目录
-
- 一、研究背景与意义
- 二、核心概念与理论基础
-
- (一)时间序列与TSC定义
- (二)TSC算法分类
-
- [1. 传统机器学习(ML)算法](#1. 传统机器学习(ML)算法)
- [2. 深度学习(DL)算法](#2. 深度学习(DL)算法)
- (三)制造业TSC数据集
- 三、实验设计与方法
- 四、核心实验结果
- 五、实践建议与研究局限
- 六、核心参考文献
一、研究背景与意义
-
制造业转型需求:制造业正迈向工业4.0驱动的智能 manufacturing 时代,传感器技术发展使智能制造系统(SMS)积累海量多样数据,其中时间序列数据(如设备振动、温度数据)对质量检测、故障诊断等关键任务至关重要,时间序列分类(TSC)成为核心任务。
-
研究缺口:过去十年TSC算法大量涌现,但缺乏针对制造业场景的系统性验证与实证对比,制造业从业者难以选择适配算法,且制造业公开数据集稀缺,阻碍TSC技术落地。
-
研究价值:通过严谨实验评估主流机器学习(ML)与深度学习(DL)算法在制造业TSC任务中的性能,为从业者提供算法选择指南,搭建计算机科学(CS)领域TSC算法与制造业应用的桥梁。
论文:Time-Series Classification in Smart Manufacturing Systems: An Experimental Evaluation of State-of-the-Art Machine Learning Algorithms
作者:Mojtaba A. Farahani, M. R. McCormick, Ramy Harik, and Thorsten Wuesta
单位:aWest Virginia University, Morgantown, University of South Carolina, Columbia, U.S.A
请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
关注微信公众号 ,获取更多资讯

二、核心概念与理论基础
(一)时间序列与TSC定义
- 时间序列类型
- 单变量时间序列(UTSC):单个传感器采集数据,维度(M=1),如单一设备振动信号。
- 多变量时间序列(MTSC):多个传感器同步采集数据,维度(M>1),如设备振动+温度+压力组合数据,当前制造业场景更常见且复杂。
- TSC任务目标:基于有标签时间序列数据训练监督学习模型,将新数据分类到对应标签类别,核心挑战包括时间依赖性、序列长度可变、非平稳性与噪声干扰。
- TSC算法框架:包含数据采集、预处理(截断/填充、标准化等)、TSC模块(可选特征工程+分类器),最终输出类别标签与决策洞察。
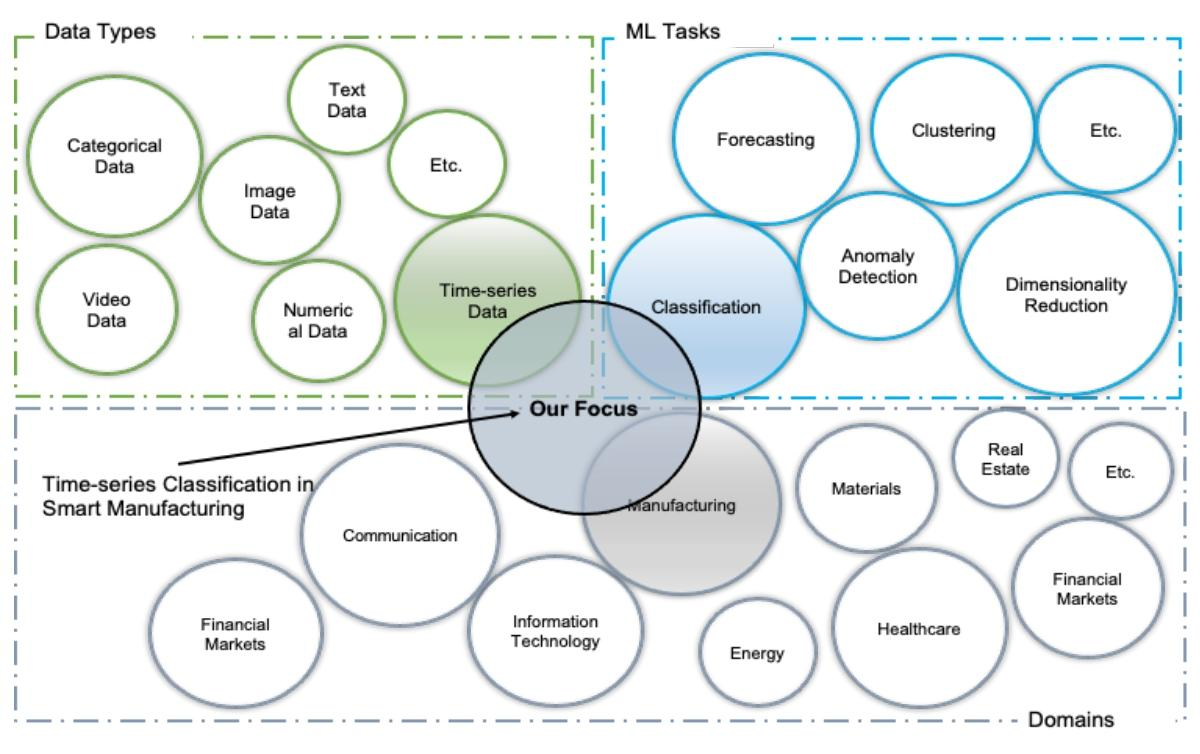
图1:工作范围的图形表示:制造中的时间序列分类
(二)TSC算法分类
1. 传统机器学习(ML)算法
基于"手工特征工程(FE)+分类器"模式,按FE技术或分类技术分类,核心类别如下:
| 分类维度 | 具体类型 | 代表算法 | 核心逻辑 |
|---|---|---|---|
| 特征工程技术 | 字典类 | BOSS、WEASEL+MUSE | 将时间序列转化为"符号/词",通过词分布计算相似度 |
| 区间类 | DrCIF、TSF、RISE | 从时间序列区间提取统计特征(均值、方差)、Catch22特征,结合决策树集成 | |
| 形状子类 | STC、LS | 挖掘具有类别区分度的"子序列(形状子)",训练随机森林等分类器 | |
| 核函数类 | ROCKET、ARSENAL | 用随机卷积核提取特征,搭配岭回归分类器,ARSENAL为ROCKET集成版 | |
| 混合类 | HIVE-COTE V2.0 | 集成多种算法(如STC、ARSENAL),性能强但计算成本高 | |
| 分类技术 | 统计类 | LR、NB、Ridge | 基于概率/最大似然计算特征相似度 |
| 距离类 | KNN-DTW、KNN-EUC | 用欧氏距离、动态时间规整(DTW)衡量序列相似度,搭配KNN | |
| 决策树集成类 | RF、XGBoost、DrCIF | 多棵决策树投票,提升稳定性与精度 | |
| 算法集成类 | EE、ARSENAL | 集成多个基础算法结果,降低单一模型偏差 |
2. 深度学习(DL)算法
基于"自动特征提取+神经网络分类",无需手工FE,核心架构如下:
| 架构类型 | 代表算法 | 核心优势 | 适配场景 |
|---|---|---|---|
| 卷积神经网络(CNN) | ResNet、InceptionTime、FCN | 1D卷积核捕捉局部时序特征,残差块/ inception块解决梯度消失 | 长序列、高噪声数据(如设备振动) |
| 循环神经网络(RNN) | LSTM、BiLSTM、TS-LSTM | 记忆单元捕捉长时依赖,BiLSTM双向建模过去与未来信息 | 序列前后关联强的场景(如故障演化) |
| CNN-RNN混合 | MALSTM-FCN、TapNet | 结合CNN局部特征与RNN时序依赖,搭配注意力机制增强关键特征 | 多变量、复杂关联数据 |
| 前馈神经网络(FFN) | MLP、DA-NET | 简单全连接结构,适合低维度、平稳序列 | 基础分类任务或基准对比 |
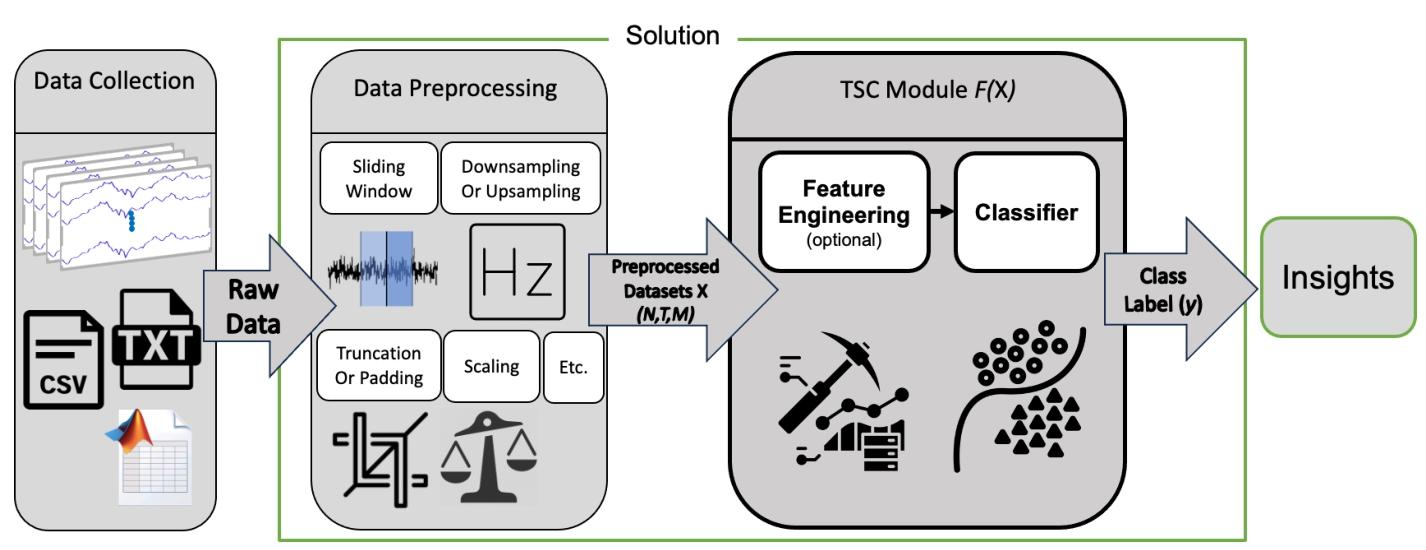
图3:TSC解决方案的一般框架
(三)制造业TSC数据集
- 数据集筛选与预处理
- 初始收集33个制造业相关数据集,排除"特征集"(非原始时序)与非分类任务数据集,最终确定22个原始时序数据集。
- 预处理标准:统一序列长度(短序列补零/均值,长序列截断)、标准化为"均值0+标准差1",避免算法内部标准化差异导致的偏差。
- 数据集特征:覆盖轴承故障诊断(CWRU、Paderborn)、液压系统状态监测(Hydraulic_sys)、半导体蚀刻(ETCHING_Multi)等10+制造业场景,包含单变量(12个)与多变量(10个)数据,序列长度60-58万不等,类别数2-12类。
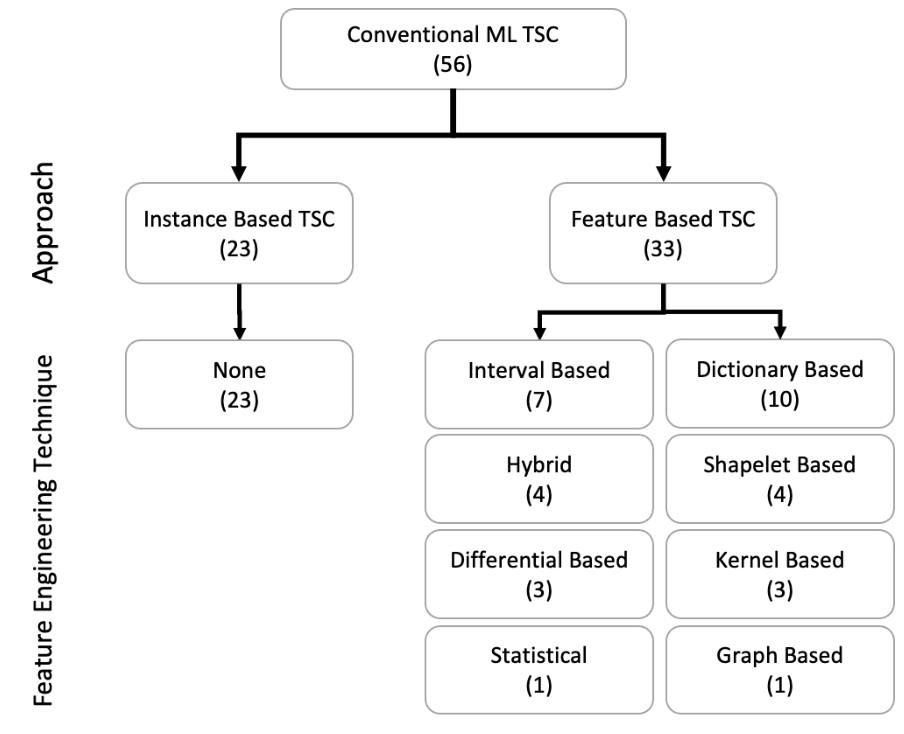
图4:传统ML - TSC算法中的FE技术
三、实验设计与方法
(一)算法选择
- 筛选逻辑 :从92个主流TSC算法中,按"同类别选最新/最具代表性、代码可获取"原则,最终选择36个算法,包括:
- 传统ML算法19个(如DrCIF、ARSENAL、HIVE-COTE V2.0);
- DL算法10个(如ResNet、InceptionTime、BiLSTM);
- 基准算法7个(如LR、RF、SVM,用于性能下限对比)。
- 参数设置:采用算法默认参数(原始论文或Python库推荐值),不进行超参调优,模拟从业者"开箱即用"场景。
(二)实验环境与流程
- 硬件配置:AMD Threadripper Pro 5975WX(32核)、2×RTX A5000(24GB)、128GB/512GB内存,单算法单数据集超时限制48小时,内存不足标记为"OOM"。
- 评估方法:5折交叉验证(80%训练/20%测试,随机洗牌5次),取平均精度与标准差;DL模型采用早停策略(50轮无损失下降则停止)确保收敛。
- 评估指标 :
- 核心指标:平均精度(AVG ACC)、获胜次数(WIN,算法优于所有其他算法的数据集数量)、平均排名(AVG Rank)、平均每类误差(MPCE,衡量类别不平衡场景鲁棒性);
- 统计检验:Friedman检验(验证算法性能差异非随机)、Wilcoxon符号秩检验( pairwise对比显著性,α=0.05)。
四、核心实验结果
(一)整体性能Top算法
- 四大最优算法 :ResNet(DL)、DrCIF(传统ML)、InceptionTime(DL)、ARSENAL(传统ML),在22个数据集上平均精度均超96.6% ,具体表现如下:
- DrCIF:平均精度最高(97.9%)、MPCE最低(0.007),区间类FE+决策树集成的代表,对制造业长序列适配性强;
- ResNet:获胜次数最多(10次)、平均排名最优(4.16),残差块解决深层CNN梯度问题,捕捉时序局部特征能力突出;
- ARSENAL:核函数类集成算法,精度96.6%,计算效率高于DL模型,适合资源有限场景;
- InceptionTime:多尺度卷积核捕捉不同时长特征,精度与ResNet持平,鲁棒性强。
- 其他优秀算法:LSTM、BiLSTM、TS-LSTM(RNN类)平均精度超91%,证明循环结构对时序依赖的捕捉能力;FCN(基础CNN)平均精度95.8%,可作为DL基准模型。
(二)单变量vs多变量TSC对比
| 任务类型 | 数据集数量 | Top算法表现 | 关键结论 |
|---|---|---|---|
| UTSC(单变量) | 12个 | ResNet(99.5%)、InceptionTime(99.5%)、ARSENAL(98.0%) | 所有Top10算法精度均超95%,无显著性能差异,ResNet略优 |
| MTSC(多变量) | 10个 | DrCIF(96.7%)、ResNet(93.7%)、InceptionTime(93.1%) | 区间类算法(DrCIF)更擅长融合多维度特征,DL算法需注意力机制增强多变量适配性 |
(三)计算效率分析
- ** runtime对比**:
- 高效算法:ARSENAL、ROCKET、RISE(平均runtime<10分钟),适合实时监测场景;
- 低效算法:HIVE-COTE V2.0、InceptionTime、ResNet(部分数据集超1000分钟),高精度但需高算力支持。
- 精度-效率权衡:ARSENAL(96.6%精度,低runtime)为"精度-效率"最优解;DrCIF(97.9%精度,中runtime)适合精度优先场景;ResNet(96.9%精度,高runtime)需GPU支持。
(四)意外发现
- 传统ML算法竞争力:DrCIF、ARSENAL性能媲美甚至超越DL算法,证明"手工FE+集成分类器"在制造业场景仍具优势,无需盲目追求DL。
- 部分经典算法局限:KNN-DTW、HIVE-COTE V2.0因计算复杂度高,在长序列数据集(如Paderborn 64KHZ)超时失败,实际应用需关注数据规模适配性。
五、实践建议与研究局限
(一)制造业TSC算法选择指南
- 优先选择清单 :
- 多变量、高精度需求:DrCIF(无GPU也可运行)、ResNet(需GPU);
- 实时性需求:ARSENAL、ROCKET(快且准);
- 单变量、资源有限:InceptionTime(DL)、TS-LSTM(RNN);
- 可解释性需求:DrCIF(决策树可解释)、STC(形状子可追溯),避免"黑箱"DL模型(如ResNet)。
- 数据预处理注意事项:必须标准化(消除量纲影响)、统一序列长度(避免算法对长度敏感),多变量数据优先选择原生支持多维度的算法(如DrCIF、ARSENAL)。
(二)研究局限
- 算法筛选偏差:假设"同类别新算法优于旧算法",可能遗漏部分适配制造业的旧算法;
- 参数未调优:未针对特定数据集优化超参,可能低估部分算法(如XGBoost)潜力;
- 数据集覆盖有限:22个数据集仍无法涵盖所有制造业场景(如3D打印、装配线),未来需扩充数据集类型。
(三)未来研究方向
- 探索Transformer、生成式AI(如GAN)在制造业TSC中的应用;
- 针对"超长序列""变量长度序列"设计轻量化算法;
- 研究数据增强技术(如时序生成)解决制造业数据稀缺问题;
- 提升DL模型可解释性(如注意力可视化、特征归因),适配制造业故障诊断需求。
六、核心参考文献
- Bagnall et al. (2016):《The Great Time Series Classification Bake Off》,TSC算法经典对比研究;
- Wang et al. (2017):《Time Series Classification from Scratch with Deep Neural Networks》,FCN/ResNet在TSC中的奠基性工作;
- Fawaz et al. (2020):《InceptionTime: Finding AlexNet for Time Series Classification》,InceptionTime算法提出;
- Middlehurst et al. (2021):《HIVE-COTE 2.0: A new meta ensemble for time series classification》,混合集成算法标杆;
- Dempster et al. (2020):《ROCKET: Exceptionally fast and accurate time series classification》,核函数类算法代表。