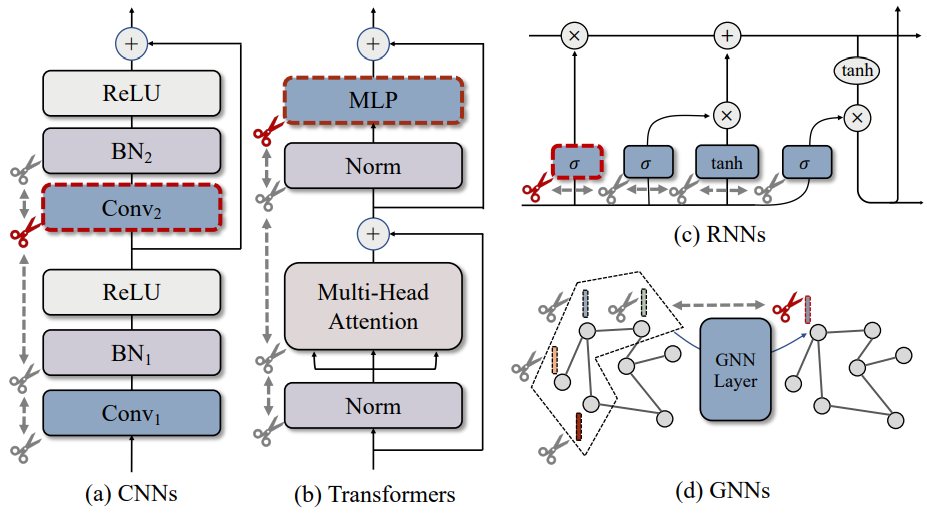
一、稀疏训练
一句话结论
稀疏训练就是通过对BN γ(gamma)添加 L1 正则,让模型自动学出"不重要的通道",从而为后续结构化剪枝提供依据。
稀疏训练原理
稀疏训练最核心的数学原理:在 BN γ 上施加 L1 正则。
YOLOv10 每个 Conv 后都有以下结构:
Conv → BN → SiLU其中:BN也就是 BatchNorm 的计算公式简述如下:
output = gamma * normalized_input + beta其中重要参数 γ(gamma) 控制当前通道的"放大/缩小"权重。
那么稀疏训练做了什么呢?
在 loss 中额外加一项 L1正则项:
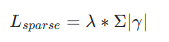
最终 loss:

其中:
-
L_{detection} 是原始任务的损失(例如目标检测);
-
γ 通常表示网络中某些可学习的缩放因子(例如在 BatchNorm 层中的可学习参数,或通道/神经元的门控权重);
-
λ 是控制稀疏正则化强度的超参数;
-
∑∣γ∣ 是对这些参数施加的 L1 正则项。
解释: 这个 λ * |γ| 会迫使部分通道的 BN gamma 值变小 ,(为什么?因为L2 正则只会让权重变小,但不会变为 0;因为靠近 0 时梯度接近 0。L1 正则(不可导,无论多小梯度不变)会产生恒定的推力,使不重要的权重直接变成 0,从而诱导稀疏性。)如此,会对模型的表达能力会带来轻微的干扰。
优化后:
-
不重要的通道 → γ 被推向 0 (γ 极小 → 通道几乎被关闭)
-
重要的通道 → γ 仍保持较大(γ 较大 → 通道被保留)
这给剪枝提供了"通道可删性"的依据。
适合稀疏化的结构
在 YOLOv10 的 Backbone 与 Neck 中,大量使用了以下结构:
-
C2f 模块
-
C2fCIB 模块
-
SCDown 模块
这些结构具有一些共同特点:
-
多分支设计、跨层特征融合频繁
-
中宽通道数量大(如 128 / 256 / 512)
-
跨层特征存在一定重复性
-
Bottleneck / CIB 等模块堆叠较深
上述特征共同带来的结果是:网络中部分通道天然冗余 ,其对应的 BatchNorm γ 参数会在训练中自然趋向于较小值 。因此,在进行稀疏化与通道剪枝时,这些模块非常容易被"压缩"而不影响整体性能------也正是 YOLOv10 特别适合稀疏剪枝的重要原因。
上手实操
在训练中加入 L1 稀疏化最简单的方式,是利用回调机制对 BN γ 参数施加 L1 正则 。具体做法是:重写 优化器 的执行流程,在梯度 unscale 之后、参数 step 之前,对 BatchNorm 的梯度额外加上 L1 项。这样即可在不改动主干训练逻辑的前提下,实现对 BN 通道的稀疏化约束。
二、(可选)基于BN的γ进行稀疏处理
GammaPruner 基于Gamma进行稀疏化处理
这个步骤一般在第一步之后,效果好些。
核心是对于bn的权重进行排序,然后按一个比例去把对应的bn层的参数置为0,完成稀疏化。
剪枝后通常需要微调(fine-tune),否则精度可能大幅下降。
三、结构化剪枝以及微调
利用torch-pruning工具对yolov10进行结构化剪枝以及微调操作。
参考官方的示例代码:Torch-Pruning/examples/yolov8/yolov8_pruning.py at master · VainF/Torch-Pruning
主要剪枝的模块如yolov8一样(事实上yolov10是在yolov8上改进而来),都主要是优化C2f结构。
但是 需要注意的是 : yolov10网络上还有C2f的衍生模块C2fCIB,这个模块继承C2f,实际上就是把C2f的Bottleneck结构换成了CIB结构,那么在替换C2f结构以及infer_shortcut部分特别要注意。
除此以外,这里还要额外解释下:为什么要重写C2f结构?
对于YOLOv8/v10中剪枝时重写C2f结构的解释
显浅的解释:主要是为了让 C2f 变成更容易 剪枝 **的结构。**您肯定会说,这不就是一句废话,那么接下来分析YOLO原版 C2f 的问题是:
原始 C2f 不适合 剪枝 (特别是 channel pruning )
先重点看原 C2f 结构:
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
y = list(self.cv1(x).chunk(2, 1))观察到:cv1 输出了 2*self.c 个通道,之后劈成两半用于不同分支
这意味着:
-
通道必须能被 2 整除
-
两个分支共享一个 conv 输出
-
一旦剪掉某些通道,会破坏 chunk 的对齐
-
剪枝后 channel 不再对称 → 网络结构直接错位、维度错误
因此:原版 C2f 是典型的"不剪不行,剪了就炸"的结构
所以各大剪枝框架(torch-pruning、slimmable、模型稀疏化)对 YOLO 的 C2f 都特别难处理。
接下来,看修改后的 C2f_v2 结构:
self.cv0 = Conv(c1, self.c, 1, 1)
self.cv1 = Conv(c1, self.c, 1, 1)也就是:用两个独立的 conv **来替代 原来 cv1 的"2c 输出 + chunk 切半"。**这带来以下4个剪枝优势:
-
每个分支现在可以独立剪枝(而不是绑定在一起)
-
移除 chunk,所有结构变为标准 Conv,便于剪枝工具解析
-
两个独立输入分支,更容易加稀疏正则(L1 on gamma)
-
新 C2f 的结构更像 ConvNeXt / ResNet 的典型可剪枝结构
-
保留原 C2f 的特性,逻辑一致,推理行为相近
最后看下 forward:
y = [self.cv0(x), self.cv1(x)]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))推理行为与原版是一致:
-
第一条分支类似于原来的 y0
-
第二条分支相当于原来的 y1
-
后面的 m 都是堆叠 residual blocks
-
最后 concat → cv2 聚合
只是把 chunk 改成了更适合剪枝的版本。
最后,总结一句话:为了剪枝,把 C2f 中原本的"2c 输出 + chunk"改成了两个独立卷积 cv0/cv1,使得每个分支可以独立剪枝,不再受 chunk 对齐限制,从而让整个结构完全可剪、完全可稀疏化。
剪枝过程中遇到的坑
剪枝后微调会报错:
"RuntimeError: Inplace update to inference tensor outside InferenceMode is not allowed.You can make a clone to get a normal tensor before doing inplace update.See https://github.com/pytorch/rfcs/pull/17 for more details."
经查资料,inference_mode()在torch 1.9.0之后的版本引入,torch-pruning工具的yolov8示例代码如果不报错那可能torch版本在这之前。
最后定位在self.scaler.step(self.optimizer)报错了,但其根本原因是因为tensor处于推理模式,这些 inference tensor 极大概率是在运行 val() 验证时,在 torch.inference_mode() 下生成并缓存到模型内部,但又继续用这个实例去训练,导致的报错。
最后解决问题的方式是:
不要用剪枝以及评估后的model去微调,重新加载这个模型,并修改更新相应的方法然后进行微调。
未完待续... 会提供完整的代码解析(可催更)