GPT5.2发布后,在多个公开benchmark上都相较于5.1有了不小提升,分享其中看到比较有意思的一个点。gpt-5.2在ARC‑AGI‑2提升非常大,而gpt-5.1-thinking在这个测评上分数才达到17.61,比opus-4.5(22.8)低5个点,与gemini-3-pro(31.1)差距巨大, 我当时看到这个指标一度怀疑是不是看错了。
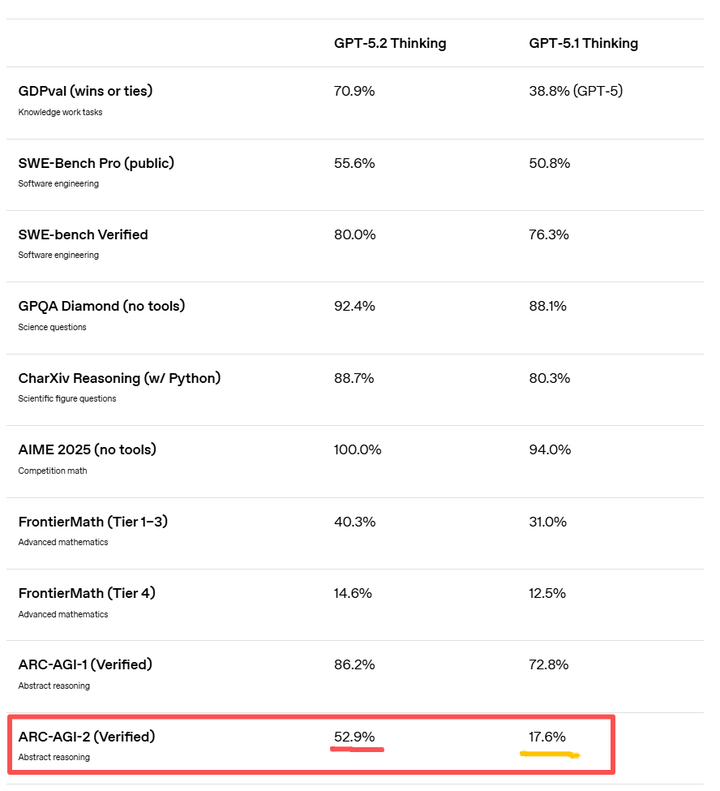
而在arc-agi-1上,gpt-5.1(72.8)的表现与在arc-agi-2截然不同,与gemini-pro-3(75.0)的差距很小,比opus 4.5(72.0)还高,但是arc-agi-2和arc-agi-1测评题目都是网格谜题这一类题,没有发生提醒上变化,官方解释区别为arc-agi-2保留了ARC-AGI-1 的核心形式,但重新策划/扩展任务集,为了在更高能力区间提供"更细颗粒度信号",并更好隔离 fluid reasoning。
比较有意思的点是这个fluid reasoning,这个概念衍生自Fluid Intelligence,是由是由心理学家雷蒙德·卡特尔提出的一个概念,一般与晶体智力(Crystallized Intelligence)对照提出,流体推理关注面对新颖、抽象的问题时,进行推理、识别模式和解决问题的能力,不依赖于后天习得的知识或经验,而晶体智能则指通过后天学习、教育和生活经验积累而来的知识与技能,是过去学习成果的"结晶"2。arc-agi测评设立的目的测评模型在有限的先验知识下,模型面对新问题,未见过的模式时,如何学会解决这些问题技能。要完成ac-agi的评估任务,参与测评的人工智能系统必须展现出基础流体智力,即适应全新、前所未见任务的能力。
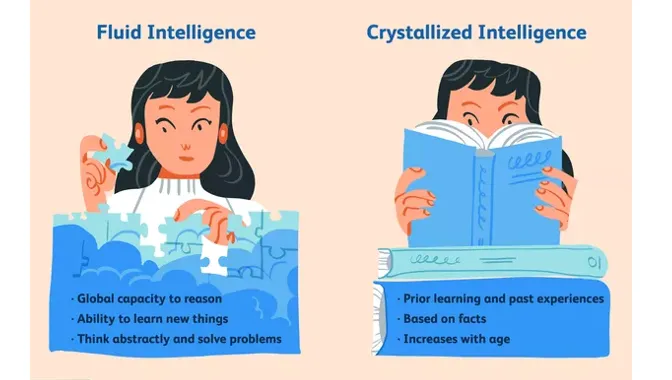
那了解arc-agi测评什么能力之后,我们来看一下arc-agi-2和arc-agi-1有什么比较大的区别?导致gpt-5.1在两代测评集上出现如此大的反差表现。根据arc-agi-2的技术报告,arc-agi-2在5月份发布时,当时最强的o3-mimni(High)模型在arc-agi-1上实现了34.5的成绩,而在arc-agi-2上只达到3.0%,但是却是表现最好的模型,claude-3.7(8k)只有0.9%,而在arc-agi-1上,claude-3.7也有21.2%3。
是什么原因导致了arc-agi-2变得如此"难",主要有三点原因:
1.ARC-AGI-1 的许多任务可以通过简单的几何变换(旋转、移动、填充)解决,这容易被模型通过"近似检索"或"简单程序搜索"破解。而 ARC-AGI-2 引入了当前 AI处理比较困难的符号解释(例如一个像素点代表路障),组合推理(同时应用多个规则,或者规则之间存在相互作用),上下文动态规则(例如在左边区域向左移动,在右边区域向右移动);
2.剥离互联网数据污染,arc-2-agi技术报告提到,ARC-AGI-1 发布 6 年来,其核心逻辑已被互联网数据"污染",许多模型的高分实际上是依靠记忆(Crystallized Intelligence)而非推理(Fluid Intelligence)获得的。ARC-AGI-2 的任务是全新设计的,切断了模型利用预训练数据中的类似题目进行"模仿"的路径。
3.加强对抗暴力破解(brute-force)设计,ARC-AGI-1 私有评估集中近半数的任务,可以通过计算密集型的穷举搜索方法完成。ARC-AGI-2大幅度扩展了搜索空间,使得暴力破解变得在计算上不太可行。
这三点改变排除了数据源的干扰性,继续提高任务难度,同时限制了暴力破解方法的实施空间,让arc-agi可以更纯粹去评估模型流体智能水平。同时arc-agi-2为了考虑暴力破解仍然存在的可能性,增加了成本维度来进行监测评估。
基于以上背景,我们大体可以来做一个简单分析。gpt-5.1的指令遵循能力很强,对复杂指令的理解比较精准,实测复杂问题的推理效果也不错,但可能是由于基模型参数量的限制,在流体智能这种偏元学习的能力上有所不足,但这种能力现在应用的场景还不算多,因为AI还没有进入到考验这个能力的应用区,加之上下文先验知识的补充,这个能力不太容易测出来。
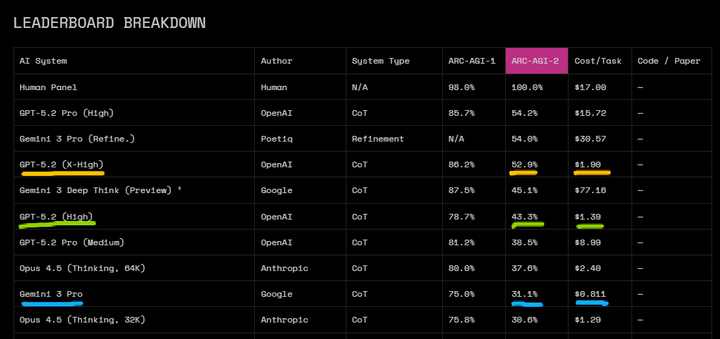
而gpt-5.2官方博客明确提到是gpt-5.2是gpt-5系列模型4,system card也没提到gpt-5.2有什么模型技术层面变化,只大概说了下openai的推理模型是基于强化学习训练,训练模型在回答问题之前进行长思维链思考5,大体可以推断没有太大架构上的更新。arc-agi-2性能成本图上gpt-5.2和gpt-5.1的成本接近(1.39 vs 1.17), 那比较可能的解释是gpt-5.2在后训练上加了把火,在没有明显增加推理成本的情况下,找到了比较有效的rl scaling方式,把这种流体智能的能力补齐,反超gemini 3 deep-think,可见test-time-scaling范式还有不小的增长空间,但到明年arc-agi-2可能也会出现饱和迹象,不过arc-agi-3明年也计划推出,是更针对agent(感知-规划-行动)的游戏场景测试,目前开放了6个游戏场景供在线试玩,感兴趣可以尝试:https://three.arcprize.org/。

补充一部分关于有的媒体发布的"gpt5.2通过增加推理token消耗来提升arc-agi-2成绩是否作弊"的判断,有必要做一点澄清。
gpt-5.2在arc-agi-2上能力的跃升大概率是rl scaling的作用,延续5.1的模型架构和参数,不太可能进行模型架构调整,但是定价比5.1贵了40%,应该RL后训练推理加深优化,long cot成本增长的原因。
long cot 推理本来就是rl训练提升的一个关键能力,不能因为gpt-5.2的推理token长就认为它作弊,long cot推理正确才是首要目的,效率逐步优化。而且从效率角度来评估,arc-agi-2 leaderboard的y轴为score,x轴为成本,本身就考虑了成本效率因素。gpt-5.2 high的分数是43.3%,成本是$1.39/task,效率用分数除以成本≈31.15,而gemini 3 pro分数为31.3,陈本为0.811,效率38.38,效率比=38.38/31.15≈1.23,如果考虑arc-agi-2的难度系数,gpt-5.2大概率比gemini3更具推理效率。
参考文献:
【1】https://openai.com/index/introducing-gpt-5-2/
【2】https://thuong.substack.com/p/fluid-intelligence-vs-crystallized
【3】https://arxiv.org/pdf/2505.11831
【4】Update to GPT-5 System Card: GPT-5.2
【5】https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf