CLIPer
动机
提示CLIP的关键在于空间特征表示的改进上。
可以利用早期的特征和注意力来改进,而不是依赖最后一层注意力或者其他VFM模型。

扩散模型对于局部细节的空间关系表示比较好,可以用于进行语义分割。
方法
早期层融合
就是把早期层的注意力图进行平均化处理,替代最后一层的注意力图 。
最后一层的FFN和残差连接进行移除。

作者还加入了一个中间特征融合 ,不止限于中间注意力图融合
细粒度特征补偿
扩散模型的注意力图的空间表示能力强,可以用于进一步修正和锐化最终得到的类别向量。
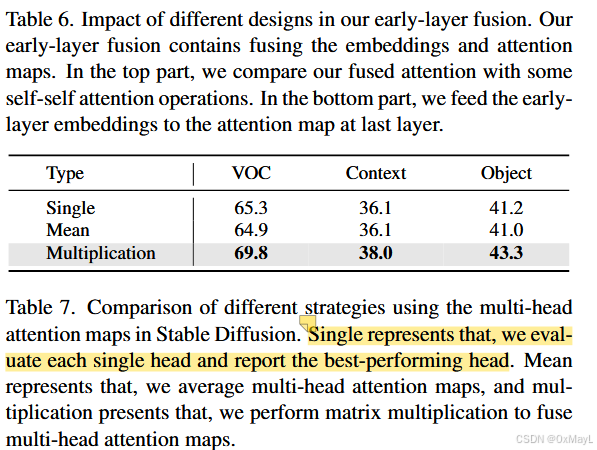
作者将扩散模型得到的注意力中多个头拆分出来,进行矩阵乘法,实现跨 head 的注意力融合

消融实验发现使用矩阵乘法效果最好。
GPT
下面按你的"论文方法深读"模板,精读 CLIPer: Hierarchically Improving Spatial Representation of CLIP for Open-Vocabulary Semantic Segmentation(Sun et al., 2024)。
0. 摘要翻译
CLIP 在多种图像级任务上具有很强的零样本分类能力,因此近年来有人尝试在不额外训练 的情况下,将 CLIP 适配到像素级的开放词汇语义分割。关键在于增强图像级 CLIP 的空间表征能力,例如用自-自注意力矩阵或视觉基础模型(VFM)注意力来替换 CLIP 最后一层的自注意力图。本文提出一种新的分层框架 CLIPer ,从层级角度提升 CLIP 的空间表征。CLIPer 包含:早期层融合模块 与细粒度补偿模块。作者观察到 CLIP 的早期层嵌入与注意力图能保留空间结构信息,因此设计早期层融合模块以产生空间一致性更好的分割图;随后用扩散模型的自注意力图补偿局部细节。作者在七个分割数据集上实验,取得了 SOTA:例如用 ViT-L 时,VOC 与 COCO Object 上 mIoU 分别为 69.8 与 43.3,较 ProxyCLIP 提升 9.2 与 4.1,并开源代码与模型。
1. 方法动机
a) 为什么提出?
作者认为现有 training-free CLIP 分割改造大多只动最后一层注意力(self-self 或 VFM attention),虽然能改善空间一致性,但仍存在两类关键缺陷:
- patch 级空间一致性不足:CLIP 是图像级对齐训练,patch token 的空间结构弱;单改最后一层不够。
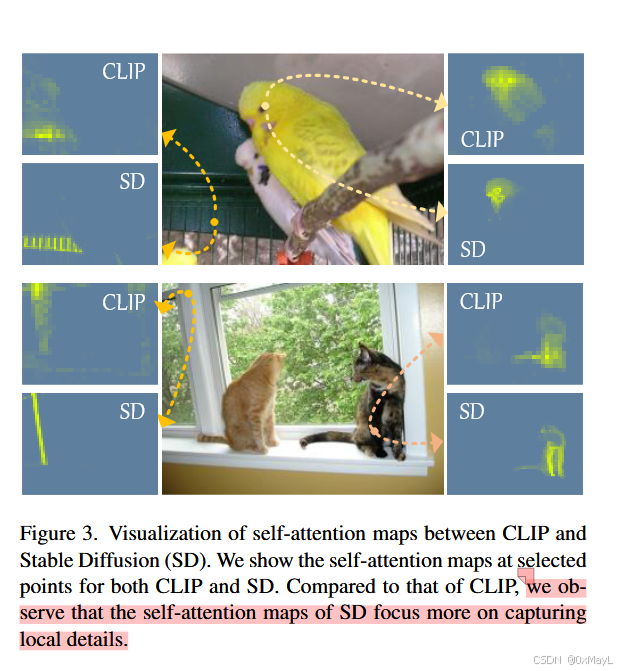
- 局部细节粗糙:patch-text 相似度图天生偏"粗",边界与细碎结构难精确。作者观察到 Stable Diffusion 的 self-attention 更"局部",能补细节。
b) 现有方法痛点/不足
- Self-self attention 系(MaskCLIP/SCLIP/ClearCLIP):替换最后一层注意力图以维持局部信息,但仍主要停留在"最后一层修补"。
- VFM attention 系(ProxyCLIP):用外部 VFM 注意力替换最后一层注意力,但依赖额外模型,且仍是"最后一层替换"。
c) 研究假设/直觉(一句话版)
早期层更保空间结构、扩散注意力更擅长局部细节;把两者分层注入到 CLIP 分割里,就能同时提升"整体空间一致性 + 边界细节"。
2. 方法设计(重点:非常细致的 pipeline + 公式解释 + 维度)
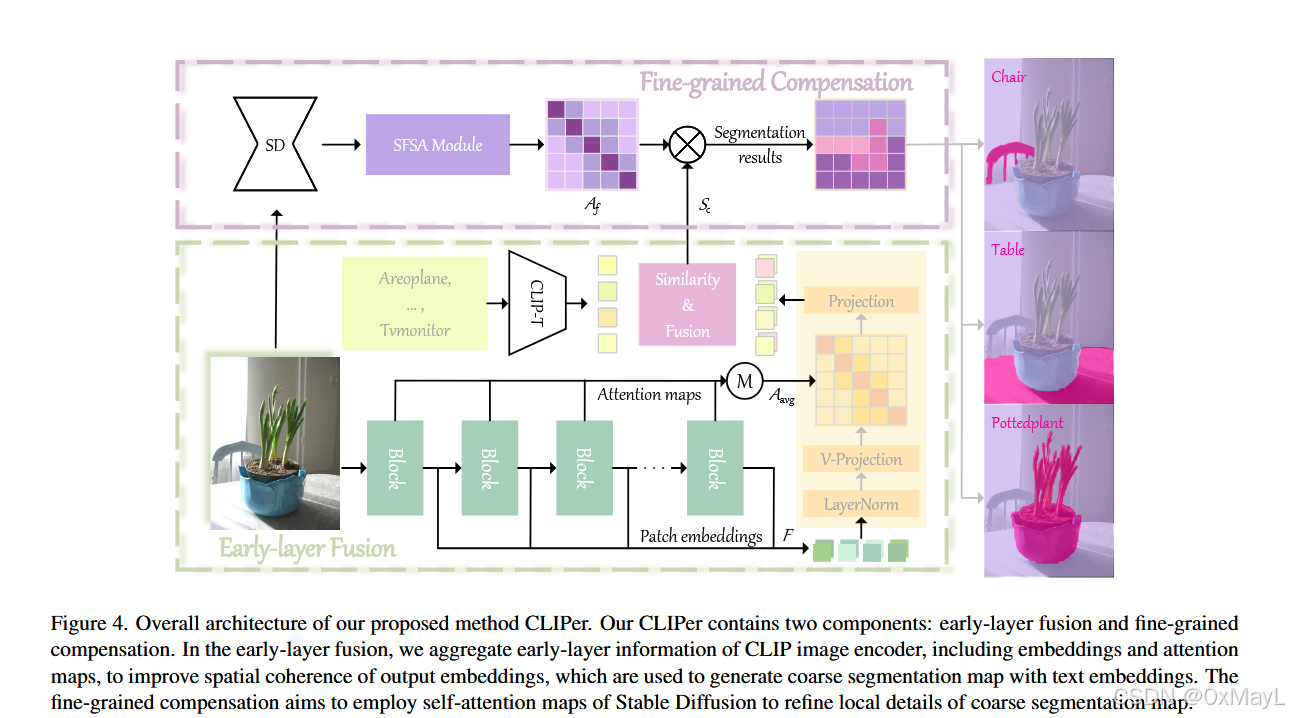
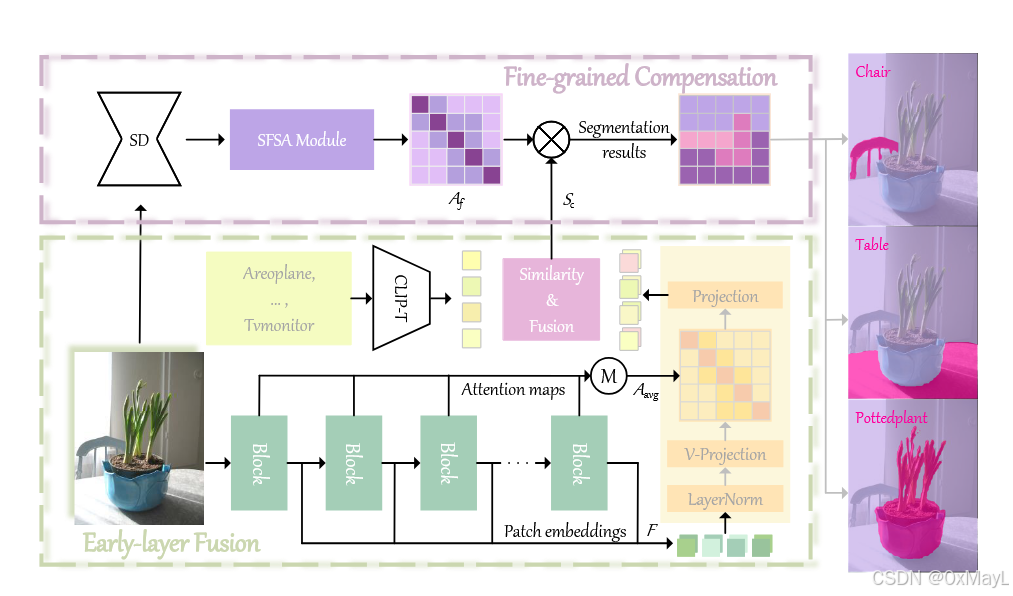
CLIPer 由两部分组成:
- Early-layer Fusion(ELF) :用 CLIP 早期层的 embeddings 与 attention 改善 patch 空间一致性,生成粗分割图。
- Fine-grained Compensation(FGC) :用 Stable Diffusion 的 self-attention 对粗分割图做细节补偿。
2a) 总体 pipeline(输入→处理→输出)
输入: 一张图像 + 一组候选类别文本(prompt)。
输出: 像素级 open-vocab 语义分割图。
Step 1:CLIP 图像编码得到 token 序列(含 cls + patch)
- 将图像切成 patch,形成初始 token embedding:
F\^{0}\\in \\mathbb{R}\^{(hw+1)\\times D}
其中 (hw) 是 patch 数,(D) 是特征维度,(+1) 对应 cls token。
Step 2:跑到倒数第二层,收集早期层的 embeddings 与 attention maps
对第 (n) 个 transformer block:
Q\^n = \\text{Proj}_q(\\text{LN}(F\^{n-1})) \\tag{3}
K\^n = \\text{Proj}_k(\\text{LN}(F\^{n-1})) \\tag{4}
V\^n = \\text{Proj}_v(\\text{LN}(F\^{n-1})) \\tag{5}
维度理解(以单尺度表示,忽略多头拆分):
- (F^{n-1}): ((hw+1)\times D)
- (Qn,Kn,V^n): ((hw+1)\times D)(本质是线性映射后的同形张量)
注意力与残差/FFN 更新:
\\bar{F}^{n}=\\text{Att}(Q^n,K^n,V^n)+F\^{n-1} \\tag{6}
F^{n}=\\text{FFN}(\\text{LN}(\\bar{F}^{n}))+\\bar{F}\^{n} \\tag{7}
- (\text{Att}(Q,K,V)=A\cdot V),其中
A=\\text{Softmax}\\left(\\frac{QK\^T}{\\sqrt{d}}\\right)
(d) 是 key 的特征维度(常见为"每个 head 的维度")。 - 因此 (A^n)(该层 attention map)维度可理解为:((hw+1)\times(hw+1))(每个 head 各一张,论文这里用统称)。
把倒数第二层之前所有层的 embeddings 与 attention 收集成集合:
- ( \mathcal{F}={F^i,|,i=1,\dots,N-1})
- ( \mathcal{A}={A^i,|,i=1,\dots,N-1})
Step 3:Early-layer Fusion:用早期层 attention 的平均值替换"最后一层 attention"
作者先做早期层 attention 平均:
A_{\\text{avg}}=\\frac{1}{N}\\sum_{n=1}^{N-1}A^n \\tag{8}
然后 用 (A_{\text{avg}}) 替换 CLIP 最后一层的原始 self-attention map ,并把"多层 embeddings"喂给最后一层,得到多个输出 embeddings。
关键工程化点:作者仿照 ClearCLIP ,在最后一个 transformer block 去掉 FFN 和残差连接,以"简化表征并更好对齐文本嵌入"。
Step 4:用文本编码器做相似度,得到粗分割图 (S_c)
- 对每个类别文本,CLIP text encoder 得到类别 embedding。
- 对"多个输出 embeddings"和"文本 embeddings"计算 cosine similarity,得到多张相似度图,再取平均作为最终相似度图;把每个 patch 映射到相似度最大的类别,得到 coarse segmentation。
直观上:ELF 解决"patch 表征空间不稳/不连续"的问题,让粗分割图更成块、更符合物体结构。
2b) Fine-grained Compensation(FGC):用 Stable Diffusion attention 补细节
Step 5:Stable Diffusion 提取最高分辨率 self-attention
输入图像 + 空(null)prompt 到 Stable Diffusion,取最高空间分辨率处的 multi-head self-attention:
A^{m}\\in\\mathbb{R}^{H\\times L\\times L}
- (H):head 数
- (L):空间位置数(把特征图展平成长度为 (L) 的序列)
Step 6:跨 head 的注意力融合(矩阵链式相乘)
A_f = A\^{m}\[0\]\\times A\^{m}\[1\]\\times \\cdots \\times A\^{m}\[H-1\] \\tag{9}
这里每个 (A{m}[i]\in\mathbb{R}{L\times L}),所以 (A_f\in\mathbb{R}^{L\times L})。
Step 7:用 (A_f) 传播/锐化粗分割图
把粗分割图先对齐到 SD 的空间尺度得到 (S_c)(可理解为 (S_c\in\mathbb{R}^{L\times C}),© 为类别数),做:
S_f = A_f \\times S_c \\tag{10}
得到 (S_f\in\mathbb{R}^{L\times C}),再上采样回原图分辨率输出最终分割。
直观上:(A_f) 像一个"局部结构传播矩阵",让同一局部结构内的像素/位置互相强化,从而边界更贴合。
3. 与其他方法对比
a) 本质不同点
-
以往 training-free CLIP 分割多是**"最后一层注意力替换"**(self-self 或 VFM)。
-
CLIPer 是分层(hierarchical):
- 先用 CLIP 早期层信息修复空间一致性(ELF)
- 再用 扩散模型 attention补局部细节(FGC)
b) 创新点与贡献度(我按"影响力"排序)
- 早期层融合(ELF):把早期层 attention/embedding 显式融合进最后层推理(不是只换最后层 attention)。
- 扩散注意力细节补偿(FGC):用 SD 的 self-attention 做细节传播与边界锐化。
- 训练自由 + 速度策略:不滑窗,直接整图进 CLIP encoder,简化流程并更快。
c) 适用场景
- 适合:需要 training-free、希望兼顾"整体结构 + 边界细节"的 open-vocab 语义分割。
- 不那么适合/代价:如果你不想引入扩散模型开销,可只用 CLIPer*(无 FGC);若对微小目标极敏感,论文承认仍有困难。
d) 表格总结(优点/缺点/改进点)
| 方法 | 核心改动位置 | 是否额外模型 | 优点 | 缺点/代价 | 相对 CLIPer 的差距 |
|---|---|---|---|---|---|
| MaskCLIP / SCLIP / ClearCLIP | 主要在最后一层 attention做替换/重构 | 否 | 简单、training-free | 仍偏"最后层修补",细节有限 | CLIPer 引入早期层 + 扩散细节补偿 |
| ProxyCLIP | 用 VFM attention 替换最后层 | 是(VFM) | 性能强 | 依赖外部模型 | CLIPer 不靠 VFM,而用早期层与 SD attention |
| CLIPer | 早期层 attention/embedding 融合 + SD attention 补细节 | 是(Stable Diffusion) | 结构更稳 + 边界更细 | FGC 增加推理时间 | --- |
4. 实验表现与优势
a) 作者如何验证有效性(实验设计)
- 7 个数据集:含/不含 background 两组设置(VOC/Context/Object;VOC20/Context59/Stuff/ADE)。
- 指标:mIoU;并额外做 image-level 分类能力评估(mAP/F1/P/R),以及 pseudo-mask 生成对比。
b) 代表性关键结果(mIoU)
- ViT-L/14:VOC 上 69.8 ,Object 上 43.3,显著超过 ProxyCLIP(VOC 60.6、Object 39.2)。
- 在多个数据集上总体达到 SOTA;作者注明:除 VOC20 + ViT-L 外均达 SOTA。
c) 哪些场景优势最明显(证据)
-
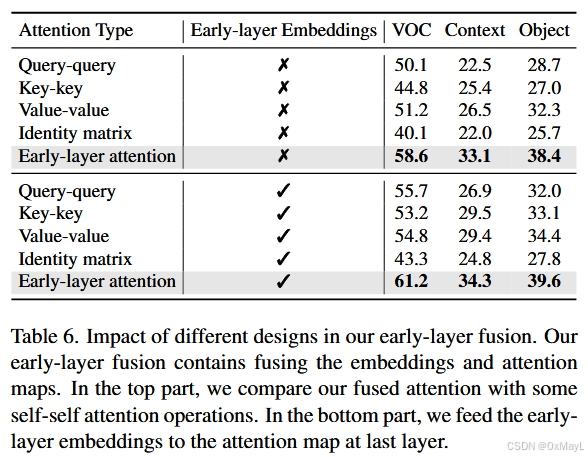
从消融看增益来源:
- baseline(value-value attention + 去 FFN/残差)在 VOC/Context/Object 为 51.2/26.5/32.3;
- +ELF → 61.2/34.3/39.6;
- +FGC → 62.8/29.7/36.4;
- 两者一起 → 69.8/38.0/43.3。说明"结构改善"和"细节补偿"是互补的。
-
FGC 融合策略:多头 attention 用"矩阵相乘"优于单头或均值融合(VOC/Context/Object 达 69.8/38.0/43.3)。
d) 局限性(论文承认/暗含)
- 论文明确指出:tiny objects 分割仍不准;未来考虑用更高分辨率输入来改善。
- 计算开销:引入 SD 的 FGC 会变慢(见下条时间对比)。
5. 学习与应用(复现视角)
a) 是否开源?
是。作者给出代码与模型页面:
b) 复现关键步骤(按实现顺序)
- 准备 CLIP(ViT-B/16 或 ViT-L/14)与文本 prompt(类别描述)。
- 取 CLIP 到倒数第二层的 embeddings + attention,算 (A_{\text{avg}}),替换最后层 attention;最后层去 FFN/残差,得到多层输出 embeddings。
- 多输出 embeddings 与文本 embeddings 逐类算 cosine similarity,并对多输出做平均,得 coarse map (S_c)。
- (可选)FGC:跑 Stable Diffusion v2.1,取 timestep 45/50 的最高分辨率 self-attention,多头矩阵链乘得 (A_f),做 (S_f=A_fS_c),上采样输出。
c) 超参数/预处理/训练细节(本文是 training-free)
- 输入:短边 resize 到 336,保持纵横比;并且不用滑窗,整图送入 CLIP encoder。
- SD:Stable Diffusion v2.1;attention 取 50 步中的第 45 步。
d) 能否迁移到其他任务?
可以类比迁移:
- ELF 是"用早期层结构信息修复后层表征",可用于任何需要更强空间一致性的 dense task(如 open-vocab instance/panoptic 的特征预处理)。
- FGC 是"用扩散注意力做局部结构传播",可迁移到边界敏感任务(显著性/交互式分割后处理等)。依据来自其"局部细节补偿"的设计目的与实证。
6. 总结
a) 20 字内核心思想
早期层修结构,扩散注意力补细节。
b) 速记版 pipeline(3--5 步、尽量不用论文术语)
- 把图像变成一串网格特征。
- 用前面多层产生的"位置关系矩阵"去改最后一层的特征更新方式。
- 把网格特征与每个类别文本算相似度,得到粗分割。
- 用扩散模型得到的"更局部的关系矩阵"传播/锐化粗分割。
- 放大回原图大小输出。
如果你希望我进一步"像做组会汇报那样"补充:ELF 为什么要同时融合 early-layer embeddings 和 early-layer attention(以及 Table 6 的两段对照到底在验证什么),我也可以继续把那一段做成逐行推导式解读(含更严格的矩阵维度展开)。