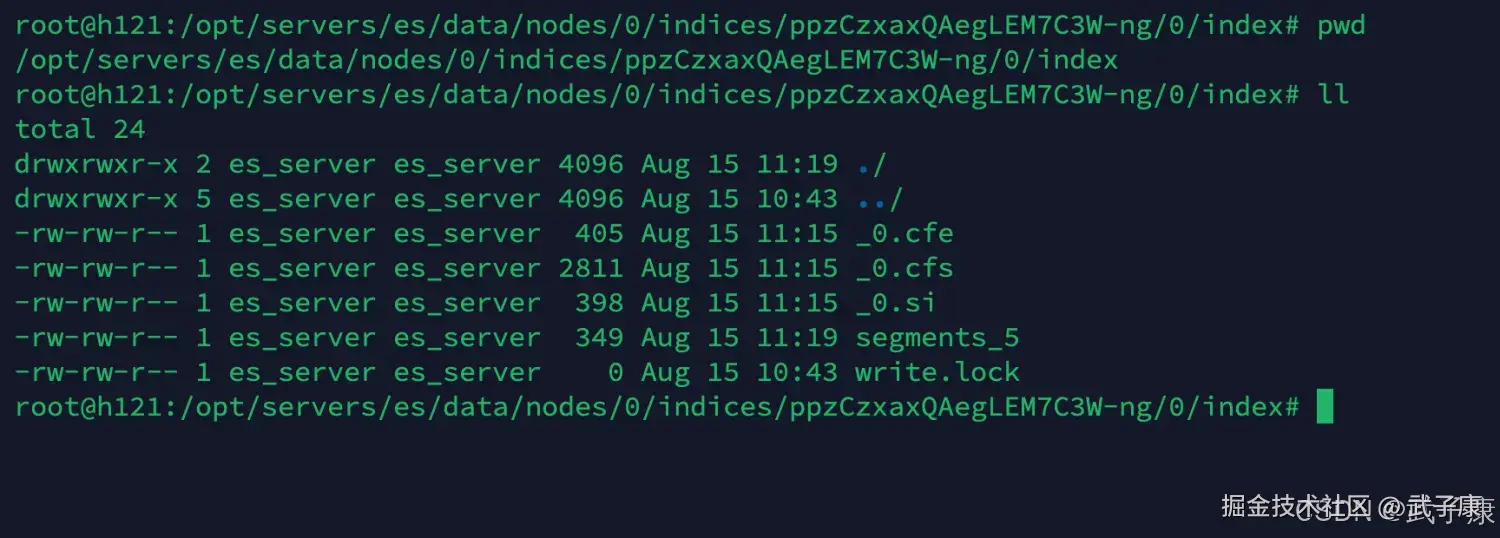 我们对当中的文件内容进行解释:
我们对当中的文件内容进行解释: 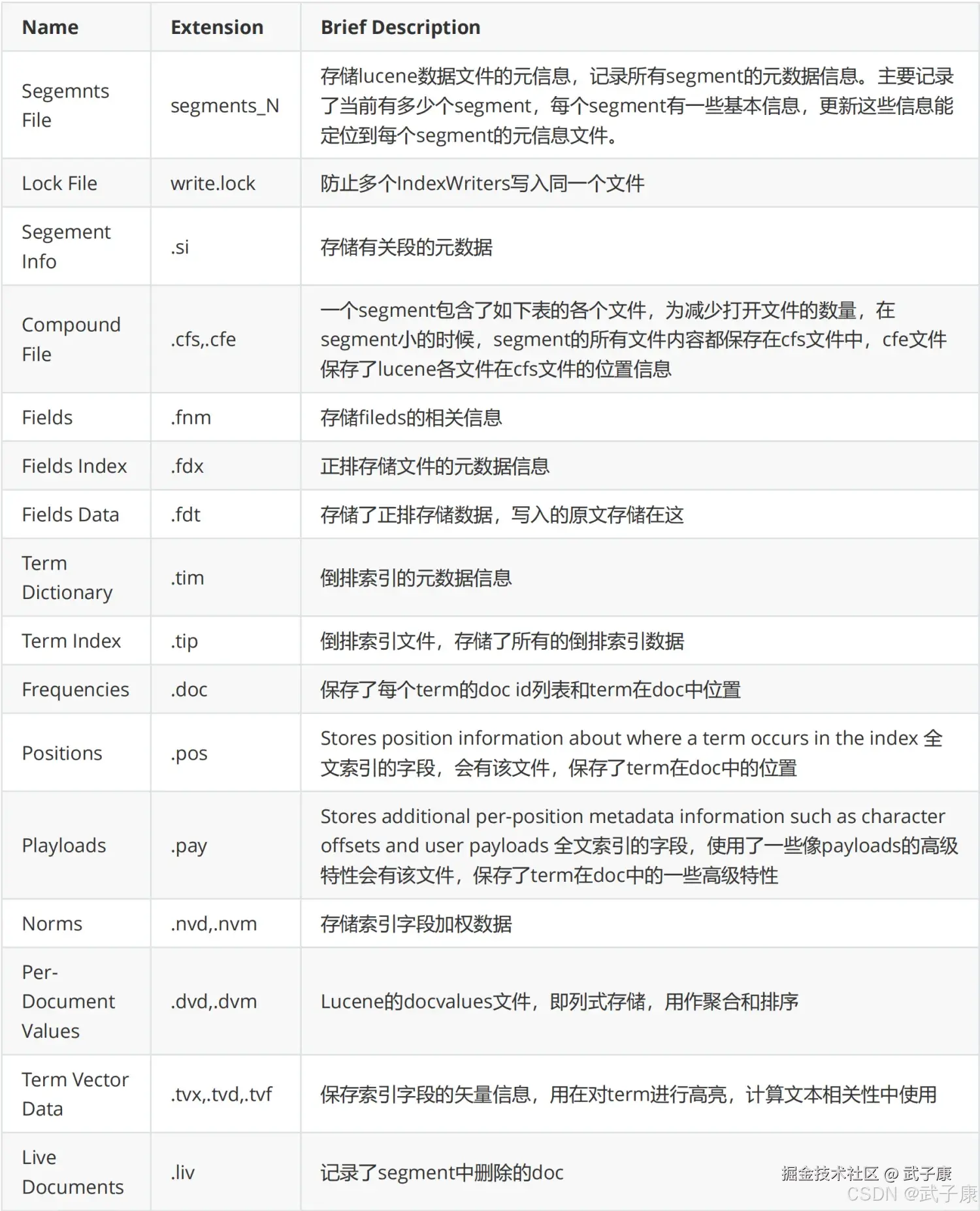
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 搜索变慢、段数量短时间暴涨 | refresh 频繁产生小段,合并跟不上 | _cat/segments 看 segments 数与大小;观察 merge backlog/IO |
提高 refresh_interval(按业务容忍);控制写入并发;必要时扩容/升级磁盘 |
| 日志索引写入被"限速/节流" | 合并落后触发保护机制,写入被抑制到更保守状态 | 看节点日志是否出现 merge/throttle 相关提示;看磁盘 IO 飙升 | 降低写入峰值;提升磁盘吞吐;按版本评估是否还存在旧的 throttle 参数 |
| 磁盘占用持续偏大,删除/更新后不回收 | 删除文档在段内打标,需 merge 才真正释放空间 | 观察 deleted docs 比例;磁盘占用与段合并节奏 | 等待后台合并;只读索引可考虑 _forcemerge,但要评估窗口与风险 |
调用 /_optimize 报 404 |
API 已废弃/移除 | 请求返回 404;查集群版本 | 改用 /_forcemerge?max_num_segments=1 |
| force merge 后反而更慢 | cache/OS page cache 被冲刷、合并开销挤压查询、段结构变化导致冷热失衡 | 对比 merge 前后查询耗时、IO、缓存命中 | 只对归档只读索引做;选低峰;限制并发;先在小索引验证 |
| merge policy 配置不生效/报未知参数 | 参数名拼写错误或版本已变更 | ES 启动日志/PUT settings 返回错误 | 校验参数名(如 floor_segment);按版本文档调整 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解