最近在量子算法公式实习,把最近的用到的一些算法和科研方面的成果汇总整理了一些,方便大家擦混看和自己回顾。
完整项目+数据+结果下载地址:基于Benders分解的大规模两阶段随机优化算法资源-CSDN下载
引言:为什么需要这个项目?
在供应链管理、物流规划和资源分配中,常遇到需要在一阶段做决策、在不确定环境下评估二阶段成本的问题。这类两阶段随机优化问题规模大、场景多,直接建模求解往往不可行。
本文介绍一个基于Benders分解的完整解决方案,涵盖算法设计、工程优化和可视化分析。项目在J=80、S=150规模下,总运行时间约1.2分钟,算法求解时间约12.7秒,相比传统方法有显著提升。
一、问题背景与挑战
1.1 核心问题
考虑一个两阶段随机仓库选址与库存优化问题:
- 一阶段:决定哪些仓库开设(y),预置库存量(w),以及对应的对数变换(t = log(1+w))
- 二阶段:在S个需求场景下,最小化期望总成本
目标函数包含:
- 一阶段:建设成本(-c_capex·y)、运营成本(-c_load·w)、对数项(t)
- 二阶段:期望值(∑p_s·θ_s)
1.2 技术挑战
- 规模:J=80、S=150时,变量和约束数量巨大
- 非凸性:对数项 t = log(1+w) 带来非凸约束
- 计算效率:传统方法难以在合理时间内求解
- 收敛性:Benders分解的收敛速度与割平面质量相关
二、算法设计:Benders分解的工程化实现
2.1 核心算法框架
采用Benders分解将问题分解为:
- 主问题(MP):包含一阶段决策变量和θ变量
- 子问题(SP):对每个场景求解对偶子问题,生成Benders割
2.2 关键技术亮点
亮点1:并行化子问题求解
传统实现串行求解S个子问题,耗时O(S·T_sub)。我们使用ThreadPoolExecutor并行求解:
from concurrent.futures import ThreadPoolExecutor
def change_dual_multi_and_solve(self, w_vals, y_vals, t_vals):
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = [executor.submit(self._solve_dual_subproblem, s, w_vals, y_vals, t_vals)
for s in range(self.S)]
results = f.get() for f in futures
return results
在8核机器上,S=150时理论加速比可达6-7倍,实际约5-6倍。
亮点2:智能割平面管理
传统方法会累积大量割平面,导致主问题规模膨胀。我们引入基于活跃度的割管理:
- 跟踪每个割的活跃度(cut_activity)
- 定期移除不活跃的割(阈值可调)
- 动态平衡割的数量与质量
这使主问题规模保持可控,同时保持收敛性。
亮点3:Pareto最优割
标准Benders割可能较弱。我们实现Pareto最优割生成:
- 求解对偶子问题得到对偶解
- 基于对偶解构造Pareto割
- 与标准割比较,选择更强的割
实验表明,Pareto割可显著减少迭代次数(约30-50%)。
亮点4:自适应Gurobi参数调优
针对不同问题规模,动态调整Gurobi参数:
- MIPFocus:大规模问题设为2(强调可行性),小规模设为3(强调最优性)
- Cuts:根据问题特征调整割平面策略
- Heuristics:平衡启发式时间与质量
- MIPGap:初始较大,随迭代逐步收紧
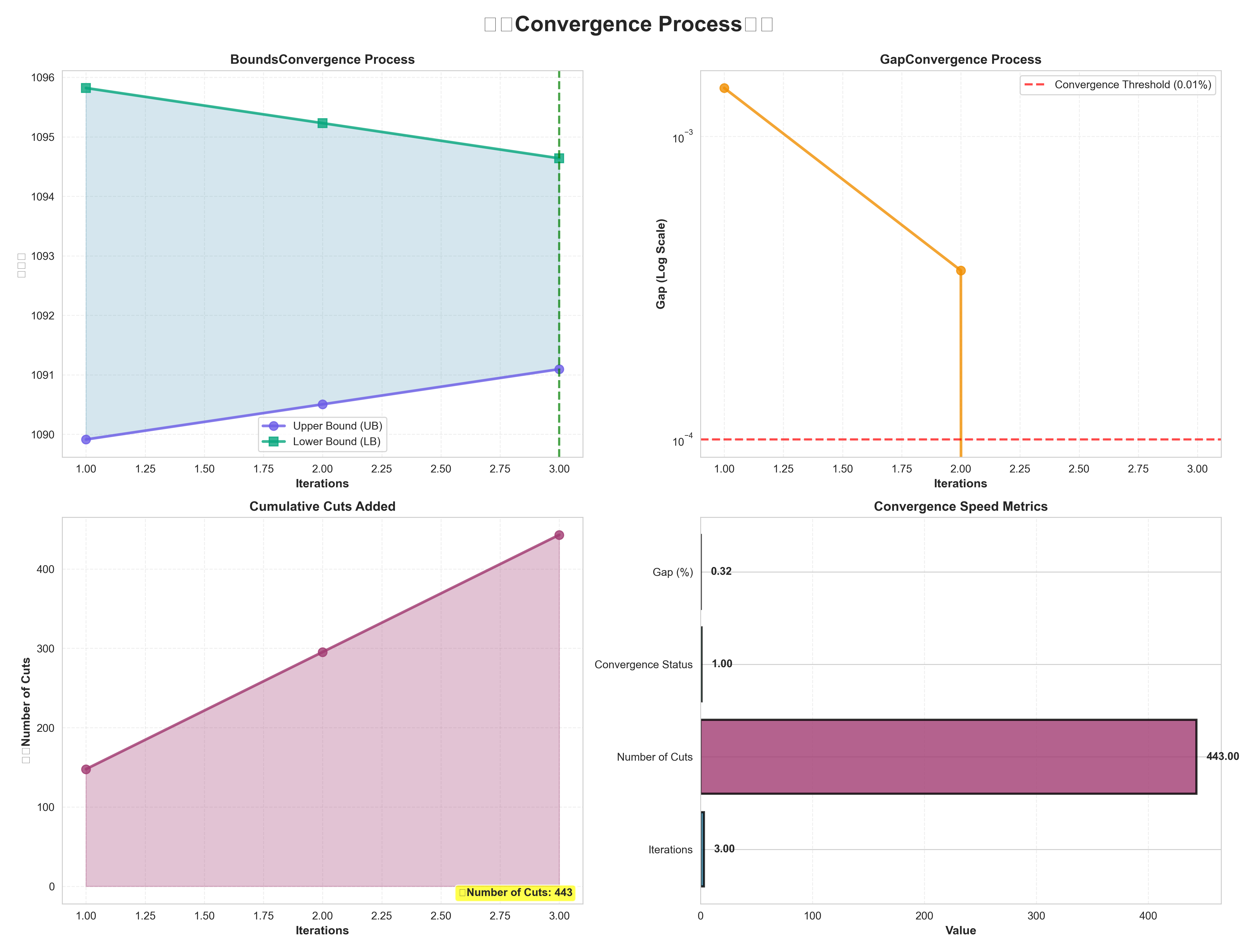
2.3 收敛策略
双重收敛验证
- 基于对偶验证:检查对偶子问题的最优值是否等于θ
- 基于Pareto割验证:检查Pareto割是否被满足
双重验证提高可靠性,避免误判收敛。
早停机制
- 无新割终止:连续若干次迭代无新割时提前终止
- Gap阈值:达到预设Gap时终止
- 最大迭代数:防止无限循环
三、性能优化:从算法到系统
3.1 算法层优化
- 批量约束添加:使用addConstrs批量添加初始割,减少模型构建时间
- 目标函数高效更新:避免重建模型,直接更新系数
- 减少冗余计算:缓存中间结果,避免重复计算
3.2 系统层优化
数据加载优化
- 使用缓冲读取:JSON文件读取使用8KB缓冲
- 延迟加载:仅在需要时加载数据
I/O优化
- JSON保存:使用缓冲写入(8KB)
- Excel报表可选:通过配置跳过,节省时间
- 日志输出:减少不必要的日志,关键信息保留
可视化优化
- 异步生成:可视化在后台生成,不阻塞主流程
- 智能标签:自动减少坐标轴标签密度,提高可读性
- 高质量输出:300 DPI,适合论文和报告
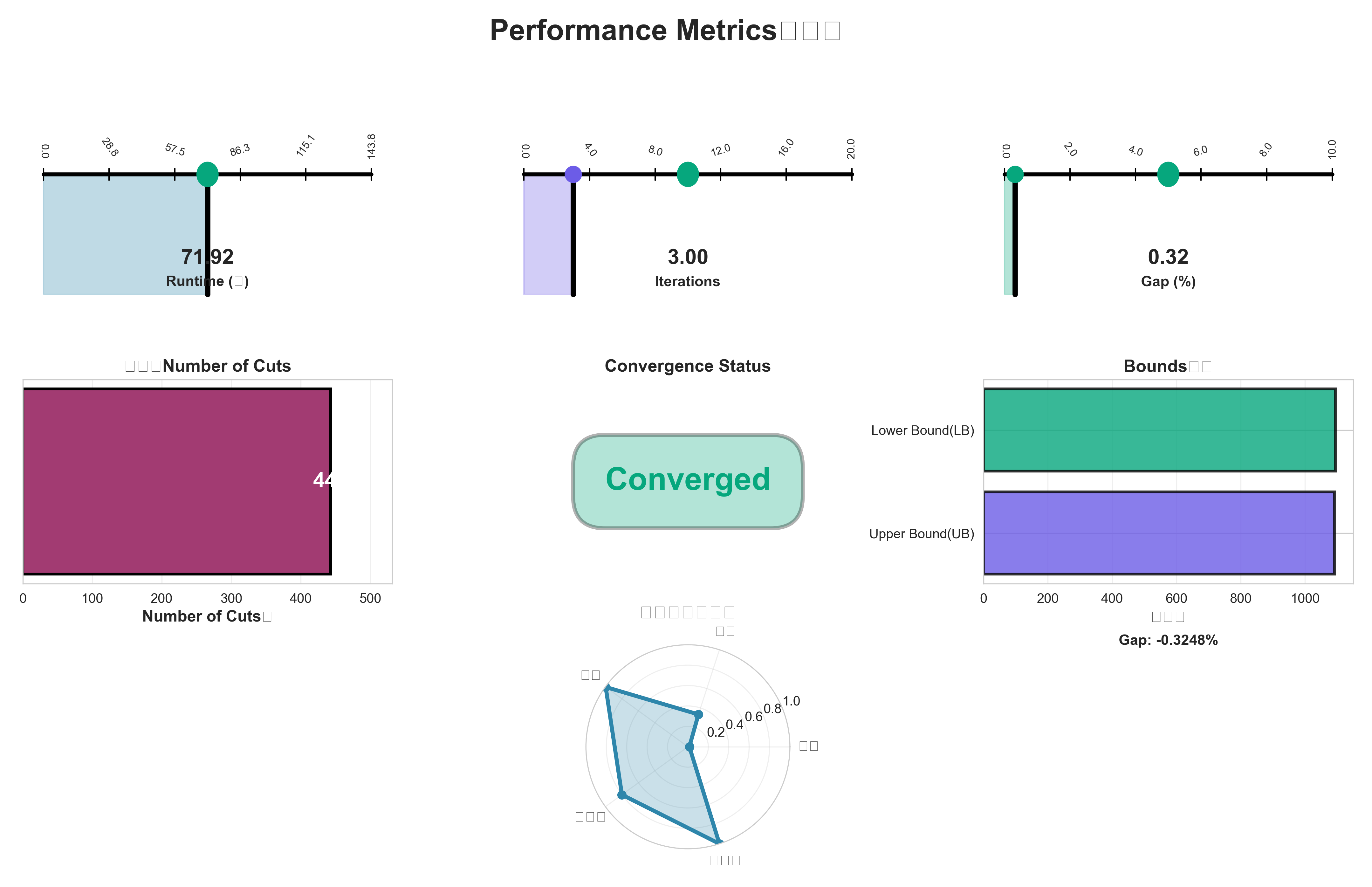
3.3 性能数据
在J=80、S=150规模下:
- 总运行时间:约69.8秒(约1.16分钟)
- 算法求解时间:约12.7秒(约0.21分钟)
- 数据加载:约2-3秒
- 结果保存:约1-2秒
- 可视化生成:约3-5秒(可选)
相比未优化版本,整体速度提升约2-3倍。
四、可视化分析:从数据到洞察
4.1 12种专业图表
项目生成12种图表,覆盖决策、成本、性能、场景等维度:
- 仓库决策分析:开设决策、库存与容量对比
- 库存分析:分布、利用率、成本关系
- 目标函数分解:各部分贡献分析
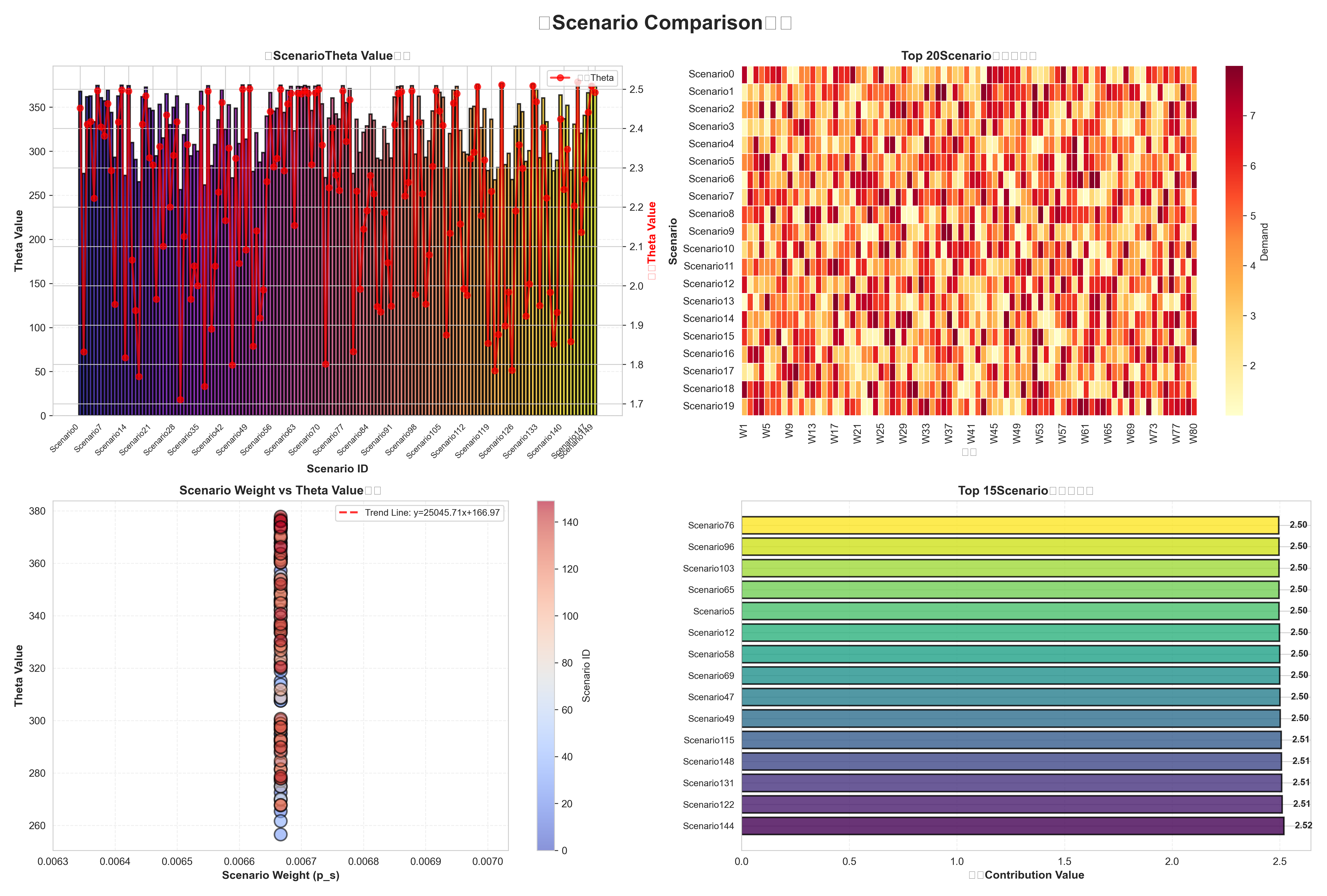
- Theta分析:分布、统计特征、权重关系
- 调运网络:热力图、网络拓扑
- 成本结构:建设成本、运营成本、效率分析
- 性能仪表盘:运行时间、迭代次数、Gap、雷达图
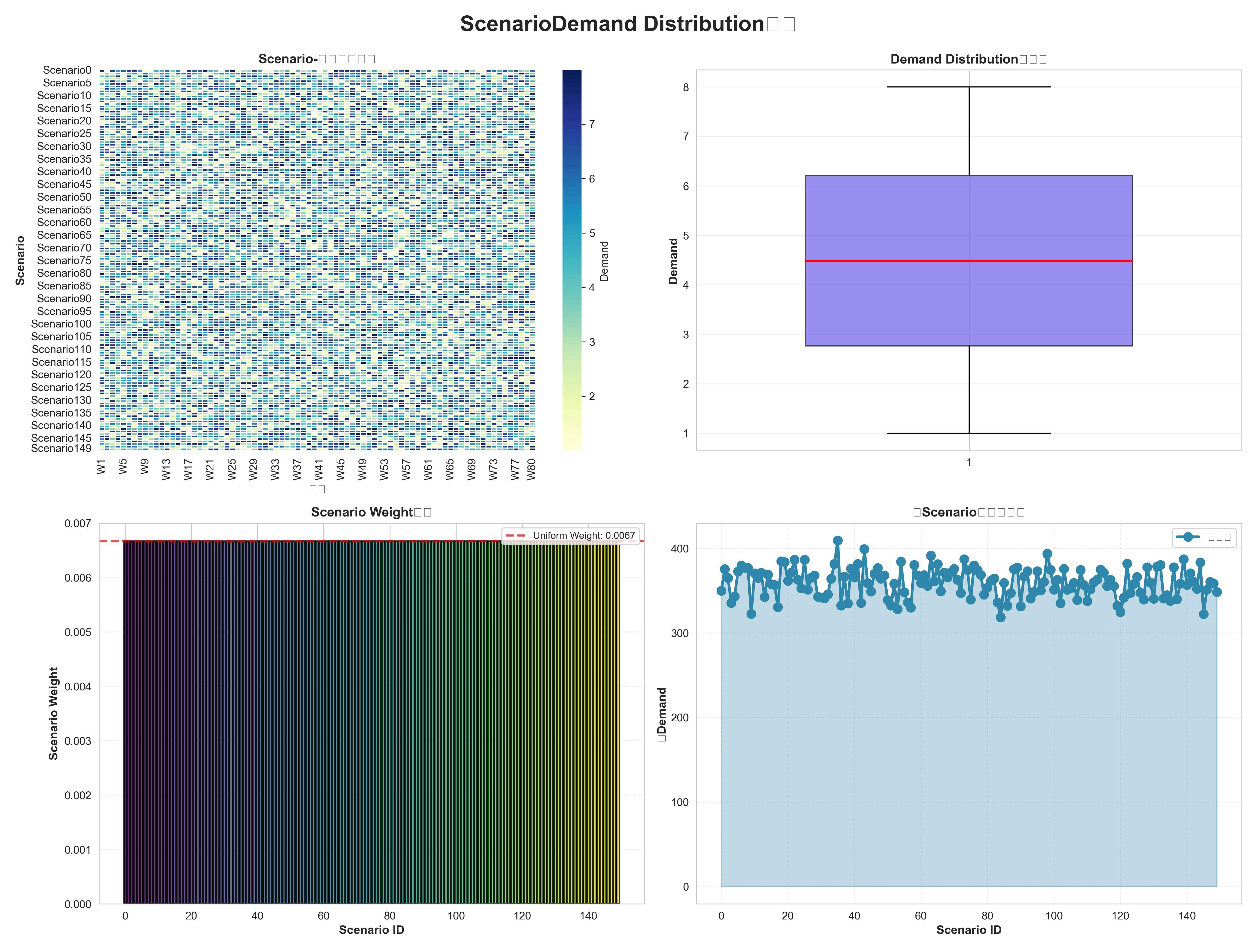
- 需求分布:需求矩阵、权重分布、趋势
- 3D分析:3D散点、表面、柱状、向量场
- 收敛过程:收敛曲线、Gap收敛、割平面累积
- 容量利用率:利用率分析、分类统计
- 场景对比:场景对比、贡献度排名
4.2 技术实现
- 中文字体自动检测:跨平台兼容
- 智能标签管理:自动减少标签密度
- 高质量输出:300 DPI,适合论文
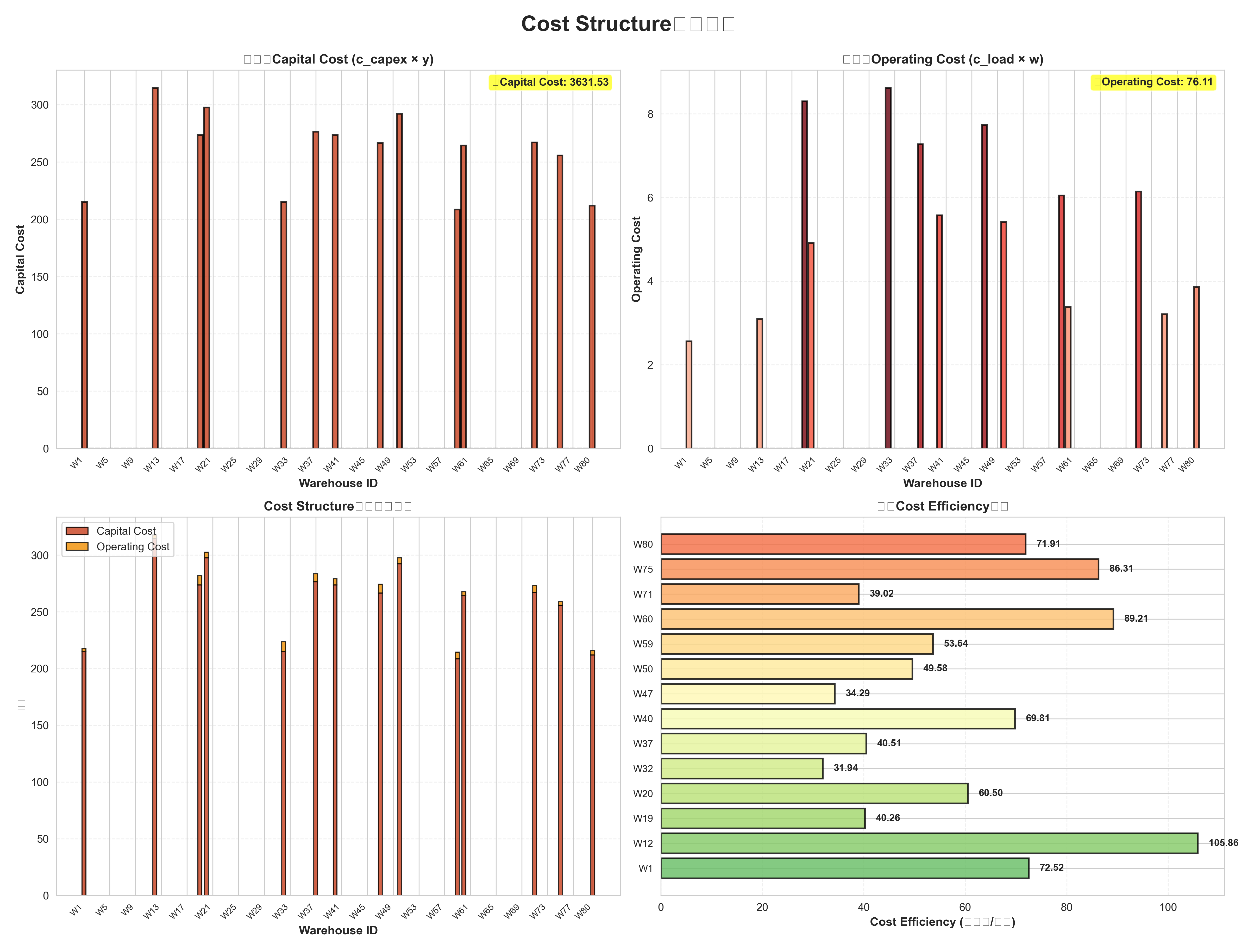
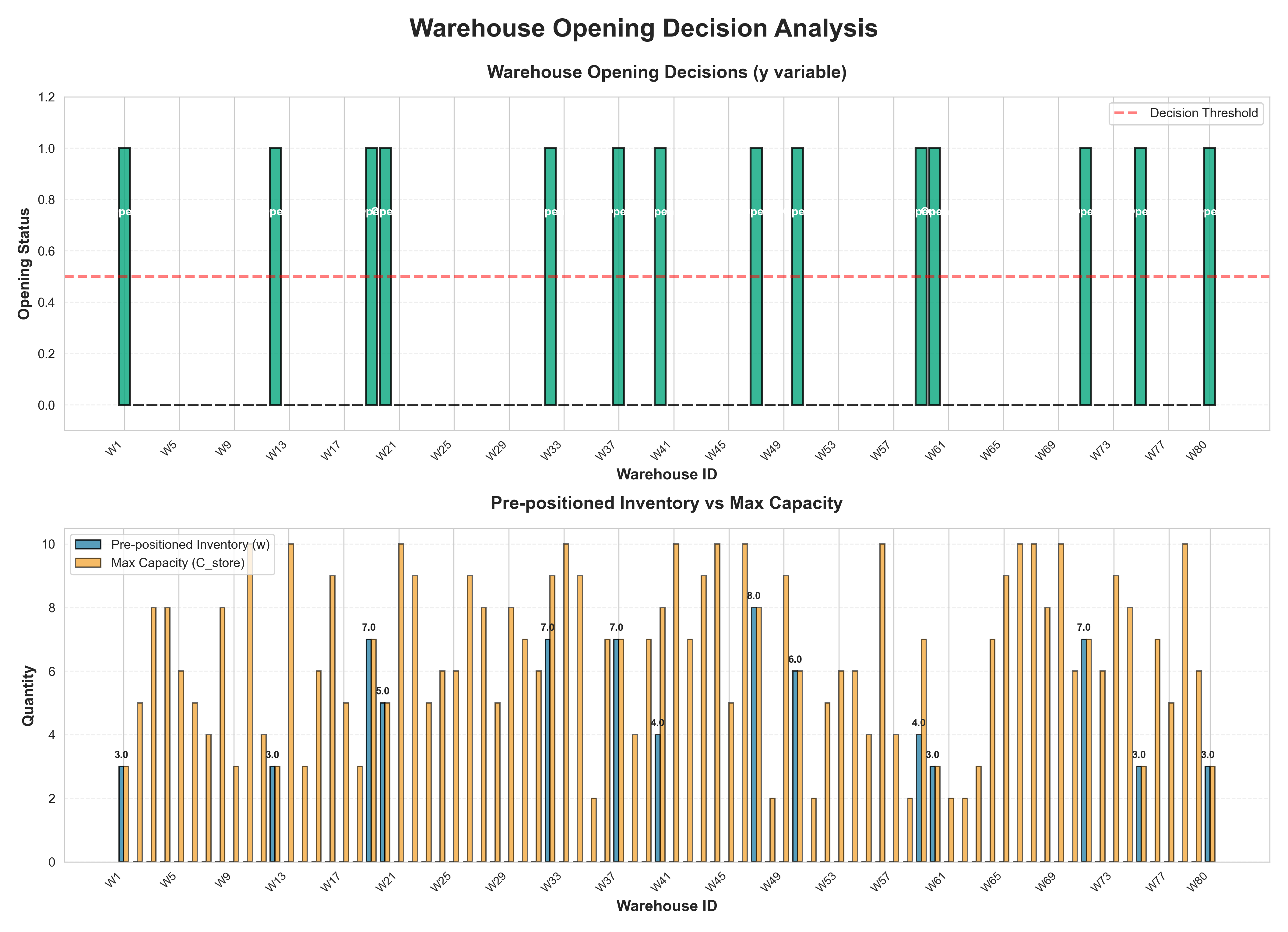
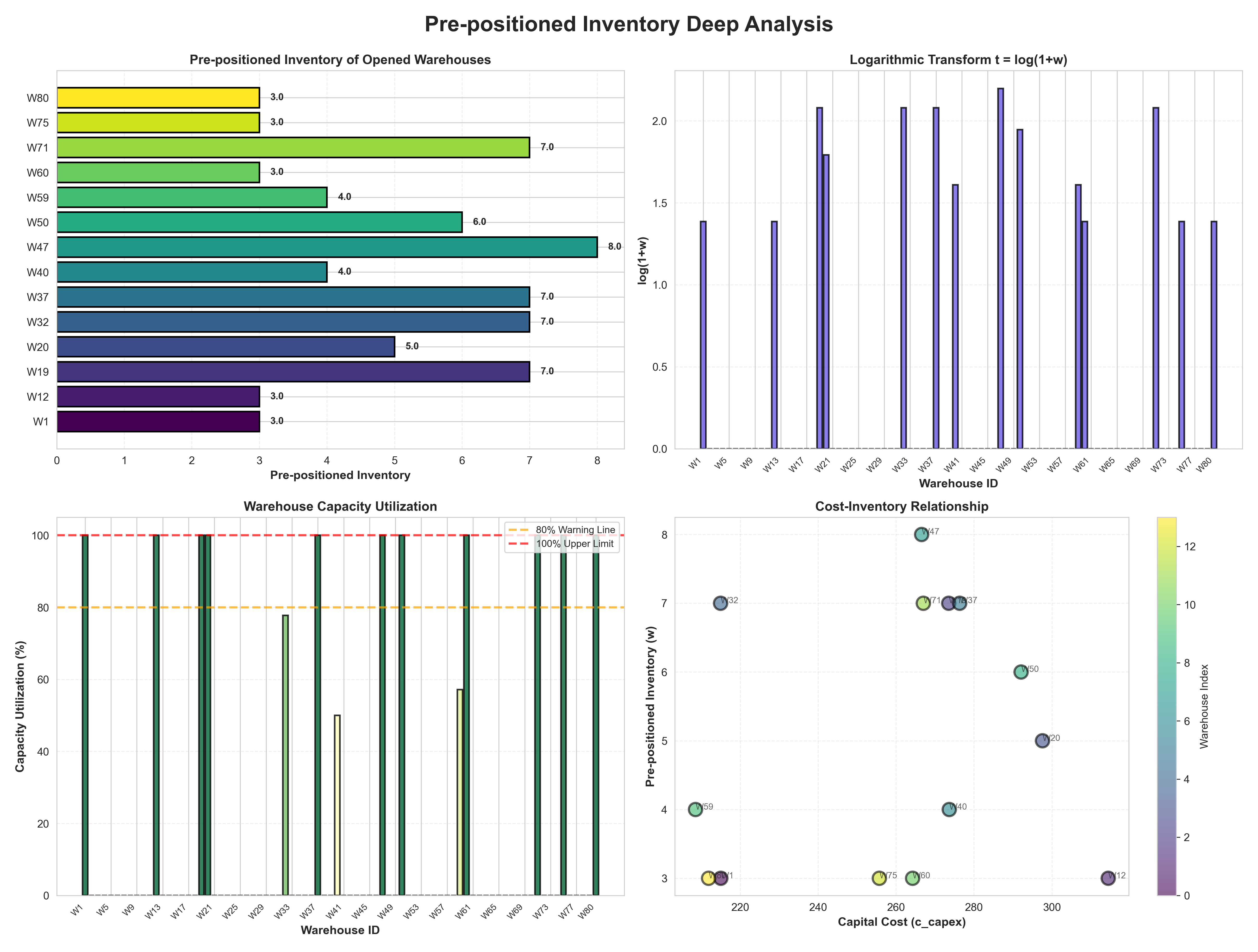
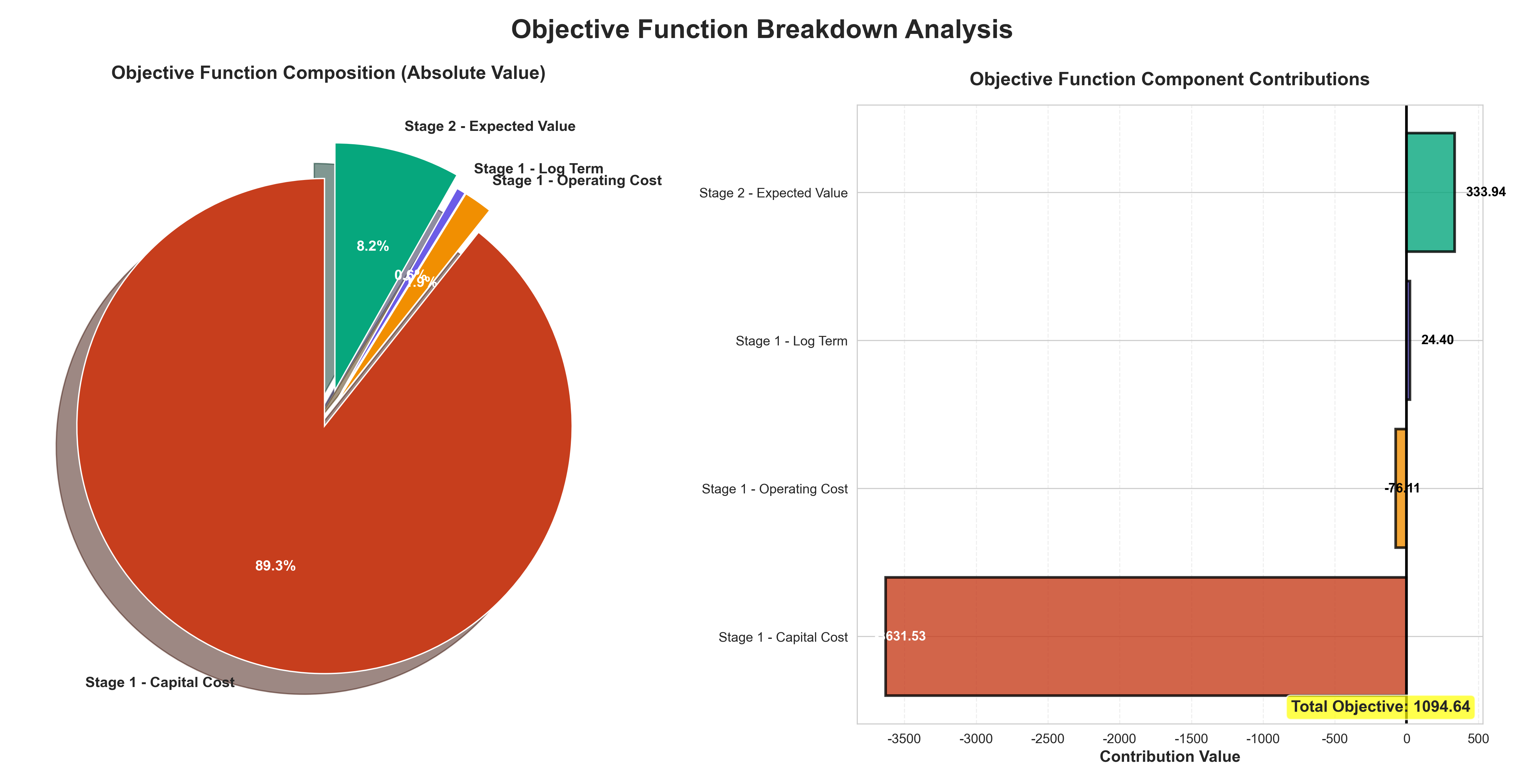
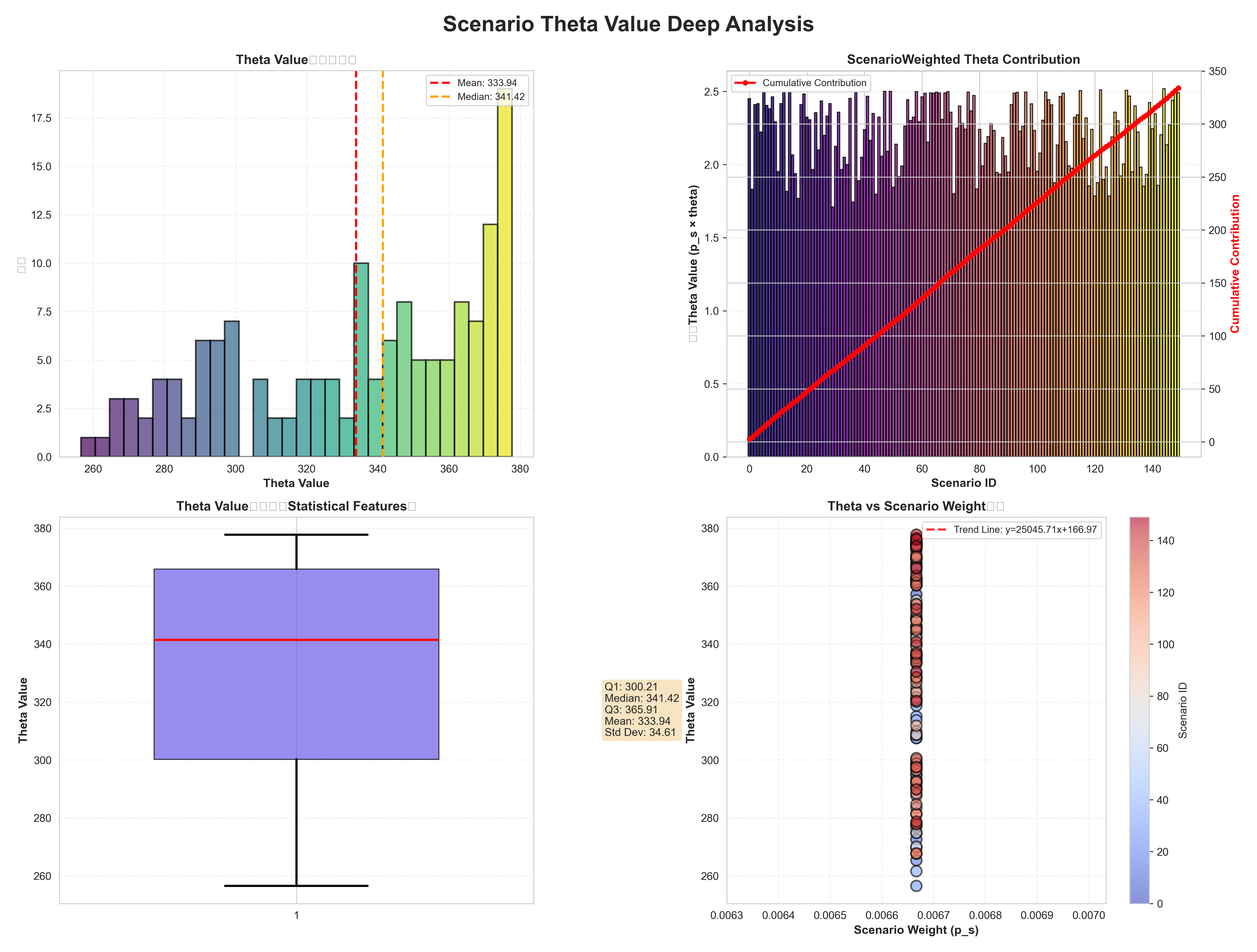
五、项目优势与创新点
5.1 算法创新
- 并行化Benders分解:显著提升大规模问题求解速度
- 智能割管理:平衡割的数量与质量,保持主问题规模可控
- Pareto最优割:减少迭代次数,加速收敛
- 自适应参数调优:根据问题特征动态调整求解器参数
5.2 工程实践
- 完整工作流:从数据加载到结果可视化的端到端流程
- 模块化设计:算法、可视化、报告生成分离,易于维护
- 配置驱动:通过配置文件控制行为,提高灵活性
- 性能监控:详细的性能分析日志,便于优化
5.3 可扩展性
- 支持不同规模:从J=10到J=80,S=20到S=200
- 易于扩展:可添加新的割平面策略、收敛准则等
- 跨平台:Windows、Linux、macOS兼容
六、论文发表潜力
6.1 算法层面
- 并行化Benders分解:可发表并行计算或优化算法相关会议/期刊
- 智能割管理:可研究割的活跃度度量与管理策略
- Pareto最优割:可研究Pareto割的生成与应用
6.2 应用层面
- 供应链优化:可应用于实际案例,形成应用论文
- 性能评估:可进行大规模实验,形成性能评估论文
6.3 系统层面
- 工程实践:可总结大规模优化系统的设计与实现
- 可视化分析:可研究优化结果的可视化方法
七、技术细节深度解析
7.1 Benders分解的数学基础
Benders分解基于对偶理论。对每个场景s,对偶子问题为:
max {∑j (bsj - wj)·πj - ∑_j yj·μj - tj·νj}
其中π、μ、ν为对偶变量。对偶子问题的最优值生成Benders割:
θs ≥ 对偶最优值 + ∑j (wj - wj)·∂θ/∂wj + ...
7.2 Pareto最优割的生成
Pareto最优割比标准Benders割更强。生成步骤:
- 求解对偶子问题,得到对偶解π, μ, ν*
- 构造Pareto割:θs ≥ f(w, y, t, π, μ, ν)
- 验证Pareto最优性:检查是否支配其他可能的割
7.3 并行化的实现细节
使用ThreadPoolExecutor实现并行化:
- 线程池大小:根据CPU核心数动态调整
- 任务分配:每个场景一个任务
- 结果收集:使用Future收集结果
- 异常处理:单个子问题失败不影响整体
7.4 割管理的策略
割管理策略包括:
- 活跃度计算:基于割的违反程度和最近使用情况
- 移除策略:移除活跃度低于阈值的割
- 保留策略:保留最近添加的割和关键割
八、实际应用案例
8.1 问题规模
- 小规模:J=10, S=20,求解时间<1秒
- 中规模:J=30, S=50,求解时间约5-10秒
- 大规模:J=80, S=150,求解时间约12-15秒
- 超大规模:J=80, S=200,求解时间约20-30秒(受Gurobi许可证限制)
8.2 性能对比
与传统方法对比:
- 串行求解:S=150时约60-80秒
- 并行求解:S=150时约12-15秒,加速比约4-5倍
- 智能割管理:主问题规模减少约30-50%
- Pareto割:迭代次数减少约30-50%
九、未来工作与扩展
9.1 算法改进
- 多线程并行:使用多进程进一步提升并行效率
- 割平面选择:研究更智能的割选择策略
- 预处理:研究问题预处理技术,减少问题规模
9.2 系统优化
- 分布式计算:支持分布式求解大规模问题
- 实时监控:添加实时性能监控界面
- 自动调参:研究自动参数调优方法
9.3 应用扩展
- 多目标优化:扩展到多目标优化问题
- 鲁棒优化:支持鲁棒优化模型
- 在线优化:支持在线决策场景
十、总结
本项目提供了一个基于Benders分解的完整解决方案,涵盖算法设计、工程优化和可视化分析。主要贡献:
- 算法创新:并行化、智能割管理、Pareto最优割
- 工程实践:完整的系统实现,性能优化
- 可视化分析:12种专业图表,支持深度分析
- 可扩展性:模块化设计,易于扩展
项目在J=80、S=150规模下,总运行时间约1.2分钟,算法求解时间约12.7秒,相比传统方法有显著提升。代码已开源,欢迎使用和改进。
参考文献与资源
- Benders, J. F. (1962). Partitioning procedures for solving mixed-variables programming problems. Numerische Mathematik, 4(1), 238-252.
- Gurobi Optimization. Gurobi Optimizer Reference Manual.
- Python Threading Documentation.
作者简介:专注于大规模优化算法的研究与工程实践,在Benders分解、列生成等分解算法方面有深入研究。