尽管近年来视觉语言模型(VLM)取得了显著进展,但现有模型在复杂视觉推理任务上的泛化能力仍面临严峻挑战。当前主流的"思维链"(Chain-of-Thought, CoT)监督微调方法,往往让模型停留在对特定推理模板的"记忆",而非真正掌握底层机制:一旦换成新场景、新视角或新的任务组合,性能便明显下滑,难以满足在自主机器人等具身智能场景下对可靠性和鲁棒性的要求。
RoboBrain 2.0 是智源面向真实物理场景打造的通用具身大脑,以统一的视觉---语言多模态架构,为机器人在感知、认知、推理与决策上的核心能力提供基础支撑。围绕 RoboBrain 2.0 的整体目标,我们不禁要问:能否构建一种更适合具身智能的大模型训练范式,使模型不仅"会算",更能"懂为什么这样算",从而在复杂多变的环境中保持稳健的推理与决策表现?
基于这一需求,智源研究院具身多模态大模型研究中心联合北京大学、中国科学院自动化研究所等合作单位,在 RoboBrain 2.0 训练管线中引入了一种创新的两阶段强化学习后训练框架 Reason-RFT 。它并非一项"单点算法",而是 RoboBrain 2.0 后训练阶段的核心推理增强模块,旨在从根本上提升 RoboBrain 系列 VLM 在空间推理、操作规划等任务上的泛化能力。
Reason-RFT 不仅在多项视觉推理与具身基准上取得了显著增益,更验证了 "SFT 激活 + 强化学习增强" 这一新型训练范式在大规模具身智能模型上的可行性:通过将 SFT 的归纳引导与 RL 的探索优化有机结合,有效缓解了过拟合与"认知僵化"问题,显著增强了 RoboBrain 在跨场景迁移和真实世界任务中的适用性。相关研究论文已被 NeurIPS 2025 接收。
Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning of Vision Language Models
开源链接:github.com/FlagOpen/Re...
1 激活与增强:RoboBrain 2.0后训练中的两阶段推理框架
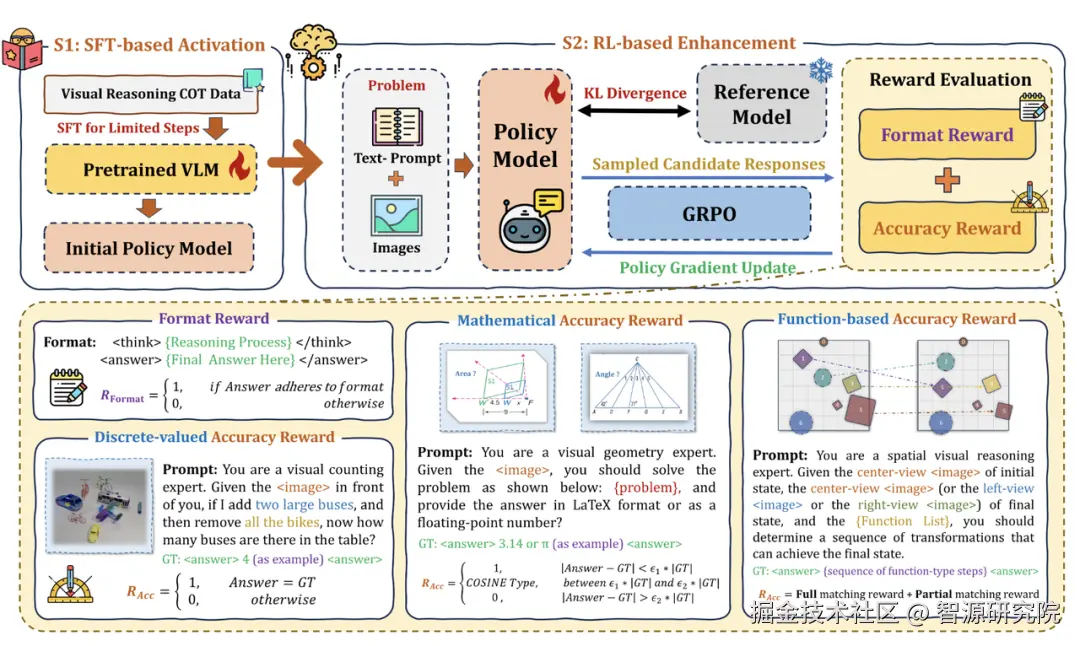
在RoboBrain 2.0 的后训练体系中,Reason-RFT 将复杂推理能力的学习过程拆分为两个紧密衔接的阶段:SFT 推理激活 与 RL 推理增强,共同构成模型的"推理后训练引擎"。
阶段一:SFT 推理激活
在这一阶段,我们并未依赖海量 CoT 数据对 RoboBrain 进行大规模 SFT------那往往会带来模式记忆与过拟合风险,而是使用一小部分精心筛选的高质量 CoT 数据,对预训练的 RoboBrain 进行短暂微调。
该阶段的目标不是追求立刻"拉满指标",而是激活模型与推理相关的潜在能力:通过接触结构化的推理过程,模型学会将复杂问题拆解为若干逻辑步骤,并以"思考---回答"的统一格式进行输出,从而形成有利于推理的归纳偏置(inductive bias),为后续强化学习在 RoboBrain 上开展高效探索打下良好起点。
阶段二:RL 推理增强
在具备基础推理范式后,RoboBrain 进入强化学习增强阶段。我们采用 GRPO 算法,让模型针对同一问题生成多条候选推理路径,在组内进行相对比较。这种"组内比较 + 相对优选"的设计,更适合推理任务解空间庞大且难以绝对打分的特性,同时在计算与工程成本上更易嵌入 RoboBrain 的大规模训练体系。
在奖励设计上,我们采用了轻量但结构化的方案,与 RoboBrain 的多任务训练深度兼容:
-
格式奖励:确保模型输出遵循统一的"推理 + 答案"结构,保证具身任务中的可解释性与稳定性;
-
准确性奖励:针对不同类型的视觉/具身推理任务(如物体计数、数值估计、空间关系判断、操作序列规划等),在"是否正确"的基础上引入适度的细粒度区分,例如对接近正确的数值或部分正确的操作序列给予正向反馈,使模型在探索过程中拥有更平滑、更可优化的奖励曲面。
通过 "激活---增强" 的两阶段流程,Reason-RFT 先在 RoboBrain 上建立起稳定的推理范式,再借助 RL 和结构化奖励持续优化推理质量与鲁棒性,在不依赖大规模 CoT 记忆的前提下,系统性提升了 RoboBrain 2.0 的视觉与具身推理泛化能力。
2 实验结果:更强的性能、泛化性能与数据效率
为了系统性评估 Reason-RFT 在 RoboBrain 2.0 上的效果,在多个时空认知基准上进行了测试。


从结果可以清晰看到,Reason-RFT 作为 RoboBrain 2.0 的后训练模块,带来了三方面的显著收益:
-
性能提升:在多个视觉推理与具身任务上,接入 Reason-RFT 的 RoboBrain 2.0 不仅全面超越主流开源模型,在若干任务上甚至超过顶尖闭源系统,展示出强大的推理与决策能力。
-
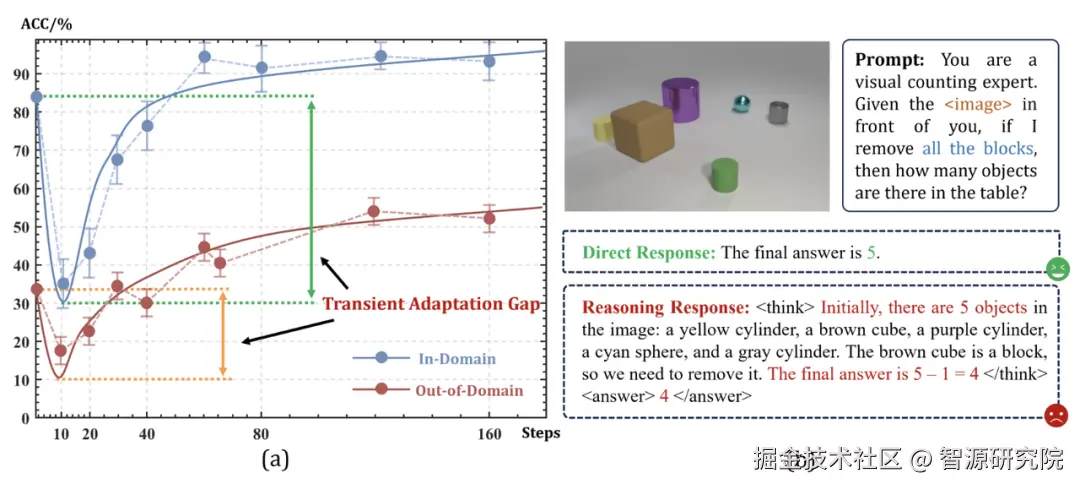
泛化能力增强:在专门构造的领域漂移(Domain-Shift)测试集上(例如,将训练阶段的中心视角图像替换为从未见过的左/右视角,或在具身场景中改变视角与物体布局),接入 Reason-RFT 的 RoboBrain 2.0 明显优于仅使用 SFT 的训练方案,表现出更强的适应性和鲁棒性。这表明模型真正学到的是"如何推理与规划",而非"如何应对某一类固定模板的题目"。
-
数据效率优越:在 RoboBrain 2.0 的整体训练中,Reason-RFT 仅使用不到 5% 的 CoT 数据进行第一阶段激活,其最终性能就可达到或超过使用 100% CoT 数据进行 SFT 训练的基线模型。这一特性对于具身智能场景中昂贵且难以大规模获取的高质量推理标注,具有重要的实际价值。
3 训练中的有趣发现:RoboBrain是如何"学会思考"的?
在 RoboBrain 2.0 集成 Reason-RFT 的过程中,我们还观察到了一些颇具启发性的现象,它们在一定程度上揭示了模型学习推理时的"内部轨迹":
- 奖励分层(Greedy Reward Stratification)
训练早期,RoboBrain 会优先追求更容易获得的"格式奖励"(例如输出格式是否规范),为了最高效地获取奖励,模型会倾向于生成简短的推理内容,导致推理长度先明显变短;在掌握格式后,训练重心逐步转向"准确性奖励",即提升内容本身的正确性与严谨性,推理链条也随之变长、逻辑结构变得更复杂。

- 瞬时适应差距(Transient Adaptation Gap)
对于完全从零开始进行 RL 训练、未经过 SFT 激活的模型,在训练起始阶段性能会经历一个短暂却显著的下滑期,然后才缓慢恢复。这可以理解为模型被迫从"直接给答案"的直觉模式,切换到"显式生成推理过程"的思考模式,在这一切换过程中存在不可避免的适应"阵痛"。
- 推理冗余(Reasoning Redundancy)
与从零 RL 训练的模型相比,经过 CoT 激活的 RoboBrain 2.0 在推理阶段往往更"健谈",即便两者在最终准确率上接近,前者倾向于生成更为详尽的思维链。这可能是因为它在第一阶段模仿了更强模型(如 GPT-4o)产生的细致推理过程,并在 RL 微调后仍保留了这种风格。这一现象为"如何让模型做到既思考充分又表述简洁"提供了有价值的研究线索。
4 展望未来:面向更泛化的RoboBrain多模态与具身智能
作为 RoboBrain 2.0 训练体系中的重要一环,Reason-RFT 为多模态大模型和具身智能提供了一种更鲁棒、更具泛化性、且数据效率更高的视觉推理与决策训练范式 。它不仅在实证上验证了 "SFT 激活 + RL 增强" 在真实场景任务中的有效性,也为后续在复杂环境下的规划、控制与协同奠定了方法基础。
RoboBrain 2.0 使用众智FlagOS多芯片开源统一技术栈进行大规模分布式训练和量化推理,并通过FlagRelease发布了多芯片的模型版本。
智源研究院已与全球 30 余家机器人企业与顶尖实验室建立合作,诚邀全球开发者、研究者与产业伙伴加入,携手共建开放、可信、繁荣的具身智能生态。
关于 BAAI RoboBrain
RoboBrain 是智源研究院推出的面向真实物理环境的"通用具身大脑"系统,集感知、推理与规划于一体,构建了从大脑认知到小脑控制的完整技术体系,包括具身大脑基座模型RoboBrain 2.0、面向3D轨迹生成的RoboBrain-SpatialTrace、用于强化学习稠密奖励生成的RoboBrain-Dopamine、通用小脑VLA模型RoboBrain-X0 Pro,以及灵巧手基座模型RoboBrain-Dex。
配合跨本体协同框架RoboOS 2.0,RoboBrain旨在为开发者提供统一、高效的具身智能基础设施,解决空间理解、时间建模与长链推理三大瓶颈,加速机器人迈向通用具身智能。