文章目录
创建ollama容器
bash
docker run -d \
--name ollama \
--restart always \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollama查看ollama容器是否已UP
bash
[root@localserver models]# docker ps | grep ollama
257d3ct479ee ollama/ollama "/bin/ollama serve" 40 minutes ago Up 40 minutes 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama进入容器内,拉取模型
bash
#进入容器内
docker exec -it ollama /bin/bash
#拉取模型(若没有此模型则会自动拉取),并以打开与模型的交互模型
ollama run tinyllama:latest
#拉取模型(不会自动进入和模型的交互模型)
ollama pull tinyllama:latest如下演示:
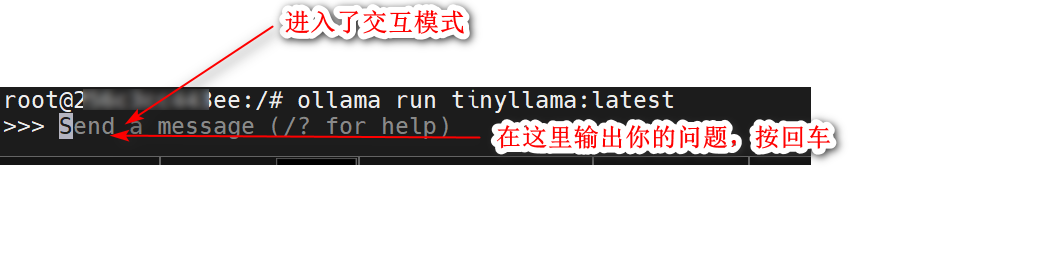
注意:ollama run tinyllama:latest 只是打开了一个和模型的交互式模式,并不是说启动了模型。

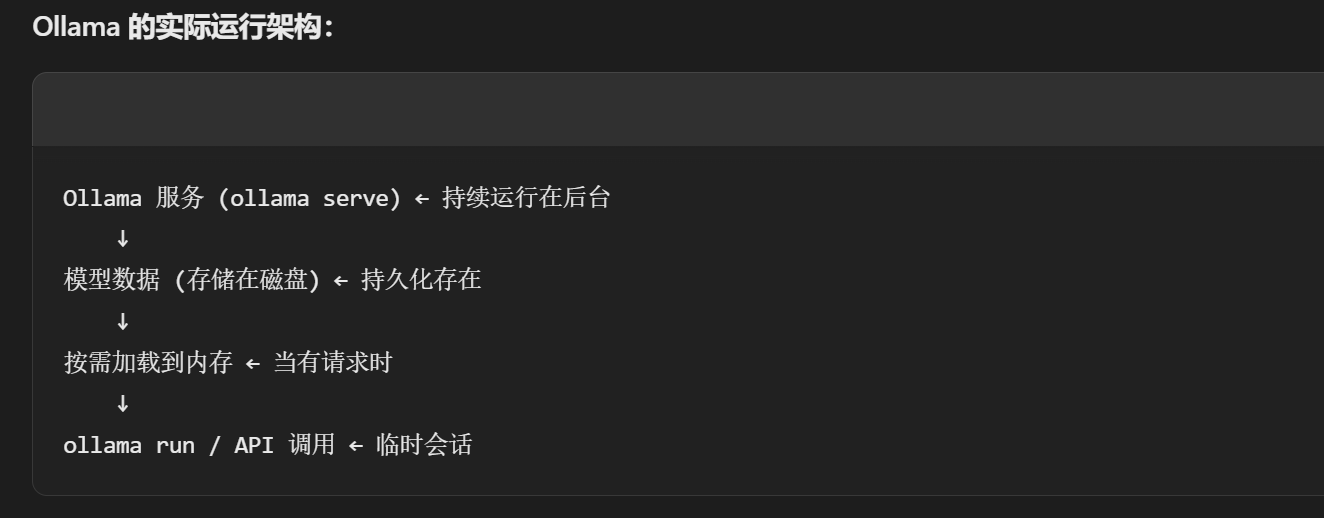
只要ollama serve进程服务还在运行,ollama pull 下来的模型,都会在被调用时按需加载指定的大模型,并提供服务,并不是像传统服务那样后台一直到在启用监听的模式。所以这里的大模型 没有启动或停止一说。
ollama pull 或 ollama run 时当模型不存在时都会主动去指定的官方仓库里下载模型,所以最好使用没有代理的网络,不然会出现各种奇奇怪怪的问题。