目录
[1. 主动更新(写时更新)](#1. 主动更新(写时更新))
[优势 ✅](#优势 ✅)
[劣势 ❌](#劣势 ❌)
[2. 读时更新(延迟加载/Cache-Aside)](#2. 读时更新(延迟加载/Cache-Aside))
[优势 ✅](#优势 ✅)
[劣势 ❌](#劣势 ❌)
[3. 定时任务(定期刷新)](#3. 定时任务(定期刷新))
[劣势 ❌](#劣势 ❌)
[1. 高一致性要求场景(银行余额、库存)](#1. 高一致性要求场景(银行余额、库存))
[2. 读多写少场景(商品信息、文章内容)](#2. 读多写少场景(商品信息、文章内容))
[3. 变化不频繁场景(配置信息、字典数据)](#3. 变化不频繁场景(配置信息、字典数据))
[4. 混合策略(电商系统)](#4. 混合策略(电商系统))
三种缓存更新策略对比分析
对比表格
| 特性 | 主动更新(写时更新) | 读时更新(延迟加载) | 定时任务(定期刷新) |
|---|---|---|---|
| 数据一致性 | 高(写后立即同步) | 较低(有延迟窗口) | 低(取决于刷新周期) |
| 实时性 | 实时 | 延迟(下次读取时) | 周期性延迟 |
| 实现复杂度 | 中等(需事务管理) | 低(最简单) | 中等(调度管理) |
| 性能影响 | 写操作变慢 | 读操作可能变慢 | 对业务操作影响小 |
| 网络开销 | 每次写都有缓存操作 | 缓存未命中时有开销 | 固定周期开销 |
| 适用场景 | 一致性要求高的业务 | 读多写少,允许延迟 | 数据变化不频繁 |
1. 主动更新(写时更新)
实现方式
java
@Transactional
public void updateProduct(Product product) {
// 1. 更新数据库
productDao.update(product);
// 2. 同步更新缓存(推荐先删后更)
redisTemplate.delete("product:" + product.getId());
// 或直接更新
// redisTemplate.opsForValue().set("product:" + product.getId(), product);
}优势 ✅
-
强一致性:数据库和缓存几乎同时更新
-
实时性好:用户总是能看到最新数据
-
缓存命中率高:热门数据一直在缓存中
-
读性能最优:读操作直接从缓存获取,无延迟
劣势 ❌
-
写性能下降:每次写操作都需要额外的缓存操作
-
实现复杂:
java@Transactional public void updateWithRetry(Product product) { // 数据库更新 productDao.update(product); // 缓存更新(需要重试机制) int retryCount = 0; while (retryCount < 3) { try { redisTemplate.opsForValue().set( "product:" + product.getId(), product, 30, TimeUnit.MINUTES ); break; } catch (Exception e) { retryCount++; if (retryCount == 3) { // 记录日志,发送告警 log.error("更新缓存失败", e); // 设置短过期时间,让缓存尽快失效 redisTemplate.opsForValue().set( "product:" + product.getId(), product, 1, TimeUnit.MINUTES ); } } } } -
缓存穿透风险:如果缓存更新失败,可能一直读到旧数据
-
事务问题:
java
// 错误示例:顺序问题导致的不一致
public void updateWrong(Product product) {
// 先更新缓存
redisTemplate.opsForValue().set("product:" + product.getId(), product);
// 数据库更新失败,但缓存已更新(数据不一致)
productDao.update(product); // 可能失败
}2. 读时更新(延迟加载/Cache-Aside)
实现方式
java
public Product getProduct(Long id) {
// 1. 先查缓存
String cacheKey = "product:" + id;
Product product = (Product) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存不存在则查数据库
if (product == null) {
product = productDao.findById(id);
if (product != null) {
// 3. 异步或同步写入缓存
redisTemplate.opsForValue().set(
cacheKey,
product,
calculateTTL(product), // 动态TTL
TimeUnit.SECONDS
);
}
}
return product;
}
// 写操作只更新数据库
public void updateProduct(Product product) {
productDao.update(product);
// 可选择删除缓存,也可不删(等过期)
// redisTemplate.delete("product:" + product.getId());
}优势 ✅
-
实现简单:逻辑清晰,易于理解和维护
-
写性能好:写操作只操作数据库
-
资源利用率高:只有被请求的数据才会进入缓存
-
容错性好:缓存服务故障不影响核心业务
-
避免冷数据占用内存:只缓存热点数据
劣势 ❌
- 数据不一致窗口:
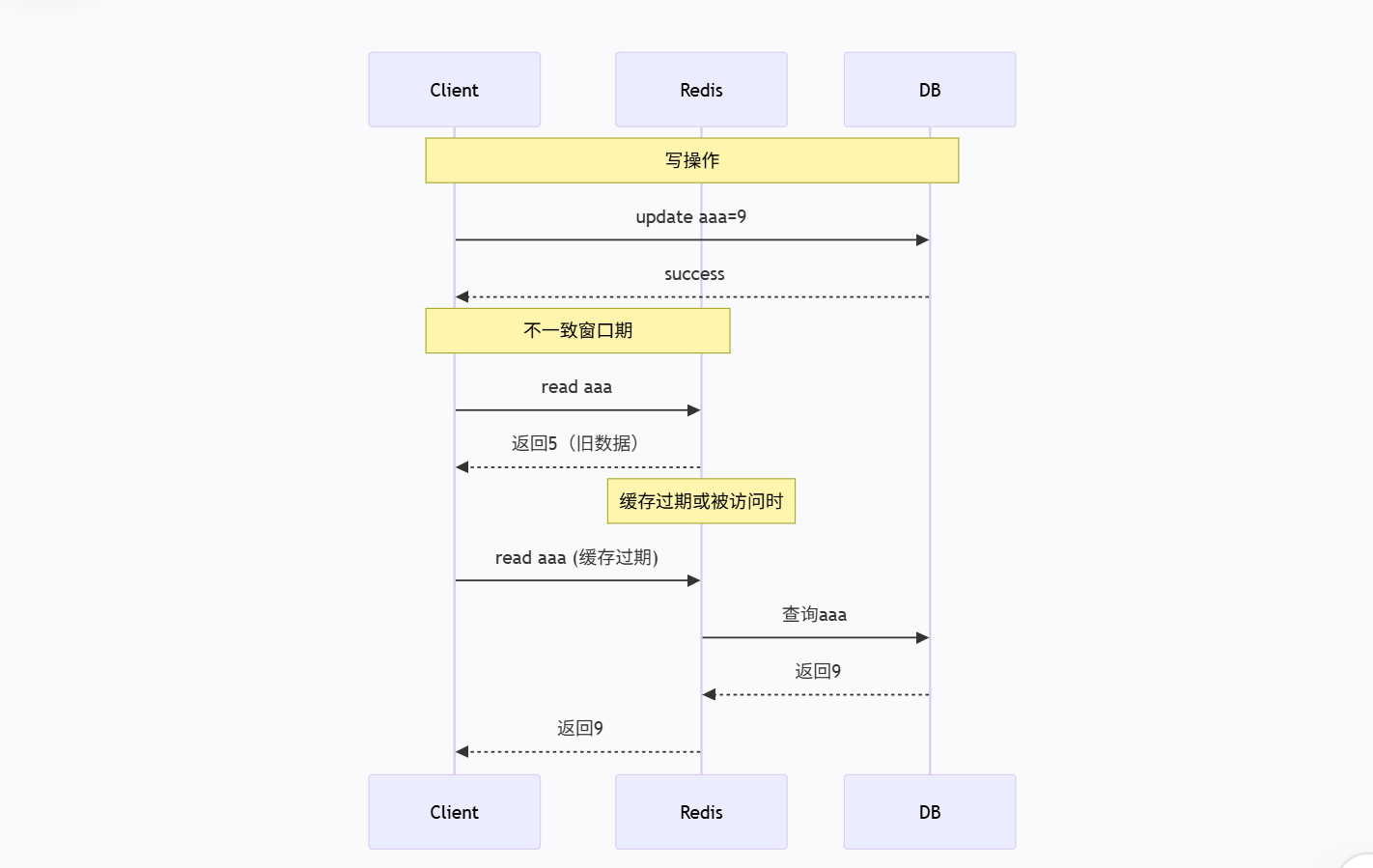
2. 首次读取延迟:缓存未命中时需要查库并写缓存
3. 缓存击穿风险:热点数据失效时大量请求打到数据库
java
// 解决方案:加分布式锁
public Product getProductWithLock(Long id) {
String cacheKey = "product:" + id;
Product product = (Product) redisTemplate.opsForValue().get(cacheKey);
if (product == null) {
String lockKey = "lock:product:" + id;
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (locked) {
try {
// 双重检查
product = (Product) redisTemplate.opsForValue().get(cacheKey);
if (product == null) {
product = productDao.findById(id);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey, product, 30, TimeUnit.MINUTES);
}
}
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 等待重试或直接查库
Thread.sleep(50);
return getProductWithLock(id);
}
}
return product;
}3. 定时任务(定期刷新)
实现方式
java
@Component
public class CacheRefreshScheduler {
@Autowired
private ProductDao productDao;
@Autowired
private RedisTemplate<String, Product> redisTemplate;
// 每5分钟刷新一次热门商品
@Scheduled(fixedRate = 5 * 60 * 1000)
public void refreshHotProducts() {
List<Long> hotProductIds = getHotProductIds(); // 获取热门商品ID
for (Long productId : hotProductIds) {
Product product = productDao.findById(productId);
if (product != null) {
redisTemplate.opsForValue().set(
"product:" + productId,
product,
10, TimeUnit.MINUTES // TTL > 刷新间隔
);
}
}
}
// 每小时全量刷新一次
@Scheduled(cron = "0 0 * * * ?")
public void refreshAllProducts() {
List<Product> allProducts = productDao.findAll();
for (Product product : allProducts) {
redisTemplate.opsForValue().set(
"product:" + product.getId(),
product,
2, TimeUnit.HOURS
);
}
}
}-
避免缓存雪崩:可控制刷新时间点
-
适合预热:系统启动时或高峰前预热数据
劣势 ❌
-
数据实时性差:最长有一个周期的不一致
-
资源浪费:可能刷新不常访问的数据
-
实现复杂:
-
需要调度框架(Quartz、Spring Scheduler)
-
需要监控任务执行情况
-
-
硬编码问题:刷新策略难以动态调整
场景选择建议
1. 高一致性要求场景(银行余额、库存)
- 推荐:主动更新 + 读时更新(双保险)
2. 读多写少场景(商品信息、文章内容)
- 推荐:读时更新 + 较长的TTL
3. 变化不频繁场景(配置信息、字典数据)
- 推荐:定时任务 + 长TTL
4. 混合策略(电商系统)
总结对比
| 考量维度 | 推荐策略 | 原因 |
|---|---|---|
| 数据强一致性 | 主动更新 | 实时同步,一致性最高 |
| 系统性能 | 读时更新 | 写操作轻量,读操作缓存命中率可通过优化提高 |
| 实现简单 | 读时更新 | 逻辑清晰,代码复杂度低 |
| 资源利用率 | 定时任务 | 可精准控制刷新范围,避免冷数据占用内存 |
| 综合方案 | 混合策略 | 根据业务特点对不同数据使用不同策略 |
实际建议 :大多数互联网应用采用 读时更新为主,结合主动删除 的策略,在一致性要求极高的场景下补充主动更新机制,并通过消息队列或定时任务做兜底刷新。