摘要
https://arxiv.org/pdf/2511.22142v1
在自动驾驶领域,基于摄像头的感知模型大多在晴朗天气数据上进行训练。专注于解决特定天气挑战的模型无法适应各种天气变化,且主要优先考虑其天气去除特性。我们的研究引入了一种用于多天气条件下目标检测的语义增强网络。在我们的分析中,语义信息可以使模型为缺失区域生成合理内容,理解目标边界,并在图像的填充和现有部分之间保持视觉连贯性和真实性,这有利于图像转换和目标识别。具体实现上,我们的架构由预处理单元(PPU)和检测单元(DTU)组成,其中PPU利用由语义增强的U形网络来优化退化图像,而DTU则使用改进的YOLO网络集成此语义信息进行目标检测。我们的方法率先将语义数据用于全天气转换,在不同天气的基准数据集上,与现有方法相比,mAP提高了1.47%至8.80%。这突显了语义在图像增强和目标检测中的强大作用,为提高目标检测性能提供了全面的方法。代码将在https://github.com/EnisZuo/SemOD发布。
索引术语---自动驾驶,目标检测,语义,恶劣天气
I. 引言
基于摄像头的感知具有极其重要的意义,不仅因为它们能够提供高分辨率的空间细节,还因为它们捕获的关键颜色信息1。尽管在自主视觉和工具方面取得了显著进展24,但存在一个普遍趋势,即模型在严重偏向晴朗天气图像的数据集上进行训练和测试5-7。不幸的是,这种偏见使它们在不利天气条件(如雾、雨或雪)下容易出现性能下降8。随着该领域不断创新,生成涵盖广泛计算机视觉任务的综合模型9,系统性地解决这些严苛条件下性能差距的问题变得至关重要,以确保自动驾驶车辆在任何环境条件下的安全性和可靠性,从而为真正普适的应用铺平道路。
传统研究主要集中在擅长缓解单一领域恶劣条件(如雾、雨或雪)10---13的模型上。虽然这些模型在加深我们对特定天气相关挑战的理解方面发挥了重要作用,但它们的狭隘关注阻碍了它们在现实世界驾驶场景中常遇到的广泛天气条件下的适用性。为了解决这一限制,最近的研究转向开发能够处理多种天气条件的模型14-16。然而,这些模型通常优先考虑天气去除性能(通过峰值信噪比(PSNR)等指标衡量),而不是自动驾驶车辆中目标检测的关键目标。
同时,出现了旨在改善恶劣天气下目标检测的整体方法17--19。这些方法通常涉及用额外的退化图像增强模型,或简单地调整检测单元以在恶劣天气条件下更好地捕获目标。尽管有这些进步,这些解决方案经常受到诸如局限于相似天气领域(例如,雾天和小雨条件)或在不同天气条件下表现不佳等限制。
为了应对领域适应和性能卓越的双重挑战,我们提出了一种用于多天气条件的语义增强目标检测网络(SemOD)。在此网络中,语义分割的先验知识为理解复杂环境提供了像素级解释,将网络从不同天气条件下的黑盒模型转变为基于语义特征图的增强模型结构。具体而言,该架构采用由预处理单元(PPU)和检测单元(DTU)组成的两层网络。PPU采用语义增强的U形网络20:其编码器解码退化图像中的特征差异,它根据在注意力嵌入解码器(AED)中优化的区域对应语义信息,在不同尺度的特征图上应用适当的转换,以消除模糊或污迹。此后,增强的图像连同获取的语义信息一起连接到下游目标检测网络(DTU)。DTU结合了YOLO网络的改进版本,擅长在其"颈部"块中将语义特征与原始骨干输出并行集成,在此过程中,专用的领域适应块(DAB)促进从语义分割领域到目标检测的无缝过渡。这种语义信息的创新编排作为一种高级注意力机制,引导PPU和DTU实现增强性能。值得注意的是,它在mAP值上比次优的当代方法提高了高达8.80%。
据我们所知,我们的工作是首次将语义信息应用于全天气图像转换和目标检测。本文的贡献如下:
- 本文提出了一种新颖的语义增强框架,专为多天气条件下的目标检测而设计,利用语义信息提高图像质量并指导检测过程。
- 本文引入了一种具有适应模块的双重使用策略,包括预处理单元(PPU)中的注意力嵌入解码器(AED)和检测单元(DTU)中的领域适应块(DAB),以最大化语义模块先验知识的益处,并显著增强模型在不同天气条件下的性能。
- 本文在多个数据集上全面评估了所提出的模型,并对域外数据集进行了详细研究,以证明模型对领域差距的适应性和性能改进。
- 本文为不同天气条件下的验证定制了更全面的数据集,并且为了造福社区,所有数据集和代码都是开源的。
II. 相关工作
A. 退化图像转换
在学术领域,关于从图像中去除天气失真的研究已取得显著进展,最初专注于解决单一天气现象,如雾、雨和雪。创新包括应用卷积神经网络(CNN)利用大气亮度和传输图进行去雾10,以及通过多输入生成控制颜色失真21。此外,金字塔CNN和视觉变换器的集成22,23丰富了去雨和去雪的方法,利用了时间数据分析、注意力机制和高级CNN架构的技术13,24-27。最近的研究旨在采用整体方法去除天气失真,在U-Net架构中用复杂模块替代传统卷积层28,并采用具有专门单元用于微小失真的单一编码器-解码器框架16。Li等人通过结合多个特定任务编码器和物理启发的张量操作,辅以对抗学习,进一步增强了这种方法15。尽管这些方法通常执行整体天气去除,但我们的方法通过结合语义信息增强该过程,从而在去除各种天气效果后保留更多原始内容。
B. 退化图像的目标检测
为了应对将图像转换集成到下游任务中以提高效率的关键需求,出现了几种创新方法。一种开创性方法采用端到端、深度学习导向的框架,能够同时处理多种天气条件。这些方法增强图像清晰度以供感知网络使用,从而增强感知结果19, 29。另一种端到端框架考虑检测中的领域适应,并在雾天和雨天条件下解决此问题30。另一种技术逐步将最初在良性天气条件下捕获的图像适应到恶劣气候场景。这种有效的插值弥合了两个不同领域之间的鸿沟,从而增强了目标检测模型的弹性17。此外,一种创新的图像自适应框架促进了单个图像增强以实现卓越的检测性能,证明其在雾天和光线不足条件下都有效31。尽管有这些进步,几个挑战仍然存在:这些技术要么将图像转换和目标识别视为单一的、连贯的任务并相应地训练,要么仅修改目标检测器。因此,尽管它们具有创新性,但这些方法通常导致局限于类似天气领域(例如,雾天和小雨条件),或在面对不同领域时表现不佳。
C. 基于语义的模型
语义分割是计算机视觉中的一个关键主题,对高级场景理解至关重要。深度学习的出现开启了准确像素级分割的时代,由全卷积网络(FCNs)32和U-Net20开创。建立在这些基础之上,大型语言模型和变换器的最新进展进一步扩展了视觉研究的范围,导致了通用分割网络的发展7,33,34。继这些成功之后,语义先验信息的集成已被积极探索,以增强相关任务,如图像转换和目标检测。特别是,由语义、纹理或类别之间的连贯性先验支持的有效修复方法,已经优化了图像重建和上下文一致性35,36。通过多尺度和联合优化策略,建立了图像恢复和语义分割之间更紧密的协同作用,实现了语义信息的优化。在视频超分辨率的并行领域,基于语义先验的模型------最著名的是37提出的GAN框架------通过利用跨语义类别的不同纹理样式,展示了显著的改进,从而通过空间特征转换减少噪声并恢复逼真的纹理。受这些见解的启发,本文将语义信息集成到退化预处理阶段和目标检测阶段。这种集成允许在退化图像中更好地恢复有意义的内容,最终提高检测准确性和去噪效果。
III. 方法论
A. 网络架构
为了从视觉受损的图像III中导出坚固的目标边界框OOO,我们采用了一种集成方法,结合了图像转换和目标检测领域的知识。如图1所示,最初,受损图像I∈RW×H^×3I\in\mathbb{R}^{W\times\hat{H}\times3}I∈RW×H^×3通过预处理单元(PPU)转换为天气中性图像I^∈RW×H×3\hat{I}\in\mathbb{R}^{W\times H\times3}I^∈RW×H×3,本质上通过消除视觉干扰的天气伪影来增强可见性。随后,通过检测单元(DTU)采用目标检测技术从结果图像中挖掘OOO。
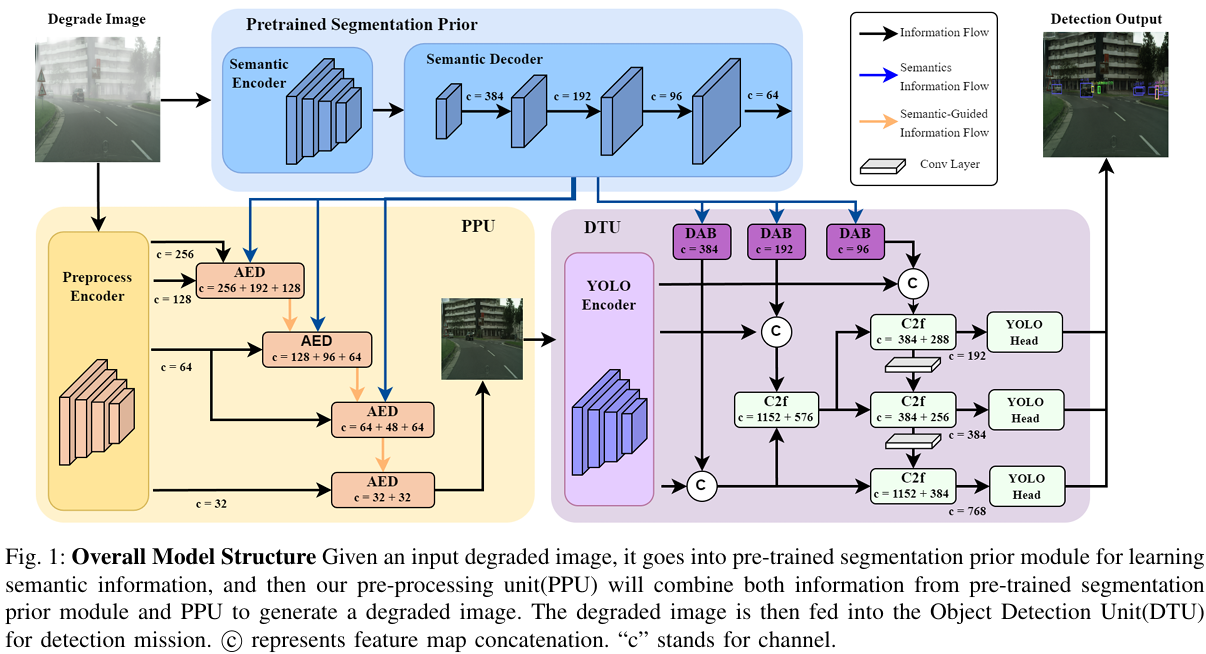
B. 预处理单元(PPU)
- 结构概述:在预处理单元中,我们的目标是在雾、雨和雪等多种天气条件下将III转换为I^\hat{I}I^。为了使转换后的图像I^\hat{I}I^尽可能接近III的晴朗天气对应物,我们对这些天气条件下的图像进行了细致检查。我们认识到,天气效果可以分为两个主要类别:由位于不同距离的天气元素(雨、雾、雪颗粒)造成的视觉障碍,以及由于光线无法穿透颗粒壁而产生的普遍模糊和不明确性。这可以用38中提出的方程的改进版本来概括:
I(x)=B(x)+∑inSi(x)m(x)+A(1−m(x))I(x)=B(x)+\sum_{i}^{n}S_{i}(x)m(x)+A(1-m(x))I(x)=B(x)+i∑nSi(x)m(x)+A(1−m(x))
其中xxx表示图像的像素索引,I(x)I(x)I(x)和B(x)B(x)B(x)分别表示视觉受损输入和清晰输出,∑i=1nSi(x)m(x)\sum_{i=1}^{n}S_{i}(x)m(x)∑i=1nSi(x)m(x)建模由介质中不同颗粒(例如,水滴、灰尘)引起的散射效应(例如,雾、霾)。这里,Si(x)S_{i}(x)Si(x)对应于位置xxx处第iii个颗粒引起的散射效应,m(x)m(x)m(x)是介质传输图,作为权重因子决定散射对观察强度的影响。AAA表示此环境的照明条件,与系数(1−m(x))(1-m(x))(1−m(x))一起,量化了未直接传输但经过大气散射后到达相机的光的比例,该项封装了由天气引起的整个图像的模糊性。
在分析了退化图像I∈RW×H×3I\in\mathbb{R}^{W\times H\times3}I∈RW×H×3的构成后,目标是通过预处理生成增强图像I^∈RW×H×3\hat{I}\in\mathbb{R}^{W\times H\times3}I^∈RW×H×3,使其尽可能接近干净图像BBB。许多研究采用了U形架构框架来实现这一目标,在仔细检查此结构后,很明显U-Net20在去除天气退化模型中的全局大气散射效应A(1−m(x))A(1-m(x))A(1−m(x))方面表现出色,这归功于其对称的收缩和扩展形式。因此,它有效地确定了映射UUU,使得:
U(I(x))=I(x)−A(1−m(x))U(I(x))=I(x)-A(1-m(x))U(I(x))=I(x)−A(1−m(x))
在这里,U-Net利用全局(通过收缩路径)和局部(通过扩展路径)特征来最小化模糊A(1−m(x))A(1-m(x))A(1−m(x)),提供噪声较少的图像B(x)+∑inSi˙(x)m˙(x)B(x)+\sum_{i}^{n}\dot{S_{i}}(x)\dot{m}(x)B(x)+∑inSi˙(x)m˙(x)。这促使我们构建预处理编码器,该编码器在各个阶段生成编码特征图---表示为Φi∣i∈{1,2,4,8,16}\Phi_{i}|i\in\{1,2,4,8,16\}Φi∣i∈{1,2,4,8,16}---用于跳跃连接,从而通过解码器丰富解码特征图,用于图像级模糊去除。
然而,从退化图像中消除SiS_{i}Si提出了重大挑战;这不仅仅是一个简单的重建任务,更像是对原本被天气颗粒遮挡的区域进行修复任务,U-Net在此方面的表现不足。这种次优表现源于U-Net中卷积的特性,这些卷积在重建过程中主要聚合局部和全局信息。然而,当图像的大部分严重退化时(例如,在暴风雨期间),或者当它们集中在图像的不相关部分时(例如,在尝试去除汽车边缘上的雪时专注于路面),这些卷积可能缺乏足够的上下文,阻止模型生成新颖的、上下文适当的内容。
为了解决这个问题,我们结合了语义先验;这些提供了高级上下文信息,从而使模型能够为缺失区域生成合理内容。模型随后理解了目标边界和与其他项目的潜在交互,由此可以应用转换以去除散射效应,数学表达如下:
B(x)=I^(x)−f(U(I(x)),Si(x),θ)B(x)=\hat{I}(x)-f(U(I(x)),S_{i}(x),\theta)B(x)=I^(x)−f(U(I(x)),Si(x),θ)
这里,fff表示我们注意力嵌入解码器的堆栈,语义信息θ\thetaθ---由预训练的HRNet39提供,该网络提供语义特征图Φsi∣i∈{2,4,8,16,32}\Phi_{s_{i}}|i\in\{2,4,8,16,32\}Φsi∣i∈{2,4,8,16,32}---作为输入。选择HRNet是因为其在各种基准数据集上的卓越表现。对一般场景的理解(通过语义)帮助模型在图像的填充和现有部分之间保持视觉连贯性和真实性。
- 注意力嵌入解码器:我们的设计包含一个接受两个特征图Φi,Φ0.5i\Phi_{i},\Phi_{0.5i}Φi,Φ0.5i和语义数据θ0.5i\theta_{0.5i}θ0.5i的解码器,并返回解码特征图Φi^∣i^=0.5i\Phi_{\hat{i}}|\hat{i}=0.5iΦi^∣i^=0.5i作为后续解码器的输入。具体而言,在对特征图进行基本上采样和连接以形成归一化输入后,根据语义信息的存在触发注意力模块。如果有语义数据可用,特征图将遍历通道注意力模块(CAM),该模块吸收了挤压和激励40的原则:
y=x⊙Fex(Fsq(x,Wsq),Wex)y=x\odot F_{ex}\big(F_{sq}(x,W_{sq}),W_{ex}\big)y=x⊙Fex(Fsq(x,Wsq),Wex)
此方程如图2所示,包括挤压和激励层FsqF_{sq}Fsq和FexF_{ex}Fex,以自适应地重新校准原始特征图。挤压线性函数FsqF_{sq}Fsq与平均池化层一起,在空间维度(高度和宽度)上聚合输入特征图,为每个通道生成通道描述符。此操作为输入特征图的每个通道生成全局理解。激励函数FexF_{ex}Fex:然后接收挤压特征向量(FsqF_{sq}Fsq的输出);通过自门控机制处理它,该机制涉及两个全连接层(一个维度减少层后跟一个维度增加层),中间有一个非线性激活函数,最后是sigmoid激活;并将输出应用于原始特征图。注意力完成后,调用最终卷积从语义先验加权特征图重建Φi^\Phi_{\hat{i}}Φi^。
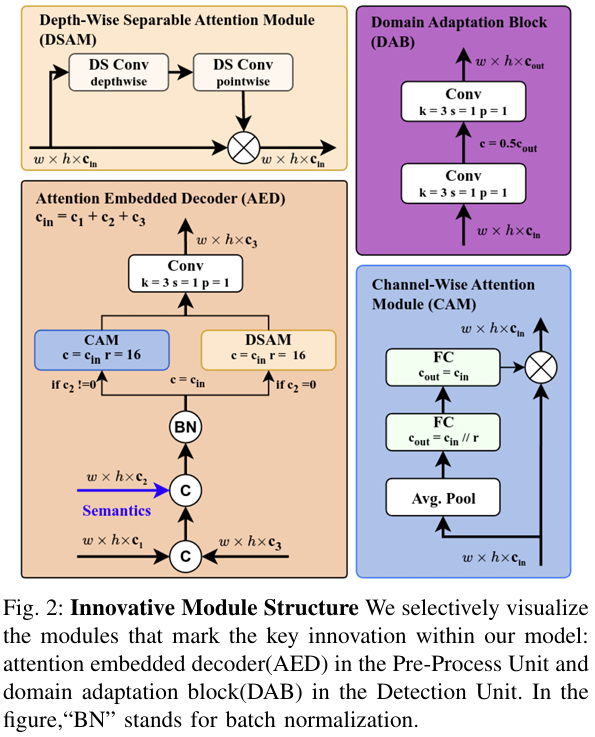
在没有语义信息的单一场景中,当最后一次解码将Φ1\Phi_{1}Φ1转换为III时,我们部署了一种基于深度分离注意力(DSAM)41的策略,如图2所示,以捕获最终图像输出的空间和通道间数据,如下所示:
y=x∘11+e−X′′y=x\circ\frac{1}{1+e^{-X^{\prime\prime}}}y=x∘1+e−X′′1
其中X′′X^{\prime\prime}X′′是两个深度分离卷积与原始输入xxx的乘积,∘\circ∘表示元素乘法。迄今为止,我们已经设计了一个解码器序列,该序列利用语义先验指导重建过程,特别是在数据稀缺但级联效应深远的初始阶段。
最终,此模块的有效性在于其优先处理需要细致修复和语义图丰富指导的区域的能力,同时减少对退化均匀或可忽略的区域的关注。这种机制使模型能够生成精确的重建,从而显著提高整体图像质量。
C. 检测单元
- 结构概述:在图像转换之后,我们通过典型YOLO6检测器的非极大值抑制PPP输出,从增强图像I^\hat{I}I^中提取目标的边界框OOO,如下所示:
P=Y(I^)=(xi,yi,wi,hi,ci1,...,cic)∣i=1,...,K\begin{aligned}P&=Y(\hat{I})\\&=(x_i,y_i,w_i,h_i,c_{i1},...,c_{ic})|i=1,...,K\end{aligned}P=Y(I^)=(xi,yi,wi,hi,ci1,...,cic)∣i=1,...,K
在此方程中,PPP表示检测器输出的预测张量,KKK表示可能的边界框的最大数量,(ci1...cic)(c_{i1}...c_{ic})(ci1...cic)指的是模型训练预测的ccc个类别中第iii个边界框的置信度分数。
我们的方法利用语义增强的YOLO框架来获得此PPP,基于YOLO-v1142架构,如图1所示。检测组件结合了增强图像I^\hat{I}I^和上下文适应的语义数据θdet\theta_{det}θdet,以产生预测张量P=⌢Y(I^,θdet)∣P∈RB×(4+C)×K^P\stackrel{\frown}{=}Y(\hat{I},\theta_{det})|P\in\mathbb{R}^{B\times(4+C)\times\hat{K}}P=⌢Y(I^,θdet)∣P∈RB×(4+C)×K^。尽管有强大的预处理单元,但精炼的图像可能仍包含与原始图像相比的残余噪声或失真,表示为I^=B+N\hat{I}=B+NI^=B+N。通过为预测函数YYY提供θdet\theta_{det}θdet,模型对噪声NNN具有更高的弹性。例如,在θdet\theta_{det}θdet中识别道路增强了YYY检测汽车的置信度,或在边界模糊时通过利用θdet\theta_{det}θdet提供的空间轮廓来指定更精确的边界框---即使图像I^\hat{I}I^包含轻微失真。
为了实现,我们结合了相同的HRNet39用于语义分割,一个用于特征解耦的骨干网络,一个用于协调语义和检测特征的领域适配器,以及一个用于特征协调和预测表达的复合颈部-头部网络。在前向传递过程中,首先通过骨干网络提取多尺度特征,随后对输入进行语义分割。骨干和语义分割输出的结果沿通道维度合并,通过原始YOLOv11网络43中提出的C2f层,从而将语义和检测特征编织成统一的画布,以实现高效检测。
- 领域适应块:领域适应块(DAB)弥合了为语义分割训练的分割先验知识与跨天气领域目标检测之间的差距。在这里,DAB对语义特征进行转换,使其与检测属性对齐,从而适应语义分割和目标检测的领域---这是一个中间步骤,我们利用它来确保语义分割的领域有效通知并增强目标检测的领域,无论天气如何,以实现稳健检测的最终目标。
如图2所示,在初始化时,模块创建一个包含卷积2d、批量归一化和SiLu激活的双重卷积。这些层旨在使来自语义分割模型Φsi∈RWi×Hi×k\Phi_{si}\in\mathbb{R}^{\frac{W}{i}\times\frac{H}{i}\times k}Φsi∈RiW×iH×k的输入特征适应,这些特征本质上是密集且像素特定的,到面向目标、稀疏的目标检测领域Φoi∈RWi×Hi×k\Phi_{oi}\in\mathbb{R}^{\frac{W}{i}\times\frac{H}{i}\times k}Φoi∈RiW×iH×k,从而增强预测函数YYY。
这种领域转换过程有助于整合图像的局部和全局上下文,从而导致检测子系统的稳健性和可验证改进的效能,进而提高整体模型的效果。
D. 训练
我们模型的训练遵循顺序多任务优化方法,其中PPU首先学习转换退化图像,然后DTU获得从增强图像中产生检测的能力。在PPU中,我们将退化图像转换为(512×512)(512\times512)(512×512),其中退化图像I~∈R512×512×3\tilde{I}\in\mathbb{R}^{512\times512\times3}I~∈R512×512×3涵盖所有恶劣天气领域;然后我们采用Charbonnier损失44作为训练损失,以最小化极端异常值的影响,如下方程所示:
LPPU=1N∑iN(Ii−I^i)2+ε2−ε,L_{\mathrm{PPU}}=\frac{1}{N}\sum_{i}^{N}\sqrt{(I_{i}-\hat{I}_{i})^{2}+\varepsilon^{2}}-\varepsilon,LPPU=N1i∑N(Ii−I^i)2+ε2 −ε,
在上述方程中,IiI_{i}Ii表示输入图像的像素强度,I^i\hat{I}_{i}I^i表示优化图像的像素强度,ε\varepsilonε表示最小常数,NNN等于图像中的总像素数。求和扩展到图像中的所有像素。
在形成稳定的I^\hat{I}I^后,我们使用YOLO损失函数45训练检测单元:
LDTU=λboxLbox+λclassLclass+λscoreLscoreL_{DTU}=\lambda_{box}L_{box}+\lambda_{class}L_{class}+\lambda_{score}L_{score}LDTU=λboxLbox+λclassLclass+λscoreLscore
这里,λbox=λclass=λscore=1\lambda_{box}=\lambda_{class}=\lambda_{score}=1λbox=λclass=λscore=1。对于检测单元,我们还将图像放大到(1024×512)(1024\times512)(1024×512),以保持目标与原始图像的比例一致。
IV. 实验
在以下部分中,我们将介绍用于测试实验的数据集、实验设置、评估指标、比较方法、定量结果和定性结果。
A. 数据集
Cityscapes数据集。在我们追求在具有挑战性的天气条件下进行稳健目标检测的过程中,我们转向了Cityscapes46数据集,该数据集在各种气候场景中具有丰富的多样性。从此集合中,我们获取了:
3,4753,4753,475张原始(晴朗)图像46。
10,42510,42510,425张雾天捕获,能见度为150、300和600米,由47提供。Foggy_Cityscapes是通过在Cityscapes图像上模拟不同强度级别的雾建立的,这基于深度图和物理模型生成了三个级别的模拟雾。
1,0621,0621,062张雨天图像,包括295张选定图像上的36种雨强度变化,由48提供。
这些数据集是社区中广泛采用的基准,为不同方法之间的公平比较提供了标准化和可重现的评估协议。
自定义数据集。为了实现对天气条件的更全面覆盖,我们在现有数据集上执行了数据增强和数据生成,以在各种天气条件下丰富和创建更多样化的数据集。遵循Transweather16,我们结合了:
• RainDrop数据集,包含1,0691,0691,069张图像13。
• Snow100K26的子集,我们从中选择了13,28313,28313,283张图像来代表雪天条件。
数据集类别。为了在所有这些数据集中提取边界框,我们的主要关注点是核心交通参与者。我们的检测类别包括汽车、行人、卡车、公共汽车、骑行者、自行车和摩托车。为了促进提取过程,我们使用了49,这使我们能够高效地获取Cityscape数据集的2D边界框。同时,对于Snow100K数据集,注释是手动完成的。此外,我们将Cityscape中的晴朗天气图像集成到增强数据集中,作为在其他天气条件下检测的基准。统一数据集和注释的访问链接可以在我们的Github存储库中找到:https://github.com/EnisZuo/SemOD
B. 实验设置
我们合并了上述数据集中相同天气条件的数据,训练数据集在保留每个数据集的独立测试集的同时随机打乱。为了更公平地评估在每种不同天气场景下普遍训练的模型性能,我们将训练集和验证集以4:1的比例分割。我们将数据集中的每个样本调整为512×512512\times512512×512的大小,作为预处理单元(PPU)的输入。PPU转换的图像随后调整为512×1024512\times1024512×1024,供检测单元(DTU)输出检测边界框---这种调整保持了目标尺寸与原始图像的一致。相同的调整和类似的图像流程应用于其他基准模型,以进行公平比较。
包括用于比较的SOTA方法在内的每个模型,都在单个Nvidia RTX 3090 GPU上以学习率0.0005进行训练和评估。训练使用训练批量大小为12,测试批量大小为16,使用SGD作为优化器,权重衰减为0.0001。所有模型在两个处理步骤中的训练都从初始50个epoch开始。遵循Transweather16和Yolo-v1142使用的方式,我们报告验证集上的指标值,其中较高值表示性能更优。
C. 评估指标和比较方法
我们使用COCO风格的平均精度51评估检测质量,报告mAP50mAP_{50}mAP50(IoU=0.50时的AP),mAP75mAP_{75}mAP75(IoU=0.75时的AP)和mAP50−95mAP_{50-95}mAP50−95,即在IoU阈值{0.50,0.55,...,0.95}\{0.50,0.55,\ldots,0.95\}{0.50,0.55,...,0.95}上平均的平均AP。我们的比较使用YOLOv11作为检测基线,它涵盖天气去除---加---检测器管道(DENet52,UEMYolo53,Urie+Yolo28和TransWeather+Yolo16),以及领域自适应检测器(DA-Faster54,UaDAN55和DA-detect30);为了公平,所有方法使用相同的调整方案和验证分割。
D. 定量结果
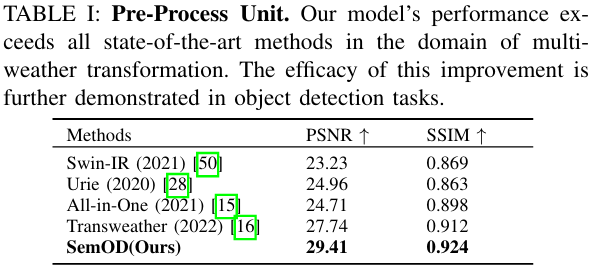
预处理单元分析。在评估预处理单元的有效性时,我们严格遵循16设定的基准,部署两个突出指标:PSNR(峰值信噪比)和SSIM(结构相似性指数测量)。PSNR量化原始图像与其修改版本之间的保真度差异,更高的PSNR表示更高的保真度。相反,SSIM评估结构细微差别、亮度和纹理的变化,提供整体的、感知上显著的评估。其值范围从-1到1,完美分数1表示相同的图像。
表I说明我们的模块超越了当代顶级模型,在PSNR中至少提高了6.02%,在SSIM中提高了1.32%。这强调了我们语义增强重建的掌握。此外,除了单纯的指标增强,我们的预处理单元还擅长强调被语义信息视为关键的区域,这在后续目标检测指标和定性分析中进一步阐明。
消融研究。为了研究每个模块在实现如此目标检测性能中的贡献,我们从普通的Yolo-v11网络开始,一个接一个地添加组件,从而确定了四个结构:(1)Yolo-v11检测模块 (2)PPU+Yolo-v11,其中PPU表示预处理单元 (3)PPU+Yolo-v11+语义模块(我们的无领域适应模块)(4)SemOD(PPU+Yolo-v11+语义模块+DAB)。所有实验都在4个跨领域数据集上使用相同的训练参数进行。表II中的消融研究清楚地证明了每个提议模块在所有数据集上的积极效果。
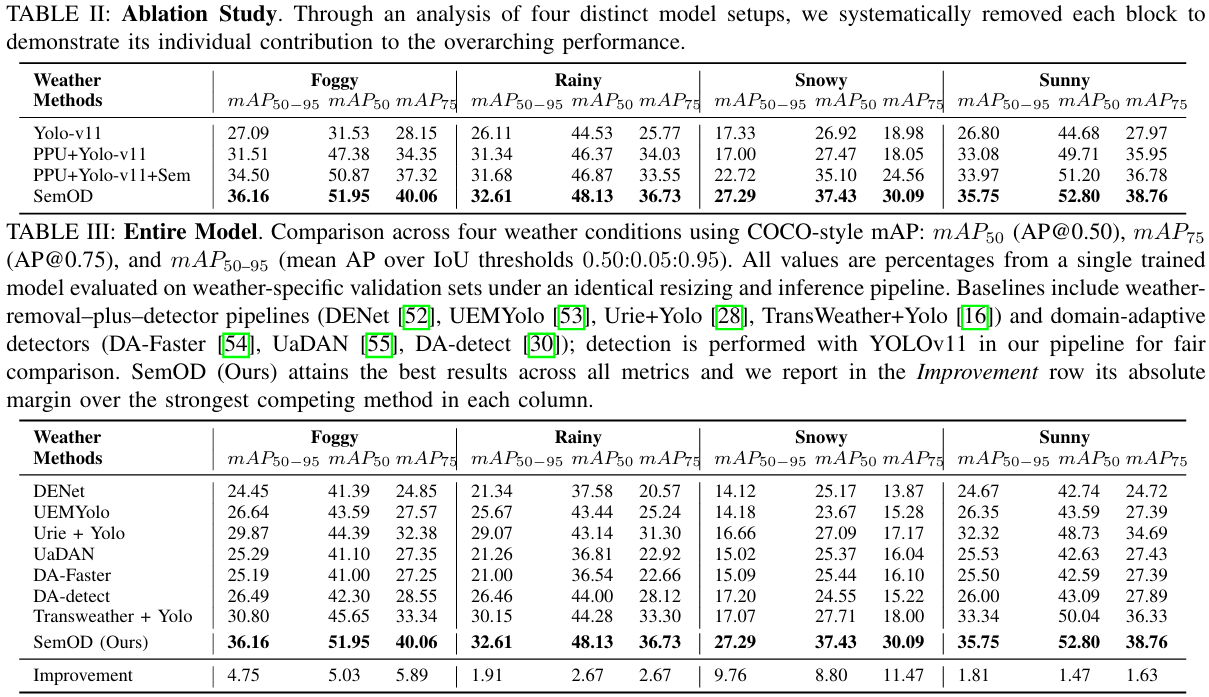
我们的预处理单元(PPU),与其他图像转换组件相似,导致目标检测效能显著提升。随后结合语义信息显著增强了检测的稳健性,特别是在存在领域差距的雪天条件下。简单的领域适应块进一步强调了这种增强,在数据集中巩固了无与伦比的性能。这些结果证明,我们的模块部署不仅在理论上合理,而且在推进语义增强目标检测范式方面实际上至关重要。
完整模型。表III中可以找到不同模型在各种天气场景下的性能比较。为了全面评估SemOD的性能,我们将其与两种专门为恶劣天气条件下目标检测设计的基于YOLO框架的集成解决方案52,53进行了比较。此外,为了评估我们的模型在天气去除方面的性能,我们将其与当前两种表现最佳的图像转换方法15,16进行了比较,并将它们与YOLO-v11集成,以在四种不同天气条件下进行比较。
如表III所示,我们的方法在所有恶劣天气条件下与次优方法相比,在mAP方面显示出显著改进,雾天提高了5.03%,雨天提高了2.67%,雪天提高了8.8%。值得注意的是,改进在基于Cityscapes的定制雪天数据集上更为明显,这是由于此数据集与基于Cityscapes的数据集之间存在更大和更明显的领域差异。在我们的语义模块支持下,我们的模型不仅展示了最佳的增强性能,还反映了这种方法大幅减少领域差异效果的更大能力。此外,值得注意的是,即使在没有恶劣天气干扰的晴朗天气条件下,我们的模型也优于YOLO-v11检测模型(提高了1.47%)。这一结果表明,通过语义模块的增强支持,检测的准确性也得到了提高。因此,通过在不同天气数据集上的定量比较,我们方法的优越性是显而易见的。

推理时间。为了解决实时适用性和计算成本问题,我们在与精度实验相同的设置下报告估计的端到端每帧延迟(单NVIDIA RTX 3090,批量=1;PPU输入512×512512\times512512×512,检测器输入512×1024512\times1024512×1024)。如表IV总结,相对于普通检测器,SemOD每帧仅增加约17--34毫秒,同时提供报告的精度增益;DAB对齐仅占总延迟的约1-3毫秒。这些结果表明,我们的方法可以在商品GPU上实时部署。
E. 定性结果

在定性评估中,我们在四种不同天气场景下将我们的模型与其次优替代方案"Transweather + Yolo-v11"进行比较,如图3所示。我们不仅比较了模型的检测性能,还评估了天气去除后的效果。通过以放大比例比较(b)和©的第一行,我们观察到我们的方法在天气去除后实现了更高水平的场景恢复。特别是,在比较图像时,如路边广告牌和文本,我们发现清晰度和锐度明显提高。检查所有类别的边界框,很明显我们的模型SemOD始终提供更高的置信度、更高的准确性和更少的误报。具体而言,SemOD的优势延伸到远离图像拍摄位置的物体。事实上,SemOD不仅纠正了不准确甚至错误的检测框,还捕获了被替代方案忽略的几个微小物体,从行人到自行车再到车辆。例如,查看晴朗天气场景下的图像,其中恶劣天气不再是干扰因素,我们的模型可以检测到一些远处的物体。这一观察证实了我们的理论分析,即没有语义先验提供的上下文信息,传统模型在生成逻辑和有意义的内容以替换天气效果以及在被不同天气严重退化的区域中提供信息边界框方面表现较差。
此外,这种定性分析证实了我们的理解,即结合语义的SemOD对不同数据集之间的领域差距更具鲁棒性:晴朗、雾天和雨天数据集都是从Cityscape数据集生成的图像。雪天图像则相反,选自Snow100K数据集,因此具有不同的照明、架构和交通模式,如我们的可视化所示。在这里,SemOD产生更清晰的天气去除图像和具有更高置信度分数的边界框,与次优替代方案相比。然而,其他模型在处理不同天气条件时牺牲了一定程度的环境可解释性,导致检测结果未达到我们的期望,特别是在存在显著领域差距的情况下,这在这些情况下更为明显。SemOD通过语义网络提供的扩展解释能力,在恶劣天气图像中获得了共同和关键的特征。
V. 结论
在本研究中,我们介绍了"SemOD",一种为在各种天气条件下(包括雾、雨、雪和晴朗天空)稳健性能而定制的语义增强目标检测网络。我们的网络包括预处理单元和检测单元。我们不仅阐明了语义信息在两个关键模型阶段---图像转换和目标检测---中的放大益处,还通过广泛的实验严格证实了这种协同作用。这种集成显著提高了目标检测的平均精度,在所有比较中超越了最先进(SOTA)水平,改进范围从晴朗天空的1.47%到雪天条件的8.80%。