基于python构建的一个完整的PMC(Policy Measurement and Comparison)政策文本量化评估系统,使用Streamlit UI。
一、系统架构概览
1. 核心架构分层
1. 前端交互层 (Streamlit UI)
├── 多页面导航系统
└── 交互式表单和可视化
2. 业务逻辑层
├── ConfigurationManager (配置管理)
├── 文本预处理模块
├── 特征提取模块
└── PMC模型计算模块
3. 数据存储层
├── Session State (内存存储)
└── JSON文件 (持久化配置)2. PMC模型理论基础
系统基于PMC(政策量化评估)模型,包含:
-
9个一级变量:政策性质、时效、激励、领域、工具、操作性、评估、受众、主题
-
多个二级变量:每个一级变量下细分的具体指标
-
权重系统:支持用户自定义各级权重
二、核心模块详解
1. 配置管理系统 (ConfigurationManager)
# 关键特性:
- 完全可配置:无预设词汇,全部由用户定义
- 支持6种配置类型:停用词、情感词、关键词库、权重、评估标准
- 导入/导出功能:ZIP格式打包所有配置
- Session State管理:实时保存用户配置2. 文本处理流水线
文本分析流程:
1. 预处理 (FullyConfigurableTextPreprocessor)
├── 中文分词 (jieba)
├── 停用词过滤
├── 情感分析(基于用户词库)
└── 可读性计算
2. 特征提取 (FullyConfigurablePolicyFeatureExtractor)
├── 关键词匹配
├── 日期提取
├── 情感倾向判断
└── 结构特征识别
3. PMC评分建议
└── 基于特征密度自动生成初步评分3. PMC计算模型
评分公式:
PMC指数 = Σ(一级变量得分 × 权重) × 9
一级变量得分 = Σ(二级变量得分 × 二级权重)三、页面功能解析
1. 🏠 系统首页
-
仪表盘展示关键指标
-
配置状态检查
-
快速开始指南
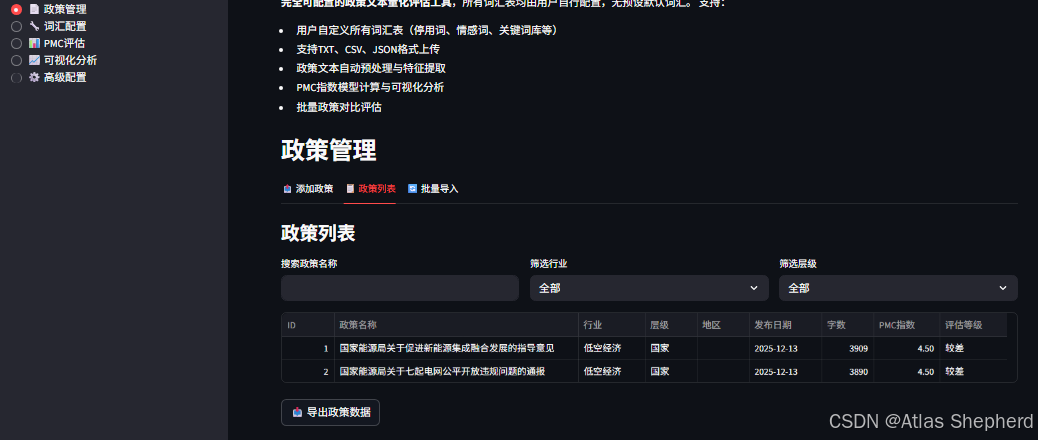
2. 📄 政策管理
# 三种添加方式:
1. 手动输入:完整表单录入
2. 文件上传:
- CSV格式(结构化数据)
- TXT格式(批量处理)
3. 文本粘贴:支持JSON和纯文本3. 🔧 词汇配置(核心特色)
-
停用词库:过滤无关词汇
-
情感词库:正向/负向词汇定义
-
特征关键词库:JSON结构化的关键词分类
-
配置持久化:本地文件存储
4. 📊 PMC评估
# 交互式评分流程:
1. 自动建议:基于关键词匹配生成初步评分
2. 人工调整:滑块手动调整0-1分值
3. 实时计算:立即显示PMC指数和等级
4. 可视化:雷达图展示各维度得分5. 📈 可视化分析
-
3D曲面图:PMC得分的空间分布
-
对比分析:多政策雷达图对比
-
热力图:变量得分矩阵
-
相关性分析:变量间关联度
6. ⚙️ 高级配置
-
权重调整:一级变量权重配置(总和为1)
-
评估标准:自定义评分等级阈值
-
系统管理:会话保存/恢复
四、技术亮点
1. 完全可配置的设计理念
# 与传统系统的区别:
传统系统:预定义词典 → 用户适应系统
本系统:用户自定义词典 → 系统适应业务2. 智能特征映射
系统自动将文本特征映射到PMC变量:
特征关键词库结构示例:
{
"预测性": ["预测", "预计", "预期"],
"监管性": ["监管", "管理", "监督"],
"人才引进": ["人才", "引进", "培养"]
}3. 多模态数据输入
支持:
-
结构化CSV
-
非结构化TXT
-
JSON格式
-
纯文本粘贴
-
文件批量上传
4. 实时可视化
-
Plotly图表:交互式3D可视化
-
Streamlit组件:原生UI控件
-
响应式设计:自动适应布局
五、应用场景
1. 政策研究机构
-
批量评估政策文本质量
-
多地区政策对比分析
-
政策演化趋势研究
2. 政府部门
-
政策草案自评估
-
政策效果预评估
-
跨部门政策协调性分析
3. 咨询公司
-
为客户提供政策评估报告
-
行业政策影响分析
-
投资环境评估
4. 学术研究
-
政策文本量化分析
-
政策工具研究
-
比较政策分析
六、后期扩展
1. 可添加的功能
1. 机器学习增强:
- 自动关键词提取
- 主题模型分析
- 情感分析模型集成
2. 协作功能:
- 多用户评估
- 专家评审系统
- 版本控制
3. 报告生成:
- 自动生成评估报告
- PDF/Word导出
- 数据可视化报告2. 性能优化
-
异步处理大批量文本
-
分布式计算支持
-
缓存机制
七、技术栈优势
-
Streamlit:快速原型开发,交互性强
-
Plotly:丰富的可视化选项
-
jieba:中文分词准确率高
-
JSON配置:灵活可扩展
-
模块化设计:便于维护和扩展
完整代码
import streamlit as st
import pandas as pd
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
from datetime import datetime, timedelta
import json
import re
import os
import sys
import warnings
from collections import defaultdict, Counter
from typing import Dict, List, Tuple, Any, Optional, Set
import jieba
import jieba.analyse
import tempfile
import hashlib
import zipfile
warnings.filterwarnings('ignore')
# 设置页面配置
st.set_page_config(
page_title="PMC政策文本量化评估系统",
page_icon="⚙️",
layout="wide",
initial_sidebar_state="expanded"
)
# 应用标题
st.title("⚙️ PMC政策文本量化评估系统")
st.markdown("""
**完全可配置的政策文本量化评估工具**,所有词汇表均由用户自行配置,无预设默认词汇。
支持:
- 用户自定义所有词汇表(停用词、情感词、关键词库等)
- 支持TXT、CSV、JSON格式上传
- 政策文本自动预处理与特征提取
- PMC指数模型计算与可视化分析
- 批量政策对比评估
""")
# ==================== 配置管理器 ====================
class ConfigurationManager:
"""配置管理器,处理用户自定义词汇表"""
def __init__(self):
self.config_dir = "./configs"
os.makedirs(self.config_dir, exist_ok=True)
def save_user_config(self, config_type: str, data: Any, config_name: str = "user_config"):
"""保存用户配置"""
config_path = os.path.join(self.config_dir, f"{config_name}_{config_type}.json")
if config_type == "stopwords":
data = list(data) if isinstance(data, set) else data
elif config_type == "feature_keywords":
if not isinstance(data, dict):
raise ValueError("特征关键词库必须是字典格式")
with open(config_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
return config_path
def load_user_config(self, config_type: str, config_name: str = "user_config"):
"""加载用户配置"""
config_path = os.path.join(self.config_dir, f"{config_name}_{config_type}.json")
if os.path.exists(config_path):
with open(config_path, 'r', encoding='utf-8') as f:
data = json.load(f)
if config_type == "stopwords":
data = set(data)
return data
else:
return None
def export_all_configs(self, config_name: str = "pmc_config"):
"""导出所有配置为ZIP文件"""
import zipfile
temp_dir = tempfile.mkdtemp()
zip_path = os.path.join(temp_dir, f"{config_name}.zip")
with zipfile.ZipFile(zip_path, 'w') as zipf:
config_types = ["stopwords", "positive_words", "negative_words",
"feature_keywords", "pmc_weights", "evaluation_criteria"]
for config_type in config_types:
config_data = self.load_user_config(config_type, config_name)
if config_data is None:
# 没有用户配置,创建空的配置文件
if config_type == "stopwords":
config_data = []
elif config_type in ["positive_words", "negative_words"]:
config_data = []
elif config_type == "feature_keywords":
config_data = {}
elif config_type == "pmc_weights":
config_data = {"primary_weights": {}, "secondary_weights": {}}
elif config_type == "evaluation_criteria":
config_data = {"levels": {}}
temp_file = os.path.join(temp_dir, f"{config_type}.json")
with open(temp_file, 'w', encoding='utf-8') as f:
json.dump(config_data, f, ensure_ascii=False, indent=2)
zipf.write(temp_file, f"{config_type}.json")
return zip_path
def import_configs_from_zip(self, zip_file):
"""从ZIP文件导入配置"""
import zipfile
temp_dir = tempfile.mkdtemp()
with zipfile.ZipFile(zip_file, 'r') as zipf:
zipf.extractall(temp_dir)
configs = {}
config_types = ["stopwords", "positive_words", "negative_words",
"feature_keywords", "pmc_weights", "evaluation_criteria"]
for config_type in config_types:
config_file = os.path.join(temp_dir, f"{config_type}.json")
if os.path.exists(config_file):
with open(config_file, 'r', encoding='utf-8') as f:
configs[config_type] = json.load(f)
return configs
# ==================== 核心模型类 ====================
class FullyConfigurableTextPreprocessor:
"""完全可配置的文本预处理器"""
def __init__(self, config_manager=None):
self.config_manager = config_manager or ConfigurationManager()
# 加载配置
self.stopwords = self._load_stopwords()
self.positive_words = self._load_positive_words()
self.negative_words = self._load_negative_words()
# 初始化jieba
try:
jieba.initialize()
except:
pass
def _load_stopwords(self) -> Set[str]:
"""加载停用词表(完全由用户配置)"""
# 先尝试加载用户配置
user_stopwords = self.config_manager.load_user_config("stopwords")
if user_stopwords is not None:
return set(user_stopwords)
# 检查session state中是否有上传的停用词
if 'user_stopwords' in st.session_state and st.session_state.user_stopwords:
user_words = set(st.session_state.user_stopwords.split('\n'))
return user_words
# 无默认停用词,返回空集合
return set()
def _load_positive_words(self) -> List[str]:
"""加载正面词汇(完全由用户配置)"""
# 先尝试加载用户配置
user_positive = self.config_manager.load_user_config("positive_words")
if user_positive is not None:
return user_positive
# 检查session state中是否有上传的正面词汇
if 'user_positive_words' in st.session_state and st.session_state.user_positive_words:
return [word.strip() for word in st.session_state.user_positive_words.split('\n') if word.strip()]
# 无默认正面词汇,返回空列表
return []
def _load_negative_words(self) -> List[str]:
"""加载负面词汇(完全由用户配置)"""
# 先尝试加载用户配置
user_negative = self.config_manager.load_user_config("negative_words")
if user_negative is not None:
return user_negative
# 检查session state中是否有上传的负面词汇
if 'user_negative_words' in st.session_state and st.session_state.user_negative_words:
return [word.strip() for word in st.session_state.user_negative_words.split('\n') if word.strip()]
# 无默认负面词汇,返回空列表
return []
def update_stopwords(self, stopwords_text: str):
"""更新停用词表"""
stopwords_list = [word.strip() for word in stopwords_text.split('\n') if word.strip()]
st.session_state.user_stopwords = stopwords_text
self.stopwords = set(stopwords_list)
def update_sentiment_words(self, positive_text: str, negative_text: str):
"""更新情感词汇"""
positive_list = [word.strip() for word in positive_text.split('\n') if word.strip()]
negative_list = [word.strip() for word in negative_text.split('\n') if word.strip()]
st.session_state.user_positive_words = positive_text
st.session_state.user_negative_words = negative_text
self.positive_words = positive_list
self.negative_words = negative_list
def preprocess_text(self, text: str) -> List[str]:
"""预处理政策文本"""
# 去除特殊字符和数字
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z]', ' ', text)
# 分词
words = jieba.lcut(text)
# 去除停用词
words = [word for word in words if word not in self.stopwords and len(word) > 1]
return words
def extract_keywords(self, text: str, top_k: int = 20) -> List[Tuple[str, float]]:
"""提取关键词"""
keywords = jieba.analyse.extract_tags(text, topK=top_k, withWeight=True)
return keywords
def analyze_sentiment(self, text: str) -> Dict[str, Any]:
"""分析文本情感"""
words = self.preprocess_text(text)
# 如果用户没有配置情感词,返回中性结果
if not self.positive_words and not self.negative_words:
return {
'sentiment_score': 0.5,
'positive_count': 0,
'negative_count': 0,
'sentiment': '中性 (未配置情感词)'
}
pos_count = sum(1 for word in words if word in self.positive_words)
neg_count = sum(1 for word in words if word in self.negative_words)
if pos_count + neg_count == 0:
sentiment_score = 0.5
else:
sentiment_score = pos_count / (pos_count + neg_count)
sentiment = '中性'
if sentiment_score > 0.6:
sentiment = '积极'
elif sentiment_score < 0.4:
sentiment = '消极'
return {
'sentiment_score': sentiment_score,
'positive_count': pos_count,
'negative_count': neg_count,
'sentiment': sentiment
}
def extract_dates(self, text: str) -> List[str]:
"""提取日期信息"""
date_patterns = [
r'\d{4}年\d{1,2}月\d{1,2}日',
r'\d{4}年\d{1,2}月',
r'\d{4}年',
r'\d{4}-\d{1,2}-\d{1,2}',
r'\d{4}至\d{4}年',
r'\d{4}---\d{4}年'
]
dates = []
for pattern in date_patterns:
matches = re.findall(pattern, text)
dates.extend(matches)
return dates
def calculate_readability(self, text: str) -> Dict[str, float]:
"""计算文本可读性指标"""
sentences = re.split(r'[。!?;;.!?]', text)
sentences = [s.strip() for s in sentences if s.strip()]
words = self.preprocess_text(text)
if not sentences or not words:
return {'avg_sentence_length': 0, 'avg_word_length': 0, 'readability_score': 0}
avg_sentence_length = len(words) / len(sentences)
avg_word_length = sum(len(word) for word in words) / len(words) if words else 0
readability_score = 100 - (avg_sentence_length * 0.5 + avg_word_length * 0.3)
return {
'avg_sentence_length': avg_sentence_length,
'avg_word_length': avg_word_length,
'readability_score': max(0, min(100, readability_score))
}
class FullyConfigurablePolicyFeatureExtractor:
"""完全可配置的政策特征提取器"""
def __init__(self, config_manager=None):
self.config_manager = config_manager or ConfigurationManager()
self.preprocessor = FullyConfigurableTextPreprocessor(config_manager)
# 加载特征关键词库
self.feature_keywords = self._load_feature_keywords()
def _load_feature_keywords(self) -> Dict[str, List[str]]:
"""加载特征关键词库(完全由用户配置)"""
# 先尝试加载用户配置
user_keywords = self.config_manager.load_user_config("feature_keywords")
if user_keywords is not None:
return user_keywords
# 检查session state中是否有上传的关键词库
if 'user_feature_keywords' in st.session_state and st.session_state.user_feature_keywords:
try:
keywords_dict = json.loads(st.session_state.user_feature_keywords)
if isinstance(keywords_dict, dict):
return keywords_dict
except:
pass
# 无默认关键词库,返回空字典
return {}
def update_feature_keywords(self, keywords_text: str):
"""更新特征关键词库"""
try:
keywords_dict = json.loads(keywords_text)
if isinstance(keywords_dict, dict):
st.session_state.user_feature_keywords = keywords_text
self.feature_keywords = keywords_dict
return True
else:
return False
except:
return False
def extract_features(self, text: str) -> Dict[str, Any]:
"""从政策文本中提取特征"""
words = self.preprocess_text(text)
word_count = len(words)
# 关键词匹配
keyword_features = {}
for category, keywords in self.feature_keywords.items():
matches = []
for keyword in keywords:
if keyword in text:
matches.append(keyword)
keyword_features[category] = {
'count': len(matches),
'keywords': matches,
'density': len(matches) / word_count if word_count > 0 else 0
}
# 情感分析
sentiment = self.preprocessor.analyze_sentiment(text)
# 日期提取
dates = self.preprocessor.extract_dates(text)
# 可读性分析
readability = self.preprocessor.calculate_readability(text)
# 提取关键词
keywords = self.preprocessor.extract_keywords(text, top_k=15)
return {
'basic_features': {
'word_count': word_count,
'unique_words': len(set(words)),
'dates_found': len(dates),
'dates': dates
},
'keyword_features': keyword_features,
'sentiment_analysis': sentiment,
'readability_analysis': readability,
'top_keywords': keywords
}
def suggest_pmc_scores(self, features: Dict[str, Any]) -> Dict[str, Dict[str, float]]:
"""基于特征提取建议PMC评分"""
pmc_suggestions = {}
# 映射关系:特征类别 -> PMC变量
feature_to_pmc = {
'预测性': ('X1', 'X1a_预测性'),
'监管性': ('X1', 'X1b_监管性'),
'建议性': ('X1', 'X1c_建议性'),
'人才引进': ('X3', 'X3a_人才引进'),
'资金支持': ('X3', 'X3b_资金支持'),
'税收优惠': ('X3', 'X3c_税收优惠'),
'法律保障': ('X3', 'X3d_法律保障'),
'基础设施建设': ('X4', 'X4a_基础设施建设'),
'技术研发': ('X4', 'X4b_技术研发'),
'产业培育': ('X4', 'X4c_产业培育'),
'市场应用': ('X4', 'X4d_市场应用'),
'供给型': ('X5', 'X5a_供给型'),
'需求型': ('X5', 'X5b_需求型'),
'环境型': ('X5', 'X5c_环境型'),
'政府部门': ('X8', 'X8a_政府部门'),
'企业': ('X8', 'X8b_企业'),
'科研机构': ('X8', 'X8c_科研机构'),
'个人': ('X8', 'X8d_个人')
}
# 根据特征密度生成建议分数
for feature_category, pmc_info in feature_to_pmc.items():
primary_var, secondary_var = pmc_info
if primary_var not in pmc_suggestions:
pmc_suggestions[primary_var] = {}
feature_data = features['keyword_features'].get(feature_category, {})
density = feature_data.get('density', 0)
# 基于密度计算分数(0-1之间)
score = min(1.0, density * 50)
pmc_suggestions[primary_var][secondary_var] = round(score, 2)
# 补充其他变量的默认值
default_scores = {
'X2': {'X2a_长期(>5年)': 0.5, 'X2b_中期(3-5年)': 0.5, 'X2c_短期(<3年)': 0.5},
'X6': {'X6a_目标明确性': 0.5, 'X6b_任务具体性': 0.5, 'X6c_责任主体清晰性': 0.5},
'X7': {'X7a_评估指标': 0.5, 'X7b_评估方法': 0.5, 'X7c_评估周期': 0.5},
'X9': {'X9a_产业激励': 0.5, 'X9b_基建驱动': 0.5, 'X9c_场景应用': 0.5}
}
for var, scores in default_scores.items():
if var not in pmc_suggestions:
pmc_suggestions[var] = {}
for sec_var, score in scores.items():
if sec_var not in pmc_suggestions[var]:
pmc_suggestions[var][sec_var] = score
return pmc_suggestions
class FullyConfigurablePMCModel:
"""完全可配置的PMC指数模型"""
def __init__(self, config_manager=None):
self.config_manager = config_manager or ConfigurationManager()
# 定义PMC变量结构
self.primary_variables = {
'X1': '政策性质',
'X2': '政策时效',
'X3': '政策激励',
'X4': '政策领域',
'X5': '政策工具',
'X6': '政策操作性',
'X7': '政策评估',
'X8': '政策受众',
'X9': '政策主题'
}
self.secondary_variables = {
'X1': ['X1a_预测性', 'X1b_监管性', 'X1c_建议性'],
'X2': ['X2a_长期(>5年)', 'X2b_中期(3-5年)', 'X2c_短期(<3年)'],
'X3': ['X3a_人才引进', 'X3b_资金支持', 'X3c_税收优惠', 'X3d_法律保障'],
'X4': ['X4a_基础设施建设', 'X4b_技术研发', 'X4c_产业培育', 'X4d_市场应用'],
'X5': ['X5a_供给型', 'X5b_需求型', 'X5c_环境型'],
'X6': ['X6a_目标明确性', 'X6b_任务具体性', 'X6c_责任主体清晰性'],
'X7': ['X7a_评估指标', 'X7b_评估方法', 'X7c_评估周期'],
'X8': ['X8a_政府部门', 'X8b_企业', 'X8c_科研机构', 'X8d_个人'],
'X9': ['X9a_产业激励', 'X9b_基建驱动', 'X9c_场景应用']
}
# 加载权重
self.weights = self._load_weights()
self.secondary_weights = self._load_secondary_weights()
# 加载评估标准
self.evaluation_criteria = self._load_evaluation_criteria()
# 初始化其他组件
self.feature_extractor = FullyConfigurablePolicyFeatureExtractor(config_manager)
self.preprocessor = FullyConfigurableTextPreprocessor(config_manager)
def _load_weights(self) -> Dict[str, float]:
"""加载权重配置"""
user_weights = self.config_manager.load_user_config("pmc_weights")
if user_weights and "primary_weights" in user_weights:
return user_weights["primary_weights"]
# 检查session state
if 'user_pmc_weights' in st.session_state and st.session_state.user_pmc_weights:
try:
weights_dict = json.loads(st.session_state.user_pmc_weights)
if isinstance(weights_dict, dict):
# 验证权重总和为1
total = sum(weights_dict.values())
if abs(total - 1.0) < 0.01: # 允许小误差
return weights_dict
except:
pass
# 无用户配置,使用等权重
num_vars = len(self.primary_variables)
equal_weight = 1.0 / num_vars
return {var: equal_weight for var in self.primary_variables.keys()}
def _load_secondary_weights(self) -> Dict[str, List[float]]:
"""加载二级权重配置"""
user_weights = self.config_manager.load_user_config("pmc_weights")
if user_weights and "secondary_weights" in user_weights:
return user_weights["secondary_weights"]
# 无用户配置,使用等权重
secondary_weights = {}
for var, sec_vars in self.secondary_variables.items():
num_sec_vars = len(sec_vars)
secondary_weights[var] = [1.0 / num_sec_vars] * num_sec_vars
return secondary_weights
def _load_evaluation_criteria(self) -> Dict[str, Any]:
"""加载评估标准"""
user_criteria = self.config_manager.load_user_config("evaluation_criteria")
if user_criteria is not None:
return user_criteria
# 检查session state
if 'user_evaluation_criteria' in st.session_state and st.session_state.user_evaluation_criteria:
try:
criteria_dict = json.loads(st.session_state.user_evaluation_criteria)
if isinstance(criteria_dict, dict):
return criteria_dict
except:
pass
# 无用户配置,使用默认评估标准
return {
"levels": {
"优秀": {"min": 8.0, "max": 9.0, "color": "#4CAF50"},
"良好": {"min": 7.0, "max": 8.0, "color": "#8BC34A"},
"及格": {"min": 6.0, "max": 7.0, "color": "#FFC107"},
"较差": {"min": 0.0, "max": 6.0, "color": "#F44336"}
}
}
def update_weights(self, weights_text: str) -> bool:
"""更新权重配置"""
try:
weights_dict = json.loads(weights_text)
if isinstance(weights_dict, dict):
st.session_state.user_pmc_weights = weights_text
self.weights = weights_dict
return True
else:
return False
except:
return False
def update_evaluation_criteria(self, criteria_text: str) -> bool:
"""更新评估标准"""
try:
criteria_dict = json.loads(criteria_text)
if isinstance(criteria_dict, dict):
st.session_state.user_evaluation_criteria = criteria_text
self.evaluation_criteria = criteria_dict
return True
else:
return False
except:
return False
def calculate_pmc_index(self, policy_data: Dict) -> float:
"""计算PMC指数"""
total_score = 0
for primary_var in self.primary_variables.keys():
if primary_var in policy_data:
secondary_scores = []
secondary_vars = self.secondary_variables[primary_var]
for i, sec_var in enumerate(secondary_vars):
if sec_var in policy_data[primary_var]:
weighted_score = policy_data[primary_var][sec_var] * self.secondary_weights[primary_var][i]
secondary_scores.append(weighted_score)
if secondary_scores:
primary_score = sum(secondary_scores)
weighted_primary = primary_score * self.weights[primary_var] * 9
total_score += weighted_primary
return round(total_score, 2)
def evaluate_policy_level(self, pmc_score: float) -> Tuple[str, str]:
"""评估政策等级"""
levels = self.evaluation_criteria.get("levels", {
"优秀": {"min": 8.0, "max": 9.0, "color": "#4CAF50"},
"良好": {"min": 7.0, "max": 8.0, "color": "#8BC34A"},
"及格": {"min": 6.0, "max": 7.0, "color": "#FFC107"},
"较差": {"min": 0.0, "max": 6.0, "color": "#F44336"}
})
for level_name, level_info in levels.items():
if level_info["min"] <= pmc_score < level_info["max"]:
return level_name, level_info["color"]
return "未知", "#9E9E9E"
def calculate_variable_scores(self, policy_data: Dict) -> Dict[str, float]:
"""计算每个一级变量的得分"""
variable_scores = {}
for primary_var in self.primary_variables.keys():
if primary_var in policy_data:
secondary_scores = []
secondary_vars = self.secondary_variables[primary_var]
for i, sec_var in enumerate(secondary_vars):
if sec_var in policy_data[primary_var]:
weighted_score = policy_data[primary_var][sec_var] * self.secondary_weights[primary_var][i]
secondary_scores.append(weighted_score)
if secondary_scores:
variable_scores[primary_var] = sum(secondary_scores)
return variable_scores
# ==================== Streamlit应用 ====================
# 初始化session state
if 'policies' not in st.session_state:
st.session_state.policies = []
if 'pmc_results' not in st.session_state:
st.session_state.pmc_results = {}
if 'analysis_history' not in st.session_state:
st.session_state.analysis_history = []
if 'config_manager' not in st.session_state:
st.session_state.config_manager = ConfigurationManager()
if 'pmc_model' not in st.session_state:
st.session_state.pmc_model = FullyConfigurablePMCModel(st.session_state.config_manager)
# 侧边栏
st.sidebar.title("⚙️ 系统配置")
# 功能选择
page = st.sidebar.radio(
"导航菜单",
["🏠 系统首页", "📄 政策管理", "🔧 词汇配置", "📊 PMC评估", "📈 可视化分析", "⚙️ 高级配置"]
)
# 首页
if page == "🏠 系统首页":
st.header("PMC政策文本量化评估系统")
col1, col2, col3, col4 = st.columns(4)
with col1:
policy_count = len(st.session_state.policies)
st.metric("政策总数", policy_count)
with col2:
evaluated_count = len(st.session_state.pmc_results)
st.metric("已评估政策", evaluated_count)
with col3:
if st.session_state.pmc_results:
avg_score = np.mean([v['pmc_score'] for v in st.session_state.pmc_results.values()])
else:
avg_score = 0
st.metric("平均PMC指数", f"{avg_score:.2f}")
with col4:
if st.session_state.pmc_results:
levels = [v.get('level', '未知') for v in st.session_state.pmc_results.values()]
excellent_count = levels.count("优秀")
else:
excellent_count = 0
st.metric("优秀政策", excellent_count)
st.markdown("---")
# 系统介绍
st.subheader("📋 系统功能概述")
features = [
{"title": "完全可配置词汇库", "desc": "所有词汇表完全由用户配置,无预设词汇", "icon": "🔤"},
{"title": "灵活上传方式", "desc": "支持文本输入、文件上传、批量处理", "icon": "📤"},
{"title": "智能文本分析", "desc": "自动提取政策特征,识别关键变量", "icon": "🤖"},
{"title": "多投入产出表", "desc": "构建标准化数据分析框架", "icon": "📈"},
{"title": "PMC指数计算", "desc": "科学量化政策质量", "icon": "📊"},
{"title": "多维可视化", "desc": "雷达图、曲面图、热力图等多种展示", "icon": "🎨"}
]
cols = st.columns(3)
for i, feature in enumerate(features):
with cols[i % 3]:
st.markdown(f"""
<div style="padding: 20px; border-radius: 10px; background-color: #f8f9fa; margin-bottom: 10px;">
<h4>{feature['icon']} {feature['title']}</h4>
<p style="color: #666; font-size: 14px;">{feature['desc']}</p>
</div>
""", unsafe_allow_html=True)
# 快速开始指南
with st.expander("🚀 快速开始指南", expanded=True):
st.markdown("""
1. **配置词汇库**:在"词汇配置"页面设置停用词、情感词、关键词库(必须配置)
2. **添加政策**:在"政策管理"页面导入或添加政策文本
3. **文本分析**:系统自动分析政策文本特征
4. **PMC评估**:在"PMC评估"页面进行量化评估
5. **可视化**:在"可视化分析"页面查看多维图表
6. **高级配置**:在"高级配置"页面调整权重和评估标准
""")
# 配置状态检查
st.subheader("🔍 配置状态检查")
config_status = {
"停用词配置": 'user_stopwords' in st.session_state and st.session_state.user_stopwords,
"正面词汇配置": 'user_positive_words' in st.session_state and st.session_state.user_positive_words,
"负面词汇配置": 'user_negative_words' in st.session_state and st.session_state.user_negative_words,
"特征关键词库配置": 'user_feature_keywords' in st.session_state and st.session_state.user_feature_keywords,
"PMC权重配置": 'user_pmc_weights' in st.session_state and st.session_state.user_pmc_weights,
"评估标准配置": 'user_evaluation_criteria' in st.session_state and st.session_state.user_evaluation_criteria
}
cols = st.columns(3)
for i, (config_name, configured) in enumerate(config_status.items()):
with cols[i % 3]:
if configured:
st.success(f"✅ {config_name}")
else:
st.warning(f"⚠️ {config_name} (未配置)")
if not all(config_status.values()):
st.info("💡 请先完成所有词汇库的配置,以获得最佳分析效果。")
# 政策管理页面
elif page == "📄 政策管理":
st.header("政策管理")
tab1, tab2, tab3 = st.tabs(["📤 添加政策", "📋 政策列表", "🔄 批量导入"])
with tab1:
st.subheader("添加新政策")
with st.form("add_policy_form"):
col1, col2 = st.columns(2)
with col1:
policy_name = st.text_input("政策名称*", placeholder="例如:低空经济发展指导意见")
policy_level = st.selectbox("政策层级*", ["国家", "省级", "地市级", "区县级", "其他"])
industry = st.selectbox("所属行业*",
["低空经济", "数字经济", "新能源", "人工智能", "生物医药", "高端制造", "其他"])
with col2:
policy_region = st.text_input("适用地区*", placeholder="例如:全国、四川省、苏州市")
policy_date = st.date_input("发布日期", datetime.now())
policy_source = st.text_input("政策来源", placeholder="例如:国务院、发改委")
policy_description = st.text_area("政策描述",
placeholder="简要描述政策的主要内容和目标", height=100)
policy_text = st.text_area("政策全文*",
placeholder="请输入政策全文内容...", height=300)
submitted = st.form_submit_button("📥 添加政策")
if submitted:
if not policy_name or not policy_text:
st.error("请填写政策名称和全文!")
else:
# 生成政策ID
new_id = max([p['id'] for p in st.session_state.policies]) + 1 if st.session_state.policies else 1
# 创建政策对象
new_policy = {
'id': new_id,
'name': policy_name,
'level': policy_level,
'region': policy_region,
'industry': industry,
'date': policy_date.strftime('%Y-%m-%d'),
'source': policy_source,
'description': policy_description,
'text': policy_text,
'created_at': datetime.now().isoformat(),
'hash': hashlib.md5(policy_text.encode()).hexdigest()[:16]
}
st.session_state.policies.append(new_policy)
# 记录分析历史
st.session_state.analysis_history.append({
'timestamp': datetime.now().isoformat(),
'action': '添加政策',
'policy_name': policy_name,
'policy_id': new_id
})
st.success(f"✅ 政策 '{policy_name}' 添加成功!ID: {new_id}")
# 自动分析文本
with st.spinner("正在自动分析政策文本..."):
try:
feature_extractor = FullyConfigurablePolicyFeatureExtractor(st.session_state.config_manager)
features = feature_extractor.extract_features(policy_text)
suggestions = feature_extractor.suggest_pmc_scores(features)
pmc_score = st.session_state.pmc_model.calculate_pmc_index(suggestions)
level, color = st.session_state.pmc_model.evaluate_policy_level(pmc_score)
variable_scores = st.session_state.pmc_model.calculate_variable_scores(suggestions)
# 保存分析结果
st.session_state.pmc_results[new_id] = {
'pmc_score': pmc_score,
'level': level,
'color': color,
'variable_scores': variable_scores,
'text_analysis': features,
'pmc_suggestions': suggestions
}
st.info(f"📊 自动分析完成!PMC指数: {pmc_score:.2f} ({level})")
except Exception as e:
st.warning(f"文本分析过程中出现错误: {str(e)}")
with tab2:
st.subheader("政策列表")
if st.session_state.policies:
# 创建数据框
policy_data = []
for policy in st.session_state.policies:
pmc_info = st.session_state.pmc_results.get(policy['id'], {})
policy_data.append({
'ID': policy['id'],
'政策名称': policy['name'],
'行业': policy.get('industry', ''),
'层级': policy['level'],
'地区': policy['region'],
'发布日期': policy['date'],
'字数': len(policy['text']),
'PMC指数': pmc_info.get('pmc_score', '未评估'),
'评估等级': pmc_info.get('level', '未评估')
})
df = pd.DataFrame(policy_data)
# 搜索和筛选
col1, col2, col3 = st.columns(3)
with col1:
search_name = st.text_input("搜索政策名称")
with col2:
filter_industry = st.selectbox("筛选行业", ["全部"] + list(df['行业'].unique()))
with col3:
filter_level = st.selectbox("筛选层级", ["全部"] + list(df['层级'].unique()))
# 应用筛选
filtered_df = df
if search_name:
filtered_df = filtered_df[filtered_df['政策名称'].str.contains(search_name, na=False)]
if filter_industry != "全部":
filtered_df = filtered_df[filtered_df['行业'] == filter_industry]
if filter_level != "全部":
filtered_df = filtered_df[filtered_df['层级'] == filter_level]
# 显示表格
st.dataframe(
filtered_df,
use_container_width=True,
column_config={
"PMC指数": st.column_config.NumberColumn(format="%.2f"),
"字数": st.column_config.NumberColumn(format="%d")
},
hide_index=True
)
# 导出数据
if st.button("📥 导出政策数据"):
csv = df.to_csv(index=False).encode('utf-8-sig')
st.download_button(
label="下载CSV",
data=csv,
file_name="policies_data.csv",
mime="text/csv"
)
else:
st.info("暂无政策数据,请先添加政策。")
with tab3:
st.subheader("批量导入政策")
upload_option = st.radio("导入方式", ["上传CSV文件", "上传TXT文件", "粘贴文本"])
if upload_option == "上传CSV文件":
uploaded_file = st.file_uploader("选择CSV文件", type=['csv'],
help="CSV文件应包含以下列:name, level, region, industry, date, source, description, text")
if uploaded_file is not None:
try:
df = pd.read_csv(uploaded_file)
# 检查必要列
required_columns = ['name', 'text']
if all(col in df.columns for col in required_columns):
progress_bar = st.progress(0)
imported_count = 0
for idx, row in df.iterrows():
new_id = max(
[p['id'] for p in st.session_state.policies]) + 1 if st.session_state.policies else 1
new_policy = {
'id': new_id,
'name': row.get('name', f"政策_{new_id}"),
'level': row.get('level', '其他'),
'region': row.get('region', '未知'),
'industry': row.get('industry', '其他'),
'date': row.get('date', datetime.now().strftime('%Y-%m-%d')),
'source': row.get('source', uploaded_file.name),
'description': row.get('description', ''),
'text': str(row.get('text', ''))[:5000],
'created_at': datetime.now().isoformat(),
'hash': hashlib.md5(str(row.get('text', '')).encode()).hexdigest()[:16]
}
st.session_state.policies.append(new_policy)
imported_count += 1
progress_bar.progress((idx + 1) / len(df))
st.success(f"✅ 成功导入 {imported_count} 条政策")
else:
st.error(f"CSV文件必须包含以下列:{', '.join(required_columns)}")
except Exception as e:
st.error(f"文件解析失败: {str(e)}")
elif upload_option == "上传TXT文件":
uploaded_files = st.file_uploader("选择TXT文件", type=['txt'], accept_multiple_files=True)
if uploaded_files:
progress_bar = st.progress(0)
imported_count = 0
for i, uploaded_file in enumerate(uploaded_files):
try:
content = uploaded_file.getvalue().decode('utf-8')
# 简单处理:每段作为一个政策
paragraphs = [p.strip() for p in content.split('\n\n') if p.strip()]
for para in paragraphs:
if len(para) > 100: # 只处理较长的段落
new_id = max([p['id'] for p in
st.session_state.policies]) + 1 if st.session_state.policies else 1
new_policy = {
'id': new_id,
'name': f"{uploaded_file.name}_{new_id}",
'level': "其他",
'region': "未知",
'industry': "其他",
'date': datetime.now().strftime('%Y-%m-%d'),
'source': uploaded_file.name,
'description': "",
'text': para[:5000],
'created_at': datetime.now().isoformat(),
'hash': hashlib.md5(para.encode()).hexdigest()[:16]
}
st.session_state.policies.append(new_policy)
imported_count += 1
progress_bar.progress((i + 1) / len(uploaded_files))
except Exception as e:
st.warning(f"文件 {uploaded_file.name} 处理失败: {str(e)}")
if imported_count > 0:
st.success(f"✅ 成功导入 {imported_count} 条政策")
elif upload_option == "粘贴文本":
text_input = st.text_area("粘贴政策文本(每行一个政策或JSON格式)", height=200)
col1, col2 = st.columns(2)
with col1:
format_type = st.selectbox("文本格式", ["每行一个政策", "JSON格式"])
with col2:
if st.button("解析文本"):
if text_input:
if format_type == "每行一个政策":
policies = [p.strip() for p in text_input.split('\n') if p.strip()]
else: # JSON格式
try:
data = json.loads(text_input)
if isinstance(data, list):
policies = data
else:
policies = [data]
except:
st.error("JSON格式不正确")
policies = []
imported_count = 0
for i, policy_text in enumerate(policies):
if isinstance(policy_text, dict):
# 如果是字典,提取文本字段
text_content = policy_text.get('text', '')
if not text_content:
continue
else:
text_content = str(policy_text)
if len(text_content) > 50:
new_id = max([p['id'] for p in
st.session_state.policies]) + 1 if st.session_state.policies else 1
new_policy = {
'id': new_id,
'name': f"粘贴政策_{new_id}",
'level': "其他",
'region': "未知",
'industry': "其他",
'date': datetime.now().strftime('%Y-%m-%d'),
'source': "文本粘贴",
'description': "",
'text': text_content[:5000],
'created_at': datetime.now().isoformat(),
'hash': hashlib.md5(text_content.encode()).hexdigest()[:16]
}
st.session_state.policies.append(new_policy)
imported_count += 1
st.success(f"✅ 成功添加 {imported_count} 条政策")
# 词汇配置页面
elif page == "🔧 词汇配置":
st.header("词汇库配置")
st.markdown("**重要提示**:本系统完全由用户配置,无预设词汇。请先配置词汇库,否则分析功能可能受限。")
tab1, tab2, tab3, tab4 = st.tabs(["📝 停用词配置", "😊 情感词配置", "🔑 关键词库配置", "📤 导入/导出配置"])
with tab1:
st.subheader("停用词配置")
st.markdown("停用词在文本分析时会被过滤掉,每行一个词")
st.warning("⚠️ 未配置停用词可能导致文本分析不准确")
# 获取当前停用词
current_stopwords = ""
if 'user_stopwords' in st.session_state:
current_stopwords = st.session_state.user_stopwords
col1, col2 = st.columns([2, 1])
with col1:
stopwords_input = st.text_area(
"停用词列表(每行一个词)",
value=current_stopwords,
height=300,
help="输入需要过滤的停用词,每行一个。例如:的、了、在、是、我、有、和、就、不、人"
)
with col2:
st.markdown("### 操作")
if st.button("💾 保存停用词", type="primary"):
if stopwords_input:
# 保存到session state
st.session_state.user_stopwords = stopwords_input
# 保存到文件
stopwords_list = [word.strip() for word in stopwords_input.split('\n') if word.strip()]
st.session_state.config_manager.save_user_config("stopwords", stopwords_list)
st.success("✅ 停用词已保存")
else:
st.warning("请输入停用词")
st.markdown("---")
# 文件上传
uploaded_file = st.file_uploader("上传停用词文件", type=['txt'])
if uploaded_file is not None:
content = uploaded_file.getvalue().decode('utf-8')
st.text_area("文件内容预览", content[:1000], height=150)
if st.button("📥 使用上传文件"):
st.session_state.user_stopwords = content
stopwords_list = [word.strip() for word in content.split('\n') if word.strip()]
st.session_state.config_manager.save_user_config("stopwords", stopwords_list)
st.success("✅ 已使用上传的停用词文件")
st.rerun()
st.markdown("---")
if st.button("🗑️ 清空停用词"):
st.session_state.user_stopwords = ""
st.success("✅ 已清空停用词")
st.rerun()
# 显示统计信息
if stopwords_input:
stopwords_count = len([word for word in stopwords_input.split('\n') if word.strip()])
st.info(f"当前停用词数量: {stopwords_count}")
else:
st.warning("⚠️ 当前未配置停用词")
with tab2:
st.subheader("情感词配置")
st.markdown("配置正面词汇和负面词汇,用于情感分析")
st.warning("⚠️ 未配置情感词将无法进行准确的情感分析")
col1, col2 = st.columns(2)
with col1:
st.markdown("#### 正面词汇")
# 获取当前正面词汇
current_positive = ""
if 'user_positive_words' in st.session_state:
current_positive = st.session_state.user_positive_words
positive_input = st.text_area(
"正面词汇列表(每行一个词)",
value=current_positive,
height=200,
help="输入正面情感词汇,每行一个。例如:促进、推动、发展、提升、加强、完善、优化、创新、支持、鼓励"
)
# 正面词汇文件上传
positive_file = st.file_uploader("上传正面词汇文件", type=['txt'], key="positive_upload")
if positive_file is not None:
positive_content = positive_file.getvalue().decode('utf-8')
if st.button("📥 使用上传的正面词汇", key="use_positive"):
st.session_state.user_positive_words = positive_content
st.success("✅ 已使用上传的正面词汇文件")
st.rerun()
with col2:
st.markdown("#### 负面词汇")
# 获取当前负面词汇
current_negative = ""
if 'user_negative_words' in st.session_state:
current_negative = st.session_state.user_negative_words
negative_input = st.text_area(
"负面词汇列表(每行一个词)",
value=current_negative,
height=200,
help="输入负面情感词汇,每行一个。例如:限制、禁止、约束、处罚、罚款、停止、取消、减少、降低、防止"
)
# 负面词汇文件上传
negative_file = st.file_uploader("上传负面词汇文件", type=['txt'], key="negative_upload")
if negative_file is not None:
negative_content = negative_file.getvalue().decode('utf-8')
if st.button("📥 使用上传的负面词汇", key="use_negative"):
st.session_state.user_negative_words = negative_content
st.success("✅ 已使用上传的负面词汇文件")
st.rerun()
# 保存按钮
col1, col2 = st.columns(2)
with col1:
if st.button("💾 保存情感词配置", type="primary"):
st.session_state.user_positive_words = positive_input
st.session_state.user_negative_words = negative_input
# 保存到文件
positive_list = [word.strip() for word in positive_input.split('\n') if word.strip()]
negative_list = [word.strip() for word in negative_input.split('\n') if word.strip()]
st.session_state.config_manager.save_user_config("positive_words", positive_list)
st.session_state.config_manager.save_user_config("negative_words", negative_list)
st.success("✅ 情感词配置已保存")
with col2:
if st.button("🗑️ 清空情感词"):
st.session_state.user_positive_words = ""
st.session_state.user_negative_words = ""
st.success("✅ 已清空情感词")
st.rerun()
# 显示统计信息
col1, col2 = st.columns(2)
with col1:
if positive_input:
positive_count = len([word for word in positive_input.split('\n') if word.strip()])
st.info(f"正面词汇数量: {positive_count}")
else:
st.warning("⚠️ 未配置正面词汇")
with col2:
if negative_input:
negative_count = len([word for word in negative_input.split('\n') if word.strip()])
st.info(f"负面词汇数量: {negative_count}")
else:
st.warning("⚠️ 未配置负面词汇")
with tab3:
st.subheader("特征关键词库配置")
st.markdown("配置政策特征关键词库,用于自动评分。JSON格式:{\"特征类别\": [\"关键词1\", \"关键词2\", ...]}")
st.warning("⚠️ 未配置特征关键词库将无法进行自动评分")
# 获取当前关键词库
current_keywords = ""
if 'user_feature_keywords' in st.session_state:
current_keywords = st.session_state.user_feature_keywords
else:
# 提供示例
current_keywords = json.dumps({
"预测性": ["预测", "预计", "预期", "展望", "规划"],
"监管性": ["监管", "管理", "监督", "检查", "规范"],
"人才引进": ["人才", "引进", "培养", "培训", "专家"],
"资金支持": ["资金", "补贴", "资助", "融资", "贷款"]
}, ensure_ascii=False, indent=2)
# 编辑关键词库
keywords_input = st.text_area(
"特征关键词库(JSON格式)",
value=current_keywords,
height=400,
help="输入JSON格式的特征关键词库"
)
col1, col2, col3 = st.columns(3)
with col1:
if st.button("💾 保存关键词库", type="primary"):
if keywords_input:
try:
keywords_dict = json.loads(keywords_input)
if isinstance(keywords_dict, dict):
st.session_state.user_feature_keywords = keywords_input
st.session_state.config_manager.save_user_config("feature_keywords", keywords_dict)
st.success("✅ 特征关键词库已保存")
else:
st.error("关键词库必须是JSON字典格式")
except json.JSONDecodeError as e:
st.error(f"JSON格式错误: {str(e)}")
else:
st.warning("请输入关键词库")
with col2:
# 文件上传
keywords_file = st.file_uploader("上传关键词库文件", type=['json', 'txt'])
if keywords_file is not None:
keywords_content = keywords_file.getvalue().decode('utf-8')
st.text_area("文件内容预览", keywords_content[:500], height=150)
if st.button("📥 使用上传文件"):
try:
keywords_dict = json.loads(keywords_content)
if isinstance(keywords_dict, dict):
st.session_state.user_feature_keywords = keywords_content
st.session_state.config_manager.save_user_config("feature_keywords", keywords_dict)
st.success("✅ 已使用上传的关键词库文件")
st.rerun()
else:
st.error("文件必须是JSON字典格式")
except json.JSONDecodeError as e:
st.error(f"JSON格式错误: {str(e)}")
with col3:
if st.button("🗑️ 清空关键词库"):
st.session_state.user_feature_keywords = ""
st.success("✅ 已清空关键词库")
st.rerun()
# 显示统计信息
if keywords_input:
try:
keywords_dict = json.loads(keywords_input)
if isinstance(keywords_dict, dict):
category_count = len(keywords_dict)
total_keywords = sum(len(keywords) for keywords in keywords_dict.values())
st.info(f"特征类别数量: {category_count}, 总关键词数量: {total_keywords}")
else:
st.warning("⚠️ 关键词库格式不正确")
except:
st.warning("⚠️ 关键词库格式不正确")
else:
st.warning("⚠️ 未配置特征关键词库")
with tab4:
st.subheader("配置导入/导出")
st.markdown("导入或导出所有配置")
col1, col2 = st.columns(2)
with col1:
st.markdown("### 导出配置")
st.markdown("导出当前所有词汇库配置为ZIP文件")
if st.button("📤 导出所有配置"):
try:
zip_path = st.session_state.config_manager.export_all_configs()
with open(zip_path, 'rb') as f:
zip_data = f.read()
st.download_button(
label="📥 下载配置ZIP文件",
data=zip_data,
file_name="pmc_configs.zip",
mime="application/zip"
)
except Exception as e:
st.error(f"导出配置失败: {str(e)}")
with col2:
st.markdown("### 导入配置")
st.markdown("从ZIP文件导入配置(将覆盖当前配置)")
uploaded_zip = st.file_uploader("选择配置ZIP文件", type=['zip'])
if uploaded_zip is not None:
if st.button("📥 导入配置"):
try:
configs = st.session_state.config_manager.import_configs_from_zip(uploaded_zip)
# 更新session state
if "stopwords" in configs:
st.session_state.user_stopwords = "\n".join(configs["stopwords"])
if "positive_words" in configs:
st.session_state.user_positive_words = "\n".join(configs["positive_words"])
if "negative_words" in configs:
st.session_state.user_negative_words = "\n".join(configs["negative_words"])
if "feature_keywords" in configs:
st.session_state.user_feature_keywords = json.dumps(configs["feature_keywords"],
ensure_ascii=False, indent=2)
if "pmc_weights" in configs:
st.session_state.user_pmc_weights = json.dumps(configs["pmc_weights"], ensure_ascii=False,
indent=2)
if "evaluation_criteria" in configs:
st.session_state.user_evaluation_criteria = json.dumps(configs["evaluation_criteria"],
ensure_ascii=False, indent=2)
st.success("✅ 配置导入成功!")
st.rerun()
except Exception as e:
st.error(f"导入配置失败: {str(e)}")
# PMC评估页面
elif page == "📊 PMC评估":
st.header("PMC指数评估")
if not st.session_state.policies:
st.info("暂无政策数据,请先在'政策管理'中添加政策。")
else:
# 检查词汇配置
config_warnings = []
if 'user_stopwords' not in st.session_state or not st.session_state.user_stopwords:
config_warnings.append("停用词")
if 'user_feature_keywords' not in st.session_state or not st.session_state.user_feature_keywords:
config_warnings.append("特征关键词库")
if config_warnings:
st.warning(f"⚠️ 以下词汇库未配置,可能影响评估准确性:{', '.join(config_warnings)}。请先配置词汇库。")
# 选择政策
policy_options = {f"{p['id']}: {p['name']}": p['id'] for p in st.session_state.policies}
selected_policy_key = st.selectbox("选择要评估的政策", list(policy_options.keys()))
selected_policy_id = policy_options[selected_policy_key]
selected_policy = next(p for p in st.session_state.policies if p['id'] == selected_policy_id)
st.subheader(f"政策评估: {selected_policy['name']}")
# 创建评估表单
with st.form("pmc_evaluation_form"):
st.write("请为政策的各个维度评分(0-1分,1分为最高):")
# 动态生成评分滑块
pmc_data = {}
for primary_var, primary_name in st.session_state.pmc_model.primary_variables.items():
st.markdown(f"### {primary_var}: {primary_name}")
sec_vars = st.session_state.pmc_model.secondary_variables.get(primary_var, [])
cols = st.columns(len(sec_vars))
pmc_data[primary_var] = {}
for i, sec_var in enumerate(sec_vars):
with cols[i]:
# 提取显示名称
display_name = sec_var.replace(f"{primary_var}_", "").replace("_", " ")
# 获取当前值
current_value = 0.5
if selected_policy_id in st.session_state.pmc_results:
suggestions = st.session_state.pmc_results[selected_policy_id].get('pmc_suggestions', {})
if primary_var in suggestions and sec_var in suggestions[primary_var]:
current_value = suggestions[primary_var][sec_var]
# 创建滑块
score = st.slider(
display_name,
min_value=0.0,
max_value=1.0,
value=current_value,
step=0.1,
key=f"{selected_policy_id}_{sec_var}"
)
pmc_data[primary_var][sec_var] = score
submitted = st.form_submit_button("计算PMC指数")
if submitted:
# 计算PMC指数
pmc_score = st.session_state.pmc_model.calculate_pmc_index(pmc_data)
level, color = st.session_state.pmc_model.evaluate_policy_level(pmc_score)
variable_scores = st.session_state.pmc_model.calculate_variable_scores(pmc_data)
# 保存结果
st.session_state.pmc_results[selected_policy_id] = {
'pmc_score': pmc_score,
'level': level,
'color': color,
'variable_scores': variable_scores,
'pmc_suggestions': pmc_data
}
st.success(f"PMC指数计算完成: **{pmc_score:.2f}** ({level})")
# 显示评估结果
if selected_policy_id in st.session_state.pmc_results:
result = st.session_state.pmc_results[selected_policy_id]
col1, col2, col3 = st.columns(3)
with col1:
st.metric("PMC指数", f"{result['pmc_score']:.2f}")
with col2:
st.metric("评估等级", result['level'])
with col3:
# 显示颜色指示
st.markdown(
f"<div style='background-color:{result['color']}; padding:10px; border-radius:5px; text-align:center; color:white;'>等级: {result['level']}</div>",
unsafe_allow_html=True)
# 显示详细得分
st.subheader("各维度得分详情")
# 创建数据框
score_data = []
for primary_var, score in result['variable_scores'].items():
score_data.append({
'一级变量': f"{primary_var}: {st.session_state.pmc_model.primary_variables[primary_var]}",
'得分': score,
'权重': st.session_state.pmc_model.weights.get(primary_var, 0),
'加权得分': score * st.session_state.pmc_model.weights.get(primary_var, 0) * 9
})
score_df = pd.DataFrame(score_data)
st.dataframe(score_df, use_container_width=True)
# 创建雷达图
st.subheader("维度得分雷达图")
variables = list(st.session_state.pmc_model.primary_variables.keys())
var_names = [st.session_state.pmc_model.primary_variables[v] for v in variables]
scores = [result['variable_scores'].get(v, 0) for v in variables]
# 创建闭合数据
scores_closed = scores + [scores[0]]
var_names_closed = var_names + [var_names[0]]
fig = go.Figure(data=
go.Scatterpolar(
r=scores_closed,
theta=var_names_closed,
fill='toself',
name='变量得分',
line=dict(color='blue', width=2),
marker=dict(size=8, color='red')
)
)
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 1]
)
),
showlegend=True,
title=f"PMC变量得分雷达图 - {selected_policy['name']}",
height=400
)
st.plotly_chart(fig, use_container_width=True)
# 续写可视化分析页面
elif page == "📈 可视化分析":
st.header("可视化分析")
if not st.session_state.policies or not st.session_state.pmc_results:
st.info("暂无评估数据,请先在'PMC评估'中评估政策。")
else:
tab1, tab2, tab3 = st.tabs(["📊 PMC曲面图", "📈 对比分析", "🔥 热力图"])
with tab1:
st.subheader("PMC曲面图")
# 选择要可视化的政策
policy_options = {f"{p['id']}: {p['name']}": p['id'] for p in st.session_state.policies
if p['id'] in st.session_state.pmc_results}
if policy_options:
selected_policy_key = st.selectbox("选择政策", list(policy_options.keys()), key="surface_select")
selected_policy_id = policy_options[selected_policy_key]
if selected_policy_id in st.session_state.pmc_results:
result = st.session_state.pmc_results[selected_policy_id]
variable_scores = result['variable_scores']
# 准备曲面图数据
variables = list(st.session_state.pmc_model.primary_variables.keys())
var_names = [st.session_state.pmc_model.primary_variables[v] for v in variables]
# 创建网格数据
theta = np.linspace(0, 2 * np.pi, len(variables), endpoint=False)
theta = np.concatenate((theta, [theta[0]])) # 闭合多边形
# 获取得分并标准化
scores = [variable_scores.get(v, 0) for v in variables]
scores = np.concatenate((scores, [scores[0]])) # 闭合多边形
# 创建极坐标图
fig = go.Figure(data=
go.Scatterpolar(
r=scores,
theta=var_names + [var_names[0]], # 闭合
mode='lines+markers',
fill='toself',
name='变量得分',
line=dict(color='blue', width=2),
marker=dict(size=8, color='red')
)
)
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 1]
)
),
showlegend=True,
title=f"PMC变量得分雷达图 - {selected_policy_key}",
height=500
)
st.plotly_chart(fig, use_container_width=True)
# 创建3D曲面图
st.subheader("3D PMC曲面图")
# 创建网格数据
x = np.array([i for i in range(len(variables))])
y = np.array([i for i in range(len(variables))])
X, Y = np.meshgrid(x, y)
# 创建Z矩阵(这里使用简单的插值)
Z = np.zeros((len(variables), len(variables)))
for i in range(len(variables)):
for j in range(len(variables)):
Z[i, j] = (scores[i] + scores[j]) / 2
fig_3d = go.Figure(data=[go.Surface(z=Z, x=x, y=y, colorscale='Viridis')])
fig_3d.update_layout(
title=f'PMC指数3D曲面图 - {selected_policy_key}',
scene=dict(
xaxis=dict(title='变量索引', ticktext=var_names, tickvals=list(range(len(variables)))),
yaxis=dict(title='变量索引', ticktext=var_names, tickvals=list(range(len(variables)))),
zaxis=dict(title='得分', range=[0, 1])
),
height=600
)
st.plotly_chart(fig_3d, use_container_width=True)
else:
st.info("暂无评估数据可用于可视化。")
with tab2:
st.subheader("对比分析")
if len(st.session_state.pmc_results) >= 2:
# 创建对比表格
comparison_data = []
for policy in st.session_state.policies:
if policy['id'] in st.session_state.pmc_results:
result = st.session_state.pmc_results[policy['id']]
row = {
'政策名称': policy['name'],
'层级': policy['level'],
'地区': policy['region'],
'PMC指数': result['pmc_score'],
'评估等级': result['level']
}
# 添加各维度得分
for var, score in result['variable_scores'].items():
row[st.session_state.pmc_model.primary_variables[var]] = f"{score:.2f}"
comparison_data.append(row)
if comparison_data:
df_comparison = pd.DataFrame(comparison_data)
st.dataframe(df_comparison, use_container_width=True)
# 创建柱状图对比
st.subheader("PMC指数对比图")
fig = go.Figure()
policies = df_comparison['政策名称'].tolist()
scores = df_comparison['PMC指数'].tolist()
# 为不同等级设置颜色
colors = []
for level in df_comparison['评估等级']:
if level == '优秀':
colors.append('#4CAF50')
elif level == '良好':
colors.append('#8BC34A')
elif level == '及格':
colors.append('#FFC107')
else:
colors.append('#F44336')
fig.add_trace(go.Bar(
x=policies,
y=scores,
text=scores,
textposition='auto',
marker_color=colors
))
fig.update_layout(
title='PMC指数对比',
xaxis_title='政策',
yaxis_title='PMC指数',
yaxis_range=[0, 9],
height=400
)
# 添加等级线
fig.add_hline(y=8.0, line_dash="dash", line_color="green", annotation_text="优秀线")
fig.add_hline(y=7.0, line_dash="dash", line_color="orange", annotation_text="良好线")
fig.add_hline(y=6.0, line_dash="dash", line_color="red", annotation_text="及格线")
st.plotly_chart(fig, use_container_width=True)
# 创建雷达图对比
st.subheader("维度得分雷达图对比")
# 选择多个政策对比
policy_options = {f"{p['id']}: {p['name']}": p['id'] for p in st.session_state.policies
if p['id'] in st.session_state.pmc_results}
if len(policy_options) >= 2:
selected_policies = st.multiselect(
"选择要对比的政策(至少2个)",
list(policy_options.keys()),
default=list(policy_options.keys())[:2] if len(policy_options) >= 2 else []
)
if len(selected_policies) >= 2:
# 创建雷达图
fig_radar = go.Figure()
for policy_name in selected_policies:
policy_id = policy_options[policy_name]
if policy_id in st.session_state.pmc_results:
result = st.session_state.pmc_results[policy_id]
variable_scores = result['variable_scores']
variables = list(st.session_state.pmc_model.primary_variables.keys())
var_names = [st.session_state.pmc_model.primary_variables[v] for v in variables]
scores = [variable_scores.get(v, 0) for v in variables]
scores = scores + [scores[0]] # 闭合
fig_radar.add_trace(go.Scatterpolar(
r=scores,
theta=var_names + [var_names[0]],
name=f"{policy_name} ({result['pmc_score']:.2f})",
fill='toself'
))
fig_radar.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 1]
)
),
showlegend=True,
title="政策对比雷达图",
height=500
)
st.plotly_chart(fig_radar, use_container_width=True)
else:
st.warning("请至少选择2个政策进行对比。")
else:
st.info("需要至少2个已评估的政策才能进行对比分析。")
with tab3:
st.subheader("热力图分析")
if len(st.session_state.pmc_results) >= 2:
# 准备热力图数据
policy_names = []
variables = list(st.session_state.pmc_model.primary_variables.keys())
var_names = [st.session_state.pmc_model.primary_variables[v] for v in variables]
scores_matrix = []
for policy in st.session_state.policies:
if policy['id'] in st.session_state.pmc_results:
policy_names.append(policy['name'])
result = st.session_state.pmc_results[policy['id']]
variable_scores = result['variable_scores']
scores = [variable_scores.get(v, 0) for v in variables]
scores_matrix.append(scores)
if scores_matrix:
scores_matrix = np.array(scores_matrix)
# 创建热力图
fig = go.Figure(data=go.Heatmap(
z=scores_matrix,
x=var_names,
y=policy_names,
colorscale='RdYlGn',
zmin=0,
zmax=1,
text=np.round(scores_matrix, 2),
texttemplate='%{text:.2f}',
textfont={"size": 10},
hovertemplate='政策: %{y}<br>变量: %{x}<br>得分: %{z:.2f}<extra></extra>'
))
fig.update_layout(
title='政策变量得分热力图',
xaxis=dict(
title='评估变量',
tickangle=-45
),
yaxis=dict(
title='政策名称'
),
height=400 + len(policy_names) * 20,
width=800
)
st.plotly_chart(fig, use_container_width=True)
# 创建相关矩阵
st.subheader("变量相关矩阵")
# 计算相关系数矩阵
corr_matrix = np.corrcoef(scores_matrix, rowvar=False)
fig_corr = go.Figure(data=go.Heatmap(
z=corr_matrix,
x=var_names,
y=var_names,
colorscale='RdBu',
zmid=0,
zmin=-1,
zmax=1,
text=np.round(corr_matrix, 2),
texttemplate='%{text:.2f}',
textfont={"size": 10},
hovertemplate='X: %{x}<br>Y: %{y}<br>相关系数: %{z:.3f}<extra></extra>'
))
fig_corr.update_layout(
title='变量相关系数矩阵',
xaxis=dict(
tickangle=-45
),
height=500,
width=600
)
st.plotly_chart(fig_corr, use_container_width=True)
else:
st.info("暂无数据可用于热力图分析。")
else:
st.info("需要至少2个已评估的政策才能进行热力图分析。")
# 高级配置页面
elif page == "⚙️ 高级配置":
st.header("高级配置")
st.markdown("配置PMC模型权重和评估标准")
tab1, tab2, tab3 = st.tabs(["⚖️ PMC权重配置", "📊 评估标准配置", "🔧 系统设置"])
with tab1:
st.subheader("PMC权重配置")
st.markdown("配置一级变量权重和二级变量权重")
col1, col2 = st.columns(2)
with col1:
st.markdown("#### 一级变量权重")
st.markdown("配置9个一级变量的权重,总和应为1.0")
# 获取当前权重
current_weights = ""
if 'user_pmc_weights' in st.session_state and st.session_state.user_pmc_weights:
current_weights = st.session_state.user_pmc_weights
else:
# 使用等权重作为示例
num_vars = len(st.session_state.pmc_model.primary_variables)
equal_weight = 1.0 / num_vars
weights_dict = {var: round(equal_weight, 3) for var in
st.session_state.pmc_model.primary_variables.keys()}
current_weights = json.dumps(weights_dict, ensure_ascii=False, indent=2)
weights_input = st.text_area(
"一级变量权重(JSON格式)",
value=current_weights,
height=300,
help='例如:{"X1": 0.1, "X2": 0.1, "X3": 0.12, "X4": 0.12, "X5": 0.12, "X6": 0.12, "X7": 0.1, "X8": 0.1, "X9": 0.12}'
)
if st.button("💾 保存权重配置", type="primary"):
if weights_input:
try:
weights_dict = json.loads(weights_input)
if isinstance(weights_dict, dict):
# 验证权重总和
total = sum(weights_dict.values())
if abs(total - 1.0) < 0.01: # 允许小误差
st.session_state.user_pmc_weights = weights_input
st.session_state.pmc_model.update_weights(weights_input)
st.success("✅ 权重配置已保存")
else:
st.error(f"权重总和应为1.0,当前为{total:.2f},请调整权重。")
else:
st.error("权重配置必须是JSON字典格式")
except json.JSONDecodeError as e:
st.error(f"JSON格式错误: {str(e)}")
else:
st.warning("请输入权重配置")
with col2:
st.markdown("#### 二级变量权重")
st.markdown("系统自动计算二级变量权重,通常无需手动配置")
# 显示当前二级权重
secondary_weights = st.session_state.pmc_model.secondary_weights
if secondary_weights:
st.markdown("当前二级权重配置:")
for var, weights in secondary_weights.items():
var_name = st.session_state.pmc_model.primary_variables.get(var, var)
sec_vars = st.session_state.pmc_model.secondary_variables.get(var, [])
st.markdown(f"**{var_name} ({var})**:")
for i, (sec_var, weight) in enumerate(zip(sec_vars, weights)):
display_name = sec_var.replace(f"{var}_", "").replace("_", " ")
st.markdown(f"- {display_name}: {weight:.2f}")
# 权重验证
st.markdown("---")
st.markdown("#### 权重验证")
if st.button("🔍 验证权重配置"):
if 'user_pmc_weights' in st.session_state and st.session_state.user_pmc_weights:
try:
weights_dict = json.loads(st.session_state.user_pmc_weights)
total = sum(weights_dict.values())
if abs(total - 1.0) < 0.01:
st.success(f"✅ 权重配置有效,总和为: {total:.2f}")
else:
st.error(f"❌ 权重配置无效,总和为: {total:.2f},应为1.0")
except:
st.error("❌ 权重配置格式错误")
else:
st.warning("⚠️ 未配置权重")
# 权重文件上传
st.markdown("---")
st.markdown("#### 权重文件上传")
weights_file = st.file_uploader("上传权重配置文件", type=['json', 'txt'])
if weights_file is not None:
weights_content = weights_file.getvalue().decode('utf-8')
st.text_area("文件内容预览", weights_content[:500], height=150)
if st.button("📥 使用上传的权重文件"):
try:
weights_dict = json.loads(weights_content)
if isinstance(weights_dict, dict):
st.session_state.user_pmc_weights = weights_content
st.session_state.pmc_model.update_weights(weights_content)
st.success("✅ 已使用上传的权重配置文件")
st.rerun()
else:
st.error("文件必须是JSON字典格式")
except json.JSONDecodeError as e:
st.error(f"JSON格式错误: {str(e)}")
with tab2:
st.subheader("评估标准配置")
st.markdown("配置PMC指数的评估等级标准")
# 获取当前评估标准
current_criteria = ""
if 'user_evaluation_criteria' in st.session_state and st.session_state.user_evaluation_criteria:
current_criteria = st.session_state.user_evaluation_criteria
else:
# 使用默认评估标准
current_criteria = json.dumps({
"levels": {
"优秀": {"min": 8.0, "max": 9.0, "color": "#4CAF50"},
"良好": {"min": 7.0, "max": 8.0, "color": "#8BC34A"},
"及格": {"min": 6.0, "max": 7.0, "color": "#FFC107"},
"较差": {"min": 0.0, "max": 6.0, "color": "#F44336"}
}
}, ensure_ascii=False, indent=2)
criteria_input = st.text_area(
"评估标准配置(JSON格式)",
value=current_criteria,
height=300,
help='配置评估等级,每个等级包含min(最小值,包含)、max(最大值,不包含)和color(颜色)'
)
col1, col2 = st.columns(2)
with col1:
if st.button("💾 保存评估标准", type="primary"):
if criteria_input:
try:
criteria_dict = json.loads(criteria_input)
if isinstance(criteria_dict, dict) and "levels" in criteria_dict:
st.session_state.user_evaluation_criteria = criteria_input
st.session_state.pmc_model.update_evaluation_criteria(criteria_input)
st.success("✅ 评估标准已保存")
else:
st.error("评估标准必须包含'levels'字段")
except json.JSONDecodeError as e:
st.error(f"JSON格式错误: {str(e)}")
else:
st.warning("请输入评估标准")
with col2:
if st.button("🗑️ 恢复默认评估标准"):
default_criteria = {
"levels": {
"优秀": {"min": 8.0, "max": 9.0, "color": "#4CAF50"},
"良好": {"min": 7.0, "max": 8.0, "color": "#8BC34A"},
"及格": {"min": 6.0, "max": 7.0, "color": "#FFC107"},
"较差": {"min": 0.0, "max": 6.0, "color": "#F44336"}
}
}
st.session_state.user_evaluation_criteria = json.dumps(default_criteria, ensure_ascii=False, indent=2)
st.success("✅ 已恢复默认评估标准")
st.rerun()
# 显示当前评估标准
st.markdown("---")
st.markdown("#### 当前评估标准")
try:
criteria_dict = json.loads(criteria_input)
if "levels" in criteria_dict:
levels = criteria_dict["levels"]
for level_name, level_info in levels.items():
col1, col2, col3 = st.columns(3)
with col1:
st.metric("等级", level_name)
with col2:
st.metric("分数范围", f"{level_info.get('min', 0)}-{level_info.get('max', 0)}")
with col3:
color = level_info.get('color', '#000000')
st.markdown(
f"<div style='background-color:{color}; padding:10px; border-radius:5px; text-align:center; color:white;'>颜色</div>",
unsafe_allow_html=True)
except:
st.warning("⚠️ 评估标准格式不正确")
with tab3:
st.subheader("系统设置")
st.markdown("#### 数据管理")
col1, col2 = st.columns(2)
with col1:
if st.button("💾 保存当前会话"):
# 保存当前所有数据
session_data = {
'policies': st.session_state.policies,
'pmc_results': st.session_state.pmc_results,
'analysis_history': st.session_state.analysis_history,
'user_stopwords': st.session_state.get('user_stopwords', ''),
'user_positive_words': st.session_state.get('user_positive_words', ''),
'user_negative_words': st.session_state.get('user_negative_words', ''),
'user_feature_keywords': st.session_state.get('user_feature_keywords', ''),
'user_pmc_weights': st.session_state.get('user_pmc_weights', ''),
'user_evaluation_criteria': st.session_state.get('user_evaluation_criteria', ''),
'saved_at': datetime.now().isoformat()
}
# 转换为JSON
session_json = json.dumps(session_data, ensure_ascii=False, indent=2)
# 提供下载
st.download_button(
label="📥 下载会话数据",
data=session_json,
file_name=f"pmc_session_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json",
mime="application/json"
)
with col2:
if st.button("📤 加载会话数据"):
uploaded_session = st.file_uploader("选择会话文件", type=['json'])
if uploaded_session is not None:
try:
session_data = json.load(uploaded_session)
# 恢复会话数据
if 'policies' in session_data:
st.session_state.policies = session_data['policies']
if 'pmc_results' in session_data:
st.session_state.pmc_results = session_data['pmc_results']
if 'analysis_history' in session_data:
st.session_state.analysis_history = session_data['analysis_history']
# 恢复配置
if 'user_stopwords' in session_data:
st.session_state.user_stopwords = session_data['user_stopwords']
if 'user_positive_words' in session_data:
st.session_state.user_positive_words = session_data['user_positive_words']
if 'user_negative_words' in session_data:
st.session_state.user_negative_words = session_data['user_negative_words']
if 'user_feature_keywords' in session_data:
st.session_state.user_feature_keywords = session_data['user_feature_keywords']
if 'user_pmc_weights' in session_data:
st.session_state.user_pmc_weights = session_data['user_pmc_weights']
if 'user_evaluation_criteria' in session_data:
st.session_state.user_evaluation_criteria = session_data['user_evaluation_criteria']
st.success("✅ 会话数据加载成功!")
st.rerun()
except Exception as e:
st.error(f"加载会话数据失败: {str(e)}")
st.markdown("---")
st.markdown("#### 系统信息")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("Python版本", f"{sys.version.split()[0]}")
with col2:
st.metric("Streamlit版本", f"{st.__version__}")
with col3:
st.metric("Pandas版本", f"{pd.__version__}")
st.markdown("---")
st.markdown("#### 系统重置")
if st.button("🔄 重置所有数据", type="secondary"):
if st.checkbox("确认重置所有数据?此操作不可撤销。"):
st.session_state.policies = []
st.session_state.pmc_results = {}
st.session_state.analysis_history = []
st.session_state.user_stopwords = ""
st.session_state.user_positive_words = ""
st.session_state.user_negative_words = ""
st.session_state.user_feature_keywords = ""
st.session_state.user_pmc_weights = ""
st.session_state.user_evaluation_criteria = ""
st.success("✅ 所有数据已重置!")
st.rerun()
# 页脚
st.markdown("---")
st.caption("PMC政策文本量化评估系统 v1.0 | 完全可配置版本 | 所有词汇表由用户自行配置")