文章目录
-
-
- 一、时序数据库(TSDB)核心概念与技术选型考量
-
- [1.1 时序数据的本质特征](#1.1 时序数据的本质特征)
- [1.2 时序数据库关键选型指标](#1.2 时序数据库关键选型指标)
- [二、Apache IoTDB 部署与实践指南](#二、Apache IoTDB 部署与实践指南)
-
- [2.1 环境准备](#2.1 环境准备)
- [2.2 单机版部署实战 (Standalone Mode)](#2.2 单机版部署实战 (Standalone Mode))
- [2.3 基本数据操作(CLI示例)](#2.3 基本数据操作(CLI示例))
-
- [1. 创建存储组 (Storage Group)](#1. 创建存储组 (Storage Group))
- [2. 创建时间序列 (Time Series)](#2. 创建时间序列 (Time Series))
- [3. 插入数据 (Insert Data)](#3. 插入数据 (Insert Data))
- [4. 查询数据 (Query Data)](#4. 查询数据 (Query Data))
- [5. 退出CLI并停止服务](#5. 退出CLI并停止服务)
- [2.4 使用Docker快速部署](#2.4 使用Docker快速部署)
-
- [步骤一:拉取IoTDB Docker镜像](#步骤一:拉取IoTDB Docker镜像)
- 步骤二:运行IoTDB容器
- [三、Apache IoTDB 典型应用场景案例分析](#三、Apache IoTDB 典型应用场景案例分析)
-
- [3.1 案例一:工业物联网(IIoT)与智能制造](#3.1 案例一:工业物联网(IIoT)与智能制造)
- [3.2 案例二:智慧能源与新能源监控](#3.2 案例二:智慧能源与新能源监控)
-
一、时序数据库(TSDB)核心概念与技术选型考量
在深入探讨具体产品之前,我们必须首先建立一个科学、统一的评估框架。本章将阐述时序数据的基本特征以及选择一款合适的TSDB时所需考量的关键技术维度。

1.1 时序数据的本质特征
时序数据,其实是按时间顺序记录的一系列数据点。每个数据点通常由两部分组成:一个明确的时间戳(Timestamp)和一个或多个在该时刻的测量值(Value)。在物联网场景下,这些数据点往往还包含描述数据来源的元数据(Metadata),如设备ID、传感器类型、地理位置等,这些元数据通常被称为标签(Tags)。
时序数据具有以下几个显著特征:
-
数据生成的高并发与持续性:数以百万计的传感器、设备或系统以极高的频率(从毫秒级到分钟级)持续不断地生成数据流。
-
写多读少的负载模式:数据的写入操作远比读取操作频繁。数据一旦写入,通常不会被修改,而是以追加(Append-Only)的方式进行。
-
海量数据规模与时间相关性:随着时间推移,数据量呈线性增长,可轻松达到TB甚至PB级别。数据的价值往往与时间紧密相关,近期数据的查询频率最高。
-
查询模式的特殊性:查询通常围绕时间维度展开,例如查询某个设备最近一小时的性能指标、对过去一周的数据进行降采样聚合(Downsampling)、或分析特定时间范围内的异常值。
- 高基数性(High Cardinality)挑战:在大型物联网应用中,设备和传感器的数量巨大,导致元数据的组合(即时间线/时间序列的数量)可以达到数亿甚至数十亿的量级,这对数据库的元数据管理和索引能力提出了极高要求。
1.2 时序数据库关键选型指标
基于时序数据的特性,我们提出一个多维度的TSDB选型评估模型,该模型将作为我们后续分析和比较的基准。
-
写入性能:
-
吞吐量 :衡量数据库每秒能够处理的数据点数量(points/sec)或请求数量(requests/sec),这是评估其承载海量设备接入能力的核心指标。
-
延迟 :单个数据点从发送到被确认写入所需的时间。低延迟对于实时监控和控制类应用至关重要。
-
高基数支持:在高基数场景下,写入性能是否会显著下降。
-
-
查询性能:
-
查询延迟:针对不同类型的典型查询,其响应时间如何。主要包括:
-
点查询 :获取特定时间点的单个或多个值。
-
范围查询 :获取某个时间段内的数据。
-
聚合查询 :对时间范围内的数值进行计算,如
AVG、SUM、MAX、MIN等。 -
降采样/分组查询 :按更大的时间粒度(如每分钟、每小时)对数据进行聚合,常用于趋势分析和可视化。
-
-
-
存储效率与成本:
-
数据压缩比 :原始数据大小与压缩后实际占用的磁盘空间之比。高压缩比意味着更低的存储成本,这对于动辄PB级的时序数据尤为关键。
-
存储引擎:采用列式存储还是行式存储,以及其底层的存储文件格式设计。
-
-
可扩展性与高可用性:
-
水平扩展能力:是否支持通过增加节点来线性提升系统的写入和查询能力。
-
集群架构:集群的管理是否复杂,数据分片和负载均衡机制是否高效。
-
高可用方案:是否提供数据副本、故障自动转移等机制来保证服务的连续性。
-
-
生态系统与易用性:
-
数据集成:是否提供与主流大数据计算框架(如Apache Spark, Apache Flink)、可视化工具(如Grafana)、以及各种编程语言的连接器(Connectors/SDKs)。
-
查询语言:是否提供类SQL的查询语言,降低开发者的学习成本。
-
部署与运维:部署流程是否简单,是否支持容器化部署(如Docker, Kubernetes),运维监控工具是否完善。
-
社区与支持:开源项目的社区活跃度、文档质量以及商业支持的可用性。
-
基于以上评估框架,我们将在接下来的章节中审视市场上的主流产品,并深度剖析Apache IoTDB的表现。
二、Apache IoTDB 部署与实践指南
本章节将提供一份手把手的实践指南,引导您在Linux环境下快速部署并体验Apache IoTDB。我们将以单机版为例,展示其简洁的部署流程和强大的CLI工具。
我们将使用当前较新的稳定版本,例如 Apache IoTDB v1.3.1 因为它的部署流程具有代表性。
2.1 环境准备
在开始之前,请确保您的部署环境满足以下基本要求 :
-
操作系统:Linux 发行版 (例如 Ubuntu 22.04, CentOS 7+)。
-
硬件资源 (建议):
-
CPU: 4 核或以上
-
内存: 8 GB 或以上
-
磁盘: 50 GB 或以上可用空间
-
-
软件依赖:
- Java Development Kit (JDK) :版本要求为 1.8 或更高。
检查Java环境:
bash
$ java -version终端输出:

2.2 单机版部署实战 (Standalone Mode)
步骤一:下载并解压IoTDB
首先,从Apache IoTDB官方镜像站点下载二进制包。
bash
# 创建工作目录
mkdir /opt/iotdb
cd /opt/iotdb
# 下载IoTDB v1.3.1二进制包 (请使用官网最新的下载链接)
# 假设我们已将安装包下载到当前目录 apache-iotdb-1.3.1-server-bin.zip
# wget https://dlcdn.apache.org/iotdb/1.3.1/apache-iotdb-1.3.1-server-bin.zip
# 解压缩
unzip apache-iotdb-1.3.1-server-bin.zip终端输出:

解压后,会得到一个名为 apache-iotdb-1.3.1-server-bin 的目录。
步骤二:启动IoTDB服务
进入IoTDB目录,执行单机版启动脚本。
bash
cd apache-iotdb-1.3.1-server-bin/
# 启动单机版服务
./sbin/start-standalone.sh终端输出:

看到 "IoTDB standalone is started" 提示,表示服务已在后台成功启动。默认情况下,服务会监听 6667 端口。
步骤三:通过命令行界面(CLI)连接并交互
IoTDB提供了一个非常方便的CLI工具,用于执行数据操作和管理命令。
bash
# 启动CLI客户端
./sbin/start-cli.sh终端输出:
当看到 IoTDB> 提示符时,恭喜您!您已经成功连接到正在运行的IoTDB服务。
2.3 基本数据操作(CLI示例)
接下来,我们在CLI中有一个简单的物联网场景:监控一个车间(workshop)里两台数控机床(cnc1, cnc2)的温度(temperature)和转速(speed)。
1. 创建存储组 (Storage Group)
存储组是IoTDB中数据划分和管理的基本单位,可以看作是一个数据库或命名空间。
sql
IoTDB> CREATE STORAGE GROUP root.workshop终端输出:
plain
Msg: The statement is executed successfully.2. 创建时间序列 (Time Series)
时间序列对应一个具体的测点。
sql
IoTDB> CREATE TIMESERIES root.workshop.cnc1.temperature WITH DATATYPE=FLOAT, ENCODING=GORILLA
IoTDB> CREATE TIMESERIES root.workshop.cnc1.speed WITH DATATYPE=INT32, ENCODING=RLE
IoTDB> CREATE TIMESERIES root.workshop.cnc2.temperature WITH DATATYPE=FLOAT, ENCODING=GORILLA
IoTDB> CREATE TIMESERIES root.workshop.cnc2.speed WITH DATATYPE=INT32, ENCODING=RLE终端输出 (以第一条为例):
plain
Msg: The statement is executed successfully.3. 插入数据 (Insert Data)
我们可以插入单条数据,也可以批量插入。
sql
-- 插入单条数据
IoTDB> INSERT INTO root.workshop.cnc1(timestamp, temperature, speed) VALUES(1733865600000, 35.8, 1500)
-- 批量插入多条数据
IoTDB> INSERT INTO root.workshop.cnc1(timestamp, temperature, speed) VALUES(1733865601000, 36.1, 1502), (1733865602000, 36.2, 1501)终端输出:
plain
Msg: The statement is executed successfully.4. 查询数据 (Query Data)
现在,让我们来查询刚刚插入的数据。
sql
-- 查询cnc1的所有数据
IoTDB> SELECT * FROM root.workshop.cnc1终端输出:

sql
-- 查询cnc1的平均温度
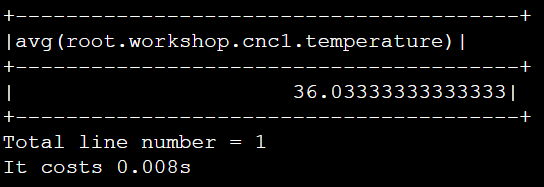
IoTDB> SELECT AVG(temperature) FROM root.workshop.cnc1终端输出:
5. 退出CLI并停止服务
sql
IoTDB> QUIT
$ ./sbin/stop-standalone.sh终端输出:
plain
Stopping IoTDB standalone...
IoTDB standalone is stopped.2.4 使用Docker快速部署
对于习惯容器化部署的开发者,使用Docker是更快捷的方式。
步骤一:拉取IoTDB Docker镜像
bash
# 拉取指定版本的镜像
docker pull apache/iotdb:1.3.1-standalone终端输出:
plain
1.3.1-standalone: Pulling from apache/iotdb
Digest: sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Status: Downloaded newer image for apache/iotdb:1.3.1-standalone
docker.io/apache/iotdb:1.3.1-standalone步骤二:运行IoTDB容器
bash
docker run -d --name iotdb-standalone -p 6667:6667 apache/iotdb:1.3.1-standalone终端输出:
plain
long_container_id_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx这条命令会在后台启动一个名为 iotdb-standalone 的容器,并将容器的6667端口映射到宿主机的6667端口。现在,您可以使用本地的CLI工具 (./sbin/start-cli.sh -h 127.0.0.1 -p 6667) 连接到这个Docker容器中的IoTDB实例了。
通过以上实践,可以看出Apache IoTDB的部署和上手过程非常简单直观,无论是传统部署还是容器化部署,都能在几分钟内完成,这极大地降低了开发和运维的门槛。
三、Apache IoTDB 典型应用场景案例分析
Apache IoTDB凭借其卓越的性能和专为物联网设计的架构,已经在众多行业中得到了成功应用。本章将选取几个典型场景,分析IoTDB如何解决其中的核心痛点。
3.1 案例一:工业物联网(IIoT)与智能制造
场景描述:
某大型制造企业拥有一条数千米长的自动化生产线,线上部署了上万个传感器,用于实时监测机器人臂的振动、电机的电流、CNC机床的温度和压力等关键参数。数据采集频率高达1000Hz。企业希望实现:
-
对所有设备进行7x24小时的状态实时监控和告警。
-
存储至少3年的历史数据,用于设备故障的根因分析和预测性维护模型的训练。
-
支持工程师对任意设备、任意时间段的数据进行快速查询和可视化分析。
挑战:
-
极高写入吞吐:每秒产生数百万甚至上千万个数据点。
-
海量数据存储:3年的数据量将达到PB级别,存储成本是巨大挑战。
-
高基数问题:设备和测点的组合构成了极高的基数。
-
复杂的查询需求:既有实时点查询,也有长周期、多维度聚合分析。
IoTDB解决方案:
-
承载海量写入:IoTDB的分布式集群能够水平扩展,通过增加DataNode即可线性提升写入能力,轻松应对千万级点/秒的写入压力 。
-
极致的存储压缩:得益于TsFile的高效编码(如GORILLA)和压缩技术,IoTDB可将原始数据压缩数十倍,极大地降低了存储PB级历史数据的硬件成本。
-
高效元数据管理:IoTDB树状的元数据组织方式和高效的索引机制,天然适合管理高基数的设备模型,写入和查询性能不会因基数增高而急剧恶化。
-
秒级响应复杂查询:通过元数据索引剪枝和列式读取,即使是跨越数月、涉及上千个测点的聚合查询,IoTDB也能在秒级甚至毫秒级返回结果,为工程师的分析和故障排查提供了强大的交互能力。
-
端云协同:在靠近产线的边缘节点部署IoTDB,可对高频原始数据(如振动波形)进行实时预处理和特征提取(如计算FFT),仅将关键结果上传至云端中心集群,有效节约了带宽并实现了边缘智能 。
图片:基于IoTDB的智能制造数据平台架构图
3.2 案例二:智慧能源与新能源监控
场景描述:
一家新能源公司运营着分布在全国各地的数百个风力发电场和光伏电站。需要实时采集每台风机的主轴转速、桨叶角度、发电机温度、电网电压、频率,以及每块光伏面板的日照强度、发电量等数据。目标是:
-
实时监控电站运行状态,优化发电效率。
-
基于历史天气数据和发电数据,构建功率预测模型,指导电网调度。
- 对关键部件(如风机齿轮箱)的运行数据进行长期趋势分析,实现预测性维护。
挑战:
-
地理位置分散:数据源分布广泛,网络条件可能不稳定。
-
数据周期性长:需要存储多年数据以分析季节性变化和设备长期衰减趋势。
-
分析的复杂性:涉及时间序列的对齐、插值以及与外部数据(如天气预报)的关联分析。
IoTDB解决方案:
-
边-云架构应对网络挑战:在每个场站部署边缘IoTDB节点,负责汇聚本地数据。即使与云端的网络暂时中断,数据也能缓存在边缘节点,待网络恢复后自动同步至云端中心集群,保证了数据的完整性 。
-
低成本长期存储:IoTDB的高压缩比使得存储多年历史数据成为可能,为长周期趋势分析和机器学习建模提供了坚实的数据基础。
-
强大的分析能力:IoTDB的类SQL语言支持丰富的聚合函数和时间窗口操作。结合Spark或Flink连接器,可以方便地实现复杂的时序分析算法,如将发电功率数据与天气数据按时间戳进行JOIN,分析相关性,从而训练更精准的预测模型 。
更多内容大家可以关注以下:
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com