一、Pod优先级
-
优先级是什么?
- 优先级代表一个Pod相对其他Pod的重要性
-
优先级有什么用
- 优先级可以保证重要的Pod被调用运行
-
如何使用优先级和抢占
-
配置优先级类PriorityClass
-
创建Pod是为其设置对应的优先级
-
-
PriorityClass
- PriorityClass是一个全局资源对象,它定义了从优先级类名称到优先级整数值的映射。优先级在values字段中指定,可以设置小于10亿的整数值,值越大,优先级越高
-
PriorityClass还有两个可选字段:
-
globalDefault:用于设置默认优先级状态,如果没有任何优先级设置,Pod的优先级为零
-
description:用来配置描述性信息,告诉用户优先级的用途
-
-
优先级策略
-
非抢占优先:指的是在调度阶段优先进行调度分配,一旦容器调度完成就不可以抢占,资源不足时,只能等待 ,对应
preemptionPolicy: Never -
抢占优先:强制调度一个Pod,如果资源不足无法被调度,调度程序会抢占(删除 )较低优先级的Pod的资源,来保证高优先级Pod的运行,对应
preemptionPolicy: PreemptLowerPriority
-
1、非抢占优先级
cpp
# 定义优先级(队列优先)
[root@k8s-master ~]# vim mypriority.yaml
---
kind: PriorityClass # 资源对象类型
apiVersion: scheduling.k8s.io/v1 # 资源对象版本
metadata:
name: high-non # 优先级名称,可在Pod中引用
globalDefault: false # 是否定义默认优先级(唯一)
preemptionPolicy: Never # 抢占策略
value: 1000 # 优先级
description: non-preemptive # 描述信息
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: low-non
globalDefault: false
preemptionPolicy: Never
value: 500
description: non-preemptive
[root@k8s-master ~]# kubectl apply -f mypriority.yaml
priorityclass.scheduling.k8s.io/high-non created
priorityclass.scheduling.k8s.io/low-non created
[root@k8s-master ~]# kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE
high-non 1000 false 12s
low-non 500 false 12s
system-cluster-critical 2000000000 false 45h
system-node-critical 2000001000 false 45hPod资源文件
cpp
# 无优先级的 Pod
[root@k8s-master ~]# cat nginx1.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx1
spec:
nodeName: k8s-node2
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"
# 低优先级 Pod
[root@k8s-master ~]# cat nginx2.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx2
spec:
nodeName: k8s-node2
priorityClassName: low-non # 指定优先级的名称
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"
# 高优先级 Pod
[root@k8s-master ~]# cat nginx3.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx3
spec:
nodeName: k8s-node2
priorityClassName: high-non # 指定优先级的名称
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"2、验证非抢占优先
cpp
[root@master ~]# kubectl apply -f nginx1.yaml
pod/nginx1 created
[root@master ~]# kubectl apply -f nginx2.yaml
pod/nginx2 created
[root@master ~]# kubectl apply -f nginx3.yaml
pod/nginx3 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 9s
nginx2 0/1 Pending 0 6s
nginx3 0/1 Pending 0 4s
[root@master ~]# kubectl delete pod nginx1
pod "nginx1" deleted
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx2 0/1 Pending 0 20s
nginx3 1/1 Running 0 18s
# 清理实验 Pod
[root@master ~]# kubectl delete pod nginx2 nginx3
pod "nginx2" deleted
pod "nginx3" deleted3、抢占策略
K8S在发生调度失败后,会基于优先级进行抢占,抢占并不是简单的将Node上的低优先级的pod"挤走",抢占的设计还是相对比较有意思的。
K8S内部在调度过程中,会维护2个队列,分别是activeQ和unschedulableQ。
activeQ
当K8S里新创建一个Pod的时候,调度器会将这个Pod入队到activeQ里面,然后调度器从这个队列里取出一个pod进行调度。
unschedulableQ
专门用来存放调度失败的pod,当一个unschedulableQ里的Pod被更新之后,调度器会自动把这个Pod移动到activeQ里。
3.1、抢占的基本流程:
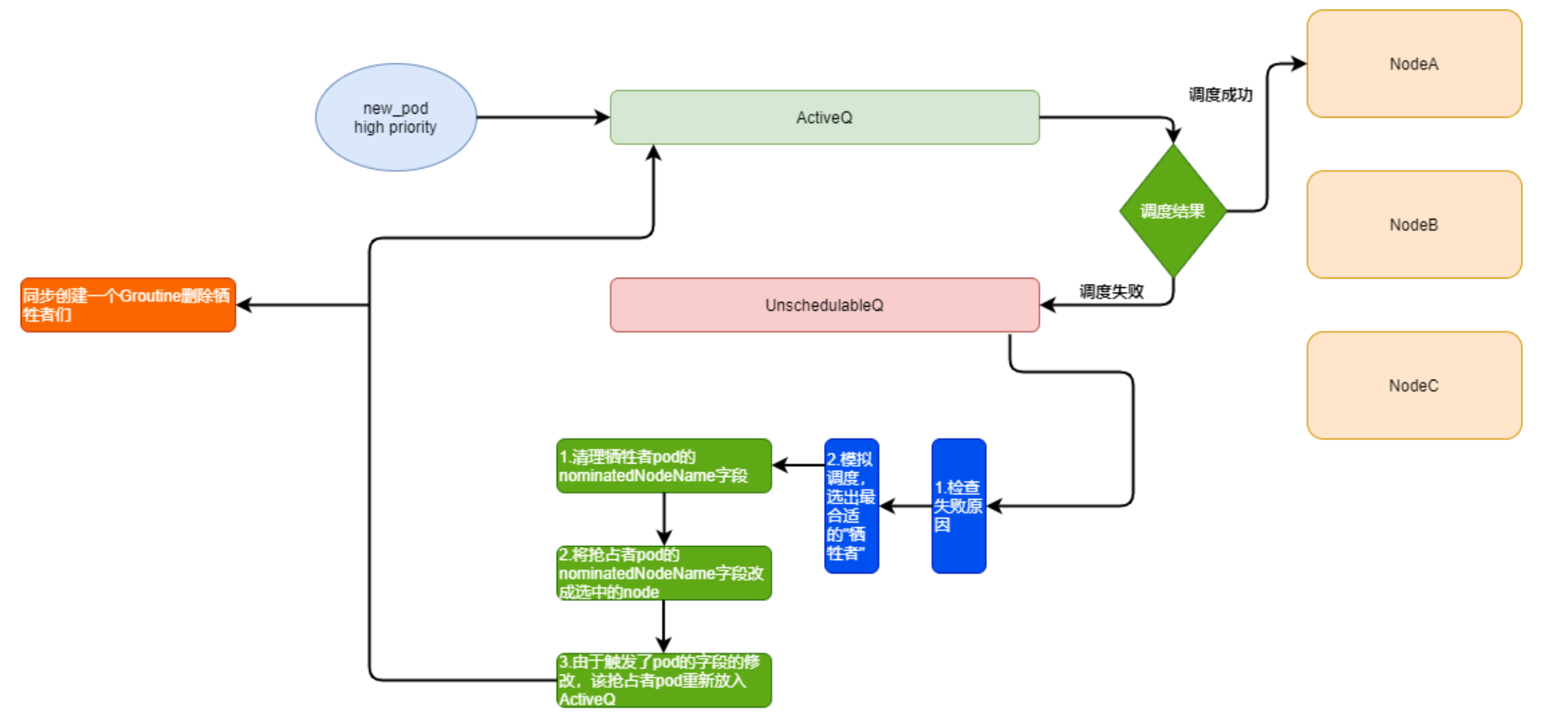
-
正常调度的pod会先放入activeQ, activeQ会经过正常的调度策略进行调度。
-
调度失败后,将这个pod放入unreachableQ里,随后出发寻找牺牲者流程。
-
在寻找牺牲者之前,先对失败原因检查下,看下是不是因为一些无法恢复的原因导致失败的,比如node-selector失败之类的。
-
确认可以触发抢占后,scheduler 会拉取所有node的缓存信息,进行一次模拟抢占流程,基于影响集群稳定性最小原则,选出了哪些node上的哪些pod,可以成为"牺牲者"。
-
对于选出的牺牲者pod,schedueler 会先清楚他们pod里的nominatedNodeName字段。
-
然后更新抢占者pod,将nominatedNodeName改成第4步选出的node名字。
-
由于抢占者pod已发生了更新,所以给他"重新做人"的机会,重新放入activeQ里。
-
同时,开启一个新的协程,清理牺牲者node上对应的牺牲者pod。
3.2、抢占的异常流程
抢占者和牺牲者其实是相对的,或者说,优先级是相对的,抢占者在第一次流程后,一般会创建在之前模拟出来的那个牺牲者node上,但是,假设同样队列里有另外一个pod也正好要调度在那个node上,K8S会对这种情况做一些特殊处理,即对该node进行2次预选操作。
-
第一次预选,假设抢占者已经在对应node上了,以这个前提进行一次预选算法。
-
第二次预选,假设抢占者不在对应node上,以这个前提进行一次预选算法。
只有这两次预选都通过了,调度器才认为这个node和pod可以绑定,再进入后续的优选算法。第二预选比较奇怪,为什么需要假设抢占者不在node上呢,这是因为删除牺牲者操作,实际是调用了标准的DELETE API进行操作的,这是一个"优雅关闭"的操作,所以存在默认30S的退出时间,而30S内,可能会有很多变故,比如再重新调度的时候,Node服务器挂了或者有更加高优先级的pod需要抢占这个node,这些都导致了重新调度的失败,所以说,抢占者不一定会调度到对应的node上。
另外还有一种情况,假设整个K8S集群有了一个比较大的变化,比如新扩容了node节点等,scheduler会执行MoveAllToActiveQueue的操作,把所调度失败的Pod从unscheduelableQ移动到activeQ里面。
另外由于亲和性的存在,当一个已经调度成功的Pod被更新时,调度器则会将unschedulableQ里所有跟这个Pod有 Affinity/Anti-affinity关系的Pod,移动到 activeQ 里面,开始调度。
cpp
[root@master ~]# vim mypriority.yaml
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: high
globalDefault: false
preemptionPolicy: PreemptLowerPriority
value: 1000
description: non-preemptive
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: low
globalDefault: false
preemptionPolicy: PreemptLowerPriority
value: 500
description: non-preemptive
[root@master ~]# kubectl apply -f mypriority.yaml
priorityclass.scheduling.k8s.io/high created
priorityclass.scheduling.k8s.io/low created
[root@master ~]# kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE
high 1000 false 12s
low 500 false 12s
system-cluster-critical 2000000000 false 45h
system-node-critical 2000001000 false 45h4、验证抢占优先级
cpp
# 默认优先级 Pod
[root@master ~]# kubectl apply -f nginx1.yaml
pod/nginx1 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 6s
# 高优先级 Pod
[root@master ~]# sed 's,-non,,' nginx3.yaml |kubectl apply -f-
pod/nginx3 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx3 1/1 Running 0 9s
# 低优先级 Pod
[root@master ~]# sed 's,-non,,' nginx2.yaml |kubectl apply -f-
pod/nginx2 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx2 0/1 Pending 0 3s
nginx3 1/1 Running 0 9s
# 清理实验 Pod
[root@master ~]# kubectl delete pod nginx2 nginx3
pod "nginx2" deleted
pod "nginx3" deleted
[root@master ~]# kubectl delete -f mypriority.yaml
priorityclass.scheduling.k8s.io "high-non" deleted
priorityclass.scheduling.k8s.io "low-non" deleted
priorityclass.scheduling.k8s.io "high" deleted
priorityclass.scheduling.k8s.io "low" deleted二、节点优先级
在 Kubernetes 中,节点优先级(Node Priority)是用于指定节点的调度权重的设置。节点优先级主要用于调度器在选择节点时进行权衡和做出选择。
1、优先级类型
1.1、静态优先级(Static Priority)
可以手动为每个节点设置一个固定的优先级值。在节点对象的注解(Annotations)中使用 scheduler.alpha.kubernetes.io/priority 注解来定义节点的优先级。较高的优先级值表示节点的优先级较高。
1.2、亲和性优先级(Affinity Priority)
可以通过节点的亲和性(Affinity)设置来隐式地设置节点的优先级。优先级是根据亲和性规则和节点的亲和性权重(weight)来计算的。
1.3、服务质量优先级(Quality of Service Priority)
可以通过指定 Pod 的服务质量等级(Quality of Service Class)来设置节点的优先级。服务质量等级包括 Guaranteed、Burstable、BestEffort。较高的服务质量等级对应较高的优先级。
1.3.1、QoS(服务质量)
Requests 和 limits 的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用:它决定了 pod 的 QoS 等级。
如果 pod 没有配置 limits ,那么它可以使用节点上任意多的可用资源。这类 pod 能灵活使用资源,但这也导致它不稳定且危险,对于这类 pod 我们一定要在它占用过多资源导致节点资源紧张时处理掉。优先处理这类 pod,而不是资源使用处于自己请求范围内的 pod 是非常合理的想法,而这就是 pod QoS 的含义:根据 pod 的资源请求把 pod 分成不同的重要性等级。
kubernetes 把 pod 分成了三个 QoS 等级:
-
Guaranteed:优先级最高,可以考虑数据库应用或者一些重要的业务应用。除非 pods 使用超过了它们的 limits,或者节点的内存压力很大而且没有 QoS 更低的 pod,否则不会被杀死
-
Burstable:这种类型的 pod 可以多于自己请求的资源(上限有 limit 指定,如果 limit没有配置,则可以使用主机的任意可用资源),但是重要性认为比较低,可以是一般性的应用或者批处理任务
-
Best Effort:优先级最低,集群不知道 pod的资源请求情况,调度不考虑资源,可以运行到任意节点上(从资源角度来说),可以是一些临时性的不重要应用。pod可以使用节点上任何可用资源,但在资源不足时也会被优先杀死
1.3.2、根据QoS进行资源回收
策略
Kubernetes 通过cgroup给pod设置QoS级别,当资源不足时先kill优先级低的 pod,在实际使用过程中,通过OOM分数值来实现,OOM分数值范围为0-1000。OOM 分数值根据OOM_ADJ参数计算得出。
对于Guaranteed级别的 Pod,OOM_ADJ参数设置成了-998,对于Best-Effort级别的 Pod,OOM_ADJ参数设置成了1000,对于Burstable级别的 Pod,OOM_ADJ参数取值从2到999。
对于 kuberntes 保留资源,比如kubelet,docker,OOM_ADJ参数设置成了-999,表示不会被OOM kill掉。OOM_ADJ参数设置的越大,计算出来的OOM分数越高,表明该pod优先级就越低,当出现资源竞争时会越早被kill掉,对于OOM_ADJ参数是-999的表示kubernetes永远不会因为OOM将其kill掉。
1.3.3、QoS pods被kill掉场景与顺序
-
Best-Effort pods:系统用完了全部内存时,该类型 pods 会最先被kill掉。
-
Burstable pods:系统用完了全部内存,且没有 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被kill 掉。
-
Guaranteed pods:系统用完了全部内存,且没有 Burstable 与 Best-Effort 类型的容器可以被 kill时,该类型的 pods 会被 kill 掉。
1.4、插件优先级(Plugin Priority)
可以编写插件来扩展调度器的功能,并为节点设置一些额外的优先级规则。
调度器在进行节点选择时,会根据节点的优先级进行权衡,优先选择具有较高优先级的节点。如果存在多个节点具有相同的优先级,则会根据其它因素(例如节点资源、亲和性规则等)进一步进行选择。
2、实战案例
2.1、静态优先级案例
场景描述
假设有一个混合了新旧硬件的Kubernetes集群。新硬件性能更优,希望调度器优先将资源密集型的应用部署到新硬件节点上。
设置步骤与示例
首先,给新硬件节点设置较高的静态优先级。假设集群中有三个节点,node-new-1和node-new-2是新硬件节点,node-old是旧硬件节点。
通过以下命令(假设可以直接修改节点注解)为新硬件节点设置优先级:
cpp
kubectl annotate node node-new-1 scheduler.alpha.kubernetes.io/priority=100
kubectl annotate node node-new-2 scheduler.alpha.kubernetes.io/priority=100
kubectl annotate node node-old scheduler.alpha.kubernetes.io/priority=50现在有一个大数据处理的Pod,需要大量的CPU和内存资源。当调度器调度这个Pod时,会首先考虑node-new-1和node-new-2这两个优先级为100的节点,因为它们的优先级高于node-old(优先级为50)。只有当新硬件节点资源不足或者不符合其他调度规则(如亲和性规则)时,调度器才会考虑node-old。
删除注解
cpp
kubectl annotate node node-old scheduler.alpha.kubernetes.io/priority-2.2、亲和性优先级案例
场景描述
考虑一个具有多个区域(zone)的多节点集群,应用需要根据区域亲和性进行部署,并且希望在满足区域亲和性的基础上,根据某种权重来优先选择节点。例如,有一个应用,它的数据存储在特定区域的存储服务中,为了减少网络延迟,希望将应用的Pod优先调度到靠近存储服务的区域的节点上,并且在这个区域内,有些节点与存储服务的网络连接质量更好,希望给这些节点更高的优先级。
设置步骤与示例
首先,为节点添加区域标签。假设存储服务在zone-a区域,节点node-1、node-2在zone-a,节点node-3在zone-b。
bash
cpp
kubectl label node node-1 zone=zone-a
kubectl label node node-2 zone=zone-a
kubectl label node node-3 zone=zone-b然后,在Pod的配置文件中设置节点亲和性和权重。假设node-1与存储服务的网络连接质量更好,希望给它更高的优先级。
cpp
apiVersion: v1
kind: Pod
metadata:
name: data-app-pod
spec:
containers:
- name: data-app-container
image: data-app-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- zone-a
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: node-name
operator: In
values:
- node-1
- weight: 40
preference:
matchExpressions:
- key: node-name
operator: In
values:
- node-2当调度data-app-pod时,调度器首先会过滤出zone-a的节点(node-1和node-2),因为有硬亲和性要求。然后,根据亲和性优先级的权重计算,node-1因为权重为80,会比node-2(权重为40)更有可能被选中。
2.3、服务质量优先级案例
场景描述
有一个在线交易系统,包括一个保证服务质量(Guaranteed)的核心交易处理服务,一个可突发(Burstable)的订单查询服务,以及一个尽力而为(BestEffort)的日志收集服务。希望核心交易处理服务的Pod能够优先调度到资源充足且稳定的节点上。
设置步骤与示例
对于核心交易处理服务的Pod,在配置文件中设置服务质量等级为Guaranteed:
limit与request的资源设置一致。
cpp
apiVersion: v1
kind: Pod
metadata:
name: trade-processing-pod
spec:
containers:
- name: trade-container
image: trade-processing-image
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
### qosClass: Guaranteed- 对于订单查询服务的Pod,设置为Burstable:
limit的资源设置小于request的资源设置
cpp
apiVersion: v1
kind: Pod
metadata:
name: order-query-pod
spec:
containers:
- name: order-container
image: order-query-image
resources:
requests:
cpu: "0.5"
memory: "512Mi"
limits:
cpu: "1"
memory: "1Gi"
### qosClass: Burstable- 对于日志收集服务的Pod,设置为BestEffort:
不进行资源限制
cpp
apiVersion: v1
kind: Pod
metadata:
name: log-collection-pod
spec:
containers:
- name: log-container
image: log-collection-image
### qosClass: BestEffort调度器在调度这些Pod时,会优先考虑将trade-processing-pod(Guaranteed)调度到资源充足且稳定的节点。因为它的服务质量等级最高,其次是order-query-pod(Burstable),最后是log-collection-pod(BestEffort)。
2.4、插件优先级案例
场景描述
假设在一个企业级的Kubernetes集群中,安全团队要求对于运行敏感数据处理应用的Pod,必须优先调度到经过特定安全加固的节点上。这些节点有额外的安全防护软件和硬件模块,并且希望通过插件来实现这种特殊的优先级设置。
设置步骤与示例
首先,开发一个自定义的调度插件。这个插件可以检查节点是否具有"security-hardened"标签(表示经过安全加固的节点),并为这些节点设置较高的优先级。
安装和配置插件后,给经过安全加固的节点添加标签:
cpp
kubectl label node node-sec-1 security-hardened=true
kubectl label node node-sec-2 security-hardened=true对于敏感数据处理应用的Pod,正常创建配置文件。当调度器运行时,由于插件的作用,会优先将这些Pod调度到带有"security-hardened"标签的节点(node-sec-1和node-sec-2)上,因为插件为这些节点设置了更高的优先级。具体的插件实现可能涉及到Go语言编程,并且需要遵循Kubernetes调度器插件的开发规范来与调度器集成。