今天给大家演示一个基于 Qwen 与 Wan2.2 的写真四角度运镜视频生成工作流,通过多模型协同、图像编辑链路和补帧插值流程,实现从静态图到多视角动态视频的完整生成效果。
工作流结合了图像理解、VAE 解码、UNet 推理、镜头编辑指令和补帧技术,让最终的视频既稳定又具有真实的镜头运动感,整体流程清晰易复用,适合对 ComfyUI 高级工作流感兴趣的同学参考。
文章目录
- 工作流介绍
-
- 核心模型
- [Node 节点](#Node 节点)
- 工作流程
- 大模型应用
-
- [TextEncodeQwenImageEditPlus 精准控制画面语义与风格](#TextEncodeQwenImageEditPlus 精准控制画面语义与风格)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流围绕四大模块展开,包括模型加载、中间特征处理、视频插帧以及镜头控制。通过 Qwen Image Edit 系列模型负责图像理解与编辑,Wan2.2 模型提供高质量的视觉生成能力,GIMM-VFI 模型承担运镜视频补帧,而大量节点则负责批量图像拆分、读取、数学表达式计算、随机数生成等辅助任务,以确保完整的视频生成链路顺畅执行。整体设计目的是让用户输入图像或提示词后,自动完成角度切换、镜头变更和动态补帧,让最终视频自然流畅。
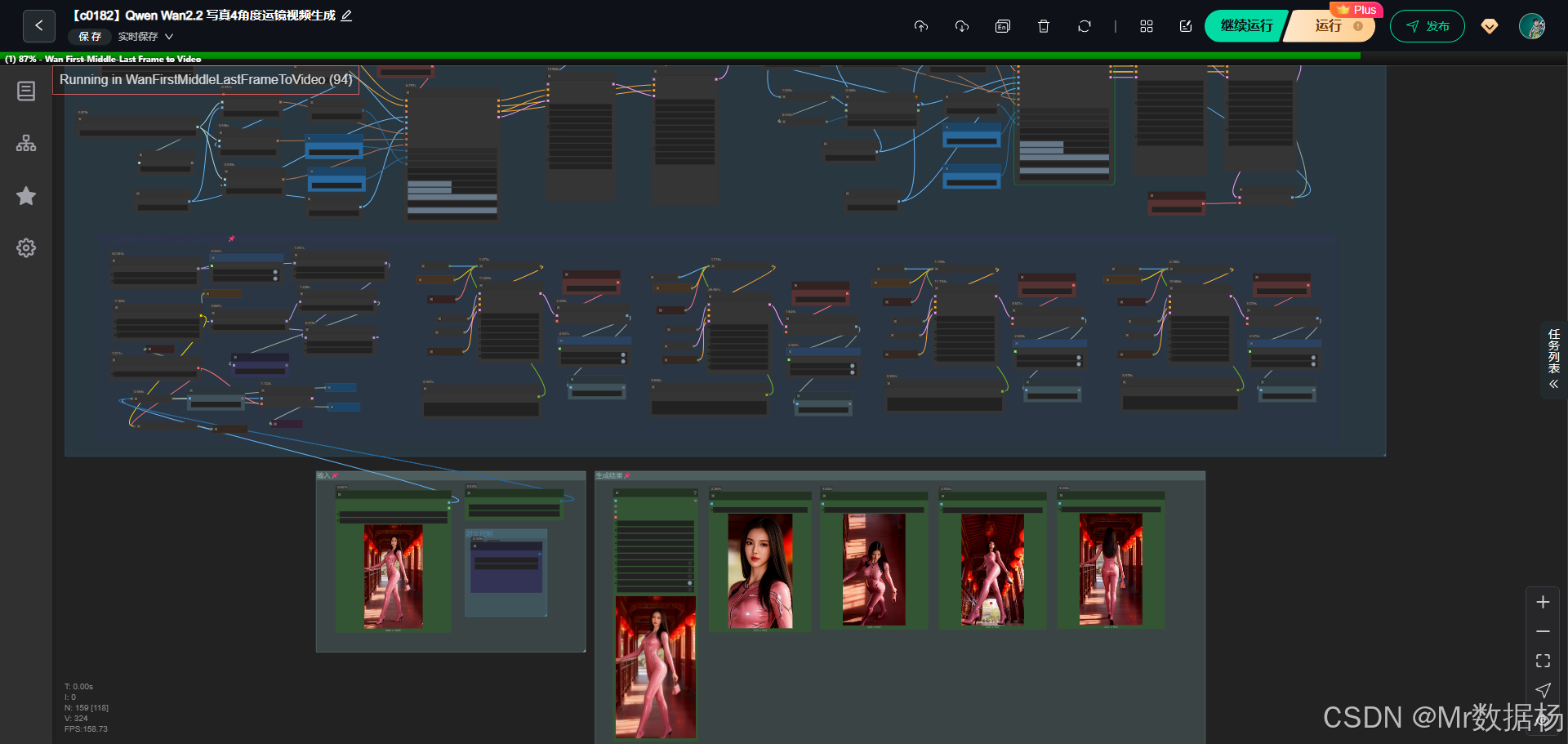
核心模型
工作流加载的核心模型包括 Wan2.2 视觉生成模型、Qwen Image Edit 系列的 CLIP、UNet 与 VAE 组件,以及用于插帧的视频补帧模型 GIMM-VFI。它们共同构成图像编辑、潜空间采样与视频重建的核心能力:Wan 负责原始视觉生成,Qwen 负责图像理解与精控编辑,而 GIMM-VFI 在生成的关键帧之间智能插入过渡帧,使镜头更连贯。
| 模型名称 | 说明 |
|---|---|
| wan_2.1_vae.safetensors | Wan2.2 视觉模型的 VAE,用于潜空间解码 |
| umt5_xxl_fp16.safetensors | Wan 模型使用的 CLIP 文本编码器 |
| qwen_image_edit_2509_bf16.safetensors | Qwen 图像编辑 UNet,用于图像局部重绘 |
| qwen_2.5_vl_7b_fp8_scaled.safetensors | Qwen 图像编辑的 CLIP,用于多模态理解 |
| qwen_image_vae.safetensors | Qwen 对应的 VAE,用于解码编辑后的潜空间 |
| gimmvfi_r_arb_lpips_fp32.safetensors | GIMM-VFI 视频插帧模型,用于补帧生成顺滑视频 |
Node 节点
工作流中涉及大量节点类型,每类节点承担不同职责:模型加载节点负责载入各类模型;数学表达式节点协助自动计算分辨率、批次数量或随机种子;图像批处理节点将生成的图片做拆分与合并;潜空间采样节点 KSampler 负责根据正负提示生成潜空间图像;图像编辑链路的节点则按 Qwen 的格式完成图像重绘;插帧链路节点调用 GIMM-VFI 在多帧之间补充细腻过渡动画,最后由 VAE Decode 节点输出最终图像或视频帧。
| 节点名称 | 说明 |
|---|---|
| VAELoader / VAEDecode | 加载与解码 VAE,完成潜空间处理 |
| CLIPLoader / CLIPVisionLoader | 文本、视觉编码器加载 |
| UNETLoader | 图像编辑 UNet 加载 |
| KSampler | 进行扩散采样生成潜空间图像 |
| GetImageSizeAndCount | 获取输入图片尺寸与帧数 |
| ImageBatch / ImageFromBatch | 图像批量合并与拆分 |
| GIMMVFI_interpolate | 补帧处理,使镜头过渡自然 |
| MathExpression / SimpleMath+ | 做数值表达式运算 |
| SetNode / GetNode | 变量存取,提高流程复用性 |
| TextEncodeQwenImageEditPlus | 用 Qwen 处理图像编辑提示词 |
工作流程
整个流程围绕"输入图像与提示词处理、潜空间生成、图像编辑、镜头角度切换、补帧生成视频"这条主线展开。前段由 Qwen 与 Wan 协作完成潜空间生成与重绘,中段通过节点对图像进行拆分、批处理与尺寸逻辑计算,后段引入 GIMM-VFI 对各角度关键帧进行插帧,让最终的视频具备稳定的四视角运镜效果。流程内部通过 SetNode 与 GetNode 保持变量一致性,让每个阶段的图像、潜空间与模型都能接续使用,确保镜头切换时不卡顿、不跳帧。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载阶段 | 加载 Wan 与 Qwen 的 UNet、CLIP、VAE,为后续潜空间与图像编辑做好准备 | UNETLoader、CLIPLoader、VAELoader |
| 2 | 图像与特征提取 | 输入原图,提取尺寸、帧数,并通过 CLIP Vision 提升图像理解能力 | GetImageSizeAndCount、CLIPVisionEncode |
| 3 | 潜空间生成 | 根据正负提示词进行扩散采样,生成用于编辑的潜空间结构 | KSampler、TextEncodeQwenImageEditPlus |
| 4 | 图像编辑与角度切换 | 利用 Qwen Image Edit 实现局部重绘与视角调整,例如"切换为背面镜头"等提示 | Qwen Edit 模块链、UNet 推理 |
| 5 | 批量图像处理 | 生成的多角度图像合并或拆分为批次,以适配后续插帧需求 | ImageBatch、ImageFromBatch |
| 6 | 视频补帧与镜头运动 | 使用 GIMM-VFI 根据关键帧生成中间帧,让镜头运动自然连贯 | GIMMVFI_interpolate |
| 7 | 最终图像解码与输出 | 将潜空间解码为最终图像序列,并写入视频流 | VAEDecode、SetNode / GetNode |
大模型应用
TextEncodeQwenImageEditPlus 精准控制画面语义与风格
这一类大模型节点主要负责将文本 Prompt 编码成可被后续生成模型理解的语义条件。它决定画面的风格、镜头语言、动作方向、细节层次等,是整个工作流的"语义大脑"。
用户输入的 Prompt 会被模型解析为清晰的语义特征,从而控制多角度的画面变化,例如俯视、仰视、特写或背面镜头。每一个 Prompt 的变化都会直接影响最终视频的镜头设计。
在此节点中,Prompt 是核心驱动因素,文字越明确,镜头越精准,模型生成的画面稳定性也越高。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlus(提示词1) | 将镜头转为俯视 | 将文字转换为"俯视视角"语义特征,影响镜头角度与主体位置 |
| TextEncodeQwenImageEditPlus(提示词2) | 将镜头转为背面镜头 | 生成与背面方向相关的语义,引导人物转向或视角翻转 |
| TextEncodeQwenImageEditPlus(提示词4) | 将镜头转为特写镜头 | 控制画面进入近距离构图,强化人物细节 |
| TextEncodeQwenImageEditPlus(提示词6) | 将镜头转为仰视,从下往上看,仰视,仰拍 | 控制其呈现仰视角度,强调主体气势或高度 |
| TextEncodeQwenImageEditPlus(其他镜头组) | 将镜头转为特写 / 背面 / 俯视(不同组别) 镜头方向变化分布在多个文本节点 | 不同文本节点负责不同组别的镜头语义,为多角度运镜提供清晰的条件编码 |
使用方法
整个工作流的逻辑是:用户提供一张主图,通过多组 Prompt 控制不同镜头角度,再由大模型逐步生成多个方向的独立画面,最后在视频部分进行运镜组合,得到一个多角度的写真类动态视频。
当用户替换新的图片后,整个流程会自动使用相同的 Prompt 模板生成多角度内容,从而达到"一张图生成多视角镜头"的效果。
主图负责提供人物基础特征,动作图或多图输入可补充细节或替代视角,而 Prompt 决定镜头语言及画面叙事方向,是驱动整个多镜头生成的关键参数。
| 注意点 | 说明 |
|---|---|
| Prompt 要清晰 | 镜头方向、距离、动作描述越明确,生成越稳定 |
| 主图质量影响大 | 清晰度越高,四角度镜头越统一 |
| 不建议使用复杂背景 | 背景越简洁,多角度越好对齐 |
| 多组 Prompt 要保持风格一致 | 避免角度变化时画面不统一 |
| 文件命名需规范 | 有助于自动输出多角度结果,避免覆盖 |
应用场景
这个工作流适用于需要从静态图快速生成多角度动态镜头视频的创作场景,例如写真拍摄模拟、人物展示短片、剧情镜头测试等。通过 Qwen 的图像编辑能力,用户可以以文字直接控制镜头,从正面切换到背面、从左侧切到右侧,再配合 Wan 的高质量生成与 GIMM-VFI 的补帧,让视频具备真实摄影中的运镜效果。无论是创作者需要预览镜头脚本,还是内容生产者批量生成角色展示视频,甚至是短视频创作,都能从这个流程中获得高效稳定的产出。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 写真级人物运镜展示 | 从单张图生成四角度动态镜头 | 写真创作者、模特展示设计师 | 前后左右四角度的视频片段 | 拥有自然转场与真实镜头运动感 |
| 角色展示短片制作 | 批量生成人物多视角动态片段 | CG 角色作者、虚拟偶像制作人 | 多角度角色展示与动作预览 | 视频平滑、补帧自然、质量稳定 |
| 剧情镜头预演 | 通过文字控制镜头方向与角度 | 导演、剧情短片制作者 | 镜头脚本对应的实际视觉效果 | 快速验证镜头语言与节奏 |
| AI 模特内容输出 | 自动生成可商用短视频素材 | 内容运营、自媒体制作者 | 人物运镜、穿搭展示 | 高质量、自动化的视频生成效果 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用