卷积神经网络(Convolutional Neural Networks, CNN)是一种专门用于处理具有网格状结构数据的深度学习算法,"卷积"一词源于同名的数学运算,它是一种常用于图像处理的特殊线性运算。卷积神经网络在图像识别、计算机视觉等领域表现出色。
文章目录
- 一、传统神经网络的缺陷
-
- [1.1 空间关联性丢失](#1.1 空间关联性丢失)
- [1.2 维度灾难与过拟合风险](#1.2 维度灾难与过拟合风险)
- [1.3 缺乏平移 / 尺度 / 旋转不变性](#1.3 缺乏平移 / 尺度 / 旋转不变性)
- 二、卷积神经网络如何识别图片
-
- [2.1 特征提取:卷积层](#2.1 特征提取:卷积层)
- [2.2 特征强化与下采样:池化层](#2.2 特征强化与下采样:池化层)
- [2.3 分类推理:全连接层](#2.3 分类推理:全连接层)
- 三、总结
一、传统神经网络的缺陷
机器无法像人类一样从整体上感知图片是什么,对于计算机来说,图片只是由像素组成的二维结构数据,每个像素代表一个值,该值表示图像中特定位置的颜色或强度。
传统神经网络(如多层感知机,MLP)在处理图像时,必须将图像数据进行展平(Flattening)操作。例如一张彩色图像通常是一个三维数组(例如 256x256像素x3 个颜色通道),在输入神经网络前,必须将这个三维数组拉伸成一个一维向量,但这种操作也带来了一系列问题和缺陷。

1.1 空间关联性丢失
首先,数据展平的操作破坏了原始图像的二维结构,减少了图像中包含的空间信息。这种信息丢失会导致传统神经网络无法理解图像中像素点之间的局部空间关系和拓扑结构。例如,识别人脸不仅要识别眼睛、鼻子或嘴巴等单个面部特征,还要理解它们之间的相对位置,传统的神经网络无法有效地解释特征之间的这种空间层次结构,这也是传统神经网络最根本的缺陷。
1.2 维度灾难与过拟合风险
同时,将图片数据作为一个整体处理还会导致模型参数量爆炸,数量随输入维度(图像像素数)呈指数级增长,最终引发 "维度灾难"。例如一张相对较小的 100 × 100 100 \times 100 100×100 像素的 RGB 图像(即 100 × 100 × 3 = 30 , 000 100 \times 100 \times 3 = 30,000 100×100×3=30,000 个输入特征),如果第一个隐藏层有 1000 个神经元,则仅这一层就需要 30 , 000 × 1 , 000 = 30 , 000 , 000 30,000 \times 1,000 = 30,000,000 30,000×1,000=30,000,000 个连接权重,训练和存储这个庞大的模型需要巨大的计算资源,且过多的参数使得模型很容易在训练集上过度拟合,从而导致在未见过的新图片上泛化能力差。
1.3 缺乏平移 / 尺度 / 旋转不变性
图像识别的核心需求之一是 "对物体的位置、大小、旋转变化不敏感",但传统神经网络对这些变化极其敏感。将物体在图片中稍微移动位置、缩放大小、旋转等操作会导致输入向量的位置变化,进而导致 MLP 无法识别它。为了让神经网络能够识别它,你需要提供大量包含该物体在各种位置的训练样本,这大大增加了训练数据的需求和难度。
二、卷积神经网络如何识别图片
CNN 识别图片是一个分层的、自动化的特征提取和分类过程:浅层学习边缘,中层学习形状,深层学习高阶特征(如"猫的眼睛"),简单点说,神经网络的前几层捕获输入图像中的基本视觉元素,随着信息流经网络的后续层,通过组合和抽象这些低级特征来学习更高级别的特征,最终这些特征被组合起来以理解图像中的内容,它模仿了人类视觉系统从低级特征(如边缘)到高级特征(如具体细节)的识别模式。
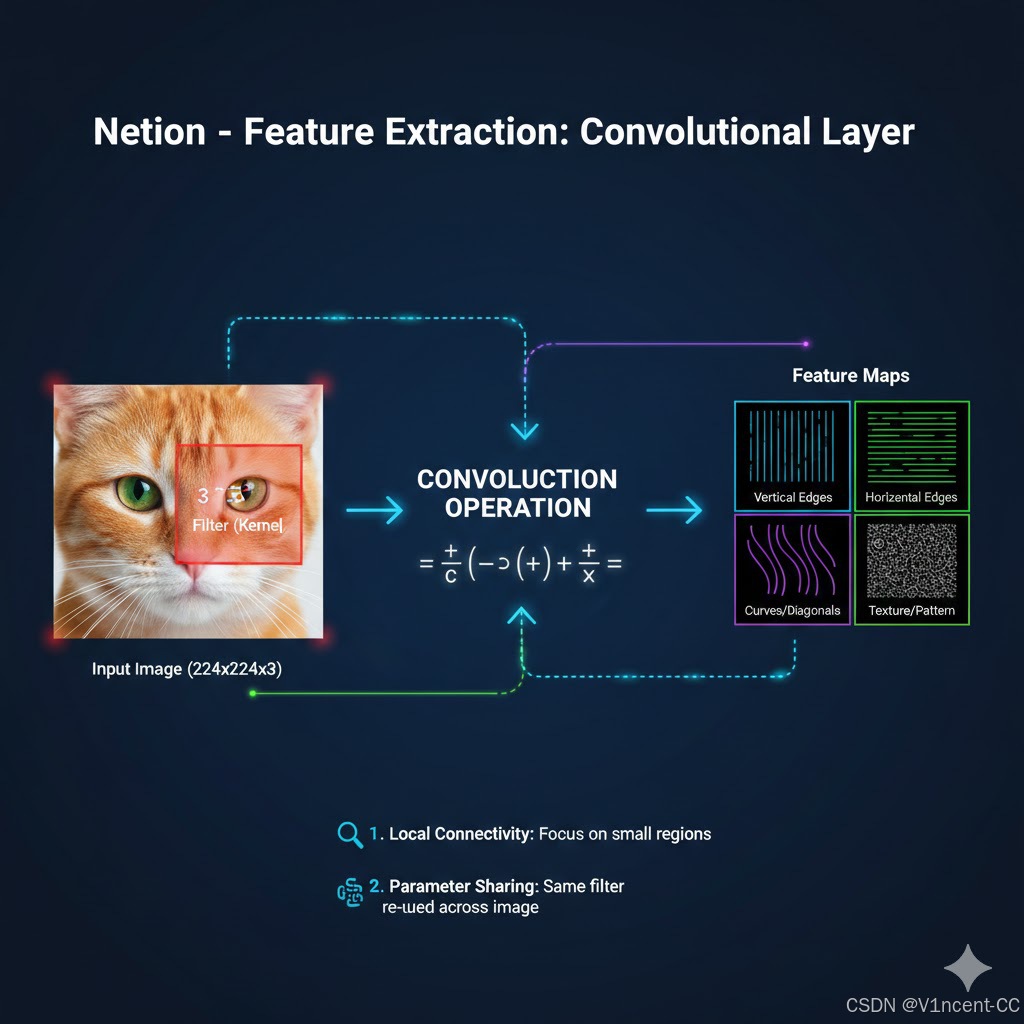
2.1 特征提取:卷积层
CNN 通过卷积层解决 MLP 的空间关联性丢失和维度灾难问题。不管图片有多大,卷积层仅使用小块的(例如3x3的像素)数据学习图像特征(只关注局部像素),每次卷积操作都产生一个输出值,将这些输出值组合起来形成特征图 (Feature Map) ,这些特征图对应的即是图片的低级特征(边缘轮廓、曲线等)。
例如,当 CNN 被训练识别猫时,它会学习检测猫的独特特征,例如猫耳朵的形状、四肢的存在以及整体身体结构,这些特征集合在不同的猫图像中始终存在,无论它们的整体位置或姿势如何,而CNN 通过捕捉这些特征之间的空间关系,可以有效地泛化和识别猫,无论它们是趴着、站立还是运动。这种方法对图像中物体的位置和失真不太敏感,即使物体的外观有所变化,模型也能够识别,从而使其能够捕捉局部模式、空间层次以及特征之间的空间关系。
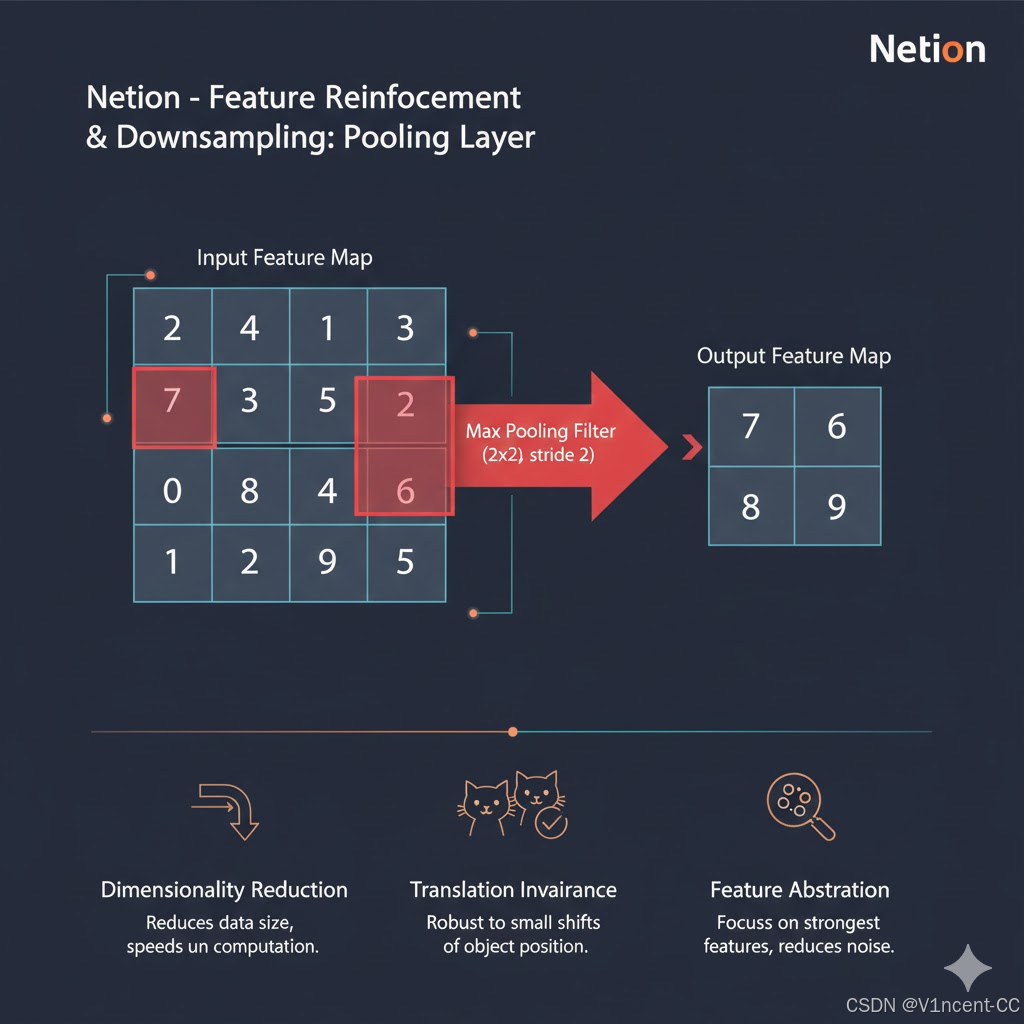
2.2 特征强化与下采样:池化层
随后,卷积神经网络(CNN)中的池化层 (Pooling Layer)会减小特征图的维度,池化层本质上是一个非线性下采样的过程,它在保留关键特征信息的前提下,对特征图进行压缩,例如通过在特征图上设置一个窗口(例如 2 × 2 2 \times 2 2×2),并按一定步长滑动,窗口内的所有值被一个代表值取代(例如最大值或平均值)。
特征图采样降低了后续层需要处理的数据量,从而减少了网络的总参数数量,减少了训练和推理阶段所需的计算资源和时间。同时池化层通过聚焦于最强的特征,而不是其确切位置,来增强网络的鲁棒性。它确保即使输入图像中的特征(例如边缘)发生了轻微的平移或扰动,网络依然能输出相似的特征值,这使得模型具有更强的鲁棒性和泛化能力,不需要为物体在不同位置的出现都学习一套新的权重。
卷积层之后CNN 会通过的池化层降低数据的维度来解决这个问题,这涉及到汇总和保留最相关的信息,从而产生更易于管理和更高效的表示。通过压缩信息,池化可以减少数据量和所需的计算次数,从而加快整个网络的速度。
池化层还通过关注重要特征而不是其确切位置来增强网络的鲁棒性,这使得网络能够识别物体,即使它们看起来略有偏移或位于图像的不同位置。
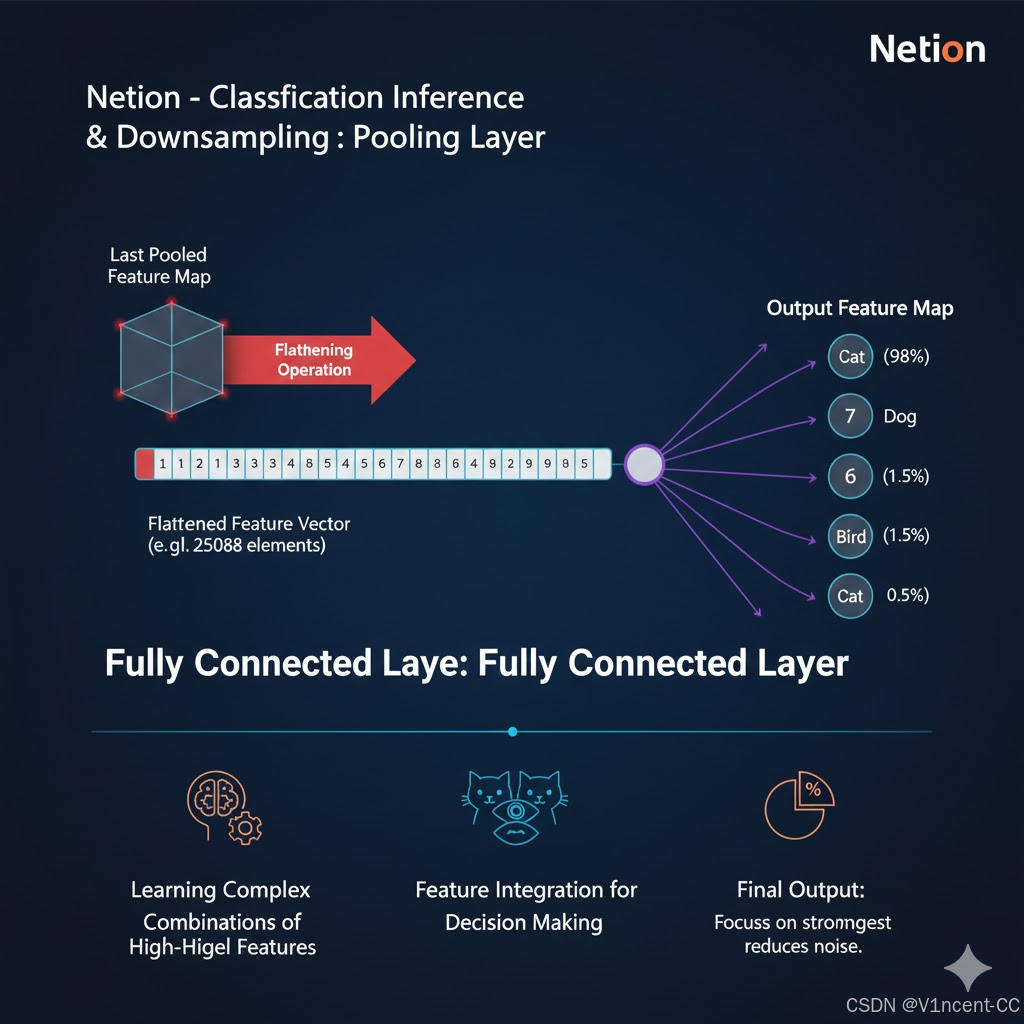
2.3 分类推理:全连接层
在经过多层卷积和池化操作后,图像的原始像素信息已经被抽象、浓缩成一个高维的特征表示,将最后一个池化层输出的多维特征图展平为一个一维向量,此时再将展平后的向量被输入到传统的多层感知机(全连接层)。
全连接层不再处理原始像素,而是处理由前面卷积层提取出的高级抽象特征,它负责学习这些抽象特征之间的复杂非线性组合关系,例如,将"猫的眼睛特征"、"猫的耳朵特征"和"猫的嘴巴特征"组合起来,判断这些特征的组合最符合哪个类别,最后,通过 Softmax 激活函数输出最终的概率分布,给出图片属于每个类别的可能性(如"是猫的概率是 98%"),完成图片识别。
三、总结
CNN 的本质是 "分层提取特征的神经网络"------ 通过卷积层从原始图像中逐层学习 "边缘 → \to → 纹理 → \to → 部件 → \to → 整体" 的特征(通过局部连接和权值共享解决空间关联性丢失和维度灾难),用池化层压缩数据、强化关键信息(实现平移不变性),最后通过全连接层整合特征并完成分类。
它之所以能 "看懂" 图片,核心是抓住了图像的 "空间关联性" 和 "局部特征复用性",完美适配视觉数据的特点。