TL;DR
场景:想把 ES「为什么快/为什么占内存/为什么写入要 merge」讲清楚,必须下沉到 Lucene 的倒排索引与文件结构 结论:查询链路本质是 Term 查找(tim/tip + FST)→ postings 读取(doc 等)→ postings 合并(SkipList/跳跃) 产出:一套从概念到文件后缀、到数据结构选择、到查询执行的可复用讲解框架

版本矩阵
| 类型 | 版本/说明 | 状态 | 用途说明 |
|---|---|---|---|
| Lucene | 最新版本:10.3.2 | 文档核对(未实测) | 用于"Lucene 当前版本/年份"表述 |
| Elasticsearch | 9.2.2 已发布 | 文档核对(未实测) | 用于"ES 9.x 已进入主线"的表述 |
| ES 迁移路径 | 迁移到 9.0 需先到最后一个 8.x | 文档核对(未实测) | 用于"8→9 升级路径"提醒 |

Elasticsearch 数据结构
倒排索引
概念概述
倒排索引是全文检索的根基,理解了倒排索引之后才能算是入门了全文检索的领域,倒排索引的概念很简单,也很好理解。
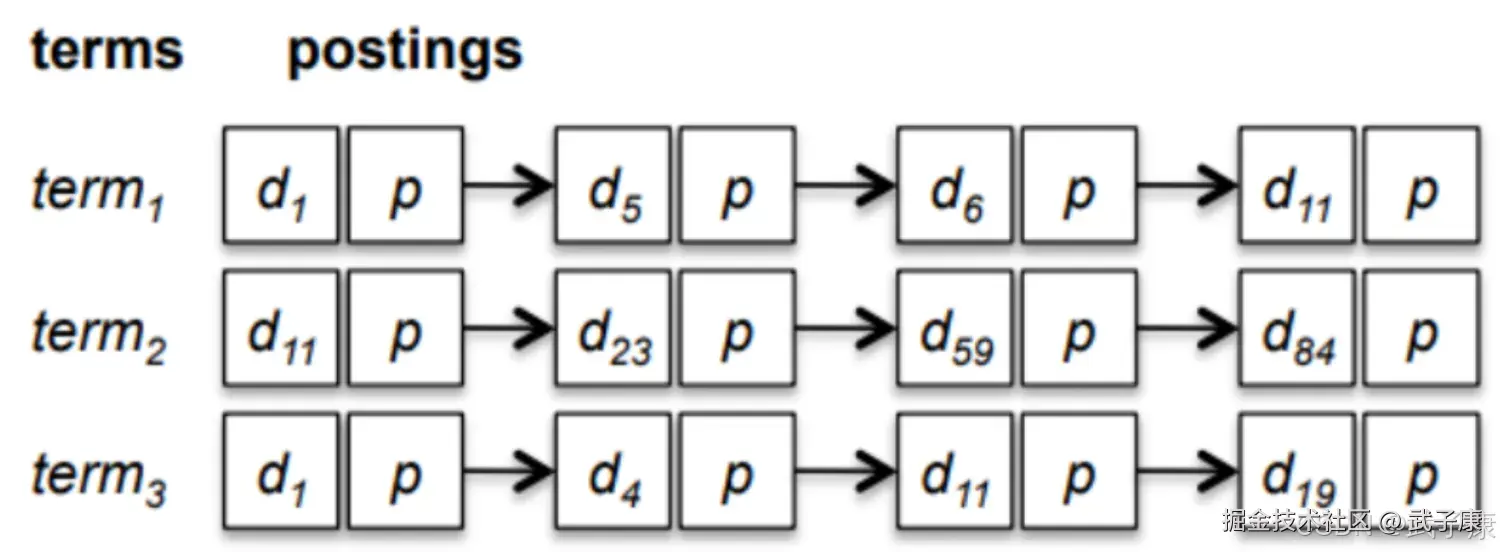 倒排索引(Inverted Index)是信息检索系统中常用的数据结构,它由两个核心部分组成:
倒排索引(Inverted Index)是信息检索系统中常用的数据结构,它由两个核心部分组成:
-
索引表(Terms Dictionary):
- 由文档集合中所有独立的关键词(Term)组成的有序列表
- 每个Term通常是经过分词和标准化处理后的结果(如转为小写、去除停用词等)
- 在实际实现中,索引表常采用B树或哈希表等数据结构来加速查找
- 示例:对于文档"the quick brown fox",处理后可能得到"quick", "brown", "fox"三个Term
-
倒排表(Posting List):
- 记录每个Term在哪些文档中出现的信息集合
- 每个Posting通常包含:
- 文档ID(DocID)
- 词频(Term Frequency)
- 位置信息(Position,用于短语查询)
- 示例:Term"fox"的Posting List可能是(doc1, 2, \[5,12), (doc3, 1, 7)],表示在doc1中出现2次(位置5和12),在doc3中出现1次(位置7)
在实际应用中(如Elasticsearch、Lucene等搜索引擎):
- 索引表通常存储在内存中以实现快速查找
- 倒排表采用压缩存储技术(如差值编码、位图等)来减少存储空间
- 还会维护额外的统计信息(如DF-文档频率)用于查询优化
如果存储一个倒排索引数据?选择哪种数据结构?
全文搜索引擎通常是需要存储大量的文本,不仅仅是Postings可能会是非常巨大,同样Dictionary的大小极可能也是非常庞大,真正的搜索引擎的倒排索引实现都极其复杂,因为它直接影响了搜索性能和功能。
 Lucene作为一款高性能的全文检索引擎库,其实现采用了多项先进技术来保证索引的高效性和可靠性。以下是其核心特性的详细说明:
Lucene作为一款高性能的全文检索引擎库,其实现采用了多项先进技术来保证索引的高效性和可靠性。以下是其核心特性的详细说明:
- 索引持久化机制:
- 采用分段(segment)存储策略,每个segment都是一个独立的倒排索引
- 支持将索引数据序列化为二进制格式存储在磁盘上
- 使用特殊的文件格式(如.fdt, .fdx等)组织索引数据
- 支持索引压缩以减少存储空间占用
- 高性能写入设计:
- 采用写入缓冲机制,先在内存中构建索引
- 定期将内存中的索引flush到磁盘形成新的segment
- 支持近实时的NRT(Near Real-Time)搜索
- 通过合并(merge)策略优化segment数量
- 核心数据结构与算法:
- 使用FST(Finite State Transducer)实现高效词典查找
- 采用跳表(SkipList)加速倒排链的遍历
- 实现基于BM25的评分算法
- 支持多种查询优化技术,如查询重写和缓存
- 实际应用场景:
- 电商平台的商品搜索(如Amazon)
- 企业文档管理系统
- 日志分析系统(如ELK Stack)
- 社交媒体的内容检索
Lucene通过这种精心设计的架构,在保证数据持久化的同时,实现了接近内存级别的搜索性能,使其成为众多商业搜索系统的基础引擎。
Lucene索引文件分析
Lucene 是一个基于 Java 的开源全文检索库,由 Doug Cutting 于 1999 年创建。Lucene 的核心功能是为应用程序提供高效的文本索引和搜索能力,它可以帮助开发者构建快速、可扩展的全文搜索功能。Lucene 本身是一个低级库,并不提供图形界面或高级应用功能,它更多是作为一个底层工具被集成到其他系统或框架中。
-
索引(Index): 索引是 Lucene 的核心组件之一,它是为了加速搜索过程而创建的数据结构。Lucene 会将文档中的文本分解为称为 "倒排索引"(inverted index)的形式。倒排索引类似于书的索引页,它列出了每个关键字在文档中的位置。这样,当用户搜索特定的词或短语时,Lucene 可以快速查找到包含该词的文档。
-
文档(Document): 在 Lucene 中,文档是搜索和索引的基本单元。每个文档由若干字段(Field)组成,字段可以包含不同类型的数据,比如标题、内容、日期等。文档在 Lucene 中通常与数据库中的一条记录相对应。
-
字段(Field): 字段是文档的组成部分,每个字段可以存储不同类型的数据,比如字符串、数字、日期等。字段可以指定是否被索引,是否被存储,以及是否可以被搜索等。
-
分词器(Analyzer): 分词器负责将输入的文本分解为词汇单元(Token),这些词汇单元是 Lucene 用来索引和搜索的基础。例如,对于中文文本,分词器需要将连续的字符切分为有意义的词汇;对于英文文本,它会移除标点符号、转换大小写等。不同的语言和需求可能需要不同的分词器。
-
查询(Query): Lucene 提供了多种类型的查询(Query),允许用户构建复杂的搜索逻辑,比如布尔查询(Boolean Query)、短语查询(Phrase Query)、范围查询(Range Query)等。查询的作用是通过匹配倒排索引来查找符合条件的文档。
-
评分(Scoring): Lucene 对搜索结果进行评分,根据文档与查询的匹配程度返回一个相关性得分(Relevance Score)。默认情况下,Lucene 使用 TF-IDF(词频-逆文档频率)算法来计算得分,确保更相关的文档排在搜索结果的前面。
-
索引器(Indexer): 索引器负责将文档中的数据转化为倒排索引。Lucene 的索引过程包括将文档分解为词汇单元,过滤掉不必要的词(如停用词),然后将有意义的词汇存入倒排索引中。索引器还负责定期优化索引以提高搜索效率。
-
存储与合并(Storage and Merging): Lucene 的索引存储是分段式的,每次索引操作会创建新的段(segment)。Lucene 会定期合并这些段以减少碎片、提高性能。段是不可变的,这样的设计使得 Lucene 能够高效地进行并发搜索和索引操作。
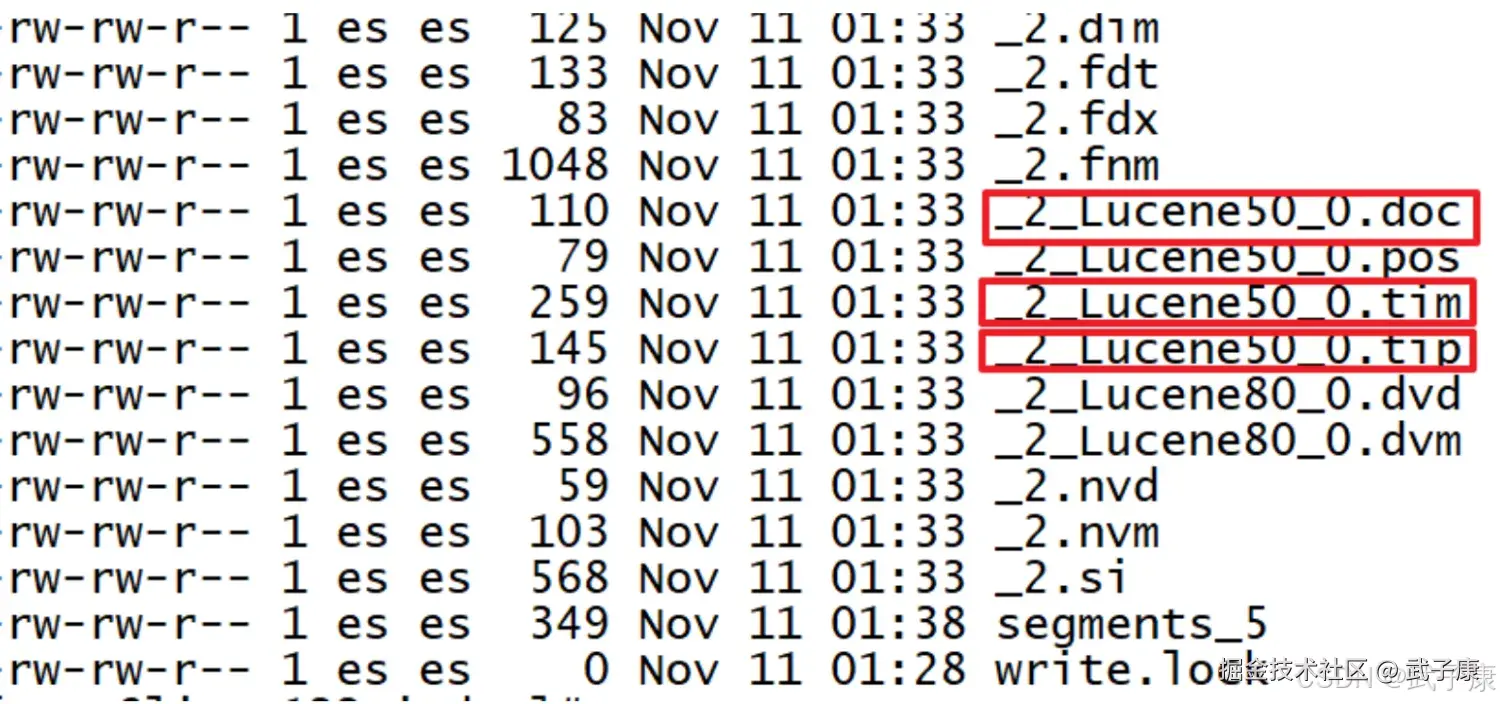 Lucene将索引文件拆分为了多个文件,这里仅讨论倒排索引的部分:
Lucene将索引文件拆分为了多个文件,这里仅讨论倒排索引的部分:
- tip:Lucene把用于存储Terms的索引文件叫Terms Index,它的后缀是:tip
- doc:把Postings信息分别存储在doc,分别记录Postings的DocId信息和Term词频信息
- tim:Terms Dictionary的文件后缀称为tim,它是Term与Positings的关系纽带,存储了Term和其对应的Postings文件指针

- Term Dictionary:把Term按字典排序,然后用二分法查找Term(存在磁盘)在Lucene,Terms Dictionary被存储在 tim 文件上,当一个Segment的文档数量越来越多的同时 Dictionary 的词汇也会越来越多,那查询效率必然也会越来越慢。如果有一个很好的结构也为Dictionary构建一个索引,将Dictionary的索引进一步压缩,这就是后来的Terms Index(.tip)。
- TermIndex:是Term Dictionary的索引,存Term的前缀,和与该前缀对应的Term Dictionary中的第一个Term的Block的位置,找到这个第一个Term后会再往后顺序查找,直到找到目标Term(存在内存)。
小节一下:
- 通过Terms Index(tip)可以快速的在Terms Dictionary(tim)中找到你想要的Term,以及它对应的Postings文件指针(指向doc)
- Terms Index 实际上一个或者多个FST组成的,Segment上每个字段都有自己的一个FST(FST Index)记录在tip上(FST类似一种TRIE树)
Trie
Trie被称作字典树、前缀树(Prefix Tree)、单词查找树:Trie搜索字符串的效率主要跟字符串的长度有关(O(len(单词长度))) 使用Trie存储: cat->1,dog->2,doggy->3,does->4,cast->5,add->6,这六个单词时,如下图:
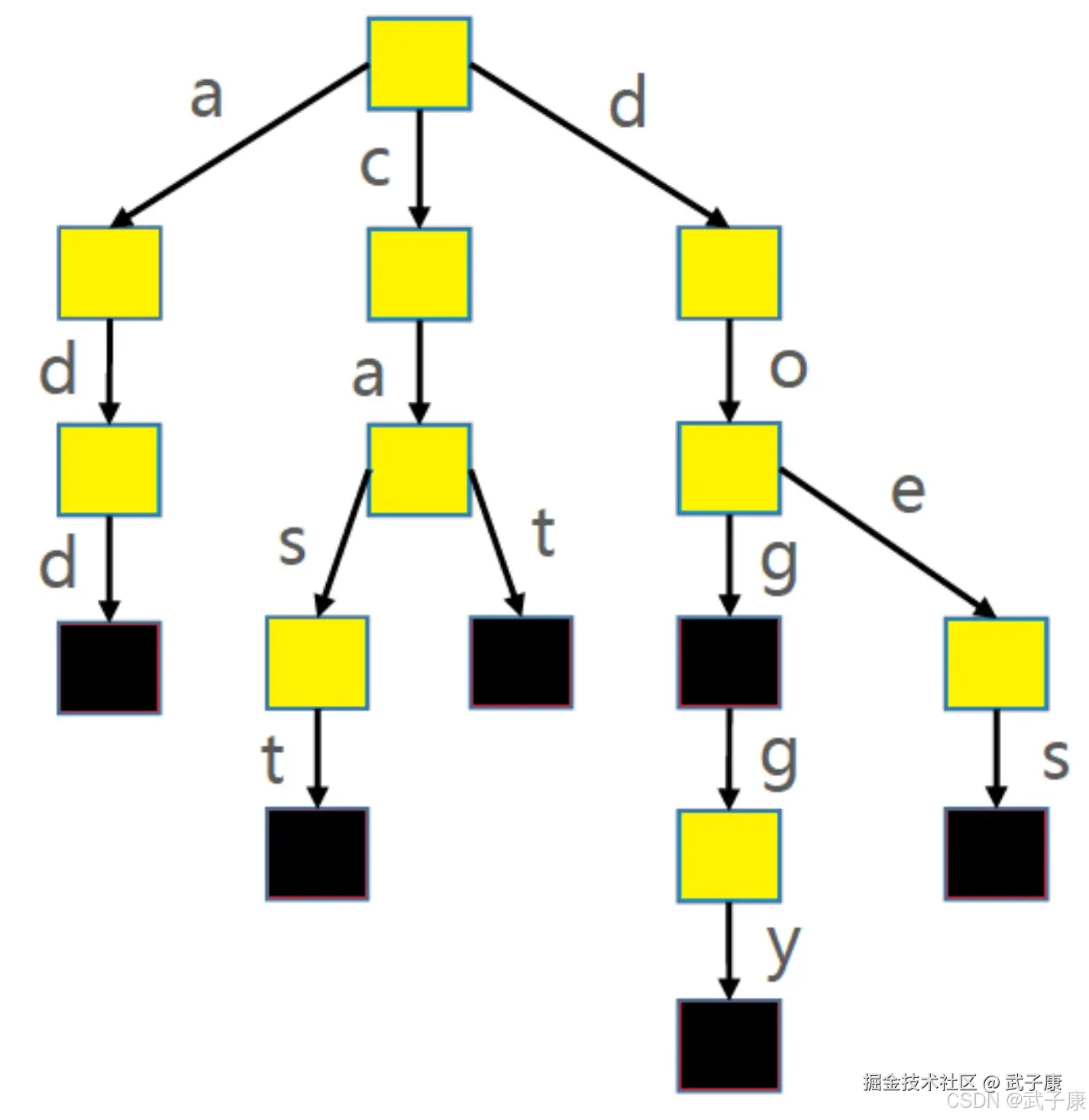 Trie(字典树)的时间复杂度为O(len(key)),其中len(key)表示查询键的长度。这种数据结构通过共享键的前缀来优化存储空间,但无法共享后缀部分。
Trie(字典树)的时间复杂度为O(len(key)),其中len(key)表示查询键的长度。这种数据结构通过共享键的前缀来优化存储空间,但无法共享后缀部分。
FST(Finite State Transducer,有限状态转换器)是一种更高级的数据结构,它不仅能够共享键的前缀,还能共享后缀。FST具有以下优势:
- 功能更全面:除了能判断查找的Key是否存在外,还能给出相应的输出(output)
- 双重优化:在时间复杂度和空间复杂度上都做了最大程度的优化
- 内存效率:优化的数据结构使得Lucene能够将整个Term Index完全加载到内存中
在实际应用中,FST的工作流程如下:
- 快速定位:通过共享前后缀的特性快速定位到目标Term
- 输出获取:在定位到Term的同时获取对应的output(即posting倒排列表)
- 性能优势:相比传统Trie,FST能显著减少内存占用并提高查询效率
典型应用场景:
- 搜索引擎索引构建(如Lucene)
- 大规模词典存储
- 需要快速前缀/后缀查询的系统
例如,在Lucene中,FST可以将数十万个Term及其对应的posting列表高效地存储在内存中,实现毫秒级的查询响应。
SkipList应用
概念概述
假设某个索引字段中有sex、address字段,检索条件为:sex='female' and address='北京'
- 给定查询过滤条件 sex='female'的过程就是先从Term index找到female在Term Dictionary的大概位置
- 再从 Term Dictionary里精确的找到 Female 这个Term,然后得到一个posting list或者一个指向posting list位置的指针
- 查询 address='北京' 的过程类似的,得到一个posting list或者一个指向posting list位置的指针
需要计算出 sex='female' and address='北京' 就是把两个 positing list做一个与合并。 ES中使用SkipList数据结构,同时遍历sex和address的posting list,相互skip。
有序集合计算交集
shell
list1: {1,2,3,4,20,21,50,60,70}
list2: {50,70}求交集 拉链法
两个指针指向首元素,比较元素的大小:
- 如果相同,放入结果集,随意移动一个指针
- 否则,移动值较小的一个指针,直到队尾
这种方法的优势:
- 集合中的元素最多被比较一次,时间复杂度O(N)
- 多个有序集合可以同时进行
求交集 跳表SkipList
有序链表集合求交集,跳表是最常用的数据结构,它可以将有序集合求交集的复杂度有O(N)降至O(Log(N)) 如果使用拉链法,会发现每个元素都要被比对但是其中很多都是无效比对,时间复杂度为O(N),所谓跳表可以把时间复杂优化至LogN,就是因为跳表可以跳过很多无效的对比。
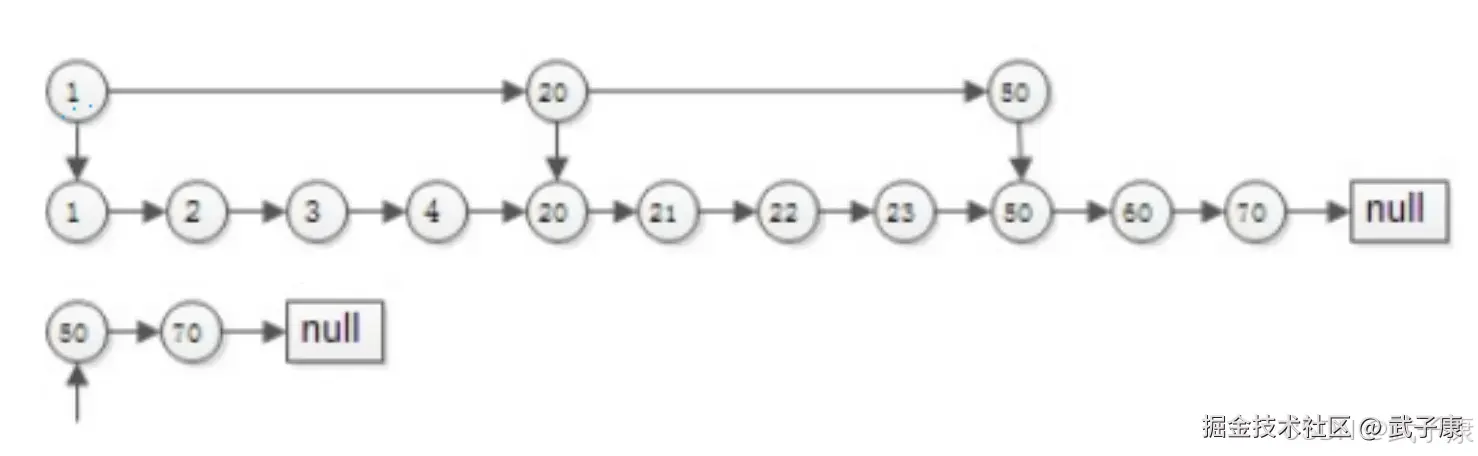 跳表的实现:
跳表的实现: 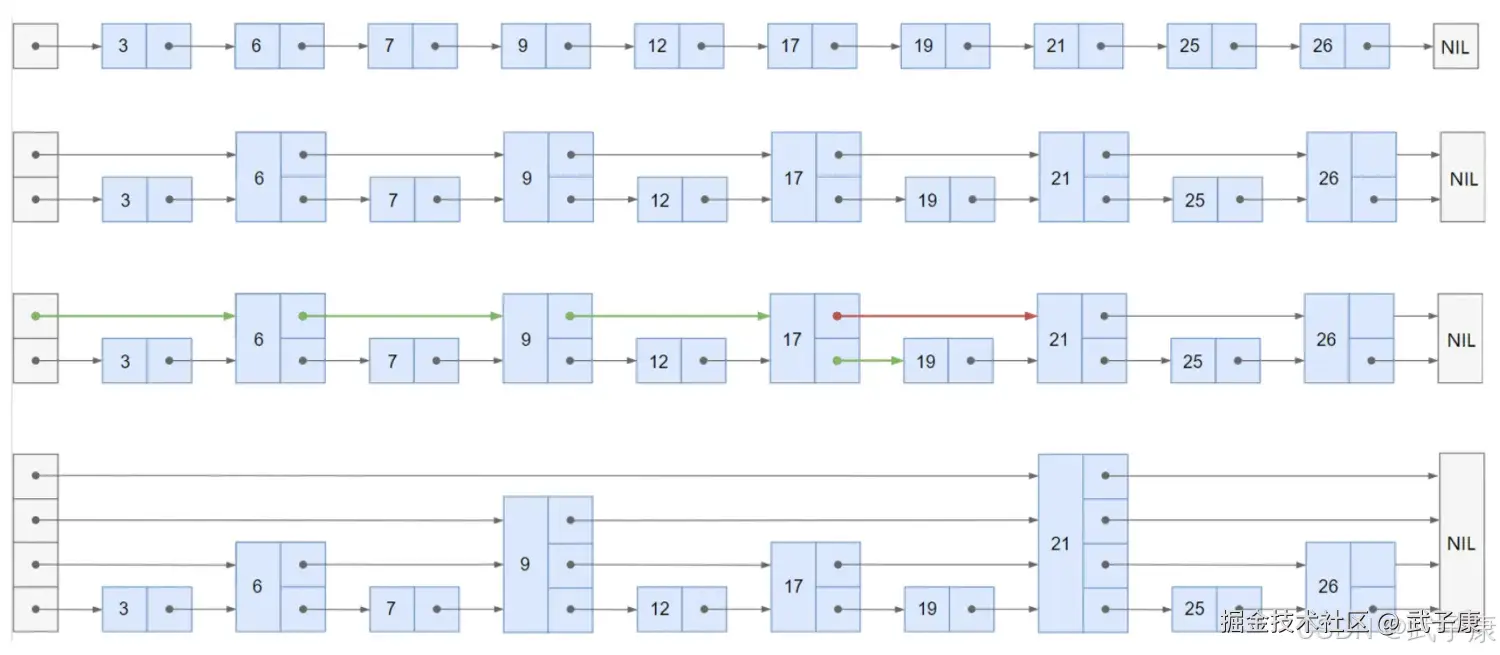 搜索的过程:
搜索的过程:
- 从顶层链表的首元素开始,从左往右搜索,直到找到一个大于或者等于目标的元素,或者到达当前层链表的尾部
- 如果该元素等于目标元素,则表明该元素已经被找到
- 如果该元素大于目标元素或已经到达链表的尾部,则退回到当前层前一个元素,然后转入下一层进行搜索
添加元素,随机决定新添加元素的层数:  删除元素,修改跳表的有效层数:
删除元素,修改跳表的有效层数: 
错误速查
| 症状 | 根因定位 | 修复方案 |
|---|---|---|
| 读者混淆Terms Dictionary、Terms Index、FST概念 | 三个层级(词典/索引/实现结构)描述混用 | 明确区分定义: - .tim为词典块 - .tip为词典索引(常由FST承载) - FST是索引结构,非词典本体 |
| "Terms Dictionary存磁盘,二分查找"表述过度具体化 | Lucene实际采用block+索引组合结构 | 修改为:"按字典序组织为block,并由.tip索引加速定位" |
| "倒排表交集复杂度从O(N)降到O(logN)"引发质疑 | 跳表主要减少比较/局部跳跃成本,整体复杂度仍与postings长度相关 | 调整为:"通过skip pointers减少无效扫描,显著降低实际耗时" |
| TF-IDF与BM25评分算法描述前后矛盾 | 文档未统一Lucene/ES的默认评分模型 | 明确说明: - 主流采用BM25 - TF-IDF作为历史/可选模型提及 |
| "索引表通常存储在内存中"被误解为全量驻留 | 未说明缓存策略的实际情况 | 修正为:".tip/FST常可加载或强缓存;.tim/postings通过mmap/OS cache提速" |
| 读者误认为.doc文件仅含docId/TF | 未说明positions/payload等分文件存储机制 | 补充说明:"不同维度数据分文件存储(如pos/pay等),结构随codec变化" |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解