在上一篇文章中,深入剖析了Redis的底层数据结构。那其实只是 Redis 的微观世界。
今天,我们将镜头拉远,来到宏观的分布式系统架构中,聊聊 Redis 在生产环境中最著名的应用场景------分布式锁。
包含如下细节:
-
"你这把锁,到底锁在了哪里?"
-
"SetNX 为什么要配合 Lua 脚本?"
-
"既然有了 SetNX,为什么大厂还要用 Redisson?"
这篇文章,我们就来彻底理清这条进化之路。
一、 上帝视角:这把锁,到底锁在了哪里?
在深入代码之前,我们必须先纠正一个常见的架构认知误区。
很多初学者容易把系统想象成"糖葫芦串"结构:客户端 -> 服务器 -> Redis -> MySQL。 这是不对的。 在真实的分布式系统中,架构更像是一个**"职能协作网络"**。
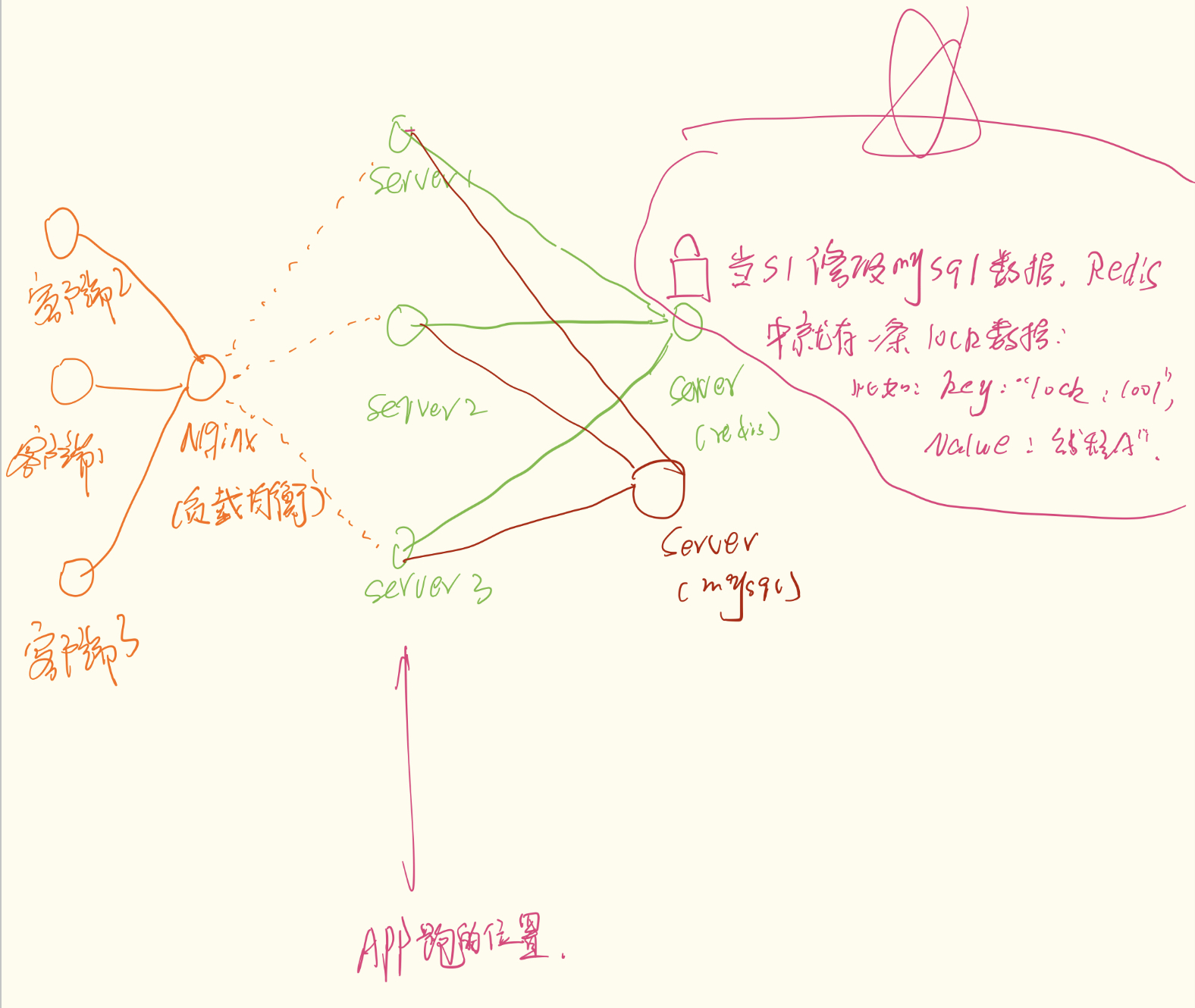
请看上图,核心逻辑如下:
-
服务器(App Server)是多台:比如 A、B、C 三台机器跑着相同的 Java 代码(集群部署)。
-
Redis 和 MySQL 是独立设施:它们是独立的服务,不依附于某台 App Server。
-
三角关系:
-
所有的 App Server 共享同一个 Redis。
-
所有的 App Server 共享同一个 MySQL。
-
注意 :Redis 和 MySQL 之间通常没有直接连线!它们都是由 App Server 来调度的。
-
那么,分布式锁到底锁的是什么?
这就好比三个办事员(App Server A, B, C)都要去唯一的档案柜(MySQL)修改同一份文件。为了防止冲突,他们在旁边的墙上挂了一个唯一的"令牌"(Redis Key)。
-
争抢:谁先在 Redis 里占到这个 Key,谁就拿到了令牌。
-
权限:拿到令牌的办事员,才有资格去连接 MySQL 修改数据。
-
归还:改完数据,把 Redis 里的 Key 删掉,把令牌让给别人。
结论 :你锁的不是代码,而是对共享资源(MySQL)的操作权。
二、 原始时代:SetNX 与 Lua 脚本
1. SetNX的理解?
虽然 SetNX 简单,但在生产环境简直是"事故制造机"。你的笔记里提到了几个核心坑,我用大白话翻译一下:
-
坑一:死锁(TTL的问题)(没释放)
-
场景:Server A 拿到锁,刚准备去改数据库,突然断电了!因为没来得及删锁,Redis 里的 Key 永远存在。Server B 和 C 永远拿不到锁,系统瘫痪。
-
解决 :必须加 TTL(过期时间),比如 10 秒后自动删。
-
-
坑二:误删(删了别人的锁)(原子性问题,可以通过Lua解决)
-
场景:
-
A 拿到锁(TTL 10秒)。
-
A 卡顿了(FullGC),卡了 15 秒。
-
第10秒:Redis 发现 A 的锁过期,自动删了。
-
B 趁虚而入,拿到了锁。
-
第15秒 :A 醒了,任务做完,执行
DEL删锁。注意!A 此时删的是 B 的锁! -
C 发现没锁了,也冲了进来。B 和 C 同时在跑,锁失效。
-
-
解决:删锁前,必须看一眼 Value 是不是自己的 ID。而且**"看一眼"和"删除"必须是原子操作**(必须用 Lua 脚本,不能分两步写)。
-
-
坑三:不可重入
-
场景:你的代码里,方法 A 拿了锁,方法 A 里又调用了方法 B,方法 B 也要拿同一把锁。
-
SetNX 会直接报错,因为它发现锁已经存在了(虽然就是你自己拿的)。这不符合 Java
ReentrantLock的习惯。
-
2. 为什么要引入 Lua 脚本?
加锁一条指令搞定了,但解锁却是一个大坑。 为了防止**"误删别人的锁"**(比如 A 线程卡顿导致锁过期,B 线程拿到锁,A 醒来后把 B 的锁删了),我们在解锁时必须遵循"先判断,再删除"的逻辑:
Java
// 伪代码
if (redis.get("lock") == "我的机器码") {
redis.del("lock");
}问题来了 :如果不加控制,上面的 get 和 del 是两步操作,不具备原子性 。 如果 A 线程刚执行完 get 判断是自己的锁,还没来得及 del,此时发生了 FullGC 或者网络波动,锁刚好过期了,B 线程拿到了锁。A 恢复后直接执行 del,还是会把 B 的锁删掉。
解决方案:Lua 脚本 Redis 执行 Lua 脚本是原子性的。我们将"判断"和"删除"写在一个脚本里发送给 Redis:
Lua
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end只有用了 Lua,才能真正保证 SetNX 方案的安全性。
3. SetNX 依然存在的硬伤
虽然加上 Lua 脚本解决了原子性问题,但 SetNX 方案在工业级场景下依然显得"简陋":
-
不可重入 :Java 的
ReentrantLock允许同一个线程多次获取同一把锁,但 SetNX 不行,因为 Key 只有一份。 -
TTL 进退两难:
-
设短了:业务没跑完,锁丢了,导致并发事故。
-
设长了:万一服务挂了,锁要很久才过期,系统吞吐量下降。
-
三、 工业革命:Redisson 的完美进化
为了解决 SetNX 的硬伤,Redisson 登场了。它不是什么黑魔法,而是把复杂的逻辑封装成了一个成熟的 SDK。
1. 解决不可重入:从 String 到 Hash
Redisson 不再使用简单的 String 结构存锁,而是利用 Hash 结构。 它在 Redis 里的存储形式如下:
-
Key :
lock:product:1001 -
Field :
机器UUID : 线程ID -
Value :
1(重入次数)
原理:
-
当同一个线程再次来抢锁时,Redisson 发现 Field 是自己,就将 Value +1。
-
释放锁时,将 Value -1 。直到减为 0,才真正删除 Key。 这样就完美实现了类似
ReentrantLock的可重入特性。
2. 解决 TTL 难题:看门狗 (WatchDog) 机制
这是 Redisson 最核心的卖点。既然我们不知道业务要跑多久,那就让锁**"自动续期"**。
工作流程:
-
当我们调用
lock()方法时,只要不指定过期时间,Redisson 默认给锁设置 30 秒 TTL。 -
同时,Redisson 会在后台启动一个定时任务(TimeTask) ,每隔 10 秒(默认 TTL 的 1/3)检查一次。
-
续期 :定时任务检测到持有锁的线程还在运行,就会通过 Lua 脚本把 Redis 里的锁 TTL 重新重置为 30 秒。
-
防死锁:如果服务宕机了,后台的定时任务也没了,没人给锁续命,30 秒后锁自动过期,不会造成死锁。
四、 最后的隐患:主从一致性与"多节点"方案
到这里,Redisson 的看门狗和可重入机制似乎已经完美了。但在 Redis 主从架构(Master-Slave) 下,还有一个物理定律级别的"硬伤"无法解决。
1. 致命场景:主从切换的时间差
Redis 的主从复制是 异步 的。这意味着,当你向 Master 写入数据后,Master 会立即告诉你"成功了",然后再在后台慢慢把数据同步给 Slave。
这就产生了一个极端的 "真空期":
-
A 线程 在 Master 拿到了锁(写入 Key 成功)。
-
Master 宕机(此时锁数据还在内存里,还没来得及同步给 Slave)。
-
Slave 上位 :Slave 升级为新 Master,但它的内存里 没有这把锁。
-
B 线程 趁虚而入,找新 Master 申请锁,也成功了。
-
灾难:A 和 B 同时持有了锁,互斥彻底失效。
怎么办?
只要你用主从架构,这个问题就无解。为了解决这个问题,Redisson 提出了一个颠覆性的思路:放弃主从复制,改用"人海战术":见如下场景帮助理解。

这就是 MultiLock(联锁) 和 RedLock(红锁) 的诞生背景。
2. 核心原理:为什么"放弃主从"反而更安全?
你可能会问:"放弃主从复制?那数据怎么备份?这不科学啊!"
这里的"放弃主从",指的是不依赖"Master 同步给 Slave"来保证数据一致性。
我们换一种玩法:部署 N 个(通常是 3 或 5 个)完全独立的 Redis Master 节点。它们之间谁也不听谁的,没有主从关系,就是 5 个平等的"记票人"。
客户端去抢锁的时候,必须同时去这 5 个节点上"拉票"。
3. 方案 A:MultiLock (联锁) ------ "一票否决制"
MultiLock 的逻辑非常简单粗暴:完美主义者。
-
定义:它将多个独立的 Redis 锁,打包成一个"超级锁"。
-
规则 :所有节点都必须加锁成功,才算成功。 只要有一个节点失败(比如宕机,或者被别人占了),整个加锁操作就宣告失败,并且会把之前已经拿到手的锁全部释放。
通俗理解:
这就好比你要集齐"七龙珠"才能召唤神龙。
-
你去 5 个 Redis 节点上加锁。
-
节点 1~4 都成功了,但节点 5 挂了。
-
结果:MultiLock 判定失败。你必须把节点 1~4 的锁也退回去。
适用场景:
它主要不是为了解决主从切换问题的,而是为了**"同时锁定多个互不相关的资源"**(比如我要同时锁定"订单表"和"库存表",这俩必须一起锁住才有意义)。但在解决主从问题上,它因为要求 100% 存活,一旦有一个 Redis 节点坏了,整个系统就没法加锁了,可用性太差。
4. 方案 B:RedLock (红锁) ------ "少数服从多数"
为了解决 MultiLock "坏一个就全死"的问题,RedLock 引入了**"容错机制"**。
这也是面试中最高频的考点。
-
定义:它是基于 MultiLock 的升级版。
-
规则 :只要有超过半数(N/2 + 1)的节点加锁成功,就算成功。
通俗理解(委员会投票):
假设有 5 台独立的 Redis Master。
-
你跑去申请锁。
-
Redis A 说:可以(成功)。
-
Redis B 说:可以(成功)。
-
Redis C 说:可以(成功)。
-
Redis D 说:我挂了(失败)。
-
Redis E 说:我挂了(失败)。
-
结果 :3 票赞成,2 票失败。3 > 5/2,恭喜你,拿到锁了!
为什么它能解决主从失效问题?
回到最开始的场景:
假如 A 拿到了锁(在 A, B, C 三台机器上成功)。哪怕其中一台机器 A 突然断电了,数据丢了。
当线程 B 想要来抢锁时,它去访问 B, C, D, E。
-
B 和 C 会告诉它:"锁被人占了"。
-
D 和 E 说:"可以"。
-
结果 :2 票赞成,2 票反对。2 < 5/2,加锁失败!
结论 :RedLock 通过空间(多台机器)换时间,利用概率论(多台机器同时挂掉的概率极低)保证了锁的强一致性。
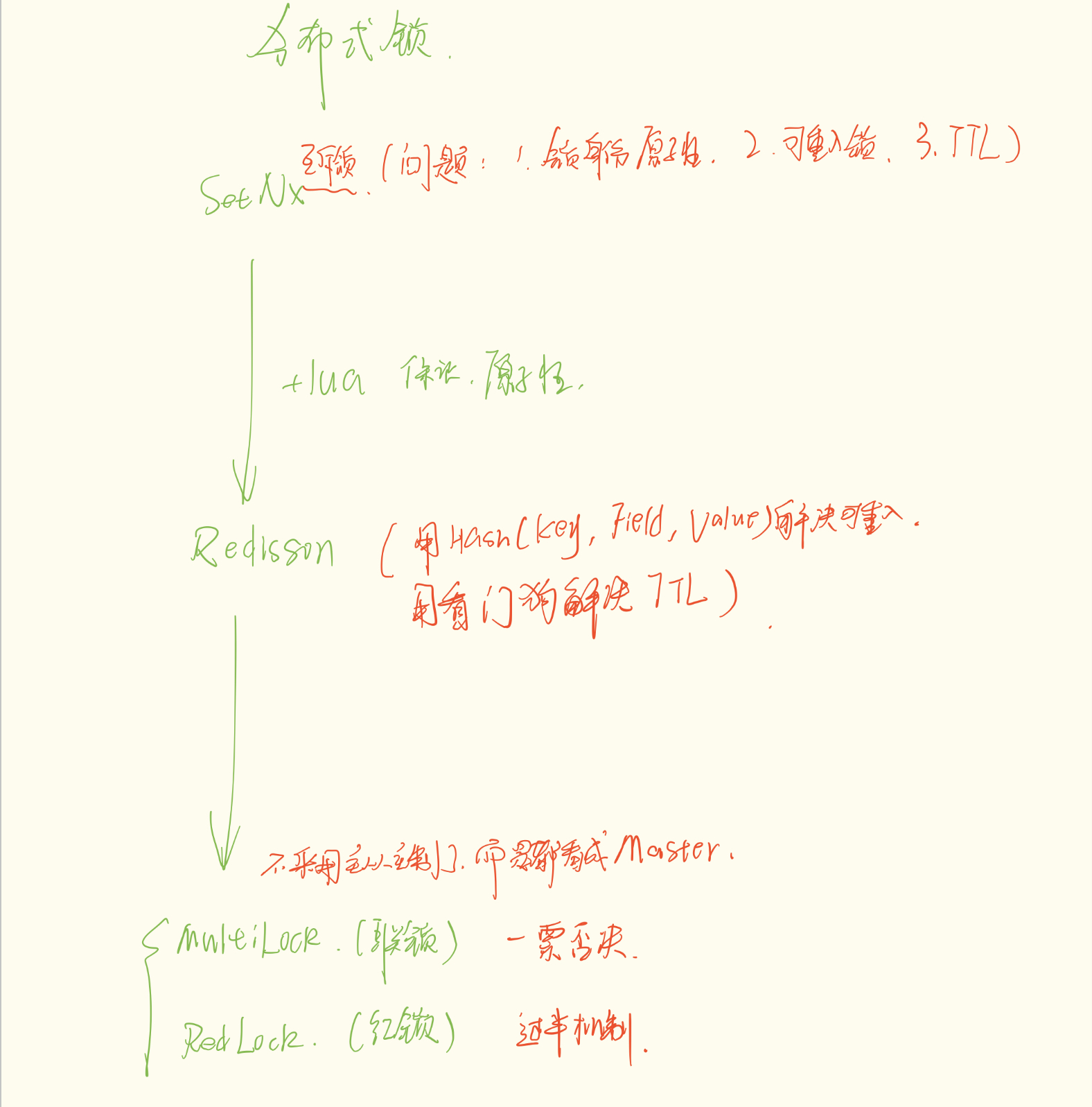
五、 总结:分布式锁的"进化金字塔"
回顾 Redis 分布式锁的进化历程,我们其实是在做一道 "安全性 vs 性能" 的选择题。
| 进化阶段 | 技术方案 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 青铜时代 | SetNX + Lua | 互斥占坑 | 简单,无依赖 | 不可重入,需自己处理原子性 | 简单的单次互斥操作 |
| 白银时代 | Redisson 普通锁 | Hash + 看门狗 | 可重入 ,自动续期 | 主从切换锁丢失 | 绝大多数生产环境(容忍极低概率的锁丢失) |
| 黄金时代 | Redisson RedLock | 多节点 + 过半机制 | 强一致性,容忍节点宕机 | 性能最差,运维成本高(需维护多个Redis) | 涉及金钱交易、决不允许锁失效的核心业务 |
最后的建议:
在实际开发中,90% 的场景直接使用 Redisson 的普通锁(白银时代)就足够了。
为什么?因为 Redis 主从切换恰好发生在"锁住的那几毫秒"的概率,比中彩票还低。为了这微乎其微的概率去部署 5 台独立的 Redis 实例(RedLock),往往属于"过度设计"。
但如果你的业务是金融转账 ,一分钱都不能差,请毫不犹豫地把 RedLock 搬出来。