推理语言模型训练策略的协同作用:预训练、中间训练与强化学习的交互机制
近年来,强化学习技术在语言模型推理能力提升方面取得了显著进展,但后训练是否真正扩展了模型在预训练期间获得的推理能力仍存在争议。这项研究通过完全可控的实验框架,揭示了预训练、中间训练和强化学习后训练之间的因果贡献关系,为理解推理语言模型训练策略提供了重要基础。
论文标题:On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
来源:arXiv:2512.07783, http://arxiv.org/abs/2512.07783
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
现代大型语言模型训练流程包含多个阶段,但各个阶段之间的相互作用机制尚不明确。大规模预训练语料库不透明,中间训练常被忽视,而强化学习目标与未知先验知识以复杂方式相互作用。这种缺乏控制的环境使得难以分离后训练的因果效应,也无法理解预训练和后训练如何共同塑造推理行为。近期关于强化学习是否能真正提升基础模型推理能力的研究得出了相互矛盾的结论,有的认为RL只是精炼现有能力,有的则提供了超越预训练的实质性推理增益证据。
研究问题
- 训练阶段控制缺失:现代训练管道中缺乏控制,大规模预训练语料库不透明,中间训练常被忽视
- 强化学习效果争议:关于强化学习是否真正扩展模型推理能力存在相互矛盾的观点
- 阶段相互作用不明:预训练、中间训练和强化学习如何共同影响语言模型的推理能力
主要贡献
- 完全可控实验框架:开发了具有明确原子操作、可解析逐步推理轨迹和系统性训练分布操作的合成推理任务框架
- 强化学习效果调和:揭示了关于强化学习有效性相互竞争观点的一致性解释,证明RL仅在特定条件下产生真正的能力提升
- 中间训练关键作用:证明了中间训练在固定计算预算下相比仅使用RL显著增强性能,突显其在训练管道中的核心作用
- 过程级奖励机制:证明了过程级奖励减少奖励破解并提高推理保真度
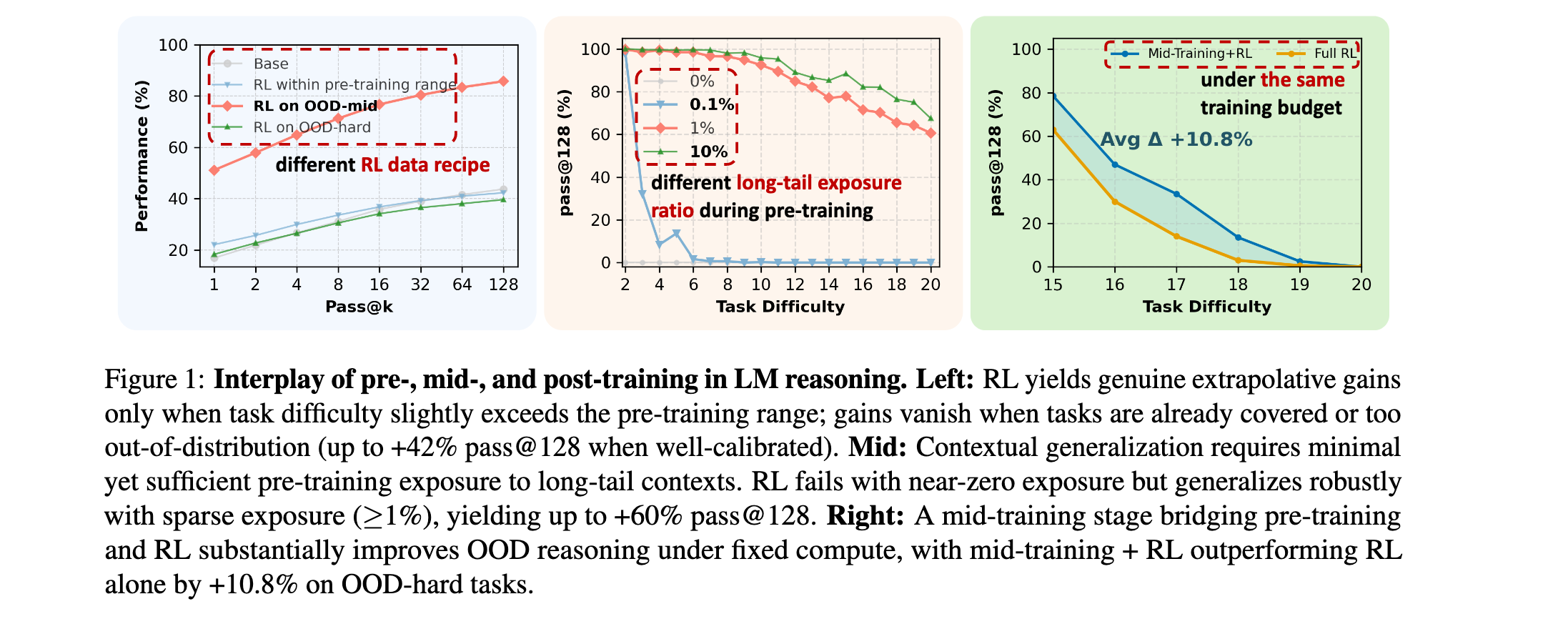
方法论精要
可控合成推理数据集
研究团队基于GSM-Infinite数据生成框架构建了具有精确控制推理结构、复杂性和上下文的测试平台。数据生成管道包含三个关键组件:
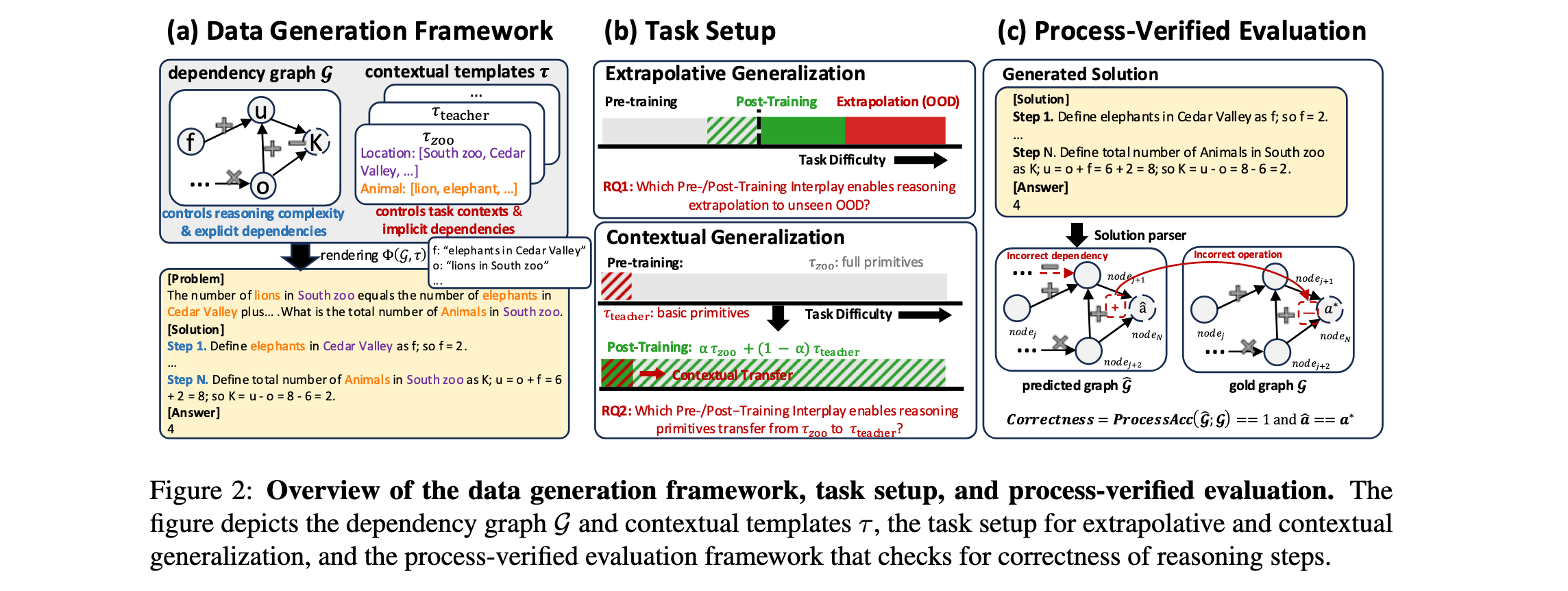
依赖图结构 :每个推理问题由有向无环图 G = ( V , E ) G = (V, E) G=(V,E)表示,其中节点 v ∈ V v \in V v∈V对应变量,有向边 e ∈ E e \in E e∈E表示依赖关系。图最终指向指定的答案节点 v ∗ v^* v∗,产生最终答案 a ∗ a^* a∗。
推理复杂性控制 :通过算术操作数量量化图复杂性: o p ( G ) = ∣ E ∣ op(G) = |E| op(G)=∣E∣,从基础算术到复杂多步推理控制任务难度。
上下文渲染 :给定预定义上下文模板 τ \tau τ(如动物-动物园、教师-学校),将依赖图 G G G渲染为完整数学问题。
这种框架的优势在于:1) 训练阶段的无污染控制;2) 结构和上下文的分解控制;3) 过程级验证能力。
任务设置与评估协议
外推泛化(深度) :评估模型在推理深度 o p ( G ) op(G) op(G)增加时保持正确性的能力,当操作链超过训练期间遇到的复杂度时,模型表现出强外推泛化。
上下文泛化(广度):衡量模型能否将推理原语转移到表面形式不同但底层推理结构相似的新领域。当底层计算图保持不变时,模型在模板或表面形式变化下保持稳定性能。
过程验证评估 :对于每个具有真实依赖图 ( G , a ∗ ) (G, a^*) (G,a∗)的实例,模型产生自由形式解决方案,解析为预测依赖图 G ^ \hat{G} G^和最终答案 a ^ \hat{a} a^。过程评估在每个黄金节点 v ∈ V v \in V v∈V的步骤级别进行,比较预测和黄金节点、它们的依赖关系和数值。过程准确性计算为所有黄金节点的平均步骤级准确性。只有当推理步骤和最终答案都匹配时,预测才被视为完全正确。
训练设置
预训练 :在10B令牌上训练100M参数的Qwen2.5风格模型,数据集包含跨模板的 o p = 2 − 10 op=2-10 op=2−10操作,使模型掌握推理同时为复杂任务保留提升空间。
中间训练:作为预训练和后训练之间的中间阶段,使用与预训练相同的目标但数据分布更接近RL,专注于模型表现出新兴但不完整能力的边界。
后训练:主要使用GRPO进行,在精心策划的子集上训练,旨在探测更深操作范围和新颖模板的泛化能力。
实验洞察
强化学习的条件性效果
实验发现,强化学习的有效性高度敏感于预训练和后训练数据制度:
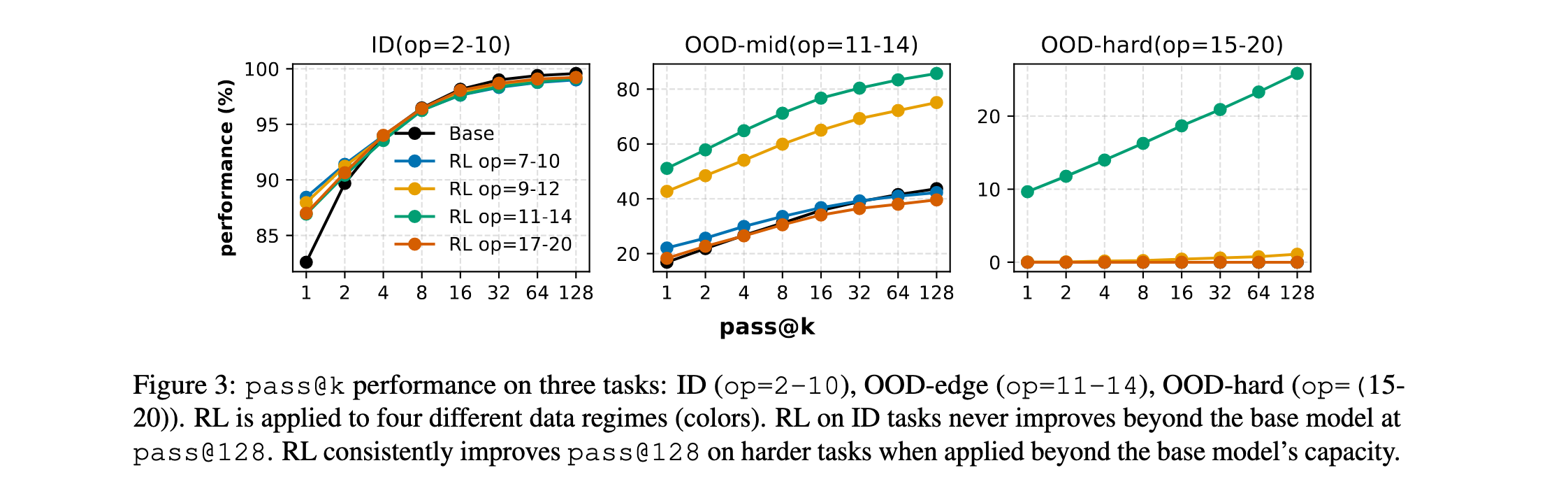
- 对于ID任务( o p = 2 − 10 op=2-10 op=2−10),在pass@1上有明显性能提升,但无论RL数据制度如何,在pass@128上都没有改善,表明RL只是精炼现有能力而非扩展能力。
- 对于OOD任务( o p = 11 − 14 op=11-14 op=11−14和 o p = 15 − 20 op=15-20 op=15−20) ,当应用于"能力边界"数据( o p = 11 − 14 op=11-14 op=11−14)时,RL始终改善pass@128性能,展示超越预训练的真正能力提升。
关键发现是:RL产生真正的能力提升(pass@128)仅当两个条件满足:(i)任务在预训练期间未被大量覆盖,为探索留下足够空间;(ii)RL数据校准到模型的能力边界,既不太容易(分布内)也不太难(分布外)。
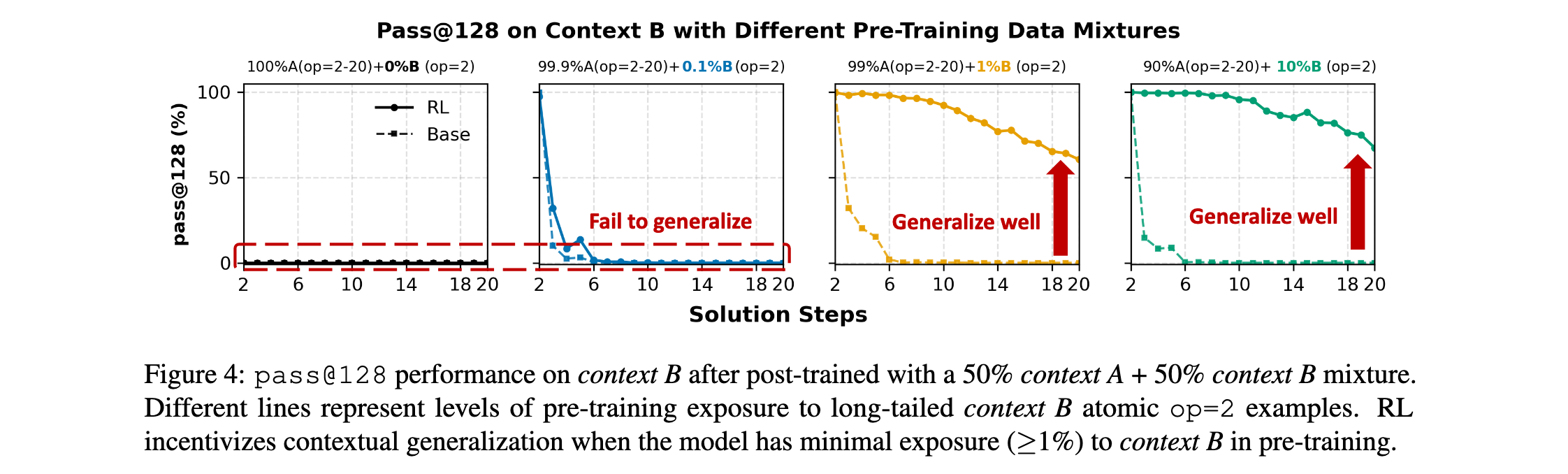
预训练暴露对后训练泛化的影响
研究通过操纵预训练期间长尾上下文B的原子操作示例比例,评估预训练暴露如何影响后训练泛化:
- 当预训练排除上下文B或提供很少暴露(0%或0.1%)时,RL无法转移到上下文B。
- 在预训练期间引入仅1%的上下文B数据显著增强了后训练泛化 ,即使是最难的任务 o p = 20 op=20 op=20也能实现。
这表明RL仅在基础模型已包含必要原语时激励上下文泛化。没有对新上下文的最小预训练暴露,RL无法诱导转移。然而即使是稀疏暴露(如≥1%)也提供充分种子,RL可以在后训练期间强化,产生强大的跨上下文泛化。
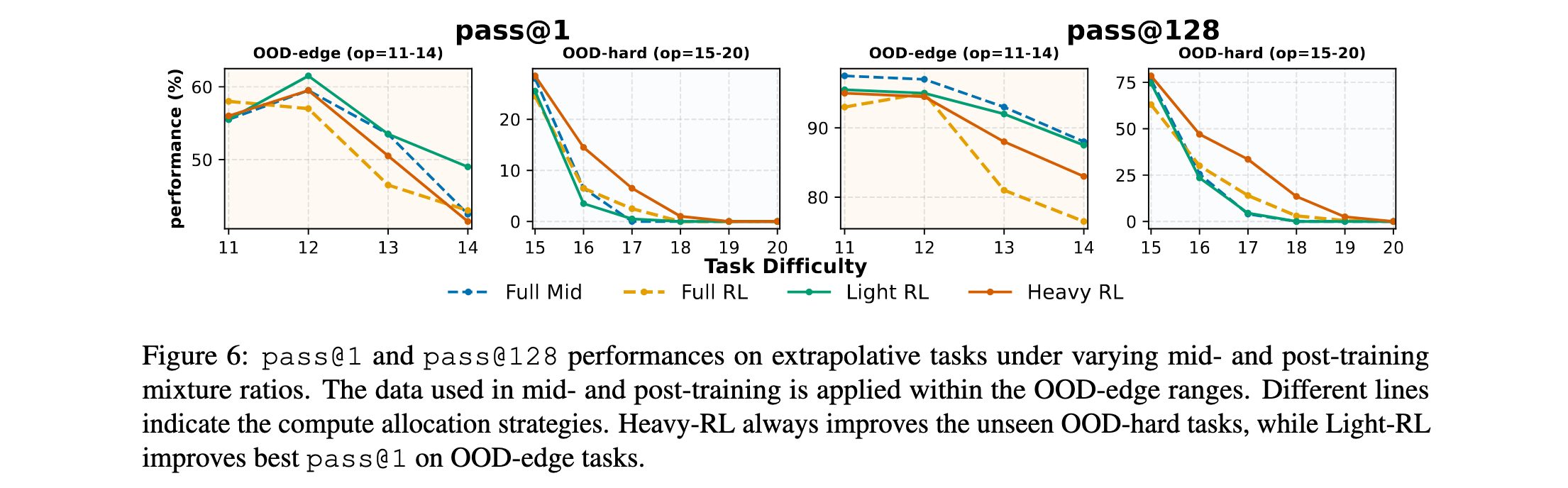
中间训练与后训练的相互作用
在固定计算预算下,研究探索了中间训练和RL的协同效应:
- 在OOD-edge任务上,完全中间训练和轻量RL的配置优于重度或完全RL的配置,轻量RL实现最佳pass@1性能。
- 对于OOD-hard任务,将更多预算重新分配给重度RL显著改善最困难实例的性能,在pass@1和pass@128上都有提升。
这些趋势表明RL驱动的探索对于泛化到更难任务不可或缺,但大量中间训练分配对于建立RL可以有效利用的先验仍然至关重要。
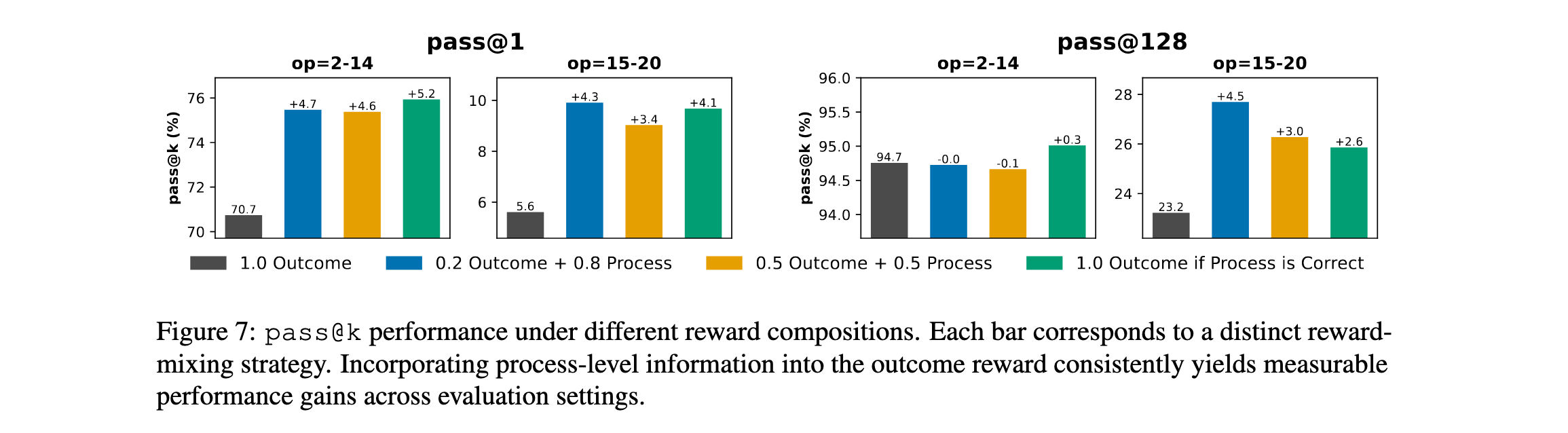
过程级奖励减少奖励破解
为鼓励模型生成不仅正确最终答案还有效中间推理步骤,研究用过程级验证增强结果奖励:
- 集成过程验证显著改善pass@1达4-5% ,在外推( o p = 15 − 20 op=15-20 op=15−20)设置中。
- **适度奖励混合(0.2结果+0.8过程)**在结果准确性和推理一致性之间实现最佳平衡,而严格奖励(仅当过程正确时给予结果)进一步增强实质性改善。
这些结果证实过程级监督有效减轻奖励破解并鼓励忠实推理行为。通过减少结构错误和强化正确中间步骤,过程感知奖励使外推设置下的改进更可靠。
结论与启示
这项研究通过完全可控的实验框架,揭示了预训练、中间训练和强化学习在推理语言模型中的相互作用机制。主要发现包括:
- 强化学习的条件性效果:RL仅在预训练留有足够空间且RL数据针对模型能力边界时产生真正的能力提升,调和了关于RL有效性的相互竞争观点。
- 预训练暴露的关键作用:上下文泛化需要最小但充分的预训练暴露,即使1%的稀疏覆盖也足以使RL实现强大的跨上下文泛化。
- 中间训练的核心地位:在固定计算预算下,中间训练显著增强性能相比仅使用RL,突显其在训练管道中核心但未被充分探索的作用。
- 过程级奖励的价值:过程级奖励减少奖励破解并提高推理保真度,使强化信号与有效推理行为保持一致。
这些发现为理解和改进推理语言模型训练策略提供了基础,为构建数据课程、设计奖励函数和跨训练阶段分配计算提供了可操作指导。未来的推理模型训练应该更加注重各个阶段之间的协同作用,而非孤立地优化单个阶段。