一条 SQL 在 MySQL 中的执行,是一个贯穿服务层 与存储引擎层 的精密过程。
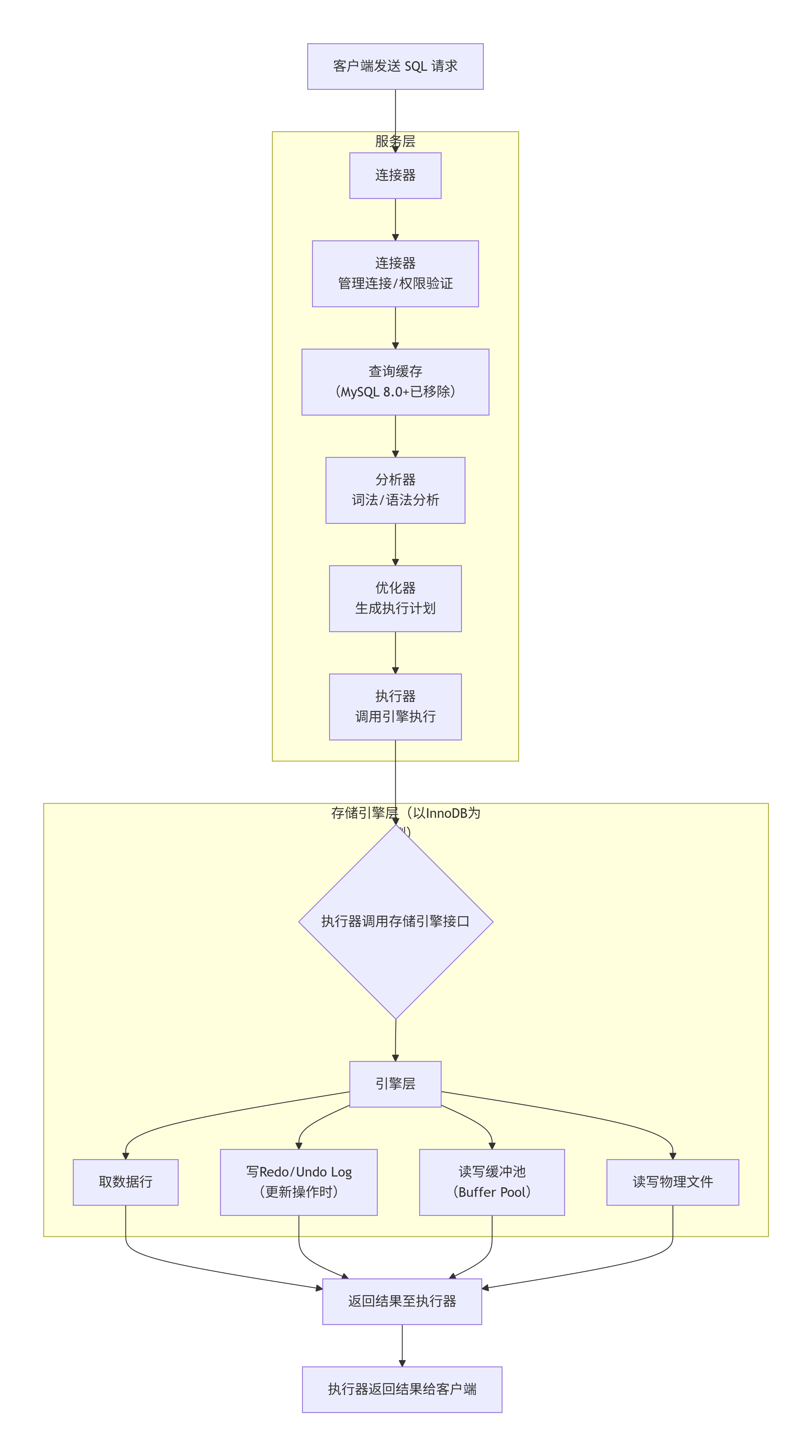
第一阶段:服务层处理(连接、解析与规划)
-
连接器
- 职责:管理客户端连接、身份认证与权限校验。
- 详细过程 :客户端通过TCP连接后,连接器验证用户名、密码和主机权限。认证通过后,连接器会从权限表加载该用户的权限信息,并在本次连接中生效。这意味着,即使中途修改了用户权限,当前已建立的连接也不会受影响,除非重新连接。
-
查询缓存(MySQL 8.0 版本已移除)
- 历史作用:在早期版本中,MySQL会先检查查询缓存。如果SQL语句(完全一致)和数据库环境(如数据库、客户端协议)命中缓存,则直接返回结果,跳过后续所有复杂步骤。
- 为何移除 :由于缓存失效非常频繁(表有任何更新,该表所有查询缓存都会清空),在读写频繁的系统中,查询缓存往往弊大于利。自MySQL 8.0起,该功能已被彻底删除。
-
分析器
- 职责:理解SQL语句的字面含义。
- 词法分析 :将SQL字符串拆解成一个个"词元"(token)。例如,识别
SELECT是查询关键字,users是表名,id是列名。 - 语法分析 :根据MySQL语法规则,检查这些"词元"组合成的SQL语句是否合法。如果语法错误(如少写了关键字),你会收到熟悉的
You have an error in your SQL syntax错误提示。
-
优化器
- 职责 :决定SQL语句的最佳执行方案。这是"大脑"决策环节。
- 核心工作 :
- 选择索引 :当表有多个索引时,优化器会根据数据分布(统计信息)、查询条件、排序等因素,估算不同索引的I/O成本 和CPU成本 ,选择它认为成本最低的索引。例如,
WHERE id = 1 AND name = 'Alice',可能选择id的索引。 - 决定连接顺序:如果是多表连接(JOIN),优化器会决定先读取哪张表(驱动表),以及连接的顺序。
- 重写查询:对条件进行一些等价转换,简化执行。
- 选择索引 :当表有多个索引时,优化器会根据数据分布(统计信息)、查询条件、排序等因素,估算不同索引的I/O成本 和CPU成本 ,选择它认为成本最低的索引。例如,
- 输出 :优化器最终生成一个执行计划 。你可以通过
EXPLAIN命令来查看这个计划。
-
执行器
- 职责 :根据执行计划,调用存储引擎的接口,逐步完成查询。
- 详细过程 :
- 在执行前,会再次检查用户对目标表是否有操作权限(如果命中查询缓存,则会在返回缓存结果时校验权限)。
- 根据执行计划,打开表,调用存储引擎接口获取数据。
第二阶段:存储引擎层处理(数据存取)
- 存储引擎
- 职责 :负责数据的实际存储和读写 。MySQL采用插件式架构,支持InnoDB、MyISAM等多种引擎(目前InnoDB是默认且绝对主流的引擎)。
- 以InnoDB执行一个SELECT为例 :
- 执行器 通过引擎接口,请求满足条件的第一行(例如,请求
id=1的行)。 - InnoDB引擎 首先检查缓冲池 中是否已有所需数据页。如果有(缓存命中),则直接返回;如果没有(缓存未命中),则从磁盘加载对应的数据页到缓冲池,然后返回数据。
- 执行器获取第一行后,会继续调用引擎接口请求"下一行",直到遍历完所有满足条件的行。
- 执行器 通过引擎接口,请求满足条件的第一行(例如,请求
- 以InnoDB执行一个UPDATE为例 (更复杂,涉及事务):
- 执行器调用引擎接口,获取满足条件的行(过程同SELECT)。
- 执行器将待更新数据传给引擎。
- 引擎 首先将旧数据写入 Undo Log(用于回滚和MVCC)。
- 然后在缓冲池 中更新数据行,并将更新操作记录到 Redo Log Buffer 中。
- 执行器提交事务 时,Redo Log 会按照一定策略刷盘(确保持久性),而数据页本身可能还在缓冲池中,等待后台线程异步刷回磁盘。这就是 WAL(Write-Ahead Logging) 技术。
第三阶段:结果返回
- 结果返回
- 执行器将获取到的所有满足条件的行组织成结果集。
- 如果是慢查询,记录会写入 Slow Query Log。
- 最终,结果集通过网络协议返回给客户端。
核心要点总结
- 两阶段分工:服务层负责SQL处理与逻辑,存储引擎负责数据存取。这种设计提供了灵活性。
- 关键优化点 :优化器选择的执行计划 和存储引擎的I/O效率(尤其是缓冲池命中率)是性能关键。
- 更新操作的区别 :更新操作会涉及事务日志(Redo Log, Undo Log),以保证ACID特性,流程比SELECT更复杂。