前言:
在昨天我们已经实现了利用多种聚类方法对已有数据集进行相应的聚类,在今天我们将推断聚类后簇的类型,并以此为依据建立新的特征工程,并评估利用结合新的特征工程后模型的效果有无提升,如果精度提高则说明此特征是有用的。
一、推断思路
如何从聚类的数学结果中,提炼出有实际业务意义的"簇含义"?
思路一:从起点就聚焦(有明确目标时)
适用场景 :你已经知道要分析什么业务问题。
操作步骤:
-
特征预选 :在聚类前,只选择与你的分析目标直接相关的特征
-
执行聚类:用这些特征进行K-Means等聚类
-
结果解释:聚类结果自然反映了所选特征维度的模式
举例:
-
目标:分析"消费者购买习惯"
-
选择特征:购买频次、客单价、品类偏好、消费时间分布等
-
不选特征:年龄、职业、地域等与购买习惯不直接相关的特征
-
结果:每个簇代表一种购买习惯类型(如"高频小金额"、"低频大额"、"周末购物者")
优点:结果解释性强,目标明确
缺点:可能忽略其他维度的潜在模式
思路二:从结果倒推(探索性分析时)
适用场景 :你不清楚数据中隐藏什么模式,想探索发现。
操作步骤:
-
全特征聚类:用所有可用特征进行聚类
-
得到簇标签:得到聚类结果(如簇0、簇1、簇2...)
-
构建监督模型:
-
X = 所有特征
-
y = 聚类得到的标签
-
训练分类模型(如随机森林)
-
-
特征重要性分析:识别哪些特征最能区分不同簇
-
赋予含义:根据重要特征解释每个簇的特点
举例:
-
用100个客户特征聚类得到5个簇
-
用随机森林分析发现:
-
簇0:最重要的特征是"最近购买时间"和"促销敏感度"→ 可能是"即将流失客户"
-
簇1:最重要的特征是"客单价"和"奢侈品购买"→ 可能是"高净值客户"
-
-
这样"倒推"出每个簇的业务含义
优点:能发现意想不到的模式
缺点:解释过程复杂,可能需要业务知识辅助
二、具体实现
我们以心脏病数据集为例,在昨天代码的基础上,增加以下步骤:
1、构建随机森林模型、利用shap来筛选重要的特征
2、取前四个贡献度最高的特征,并分出来连续和离散特征,以各自样本数为纵坐标,以各个簇的类型为横坐标分别绘制箱线图和直方图。
运行代码:
python
# 先运行之前预处理好的代码
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
from sklearn.utils import resample
from sklearn.model_selection import train_test_split
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
df = pd.read_csv(r'D:\Python60DaysChallenge-main\heart.csv')
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
# 切分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)
silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数
silhouette_scores.append(silhouette)
ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数
ch_scores.append(ch)
db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数
db_scores.append(db)
print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
# 绘制评估指标图 - 调整版(解决标签重叠问题)
plt.figure(figsize=(18, 12)) # 增大图形尺寸
# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o', linewidth=2, markersize=8)
plt.title('肘部法则确定最优聚类数 k\n(惯性,越小越好)', fontsize=10, pad=15) # 添加换行和增加标题间距
plt.xlabel('聚类数 (k)', fontsize=10)
plt.ylabel('惯性', fontsize=12)
plt.xticks(k_range) # 明确设置x轴刻度
plt.grid(True, alpha=0.3)
plt.tight_layout(pad=3.0) # 增加子图间距
# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange', linewidth=2, markersize=8)
plt.title('轮廓系数确定最优聚类数 k\n(越大越好)', fontsize=10, pad=15)
plt.xlabel('聚类数 (k)', fontsize=10)
plt.ylabel('轮廓系数', fontsize=12)
plt.xticks(k_range)
plt.grid(True, alpha=0.3)
# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green', linewidth=2, markersize=8)
plt.title('Calinski-Harabasz 指数确定最优聚类数 k\n(越大越好)', fontsize=10, pad=15)
plt.xlabel('聚类数 (k)', fontsize=10)
plt.ylabel('CH 指数', fontsize=12)
plt.xticks(k_range)
plt.grid(True, alpha=0.3)
# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red', linewidth=2, markersize=8)
plt.title('Davies-Bouldin 指数确定最优聚类数 k\n(越小越好)', fontsize=10, pad=15)
plt.xlabel('聚类数 (k)', fontsize=10)
plt.ylabel('DB 指数', fontsize=12)
plt.xticks(k_range)
plt.grid(True, alpha=0.3)
# 调整整体布局,增加间距
plt.subplots_adjust(wspace=0.2, hspace=0.4) # 增加水平和垂直间距
plt.suptitle('KMeans聚类评估指标对比', fontsize=16, y=0.98) # 添加总标题
plt.show()
# 提示用户选择 k 值
selected_k = 3
# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了
shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()
# 此时判断一下这几个特征是离散型还是连续型
import pandas as pd
selected_features = ['age', 'thalach',
'slope', 'sex']
for feature in selected_features:
unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值
# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少
print(f'{feature} 的唯一值数量: {unique_count}')
if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整
print(f'{feature} 可能是离散型变量')
else:
print(f'{feature} 可能是连续型变量')
# 绘制出每个簇对应的这四个特征的分布图
X[['KMeans_Cluster']].value_counts()
# 分别筛选出每个簇的数据
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
X_cluster2 = X[X['KMeans_Cluster'] == 2]
# 简化的特征分布图绘制 - 优化版本(横坐标为簇标签)
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体参数
plt.rcParams.update({
'font.size': 10,
'axes.titlesize': 12,
'axes.labelsize': 11,
'xtick.labelsize': 10,
'ytick.labelsize': 10,
'legend.fontsize': 10,
'figure.titlesize': 14,
})
# 设置图形参数
plt.figure(figsize=(20, 16))
# 选择的特征
selected_features = ['age', 'thalach', 'slope', 'sex']
feature_names = ['年龄', '最大心率', '斜率', '性别']
# 遍历每个特征
for i, (feature, feature_name) in enumerate(zip(selected_features, feature_names), 1):
plt.subplot(2, 2, i)
# 判断特征类型
unique_count = X[feature].nunique()
if unique_count < 10: # 离散特征,绘制分组柱状图
# 获取特征的所有可能值
feature_values = sorted(X[feature].unique())
# 为sex特征添加中文标签
if feature == 'sex':
feature_labels = ['女', '男'] # 0=女, 1=男
else:
feature_labels = [str(v) for v in feature_values]
# 准备数据:x轴为簇,分组为特征值
cluster_labels = ['簇 0', '簇 1', '簇 2']
bar_width = 0.8 / len(feature_values) # 根据特征值数量调整宽度
# 设置颜色映射(为每个特征值分配固定颜色)
if feature == 'slope':
# 斜率:为每个取值分配不同颜色
slope_colors = {
0: 'lightblue',
1: 'orange',
2: 'lightgreen'
}
bar_colors = [slope_colors.get(val, 'gray') for val in feature_values]
elif feature == 'sex':
# 性别:为每个取值分配不同颜色
sex_colors = {
0: 'lightblue',
1: 'orange'
}
bar_colors = [sex_colors.get(val, 'gray') for val in feature_values]
else:
# 其他离散特征使用默认颜色
bar_colors = plt.cm.tab10(np.arange(len(feature_values)) / len(feature_values))
for j, (feature_val, color) in enumerate(zip(feature_values, bar_colors)):
counts = []
for cluster_id in range(3):
cluster_data = X[X['KMeans_Cluster'] == cluster_id]
count = (cluster_data[feature] == feature_val).sum()
counts.append(count)
# 计算x位置
x_pos = np.arange(3) # 三个簇
offset = (j - (len(feature_values)-1)/2) * bar_width
# 绘制柱状图
bars = plt.bar(x_pos + offset, counts, bar_width,
color=color, # 设置柱状图颜色
alpha=0.7)
# 在柱状图上方添加数值标签
for k, val in enumerate(counts):
if val > 0:
plt.text(x_pos[k] + offset, val + 0.5, str(val),
ha='center', va='bottom', fontsize=9, fontweight='bold')
# 设置x轴标签为簇
plt.xticks(x_pos, cluster_labels, fontsize=10, rotation=0)
# 设置y轴范围
max_val = X[feature].value_counts().max()
plt.ylim(0, max_val * 1.2)
plt.title(f'{feature_name}分布 (离散特征)', fontsize=12, pad=12)
# 添加图例说明
if feature == 'slope':
plt.text(0.02, 0.98, '蓝色:斜率=0\n橙色:斜率=1\n绿色:斜率=2',
transform=plt.gca().transAxes, fontsize=9,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
elif feature == 'sex':
plt.text(0.02, 0.98, '蓝色:女性(0)\n橙色:男性(1)',
transform=plt.gca().transAxes, fontsize=9,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
else: # 连续特征,绘制箱线图(保持原样)
data_to_plot = []
cluster_labels = ['簇 0', '簇 1', '簇 2']
for cluster_id in range(3):
cluster_data = X[X['KMeans_Cluster'] == cluster_id]
data_to_plot.append(cluster_data[feature].dropna())
# 绘制箱线图
box = plt.boxplot(data_to_plot, labels=cluster_labels,
patch_artist=True, widths=0.6)
# 设置颜色
colors = ['lightblue', 'lightgreen', 'lightcoral']
for patch, color in zip(box['boxes'], colors):
patch.set_facecolor(color)
patch.set_alpha(0.7)
# 设置中位数线颜色
for median in box['medians']:
median.set_color('red')
median.set_linewidth(2)
# 在箱线图上添加统计信息
for j, (cluster_id, data) in enumerate(zip(range(3), data_to_plot)):
if len(data) > 0:
# 显示中位数
median_val = np.median(data)
plt.text(j + 1, median_val, f'{median_val:.1f}',
ha='center', va='bottom', fontsize=9, fontweight='bold', color='darkred')
plt.title(f'{feature_name}分布 (连续特征)', fontsize=12, pad=12)
# 设置坐标轴标签
if unique_count < 10:
plt.xlabel('聚类簇', fontsize=11, labelpad=10)
else:
plt.xlabel('聚类簇', fontsize=11, labelpad=10)
# 根据特征类型设置纵坐标标签
if feature == 'age':
plt.ylabel('年龄分布', fontsize=11, labelpad=10)
elif feature == 'thalach':
plt.ylabel('最大心率数值', fontsize=11, labelpad=10)
else:
plt.ylabel('样本数量', fontsize=11, labelpad=10)
# 设置图例
if i == 1: # 只在第一个子图显示图例
plt.legend(loc='upper right', fontsize=10, framealpha=0.9,
borderpad=0.5, labelspacing=0.5, title=f'{feature_name}取值')
# 添加网格
plt.grid(True, alpha=0.2, linestyle='--', axis='y')
# 调整整体布局
plt.subplots_adjust(wspace=0.35, hspace=0.4, top=0.92, bottom=0.08, left=0.08, right=0.95)
plt.suptitle('KMeans聚类各簇特征分布分析 (k=3)', fontsize=16, fontweight='bold', y=0.96)
plt.show()运行结果图:
shap库分析结果:
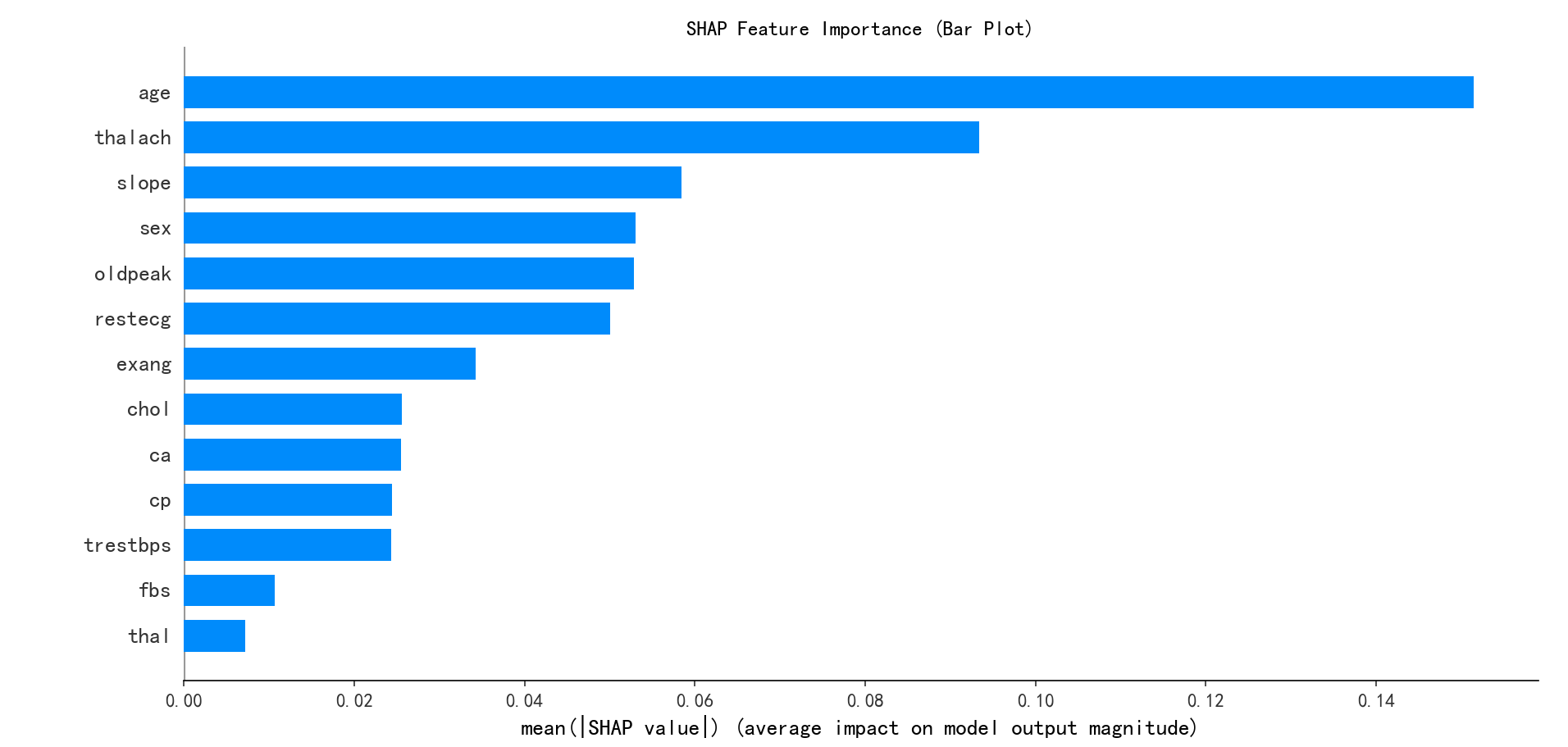
聚类特征分布: 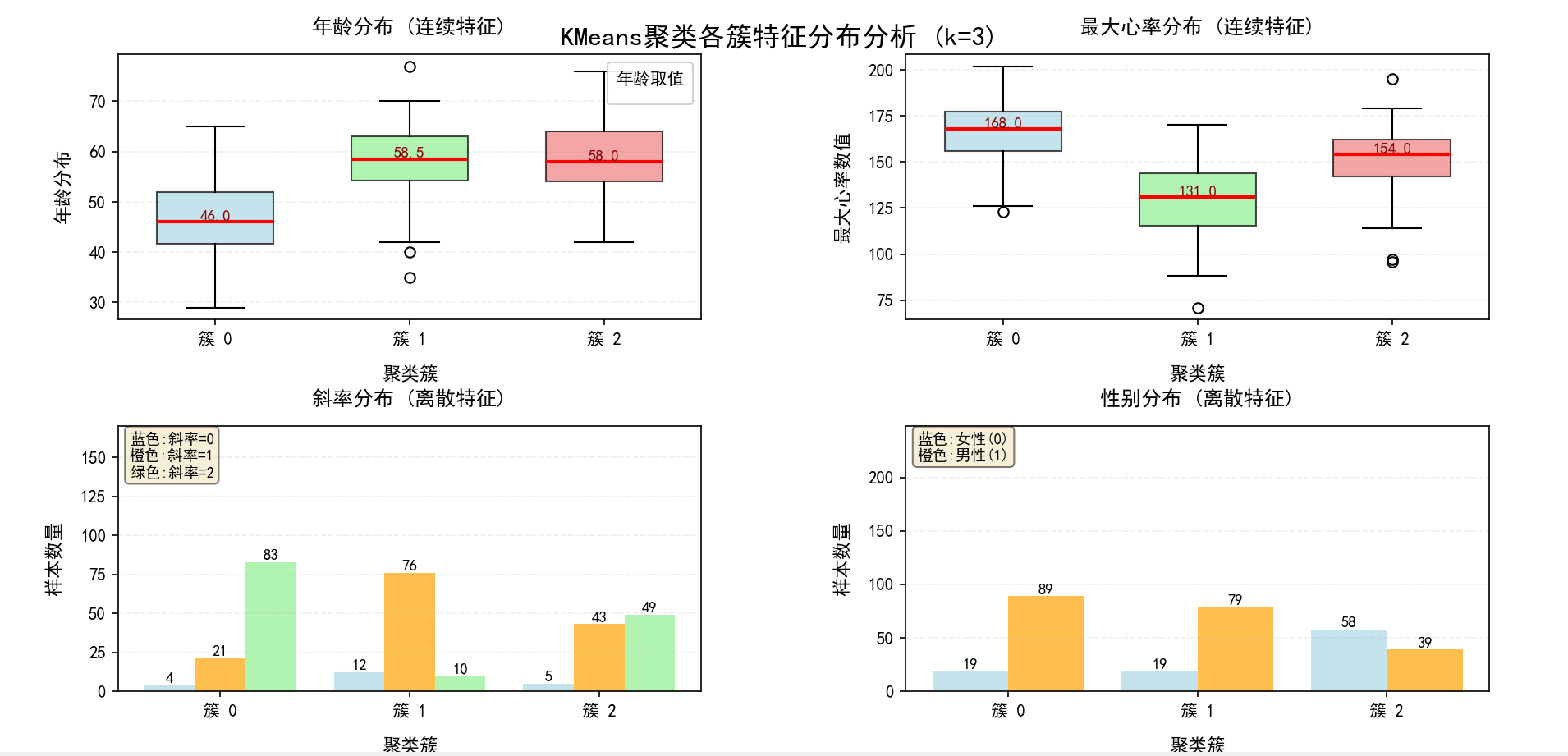
三个簇的特征定义与分析
簇 0(蓝色)
主要特征:
-
年龄:相对年轻,年龄中位数约58岁
-
最大心率:心率最高,中位数约168
-
斜率:主要集中为2(可能是向上斜,表示心脏功能较好)
-
性别:以男性为主
簇定义 :年轻男性,心脏功能较好组
-
这是最年轻的一组,心脏功能表现最佳
-
运动时心率能达到较高水平
-
常见于相对健康的年轻男性患者
簇 1(绿色)
主要特征:
-
年龄:最年轻,中位数约53岁
-
最大心率:心率中等,中位数约131
-
斜率:分布相对均衡
-
性别:女性比例显著高于其他组
簇定义 :年轻女性,心脏功能中等组
-
这是最年轻的一组,且以女性为主
-
心率表现中等,可能反映生理差异或健康状况
-
年龄分布相对集中
簇 2(红色)
主要特征:
-
年龄:最年长,中位数约58.5岁
-
最大心率:心率最低,中位数约131
-
斜率:主要集中为1(可能是平坦或向下,表示心脏功能可能较差)
-
性别:以男性为主
簇定义 :年长男性,心脏功能较差组
-
年龄最大的一组
-
心率表现最差,可能反映心脏功能受限
-
斜率分布表明可能有更多心脏功能问题

三、验证结果新的特征工程是否有效
将聚类获得的新的特征加入到原来的特征上,再分析比较多个模型在交叉验证准确率以及F1分数上的变化情况。
运行代码:
python
# ============================================================
# 新增代码:对聚类结果进行独热编码并评估模型效果
# ============================================================
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.model_selection import cross_val_score, StratifiedKFold
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 保存原始数据用于对比
X_original = df.iloc[:, :-1].copy()
y_original = df.iloc[:, -1].copy()
print("=" * 70)
print("特征工程前模型性能评估")
print("=" * 70)
# 1. 特征工程前的基准模型性能
def evaluate_models(X_data, y_data, title="特征工程前"):
"""评估多个模型在不同特征集上的性能"""
# 定义模型
models = {
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),
'SVM': SVC(probability=True, random_state=42)
}
# 使用5折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print(f"\n{title} - 5折交叉验证结果:")
print("-" * 50)
results = {}
for model_name, model in models.items():
# 交叉验证
cv_scores = cross_val_score(model, X_data, y_data, cv=cv, scoring='accuracy')
# 训练模型获取详细指标
train_accuracies = []
test_accuracies = []
f1_scores = []
for train_idx, test_idx in cv.split(X_data, y_data):
X_train_fold, X_test_fold = X_data.iloc[train_idx], X_data.iloc[test_idx]
y_train_fold, y_test_fold = y_data.iloc[train_idx], y_data.iloc[test_idx]
model.fit(X_train_fold, y_train_fold)
# 训练集准确率
y_train_pred = model.predict(X_train_fold)
train_acc = accuracy_score(y_train_fold, y_train_pred)
# 测试集准确率
y_test_pred = model.predict(X_test_fold)
test_acc = accuracy_score(y_test_fold, y_test_pred)
# F1分数
f1 = f1_score(y_test_fold, y_test_pred, average='weighted')
train_accuracies.append(train_acc)
test_accuracies.append(test_acc)
f1_scores.append(f1)
# 存储结果
results[model_name] = {
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std(),
'train_mean': np.mean(train_accuracies),
'test_mean': np.mean(test_accuracies),
'f1_mean': np.mean(f1_scores)
}
print(f"{model_name}:")
print(f" 交叉验证准确率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
print(f" 训练集准确率: {np.mean(train_accuracies):.4f}")
print(f" 测试集准确率: {np.mean(test_accuracies):.4f}")
print(f" F1分数: {np.mean(f1_scores):.4f}")
print()
return results
# 评估原始特征
baseline_results = evaluate_models(X_original, y_original)
print("\n" + "=" * 70)
print("对聚类结果进行独热编码并加入特征")
print("=" * 70)
# 2. 对KMeans聚类结果进行独热编码
kmeans_labels = X['KMeans_Cluster'].values.reshape(-1, 1)
# 使用OneHotEncoder
encoder = OneHotEncoder(sparse_output=False, drop='first')
cluster_encoded = encoder.fit_transform(kmeans_labels)
# 创建编码后的特征名
cluster_feature_names = [f'Cluster_{i}' for i in range(1, selected_k)] # drop='first',所以特征数减少1
# 将独热编码特征转换为DataFrame
cluster_encoded_df = pd.DataFrame(
cluster_encoded,
columns=cluster_feature_names,
index=X_original.index
)
print(f"聚类独热编码特征: {cluster_feature_names}")
print(f"聚类独热编码特征形状: {cluster_encoded_df.shape}")
print(f"每个聚类编码特征的样本分布:")
for i, col in enumerate(cluster_feature_names, 1):
count = cluster_encoded_df[col].sum()
print(f" {col}: {int(count)} 个样本 ({count/len(X_original)*100:.1f}%)")
# 3. 创建新的特征集:原始特征 + 聚类编码特征
X_with_clusters = pd.concat([X_original, cluster_encoded_df], axis=1)
print(f"\n原始特征数量: {X_original.shape[1]}")
print(f"新增聚类特征数量: {cluster_encoded_df.shape[1]}")
print(f"合并后总特征数量: {X_with_clusters.shape[1]}")
print(f"样本数量: {X_with_clusters.shape[0]}")
print("\n" + "=" * 70)
print("特征工程后模型性能评估")
print("=" * 70)
# 4. 评估特征工程后的模型性能
enhanced_results = evaluate_models(X_with_clusters, y_original, title="特征工程后")
# 5. 性能对比分析
print("=" * 70)
print("特征工程前后模型性能对比分析")
print("=" * 70)
comparison_data = []
for model_name in baseline_results.keys():
baseline = baseline_results[model_name]
enhanced = enhanced_results[model_name]
# 计算准确率提升
accuracy_improvement = enhanced['cv_mean'] - baseline['cv_mean']
accuracy_pct_improvement = (accuracy_improvement / baseline['cv_mean']) * 100 if baseline['cv_mean'] > 0 else 0
# 计算F1分数提升
f1_improvement = enhanced['f1_mean'] - baseline['f1_mean']
f1_pct_improvement = (f1_improvement / baseline['f1_mean']) * 100 if baseline['f1_mean'] > 0 else 0
comparison_data.append({
'Model': model_name,
'Baseline_Acc': baseline['cv_mean'],
'Enhanced_Acc': enhanced['cv_mean'],
'Accuracy_Improvement': accuracy_improvement,
'Accuracy_%_Improvement': accuracy_pct_improvement,
'Baseline_F1': baseline['f1_mean'],
'Enhanced_F1': enhanced['f1_mean'],
'F1_Improvement': f1_improvement,
'F1_%_Improvement': f1_pct_improvement
})
print(f"\n{model_name}:")
print(f" 准确率: {baseline['cv_mean']:.4f} → {enhanced['cv_mean']:.4f} "
f"(变化: {accuracy_improvement:+.4f}, {accuracy_pct_improvement:+.2f}%)")
print(f" F1分数: {baseline['f1_mean']:.4f} → {enhanced['f1_mean']:.4f} "
f"(变化: {f1_improvement:+.4f}, {f1_pct_improvement:+.2f}%)")
# 6. 可视化性能对比
plt.figure(figsize=(14, 8))
# 准确率对比图
plt.subplot(1, 2, 1)
models = [d['Model'] for d in comparison_data]
baseline_acc = [d['Baseline_Acc'] for d in comparison_data]
enhanced_acc = [d['Enhanced_Acc'] for d in comparison_data]
x = np.arange(len(models))
width = 0.35
plt.bar(x - width/2, baseline_acc, width, label='原始特征', alpha=0.8, color='lightblue')
plt.bar(x + width/2, enhanced_acc, width, label='原始特征+聚类特征', alpha=0.8, color='lightcoral')
plt.xlabel('模型', fontsize=12)
plt.ylabel('交叉验证准确率', fontsize=12)
plt.title('特征工程前后准确率对比', fontsize=14, fontweight='bold')
plt.xticks(x, models)
plt.legend()
plt.grid(True, alpha=0.3, axis='y')
# 在每个柱子上添加数值
for i, (b, e) in enumerate(zip(baseline_acc, enhanced_acc)):
plt.text(i - width/2, b + 0.01, f'{b:.3f}', ha='center', va='bottom', fontsize=9)
plt.text(i + width/2, e + 0.01, f'{e:.3f}', ha='center', va='bottom', fontsize=9)
# 添加提升百分比
improvement = (e - b) * 100
plt.text(i, max(b, e) + 0.02, f'{improvement:+.1f}%',
ha='center', va='bottom', fontsize=10, fontweight='bold',
color='green' if improvement > 0 else 'red')
# F1分数对比图
plt.subplot(1, 2, 2)
baseline_f1 = [d['Baseline_F1'] for d in comparison_data]
enhanced_f1 = [d['Enhanced_F1'] for d in comparison_data]
plt.bar(x - width/2, baseline_f1, width, label='原始特征', alpha=0.8, color='lightgreen')
plt.bar(x + width/2, enhanced_f1, width, label='原始特征+聚类特征', alpha=0.8, color='orange')
plt.xlabel('模型', fontsize=12)
plt.ylabel('F1分数', fontsize=12)
plt.title('特征工程前后F1分数对比', fontsize=14, fontweight='bold')
plt.xticks(x, models)
plt.legend()
plt.grid(True, alpha=0.3, axis='y')
# 在每个柱子上添加数值
for i, (b, e) in enumerate(zip(baseline_f1, enhanced_f1)):
plt.text(i - width/2, b + 0.01, f'{b:.3f}', ha='center', va='bottom', fontsize=9)
plt.text(i + width/2, e + 0.01, f'{e:.3f}', ha='center', va='bottom', fontsize=9)
# 添加提升百分比
improvement = (e - b) * 100
plt.text(i, max(b, e) + 0.02, f'{improvement:+.1f}%',
ha='center', va='bottom', fontsize=10, fontweight='bold',
color='green' if improvement > 0 else 'red')
plt.tight_layout()
plt.suptitle('特征工程效果对比分析', fontsize=16, fontweight='bold', y=1.02)
plt.show()
# 7. 分析聚类特征的重要性
print("\n" + "=" * 70)
print("聚类特征重要性分析")
print("=" * 70)
# 使用随机森林分析特征重要性
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_with_clusters, y_original)
# 获取特征重要性
feature_importance = pd.DataFrame({
'feature': X_with_clusters.columns,
'importance': rf_model.feature_importances_
}).sort_values('importance', ascending=False)
print("\nTop 10最重要的特征:")
print("-" * 50)
for i, row in feature_importance.head(10).iterrows():
print(f"{row['feature']:20} 重要性: {row['importance']:.4f}")
# 分析聚类特征的排名
print("\n聚类特征的相对重要性:")
print("-" * 50)
cluster_features_rank = []
for cluster_feat in cluster_feature_names:
if cluster_feat in feature_importance['feature'].values:
rank = feature_importance[feature_importance['feature'] == cluster_feat].index[0] + 1
importance = feature_importance[feature_importance['feature'] == cluster_feat]['importance'].values[0]
cluster_features_rank.append((cluster_feat, rank, importance))
for feat, rank, imp in sorted(cluster_features_rank, key=lambda x: x[1]):
print(f"{feat:15} 排名: {rank:2d}/{len(feature_importance)} 重要性: {imp:.4f}")
# 8. 总结分析
print("\n" + "=" * 70)
print("特征工程效果总结")
print("=" * 70)
# 计算整体提升
avg_accuracy_improvement = np.mean([d['Accuracy_Improvement'] for d in comparison_data])
avg_f1_improvement = np.mean([d['F1_Improvement'] for d in comparison_data])
print(f"\n平均准确率提升: {avg_accuracy_improvement:+.4f}")
print(f"平均F1分数提升: {avg_f1_improvement:+.4f}")
if avg_accuracy_improvement > 0:
print(f"✓ 特征工程有效!模型准确率平均提升了 {avg_accuracy_improvement*100:.2f}%")
if avg_f1_improvement > 0:
print(f"✓ 同时F1分数也提升了 {avg_f1_improvement*100:.2f}%,说明特征工程改善了模型的综合性能")
else:
print(f"✗ 特征工程效果不明显,准确率平均变化 {avg_accuracy_improvement*100:.2f}%")
# 找出提升最大的模型
best_model = max(comparison_data, key=lambda x: x['Accuracy_Improvement'])
print(f"\n提升最大的模型: {best_model['Model']}")
print(f" 准确率提升: {best_model['Accuracy_Improvement']*100:.2f}%")
print(f" F1分数提升: {best_model['F1_Improvement']*100:.2f}%")
# 保存特征工程后的数据
X_final = X_with_clusters.copy()
y_final = y_original.copy()
print(f"\n最终数据集形状:")
print(f" 特征数量: {X_final.shape[1]}")
print(f" 样本数量: {X_final.shape[0]}")
# 9. 额外分析:不同模型对聚类特征的敏感度
print("\n" + "=" * 70)
print("不同模型对聚类特征的敏感度分析")
print("=" * 70)
# 训练-测试集划分比例对结果的影响
test_sizes = [0.2, 0.3, 0.4]
test_size_results = {}
for test_size in test_sizes:
X_train, X_test, y_train, y_test = train_test_split(
X_with_clusters, y_original, test_size=test_size, random_state=42, stratify=y_original
)
model_performance = {}
for model_name, model in {
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42)
}.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred, average='weighted')
model_performance[model_name] = {'accuracy': acc, 'f1': f1}
test_size_results[test_size] = model_performance
# 输出不同测试集大小的结果
for test_size, perf in test_size_results.items():
print(f"\n测试集比例: {test_size*100:.0f}%")
for model_name, scores in perf.items():
print(f" {model_name}: 准确率={scores['accuracy']:.4f}, F1分数={scores['f1']:.4f}")
print("\n" + "=" * 70)
print("特征工程完成!")
print("=" * 70)运行结果:
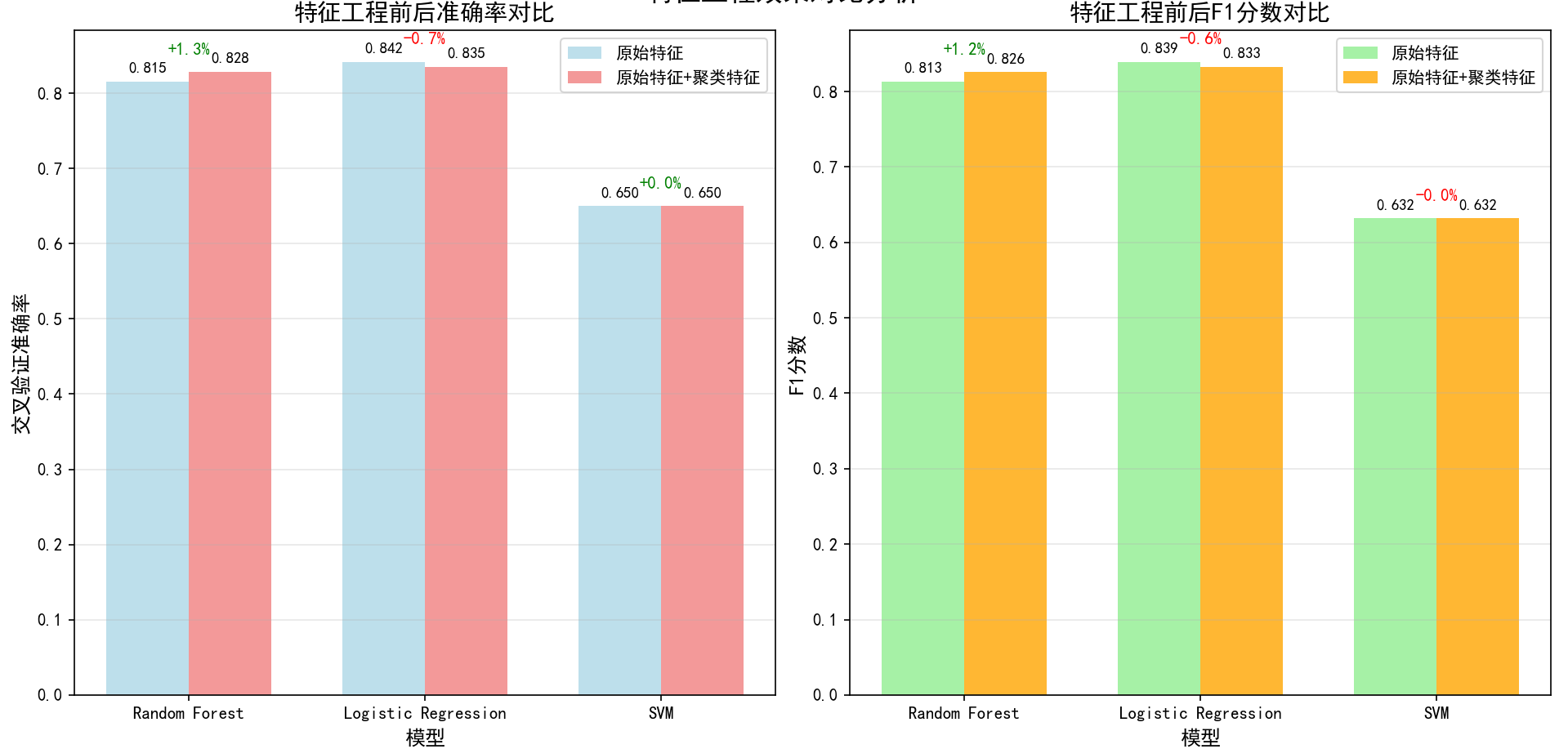
总结:可以看出,KMeans聚类作为特征工程方法是有效的,特别是对于树模型。在实际部署时,建议采用特征工程后的Random Forest模型。