文章目录
- [Ⅰ. Stack(不推荐使用了☠)](#Ⅰ. Stack(不推荐使用了☠))
- [Ⅱ. Queue](#Ⅱ. Queue)
- [Ⅲ. Deque](#Ⅲ. Deque)
- [Ⅳ. PriorityQueue](#Ⅳ. PriorityQueue)
- [Ⅴ. Map](#Ⅴ. Map)
- [Ⅵ. Set](#Ⅵ. Set)

Ⅰ. Stack(不推荐使用了☠)
常见方法如下所示:
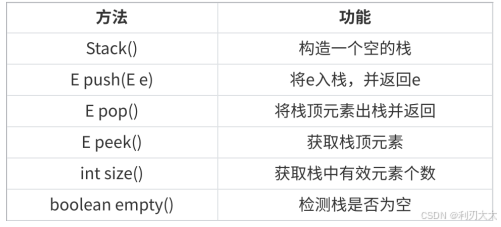
其中
peek()就相当于是std::stack中的top()。
注意事项:
-
在比较元素相同的时候,要使用
equals(),因为就算存储的是整数Stack<Integer>类型,里面仍然是引用类型,不能直接通过==来比较! -
因为
Stack继承于Vector,而Vector中还有很多实用的方法比如size()方法等,都是可以使用的,但由于Vector比较老,并且这种设计违反了最小接口原则 ,所以现在不推荐使用Stack,而是用Deque来替代!(如下面代码所示)-
Java推荐使用Deque接口的实现类,比如:ArrayDequeLinkedList
javaDeque<Integer> stack = new ArrayDeque<>(); // 使用Deque代替Stack stack.push(1); // 入栈 stack.pop(); // 出栈 stack.peek(); // 查看栈顶 stack.isEmpty(); // 是否为空
-

Ⅱ. Queue
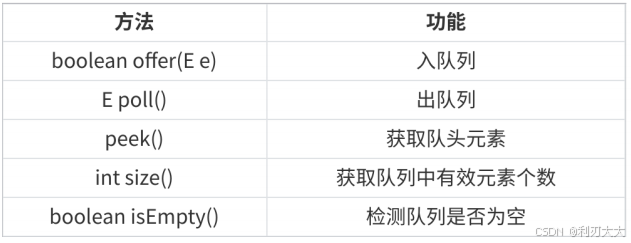
注意事项:
- Queue 是一个接口,要使用实现类来实现,常用
LinkedList、ArrayDeque、PriorityQueue来实现! - 一个队列可以实现 栈,但是一个栈实现不了 队列!225. 用队列实现栈、232. 用栈实现队列
Ⅲ. Deque
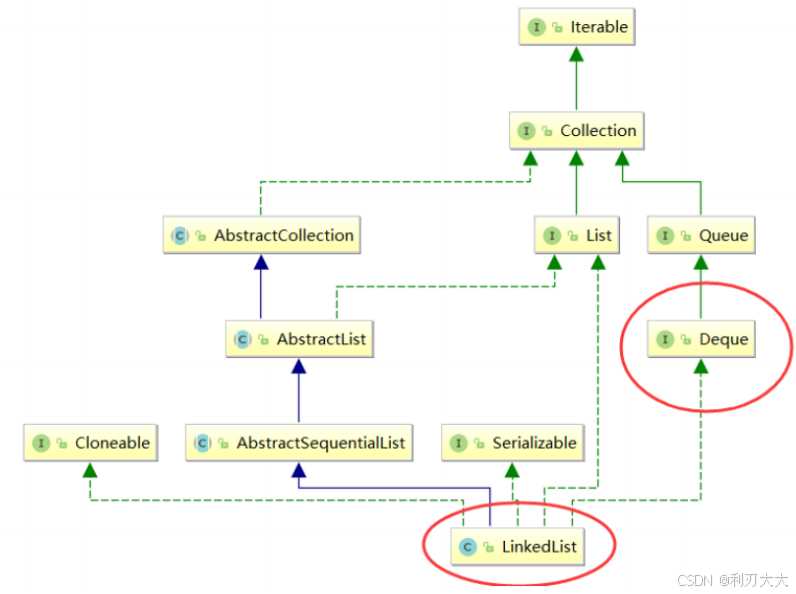
Deque 是一个接口,使用时必须创建 LinkedList 或者 ArrayDeque 类型的对象 。在实际工程中,使用 Deque 接口是比较多的,栈和队列均可以使用该接口。
java
Deque<Integer> stack = new ArrayDeque<>(); // 双端队列的线性实现
Deque<Integer> queue = new LinkedList<>(); // 双端队列的链式实现| 操作类型 | 方法名 | 描述 | 抛出异常版本 | 返回特殊值版本 |
|---|---|---|---|---|
| 插入 | addFirst(e) | 在队首插入元素 | 如果容量受限会抛出IllegalStateException | offerFirst(e) - 失败返回false |
| addLast(e) | 在队尾插入元素 | 同上 | offerLast(e) - 失败返回false | |
| 移除 | removeFirst() | 移除并返回队首元素 | 队列为空时抛出NoSuchElementException | pollFirst() - 队列为空返回null |
| removeLast() | 移除并返回队尾元素 | 同上 | pollLast() - 队列为空返回null | |
| 查看 | getFirst() | 查看队首元素(不移除) | 队列为空时抛出NoSuchElementException | peekFirst() - 队列为空返回null |
| getLast() | 查看队尾元素(不移除) | 同上 | peekLast() - 队列为空返回null | |
| 栈操作 | push(e) | 将元素压入栈 | 可能抛出IllegalStateException | 无 |
| pop() | 弹出栈顶元素 | 栈为空时抛出NoSuchElementException | 无 | |
| 其他 | size() | 返回队列中元素数量 | - | - |
| isEmpty() | 判断队列是否为空 | - | - | |
| contains(o) | 判断是否包含指定元素 | - | - | |
| remove(o) | 移除第一个匹配的元素 | 元素不存在时抛出NoSuchElementException | 无 |
Ⅳ. PriorityQueue
Java 集合框架中提供了 PriorityQueue 和 PriorityBlockingQueue 两种类型的优先级队列,PriorityQueue 是线程不安全的,PriorityBlockingQueue 是线程安全的,下面主要介绍 PriorityQueue。
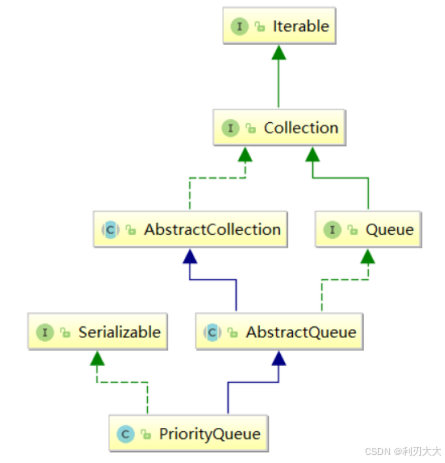
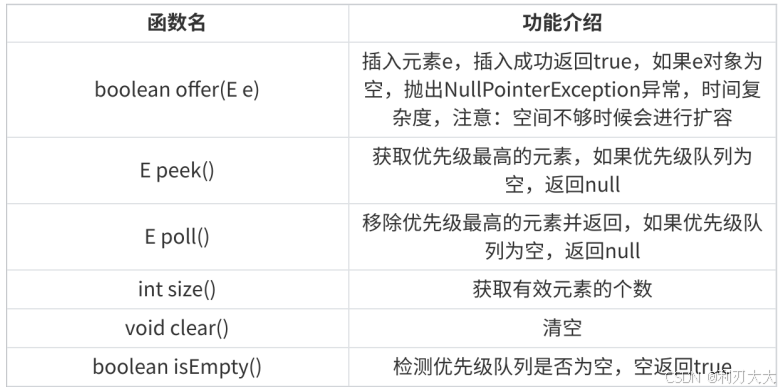
使用注意事项:
- 使用时必须导入包:
import java.util.PriorityQueue; PriorityQueue中放置的元素必须要能够比较大小 ,不能插入无法比较大小的对象,否则会抛出ClassCastException异常。- 不能插入
null对象 ,否则会抛出NullPointerException。 PriorityQueue默认情况下是小堆。- 创建自定义大小堆的比较器写法如下所示:(以
Integer为例)
java
// 推荐使用 Comparator 而不是 Comparable,因为前者比较灵活、侵入性小
// 创建小堆
class lesscmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
}
// 创建大堆
class greatercmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
}
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>(); // 默认为小堆
pq.add(10);
pq.add(20);
pq.add(15);
while(!pq.isEmpty()) {
System.out.println(pq.poll());
};
PriorityQueue<Integer> pq1 = new PriorityQueue<>(new greatercmp());
pq1.add(10);
pq1.add(20);
pq1.add(15);
while(!pq1.isEmpty()) {
System.out.println(pq1.poll());
}
// 使用lambda表达式创建大堆
PriorityQueue<Integer> pq2 = new PriorityQueue<>((o1, o2) -> {return o1.compareTo(o2)});
pq2.add(10);
pq2.add(20);
pq2.add(15);
while(!pq2.isEmpty()) {
System.out.println(pq2.poll());
}
}
// 运行结果
10
15
20
20
15
10
20
15
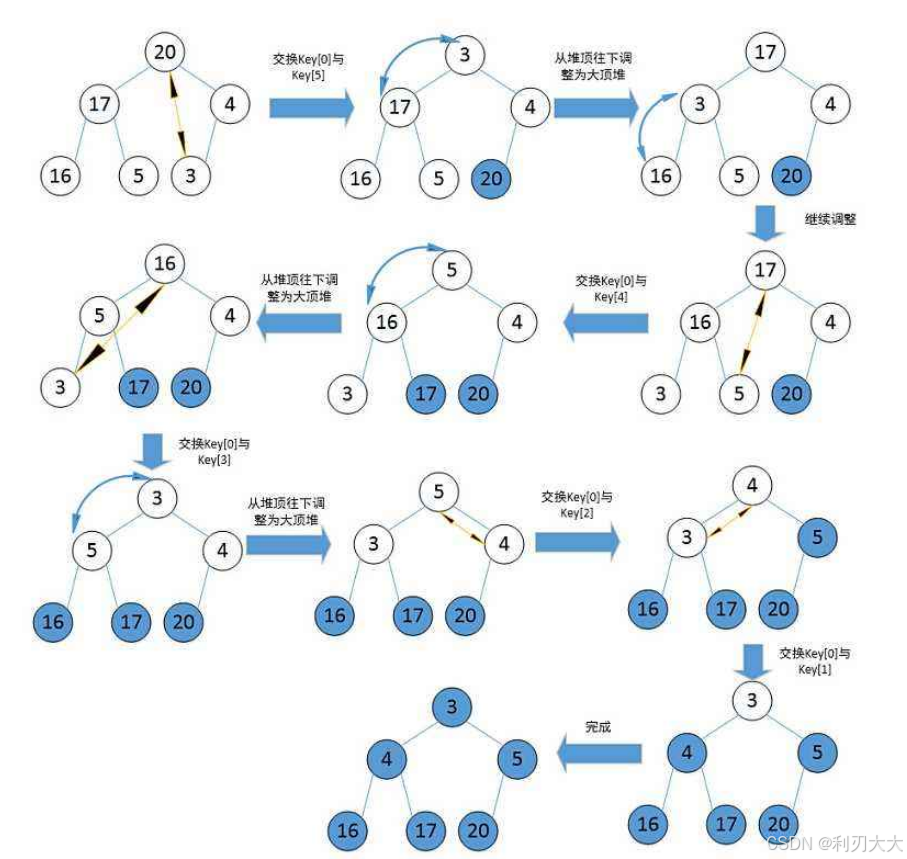
10堆排序
- 升序:建大堆
- 降序:建小堆
- 时间复杂度:O(nlogn)
Ⅴ. Map
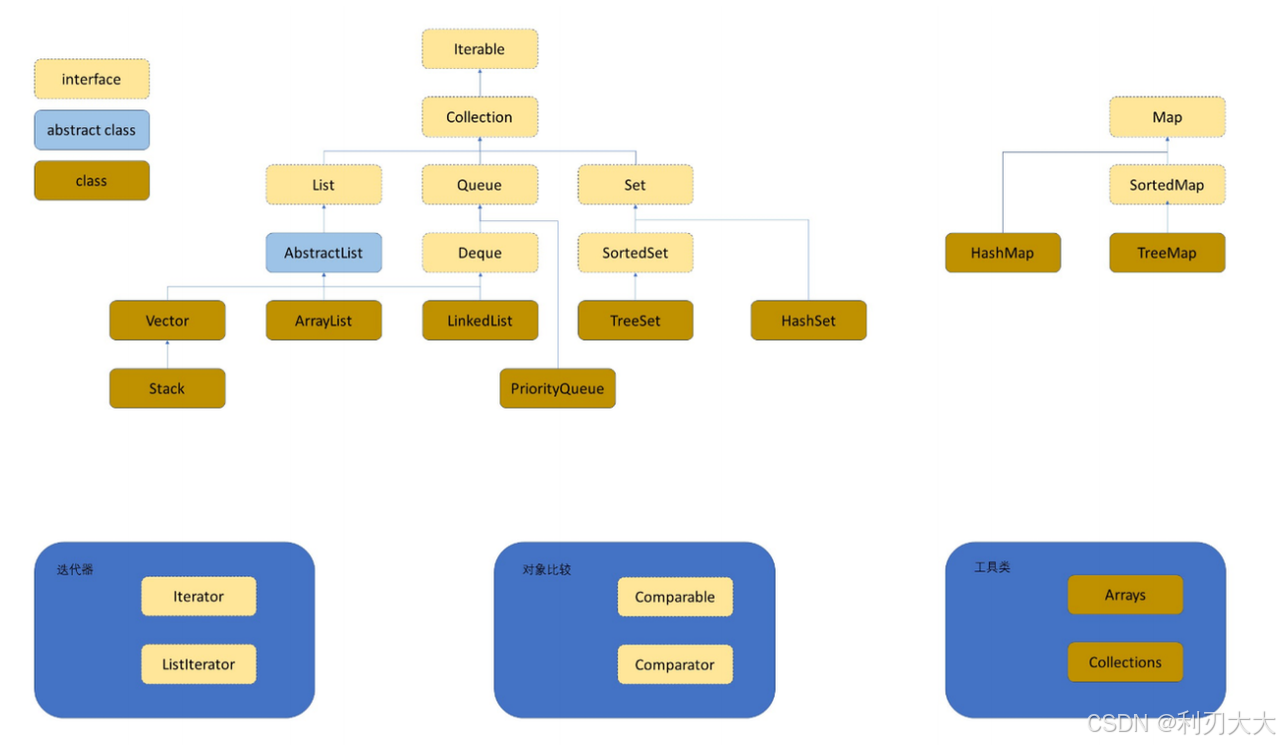
Map 是一个接口类 ,该类没有继承自 Collection,该类中存储的是 <K,V> 结构的键值对,并且 K 一定是唯一的,不能重复。
https://docs.oracle.com/javase/8/docs/api/index.html
☠注意事项:
- 内置类型不能直接来实例化
HashMap,必须要找其对应的包装类型 - 在
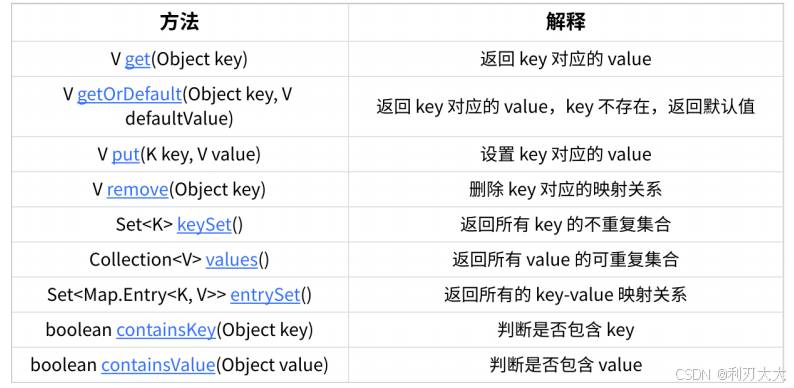
TreeMap中的key不能为空 ,否则就会抛NullPointerException异常,value可以为空;而HashMap的key和value都可以为空。 Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。HashMap的底层实现中,当某个桶中链表元素超过8个,并且桶的个数超过64个,此时会将该桶中的链表转化为红黑树维护,降低高度!- 采用方法如下所示:
-
其中
getOrDefalut()方法通常用于统计次数的时候简化代码,如下所示:javapublic List<String> topKFrequent(String[] words, int k) { // 统计字符串出现个数 Map<String, Integer> hash = new HashMap<>(); for(int i = 0; i < words.length; ++i) { hash.put(words[i], hash.getOrDefault(words[i], 0) + 1); // 这样子来简化代码 } ... } -
Map(如HashMap、TreeMap等) 自身没有迭代器 ,即没有实现Iterator接口,但它的视图对象(keySet、entrySet、values)都可以迭代,如下所示:java// 遍历 keySet()(只要 key) for (K key : map.keySet()) { System.out.println(key); } // 遍历 values()(只要 value) for (V value : map.values()) { System.out.println(value); } // 遍历 entrySet()(需要 key 和 value)⭐⭐⭐⭐⭐⭐⭐(推荐) for (Map.Entry<K, V> entry : map.entrySet()) { System.out.println(entry.getKey() + " = " + entry.getValue()); } -
上述的
entrySet()是Map接口中的一个方法,返回一个包含了所有 键值对 的Set集合 ,这些键值对就是Map.Entry<K, V>对象,它们每一个都包含两个元素:key和value。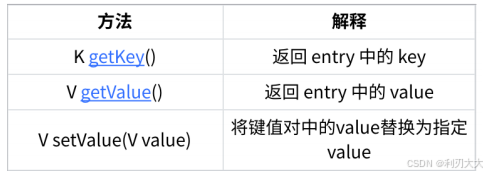 java
java// 也就是说上面的for-each可以转化为迭代器来处理,如下所示:(这里只举例entrySet) Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); while(it.hasNext()) { System.out.println(it.next().getKey() + " " + it.next().getValue()); } -
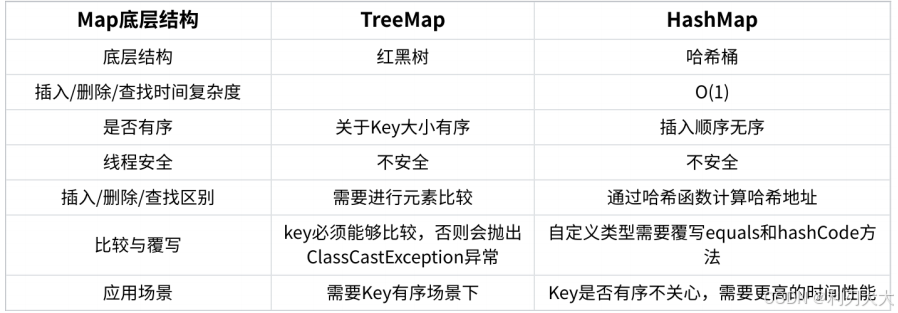
TreeMap和HashMap的区别如下图所示。其中因为HashMap在比较内容的时候是根据hashCode()来确定key是在哪个桶中的,而根据equals()来确定是桶中的哪个元素,所以在HashMap中存放自定义类型的时候,需要重写该自定义类型的equals()和hashCode()方法。
Ⅵ. Set
Set 与 Map 主要的区别:
Set是继承自Collection的接口类Set中只存储了Key。
但实际上底层源码实现是让 Set 去调用 Map 的接口 ,只不过传入的 value 是一个默认的 Object 对象,而只需要关心 key 即可。
常用方法如下所示:
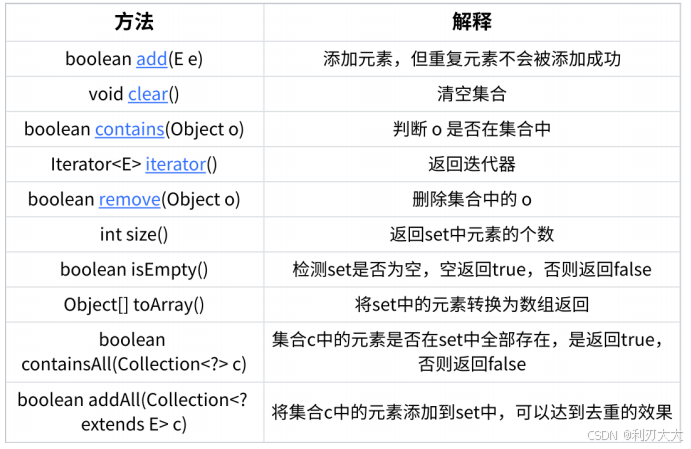
注意事项:
Set最大的功能就是对集合中的元素进行去重- 实现
Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。 TreeSet中不能插入null的key,而HashSet可以。