一前言
今天的更新依旧是周末合刊,而且这是OPENCV的第一阶段的最后一次更新了,我们的下一个系列是YOLOv8,不过需要时间,可能未来一周都不会更新,而且我会同时开一个系列,是关于蓝桥杯JAVA赛道的备赛之路,说实话,我没有一点JAVA基础,所以这是真的零基础备赛,至于这两个系列怎么安排,我也会调整。今天的章节也很有意思,我和十八似乎有种缘分,我家是十八层,高中是十八中,我现在十八岁。哈哈哈
二主要内容
蛮力匹配的基础知识
蛮力匹配器很简单。它采用第一组中的一个特征点描述子,并使用一些距离计算与第二组中的所有其他特征点匹配。并返回距离最近的一个特征点。
对于 BF 匹配器,首先我们必须使用 cv.BFMatcher()
bf = cv.BFMatcher(normType=cv.NORM_L2, crossCheck=False)
创建 BFMatcher 对象。它需要两个可选的参数。第一个是 normType。它指定要使用的距离测量方法。默认情况下,它是 cv.NORM_L2 。它很适合于 SIFT 和 SURF 等( cv.NORM_L1 也可以)。对于基于二进制字符串的描述子,如 ORB,BRIEF,BRISK 等,应使用 cv.NORM_HAMMING ,它使用汉明距离作为度量。如果 ORB 使用 WTA_K == 3 或 4,则应使用 cv.NORM_HAMMING2 。
第二个参数是布尔变量 crossCheck,默认为 false。如果为 True,则 Matcher 仅返回具有值(i,j)的匹配,使得集合 A 中的第 i 个描述子具有集合 B 中的第 j 个描述子作为最佳匹配,反之亦然。也就是说,两组中的两个特征点应该相互匹配。它提供了一致的结果,是 D.Lowe 在 SIFT 论文中提出的比率测试的一个很好的替代方案。
一旦创建,两个重要的方法是 BFMatcher.match() 和 BFMatcher.knnMatch()。第一个返回最佳匹配。第二种方法返回 k 个最佳匹配,其中 k 由用户指定。当我们需要做更多的工作时,它可能会有用。
BFMatcher.match() 和 BFMatcher.knnMatch() 对比
| 特性 | match() |
knnMatch() |
|---|---|---|
| 返回数量 | 1个最佳匹配 | k个最佳匹配 |
| 返回值类型 | List[DMatch] |
List[List[DMatch]] |
| 常用筛选方法 | 按距离阈值筛选 | Lowe's ratio test |
| 计算复杂度 | 较低 | 较高(需计算k个) |
| 匹配质量 | 可能有误匹配 | 通过ratio test可提高准确性 |
就像我们使用 cv.drawKeypoints()绘制特征点一样, cv.drawMatches() (之前我们的文章有过介绍)帮助我们绘制匹配。它水平堆叠两个图像,并从第一个图像到第二个图像绘制线条,显示最佳匹配。还有 cv.drawMatchesKnn ,它绘制了所有 k 个最佳匹配。如果 k = 2,它将为每个关键点绘制两条匹配线。因此,如果我们想要有选择地绘制它,我们必须传递一个掩模。
对 ORB 描述子使用蛮力匹配
在这里,我们将看到一个关于如何匹配两个图像之间的特征的简单示例。在这种情况下,我有一个 queryImage 和一个 trainImage。我们将尝试使用特征匹配在 trainImage 中查找 queryImage。 (图片为/samples/c/box.png 和/samples/c/box_in_scene.png)
我们使用 ORB 描述符来匹配功能。所以让我们从加载图像,查找描述子等开始。
我们使用 cv.NORM_HAMMING (因为我们使用的是 ORB)创建一个 BFMatcher 对象并且启用了 crossCheck 以获得更好的结果。然后我们使用 Matcher.match()方法在两个图像中获得最佳匹配。我们按照距离的升序对它们进行排序,以便最佳匹配(距离最小)出现在前面。然后我们只画出前 10 个匹配(仅为了能见度,你可以随意增加匹配的个数)。
代码如下
python
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 读取查询图像和训练图像
img1 = cv.imread(r'D:\python_code\pic\sumoiao.webp', 0) # queryImage
img2 = cv.imread(r'D:\python_code\pic\smt.png', 0) # trainImage
# 初始化ORB检测器
orb = cv.ORB_create()
# 使用ORB检测关键点和描述符
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# 创建BFMatcher对象
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# 匹配描述符
matches = bf.match(des1, des2)
# 根据距离排序匹配结果
matches = sorted(matches, key=lambda x: x.distance)
# 绘制前10个匹配点
img3 = cv.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2)
# 显示匹配结果
plt.imshow(img3)
plt.show()
这里的图片可以使用一张图片然后截一部分,就有了两张图片,完整的放上面,截图放下面
效果如下

这个匹配器对象是什么?
matches = bf.match(des1,des2)的结果是 DMatch 对象的列表。此 DMatch 对象具有以下属性:
- DMatch.distance - 描述子之间的距离。越低越好。
- DMatch.trainIdx - 目标图像中描述子的索引
- DMatch.queryIdx - 查询图像中描述子的索引
- DMatch.imgIdx - 目标图像的索引。
对 SIFT 描述符进行蛮力匹配和比率测试
这一次,我们将使用 BFMatcher.knnMatch()来获得最佳匹配。在这个例子中,我们将采用 k = 2,以便我们可以在使用 D.Lowe 论文中的比率测试。
代码如下
python
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
# 图像路径设置
query_img_path = r'D:\python_code\pic\sumoiao.webp'
train_img_path = r'D:\python_code\pic\smt.png'
# 灰度模式读取图像
img1 = cv.imread(query_img_path, 0)
img2 = cv.imread(train_img_path, 0)
# 初始化SIFT检测器
sift = cv.SIFT_create()
# 关键点检测与描述符计算
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建暴力匹配器
bf = cv.BFMatcher(cv.NORM_L2, crossCheck=False)
# K近邻匹配
matches = bf.knnMatch(des1, des2, k=2)
# Lowe's比率测试筛选
ratio_threshold = 0.75
good_matches = []
for m,n in matches:
if m.distance < ratio_threshold * n.distance:
good_matches.append(m)
# 匹配结果可视化
if len(good_matches) > 10: # 仅当有足够匹配时才绘制
result_img = cv.drawMatches(img1, kp1, img2, kp2,
good_matches[:50],
None,
flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.figure(figsize=(15,10))
plt.imshow(result_img)
plt.axis('off')
plt.show()
else:
print("未找到足够数量的可靠匹配点")
效果如下
还是很精准的,效果很不错
基础
那我们上面做了什么?我们使用了一个 queryImage,在其中找到了一些特征点,我们采用了另一个 trainImage,找到了该图像中的特征,最后找到它们之间特征点的最佳匹配。简而言之,我们在另一个杂乱的图像中找到了一个对象的某些部分的位置。这些信息足以在 trainImage 上准确找到对象。
为此,我们可以使用来自 calib3d 模块的函数,即 cv.findHomography() 。
H, mask = cv.findHomography(srcPoints, dstPoints, method=None, ransacReprojThreshold=None, maxIters=None, confidence=None)
参数详解
输入参数表格
| 参数名称 | 类型 | 描述 | 默认值 | 常用值 |
|---|---|---|---|---|
srcPoints |
np.ndarray |
源图像中的点坐标 | 必需 | 形状: (N, 2) 或 (N, 1, 2) |
dstPoints |
np.ndarray |
目标图像中的对应点 | 必需 | 形状与 srcPoints 相同 |
method |
int |
计算方法 | 0 |
选项见下方方法表格 |
ransacReprojThreshold |
float |
RANSAC重投影误差阈值 | - | 1.0-5.0 |
maxIters |
int |
RANSAC最大迭代次数 | 2000 |
1000-5000 |
confidence |
float |
置信度 | 0.995 |
0.95-0.999 |
返回值表格
| 返回值 | 类型 | 描述 | 可能值 |
|---|---|---|---|
H |
np.ndarray |
3×3单应性矩阵 | 形状: (3, 3) 或 None |
mask |
np.ndarray 或 None |
内点掩码 | 形状: (N,),仅当使用RANSAC/LMEDS时返回 |
这就是cv.findHomography()的详细用法。它在计算机视觉的许多应用中都非常重要,特别是图像配准、全景拼接和增强现实等领域。
如果将两个图像中的特征点集传递给这个函数,它将找到该对象的透视变换。然后我们可以使用 cv.perspectiveTransform()
dst = cv.perspectiveTransform(src, M)
参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
src |
np.ndarray |
输入点集,形状为 (N, 1, 2) 或 (N, 2) |
M |
np.ndarray |
3×3 透视变换矩阵 |
dst |
np.ndarray |
输出点集,形状与输入相同 |
来查找对象。它需要至少四个正确的点来找到这种变换。
我们已经看到匹配时可能存在一些可能的错误,这可能会影响结果。为了解决这个问题,算法使用 RANSAC 或 LEAST_MEDIAN(可以由标志位决定)。因此,提供正确估计的良好匹配称为内点,剩余称为外点。 cv.findHomography() 返回一个指定了内点和外点的掩模。
代码
首先,像往常一样,让我们在图像中找到 SIFT 特征并应用比率测试来找到最佳匹配。
代码如下
python
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10
img1 = cv.imread(r'D:\python_code\pic\sumoiao.webp',0) # 查询图像
img2 = cv.imread(r'D:\python_code\pic\smt.png',0) # 训练图像
# 初始化SIFT检测器
sift = cv.SIFT_create()
# 检测关键点并计算描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 设置FLANN匹配器参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
# 创建FLANN匹配器
flann = cv.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1,des2,k=2)
# 应用Lowe's比率测试筛选优质匹配点
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
# 如果找到足够多的匹配点,计算单应性矩阵
if len(good) > MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)
# 使用RANSAC方法计算单应性矩阵
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
# 获取查询图像的尺寸
h,w = img1.shape
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
# 对查询图像的四个角点进行透视变换
dst = cv.perspectiveTransform(pts,M)
# 在训练图像上绘制匹配区域的多边形
img2_with_box = img2.copy()
img2_with_box = cv.polylines(img2_with_box,[np.int32(dst)],True,255,3, cv.LINE_AA)
else:
print(f"Not enough matches are found - {len(good)}/{MIN_MATCH_COUNT}")
matchesMask = None
img2_with_box = img2
# 设置绘制参数
draw_params = dict(matchColor = (0,255,0),
singlePointColor = None,
matchesMask = matchesMask,
flags = 2)
# 绘制匹配结果
img3 = cv.drawMatches(img1,kp1,img2_with_box,kp2,good,None,**draw_params)
# 显示结果
plt.imshow(img3, 'gray')
plt.show()
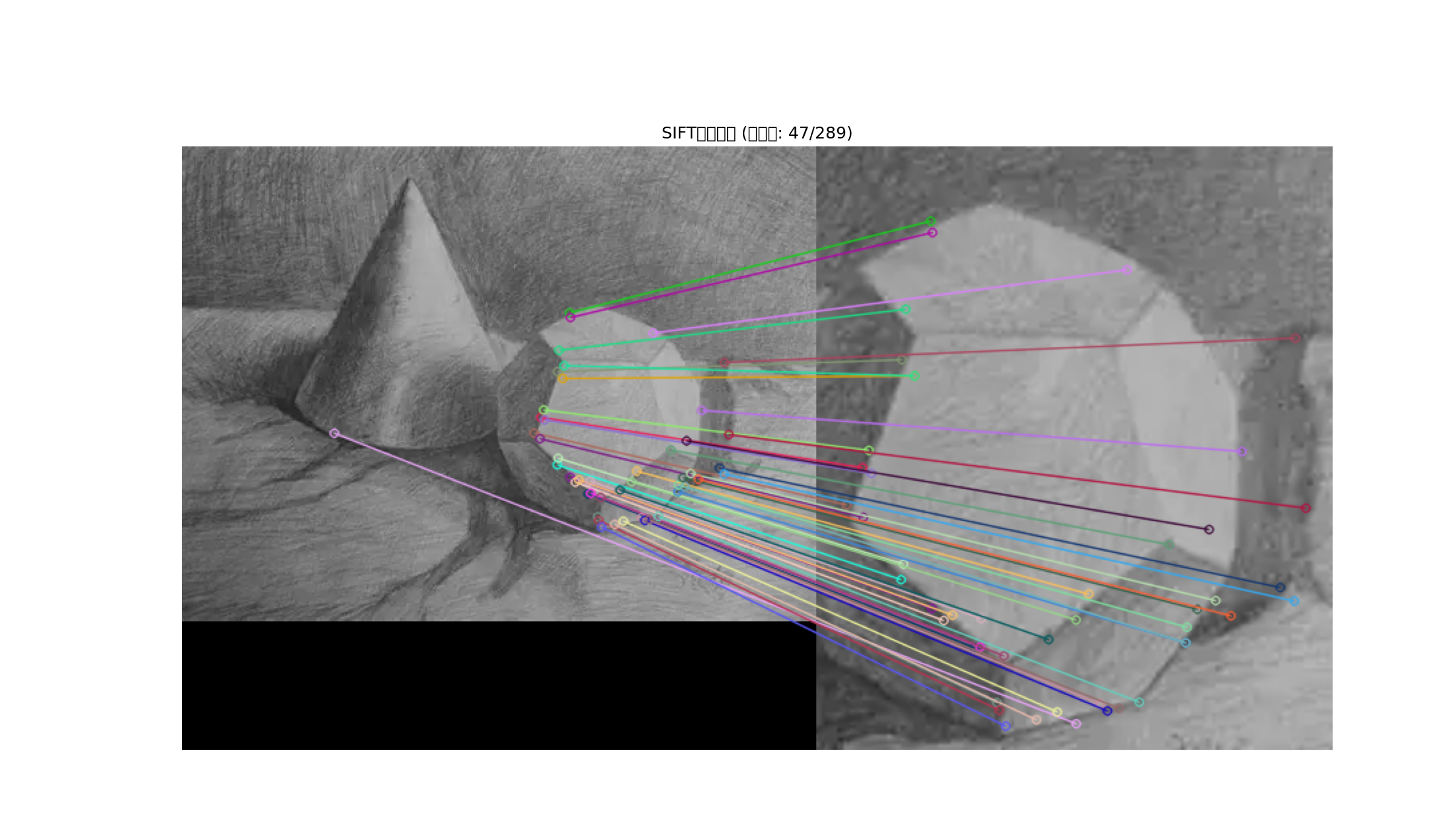
效果如下

这个效果更加明显,效果更好
三最后一语
其实我也很想继续写下去,但是我想你们也应该感觉过迷茫,不知道该如何使用,不知道学习这个对比赛或是项目有这个那么用,我也感受到了,所以为了尽快到达比赛水平,我将采取学用结合,我会买一块k230的板子进行研究,大家一起努力吧。
我祝福你
愿你经得起长久的离别
种种考验、古凶未卜的折磨
漫长的昏暗的路程
依照你的意愿安排生活吧
只要你觉得好就行
------帕斯捷尔纳克《日瓦戈医生》
感谢观看,定会再见,共勉!!