在网络通信领域,传输层协议的设计决策直接决定了应用层开发者的编程模型。作为架构师,理解传输层协议的核心差异及其对应用设计的影响,是构建高性能、可靠网络系统的基石。TCP(传输控制协议)和UDP(用户数据报协议)作为传输层的两大支柱,采用了截然不同的数据传输模型,这直接导致了"粘包"这一经典问题的产生。
TCP粘包问题并非协议缺陷,而是字节流模型 的必然结果。当应用程序通过TCP发送两条独立消息时,接收方可能一次性接收到两条消息的合并数据,这就是所谓的"粘包"现象。这一现象背后反映的是TCP协议设计的根本哲学------提供可靠的、有序的字节流传输服务,而非消息边界保护服务。
本文将深入剖析TCP粘包的技术根源,对比UDP为何不存在这一问题,探讨UDP长度字段的真正意义,并从历史演进和工程实践角度,呈现网络协议设计的权衡艺术。

TCP协议本质:面向流的字节传输模型
TCP核心特性与设计哲学
TCP是一种面向连接的、可靠的、基于字节流 的传输层通信协议。其设计目标是在不可靠的IP网络之上构建可靠的数据传输通道。这一目标通过多种机制实现:三次握手建立连接 、数据包确认与重传 、序列号保证有序性 、滑动窗口实现流量控制以及拥塞控制机制。
TCP的字节流特性是理解粘包问题的关键。应用程序通过TCP发送的数据被转换为连续的字节流,这些字节之间没有任何边界标记。TCP协议栈会将应用层数据分割成适合网络传输的TCP段(segment),接收方则按序重组这些字节,还原成连续的字节流交付给上层应用。
python
# TCP字节流传输示例
import socket
# 创建TCP socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = ('0.0.0.0', 8888)
server_socket.bind(server_address)
server_socket.listen(5)
while True:
# 接受客户端连接
client_socket, client_address = server_socket.accept()
# 接收数据 - TCP以字节流方式交付,无消息边界
data = client_socket.recv(1024) # 可能包含多条消息的合并数据
# 应用程序需要自行解析消息边界TCP粘包产生的技术根源
TCP粘包现象的产生有多方面原因,可以概括为发送端和接收端两类因素。
发送端原因主要与Nagle算法相关。该算法是TCP协议的一项优化机制,旨在减少小数据包的数量,提高网络利用率。当应用频繁发送小数据包时,Nagle算法会将它们缓冲合并,等待达到一定大小或超时后再发送。虽然这减少了网络IO压力,但也导致了数据包合并,形成粘包。
java
// Nagle算法工作原理示意
public class NagleAlgorithm {
// 发送小数据包时,Nagle算法可能将其合并
public void sendSmallPackets() {
// 应用程序发送两条消息
send("Hello");
send("World");
// TCP可能将两条消息合并为一个TCP段发送
// 接收方收到的是"HelloWorld"合并数据
}
// 可通过TCP_NODELAY选项禁用Nagle算法
public void disableNagle(Socket socket) throws SocketException {
socket.setTcpNoDelay(true); // 立即发送,不缓冲合并
}
}接收端原因则与接收缓冲区有关。当数据到达接收端时,首先进入内核的接收缓冲区。如果应用层未能及时读取数据,多条消息可能在缓冲区中累积,应用再次读取时就会一次性获得多条消息。网络传输的不确定性会加剧这一问题,即使发送方均匀发送数据包,网络拥塞、路由变化等因素也可能导致数据包在接收端聚集。
UDP协议分析:面向消息的数据报传输
UDP核心特性与设计哲学
与TCP不同,UDP是一种无连接的、不可靠的、面向消息 的数据报协议。UDP的设计哲学是简单高效,它不建立连接,直接将数据报发送出去,不保证它们一定能到达、按序到达或不重复。
UDP的消息边界保护特性是其与TCP的根本区别之一。每个UDP数据报都保持完整的边界,应用程序发送和接收的都是独立的数据报。这一特性使得UDP天然不存在粘包问题,因为每个数据报都是自包含的独立消息。
python
# UDP数据报传输示例
import socket
# 创建UDP socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_address = ('0.0.0.0', 9999)
udp_socket.bind(server_address)
while True:
# 接收UDP数据报 - 每个recv调用返回一个完整数据报
data, client_address = udp_socket.recvfrom(1024)
# data是一个完整的UDP数据报,不会被截断或合并UDP长度字段的冗余性分析
UDP头部包含一个16位的长度字段,表示整个UDP数据报的长度(包括头部和数据部分),最小值为8字节(仅头部)。有趣的是,IP头部也包含一个总长度字段,这使得UDP长度字段在理论上显得冗余。
UDP长度字段的存在主要基于以下考量:
-
协议独立性:UDP设计时希望保持与下层协议的独立性。虽然UDP通常运行在IP之上,但理论上它可以运行在其他网络层协议上。
-
完整性校验:长度字段提供了额外的数据完整性检查机制。接收方可以对比IP长度字段和UDP长度字段,检测数据是否在传输过程中被篡改。
-
伪头部校验:UDP校验和计算时使用了"伪头部",其中包含了UDP长度字段。这增强了校验的可靠性,防止数据报被误传到错误的目的地。
cpp
// UDP伪头部结构(用于校验和计算)
struct pseudohdr {
u_int32_t src_addr; // 源IP地址
u_int32_t dst_addr; // 目的IP地址
u_int8_t zero; // 全0填充
u_int8_t protocol; // 协议类型(UDP为17)
u_int16_t udp_length; // UDP数据报长度(包括头部)
};
// UDP头部结构
struct udphdr {
u_int16_t src_port; // 源端口
u_int16_t dst_port; // 目的端口
u_int16_t length; // UDP数据报长度
u_int16_t checksum; // 校验和(基于伪头部计算)
};协议演进与历史背景
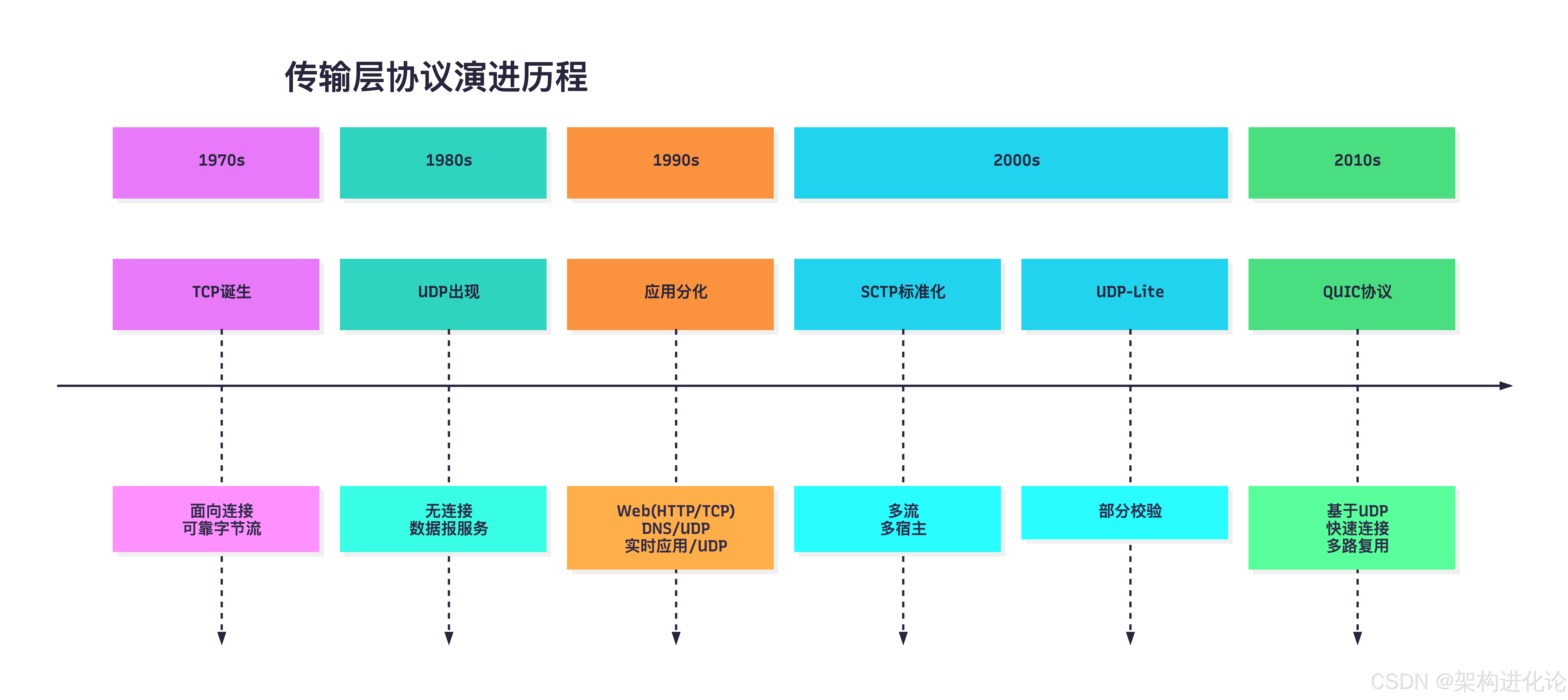
TCP/UDP设计的历史背景
TCP和UDP协议的设计反映了不同历史时期的需求和技术约束。TCP最早于1973年开发,当时网络环境不可靠且带宽有限,因此设计重点放在了可靠性和有序性上。字节流模型简化了应用层处理连续数据的复杂度,适合文件传输、远程登录等场景。
到了1980年代,随着网络应用的多样化,人们发现TCP的严格可靠性要求在某些场景下并不必要。实时应用如音视频传输、DNS查询等更看重低延迟和简单性,而非绝对可靠。UDP应运而生,提供了轻量级的传输方案。
传输层协议的演进与变体
随着互联网应用的发展,TCP和UDP的局限性逐渐显现,催生了一些新的传输层协议或变体:
-
SCTP(流控制传输协议) :结合了TCP和UDP的优点,提供多流支持 和多宿主能力。SCTP是面向消息的(如UDP),但也提供可靠的传输(如TCP)。当一条流阻塞时,其他流仍可继续传输数据。
-
UDP-Lite:UDP的变体,允许部分数据不参与校验和计算。这对于容忍一定数据错误的实时多媒体应用非常有用。
-
QUIC :基于UDP的现代传输协议,由Google开发,现已成为HTTP/3的基础。QUIC在用户空间实现TCP-like的可靠性,同时减少了连接建立延迟,支持多路复用而无队头阻塞。(扩展阅读:QUIC协议深度解析:重塑互联网传输层的创新架构、HTTP/3与QUIC深度解析:下一代Web传输技术的革命性融合)
下面的架构图展示了主要传输层协议的演进关系:
TCP粘包的解决方案与工程实践
应用层解决方案
由于TCP协议本身不提供消息边界,解决粘包问题需要在应用层实现消息帧化。主流的解决方案包括:
定长消息法:每条消息固定长度,不足部分填充。这种方法简单高效,但可能浪费带宽。
python
# 定长消息法示例
def send_fixed_length(socket, message, length):
# 填充消息到固定长度
if len(message) < length:
message = message.ljust(length, '\0')
socket.sendall(message.encode())
def recv_fixed_length(socket, length):
# 接收固定长度的消息
data = socket.recv(length)
return data.decode().rstrip('\0')分隔符法:使用特殊字符或字符串作为消息分隔符。这种方法灵活,但需要确保分隔符不会出现在消息内容中。
java
// 分隔符法示例
public class DelimiterBasedDecoder {
private static final String DELIMITER = "\r\n"; // 使用CRLF作为分隔符
public void sendWithDelimiter(Socket socket, String message) throws IOException {
// 在消息末尾添加分隔符
String framedMessage = message + DELIMITER;
socket.getOutputStream().write(framedMessage.getBytes());
}
public String readWithDelimiter(BufferedReader reader) throws IOException {
// 读取直到遇到分隔符
return reader.readLine(); // readLine()默认使用CRLF作为分隔符
}
}长度前缀法:在消息前添加长度字段,指示消息体的长度。这是最常用且最可靠的方法。
python
# 长度前缀法示例
import struct
def send_with_length(socket, message):
# 将消息长度打包为4字节网络字节序整数
message_bytes = message.encode('utf-8')
length = len(message_bytes)
# 发送长度前缀
socket.sendall(struct.pack('>I', length))
# 发送消息体
socket.sendall(message_bytes)
def recv_by_length(socket):
# 接收4字节长度前缀
length_data = socket.recv(4)
if len(length_data) < 4:
return None # 连接已关闭
# 解析长度
length = struct.unpack('>I', length_data)[0]
# 接收指定长度的消息体
chunks = []
bytes_received = 0
while bytes_received < length:
chunk = socket.recv(min(length - bytes_received, 2048))
if not chunk:
raise ConnectionError("连接中断")
chunks.append(chunk)
bytes_received += len(chunk)
return b''.join(chunks).decode('utf-8')网络框架中的粘包处理
现代网络框架如Netty内置了强大的粘包处理能力,通过可插拔的编解码器简化了消息帧化处理。
java
// Netty中使用LengthFieldBasedFrameDecoder处理粘包
public class NettyServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
// 添加长度域解码器解决粘包问题
// 参数说明:最大帧长度、长度域偏移量、长度域长度
pipeline.addLast(new LengthFieldBasedFrameDecoder(
1024 * 1024, // 最大帧长度:1MB
0, // 长度域偏移量
4, // 长度域长度:4字节
0, // 长度调整值
4 // 需要跳过的字节数
));
// 添加字符串解码器
pipeline.addLast(new StringDecoder(CharsetUtil.UTF_8));
// 添加业务处理器
pipeline.addLast(new BusinessHandler());
}
}Netty的Pipeline机制将粘包处理与业务逻辑解耦,开发者可以专注于业务实现,而将协议解析交给专门的Handler。这种设计体现了关注点分离原则,提高了代码的可维护性和复用性。
现代协议对消息边界的处理
HTTP/2与gRPC的帧化机制
现代应用层协议如HTTP/2和基于它的gRPC,在设计之初就考虑了消息边界问题。HTTP/2引入了二进制分帧层,将消息分解为独立的帧,每个帧包含长度字段和类型标识。
gRPC作为云原生时代的通信标准,基于HTTP/2构建,天然继承了其帧化机制。gRPC消息使用长度前缀编码:每个消息前都有一个压缩标志位和4字节的消息长度字段。
java
// gRPC协议中的长度前缀消息格式
message LengthPrefixedMessage {
// 1字节压缩标志(0表示未压缩,1表示压缩)
// 4字节消息长度(大端序)
// 实际消息内容
}
// gRPC请求示例
HEADERS (flags = END_HEADERS)
:method = POST
:scheme = http
:path = /demo.hello.Greeter/SayHello
content-type = application/grpc
DATA (flags = END_STREAM)
<Length-Prefixed Message> // 包含长度前缀的gRPC消息WebSocket的消息帧化
WebSocket协议同样需要处理消息边界问题。与TCP的字节流不同,WebSocket是面向消息的协议,每个消息由一个或多个帧组成。WebSocket帧头包含操作码 和载荷长度字段,明确标识了消息边界和类型。
javascript
// WebSocket帧结构
// 0 1 2 3
// 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
// +-+-+-+-+-------+-+-------------+-------------------------------+
// |F|R|R|R| opcode|M| Payload len | Extended payload length |
// |I|S|S|S| (4) |A| (7) | (16/64) |
// |N|V|V|V| |S| | (if payload len==126/127) |
// | |1|2|3| |K| | |
// +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
// | Extended payload length continued, if payload len == 127 |
// + - - - - - - - - - - - - - - - +-------------------------------+
// | |Masking-key, if MASK set to 1 |
// +-------------------------------+-------------------------------+
// | Masking-key (continued) | Payload Data |
// +-------------------------------- - - - - - - - - - - - - - - - +
// : Payload Data continued ... :
// + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
// | Payload Data continued ... |
// +---------------------------------------------------------------+架构师视角:协议选择与系统设计
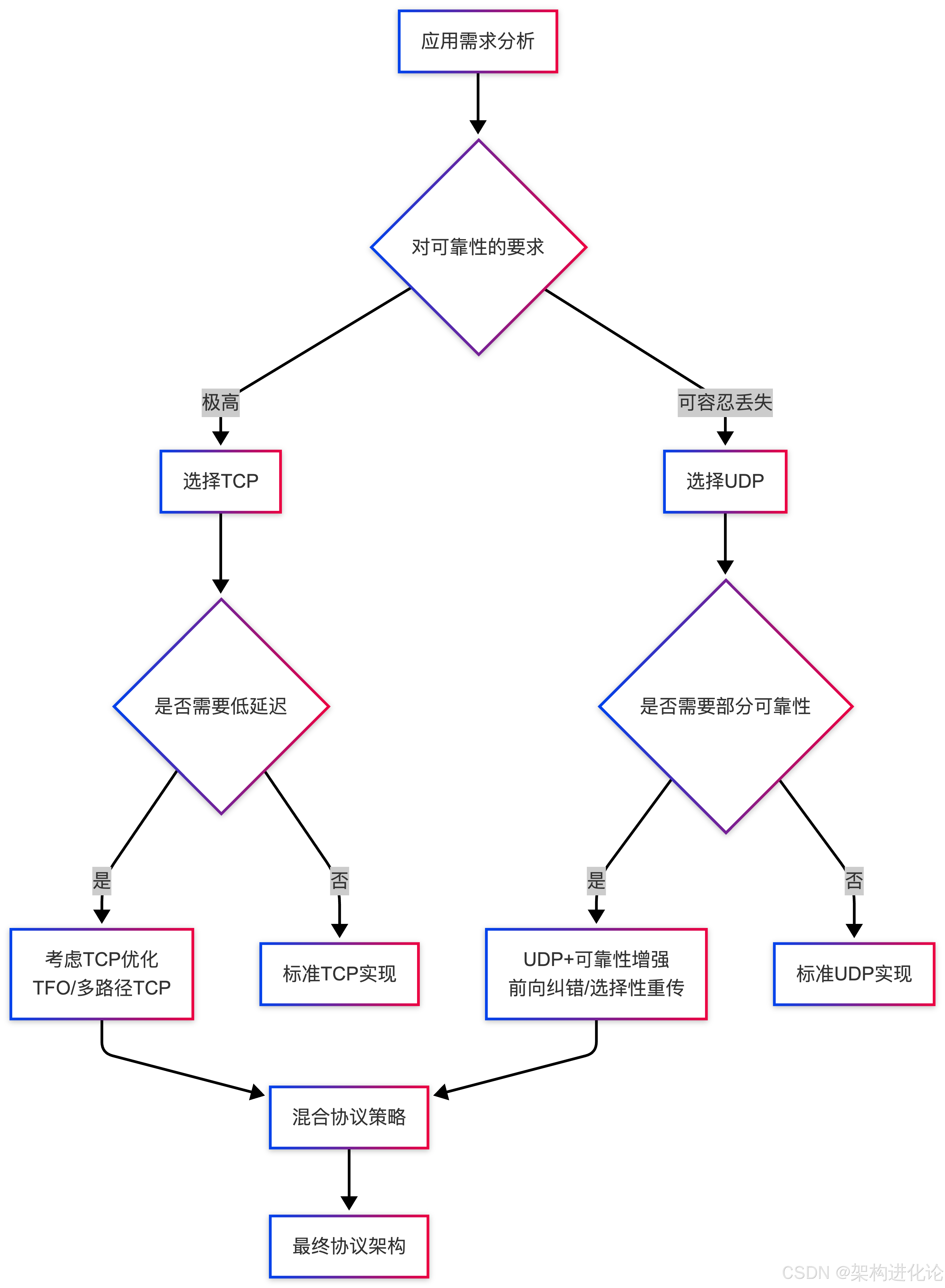
TCP与UDP的选择考量
作为架构师,在TCP和UDP之间的选择需要基于应用需求进行全面权衡:
| 考量维度 | TCP优势场景 | UDP优势场景 |
|---|---|---|
| 可靠性 | 要求数据完整到达(文件传输、HTTP) | 容忍数据丢失(实时视频、语音) |
| 延迟 | 可接受较高延迟以换取可靠性 | 要求最低延迟(在线游戏、DNS查询) |
| 连接开销 | 长期连接、多次交互(数据库连接) | 短时连接、一次性查询(DHCP请求) |
| 流量控制 | 需要防止发送方淹没接收方 | 发送速率优先(音视频广播) |
| 消息边界 | 需应用层处理消息边界 | 协议天然维护消息边界 |
实时音视频系统是UDP的典型应用场景。在这些系统中,丢失少量数据包对用户体验影响有限,但延迟和卡顿是难以接受的。UDP的无连接特性避免了TCP重传机制引入的延迟,提高了实时性。
金融交易系统则倾向于使用TCP。每一笔交易数据都必须可靠传输,延迟通常在可接受范围内。TCP的可靠性和有序性保证了交易数据的完整性和一致性。
混合策略与协议创新
在实际系统设计中,常常采用混合策略或协议创新来解决特定问题:
-
TCP快速打开(TFO):减少TCP握手延迟,在握手过程中携带应用数据。
-
UDP可靠性增强:在UDP基础上实现选择性重传、前向纠错等机制,在可靠性和延迟间取得平衡。
-
多路径传输:同时使用多条网络路径传输数据,提高吞吐量和可靠性。
总结与展望
TCP粘包现象是字节流传输模型的自然结果,而非协议缺陷。这一设计选择反映了TCP协议的可靠性优先哲学,适合需要严格数据完整性的应用场景。UDP作为TCP的补充,采用面向消息的数据报模型,天然维护消息边界,适合实时性要求高的应用。
从历史演进看,传输层协议的设计始终在可靠性与实时性 、复杂性与简单性之间权衡。现代协议如HTTP/2、gRPC、QUIC等,在更高层次上重新思考了消息边界和传输效率的问题,提供了更优的解决方案。
作为架构师,理解这些底层机制不仅有助于解决粘包等具体问题,更重要的是培养协议感知的系统设计能力。在微服务、云原生时代,网络通信性能往往是系统瓶颈所在,深入理解传输层特性,合理选择与设计通信协议,是构建高性能分布式系统的关键。
未来,随着5G、物联网、边缘计算等新技术的发展,网络环境将更加复杂多样,对传输层协议也会提出新的要求。我们可能会看到更多上下文感知的传输协议,能够根据应用需求、网络状况动态调整传输策略,在可靠性、实时性和效率之间实现更精细的平衡。