文章目录
- [第一章 数据结构与算法基本概念](#第一章 数据结构与算法基本概念)
-
- [1.4 时间复杂度](#1.4 时间复杂度)
-
- [1.4.1 统计时间增长趋势](#1.4.1 统计时间增长趋势)
- [1.4.2 函数渐进上界](#1.4.2 函数渐进上界)
- [1.4.3 推算方法](#1.4.3 推算方法)
- [1.4.4 常见的时间复杂度](#1.4.4 常见的时间复杂度)
-
- [1 常数阶O(1)](#1 常数阶O(1))
- [2 对数阶O(logn)](#2 对数阶O(logn))
- [3 线性阶 𝑂(𝑛)](#3 线性阶 𝑂(𝑛))
- [4. 线性对数阶 𝑂(𝑛 log 𝑛)](#4. 线性对数阶 𝑂(𝑛 log 𝑛))
- [5 平方阶 𝑂(n^2)](#5 平方阶 𝑂(n^2))
- [6 指数阶𝑂(2^n)](#6 指数阶𝑂(2^n))
- [7 阶乘阶 𝑂(𝑛!)](#7 阶乘阶 𝑂(𝑛!))
本文介绍数据结构与算法之时间复杂度。
第一章 数据结构与算法基本概念
1.4 时间复杂度
1.4.1 统计时间增长趋势
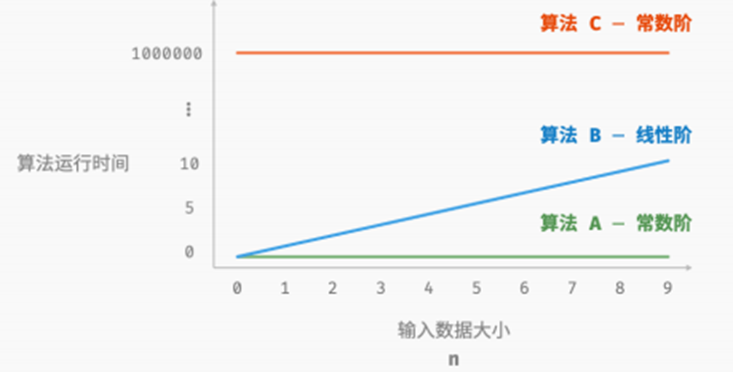
时间复杂度的分析统计不是算法的运行时间,而是算法运行时间随着数据量变大时的增长趋势。下面举例子说明什么是时间增长趋势。
cpp
// 算法 A 的时间复杂度:常数阶
void algorithm_A(int n) {
cout << 0 << endl;
}
// 算法 B 的时间复杂度:线性阶
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
cout << 0 << endl;
}
}
// 算法 C 的时间复杂度:常数阶
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
cout << 0 << endl;
}
}- 算法 A 只有 1 个打印操作,算法运行时间不随着 𝑛 增大而增长。我们称此算法的时间复杂度为"常数阶"。
- 算法 B 中的打印操作需要循环 𝑛 次,算法运行时间随着 𝑛 增大呈线性增长。此算法的时间复杂度被称为"线性阶"。
- 算法 C 中的打印操作需要循环 1000000 次,虽然运行时间很长,但它与输入数据大小 𝑛 无关。因此 C的时间复杂度和 A 相同,仍为"常数阶"。
1.4.2 函数渐进上界
函数渐近上界
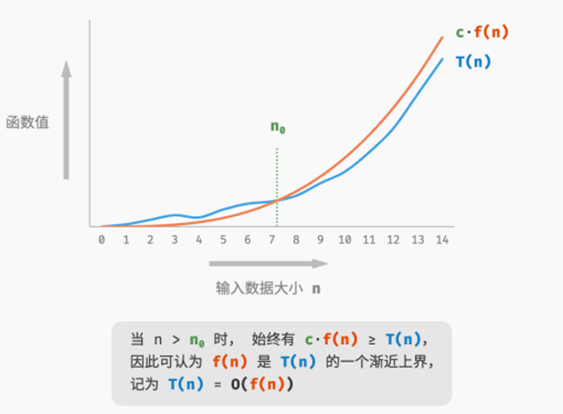
若存在正实数 𝑐 和实数 𝑛0 ,使得对于所有的 𝑛 > 𝑛0 ,均有 𝑇(𝑛) ≤ 𝑐 ⋅ 𝑓(𝑛) ,则可认为 𝑓(𝑛) 给 出了 𝑇(𝑛) 的一个渐近上界,记为 𝑇(𝑛) = 𝑂(𝑓(𝑛)) 。
例如:
cpp
void algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// 循环 n 次
for (int i = 0; i < n; i++) { // +1(每轮都执行 i ++)
cout << 0 << endl; // +1
}
}设算法的操作数量是一个关于输入数据大小 𝑛 的函数,记为 𝑇(𝑛) ,则以上函数的操作数量为:
𝑇(𝑛) = 3 + 2𝑛
𝑇(𝑛) 是一次函数,说明其运行时间的增长趋势是线性的,因此它的时间复杂度是线性阶。我们将线性阶的时间复杂度记为 𝑂(𝑛) ,这个数学符号称为大 𝑂 记号(big‑𝑂 notation),表示函数 𝑇(𝑛) 的渐近上界(asymptotic upper bound)。
1.4.3 推算方法
- 忽略 𝑇(𝑛) 中的常数项。因为它们都与 𝑛 无关,所以对时间复杂度不产生影响。
- 省略所有系数。例如,循环 2𝑛 次、5𝑛 + 1 次等,都可以简化记为 𝑛 次,因为 𝑛 前面的系数对时间复杂度没有影响。
- 循环嵌套时使用乘法。总操作数量等于外层循环和内层循环操作数量之积,每一层循环依然可以分别
套用第 1. 点和第 2. 点的技巧。
cpp
void algorithm(int n) {
int a = 1;
// +0(技巧 1)
a = a + n;
// +0(技巧 1)
// +n(技巧 2)
for (int i = 0; i < 5 * n + 1; i++) {
cout << 0 << endl;
}
// +n*n(技巧 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
cout << 0 << endl;
}
}
}上面代码的时间复杂度统计:
𝑇(𝑛) = 2𝑛(𝑛 + 1) + (5𝑛 + 1) + 2 完整统计(‑.‑|||)
= 2𝑛2 + 7𝑛 + 3
𝑇(𝑛) = 𝑛2 + 𝑛 偷懒统计(o.O)
时间复杂度由 𝑇(𝑛) 中最高阶的项来决定。这是因为在 𝑛 趋于无穷大时,最高阶的项将发挥主导作用,其他项的影响都可以忽略。

1.4.4 常见的时间复杂度
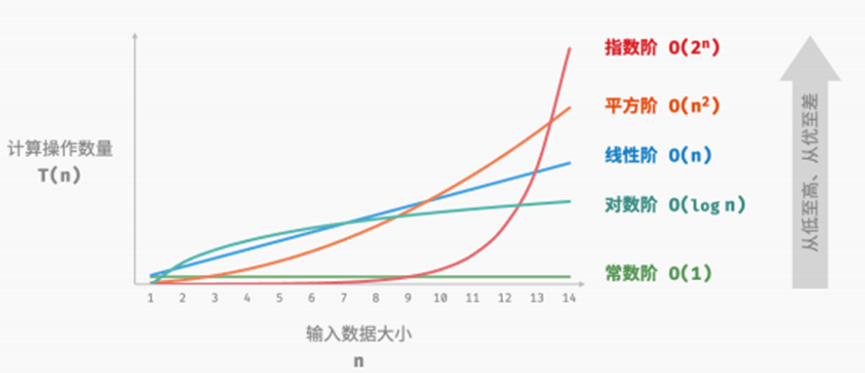
𝑂(1) < 𝑂(log 𝑛) < 𝑂(𝑛) < 𝑂(𝑛 log 𝑛) < 𝑂(𝑛2 ) < 𝑂(2𝑛) < 𝑂(𝑛!)
常数阶 < 对数阶 < 线性阶 < 线性对数阶 < 平方阶 < 指数阶 < 阶乘阶
1 常数阶O(1)
常数阶的操作数量与输入数据大小 𝑛 无关,即不随着 𝑛 的变化而变化。在以下函数中,尽管操作数量 size 可能很大,但由于其与输入数据大小 𝑛 无关,因此时间复杂度仍为 𝑂(1)。
cpp
/* 常数阶 */
int constant(int n)
{
int count = 0;
int size = 100000;
for (int i = 0; i < size; i++)
count++;
return count;
}2 对数阶O(logn)
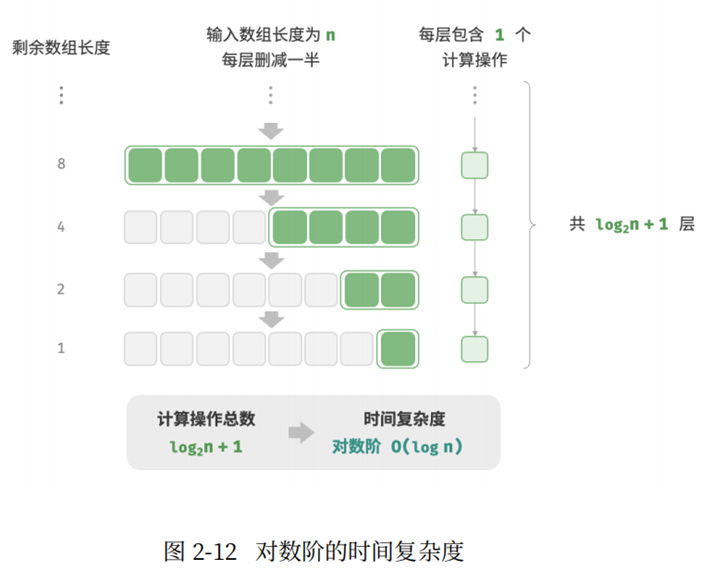
对数阶反映了 "每轮缩减到一半" 的情况。设输入数据大小为n, 由于每轮缩小到一半,因此循环次数为log2n,即2^n 相反数。
cpp
// 对数阶 循环实现
int logarithmic(int n)
{
int count = 0;
// 循环次数与数据大小n的对数成正比
while (n > 1)
{
n /= 2; // 这里体现了对数的特性
++count;
}
return count;
}推倒上面代码的时间复杂度:
初始状态:当n开始时是一个正整数;
循环体:每次循环,n = n/2, 每次循环n减半。如果循环共执行了k次,那么n被除以2^k次。
循环终止条件:n <= 1,循环停止。
与指数类似,对数阶也常出现在递归函数中,以下代码形成了一颗高度为 log2 n的递归树。
cpp
int logRecur(int n)
{
// 递归终止条件
if (n <= 1)
{
return 1;
}
// 递归调用
return logRecur(n / 2) + 1;
}对数阶常出现于基于分治策略的算法中,体现了"一分为多"和"化繁为简"的算法思想。它增长缓慢,是仅次于常数阶的理想的时间复杂度。

3 线性阶 𝑂(𝑛)
线性阶的操作数量相对于输入数据大小 𝑛 以线性级别增长。线性阶通常出现在单层循环中:
cpp
/* 线性阶 */
int linear(int n) {
int count = 0;
for (int i = 0; i < n; i++)
count++;
return count;
}遍历数组和遍历链表等操作的时间复杂度均为 𝑂(𝑛) ,其中 𝑛 为数组或链表的长度:
/* 线性阶(遍历数组) */
cpp
int arrayTraversal(vector<int> &nums)
{
int count = 0;
// 循环次数与数组长度成正比
for (int num : nums)
{
count++;
}
return count;
}4. 线性对数阶 𝑂(𝑛 log 𝑛)
线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 𝑂(log 𝑛) 和 𝑂(𝑛) 。
cpp
int linearRecur(int n)
{
if (n <= 1)
{
return 1;
}
int count = linearRecur(n / 2) + linearRecur(n / 2);
for (int i = 0; i < n; ++i)
{
++count;
}
return count;
}下图展示了线性对数阶的生成方式。二叉树的每一层的操作总数都为 𝑛 ,树共有 log2𝑛 + 1 层,因此时间复杂度为 𝑂(𝑛 log 𝑛) 。
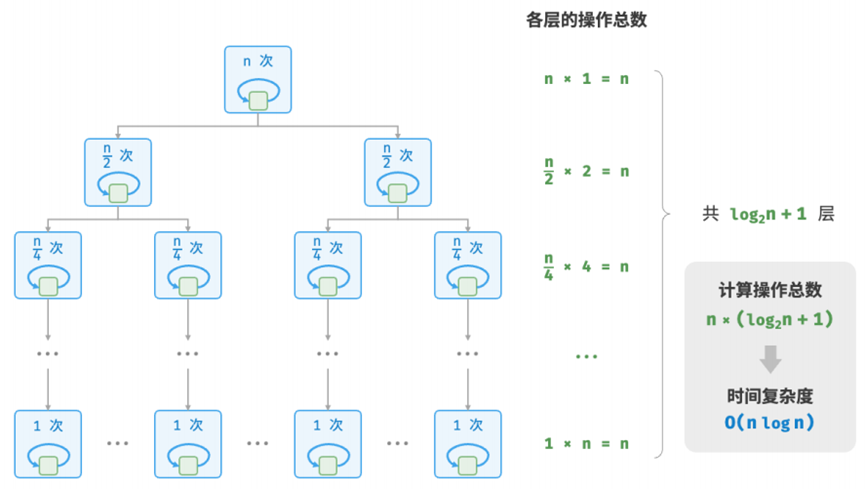
主流排序算法的时间复杂度通常为 𝑂(𝑛 log 𝑛) ,例如快速排序、归并排序、堆排序等。
5 平方阶 𝑂(n^2)
平方阶的操作数量相对于输入数据大小 𝑛 以平方级别增长。平方阶通常出现在嵌套循环中,外层循环和内层循环的时间复杂度都为 𝑂(𝑛) ,因此总体的时间复杂度为 𝑂(𝑛2 ) :
cpp
int quadratic(int n)
{
int count = 0;
// 循环次数与数据大小n的平方成正比
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < n; ++j)
{
++count;
}
}
return count;
}以冒泡排序为例:外层循环执行 𝑛 − 1 次,内层循环执行 𝑛 − 1、𝑛 − 2、...、2、1 次,平均为 𝑛/2 次,因此时间复杂度为 𝑂((𝑛 − 1)𝑛/2) = 𝑂(𝑛2) :
cpp
int bubbleSort(vector<int>& nums)
{
int count = 0;
// 外层循环 :未排序区间 [0 , i]
for (int i = nums.size() - 1; i > 0; --i)
{
// 内循环:将[0,i]中的最大元素交换至该区间的最右端
for (int j = 0; j < i; ++j)
{
if (nums[j] > nums[j + 1])
{
swap(nums[j], nums[j + 1]);
}
++count;
}
}
}6 指数阶𝑂(2^n)
生物学的"细胞分裂"是指数增长的典型例子:初始状态是1个细胞,分裂一轮后为2个细胞,分裂两轮后4个细胞,分裂n轮后为2^n个细胞。
下面代码模拟细胞分裂过程,时间复杂度为O(2^n).
cpp
// 指数阶
int exponential(int n)
{
int count = 1;
int base = 1;
// 循环次数与数据大小n的指数成正比
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < base; ++j)
{
++count;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + ... + 2^(n-1) = 2^n - 1
return count;
}等比数列前n项和。
计算方法是:等比数列前n项和,Sn=a1(1-q^n)/(1-q)
在实际中,指数阶常出现在递归函数中,在下面代码中,递归地一分为二,经过n次分裂后停止:
cpp
int expRecur(int n)
{
// 递归终止条件
if (n == 1)
{
return 1;
}
// 递归调用
return expRecur(n - 1) + expRecur(n - 1); // 表示每层的数量 比如,expRecur(3) = 8 expRecur(2) = 4
return expRecur(n - 1) + expRecur(n - 1) + 1; // 表示总的数量,比如 expRecur(3) = 15 expRecur(2) = 7
}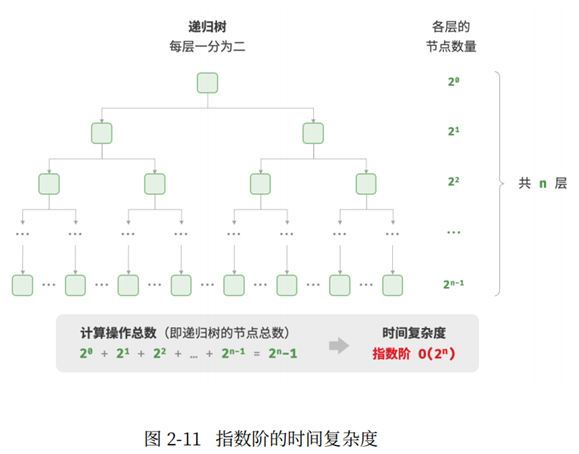
指数阶增长非常迅速,在穷举法(搜索,回溯)中比较常见。对于规模较大的问题,指数阶次是不可接收的,通常使用动态规划和贪心算法解决。
7 阶乘阶 𝑂(𝑛!)
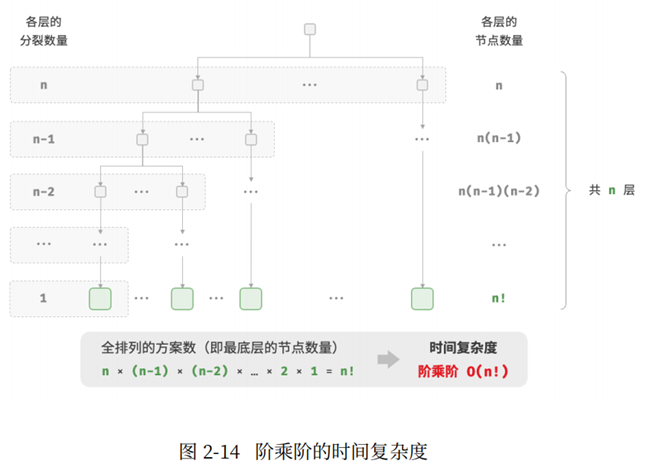
阶乘阶对应数学上的"全排列"问题。给定 𝑛 个互不重复的元素,求其所有可能的排列方案,方案数量为:
𝑛! = 𝑛 × (𝑛 − 1) × (𝑛 − 2) × ⋯ × 2 × 1
阶乘通常使用递归实现。如图 2 14 和以下代码所示,第一层分裂出 𝑛 个,第二层分裂出 𝑛 − 1 个,以此类推,直至第 𝑛 层时停止分裂:
cpp
int factorRecur(int n)
{
if (n == 0)
{
return 1;
}
int count = 0;
// 从1个分裂出n个
for (int i = 0; i < n; ++i)
{
count += factorRecur(n - 1);
}
return count;
}
请注意,因为当 𝑛 ≥ 4 时恒有 𝑛! > 2𝑛 ,所以阶乘阶比指数阶增长得更快,在 𝑛 较大时也是不可接受的。