1、最短路径相关定义
我们知道,在上图中,每一个城市间都是有代价的,代价可以是距离、时间、费用等,这样我们在选择最短路径时的标准则是这些代价之和最低,这并没有什么问题;若是每条路径都没有代价,或者说代价都相同(一个单位代价),那么我们选择的标准就成了路径上边的数量最少。
所以说,对于网图来说,最短路径是指两顶点之间经过的边上权值之和最少的路径 ,我们称这条路径上的第一个顶点为源点 (Source),最后一个顶点为终点(Destination)。
同样,我们还是先给出部分约定:
-
只考虑连通图:当一个图不是连通图时,图中有些顶点是无法到达的,它们之间连路径都没有,更谈不上最短路径了。
-
边的权值不同:若存在几条边的权值相同,此时找出的最短路径可能不唯一。
-
边的权值非负:若存在边的权值为负数,此时可能会出现环路,使得路径权值无限减小,无法找到最短路径。
-
最短路径都是简单路径:即我们不考虑存在自环的情况。
首先我们先来认识一个算法------Dijkstra算法,它是由荷兰计算机科学家Edsger W. Dijkstra在1956年提出的,在记住算法的同时请记住这个人,他多半还会再次出现在你的计算机学习过程中。
2、迪杰斯特拉(Dijkstra)算法
首先我们来想一个问题,若我们类似上一节中所讲的Prim算法一样,每次都选择当前路径权值最小的边加入到路径中,最终是不是就会得到一个最短路径呢?答案是否定的,我们先来看下面这个例子:
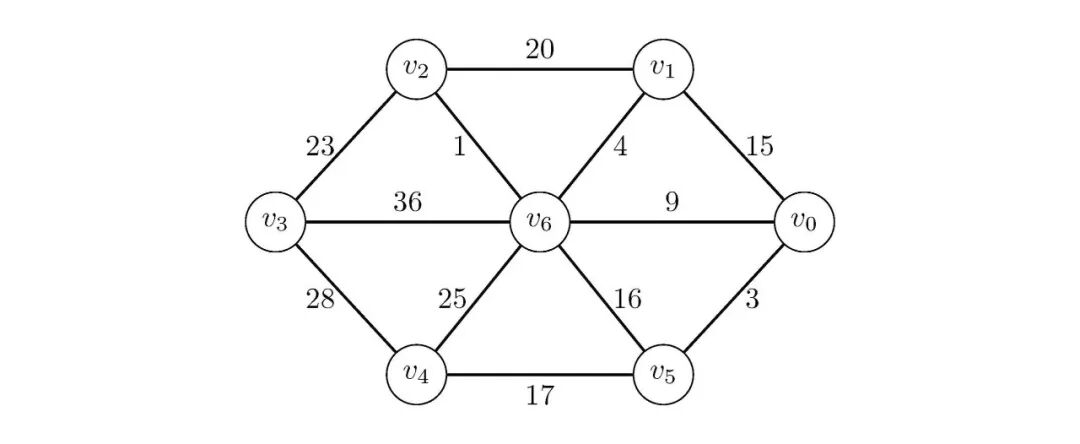
图2:一个图
假设我们要从顶点出发去,我们按上述策略就会找出、和这三条边,路径权值为;然而,显然和这两条边的路径权值为,更短。所以说,这种策略并不适用于最短路径问题。
那么,我们该如何解决这个问题呢?实际上,Dijkstra算法的思路与我们Prim算法的代码实现出的策略十分相似,我们在代码过程中会维护一个数组lowcost,它所记录的是当前生成树到各顶点的最小代价,只是我们现在要做的不是将其更新成0(表示它在最小生成树中),而是将其更新成当前路径的最小代价。具体来说,Dijkstra算法的策略如下:
-
选择一个源点,将其加入到集合中,表示当前已经找到从源点出发的最短路径的顶点集合;同时,初始化一个数组
dist,数组元素dist[i]表示从源点到顶点的当前已知最短路径长度,初始时,dist[s]为0,目前无法到达的顶点设为无穷大。 -
在集合中选择一个顶点,要求满足
dist[k]是dist数组中当前最小的,将其加入集合中。 -
对于每个不在集合中的顶点,如果通过到达的路径长度小于当前
dist[j],则更新dist[j]为通过到达的路径长度。 -
重复步骤2和3,直到所有顶点都被加入集合,或
dist数组中的所有值都不再更新。
实际上,我们维护的dist数组可以被当作一个"备忘录",它记录了从源点到各个顶点的当前已知最短路径长度,而等我们的更新操作全部结束后,它所存储的值就是从源点到各个顶点的最短路径长度。
我们可以先来看一下我们这个策略的过程,还是按照上图来进行说明,假设我们要从顶点出发,去顶点,我们先初始化:
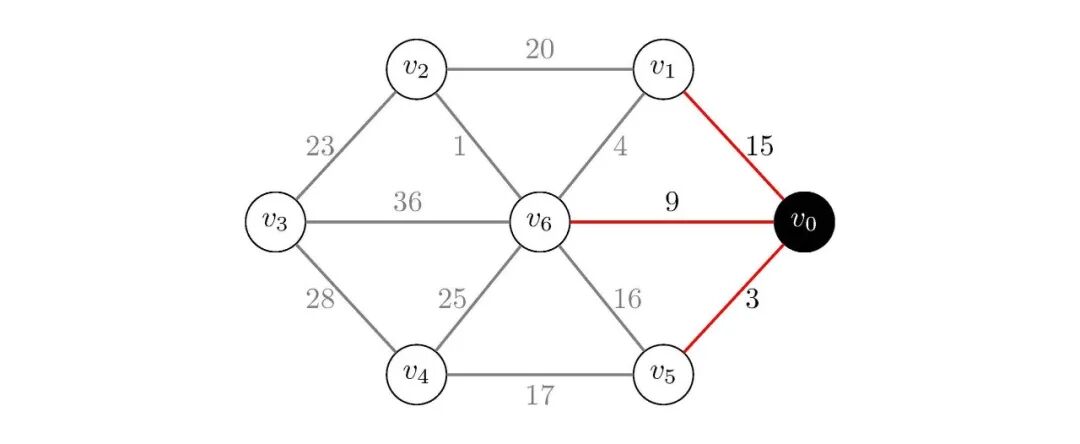
图3:Dijkstra策略初始化
然后,我们在中选择dist值最小的顶点,加入到集合中,并更新dist数组:
我们看到从出发,我们可以到达、和,同时我们知道已经在集合中,不需要更新;而和的dist值分别为无穷大和,而通过到达它们的路径长度分别为和,显然,小于无穷大,说明经过到达的路径长度更小,所以我们更新dist[4]为,而大于,说明经过到达的路径长度更大,所以不更新dist[6],此时,我们得到:
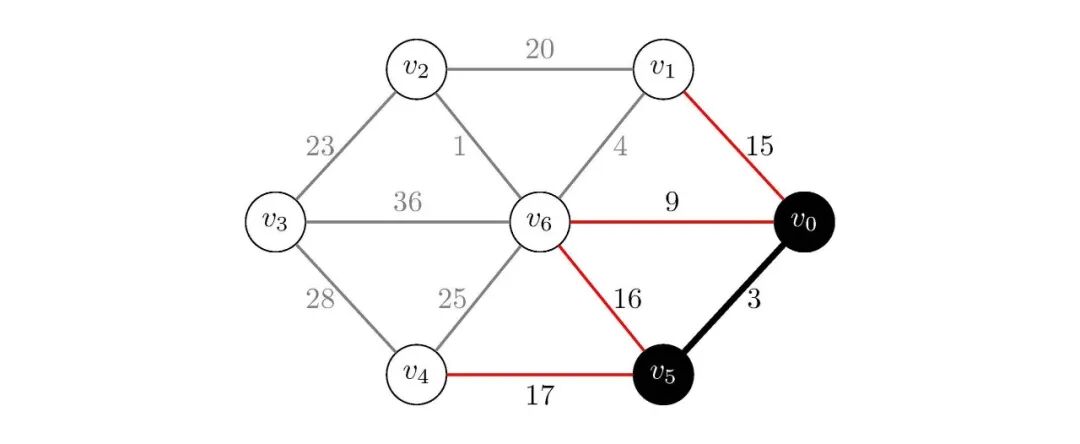
图4:Dijkstra策略第一次更新
接下来,我们在中选择dist值最小的顶点,将其加入到集合中,并更新dist数组:
从出发,我们可以到达图中其余所有顶点(~),权值分别为、、、、、,而、已经在集合中,不需要更新;通过到达的路径长度为,小于当前dist[1]的15,所以更新dist[1]为;通过到达的路径长度为,小于当前dist[2]的无穷大,所以更新dist[2]为;通过到达的路径长度为,大于当前dist[3]的,不更新;通过到达的路径长度为,大于当前dist[4]的,不更新。此时,我们得到:
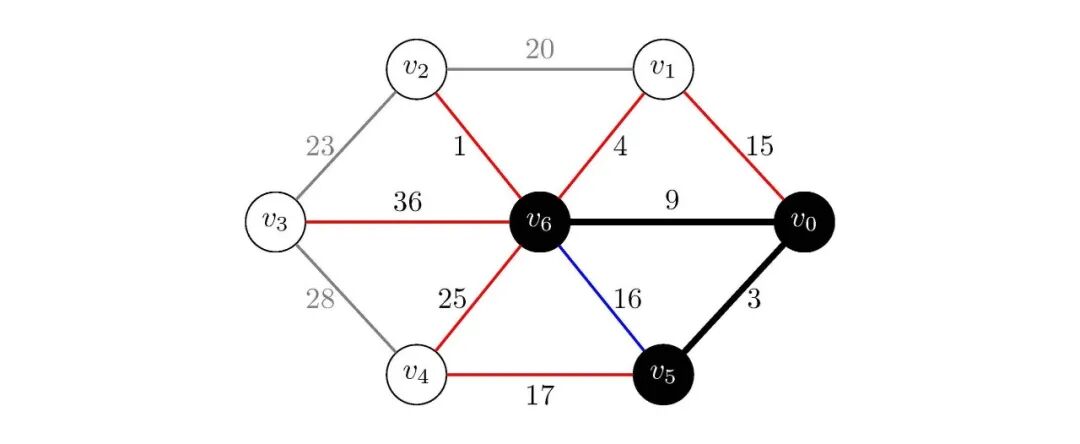
图5:Dijkstra策略第二次更新
后续的过程就不再赘述了,与上面操作一致,就是不断更新dist数组。最终,我们可以得到从源点到各个顶点的最短路径长度。
但是有同学会产生疑问,为什么我们每次选择dist值最小的顶点加入集合中,就能保证这个顶点的dist值是最终的最短路径长度呢?万一存在一条更短的路径通过其他顶点到达这个顶点呢?
实际上,这个问题同样可以通过反证法来证明,若是接下来的证明过程看不懂,可以先跳过,先将其当作一个结论来使用。
首先明确我们要证明的是:
当一个顶点被选中加入集合(即已确定最短路径的顶点集合)时,它的dist[k]值一定是从起点到它的真正最短路径长度,不可能还有更短的路径。
假设我们选了一个当前 dist 值最小的顶点,但它的 dist[k] 并不是最终的真正最短路径长度。也就是说,存在一条更短的路径可以到达,只是我们还没发现。这条更短的路径可能是这样的:
而且这条路径上,至少有一个顶点不在集合中(即还没被处理过)。
为什么一定有这样的顶点 ?
因为如果这条路径上的所有顶点都已经在中了,那说明我们早就通过它们更新过 的
dist值了,那dist[k]就应该是这条更短路径的长度,而不是现在的值,这就和我们最初的假设矛盾了。所以,这条更短的路径上,至少有一个顶点还没被处理(不在中)。
我们设这条路径上,第一个不在中的顶点是。也就是说,从起点到之前的所有顶点(比如)都已经在中。
根据Dijkstra算法的做法,当我们把这些顶点加入时,已经用它们来更新过它们邻接点的dist值了。所以,dist[i] 的值一定已经通过更新过了,也就是说,我们已经找到了从起点到的一条最短路径(至少是目前已知的最短路径)。
而且,因为是在之前被访问的(它是路径上第一个不在中的顶点),所以dist[i] 的值一定小于或等于 dist[k]。
换句话说,从起点到的路径长度,已经比到的路径更短或相等。
那既然我们能通过走到,而且这时的 dist 值更小,那我们应该先处理,而不是。这就说明:我们不可能先选到,再去发现一条更短的路径通过 ------ 这是因为若的 dist 值更小,它应该更早被选中。所以假设不成立。
我们一开始假设 "dist[k] 不是最短路径长度",但推着推着就发现:如果真有更短的路径,那它上面的第一个未处理顶点应该比更早被选中。这就和"我们选了"矛盾了。
总归,看文字不如看图直观,我们给出这样一张图
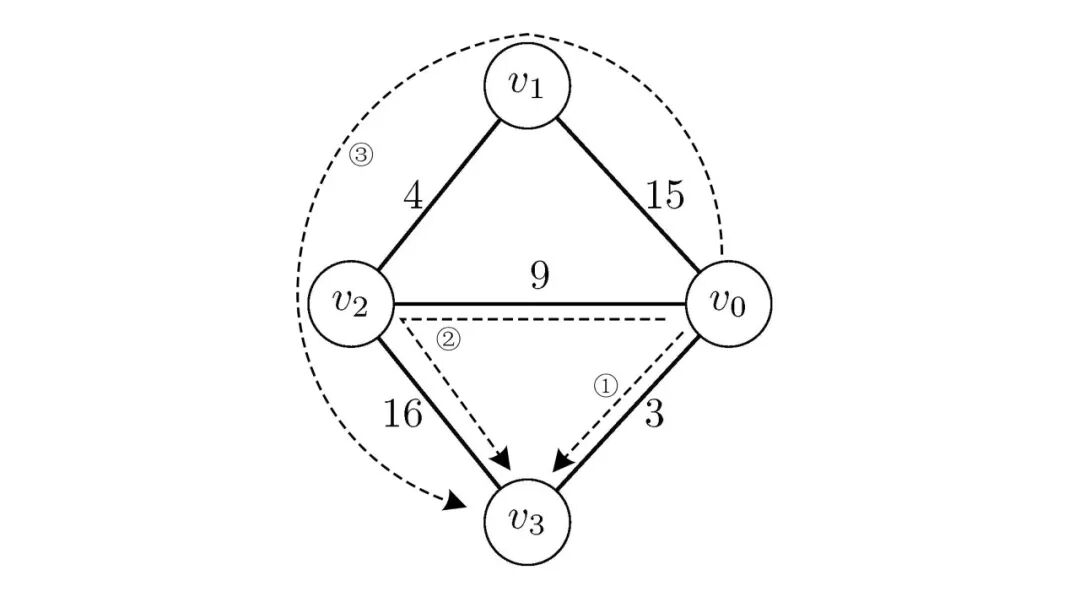
图6:反证法示例图
我们可以看到,从图中到有三条简单路径可以走,可以直观看出路径是最短路径,选择过程中也是先被选择进,我们能想办法让这条路径更短吗?我们可以让的权值为,的权值为,这样一来,这条路径的权值为,小于;但是,我们发现,的权值为时,我们就会先选择,而不是,因为此时dist[2]为,dist[3]为,所以会先被选择进,然后再通过更新dist[3],最终我们还是能找到最短路径。
所以说我们若想让这条路径更短,就要使得
但是,想要满足上式,我们知道必有,所以此时会先被选择进,自然就不会出现先被选择进的情况。
由此,我们知道,Dijkstra算法中,每次选择dist值最小的顶点加入集合中,是合理且正确的。同时,以上证明过程还隐含着这样一个引理:
最短路径的子路径也是最短路径:给定一个图,设是从顶点到顶点的最短路径,那么对于路径上的任意两个顶点和(),路径也是从到的最短路径。
同时,我们也能理解为什么要求边的权值非负了,若是存在负权边,比如上图中,我们若将的权值设为,那么我们就会发现,在一开始将加入后(dist[3]=),等我们探索到时,发现通过到达的路径长度为,这样就会出现我们在上述问题中所担心的情况,即当前根据dist值选择的顶点走向并不是最终的最短路径的走向。
接下来,我们来看一下Dijkstra算法的邻接矩阵代码实现:
void Dijkstra(GraphAdjMatrix G, int s, int dist[], int path[])
{
int i, j, k, min;
intfinal[MAXVEX]; // final[i]为1表示顶点vi已加入集合S中,0表示未加入
// 初始化
for (i = 0; i < G.numVertexes; i++)
{
final[i] = 0; // 全部顶点初始化为未加入S
dist[i] = G.arc[s][i]; // dist数组初始化为源点到各顶点的权值
if (dist[i] < INFINITY)
path[i] = s; // 初始化路径数组
else
path[i] = -1; // -1表示路径不存在
}
dist[s] = 0; // 源点到自身距离为0
final[s] = 1; // 源点加入集合S中
// 主循环,寻找最短路径
for (i = 1; i < G.numVertexes; i++)
{
min = INFINITY; // 初始化min为无穷大,表示当前最小距离
for (j = 0; j < G.numVertexes; j++)
{ // 在V-S中选择dist值最小的顶点
if (!final[j] && dist[j] < min)
{
min = dist[j]; // 更新当前最小距离
k = j; // 记录当前最小距离的顶点
}
}
final[k] = 1; // 将选中的顶点k加入集合S中
// 更新dist和path数组
for (j = 0; j < G.numVertexes; j++)
{
if (!final[j] && (min + G.arc[k][j] < dist[j]))
{ // 若顶点j不在S中,且经过k顶点到达j的距离更小
dist[j] = min + G.arc[k][j]; // 更新dist值
path[j] = k; // 更新路径
}
}
}
} 按照惯例,参考上述给出的图,我们来分析一下调用Dijkstra(G, 0, dist, path)时的过程:
- 首先,代码3 ~ 16行都是初始化操作,我们初始化
final数组为全,表示所有顶点都未加入集合中;初始化dist数组,表示从源点到各顶点的当前已知最短路径长度;初始化path数组,表示从源点到各顶点的路径前驱节点。之后,我们设置dist[0]的值为,表示源点到自身的距离为,并将final[0]设为,表示源点已经加入集合中。
初始化后,dist数组和path数组的值分别为:
- 然后,代码18 ~ 41行是Dijkstra算法的主循环,循环
G.numVertexes-1次,每次循环中,我们先在final数组中选择一个dist值最小的顶点,将其加入集合中,然后更新dist和path数组。
第一次循环时,我们先初始化min为无穷大,它表示当前最小距离,然后我们遍历dist数组,找到其中值最小且未被加入集合(即final[j] == 0)的顶点,这里是,它的dist值为,所以我们将min更新为,并将k更新为5,表示当前最小距离的顶点是。然后,我们将final[5]设为,表示顶点已经加入集合中。此时:
接下来第33 ~ 40行,我们遍历所有顶点,更新dist和path数组。我们发现,顶点可以到达、和,其中已经在集合中,不需要更新;而和的dist值分别为无穷大和,而通过到达它们的路径(即找到的路径为和)长度分别为和,显然,小于无穷大,所以我们更新dist[4]为,并将path[4]设为,表示到的路径前驱节点是;而大于,所以不更新dist[6]。此时:
结束后,我们进入第二次外层循环,再次初始化min为无穷大,然后遍历dist数组,找到值最小且未被加入集合的顶点,它的dist值为,所以我们将min更新为,并将k更新为,表示当前最小距离的顶点是。然后,我们将final[6]设为,表示顶点已经加入集合中。此时:
接下来再到第33 ~ 40行,我们遍历所有顶点,更新dist和path数组。顶点可以到达图中其余所有顶点(~),权值分别为、、、、、,而、已经在集合中,不需要更新;通过到达的路径(即找到的路径为)长度为,小于当前dist[1]的,所以更新dist[1]为,并将path[1]设为,表示到的路径前驱节点是;通过到达的路径(即找到的路径为)长度为,小于当前dist[2]的,所以更新dist[2]为,并将path[2]设为,表示从的路径前驱节点是;通过到达的路径(即找到的路径为)长度为,小于当前dist[3]的无穷大,更新dist[3]为,并将path[3]设为,表示到的路径前驱节点是;通过到达的路径(即找到的路径为)长度为,大于当前dist[4]的,不更新。此时:
此时,我们找到了从到和的最短路径,分别是和。在第三次外层循环时,我们会选择dist值最小的顶点,并将其加入集合中,然后更新dist和path数组,最终我们会找到从到的最短路径为。其余步骤不再赘述,与上述过程一致。我们可以绘制出一张求解路径过程的表格:
| 步骤 | 选中 | dist数组 | path数组 | final数组 | 说明 |
|---|---|---|---|---|---|
| - | - | 0, 15, ∞, ∞, ∞, 3, 9 | 0, 0, -1, -1, -1, 0, 0 | 1, 0, 0, 0, 0, 0, 0 | 初始化 |
i=1 |
0, 15, ∞, ∞, 20, 3, 9 | 0, 0, -1, -1, 5, 0, 0 | 1, 0, 0, 0, 0, 1, 0 | 选择,更新 | |
i=2 |
0, 13, 10, 45, 20, 3, 9 | 0, 6, 6, 6, 5, 0, 0 | 1, 0, 0, 0, 0, 1, 1 | 选择,更新、和 | |
i=3 |
0, 13, 10, 33, 20, 3, 9 | 0, 6, 6, 2, 5, 0, 0 | 1, 0, 1, 0, 0, 1, 1 | 选择,无更新 | |
i=4 |
0, 13, 10, 33, 20, 3, 9 | 0, 6, 6, 2, 5, 0, 0 | 1, 1, 1, 0, 0, 1, 1 | 选择,无更新 | |
i=5 |
0, 13, 10, 33, 20, 3, 9 | 0, 6, 6, 2, 5, 0, 0 | 1, 1, 1, 0, 1, 1, 1 | 选择,无更新 | |
i=6 |
0, 13, 10, 33, 20, 3, 9 | 0, 6, 6, 2, 5, 0, 0 | 1, 1, 1, 1, 1, 1, 1 | 选择,无更新 |
之前我们已经提到,我们最后的dist数组中存储的值就是从源点到各个顶点的最短路径长度,也就是说,最后得到的其实不是一个点到一个点的最短路径,而是一个点到所有点的最短路径。因为我们并不知道我们想要的终点会在什么时候被选择进集合中,可能是第一个,也可能是最后一个,所以我们最快也只能等到刚好我们想要的终点被选择进集合中时,才能得到它的最短路径长度,可以在代码中添加一个判断语句,当我们选择的顶点是我们想要的终点时,直接跳出循环即可。但不可避免的是,我们还是需要等到它被选择进集合中时,才能得到它的最短路径长度。
另外,我们在代码中还维护了一个path数组,它记录了从源点到各个顶点的路径前驱节点,这样我们就能通过它来反向推导出从源点到某个顶点的具体路径,比如我们要找从到的路径,我们发现path[2]为,说明的前驱节点是,然后我们再看path[6],它为,说明的前驱节点是,而path[0]为,说明是源点,所以我们最终得到从到的路径为。我们便可以通过path数组来反向推导出从源点到各个顶点的具体路径,代码如下:
void PrintPath(int path[], int v)
{
if (path[v] == -1)
{
printf("No path from source to vertex %d\n", v);
return;
}
if (path[v] == v)
{
printf("%d ", v); // 到达源点,打印源点
return;
}
PrintPath(path, path[v]); // 递归打印前驱节点
printf("%d ", v); // 打印当前节点
} 假设我们要打印从到的路径,我们调用PrintPath(path, 2),在该函数中会递归调用PrintPath(path, 6),然后再递归调用PrintPath(path, 0),此时path[0]为,说明是源点,打印,然后返回上一层,打印,再返回上一层,打印,最终我们得到从到的路径为0 6 2。
最后,我们来分析一下Dijkstra算法的时间复杂度,假设图中有个顶点,条边,那么Dijkstra算法的时间复杂度为,这是因为我们在每次选择dist值最小的顶点时,需要遍历整个dist数组,时间复杂度为,而我们需要进行次这样的操作,所以总的时间复杂度为。
当我们想要得知各个顶点到其余各个顶点的最短路径时,我们可以对每个顶点进行一次Dijkstra算法,这样总的时间复杂度就变成了。我们也可以使用Floyd-Warshall(亦称Floyd)算法来解决这个问题,它的时间复杂度也是,但是它的实现更为简单。
3、弗洛伊德(Floyd)算法
我们在上一节中得知了一个定理:最短路径的子路径也是最短路径。根据这个定理,我们可以得知,当我们找出一条最短路径时,它的子路径和也都是最短路径,同理,的子路径也是最短路径,的子路径也是最短路径。也就是说,一条最短路径可以拆分成若干条更小的最短路径。这样一来,我们就可以把求到的最短路径的问题,拆分成求到的最短路径和到的最短路径的问题。
这个性质告诉我们:大问题的最优解可以由小问题的最优解组合而成,自然,我们就会思考,我们可不可以"从小到大"一步一步拼出最短路径。
一开始,我们只知道图中直接相连的边的长度,也就是我们的邻接矩阵,我们将其命名为,其中表示从顶点到顶点的路径长度,最后用它来存储从顶点到顶点的最短路径长度。
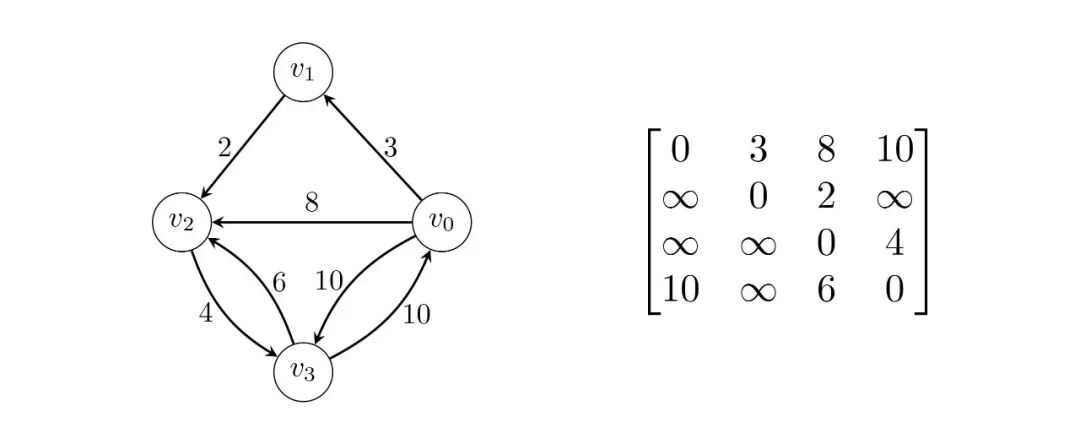
图7:一个图及邻接矩阵
我们能不能通过引入一些"中间点",来一步步缩短这个矩阵中的距离呢?
即我们的思路如下:
-
一开始,不允许经过任何中间点,我们能走的就只有直接相连的边。
-
然后,我们允许经过,看看能不能缩短部分路径。
-
接着,我们允许经过和,看看能不能缩短更多路径。
-
直到我们允许经过所有顶点,就得到了考虑过所有情况的最短路径。
就如图中我们认为为,即无法直接到达,然而,当我们试着引入中间点时,我们发现通过到达的路径长度为,小于,所以我们就将更新为,表示我们可以缩短到的路径;而为,表示可以直接到达,但是我们发现通过到达的路径长度为,大于,并没有缩短,我们就不更新它。
此时我们的矩阵变为:
然后,我们再引入中间点,我们发现为,但是我们发现通过到达的路径长度为,小于,所以我们就将更新为;而为,但是我们发现通过到达的路径长度为,并没有缩短,我们就不更新它。
此时的矩阵变为:
接下来,我们将其推广,让每一个顶点都尝试作为中间点,并使用一个三维矩阵来表示只允许前个顶点作为中间点时,从顶点到顶点的最短路径长度。那么,我们最终的目标就变为了:求出,其中为图中顶点的数量,也就是允许所有顶点作为中间点时,从顶点到顶点的最短路径长度。
我们从上面的过程中发现从到的变化过程中对于每一对顶点,我们都有两种选择:
-
不经过,那么当前最短路径长度就是;
-
尝试经过,那么此时路径就是,而根据我们知道的"最短路径的子路径也是最短路径"定理,这两段也肯定是在前个顶点中选出的最短路径,所以从到的最短路径长度是,从到的最短路径长度是,最短路径长度是。
而我们做选择的策略也非常简单,谁更小选谁就完事了,于是我们得到一个等式:
我们可以看到,这个等式中,只与、和有关,也就是说,我们要计算第层的值,只需要知道第层的值就可以了,所以我们其实并不需要三维矩阵来存储这些值,我们只需要一个二维矩阵来存储当前的dist值,然后每次更新时,直接在原地更新。
于是,我们得到了Floyd算法的核心思想:
与Dijstra算法中的dist数组一样,我们在Floyd算法中的dist数组也只能告诉我们到的最短路径长度。我们还需要知道具体的路径,所以我们同样需要维护一个path数组,这里的path数组也得是二维的,path[i][j]表示从顶点到顶点的路径上的前一个顶点是谁,初始时,如果和之间有边相连,那么path[i][j]就设为的下标,表示此时的前驱是,否则设为,表示路径不存在。当我们更新dist[i][j]时,我们就将path[i][j]设为path[k][j],因为我们得到的新路径是,所以的前驱肯定在路径上,而path[k][j]正好记录了到的路径上的前驱。
接下来,我们来看一下Floyd算法的邻接矩阵代码实现:
void Floyd(GraphAdjMatrix G, int dist[][MAXVEX], int path[][MAXVEX])
{
int i, j, k;
// 初始化dist和path数组
for (i = 0; i < G.numVertexes; i++)
{
for (j = 0; j < G.numVertexes; j++)
{
dist[i][j] = G.arc[i][j]; // 初始化dist数组为邻接矩阵
if (G.arc[i][j] < INFINITY && i != j)
path[i][j] = i; // 初始化path数组
else
path[i][j] = -1; // -1表示路径不存在
}
}
// 主循环,寻找最短路径
for (k = 0; k < G.numVertexes; k++)
{ // 枚举中间点
for (i = 0; i < G.numVertexes; i++)
{ // 枚举起点
for (j = 0; j < G.numVertexes; j++)
{ // 枚举终点
if (dist[i][k] + dist[k][j] < dist[i][j])
{ // 如果经过k点路径更短
dist[i][j] = dist[i][k] + dist[k][j]; // 更新dist值
path[i][j] = path[k][j]; // 更新路径
}
}
}
}
} 按照惯例,参考上述给出的图,我们来分析一下调用Floyd(G, dist, path)时的过程:
- 首先,代码5 ~ 15行都是初始化操作,我们初始化
dist数组为邻接矩阵,表示从顶点到顶点的路径长度;初始化path数组,表示从顶点到顶点的路径上的前驱节点。如果和之间有边相连,那么path[i][j]就设为,否则设为。
初始化后,dist数组和path数组的值分别为:
-
然后,代码18 ~ 31行是Floyd算法的主循环,循环
G.numVertexes次,每次循环中,我们枚举一个中间点,然后枚举所有起点和终点,尝试通过中间点来缩短从到的路径长度。 -
我们首先从开始,表示我们允许经过作为中间点。然后,我们枚举所有起点和终点,尝试通过中间点来缩短从到的路径长度。
当时,我们发现无论为何值,dist[0][j]都无法通过来缩短,因为此时是我们的起点,无法通过自己来缩短到达其他顶点的路径长度,所以不更新。
当时,我们发现dist[1][0]为,表示无法直接到达,这时无论为何值,dist[1][j]都无法通过来缩短,因为通过到达它们的路径长度都会加上,所以不可能缩短。但是算法并不会管这些,它只会照着代码走一遍,发现不满足条件就不更新。
注:代码实现中没有处理的情况,实际应用中需要注意避免这种情况,以防止整数溢出或错误的路径计算。
当时,我们发现dist[2][0]为,即无法直接到达,情况同上。
当时,我们发现dist[3][0]为,表示可以到达,通过到达的情况就不用说,然后我们发现通过到达的路径长度为,小于现在的,所以我们就将dist[3][1]更新为,并将path[3][1]设为path[0][1],即,表示的前驱节点是;而dist[3][2]为,表示可以直接到达,我们发现通过到达的路径长度为,大于,并没有缩短,我们就不更新它。
此时我们的dist矩阵和path矩阵变为:
- 接下来,我们将更新为1,表示我们允许经过作为中间点。然后,我们枚举所有起点和终点,尝试通过中间点来缩短从到的路径长度。
当时,不用说;也不用说;当时,我们发现dist[0][2]为,但是我们发现通过到达的路径长度为,小于8,所以我们就将dist[0][2]更新为,并将path[0][2]设为path[1][2],即,表示的前驱节点是;当时,我们发现dist[0][3]为,但是,不更新。
后续步骤与上述过程一致,接下来给出每一步的dist矩阵和path矩阵,使用表示允许经过前个顶点作为中间点时的dist矩阵,表示对应的path矩阵:
同样地,我们还要想办法通过path数组来反向推导出从到的具体路径,代码与Dijkstra算法中的类似:
void PrintPath(int path[][MAXVEX], int i, int j)
{
if (path[i][j] == -1)
{
printf("No path from vertex %d to vertex %d\n", i, j);
return;
}
if (path[i][j] == i)
{
printf("%d ", i); // 到达源点,打印源点
return;
}
PrintPath(path, i, path[i][j]); // 递归打印前驱节点
printf("%d ", j); // 打印当前节点
} 假设我们要打印从到的路径,我们调用PrintPath(path, 0, 3),它会递归调用PrintPath(path, 0, 2),然后再递归调用PrintPath(path, 0, 1),然后再递归调用PrintPath(path, 0, 0),此时path[0][0]为,说明是源点,打印,然后返回上一层,打印,再返回上一层,打印,再返回上一层,打印,最终我们得到从到的路径为0 1 2 3。
Floyd算法真是十分简洁,关键代码只有那个三重循环,但是也正因为这个三重循环,该算法的时间复杂度为。代码虽简洁,但要理解还是较为困难的,尤其是理解为什么要这样更新dist数组和path数组。希望通过上面的分析,能帮助大家更好地理解Floyd算法。