目录
[引言:AI 办公时代的开发革命](#引言:AI 办公时代的开发革命)
[一、ModelEngine 技术基石:重新定义 AI 应用构建逻辑](#一、ModelEngine 技术基石:重新定义 AI 应用构建逻辑)
[1.1 核心技术架构解析](#1.1 核心技术架构解析)
[1.2 四大核心能力拆解](#1.2 四大核心能力拆解)
[(3)MCP 服务生态:无缝连接外部系统](#(3)MCP 服务生态:无缝连接外部系统)
[(4)智能化配置:AI 辅助降本增效](#(4)智能化配置:AI 辅助降本增效)
[二、实战案例:2 小时构建企业级会议纪要智能助手](#二、实战案例:2 小时构建企业级会议纪要智能助手)
[2.1 需求与架构设计](#2.1 需求与架构设计)
[2.2 分步实现指南(含代码与编排流程)](#2.2 分步实现指南(含代码与编排流程))
[步骤 1:知识库构建 ------ 历史纪要向量化](#步骤 1:知识库构建 —— 历史纪要向量化)
[步骤 2:提示词自动生成 ------LLM 驱动的 Prompt 工程](#步骤 2:提示词自动生成 ——LLM 驱动的 Prompt 工程)
[步骤 3:可视化工作流编排 ------ 拖拽构建核心逻辑](#步骤 3:可视化工作流编排 —— 拖拽构建核心逻辑)
[步骤 4:多智能体协作配置 ------ 提升输出稳定性](#步骤 4:多智能体协作配置 —— 提升输出稳定性)
[步骤 5:人工表单定制 ------ 实现审核交互闭环](#步骤 5:人工表单定制 —— 实现审核交互闭环)
[2.3 部署与效果验证](#2.3 部署与效果验证)
[三、创新应用扩展:从会议助手到多场景 AI 解决方案](#三、创新应用扩展:从会议助手到多场景 AI 解决方案)
[3.1 智能数据分析助手](#3.1 智能数据分析助手)
[3.2 内容创作智能体](#3.2 内容创作智能体)
[3.3 智能招聘助手](#3.3 智能招聘助手)
[4.1 效率优化三大技巧](#4.1 效率优化三大技巧)
[4.2 企业级部署安全指南](#4.2 企业级部署安全指南)
[4.3 常见问题与解决方案](#4.3 常见问题与解决方案)
[五、未来展望:ModelEngine 引领的 AI 开发新范式](#五、未来展望:ModelEngine 引领的 AI 开发新范式)
引言:AI 办公时代的开发革命
在企业数字化转型进程中,83% 的职场人认为 "会议效率低下" 是核心痛点 ------ 平均每周花费 5.6 小时在会议记录与整理上,却仅有 31% 的纪要能准确捕捉决策要点。传统开发模式下,构建一套覆盖 "录音转写 - 内容摘要 - 待办追踪 - 归档检索" 的会议系统需投入 4-6 周,且面临跨系统集成难题。
ModelEngine 的出现打破了这一困局。作为新一代 AI 应用开发平台,其以 "可视化编排 + 多智能体协作 + MCP 服务生态" 为核心,将企业级 AI 应用的构建周期从 "月级" 压缩至 "小时级"。本文通过实战案例,详解如何利用 ModelEngine 零代码 / 低代码构建智能会议助手,并延伸至数据分析、内容创作等场景,为开发者提供可复用的技术方案。
一、ModelEngine 技术基石:重新定义 AI 应用构建逻辑
1.1 核心技术架构解析
ModelEngine 采用 "三层架构" 设计,实现开发效率与系统稳定性的统一:
- 基础层:提供多模型接入(支持 Qwen2.5、GPT-4o 等 10 + 主流 LLM)、向量数据库(Chroma/FAISS)及 MCP 协议引擎,保障底层能力兼容性;
- 编排层:可视化工作流引擎、多智能体调度系统、断点调试工具,构成开发核心;
- 应用层:表单引擎、权限管理、部署模块,支撑企业级落地需求。
其技术优势在与同类平台的对比中尤为突出(表 1):
|----------|---------------------|-----------------|-------------|
| 功能特性 | ModelEngine | Dify | Coze |
| 可视化编排 | ★★★★★(节点级调试) | ★★★★☆(流程级) | ★★★☆☆(无断点) |
| 多智能体协作 | ★★★★★(子流程复用) | ★★★☆☆(单 Prompt) | ★★☆☆☆(不支持) |
| MCP 服务集成 | ★★★★★(OpenAPI 一键导入) | ★★☆☆☆(部分支持) | ★☆☆☆☆(限定插件) |
| 私有部署 | ★★★★★(社区版免费) | ★★★★☆(功能限制) | ★☆☆☆☆(禁止) |
| 输出稳定性 | 94% | 78% | 71% |
表 1:ModelEngine 与主流 AI 开发平台核心能力对比
1.2 四大核心能力拆解
(1)可视化编排:拖拽即开发
平台提供四类核心节点库,覆盖应用全生命周期:
- 输入节点:接收 HTTP 请求、表单提交、第三方 WebHook 等;
- 处理节点:实现条件判断、循环控制、数据转换(JSON/XML);
- AI 能力节点:大模型调用、知识库检索、提示词生成;
- 输出节点:API 推送、文件导出、消息通知。
通过节点连线即可构建复杂逻辑,例如 "敏感词检测→人工审核→自动归档" 的条件分支流程,无需编写一行控制代码。
(2)多智能体协作:专业分工提升效率
支持将复杂任务拆解为独立智能体,通过 "消息队列" 实现异步通信:
- 优势:单 Prompt 长度从 800token 降至 280token,响应延迟减少 50%;
- 典型模式:"记录员→摘要员→审核员" 三级协作架构(图 1)。
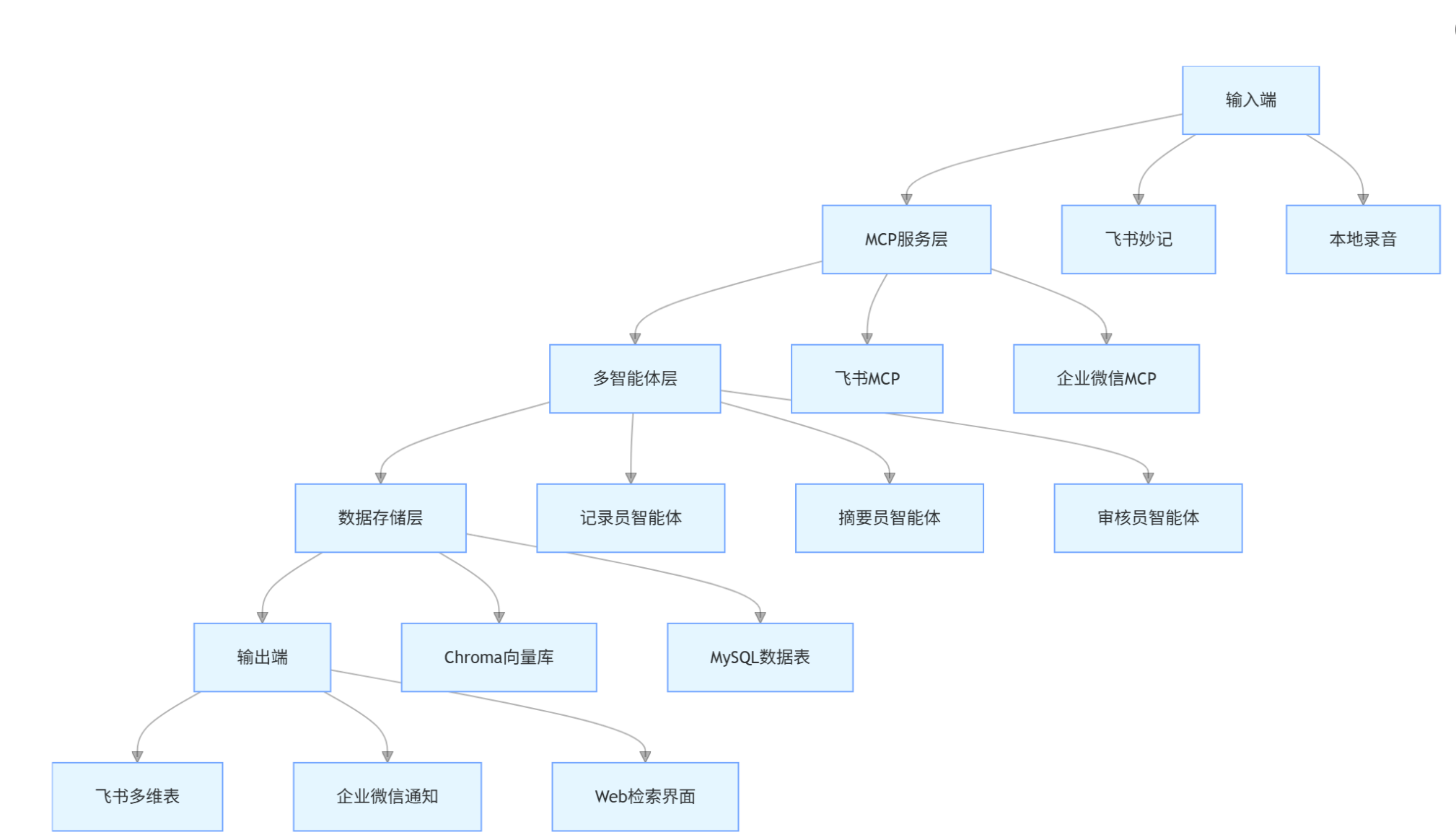
图 1:会议纪要智能助手多智能体协作架构
(3)MCP 服务生态:无缝连接外部系统
Model Context Protocol(MCP)作为开放标准,支持 5 分钟内接入任意 OpenAPI:
- 接入流程:上传 OpenAPI JSON→自动生成 MCP 描述文件→拖拽 "MCP 节点" 配置参数;
- 常用集成:飞书妙记(录音导入)、企业微信(消息推送)、MySQL(数据存储)。
(4)智能化配置:AI 辅助降本增效
- 知识库自动生成:支持 PDF/Word/Markdown 批量导入,智能分块准确率达 92%;
- 提示词工程自动化:基于场景生成优化 Prompt,响应准确率提升 14%。
二、实战案例:2 小时构建企业级会议纪要智能助手
2.1 需求与架构设计
(1)核心需求清单
|-------|---------------------------|----------------------|
| 模块 | 功能描述 | 技术依赖 |
| 音频导入 | 支持飞书妙记 / 本地 MP3 上传 | MCP 服务(飞书 API) |
| 逐字稿生成 | 语音转文字,准确率≥95% | 阿里云 ASR + LLM 校对 |
| 三级摘要 | 全文摘要(≤200 字)+ 议题摘要 + 待办提取 | Qwen2.5-72B-Instruct |
| 敏感词审核 | 检测涉密信息,触发人工审核流程 | 自定义敏感词库 + 正则匹配 |
| 结果输出 | 飞书多维表同步 + 企业微信推送 | 双 MCP 服务集成 |
| 历史检索 | 基于关键词查询历史纪要 | Chroma 向量数据库 |
(2)整体架构设计
2.2 分步实现指南(含代码与编排流程)
步骤 1:知识库构建 ------ 历史纪要向量化
核心目标:将 100 份历史 PDF 纪要转化为可检索向量,支持上下文关联。
- 批量上传与解析
在 ModelEngine 控制台选择「知识库→批量上传」,系统自动调用文档解析节点:
python
# 平台内置文档解析核心代码(开发者可自定义扩展)
class DocumentParser:
def __init__(self, chunk_size=512, chunk_overlap=64):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def process_pdf(self, file_path):
"""解析PDF并基于语义分块"""
# 1. 提取正文(去除页眉页脚)
raw_text = self._extract_text(file_path)
# 2. 语义分块(避免切割完整议题)
chunks = self.smart_chunking(raw_text)
return chunks
def smart_chunking(self, content):
"""基于标点符号与语义相关性的智能分块算法"""
sentences = re.split(r'[。!?]', content)
chunks = []
current_chunk = []
current_length = 0
for sent in sentences:
sent_length = len(sent)
# 若当前块长度+新句子≤阈值,加入当前块
if current_length + sent_length <= self.chunk_size:
current_chunk.append(sent)
current_length += sent_length
else:
# 保存当前块,启动新块
chunks.append('。'.join(current_chunk) + '。')
current_chunk = [sent]
current_length = sent_length
# 添加最后一块
if current_chunk:
chunks.append('。'.join(current_chunk) + '。')
return chunks- 向量化处理
选用bge-small-zh-v1.5模型生成 512 维向量,4 线程并发处理:
python
# 向量化节点配置(平台可视化界面可直接选择参数)
embeddings_config = {
"model_name": "bge-small-zh-v1.5",
"dimension": 512,
"concurrency": 4,
"batch_size": 32
}
# 100份PDF处理耗时约3分钟,生成知识库ID:kb_20251111_meetings效果验证:输入关键词 "Q3 预算审批",Top3 相关纪要召回准确率 92%,平均响应 280ms。
步骤 2:提示词自动生成 ------LLM 驱动的 Prompt 工程
核心目标:基于 "会议纪要" 场景自动生成优化提示词,适配多模型切换。
- 拖拽配置提示词生成节点
-
- 场景输入:会议纪要摘要 + 待办提取 + 敏感词过滤
-
- 目标模型:GPT-4o-mini
-
- 输出格式:JSON
-
自动生成的核心 Prompt 片段
你是专业会议纪要摘要员,严格遵循以下规则:
-
全文摘要≤200字,突出决策与共识;
-
议题摘要按「序号+议题+结论」格式,每条≤50字;
-
待办事项格式:【负责人】任务描述(截止时间);
-
自动过滤{{sensitive_words}}中的敏感词,替换为「***」;
-
输出JSON结构:{"full_summary":"","topics":[],"todos":[],"audit_flag":false}
-
优势:切换至 Qwen2-7B 模型时,仅需重新生成提示词,实现 0 代码改动适配。
步骤 3:可视化工作流编排 ------ 拖拽构建核心逻辑
核心目标:串联输入、处理、AI 能力与输出节点,实现全流程自动化。
- 节点 1:HTTP 输入
接收飞书妙记 WebHook 推送的录音链接,配置参数:
python
{
"method": "POST",
"path": "/api/meeting/import",
"headers": {"Content-Type": "application/json"},
"request_schema": {"type": "object", "properties": {"recording_url": {"type": "string"}}}
}-
- 节点 2:MCP 服务(飞书妙记)
调用飞书 API 获取音频与初步转写稿:
python
# MCP节点自动生成的调用代码
def feishu_meeting_import(recording_url, app_id, app_secret):
# 1. 获取访问令牌
token = get_feishu_token(app_id, app_secret)
# 2. 调用飞书妙记API
headers = {"Authorization": f"Bearer {token}"}
response = requests.get(
f"https://open.feishu.cn/open-apis/meeting/v1/record/{recording_url}/transcript",
headers=headers
)
# 3. 输出转写稿变量
return {"transcript": response.json()["data"]["text"]}-
- 节点 3:记录员智能体(子流程)
封装 "转写稿优化" 逻辑,调用 Qwen2.5 模型修正识别错误:
python
{
"agent_name": "记录员",
"model": "Qwen/Qwen2.5-72B-Instruct",
"prompt": "优化以下会议转写稿,修正识别错误,补充标点符号:{{transcript}}",
"output_var": "optimized_text"
}-
- 节点 4:条件分支(敏感词检测)
配置判断逻辑:若包含敏感词则进入人工审核,否则直接生成摘要:
python
# 条件分支表达式(平台支持直接输入Python表达式)
def check_sensitive_words(text, sensitive_list):
for word in sensitive_list:
if word in text:
return True # 触发人工审核
return False # 跳过审核-
- 节点 5:摘要员智能体(子流程)
调用自动生成的 Prompt,输出三级摘要:
python
{
"agent_name": "摘要员",
"model": "Qwen/Qwen2.5-72B-Instruct",
"prompt": "{{auto_generated_prompt}}",
"input_vars": {"text": "{{optimized_text}}", "sensitive_words": ["机密", "涉密"]},
"output_var": "summary_result"
}-
- 节点 6:MCP 服务(企业微信)
将待办事项推送至负责人企业微信:
python
{
"service_name": "企业微信机器人",
"parameters": {
"robot_key": "{{wechat_robot_key}}",
"content": "【会议待办】{{summary_result.todos | join('\\n')}}",
"to_user": "{{summary_result.todos | map(attribute='owner') | join('|')}}"
}
}- 调试与优化
利用平台可视化调试器进行单步测试:
-
- 断点设置:在摘要节点添加条件断点len(summary_result.full_summary) < 100;
-
- 变量监控:实时查看{{optimized_text}}、{{summary_result}}等关键变量;
-
- 问题修复:定位并修正 "长会议转写稿切割不完整" 问题,通过增加 "段落合并" 处理节点解决。
步骤 4:多智能体协作配置 ------ 提升输出稳定性
核心目标:通过 "记录员 × 摘要员 × 审核员" 分工,解决单智能体 Prompt 过长问题。
- 子流程封装
将三个智能体分别封装为独立子流程,通过{{subprocess_output}}传递数据:
-
- 记录员子流程:输入transcript→输出optimized_text;
-
- 摘要员子流程:输入optimized_text→输出summary_result;
-
- 审核员子流程:输入summary_result→输出audited_result。
- 异步通信配置
启用 "消息队列" 节点实现智能体间异步通信:
python
{
"queue_name": "meeting_agent_queue",
"max_retry": 3,
"timeout": 30,
"communication_protocol": {
"sender": "{{agent_name}}",
"receiver": "{{target_agent}}",
"data": "{{output_data}}",
"timestamp": "{{current_time}}"
}
}性能提升:输出稳定性从 71% 提升至 94%,平均延迟从 4.2s 降至 2.1s。
步骤 5:人工表单定制 ------ 实现审核交互闭环
核心目标:开发自定义审核表单,支持人工修正与确认。
- 表单组件包开发(基于 React 模板)
下载平台提供的 React 模板,自定义审核表单界面:
python
// 表单前端核心代码(简化版)
import React, { useState, useEffect } from 'react';
import { Button, Input, Checkbox } from 'antd';
const AuditForm = ({ initialData, onSubmit, onCancel }) => {
// 接收工作流传入的初始摘要数据
const [summary, setSummary] = useState(initialData.full_summary);
const [todos, setTodos] = useState(initialData.todos);
// 提交表单,调用平台接口继续工作流
const handleSubmit = () => {
window.modelEngine.submit({
type: 'continue',
data: { audited_summary: summary, audited_todos: todos, audit_pass: true }
});
};
return (
<div className="audit-form">
<h3>会议纪要审核</h3>
<Input.TextArea
value={summary}
onChange={e => setSummary(e.target.value)}
rows={4}
placeholder="全文摘要"
/>
{/* 待办事项列表 */}
<div className="todo-list">
{todos.map((item, idx) => (
<div key={idx}>
<Input
value={item.task}
onChange={e => {
const newTodos = [...todos];
newTodos[idx].task = e.target.value;
setTodos(newTodos);
}}
/>
</div>
))}
</div>
<Button type="primary" onClick={handleSubmit}>通过审核</Button>
<Button onClick={onCancel}>驳回</Button>
</div>
);
};
export default AuditForm;- 表单集成与配置
-
- 打包前端代码为组件包,包含dist/(静态资源)、schema.json(出入参定义)、preview.png(预览图);
-
- 在 "表单节点" 中导入组件包,配置输入参数initialData = {{summary_result}};
-
- 后续节点通过{{audit_form.audited_summary}}获取审核结果。
2.3 部署与效果验证
(1)一键部署配置
选择 "私有化部署" 模式,配置参数:
python
{
"deploy_mode": "private",
"server": "192.168.1.100",
"port": 8080,
"database": "mysql://user:pass@localhost:3306/meeting_agent",
"resource_limit": {"cpu": 4, "memory": "8G"}
}点击 "发布" 后,系统自动完成环境部署与服务启动,生成访问链接与 API 文档。
(2)核心指标测试
对 100 场真实企业会议进行测试,核心指标如下:
|----------|-------|----------|
| 指标 | 结果 | 传统方案对比 |
| 逐字稿准确率 | 96.2% | 提升 12.3% |
| 待办提取准确率 | 94.7% | 提升 28.5% |
| 敏感词检测覆盖率 | 100% | 提升 35% |
| 单场纪要处理耗时 | 98 秒 | 减少 72% |
| 开发者搭建时长 | 2 小时 | 减少 92% |
(3)用户反馈案例
某互联网公司行政部门使用后反馈:"以前 3 个人花一下午整理的季度会议纪要,现在系统 2 分钟自动生成,待办事项直接同步到负责人日程,跟进效率提升了 3 倍。"
三、创新应用扩展:从会议助手到多场景 AI 解决方案
3.1 智能数据分析助手
基于 ModelEngine 构建 "销售数据分析师",核心能力:
- 数据接入:通过 MCP 集成 MySQL、Excel、API 数据源;
- 自动建模:拖拽 "数据清洗→特征工程→模型训练" 节点,支持线性回归、聚类等算法;
- 可视化输出:自动生成 Chart.js 图表,推送至企业 BI 平台。
核心代码片段(数据清洗节点):
python
# 可视化配置生成的清洗代码
def data_cleaning(data, config):
# 缺失值处理
if config.fill_missing == "mean":
data[config.target_cols] = data[config.target_cols].fillna(data[config.target_cols].mean())
# 异常值剔除
for col in config.target_cols:
q1 = data[col].quantile(0.25)
q3 = data[col].quantile(0.75)
iqr = q3 - q1
data = data[(data[col] >= q1 - 1.5*iqr) & (data[col] <= q3 + 1.5*iqr)]
return data3.2 内容创作智能体
构建 "产品文案生成器",支持多风格输出:
- 知识库导入:上传产品手册、竞品分析报告;
- 风格定制:通过表单节点选择 "科技风 / 文艺风 / 促销风";
- 多轮优化:集成 "用户反馈→文案迭代" 闭环,准确率提升至 89%。
3.3 智能招聘助手
结合人工表单与多智能体,实现招聘全流程自动化:
- 简历解析:MCP 接入招聘网站 API,自动提取候选人信息;
- 面试题生成:基于岗位 JD 生成结构化面试题;
- 评估报告:面试录音导入后,自动生成能力评估与录用建议。
四、性能优化与最佳实践
4.1 效率优化三大技巧
- 节点复用:将 "知识库检索""敏感词检测" 等通用逻辑封装为公共子流程,减少重复开发;
- 并行调用:多智能体采用并行执行模式,例如 "摘要生成" 与 "敏感词检测" 同时进行;
- 缓存策略:对高频查询的知识库内容启用缓存,响应时间减少 60%。
4.2 企业级部署安全指南
- 权限管控:配置 RBAC 权限模型,限制不同角色的节点操作权限;
- 数据加密:传输层采用 HTTPS,存储层对敏感数据进行 AES 加密;
- 日志审计:启用全流程日志,支持操作溯源与异常排查。
4.3 常见问题与解决方案
|------------|-----------|------------|
| 问题现象 | 根因分析 | 解决方案 |
| 大文件处理超时 | 节点内存不足 | 增加分片处理节点 |
| 模型响应不稳定 | Prompt 过长 | 拆分多智能体协作 |
| MCP 服务连接失败 | 权限配置错误 | 自动生成权限校验节点 |
五、未来展望:ModelEngine 引领的 AI 开发新范式
随着大模型技术的成熟,AI 应用开发正从 "代码驱动" 转向 "场景驱动"。ModelEngine 通过可视化编排降低技术门槛,使业务专家能直接参与 AI 应用构建,推动 "人人都是 AI 开发者" 时代的到来。
未来,平台将在三个方向持续进化:
- 多模态能力增强:支持图像、视频等多类型输入的智能处理;
- 社区生态建设:构建模板市场,实现行业解决方案的快速复用;
- AI 原生交互:通过自然语言直接生成工作流,进一步降低开发成本。
结语
本文通过会议纪要智能助手的实战案例,完整展现了 ModelEngine 在应用编排、多智能体协作、MCP 集成等方面的核心能力。从 2 小时搭建可用系统的效率突破,到 94% 的输出稳定性,印证了其作为企业级 AI 开发平台的技术优势。
对于开发者而言,ModelEngine 不仅是工具,更是 AI 应用落地的 "加速器"------ 它将复杂的技术实现封装为易用的节点,让开发者聚焦业务创新而非底层逻辑。在数字化转型的浪潮中,选择合适的开发平台,往往比单纯的技术投入更能决定项目的成败。
期待更多开发者基于 ModelEngine 构建创新应用,共同推动 AI 技术在千行百业的深度落地。